Scene Text Detection in Natural Images: A Review

Abstract
:1. Introduction
2. Background
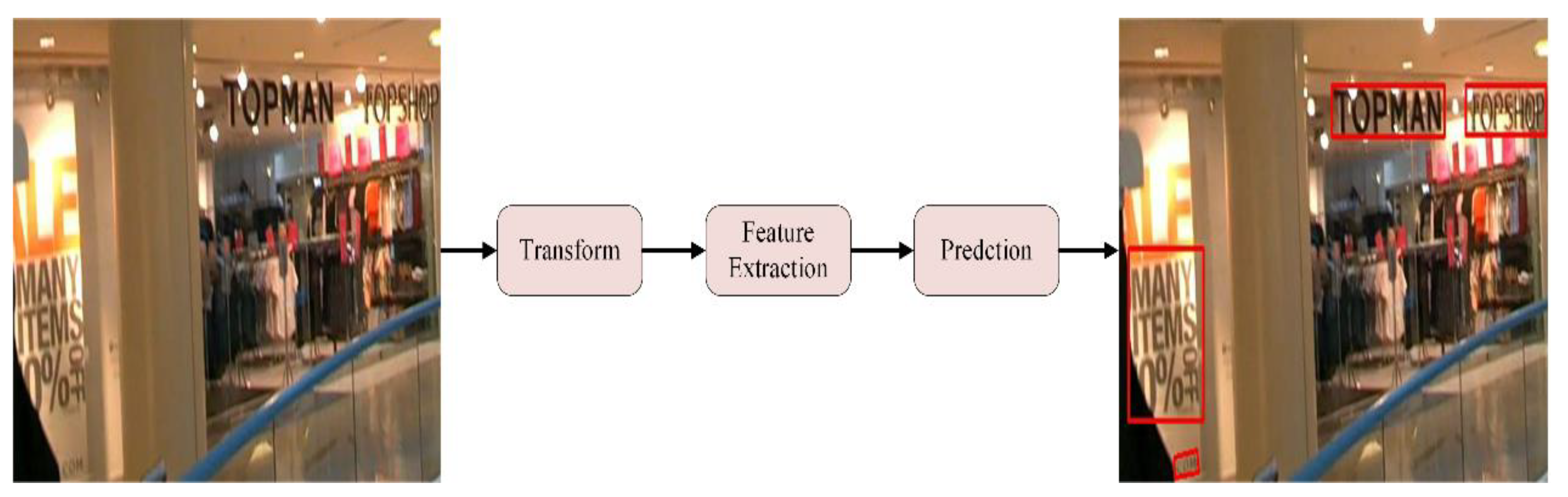
2.1. What Is STD?
- Transformation. In this stage, the input image is transformed into a new one using a spatial transformation network (STN) [18] framework, while any text contained in it is rectified. The rectification process facilitated subsequent stages. It is powered by a flexible thin-plate spline (TPS) transformation, which can handle a variety of text irregularities [19] and diverse aspect ratios of text lines [20].
- Feature Extraction. This stage maps the input image to a representation that focuses on the attributes relevant for character recognition while suppressing irrelevant features, such as font, color, size, and background. With convolutional networks entering a phase of rapid development after AlexNet’s [21] success at the 2012 ImageNet competition, Visual Geometry Group Network (VGGNet), GoogleNet [22], RestNet [23], and DetNet [24] are often used as a feature extractor.
- Prediction. Predicts the position of the text in the image, usually expressed as a coordinate point.
2.2. Features of Scene Text
- Multiple languages may be mixed.
- Characters may occur in different sizes, fonts, colors, brightness, contrast, etc.
- Text lines may be horizontal, vertical, curved, rotated, twisted, or in other patterns.
- The text area in the image may also be distorted (perspective, affine transformation), suffer defects, blurring, or other phenomena.
- The background of scene images is extremely diverse, and text may appear on a plane, surface, or folded surface; the text region may be near complex interference textures, or non-text areas may have textures that approximate text, such as sand, grass, fences, brick walls, etc.
3. Traditional Methods for STD
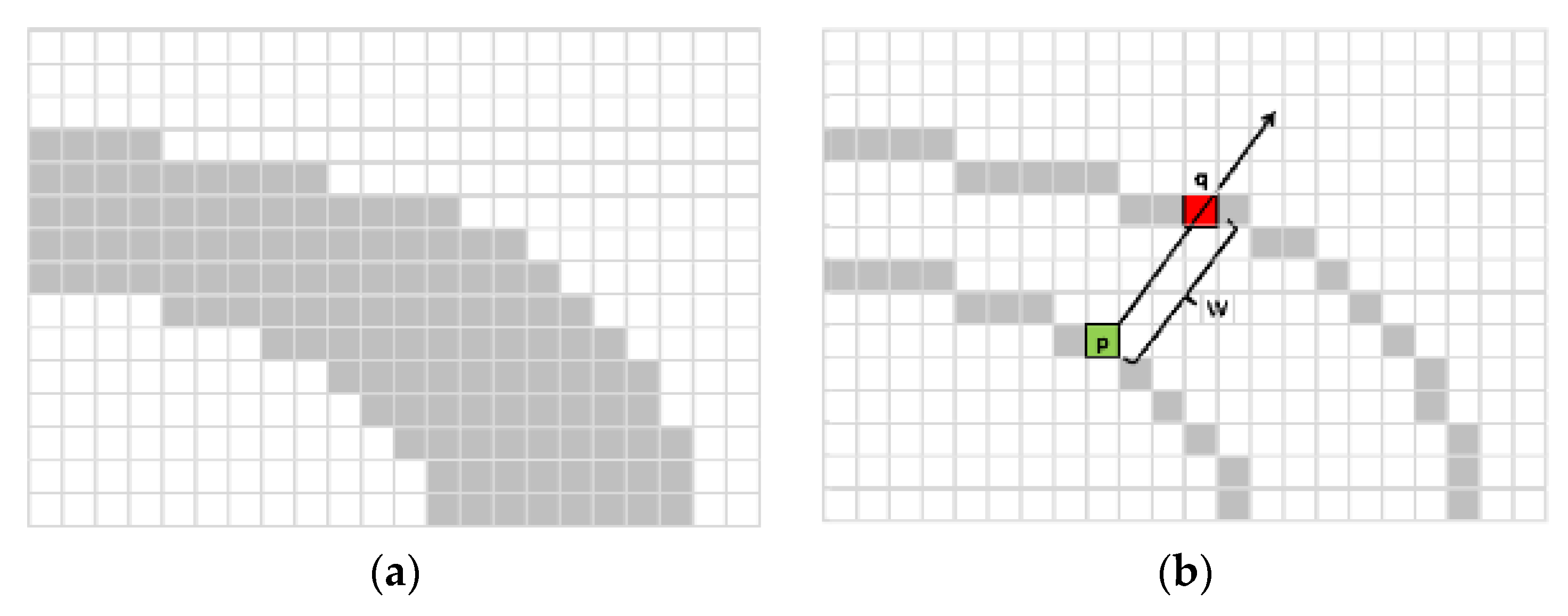
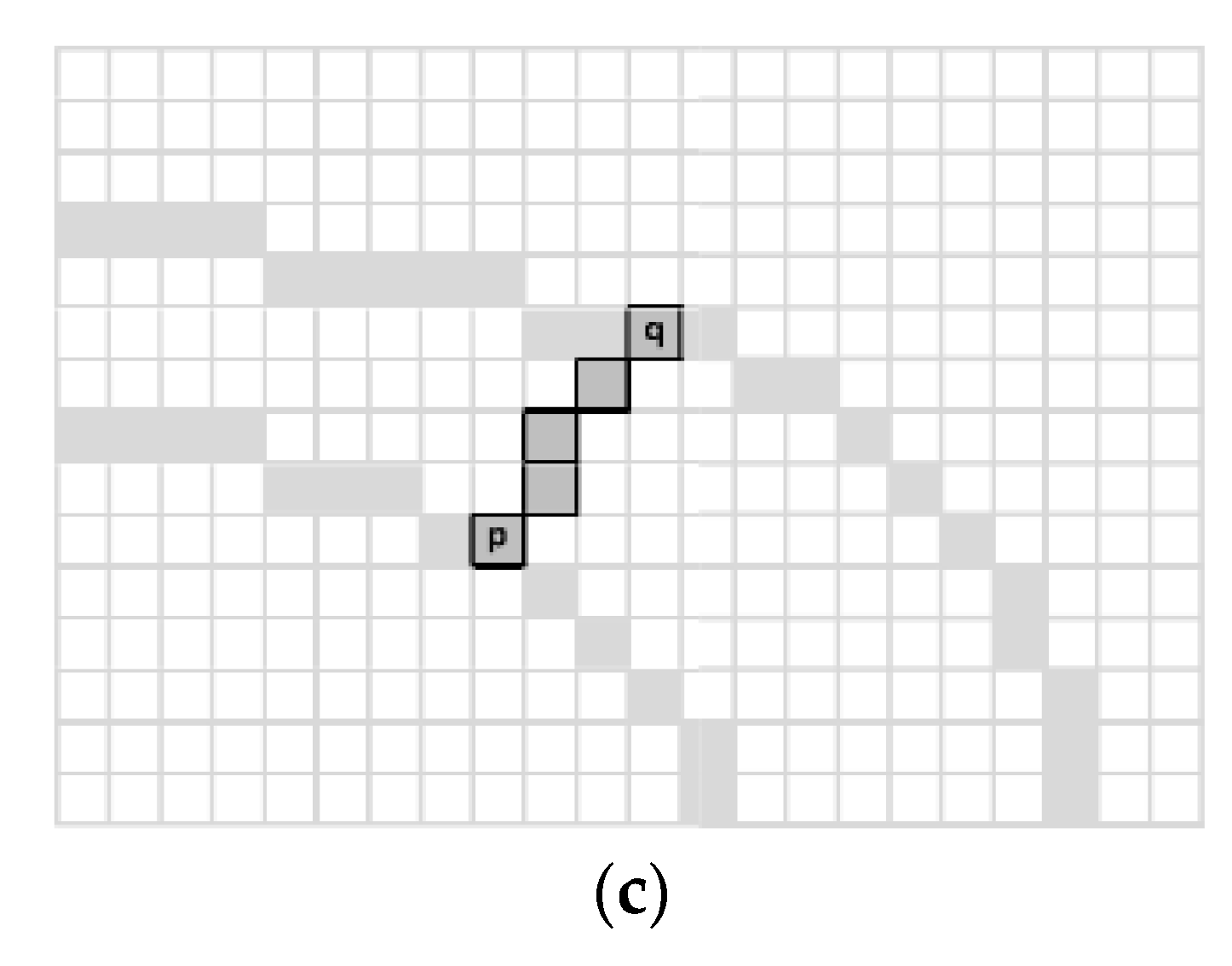
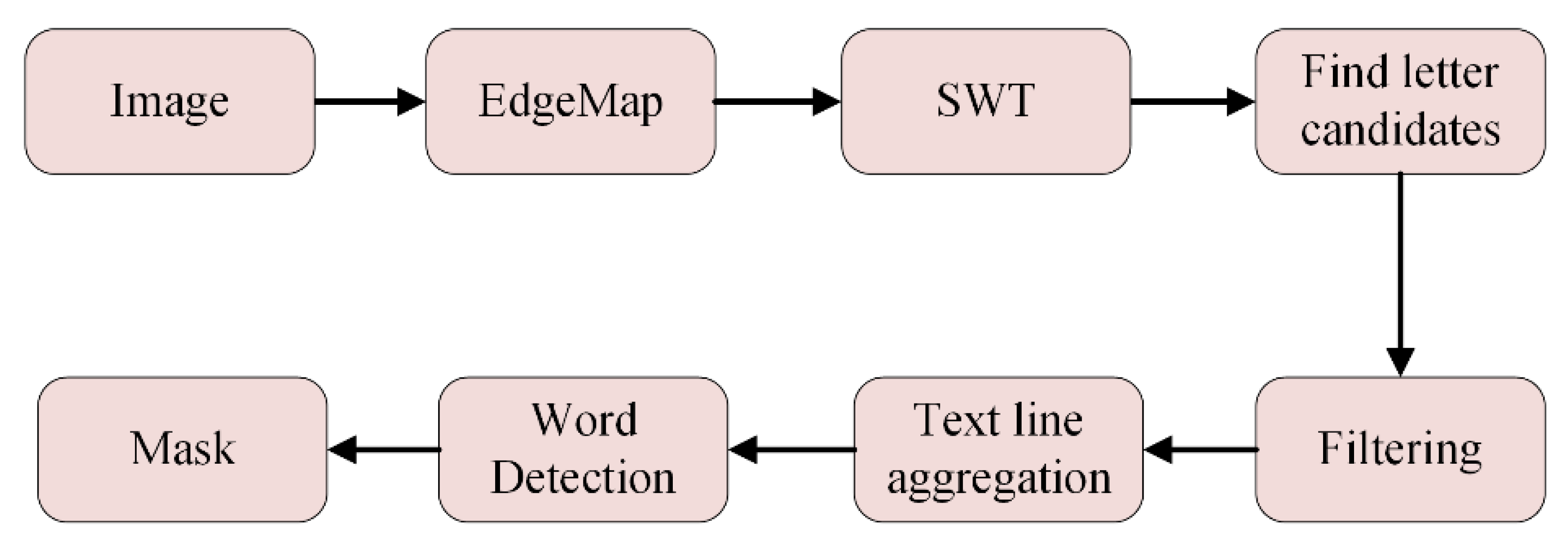
3.1. SDW Methods
3.2. CCA Methods
4. Deep Learning Approaches for STD
4.1. Region Proposal-Based Methods
4.2. Image Segmentation-Based Methods
4.3. Hybrid Methods
5. STD Resources: Datasets
6. Evaluations
6.1. Evaluation Metrics for STD
6.1.1. ICDAR Evaluation Protocols
6.1.2. AP-Based Evaluation Methods
6.1.3. Tightness-Aware Intersection-Over-Union (TIoU) Evaluation Protocol
6.1.4. Discussion
6.2. Results on Benchmark Datasets
7. Conclusions and Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Greenhalgh, J.; Mirmehdi, M. Recognizing Text-Based Traffic Signs. IEEE Trans. Intell. Transp. 2015, 16, 1360–1369. [Google Scholar] [CrossRef]
- Yin, X.-C.; Zuo, Z.-Y.; Tian, S.; Liu, C.-L. Text Detection, Tracking and Recognition in Video: A Comprehensive Survey. IEEE Trans. Image Process. 2016, 25, 2752–2773. [Google Scholar] [CrossRef] [PubMed]
- Ham, Y.K.; Kang, M.S.; Chung, H.K.; Park, R.-H.; Park, G.T. Recognition of raised characters for automatic classification of rubber tires. Opt. Eng. 1995, 34, 102. [Google Scholar] [CrossRef]
- Shilkrot, R.; Huber, J.; Liu, C.; Maes, P.; Nanayakkara, S.C. FingerReader: A wearable device to support text reading on the go. In CHI’14 Extended Abstracts on Human Factors in Computing Systems; ACM: New York, NY, USA, 2014; pp. 2359–2364. [Google Scholar]
- Hedgpeth, T.; Black, J.A., Jr.; Panchanathan, S. A demonstration of the iCARE portable reader. In Proceedings of the 8th International ACM SIGACCESS Conference on Computers and Accessibility, New York, NY, USA, 23 October 2006; Volume 279. [Google Scholar]
- Smith, R. A simple and efficient skew detection algorithm via text row accumulation. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 2, pp. 1145–1148. [Google Scholar] [CrossRef]
- LEE, C.-M.; Kankanhalli, A. Automatice extraction of characters in complex scene images. Int. J. Pattern Recogn. 1995, 9, 67–82. [Google Scholar] [CrossRef]
- Zhong, Y.; Karu, K.; Jain, A.K. Locating text in complex color images. Pattern Recognit. 1995, 1, 146–149. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Richardson, E.; Azar, Y.; Avioz, O.; Geron, N.; Ronen, T.; Avraham, Z.; Shapiro, S. It’s All about the Scale—Efficient Text Detection Using Adaptive Scaling. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision(WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1833–1842. [Google Scholar] [CrossRef]
- Yang, Q.; Cheng, M.; Zhou, W.; Chen, Y.; Qiu, M.; Lin, W.; Chu, W. IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection. arXiv 2018, arXiv:1805.01167. [Google Scholar]
