SAAE-DNN: Deep Learning Method on Intrusion Detection


Abstract
1. Introduction
- A deep learning model SAAE-DNN is proposed, which consists of SAE, attention mechanism, and DNN. SAAE-DNN improves the accuracy of IDS and provides a new research method for intrusion detection;
- We introduce attention mechanism to highlight the key inputs in the SAE model. The attention mechanism learns the latent layer features of SAE, and the obtained feature information is reasonable and accurate;
- We use a real NSL-KDD dataset to evaluate our proposed network. The experimental results show that SAAE-DNN has better performance than traditional methods.
2. Related Work
3. Background
3.1. AutoEncoder
3.2. Stacked AutoEncoder
3.3. Attention Mechanism
3.4. Deep Neural Network
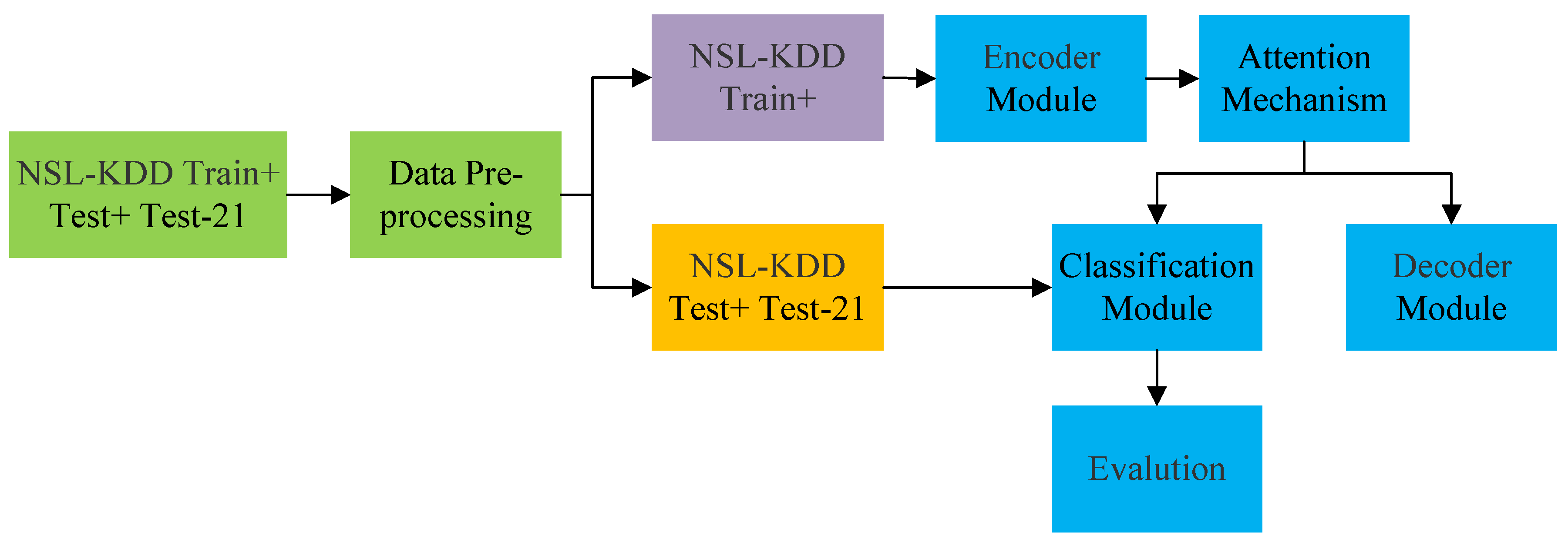
4. The Proposed Intrusion Detection Method
4.1. Data Preprocessing
4.1.1. Data Normalization
4.1.2. One-Hot-Encoding
4.1.3. Statistical Filtering
4.2. Proposed Attention Autoencoder (AAE) and Stacked Attention AutoEncoder (SAAE)
4.3. Classification
| Algorithm 1 The Intrusion Detection Algorithm with SAAE and DNN |
Input: Training dataset KDDTrain+, Testing dataset KDDTest+ and KDDTest-21; Output: Classification results: accuracy, precision, recall, and F1-score;
|
5. Experimental Results and Analysis
5.1. Experimental Environment
5.2. Performance Metrics
5.3. Description of the Benchmark Dataset
5.4. Experimental Step
5.5. Results and Discussion
5.6. Additional Comparison
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IDS | Intrusion Detection System |
| AE | Autoencoder |
| SAE | Staked Autoencoder |
| DAE | Denoising Autoencoder |
| R2L | Remote-to-Local |
| U2R | User-to-Root |
| DoS | Denial-of-Service |
| AAE | Attention-AutoEncoder |
| SAAE | Attention-Stacked-AutoEncoder |
| DNN | Deep Neural Networks |
| TP | True Positives |
| TN | True Negatives |
| FP | False Positives |
| FN | False Negatives |
References
- Liu, C.; Liu, Y.; Yan, Y.; Wang, J. An Intrusion Detection Model With Hierarchical Attention Mechanism. IEEE Access 2020, 8, 67542–67554. [Google Scholar] [CrossRef]
- Dwivedi, S.; Vardhan, M.; Tripathi, S.; Shukla, A.K. Implementation of adaptive scheme in evolutionary technique for anomaly-based intrusion detection. Evol. Intell. 2020, 13, 103–117. [Google Scholar] [CrossRef]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep Learning Methods on Network Intrusion Detection Using NSL-KDD Dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Alagrash, Y.; Drebee, A.; Zirjawi, N. Comparing the Area of Data Mining Algorithms in Network Intrusion Detection. J. Inf. Secur. 2020, 11, 1–18. [Google Scholar] [CrossRef][Green Version]
