2. MTD Model and Its Optimization
Let
be a categorical random variable that takes values in the finite set
. In an
f-order MTD model, each lag of the random variable (
) influences
independently as
where
represents a transition matrix, and where
,
, are the weights associated to each lag. The transition probabilities in the matrix
Q and the weights associated with each lag are estimated by optimization of the log-likelihood of the model [
13]. The MTDg model is a generalization of the MTD model wherein a different transition matrix,
,
, etc., is used to represent the link between each lag of the model and
. Moreover, covariates can be added to the model [
14]. For more details about the concept of the MTD model and its usefulness, readers can refer to the review article by Berchtold and Raftery [
15].
Mixture models are notoriously difficult to optimize [
16], and the MTD model is not an exception, especially when a different transition matrix is used for each lag and/or when covariates are added to the model. The problem arises from the fact that as the complexity of the model increases, the solution space can become very irregular, with many different local optima. Standard estimation algorithms such as the EM algorithm are very efficient in finding a solution; however, they are trapped inside the basin of attraction of one specific optimum. An ad hoc estimation algorithm belonging to the hill-climbing family was proposed for the MTD model [
13]; however, even if this algorithm is efficient in most scenarios—similarly to the EM algorithm—it sometimes fails to identify the global optimum of the solution space because (1) the re-estimation of each parameter is considered separately, and (2) some parts of the solution space are not explored at all. These issues indicate that finding the global optimum is related to the set of initial conditions: If the starting point of the optimization process lies inside the basin of attraction of the global optimum, it will be found. Otherwise, the algorithm will converge to another (local) optimum.
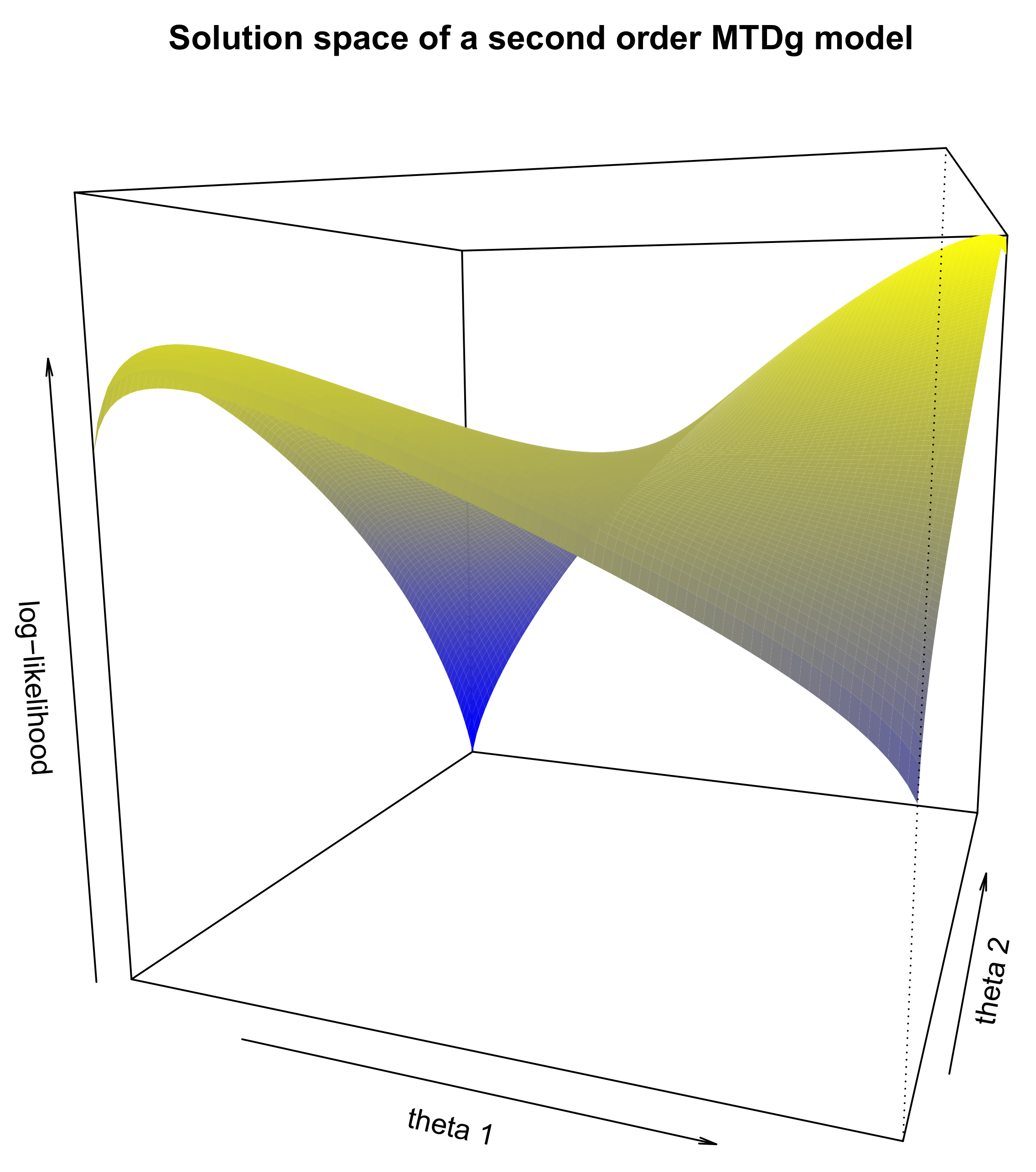
To illustrate this point, we defined the following second-order MTDg model: The vector of the lag weights is
and the transition matrices corresponding to the first and second lags are
The model was applied to a dataset of
n = 845 sequences of length 13 of a dichotomous variable using the hill-climbing optimization algorithm. Refer to
Section 5 for a description of the dataset.
Figure 1 shows the solution space of this model for all combinations of
and
. We can see that there are two optima, a local one on the left and the global one on the right. If we optimize the MTDg model starting from each point on the figure and by applying the HC algorithm [
13], the model will then converge to two different values of the log-likelihood, −3348.3 corresponding to the local optimum and −2057.9 corresponding to the global one. Therefore, converging to the global optimum rather than to the local optimum depends on the starting point of the optimization algorithm.
The above example is not fully realistic because it involves a model with many constraints on its parameters; however, these constraints were necessary to visualize the solution space. Despite this limitation, this example correctly illustrates the types of issues that occur with mixture models. It is absolutely necessary to explore the entire solution space to identify the basin of attraction of the global maximum, and thereby, the global maximum itself.
