1. Introduction
The structural analysis of graphs and networks found in the real world aims at extracting high-level features or summarizing relevant properties of large data sets. That analysis can be carried out at different levels, depending on specific goals and viewpoints. A microscopic, node-level analysis intends to discover which network elements are most relevant for e.g., network cohesion and functioning, information or epidemic diffusion, or flow control. At the other extreme, one may want to concisely describe a quantitative property of a given network by one or a few numbers, for example, the overall number of nodes or edges and the average node degree, which quantify how large is a network and how strongly is connected, respectively.
A third approach to network analysis, which lies in between these two extremes, is the so-called network clustering or block-modeling [
1,
2,
3]. Roughly speaking, it consists of detecting the presence of various types of intermediate structures, typically consisting of groups of nodes that exhibit very specific patterns of relationships in their interior and with the rest of the network. For instance, a group of nodes that is rich in internal connections but is loosely connected with the exterior can be identified as a community. Community detection problems have received considerable attention in the network science literature because communities emerge naturally in many social, biological, or collaboration networks [
3,
4]. Besides communities, other network structures can be recognized and are attracting considerable interest nowadays. For example, in the analysis of biological networks including predator and prey species or social networks with ties representing hostilities, an important task is the identification of anti-communities, namely, groups of nodes being poorly connected internally but having many links between different groups. Communities and anti-communities may coexist, for instance in communication and social networks, giving rise to nested block structures that are difficult to disentangle [
1,
5,
6].
Another block structure recurring in the analysis of complex networks is the core–periphery structure, whose investigation has been popularized by the seminal works by Borgatti and Everett [
7]. In the last two decades the interest toward core–periphery structures had a remarkable growth in the network science literature [
6,
8,
9,
10]. In its simplest form, a core–periphery structure can be described as a partitioning of a given graph or network into two groups of nodes, called core and periphery. The core nodes are tightly interconnected and share connections with peripheral nodes, while peripheral nodes are loosely connected to core nodes and to other peripheral nodes. The presence of core–periphery structures has been detected in a large variety of complex systems, such as social networks, trade networks, and financial networks, see e.g., [
9,
11,
12].
These network structures are well described by means of suitable block partitionings of an adjacency matrix representing idealized situations [
1,
2,
3]. Various basic mesoscale network structures that can be described by a block partitioning of the adjacency matrix are illustrated in
Figure 1. Darker shadings represent matrix blocks having more nonzero entries, and denote the presence of stronger connections between the corresponding node sets. These idealized block structures can be identified by a variety of statistical and matrix analysis tools, give a reasonable approximation of structured real-world networks and can be easily reproduced synthetically.
In this paper, we address the case where a core–periphery structure is present in a given graph and must be discovered. We consider a core–periphery bipartitioning method considered by Brusco in [
13]. This method is based on a block model where off-diagonal blocks are neglected, and identifies the core nodes as belonging to a subset that minimizes a certain objective function. Our main result is an algorithm that exactly solves that combinatorial optimization problem with a computational cost that grows at most quadratically in the number of nodes. This significantly improves the computational time required to solve the problem with respect to the branch-and-bound procedure proposed in [
13]. The combination of computational efficiency and theoretical justification makes our algorithm attractive for the analysis of large networks.
In the next section, we introduce the combinatorial optimization problem we adopt to define the core–periphery partitioning and derive an exact algorithm to solve it. Since that problem may have multiple optimal solutions, we also provide a complete description of the optimal solution set and show a pleasant symmetry in our approach with respect to graph complementation. At first, we consider the core–periphery partitioning problem in loopless graphs whose adjacency matrix is symmetric. In
Section 3 we extend our optimization approach to graphs with loops and to directed graphs.
Section 4 is devoted to applications of our methodology to two real-world networks and two graph families that are relevant to complex network analysis, that is, equitable graphs and power-law networks.
1.1. Related Work
Core–periphery models are basically divided into discrete and continuous models. Discrete models induce a binary classification of the nodes as belonging either to the core, which has a high edge density, or to the periphery, whose edge density is low. The sought partitioning is determined by maximizing a correlation index or other matrix nearness measures between the adjacency matrix and an idealized block structure, see e.g., [
12,
13,
14,
15]. In continuous models each node obtains a value describing its “coreness”; unlike in discrete models, that value is a real, positive number. Continuous models may be based on a matrix similarity criterion, analogously to discrete models [
6,
10], or on a node-level centrality index quantifying the extent to which a vertex controls the information that flows through the network. To the latter class belong various bipartitioning algorithms based on closeness or betweenness indices [
9,
14] and other measurements based on random walks [
11,
16]. Both continuous and discrete models have been pioneered by Borgatti and Everett [
7]. They proposed two prototypical block structures for core–periphery partitionings, namely, those depicted in
Figure 1c,d. The basic assumption is that every two core nodes are directly connected while peripheral nodes have no direct links. Connections between core nodes and peripheral nodes may be requested (see
Figure 1c) or not (see
Figure 1d). Recent reviews on modeling and analyzing core–periphery structures, together with the related concepts of degree assortativity, rich-clubs, and nested network structures, can be found in [
6,
8,
14,
16].
