Abstract
In this article, the slashed Lomax distribution is introduced, which is an asymmetric distribution and can be used for fitting thick-tailed datasets. Various properties are explored, such as the density function, hazard rate function, Renyi entropy, r-th moments, and the coefficients of the skewness and kurtosis. Some useful characterizations of this distribution are obtained. Furthermore, we study a slashed Lomax regression model and the expectation conditional maximization (ECM) algorithm to estimate the model parameters. Simulation studies are conducted to evaluate the performances of the proposed method. Finally, two sets of data are applied to verify the importance of the slashed Lomax distribution.
1. Introduction
The Lomax distribution, which was introduced by Lomax [1], has been regarded as the mixed distribution of the exponential distribution and gamma distribution. It has a heavy-tailed probability distribution, often used in business, economics, and actuarial modeling. Let X be a non-negative random variable with a Lomax distribution, then its probability density function (pdf) is given by,
where and , and it is denoted by . The Lomax distribution contains the monotone decreasing failure rate and the monotone increasing failure rate, which have been regarded as a quantitative life distribution. It has been applied broadly in practical production and real life. For example: Myhre and Saunders [2] applied the Lomax distribution to right censored data; Balakrishnan and Ahsanullah [3] discussed some important statistical properties of the Lomax distribution; Childs et al. [4] studied the properties of right-truncated Lomax distributions and discussed some practical applications; and Howlader and Hossain [5] considered estimating the survival function of the Lomax distribution with the Bayesian method.
The slashed distribution was proposed to model the bell shaped data with a heavier tail, by Rogers and Tukey [6], which is thicker than the tail of the normal distribution and is itself a symmetric distribution. It has a stochastic representation as , where , is independent of , and is called the canonical slashed distribution when . After that, statisticians have done in-depth research on and promoted this model; see Wang and Genton [7], Gomez et al. [8], Arslan and Genc [9], Reyes et al. [10], and Tian et al. [11,12]. Recently, there has been a new extension of the slashed distribution: Gui [13] introduced a three-parameter extension model called the Lindley slashed distribution; Iriarte et al. [14,15] proposed the slashed Rayleigh distribution and modified slashed Rayleigh distribution, which have a more flexible kurtosis than the Rayleigh distribution; Reyes et al. [16] discussed the modified slashed Birnbaum–Saunders distribution and concluded that it has greater kurtosis values than the usual BSdistribution. Similar to this methodology, the slashed Lindley–Weibull distribution was introduced by Reyes et al. [17]; the slashed power Lindley distributions was studied by Iriarte et al. [18]; and the modified slashed generalized exponential distribution was introduced by Astorga et al. [19].
Regression models are undoubtedly the most widely used, but the normality assumption of the residual errors is more restrictive. Recently, the error term subject to a more flexible distribution has been studied: Gómez [20] analyzed the regression model of the slashed half-normal distribution; Jamal [21] studied the properties of the Topp–Leone–Weibull Lomax distribution and its regression model; and Hamedani et al. [22] analyzed the regression model of the Burr XII distribution.
Based on the previous research, we propose the slashed Lomax distribution, which has a thicker tail than the Lomax distribution and has more flexibility in kurtosis. Furthermore, the construction of the slashed Lomax distribution makes it possible to estimate the parameters in a variety of ways. Therefore, the proposed new distribution can be used not only for fitting thick-tailed datasets, but also can analyze some phenomena in real life. The rest of the paper is organized as follows. In Section 2, we introduce the slashed Lomax distribution and obtain some of its properties. The ECM algorithm for the parameter estimation and simulation studies is proposed in Section 3. The slashed Lomax regression model is studied in Section 4. Two applications to real data are investigated in Section 5. Some conclusions are offered in Section 6.
2. Slashed Lomax Distribution
In this section, some basic properties of the slashed Lomax distribution are described.
Definition 1.
A random variable Y follows a slashed Lomax distribution, denoted as , if it can be represented as:
where and are independent random variables and .
Proposition 1.
Let , then its pdf can be written as:
Proof.
Using the stochastic representation in Equation (1), we have the joint density function of as:
and the pdf of Y is obtained by marginalizing the distribution with respect to V. □
Corollary 1.
Let .
- (i)
- For ,where is the hyper geometric function.
- (ii)
- and are positive integers, and ,where is the incomplete beta function.
Remark 1.
