1. Introduction
Key person identification within a social network means to find persons who can change the feelings, attitudes, or behaviors of other persons though network relationships [
1] and, therefore, this is a critical issue in the fields of viral marketing [
2], spread of opinions [
3], rumor restraint [
3], and innovation dissemination [
4]. As we know, one of the major properties within social networks is its symmetry between nodes. Many algorithms have been proposed to identify important persons within a social network based on the concept of vertex centralities.
Vertex centrality measures the importance of persons within a network according to their position relative to others. These measures can be divided into local measures, short path-based measures, and iterative calculation-based measures [
5]. The most famous local measure is degree centrality, which is used [
6,
7] to identify the most influential persons within a social network. However, it only reflects the influence of an ego’s neighbors and ignores the influence of further persons [
8] Note that an ego is the vertex which we focus on within a social network.
By contrast, short path-based measures calculate the influence of an ego by considering the shortest paths between any two vertices. These measures include closeness, betweenness, and Katz centralities. The person with the shortest path between vertices is viewed as the most prominent vertex. The short path-based centralities have also been used to identify key persons within a social network, e.g., in the work by Catanese et al. [
9] and Zhao et al. [
10].
Iterative calculation-based measures account for all network paths to calculate the importance of an ego. Each vertex contributes its ranking value to its output neighbors and updates the value in each iteration round until a steady state is achieved. Two famous measures in this classification are eigenvector centrality and PageRank-based algorithms, e.g., TunkRank (Tunkelang, 2009), TwitterRank [
11], and ProfileRank [
12]. PageRank-based algorithms are the most popular approach to identify key persons within a social network, e.g., those featured in the work by Jabeur et al. [
13], Ding et al. [
14], Pei et al. [
15].
However, we should consider more important factors which are not accounted for by PageRank-based algorithms to determine which persons are prominent within a social network. For example, conventional PageRank-based algorithms only consider the influence of the authority but ignore the influence of the hub [
16]. A similar concept has also been proposed by Fogaras [
17], Gyongyi et al. [
18], and Bar-Yossef and Mashiach [
19] to consider a reverse PageRank algorithm to account for the centrality of the hub. In addition, the iterative process of calculating the centrality in PageRank-based algorithms is a linear transition and ignores the possibility of non-linear functions. Finally, these algorithms usually normalize the centrality by dividing the out-degree of the ego. However, we can describe the details of the normalization method, which should be modified to obtain a more accurate result later.
In this paper, we propose a novel algorithm by considering the above problems of the PageRank algorithm. The distinctions of the proposed algorithm from others are described as follows. First, the proposed algorithm accounts for the both centralities of the authority and hub. Second, the algorithm considers different nonlinear functions to be the transition function of the update status. Third, we consider a different normalization factor instead of the out-degree of the ego to obtain a diversity result. Besides, we consider two social networks, namely, the Marvel University characteristic network and the Facebook social network, to illustrate the proposed algorithm and compare the results with others. The empirical results indicate that the proposed algorithm is flexible and that the derived centrality can be considered as a synthesized index to determine key persons within a social network.
2. Introduction of Centralities
The most common centralities in social network analysis are the degree, closeness, and betweenness to account for key persons. The degree centrality is defined by the number of direct neighbors as an indicator of the influence of a network member’s interconnectedness (Nieminen, 1974). Let a network represented by a graph
G(
V,
E), where
V and
E denote the sets of vertices and edges, respectively. Then, the degree of the
i-th vertex,
vi, can be represented as follows:
where deg(·) is the degree of the vertex. If the graph is directed, we should account for the in- and out-degrees separately. In-degree centrality measures the popularity/prestige of a person and out-degree, by contrast, accounts for the sociality of a user [
20,
21].
Next, the thought of the closeness centrality is that a vertex that is closer to others can spread information very productively via the network [
22], and therefore it is important. The closeness centrality can be measured by the sum of the vertex’s distance from all others:
where
d(·) denotes the distance between vertices. Finally, we can define the betweenness centrality as a bridge along the shortest path between two vertices as follows:
where
denotes the number of shortest paths from vertex
vj to
vk and
is the number of shortest paths from
vj to
vk that pass through
vi. Although the previous three centralities are easily calculated, they only reflect the influence of vertices with respect to others in the topology of a social network without considering the influence of their neighbors/friends and cannot be used as a comprehensive centrality for measuring key persons. Hence, the eigenvector centrality is proposed to reflect the importance of neighbors.
