Buffer Occupancy-Based Transport to Reduce Flow Completion Time of Short Flows in Data Center Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Design Rationale
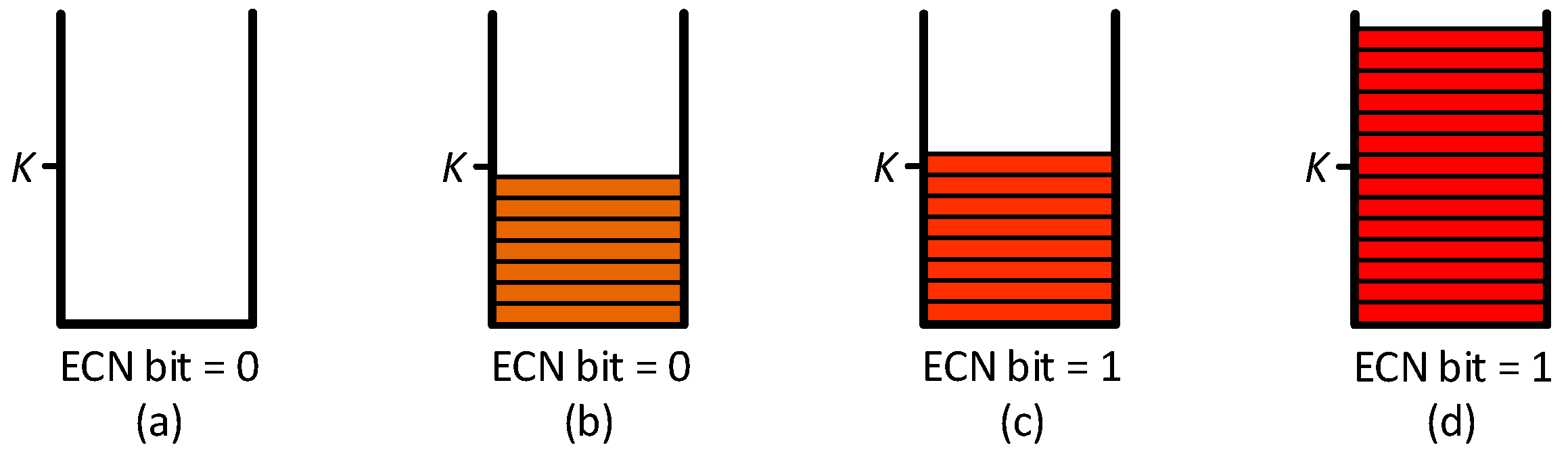
3.1. Proposed Congestion Signal
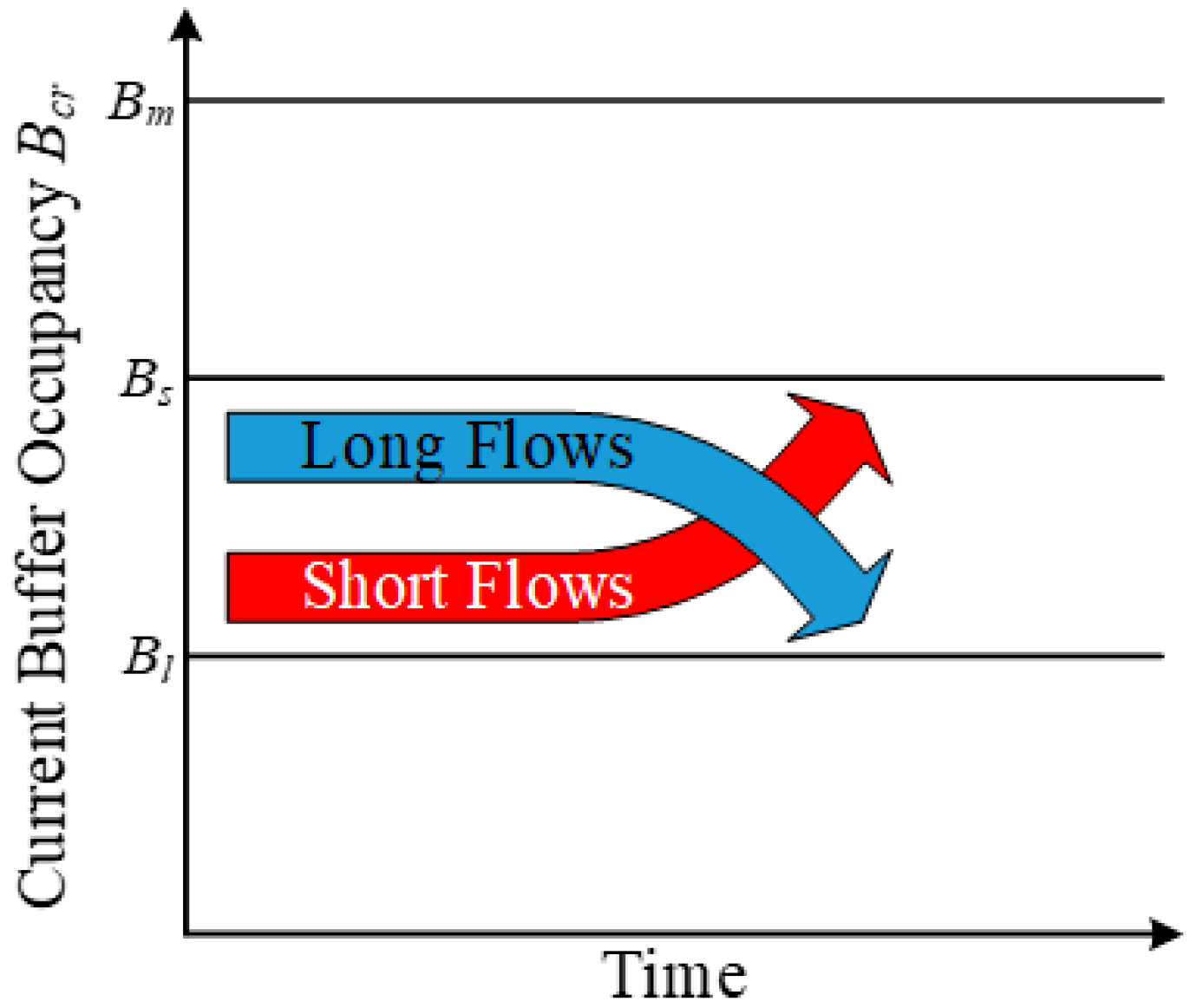
3.2. Design of Buffer Occupancy-Based Transport
- Cb = buffer capacity at output port of bottleneck link
- Bcr = current buffer occupancy at output port of bottleneck link
- Bs = allowed buffer occupancy at output port of bottleneck link, for short flows
- Bl = allowed buffer occupancy at output port of bottleneck link, for long flows