1.2. Notation
For the purposes of this work, we borrow some basic notions from graph theory [
4,
17]. A graph or network
G consists of a finite set
V of nodes or vertices and a set
E of edges. Each edge
is an unordered pair of nodes. If
then we say that nodes
i and
j are adjacent, and that
e is incident to both
i and
j. For notational simplicity, we identify
V with
and we denote by
the edge
. Note that
. A complete graph is a graph in which all nodes are adjacent to each other. In some cases, it is useful to admit the presence of loops, that is, edges having the form
. Unless otherwise specified, we mainly consider simple graphs, i.e., graphs without loops and parallel edges, that is, edges incident to the same node pair.
A weighted graph is a graph endowed with an edge weight, that is a function assigning a real (usually positive) number to every edge. We denote the weight of the edge . Clearly, .
The adjacency matrix of a simple graph
G with
n nodes is the
symmetric matrix
such that
if
is an edge in
G and
otherwise. If the graph is weighted then
if
is an edge in
G and
otherwise. For
define
In an unweighted graph is the degree of node i, that is, the number of edges incident to it. If the graph is weighted, then the number is usually called strength or generalized degree of i. It represents the total weight of edges incident to i, and may not be an integer. In what follows, we simply call the degree of node i, both in weighted and unweighted graphs.
The sets
form a partition of
V if
and
for
. The cardinality of a subset
is denoted by
, and the complementary set
by
. The pair
is a bipartition of
V. The subgraph induced by
S is the graph
where
iff
and
. Equivalently, if
A is the adjacency matrix of
G then the adjacency matrix of
is the submatrix of
A extracted from rows and columns with indices in
S. Finally, the volume of
is
2. Identifying a Core–Periphery Bipartition
Let be a weighted graph and let A be its adjacency matrix. We assume that every edge is endowed with a positive weight , so that the entries of A belongs to the interval . We may think of as a relative measure, or fraction, of the strength of the interaction between nodes i and j with respect to a maximal capacity: If then the bond between the two nodes is perfect, or as strong as possible, while if then the two nodes do not interact; all intermediate values between these two extremes can be allowed. Obviously, this assumption includes trivially the case where the graph to be considered is unweighted, in which case for every .
In this section, we address the problem of identifying a core–periphery bipartition of
G that we suppose to exist in the graph. Note that we are not considering the problem of deciding whether or not that bipartition actually exists, that is, measuring the statistical significance of that structure, which is a different problem considered in, e.g., [
9,
11]. For the moment, we restrict ourselves to the case where
G has no loops or they must be ignored if present, as is common in most network applications. Consider the following function defined over subsets of
V:
The first term counts the overall weight that is missing in the subgraph induced by
S with respect to the ideal situation where all node pairs are perfectly connected, while the second term is the overall weight of edges that are present in the subgraph induced by the complementary set
. Thus, if
is close to zero then
S can be recognized as a core in the graph since its nodes are tightly connected to each other; at the same time, the nodes in
induce a subgraph with few or no edges, hence
represents a peripheral zone of the network. Therefore, the localization of a core–periphery structure in
G can be carried out by looking for a set
attaining a minimal value of
. In the sequel we will analyze the following combinatorial optimization problem, also considered in [
13]:
2.1. A Greedy Algorithm for Problem (2)
For any vertex set define the following auxiliary quantities:
the overall weight of the edges in the subgraph induced by S is
the overall weight of the edges having exactly one node in S is .
It is immediate to see that
. Moreover, owing to the symmetry of
A, we have
. Hence the function
can be rewritten as follows:
The last passage comes from the identity .
Observe that Problem (
2) can be restated equivalently as
With this restatement we can reduce the solution of Problem (
2) to that of at most
n subproblems endowed with a cardinality constraint. Finding a set
that minimizes
having a prescribed cardinality is an easy task. In fact, owing to the previous arguments, if
then
, where
is the overall weight of edges in
G. However, since
v does not depend on
k, its presence is unessential in the solution of Problem (
2), and an optimal solution of the
k-th subproblem consists of a set
S with cardinality
k and maximum volume. Such set can be easily computed by the greedy strategy described here below.