3. Eigenvector Centrality
First, we assume that the importance of a vertex within an undirected network is only determined by the influence of others and that a vertex achieves more centrality if it receives more in-degree flows from others. Hence, let
n criteria be considered to determine their weights. The eigenvector centrality of the
ith ego can be represented as follows:
where
Aj,i is the element at the
jth row and
ith column of the adjacency matrix which indicates the relationship from one vertex (row) to another (column) and
λ is a fixed constant. For simplicity, we can represent Equation (4) as a matrix form:
Equation (5) indicates the eigenvector centrality vector,
EC(
v), which is an eigenvector of
ATand
λ is the corresponding eigenvalue. Note that the initial
EC(
v) can be set as 1, i.e., the all-one vector. Usually, we select the maximum eigenvalue,
λmax, to ensure
EC(
v) is large than the zero vector. According to the Perron–Frobenius theorem [
23], for any
aij > 0,
EC(
v) of
A with eigenvalue
λmax such that ∀
EC(
vj) > 0.
We can also let
AT be a row stochastic matrix, i.e., normalized
AT such that all sums of each row exactly equal to one. We can rewrite Equation (5) as follows:
The advantage of Equation (6) is that the eigenvector can be easily be derived since λmax = 1. In addition, we can also derive the eigenvector by calculating the limiting power of AT according to Markov chain theory.
7. Fuzzy Cognitive Map
The fuzzy cognitive map (FCM) approach was proposed by Kosko [
27] to extend cognitive maps [
28] by considering the fuzzy degrees of interrelationship between concepts. The FCM is used to reflect the influence of vertices, called concepts here, to others via cause-effect relationships, which are quantified and usually normalized to the [−1, 1] interval.
Let
wij ∈ [−1, 1] be the degree of influence from the
ith concept,
Ci, to the
jth concept,
Cj, where the sign indicates the positive or negative influence and −1 denotes a full negative impact and 1 expresses a full positive impact. Then, the influence of concept,
x, can be calculated by the following equation:
where
n is the number of concepts and
f(·) denotes the transfer function to squeeze the result of the multiplication into a specific range, e.g., [0, 1] or [−1, 1]. Usually, bivalent, trivalent, and sigmoid functions are used in the FCM.
A modified Kosko’s version of the FCM was proposed by Stylios and Groumpos [
29] to consider the previous value of each concept, i.e., observing the self-loop effect. Hence, Equation (16) can be modified and extended as follows:
Another variant of the FCM is that which is used for rescale inference and is presented as follows:
The positive and negative influences in the FCM indicate that the centrality of a vertex within a graph should consider two opposite forces to aggregate the final centrality.
Let us consider an example to illustrate the above concept. Assume a graph is given as shown in
Figure 1.
The influences between the concepts are quantified by an expert and are shown in
Table 1.
In order to show the different centralities of positive and negative influences, we consider all positive and negative influences, respectively, in the influence matrix. Then, we use the modified Kosko’s inference rule and logistic function to derive the influences and ranks of the concepts, as shown in
Table 2.
Table 2 shows that the positive and negative influences from concept to concept exert two opposite forces on the synthesized centrality of a concept in the FCM. In addition, the transform functions squash the influence of vertices into a specific range with the nonlinear function. However, the FCM is not adequate in handing the problem directly here because the influence matrix in a social network is usually unavailable. The only information we can get is the graph of a social network, i.e., the adjacency matrix. In addition, negative influences between vertices are not considered due to the lack of the information. However, the concept of transform functions could be incorporated into the proposed algorithm.
