Chemometrics for Selection, Prediction, and Classification of Sustainable Solutions for Green Chemistry—A Review



Abstract
:1. Introduction
2. The Outline of Chemometric Tools
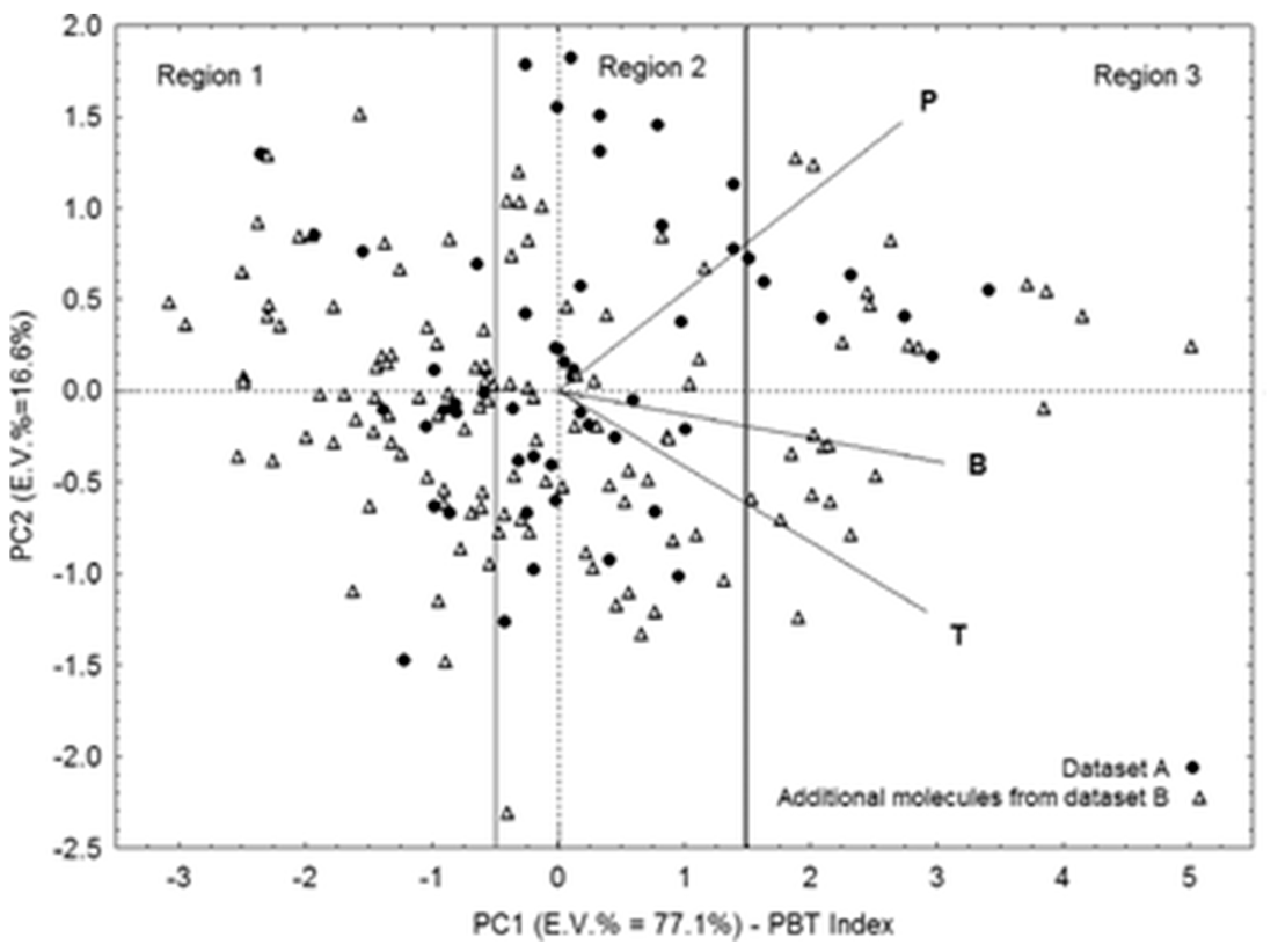
3. Selection
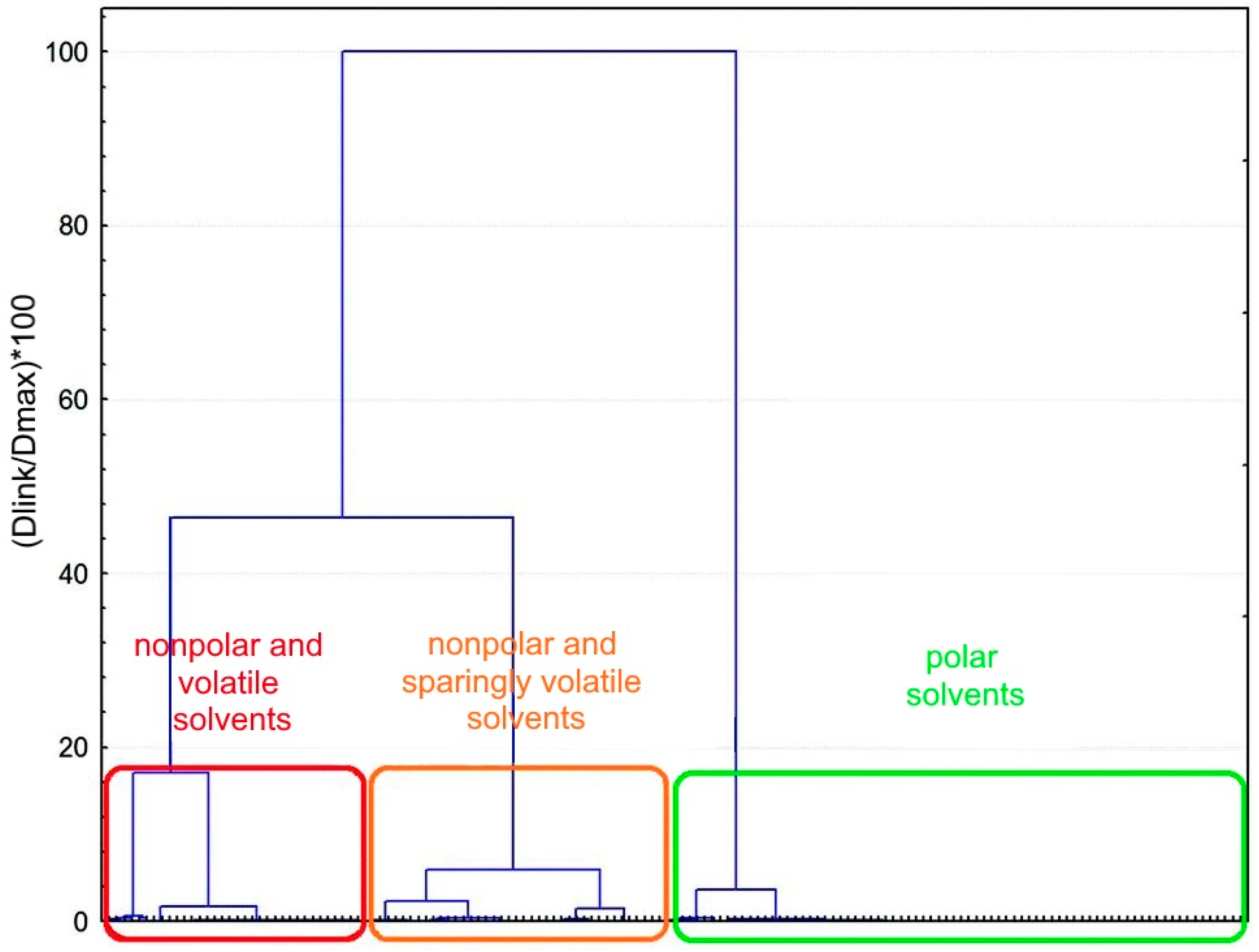
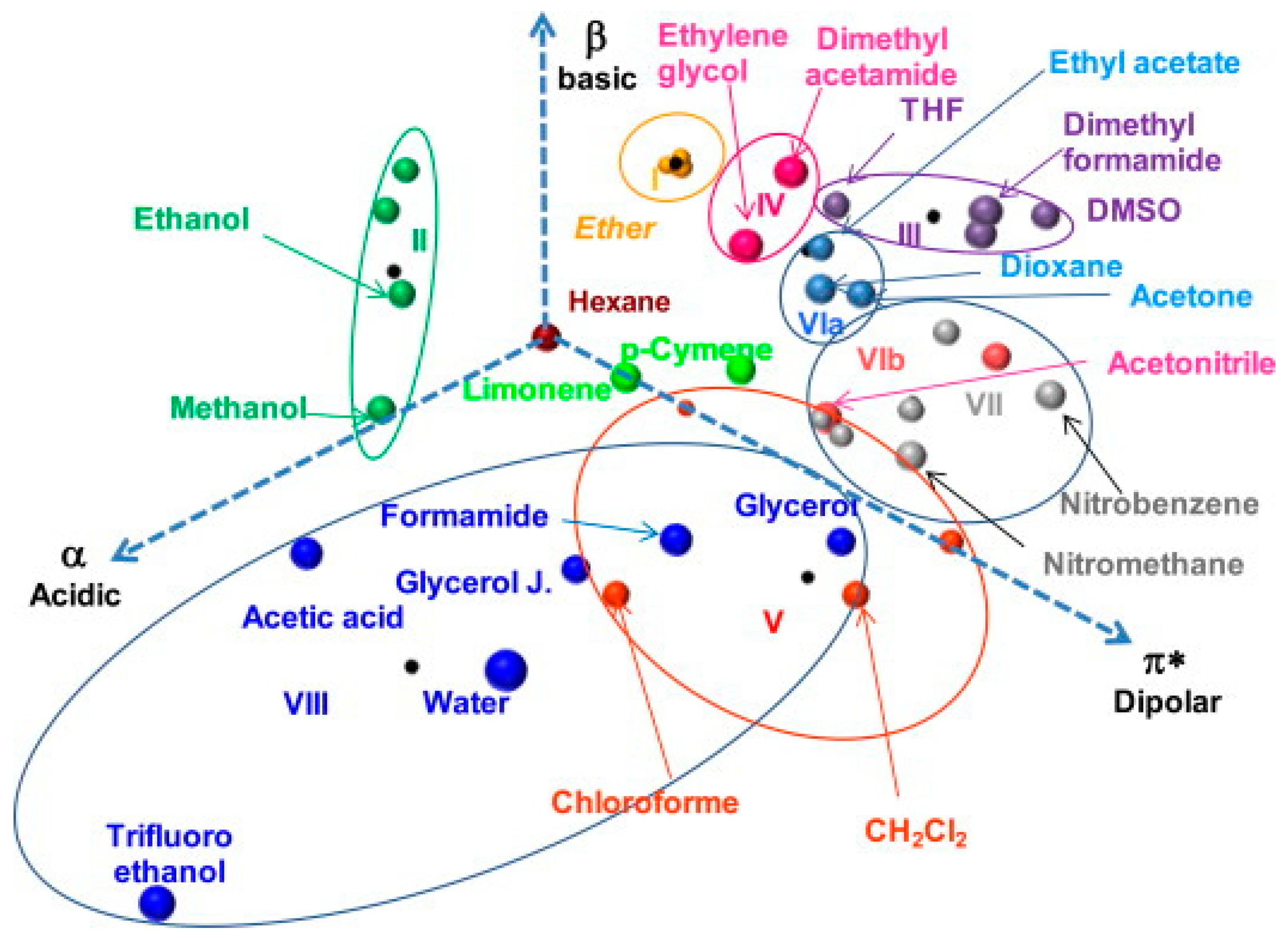
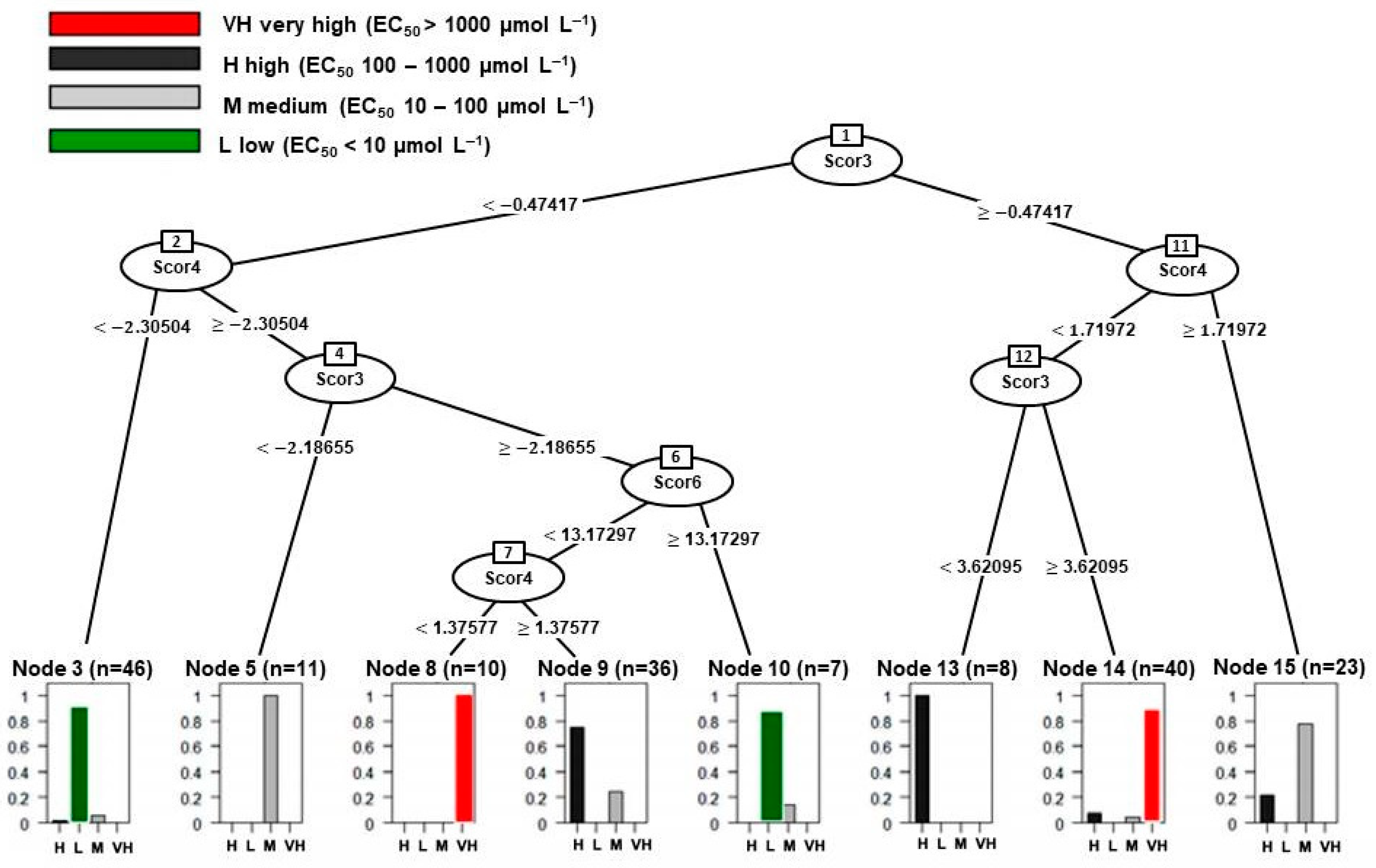
4. Classification
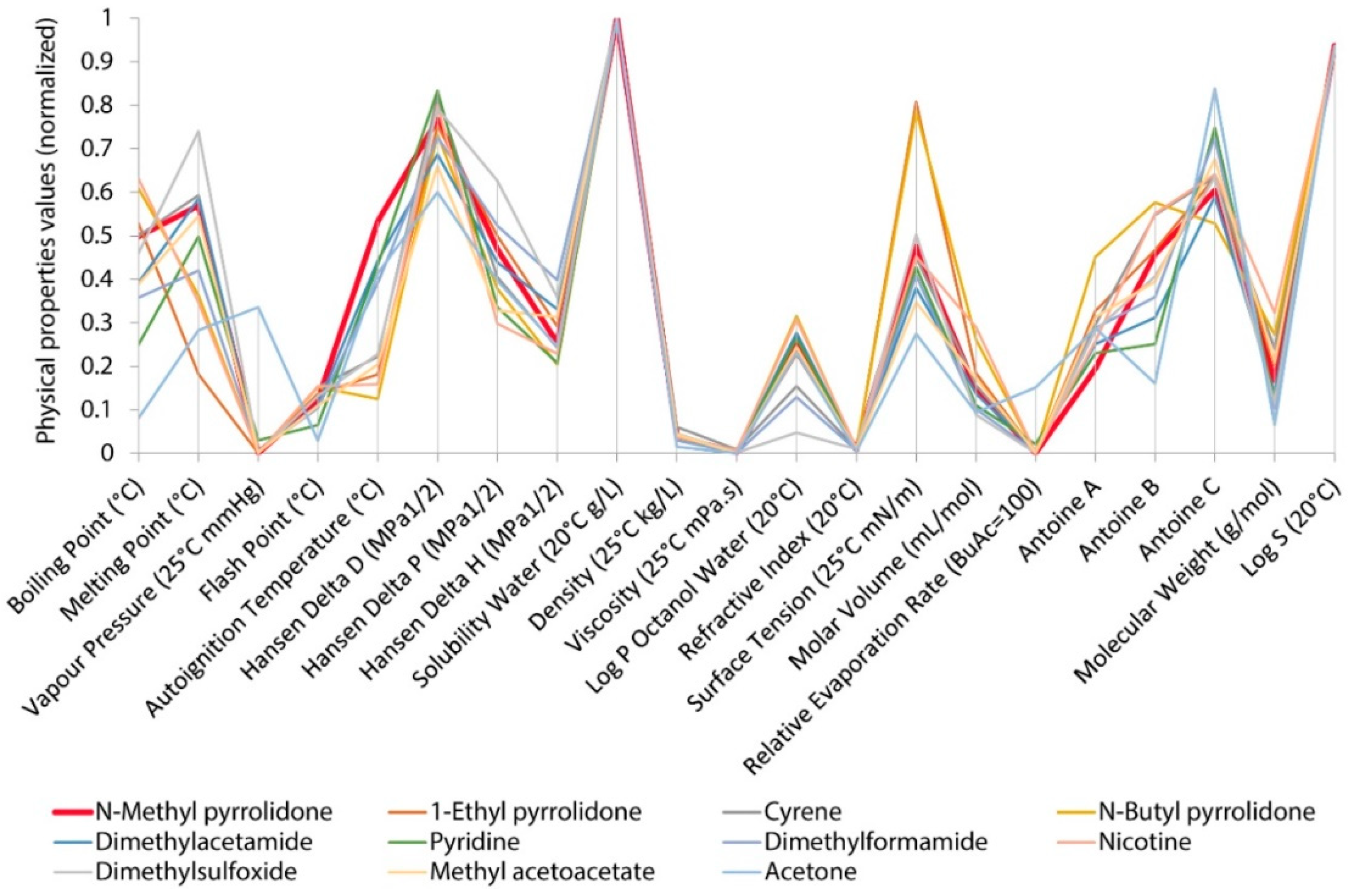
5. Properties (Prediction and Correlation)
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Brereton, R.G. Chemometrics in analytical chemistry. A review. Analyst 1987, 112, 1635–1657. [Google Scholar] [CrossRef]
- Kiralj, R.; Ferreira, M.M.C. The past, present, and future of chemometrics worldwide: Some etymological, linguistic, and bibliometric investigations. J. Chemom. 2006, 20, 247–272. [Google Scholar] [CrossRef]
- Brereton, R.G.; Jansen, J.; Lopes, J.; Marini, F.; Pomerantsev, A.; Rodionova, O.; Roger, J.M.; Walczak, B.; Tauler, R. Chemometrics in analytical chemistry—Part I: History, experimental design and data analysis tools. Anal. Bioanal. Chem. 2017, 409, 5891–5899. [Google Scholar] [CrossRef] [PubMed]
- Santos, M.C.; Nascimento, P.; Guedes, W.N.; Pereira-Filho, E.R.; Filletti, É.R.; Pereira, F.V. Chemometrics in analytical chemistry—An overview of applications from 2014 to 2018. Eclética Química J. 2019, 44, 11–25. [Google Scholar] [CrossRef] [Green Version]
- Defernez, M.; Kemsley, E. The use and misuse of chemometrics for treating classification problems. TrAC Trends Anal. Chem. 1997, 16, 216–221. [Google Scholar] [CrossRef]
- Rácz, A.; Bajusz, D.; Héberger, K. Chemometrics in Analytical Chemistry. In Applied Chemoinformatics: Achievements and Future Opportunities; Engel, T., Gasteiger, J., Eds.; Wiley-VCH: Weinheim, Germany, 2018; pp. 471–499. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Vončina, D.B. Chemometrics in analytical chemistry. Nova Biotechnol. 2009, 211, 211–216. [Google Scholar]