- Khammassi, C.; Krichen, S. A NSGA2-LR wrapper approach for feature selection in network intrusion detection. Comput. Netw. 2020, 172, 107183. [Google Scholar] [CrossRef]
- Gauthama Raman, M.R.; Somu, N.; Jagarapu, S.; Manghnani, T.; Selvam, T.; Krithivasan, K.; Shankar Sriram, V.S. An efficient intrusion detection technique based on support vector machine and improved binary gravitational search algorithm. Artif. Intell. Rev. 2020, 53, 3255–3286. [Google Scholar] [CrossRef]
- Ieracitano, C.; Adeel, A.; Morabito, F.C.; Hussain, A. A Novel Statistical Analysis and Autoencoder Driven Intelligent Intrusion Detection Approach. Neurocomputing 2020, 387, 51–62. [Google Scholar] [CrossRef]
- Dey, S.K.; Rahman, M.M. Effects of Machine Learning Approach in Flow-Based Anomaly Detection on Software-Defined Networking. Symmetry 2020, 12, 7. [Google Scholar] [CrossRef]
- Elmasry, W.; Akbulut, A.; Zaim, A.H. Evolving deep learning architectures for network intrusion detection using a double PSO metaheuristic. Comput. Netw. 2020, 168, 107042. [Google Scholar] [CrossRef]
- Iwendi, C.; Khan, S.; Anajemba, J.H.; Mittal, M.; Alenezi, M.; Alazab, M. The Use of Ensemble Models for Multiple Class and Binary Class Classification for Improving Intrusion Detection Systems. Sensors 2020, 20, 2559. [Google Scholar] [CrossRef] [PubMed]
- Mikhail, J.W.; Fossaceca, J.M.; Iammartino, R. A semi-boosted nested model with sensitivity-based weighted binarization for multi-domain network intrusion detection. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–27. [Google Scholar] [CrossRef]
- Kumar, G. An improved ensemble approach for effective intrusion detection. J. Supercomput. 2020, 76, 275–291. [Google Scholar] [CrossRef]
- Safara, F.; Souri, A.; Serrizadeh, M. Improved intrusion detection method for communication networks using association rule mining and artificial neural networks. IET Commun. 2020, 14, 1192–1197. [Google Scholar] [CrossRef]
- Amouri, A.; Alaparthy, V.T.; Morgera, S.D. A Machine Learning Based Intrusion Detection System for Mobile Internet of Things. Sensors 2020, 20, 461. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Wang, J.; Zhu, Y.; Yang, T. Dynamic Deep Forest: An Ensemble Classification Method for Network Intrusion Detection. Electronics 2019, 8, 968. [Google Scholar] [CrossRef]
- Velliangiri, S. A hybrid BGWO with KPCA for intrusion detection. J. Exp. Theor. Artif. Intell. 2020, 32, 165–180. [Google Scholar] [CrossRef]
- Karthikeyan, D.; Mohanraj, V.; Suresh, Y.; Senthilkumar, J. Hybrid Intrusion Detection System Security Enrichment Using Classifier Ensemble. J. Comput. Theor. Nanosci. 2020, 17, 434–438. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mané, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing dataflow graphs of deep learning models in TensorFlow. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef]