- Yang, P.; Yang, G.; Gong, X.; Wu, P.; Han, X.; Wu, J.; Chen, C. Instance Segmentation Network With Self-Distillation for Scene Text Detection. IEEE Access 2020, 8, 45825–45836. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, C.; Shen, W.; Yao, C.; Liu, W.; Bai, X. Multi-oriented Text Detection with Fully Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4159–4167. [Google Scholar]
- Liu, J.; Liu, X.; Sheng, J.; Liang, D.; Li, X.; Liu, Q. Pyramid Mask Text Detector. arXiv 2019, arXiv:1903.11800. [Google Scholar]
- Christen, M.; Saravanan, A. RFBTD: RFB Text Detector. arXiv 2019, arXiv:1907.02228. [Google Scholar]
- Huang, W.; Qiao, Y.; Tang, X. Robust Scene Text Detection with Convolution Neural Network Induced MSER Trees. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 497–511. [Google Scholar]
- Tang, Y.; Wu, X. Scene Text Detection and Segmentation Based on Cascaded Convolution Neural Networks. IEEE Trans. Image Process. 2017, 26, 1509–1520. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 2. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. ASTER: An Attentional Scene Text Recognizer with Flexible Rectification. IEEE Trans. Pattern. Anal. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Robust Scene Text Recognition with Automatic Rectification. arXiv 2016, arXiv:1603.03915. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. Acm. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tychsen-Smith, L.; Petersson, L. DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 428–436. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on Robust Reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Gopalan, C.; Manjula, D. Sliding window approach based Text Binarisation from Complex Textual images. arXiv 2010, arXiv:1003.3654. [Google Scholar]
- Hutchison, D.; Kanade, T.; Kittler, J.; Kleinberg, J.M.; Mattern, F.; Mitchell, J.C.; Naor, M.; Nierstrasz, O.; Rangan, C.P.; Steffen, B.; et al. Word Spotting in the Wild. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 591–604. [Google Scholar]
- Fabrizio, J.; Marcotegui, B.; Cord, M. Text detection in street level images. Pattern Anal. Appl. 2013, 16, 519–533. [Google Scholar] [CrossRef] [Green Version]
- He, T.; Huang, W.; Qiao, Y.; Yao, J. Text-Attentional Convolutional Neural Network for Scene Text Detection. IEEE Trans. Image Process. 2016, 25, 2529–2541. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Yuille, A.L. Detecting and reading text in natural scenes. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 366–373. [Google Scholar]
- Lee, J.-J.; Lee, P.-H.; Lee, S.-W.; Yuille, A.; Koch, C. AdaBoost for Text Detection in Natural Scene. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 429–434. [Google Scholar]
- Wei, Y.C.; Lin, C.H. A robust video text detection approach using SVM. Expert Syst. Appl. 2012, 39, 10832–10840. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Xiao, B.; Shi, C. A New Method for Text Verification Based on Random Forests. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italy, 18–20 September 2012; pp. 109–113. [Google Scholar]
- Shi, C.; Wang, C.; Xiao, B.; Gao, S.; Hu, J. End-to-end scene text recognition using tree-structured models. Pattern Recogn. 2014, 47, 2853–2866. [Google Scholar] [CrossRef]
- Li, H.; Doermann, D.; Kia, O. Automatic text detection and tracking in digital video. IEEE Trans. Image Process. 2020, 9, 147–156. [Google Scholar] [CrossRef]
- Hanif, S.M.; Prevost, L. Text Detection and Localization in Complex Scene Images using Constrained AdaBoost Algorithm. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, X.; Lin, K.-H.; Fu, Y.; Hu, Y.; Liu, Y.; Huang, T.S. Text from Corners: A Novel Approach to Detect Text and Caption in Videos. IEEE Trans. Image Process. 2011, 20, 790–799. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Chen, X.; Yang, J. Detection of Text on Road Signs from Video. IEEE Trans. Intell. Transp. Syst. 2005, 6, 378–390. [Google Scholar] [CrossRef]
- Ye, Q.; Huang, Q.; Gao, W.; Zhao, D. Fast and robust text detection in images and video frames. Image Vis. Comput. 2005, 23, 565–576. [Google Scholar] [CrossRef]
- Neumann, L.; Matas, J. Real-Time Scene Text Localization and Recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, Rhode Island, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Mancas-Thillou, C.; Gosselin, B. Color text extraction with selective metric-based clustering. Comput. Vis. Image Und. 2007, 107, 97–107. [Google Scholar] [CrossRef]
- Wang, K.; Kangas, J.A. Character location in scene images from digital camera. Pattern Recogn. 2003, 36, 2287–2299. [Google Scholar] [CrossRef]
- Zhu, Y.; Yao, C.; Bai, X. Scene text detection and recognition: Recent advances and future trends. Front. Comput. Sci. 2015, 10, 19–36. [Google Scholar] [CrossRef]