- Camacho, J.; Picó, J.; Ferrer, A. Data understanding with PCA: Structural and Variance Information plots. Chemom. Intell. Lab. Syst. 2010, 100, 48–56. [Google Scholar] [CrossRef]
- Huang, B.K.; Huang, L.Q.; Qin, L.P. Cluster analysis of NIR fingerprint of four species plants in Valeriana officinalis L. J. Chin. Med. Mater. 2008, 31, 1494–1496. [Google Scholar]
- Mohsin, G.F.; Schmitt, F.-J.; Kanzler, C.; Hoehl, A.; Hornemann, A. PCA-based identification and differentiation of FTIR data from model melanoidins with specific molecular compositions. Food Chem. 2019, 281, 106–113. [Google Scholar] [CrossRef]
- Guo, Y.; Ni, Y.; Kokot, S. Evaluation of chemical components and properties of the jujube fruit using near infrared spectroscopy and chemometrics. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2016, 153, 79–86. [Google Scholar] [CrossRef]
- Massart, D.L. The Interpretation of Analytical Chemical Data by the Use of Cluster Analysis; John Wiley & Sons: New York, NY, USA, 1983. [Google Scholar]
- Liang, Y.Z.; Xie, P.; Chan, K. Quality control of herbal medicines. J. Chromatogr. B 2004, 812, 53–70. [Google Scholar] [CrossRef]
- Wesołowski, M.; Konieczynski, P. Thermoanalytical, chemical and principal component analysis of plant drugs. Int. J. Pharm. 2003, 262, 29–37. [Google Scholar] [CrossRef]
- Bansal, A.; Chhabra, V.; Rawal, R.K.; Sharma, S. Chemometrics: A new scenario in herbal drug standardization. J. Pharm. Anal. 2014, 4, 223–233. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Ng, T.-T.; Yao, Z.P. Quantitative analysis of blended oils by matrix-assisted laser desorption/ionization mass spectrometry and partial least squares regression. Food Chem. 2020, 334, 127601. [Google Scholar] [CrossRef] [PubMed]
- Wold, S.; Kettaneh, N.; Tjessem, K. Hierarchical multiblock PLS and PC models for easier model interpretation and as an alternative to variable selection. J. Chemom. 1996, 10, 463–482. [Google Scholar] [CrossRef]