Without loss of generality, we can assume that the nodes of
G are numbered in non-increasing order of their degrees:
Then, for each given
, a set which minimizes
is
. Consequently, the optimal value of
under the constraint
is given by
Finally, denoting by
the optimal value of Problem (
2), it holds
. Letting
, we have the equivalent characterization
. In conclusion, Problem (
2) can be solved by the following three-step procedure:
The computation of the optimal index
can be simplified by noting that the numbers
form a strictly increasing sequence:
This implies that the sequence
is convex, and its minimum is attained at the largest integer
such that
. Hence, the step 2 in the preceding procedure needs to be performed only as long as
, that is,
. In summary, the previous procedure can be better described by the Algorithm 1 here below, which provides an optimal solution to Problem (
2). This fact, and the possible existence of other optimal solutions, is formalized in the subsequent results.
| Algorithm 1: Computing an optimal solution of Problem (2) |
Input: symmetric adjacency matrix of size n
Output: integer , core set

Compute a permutation of such that

Define the core set |
Theorem 1. Under the node ordering Formula (3), let be the integer defined as Then, Problem (2) has an optimal solution having cardinality , that is, One such optimal solution is given by . That solution is the unique optimal solution with cardinality if and only if .
Proof. The fact that
solves Problem (
2) has been shown by the previous arguments. In fact, the inequality
appearing in Equation (
5) is equivalent to the condition
. Note that that condition cannot be replaced by
since
may not be an integer if the graph
G is weighted. Uniqueness holds if and only if there is exactly one way to choose
nodes whose degree is not smaller than
, that is,
. □
Remark 1. The integer in Equation (5) can be defined equivalently as the smallest integer k such that . Since , we have the following alternative characterization: Corollary 1. Every optimal solution to Problem (2) has cardinality either or . Moreover, an optimal solution of cardinality exists if and only if . Proof. Since the optimal value of Problem (
2) is
, there exists an optimal solution
with
if and only if
. In that case, if
then we obtain
So the identity
is equivalent to the existence of a solution
with
. To prove that no solution with cardinality larger than
can exist it is sufficient to observe that from Equation (
4) for any
k we get
Hence the identity is impossible. □
In conclusion, assuming that the degree sequence
is ordered as in Formula (
3), the optimal solution set of Problem (
2) falls into one of the following alternatives:
If and then is the unique optimal solution.
If and there exists an integer such that then both and are optimal solutions, for every .
If there exists an integer such that then the problem is solved by any set made by either or vertices whose degree is not smaller than and containing all the vertices whose degree is greater than .
Example 1. Consider the following simple graphs:
In both graphs the nodes are already ordered according to Formula (3), and we have . In , Problem (2) has three optimal solutions, namely , and , since the uniqueness condition in Theorem 1 is broken and . In we have , hence Corollary 1 indicates the existence of solutions having cardinality 2 and 3. Moreover, the smallest solution is unique, since . In fact, the solutions are , and . Remark 2. The computational cost (in terms of elementary arithmetic-logical operations) of Algorithm 1 can be analyzed as follows.
- 1.
If the matrix A is given in a sparse format or, equivalently, the graph G is represented by an adjacency list, the degrees can be computed in operations where m is the number of edges in G. In any case, that cost is not larger than .
- 2.
Standard sorting algorithms can reorder the numbers in non-increasing order in operations, in the worst case.
- 3.
The computation of the integer in Equation (5) requires no more than operations.
Thus, Algorithm 1 requires operations, that is operations in the worst case. We point out that the complexity of the branch-and-bound algorithm in [13] to solve Problem (2) is unknown, but the timings reported in that paper suggest an exponential behavior in n. 2.2. A Symmetry Property
The formalization of the core–periphery problem proposed in Problem (
2) has a pleasant symmetry with respect to graph complementation. Given a loopless graph
with adjacency matrix
let
be its complementary graph, that is, the graph whose adjacency matrix is
where
If
G is unweighted then any two distinct vertices are adjacent in
if and only if they are not adjacent in
G. It is not hard to see that if
S is a core for
G then
is a core for
. Indeed, let
and
be the function
z in Equation (
1) computed in
G and
, respectively. Then, from Equation (
7) we have
Thus,
S is a solution of Problem (
2) in
G if and only if
solves Problem (
2) in
.
3. Allowing Loops and Directed Edges
In this section we extend the core–periphery partitioning algorithm discussed previously to two different settings. Firstly, we consider the case where loops are present and must be taken into consideration; afterwards, we address directed graphs, that is, graphs where node adjacency relationships are unsymmetric.
