1. Introduction
A point cloud is a set of discrete data points defined in a given coordinate space—for example 3D Cartesian coordinate system, representing samples of surfaces of objects, urban landscapes or other three-dimensional physical entities. To create point clouds, active or passive methods can be used. Examples of active methods include processes based on structured light, scanning laser ranging and full-front laser or radio-frequency sensing, while passive methods include capturing multi-view images and videos followed by a triangulation procedure to generate the cloud of points representing the scene or object(s). Point cloud displaying can be done directly, showing the raw points on 2D or 3D displays or by displaying approximating surfaces after applying a suitable reconstruction algorithm [
1]. An example point cloud, “dragon”, from [
2], is shown in
Figure 1, where the left image shows the point cloud points rendered directly and viewed from a specific observation point and the right image shows the same point cloud after surface reconstruction using volumetric merging [
3] (viewed from the same point).
Point clouds can have from a few hundred thousand to several million points and require tens of megabytes for storing the set of point coordinates and (optional) point attributes such as color and normal vector information. Efficient storage and transmission of such massive data volumes thus requires the use of compression techniques. Several recent point cloud compression methods are briefly described next, covering geometry-based compression algorithms (e.g., Geometry-based Point Cloud Compression, G-PCC) and projection-based compression algorithms (e.g., Video-based Point Cloud Compression, V-PCC). New neural network based compression methods are also presented.
Recently, the JPEG standardization committee (ISO/IEC JTC 1/SC 29/WG 1) created a project called
JPEG Pleno aimed at fostering the development and standardization of a framework for coding new image modalities such as light field images, holographic volumes, and point cloud 3D representations [
4]. As part of this effort, a JPEG Ad Hoc Group on Point Clouds compression (JPEG PC AhG) was created within
JPEG Pleno, with mandates to first define different subjective quality assessment protocols and objective measures for use with point clouds and later lead activities geared towards standardization of static point cloud compression technologies.
This paper presents an overview of existing methods for point cloud compression and the research problems involved in evaluating the perceived (subjective) visual quality of point clouds and estimating that quality using computable models, using some of the activities of the JPEG PC AhG as a case study. The paper is focused on these specific activities first and foremost because they are the first large-scale series of studies aiming at evaluating the subjective and objective quality of point clouds in a systematic and organized way and secondly because of the direct involvement of the authors in conducting a significant part of that work.
The structure of this article is as follows.
Section 2 presents recent coding solutions that have been proposed for compressing point cloud data.
Section 3 describes the materials and methods involved in subjective evaluation of point clouds quality. A list of some recent point cloud test datasets is presented, and then the protocols that have been proposed to evaluate the subjective quality of point clouds are described.
Section 4 presents point cloud objective quality measures/estimators for the geometry and attribute components, some operating on the 3D point cloud information and others based on the projection of the points onto 2D surfaces.
Section 5 present protocols to process and analyze subjective mean opinion scores (MOS) and different correlation measures used to compute the agreement between subjective quality scores and objective quality measures/estimates.
Section 6 describes one case study involving a subjective evaluation of compressed point clouds and respective objective quality computations. Finally,
Section 7 closes the article with some conclusions.
2. Point Cloud Coding Solutions
In [
5], an efficient octree-based method used to store and compress 3D data without loss of precision is proposed. The authors demonstrated its usage in an open file format for interchange of point cloud information, fast point cloud visualization and to speed-up 3D scan matching and shape detection algorithms. This octree-based compression algorithm (with arbitrarily chosen octree depth), is a part of the “3DTK—The 3D Toolkit” [
6]. As described in [
7], octree-based representations can be used with nearest neighbor search (NNS) algorithms, in applications such as shape registration and, as explained below, in geometry-based point cloud objective quality measures.
MPEG’s
G-PCC (Geometry based Point Cloud Compression) codec [
8] is a geometry octree-based point cloud compression codec which can use trisoup surface approximations. It merges the L-PCC (LIDAR point cloud compression for dynamic point clouds) coder and the S-PCC (Surface point cloud compression for for static point clouds) coder, previously defined by the MPEG standards committee, into a coding method that is appropriate for sparse point clouds. Currently,
G-PCC only supports intra prediction, that is, it does not use any temporal prediction tool.
G-PCC encodes the content directly in 3D space in order to create the compressed point cloud. In lossless intra-frame mode, the
G-PCC codec currently provides an estimated compression ratio up to 10:1, while lossy coding with acceptable quality can be done with compression ratios up to 35:1. In
G-PCC, geometry and attribute information are encoded separately. However, attribute coding depends on geometry, thus geometry coding is performed first. Geometry encoding starts with a coordinate transformation followed by a voxelization, after which a geometry analysis is done either using an octree decomposition or a trisoup (“triangle soup”) surface approximation scheme. Finally, arithmetic coding is applied to achieve lower bitrates. Regarding the attribute coding, three options are available: Region Adaptive Hierarchical Transform (RAHT), Predicting Transform, and a Lifting Transform. After application of one of these transforms, the coefficients are quantized and arithmetically encoded.
MPEG’s
V-PCC (Video based Point Cloud Compression) codec [
9] projects the 3D points onto a set of 2D patches that are encoded using legacy video technologies, such as H.265/HEVC video compression [
10]. The current
V-PCC encoder compresses dynamic point cloud with acceptable quality with a compression ratio up to 125:1; thus, for example, a dynamic point cloud with one million points could be encoded at 8 Mbit/s.
V-PCC firstly generates 3D surface segments by dividing the point cloud into a number of connected regions, using information from normal vectors from each point. Those 3D surface segments are called patches and each 3D patch is afterwards independently projected into a 2D patch. This approach helps to reduce projection issues, such as occlusions and hidden surfaces. Each 2D patch is represented by a binary image, the occupancy map, which signals if a pixel is present in 3D projected point, a geometry image that contains the depth information (depth map) and a set of images that represent the projected points attributes (e.g., R, G, B channels for full-color point clouds or a luminance channel for grayscale point clouds). The 2D patches are packed/padded in a 2D image/plane with several optimizations to use the minimum possible space 2D space. This procedure is applied to the occupancy map, the geometry map, and the texture map. Additionally, different algorithms are used to smooth transitions between patches in the same image, and to adjust subsequent patches in time for better compression efficiency. After the sequences of 2D images containing the packed patches are created, they are compressed using H.265/HEVC video compression, although any other compression might be used as well. The geometry images are represented in the YUV420 color space, with information in the luminance channel only. The texture images are represented in RGB444 and then converted to YUV420 before coding. The occupancy map is a binary image that is coded using specifically developed lossless video encoder [
11], but lossy encoding can also be used [
12]. Recently, the
V-PCC codec for dynamic point clouds has been tested [
13] with very good results. For more details about
G-PCC and
V-PCC, please check [
14,
15].
Other point cloud coding solutions have also been proposed in recent years. He et al. [
16] proposed a best-effort projection scheme, which uses joint 2D coding methods to effectively compress the attributes of the original 3D point cloud. The scheme includes lossless and lossy modes, which can be selected according to different requirements. In [
17], the authors presented a point cloud compression algorithm based on projections. Different projection types have been tested, using the framework from “3DTK—The 3D Toolkit” [
6], namely equirectangular, Mercator, cylindrical, Pannini, rectilinear, stereographic, and Albers equal-area conic projections. Different compression ratios are achieved by using different resolution for projection images. In [
18], the same authors proposed compressing 3D point clouds using panorama images generated with equirectangular projection, to encode the range, reflectance, and color information of each point. Lossless and JPEG lossy compression methods have been tested to encode the projections.
