2.1. Semantic Analysis of Model Set
In order to detect the connotation of a high-level semantic model better and more accurately, the semantic analysis of a model set is divided into the consistent segmentation of models within the same style, the component correspondence of models between different styles, and the clustering of shape and content.
(1) Consistent segmentation of models within the same style class
Assuming that the input model set is clustered according to the shape style, the next step is to segment the models in each style class uniformly.
The method in this paper is based on the abstract representation of a model-directed bounding box graph. The geometric properties of the directed bounding box are easier to calculate. In addition, since the number of bounding boxes is far less than the number of triangular patches on the model mesh, hierarchical clustering based on the bounding box graph is more efficient [
12,
13]. Although the bounding box is only an approximate representation of each part of the model, experiments show that the method can achieve correct and consistent segmentation results for the model within the style class.
In this paper, we need to define the measure of concavity and correspondence degree at the directed bounding box level. Suppose that and are two adjacent bounding boxes on the same model, which can be either the initial bounding box or the newly generated bounding box after merging. The concave measure of the combined shape of and is defined as: , where is the bounding box of the combined shape of and .
If and belong to two different models, the optimal alignment of the two models is first calculated by Global iterative nearest point method (GIP). To sum up, the corresponding degree of and can be defined as: . Among them, represents the area of the directed bounding box and represents the set of compatible patch pairs of and under the optimal alignment condition.
(2) Component correspondence of models between different styles
This paper introduces how to calculate the consistent segmentation of all models based on the consistent segmentation within each style class. For this reason, we only need to establish component correspondence for each style cluster. The matching method based on deformation is used to calculate the component correspondence. This method calculates the optimal correspondence between the source 3D model and the target 3D model by finding the minimum cost deformation. The corresponding mass of the model is measured by deformation energy or deformation cost.
Consider two 3D models from different styles. Since the models within each style class have been uniformly segmented, based on their respective consistent segmentation results, a directed bounding box graph can be established for the two models respectively [
14,
15]. First, the directed bounding box is divided into three types: linear bounding box (1D type), planar bounding box (2D type), and spherical bounding box (3D type). Specifically, the three indexes
,
, and
with moderate anisotropy in Equation (1) are used to classify the bounding box; that is, the type with the largest value among the three indexes is the type of bounding box. However, the anisotropic characteristics of some bounding boxes are not obvious, which shows that none of them is significantly larger than the other two. At this time, in order to avoid matching errors caused by hard classification, two or even three types of bounding boxes are given to this class.
Since the result of consistent segmentation generally corresponds to the decomposition of functional components of the model, the number of nodes of a directed bounding box graph based on the result of consistent segmentation is generally small. Due to the small search space, it is feasible to use a shape matching method similar to deformation driven. In order to further reduce the search cost, the largest node in the bounding box graph of the source model is selected as the root node. For the target model, all bounding box nodes with the same root type as the source model are selected as the root nodes to generate multiple candidate search trees. The specific priority tree search process is matching sparse feature points on the dimensional model. This method constructs a search tree of feature points for the input model and uses pruning priority to search global optimal matching. Each node of the search tree corresponds to the matching of a pair of feature points. A path starting from the root node whose length is equal to the number of feature points is a complete matching of all feature points of the model.
For a 3D model based on a directed bounding box graph, its deformation is defined as relative rigid motion (including translation and rotation) between bounding boxes and scaling along the axis of the bounding box. For any two adjacent directed bounding boxes, according to their respective types, it is necessary to define the allowable relative rigidity transformation between them and the range parameters of each allowable transformation. For the translation range, only two parts in contact with each other should not be separated. The directed bounding box corresponds to the functional parts of the model, and the relative pose between these functional parts is very common in different instance models of artificial objects. For example, the angle between the seat and the leg of the chair changes within a certain range, and the position of the leg relative to the seat changes within a certain range, which are reasonable relative changes between the functional components. These relative postures reflect the different design of the chair. Therefore, if the relative transformation between these features exceeds the allowable range, the semantics of the model will be destroyed. Therefore, in the process of using a priority tree to search the optimal correspondence, we can exclude (prune) invalid correspondence by allowing relative rigidity transformation.
There is often more than one effective correspondence between two bounding box graphs. The following deformation energy is used to measure and compare the corresponding advantages and disadvantages:
Among them, represents the percentage of the volume of the bounding box that is not matched to the total volume, and represents the root mean square of the volume difference of the bounding box that is matched. and represent the weight.
(3) Shape content clustering
So far, we have obtained the consistent segmentation of the input model set. This paper introduces how to use the above analysis results to further analyze the shape and content of the model. The shape content here refers to the geometry of the model, including the composition and shape of the components.
Content-based 3D model classification and retrieval has been studied a great deal. However, the existing algorithms can only deal with different models, such as the classification of cars and tables [
16]. The models in the input set belong to the same kind of objects, and we hope to further distinguish different instances of the same kind of objects. The traditional global shape descriptors cannot meet the requirements of discrimination. Therefore, with the help of consistent segmentation of all input models, a shape descriptor at the component level is proposed to achieve fine-grained model classification.
Firstly, all models after uniform segmentation are classified according to the number of parts after segmentation. Then, for the model with the same number of components in each class, the content distance between the models is defined as the maximum of the Euclidean distance of the light field descriptor (LFD) of all corresponding components.
where
represents the set of corresponding component pairs of model
and
. It should be noted that since
and
may have different component proportions, when calculating the light field descriptors, it is necessary to first put the corresponding components in the same size, so as to better reflect the differences in their geometry.
