Deep Generative Adversarial Networks for Image-to-Image Translation: A Review


Abstract
1. Introduction
2. Deep Generative Models
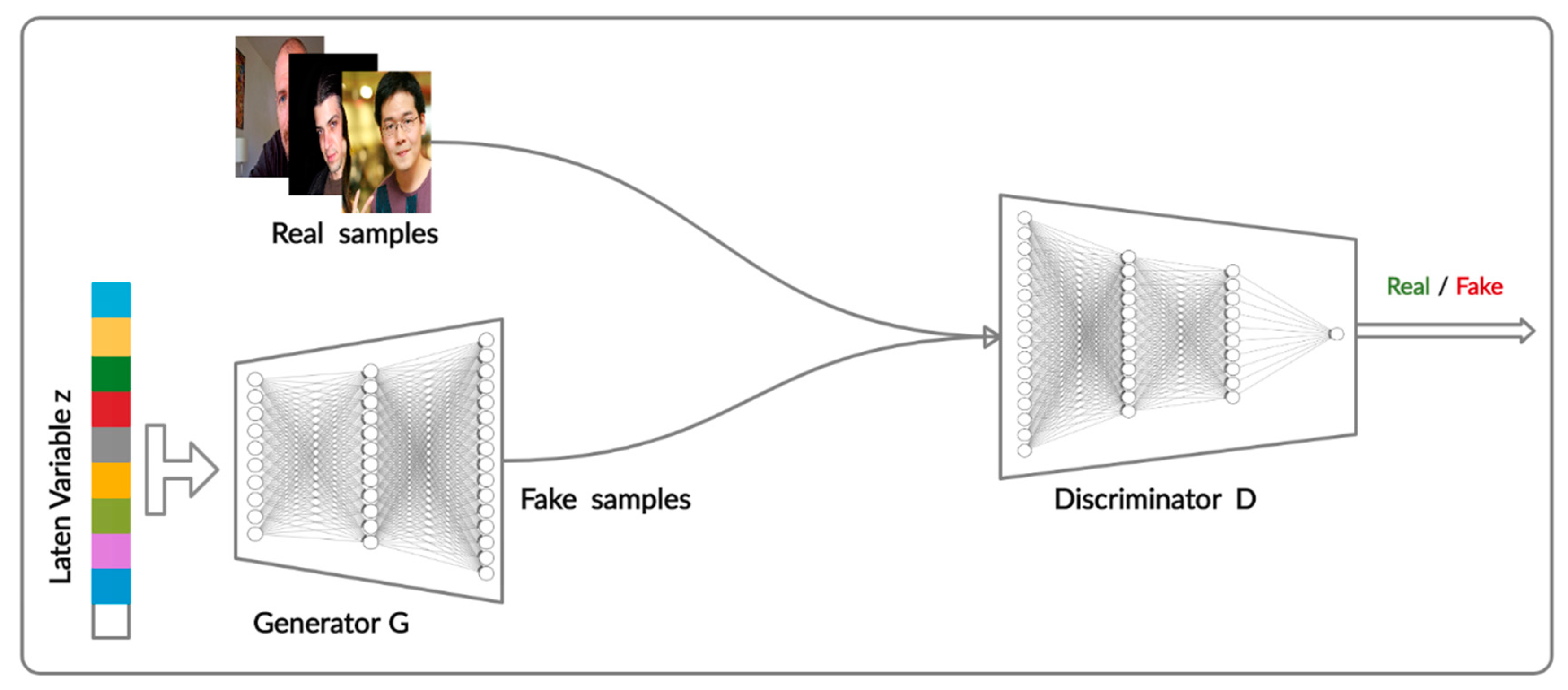
2.1. Generative Adversarial Networks
2.2. Image-To-Image Translation
2.3. Definitions
- Attribute: a meaningful feature, such as hair color, gender, size or age.
- Domain: a set of images sharing similar attributes.
- Unimodal image-to-image translation: a task in which the goal is to learn a one-to-one mapping. Given an input image in the source domain, the model learns to produce a deterministic output.
- Multimodal image-to-image translation: aims to learn a one-to-many mapping between the source domain and the target domain with the goal of enabling the model to generate many diverse outputs.
- Domain-independent features: those pertaining to the underlying spatial structure, known as the content code.
- Domain-specific features: those pertaining to the rendering of the structure, known as the style code.
- Image generation: a process of directly generating an image from a random noise vector.
- Image translation: a process of generating an image from an existing image and modifying it to have specific attributes.