- Denham, M.C. Choosing the number of factors in partial least squares regression: Estimating and minimizing the mean squared error of prediction. J. Chemom. 2000, 14, 351–361. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Goudarzi, N.; Goodarzi, M. Prediction of the logarithmic of partition coefficients (log P) of some organic compounds by least square-support vector machine (LS-SVM). Mol. Phys. 2008, 106, 2525–2535. [Google Scholar] [CrossRef]
- Lee, H.; Park, Y.M.; Lee, S. Principal Component Regression by Principal Component Selection. Commun. Stat. Appl. Methods 2015, 22, 173–180. [Google Scholar] [CrossRef] [Green Version]
- Tong, W.; Hong, H.; Xie, Q.; Shi, L.; Fang, H.; Perkins, R. Assessing QSAR Limitations—A Regulatory Perspective. Curr. Comput. Aided Drug Des. 2005, 1, 195–205. [Google Scholar] [CrossRef] [Green Version]
- Tropsha, A.; Golbraikh, A. Predictive QSAR Modeling Workflow, Model Applicability Domains, and Virtual Screening. Curr. Pharm. Des. 2007, 13, 3494–3504. [Google Scholar] [CrossRef] [PubMed]
- Hibbert, D.B. Genetic algorithms in chemistry. Chemom. Intell. Lab. Syst. 1993, 19, 277–293. [Google Scholar] [CrossRef]
- Mehrotra, K.; Mohan, C.K.; Ranka, S. Elements of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Attia, K.A.; Nassar, M.W.; El-Zeiny, M.B.; Serag, A. Effect of genetic algorithm as a variable selection method on different chemometric models applied for the analysis of binary mixture of amoxicillin and flucloxacillin: A comparative study. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2016, 156, 54–62. [Google Scholar] [CrossRef] [PubMed]
- Golmohammadi, H.; Dashtbozorgi, Z. Quantitative structure–property relationship studies of gas-to-wet butyl acetate partition coefficient of some organic compounds using genetic algorithm and artificial neural network. Struct. Chem. 2010, 21, 1241–1252. [Google Scholar] [CrossRef]
- Fatemi, M.H.; Jalali-Heravi, M.; Konuze, E. Prediction of bioconcentration factor using genetic algorithm and artificial neural network. Anal. Chim. Acta 2003, 486, 101–108. [Google Scholar] [CrossRef]
