Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners



Abstract
1. Introduction
- A real-time system which provides top-ranked Twitter user networks to e-learners from Twitter, according to their context, history and profiles.
- The proposed system recommends top-ranked articles according to the e-learner’s context, e-learner’s history, and e-learner’s profiles from DBLP.
- The system also makes recommendations to e-learners from a local database.
- The main objective of this study is the use of data mining and machine learning approaches for social media content recommendation.
2. Literature Review
2.1. Recommendation System
2.2. Twitter Recommendation
2.3. DBLP Recommendation
2.4. Reinforcement Learning Recommendation
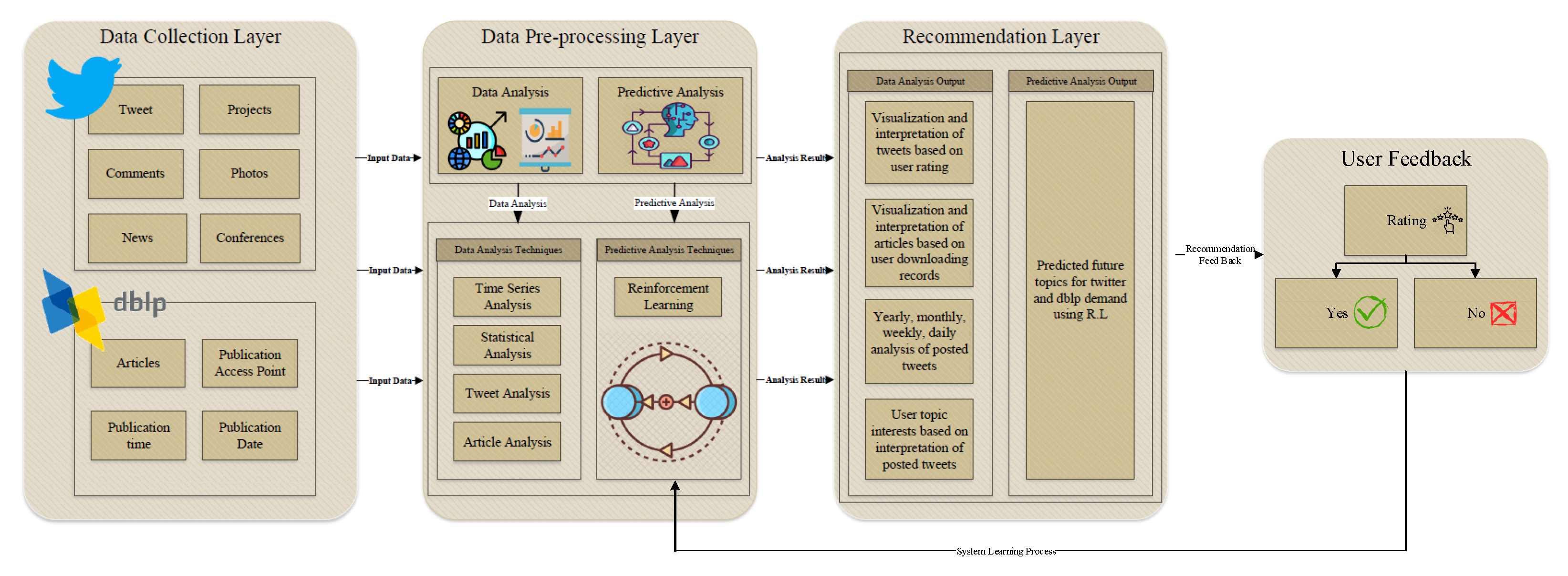
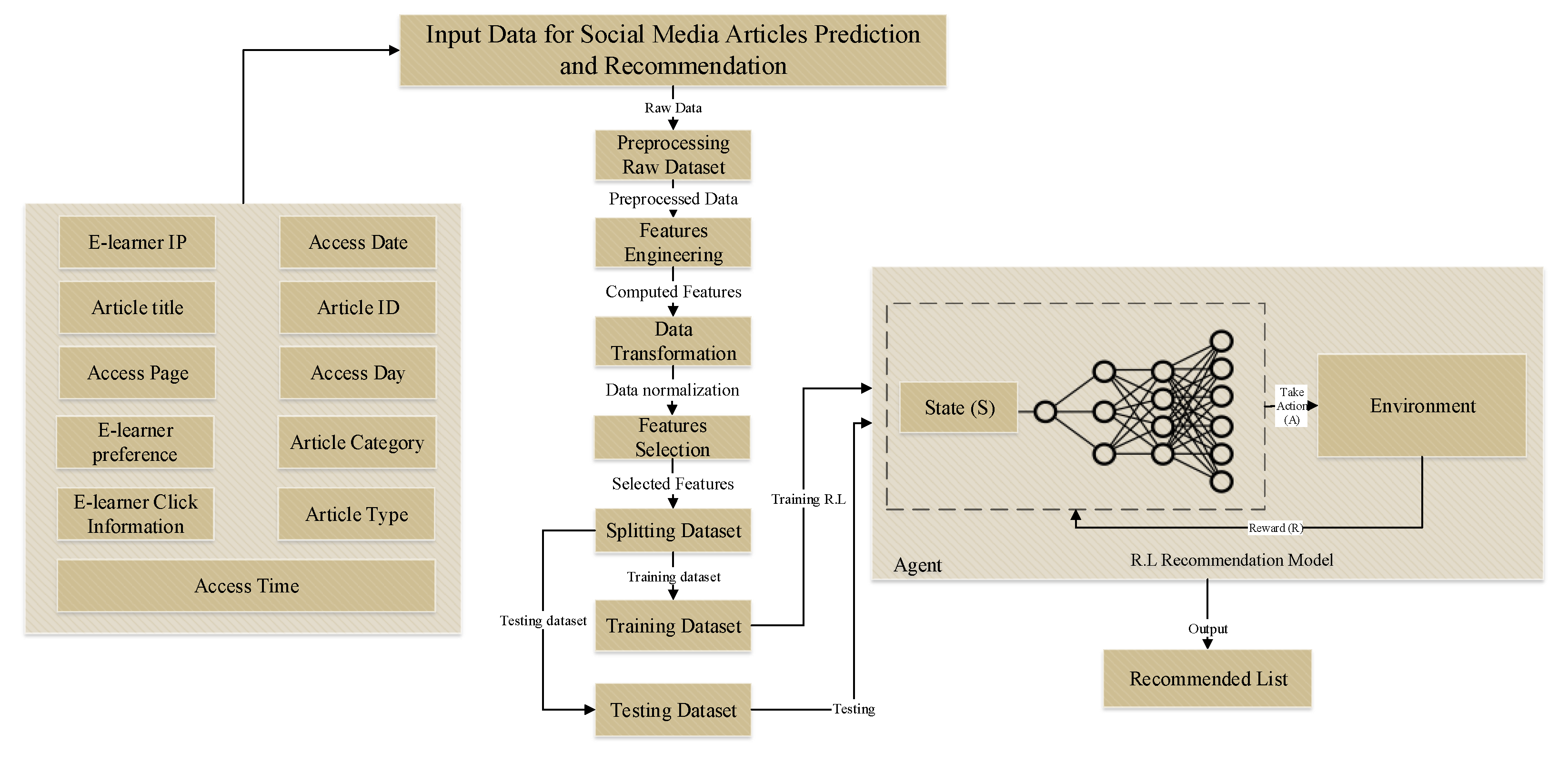
3. Social Media Content Recommendation for E-Learners
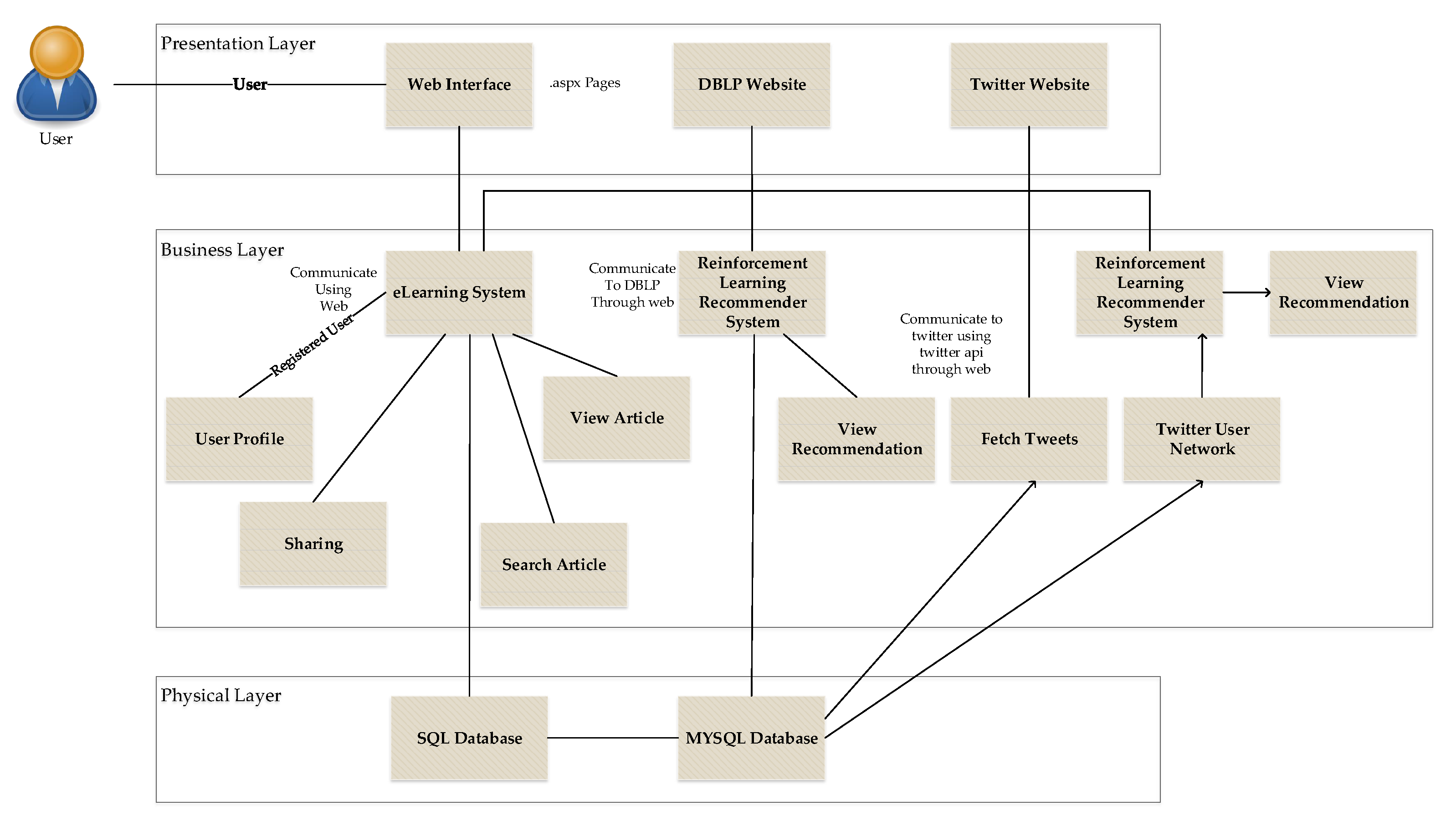
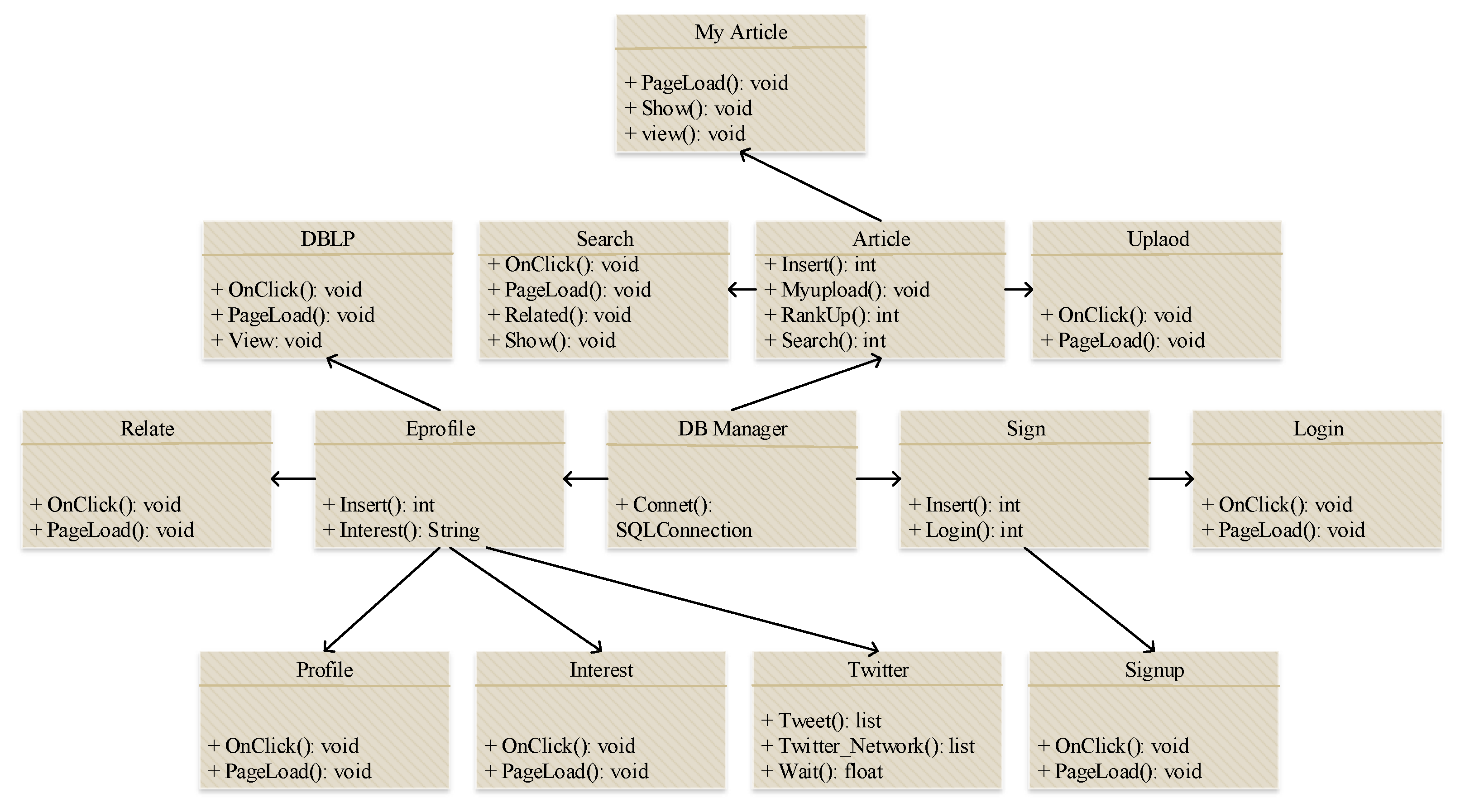
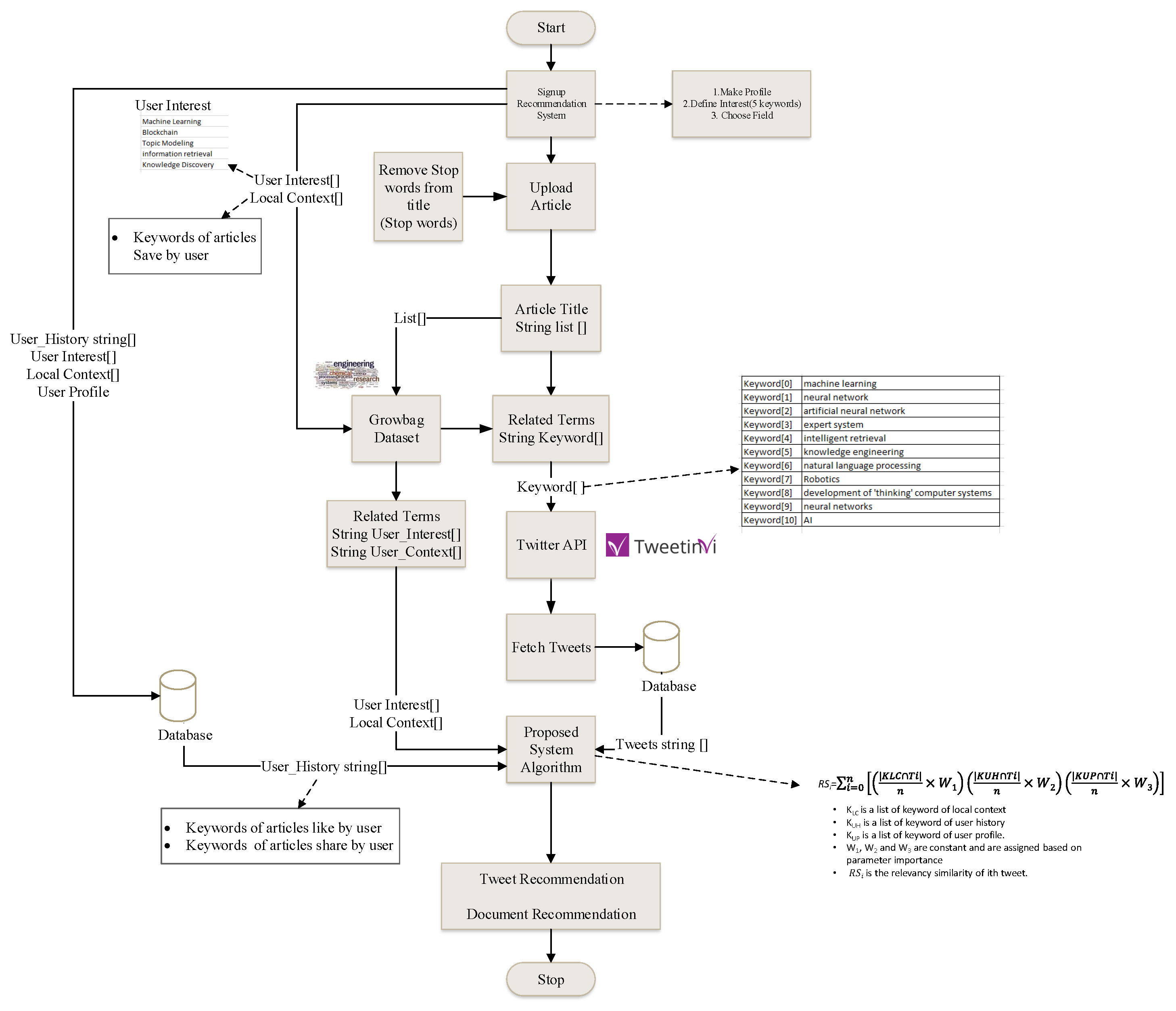
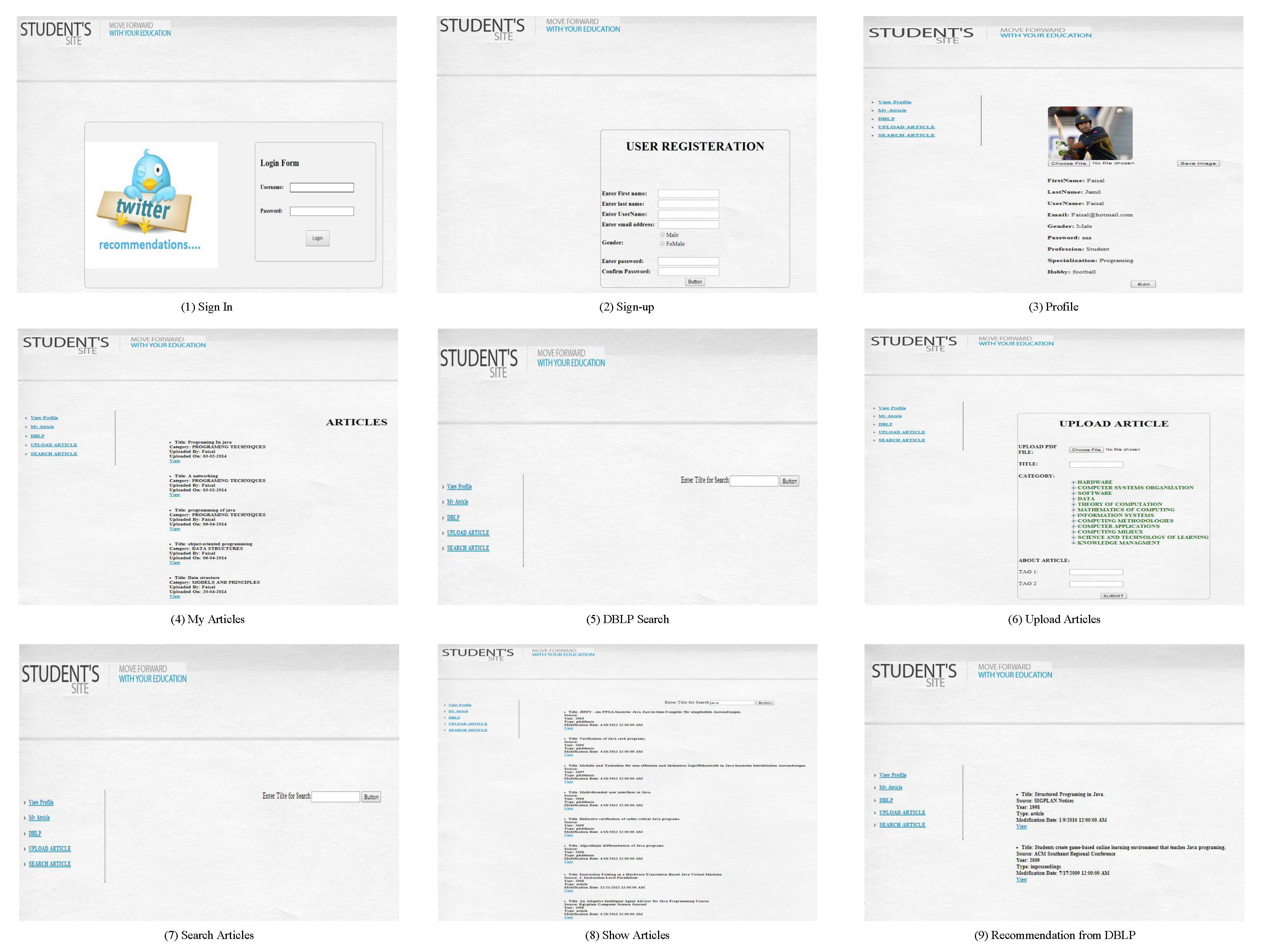
3.1. E-Learners Recommendation System
3.2. Dataset
- Collecting data;
- Cleaning data;
- Manipulate missing values;
- Missing value extraction;
- Discovering the available features.
3.3. Data Mining and Visualization
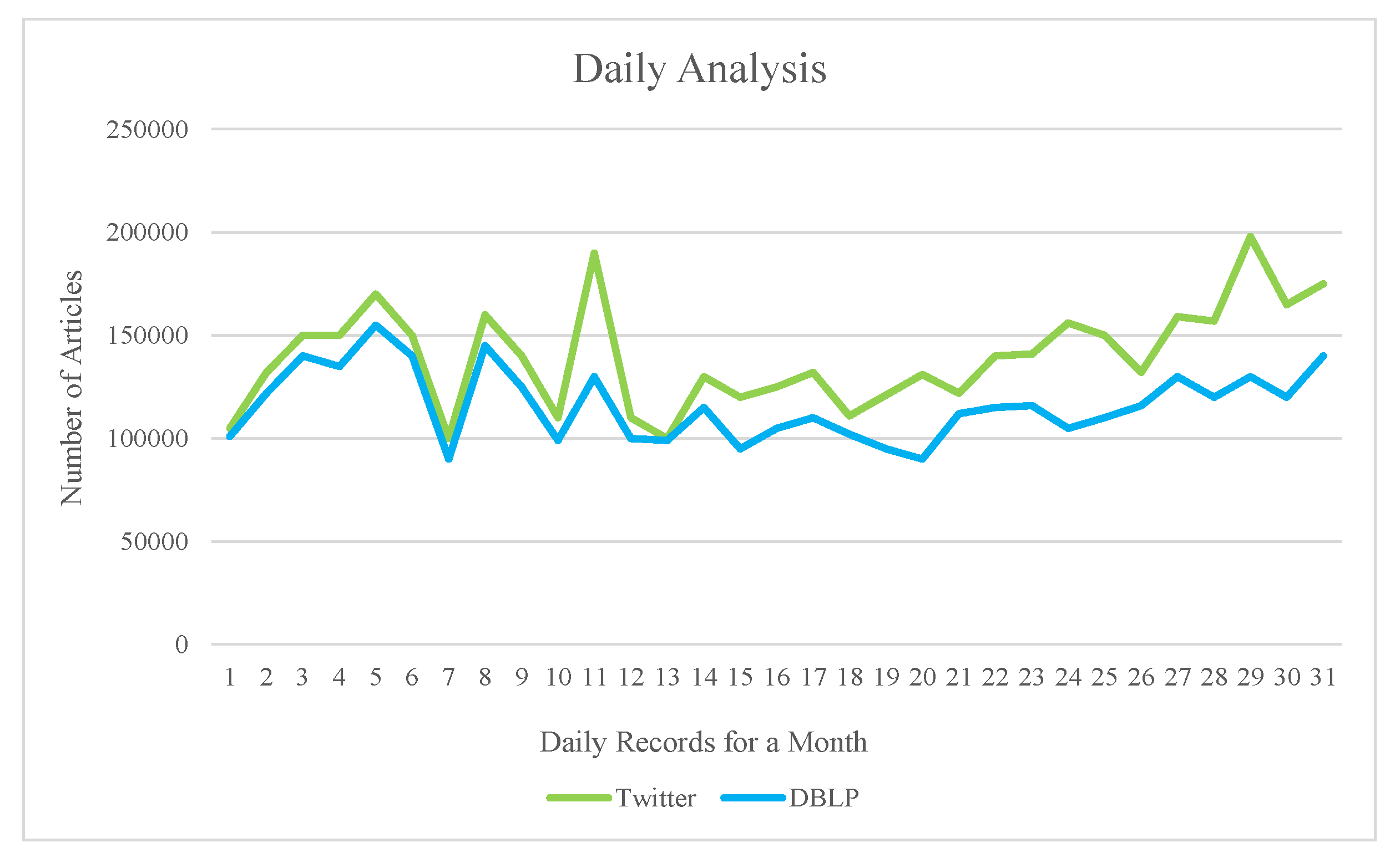
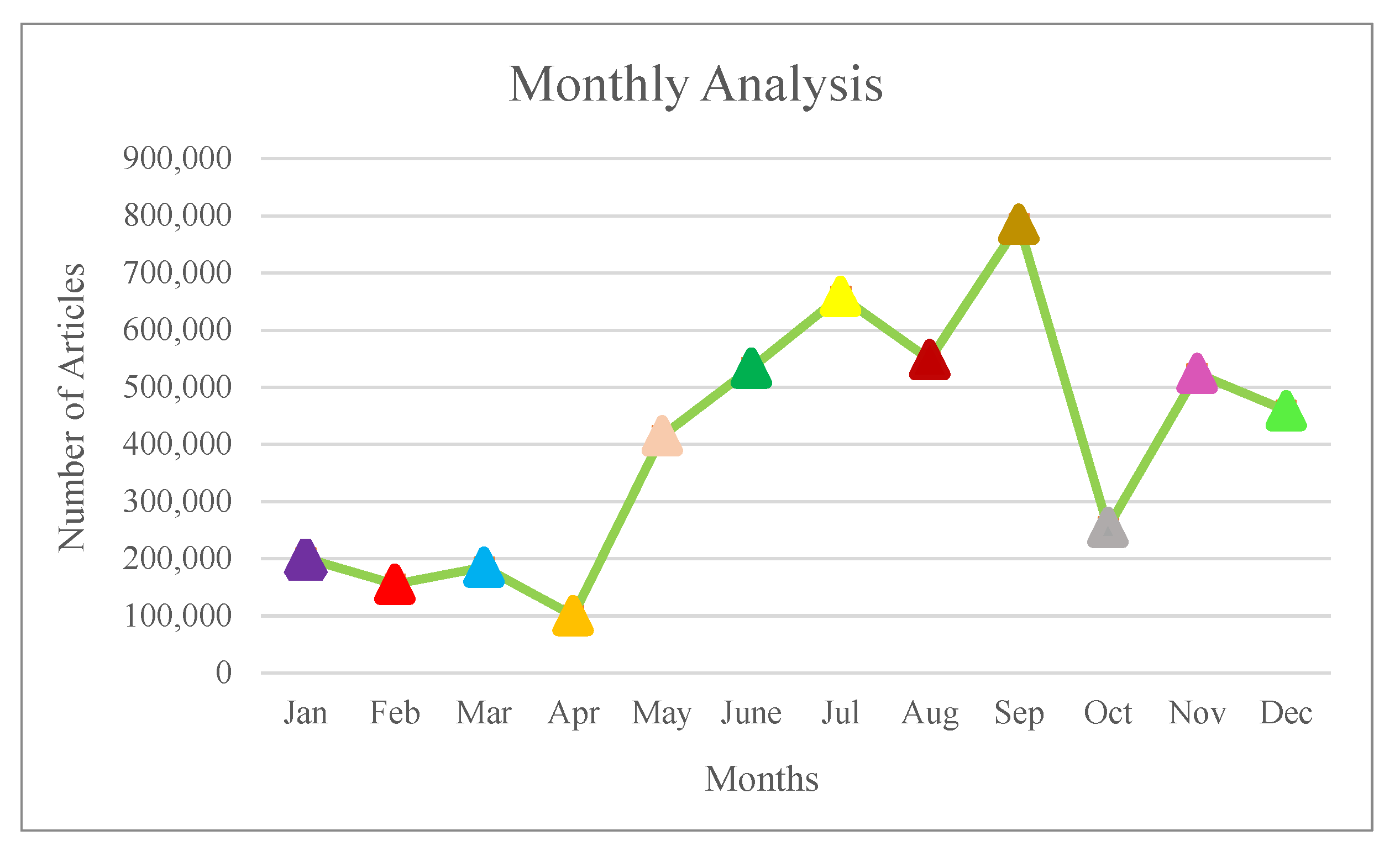
- Twitter and DBLP article recommendation for e-learners based on tweet frequency, selected articles and user preference;
- Time series analysis based on Monthly and daily analysis;
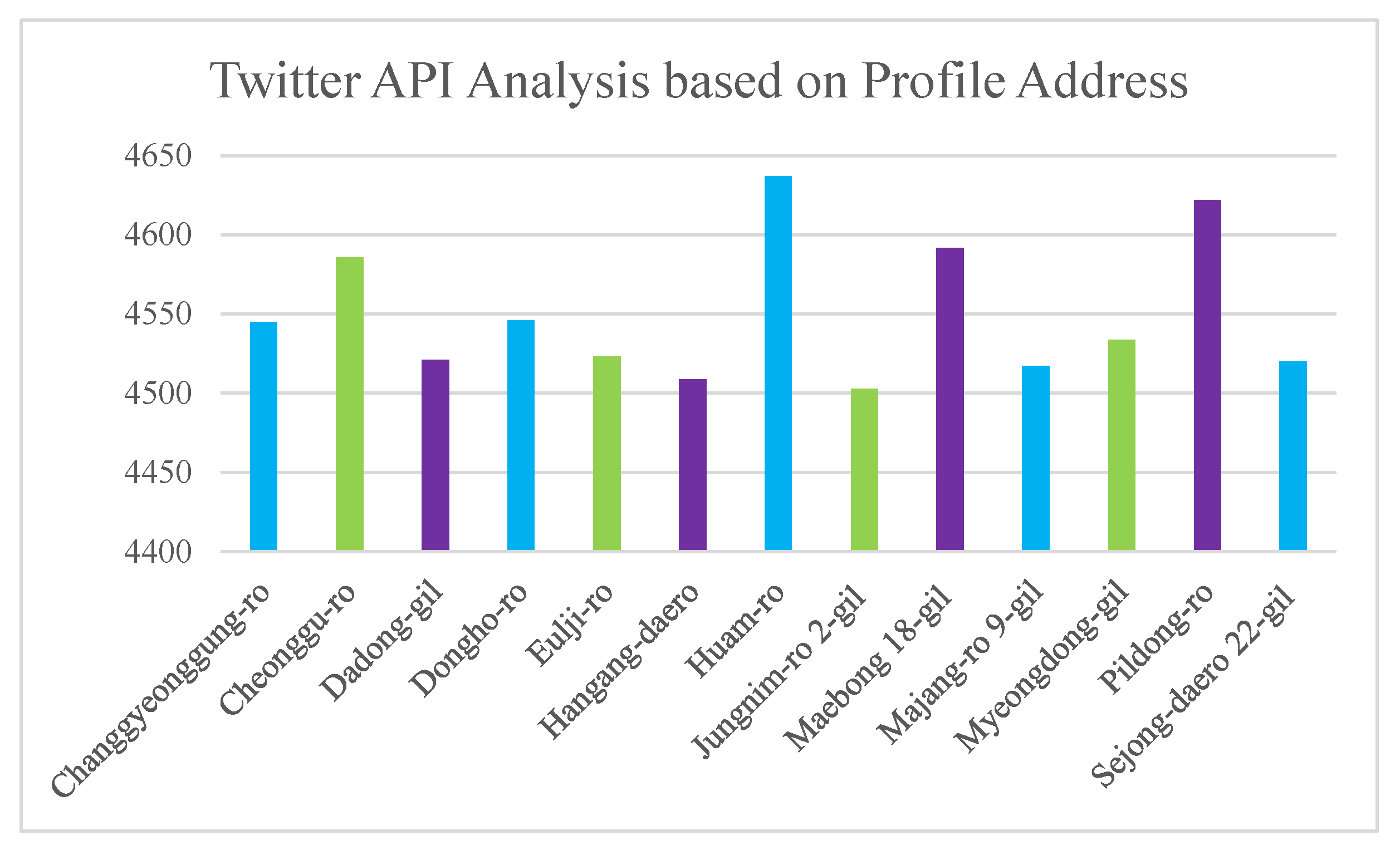
- Twitter and DBLP platform analysis based on e-learner preferences;
- Twitter and DBLP platform analysis based on e-learner clicked links;
3.3.1. Time Series Analysis
3.3.2. Twitter API Analysis Based on Profile Address
3.4. Discover Patterns and Features
3.5. Interaction Model for the Proposed Recommendation Platform
4. Predictive Analysis of Twitter and DBLP Data Using Reinforcement Learning
Reinforcement Learning Optimization
5. Prediction Result of Twitter and DBLP Platform
5.1. Experimental Environment and Setup
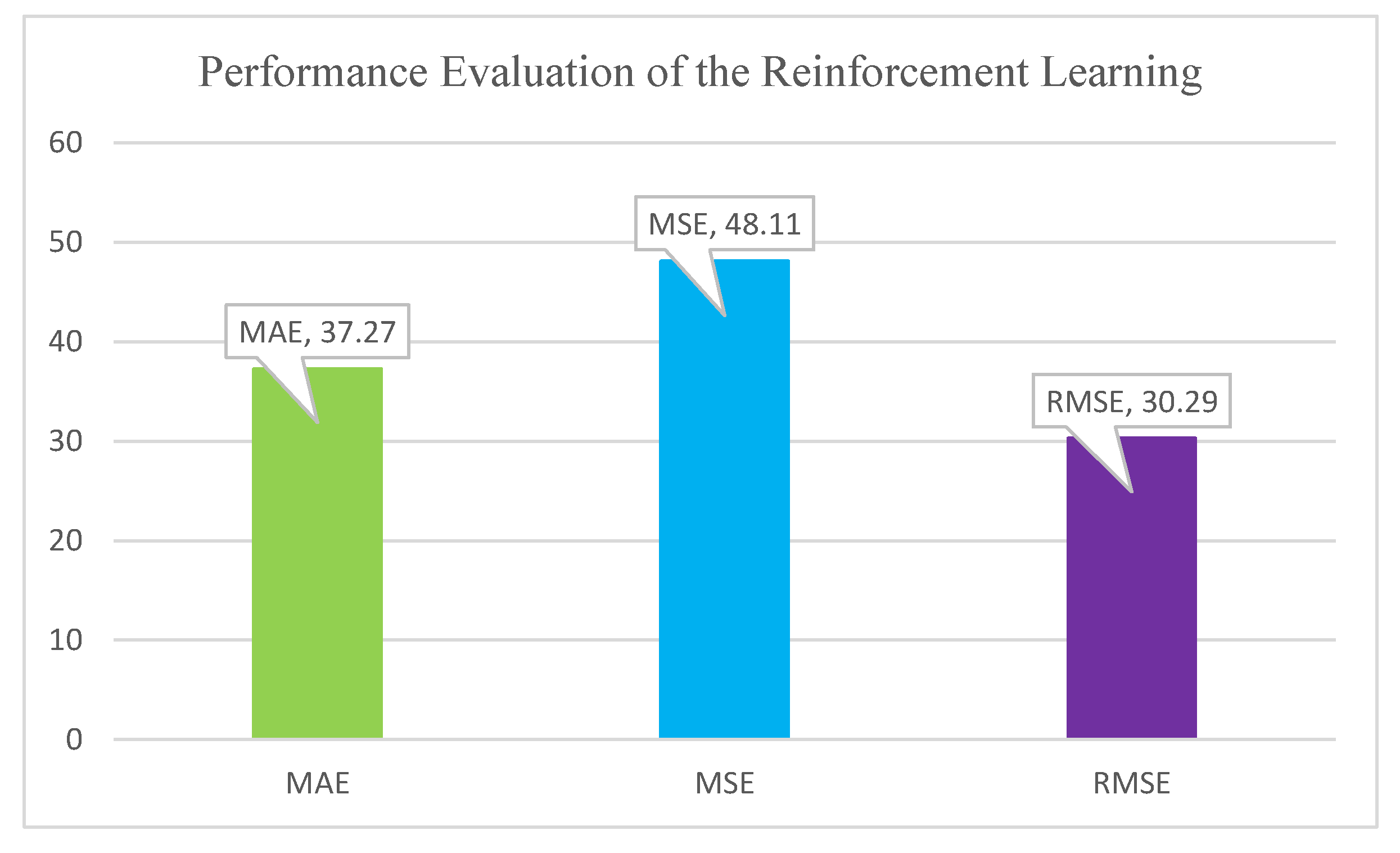
5.2. Performance Evaluation
- Mean Square Error This statistical evaluation measure the relationship between predicted value and actual value based on the mentioned Equation (9).
- Mean Absolute ErrorThis statistical evaluation measures the square of differences between predicted value and actual value based on the mentioned Equation (10).
- Root Mean Square ErrorThis statistical evaluation measure the error rate, error size based on the target value which mentioned in Equation (11).
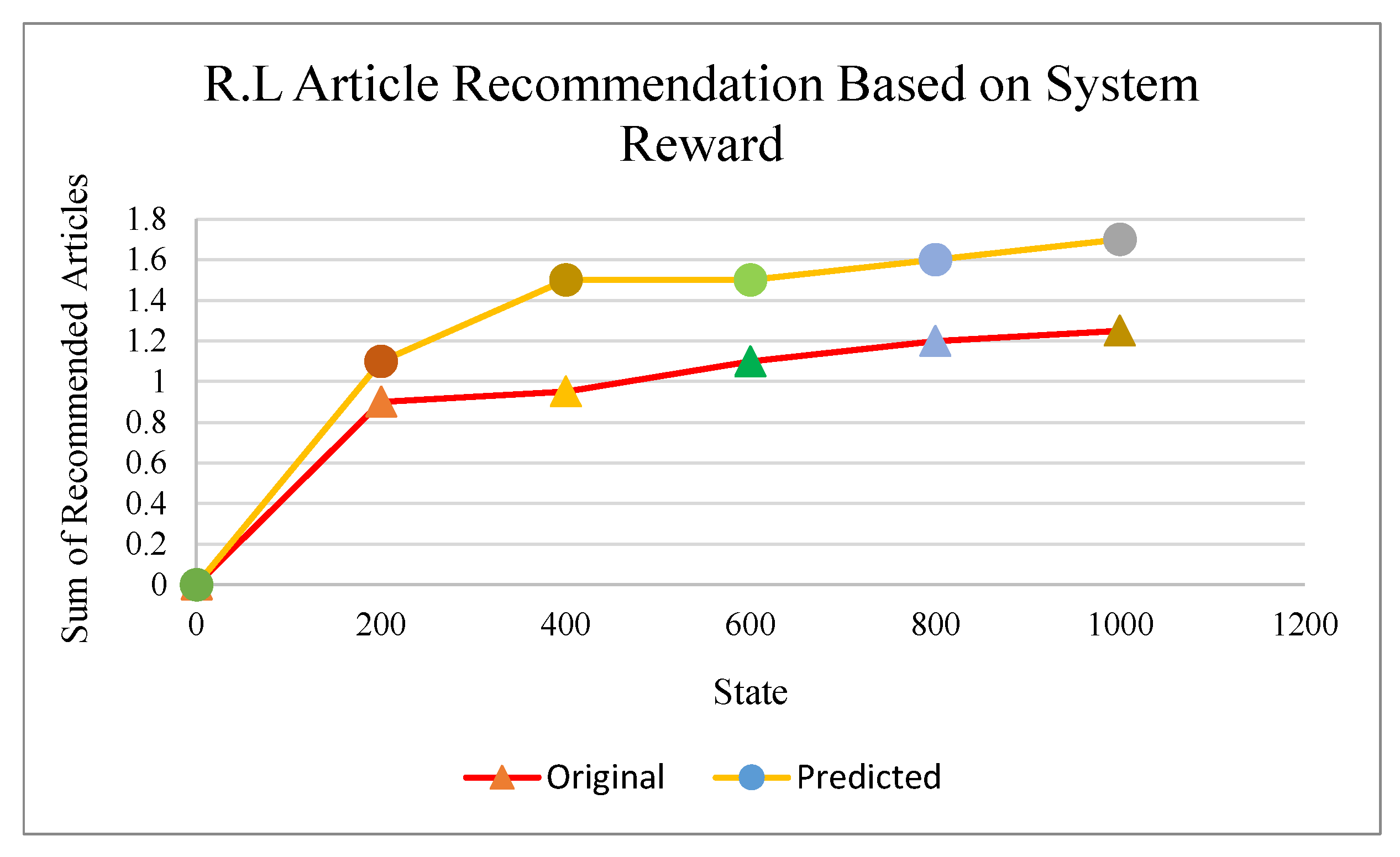
5.3. Prediction Results
5.4. Recommendation Results
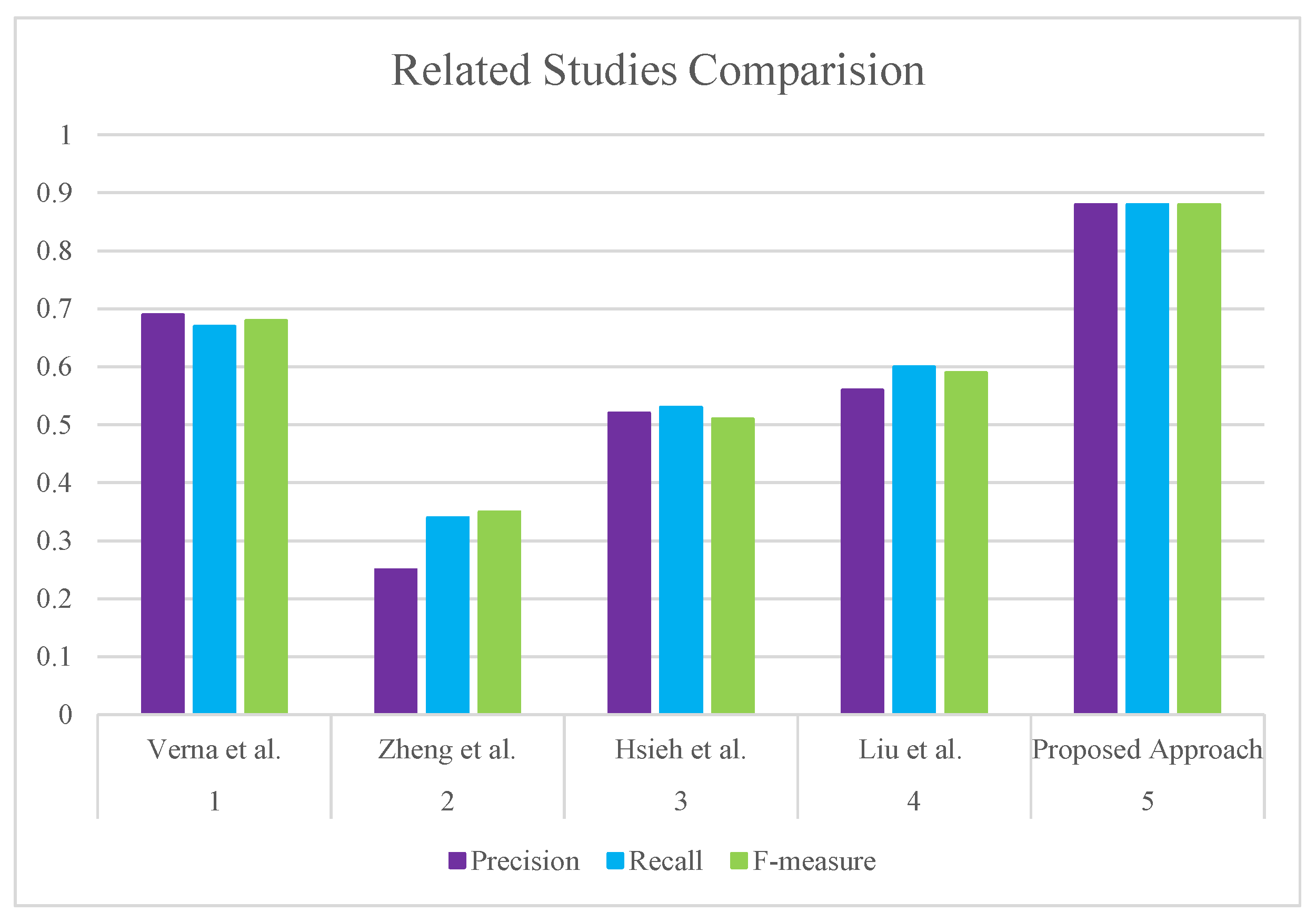