- Jamil, A.; Siddiqi, I.; Arif, F.; Raza, A. Edge-Based Features for Localization of Artificial Urdu Text in Video Images. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1120–1124. [Google Scholar]
- Liu, X.; Samarabandu, J. Multiscale Edge-Based Text Extraction from Complex Images. IEEE Int. Conf. Multimed. Expo 2006, 52, 1721–1724. [Google Scholar]
- Buta, M.; Neumann, L.; Matas, J. FASText: Efficient Unconstrained Scene Text Detector. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, CL, USA, 11–18 December 2015; pp. 1206–1214. [Google Scholar]
- Liu, C.; Wang, C.; Dai, R. Text detection in images based on unsupervised classification of edge-based features. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Korea, 31 August–1 September 2005; Volume 2, pp. 610–614. [Google Scholar]
- Epshtein, B.; Ofek, E.; Wexler, Y. Detecting text in natural scenes with stroke width transform. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2963–2970. [Google Scholar]
- Neumann, L.; Matas, J. A Method for Text Localization and Recognition in Real-World Images. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2011; Springer: Berlin/Heidelberg, Germany, 2011; Volume 770–783. [Google Scholar]
- Mosleh, A.; Bouguila, N.; Hamza, A.B. Image Text Detection Using a Bandlet-Based Edge Detector and Stroke Width Transform. In Proceedings of the BMVC, Guildford, UK, 3–7 September 2012; pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Lin, Z.; Yang, J.; Wang, J. Text Localization in Natural Images Using Stroke Feature Transform and Text Covariance Descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1241–1248. [Google Scholar]
- Karthikeyan, S.; Jagadeesh, V.; Manjunath, B.S. Learning bottom-up text attention maps for text detection using stroke width transform. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 3312–3316. [Google Scholar]
- Jameson, J.; Abdullah, S.N.H.S. Extraction of arbitrary text in natural scene image based on stroke width transform. In Proceedings of the 2014 14th International Conference on Intelligent Systems Design and Applications, Okinawa, Japan, 28–30 November 2014; pp. 124–128. [Google Scholar] [CrossRef]
- Jian, H.; Xiaopei, L.; Qian, Z. A SWT Verified Method of Natural Scene Text Location. In Proceedings of the 2016 International Symposium on Computer, Consumer and Control (IS3C), Xi’an, China, 4–6 July 2016; pp. 980–984. [Google Scholar] [CrossRef]
- Titijaroonroj, T. Modified Stroke Width Transform for Thai Text Detection. In Proceedings of the 2018 International Conference on Information Technology (InCIT), Khon Kaen, Thailand, 24–25 October 2018; pp. 1–5. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Shi, C.; Wang, C.; Xiao, B.; Zhang, Y.; Gao, S. Scene text detection using graph model built upon maximally stable extremal regions. Pattern Recogn. Lett. 2013, 34, 107–116. [Google Scholar] [CrossRef]
- Gomez, L.; Karatzas, D. MSER-Based Real-Time Text Detection and Tracking. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Washington, DC, USA, 24–28 August 2014; pp. 3110–3115. [Google Scholar]
- Feng, Y.; Song, Y.; Zhang, Y. Scene text localization using extremal regions and Corner-HOG feature. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015; pp. 881–886. [Google Scholar]
- Zhang, X.; Gao, X.; Tian, C. Text detection in natural scene images based on color prior guided MSER. Neurocomputing 2018, 307, 61–71. [Google Scholar] [CrossRef]
- Agrahari, A.; Ghosh, R. Multi-Oriented Text Detection in Natural Scene Images Based on the Intersection of MSER With the Locally Binarized Image. Procedia Comput. Sci. 2020, 171, 322–330. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Structured Output Learning for Unconstrained Text Recognition. arXiv 2014, arXiv:1412.5903. [Google Scholar]
- Liu, X.; Liang, D.; Yan, S.; Chen, D.; Qiao, Y.; Yan, J. FOTS Fast Oriented Text Spotting with a Unified Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; Volume 1801, pp. 1–10. [Google Scholar]
- Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; Wang, L. ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network**YL and HC contributed equally to this work. This work was done when Yuliang Liu was visiting The University of Adelaide. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9806–9815. [Google Scholar]
- Lyu, P.; Yao, C.; Wu, W.; Yan, S.; Bai, X. Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-Time Scene Text Detection with Differentiable Binarization. AAAI 2020, 34, 11474–11481. [Google Scholar] [CrossRef]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. EAST: An Efficient and Accurate Scene Text Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1704, pp. 2642–2651. [Google Scholar]