3.1. Allowing Loops
Certain networks include loops, that is, edges of the form
, which must be taken in due consideration in the structural analysis of the network. In that case, some diagonal entries of the adjacency matrix are nonzero. In fact, it is customary to set
in the adjacency matrix of an unweighted graph when the loop
is present in the graph. In order to tackle appropriately the presence of loops, it is reasonable to modify the Definition (
1) by including the contribution of the diagonal entries of
A in the summations. Hereafter, we sketch briefly the consequent changes in the solution of the corresponding optimization Problem (
2) with respect to the previous paragraphs.
Following the same arguments considered in the loopless case, the expression of
becomes
The optimal value of
under the constraint
is given by
, and the index
characterizing the (least) cardinality of a core is
Anyway, the symmetry property described in the previous paragraph continues to hold. Indeed, when loops are allowed, the adjacency matrix of the complementary graph is with .
3.2. Directed Graphs
A directed graph, or digraph, differs from a graph in that the incidence relation is unsymmetric. For definiteness, a directed graph is a pair where V is a set of vertices or nodes and . Hence, any element is an ordered pair of nodes, , called directed edge or arc. In this paragraph we consider directed unweighted graphs, so the adjacency matrix of G is the matrix such that if and otherwise. In a directed graph, loops are usually admitted.
The identification of a core–periphery partitioning in a directed graph can be carried out by extending to the present setting the principle adopted in the undirected case. That is, we argue that core nodes should form a well-connected subset, inducing a subgraph that is as most complete as possible, while the number of arcs running between peripheral nodes should be kept as small as possible. In our approach, the number of arcs between core nodes and peripheral nodes is unimportant. This principle can be formalized as follows. Let
A be the adjacency matrix of a directed graph
G. We define the core of
G as a set
which minimizes the objective function
Hereafter, we describe how the optimization of this function can be carried out with the help of the algorithm devised in the previous section.
Suppose we are given the adjacency matrix A of a directed unweighted graph , and let . We can think of as the adjacency matrix of an undirected graph having the same vertex set of the original graph and where each edge is endowed by a weight whose value is either 1 or . In fact, when we have iff both and , while iff exactly one of and is true. Obviously, means that both edges and are absent in G (and in , too). Also loops in G and are the same, since . Moreover, for any subset we have the identity . Finally, note that if every arc in G has its own reciprocal, that is , then A is symmetric and .