For , is reduced to the canonical slashed Lomax distribution, and the pdf is:
For an illustration of the new family of slashed Lomax distributions, we draw the density curves, with different values of , , and , as follows. After fixing two of the three parameters, we find that the slashed Lomax distributions have a heavier tail as increases (and the same for , but the opposite for ).
Proposition 2.
Let .
- (i)
- The reliability (survival) function of Y is given by:where .
- (ii)
- The hazard rate function of Y is given by:
- (iii)
- The reversed hazard rate of Y is given by:
Figure 1 shows probability density function curve of the slashed Lomax distribution with several different parameters. Figure 2 shows the curves of hazard rate functions under different parameters. It can be seen that the values of the hazard rate function based on , with and fixed, have small differences as y increases in these figures.
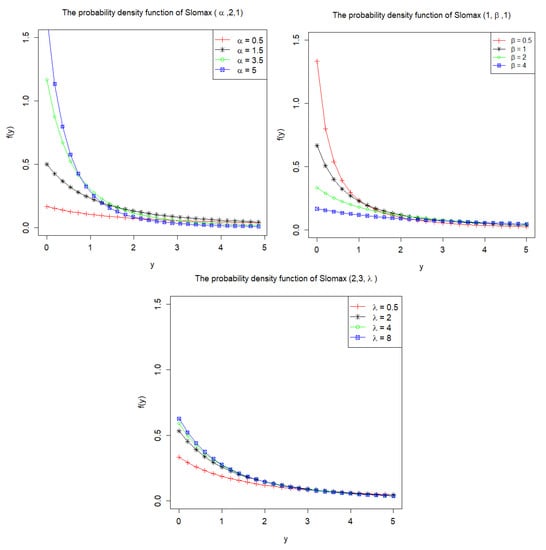
Figure 1.
The probability density function plots of Slomax ().
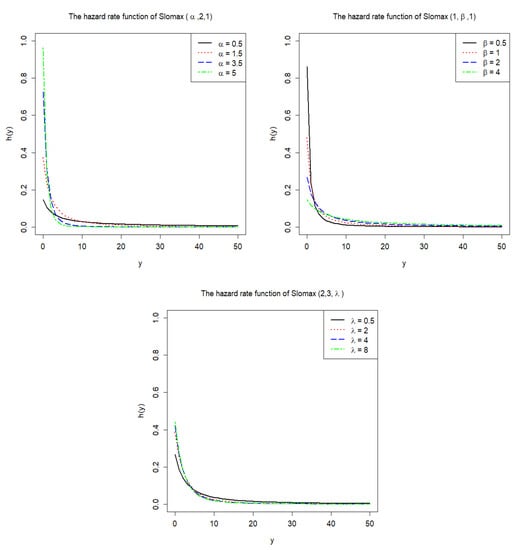
Figure 2.
Hazard rate function plots of Slomax ().
Next, the Renyi entropy and distributional moments of the slashed Lomax distribution are derived. In addition, the coefficients of skewness and kurtosis are calculated.
Proposition 3.
Let ; the Renyi entropy of order δ for Y is given by,
where and .
Proof.
Renyi entropy is an important diversity index in ecology and statistics, which is defined as . Therefore, we have:
□
Proposition 4.
Let Slomax; the r-th moment of Y, for and , is given by:
where is the gamma function.
Proof.
Using Equation (1), we have,
According to the properties of the beta distribution and the Lomax distribution, we have that for , and . Thus, the result is obtained. □
Corollary 2.
Let Slomax ; the mean and variance of Y are given by:
Corollary 3.
Let Slomax ; the coefficients of skewness and kurtosis for Y, and , are given by:
where and .
Proof.
From Proposition 4, and ; thus, the results are obtained directly. □
In the following propositions, we consider the linear transformation of the slashed Lomax distribution and discuss its scale mixture representation.
Proposition 5.
Let and the scalar , then .
Proof.
Let , and is a scalar; we have . Therefore, the result is obtained by Equation (1). □
Proposition 6.
If and V∼ beta (), then Y∼ Slomax().
Proof.
The result can be obtained by Equation (1) and Proposition 1. □
3. ECM Algorithm for Parameter Estimation
In this section, we consider the maximum likelihood (ML) estimation for the parameters of the slashed Lomax distribution. It is well known that the EM algorithm is an important tool for ML estimation when no data or potential variables are observed. The E-step is used to find the expectation of the incomplete data based on the observed values, and the M-step works for the maximization. Usually, the M-step calculation is difficult when the maximum likelihood of the complete data is complex. Meng and Rubin [23] proposed an ECM algorithm that was an extension of the EM algorithm and satisfied all the properties of the EM algorithm. The basic idea of the ECM algorithm is to decompose the M-step of the EM algorithm into k times conditional maximization.