- Yao, C.; Bai, X.; Sang, N.; Zhou, X.; Zhou, S.; Cao, Z. Scene Text Detection via Holistic, Multi-Channel Prediction. arXiv 2016, arXiv:1606.09002. [Google Scholar]
- He, T.; Tian, Z.; Huang, W.; Shen, C.; Qiao, Y.; Sun, C. An End-to-End TextSpotter with Explicit Alignment and Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5020–5029. [Google Scholar]
- Kim, K.-H.; Hong, S.; Roh, B.; Cheon, Y.; Park, M. PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection. arXiv 2016, arXiv:1608.08021. [Google Scholar]
- Deng, D.; Liu, H.; Li, X.; Cai, D. PixelLink: Detecting Scene Text via Instance Segmentation. arXiv 2018, arXiv:1801.01315. [Google Scholar]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. TextField: Learning a Deep Direction Field for Irregular Scene Text Detection. IEEE Trans. Image Proc. 2019, 28, 5566–5579. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wu, Z.; Zhao, S.; Wu, X.; Kuang, Y.; Yan, Y.; Ge, S.; Wang, K.; Fan, W.; Chen, X.; et al. PSENet: Psoriasis Severity Evaluation Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 800–807. [Google Scholar]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting Text in Natural Image with Connectionist Text Proposal Network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 56–72. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. arXiv 2017, arXiv:1703.01086. [Google Scholar] [CrossRef] [Green Version]
- Lyu, P.; Liao, M.; Yao, C.; Wu, W.; Bai, X. Mask TextSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, Y.; Zhang, S.; Jin, L.; Xie, L.; Wu, Y.; Wang, Z. Omnidirectional Scene Text Detection with Sequential-free Box Discretization. arXiv 2019, arXiv:1906.02371. [Google Scholar]
- Shi, B.; Bai, X.; Belongie, S. Detecting Oriented Text in Natural Images by Linking Segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3482–3490. [Google Scholar]
- He, P.; Huang, W.; He, T.; Zhu, Q.; Qiao, Y.; Li, X. Single Shot Text Detector with Regional Attention. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3066–3074. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. TextBoxes++—A Single-Shot Oriented Scene Text Detector. IEEE Trans. Image Proc. 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.-S.; Bai, X. Rotation-Sensitive Regression for Oriented Scene Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Volume 1803, pp. 5909–5918. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, September 8–14, 2018, Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–35. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character Region Awareness for Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading Text in the Wild with Convolutional Neural Networks. Int. J. Comput. Vis. 2015, 116, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Jin, L.; Zhang, S.; Feng, Z. DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images. arXiv 2016, arXiv:1605.07314. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, CL, USA, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Xiang, D.; Guo, Q.; Xia, Y. Robust Text Detection with Vertically-Regressed Proposal Network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 351–363. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. TextBoxes: A Fast Text Detector with a Single Deep Neural Network. arXiv 2016, arXiv:1611.06779. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Liu, Y.; Jin, L. Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3454–3461. [Google Scholar]
- Wang, S.; Liu, Y.; He, Z.; Wang, Y.; Tang, Z. A quadrilateral scene text detector with two-stage network architecture. Pattern Recogn. 2020, 102, 107230. [Google Scholar] [CrossRef]
- Deng, L.; Gong, Y.; Lin, Y.; Shuai, J.; Tu, X.; Zhang, Y.; Ma, Z.; Xie, M. Detecting Multi-Oriented Text with Corner-based Region Proposals. Neurocomputing 2019, 334, 134–142. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Gong, Y.; Lu, X.; Lin, Y.; Ma, Z.; Xie, M. STELA: A Real-Time Scene Text Detector with Learned Anchor. IEEE Access 2019, 7, 153400–153407. [Google Scholar] [CrossRef]
- Cai, Y.; Wang, W.; Ren, H.; Lu, K. SPN: Short path network for scene text detection. Neural Comput. Appl. 2019, 32, 6075–6087. [Google Scholar] [CrossRef]
- Xue, C.; Lu, S.; Zhang, W. MSR: Multi-Scale Shape Regression for Scene Text Detection. arXiv 2019, arXiv:1901.02596. [Google Scholar]
- Wang, Y.; Xie, H.; Zha, Z.; Xing, M.; Fu, Z.; Zhang, Y. ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Wang, Y.; Xie, H.; Fu, Z.; Zhang, Y. DSRN: A Deep Scale Relationship Network for Scene Text Detection. IJCAI 2019, 947–953. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Liang, B.; Huang, Z.; En, M.; Han, J.; Ding, E.; Ding, X. Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes. arXiv 2019, arXiv:1904.06535. [Google Scholar]
