Optimal Transport with Dimensionality Reduction for Domain Adaptation

Abstract
:1. Introduction
- (1)
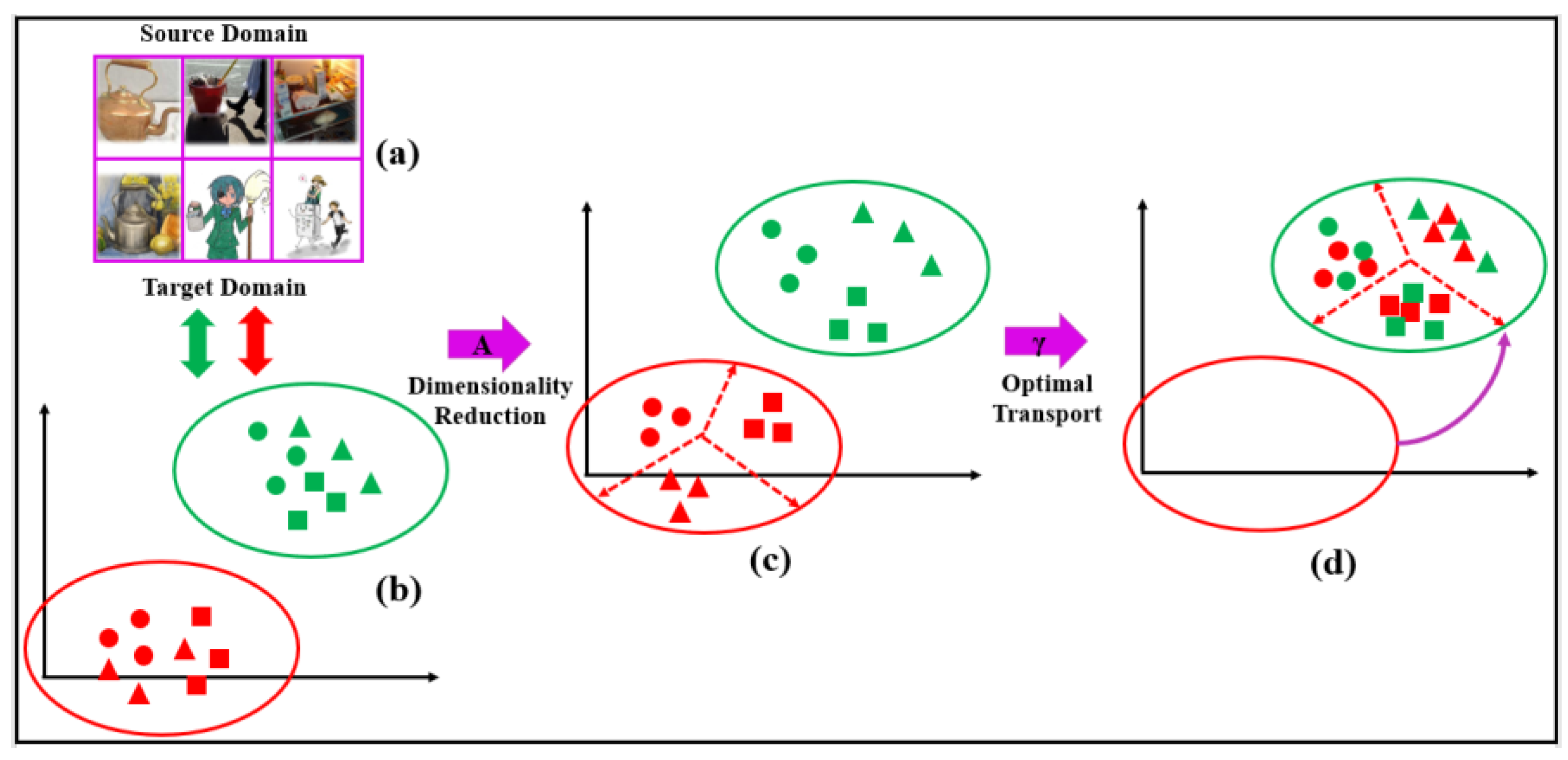
- In combination with optimal transport and dimensionality reduction, a two-stage feature-based adaptation is proposed for domain adaptation. Compared with global feature alignment methods, our approach can preserve local information of the domains and has a relatively simple structure, which does not need continuous iteration to learn pseudo tags of the target domain;
- (2)
- To address the source sample crowding problem generated by previous regularized optimal transport methods which transform the source data in the original space, we solve OT problem in a low-dimensional space where the intradomain instances are dispersed as much as possible. In this way, the solution OTP will have larger variance, and the separability of the source samples will be enhanced with the new representation generated by the OTP;
- (3)
- To enhance the discriminability of source data, we consider the source label information and add the source intraclass compactness regularization to the dimensionality reduction frame in the first stage. Besides, we add a class-based regularization to the OT problem in the second stage. By solving the OT problem, we obtain the OTP, which makes a target instance more likely to be associated with all source domain instances from only one of the classes. Therefore, the OTP can generate a more discriminative representation of the source domain;
- (4)
- Comprehensive experiments on several image datasets with shallow or deep features demonstrate that the proposed approach is competitive compared to several traditional and deep DA methods.