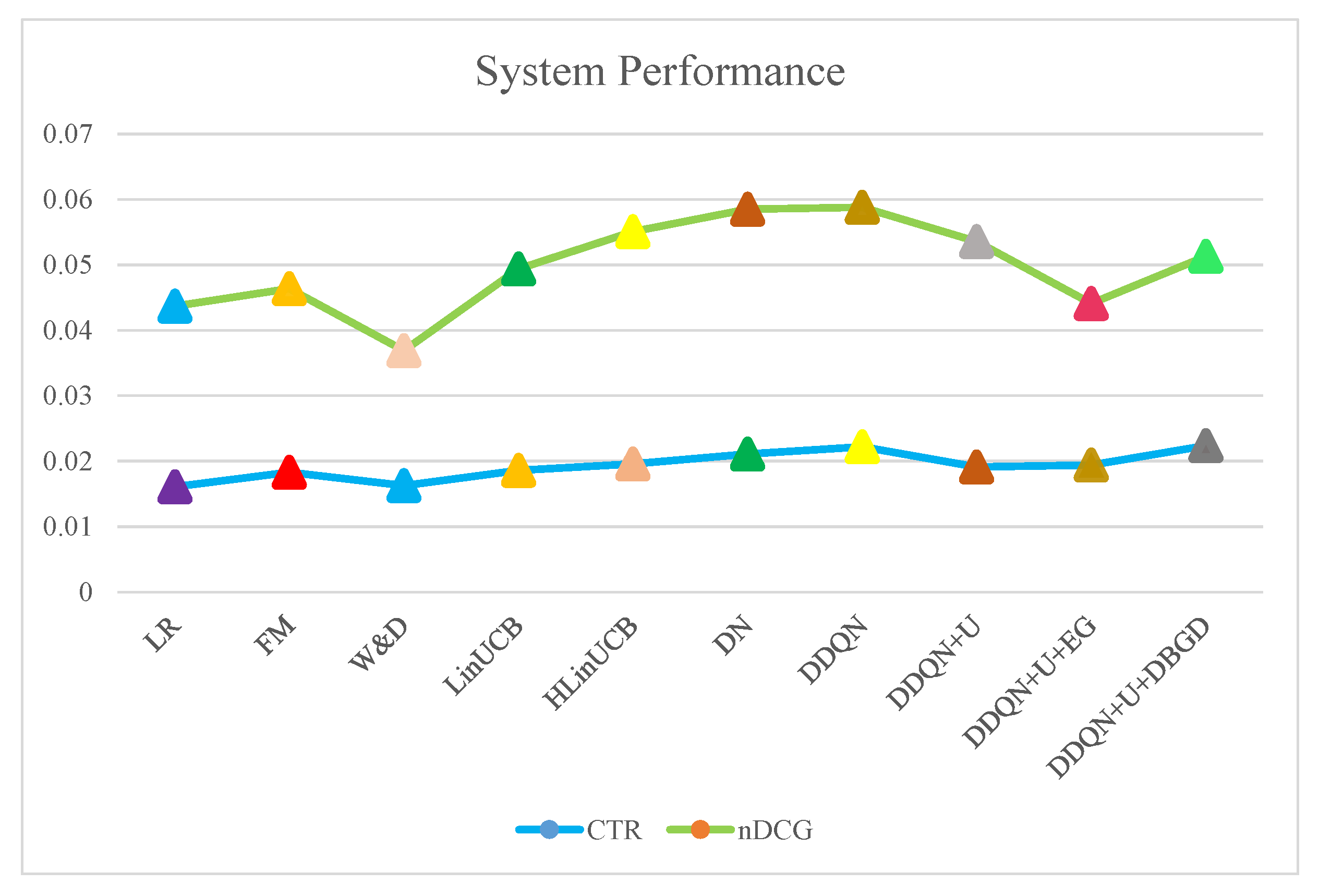
Comparison and Baseline
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Rabiu, I.; Salim, N.; Da’u, A.; Osman, A. Recommender System Based on Temporal Models: A Systematic Review. Appl. Sci. 2020, 10, 2204. [Google Scholar] [CrossRef]
- Pornwattanavichai, A.; Jirachanchaisiri, P.; Kitsupapaisan, J.; Maneeroj, S. Enhanced Tweet Hybrid Recommender System Using Unsupervised Topic Modeling and Matrix Factorization-Based Neural Network. In Supervised and Unsupervised Learning for Data Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 121–143. [Google Scholar]
- Yan, L.; Liu, Y. An Ensemble Prediction Model for Potential Student Recommendation Using Machine Learning. Symmetry 2020, 12, 728. [Google Scholar] [CrossRef]
- Jun, H.J.; Kim, J.H.; Rhee, D.Y.; Chang, S.W. “SeoulHouse2Vec”: An Embedding-Based Collaborative Filtering Housing Recommender System for Analyzing Housing Preference. Sustainability 2020, 12, 6964. [Google Scholar] [CrossRef]
- Sánchez-Moreno, D.; López Batista, V.; Muñoz Vicente, M.D.; Sánchez Lázaro, Á.L.; Moreno-García, M.N. Exploiting the User Social Context to Address Neighborhood Bias in Collaborative Filtering Music Recommender Systems. Information 2020, 11, 439. [Google Scholar] [CrossRef]
- Bai, Y.; Jia, S.; Wang, S.; Tan, B. Customer Loyalty Improves the Effectiveness of Recommender Systems Based on Complex Network. Information 2020, 11, 171. [Google Scholar] [CrossRef]
- Jebur, A.A.; Atherton, W.; Al Khaddar, R.M.; Loffill, E. Settlement prediction of model piles embedded in sandy soil using the Levenberg–Marquardt (LM) training algorithm. Geotech. Geol. Eng. 2018, 36, 2893–2906. [Google Scholar] [CrossRef]
- Luh, D.; Yang, T. Museum recommendation system based on lifestyles. In Proceedings of the 2008 9th International Conference on Computer-Aided Industrial Design and Conceptual Design, Kunming, China, 22–25 November 2008; pp. 884–889. [Google Scholar]
- Molnár, G. Challenges and opportunities in virtual and electronic learning environments. In Proceedings of the 2013 IEEE 11th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 26–28 September 2013; pp. 397–401. [Google Scholar]
- Kim, J.; Wi, J.; Jang, S.; Kim, Y. Sequential Recommendations on Board-Game Platforms. Symmetry 2020, 12, 210. [Google Scholar] [CrossRef]
- Cintia Ganesha Putri, D.; Leu, J.S.; Seda, P. Design of an Unsupervised Machine Learning-Based Movie Recommender System. Symmetry 2020, 12, 185. [Google Scholar] [CrossRef]
- Tan, Z.; He, L. An efficient similarity measure for user-based collaborative filtering recommender systems inspired by the physical resonance principle. IEEE Access 2017, 5, 27211–27228. [Google Scholar] [CrossRef]