Novel neural network based point cloud compression methods have also been proposed recently. In [
19], the authors proposed a new method for static point cloud data-driven geometric compression based on learned convolutional transform and uniform quantization. In terms of rate-distortion, the proposed method is superior to the MPEG reference software. Wang et al. [
20] proposed deep neural network-based variational autoencoders to efficiently compress point cloud geometry information. the reported results show higher compression efficiency than that of MPEG’s
G-PCC.
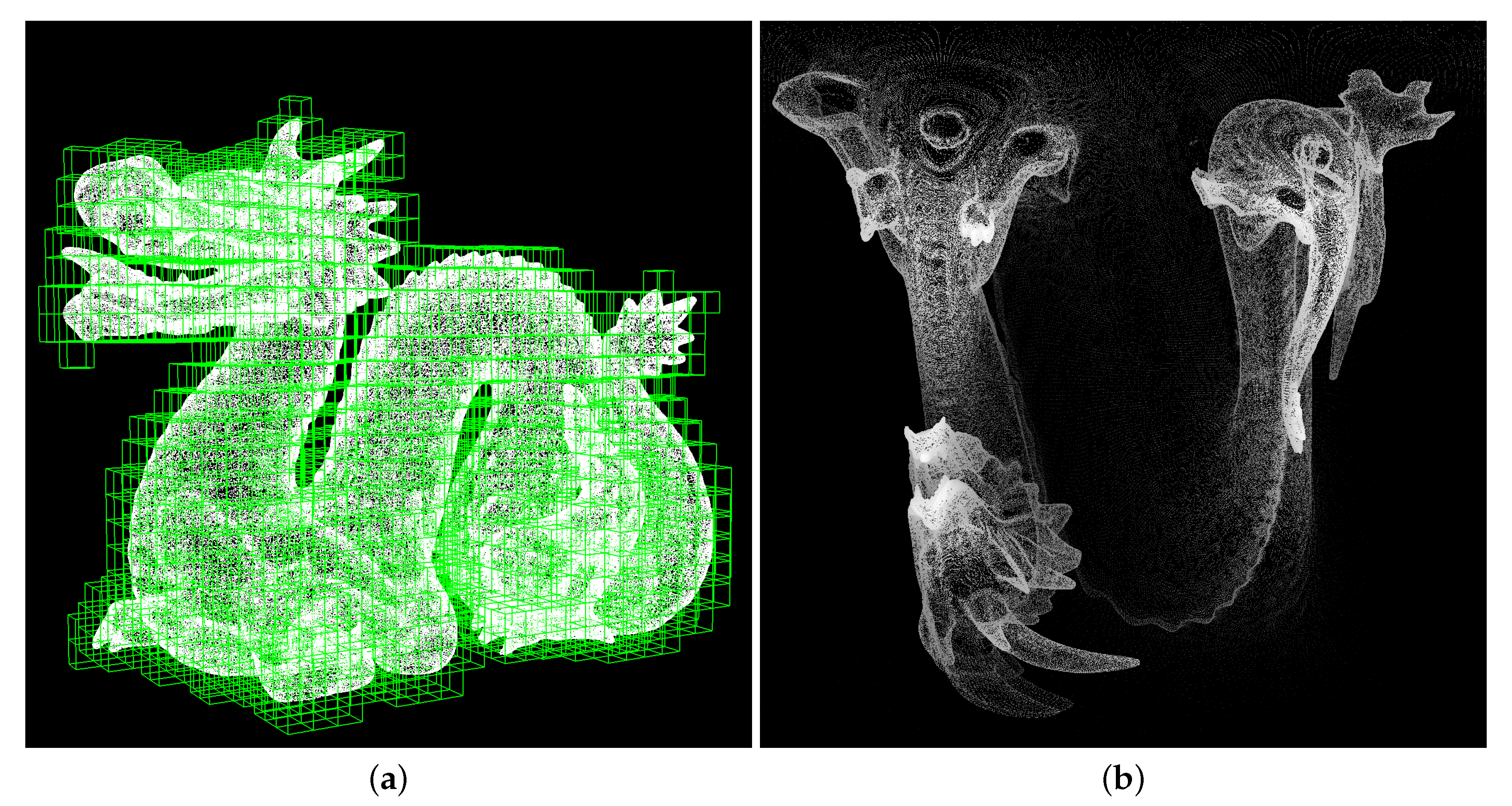
Figure 2 shows two examples of representations using 3D structures and 2D images. The left image shows an octree decomposition (with five levels) of the “dragon” point cloud, obtained using CloudCompare [
21], and on the right an equirectangular 2D projection of the same point cloud computed using 3DTK toolkit [
6] is presented.
3. Subjective Assessment of Point Cloud Quality
Quality of experience is defined, according to the COST Action Qualinet, as “The degree of delight or annoyance of the user of an application or service” [
22]. QoE is influenced by several factors that can be generally divided into three main categories: human-related, system-related, and context-related factors. To measure QoE of different multimedia signals, subjective assessment of the quality can be performed, representing quality of each tested content item by a single number (which, in some cases, may be not enough to fully describe QoE [
23]). For example, in a typical subjective image or video quality assessment campaign, observers watch a series of original and degraded images or video sequences and rate their quality numerically. The subjective quality of a specific image or video is measured by the average of all users ratings for that image or video, i.e., using a Mean Opinion Score (MOS), which is regarded as the quality score that the average viewer would assign to that particular image or video. MOS scores are collected according to the well-defined methods and procedures proposed in recent decades and aimed at guaranteeing the use of the same experimental settings and conditions during different assessments.
Commonly used subjective image and video quality assessment methods are proposed in recommendation ITU-R BT.500-14 [
24]. This recommendation (and others related) defines single or double stimulus methods to perform subjective quality assessment, depending on how the content is shown to the observer. Some of the methods defined are “Single-Stimulus” (SS), “Double Stimulus Continuous Quality Scale” (DSCQS), “Stimulus-Comparison” (SC), and “Single Stimulus Continuous Quality Evaluation“ (SSCQE). The most common subjective quality assessment method is the DSCQS procedure, in which the observer grades a pair of images or video sequences coming from the same source, one of which, the original or reference signal, is observed directly without any further processing and the other goes through a test system which is either real or simulates a real system, resulting in the processed or test signal. The observer grades both the original and processed signals, usually on a differences scale, resulting in a group of scores that represent the perceptual difference between the reference and test videos (or images). Alternative methods for estimating image or video sequences have been proposed, such as the one-step continuous quality evaluation (SSCQE) procedure, in which users evaluate images or video sequences that contain impairments that differ over time, such as those obtained by different encoding parameters.
Currently, subjective evaluation of point clouds is not standardized yet; however, similar procedures can be adapted as in the usual image/video quality assessment methods that are defined in in ITU-R BT.500-14 [
24]. Possible subjective evaluations of point clouds include interactive or passive presentation, different viewing technologies (e.g., 2D, 3D, immersive video, and image displays), and raw point clouds or point clouds after surface reconstruction. Surface reconstruction may be used because observers can easier observe and afterwards grade them. However, for more complex point clouds, as well as noisy point clouds, surface reconstruction may produce unwanted artifacts not directly related to compression or take too long to compute. If subjective experiments are being made using raw point clouds, point size is usually adjusted by expert viewing to obtain watertight surfaces. Virtual camera distance and camera parameters may also be adjusted according to the expected screen resolution.
The next subsections describe different protocols that have been proposed to evaluate the subjective quality of different point cloud datasets.