Hence, for any
, the value of
computed in the directed graph
G via Equation (
8) is the same as the value of
computed in the symmetrised and weighted graph
. Thus the only modification needed in the algorithm in the preceding section to deal with directed graphs is to define the numbers
as
The computation of the solution can be carried out as outlined in the previous paragraph.
4. Examples
In this section, we discuss the application of our bipartitioning algorithm to two real-world networks that are popular benchmarks for graph blockmodel problems, and to two graph families often encountered as idealized models of complex networks, namely, the equitable graphs and the graphs having a power-law degree profile.
4.1. Two Real-World Networks
In this paragraph, we report the results of the application of Algorithm 1 to two real-world networks that are available in the Pajek network repository [
18].
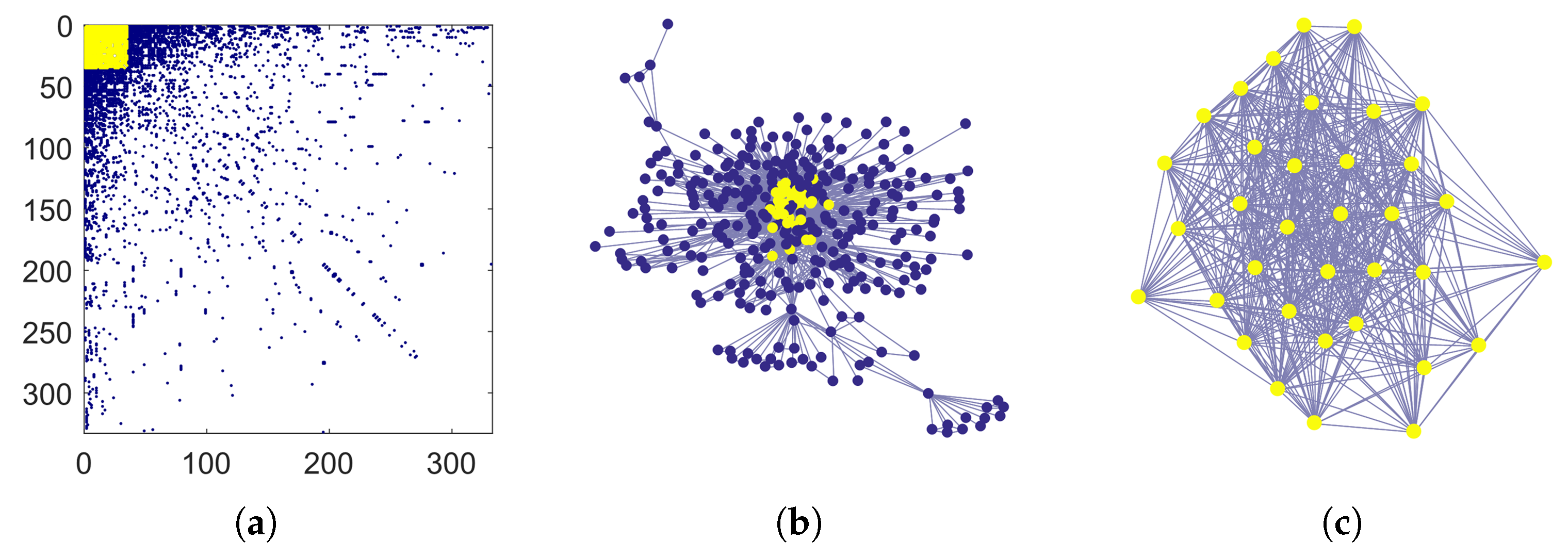
The USAir97 dataset is a graph built from the USA national aerial flights in 1997. Each node represents an airport, and two nodes are connected by an undirected edge if the corresponding airports are served by a direct flight in either direction. The graph has 332 nodes and 2126 edges, so the average degree is about
. Algorithm 1 identifies as core a well connected set of
nodes. The left panel in
Figure 2 shows the adjacency matrix once the nodes have been reordered according to their degree, as in Equation (
3). Colored dots are placed in correspondence with nonzero matrix entries. The matrix entries corresponding to the core nodes are shown in yellow. That submatrix is very dense, due to the fact that the subgraph induced by core nodes has 505 edges and the average degree in that subgraph is about
. A graphical layout of USAir97 is shown in the central panel in
Figure 2, where core nodes are colored in yellow. The subgraph induced by the core nodes is displayed in the right panel. Incidentally, we note that in this example Problem (
2) has also an optimal solution with 36 nodes, since
,
and
.
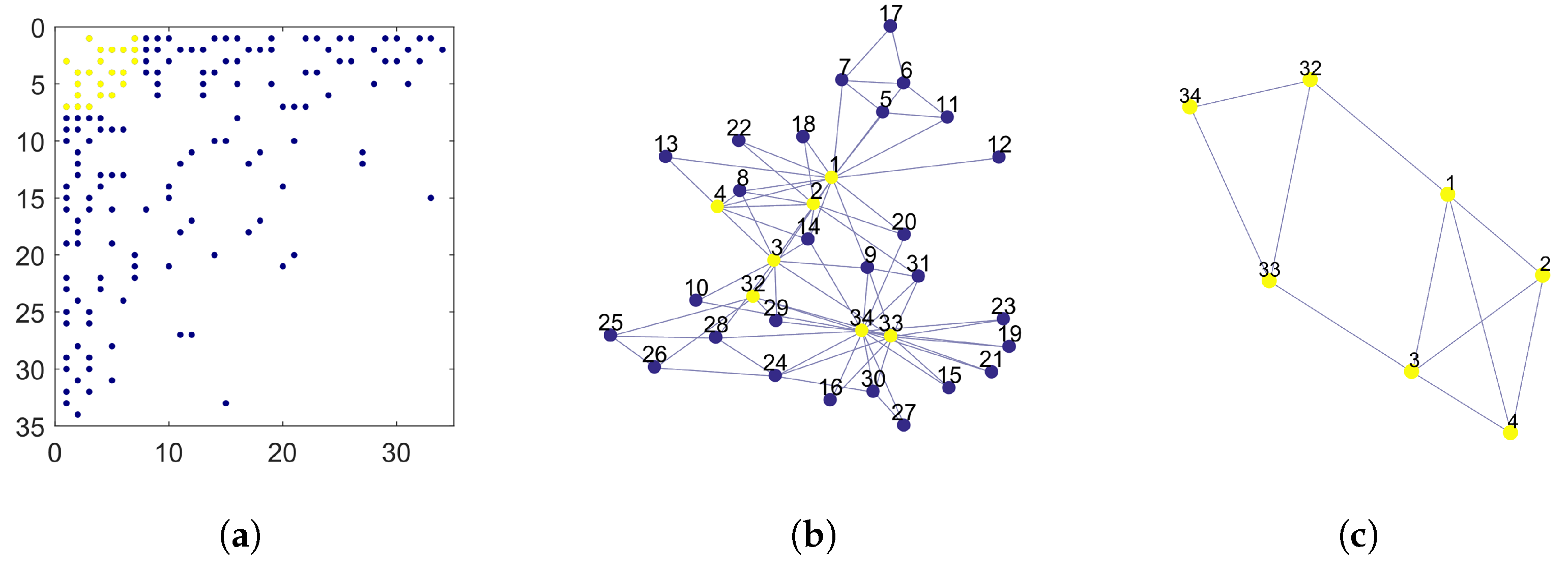
The Zachary dataset represents a small social network made by members of a karate club [
19]. The graph has 34 nodes and 78 edges representing ties among club members. This network is one of the most widely used testbeds for community detection algorithms. Here below, we compare the core identified by Algorithm 1 in this network with those identified by other algorithms in the recent literature [
15,
16]. For this network, Problem (
2) has two optimal solutions with six nodes and one optimal solution with seven nodes. We consider the latter as core in the following discussion. The left panel in