- Gere, A.; Rácz, A.; Bajusz, D.; Károly, H. Multicriteria decision making for evergreen problems in food science by sum of ranking differences. Food Chem. 2020, 128617. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Cao, D.-S.; Dong, J.; Wang, N.-N.; Wen, M.; Deng, B.-C.; Zeng, W.-B.; Xu, Q.-S.; Liang, Y.-Z.; Lu, A.-P.; Chen, A.F. In silico toxicity prediction of chemicals from EPA toxicity database by kernel fusion-based support vector machines. Chemom. Intell. Lab. Syst. 2015, 146, 494–502. [Google Scholar] [CrossRef]
- Li, X.; Kong, W.; Shi, W.; Shen, Q. A combination of chemometrics methods and GC–MS for the classification of edible vegetable oils. Chemom. Intell. Lab. Syst. 2016, 155, 145–150. [Google Scholar] [CrossRef]
- García, J.I.; Garcia-Marin, H.; Mayoral, J.A.; Pérez, P. Quantitative structure–property relationships prediction of some physico-chemical properties of glycerol based solvents. Green Chem. 2013, 15, 2283–2293. [Google Scholar] [CrossRef]
- Tobiszewski, M.; Tsakovski, S.; Simeonov, V.; Namieśnik, J.; Pena-Pereira, F. A solvent selection guide based on chemometrics and multicriteria decision analysis. Green Chem. 2015, 17, 4773–4785. [Google Scholar] [CrossRef]
- Alfonsi, K.; Colberg, J.; Dunn, P.J.; Fevig, T.; Jennings, S.; Johnson, T.A.; Kleine, H.P.; Knight, C.; Nagy, M.A.; Perry, D.A.; et al. Green chemistry tools to influence a medicinal chemistry and research chemistry based organisation. Green Chem. 2008, 10, 31–36. [Google Scholar] [CrossRef]
- Henderson, R.K.; Jiménez-González, C.; Constable, D.J.C.; Alston, S.R.; Inglis, G.G.A.; Fisher, G.; Sherwood, J.; Binks, S.P.; Curzons, A.D. Expanding GSK’s solvent selection guide–embedding sustainability into solvent selection starting at medicinal chemistry. Green Chem. 2011, 13, 854–862. [Google Scholar] [CrossRef]
- Hargreaves, C.R.; Manley, J.B. ACS GCI Pharmaceutical Roundtable–Collaboration to Deliver a Solvent Selection Guide for the Pharmaceutical Industry. 2008. Available online: http://www.acs.org/content/dam/acsorg/greenchemistry/industriainnovation/roundtable/solvent-selection-guide.pdf (accessed on 3 August 2020).