Section 3.1 identifies and describes the point cloud datasets publicly available that have been used in recent works, and
Section 3.2 reviews recent subjective point cloud quality evaluation studies summarizing the procedures followed in preparing the point clouds for presentation to the graders/observers, the choice of rendering method (raw point vs. rendered surface), the presentation protocols adopted (interactive or passive), and the viewing technologies employed.
3.1. Point Cloud Datasets
Many different point cloud datasets have been proposed recently, for studies related to different application tasks such as shape classification, object classification, semantic segmentation, shape generation, and representation learning. Point cloud datasets used to train and test deep learning algorithms for different applications are described in detail in [
25,
26]. Here, we briefly mention some of the point cloud datasets that have been used in applications where the end user is a human being, namely those proposed in the context of JPEG standard creation activities. One of the first tasks undertaken by the participants of the
JPEG Pleno project was the collection and organization of raw point cloud datasets to be used in the activities planned to follow. Several static point clouds with different sources were collected and made publicly available at the
JPEG Pleno test content archive [
27]. The dataset includes point clouds originally sourced from “8i Voxelized Full Bodies (8iVFB v2)” [
28], “Microsoft Voxelized Upper Bodies”, “ScanLAB Projects: Science Museum Shipping Galleries point cloud data set”, “ScanLAB Projects: Bi-plane point cloud data set”, “UPM Point-cloud data”, and “Univ. Sao Paulo Point Cloud dataset.” For details, see information provided in [
27]. Another repository for 3D point clouds from robotic experiments can be found in [
29], a part of the 3DTK toolkit datasets.
Figure 3 shows one example point cloud from each of those datasets: (a) “8i Voxelized Full Bodies (8iVFB v2)”; (b) “Microsoft Voxelized Upper Bodies”; (c) “ScanLAB Projects: Science Museum Shipping Galleries point cloud data set”; (d) “ScanLAB Projects: Bi-plane point cloud data set”; (e) “UPM Point-cloud data”; (f) “Univ. Sao Paulo Point Cloud dataset”; and (g) 3DTK dataset.
3.2. Subjective Evaluation of Point Clouds
In [
30], a novel compression framework is proposed for progressive encoding of time-varying point clouds for 3D immersive and augmented video. Several point cloud coding improvements have been proposed, including generic compression framework, inter-predictive point cloud coding, efficient lossy color attribute coding, progressive decoding, and real-time implementation. Subjective experiments were done, concluding that the proposed compression framework shows similar results, compared to the original reconstructed point clouds.
In [
31], the authors presented a new subjective evaluation model for point clouds. Point clouds were degraded by downsampling, geometry noise, and color noise. Subjective quality assessment was performed using procedures defined in ITU-R BT.500 Recommendation. Point clouds were directly shown to the observers, without surface reconstruction, and were displayed using a typical 2D monitor.
Javaheri et al. [
32] presented a study on subjective quality assessment of point clouds, firstly degraded with impulse noise and afterwards denoised, using outlier removal and position denoising algorithms. Point clouds were presented to the observer according to the procedures defined in ITU-R BT.500-13, after surface reconstruction. In addition, different objective quality measures for point clouds are calculated and compared with subjective results. Overall, the authors concluded that point2plane measure (using root mean square error as a distance) has better correlation with MOS scores.
In [
33], the authors evaluated the subjective quality of rendered point clouds, after compression using two different methods: octree-based and projection-based method. The subjective evaluations were done using crowdsourced workers and expert viewers. Four test stimuli were used, namely “Chapel”, “Church”, “Human”, and “Text”, each with approximately 200 million geometry points. The authors concluded that the projection-based method was preferred, compared to an octree-based method, while having similar compression ratios.
In [
34], the authors used PCC-DASH protocol for HTTP adaptive streaming, to create different degradations while streaming scenes that include several dynamic point clouds. Original point clouds were taken from the “8i Voxelized Full Bodies (8iVFB v2)” dataset [
28] and were encoded using the
V-PCC coder described above, with five different bitrates. Afterwards, objective image and video quality measures were calculated (between generated video sequences from the original and degraded point cloud sequences), with the objective quality estimates showing high correlation with subjective scores.
In [
35], the authors presented subjective quality evaluation of point clouds that were encoded directly using
V-PCC, or by encoding their mesh representations (in which case both their atlas images and vertices had to be compressed). They also proposed no-reference objective quality measure, depending on the used bitrate and observers’ distance from the screen.
In [
36], the authors conducted a detailed investigation of the following aspects for point cloud streaming: encoding, decoding, segmentation, viewport movement patterns, and viewport prediction. In addition, they proposed ViVo, a mobile volumetric video streaming system with three visibility-aware optimizations. ViVo determines the video content to fetch based on how, what, and where a viewer perceives for reducing bandwidth consumption of volumetric video streaming. ViVo showed that, on average, it can save approximately 40% of data usage (up to 80%) with no drop in subjective quality.
5. Common Methods for the Analysis and Presentation of the Results from Subjective Assessment
To be able to compare subjective MOS grades between different laboratories, or to compare subjective Mean opinion score (MOS) grades with different objective quality estimators, different correlation measures can be used. The most common are Pearson’s Correlation Coefficient (Pcc), Spearman’s Rank Order Correlation Coefficient (SROCC), and Kendall’s Rank Order Correlation Coefficient (KROCC). Pearson’s correlation coefficient measures the agreement between two variables
x and
y observed through
n samples and is defined in Equation (
9)
where
and
are sample values (e.g.,
x can be MOS values from the first laboratory, while
y can be MOS values from the second laboratory; alternatively,
x can be MOS values and
y objective scores after nonlinear regression), whereas
and
are sample mean and
and
are corrected sample standard deviations from
x and
y. Spearman’s rank order correlation coefficient [
45] is another useful correlation measure to compare ordinal association between two variables. Unlike PCC that calculates linearity, SROCC calculates monotonicity of the relationship between them. To calculate SROCC, each variable has to be ranked firstly (for all tied ranks, mean rank is assigned) and afterwards PCC can be calculated over the ranked variables. Kendall’s rank order correlation coefficient [
46] is also a correlation measure that, similarly to SROCC, calculates ordinal association between two variables. After both variables are ranked, pair observations over them need to be found: concordant pairs, discordant pairs, and possibly tied pairs (neither concordant nor discordant). Generally, three types of KROCC are defined, usually called
,
, and
. While
does not take into account tied pairs,
and
do. In addition,
is usually used for variables that have the same number of possible values (before ranking), while
also takes into account different number of possible values. We use
coefficient below.
When using PCC, usually a nonlinear regression function is used to better fit objective measures with subjective MOS scores. For comparison between different MOS scores (e.g., to compare results from different laboratories), linear regression can also be used. Equations (
10)–(
13) show some common fitting functions used in the context of visual stimuli quality evaluations.
Equations (
10) and (
11) describe logistic fittings and were used by Sheikh and Bovik [
47] and Larson and Chandler [
48], respectively, while Equations (
12) and (
13) describe cubic and linear fittings.
An important step in the processing of the MOS scores is outlier detection, used, e.g., in the DSIS subjective assessment method described in ITU-R BT.500-14 [
24]. Firstly, according to Equation (
14), kurtosis
and standard deviation
are calculated for all video sequences
. Afterwards, a screening rejection algorithm is applied, as described in (
15).
Another goodness of fit measure is root mean squared error (RMSE), defined by Equation (
16)
Outlier ratio (OR) is also used for comparison between two sets of grades, e.g., from two different laboratories, and can be defined as a number of grades that satisfy Equation (
17).