Figure 3 shows the pattern of the adjacency matrix after nodes are rearranged in non-increasing order by degree. Yellow dots mark the position of the non-zero entries in the core block. The central panel represents a graphical layout of the network. Each node is marked by its original node number to allow comparisons with related works, as shown in
Table 1. Core nodes are marked in yellow. The rightmost panel represents the subgraph induced by the core nodes. Finally,
Table 1 collects the results of Algorithm 1 together with those by three core–periphery partitioning algorithms presented in [
15] (called BE-KL, 2-step, and divisive) and the rich-core algorithm in [
16]. For each algorithm, we list the core nodes identified by it by their original node numbers. It is worth noting that, according to the analysis presented in [
15], the Zachary network actually contains two distinct communities comprising a large part of the network, each community having an internal core–periphery structure.
4.2. Equitable Graphs
Let
be a graph with adjacency matrix
A. A partition
of
V is equitable if there exists an
matrix
, called the partition matrix, such that for all
,
Simply put, every node in the
h-th block is connected with exactly
nodes in the
k-th block. In that case, the graph
G is called equitable with respect to the given partition. The subsets
are the blocks of the graph. For the Equation (
9) to have solution, the entries of the partition matrix must fulfill the identities
Equitable graphs have been used in many problems in combinatorics, algebraic graph theory, and community detection problems [
20,
21]. They represent the deterministic counterpart of the stochastic block models, which are random graphs where the probability that two nodes are adjacent depends on their block indices [
1,
2,
3].
The idealized core–periphery structures introduced in [
7] and shown in
Figure 1c,d are defined by equitable graphs with two blocks.
Let G be an equitable graph with respect to the partition and let P be the partition matrix. Note that the degree of a node depends only on its block index. Indeed, let denote the block index of node . Then, . Thus if then . The goal of this paragraph is to analyze to what extent the core–periphery algorithm proposed here recognizes the nodes with largest degree as core nodes in an equitable graph. For let be the degree of each node in . We assume for .
Hence, the candidate core nodes are those in the first block. The following result describes the relationship between and the core set identified by the proposed algorithm.
Corollary 2. In the hypotheses stated above, let .
- 1.
If then every optimal solution of Problem (2) is a subset of , - 2.
if then every optimal solution of Problem (2) contains as subset.
Proof. Assume, without loss in generality, that the nodes are ordered as in Formula (
3). Let
be the index defined in Equation (
5) and let
.