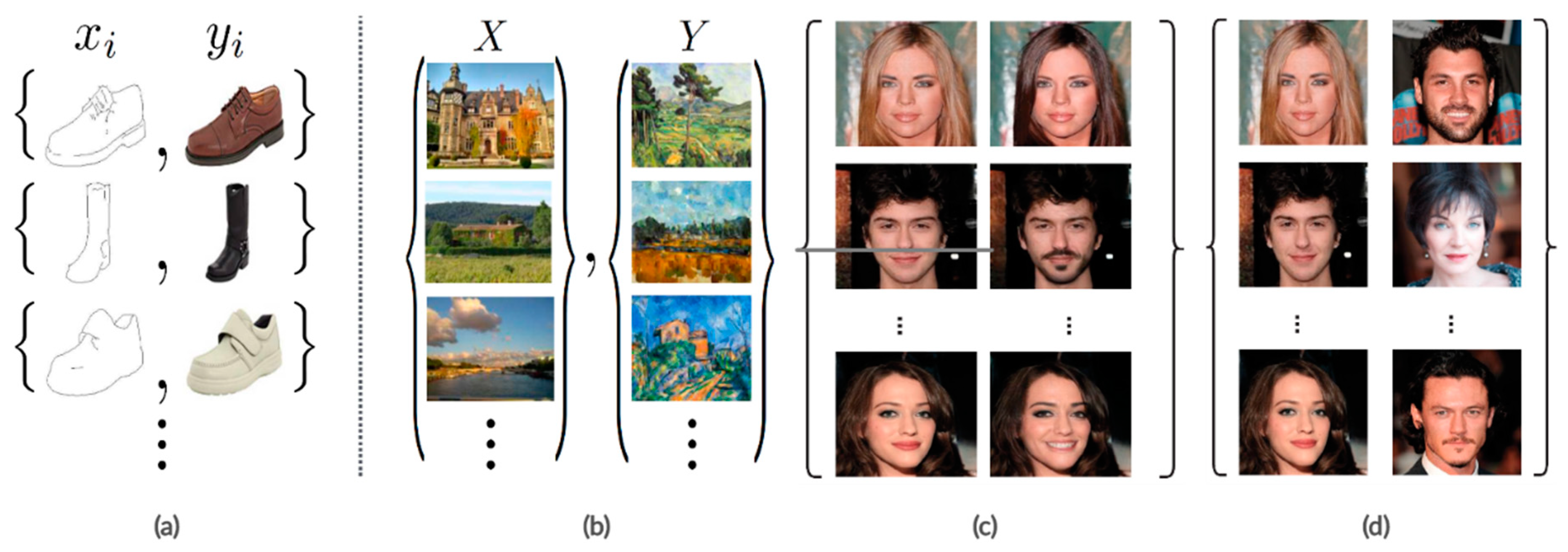
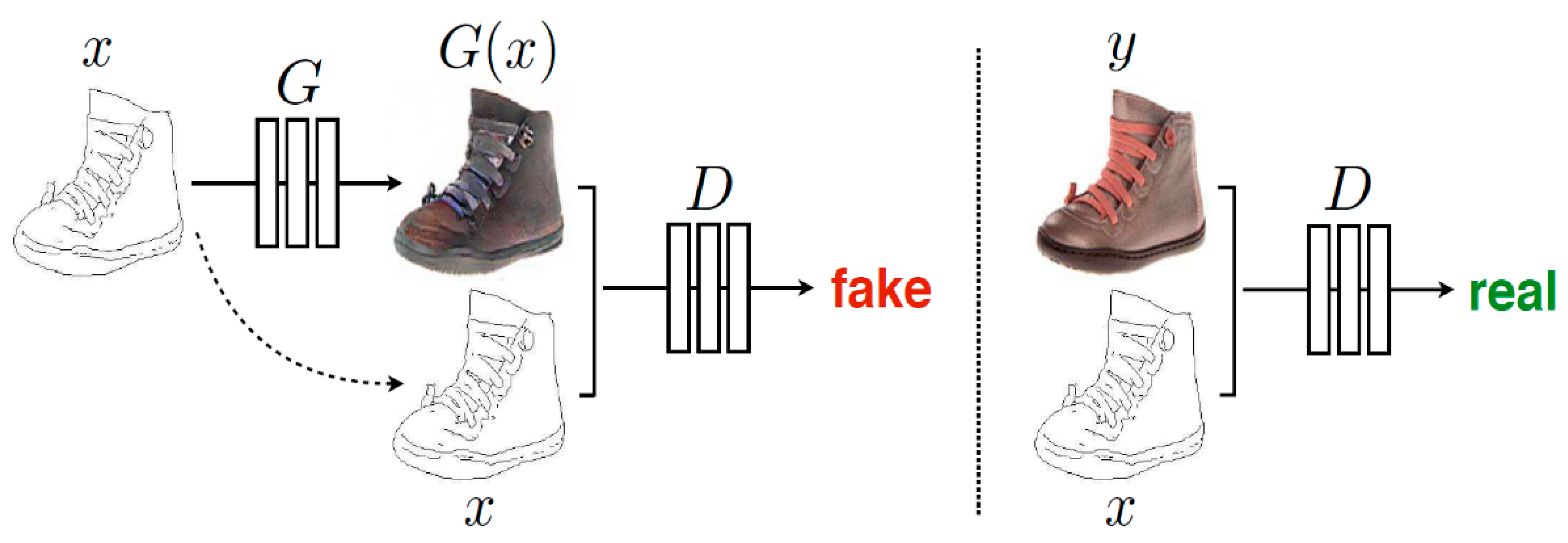
- Paired image-to-image translation: source images X and the corresponding images Y are provided as a training set of aligned image pairs, as shown in Figure 2a,c.
- Unpaired image-to-image translation: a source image X and a corresponding image Y are from two different domains, as shown in Figure 2b,d.
2.4. Motivation and Contribution
- This review article provides a comprehensive review including general generative adversarial network algorithms, objective function, and structure.
- Image-to-image translation approaches are classified into supervised and unsupervised types with in-depth explanations.
- This review article also summarizes the benchmark datasets, evaluation metric, and image-to-image translation applications.
- Limitations, open challenges, and directions for future research are among the topics discussed, illustrated, and investigated in depth.
3. Generative Adversarial Networks’ Algorithms
3.1. Fully Connected GAN