- Xing, L.; Tian, Z.; Huang, W.; Scott, M.R. Convolutional Character Networks. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 2 November 2019; Volume 1910. [Google Scholar]
- Zhang, S.; Liu, Y.; Jin, L.; Wei, Z.; Shen, C. OPMP: An Omni-directional Pyramid Mask Proposal Network for Arbitrary-shape Scene Text Detection. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Li, X.; Wang, W.; Hou, W.; Liu, R.-Z.; Lu, T.; Yang, J. Shape Robust Text Detection with Progressive Scale Expansion Network. arXiv 2018, arXiv:1806.02559. [Google Scholar]
- Tang, J.; Yang, Z.; Wang, Y.; Zheng, Q.; Xu, Y.; Bai, X. SegLink++: Detecting Dense and Arbitrary-shaped Scene Text by Instance-aware Component Grouping. Pattern Recogn 2019, 96, 106954. [Google Scholar] [CrossRef]
- Huang, Z.; Zhong, Z.; Sun, L.; Huo, Q. Mask R-CNN with Pyramid Attention Network for Scene Text Detection. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 764–772. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Wu, S.; Kong, S.; Zheng, Y.; Ye, H.; Chen, L.; Pu, J. Curve Text Detection with Local Segmentation Network and Curve Connection. arXiv 2019, arXiv:1903.09837. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Du, C.; Wang, C.; Wang, Y.; Feng, Z.; Zhang, J. TextEdge: Multi-oriented Scene Text Detection via Region Segmentation and Edge Classification. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 375–380. [Google Scholar] [CrossRef]
- Kobchaisawat, T.; Chalidabhongse, T.H.; Satoh, S. Scene Text Detection with Polygon Offsetting and Border Augmentation. Electronics 2020, 9, 117. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Yin, F.; Liu, C.-L. Scene Text Detection with Novel Superpixel Based Character Candidate Extraction. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 929–934. [Google Scholar] [CrossRef]
- Xue, C.; Lu, S.; Zhan, F. Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Tian, Z.; Shu, M.; Lyu, P.; Li, R.; Zhou, C.; Shen, X.; Jia, J. Learning Shape-Aware Embedding for Scene Text Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 4229–4238. [Google Scholar]
- Zhong, Z.; Sun, L.; Huo, Q. An anchor-free region proposal network for Faster R-CNN-based text detection approaches. Int. J. Doc. Anal. Recognit. Ijdar. 2018, 22, 315–327. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Zheng, Y.; Betke, M. SA-Text: Simple but Accurate Detector for Text of Arbitrary Shapes. arXiv. 2019, arXiv:1911.07046. [Google Scholar]
- Wu, W.; Xing, J.; Zhou, H. TextCohesion: Detecting Text for Arbitrary Shapes. arXiv 2019, arXiv:1904.12640. [Google Scholar]
- Liu, Z.; Lin, G.; Yang, S.; Liu, F.; Lin, W.; Goh, W.L. Towards Robust Curve Text Detection with Conditional Spatial Expansion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 7261–7270. [Google Scholar]
- Lucas, S.M.; Panaretos, A.; Sosa, L.; Tang, A.; Wong, S.; Young, R. ICDAR 2003 Robust Reading Competitions. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, UK, 6 August 2003; pp. 682–687. [Google Scholar]
- Lee, S.; Cho, M.; Jung, K.; Kim, J.H. Scene Text Extraction with Edge Constraint and Text Collinearity. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3983–3986. [Google Scholar]
- Shahab, A.; Shafait, F.; Dengel, A. ICDAR 2011 Robust Reading Competition Challenge 2: Reading Text in Scene Images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 18–21 September 2011; Volume 1, pp. 1491–1496. [Google Scholar]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, Rhode Island, 16–21 June 2012; Volume 1, pp. 1083–1090. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; Bigorda, L.G.i.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; De Las Heras, L.P. ICDAR 2013 Robust Reading Competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1484–1493. [Google Scholar] [CrossRef] [Green Version]
- Yin, X.-C.; Yin, X.; Huang, K.; Hao, H.-W. Robust Text Detection in Natural Scene Images. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 970–983. [Google Scholar]
- Veit, A.; Matera, T.; Neumann, L.; Matas, J.; Belongie, S. COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images. arXiv 2016, arXiv:1601.07140. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic Data for Text Localisation in Natural Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2315–2324. [Google Scholar]
- Yuan, T.-L.; Zhu, Z.; Xu, K.; Li, C.-J.; Hu, S.-M. Chinese Text in the Wild. arXiv 2018, arXiv:1803.00085. [Google Scholar]
