1. Introduction
La filosofia è scritta in questo grandissimo libro che continuamente ci sta aperto innanzi a gli occhi (io dico l’universo), ma non si può intendere se prima non s’impara a intender la lingua, e conoscer i caratteri, ne’ quali è scritto. Egli è scritto in lingua matematica, e i caratteri son triangoli, cerchi, ed altre figure geometriche, senza i qualimezi è impossibile a intenderne umanamente parola; senza questi è un aggirarsi vanamente per un oscuro laberinto.
(Galileo Galilei (1564–1642), Il Saggiatore, cap. 6).
Until now, deciphering the code of life [
1,
2,
3,
4,
5,
6,
7,
8]—the genetic code—has not been fully successful although theories have been proposed before [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. How is our new attempt different from earlier trials? Our mathematical approach lies at the crossroads of finite group theory and quantum information in line with other papers mainly devoted to quantum computing [
33] but also focused on elementary particles [
34].
Life cells need a macromolecule called deoxyribonucleic acid (or DNA) to be packed in a chromosome during cell mitosis. DNA unwinds when it is copied during DNA replication or when its code is used to make proteins. DNA is a helix consisting of two parallel polynucleotide chains carrying genetic instructions in 4 nitrogeneous bases for the growth and reproduction of all living organisms. The genetic code is organized in triples of bases called codons. There are codons but only 20 standard amino acids, meaning a high redundancy of the code. In our approach, we use the characters and corresponding representations of a well-defined finite group G to explain the mapping of the nitrogeneous bases to amino acids. The group characters may be used to build minimal and informationally complete quantum measurements, one for each character and corresponding amino acid.
Section 2.1 details the discovery and main properties of DNA and the genetic code.
Section 2.2 reports the main efforts already accomplished towards the understanding and origin of the genetic code.
Section 3 recalls how minimal informationally complete quantum measurements are performed and the necessary elements of character theory of finite groups. In
Section 4, the assignment of characters of the small group
to amino acids is detailed. In
Section 5, we provide a justification for the fact that minor and major grooves in the DNA double helix have periods whose ratio approximates the golden ratio. This is based on the study of points over a hyperelliptic curve occuring in the character table.
2. DNA and the Genetic Code
In this section, we summarize the main aspects of DNA from a historical perspective (in
Section 2.1) and some previous attempts to explain the degeneracies in the mapping of codons to proteins (in
Section 2.2).
2.1. Main Properties of DNA and the Genetic Code
The discovery of DNA is attributed to Watson and Crick in 1953 [
1]. However, the phosphorous-containing substance now called DNA was first isolated by F. Miescher in 1869 in the nuclei of white blood cells under the name of ‘nuclein’ (a nucleic acid) paving the way for its recognition as the carrier of inheritance [
2]. In 1909, P. Levene found that DNA contains the pentoses (A), guanine (G), thymine (T), cytosine (C), a deoxyribose, and a phosphate group. At that time, it was still believed that the protein component of chromosomes was the true basis of heredity. The recognition that DNA rather than proteins could be the genetic material was suggested by the E. Chargaff’s rules, which proposed in 1940 that the four bases are present in the percentages:
and
for all species [
3]. Subsequent X-ray crystallography work by English researchers R. Franklin and M. Wilkins contributed to Watson and Crick’s derivation of the three-dimensional, double-helical model for the structure of DNA [
4].