- Jamil, F.; Hang, L.; Kim, K.; Kim, D. A novel medical blockchain model for drug supply chain integrity management in a smart hospital. Electronics 2019, 8, 505. [Google Scholar] [CrossRef]
- Jamil, F.; Iqbal, M.A.; Amin, R.; Kim, D. Adaptive thermal-aware routing protocol for wireless body area network. Electronics 2019, 8, 47. [Google Scholar] [CrossRef]
- Jamil, F.; Ahmad, S.; Iqbal, N.; Kim, D.H. Towards a Remote Monitoring of Patient Vital Signs Based on IoT-Based Blockchain Integrity Management Platforms in Smart Hospitals. Sensors 2020, 20, 2195. [Google Scholar] [CrossRef] [PubMed]
- Jamil, F.; Kim, D.H. Improving Accuracy of the Alpha–Beta Filter Algorithm Using an ANN-Based Learning Mechanism in Indoor Navigation System. Sensors 2019, 19, 3946. [Google Scholar] [CrossRef]
- Jamil, F.; Iqbal, N.; Ahmad, S.; Kim, D.H. Toward Accurate Position Estimation Using Learning to Prediction Algorithm in Indoor Navigation. Sensors 2020, 20, 4410. [Google Scholar] [CrossRef]
- Ahmad, S.; Jamil, F.; Khudoyberdiev, A.; Kim, D. Accident risk prediction and avoidance in intelligent semi-autonomous vehicles based on road safety data and driver biological behaviours. J. Intell. Fuzzy Syst. 2020, 38, 4591–4601. [Google Scholar] [CrossRef]
- Jamil, F.; Kim, D. Payment Mechanism for Electronic Charging using Blockchain in Smart Vehicle. Korea 2019, 30, 31. [Google Scholar]
- Shahbazi, Z.; Byun, Y.C. Towards a Secure Thermal-Energy Aware Routing Protocol in Wireless Body Area Network Based on Blockchain Technology. Sensors 2020, 20, 3604. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y. A Blockchain-Based Secure Image Encryption Scheme for the Industrial Internet of Things. Entropy 2020, 22, 175. [Google Scholar]
- Khan, P.W.; Byun, Y.C.; Park, N. IoT-Blockchain Enabled Optimized Provenance System for Food Industry 4.0 Using Advanced Deep Learning. Sensors 2020, 20, 2990. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Hazra, D.; Park, S.; Byun, Y.C. Toward Improving the Prediction Accuracy of Product Recommendation System Using Extreme Gradient Boosting and Encoding Approaches. Symmetry 2020, 12, 1566. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.C. Product Recommendation Based on Content-based Filtering Using XGBoost Classifier. Int. J. Adv. Sci. Technol. 2019, 29, 6979–6988. [Google Scholar]
- Hwang, S.Y.; Lai, C.Y.; Jiang, J.J.; Chang, S. The identification of noteworthy hotel reviews for hotel management. Pac. Asia J. Assoc. Inf. Syst. 2014, 6, 1. [Google Scholar] [CrossRef]
- Jannach, D.; Gedikli, F.; Karakaya, Z.; Juwig, O. Recommending Hotels Based on Multi-Dimensional Customer Ratings. ENTER. aau.at. 2012, pp. 320–331. Available online: https://link.springer.com/chapter/10.1007/978-3-7091-1142-0_28 (accessed on 30 August 2020).