- Bm = maximum allowed buffer occupancy at output port of bottleneck link
- N = number of flows with same bottleneck link
- BDPi = bandwidth-delay product of path of flow i
- Di = current value of amount of data that the flow i is allowed to send in one RTT, i.e., congestion window of flow i represented in units of MSS
- Normal flow load: If Di ≥ 1 MSS ∀ i ∊ {1, 2, …, N} and Bcr ≤ Bs.
- Heavy flow load: If Di ≥ 1 MSS ∀ i ∊ {1, 2, …, N} and Bs < Bcr ≤ Bm.
- Extreme flow load: If Di < 1 MSS ∀ i ∊ {1, 2, …, N} and Bcr > Bs.
3.2.1. Sending Rate of Long Flows
3.2.2. Sending Rate of Short Flows
3.3. Reducing Flow Completion Time of Short Flows
3.4. Minimizing Packet Drops and Achieving High Utilization
3.5. Overall Throughput of Long Flows
4. Buffer Occupancy-Based Transport
4.1. Buffer Occupancy Feedback (BOF)
4.2. Buffer Occupancy-Based Congestion Control (BOCC)
| Procedure 1: CONGESTION_WINDOW_CALCULATION |
| Global Constants |
| Allowed buffer occupancy for short flows ‘Bs’ |
| Allowed buffer occupancy for long flows ‘Bl’ |
| Maximum allowed buffer occupancy ‘Bm’ |
| Global Variables |
| Current buffer occupancy ‘Bcr’ |
| Congestion window ‘cw’ |
| Flow type ‘ft’ ▷ flow type is ‘short’ by default and is turn to ‘long’ after X number of bytes sent |
| Procedure CONGESTION_WINDOW () |
| 1 IF cw ≥ 1 |
