Abstract
In this paper, we introduce a novel parametric quantile regression model for asymmetric response variables, where the response variable follows a power skew-normal distribution. By considering a new convenient parametrization, these distribution results are very useful for modeling different quantiles of a response variable on the real line. The maximum likelihood method is employed to estimate the model parameters. Besides, we present a local influence study under different perturbation settings. Some numerical results of the estimators in finite samples are illustrated. In order to illustrate the potential for practice of our model, we apply it to a real dataset.
1. Introduction
Frequently, in real life, we find continuous data on the real line that are asymmetrical; these data cannot be modeled by known symmetric distributions as the normal, Student-t, Cauchy, Laplace, and logistic distributions. It is therefore more interesting to propose more flexible models that will be useful for modeling highly skewed data which arises in several areas.
In this context, the seminal work in Azzalini [] introduces a skew-symmetric family of distributions, where this last is established by using a symmetric distribution as a kernel. When this last follows a normal distribution, it rises the well-know skew-normal (SN) distribution. The SN distribution has a skewness parameter which makes possible to have a reasonable model for a skewed distribution. Furthermore, the SN distributions include the normal distribution and possesses several properties which coincide or are similar to the ones of the normal distribution (Azzalini [,]). However, the SN distribution is limited in terms of flexibility, that is, for moderate values of the skewness parameter nearly all the mass accumulates either on the positive or negative real line, as determined by the sign of the skewness parameter. In such cases, the SN distribution closely resembles the half-normal density, with a nearly linear shape in the side with smaller mass (Arellano-Valle et al. []).
Another alternative to model skewed data is using the family of power-symmetric distributions (see Pewsey et al. []) of which the most widely used is the power-normal (PN) distribution. Some references where this family is discussed are Lehmann [], Durrans [], Gupta and Gupta [], Castillo et al. [], among others. In a series of papers by Martínez-Flórez et al. ([,,,,]) extensions and applications of the PN distribution can be found.
An unification of the SN and PN distributions was proposed by Martínez-Flórez et al. [], namely the power skew-normal (PSN) which is a generalization of the SN and PN distributions. Even though sample information about the SN distribution has been widely studied, there is not the same scope for the PSN distribution, which being a generalization of the first one, has characteristics of interest such as: (i) the SN and PN distributions as particular cases, and (ii) the PSN distribution provides greater range for skewness and kurtosis coefficients compared with the SN distribution (see Table 1), being more flexible to model highly skewed data, which arises frequently in many practical situations. However, the expectation and variance of the PSN distribution cannot be expressed in closed form (have complicated forms), which makes these distributions unsuitable for regression modeling (Martínez-Flórez et al. []). Fortunately, the cumulative distribution function (cdf) of the PSN distribution has a simple form that depends on Owen’s T function (to be defined in the next section). This facilitates the calculation of the quantile function (inverse of the cdf), allowing its utilization in the quantile regression (QR) framework. Quantile regression quantifies the association of the explanatory variables with a given quantile of a dependent variable. In this study, we propose a quantile linear regression model based on the PSN distribution, adopting a new parametrization of this model indexed by the quantile, precision and shape parameters. In particular, for this work, inference is conducted via maximum likelihood.

Table 1.
Range for skewness and kurtosis coefficients for SN, PN and PSN models.
The rest of the paper proceeds as follows. In Section 2, we introduce a new parameterization of the PSN distribution that is indexed by the location, precision and shape parameters and its association with a quantile regression model. In addition, elements related to the maximum likelihood (ML) method are presented as well. Section 3 presents local influence measures under three different perturbation schemes, whereas in Section 4 a real data analysis is conducted in order to show the applicability of our proposed reparametrized PSN (RPSN) based QR model. Final section summarizes the contributions of the paper.