3.2. Conditional GAN
3.3. Information GAN
3.4. BigGAN
4. GAN Objective Functions
5. GAN Structure
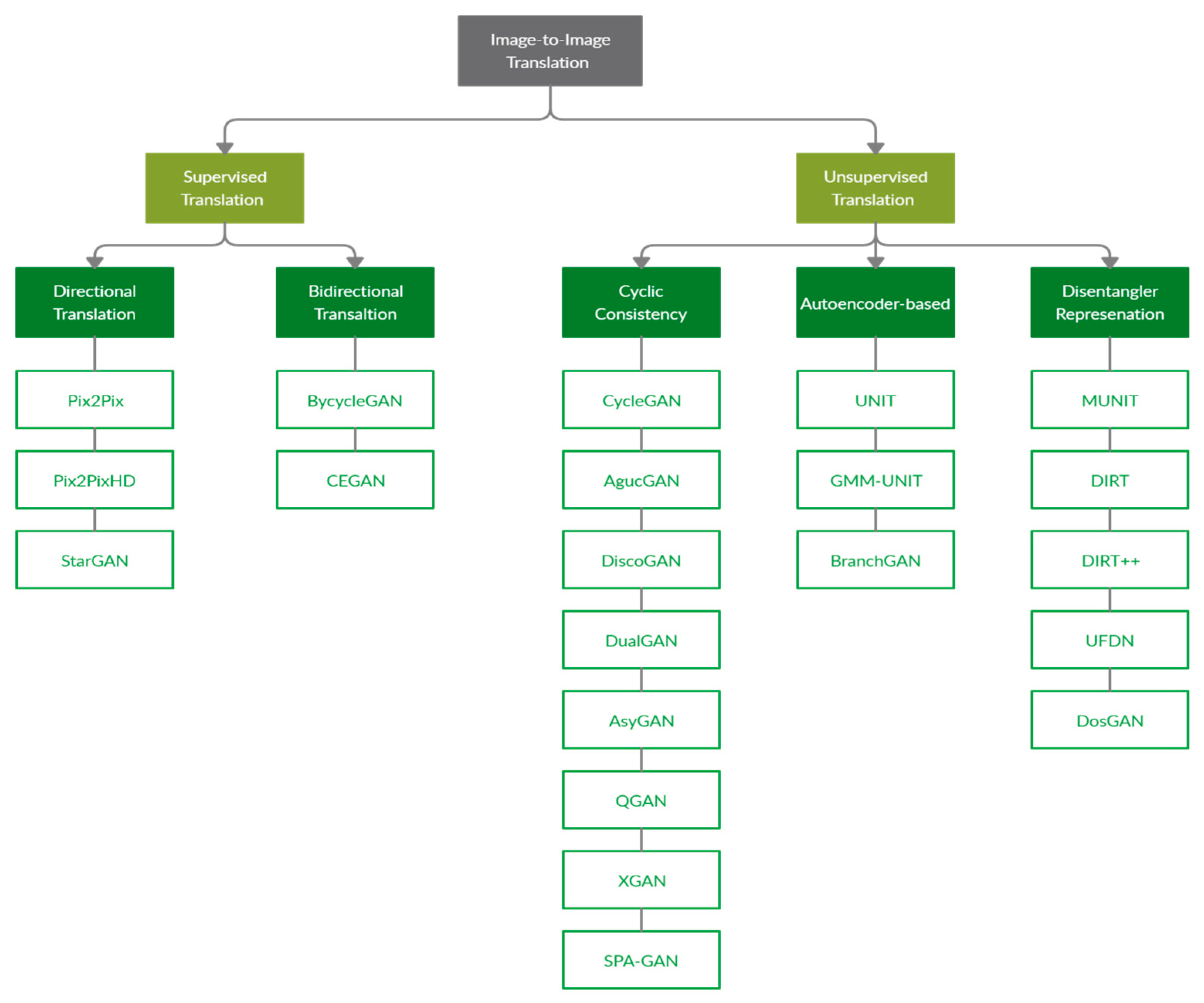
6. Image-to-Image Translation Techniques
6.1. Supervised Translation
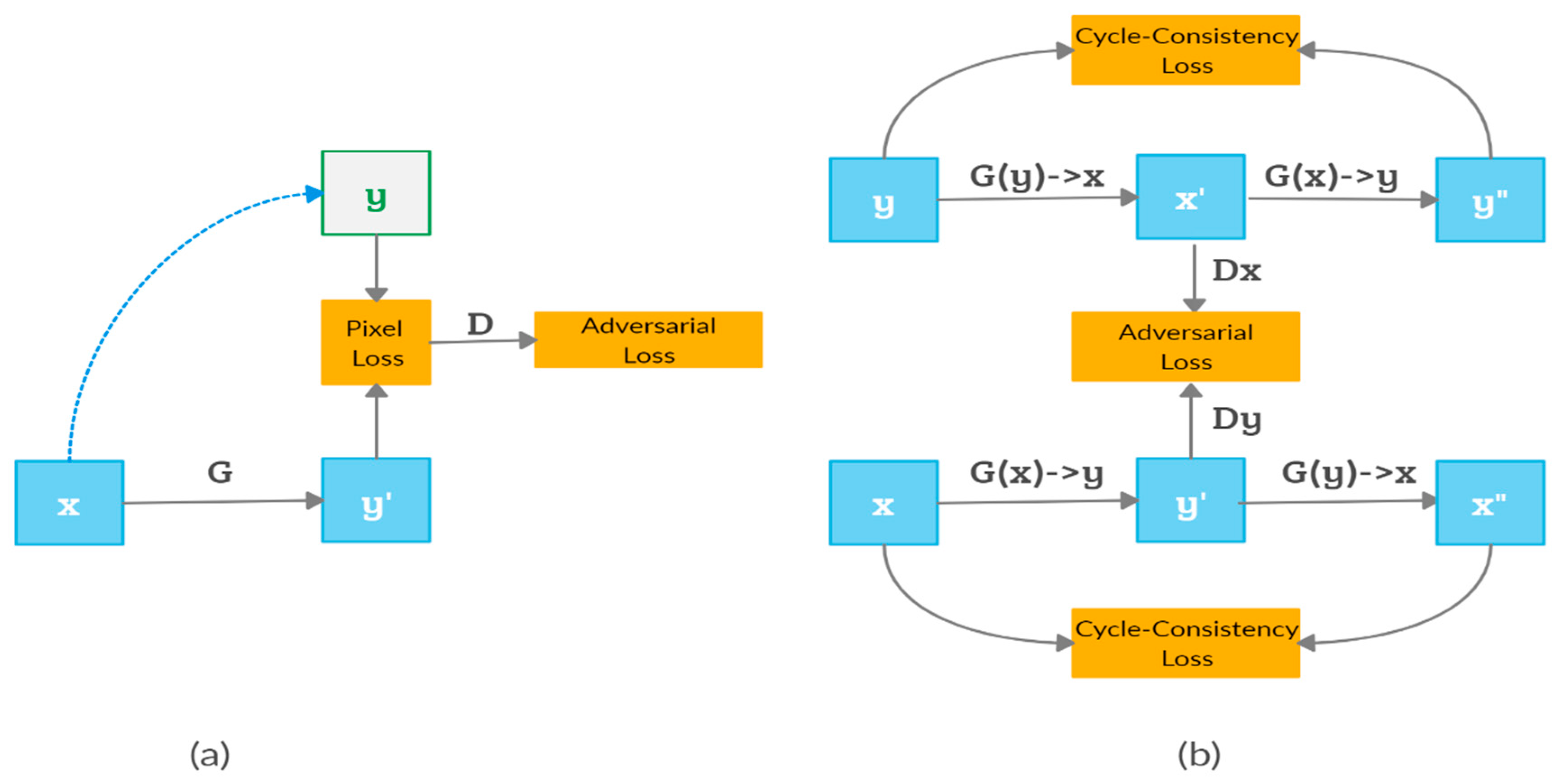
6.1.1. Directional Supervision
6.1.2. Bidirectional Supervision
6.2. Unsupervised Translation
6.2.1. Unsupervised Translation with Cycle Consistency
6.2.2. Unsupervised Translation with Autoencoder-Based Models
6.2.3. Unsupervised Translation with the Disentangled Representation
7. Image-to-Image Translation Applications
7.1. Datasets
7.2. Evaluation Metrics
- The inception score (IS) [104] is an automated metric for evaluating the visual quality of generated images by computing the KL divergence between the conditional class distribution and the marginal class distribution via inception networks. IS aims to measure the image quality and diversity. However, the IS metric has two limitations: (1) a high sensitivity to small changes and (2) a large variance of scores [105].