- Prat, D.; Pardigon, O.; Flemming, H.-W.; Letestu, S.; Ducandas, V.; Isnard, P.; Guntrum, E.; Senac, T.; Ruisseau, S.; Cruciani, P.; et al. Sanofi’s Solvent Selection Guide: A Step Toward More Sustainable Processes. Org. Process. Res. Dev. 2013, 17, 1517–1525. [Google Scholar] [CrossRef]
- Prat, D.; Hayler, J.; Wells, A. A survey of solvent selection guides. Green Chem. 2014, 16, 4546–4551. [Google Scholar] [CrossRef]
- Sels, H.; De Smet, H.; Geuens, J. SUSSOL—Using Artificial Intelligence for Greener Solvent Selection and Substitution. Molecules 2020, 25, 3037. [Google Scholar] [CrossRef] [PubMed]
- Papa, E.; Gramatica, P. QSPR as a support for the EU REACH regulation and rational design of environmentally safer chemicals: PBT identification from molecular structure. Green Chem. 2010, 12, 836–843. [Google Scholar] [CrossRef]
- Chastrette, M.; Rajzmann, M.; Chanon, M.; Purcell, K.F. Approach to a general classification of solvents using a multivariate statistical treatment of quantitative solvent parameters. J. Am. Chem. Soc. 1985, 107, 1–11. [Google Scholar] [CrossRef]
- Dutkiewicz, M. Classification of organic solvents based on correlation between dielectric β parameter and empirical solvent polarity parameter ENT. J. Chem. Soc. Faraday Trans. 1990, 86, 2237–2241. [Google Scholar] [CrossRef]
- Pytela, O. A new classification of solvents based on chemometric empirical scale of parameters. Collect. Czechoslov. Chem. Commun. 1990, 55, 644–652. [Google Scholar] [CrossRef]
- Gramatica, P.; Navas, N.; Todeschini, R. Classification of organic solvents and modelling of their physico-chemical properties by chemometric methods using different sets of molecular descriptors. TrAC Trends Anal. Chem. 1999, 18, 461–471. [Google Scholar] [CrossRef]
- Pushkarova, Y.; Kholin, Y.V. A procedure for meaningful unsupervised clustering and its application for solvent classification. Cent. Eur. J. Chem. 2014, 12, 594–603. [Google Scholar] [CrossRef]
- Levet, A.; Bordes, C.; Clément, Y.; Mignon, P.; Chermette, H.; Forquet, V.; Morell, C.; Lantéri, P. Solvent database and in silico classification: A new methodology for solvent substitution and its application for microencapsulation process. Int. J. Pharm. 2016, 509, 454–464. [Google Scholar] [CrossRef] [PubMed]
- Guidea, A.; Sârbu, C. Fuzzy characterization and classification of solvents according to their polarity and selectivity. A comparison with the Snyder approach. J. Liq. Chromatogr. Relat. Technol. 2020, 43, 336–343. [Google Scholar] [CrossRef]
- Salahinejad, M. Application of classification models to identify solvents for single-walled carbon nanotubes dispersion. RSC Adv. 2015, 5, 22391–22398. [Google Scholar] [CrossRef]
- Katritzky, A.R.; Fara, D.C.; Kuanar, M.; Hür, E.; Karelson, M. The Classification of Solvents by Combining Classical QSPR Methodology with Principal Component Analysis. J. Phys. Chem. A 2005, 109, 10323–10341. [Google Scholar] [CrossRef]
- Tobiszewski, M.; Nedyalkova, M.; Madurga, S.; Pena-Pereira, F.; Namieśnik, J.; Simeonov, V. Pre-selection and assessment of green organic solvents by clustering chemometric tools. Ecotoxicol. Environ. Saf. 2018, 147, 292–298. [Google Scholar] [CrossRef] [Green Version]
- Nedyalkova, M.; Sârbu, C.; Tobiszewski, M.; Simeonov, V. Fuzzy Divisive Hierarchical Clustering of Solvents According to Their Experimentally and Theoretically Predicted Descriptors. Symmetry 2020, 12, 1763. [Google Scholar] [CrossRef]
- González-Álvarez, J.; Mangas-Alonso, J.J.; Arias-Abrodo, P.; Gutiérrez-Álvarez, M.D. A chemometric approach to characterization of ionic liquids for gas chromatography. Anal. Bioanal. Chem. 2014, 406, 3149–3155. [Google Scholar] [CrossRef]
- Izadiyan, P.; Fatemi, M. Chemometric classification of 227 Ionic Liquids and their related salts according to their toxicities to Rat Cell Lines. In Proceedings of the Iranian Biennial Chemometrics Seminar, Tabriz, Iran, 9–10 November 2011. [Google Scholar]
- Lesellier, E. Σpider diagram: A universal and versatile approach for system comparison and classification: Application to solvent properties. J. Chromatogr. A 2015, 1389, 49–64. [Google Scholar] [CrossRef]
- Adamska, K.; Voelkel, A.; Héberger, K. Selection of solubility parameters for characterization of pharmaceutical excipients. J. Chromatogr. A 2007, 1171, 90–97. [Google Scholar] [CrossRef] [PubMed]
- Sild, S.; Piir, G.; Neagu, D.; Maran, U. Storing and Using Qualitative and Quantitative Structure–Activity Relationships in the Era of Toxicological and Chemical Data Expansion. In Big Data in Predictive Toxicology; Neagu, D., Richarz, A.N., Eds.; Royal Society of Chemistry: London, UK, 2020; pp. 185–213. [Google Scholar] [CrossRef]
- EPA Website. Available online: https://www.epa.gov/tsca-screening-tools/epi-suitetm-estimation-program-interface (accessed on 30 January 2020).