Different solutions to the exploration of the solution space problem were proposed in the literature, either based on a modification of the standard EM algorithm to allow it to escape from a specific basin of attraction (e.g., SEM, CEM [
17]), or based on a better exploration of the entire solution space. In the second category, we find that different nature-inspired optimization algorithms, i.e., algorithms that attempt to mimic life or genetic behaviors, for instance, by recombining different potential solutions, allow the emergence of even better solutions [
18]. These evolutionary algorithms have the theoretical capacity to explore the solution space of a problem fully to identify its global optimum. However, the drawback is that they can be extremely slow to converge. Therefore, a good solution is to perform two-step optimization. In the first step, an evolutionary algorithm is used to identify the region of the solution space that contains the optimum, and in the second step, a faster algorithm is used to converge to this optimum. Such an approach is feasible in the case of the MTD model by combining the different algorithms implemented in the
march package.
3. Main Features of the march Package
As noted before, there remains a lack of available software for the computation of Markovian models adapted to categorical variables. The
march package for R was developed to fill this gap. It was developed around the double chain Markov model (DCMM) [
19,
20], a general framework that includes many different Markovian models. This framework is characterized by a two-level approach similar to a standard hidden Markov model, but with a direct link between successive observations of the visible variable
Y, which is similar to standard homogeneous Markov chains (
Figure 2). The DCMM model is a method of modeling heterogeneous observed behaviors; however, this framework is sufficiently flexible to include many other specific models as subcases. For instance, by removing the direct link between successive values of the observed variable, the DCMM becomes a standard HMM. By allowing only one state for the hidden variable
X, we suppress the influence of this latent process upon the visible level, transforming the DCMM into a homogeneous Markov chain. By constraining the hidden transition matrix with the identity matrix, the DCMM becomes a clustering tool. If we consider dependence orders larger than one for either the hidden process or the visible one, then we can also replace these processes with MTD modelings. Finally, covariates can also be included at both levels.
Three different optimization algorithms are implemented in the
march package, and they can be combined to improve the speed of convergence and the quality of the solution. First, the DCMM is traditionally optimized using the Baum–Welch algorithm, a customized version of the EM algorithm [
19]. In particular, to fulfill all constraints inherent to the model, we implemented a general EM (GEM) algorithm, which is an EM algorithm in which the M-step ensures a monotonous increase in the log-likelihood but not necessarily the best possible improvement of the log-likelihood [
21].