2. A PSN Distribution Parameterized by Its Quantile Parameter, and Its Associated Quantile Regression Model
In this section, we briefly study the PSN distribution based on Martínez-Flórez et al. []. We introduce a RPSN distribution which is characterized by its quantile, which allows us to use this distribution in the context of QR models.
The probability density function (pdf) of the PSN distribution is given by
where , and and denote the pdf and cdf of the (standard) skew normal model given by
where and denote the pdf and cdf of the standard normal distribution and is the Owen’s T function defined as
Moreover, the cdf of the PSN model is given by
Note that and corresponds to the very well known SN and PN models, respectively. The main advantage of the PSN model is that provides greater range for skewness and kurtosis coefficients compared with the SN and PN models. Table 1 shows the range for those coefficients.
The r-th moment of the distribution depends on the expected value of , , where Y have beta distribution with shape parameters and 1, respectively. For this reason, some interesting characteristic of the model, such as mean and variance, have cumbersome forms. On the other hand, quantiles of the model also need to be computed numerically since non-closed form are available for the distribution. For this reason, non-interpretation and useful reparametrizations can be performed for this model. Besides, as the Owen’s T function satisfies , we note that
For this reason, if we consider the restriction
we have that with representing directly the -th quantile of the distribution. For a fixed and considering as in (1), we have a flexible model for quantile regression. This parametrization has not been proposed in the statistical literature. Hence, we can rewrite the PSN distribution according to the parameters and , whose cumulative distribution function is now given by
where the quantile is assumed to be known. Hereafter, we use the notation to indicate that Y is a random variable following a restricted PSN distribution with quantile parameter , precision parameter , and shape parameter . Figure 1 shows the density function for the RPSN model with location and scale parameters fixed at 0 and 1, respectively. Note that in all the curves, the zero represents the specified quantile . We also note that the curves are not necessarily symmetric for (the median case).
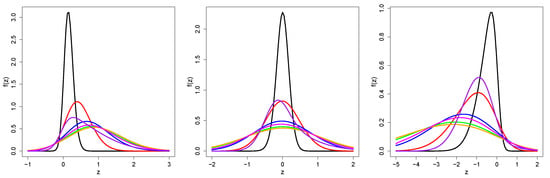
Figure 1.
Pdf for the RPSN for different values of : (left panel); (center panel); (right panel). Values for are: (black line), (red line), (blue line), 0 (green line), (orange line), (magenta line) and 5 (purple line).
Let be the n independent random variables, where each , follows the distribution with quantile parameter , precision parameter , and shape parameter . Suppose that, for a given , the location, precision and shape parameters for the RPSN satisfy the following functional relations
where , , are vectors of unknown regression coefficients which are assumed to be functionally independent, , with , are the linear predictors, and , are observations on , and known regressors, for . Moreover covariate matrices are assumed to have rank , for . Link functions , and in (2) must be strictly monotone and at least twice differentiable, and is also required to be a positive function. Such functions also satisfy that , and , with being the inverse function of .
The log-likelihood function for has the form , where
The score vector of the model is given by
where , , , , , for , with . Such elements are specified in the Appendix A.1 Section.
The Hessian for the model is
where , for , with . Such elements are detailed in the Appendix A.1.
The ML estimators , and of , and , respectively, can be obtained by solving simultaneously the nonlinear system of equations , where denotes a vector of zeros with dimension r. Unfortunately, it is not possible to obtain analytical expressions for the ML estimators above, so numerical methods for solving nonlinear equations system are required.
3. Local Influence
Global influence is related to case deletion, i.e, the effect of dropping a case from the dataset Cook []. The likelihood distance (LD) is defined as LD, where is the ML estimate of under a perturbed model related to , a perturbation vector. Cook [] studied the LD around the non-perturbed vector such as . The normal curvature for at the direction of the orthonormal vector is defined as , where is the Hessian of evaluated at and and both, and are evaluated at . Hence, is the largest eigenvalue of and the corresponding orthonormal eigenvector. The index plot of the matrix suggests how to perturb the model (or data) to obtain large changes in the estimates of .