In the following, an ECM algorithm is proposed for obtaining the estimator of from the slashed Lomax distribution. Let be a random sample from . According to Equation (1), we have,
Let and be observed data, then (), are the complete dataset. Therefore, the log-likelihood function for the complete data , , is given by:
E-Step: Compute the conditional expectation of the log-likelihood function, , by using the following equation,
where .
CM-Steps: Maximize with respect to to obtain .
Denote ; the following equations are obtained for the maximization.
- (i)
- Set up , then:where
- (ii)
- Set up , then:where
- (iii)
- Set up , then:where
The iterations are repeated until a suitable convergence rule is satisfied, say , where is the Euclidean norm and is sufficiently small.
In the following, we conduct simulation studies to test the efficiency of the estimation procedure discussed above. The random values following the slashed Lomax distribution can be generated by Equation (1). The parameters are set up as: (2,1,0.5), (2,1,1), (2,1,1.5), (1,0.5,1), (1,1,1), (1,2,1), (0.5,2,2), (2,2,1), (4,2,1). The sample sizes n = 50, 100, and 200. The following procedure is for generating a random number with size n from ,
- set , and n;
- simulate ;
- simulate ;
- compute ;
- compute .
For each scenario, we repeat the process times. The ECM algorithm is applied, and the results are computed using the software R. The procedures are put in the same conditions (same initial values, and ). The estimators are obtained by applying the nleqslvfunction in Equations (4)–(6). The mean values of the parameters and the corresponding standard deviation (SD) are shown in Table 1. The empirical estimated mean value and SDs based on the 1000 replicates are calculated by:
where is the interesting parameter, , respectively.

Table 1.
Estimates for parameters of the slashed Lomax distribution.
From Table 1, it can be seen that as the sample size increases, the mean value of estimators comes closer to the true values, and the SD decreases in all case.
4. Slashed Lomax Regression Model
In this section, we study the slashed Lomax regression model and propose the ECM algorithm to estimate the parameters.
Definition 2.
The slashed Lomax regression model is defined as:
where , is a p-dimensional vector of regression parameters, is a known matrix, with for , and .
Let come from the slashed Lomax regression model with X the given design matrix x. The log-likelihood function of can be written as:
where .
Now, given , we can get the complete log-likelihood function:
and the conditional expectation of ,
where .
In the following, we illustrate the steps for the ECM algorithm for estimating the parameters in the regression model.
E-step: Given , find the expectation of the condition.
CM-step I: must be updated as:
CM-step : must be updated as:
CM-step : must be updated as:
CM-step : must be updated as:
The iterations are repeated until a suitable convergence rule is satisfied, say sufficiently small. On the basis of this theory, a simulation experiment is carried out. We take the two-dimensional regression model to carry out the numerical simulation. The value of the parameters for are chosen as (2,2,1), (1,1,1), (1,4,0.5),(0.5,3,0.5), and the regression parameters are set to (1,4), (−2,3), and (−3,−5); , for , are uncorrelated. For each scenario, we generate samples of size n = 50, 100, and 200, respectively. The empirical estimated mean value and SDs for the corresponding parameters based on the 1000 replicates are shown in Table 2, Table 3 and Table 4.
Table 2.
Estimates for the parameters of the Slomax regression model (n = 50).
Table 3.
Estimates for the parameters of the Slomax regression model (n = 100).
Table 4.
Estimates for the parameters of the Slomax regression model (n = 300).
From the simulation results, we can see that, as the sample size increases, the standard deviations between the estimated parameters decrease, and the estimated values are close to the actual values.
5. Application
Next, we use the real data to verify the practicability of the slashed Lomax distribution. We compare the performance of the slashed Lomax distribution to that of the beta Lomax (Blomax) distribution (Lemonte and Cordeiro [24]), the exponentiated standard Lomax (ESlomax) distribution, and the Gumbel Lomax (Gulomax) distribution (Tahir et al. [25]). The measures of the goodness of fit including the Akaike information criterion (AIC) and Bayesian information criterion (BIC) values are computed to compare the fitted model and regression model.
Data 1: This dataset has 214 observations and describes the successive failure of the air conditioning systems in a fleet of 13 Boeing 720 jet airplanes, which was studied by Kus [26], Tahir et al. [25], and many others.