- The Amazon Mechanical Turk (AMT) is used to measure the realism and faithfulness of the translated images that are based on human perception. Workers (“turkers”) are given an input image and translated images and are instructed to choose or score the best image based on quality and perceptual realism. The number of validated turkers varies by experiment.
- The Frechet inception distance (FID) is used to construct the FID score [106] that is used to evaluate the quality of the generated images and measure the similarity between two different datasets [80]. It is used to measure the distance between the generated images’ distribution and the real image distribution by computing the Frechet inception distance using the inception network. FID very accurately captures the distribution and it is considered to be more consistent than IS with noise level. Lower FID values indicate better quality of the generated images’ sample [107].
- The kernel inception distance (KID) [108] is an improved measure of GAN convergence that has a simple unbiased estimator with no unnecessary assumptions regarding the form of the activations’ distribution. KID involves a computation of the squared maximum mean discrepancy between representations of reference and generated distributions [87]. A lower KID score signifies better visual quality of generated images
- The learned perceptual image patch similarity (LPIPS) distance [109] measures the image translation diversity by computing the average feature distance between the generated images. LPIPS is defined as a weighed L2 distance between deep features of two images. A higher LPIPS value indicates greater diversity among the generated images.
- Fully Convolutional Networks (FCN) [110] can be used to compute the FCN-score that uses the FCN model as a performance metric in order to evaluate the image quality by segmenting the generated image and comparing it with the ground truth label using a well-trained segmentation FCN model. A smaller value of the FCN-score between the generated image and ground truth means better performance. The FCN-score is calculated based on three parts: per-pixel accuracy, per-class accuracy, and class intersection-over-union (IOU).
7.3. Practical Applications
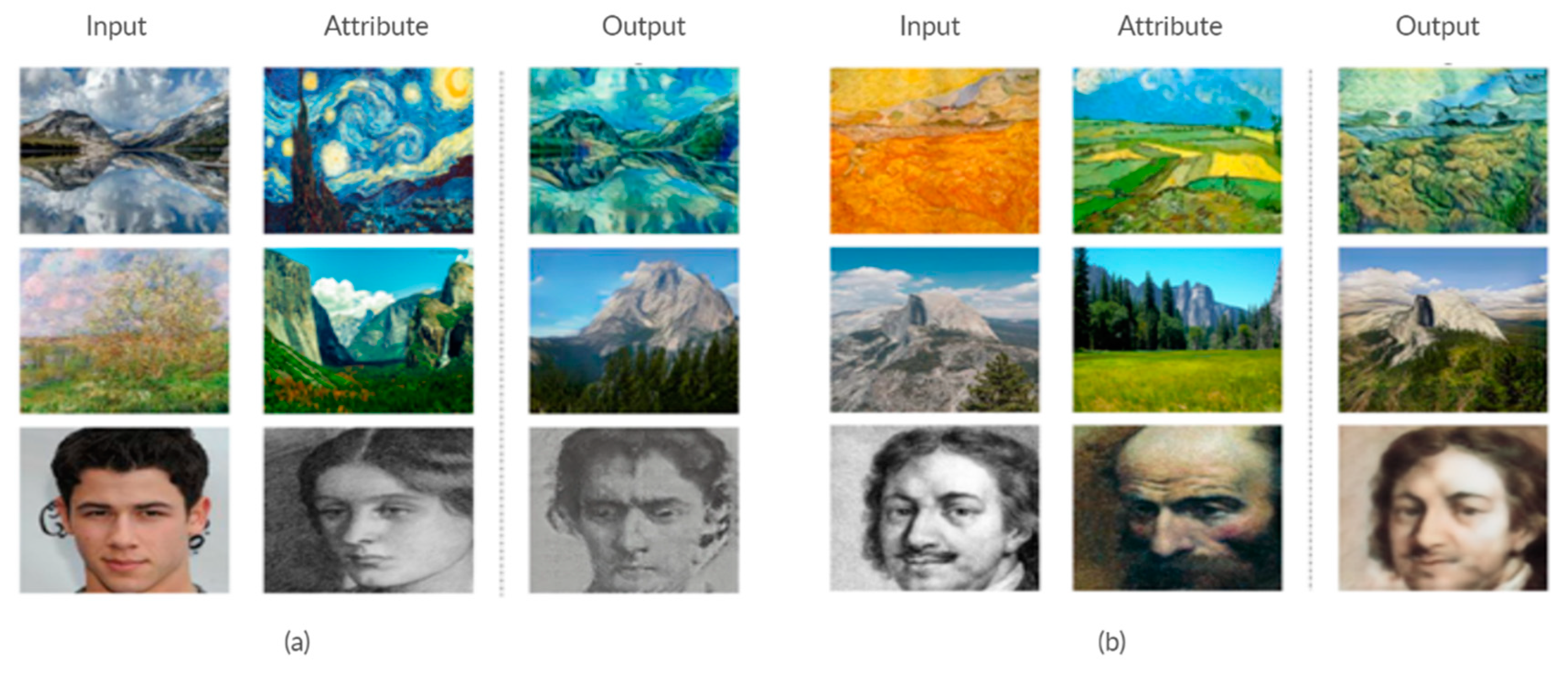
7.3.1. Super-Resolution
7.3.2. Style Transfer
7.3.3. Object Transfiguration
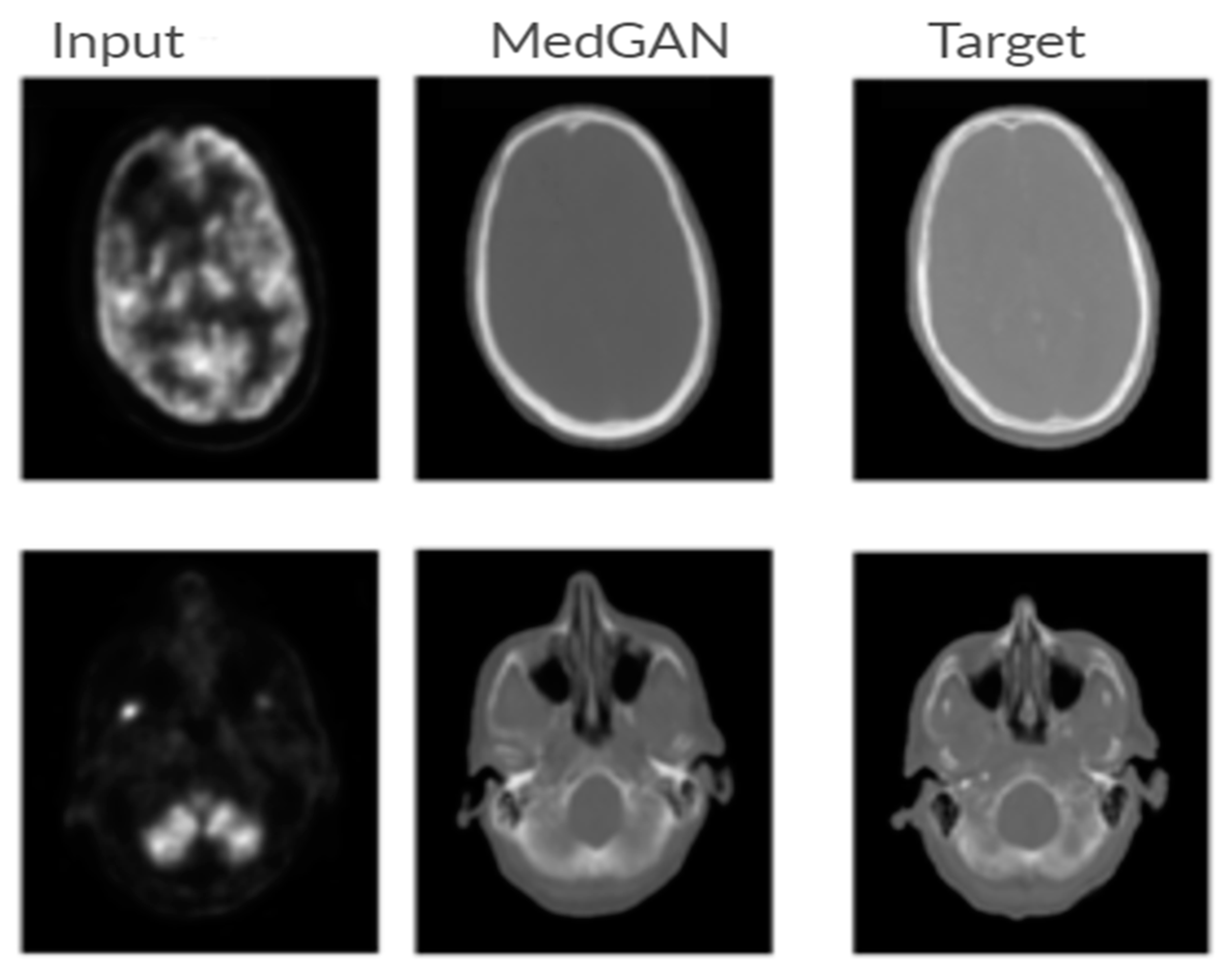
7.3.4. Medical Imaging
8. Discussion and Directions for Future Research
8.1. Open Challenges
- Mode Collapse
- Lack of evaluation metrics
- Lack of diversity
8.2. Directions of Future Research
9. Conclusions
Funding
Conflicts of Interest
Appendix A

| GAN Model | Full Name | Publication Year | Authors |
|---|---|---|---|
| GAN | Generative Adversarial Network | 2014 | Goodfellow et al. [32] |
| CGAN | Conditional GAN | 2014 | Mirza, M. & Osindero, S. [53] |
| LAPGAN | Laplacian Pyramid GAN | 2015 | Denton et al. [74] |
| DCGAN | Deep convolutional GAN | 2016 | Radford et al. [71] |
| InfoGAN | Information-Maximizing GAN | 2016 | Chen et al. [54] |
| CoGAN | Coupled GAN | 2016 | Liu et al. [89] |
| VAE-GAN | Variational encoder-decoder GAN | 2016 | Larsen et al. [75] |
| WGAN | Wasserstein GAN | 2017 | Arjovsky et al. [62] |
| WGAN-PG | Wasserstein GAN with a Gradient Penalty | 2017 | Gulrajani et al. [69] |
| BEGAN | Boundary Equilibrium GAN | 2017 | Berthelot et al. [67] |
| EBGAN | Energy-Based GAN | 2017 | Zhao et al. [66] |
| MAGAN | Margin Adaption GAN | 2017 | Wang et al. [68] |
| CycleGAN | Cycle-Consistent GAN | 2017 | Zhu et al. [41] |
| MMDGAN | Maximum Mean Discrepancy GAN | 2017 | Li et al. [65] |
| DiscoGAN | Discover Cross-Domain GAN | 2017 | Kim et al. [83] |
| LSGAN | Least-Squares GAN | 2017 | Mao et al. [59] |
| ACGAN | Auxiliary Classifier GAN | 2017 | Odena et al. [126] |
| Pix2Pix | Pixel-to-Pixel | 2017 | Isola et al. [76] |
| DualGAN | Dual Learning GAN | 2017 | Yi et al. [84] |
| UNIT | Unsupervised Image-to-Image Translation | 2017 | Lui et al. [88] |
| SRGAN | Super-Resolution GAN | 2017 | Leding et al. [115] |
| PROGAN | Progressive Growing GAN | 2018 | Karras et al. [73] |
| Pix2PixHD | Pixel-to-Pixel High-Resolution | 2018 | Wang et al. [77] |
| MUNIT | Multimodal Unsupervised Image-to-Image Translation | 2018 | Huang et al. [42] |
| DRIT | Diverse Image-to-Image Translation | 2018 | Lee at al. [79] |
| UFDN | Unified Feature Disentangler | 2018 | Liu et al. [92] |
| AguGAN | Augmented Cycle GAN | 2018 | Almahairi et al. [82] |
| BigGAN | Large-Scale (Big) GAN | 2019 | Brock et al. [58] |