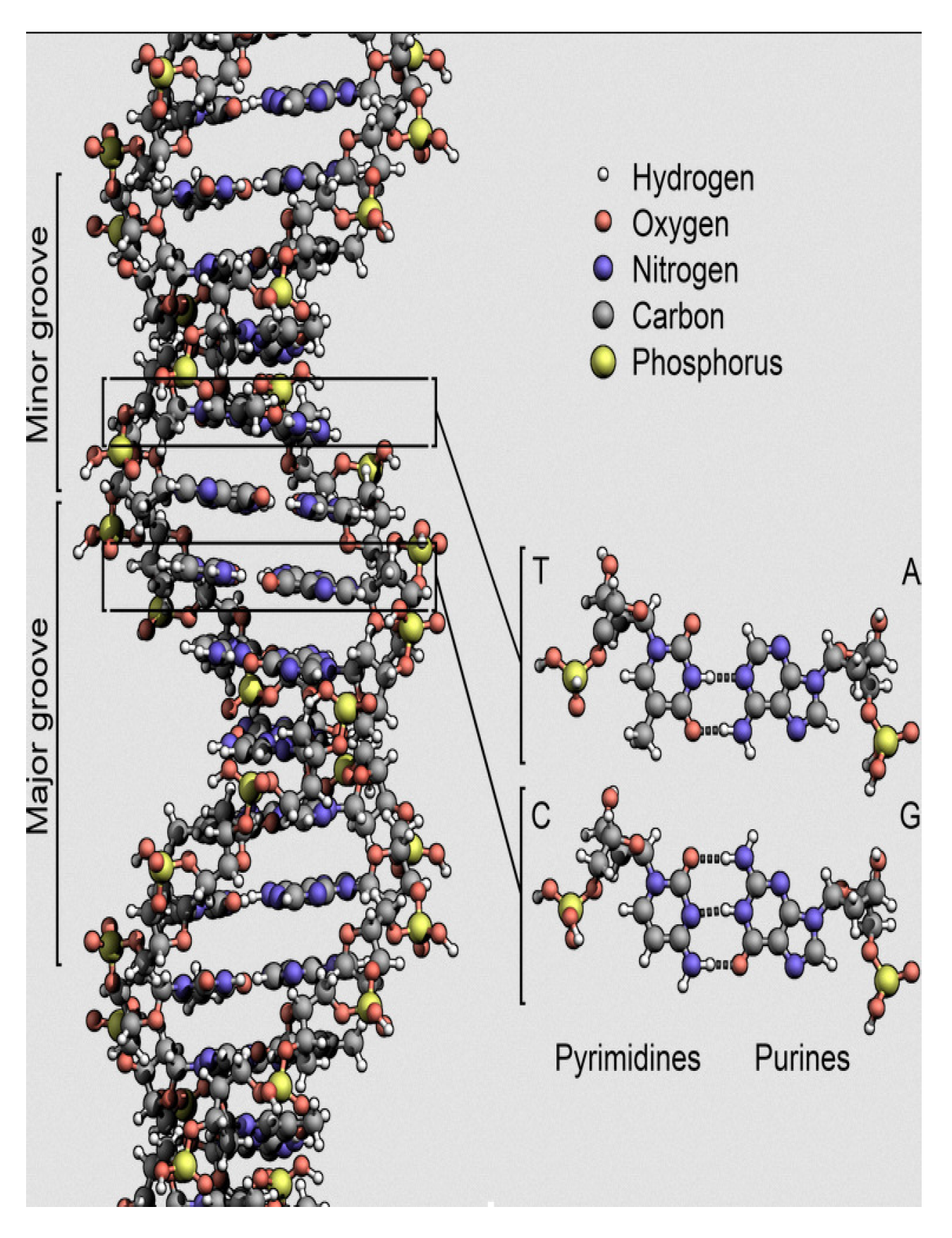
As shown in
Figure 1, DNA is a double helix, with the two strands connected by hydrogen bonds. In the most current form of DNA (called B-DNA), the ratio of the diameter
to the period
and the ratio between the minor groove
and major groove
are both close to the golden ratio
[
35].
G. Gamow (also a cosmologist) observed that the
possible permutations of the four DNA bases A, T, G, and C, taken three at a time (as codons), could be reduced to 20 distinct combinations and might code for the 20 amino acids which, he suggested, might well be the sole constituents of all proteins [
5]. However the lack of overlapping of codons (not assumed by Gamow) and the demonstration that the genetic code is made up of a series of three base pair codons, which code for individual amino acids, dates back to 1961 with the Crick, Brenner et al. experiment [
6]. Now we know that the peculiar non ambiguous and non overlapping assignment of all 64 codons to the 20 amino acids is nearly universal [
7].
The ‘genetic code’ is the set of rules used by living cells to translate information encoded within genetic material (DNA or messenger RNA sequences of nucleotide triplets, or codons) into proteins. Translation is accomplished by the ribosome, which links amino acids in an order specified by messenger RNA (mRNA), using transfer RNA (tRNA) molecules to carry amino acids, and to read the mRNA, three nucleotides at a time.