- He, D.; Qiao, Q.; Gao, Y.; Zheng, J.; Chan, S.; Li, J.; Guizani, N. Intrusion Detection Based on Stacked Autoencoder for Connected Healthcare Systems. IEEE Netw. 2019, 33, 64–69. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Yang, Y.; Horng, S. Multivariate Time Series Forecasting via Attention-based Encoder-Decoder Framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Chiba, Z.; Abghour, N.; Moussaid, K.; Omri, A.E.; Rida, M. Intelligent approach to build a Deep Neural Network based IDS for cloud environment using combination of machine learning algorithms. Comput. Secur. 2019, 86, 291–317. [Google Scholar] [CrossRef]
- Javaid, A.Y.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. EAI Endorsed Trans. Secur. Saf. 2016, 3, 21–26. [Google Scholar]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Anwer, H.M.; Farouk, M.; Abdel-Hamid, A. A framework for efficient network anomaly intrusion detection with features selection. In Proceedings of the 2018 9th International Conference on Information and Communication Systems, Irbid, Jordan, 3–5 April 2018; pp. 157–162. [Google Scholar]
- Mighan, S.N.; Kahani, M. A novel scalable intrusion detection system based on deep learning. Int. J. Inf. Secur. 2020, 1–17. [Google Scholar] [CrossRef]
- Jo, W.; Kim, S.; Lee, C.; Shon, T. Packet Preprocessing in CNN-Based Network Intrusion Detection System. Electronics 2020, 9, 1151. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, French, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Yang, T.; Hu, Y.; Li, Y.; Hu, W.; Pan, Q. A Standardized ICS Network Data Processing Flow With Generative Model in Anomaly Detection. IEEE Access 2020, 8, 4255–4264. [Google Scholar] [CrossRef]
- Kunang, Y.N.; Nurmaini, S.; Stiawan, D.; Zarkasi, A.; Jasmir, F. Automatic Features Extraction Using Autoencoder in Intrusion Detection System. In Proceedings of the International Conference on Electrical Engineering and Computer Science (ICECOS), Pangkal Pinang, Indonesia, 2–4 October 2018; pp. 219–224. [Google Scholar]
- Montañez, C.A.C.; Fergus, P.; Chalmers, C.; Malim, N.H.A.H.; Abdulaimma, B.; Reilly, D.; Falciani, F. SAERMA: Stacked Autoencoder Rule Mining Algorithm for the Interpretation of Epistatic Interactions in GWAS for Extreme Obesity. IEEE Access 2020, 8, 112379–112392. [Google Scholar] [CrossRef]
- Swetha, A. Churn Prediction using Attention Based Autoencoder Network. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 725–730. [Google Scholar]
- Feng, F.; Liu, X.; Yong, B.; Zhou, R.; Zhou, Q. Anomaly detection in ad-hoc networks based on deep learning model: A plug and play device. Ad Hoc Netw. 2019, 84, 82–89. [Google Scholar] [CrossRef]