2.2. Self-Symmetry Detection of High-Level Semantic Model Based on Skeleton
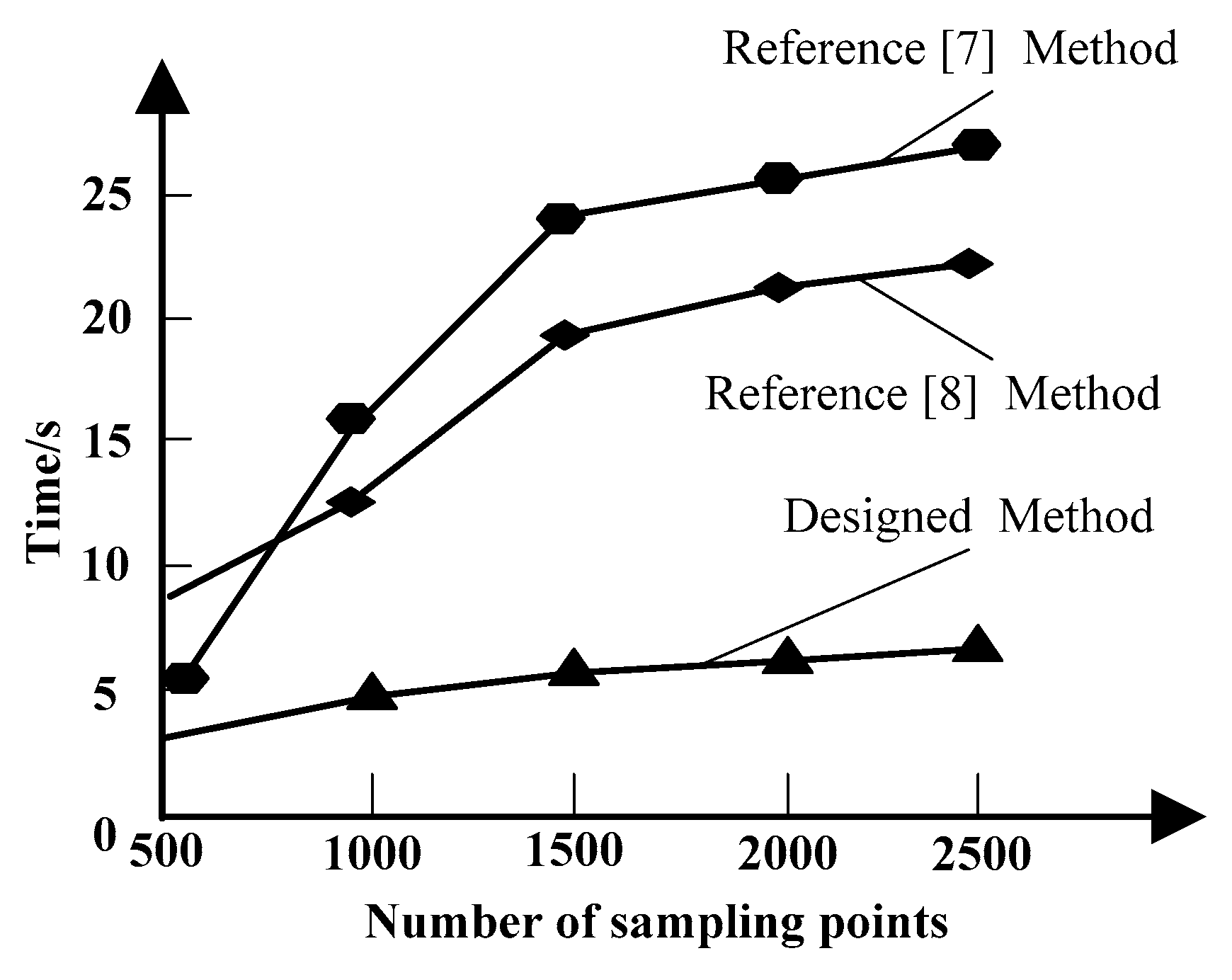
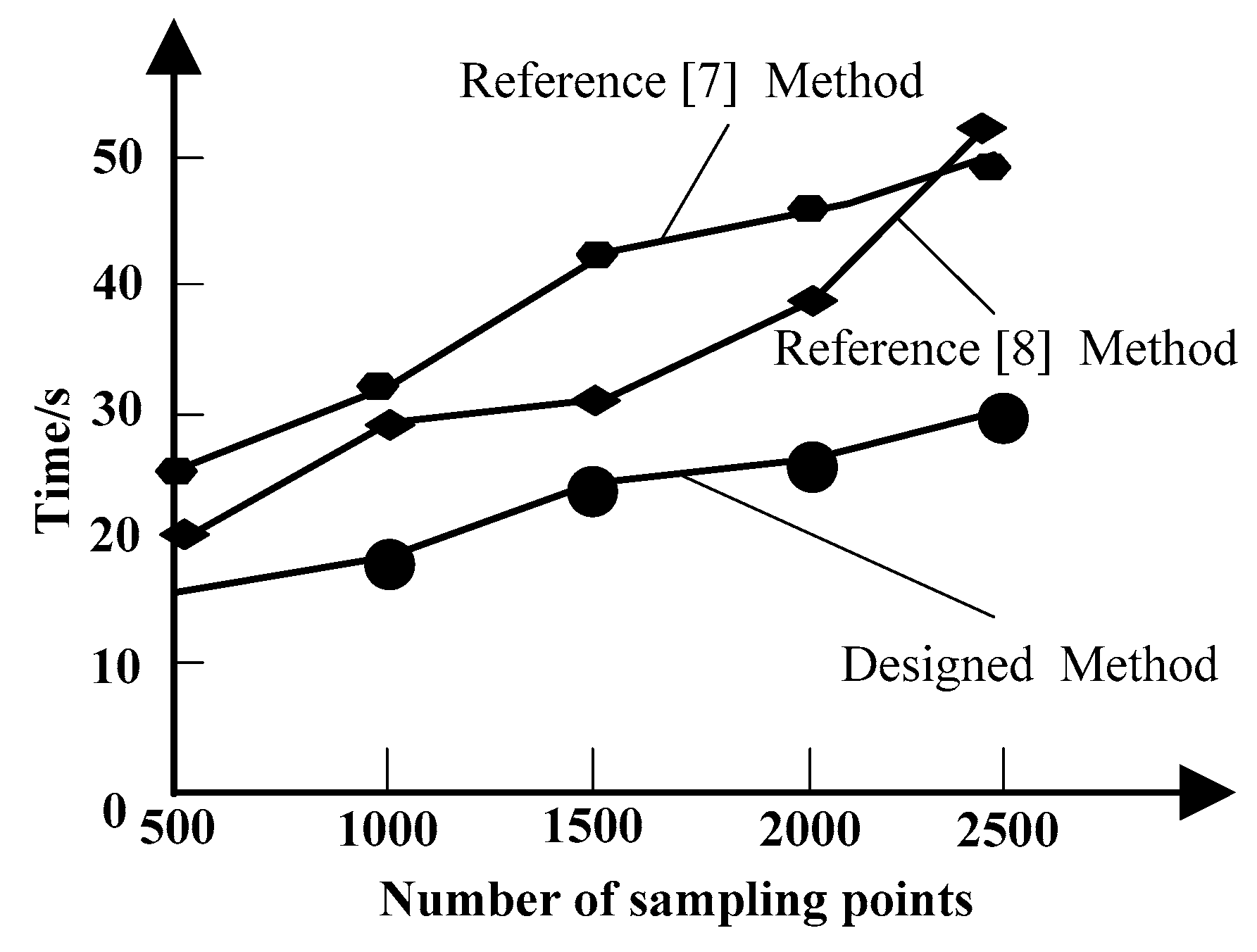
Based on the above clustering results, the intrinsic self-symmetry detection of a high-level semantic model based on skeleton is divided into two parts: obtaining candidate symmetry point pairs and skeleton-based symmetry detection. The specific process is as follows: select samples; preprocess the sample data; remove interference noise through local similarity filtering; realize the construction of the original 3D point cloud model; obtain the symmetric decomposition distance; and complete the intrinsic self-symmetric detection.