2. Related Works
2.1. Dimensionality Reduction for Domain Adaptation
2.1.1. Subspace Alignment
2.1.2. Distribution Alignment
2.1.3. Joint Subspaces Alignment and Distribution Alignment
2.2. Optimal Transport for Domain Adaptation
3. Theoretical Background
4. Proposed Approach
4.1. Motivation and Main Idea
4.2. A Dimensionality Reduction Framework
4.3. OT Based on Low-Dimensional Representation
| Algorithm 1: OTDR |
| Input: Data set parameters |
| 1: Construct a symmetric matrix using Equation (7). |
| 2: Obtain the transformation matrix by calculating the –smallest eigenvectors of Equation (9). |
| 3: Let , and compute the cost matrix by Equation (10). |
| 4: Adopt the GCG algorithm, and obtain the optimal transport plan by solving Equation (11). |
| 5: Generate by Equation (12), and train an adaptive classifier on |
| Output: transformation matrix , optimal transport plan , and adaptive classifier . |
5. Experiments
5.1. Data Descriptions
5.2. Experimental Setting
5.3. Experimental Results
6. Discussion
6.1. Distribution of the OPT Matrix
6.2. Statistics of Feature Discriminability
6.3. Feature Visualization of Source Domain
6.4. Ablation Study
6.5. Parameter Sensitivity
7. Conclusions
8. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Paszkiel, S. Using Neural Networks for Classification of the Changes in the EEG Signal Based on Facial Expressions. In Analysis and Classification of EEG Signals for Brain—Computer Interfaces; Kacprzyk, J., Ed.; Springer: Cham, Switzerland, 2020; Volume 852, pp. 41–69. [Google Scholar]
- Paszkiel, S. The use of facial expressions identified from the level of the EEG signal for controlling a mobile vehicle based on a state machine. In Proceedings of the Conference on Automation, Warsaw, Poland, 18–20 March 2020; pp. 227–238. [Google Scholar]
- Paszkiel, S.; Dobrakowski, P.; Łysiak, A. The impact of different sounds on stress level in the context of EEG, Cardiac Measures and Subjective Stress Level: A Pilot Study. Brain Sci. 2020, 10, 728. [Google Scholar] [CrossRef] [PubMed]
- Paszkiel, S.; Sikora, M. The use of brain-computer interface to control unmanned aerial vehicle. In Proceedings of the Conference on Automation, Warsaw, Poland, 27–29 March 2019; pp. 583–598. [Google Scholar]
- Gopalan, A.B.; Li, R.; Chellappa, R. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 999–1006. [Google Scholar]
- Zhang, L.; Yang, J.; Zhang, D. Domain class consistency based transfer learning for image classification across domains. Inf. Sci. 2017, 418, 242–257. [Google Scholar] [CrossRef]
- Griffin, G.; Holub, A.; Perona, P. Caltech-256 Object Category Dataset, Technical Report 7694 Caltech. 2007. Available online: http://www.vision.caltech.edu/archive.html (accessed on 15 November 2006).