In Equation (
17),
x and
y are MOS values from two different laboratories, while CI is defined as Equation (
18)
where
m is a number of gathered scores per video sequence,
t(
m − 1) is Student’s t inverse cumulative distribution function (defined for the 95% confidence interval below, two-tailed test) with
degrees of freedom, and
and
are standard deviations for all gathered scores for video sequence
i.
The outlier ratio (OR) can also be used to compare MOS scores and objective scores, by counting the number of grades that satisfy Equation (
19)
where
represents objective score for video sequence
i,
represents MOS score for video sequence
i, and
is the standard deviation for all gathered subjective scores for video sequence
i.
6. Point Cloud Subjective and Objective Quality Evaluation—A Case Study
In this section, we describe a case study on the evaluation of point clouds subjective and objective quality. This study involved two research laboratories, one in the University of Coimbra (UC), Portugal and the other in University North (UNIN), Croatia. The study included collection of subjective quality scores using observers in both laboratories. The scores were evaluated calculating correlations between the scores collected at UC and UNIN. Further, correlations between objective measures and subjective MOS grades were computed both for UC and UNIN scores.
Part of these results is also presented in [
49]. The objective quality measures were computed according to Tian et al. [
40].
Figure 5 Illustrates the point clouds used in the study. All point clouds are publicly available in
JPEG Pleno Point Cloud datasets [
27,
28].
6.1. Inter-Laboratory Correlation Results
The details of the subjective evaluation are described in [