For three common perturbation schemes we compute the matrix
where .
3.1. Case Weights Perturbation
For this case, the perturbed log-likelihood function is defined as , where is defined in (3) and , for . In this case, and
3.2. Case Response Perturbation
We consider now an additive perturbation on the ith response (say by making , where and is a scale factor. An usual consideration for such scale factor is , with denoting the sample standard deviation of Y. Note that . Therefore, under the scheme of response perturbation, the log-likelihood function is given by , where and
3.3. Case Continuous Covariate Perturbation
Consider an additive perturbation on a particular continuous covariate including on the quantile parameter, namely , for , by making , where is a scale factor. Again, a usual consideration is , with the sample standard deviation for . Note that . Then, under the scheme of response perturbation, the log-likelihood function is given by , where and , with a vector of dimension with zeros, except in the t-th element where is a one. Finally
4. Real Data Analysis
In this section, we present an application to 202 Australian athletes from the Australian Institute of Sport. Such data were discussed in Cook and Weisberg []. In order to exemplify the proposed model, we consider the following quantile regression model: , where and
Here, the response bmi represents the body mass index, while the covariates lbm and sex represent the lean body mass and sex of the athletes, respectively. Note that is not modeled by covariates and was not included in the scale parameter because in preliminary analysis we found the coefficient related to such term was not significant (to any ). This same problem was illustrated in Galarza et al. [] with a class of skew distributions (SKD), but considering a regression scheme only in the quantile parameter. For comparison purpose, we considered the skewed normal (SKN) and skewed Student-t (SKT) models, that are models belonging to the SKD class. Additionally, we also considered the Gamma-Sinh Cauchy (GSC) model, including covariates only in the quantile parameter. Table 2 shows the Akaike Information Criterion (AIC, Akaike; []) for the referred models. Note that, except for , the RPSN-QR model attached the minimum AIC for the considered quantiles.
Table 2.
AIC criterion for different models parameterized in terms of the quantile.
Table 2 displays the MLEs with corresponding standard errors (SE) for the fitted proposed model for each and . Note that we have a positive relationship between the response variable (bmi) and lbm in all quantiles. We also observe that the quantile intercepts increases as increases. Regarding the parameter , the greater , the greater the estimate of .
Figure 2 shows point estimates and confidence intervals (CIs) for model parameters under the RPSN-QR model for different quantiles. It can be seen that as increases the coefficient of lean body mass and the coefficient of gender become larger. Moreover, bmi and lbm are significant in explaining all the quantile modeled in . Figure 3 presented the estimated quantiles and for the bmi in terms of lbm and the sex of the athlete.
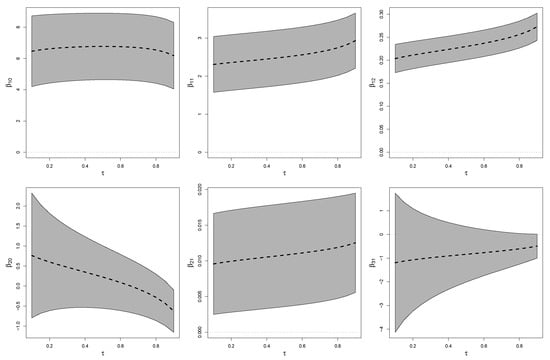
Figure 2.
Athletes dataset: Point estimates (center line) and 95% confidence intervals (CIs) for model parameters under RPSN-QR model.
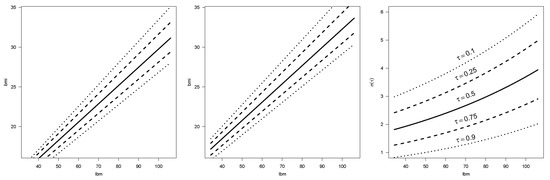
Figure 3.