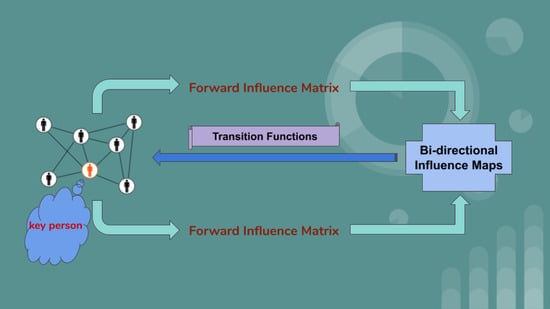
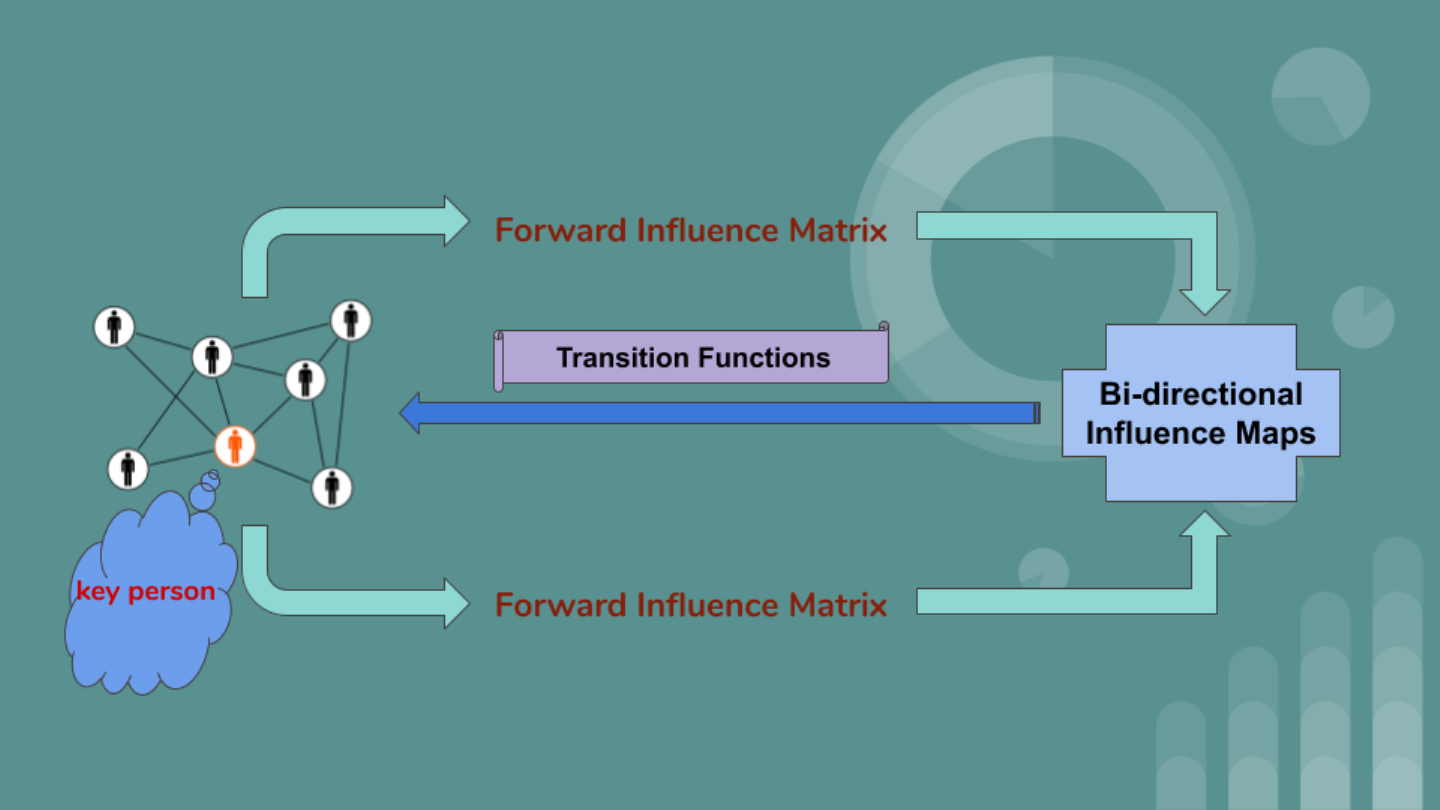
8. Bi-Directional Influence Maps (BIM)
After viewing the previous research, we can conclude that two types of importance of a node should be identified, namely, the authority and hub [
16]. An authority can be defined by other vertices inflow to an ego and a hub can be measured by the total outflow points to others. However, previous models only focus on the one side and we can incorporate both forms of information to form the centrality of a vertex here as follows:
where
and
denote the inflow and outflow influence matrices which have been normalized to stochastic matrices and
γ and (1 −
γ) denote the weights of the authority and hub. Note that we use the influence matrix above rather than the adjacency matrix because we will consider another method to modify the conventional adjacency matrix for more rational results. This is described in detail below.