The parameter estimates, AIC, and BIC for all fitted distributions are shown in Table 5. Both criteria provide evidence in favor of the slashed Lomax distribution for this dataset, corroborating that the slashed Lomax distribution can be seen as a competitive distribution of practical interest in the real world.
Table 5.
Parameter estimates and log-likelihood values for different models. Gulomax, Gumbel Lomax; Blomax, beta Lomax; ESlomax, exponentiated standard Lomax.
Figure 3 displays the fitted models for the dataset. The left panel of Figure 3 shows the fitted densities to the dataset histogram and some estimated distributions, and the right panel displays the empirical distribution function for the dataset and the estimated distributions. Both figures reveal that the slashed Lomax distribution provides a qualified fit for the dataset.
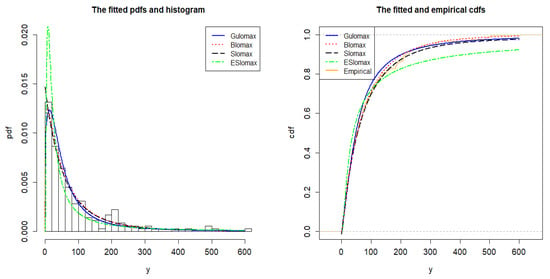
Figure 3.
Fitted curves of the Gulomax, Blomax, ESlomax, and Slomax distribution.
Data 2: This dataset is about the lifespan of patients with heart failure and contains 96 patients with heart failure, the detailed information of which was provided by Tanvir Ahmad [27].
The numerical variables considered here are ejection fraction , serum creatinine , serum sodium , and age as potential variables that explain cardiovascular mortality . We apply the slashed Lomax regression model developed in Section 4 to this dataset. The resulting estimates and other regression models are given in Table 6.
Table 6.
Parameter estimates and log-likelihood values for different models.
As can be noted from Table 6, the slashed Lomax regression model has the lowest AIC and BIC values among those of the other regression models. The values of these statistics indicate that the slashed Lomax regression model provides the best fit to the data. In addition, the increase of the content of serum creatinine will shorten the lifespan of patients and increase the risk of death, which are consistent with the conclusions by Tanvir Ahmad [27].
6. Discussion
In this article, the slashed Lomax distribution and its corresponding statistical properties are introduced. Maximum likelihood estimators through the ECM algorithm and simulation studies are discussed. In addition, the slashed Lomax regression model is studied. Applications to real data demonstrate the importance of the proposed distribution. In the future, we will consider extending this proposed model to the multivariate case and study its extremal properties, aiming to explore more practical values.
Author Contributions
W.T.: Conceptualization, Methodology, Validation, Investigation, Resources, Supervision, Project Administration, Visualization, Writing–review and editing; H.L.: Software, Formal analysis, Data curation, Writing–original draft preparation, Visualization. Both the authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
The authors would like to thank the Editor and two anonymous referees for their careful reading of this article and for their constructive suggestions, which considerably improved this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lomax, K.S. Business failures: Another example of the analysis of failure data. J. Am. Stat. Assoc. 1954, 49, 847–852. [Google Scholar] [CrossRef]
- Myhre, J.; Saunders, S. Screen testing and conditional probability of survival. Lect. Notes-Monogr. Ser. 1982, 2, 166–178. [Google Scholar]
- Balakrishnan, N.; Ahsanullah, M. Relations for single and product moments of record values from Lomax distribution. Sankhy Indian J. Stat. Ser. B 1994, 56, 140–146. [Google Scholar]
- Childs, A.; Balakrishnan, N.; Moshref, M. Order statistics from non-identical right-truncated Lomax random variables with applications. Stat. Pap. 2001, 42, 187–206. [Google Scholar] [CrossRef]