(1) Obtain candidate symmetry point pairs
Assuming that the skeleton of the point cloud model and the corresponding relationship between the skeleton node and the model surface vertex have been obtained, the intrinsic symmetry of the point cloud model can be detected according to the skeleton. The following algorithm gives a detailed description of the skeleton-based intrinsic symmetry detection algorithm, which is divided into five steps:
Step 1: Preprocess, calculate the shape radial function descriptor at the skeleton node, and calculate the distance along the skeleton between skeleton nodes.
Step 2: Get the votes of symmetrical point pairs. The votes contain some candidate point pairs. The two skeleton nodes corresponding to these point pairs may reflect the symmetry of the model. These votes are all point pairs between skeletons and are filtered by a series of point pairs.
Step 3: Select the symmetry point pairs. According to the symmetry point pairs, these symmetry point pairs represent the symmetry of the model between the two corresponding skeleton nodes.
Step 4: Transfer the symmetry on the skeleton node to the model vertex and establish the symmetry correspondence matrix.
Step 5: Perform spectrum analysis, using the spectrum method to analyze the symmetric correspondence matrix, obtain the symmetrical region of the model surface vertices, and complete the intrinsic symmetry detection of the point cloud model.
The algorithm is described in detail as follows:
For a given point cloud model, represents its sampling, the number of sampling vertices is , the corresponding curve skeleton is , and the skeleton nodes are . Suppose and keep the same topology.
During the operation of the algorithm, the input is defined as the skeleton of the 3D point cloud model , and the output is defined as the symmetrical region.
Step 1: Preprocess, calculate the shape radial function descriptor at the skeleton node, and calculate the distance along the skeleton between skeleton nodes.
Step 2: Get the vote according to the distance between the local feature attribute and the skeleton node.
Step 3: Select symmetry point pairs.
Step 4: Establish the symmetric correspondence matrix according to the symmetric point pair.
Step 5: Use the spectral method to analyze the symmetric correspondence matrix to obtain the symmetric region of the point cloud model.
Pretreatment: The algorithm looks for the symmetry point pair in the skeleton node, and the symmetry point pair contains two skeleton nodes, indicating that these two skeleton nodes reflect the symmetry of the model. However, because the curve skeleton is a simplified representation of the point cloud model, it may lose important geometric information, making errors in the symmetry detection, and it is difficult to obtain the symmetry point pair directly. Therefore, the election method is considered to obtain the symmetry point pair. First, obtain symmetrical point pair votes through a series of filtering operations. The votes contain several candidate symmetrical point pairs. These candidate point pairs indicate that these skeleton nodes may reflect the symmetry of the point cloud model. A vote cannot contain all the intrinsic symmetry of the point cloud model. The candidate point pairs in the votes may not correctly reflect the symmetry of the point cloud model. Therefore, the first step is to calculate a large number of votes, according to these votes for the election, the point pair with more votes is considered to be the correct symmetry point pair, reflecting the reasonable symmetry on the point cloud model.
Before getting symmetrical votes through filtering, we need to preprocess the skeleton and calculate the relevant attributes to speed up the online symmetry detection. For the 3D point cloud model, the current curve skeleton extraction algorithm can only get a skeleton with lower resolution (skeleton contains fewer nodes) that is not smooth enough. In order to improve the accuracy of symmetry detection, it is necessary to further refine the skeleton, insert new nodes in the adjacent skeleton nodes, and update the connection between skeleton nodes, as well as skeleton nodes and model table until the distance between all adjacent vertices meets a certain limit condition, which is usually limited to
, where
is the maximum length along the skeleton path between two nodes on the skeleton. In order to reduce the calculation time of the algorithm, the uniform sampling method is used to sample the input point cloud model and carry out symmetry detection according to the sampling points, and finally transfer the symmetry to the input original point cloud model. In the preprocessing stage, some necessary operations are also performed on some attributes, such as the distance
along the skeleton between the nodes on the skeleton:
Among them,
and
are two skeleton nodes,
is the Euclidean distance between nodes,
is the adjacent node pair on the path from node
to
, and the symmetric invariant local shape descriptor is calculated by the method similar to the shape radial function:
Among them, is the set of model surface vertices corresponding to node , is the Euclidean distance between model surface vertices and skeleton nodes, and the pre calculated attributes will be applied to later symmetry detection.
Local similarity filtering: For two nodes, the
distance between their profile radial function descriptors is used to judge the difference of local geometric attributes between nodes. The profile radial function distance between two nodes
and
is
where
is the profile radial function distance,
is the profile radial function descriptor at node
, and according to the profile radial function distance, the geometric constraint conditions are constructed as follows:
Among them, is the threshold value of the profile radial function distance and is the maximum value of profile radial function distance between all nodes. Since the threshold value of the profile radial function distance is related to the size of the model, the relative threshold value is adopted. When the difference between the two nodes’ profile radial function distance is less than a certain threshold value, it is considered that the geometric properties between the two nodes are close and satisfy the constraint condition of the local similarity degree. The point pair formed by the two nodes may be symmetrical.