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Dai, Y.; Zhang, J.; Yuan, S.; Xu, Z. A two-stage multi-task learning-based method for selective unsupervised domain adaptation. In Proceedings of the International Conference on Data Mining Workshops, Beijing, China, 8–11 November 2019; pp. 863–868. [Google Scholar]
- Dai, W.; Yang, Q.; Xue, G.R.; Yu, Y. Boosting for transfer learning. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 193–200. [Google Scholar]
- Huang, J.; Gretton, A.; Borgwardt, K.; Schölkopf, B.; Smola, A.J. Correcting sample selection bias by unlabeled data. In Advances in Neural Information Processing Systems, Proceedings of the Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; MIT Press: Cambridge, MA, USA, 2007; pp. 601–608. [Google Scholar]
- Tao, J.; Chung, F.L.; Wang, S. On minimum distribution discrepancy support vector machine for domain adaptation. Pattern Recognit. 2012, 45, 3962–3984. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Ding, G.; Pan, S.J.; Philip, S.Y. Adaptation regularization: A general framework for transfer learning. IEEE Trans. Knowl. Data Eng. 2014, 26, 1076–1089. [Google Scholar] [CrossRef]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 2200–2207. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D. Domain adaptation with regularized optimal transport. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Nancy, France, 15–19 September 2014; pp. 274–289. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Das, D.; Lee, C.S.G. Sample-to-sample correspondence for unsupervised domain adaptation. Eng. Appl. Artif. Intell. 2018, 73, 80–91. [Google Scholar] [CrossRef] [Green Version]
- Tahmoresnezhad, J.; Hashemi, S. Visual domain adaptation via transfer feature learning. Knowl. Inf. Syst. 2017, 50, 585–605. [Google Scholar] [CrossRef]
- Li, S.; Song, S.; Huang, G.; Ding, Z.; Wu, C. Domain invariant and class discriminative feature learning for visual domain adaptation. IEEE Trans. Image Process. 2018, 27, 4260–4273. [Google Scholar] [CrossRef] [PubMed]
- Baktashmotlagh, M.; Harandi, M.T.; Lovell, B.C.; Salzmann, M. Unsupervised domain adaptation by domain invariant projection. In Proceedings of the IEEE International Conference on Computer Vision, Portland, OR, USA, 23–28 June 2013; pp. 769–776. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2058–2065. [Google Scholar]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal transport for domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1853–1865. [Google Scholar] [CrossRef] [PubMed]
- Kantorovich, L. On the translocation of masses. Manag. Sci. 1958, 5, 1–142. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Ogunbona, P. Joint geometrical and statistical alignment for visual domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 24–30 June 2017; pp. 5150–5158. [Google Scholar]
- Li, J.; Jing, M.; Lu, K.; Shen, H.T. Locality preserving joint transfer for domain adaptation. IEEE Trans. Image Process. 2019, 28, 6103–6115. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Lu, K.; Huang, Z.; Zhu, L.; Shen, H. Transfer independently together: A generalized framework for domain adaptation. IEEE Trans. Cybern. 2019, 49, 2144–2155. [Google Scholar] [CrossRef]
- Ferradans, S.; Papadakis, N.; Peyré, G.; Aujol, J. Regularized discrete optimal transport. SIAM J. Imaging Sci. 2013, 7, 428–439. [Google Scholar]