- Ishtiaq, S.; Majeed, N.; Maqsood, M.; Javed, A. Improved scalable recommender system. Nucleus 2016, 53, 200–207. [Google Scholar]
- Jazayeriy, H.; Mohammadi, S.; Shamshirband, S. A fast recommender system for cold user using categorized items. Math. Comput. Appl. 2018, 23, 1. [Google Scholar] [CrossRef]
- Kanimozhi, K.S.M.L. Item Based Collaborative Filtering Approach for Big Data Application. Semantic Scholar. 2014. Available online: https://www.semanticscholar.org/paper/Item-based-Collaborative-filtering-approach-for-Big-Sudha-Lavanya/ffacdc02904cb34614a59c26645e031af32c4a28?p2df (accessed on 30 August 2020).
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Manu, M.; Ramesh, B. Single-criteria collaborative filter implementation using Apache Mahout in big data. Int. J. Comput. Sci. Eng. Open Access 2017, 5, 7–13. [Google Scholar]
- Morozov, S.; Zhong, X. The evaluation of similarity metrics in collaborative filtering recommenders. In Proceedings of the Hawaii University International Conferences, Honolulu, HI, USA, 10–12 June 2013. [Google Scholar]
- Shambour, Q.; Hourani, M.; Fraihat, S. An item-based multi-criteria collaborative filtering algorithm for personalized recommender systems. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 274–279. [Google Scholar] [CrossRef]
- Gupta, V.; Hewett, R. Real-Time Tweet Analytics Using Hybrid Hashtags on Twitter Big Data Streams. Information 2020, 11, 341. [Google Scholar] [CrossRef]
- Doulamis, A.; Voulodimos, A.; Protopapadakis, E.; Doulamis, N.; Makantasis, K. Automatic 3D Modeling and Reconstruction of Cultural Heritage Sites from Twitter Images. Sustainability 2020, 12, 4223. [Google Scholar] [CrossRef]
- Resende de Mendonça, R.R.d.; Felix de Brito, D.F.d.; de Franco Rosa, F.d.F.; dos Reis, J.C.; Bonacin, R. A Framework for Detecting Intentions of Criminal Acts in Social Media: A Case Study on Twitter. Information 2020, 11, 154. [Google Scholar] [CrossRef]
- Magdy, W.; Sajjad, H.; El-Ganainy, T.; Sebastiani, F. Distant supervision for tweet classification using youtube labels. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Jaeel, A.J.; Al-wared, A.I.; Ismail, Z.Z. Prediction of sustainable electricity generation in microbial fuel cell by neural network: Effect of anode angle with respect to flow direction. J. Electroanal. Chem. 2016, 767, 56–62. [Google Scholar] [CrossRef]
- Nguyen-Truong, H.T.; Le, H.M. An implementation of the Levenberg–Marquardt algorithm for simultaneous-energy-gradient fitting using two-layer feed-forward neural networks. Chem. Phys. Lett. 2015, 629, 40–45. [Google Scholar] [CrossRef]
- Ley, M. DBLP: Some lessons learned. Proc. VLDB Endow. 2009, 2, 1493–1500. [Google Scholar] [CrossRef]