The second optimization algorithm is an evolutionary algorithm (EA) that can be used to better explore the solution space of complex models [
18]. Starting from an initial randomly generated population of possible solutions, new generations of the population are built by applying three different operators: simulated binary crossover [
22], Gaussian mutation, and fitness proportional selection [
23]. Each possible solution is evaluated using a measure of its fitness, defined as
−1/log-likelihood. The algorithm itself is a Lamarckian EA, where a new generation is potentially composed of children and parents. In particular, if
denotes the size of the population, the following operations are performed to build the next generation:
Two members of the current population are randomly selected, and their probabilities of selection are proportional to their fitness values.
A random crossover occurs between the two selected members of the population with a probability that can be selected by the user (default: 50%). This operation leads to two children solutions.
A mutation is applied to the two children by adding a Gaussian distributed noise to each parameter with a probability that can be chosen by the user (default: 5%).
The two children are improved using the GEM algorithm, with a number of iterations that can be chosen by the user (default: 2).
The fitness of each children is computed.
The five steps above are repeated until the size of the children’s population equals that of the parent population. Then, the populations of parents and children are aggregated, and a reduction operation is applied to return to the original population size. solutions are selected randomly to constitute the new generation, with probabilities of selection proportional to their fitness values. The algorithm then iterates to build the next generation until the planned number of iterations is reached.
By using fitness proportional selection, we allow that in some cases none of the best current members of the population are selected. This provides the algorithm a better capability to explore the full solution space. Simulated binary crossover and Gaussian mutation are also helpful in dealing with the real-valued genome representation, which is used to encode the different parameters of the DCMM. Indeed, using bit-flip operations would induce problems in bit-encoded real values; for instance, mutating the sign bit of a number creates a very different individual. The user can choose to suppress some parts of the above algorithm by setting the crossover probability, mutation probability, or number of GEM iterations to zero.
Combining the two previous optimization algorithms, a typical estimation procedure for the DCMM consists of the following two steps:
The EA algorithm is used to identify a candidate solution in the attraction basin of the global optimum.
Starting from this candidate solution, the GEM algorithm is used to optimize the model until reaching the global optimum.
The third estimation algorithm included in
march specifically concerns the MTD model and comprises an implementation of the ad hoc hill-climbing (HC) algorithm proposed by Berchtold [
13]. This HC algorithm is used in two different manners within
march: On the one hand, when the MTD model is viewed as a special case of the DCMM, it is estimated with the EA + GEM algorithm, and in this case, the HC algorithm is part of the GEM algorithm. On the other hand, when a MTD model is defined directly, without reference to the DCMM framework, the HC algorithm is used directly to compute the model. The main difference between the two cases is that in the first case, the HC algorithm is reinitialized at the beginning of each iteration of the GEM algorithm to account for the possible other changes performed by the algorithm. In contrast, when used independently of the DCMM framework, the HC algorithm is initialized only once, and then it runs until reaching an optimum. Therefore, depending on the context of use, the HC algorithm can possibly lead to different (local) optima of the solution space.
In addition to being able to optimize many models within the DCMM framework, and to have a dedicated function for the MTD model, the march package includes optimized functions for the computation of the independence model, of homogeneous Markov chains of any order, of confidence intervals, and of the Akaike and Bayesian information criteria. Moreover, covariates can be added to most models, even if the resulting models are no longer Markovian.
5. Example
We used the
Employment.2 dataset, which has been included in the
march package since version 3.2.5. This dataset contains
n = 845 sequences of the 13 successive observations of a categorical variable representing the professional activity categorized into two categories: 1 = “Full time employee”; 2 = “Other situation”. The first observation of each sequence corresponds to the status of the respondent at age 20, and then the following data were observed every two years, the last observation corresponding to the status at age 44. In addition, two covariates were also provided in the dataset. The first one is a fixed covariate representing gender (1 = “Female”; 2 = “Male”), and the second one is a time-varying covariate representing health status (1 = “Good”; 2 = “Bad”). The example discussed in
Section 2 was based on the same dataset.
We considered a second-order MTDg model, which is a model whose current observation is explained by the last two observations, and in which two different transition matrices are used to represent the relationship between each of the two lags and the present. Further, we included the gender and health covariates in the model. This model was chosen for the convenience of the presentation, and it is not necessarily the best model to explain the dataset. This question is beyond the scope of the present article.