- Rabin, J.; Ferradans, S.; Papadakis, N. Adaptive color transfer with relaxed optimal transport. In Proceedings of the IEEE International Conference on Image Processing, Columbus, OH, USA, 24–27 June 2014; pp. 4852–4856. [Google Scholar]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2292–2300. [Google Scholar]
- Courty, N.; Flamary, R.; Habrard, A.; Rakotomamonjy, A. Joint distribution optimal transportation for domain adaptation. In Advances in Neural Information Processing Systems, Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; MIT Press: Cambridge, MA, USA, 2017; pp. 3733–3742. [Google Scholar]
- Zhang, Z.; Wang, M.; Nehorai, A. Optimal transport in reproducing kernel Hilbert spaces: Theory and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1741–1754. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Wong, Y.; Kankanhalli, M.; Zhao, Q. G-Softmax: Improving intraclass compactness and interclass separability of features. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 685–699. [Google Scholar] [CrossRef]
- Bredies, K.; Lorenz, D.A.; Maass, P. A generalized conditional gradient method and its connection to an iterative shrinkage method. Comput. Optim. Appl. 2009, 42, 173–193. [Google Scholar] [CrossRef]
- Saenko, K.; Kulis, B.; Fritz, M.; Darrell, T. Adapting visual category models to new domains. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 647–655. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Venkateswara, H.; Eusebio, J.; Chakraborty, S.; Panchanathan, S. Deep hashing network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 24–30 June 2017; pp. 5385–5394. [Google Scholar]
- Kang, Q.; Yao, S.; Zhou, M.C.; Zhang, K.; Abusorrah, A. Enhanced subspace distribution matching for fast visual domain adaptation. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1047–1057. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 97–105. [Google Scholar]
- Zhang, W.; Ouyang, W.; Li, W.; Xu, D. Collaborative and adversarial network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3801–3809. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. In Advances in Neural Information Processing Systems, Proceeding of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 2–8 December 2018; MIT Press: Cambridge, MA, USA, 2018; pp. 1647–1657. [Google Scholar]
- Fang, X.; Bai, H.; Guo, Z.; Shen, B.; Hoi, S.; Xu, Z. DART: Domain-adversarial residual-transfer networks for unsupervised cross-domain image classification. Neural Netw. 2020, 127, 182–192. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, Y.; Zhuang, F.; Wang, J.; Chen, J.; Shi, Z.; Wu, W.; He, Q. Multi-representation adaptation network for cross-domain image classification. Neural Netw. 2019, 119, 214–221. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Long, M.; Wang, J.; Jordan, M.I. Transferable adversarial training: A general approach to adapting deep classifiers. In Proceedings of the International Conference on Machine Learning, Berkeley, CA, USA, 9–15 June 2019; pp. 4013–4022. [Google Scholar]
- Jing, M.; Li, J.; Lu, K.; Zhu, L.; Yang, Y. Learning explicitly transferable representations for domain adaptation. Neural Netw. 2020, 130, 39–48. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Zhao, Q.; Wang, Y. Hybrid adversarial network for unsupervised domain adaptation. Inf. Sci. 2020, 514, 44–55. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | #Samples | #Classes | #Features | Domains |