Data analysis: Fitted RPSN-QR model lines for the response (left panel for males, center panel for females) and scale parameter (right panel) over the grid .
We also present in Table 4 the p-value to validate the normality hypothesis based on the Kolmogorov–Smirnov (KS; Kolmogorov, []) for the quantile residuals (Dunn and Smyth, []) using different quantile of such residuals. In all cases, the KS test did not reject the null hypothesis of normality. Therefore, the RPSN is appropriated to model all the quantile in this problem.
Table 4.
p-values for normality K-S test for residuals under our RPSN-QR model for the athletes dataset for different quantiles ’s.
We also performed a local influence analysis. Figure 4 shows such analysis under the three perturbation schemes discussed in Section 3 for . The Appendix A.2 shows the analysis for other quantiles and . Note that observations 75, 162 and 178 are detected as potentially influent for all the mentioned quantiles and the observation 53 appears for the quantile .
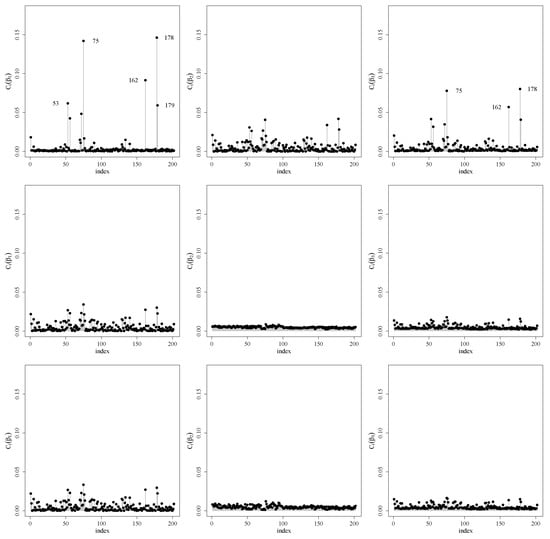
Figure 4.
Index plots for (left), (center) and (right) under the weight perturbation (upper), response perturbation (center) and covariate perturbation (lower) schemes for RPSN model for .
To check the impact on the inference of possible influential cases, we consider the relative change (RC), which is computed by removing the possible influential cases for each parameter and its SE as
where is any component of the vector , where and denote the ML estimate of and its corresponding SE, respectively, after dropping the i-th observation. Table 5 shows such RC for the non-intercept regression coefficients when observations 53, 75, 162 and 178 are removed. Note that the RC is greater for the estimated parameters than its estimated SE. However, the significance of and is maintained whereas is not significant with a 5%. More combinations of dropped observations are presented in the Appendix A.2.
Table 5.
Relative changes (RC) (in %) in ML estimates and their corresponding SE’s for the indicated parameter and respective p-values for the athletes dataset when observations 53, 75, 162 and 178 are dropped.
5. Concluding Remarks
Extending the quantile regression methods to include asymmetric response variables on the real line is promising area of research. In this paper, we have introduced a novel flexible parametric quantile regression model for asymmetric response variables, which can be very useful in modeling response variables on the real line at different quantiles. The proposed quantile regression model was built based on PSN distribution using a new parameterization of this distribution that is indexed by quantile, precision and shape parameters, in which a function of any quantile of the response variable is given by a linear predictor that is defined by regression parameters and explanatory variables. We consider a frequentist approach to estimate the model parameters, and the maximum likelihood inference is employed to estimate the model parameters. An application using a real dataset was presented and discussed. Results of the application showed that the model is adequate; it elaborately showed which covariates influence the response at different levels of quantiles. Finally, there are many possible extensions of the current work, for instance, mixtures of RPSN regression models in order to accommodate multimodality, a semi-parametric component to include a functional covariate to model nonlinearity of the response, and measurement errors, among others. An in-depth investigation of these topics is beyond the scope of this work, and will be considered elsewhere.