Distance filtering: Through observation, it can be found that the symmetrical part of the point cloud model lies in the similar position on the model. For the vertices on the model, a global descriptor can be designed to measure this global attribute of the model [
17,
18]. Set a number of feature points on the model and calculate the distance from other vertices to feature points. Using these distances as descriptors, we can measure the global attributes of the model. We should select the points containing important features as feature points, usually the vertices located at the boundary of the model.
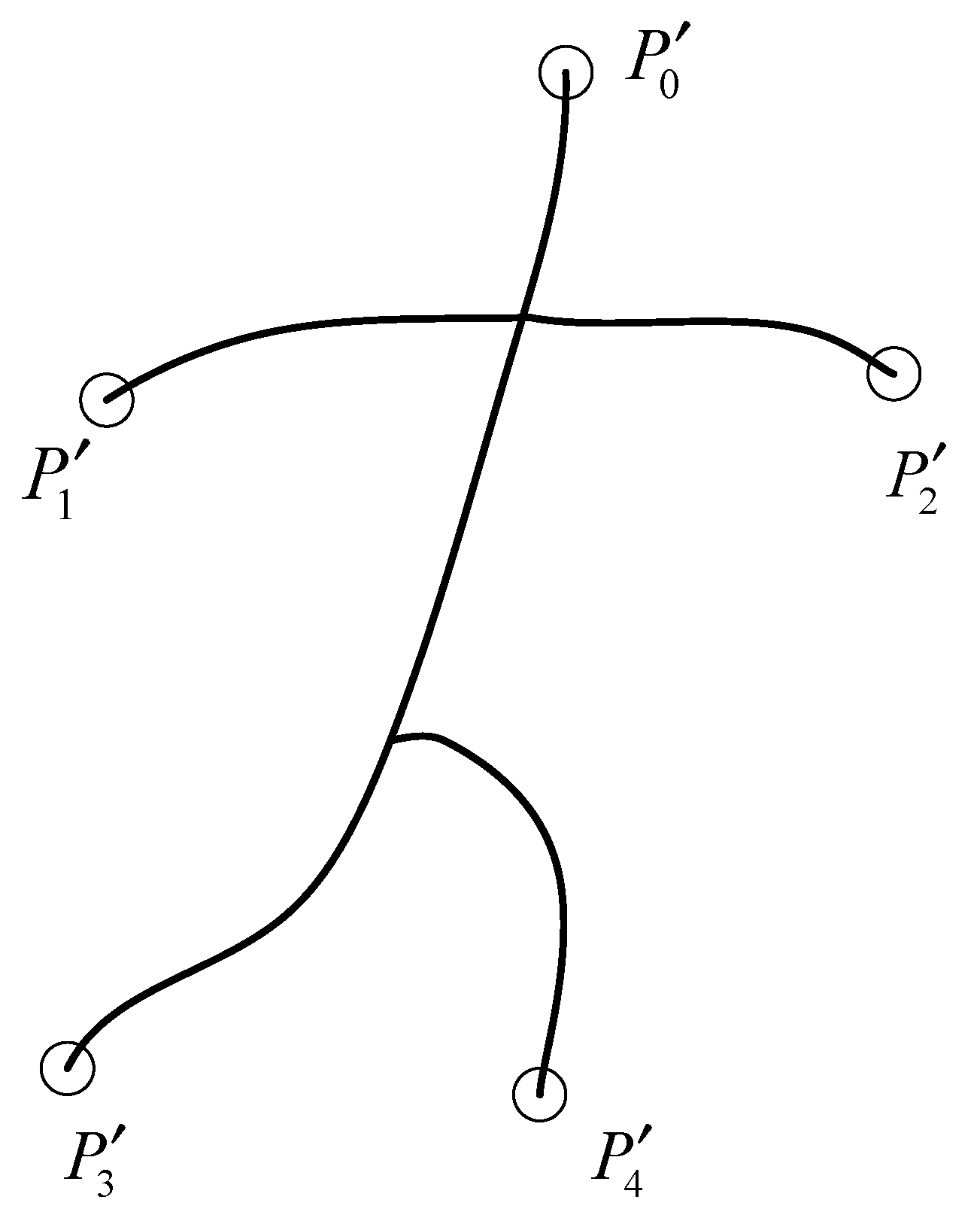
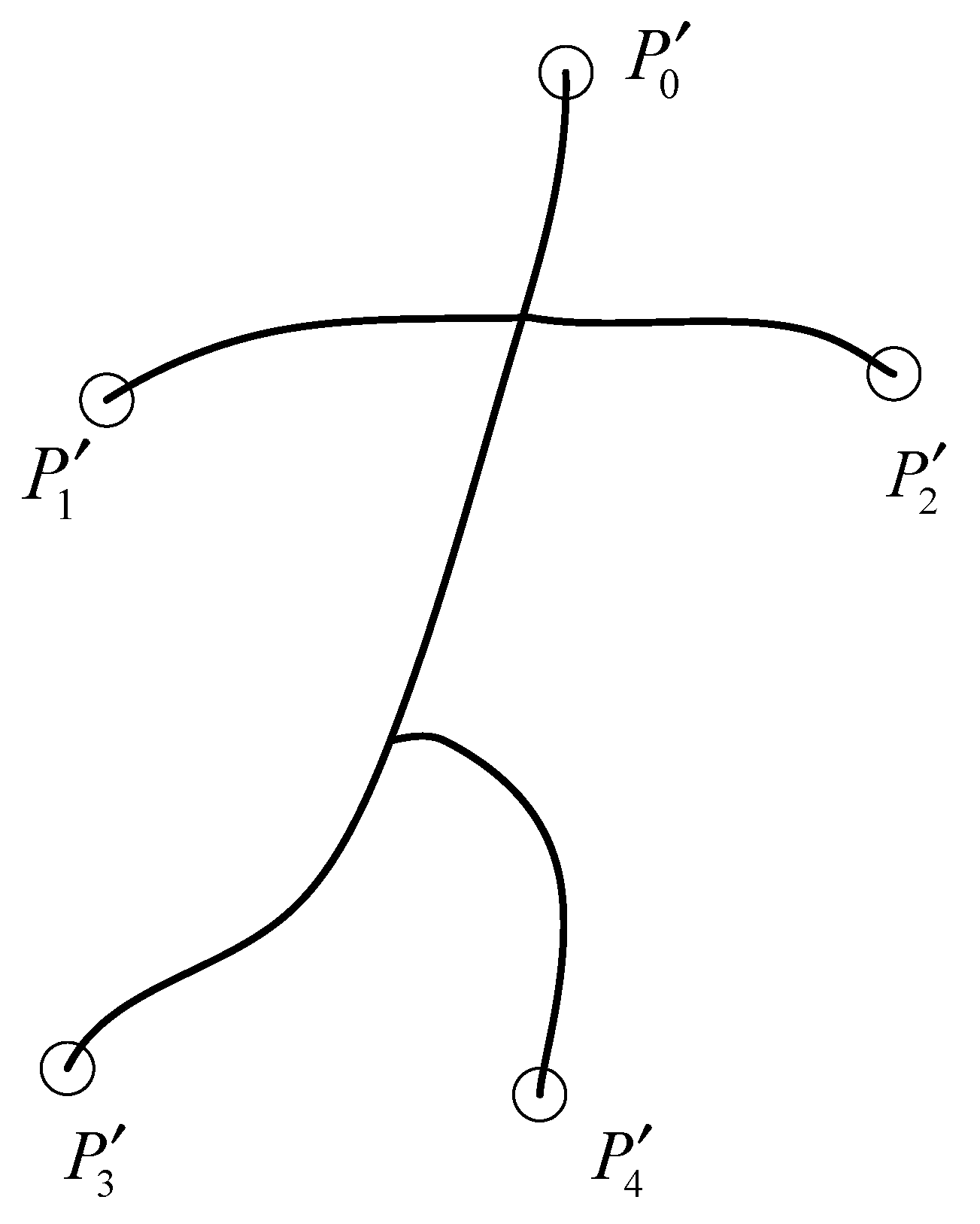
Since the skeleton of the 3D geometric model retains the main global attributes of the original model, the skeleton is equidistant, and there is a corresponding relationship between the skeleton nodes and the model surface vertices; the above findings can be extended to the skeleton of the model. With the help of the skeleton to design the global descriptor, the skeleton end points correspond to the boundary positions of the model, which can be used as feature points, and the skeleton end points are easy to obtain by selecting a node with a degree of 1. See
Figure 1 for the skeleton and its endpoint, where
,
,
,
, and
are the skeleton endpoints.
Analyzing
Figure 1 shows that for a given skeletal model, the skeletal endpoint is the longest point pair, so the global descriptor can be constructed based on its distance to the feature point. Given a skeleton node, we can construct a
dimension global descriptor, where
is the number of skeleton endpoints; we calculate the distance along the skeleton from them to the skeleton endpoints, and arrange these distances in ascending order to get the
dimension descriptor
. Then we can use
distance to measure the difference between the vector descriptors:
where
is the global descriptor gap,
is the global descriptor at node
, and the global attribute constraints are constructed as follows:
where
is the global descriptor distance threshold and
is the maximum distance along the skeleton between all nodes. When the global descriptor distance of two nodes is less than a certain threshold, it is considered that the two nodes are close in the global position of the model, meeting the global attribute constraints, then the point pair formed by the two nodes may be a symmetrical point pair, which can be further judged.