- Gerrity, D.; Stanford, B.D.; Trenholm, R.A.; Snyder, S.A. An evaluation of a pilot-scale nonthermal plasma advanced oxidation process for trace organic compound degradation. Water Res. 2010, 44, 493–504. [Google Scholar] [CrossRef] [PubMed]
- Coleman, D.; Gathergood, N. Biodegradation studies of ionic liquids. Chem. Soc. Rev. 2010, 39, 600–637. [Google Scholar] [CrossRef] [PubMed]
- Siedlecka, E.M.; Czerwicka, M.; Neumann, J.; Stepnowski, P.; Fernández, J.F.; Thöming, J. Ionic Liquids: Methods of Degradation and Recovery. In Ionic Liquids: Theory, Properties, New Approaches; Kokorin, A., Ed.; IntechOpen: Rijeka, Croatia, 2011; pp. 701–722. [Google Scholar] [CrossRef] [Green Version]
- Matzke, M.; Thiele, K.; Müller, A.; Filser, J. Sorption and desorption of imidazolium based ionic liquids in different soil types. Chemosphere 2009, 74, 568–574. [Google Scholar] [CrossRef] [PubMed]
- Stepnowski, P.; Mrozik, W.; Nichthauser, J. Adsorption of Alkylimidazolium and Alkylpyridinium Ionic Liquids onto Natural Soils. Environ. Sci. Technol. 2007, 41, 511–516. [Google Scholar] [CrossRef]
- Stolte, S.; Arning, J.; Bottin-Weber, U.; Müller, A.; Pitner, W.-R.; Welz-Biermann, U.; Jastorff, B.; Ranke, J. Effects of different head groups and functionalised side chains on the cytotoxicity of ionic liquids. Green Chem. 2007, 9, 760–767. [Google Scholar] [CrossRef]
- Bystrzanowska, M.; Pena-Pereira, F.; Marcinkowski, Ł.; Tobiszewski, M. How green are ionic liquids?—A multicriteria decision analysis approach. Ecotoxicol. Environ. Saf. 2019, 174, 455–458. [Google Scholar] [CrossRef]
- Torrecilla, J.S.; Palomar, J.; García, J.; Rojo, E.; Rodríguez, F. Modelling of carbon dioxide solubility in ionic liquids at sub and supercritical conditions by neural networks and mathematical regressions. Chemom. Intell. Lab. Syst. 2008, 93, 149–159. [Google Scholar] [CrossRef]
- Torrecilla, J.S.; Rodríguez, F.; Bravo, J.L.; Rothenberg, G.; Seddon, K.R.; López-Martin, I. Optimising an artificial neural network for predicting the melting point of ionic liquids. Phys. Chem. Chem. Phys. 2008, 10, 5826–5831. [Google Scholar] [CrossRef]
- Valderrama, J.O.; Muñoz, J.M.; Rojas, R.E. Viscosity of ionic liquids using the concept of mass connectivity and artificial neural networks. Korean J. Chem. Eng. 2011, 28, 1451–1457. [Google Scholar] [CrossRef]
- Cao, Y.; Yu, J.; Song, H.; Wang, X.; Yao, S. Prediction of electric conductivity for ionic liquids by two chemometrics methods. J. Serbian Chem. Soc. 2013, 78, 653–667. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, Y.; Zeng, S.; Zhang, S.; Zhang, S. Density Prediction of Mixtures of Ionic Liquids and Molecular Solvents Using Two New Generalized Models. Ind. Eng. Chem. Res. 2014, 53, 15270–15277. [Google Scholar] [CrossRef]
- Barycki, M.; Sosnowska, A.; Piotrowska, M.; Urbaszek, P.; Rybińska, A.; Grzonkowska, M.; Puzyn, T. ILPC: Simple chemometric tool supporting the design of ionic liquids. J. Cheminform. 2016, 8, 40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Studzińska, S.; Stepnowski, P.; Buszewski, B. Application of Chromatography and Chemometrics to Estimate Lipophilicity of Ionic Liquid Cations. QSAR Comb. Sci. 2007, 26, 963–972. [Google Scholar] [CrossRef]
- Kurtanjek, Ž. Chemometric versus Random Forest Predictors of Ionic Liquid Toxicity. Chem. Biochem. Eng. Q. 2014, 28, 459–463. [Google Scholar] [CrossRef]
- Sosnowska, A.; Barycki, M.; Zaborowska, M.; Rybińska-Fryca, A.; Puzyn, T. Towards designing environmentally safe ionic liquids: The influence of the cation structure. Green Chem. 2014, 16, 4749–4757. [Google Scholar] [CrossRef]
- Zhu, P.; Kang, X.; Zhao, Y.; Latif, U.; Zhang, H. Predicting the Toxicity of Ionic Liquids toward Acetylcholinesterase Enzymes Using Novel QSAR Models. Int. J. Mol. Sci. 2019, 20, 2186. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.; Li, W.; Chen, M.; Zhou, Y.; Zhang, Q. Estimation of Ionic Liquids Toxicity against Leukemia Rat Cell Line IPC-81 based on the Empirical-like Models using Intuitive and Explainable Fingerprint Descriptors. Mol. Inform. 2020, 39, 2000102. [Google Scholar] [CrossRef]
- Allus, M.A.; Brereton, R.G.; Nickless, G. Chemometric studies of the effect of toxic metals on plants: The use of response surface methodology to investigate the influence of Tl, Cd and Ag on the growth of cabbage seedlings. Environ. Pollut. 1988, 52, 169–181. [Google Scholar] [CrossRef]
- Dearden, J.C.; Cronin, M.T.D.; Schultz, T.W.; Lin, D.T. QSAR Study of the Toxicity of Nitrobenzenes toTetrahymena pyriformis. Quant. Struct. Relatsh. 1995, 14, 427–432. [Google Scholar] [CrossRef]
- Niazi, A.; Jameh-Bozorghi, S.; Nori-Shargh, D. Prediction of toxicity of nitrobenzenes using ab initio and least squares support vector machines. J. Hazard. Mater. 2008, 151, 603–609. [Google Scholar] [CrossRef] [PubMed]
- Roy, K.; Ghosh, G. QSTR with Extended Topochemical Atom Indices. 10. Modeling of Toxicity of Organic Chemicals to Humans Using Different Chemometric Tools. Chem. Biol. Drug Des. 2008, 72, 383–394. [Google Scholar] [CrossRef] [PubMed]
- Tan, N.X.; Li, P.; Rao, H.B.; Li, Z.-R.; Li, X.-Y. Prediction of the acute toxicity of chemical compounds to the fathead minnow by machine learning approaches. Chemom. Intell. Lab. Syst. 2010, 100, 66–73. [Google Scholar] [CrossRef]
- Kar, S.; Roy, K. QSAR modeling of toxicity of diverse organic chemicals to Daphnia magna using 2D and 3D descriptors. J. Hazard. Mater. 2010, 177, 344–351. [Google Scholar] [CrossRef] [PubMed]
- Bhhatarai, B.; Gramatica, P. Oral LD50 toxicity modeling and prediction of per- and polyfluorinated chemicals on rat and mouse. Mol. Divers. 2011, 15, 467–476. [Google Scholar] [CrossRef]
- Hamadache, M.; Hanini, S.; Benkortbi, O.; Amrane, A.; Khaouane, L.; Moussa, C.S. Artificial neural network-based equation to predict the toxicity of herbicides on rats. Chemom. Intell. Lab. Syst. 2016, 154, 7–15. [Google Scholar] [CrossRef]
- Khan, P.M.; Roy, K.; Benfenati, E. Chemometric modeling of Daphnia magna toxicity of agrochemicals. Chemosphere 2019, 224, 470–479. [Google Scholar] [CrossRef]