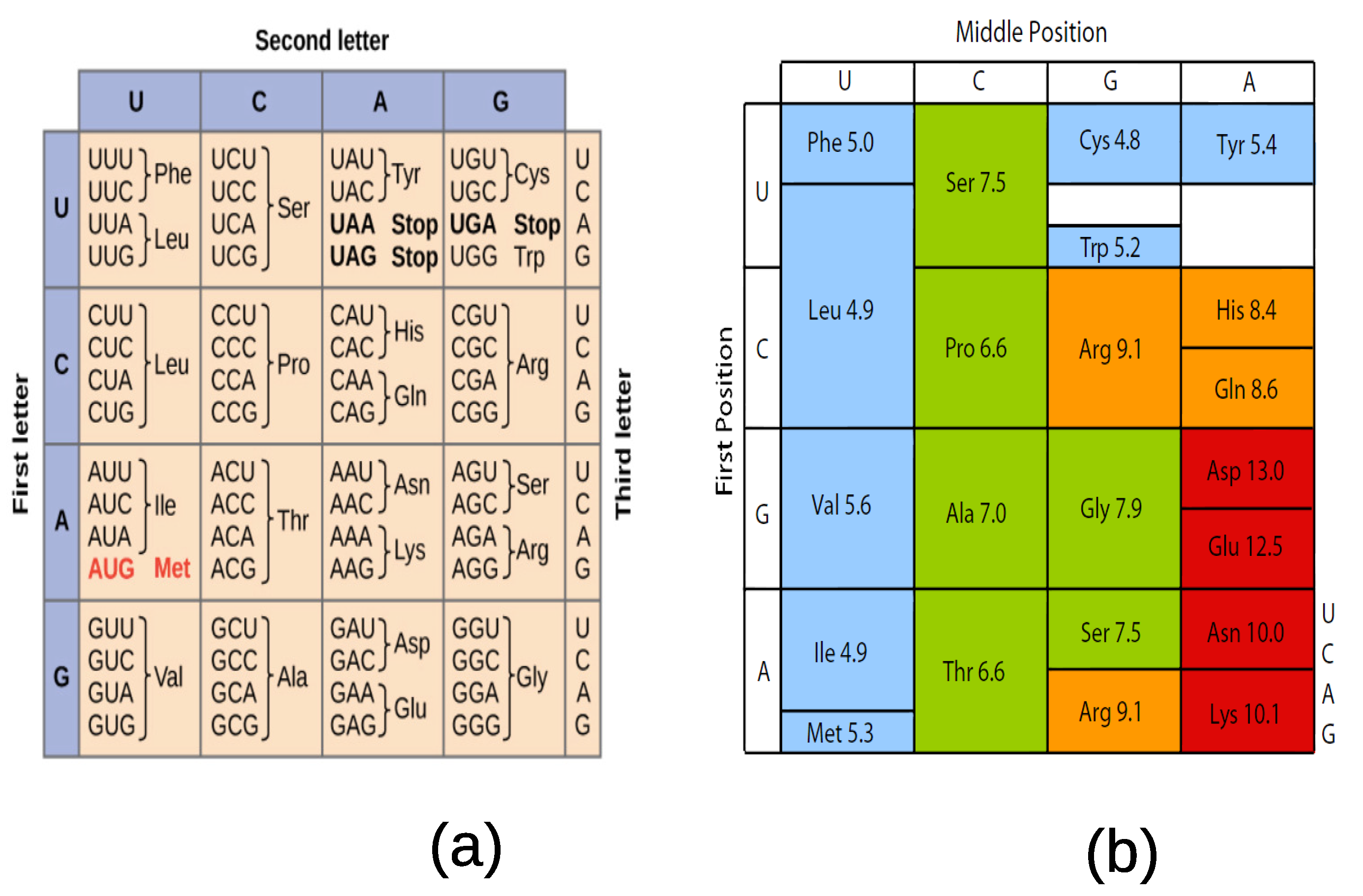
The codons which code for the same amino acids form multiplets and are organized as:
Met, Trp: 2 singlets;
Asn, Asp, Cys, Gln, Glu, His, Lys, Phe, Tyr: 9 doublets;
Ile, Term: 2 triplets;
Ala, Gly, Pro, Thr, Val: 5 quadruplets;
Arg, Leu, Ser: 3 sextets.
A 21st proteinogenic amino acid Selenocysteine (symbol Sec) was found present in some enzymes and a 22st amino acid Pyrrolysine (Symbol Pyl) in some archaea and bacteria.
The assignment of three-letter codons to the standard 20 amino acids is shown in
Figure 2a. It is clearly seen in this table that the assignment of codons to amino acids is not random but follows underlying rules to be discovered.
2.2. Theories about the Degeneracies within the Genetic Code
Woese and collaborators introduced the concept of polar requirement to express stereochemical associations between amino acids and nucleobases in solution [
8,
9]. Taking dimethylpyridine (or DMP) as a solvant, the polar requirement is found as in
Figure 2b [
11,
12]. For more recent predictors of the stereochemical associators the reader may read reference [
13]. While the polar requirement is correlated with the organization of the codon table, it does not provide a clue about the type of degeneracies selected almost universally in extant organisms.