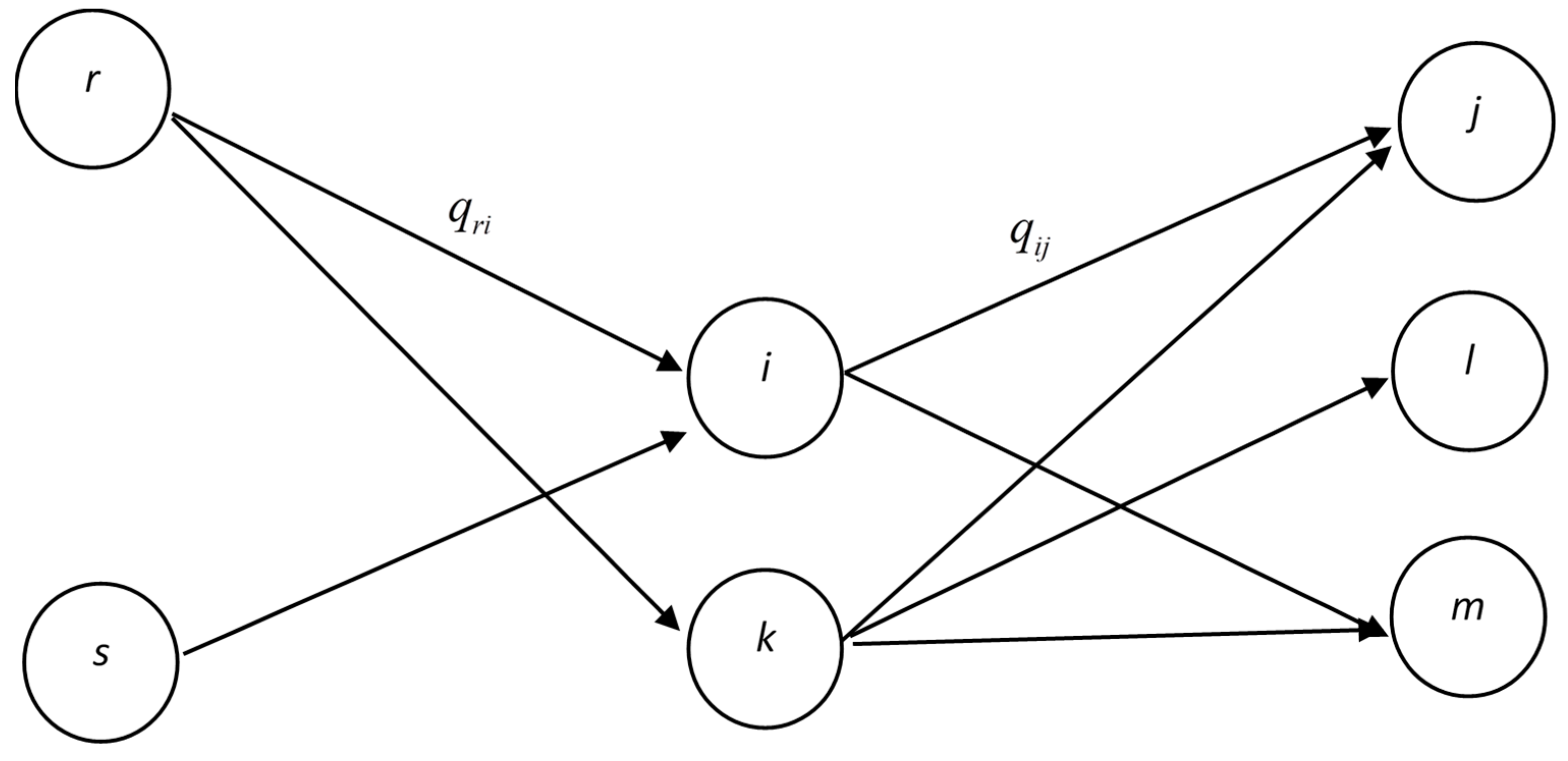
Assume that a network structure is depicted as shown in
Figure 2, where the circles denote different vertices, and values
qri denote the flows from vertex
r to vertex
i. We consider the centrality of a vertex in terms of two factors, namely, the amounts of inflow and outflow. In addition, we also define the reference of vertex
i,
R, as the vertex which link to vertex
i (e.g., vertices
r and
s). For example, in the path from
r to
i, denoted by
r →
i, vertex
r is the reference of vertex
i.