49]. Concisely, six point clouds were used for subjective assessment, each compressed with two MPEG codecs (
G-PCC Oct-tree,
G-PCC Tri-soup, and
V-PCC), each with five compression levels, adjusted to represent diverse visual impairments. Target bitrates were chosen similarly to the MPEG point cloud coding Common Test Conditions (CTC) [
42], with some differences explained in [
49]. DSIS evaluation protocol was used, simultaneously showing original and degraded point cloud and a five-point rating was adopted (very annoying; annoying; slightly annoying; perceptible, but not annoying; and imperceptible). Overall, 96 point clouds were used in the subjective evaluation, including six hidden reference (original) point clouds (six point clouds, three different encoder types, and five levels of compression per encoder plus the six originals equals 6 × 3 × 5 + 6 = 96 point clouds). Each point cloud was rotated around its vertical axis by 0.5 per frame, giving overall 720 frames per tested point cloud. All frames were packed in video sequences with 12 s duration and 60 fps (12 × 60 = 720 frames), using FFmpeg and H.264/AVC compression with lower constant rate factor (crf), producing near lossless quality. Finally, video sequences were presented to the observers using customized MPV video player, with overall duration of 96 × 12 = 1152 s or around 20 min, in addition to the time needed to enter the score. Sequences were shown to the observers randomly, but taking into account that the same content is not shown consecutively. Equipment characteristics and observers demographic statistics are presented in
Table 1.
Outlier rejection was performed according to Equation (
15) and no outliers were found. Afterwards, MOS scores and CI were calculated according to Equation (