It is common to distinguish several levels in DNA structure. The primary structure consists of the sequence of amino acids, the secondary structure consists of the base pairings and can be decomposed into stems, loops, or their combinations and the tertiary structure corresponds to their three-dimensional embedding. As a last resort, the symmetries of the tertiary structure are responsible for the structure of the genetic code.
The physical link between messenger RNA (mRNA) and the amino acid sequence of proteins is a transfer RNA (tRNA). Corresponding to the three bases of an mRNA codon is an anticodon. Each tRNA has a distinct anticodon triplet sequence that can form three complementary base pairs to one or more codons for an amino acid. Some anticodons pair with more than one codon due to so-called wobble base pairing. Considering the secondary and tertiary structure of tRNA, as well as the fact that the third position in the codon is not strictly read by the anticodon according to Watson–Crick pairing rules, Crick hypothesized that codon translation into a proteins is mainly due to the first two positions of the codon [
14,
15]. There are 16 groups of codons specified by the first two codonic positions and the level of degeneracy can be dermined by them according to Lagerkvist’s rules [
16,
17].
In the same line of thoughts, doublet codings may have been associated to reverse recognition in earlier times of life organisms [
18,
19]. This prompted the authors of [
21,
22] to propose a model of the genetic code and its degeneracy distribution based on a boolean number system and/or a tessera code. See also [
23] about the ribosomal translation and [
24,
25] about the hypothesis that life on earth and the genetic code evolved around tRNA and the corresponding anticodons.
A completely different approach of the genetic code has been based on a Lie group
G and a chain of subgroups derived by a symmetry breaking process [
26,
27]. This view is reminiscent of the one used to explain the periodic table of chemical elements as well as the multiplet structure of massive elementary particles such as quarks. The most satisfactorily theory of the genetic code would result from the symplectic algebra
through the appropriate symmetry breaking chain. A similar program has been proposed for finite simple groups [
28,
29].
Finally, there exist many other attempts to map the codons to multiplets of the genetic code thanks to an appropriate algebraic geometric object. Let us mention [
30], which describes the genetic code thanks to an hypercube
, Ref. [
31] which makes use of the symmetries of the polyhedral symmetries of a quasi-28-gon, and [
32] which parametrizes the codons in terms of integer quaternions.
3. Symmetries and Quantum Information from the Characters of a Finite Group
There are two important ingredients in our approach. One topic follows from our earlier work on ‘magic state’ quantum computing [
33] and consists of performing a generalized quantum measurement while keeping complete information in the process, as explained in
Section 3.1. The second (more recent) topic consists of finding the ‘magic states’ in the bank of characters of a selected finite group. The latter approach recalled in
Section 3.2 was found successful in the context of symmetries of elementary matter particles [
34].
3.1. Minimal Informationally Complete Quantum Measurements
Let be a d-dimensional complex Hilbert space and be a collection of positive semi-definite operators (POVM) that sum up to the identity. Taking the unknown quantum state as a rank 1 projector (with and ), the i-th outcome is obtained with a probability given by the Born rule . A minimal and informationally complete POVM (or MIC) requires one-dimensional projectors , with , such that the rank of the Gram matrix with elements , is precisely .
With a MIC, the complete recovery of a state
is possible at a minimal cost from the probabilities
. In the best case, the MIC is symmetric and called a SIC with a further relation
so that the density matrix
can be made explicit [
37].
In our earlier references, starting with [
33], a large collection of MICs are derived. They correspond to Hermitian angles
belonging to a discrete set of values of small cardinality
l. They arise from the action of a Pauli group
[
38] on an appropriate magic state pertaining to the coset structure of subgroups of index
d of a free group with relations.
Let us illustrate our topic with the derivation of a 3-dimentional MIC. The qutrit Pauli group is generated by the shift (X) and clock (Z) operators as follows:
with
and
j takes the three values 0, 1, and 2. The generators are:
It is not difficult to check that a qutrit magic state can be taken as:
The nine qutrit Pauli matrices are:
Taking the action of Pauli matrices, one arrives at the so-called Hesse SIC [
33] (
Figure 1).
Similarly, the generalized Pauli group for a
d-dimensional qudit is generated by shift (
X) and clock (
Z) operators:
with
and
j takes the values from 0 to
. The challenge is to find an appropriate
d-dimensional magic state
so that a MIC results from the action of the Pauli group on the projector
.