- Laender, A.H.; de Lucena, C.J.; Maldonado, J.C.; de Souza e Silva, E.; Ziviani, N. Assessing the research and education quality of the top Brazilian Computer Science graduate programs. ACM SIGCSE Bull. 2008, 40, 135–145. [Google Scholar] [CrossRef]
- Tan, H.; Lu, Z.; Li, W. Neural network based reinforcement learning for real-time pushing on text stream. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 913–916. [Google Scholar]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 167–176. [Google Scholar]
- Hu, Y.; Da, Q.; Zeng, A.; Yu, Y.; Xu, Y. Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 368–377. [Google Scholar]
- Zhao, X.; Xia, L.; Zhang, L.; Ding, Z.; Yin, D.; Tang, J. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 95–103. [Google Scholar]
- Zhao, X.; Zhang, L.; Ding, Z.; Xia, L.; Tang, J.; Yin, D. Recommendations with negative feedback via pairwise deep reinforcement learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1040–1048. [Google Scholar]
- Chen, X.; Li, S.; Li, H.; Jiang, S.; Qi, Y.; Song, L. Generative adversarial user model for reinforcement learning based recommendation system. arXiv 2018, arXiv:1812.10613. [Google Scholar]
- Zhao, X.; Xia, L.; Tang, J.; Yin, D. “ Deep reinforcement learning for search, recommendation, and online advertising: A survey” by Xiangyu Zhao, Long Xia, Jiliang Tang, and Dawei Yin with Martin Vesely as coordinator. ACM SIGWEB Newsl. 2019, 4, 1–15. [Google Scholar] [CrossRef]
- Dulac-Arnold, G.; Evans, R.; van Hasselt, H.; Sunehag, P.; Lillicrap, T.; Hunt, J.; Mann, T.; Weber, T.; Degris, T.; Coppin, B. Deep reinforcement learning in large discrete action spaces. arXiv 2015, arXiv:1512.07679. [Google Scholar]
- Lu, Z.; Yang, Q. Partially observable Markov decision process for recommender systems. arXiv 2016, arXiv:1608.07793. [Google Scholar]
- Mahmood, T.; Ricci, F. Learning and adaptivity in interactive recommender systems. In Proceedings of the Ninth International Conference on Electronic Commerce, Minneapolis, MN, USA, 19–22 August 2007; pp. 75–84. [Google Scholar]
- Rojanavasu, P.; Srinil, P.; Pinngern, O. New recommendation system using reinforcement learning. Spec. Issue Intl. J. Comput. Internet Manag. 2005, 13, 23–28. [Google Scholar]
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6, 1265–1295. [Google Scholar]
- Taghipour, N.; Kardan, A.; Ghidary, S.S. Usage-based web recommendations: A reinforcement learning approach. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 113–120. [Google Scholar]
- Zhao, L.; Liu, Z. A genetic algorithm for reinforcement learning. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; Volume 2, pp. 1056–1060. [Google Scholar]
- Alhijawi, B.; Kilani, Y. The recommender system: A survey. Int. J. Adv. Intell. Paradig. 2020, 15, 229–251. [Google Scholar] [CrossRef]