|---|---|---|---|---|
| Office10 + Caltech10 | 2533 | 10 | 800/4096 | A10, W10, D10, C10 |
| Office-31 | 4652 | 31 | 2048 | A31, W31, D31 |
| ImageCLEF-DA | 1800 | 12 | 2048 | P12, T12, C12 |
| Office-Home | 15,500 | 65 | 2048 | A65, C65, P65, R65 |
| Tasks | OT-IT | OT-GL | JDOT | KGOT | STSC | GFK | SA | TCA | JDA | DICD | ESDM | JGSA | OTDR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C10→A10 | 37.5 | 48.4 | 50.4 | 49.4 | 44.1 | 41.0 | 49.3 | 43.4 | 44.8 | 47.3 | 42.8 | 51.5 | 55.2 |
| C10→W10 | 32.2 | 50.2 | 54.6 | 43.1 | 31.5 | 40.7 | 40.0 | 37.3 | 41.7 | 46.4 | 45.1 | 45.4 | 53.2 |
| C10→D10 | 36.3 | 47.8 | 50.3 | 51.0 | 39.5 | 41.4 | 39.5 | 44.0 | 45.2 | 49.7 | 45.9 | 45.9 | 49.0 |
| A10→C10 | 35.4 | 37.9 | 40.9 | 39.9 | 36.1 | 40.3 | 40.0 | 38.2 | 39.4 | 42.4 | 40.3 | 41.5 | 45.1 |
| A10→W10 | 29.8 | 42.0 | 45.1 | 42.0 | 33.6 | 40.0 | 33.2 | 38.0 | 38.0 | 45.1 | 45.4 | 45.8 | 51.2 |
| A10→D10 | 35.0 | 44.6 | 40.8 | 42.0 | 36.9 | 36.3 | 33.8 | 30.6 | 39.5 | 38.9 | 45.2 | 47.1 | 51.6 |
| W10→C10 | 29.4 | 36.6 | 33.3 | 36.6 | 29.7 | 30.7 | 35.2 | 29.7 | 31.2 | 33.6 | 37.4 | 33.2 | 38.8 |
| W10→A10 | 33.1 | 39.6 | 38.7 | 38.0 | 38.3 | 31.8 | 39.3 | 32.3 | 32.8 | 34.1 | 41.7 | 39.9 | 40.2 |
| W10→D10 | 89.2 | 85.4 | 75.2 | 91.7 | 87.9 | 87.9 | 75.2 | 85.4 | 89.2 | 89.8 | 92.4 | 90.5 | 89.2 |
| D10→C10 | 32.2 | 34.3 | 33.0 | 34.6 | 30.5 | 30.1 | 34.6 | 30.9 | 31.5 | 34.6 | 33.5 | 29.9 | 34.8 |
| D10→A10 | 31.2 | 37.9 | 35.2 | 37.1 | 34.9 | 32.1 | 39.9 | 29.3 | 33.1 | 34.5 | 37.8 | 38.0 | 39.6 |
| D10→W10 | 90.5 | 87.8 | 76.3 | 87.5 | 88.5 | 84.4 | 77.0 | 84.8 | 89.5 | 91.2 | 88.1 | 91.9 | 88.5 |
| average | 42.7 | 49.4 | 47.8 | 49.4 | 44.3 | 44.7 | 44.8 | 43.7 | 46.3 | 49.0 | 49.6 | 50.1 | 53.0 |
| Tasks | OT-IT | OT-GL | JDOT | KGOT | STSC | GFK | SA | TCA | JDA | DICD | JGSA | OTDR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C10→A10 | 88.7 | 92.1 | 91.5 | 91.4 | 89.9 | 88.2 | 89.4 | 90.2 | 90.3 | 91.0 | 91.4 | 93.0 |
| C10→W10 | 75.2 | 84.2 | 88.8 | 87.1 | 81.2 | 77.6 | 81.4 | 77.0 | 85.1 | 92.2 | 86.8 | 91.2 |
| C10→D10 | 83.4 | 87.3 | 89.8 | 92.4 | 87.5 | 86.6 | 90.5 | 85.4 | 89.2 | 93.6 | 93.6 | 89.8 |
| A10→C10 | 81.7 | 85.5 | 85.2 | 85.7 | 85.6 | 79.2 | 80.6 | 82.7 | 84.0 | 86.0 | 84.9 | 87.0 |
| A10→W10 | 78.9 | 83.1 | 84.8 | 82.4 | 81.4 | 70.9 | 83.1 | 74.6 | 78.6 | 81.4 | 81.0 | 88.8 |
| A10→D10 | 85.9 | 85.0 | 87.9 | 86.6 | 87.1 | 82.2 | 89.2 | 80.3 | 80.9 | 83.4 | 88.5 | 87.3 |
| W10→C10 | 74.8 | 81.5 | 82.6 | 85.0 | 81.6 | 69.7 | 79.8 | 79.9 | 84.2 | 84.0 | 85.0 | 85.0 |
| W10→A10 | 81.0 | 90.6 | 90.7 | 89.7 | 88.9 | 76.8 | 83.8 | 84.5 | 90.1 | 89.7 | 90.7 | 92.5 |
| W10→D10 | 95.6 | 96.3 | 98.1 | 100.0 | 99.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| D10→C10 | 77.7 | 84.1 | 84.3 | 85.6 | 83.7 | 71.4 | 81.4 | 82.5 | 85.0 | 86.1 | 86.2 | 86.4 |
| D10→A10 | 87.2 | 92.3 | 88.1 | 91.8 | 92.7 | 76.3 | 87.1 | 88.2 | 91.0 | 92.2 | 92.0 | 92.4 |
| D10→W10 | 93.8 | 96.3 | 96.6 | 99.3 | 96.1 | 99.3 | 99.3 | 99.7 | 100.0 | 99.0 | 99.7 | 99.3 |
| average | 83.7 | 88.5 | 89.2 | 89.8 | 87.9 | 81.5 | 87.1 | 85.4 | 88.2 | 89.9 | 90.0 | 91.1 |
| Tasks | OT-GL | JGSA | ARTL | DAN | DANN | JAN | CAN | DART | MRAN | OTDR |