- Howlader, H.A.; Hossain, A.M. Bayesian survival estimation of Pareto distribution of the second kind based on failure-censored data. Comput. Stat. Data Anal. 2002, 38, 301–314. [Google Scholar] [CrossRef]
- Rogers, W.H.; Tukey, J.W. Understanding some long-tailed symmetrical distributions. Stat. Neerl. 1972, 26, 211–226. [Google Scholar] [CrossRef]
- Wang, J.; Genton, M.G. The multivariate skew slash distribution. J. Stat. Plan. Inference 2006, 136, 209–220. [Google Scholar] [CrossRef]
- Gómez, H.W.; Quintana, F.A.; Torres, F.J. A new family of slash-distributions with elliptical contours. Stat. Probab. Lett. 2007, 77, 717–725. [Google Scholar] [CrossRef]
- Arslan, O.; Genc, A.I. A generalization of the multivariate slash distribution. J. Stat. Plan. Inference 2009, 139, 1164–1170. [Google Scholar] [CrossRef]
- Reyes, J.; Gomez, H.W.; Bolfarine, H. Modified slash distribution. Statistics 2013, 47, 929–941. [Google Scholar] [CrossRef]
- Tian, W.; Wang, T.; Gupta, A.K. A new family of multivariate skew slash distribution. Commun. Stat. Theory Methods 2018, 47, 5812–5824. [Google Scholar] [CrossRef]
- Tian, W.; Han, G.; Wang, T.; Pipitpojanakarn, V. EM estimation for multivariate skew slash distribution. In Robustness in Econometrics; Springer: Cham, Switzerland, 2017; pp. 235–248. [Google Scholar]
- Gui, W. Statistical properties and applications of the Lindley slash distribution. J. Appl. Stat. Sci. 2012, 20, 283. [Google Scholar]
- Iriarte, Y.A.; Gomez, H.W.; Varela, H.; Bolfarine, H. Slashed rayleigh distribution. Rev. Colomb. Estadstica 2015, 38, 31–44. [Google Scholar] [CrossRef]
- Iriarte, Y.A.; Castillo, N.O.; Bolfarine, H.; Gomez, H.W. Modified slashed-Rayleigh distribution. Commun. Stat. Theory Methods 2018, 47, 3220–3233. [Google Scholar] [CrossRef]
- Reyes, J.; Vilca, F.; Gallardo, D.I.; Gomez, H.W. Modified slash Birnbaum–Saunders distribution. Hacet. J. Math. Stat. 2017, 46, 969–984. [Google Scholar] [CrossRef]
- Reyes, J.; Iriarte, Y.A.; Jodr, P.; Gomez, H.W. The Slash Lindley–Weibull Distribution. Methodol. Comput. Appl. Probab. 2019, 21, 235–251. [Google Scholar] [CrossRef]
- Iriarte, Y.A.; Rojas, M.A. Slashed power-Lindley distribution. Commun. Stat. Theory Methods 2019, 48, 1709–1720. [Google Scholar] [CrossRef]
- Astorga, J.M.; Iriarte, Y.A.; Gomez, H.W.; Bolfarine, H. Modified slashed generalized exponential distribution. Commun. Stat. Theory Methods 2019, 49, 4603–4617. [Google Scholar] [CrossRef]
- Gómez, Y.M.; Gallardo, D.I.; de Castro, M. A regression model for positive data based on the slashed half-normal distribution. Available online: https://www.ine.pt/revstat/pdf/Aregressionmodelforpositivedata.pdf (accessed on 1 January 2020).
- Jamal, F.; Reyad, H.M.; Nasir, M.A.; Chesneau, C.; Shah, M.A.A.; Ahmed, S.O. Topp-Leone Weibull-Lomax distribution: Properties, Regression Model and Applications. 2019. Available online: https://hal.archives-ouvertes.fr/hal-02270561/ (accessed on 1 January 2020).
- Hamedani, G.G.; Rasekhi, M.; Najibi, S.M.; Yousof, H.M.; Alizadeh, M. Type II general exponential class of distributions. Pak. J. Stat. Oper. Res. 2019, 15, 503–523. [Google Scholar] [CrossRef]
- Meng, X.L.; Rubin, D.B. Maximum likelihood estimation via the ECM algorithm: A general framework. Biometrika 1993, 80, 267–278. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cordeiro, G.M. An extended Lomax distribution. Statistics 2013, 47, 800–816. [Google Scholar] [CrossRef]
- Tahir, M.H.; Hussain, M.A.; Cordeiro, G.M.; Hamedani, G.G.; Mansoor, M.; Zubair, M. The Gumbel-Lomax distribution: Properties and applications. J. Stat. Theory Appl. 2016, 15, 61–79. [Google Scholar] [CrossRef]
- Kus, C. A new lifetime distribution. Comput. Stat. Data Anal. 2007, 51, 4497–4509. [Google Scholar] [CrossRef]
- Ahmad, T.; Munir, A.; Bhatti, S.H.; Aftab, M.; Raza, M.A. Survival analysis of heart failure patients: A case study. PLoS ONE 2017, 12, e0181001. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).