The inflow from vertex
r to vertex
i at time
t in this paper can be defined by the following equation:
where
and
Ii indicates the input degree (number of inflows) of vertex
i. Then, the outflow vertex from vertex
i to vertex
j at time
t can be calculated as follows here:
where
and
Oi indicates the output degree (number of outflows) of vertex
i.
After obtaining the above indices, we can construct the inflow and outflow matrices, respectively, as follows:
where we reflect the influence of the feedback flows in the inflow and outflow matrices. We use the following example to demonstrate the indices defined here. This example has six vertices that contain directed and feedback links between vertices, as shown in
Figure 3.
The inflow and outflow matrices can be derived, respectively, as follows:
Next, if we consider the update process from one status to the next status, this can be represented by a transition function. We propose the final model here as follows:
where
f(·) is a transition function, e.g., a sigmoid or linear function.
Sigmoid functions, e.g., logistic or hyperbolic-tangent functions, are widely used in many methods, e.g., neural networks and fuzzy cognitive maps, to squash values into a specific range. For example, the logistic function can squash any real number into (0, 1) and the hyperbolic-tangent function can squash a real number into (−1, 1). Sigmoid functions are popular because they can reflect situations of the real world. However, conventional sigmoid functions are not suitable here, since the centrality of a vertex is always positive and falls into the range of [0, 1] instead of a real number. Note that
M(
vi(
t + 1)) in Equation (22) satisfies
M(
vi(
t + 1)) ∈ (0, 1) and
. Hence, in this paper, we introduce two sigmoid functions, namely, the smoothstep and inverted smoothstep functions, to reflect the
s-shape situation of updated centralities and restrict the input range between [0, 1], as shown in
Figure 4.
In addition, we also consider the softmax and restricted logistic functions to see the distinct from the linear function. The transition functions used in this paper are summarized in
Table 3.
Next, for simplicity, we can let the following be true:
Since
and
are column stochastic matrices, we can ensure the linear combination of two column stochastic matrices,
, is also a column stochastic matrix. Then, we can rewrite Equation (22) as follows:
The matrix form is written as follows:
where we set
α = 0.85 as the suggestion of the PageRank algorithm. Note that in large-scale networks, we can first set
to avoid the convergent problem of the proposed algorithm before processing in Equation (24).
We can highlight the difference between the PageRank and bi-directional influence map (BIM) algorithms as follows. First, the PageRank algorithm considers the importance of a vertex as the all paths from others, i.e., the inflow matrix. However, the BIM algorithm considers the inflow and outflow matrices to balance the influences of both powers. In addition, taking the above graph as example, the inflow matrices of two algorithms (
, PageRank algorithm;
, BIM algorithm) also show distinct differences:
Next, we can use the proposed algorithm to handle the example in
Figure 3 and rank the vertices with different settings of the parameters, i.e., transition functions and
γ, and compare the results with the PageRank algorithm, as shown in
Table 4.
The results of
Table 5 indicate that the weights between the inflow and outflow matrices play different forces in regard to affecting the importance of a vertex. If we only consider the inflow matrix, the ranking result is similar to that of the PageRank algorithm. By contrast, if only the outflow matrix is used, the ranking result is just the reverse of that of the PageRank algorithm. However, we think both forms of information should be considered to be the centrality of a vertex. In addition, the different functions here show the consistent results and indicates the robustness of the proposed algorithm.