Symmetry supports filtering: Due to the relatively few nodes on the skeleton of the 3D point cloud model, all skeleton point pairs can be filtered as above. Through the skeleton point pairs of three filters, the set of point pairs
is formed. These point pairs may be symmetrical point pairs. For these point pairs, the following methods are used to obtain the support point pairs of each point pair. For two skeleton nodes
, according to the proposed symmetry criterion, the condition that two skeleton nodes reflect a symmetry together is set as follows:
Among them,
is the distance between the skeleton nodes
and
along the skeleton,
is the threshold value of the distance along the skeleton, and
is the maximum value of the distance along the skeleton between all vertices. The two point pairs that meet the conditions may reflect an intrinsic symmetry on the model together; the relationship between the two point pairs is called mutual support, that is, mutual support point pairs, and the schematic diagram of support point pairs is shown in
Figure 2.
For a skeleton point pair
.The support point pair set
is calculated as:
When the number of point pairs in this set is more than a certain threshold, it is considered that all point pairs in this set together reflect an intrinsic symmetry of the model. The support point pair of point pair
covers all the corresponding vertices on the surface of the model, which is called the support domain of point pair
and the model may have symmetry in the support domain of
. Among them:
where
is the threshold of the number of support point-to-set and
is the number of nodes on the skeleton.
The skeleton point pair and its support point pair formed a vote through symmetric support filtering. All the point pairs in the vote together reflect symmetry in the model. The support point pair set in the model is usually not exactly symmetric. For each vote, the degree of asymmetry can be measured by the average of the degree of asymmetry between the two point pairs. Among them:
where
is the number of candidate skeleton point pairs in the ballot.