| 2 IF ft = ‘short’ |
| 3 IF Bcr ≤ Bs |
| 4 INCREASE_CONGESTION_WINDOW (Bs) |
| 5 ELSE |
| 6 DECREASE_CONGESTION_WINDOW (Bs, Bm) |
| 7 ELSE |
| 8 IF Bcr ≤ Bl |
| 9 INCREASE_CONGESTION_WINDOW (Bl) |
| 10 ELSE |
| 11 DECREASE_CONGESTION_WINDOW (Bl, Bs) |
| 12 ELSE |
| 13 SUB_MSS_CONGESTION_WINDOW () |
| Procedure 2: INCREASE_CONGESTION_WINDOW (B) |
| 1 IF (Bcr × 2) ≤ B |
| 2 cw ← cw + 1 |
| 3 ELSE |
| 4 cw ← cw + ((B − Bcr)/Bcr) |
| Procedure 3: DECREASE_CONGESTION_WINDOW (B1, B2) |
| 1 IF (Bcr > B1) AND (Bcr ≤ B2) |
| 2 cw ← MAX (cw − ((Bcr − B1)/Bcr), 1) |
| 3 ELSE |
| 4 IF ft = ‘long’ |
| 5 IF (Bcr > Bs) AND (Bcr ≤ Bm) |