- Ruotsalo, T.; Haav, K.; Stoyanov, A.; Roche, S.; Fani, E.; Deliai, R.; Mäkelä, E.; Kauppinen, T.; Hyvönen, E. Smartmuseum: A mobile recommender system for the Web of Data. J. Web Semant. 2013, 20, 50–67. [Google Scholar] [CrossRef]
- Braunhofer, M.; Elahi, M.; Ricci, F. Usability assessment of a context-aware and personality-based mobile recommender system. In International Conference on Electronic Commerce and Web Technologies, Proceedings of the EC-Web 2014: E-Commerce and Web Technologies, Munich, Germany, 1–4 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 77–88. [Google Scholar]
- Elahi, M.; Braunhofer, M.; Ricci, F.; Tkalcic, M. Personality-based active learning for collaborative filtering recommender systems. In Congress of the Italian Association for Artificial Intelligence, Proceedings of the AI*IA 2013: AI*IA 2013: Advances in Artificial Intelligence, Turin, Italy, 4–6 December 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 360–371. [Google Scholar]
- Ostuni, V.C.; Di Noia, T.; Di Sciascio, E.; Mirizzi, R. Top-n recommendations from implicit feedback leveraging linked open data. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 85–92. [Google Scholar]
- Braunhofer, M.; Elahi, M.; Ge, M.; Ricci, F. Context dependent preference acquisition with personality-based active learning in mobile recommender systems. In International Conference on Learning and Collaboration Technologies, Proceedings of the LCT 2014: Learning and Collaboration Technologies. Technology-Rich Environments for Learning and Collaboration, Heraklion, Crete, Greece, 22–27 June 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 105–116. [Google Scholar]
- Noguera, J.M.; Barranco, M.J.; Segura, R.J.; MartíNez, L. A mobile 3D-GIS hybrid recommender system for tourism. Inf. Sci. 2012, 215, 37–52. [Google Scholar] [CrossRef]
- Bouneffouf, D.; Bouzeghoub, A.; Gançarski, A.L. A contextual-bandit algorithm for mobile context-aware recommender system. In International Conference on Neural Information Processing, Proceedings of the ICONIP 2012: Neural Information Processing, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 324–331. [Google Scholar]
- Ge, Y.; Xiong, H.; Tuzhilin, A.; Xiao, K.; Gruteser, M.; Pazzani, M. An energy-efficient mobile recommender system. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 899–908. [Google Scholar]
- Zou, L.; Xia, L.; Ding, Z.; Song, J.; Liu, W.; Yin, D. Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2810–2818. [Google Scholar]
- Verma, A.; Virk, H. A hybrid genre-based recommender system for movies using genetic algorithm and knn approach. Int. J. Innov. Eng. Technol. 2015, 5, 48–55. [Google Scholar]