| SAGAN | Self-Attention GAN | 2019 | Zhang et al. [72] |
| CEGAN | Consistent Embedded GAN | 2019 | Xiong et al. [80] |
| MSGAN | Mode Seek GAN | 2019 | Mao et al. [107] |
| QGAN | Quality-Aware GAN | 2019 | Chen et al. [86] |
| DRIT++ | Diverse Image-to-Image Translation | 2019 | Lee et al. [95] |
| AsyGAN | Asymmetric GAN | 2019 | Li et al. [85] |
| RelGAN | Relative Attributes GAN | 2019 | Wu et al. [96] |
| Gated-GAN | Adversarial Gated Network | 2019 | Chen et al. [116] |
| DOSGAN | Domain-Supervised GAN | 2019 | Lin et al. [93] |
| SPA-GAN | Spatial Attention GAN | 2020 | Emami et al. [87] |
| GMM-UNIT | Gaussian Mixture Modeling UNIT | 2020 | Liu et al. [90] |
| GANILLA | GAN for Image-to-Illustration Translation | 2020 | Hicsonmez et al. [117] |
| XGAN | Cross GAN | 2020 | Royer et al. [43] |
References
- Huang, H.; Yu, P.S.; Wang, C. An introduction to image synthesis with generative adversarial nets. arXiv 2018, arXiv:1803.04469. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef]
- Zhao, D.; Zhu, D.; Lu, J.; Luo, Y.; Zhang, G. Synthetic medical images using F&BGAN for improved lung nodules classification by multi-scale VGG16. Symmetry 2018, 10, 519. [Google Scholar]
- Ma, B.; Ban, X.; Huang, H.; Chen, Y.; Liu, W.; Zhi, Y. Deep learning-based image segmentation for Al-La alloy microscopic images. Symmetry 2018, 10, 107. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Alotaibi, A.; Mahmood, A. Deep face liveness detection based on nonlinear diffusion using convolution neural network. SignalImage Video Process 2017, 11, 713–720. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, W.; Wang, J.; Wang, S. Deep multimodal representation learning: A survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; pp. 841–848. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Li, C.; Wang, L.; Cheng, S.; Ao, N. Generative Adversarial Network-Based Super-Resolution Considering Quantitative and Perceptual Quality. Symmetry 2020, 12, 449. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Bhattacharjee, D.; Kim, S.; Vizier, G.; Salzmann, M. DUNIT: Detection-Based Unsupervised Image-to-Image Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4787–4796. [Google Scholar]
- Venkateswara, H.; Chakraborty, S.; Panchanathan, S. Deep-learning systems for domain adaptation in computer vision: Learning transferable feature representations. IEEE Signal Process. Mag. 2017, 34, 117–129. [Google Scholar] [CrossRef]
- Cao, Y.-J.; Jia, L.-L.; Chen, Y.-X.; Lin, N.; Yang, C.; Zhang, B.; Liu, Z.; Li, X.-X.; Dai, H.-H. Recent advances of generative adversarial networks in computer vision. IEEE Access 2018, 7, 14985–15006. [Google Scholar] [CrossRef]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.-Y. Generative adversarial networks: Introduction and outlook. IEEE/CAA J. Autom. Sin. 2017, 4, 588–598. [Google Scholar] [CrossRef]
- Rasmussen, C.E. The infinite Gaussian mixture model. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 6 December 2020; pp. 554–560. [Google Scholar]
- Jiang, L.; Zhang, H.; Cai, Z. A novel Bayes model: Hidden naive Bayes. IEEE Trans. Knowl. Data Eng. 2008, 21, 1361–1371. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Maaløe, L.; Sønderby, C.K.; Sønderby, S.K.; Winther, O. Auxiliary deep generative models. arXiv 2016, arXiv:1602.05473. [Google Scholar]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Oussidi, A.; Elhassouny, A. Deep generative models: Survey. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–8. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. Deep boltzmann machines. In Proceedings of the Artificial Intelligence and Statistics, Clearwater, FL, USA, 16–19 April 2009; pp. 448–455. [Google Scholar]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Abbasnejad, M.E.; Shi, Q.; van den Hengel, A.; Liu, L. A generative adversarial density estimator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 10782–10791. [Google Scholar]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. arXiv 2019, arXiv:1906.01529. [Google Scholar]
- Tang, H.; Xu, D.; Liu, H.; Sebe, N. Asymmetric Generative Adversarial Networks for Image-to-Image Translation. arXiv 2019, arXiv:1912.06931. [Google Scholar]
- Regmi, K.; Borji, A. Cross-view image synthesis using conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 3501–3510. [Google Scholar]
- Lin, C.-H.; Yumer, E.; Wang, O.; Shechtman, E.; Lucey, S. St-gan: Spatial transformer generative adversarial networks for image compositing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 9455–9464. [Google Scholar]