Author Contributions
Conceptualization, D.I.G., M.B. and C.E.G.; Formal analysis, D.I.G., M.B., C.E.G. and H.W.G.; Investigation, D.I.G., M.B., C.E.G. and H.W.G.; Methodology, D.I.G., M.B. and C.E.G.; Software, D.I.G. and M.B.; Supervision, C.E.G. and H.W.G.; Validation, D.I.G. and M.B. All authors have read and agreed to the published version of the manuscript.
Funding
The research of H.W. Gómez was supported by Grant PUENTE UA, Chile.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Details for Score and Hessian
For the score vector in Equation (4), the elements of the form , with are given by
where .
For the Hessian in Equation (5), the elements of the form , with are given by
where .
Appendix A.2. Local Influence
In this section, we present additional information for the local influence analysis in the Athletes dataset discussed in Section 5.

Figure A1.
Index plots for (left), (center) and (right) under the weight perturbation (upper), response perturbation (center) and covariate perturbation (lower) schemes for RPSN model for .

Figure A2.
Index plots for (left), (center) and (right) under the weight perturbation (upper), response perturbation (center) and covariate perturbation (lower) schemes for RPSN model for .


Figure A3.
Index plots for (left), (center) and (right) under the weight perturbation (upper), response perturbation (center) and covariate perturbation (lower) schemes for RPSN model for .


Figure A4.
Index plots for (left), (center) and (right) under the weight perturbation (upper), response perturbation (center) and covariate perturbation (lower) schemes for RPSN model for .
Table A1.
RCs (in %) in ML estimates and their corresponding SEs for the indicated parameter and respective p-values for the athletes dataset when observation 75 and 178 are dropped separately.
Table A1.
RCs (in %) in ML estimates and their corresponding SEs for the indicated parameter and respective p-values for the athletes dataset when observation 75 and 178 are dropped separately.
| Dropped | |||||||
|---|---|---|---|---|---|---|---|
| Cases | Parameter | 0.10 | 0.25 | 0.50 | 0.75 | 0.90 | |
| 75 | RC | 5.31 | 7.22 | 10.82 | 16.2 | 22.57 | |
| RCSE | 0.23 | 0.20 | 0.17 | 0.11 | 0.04 | ||
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 1.82 | 5.03 | 10.02 | 16.09 | 22.08 | ||
| RCSE | 0.15 | 0.05 | 0.08 | 0.07 | 0.17 | ||
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 6.77 | 9.84 | 14.27 | 19.20 | 23.84 | ||
| RCSE | 0.65 | 0.93 | 1.05 | 0.71 | 0.33 | ||
| p-value | 0.0118 | 0.0105 | 0.0095 | 0.0086 | 0.0078 | ||
| 178 | RC | 0.72 | 2.62 | 6.30 | 11.88 | 18.50 | |
| RC | 0.17 | 0.15 | 0.12 | 0.07 | 0.00 | ||
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 0.12 | 3.36 | 8.60 | 14.88 | 21.06 | ||
| RC | 0.13 | 0.06 | 0.09 | 0.07 | 0.18 | ||
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 22.91 | 25.43 | 29.09 | 33.17 | 37.01 | ||
| RC | 0.75 | 0.47 | 0.31 | 0.61 | 1.61 | ||
| p-value | 0.0449 | 0.0418 | 0.0393 | 0.0371 | 0.0352 | ||
Table A2.
RCs (in %) in ML estimates and their corresponding SEs for the indicated parameter and respective p-values for the athletes dataset when observations {75, 178} and {75, 162, 178} are dropped separately.
Table A2.