- Shi, B.; Yao, C.; Liao, M.; Yang, M.; Xu, P.; Cui, L.; Belongie, S.; Lu, S.; Bai, X. ICDAR2017 Competition on Reading Chinese Text in the Wild (RCTW-17). In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1429–1434. [Google Scholar] [CrossRef] [Green Version]
- Ch’ng, C.K.C.; Chan, C.S. Total-Text: A Comprehensive Dataset for Scene Text Detection and Recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 935–942. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Jin, L.; Zhang, S.; Luo, C.; Zhang, S. Curved Scene Text Detection via Transverse and Longitudinal Sequence Connection. Pattern Recogn. 2019, 90, 337–345. [Google Scholar] [CrossRef]
- Nayef, N.; Yin, F.; Bizid, I.; Choi, H.; Feng, Y.; Karatzas, D.; Luo, Z.; Pal, U.; Rigaud, C.; Chazalon, J.; et al. ICDAR2017 Robust Reading Challenge on Multi-Lingual Scene Text Detection and Script Identification—RRC-MLT. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1454–1459. [Google Scholar] [CrossRef]
- Chng, C.-K.; Liu, Y.; Sun, Y.; Ng, C.C.; Luo, C.; Ni, Z.; Fang, C.; Zhang, S.; Han, J.; Ding, E.; et al. ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT). In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 22–25 September 2019. [Google Scholar]
- Nayef, N.; Patel, Y.; Busta, M.; Chowdhury, P.N.; Karatzas, D.; Khlif, W.; Matas, J.; Pal, U.; Burie, J.-C.; Liu, C.; et al. ICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition—RRC-MLT-2019. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 22–25 September 2019. [Google Scholar]
- Sun, Y.; Liu, J.; Liu, W.; Han, J.; Ding, E.; Liu, J. Chinese Street View Text: Large-scale Chinese Text Reading with Partially Supervised Learning. In Proceedings of the IEEE International Conference on Computer Vision; Seoul, Korea, 27 October–2 November 2020; pp. 9085–9094. [Google Scholar]
- Xie, E.; Zang, Y.; Shao, S.; Yu, G.; Yao, C.; Li, G. Scene Text Detection with Supervised Pyramid Context Network. arXiv 2018, arXiv:1811.08605. [Google Scholar] [CrossRef] [Green Version]
- Hu, H.; Zhang, C.; Luo, Y.; Wang, Y.; Han, J.; Ding, E. WordSup: Exploiting Word Annotations for Character Based Text Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 29 October 2017; pp. 4950–4959. [Google Scholar]
- Xing, D.; Li, Z.; Chen, X.; Fang, Y. ArbiText: Arbitrary-Oriented Text Detection in Unconstrained Scene. arXiv 2017, arXiv:1711.11249. [Google Scholar]
- Zhu, X.; Jiang, Y.; Yang, S.; Wang, X.; Li, W.; Fu, P.; Wang, H.; Luo, Z. Deep Residual Text Detection Network for Scene Text. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 807–812. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Lin, G.; Yang, S.; Feng, J.; Lin, W.; Goh, W.L. Learning Markov Clustering Networks for Scene Text Detection. arXiv 2018, arXiv:1805.08365. [Google Scholar]
- Mohanty, S.; Dutta, T.; Gupta, H.P. Recurrent Global Convolutional Network for Scene Text Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2750–2754. [Google Scholar] [CrossRef]
- Roy, S.; Shivakumara, P.; Pal, U.; Lu, T.; Kumar, G.H. Delaunay triangulation based text detection from multi-view images of natural scene. Pattern Recogn. Lett. 2020, 129, 92–100. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, C.; Qi, F.; Huang, Z.; En, M.; Han, J.; Liu, J. A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning. In Proceedings of the 27th ACM International Conference on Multimedia, New York, NY, USA, 21–25 October 2019; pp. 1277–1285. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Du, J. Sliding Line Point Regression for Shape Robust Scene Text Detection. arXiv 2018, arXiv:1801.09969. [Google Scholar]
- Kang, L.; Li, Y.; Doermann, D. Orientation Robust Text Line Detection in Natural Images. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 4034–4041. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Xiao, H.; Yang, L.; Zhu, G.; Shah, S.A.; Bennamoun, M.; Shen, P. Efficient Scene Text Detection with Textual Attention Tower. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Liu, H.; Guo, A.; Jiang, D.; Hu, Y.; Ren, B. PuzzleNet: Scene Text Detection by Segment Context Graph Learning. arXiv 2020, arXiv:2002.11371. [Google Scholar]
- Dasgupta, K.; Das, S.; Bhattacharya, U. Scale-Invariant Multi-Oriented Text Detection in Wild Scene Images. arXiv 2020, arXiv:2002.06423. [Google Scholar]


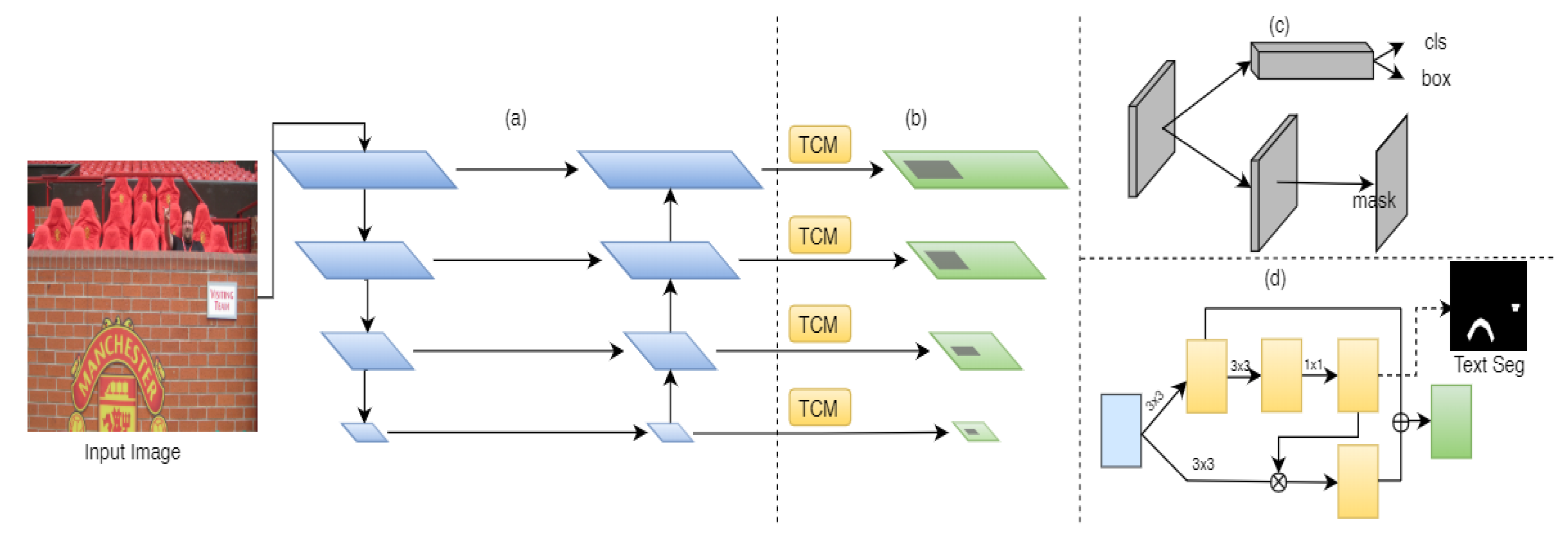
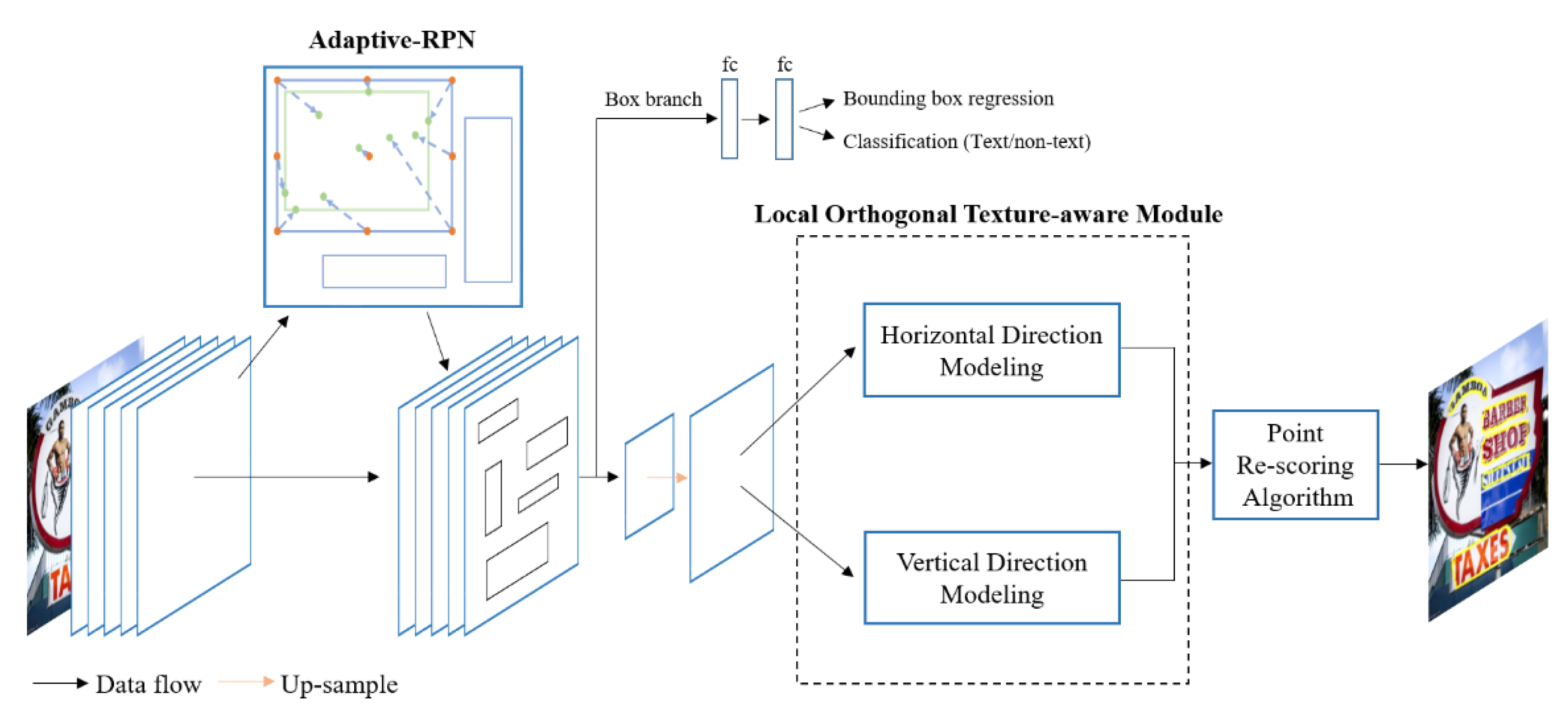
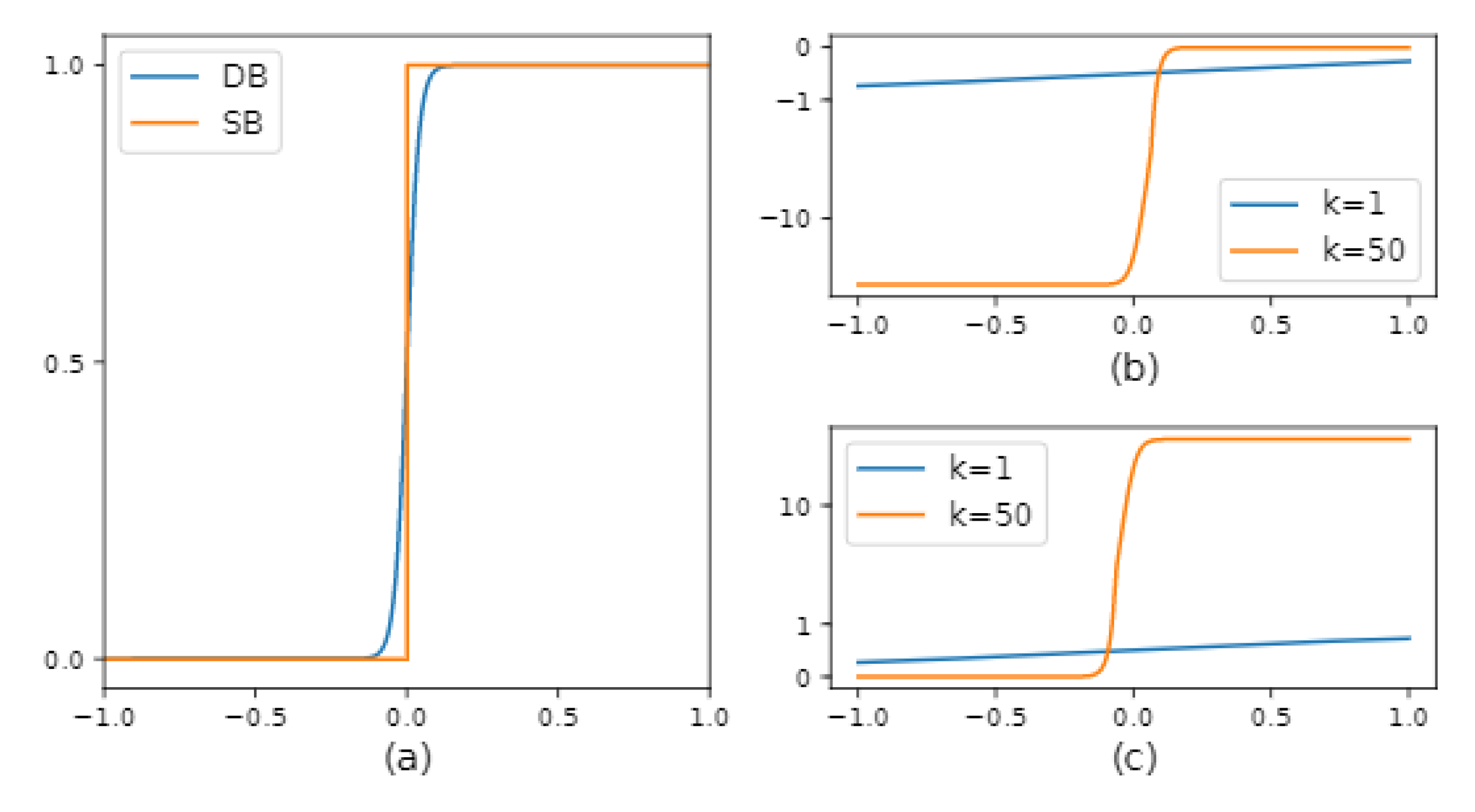

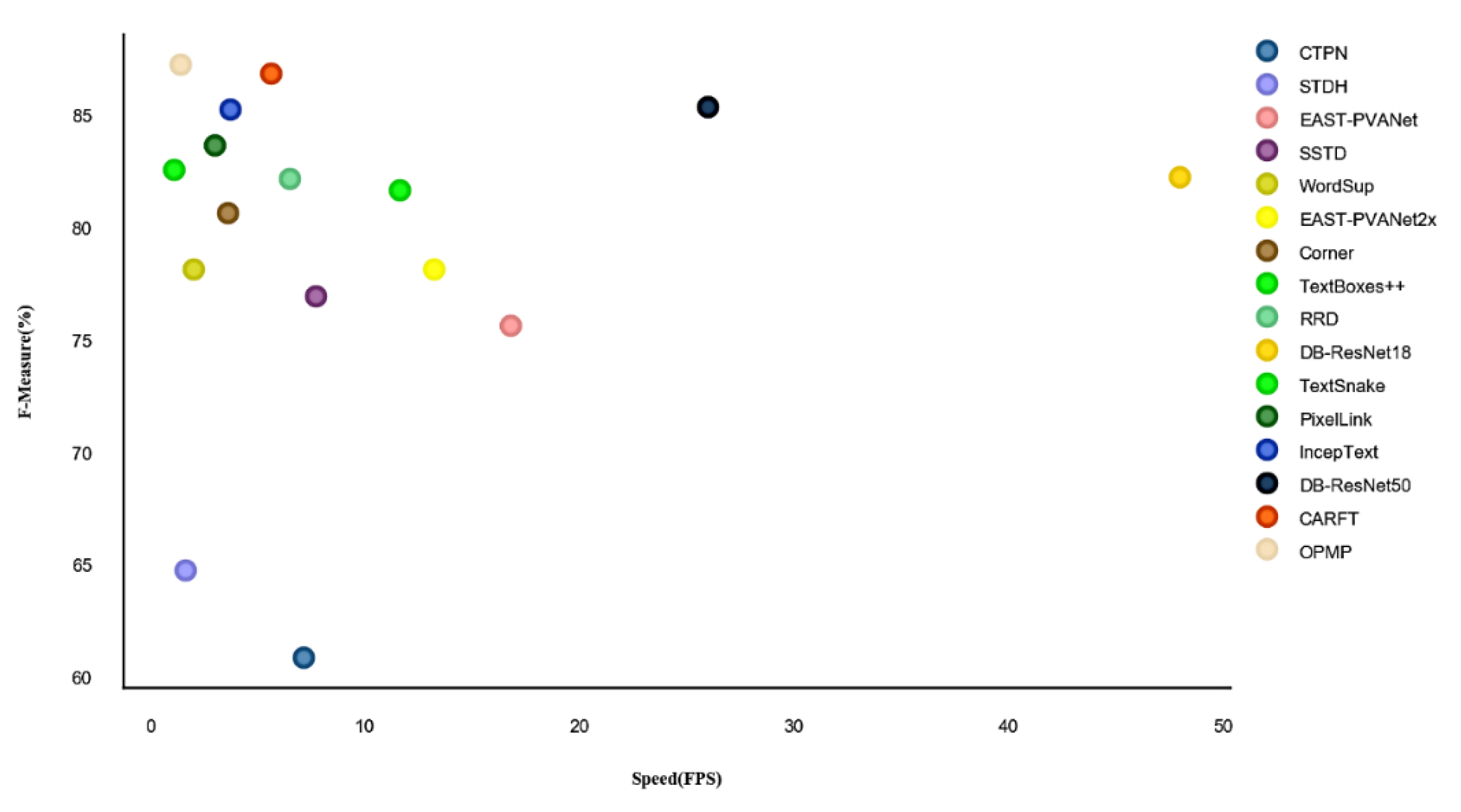

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model_Based | Work | Source | Code | Backbone | Supervised | Training Datasets | Contributions | ||
|---|---|---|---|---|---|---|---|---|---|
| S | SS | US | First-Stage | Fine-Tune | |||||