18). The results for UC and UNIN are presented in
Figure 6 and
Figure 7. Outlier numbers are presented in
Table 1 too.
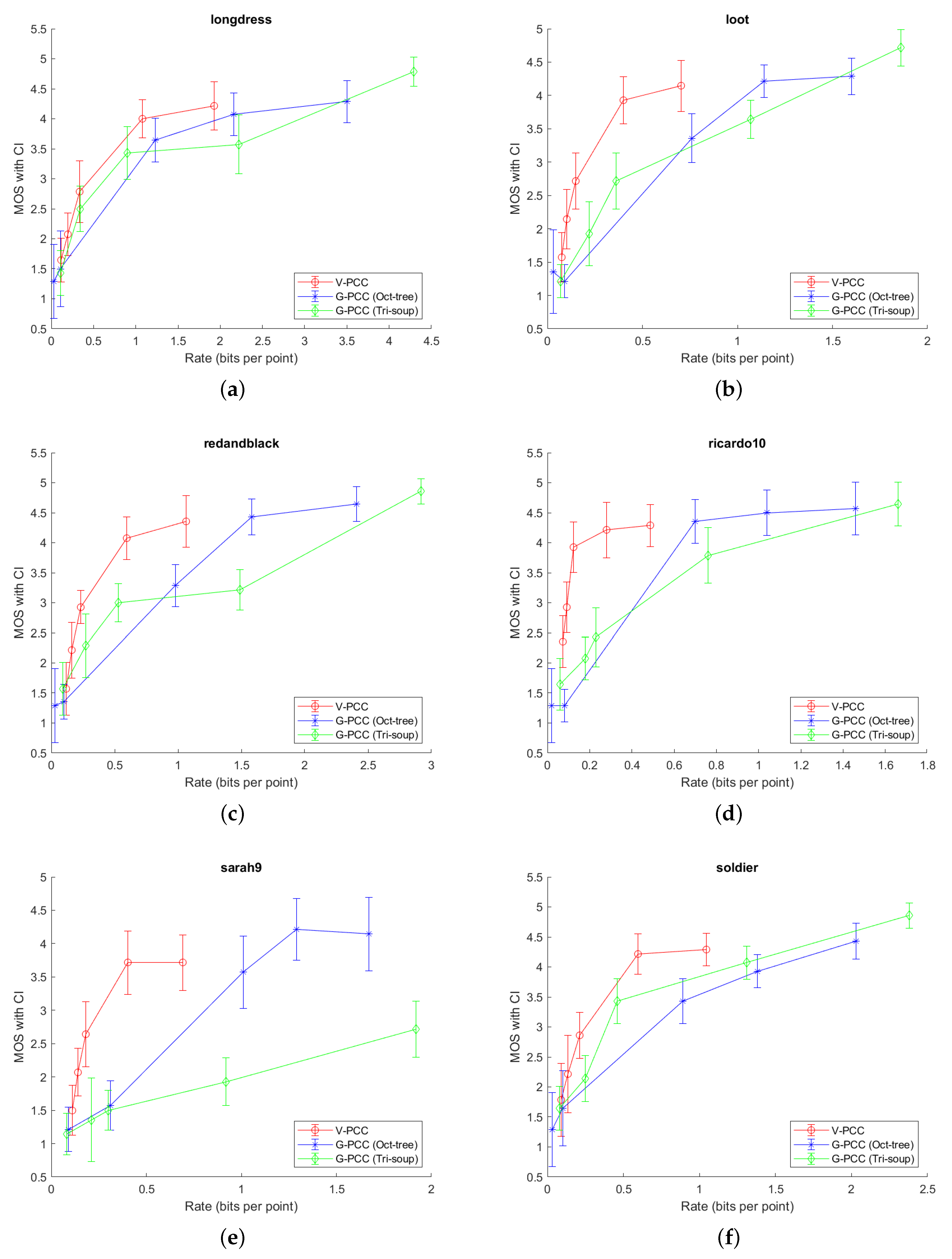
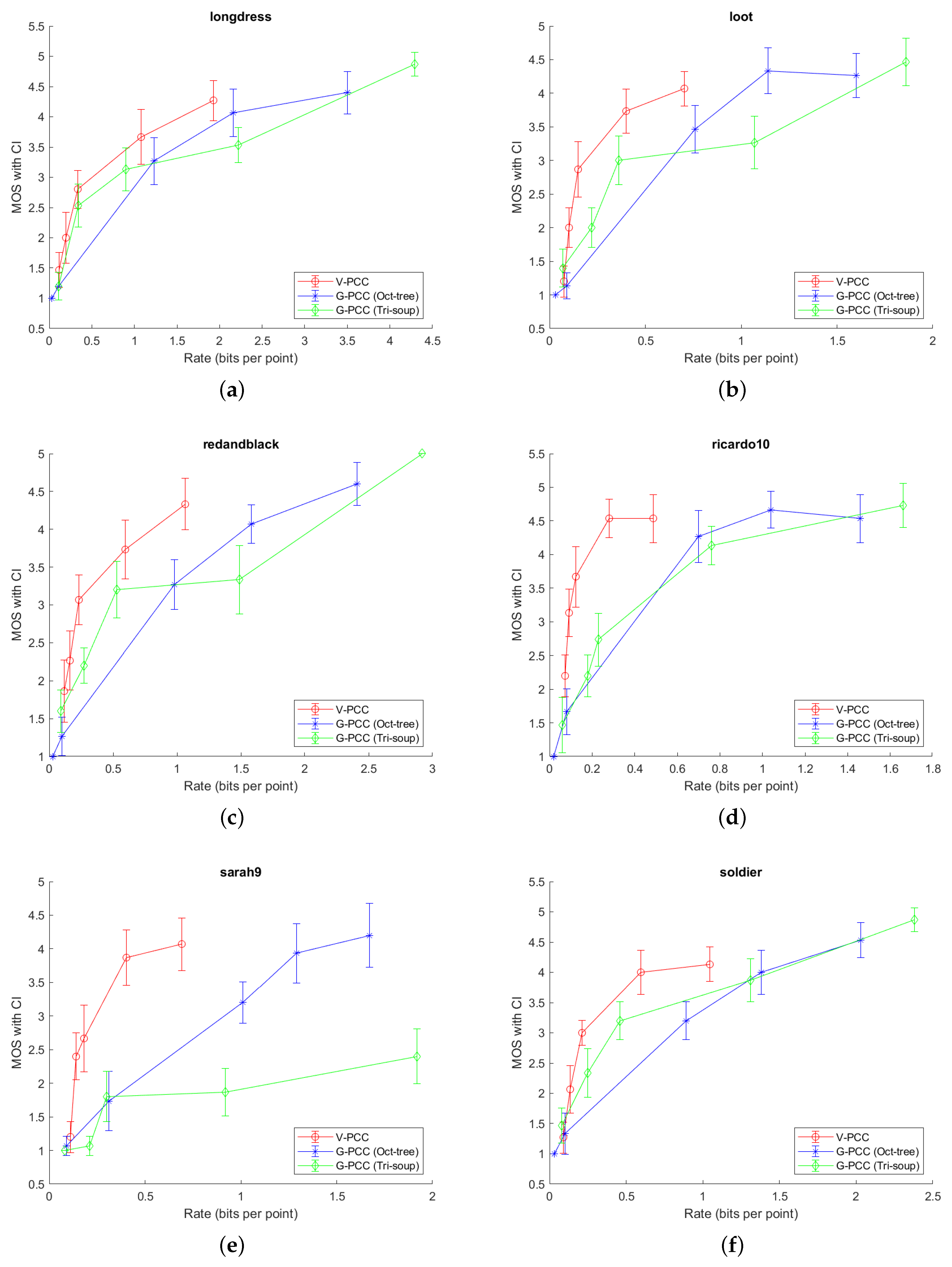
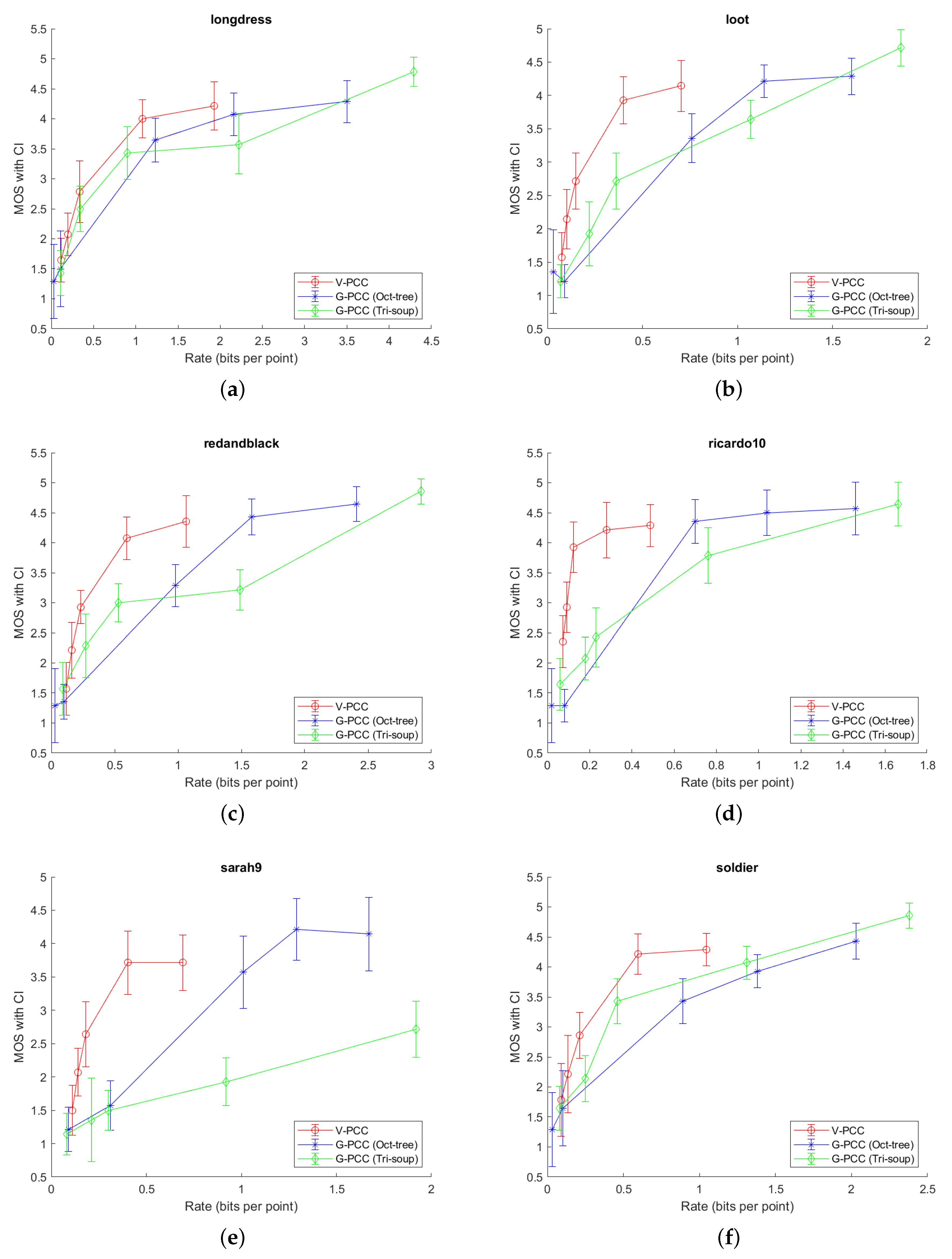
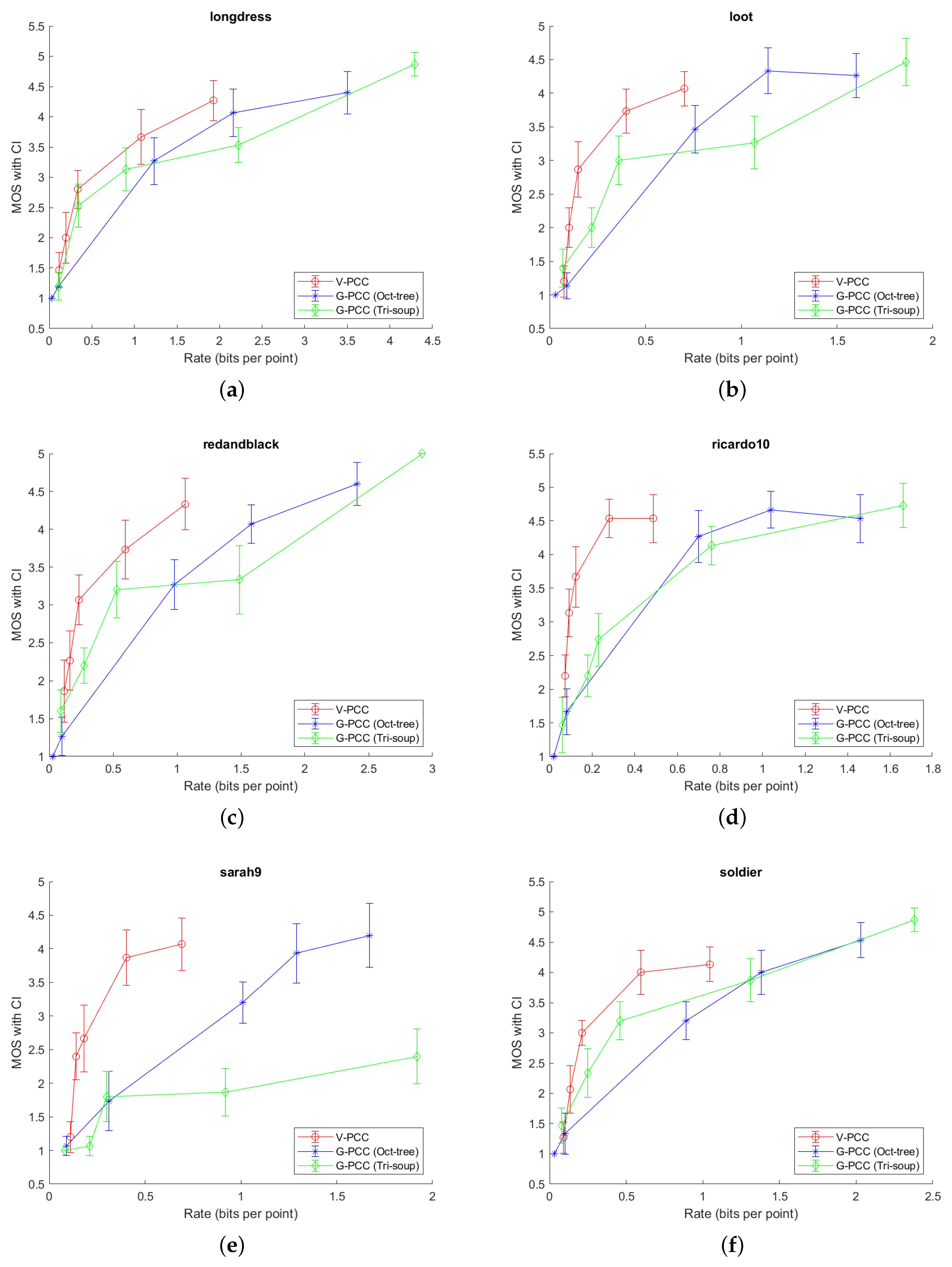
In
Figure 6 and
Figure 7, it can be generally seen that
V-PCC coder outperforms
G-PCC for all tested point clouds, or, alternatively, needs less bits per point (bpp) for the similar MOS score. However, in this experiment, we tested only one type of content, which may be better suited for
V-PCC encoder. A different content type (e.g., in sensor-based navigation) might obtain better results with different encoder. In addition, it can be seen that Longdress point cloud needs more bpp, to obtain higher MOS score, compared to the all other point clouds. Redandblack and soldier point clouds are in the middle, when comparing needed bpp and higher MOS. Loot, Ricardo10 and Sarah9 need less bpp to obtain higher MOS score, when comparing with the other three point clouds. This can be explained because of the different complexity of each compressed point cloud. Longdress, Redanblack and Soldier have more details, comparing to, e.g., Ricardo10 and Sarah9 point clouds, which can be also seen in
Figure 5. Another problem with point clouds Ricardo10 and Sarah9 may be the noise which is present even in the original point clouds (
Figure 5); thus, observers might not notice finer differences when comparing them with (not highly) compressed point clouds.
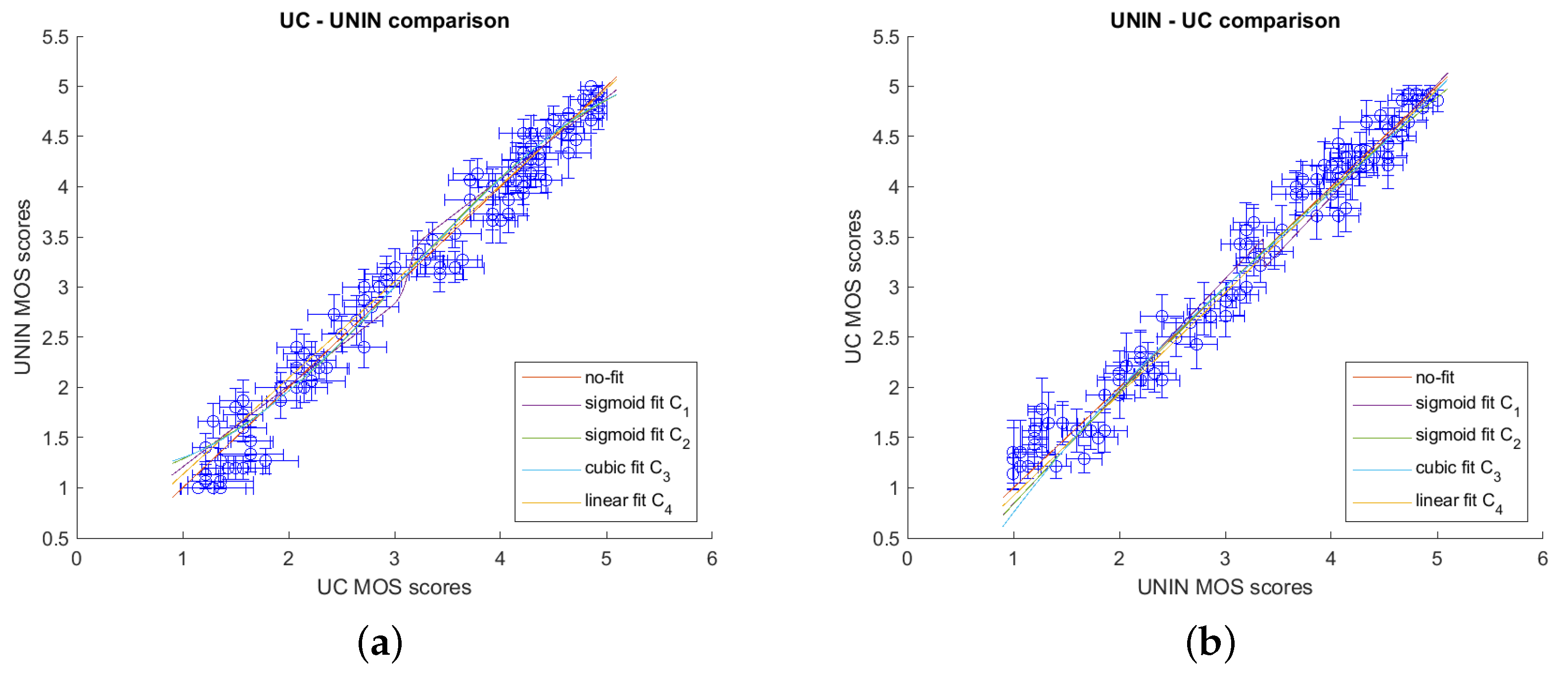
Afterwards, a comparison between laboratories was performed computing correlations for the pairs UC-UNIN and UNIN-UC using Equations (
10)–(
13) as fitting functions.