In [
33] (
Table 1) and later references of the first author, e.g., [
39], a number of cases are provided with
obtained from permutation groups. In reference [
34], an entirely new class of MICs in the Hilbert space
, relevant for the lepton and quark mixing patterns, is obtained by taking fiducial/magic states as characters of a finite group
G possessing
d conjugacy classes and using the action of a Pauli group
on them. The same approach is used in this paper.
3.2. The Character Table of a Finite Group and Quantum Information
Let G be a finite group, V a finite-dimensional vector space over a field F, and let be a representation of G on V. The character associates to an element the trace of the corresponding matrix . A character is called irreducible if r is an irreducible representation. The degree of the character is called the dimension of the representation.
Assume that
G is made of
d conjugacy classes of elements. One introduces class functions on
G from the ring of complex-valued functions on
G that are constant on conjugacy classes. In fact we restrict ourselves to functions with values in cyclotomic fields [
40].
The table of irreducible characters of G, or character table for short, is a way to summarize the properties of irreducible representations of elements g of G.
Let us take the case of the symmetric group
, also called the small group
(number 12 in the range of 15 groups of order 24). The character table is in
Table 1. It makes explicit the five irreducible characters of
G, the corresponding dimension
of the representation, as well as the size and order of an element in each class. For each class, we added the calculation of the rank of the Gram matrix that corresponds to the POVM obtained by the action of the 5-dit Pauli group over the irreducible character
of the class. For the classes 3 to 5, the rank of the Gram matrix is
so that the POVM is a MIC.
As a second example, one takes the binary octahedral group
also called the small group
(number 28 in the range of 52 groups of order 48). Group
is an important ingredient of our model of the genetic code, as shown in
Section 4. The character table is shown in
Table 2. It makes explicit the eight irreducible characters of
G, the corresponding dimension of the representation, as well as the size and order of an element in each class. At the right hand side of the column, one finds the rank of the Gram matrix that corresponds to the POVM obtained by the action of the 8-dit Pauli group over the irreducible character
of the class. None of the characters of the group
is informationally complete.
4. Symmetries and Quantum Information in the Genetic Code
As shown in the previous section, there may exist several representations of a given dimension in a finite group. Does a group G exist whose multiplets map to the multiplets of the genetic code in a satisfactorily way? We shall impose the constraint that there are enough n-plets to embed the mappings to the proteinogenic amino acids for dimensions , 2, 3, and 4 and that there are at least 2 sextuplets. Small groups and (with 22 conjugacy classes) and and (with 28 conjugacy classes) are the group candidates with the smallest cardinality. All of them have two 6-dimensional representations. We could not find another candidate group of a higher cardinality. The most economical groups are thus the former two groups and the latter two are different only in the sense that there are 6 one-dimensional representations instead of two.
The first group has signature where is isomorphic to the binary octahedral group and is the symmetric group on four letters/bases. The second group has signature and points out a threefold symmetry of base pairings. For those groups, the representations for the 22 conjugacy classes of G are almost in one-to-one correspondence with the multiplets encoding the proteinogenic amino acids. The assignment is not perfect in the sense that there are only two representations of dimension 6 while there are three sextuplets in the genetic code.
The 22 characters of the group
are investigated in
Section 5. A sketch of the character properties of
G is in
Table 3. It includes the dimension of the representation associated to each character, the order of an element in each class, and additionally the rank of the Gram matrix when one builds a POVM based on the character as a magic/fiducial state as in
Section 3.1.
Table 3 proposes a one-to-one assignment of the representations of
G to amino acids. A given degeneracy of an amino acid in the genetic code corresponds to the dimension of the selected representations of
G. The amino acids of a given degeneracy/dimension in the table are ordered according to their increasing polar requirement value (given in
Figure 2b) and thus follows the order of a group element in the corresponding class. Most representations are informationally complete with the rank of the Gram matrix equal to
. The exceptions are for the 3-dimensional slot for the Stop codon and the 4-dimensional slot that we associate to the amino-acid Leu and the 2 extra amino acids Pyl and Sec. There is an ambiguity in the assignment of codons UAG and UGA that code for Stop, and for Pyl (with the codon UAG) and Sec (with the codon UGA). Thus the slight ambiguity of nature in coding the amino acids is recovered in our approach. The assignments to codons is displayed in detail in
Table 4. According to our approach, this ambiguity is reflected into three characters being non informationally complete.