- Zhang, J.; Peng, Q.; Sun, S.; Liu, C. Collaborative filtering recommendation algorithm based on user preference derived from item domain features. Phys. A Stat. Mech. Appl. 2014, 396, 66–76. [Google Scholar] [CrossRef]
- Hsieh, M.Y.; Chou, W.K.; Li, K.C. Building a mobile movie recommendation service by user rating and APP usage with linked data on Hadoop. Multimed. Tools Appl. 2017, 76, 3383–3401. [Google Scholar] [CrossRef]
- Liu, H.; He, J.; Wang, T.; Song, W.; Du, X. Combining user preferences and user opinions for accurate recommendation. Electron. Commer. Res. Appl. 2013, 12, 14–23. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Objective | Advantage |
|---|---|---|
| Long Zhao et al., Zemin Liu et al. (2020) [55] | Solving the large action space issue based on the Reinforcement Learning Algorithm. | Reinforcement learning solves the large action space issue. |
| Bushra Alhijawi et al. [56], Yousef Kilani et al. (2020) | Recommendation system classification on MRS, TPCRS, SRS and CRS | Classifying recommendation system to avoid the overloading issue. |
| Ruotsalo et al. [57] (2013) | Raising the digital cultural heritage accessibility | It is useful to apply to any data. |
| Braunhofer et al. [58] (2014) | Place of interest (POI) recommendation | Generate related recommendations with higher useability. |
| Elahi et al. (2013) [59] | POI-based user personality recommendation | Desist the cold start issue. |
| Ostuni et al. [60] (2013) | Movie theatre recommendation | Clear the content-based recommendation results. |
| Braunhofer et al. [61] (2014) | User personality recommendation based on contact preferences | Presenting more related recommendations based on the higher rating. |
| Noguera et al. (2012) [62] | Users’ physical locations recommendation | Useful in e-tourism. The ability to have a 3D map. |
| Bouneffouf et al. [63] (2012) | Dynamic exploration recommendation | Optimal value selection while avoiding the traditional algorithms. |
| Ge et al. (2010) [64] | Parking position recommendation | Increasing business success probability. Providing various optimal driving routes based on online processing time. |
| Statistics | Numerical Values |
|---|---|
| Number of directions | 744.456 |
| Number of articles | 567.916 |
| Number of Users | 582.933 |
| Avg/Max/Min of time | 3.5/6.4/1.6 |
| Training Data | 70% |
| Test Data | 30% |
| # | Features | Description |
|---|---|---|
| 1 | Tweet | The information which users share together |
| 2 | Projects | The information of various projects (question and answer) |
| 3 | Comments | Comments for shared topic |
| 4 | Photos | Shared photos by various users |
| 5 | News | Shared daily news |
| 6 | Conferences | Upcoming conferences or opinions about previous conferences |
| 7 | Articles | Published articles |