- Mo, S.; Cho, M.; Shin, J. Instagan: Instance-aware image-to-image translation. arXiv 2018, arXiv:1812.10889. [Google Scholar]
- Kahng, M.; Thorat, N.; Chau, D.H.P.; Viégas, F.B.; Wattenberg, M. Gan lab: Understanding complex deep generative models using interactive visual experimentation. IEEE Trans. Vis. Comput. Graph. 2018, 25, 1–11. [Google Scholar] [CrossRef]
- Hertzmann, A.; Jacobs, C.E.; Oliver, N.; Curless, B.; Salesin, D.H. Image analogies. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 327–340. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Huang, X.; Liu, M.-Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Royer, A.; Bousmalis, K.; Gouws, S.; Bertsch, F.; Mosseri, I.; Cole, F.; Murphy, K. Xgan: Unsupervised image-to-image translation for many-to-many mappings. In Domain Adaptation for Visual Understanding; Springer: Berlin/Heidelberg, Germany, 2020; pp. 33–49. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 8789–8797. [Google Scholar]
- Zhao, B.; Chang, B.; Jie, Z.; Sigal, L. Modular generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 150–165. [Google Scholar]
- Tao, R.; Li, Z.; Tao, R.; Li, B. ResAttr-GAN: Unpaired Deep Residual Attributes Learning for Multi-Domain Face Image Translation. IEEE Access 2019, 7, 132594–132608. [Google Scholar] [CrossRef]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How generative adversarial networks and their variants work: An overview. ACM Comput. Surv. (CSUR) 2019, 52, 1–43. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent progress on generative adversarial networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. arXiv 2020, arXiv:2001.06937. [Google Scholar]
- Wang, L.; Chen, W.; Yang, W.; Bi, F.; Yu, F.R. A State-of-the-Art Review on Image Synthesis with Generative Adversarial Networks. IEEE Access 2020, 8, 63514–63537. [Google Scholar] [CrossRef]
- Wu, X.; Xu, K.; Hall, P. A survey of image synthesis and editing with generative adversarial networks. Tsinghua Sci. Technol. 2017, 22, 660–674. [Google Scholar] [CrossRef]
- Gonog, L.; Zhou, Y. A review: Generative adversarial networks. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 505–510. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Spurr, A.; Aksan, E.; Hilliges, O. Guiding infogan with semi-supervision. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; pp. 119–134. [Google Scholar]
- Kurutach, T.; Tamar, A.; Yang, G.; Russell, S.J.; Abbeel, P. Learning plannable representations with causal infogan. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 8733–8744. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 271–279. [Google Scholar]
- Mroueh, Y.; Sercu, T. Fisher gan. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2513–2523. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Mroueh, Y.; Sercu, T.; Goel, V. Mcgan: Mean and covariance feature matching gan. arXiv 2017, arXiv:1702.08398. [Google Scholar]
- Li, Y.; Swersky, K.; Zemel, R. Generative moment matching networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1718–1727. [Google Scholar]
- Li, C.-L.; Chang, W.-C.; Cheng, Y.; Yang, Y.; Póczos, B. Mmd gan: Towards deeper understanding of moment matching network. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2203–2213. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Wang, R.; Cully, A.; Chang, H.J.; Demiris, Y. Magan: Margin adaptation for generative adversarial networks. arXiv 2017, arXiv:1704.03817. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Pan, Z.; Yu, W.; Wang, B.; Xie, H.; Sheng, V.S.; Lei, J.; Kwong, S. Loss Functions of Generative Adversarial Networks (GANs): Opportunities and Challenges. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 500–522. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 7354–7363. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1486–1494. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1558–1566. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 8798–8807. [Google Scholar]
- Zhu, J.-Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 465–476. [Google Scholar]
- Lee, H.-Y.; Tseng, H.-Y.; Huang, J.-B.; Singh, M.; Yang, M.-H. Diverse image-to-image translation via disentangled representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Xiong, F.; Wang, Q.; Gao, Q. Consistent Embedded GAN for Image-to-Image Translation. IEEE Access 2019, 7, 126651–126661. [Google Scholar] [CrossRef]
- Tripathy, S.; Kannala, J.; Rahtu, E. Learning image-to-image translation using paired and unpaired training samples. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 51–66. [Google Scholar]