To find the best solution of the model in terms of statistical criteria, the first possibility is to rely on the sole HC algorithm by using the syntax:
set.seed(1234)
Model.1 <- march.mtd.construct(Employment.2,order=2, MCovar=c(1,1), init="best",
mtdg=T, llStop=0.0001, maxIter = 1000, maxOrder=2)
print(Model.1)
march.BIC(Model.1)
In the above code, the set.seed(1234) command is used to allow reproducible results by setting the R random generator to a specific point (here: 1234). Using another seed is likely to produce slightly different results. The march.mtd.construct() function is used to define the model and then optimize it using the pure HC algorithm. The march.BIC() command computes the Bayesian information criterion of the solution. We obtained a log-likelihood of −1813.737 for 10 independent parameters and a BIC value of 3718.846.
In the above syntax, the init= "best" option means that the initial transition matrix between each lag of the MTDg model and the present is the corresponding empirical transition matrix computed from the entire dataset. The use of another seed would not change that, but another possibility is to use the init="random" option that replace the empirical transition matrices by randomly created transition matrices as the starting points of the optimization procedure. In practice, using the init="random" option with seed 1234 did not change the results, and the same was observed with other seeds such as 233 and 984. Other options used in the march.mtd.construct function indicate that the model is an MTDg rather than an MTD model (mtdg = T); the algorithm will stop when the difference in the log-likelihood between two successive iterations is below 0.0001 (llStop = 0.0001); the maximal number of iterations of the algorithm is fixed to 1000 (maxIter = 1000); and the model is computed considering a maximal possible order of two for comparison with other model specifications (maxOrder = 2).
A second possibility is to estimate the model using the GEM algorithm. Using the following syntax,
set.seed(1234)
Model.2 <- march.dcmm.construct(Employment.2, orderHC=1, orderVC=2, M=1,
gen=1, popSize=1, iterBw=100, stopBw = 0.01,
CMCovar=c(1,1), Cmodel="mtdg", maxOrder=2)
print(Model.2)
march.BIC(Model.2)
we obtained a log-likelihood of −1813.782 for 10 independent parameters and a BIC value of 3718.935. Here, we allowed for a maximum of 100 iterations of the algorithm (iterBw = 100), and the algorithm had to stop whenever the difference in log-likelihood between two successive iterations became lower than 0.01 (stopBw = 0.01). Moreover, the options gen = 1 and popSize = 1 ensured that only the GEM part of the function was used, completely bypassing the evolutionary algorithm.
A third option is to first explore the solution space using an evolutionary algorithm before optimizing the best candidate using either the GEM or HC algorithm. The following syntax starts a search in the entire solution space with a population of 20 candidate solutions and 20 iterations of the EA algorithm:
set.seed(1234)
Model.3 <- march.dcmm.construct(Employment.2, orderHC=1, orderVC=2, M=1,
gen=20, popSize=20, pMut=0.05, pCross=0.5, iterBw=0,
CMCovar=c(1,1), Cmodel="mtdg", maxOrder=2)
print(Model.3)
march.BIC(Model.3)
In the above syntax, the crossover and mutation operators were allowed with respective probabilities 0.5 and 0.05; however, no improvement of children solutions with the GEM algorithm did occur (option iterBw = 0). As expected, the solution reached after this pure EA with a very limited number of generations (20) was far from optimal with a log-likelihood of −1895.900 for six independent parameters and a BIC value of 3846.624. However, it was possible to improve it, by using either the HC algorithm
set.seed(1234)
Model.3a <- march.mtd.construct(Employment.2, order=2, MCovar=c(1,1),
mtdg=T, llStop=0.0001, maxIter = 1000, maxOrder=2,
seedModel=Model.3)
print(Model.3a)
march.BIC(Model.3a)
or the GEM algorithm
set.seed(1234)
Model.3b <- march.dcmm.construct(Employment.2, orderHC=1, orderVC=2, M=1,
gen=1, popSize=1, iterBw=100, stopBw = 0.01,
CMCovar=c(1,1), Cmodel="mtdg", maxOrder=2,
seedModel = Model.3)
print(Model.3b)
march.BIC(Model.3b)
In both of the above codes, the seedModel option indicates that the optimization must start from the model stored in the Model.3 object containing the best solution at the end of the EA algorithm. The HC algorithm then leads to a log-likelihood of −1818.598 for six independent parameters and a BIC value of 3692.019, when the GEM algorithm leads to a solution with a log-likelihood of −1813.955 for eight independent parameters and a BIC value of 3701.008.