- Khare, N.; Devan, P.; Chowdhary, C.L.; Bhattacharya, S.; Singh, G.; Singh, S.; Yoon, B. SMO-DNN: Spider Monkey Optimization and Deep Neural Network Hybrid Classifier Model for Intrusion Detection. Electronics 2020, 9, 692. [Google Scholar] [CrossRef]
- Duan, B.; Han, L.; Gou, Z.; Yang, Y.; Chen, S. Clustering Mixed Data Based on Density Peaks and Stacked Denoising Autoencoders. Symmetry 2019, 11, 163. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 10, 1–13. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Yang, Y.; Zheng, K.; Wu, B.; Yang, Y.; Wang, X. Network Intrusion Detection Based on Supervised Adversarial Variational Auto-Encoder With Regularization. IEEE Access 2020, 8, 42169–42184. [Google Scholar] [CrossRef]
- Wu, K.; Chen, Z.; Li, W. A Novel Intrusion Detection Model for a Massive Network Using Convolutional Neural Networks. IEEE Access 2018, 6, 50850–50859. [Google Scholar] [CrossRef]
- Li, Z.; Qin, Z.; Huang, K.; Yang, X.; Ye, S. Intrusion Detection Using Convolutional Neural Networks for Representation Learning. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 October 2017; pp. 858–866. [Google Scholar]
- Yang, Y.; Zheng, K.; Wu, C.; Niu, X.; Yang, Y. Building an Effective Intrusion Detection System Using the Modified Density Peak Clustering Algorithm and Deep Belief Networks. Appl. Sci. 2019, 9, 238. [Google Scholar] [CrossRef]
- Alqatf, M.; Lasheng, Y.; Alhabib, M.; Alsabahi, K. Deep Learning Approach Combining Sparse Autoencoder With SVM for Network Intrusion Detection. IEEE Access 2018, 6, 52843–52856. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Attack | Predicted Normal | |
|---|---|---|
| Actual attack | TP | FN |
| Actual normal | FP | TN |
| Category | Attack | Training Dataset | Testing Dataset | |
|---|---|---|---|---|
| KDDTrain+ | KDDTest+ | KDDTest-21 | ||
| Normal | normal | 67,343 | 9711 | 2152 |
| Subtotal | 67,343 | 9711 | 2152 | |
| Subtotal Percentage | 53.46% | 43.07% | 18.16% | |
| Probe | ipsweep | 3599 | 141 | 141 |
| satan | 1493 | 735 | 727 | |
| portsweep | 2931 | 157 | 156 | |
| nmap | 3633 | 73 | 73 | |
| saint | / | 319 | 309 | |
| mscan | / | 996 | 996 | |
| Subtotal | 11,656 | 2421 | 2402 | |
| Subtotal Percentage | 9.25% | 10.74% | 20.27% | |
| DoS | neptune | 41,214 | 4657 | 1579 |
| smurf | 2646 | 665 | 627 | |
| back | 956 | 359 | 359 | |
| teardrop | 892 | 12 | 12 | |
| pod | 201 | 41 | 41 | |
| land | 18 | 7 | 7 | |
| apache2 | / | 737 | 737 | |
| mailbomb | / | 293 | 293 | |
| processtable | / | 685 | 85 | |
| udpstorm | / | 2 | 2 | |
| Subtotal | 45,927 | 7458 | 4342 | |
| Subtotal Percentage | 36.46% | 33.08% | 36.64% | |