|---|---|---|---|---|---|---|---|---|---|---|
| A31→W31 | 81.3 | 86.5 | 85.0 | 80.5 | 82.0 | 85.4 | 81.5 | 87.3 | 91.4 | 88.4 |
| D31→W31 | 93.7 | 98.4 | 94.2 | 97.1 | 96.9 | 97.4 | 98.2 | 98.4 | 96.9 | 96.5 |
| W31→D31 | 96.0 | 99.8 | 97.2 | 99.6 | 99.1 | 99.8 | 99.7 | 99.9 | 99.8 | 98.6 |
| A31→D31 | 86.8 | 90.0 | 82.5 | 78.6 | 79.7 | 84.7 | 85.5 | 91.6 | 86.4 | 91.2 |
| D31→A31 | 66.6 | 71.1 | 71.0 | 63.6 | 68.2 | 68.6 | 65.9 | 70.3 | 68.3 | 71.1 |
| W31→A31 | 67.7 | 71.4 | 70.7 | 62.8 | 67.4 | 70.0 | 63.4 | 69.7 | 70.9 | 72.1 |
| I12→P12 | 78.3 | 77.5 | 71.3 | 74.5 | 66.5 | 76.8 | 78.2 | 78.3 | 78.8 | 79.5 |
| P12→I12 | 89.0 | 86.7 | 84.2 | 82.2 | 81.8 | 88.0 | 87.5 | 89.3 | 91.7 | 91.0 |
| I12→C12 | 96.0 | 95.0 | 87.2 | 92.8 | 89.0 | 94.7 | 94.2 | 95.3 | 95.0 | 97.2 |
| C12→I12 | 93.3 | 93.2 | 84.7 | 86.3 | 79.8 | 89.5 | 89.5 | 91.0 | 93.5 | 93.5 |
| C12→P12 | 77.7 | 76.8 | 70.3 | 69.2 | 63.5 | 74.2 | 75.8 | 75.2 | 77.7 | 78.8 |
| P12→C12 | 92.5 | 88.3 | 87.2 | 89.8 | 88.7 | 93.5 | 89.2 | 93.1 | 95.3 | 95.3 |
| average | 85.0 | 86.2 | 82.1 | 81.4 | 80.2 | 85.2 | 84.1 | 86.6 | 87.1 | 87.8 |
| Tasks | OT-GL | JGSA | ARTL | DAN | DANN | JAN | CDAN | CDAN + E | TAT | LETR | HAN | OTDR |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A65→C65 | 45.9 | 48.6 | 53.9 | 43.6 | 45.6 | 45.9 | 49.0 | 50.7 | 51.6 | 52.0 | 52.0 | 55.9 |
| A65→P65 | 68.2 | 71.6 | 75.0 | 57.0 | 59.3 | 61.2 | 69.3 | 70.6 | 69.5 | 72.6 | 72.0 | 75.9 |
| A65→R65 | 71.5 | 76.1 | 75.6 | 67.9 | 70.1 | 68.9 | 74.5 | 76.0 | 75.4 | 78.2 | 75.8 | 80.5 |
| C65→A65 | 52.6 | 48.7 | 53.4 | 45.8 | 47.0 | 50.4 | 54.4 | 57.6 | 59.4 | 58.2 | 59.6 | 58.8 |
| C65→P65 | 65.2 | 68.4 | 72.4 | 56.5 | 58.5 | 59.7 | 66.0 | 70.0 | 69.5 | 69.8 | 71.8 | 73.6 |
| C65→R65 | 65.5 | 67.5 | 70.6 | 60.4 | 60.9 | 61.0 | 68.4 | 70.0 | 68.6 | 70.3 | 71.2 | 72.0 |
| P65→A65 | 54.8 | 53.8 | 56.2 | 44.0 | 46.1 | 45.8 | 55.6 | 57.4 | 59.5 | 62.9 | 58.7 | 58.2 |
| P65→C65 | 46.6 | 44.2 | 51.4 | 43.6 | 43.7 | 43.4 | 48.3 | 50.9 | 50.5 | 47.8 | 51.3 | 51.3 |
| P65→R65 | 74.4 | 76.7 | 76.1 | 67.7 | 68.5 | 70.3 | 75.9 | 77.3 | 76.8 | 78.1 | 77.7 | 78.1 |
| R65→A65 | 62.5 | 61.7 | 65.3 | 63.1 | 63.2 | 63.9 | 68.4 | 70.9 | 70.9 | 70.6 | 72.8 | 65.5 |
| R65→C65 | 50.8 | 51.9 | 56.7 | 51.5 | 51.8 | 52.4 | 55.4 | 56.7 | 56.6 | 55.3 | 57.7 | 55.9 |
| R65→P65 | 77.5 | 78.7 | 81.0 | 74.3 | 76.8 | 76.8 | 80.5 | 81.6 | 81.6 | 82.5 | 82.3 | 82.9 |
| average | 61.3 | 62.3 | 65.6 | 56.3 | 57.6 | 58.3 | 63.8 | 65.8 | 65.8 | 66.5 | 66.9 | 67.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Ni, Z.; Zhu, X.; Song, J.; Wu, W. Optimal Transport with Dimensionality Reduction for Domain Adaptation. Symmetry 2020, 12, 1994. https://doi.org/10.3390/sym12121994
Li P, Ni Z, Zhu X, Song J, Wu W. Optimal Transport with Dimensionality Reduction for Domain Adaptation. Symmetry. 2020; 12(12):1994. https://doi.org/10.3390/sym12121994
Chicago/Turabian StyleLi, Ping, Zhiwei Ni, Xuhui Zhu, Juan Song, and Wenying Wu. 2020. "Optimal Transport with Dimensionality Reduction for Domain Adaptation" Symmetry 12, no. 12: 1994. https://doi.org/10.3390/sym12121994
APA StyleLi, P., Ni, Z., Zhu, X., Song, J., & Wu, W. (2020). Optimal Transport with Dimensionality Reduction for Domain Adaptation. Symmetry, 12(12), 1994. https://doi.org/10.3390/sym12121994