- Nedyalkova, M.; Donkova, B.V.; Simeonov, V. Chemometrics Expertise in the Links Between Ecotoxicity and Physicochemical Features of Silver Nanoparticles: Environmental Aspects. J. AOAC Int. 2017, 100, 359–364. [Google Scholar] [CrossRef]
- Nedyalkova, M.; Dimitrov, D.; Donkova, B.; Simeonov, V. Chemometric Evaluation of the Link between Acute Toxicity, Health Issues and Physicochemical Properties of Silver Nanoparticles. Symmetry 2019, 11, 1159. [Google Scholar] [CrossRef] [Green Version]
- Waring, M.J. Lipophilicity in drug discovery. Expert Opin. Drug Discov. 2010, 5, 235–248. [Google Scholar] [CrossRef]
- Chen, M.; Borlak, J.; Tong, W. High lipophilicity and high daily dose of oral medications are associated with significant risk for drug-induced liver injury. Hepatology 2013, 58, 388–396. [Google Scholar] [CrossRef] [PubMed]
- Puzyn, T.; Falandysz, J. Computational estimation of logarithm of n-octanol/air partition coefficient and subcooled vapor pressures of 75 chloronaphthalene congeners. Atmos. Environ. 2005, 39, 1439–1446. [Google Scholar] [CrossRef]
- Golmohammadi, H.; Dashtbozorgi, Z. Prediction of water-to-polydimethylsiloxane partition coefficient for some organic compounds using QSPR approaches. J. Struct. Chem. 2010, 51, 833–846. [Google Scholar] [CrossRef]
- Yang, S.-S.; Lu, W.C.; Gu, T.-H.; Yan, L.-M.; Li, G.-Z. QSPR Study of n -Octanol/Water Partition Coefficient of Some Aromatic Compounds Using Support Vector Regression. QSAR Comb. Sci. 2008, 28, 175–182. [Google Scholar] [CrossRef]
- Goudarzi, N.; Goodarzi, M. QSPR study of partition coefficient (Ko/w) of some organic compounds using radial basic function-partial least square (RBF-PLS). J. Braz. Chem. Soc. 2010, 21, 1776–1783. [Google Scholar] [CrossRef]
- Gu, W.; Chen, Y.; Zhang, L.; Li, Y. Prediction of octanol-water partition coefficient for polychlorinated naphthalenes through three-dimensional QSAR models. Hum. Ecol. Risk Assess. Int. J. 2017, 23, 40–55. [Google Scholar] [CrossRef]
- Zhu, T.; Gu, L.; Chen, M.; Sun, F. Exploring QSPR models for predicting PUF-air partition coefficients of organic compounds with linear and nonlinear approaches. Chemosphere 2020, 128962. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Object | Chemometric Tool | Evaluated Parameters | Results—Groups of Solvents | Ref. |
|---|---|---|---|---|
| 83 organic solvents | PCA |
| 9 groups of solvents:
| Chastrette et al. (1985) [43] |
| 101 organic solvents | Parker–Reichardt classification | correlation between dielectric β parameter and empirical solvent polarity parameter | 4 groups (and 2 subgroups) of solvents:
| Dutkiewicz (1990) [44] |
| 51 solvents | KNN | Empirical scale parameters:
| 8 groups of solvents:
| Pytela (1989) [45] |
| 152 organic solvents | KNN, CP-ANN, QSPR | 4 molecular descriptors (theoretical descriptions of the molecular structure) | 5 groups of solvents:
| Gramatica et al. (1999) [46] |
| 76 solvents | ANN | 9 characteristics (application in a field of C60 fullerene solubility) | 9 groups of solvents:
| Pushkarova and Kholin (2014) [47] |
| 236 industrial solvents | PCA, CA | quantum and experimental parameters | 10 groups of solvents:
| Levet et al. (2016) [48] |
| 72 solvents | FCM, FLDA | Chemical parameters connected with polarity and selectivity developed by Snyder (related to different polar interactions):
| FCM—8 groups (selected examples):
| Guidea and Sârbu(2020) [49] |
| Predicted Property | Chemometric Tools | Evaluated Objects | Way of Estimation | Ref. |
|---|---|---|---|---|
| Carbon dioxide solubility | RB, MLP, MQR, MPE |
| experimental thermodynamic data and molecular structure information | Torrecilla et al. (2008) [67] |
| Melting point | ANN | 97 imidazolium salts with varied anions | 14 molecular descriptors | Torrecilla et al. (2008) [68] |
| Viscosity | ANN | 58 ionic liquids at several temperatures | molecular mass of the anion and cation, the mass connectivity index, and the density at 298 K | Valderrama et al. (2011) [69] |
| Electric conductivity | MLR, BP-ANN | 35 ILs at different temperatures | structural descriptors | Cao et al. (2013) [70] |
| Density | ER, ANN | mixtures of ionic liquids and molecular solvents (water, alcohols, ketones, ethers, hydrocarbons, esters, and acetonitrile) | molar mass, critical volume, temperature, acentric factor of each component of the IL mixtures | Huang et al. (2014) [71] |
| Design of ionic liquids | PCA, CA | 172 ILs | structural similarity and identification of structure aspects responsible for a given IL physicochemical properties (viscosity, n-octanol–water partition coefficient, solubility and enthalpy of fusion via ILPC predictor) | Barycki et al. (2016) [72] |
| Lipophilicity | QSPR, PCA | selected ionic liquid (only imidazolium-based cations) | comparison of hydrophobic or hydrophilic character according to some methods: chromatographic analysis, statistical, and chemometric approach | Studzińska et al. (2007) [73] |
| Toxicity | PCR, PLS, decision tree(s) model | various combinations of cations (imidazole, pyridinium, quinolinium, ammonium, phosphonium) and anions (BF4, Cl, PF6, Br, CFNOS, NCN2, C6F18PBF4, C6F18P) | molecular descriptors and EC50 concentrations for inhibition of acetylcholinesterase | Ž. Kurtanjek (2014) [74] |
| Toxicity | PCA | 375 ILs with six different types of cations namely, imidazolium, ammonium, phosphinium, pyridinium, pyrolidinium, and sulfonium | multiple endpoints for various organisms based on WHIM descriptors | Sosnowska et al. (2014) [75] |
| Toxicity | QSAR, MLR, ELM | 160 ILs with 57 cations and 21 anions | toxicity towards AChE based on theSEP area and the screening charge density distribution area (S ) descriptors | Zhu et al. (2019) [76] |