(2) Symmetry detection based on skeleton
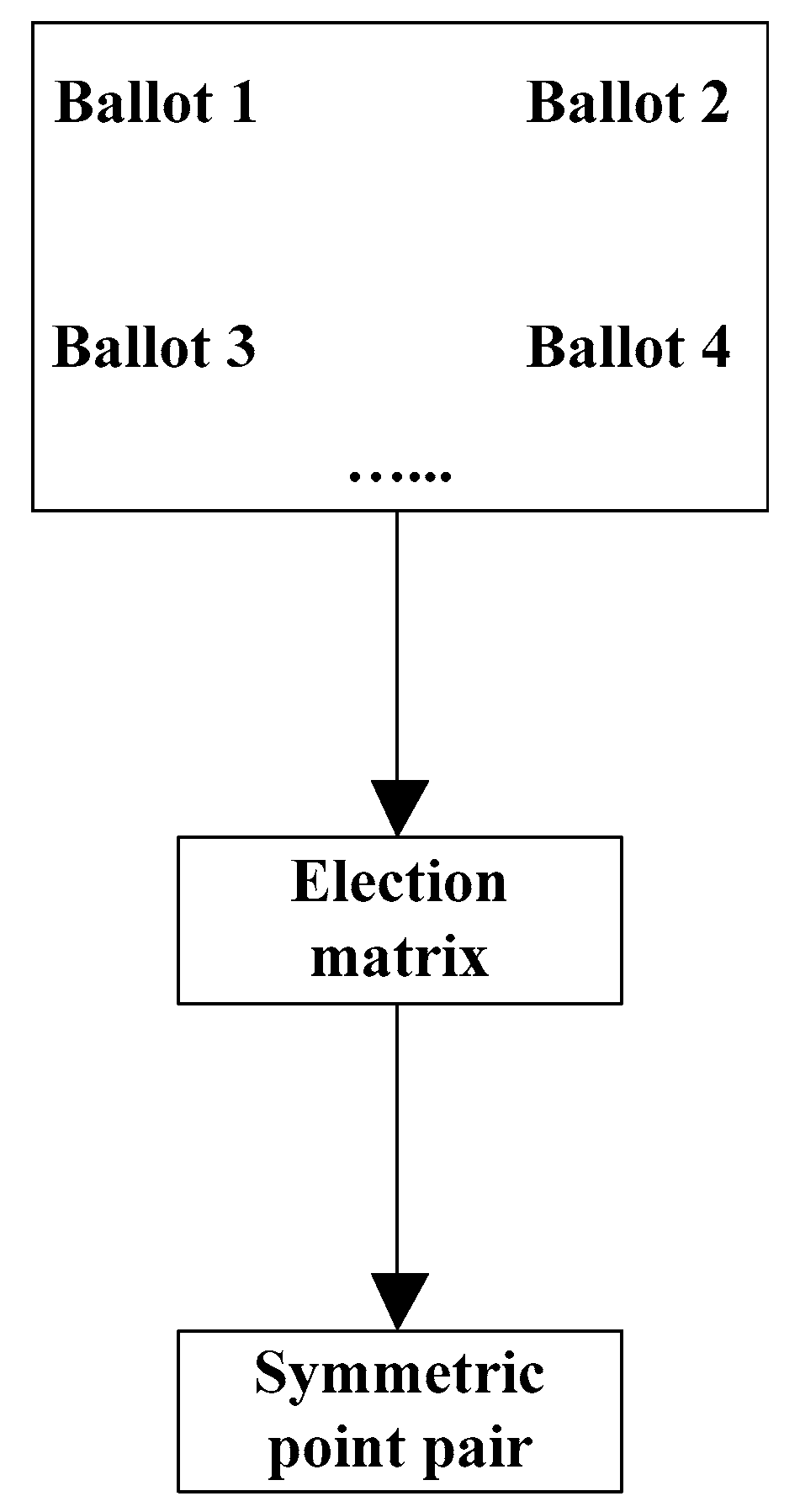
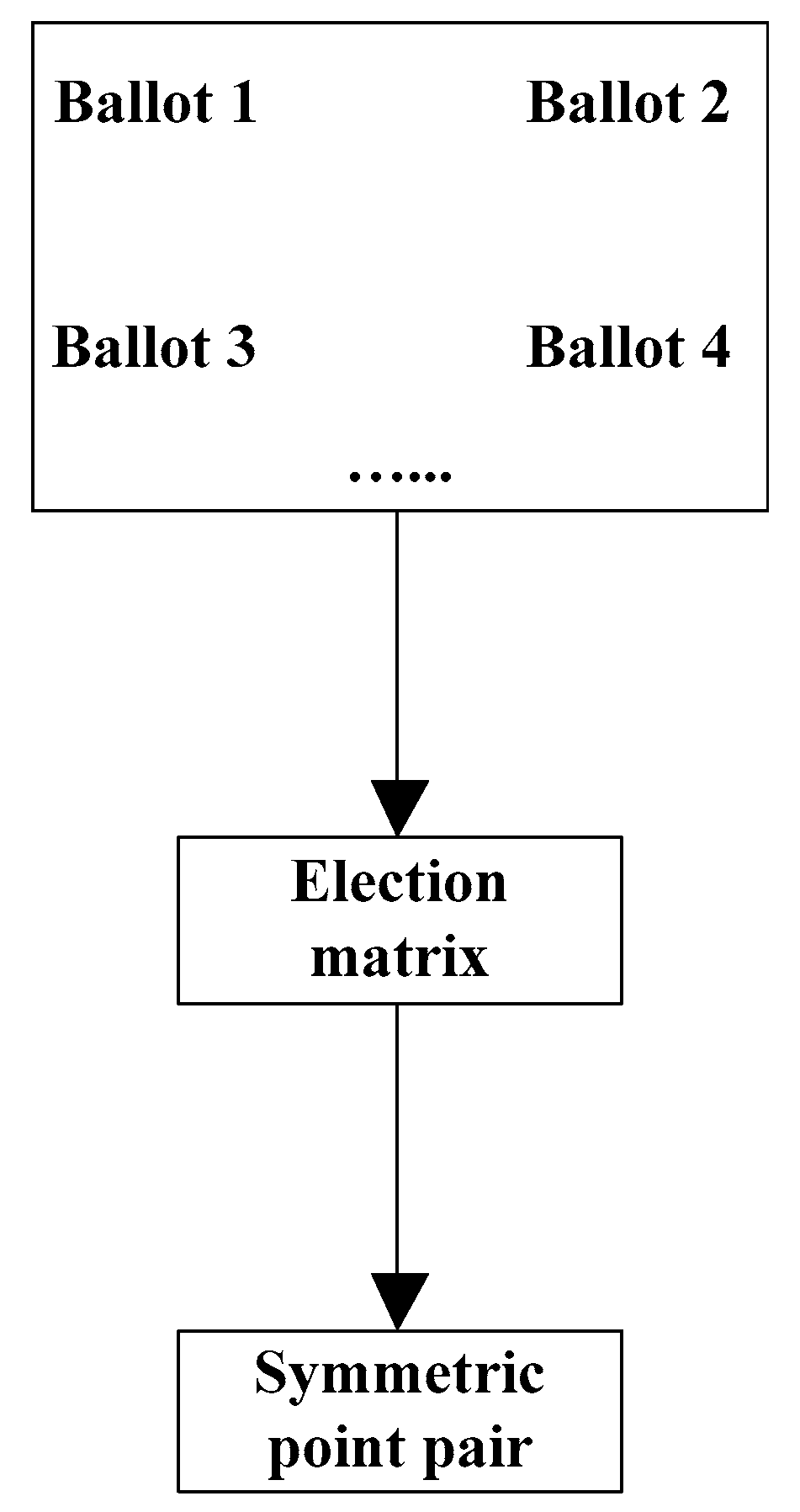
Election symmetry point pair: The vote contains candidate pairs that may reflect the symmetry of the point cloud model. According to these votes, a simple election method is adopted to obtain a symmetrical point pair reflecting symmetry. As shown in
Figure 3, a series of symmetrical point pair votes obtained, and
Figure 3 shows a symmetrical point pair election matrix in which each item in the matrix corresponds to a skeleton point pair. If the point pair appears once in the votes, then add 1 to the corresponding item in the matrix, that is, each item in the matrix. When the number of occurrences of the corresponding point pair is greater than a certain threshold, the skeleton point pair corresponding to this term is considered to reflect the symmetry of the model. This threshold is usually set as
, where
is the maximum value of all items in the matrix. In
Figure 3 the skeleton symmetry point pair is obtained through election, and
is the set of symmetry point pairs. These point pairs reflect the original three-dimensional point cloud symmetry of the model.