Another possible assignment of amino acids to the representations of group
is possible. This group has similar dimensions of representations than group
with slight differences in the order of an element in each class and the rank of the Gram matrix for the corresponding POVM, as shown in
Table 5. One may postulate that it encodes the D-amino acids while the group
encodes proteinogenic L-amino acids. For most naturally-occurring amino acids, the carbon alpha to the amino group has the L-configuration. D-amino acids are most occasionally found in nature as residues in proteins.
Normal subgroups
of the group
and
of the group
may be used to encode some of the so-called essential amino-acids in humans as shown in
Table 6 [
41]. The distinction between essential and non-essential amino acid is of course non universal. While humans lack metabolic pathways to synthesize Trp, Lys, and Thr, it is known that bacteria can synthesize all 20 amino acids. One observes that apart from two exceptions for the 4-dimensional slots of
, the characters of these groups are not informationally complete.
5. Symmetries of the Genetic Code, the Golden Ratio, and a Hyperelliptic Curve
If one accepts the validity of the aforementioned group theoretical model of the genetic code, one can provide clues why nature selected these particular symmetries. One clue is contained in the detailed structure of the characters of the group and its cousin group . The golden ratio is playing a role in accordance with the DNA structure.
The list of 22 characters for the group
is in
Table 7. A closely related table (not shown) is found for the group
. The entries in the character table are shown to be either rational numbers, quadratic irrationalities such as
,
,
,
and their algebraic conjugates, or
where
is one of the four roots
of the quartic polynomial
, where
,
,
, and
.
It is known that such a quartic contains the golden ratio
and the irrational
in its structure. Following [
42] (
Section 3), the inflection secant
S has segments whose length ratio is
. In addition, the double tangent, the inflection secant, and the straight line passing through the third tangent point and parallel to them separate areas whose ratio is
.
It may be that some other clues in the mystery of the genetic code (and a possible connection to the present approach) are in a concept introduced under the name of Boerdijk–Coxeter (BC) helix—an helix made of contiguous tetrahedra—more or less at the same time than the discovery of DNA [
43]. The concept was revisited to arrive at a BC helix exhibiting a connection to aperiodicity and the golden ratio [
44,
45].
From now, we consider the (genus one) hyperelliptic curve
:
as a potential model of many features of DNA double helix.
The characters responsible of the quadratic irrationalities and roots of the quartic are defined over the cyclotomic fields and , respectively, where is a primitive n-th complex root of unity. Thus we focus on with points over such cyclotomic fields.
5.1. Points of over Cyclotomic Fields
As usual for elliptic and hyperelliptic curves of genus
g,
is embedded in a weighted projective plane, with weights 1,
, and 1, respectively on coordinates
x,
y, and
z. Therefore, point triples are such that
,
in the field of definition, and the points at infinity take the form
. Below, the software Magma is used for the calculation of points of
[
40]. For the points of
, there is a parameter called ‘bound’ that loosely follows the heights of the
x-coordinates found by the search algorithm.
Let us start with points on with entries over the cyclotomic field .
For points whose entries are bounded by modulus 1, one gets 8 cases (the points at infinity), , and . For points whose entries are bounded by modulus 2, one gets 10 extra cases , , , , and . For points whose entries are bounded by modulus 10, one gets 8 extra cases , , , and .
Let us continue with points on with entries over . Points with integer entries are as those given over . In addition, the points whose entries are bounded by modulus 1 are , , , (where is one of the four roots of the quartic polynomial above), [the latter 2 points are on ] The non rational points whose entries are bounded by modulus 2 are , [the latter 2 points are on ], and . For non rational points whose entries are bounded by modulus 7, one gets 8 extra cases and no more up to bound 10. The entries could not be found related to simple irrationalities and are approximated as , , , and .
Over both cyclotomic fields, there are plenty of extra points where the entries have higher modulus but we do not list them here.
5.2. The Group Law on the Jacobian J of the Hyperelliptic Curve
There exists a group law on the Jacobian
J of a hyperelliptic curve [
46]. Using Magma we provide some results for the operations in
defined over
.
Let focus on the 8 elements
of bound 1 in the Jacobian. In the Mumford representation of Jacobian elements,
,
,
,
,
,
,
, and
In
Table 8, the inverses or elements
are shown. In
Table 9, one explicits the sums
between two elements of bound 1 in the Jacobian.
A similar group law exists for defined over but it is more difficult to explicit the points and we do not give details here.






{kind=link}
{kind=link}