| Toxicity | QSPR, MLR | 304 ILs of different combinations of 8 cations (ammonium, imidazolium, morpholinium, phosphonium, piperidinium, pyridinium, pyrrolidinium, quinolinium) and 12 anions (chloride, bis(trifluoromethylsulfonyl) amide, bromide, iodide ion, sulfonate, borate, phosphate, fatty acid, dicyanamide, formate, thiocyanate, acetate, etc.) | toxicity against leukaemia rat cell line IPC-81 (logEC50) based on 33 descriptors describing the structural features of ionic liquids related to toxicity (i.e., chain length of the cationic head group) | Wu et al. (2020) [77] |
| Abbreviations: AChE—Acetylcholinesterase; BP-ANN—Back Propagation Artificial Neural Network; ELM—Extreme Learning Machine; ILPC—Ionic Liquid PhysicoChemical; MPE—Mean Prediction Error; SEP—Surface Electrostatic Potential; WHIM descriptors—Weighted Holistic Invariant Molecular descriptors | ||||
| Chemical Compound | Chemometric Tool | Organism | Toxicity Results | Ref. |
|---|---|---|---|---|
| Metals as: TI, Cd, and Ag | RSM | growth of cabbage seedlings | Ag is observed to be the most toxic, while Tl and Cd, although toxic, exhibited fairly similar effects. | Allus et al. (1988) [78] |
| Nitrobenzenes | LS-SVM, QSPR, PLS, PCA, GA-PLS, MLR | Tetrahymena pyriformis [79] | n/a | Niazi et al. (2007) [80] |
| Organic compounds (including some pharmaceuticals) | QSTR, PLS | human (human lethal concentration) | The ETA models suggest that the toxicity increases with bulk, chloro (hydrophobic) functionality, presence of heteroatoms within a chain or a ring and unsaturation, and decreases with hydroxyl (polar) functionality and branching. | Roy and Ghosh (2008) [81] |
| Chemical compounds | SVM, ANN | Pimephales promelas | n/a | Tan et al. (2010) [82] |
| Organic chemicals | QSAR, MLR, PLS, GFA, G/PLS | Daphnia magna | Higher lipophilicity and electrophilicity, less negative charge surface area and presence of ether linkage, hydrogen bond donor groups and acetylenic carbons are responsible for greater toxicity of chemicals. Diversity in chemically different compounds in mechanisms of toxic actions is observed. | Kar and Roy (2010) [83] |
| Per- and polyfluorinated (PFCs) chemicals | PCA, QSAR, MLR, GA, | rodents (oral) | The importance of negative hydrophobicity and positive electronegativity for the overall toxicity of PFCs for rodents. | Bhhatarai and Gramatica (2011) [84] |
| Herbicides | ANN, QSAR | rat (oral) | n/a | Hamadache et al. (2016) [85] |
| Agrochemicals (fungicides, herbicides, insecticides, and microbiocides) | QSAR | Daphnia magna | The toxicity increases with lipophilicity and decreases with polarity. | Khan et al. (2019) [86] |
| Silver nanoparticles | CA, PCA | links between ecotoxicity and physicochemical features (Daphnia magna, Thamnocephalus platyurus, and Daphnia galeata) | n/a | Nedyalkova et al. (2017) [87] |
| Silver nanoparticles | PCA, CA, k-means clustering, MLR | Daphnia magna, Thamnocephalus platyurus, Escherichia coli, Pseudomonas fluorescens, Pseudokirchneriella subcapitata, Pseudomonas putida, Pseudomonas aeruginosa, Staphylococcus aureus, mammalian cells, algae, yeast, and fungi | The relation AT/ZP (acute toxicity measure, EC50/LC50/zeta potential of nanomaterial in the test) is not very indicative for the toxic impact of the AgNPs studied. | Nedyalkova et al. (2019) [88] |
| Abbreviations: ETA—Extended Topochemical Atom; GA-PLS—Genetic Algorithm-Partial Least Square; GFA—Genetic Function Approximation; G/PLS—Genetic Partial Least Squares; QSTR—Quantitative Structure Toxicity Relationship; RSM—Response Surface Methodology | ||||
| Partition Coefficient | Chemometrics Tool | Evaluated Objects | Way of Estimation | Ref. |
|---|---|---|---|---|
| n-octanol-ir partition coefficient | QSAR/QSPR, PCA, PCR | chloronaphthalene congeners | 190 different quantum-chemical, thermodynamical, and topological characteristics of chloronaphthalenes as descriptors | Puzyn and Falandysz (2005) [91] |
| Water-polydimethylsiloxane partition coefficient | QSPR, GA, MLR, ANN | organic compounds | molecular descriptors: minimum atomic orbital electronic population, Kier shape index, polarity parameter/square distance, and complementary information content | Golmohammadi and Dashtbozorgi (2010) [92] |
| n-octanol-water partition coefficient | LS-SVM, QSPR, MLR, SVR, ANN | organic compounds (derivative phenolic compounds) | n/a | Goudarzi and Goodarzi (2008) [21] |
| n-octanol-water partition coefficient | QSPR, mRMR-GA-SVR | aromatic compounds | 68 molecular descriptors derived solely from the structures of the aromatic compounds | Yang et al. (2008) [93] |
| n-octanol-water partition coefficient | QSPR, MLR/PLS/RBF-PLS | organic compounds | Goudarzi and Goodarzi (2010) [94] | |
| n-octanol-water partition coefficient | QSAR, CoMFA, CoMSIA | 21 polychlorinated naphthalenes (PCNs) congener | 3D descriptors according to the experimental values of logKOW for 21 PCNs | Gu et al. (2017) [95] |
| polyurethane foam-air partition coefficients | QSPR, MLR, ANN, SVM | 170 organic compounds comprising 9 distinct classes (PAHs, benzenes, esters, aliphatic and cyclic hydrocarbons, polychlorinated biphenyls, musk, nitrogen and sulphur compounds, pesticides, other compounds) | 368 molecular descriptors | Zhu et al. (2020) [96] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bystrzanowska, M.; Tobiszewski, M. Chemometrics for Selection, Prediction, and Classification of Sustainable Solutions for Green Chemistry—A Review. Symmetry 2020, 12, 2055. https://doi.org/10.3390/sym12122055
Bystrzanowska M, Tobiszewski M. Chemometrics for Selection, Prediction, and Classification of Sustainable Solutions for Green Chemistry—A Review. Symmetry. 2020; 12(12):2055. https://doi.org/10.3390/sym12122055
Chicago/Turabian StyleBystrzanowska, Marta, and Marek Tobiszewski. 2020. "Chemometrics for Selection, Prediction, and Classification of Sustainable Solutions for Green Chemistry—A Review" Symmetry 12, no. 12: 2055. https://doi.org/10.3390/sym12122055
APA StyleBystrzanowska, M., & Tobiszewski, M. (2020). Chemometrics for Selection, Prediction, and Classification of Sustainable Solutions for Green Chemistry—A Review. Symmetry, 12(12), 2055. https://doi.org/10.3390/sym12122055