- Almahairi, A.; Rajeswar, S.; Sordoni, A.; Bachman, P.; Courville, A. Augmented cyclegan: Learning many-to-many mappings from unpaired data. arXiv 2018, arXiv:1802.10151. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. arXiv 2017, arXiv:1703.05192. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Li, Y.; Tang, S.; Zhang, R.; Zhang, Y.; Li, J.; Yan, S. Asymmetric GAN for unpaired image-to-image translation. IEEE Trans. Image Process. 2019, 28, 5881–5896. [Google Scholar] [CrossRef]
- Chen, L.; Wu, L.; Hu, Z.; Wang, M. Quality-aware unpaired image-to-image translation. IEEE Trans. Multimed. 2019, 21, 2664–2674. [Google Scholar] [CrossRef]
- Emami, H.; Aliabadi, M.M.; Dong, M.; Chinnam, R. Spa-gan: Spatial attention gan for image-to-image translation. IEEE Trans. Multimed. 2020. [Google Scholar] [CrossRef]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Liu, M.-Y.; Tuzel, O. Coupled generative adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 469–477. [Google Scholar]
- Liu, Y.; De Nadai, M.; Yao, J.; Sebe, N.; Lepri, B.; Alameda-Pineda, X. GMM-UNIT: Unsupervised Multi-Domain and Multi-Modal Image-to-Image Translation via Attribute Gaussian Mixture Modeling. arXiv 2020, arXiv:2003.06788. [Google Scholar]
- Zhou, Y.-F.; Jiang, R.-H.; Wu, X.; He, J.-Y.; Weng, S.; Peng, Q. Branchgan: Unsupervised mutual image-to-image transfer with a single encoder and dual decoders. IEEE Trans. Multimed. 2019, 21, 3136–3149. [Google Scholar] [CrossRef]
- Liu, A.H.; Liu, Y.-C.; Yeh, Y.-Y.; Wang, Y.-C.F. A unified feature disentangler for multi-domain image translation and manipulation. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 2590–2599. [Google Scholar]
- Lin, J.; Chen, Z.; Xia, Y.; Liu, S.; Qin, T.; Luo, J. Exploring explicit domain supervision for latent space disentanglement in unpaired image-to-image translation. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Lee, H.-Y.; Tseng, H.-Y.; Mao, Q.; Huang, J.-B.; Lu, Y.-D.; Singh, M.; Yang, M.-H. Drit++: Diverse image-to-image translation via disentangled representations. Int. J. Comput. Vis. 2020, 1–16. [Google Scholar] [CrossRef]
- Wu, P.-W.; Lin, Y.-J.; Chang, C.-H.; Chang, E.Y.; Liao, S.-W. Relgan: Multi-domain image-to-image translation via relative attributes. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5914–5922. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Tyleček, R.; Šára, R. Spatial pattern templates for recognition of objects with regular structure. In Proceedings of the German Conference on Pattern Recognition, Saarbrücken, Germany, 3–6 September 2013; pp. 364–374. [Google Scholar]
- Shen, Z.; Huang, M.; Shi, J.; Xue, X.; Huang, T.S. Towards instance-level image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3683–3692. [Google Scholar]
- Ng, H.-W.; Winkler, S. A data-driven approach to cleaning large face datasets. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 343–347. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Le, V.; Brandt, J.; Lin, Z.; Bourdev, L.; Huang, T.S. Interactive facial feature localization. In Proceedings of the European Conference on Computer Vision, Providence, RI, USA, 16–21 June 2012; pp. 679–692. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Shmelkov, K.; Schmid, C.; Alahari, K. How good is my GAN? In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 213–229. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Mao, Q.; Lee, H.-Y.; Tseng, H.-Y.; Ma, S.; Yang, M.-H. Mode seeking generative adversarial networks for diverse image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1429–1437. [Google Scholar]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying mmd gans. arXiv 2018, arXiv:1801.01401. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 586–595. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet domain generative adversarial network for multi-scale face hallucination. Int. J. Comput. Vis. 2019, 127, 763–784. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. Ranksrgan: Generative adversarial networks with ranker for image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3096–3105. [Google Scholar]
- Wang, Y.; Perazzi, F.; McWilliams, B.; Sorkine-Hornung, A.; Sorkine-Hornung, O.; Schroers, C. A fully progressive approach to single-image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 864–873. [Google Scholar]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Chen, X.; Xu, C.; Yang, X.; Song, L.; Tao, D. Gated-gan: Adversarial gated networks for multi-collection style transfer. IEEE Trans. Image Process. 2018, 28, 546–560. [Google Scholar] [CrossRef] [PubMed]