| Convolutional Neural Network (CNN) | RSTD [16] | ECCV’14 | - | - | ✓ | - | - | - | IC11, IC15 |
| DSOL [62] | ICLR’15 | - | - | ✓ | - | - | MJSynth | - | |
| FOTS [63] | CVPR’18 | ✓ | ResNet-50 | ✓ | - | - | ST | IC13, IC15, IC17 | |
| ABCNet [64] | CVPR’2020 | ✓ | ResNet-50 | ✓ | - | - | ST, COCO | ToT, CTW | |
| Corner [65] | CVPR’18 | ✓ | VGG-16 | ✓ | - | - | ST | IC13, 1C15 | |
| DB [66] | AAAI’20 | ✓ | ResNet | ✓ | - | - | ST | M500, CTW, ToT, IC15, IC17 | |
| Fully Convolutional Neural Network (FCN) | MOTD [13] | CVPR’16 | ✓ | VGG-16 | ✓ | - | - | - | IC13, IC15, M500 |
| EAST [67] | CVPR’17 | ✓ | VGG-16 | ✓ | - | - | - | IC15, COCO, M500 | |
| STDH [68] | 2016 | ✓ | VGG-16 | ✓ | - | - | - | IC13, IC15, M500 | |
| E2ET [69] | CVPR’18 | ✓ | PVANet [70] | ✓ | - | - | ST | IC13, IC15 | |
| PixelLink [71] | AAAI’18 | ✓ | VGG-16 | ✓ | - | - | IC15 | IC13, IC15, M500 | |
| Textfield [72] | 2019 | ✓ | VGG-16 | ✓ | - | - | ST | IC15, M500, ToT, CTW | |
| Feature Pyramid Network (FPN) | PSENet [73] | AAAI’20 | ✓ | ResNet | ✓ | - | - | IC17 | IC13 or IC15 |
| Faster R-CNN | CTPN [74] | ECCV’16 | ✓ | VGG-16 | ✓ | - | - | - | IC13 |
| R2CNN [75] | arXiv’17 | ✓ | VGG-16 | ✓ | - | - | IC15 | - | |
| RRPN [76] | 2018 | ✓ | VGG-16 | ✓ | - | - | M500 | IC13, IC15 | |
| Mask-RCNN | MTSpotter [77] | ECCV’18 | ✓ | ResNet-50 | ✓ | - | - | ST | IC13, IC15, ToT |
| PMTD [14] | CoRR’19 | ✓ | ResNet-50 | ✓ | - | - | IC17 | IC13 or IC15 | |
| MB [78] | 2019 | ✓ | ResNet-101 | ✓ | - | - | ST | IC15, IC17, M500 | |
| Single Shot Detector (SSD) | SegLink [79] | CVPR’17 | ✓ | VGG-16 | ✓ | - | - | ST | IC13, IC15 or M500 |
| SSTD [80] | CVPR’17 | ✓ | VGG-16 | ✓ | - | - | - | IC13 or IC15 | |
| TextBoxes++ [81] | 2018 | ✓ | VGG-16 | ✓ | - | - | ST | IC15 | |
| RRD [82] | CVPR’18 | - | VGG-16 | ✓ | - | - | ST | IC13, IC15, COCO, M500 | |
| U-Net | TextSnake [83] | ECCV’18 | ✓ | VGG-16 | ✓ | - | - | ST | IC15, M500, ToT, CTW |
| CRAFT [84] | CVPR’19 | ✓ | VGG-16 | - | ✓ | - | ST | IC13, IC15, IC17 | |
| Method | Strength | Weakness |
|---|---|---|
| Region proposal-based | Higher detection accuracy and recall rates | Rely on complex frame designs and computationally intensive |
| Image segmentation-based | Be insensitive to font variation, noise, blur, and orientation | Weak detection of sticky or overlapping text |
| Hybrid methods | Can handle arbitrary strings and is robust to detection | Need to design innovative detection frameworks |
| Datasets | Total | Train | Test | Arbitrary-Shape | Multi-Oriented | Annotation | ||
|---|---|---|---|---|---|---|---|---|
| Char | Word | Text-Line | ||||||
| IC03 | 509 | 258 | 251 | ✕ | ✕ | ✕ | ✓ | ✕ |
| SVT | 350 | 100 | 250 | ✓ | ✕ | ✓ | ✓ | ✕ |
| KAIST | 3000 | - | - | ✕ | ✕ | ✕ | ✓ | ✕ |
| IC11 | 484 | 229 | 255 | ✕ | ✕ | ✓ | ✓ | ✕ |
| M500 | 500 | 300 | 200 | ✓ | ✕ | ✕ | ✕ | ✓ |
| IC13 | 462 | 229 | 233 | ✕ | ✕ | ✓ | ✓ | ✕ |
| USTB-SV1K | 1000 | 500 | 500 | ✓ | ✕ | ✕ | ✓ | ✕ |
| IC15 | 1500 | 1000 | 500 | ✓ | ✕ | ✕ | ✓ | ✕ |
| COCO-Text | 63,686 | 43,686 | 20,000 | ✓ | ✕ | ✕ | ✓ | ✕ |
| SynthText | 85,8750 | - | - | ✕ | ✕ | ✓ | ✓ | ✕ |
| CTW | 32,285 | 25,887 | 6398 | ✓ | ✕ | ✓ | ✓ | ✕ |
| RCTW-17 | 12,514 | 15,114 | 1000 | ✓ | ✕ | ✕ | ✕ | ✓ |
| ToT | 1525 | 1225 | 300 | ✓ | ✓ | ✕ | ✓ | ✓ |
| CTW | 1500 | 1000 | 500 | ✓ | ✓ | ✕ | ✓ | ✓ |
| MLT17 | 18,000 | 7200 | 10,800 | ✓ | ✕ | ✕ | ✓ | ✕ |
| ArTs19 | 10,166 | 5603 | 4563 | ✓ | ✓ | ✕ | ✓ | ✕ |
| MLT19 | 20,000 | 10,000 | 10,000 | ✓ | ✕ | ✕ | ✓ | ✕ |
| LSVT19 | 450,000 | 430,000 | 20,000 | ✓ | ✓ | ✕ | ✓ | ✓ |
| Evaluation Protocols | Match Type | Strength and Weakness |
|---|---|---|
| IC03 Evaluation Protocol | One-to-One | The IC03 metric calculates precision, recall, and the standard F-measure for one-to-one matches. However, it is unable to handle one-to-many and many-to-many matches between the ground truth and detections. |
| IC13 Evaluation Protocol | One-to-One One-to-Many Many-to-one | This method takes into account one-to-one, one-to-many, and many-to-one cases but cannot handle many-to-many cases. |
| IC15 Evaluation Protocol | One-to-One One-to-Many Many-to-one | This method uses the ICDAR15 intersection over union (IoU) metric and IoU ≥ 0.5 as a threshold for counting a correct detection. This method is the most commonly used evaluation method and is simple to calculate. |
| TIoU Evaluation Protocol | One-to-one One-to-many Many-to-one many-to-many | This method can quantify the completeness of ground truth, the compactness of detection, and the tightness of the matching degree. However, it is relatively complex to calculate. |
| Work | Source | P | R | F |
|---|---|---|---|---|
| FASText [46] | CVPR’15 | 84 | 69 | 77 |