As explained in
Section 3, the exploration of the solution space by the EA algorithm can be improved when a few number of GEM iterations are applied to each child solution. This is performed by the following syntax. Compared to the syntax used for the
Model.3, the
iterBw option is now set to two iterations:
set.seed(1234)
Model.4 <- march.dcmm.construct(Employment.2, orderHC=1, orderVC=2, M=1,
gen=20, popSize=20, pMut=0.05, pCross=0.5, iterBw=2,
CMCovar=c(1,1), Cmodel="mtdg", maxOrder=2)
print(Model.4)
march.BIC(Model.4)
With this optimization procedure, we obtained a log-likelihood of −1813.735 for 11 independent parameters and a BIC value of 3727.979. Similarly to what was done for
Model.3, we attempted to improve this solution by using either the HC algorithm or the GEM algorithm, but none of these algorithms could find a better solution. The results from the different optimization procedures are summarized in
Table 1.
To summarize, depending on the optimization procedure, we obtained different solutions with close log-likelihoods, but with different numbers of parameters and hence BIC values. The solution achieved by the pure HC algorithm reads
where the four weights correspond to the first and second lags, respectively, and to the
Gender and
Health covariates. The transition matrices corresponding to the first and second lags are
and the transition matrices corresponding to the two covariates are
At the sample level, the four explanatory elements are all useful because their weights are all larger than zero; however, the first lag is clearly the most important explanatory element, followed by the Gender covariate.
The solution provided by the combination EA + HC reads
Contrarily to the solution given by parameters (1a)–(1c), the second lag is inactive (its weight is zero), and therefore, the corresponding transition matrix is not used, which explains in part the reduced number of parameters. Further, it can be noticed that the weight associated with the Health covariate is very small, and that it could be interesting to recompute the model without it. Moreover, the transition matrix associated with each covariate has a transition that is certain (with a probability of 1), what implies one less independent parameter for each matrix.
Finally, the solution given by the combination EA + GEM reads
Here, the second lag of the dependent variable is active, on the contrary of the Health covariate.
The computation using only the HC algorithm did not reach the best solution, at least when evaluated by the BIC. We attempted different alternatives to this algorithm by choosing other initial values through the init option of the march.mtd.construct function; however, the algorithm converged each time to the same suboptimal solution. Indeed, multiplying the number of trials with each time a different seed value for the random generator of R could possibly lead to a better solution, but such an approach is certainly not the most efficient way of exploring the entire solution space.
A second important point is that the two final models obtained with the two-step procedures (EA + HC, parameters (2a)–(2c), and EA + GEM, parameters (3a)–(3c)) are considerably different. From a strict statistical perspective, the EA + HC solution seems very interesting with the lowest BIC of all models (3692.019), owing to its parsimony. However, the best fit to the data, as measured by the log-likelihood, is provided by the solution from the EA + GEM procedure with a log-likelihood of −1813.955. In terms of interpretation, the two models also differ because the first one places more importance on the first lag (2a), but with more chances to switch from the first state to the second one, and conversely (2b), when the second model also uses the second lag (3a), thereby indicating a more persistent influence of the past on the present. The role of the two covariates is similar in both models, and only the Gender has an influence on the dependent variable.
In both models obtained with a combination of algorithms, the transition matrix associated with the Health covariate is similar (parameters (2c) and (3c)). Since both models were obtained starting from the same seed model, this transition matrix was not reestimated during the second part of the estimation procedure, which is not surprising given the very low weight attributed to this covariate.
Even if this article is directed toward the estimation of the MTD model, the
march package can optimize a larger set of models from the Markovian family. The second part of
Table 1 summarizes the main characteristics of some of these models, and
Appendix A provides the corresponding syntaxes. First,
Table 1 shows that models without direct dependence between successive observations of the dependent variable (independence, HMM2, HMM3) fitted the dataset very poorly, with their log-likelihood being the lowest. The second-order MTD model without covariates obtained a log-likelihood between the ones of the first- and second-order homogeneous Markov chains, which was expected; however, it is preferred to the second-order Markov chain on the basis of BIC because of its parsimony.
Interestingly, the second-order MTD and MTDg models without covariates reached exactly the same log-likelihood, even if their parameters were different; however, this is only a coincidence. Finally, none of the models in the second part of
Table 1 came close to the second-order MTDg model with covariates, which indicates that the use of covariates really improved the overall quality of the modeling.




{kind=link}
{kind=link}