| U2R | buffer_overflow | 30 | 20 | 20 |
| rootkit | 10 | 13 | 13 | |
| loadmodule | 9 | 2 | 2 | |
| perl | 3 | 2 | 2 | |
| httptunnel | / | 133 | 133 | |
| ps | / | 15 | 15 | |
| sqlattack | / | 2 | 2 | |
| xterm | / | 13 | 13 | |
| Subtotal | 52 | 200 | 200 | |
| Subtotal Percentage | 0.04% | 0.89% | 1.69% | |
| R2L | guess_passwd | 53 | 1231 | 1231 |
| warezmaster | 20 | 944 | 944 | |
| imap | 11 | 1 | 1 | |
| multihop | 7 | 18 | 18 | |
| phf | 4 | 2 | 2 | |
| ftp_write | 8 | 3 | 3 | |
| spy | 2 | / | / | |
| warezclient | 890 | / | / | |
| named | / | 17 | 17 | |
| sendmail | / | 14 | 14 | |
| xlock | / | 9 | 9 | |
| xsnoop | / | 4 | 4 | |
| worm | / | 2 | 2 | |
| snmpgetattack | / | 178 | 178 | |
| snmpguess | / | 331 | 331 | |
| Subtotal | 995 | 2754 | 2754 | |
| Subtotal Percentage | 0.79% | 12.22% | 23.24% | |
| Total | 125,973 | 22,544 | 11,850 |
| Methods | Binary-Classification | Multi-Classification | ||
|---|---|---|---|---|
| KDDTest+ | KDDTest-21 | KDDTest+ | KDDTest-21 | |
| PCA-DNN | 79.13 | 67.89 | 71.23 | 56.92 |
| CHI2-DNN | 78.38 | 72.78 | 67.89 | 59.323 |
| SAAE-DNN | 87.74 | 82.97 | 82.14 | 77.57 |
| Methods | Binary-Classification | Multi-Classification | ||
|---|---|---|---|---|
| KDDTest+ | KDDTest-21 | KDDTest+ | KDDTest-21 | |
| DT | 78.34 | 62.09 | 76.5 | 56.84 |
| XGBoost | 75.85 | 54.059 | 75.62 | 53.68 |
| LightGBM | 77.4 | 57.15 | 68.54 | 44.4 |
| GBDT | 78.29 | 58.84 | 70.96 | 52.25 |
| LR | 75.4 | 53.42 | 75.04 | 52.65 |
| RF | 77.75 | 57.75 | 76.22 | 55.22 |
| SAAE-DNN | 87.74 | 82.97 | 82.14 | 77.57 |
| Methods | Binary-Classification | Multi-Classification | ||
|---|---|---|---|---|
| KDDTest+ | KDDTest-21 | KDDTest+ | KDDTest-21 | |
| RNN [23] | 83.28 | 68.55 | 81.29 | 64.67 |
| CNN [40] | N/A | N/A | 79.48 | 60.71 |
| ResNet [41] | 79.14 | 81.57 | N/A | N/A |
| GoogLeNet [41] | 77.04 | 81.84 | N/A | N/A |
| MDPCA-DBN [42] | N/A | N/A | 82.08 | 66.18 |
| SAE-SVM [43] | 84.96 | N/A | 80.48 | N/A |
| SAAE-DNN | 87.74 | 82.97 | 82.14 | 77.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, C.; Luktarhan, N.; Zhao, Y. SAAE-DNN: Deep Learning Method on Intrusion Detection. Symmetry 2020, 12, 1695. https://doi.org/10.3390/sym12101695
Tang C, Luktarhan N, Zhao Y. SAAE-DNN: Deep Learning Method on Intrusion Detection. Symmetry. 2020; 12(10):1695. https://doi.org/10.3390/sym12101695
Chicago/Turabian StyleTang, Chaofei, Nurbol Luktarhan, and Yuxin Zhao. 2020. "SAAE-DNN: Deep Learning Method on Intrusion Detection" Symmetry 12, no. 10: 1695. https://doi.org/10.3390/sym12101695
APA StyleTang, C., Luktarhan, N., & Zhao, Y. (2020). SAAE-DNN: Deep Learning Method on Intrusion Detection. Symmetry, 12(10), 1695. https://doi.org/10.3390/sym12101695