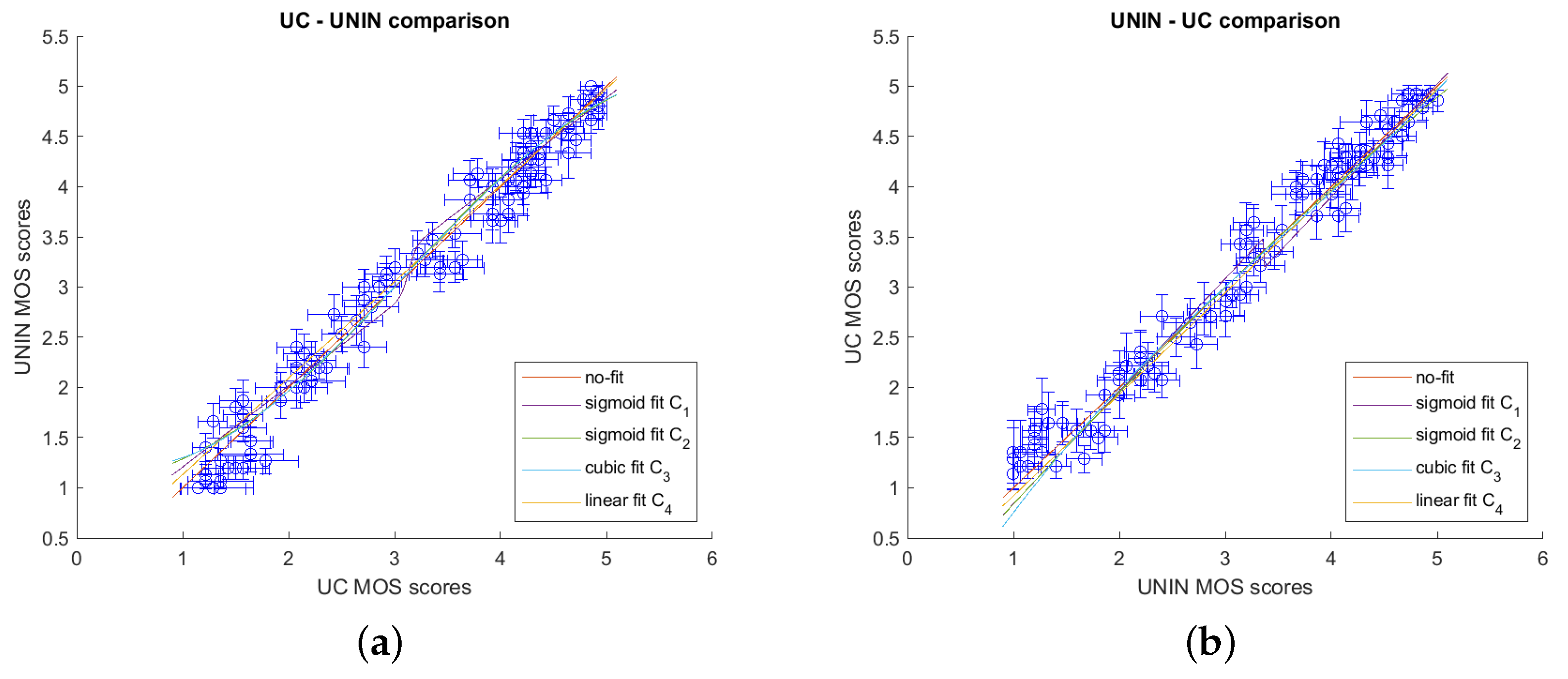
Figure 8 presents the comparison between laboratories in graphical form, while
Table 2 and
Table 3 present correlation results using PCC ((
9)), SROCC, KROCC, RMSE ((
16)), and OR ((
17)). From the results, it can be seen that correlation between both laboratories is high, meaning that the subjective assessment was correctly performed.
6.2. Objective Quality Measures and Correlation with MOS Scores
In this section, we present correlation results of the subjective scores from UC and UNIN laboratories as well as with different objective measures described above. The results are calculated using only 84 MOS scores: six were skipped because they belonged to the original undegraded reference point clouds and six were encoded using G-PCC coder with parameters for lossless geometry.
Agreements between scores were calculated using PCC ((
9)), SROCC, KROCC, RMSE ((
16)), and OR ((
19)). PCC was calculated after nonlinear regression using C
1 ((
10)), C
2 ((
11)), and C
3 ((
12)) functions. The RMSE
p2p measure was used as square root of MSE (Equation (
3)), while Hausdorff
p2p distance used (
1). RMSE
p2pl was calculated as Equation (
5) and Hausdorff
p2pl as Equation (
6). PSNR values were calculated similarly to Equation (
7), but with
in numerator and
p value being defined as the largest diagonal distance of a bounding box of the point cloud, as defined in [
40]. From the results in
Table 4 and
Table 5 and
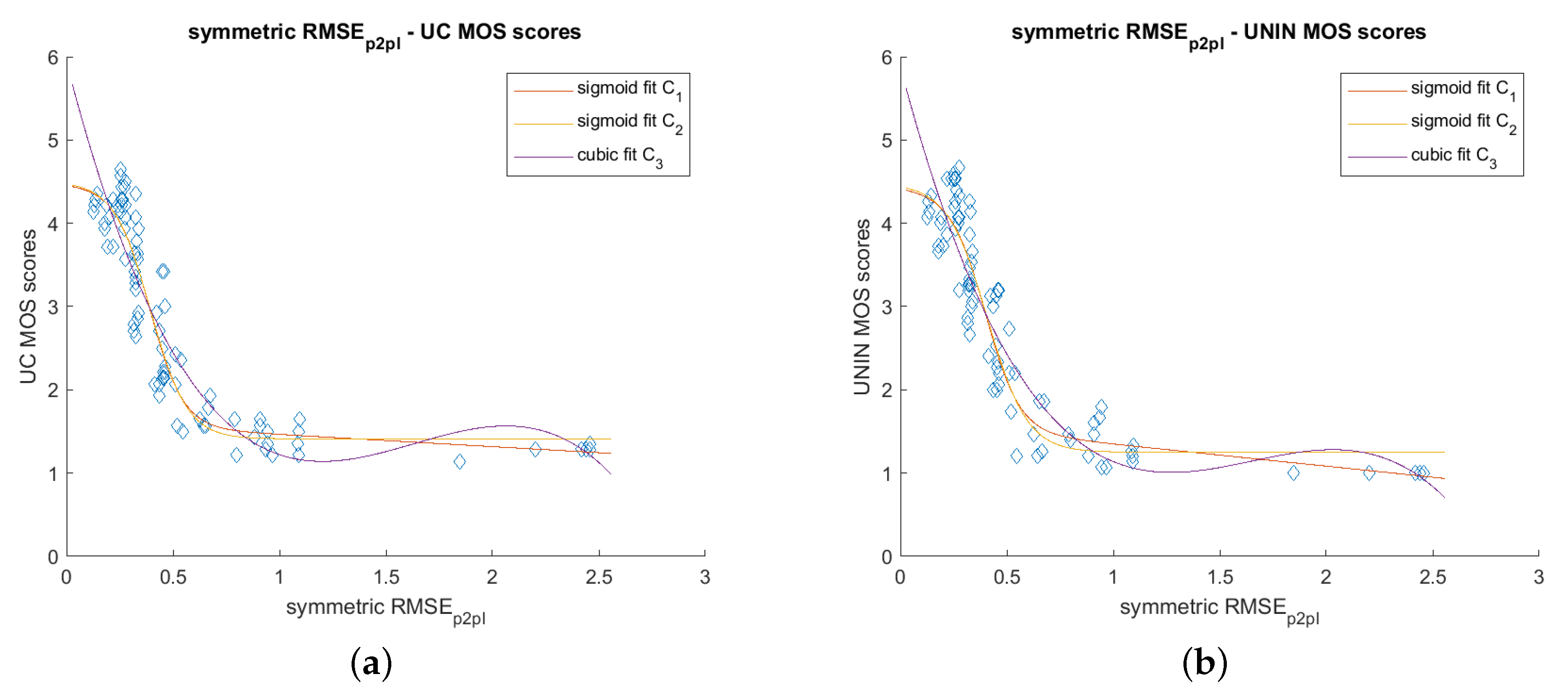
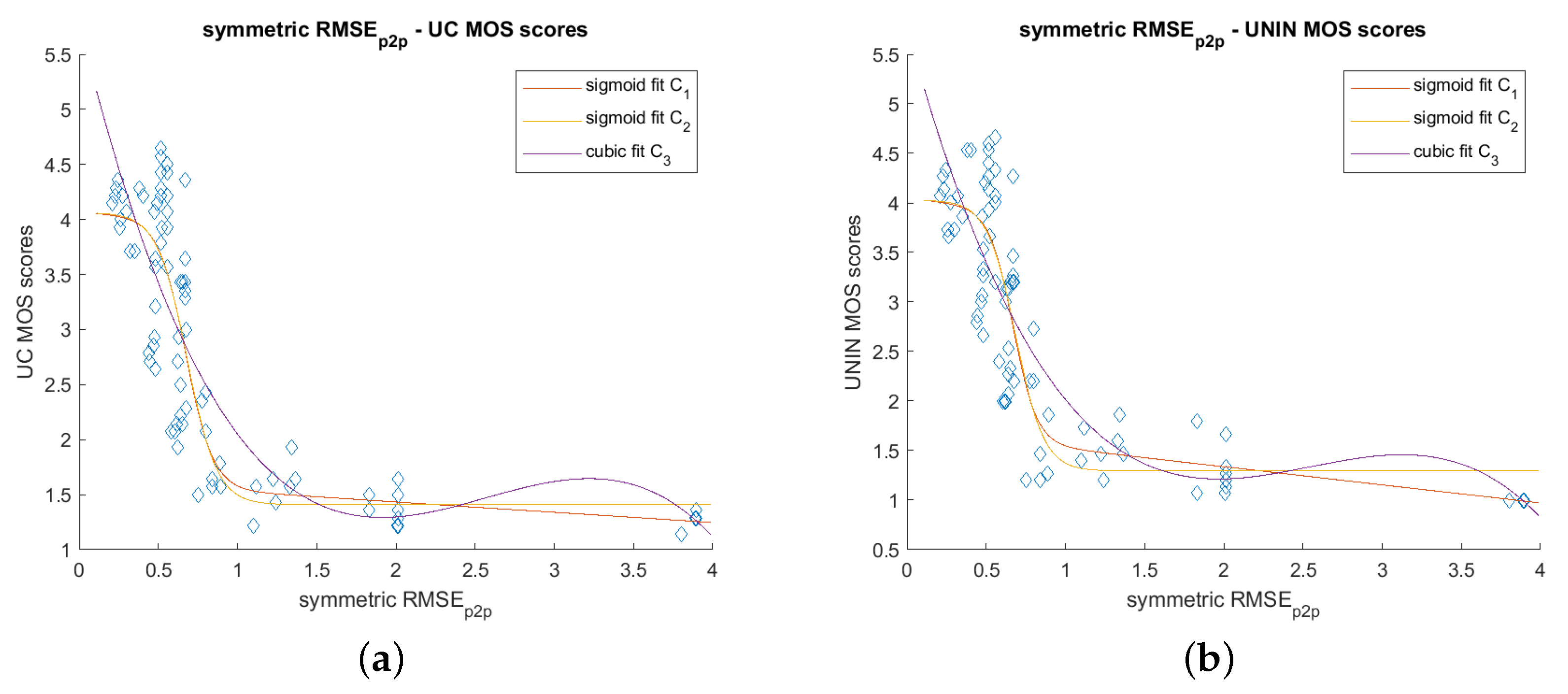
Figure 9, it can be seen that the best performing objective measure is RMSE
p2pl, in both UC and UNIN laboratories. The second best measure is RMSE
p2p, also in both tested laboratories (
Table 4 and
Table 5 and
Figure 10). Other objective measures have lower correlation scores.
When comparing different nonlinear regression functions used in experiments, best results were obtained using C1 as fitting function for PCC calculation, in both UC and UNIN laboratories. The second best is C2, also in both laboratories, being only slightly lower than case with C1. When comparing RMSEp2p with PSNRRMSE,p2p and RMSEp2pl with PSNRRMSE,p2pl, it can be noticed that PSNR obtained lower correlation than RMSE. PSNR was calculated using p value defined as the largest diagonal distance of a bounding box of the point cloud.