RCs (in %) in ML estimates and their corresponding SEs for the indicated parameter and respective p-values for the athletes dataset when observations {75, 178} and {75, 162, 178} are dropped separately.
| Dropped | |||||||
|---|---|---|---|---|---|---|---|
| Cases | Parameter | 0.10 | 0.25 | 0.50 | 0.75 | 0.90 | |
| 75 and | RC | 6.30 | 8.16 | 11.69 | 17.01 | 23.29 | |
| 178 | RCSE | 0.41 | 0.39 | 0.34 | 0.28 | 0.19 | |
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 1.75 | 5.32 | 10.58 | 16.84 | 22.97 | ||
| RCSE | 0.29 | 0.08 | 0.03 | 0.18 | 0.27 | ||
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 31 | 33.34 | 36.67 | 40.38 | 43.87 | ||
| RCSE | 0.04 | 0.27 | 0.42 | 0.11 | 0.91 | ||
| p-value | 0.0674 | 0.0633 | 0.0600 | 0.0572 | 0.0546 | ||
| 75, 162 | RC | 5.43 | 7.27 | 10.80 | 16.13 | 22.45 | |
| and 178 | RCSE | 0.57 | 0.54 | 0.50 | 0.43 | 0.34 | |
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 1.36 | 5.12 | 10.53 | 16.91 | 23.14 | ||
| RCSE | 0.39 | 0.18 | 0.12 | 0.26 | 0.35 | ||
| p-value | <0.0001 | <0.0001 | <0.0001 | <0.0001 | <0.0001 | ||
| RC | 43.37 | 45.46 | 48.35 | 51.53 | 54.51 | ||
| RCSE | 0.29 | 0.61 | 0.77 | 0.46 | 0.56 | ||
| p-value | 0.1300 | 0.1251 | 0.1212 | 0.1178 | 0.1149 | ||
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Azzalini, A. Further results on a class of distributions which includes the normal ones. Statistica 1986, 46, 199–208. [Google Scholar]
- Arellano-Valle, R.B.; Gómez, H.W.; Quintana, F.A. A New Class of Skew-Normal Distributions. Commun. Stat. Theory Methods 2004, 33, 1465–1480. [Google Scholar] [CrossRef]
- Pewsey, A.; Gómez, H.W.; Bolfarine, H. Likelihood-based inference for power distributions. Test 2012, 21, 775–789. [Google Scholar] [CrossRef]
- Lehmann, E.L. The power of rank tests. Ann. Math. Statist. 1953, 24, 23–43. [Google Scholar] [CrossRef]
- Durrans, S.R. Distributions of fractional order statistics in hydrology. Water Resour. Res. 1992, 28, 1649–1655. [Google Scholar] [CrossRef]
- Gupta, D.; Gupta, R.C. Analyzing skewed data by power normal model. Test 2008, 17, 197–210. [Google Scholar] [CrossRef]
- Castillo, N.O.; Gallardo, D.I.; Bolfarine, H.; Gómez, H.W. Truncated power-normal distribution with application to non-negative measurements. Entropy 2018, 20, 433. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Arnold, B.C.; Bolfarine, H.; Gómez, H.W. The alpha-power tobit model. Commun. Stat. Theory Methods 2013, 42, 633–643. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Doubly censored power-normal regression models with inflation. Test 2015, 24, 265–286. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Skew-normal alpha-power model. Statistics 2014, 48, 1414–1428. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. The log alpha-power asymmetric distribution with application to air pollution. Environmetrics 2014, 25, 44–56. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. Asymmetric regression models with limited responses with an application to antibody response to vaccine. Biom. J. 2013, 55, 156–172. [Google Scholar] [CrossRef] [PubMed]
- Cook, R.D. Detection of influential observation in linear regression. Technometrics 1977, 19, 15–18. [Google Scholar]
- Cook, R.D.; Weisberg, S. An Introduction to Regression Graphics; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Galarza, C.E.; Lachos, V.H.; Barbosa, C.; Castro, L.M. Robust quantile regression using a generalized class of skewed distributions. Stat 2017, 6, 113–130. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Sulla determinazione empirica di una legge di distribuzionc. Giorn. Ist. Ital. Attuar. 1933, 4, 83–91. [Google Scholar]
- Dunn, P.; Smyth, G. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).