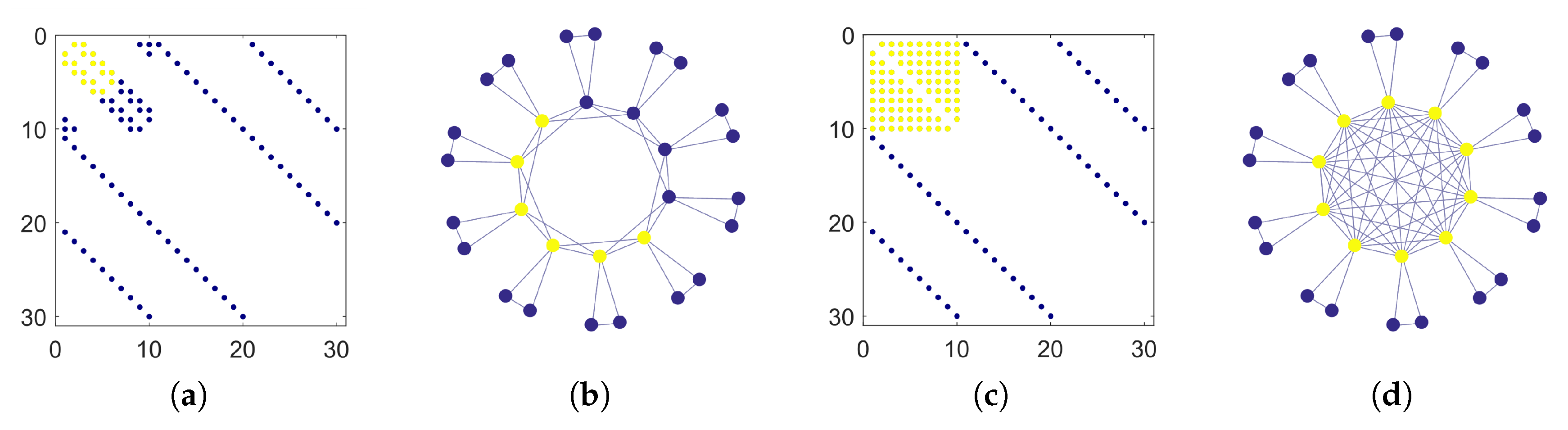
Figure 4 shows the adjacency matrices and the graphical layouts of two equitable graphs with
,
and
. Letting
the associated partition matrices are
(leftmost panels) and
(rightmost panels), respectively. As in the preceding paragraph, the core nodes identified by Algorithm 1 are marked in yellow. When
the core is a proper subset of the first block, due to its scarce internal density. In fact, in this case we have
and
. In the other case
,
, the subgraph induced by the first block is complete and the core coincides exactly with the first block.
Remark 3. The two idealized core–periphery structures introduced by Borgatti and Everett (in the loopless case), which are depicted in Figure 1c,d, correspond to equitable graphs with a 2-block partition and the two partition matricesrespectively, where for . The following are immediate consequences of Corollary 2. In the first case we have while . Hence and the set identified by our algorithm is except one node. However, since , from Corollary 1 we obtain that also is a solution of Problem (2). In the second case we have while . Also in this case and is a core. However, we also have . Hence by Corollary 1 any set having the form with is also a solution of Problem (2).
4.3. Power-Law Networks
A graph or network is considered to have a power-law degree distribution with exponent
if the number
of nodes having degree
k is approximately given by
, where
is a coefficient that depends on the size of the graph ([
4] Chap. 4). Many interesting real-world networks have a power-law degree distribution with an exponent
. In fact, power-law degree distributions arise naturally in networks evolving in time by the addition of new nodes and edges according to the so-called preferential attachment rules, see e.g., ([
4] Chap. 6) or ([
17] Chap. 3). For that reason, a power-law network is usually intended as belonging to a sequence of networks with increasing sizes having a power-law degree distribution whose exponent
is independent on the network size.
Power-law networks are often deemed as having a core–periphery structure [
9,
17]. In this paragraph we examine the outcome of our bipartitioning algorithm when applied to power-law networks. The next result describes the asymptotic behavior of the core identified by Algorithm 1 when the network size
n diverges. In what follows, the notation
means that
as
.
Corollary 3. Let G be a power-law network with exponent and no isolated nodes. Assuming that the average degree in G does not depend on n, the number of nodes in the core set is .
Proof. Let
be the degree profile of
G, where
depends on