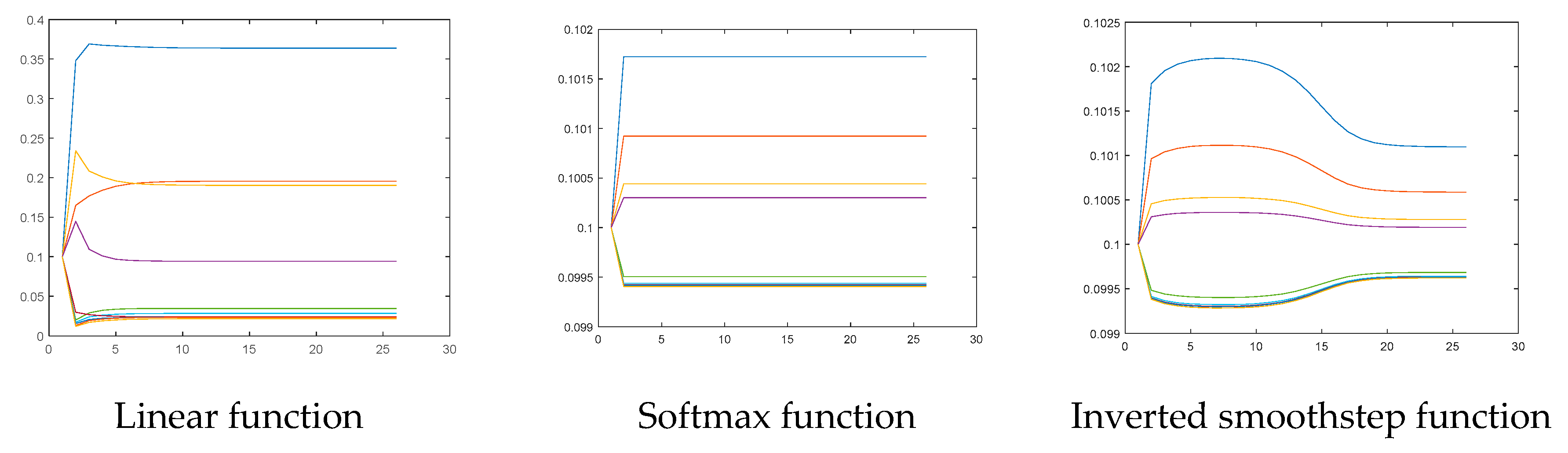
Next, we can examine the transition functions to understand the convergence and influence on the centralities and ranking of vertices. First, the centralities of the vertices in each iteration are normalized to the sum of them as one. Then, we can depict the iterative processes of all transition functions here with
, as shown in
Figure 5.
The convergence status of the proposed model is very quick, no matter which transition functions are considered, and the softmax and inverted smoothstep functions seem to be better choices here because the centralities of the vertices are more significantly different than those of others. By contrast, the restricted sigmoid and smoothstep functions find it hard to clearly separate the centralities. We should highlight that although the linear function also shows an acceptable property, the different transition functions do play an important role to determine the ranking of vertices and might not be the same.
10. Discussion
Centrality measures the importance of a vertex within a network and has been applied to various applications, e.g., information diffusion [
30], leader roles [
31], and psychological network [
32]. Nowadays, the technologies of social media link people into a huge network and more companies access social networks of people as an important tool for marketing and diffusion strategies [
33,
34]. Key person identification within a social network is one of the important issues of a successful social network strategy. Hence, many kinds of centrality have been proposed based on different considerations and theories to measure the importance of a vertex within a social network. However, human sociality usually is complicated and needs more sophisticated algorithms to achieve the above purpose.
Among the various algorithms of centrality, PageRank-based algorithms are the most popular because they can consider the influence from all the paths of vertices to an ego. However, they only consider one kind of influence of an ego, i.e., either an in-flow or out-flow matrix, rather than a comprehensive perspective. In this paper, we propose a novel centrality which accounts for both in-flow and out-flow influence matrices to balance the different influences of an ego. In addition, we extend the transition function from the linear type to a non-linear status, including softmax, restricted sigmoid, smoothstep, and inverted smoothstep functions to consider more complicated situations.
The empirical results show several advantages of the proposed algorithms. First, the proposed algorithm can derive a synthesized centrality which can reflect different perspectives of a key vertex based on the results of the Facebook network. Second, the results of the Marvel universe network are consistent with the results of the PageRank algorithm and the top five key characters are rational, even when considering different parameters. Third, the transition functions show the usefulness and diversity to find key persons within a social network. Finally, the proposed algorithm shows a good property to converge under an acceptable number of iterations.
The limitations of the algorithm can be described as follows. The social networks used in this paper are artificial datasets. Although the results found in the Marvel universe network seem to be reasonable, it is hard to confirm if it is also useful for application to real data. Hence, further research may consider a real and large network to carefully test the proposed algorithm with different parameters. In addition, the proposed algorithm can also be used to compare some new centrality measures, e.g., Rodríguez-Velázquez & Balaban [
35].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}