| 8 | Publication Access Point | Reference pages or article access information |
| 9 | Publication Time | Article publication time |
| 10 | Publication Date | Article publication date |
| # | Features | Description |
|---|---|---|
| 1 | Time series | Applying time series analysis in this system causes us to extract the information related to visited links per day or download and sharing information per day and, similarly, total average per month |
| 2 | E-learner profile details | Based on the e-learners profile, the major interest of the user on various topics and user clicks and shared tweets, news and articles are extracted. |
| 3 | statistical features | Extract the histogram, error rate, etc. from raw dataset for articles frequency. |
| 4 | Article types | Generate various article topics, titles, etc. |
| 5 | Tweet types | Generate different tweet information, comments, news and shared links. |
| Component | Description |
|---|---|
| Programming language | WinPython–3.6.2, IDE Jupyter Notebook |
| Operating system | Windows 10 64bit |
| Browser | Google Chrome, opera |
| GPU | Nvidia GForce 1080 |
| Library and framework | Web Service |
| CPU | Intel(R) Core(TM) i7-8700 CPU @3.20 GHz |
| Memory | 32 GB |
| Recommendation Modules | Reinforcement Learning |
| Optimization Algorithm | Model Free optimization |
| Number | Loading T. (sec) | Searching T. (sec) | Execution T. (sec) |
|---|---|---|---|
| 1 | 2.0883 | 0.0350 | 2.4505 |
| 2 | 0.5101 | 0.0348 | 0.5601 |
| 3 | 0.0012 | 0.0377 | 0.0401 |
| 4 | 1.7510 | 0.0627 | 1.8237 |
| 5 | 2.0883 | 0.0344 | 2.1331 |
| 6 | 2.0883 | 0.0344 | 2.4433 |
| 7 | 1.7510 | 0.0616 | 1.8226 |
| 8 | 1.7510 | 0.0358 | 1.8068 |
| 9 | 2.0883 | 0.0013 | 2.1017 |
| 10 | 1.7510 | 0.0400 | 1.8058 |
| Technique | Recommendation Diversity |
|---|---|
| LR | 0.2944 |
| FM | 0.3125 |
| W&D | 0.1758 |
| LinUCB | 0.3747 |
| HLinUCB | 0.2434 |
| DN | 0.2657 |
| DDQN | 0.2146 |
| DDQN + U | 0.2824 |
| DDQN + U + EG | 0.2118 |
| DDQN + U + DBGD | 0.2327 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahbazi, Z.; Byun, Y.C. Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners. Symmetry 2020, 12, 1798. https://doi.org/10.3390/sym12111798
Shahbazi Z, Byun YC. Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners. Symmetry. 2020; 12(11):1798. https://doi.org/10.3390/sym12111798
Chicago/Turabian StyleShahbazi, Zeinab, and Yung Cheol Byun. 2020. "Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners" Symmetry 12, no. 11: 1798. https://doi.org/10.3390/sym12111798
APA StyleShahbazi, Z., & Byun, Y. C. (2020). Toward Social Media Content Recommendation Integrated with Data Science and Machine Learning Approach for E-Learners. Symmetry, 12(11), 1798. https://doi.org/10.3390/sym12111798