| FCRN [124] | CVPR’16 | 93.8 | 76.4 | 84.2 |
| CTPN [74] | ECCV’16 | 93 | 83 | 88 |
| WordSup [134] | CVPR’17 | 93.3 | 87.5 | 90.3 |
| DMPNet [91] | CVPR’17 | 93 | 83 | 87 |
| ArbiText [135] | 2017 | 82.6 | 93.6 | 87.7 |
| SSTD [80] | CVPR’17 | 89 | 86 | 88 |
| SegLink [79] | CVPR’17 | 87.7 | 83 | 85.3 |
| RTN [136] | IAPR’17 | 94 | 89 | 91 |
| EAST [67] | CVPR’17 | 93 | 83 | 87 |
| AF-RPN [113] | ICDAR’17 | 94 | 90 | 92 |
| PixelLink [71] | AAAI’18 | 88.6 | 87.5 | 88.1 |
| MCN [137] | 2018 | 88 | 87 | 88 |
| Border [111] | 2018 | 91.5 | 87.1 | 89.2 |
| TextBoxes++ [81] | 2018 | 92 | 86 | 89 |
| RRPN [76] | 2018 | 95 | 89 | 91 |
| RGC [138] | ICIP’18 | 89 | 77 | 83 |
| SPCNet [133] | AAAI’19 | 93.8 | 90.5 | 92.1 |
| MSR [96] | 2019 | 91.8 | 88.5 | 90.1 |
| Roy et al. [139] | 2020 | 90.4 | 88 | 89.1 |
| Work | Source | ToT | CTW | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| TextSnake [83] | ECCV’18 | 82.7 | 74.5 | 78.4 | 67.9 | 85.3 | 75.6 |
| CRAFT [84] | CVPR’19 | 87.6 | 79.9 | 83.6 | 86 | 81.1 | 83.5 |
| Liu et al. [116] | 2019 | 81.4 | 79.1 | 80.2 | 78.7 | 76.1 | 77.4 |
| Seglink++ [104] | 2019 | 82.9 | 80.9 | 81.5 | 82.8 | 79.8 | 81.3 |
| SAST [140] | 2019 | 85.57 | 75.49 | 80.2 | 81.19 | 81.71 | 81.45 |
| PAN [107] | CVPR’19 | 89.3 | 81 | 85 | 86.4 | 81.2 | 83.7 |
| SPCNet [133] | AAAI’19 | 83 | 83 | 83 | - | - | - |
| MSR [96] | 2019 | 85.2 | 73 | 76.8 | 83.8 | 77.8 | 80.7 |
| LOMO [99] | CVPR’19 | 87.6 | 79.3 | 83.3 | - | - | - |
| SLPR [141] | 2018 | - | - | - | 80.1 | 70.1 | 74.8 |
| CTD+TLOC [128] | 2019 | - | - | - | 77.4 | 69.8 | 73.4 |
| PSENet [73] | AAAI’20 | 84 | 77.9 | 80.9 | 84.8 | 79.7 | 82.2 |
| Tian et al. [112] | CVPR’19 | - | - | - | 81.7 | 84.2 | 80.1 |
| Wang et al. [97] | 2020 | 86.9 | 83.9 | 85.4 | 83.7 | 84.1 | 83.9 |
| Roy et al. [139] | 2020 | 88 | 79 | 83.25 | 85 | 82 | 83.47 |
| OPMP [101] | 2020 | - | - | - | 85.1 | 80.8 | 82.9 |
| DB [66] | AAAI’20 | 87.1 | 82.5 | 84.7 | 86.9 | 80.2 | 83.4 |
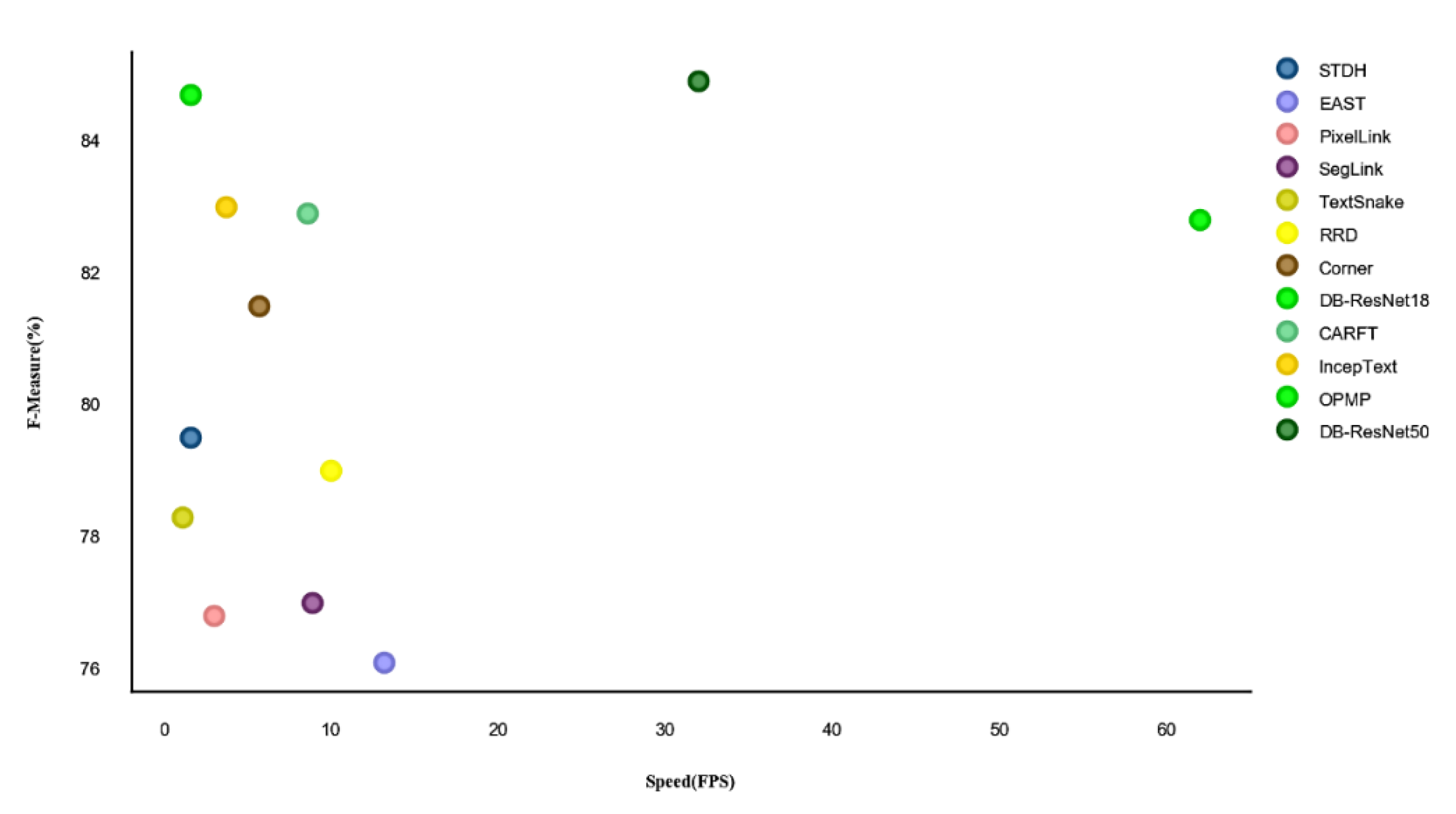
| Work | Source | M500 | IC15 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F | FPS | P | R | F | FPS | ||
| Kang et al. [142] | 2014 | 71 | 62 | 66 | - | - | - | - | - |
| Zhang et al. [13] | 2016 | 83 | 67 | 74 | - | 71 | 43 | 54 | - |
| CTPN [74] 1 | ECCV’16 | - | - | - | - | 74.2 | 51.6 | 60.9 | 7.14 |
| STDH [68] | 2016 | - | - | - | 1.61 | 72.26 | 58.69 | 64.77 | 1.61 |
| WordSup [134] | CVPR’17 | - | - | - | - | 79.3 | 77 | 78.2 | 2 |
| SSTD [80] | 2017 | - | - | - | - | 80 | 73 | 77 | 7.7 |
| EAST-PVANet [67] 2 | CVPR’17 | 87.28 | 67.43 | 76.08 | 13.2 | 83.27 | 78.33 | 80.72 | 13.2 |
| TextBoxes++ [81] 3 | 2018 | 87.8 | 78.5 | 82.9 | - | - | - | - | 11.6 |
| Border [111] | 2018 | 78.2 | 58.8 | 67.1 | - | - | - | - | - |
| RRD [96] | CVPR’18 | 59.1 | 77.5 | 67 | 10 | - | - | - | 6.5 |
| TextSnake [83] 4 | ECCV’18 | 83.2 | 73.9 | 78.3 | 1.1 | 84.9 | 80.4 | 82.6 | 1.1 |
| IncepText [11] | 2018 | 87.5 | 79 | 83 | 3.7 | 93.8 | 87.3 | 90.5 | 3.7 |
| Corner [65] 5 | CVPR’18 | 87.6 | 76.2 | 81.5 | 5.7 | 94.1 | 70.7 | 80.7 | 3.6 |
| PixelLink [71] 6 | AAAI’18 | - | - | - | 3 | 85.5 | 82 | 83.7 | 3 |
| PMTD [14] 7 | 2019 | - | - | - | - | 91.3 | 87.4 | 89.3 | - |
| CRAFT [84] 8 | CVPR’19 | - | - | - | 8.6 | 89.8 | 84.3 | 89.8 | 5.6 |
| PSENet [73] | AAAI’20 | - | - | - | - | 86.9 | 84.5 | 85.7 | - |
| LOMO [143] | 2019 | 79.1 | 60.2 | 68.4 | - | 89 | 86 | 88 | - |
| PuzzleNet [144] | 2020 | - | - | - | - | 88.9 | 88.1 | 88.5 | - |
| DB-ResNet18 [66] 9 | AAAI’20 | 90.4 | 76.3 | 82.8 | 62 | 84.8 | 77.5 | 81 | 55 |
| DB-ResNet50 [66] 9 | AAAI’20 | 91.5 | 79.2 | 84.9 | 32 | 86.9 | 80.2 | 83.5 | 22 |
| Roy et al. [139] | 2020 | 88 | 78 | 82.6 | - | 91.1 | 83.1 | 86.9 | - |
| OPMP [101] | 2020 | 86 | 83.4 | 84.7 | 1.6 | - | - | - | 1.4 |
| Dasgupta et al. [145] | 2020 | 81.6 | 88.2 | 84.7 | - | 91.3 | 89.2 | 90.2 | - |
| ContourNet [97] | CVPR’20 | 87.6 | 86.1 | 86.9 | - | - | - | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, D.; Zhong, Y.; Wang, L.; He, Y.; Dang, J. Scene Text Detection in Natural Images: A Review. Symmetry 2020, 12, 1956. https://doi.org/10.3390/sym12121956
Cao D, Zhong Y, Wang L, He Y, Dang J. Scene Text Detection in Natural Images: A Review. Symmetry. 2020; 12(12):1956. https://doi.org/10.3390/sym12121956
Chicago/Turabian StyleCao, Dongping, Yong Zhong, Lishun Wang, Yilong He, and Jiachen Dang. 2020. "Scene Text Detection in Natural Images: A Review" Symmetry 12, no. 12: 1956. https://doi.org/10.3390/sym12121956
APA StyleCao, D., Zhong, Y., Wang, L., He, Y., & Dang, J. (2020). Scene Text Detection in Natural Images: A Review. Symmetry, 12(12), 1956. https://doi.org/10.3390/sym12121956