Symmetrical transfer: Since the goal is to obtain the symmetrical region on the point cloud model, it is necessary to transfer the symmetry reflected by the skeleton node to the point cloud model surface vertex. The symmetric correspondence matrix of module vertices is established according to the symmetric point pair. The symmetric correspondence matrix is an affine symmetric matrix. Each term of the matrix represents the degree of asymmetry of the point cloud model at the corresponding two vertices. The degree of asymmetry between vertices is calculated according to the degree of asymmetry between skeleton nodes [
19,
20]. For a symmetrical point pair, first find all the votes containing the point pair, and the least asymmetry of all the votes containing the point pair is the asymmetry of the point pair, as shown in the formula:
There is a corresponding relationship between skeleton nodes and model vertices. The asymmetry degree of skeleton symmetry point pair can be transferred to the vertices of the point cloud model by linear interpolation. According to the distance from the vertex to the skeleton node, the set of vertices affected by the skeleton node
and
are
and
, respectively. For the point pair
composed of two vertices
and
of the point cloud model, the skeleton nodes reflecting its symmetry include:
Then the degree of asymmetry of the two vertices can be obtained by simple interpolation:
The weight of linear interpolation is:
where
is the distance from the point pair to the symmetrical point pair that affects it, and
is the maximum distance from the point pair to the symmetrical point pair that affects it. Then:
According to the degree of asymmetry between pairs of points, the degree matrix of asymmetry of vertices is established, the degree matrix of asymmetry is processed, and the symmetric correspondence matrix is constructed. According to the symmetric correspondence matrix, the symmetric correspondence matrix is analyzed by the spectral method, and the distance of symmetric solution between model vertices is obtained. The model vertices are clustered by the spectral clustering method, and the symmetric region of the model is obtained.
In order to establish the symmetric correspondence matrix, the first step is to calculate the asymmetry degree matrix, which is also the
matrix, where
is the number of vertices on the model, and each term of the matrix corresponds to a point pair on the model, and its value is the asymmetry degree of two points on the model. For a three-dimensional geometric model
, its asymmetry degree matrix is
,and the term
is all transformations from
to
. The minimum distance between the vertex near
and the vertex near
after transformation is the degree of asymmetry after transformation:
Among them, represents the intrinsic transformation on the model, and represents the gap between the model and the original model after transformation.
All the symmetries in the model are reflected in the matrix of degree of asymmetry. After the asymmetric degree matrix is obtained, the symmetric correspondence matrix is constructed. First, Gaussian filtering is performed on each term of the asymmetric degree matrix to obtain the matrix
:
Among them,
is the bandwidth of Gaussian filter,
is the maximum value of all items in the matrix of asymmetry degree, and then the matrix of symmetry correspondence
is obtained by uniting. The method of uniting is as follows:
After unitization, the eigenvalues of the symmetric correspondence matrix are limited between 0 and 1. In this algorithm, the symmetric point pairs are obtained by election method, and the symmetric correspondence matrix is constructed.
According to the above calculation and analysis, the symmetrical decomposition distance between vertices is constructed according to this feature, and the smaller the symmetrical decomposition distance between vertices with a high degree of symmetry. Firstly, the symmetric correspondence matrix is embedded in the spectral space:
where
is the
eigenvalue of the matrix,
is the term corresponding to the vertex
in the
eigenvector of the matrix,
is the diffusion time, and
is the number of eigenvalues. In the spectral space, the Euclidean distance is used to measure the degree of symmetry of vertices. The symmetry decomposition distance is as follows:
After obtaining the symmetrical decomposition distance between the model vertices, the spectral clustering method can be used to cluster the vertices on the model conveniently. The vertices in each cluster have symmetry, which is equivalent to being located in the same orbit of the symmetric correspondence matrix, and the symmetrical region detection of the model is realized.