PSNR achieves higher correlation if it is calculated as defined in Equation (
7), e.g., with
in numerator and
p value being defined as the peak constant value (e.g., 511 for 9-bit precision, for Sarah9 point cloud and 1023 for 10-bit precision for other tested point clouds;
Table 6). In this case, RMSE and PSNR have similar correlation scores, e.g., PCC_C
1 between PSNR
RMSE,p2pl and MOS is around 0.94 and PCC_C
1 between PSNR
RMSE,p2p and MOS is around 0.87, in both UC and UNIN laboratories. In addition, best results were obtained using C
1 as fitting function for PCC calculation, in both UC and UNIN laboratories, while C
2 produces slightly lower PCC correlation between PSNR and MOS.
7. Conclusions
In this paper, we present a general framework for subjective evaluation of point clouds, as well as currently proposed objective metrics for point cloud quality measurement. Afterwards, we present a case study using results from subjective evaluations of point clouds performed in a collaboration between two international laboratories at the University of Coimbra in Portugal and the University North in Croatia. The results as well as their analysis show that the correlation between both laboratories is high, meaning that the subjective assessments were performed correctly. When comparing different geometry-based objective measures, the objective quality estimates that were found to be better correlated with subjective scores were obtained using a symmetric RMSEp2pl measure, in both laboratories, while second best was RMSEp2p measure, also for both laboratories subjective scores sets.
In view of the results obtained, it is clear that new objective metrics should be developed aiming at better correlation with subjective grades. Due to the joint importance of geometry and attribute (color) information, new measures should be based on these two sets of point cloud information. It is also clear that new point cloud test datasets should be compiled, representing different objects and diverse environments, as current datasets are mostly constituted by small objects and a few human figures. These activities will be the focus of future research by the authors.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}