- Hicsonmez, S.; Samet, N.; Akbas, E.; Duygulu, P. GANILLA: Generative adversarial networks for image to illustration translation. Image Vis. Comput. 2020, 95, 103886. [Google Scholar] [CrossRef]
- Ma, S.; Fu, J.; Wen Chen, C.; Mei, T. Da-gan: Instance-level image translation by deep attention generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 5657–5666. [Google Scholar]
- Chen, X.; Xu, C.; Yang, X.; Tao, D. Attention-gan for object transfiguration in wild images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 164–180. [Google Scholar]
- Yi, X.; Walia, E.; Babyn, P. Generative adversarial network in medical imaging: A review. Med. Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef]
- Armanious, K.; Jiang, C.; Fischer, M.; Küstner, T.; Hepp, T.; Nikolaou, K.; Gatidis, S.; Yang, B. MedGAN: Medical image translation using GANs. Comput. Med. Imaging Graph. 2020, 79, 101684. [Google Scholar] [CrossRef]
- Borji, A. Pros and cons of gan evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef]
- Furuta, R.; Inoue, N.; Yamasaki, T. Fully convolutional network with multi-step reinforcement learning for image processing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3598–3605. [Google Scholar]
- Kosugi, S.; Yamasaki, T. Unpaired image enhancement featuring reinforcement-learning-controlled image editing software. arXiv 2019, arXiv:1912.07833. [Google Scholar] [CrossRef]
- Ganin, Y.; Kulkarni, T.; Babuschkin, I.; Eslami, S.; Vinyals, O. Synthesizing programs for images using reinforced adversarial learning. arXiv 2018, arXiv:1804.01118. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





| Notation | Explanation |
|---|---|
| Real Sample | |
| Fake sample | |
| (z) | Random noise vector |
| p(x|y) | Conditional probability |
| P(x,y) | Joint probability |
| Generator Network | |
| Discriminator Network | |
| (y) | Discriminator output |
| Discriminator loss | |
| Generator loss |
| Subject | Details | Reference |
|---|---|---|
| Objective function | f-divergence | GAN [32], LSGAN [59], f-GAN [60] |
| Integral Probability Metric (IMP) | Fisher GAN [61], WGAN [62], McGAN [63], GMMN [64],MMGAN [65] | |
| Autoencoder | Energy function | EBGAN [66], BEGAN [67], MAGAN [68] |
| Model | Generator Loss | Discriminator Loss |
|---|---|---|
| GAN [32] | ||
| LSGAN [59] | ||
| WGAN [62] | ||
| EBGAN [66] | ||
| BEGAN [67] | ||
| MAGAN [68] |
| Dataset | Source | Year | Total | Classes | Application | Citations |
|---|---|---|---|---|---|---|
| CelebA(CelebFaces) | [94] | 2015 | 202,599 | 10177 | Facial attributes | [44,79,82,83,85,88,89,90,91,93,95,96] |
| RaFD | [97] | 2010 | 8040 | 67 | Facial expressions | [35,44,70] |
| CMP Facades | [98] | 2013 | 606 | 12 | Façade images | [35,76,80,85,91,99] |
| Facescrub | [100] | 2014 | 106,863 | 153 | Faces | [87,93] |
| Cityscapes | [101] | 2016 | 70,000 | 30 | Semantic | [41,76,77,80,85,87,88,91,95,99] |
| Helen Face | [102] | 2012 | 2330 | - | Face Parsing | [77,85] |
| CartoonSet | [43] | 2018 | 10,000 | - | Cartoon Faces | [43] |
| ImageNet | [103] | 2009 | 3.2 m | 12 subtrees | Diverse | [76,87] |
| Method | Unpaired Images | Multi-Domain Translation | Multi-Modal Translation | Unified Structure | Bidirectional Translation | Shared Representation | Feature Disentanglement |
|---|---|---|---|---|---|---|---|
| Pix2Pix [76] | - | - | - | - | - | - | - |
| BicycleGAN [78] | - | - | ✓ | - | ✓ | ✓ | - |
| StarGAN [44] | ✓ | ✓ | - | ✓ | ✓ | - | - |
| CycleGAN [41] | ✓ | - | - | - | ✓ | - | - |
| UNIT [88] | ✓ | - | - | - | ✓ | ✓ | - |
| GMM-UNIT [90] | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ |
| MUNIT [42] | ✓ | - | ✓ | - | ✓ | ✓ | ✓ |
| DIRT [79] | ✓ | - | ✓ | - | ✓ | ✓ | ✓ |
| DIRT++ [95] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| UFDN [92] | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, A. Deep Generative Adversarial Networks for Image-to-Image Translation: A Review. Symmetry 2020, 12, 1705. https://doi.org/10.3390/sym12101705
Alotaibi A. Deep Generative Adversarial Networks for Image-to-Image Translation: A Review. Symmetry. 2020; 12(10):1705. https://doi.org/10.3390/sym12101705
Chicago/Turabian StyleAlotaibi, Aziz. 2020. "Deep Generative Adversarial Networks for Image-to-Image Translation: A Review" Symmetry 12, no. 10: 1705. https://doi.org/10.3390/sym12101705
APA StyleAlotaibi, A. (2020). Deep Generative Adversarial Networks for Image-to-Image Translation: A Review. Symmetry, 12(10), 1705. https://doi.org/10.3390/sym12101705