n. For
let
be the number of nodes with degree greater than or equal to
k. With these notations, the integer
in Equation (
5) can be characterized by the identity
For large
n, the number
can be approximated by
Let
and
be the smallest and largest degree in
G, respectively. The average degree
in
G is
where
. By hypotheses,
C is bounded above and below by positive constants, hence we have
, since
does not depend on
n. By Equation (
11), we can estimate
as the solution of the equation
, that is,
and the claim follows. □
To validate experimentally the claim of the previous corollary, we performed a series of simulations with power-law networks generated by means of the algorithm described in [
22]. That algorithm generates random graphs in the Chung–Lu model [
17], which is a flexible, very popular random graph model with nice theoretical properties. We generated random power-law networks with size
for
and average degree equal to 3, in expectation. In
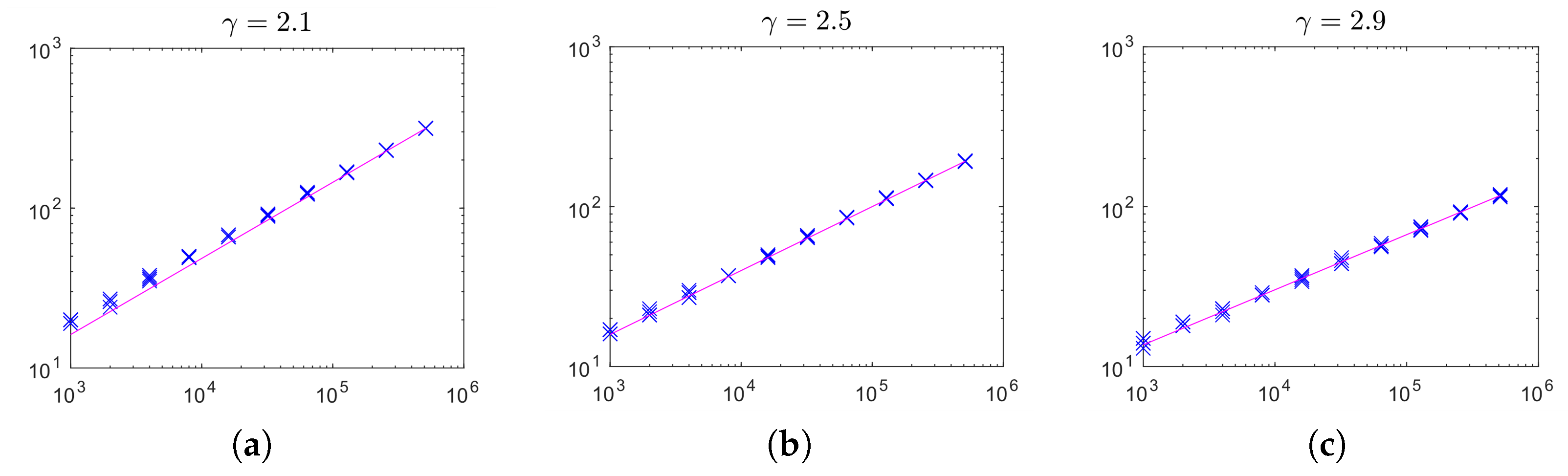
Figure 5, we display the core size versus the network size for networks with exponent
(left),
(center) and
(right). Each cross represents the result for one network. The solid lines plot functions
where
is chosen to fit the results obtained with the largest size
n. As is clearly visible, the core sizes approach very closely the theoretical behavior estimated in Corollary 3 over a very large range of
n.
5. Conclusions
In a variety of complex real-world systems that are modeled as networks, one often observes the presence of a group of densely interconnected nodes, while the remaining nodes form a sparse peripheral area with few internal links. This particular pattern is called core–periphery, and is one of the key mesoscopic structures that are relevant to the analysis of complex networks.
In this work we proposed a fast and theoretically well-founded algorithm for the localization of core–periphery structures in both oriented and non-oriented complex networks, assuming the presence of that structure. Basically, the set of core nodes is identified by a certain combinatorial optimization problem that has been introduced earlier by Brusco in [
13]. We provided a complete description of the set of optimal solutions to that optimization problem. Our algorithm has a very low computational cost, both in terms of memory space and operation count, which makes it suitable for the analysis of large networks. The applicability of the algorithm has been demonstrated experimentally on both real-world and synthetic networks.











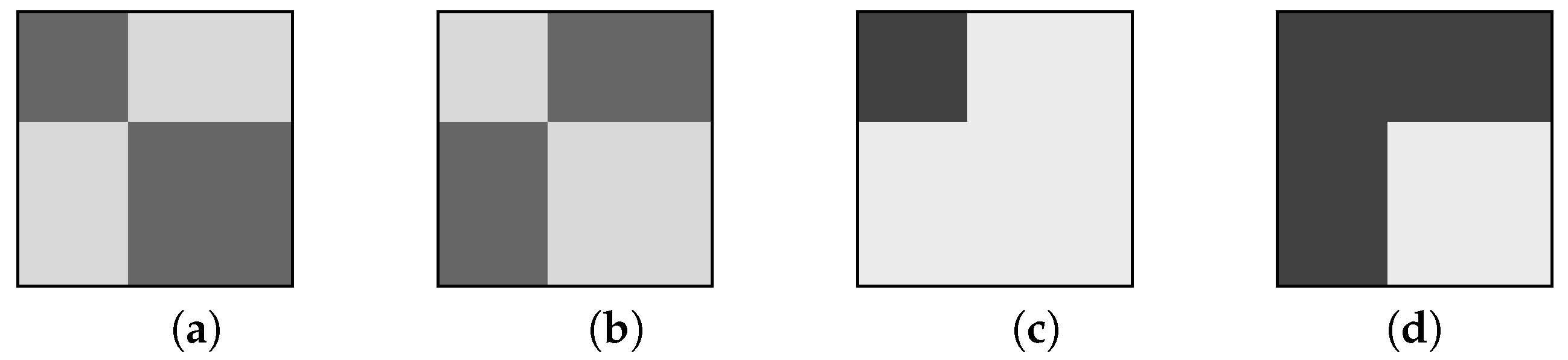{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}