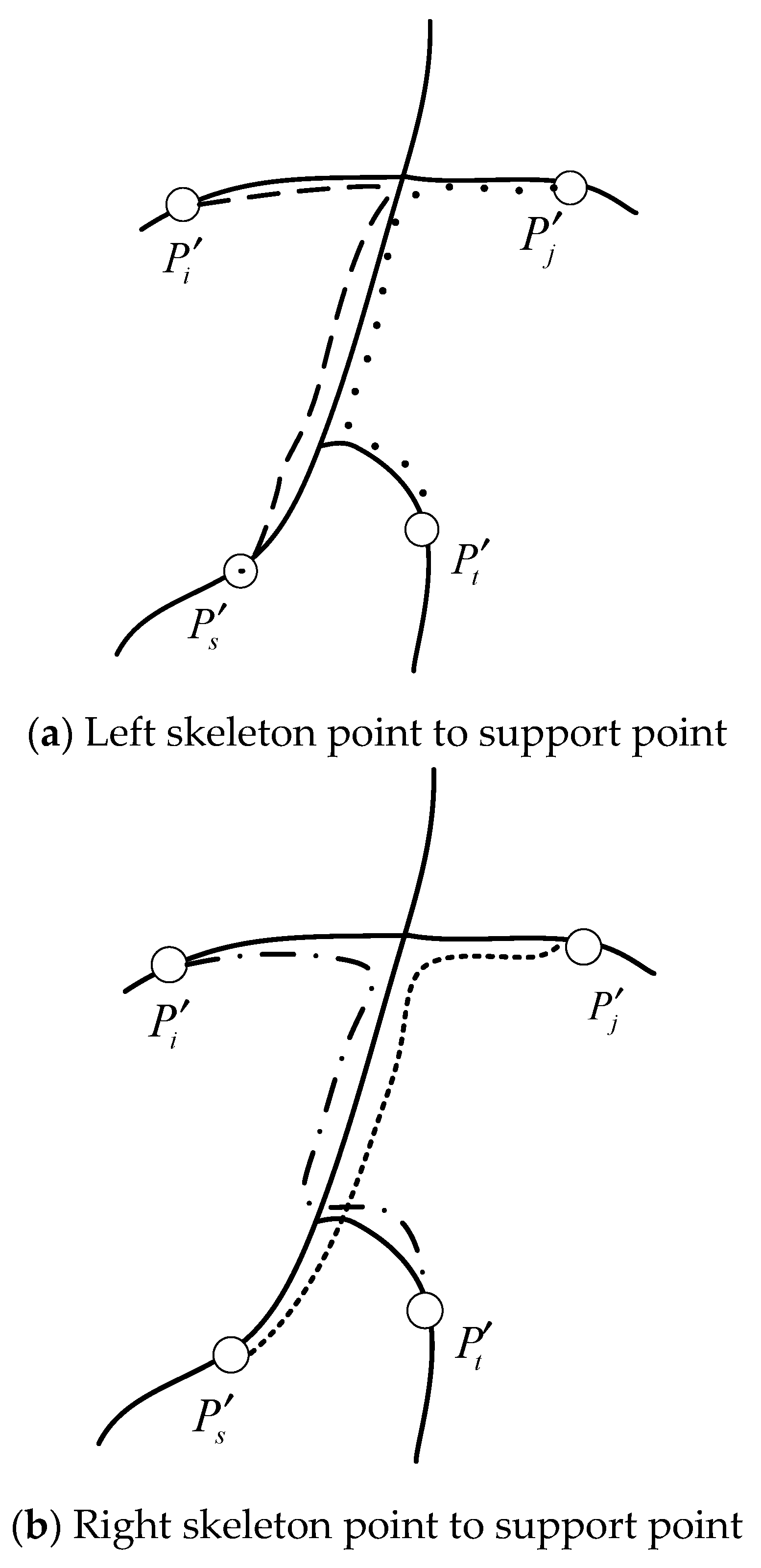

{kind=link}
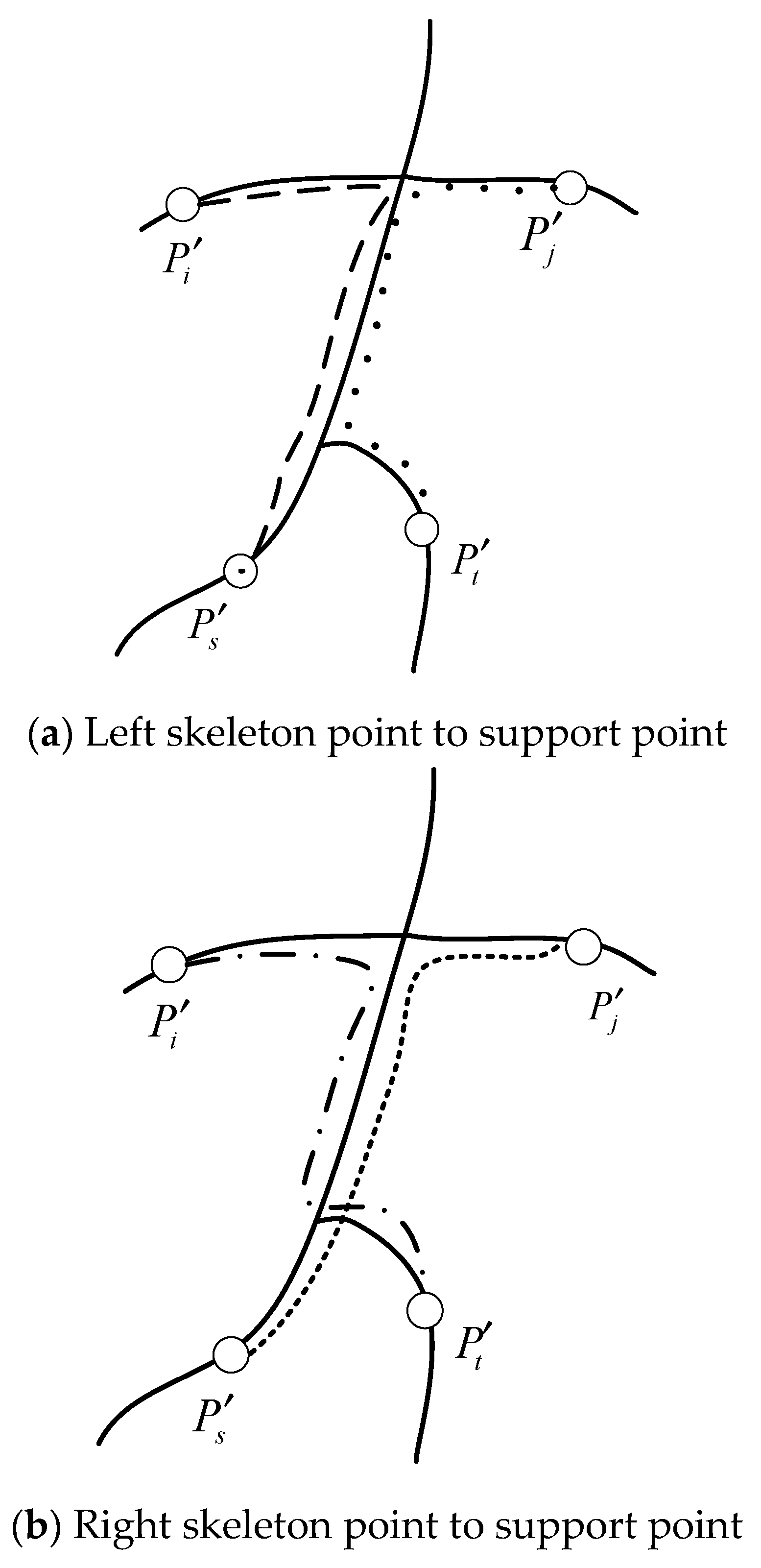{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}