| 6 cw ← MAX ((cw − 0.5), 1) |
| 7 ELSE |
| 8 cw ← cw − 0.5 |
| 9 ELSE |
| 10 cw ← cw − 0.5 |
| Procedure 4: SUB_MSS_CONGESTION_WINDOW () |
| 1 IF Bcr ≤ Bs |
| 2 IF (Bcr × 2) ≤ Bs |
| 3 cw ← cw × 2 |
| 4 ELSE |
| 5 cw ← MIN (cw × 2, 1) |
| 6 ELSE |
| 7 IF (Bcr > Bs) AND (Bcr ≤ Bm) |
| 8 cw ← MIN (cw × (1 + ((Bm − Bcr)/Bcr)), 1) |
| 9 ELSE |
| 10 cw ← cw × (1 − ((Bcr − Bm)/Bcr)) |
4.3. Short vs Long Flows
4.4. Overhead
4.5. Time Complexity
4.6. Same Treatment of Short and Long Flows
- Heavy and extreme flow load: In both heavy and extreme flow loads, the short and long flows are treated indifferently.
- Short and long flows start at same time: Short and long flows are differentiated on the basis of the amount of sent data. Hence, each new flow is treated as a short flow in the beginning until the data sent exceeds a specified number of bytes. Therefore, if short and long flows start at around same time, then long flows will be treated as short flows.
5. Results and Discussion
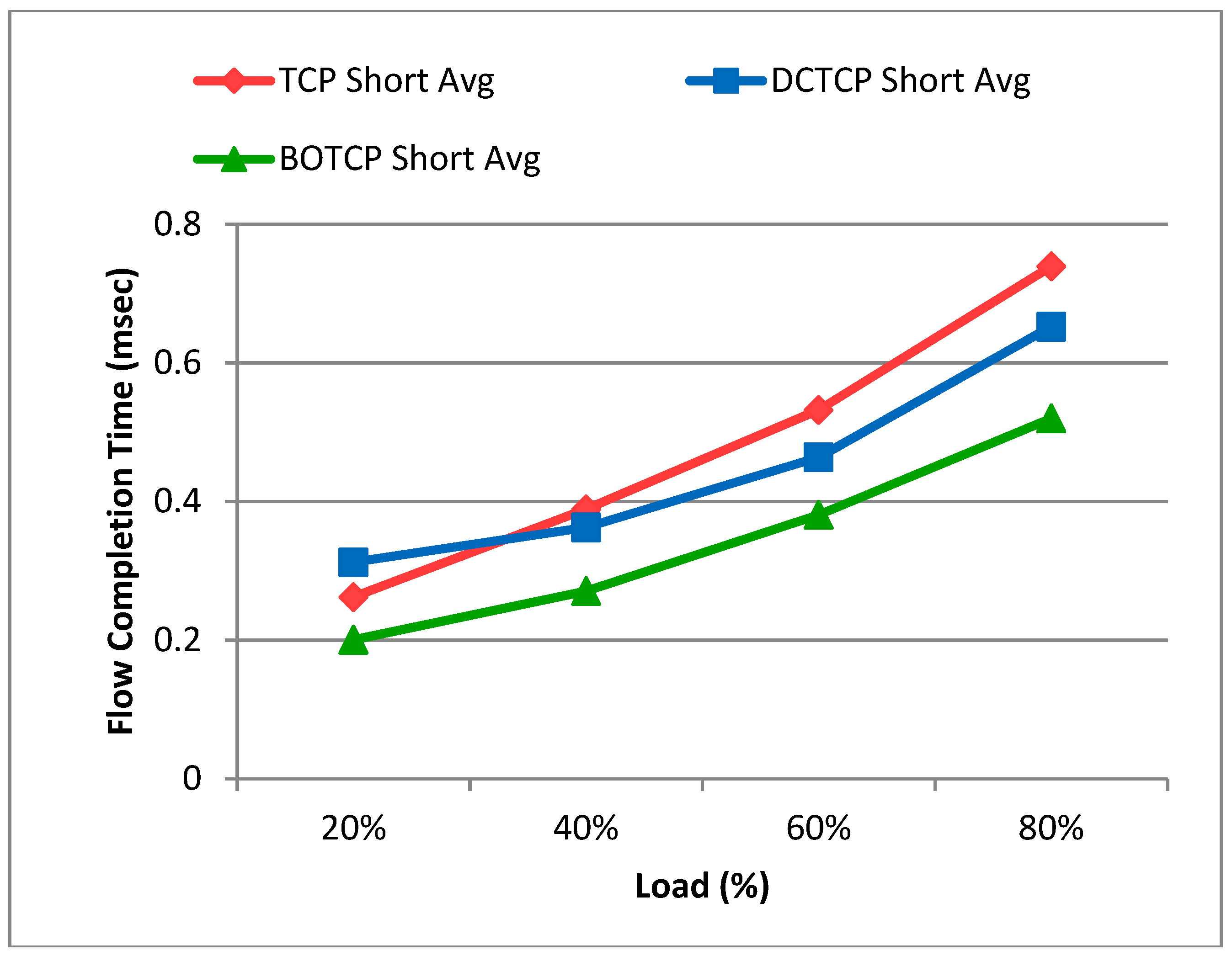
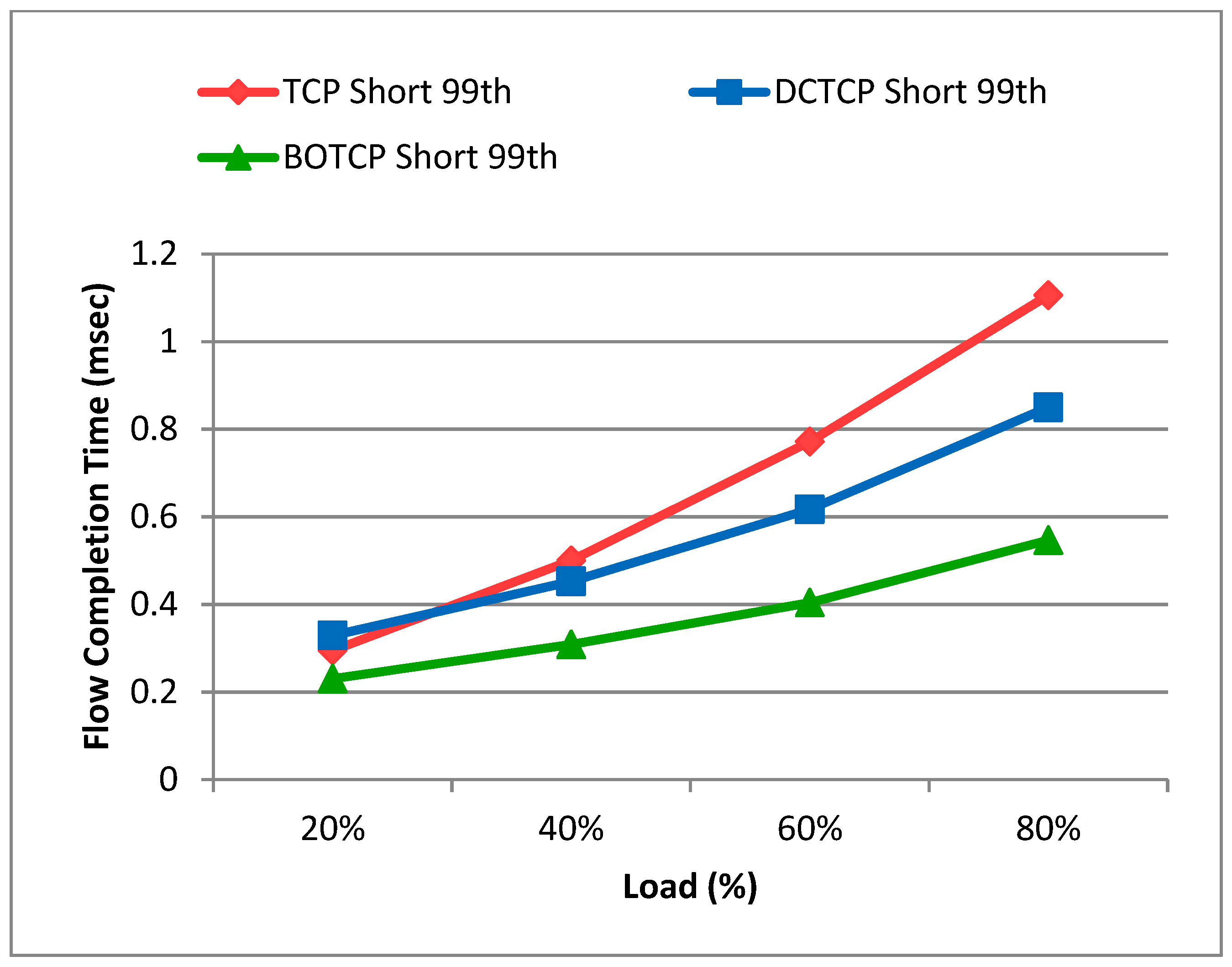
5.1. Flow Completion Time of Short Flows
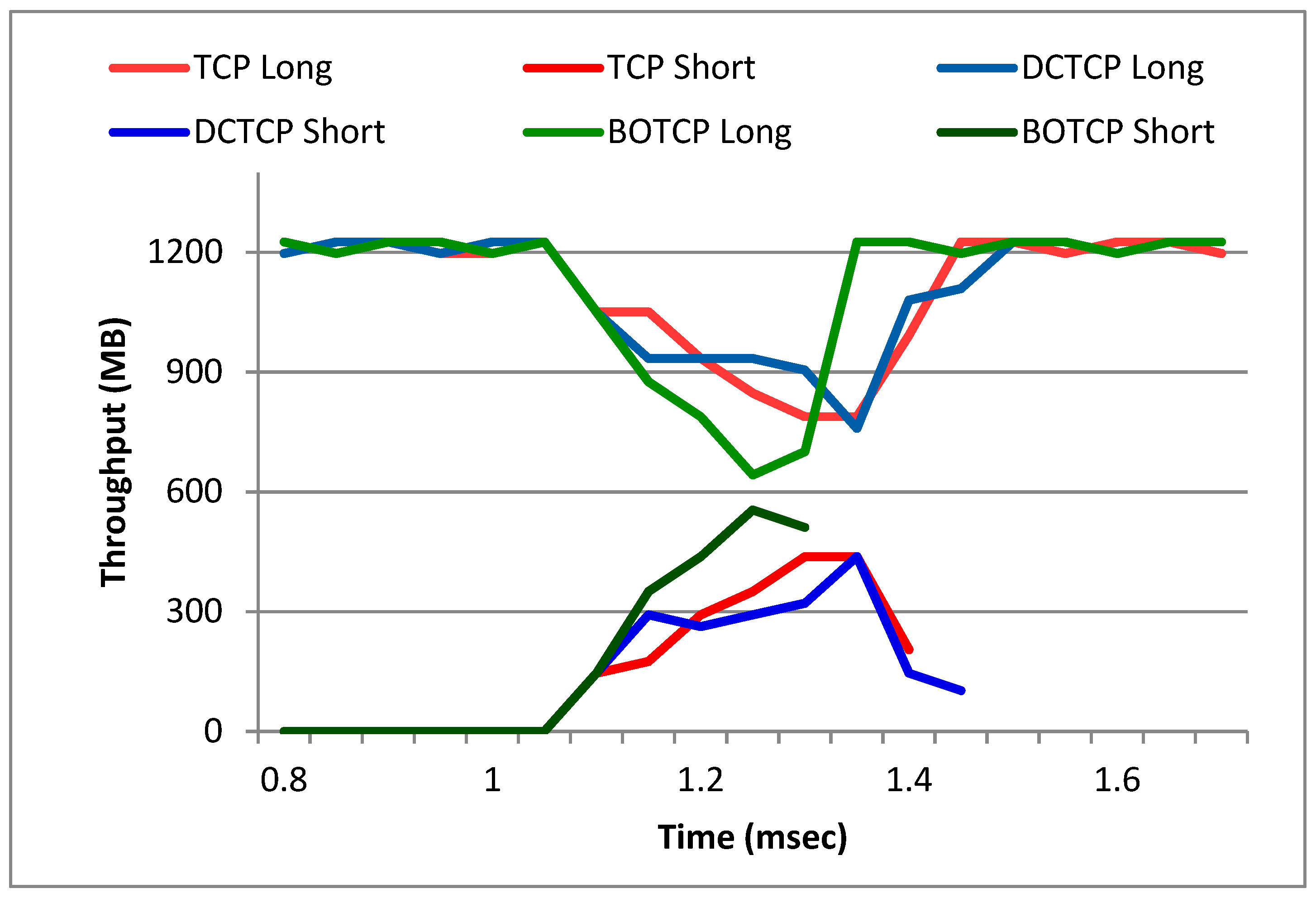
5.2. Bandwidth Sharing between Short and Long Flows
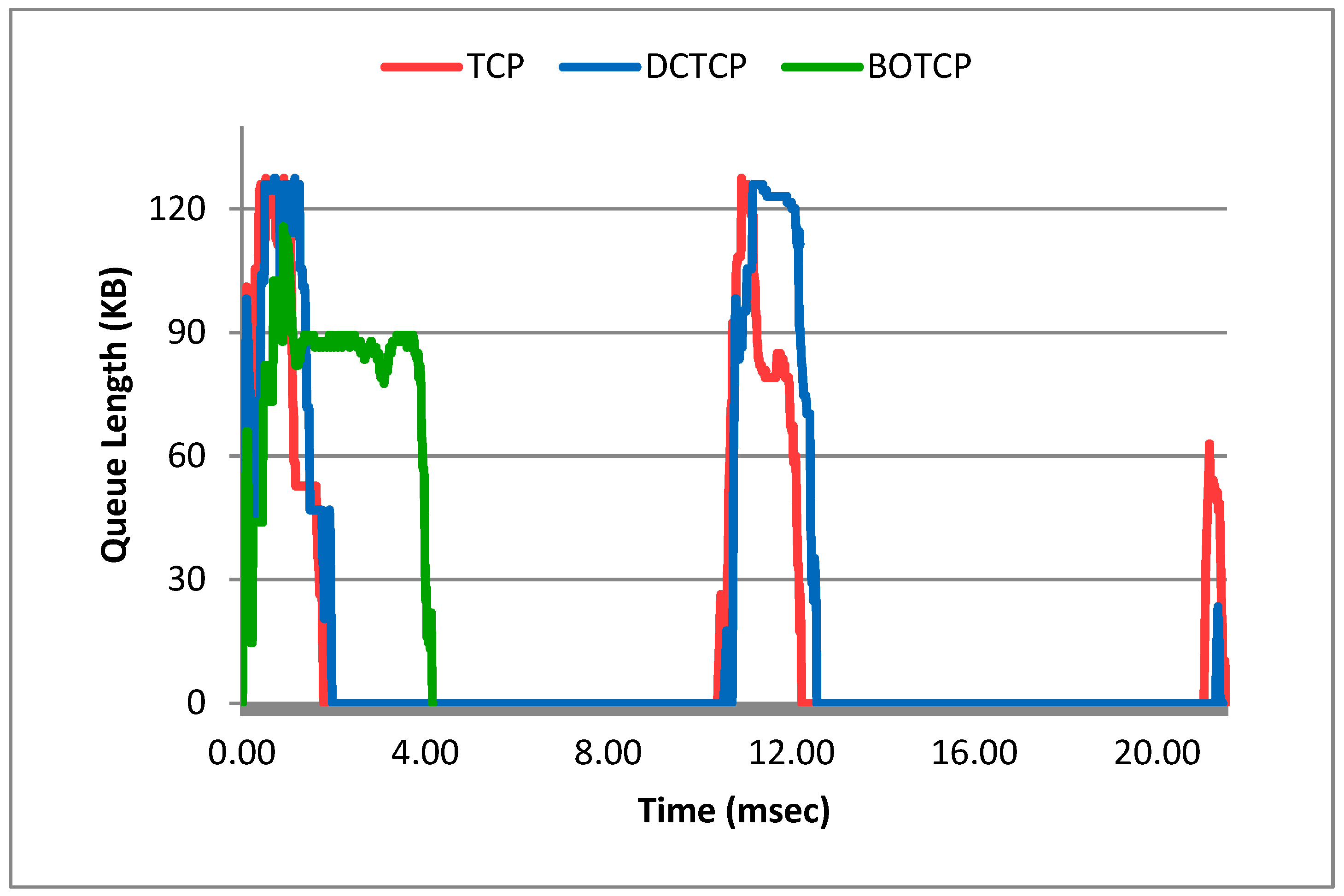
5.3. Packet Drops
A Case of Extreme Flow Load
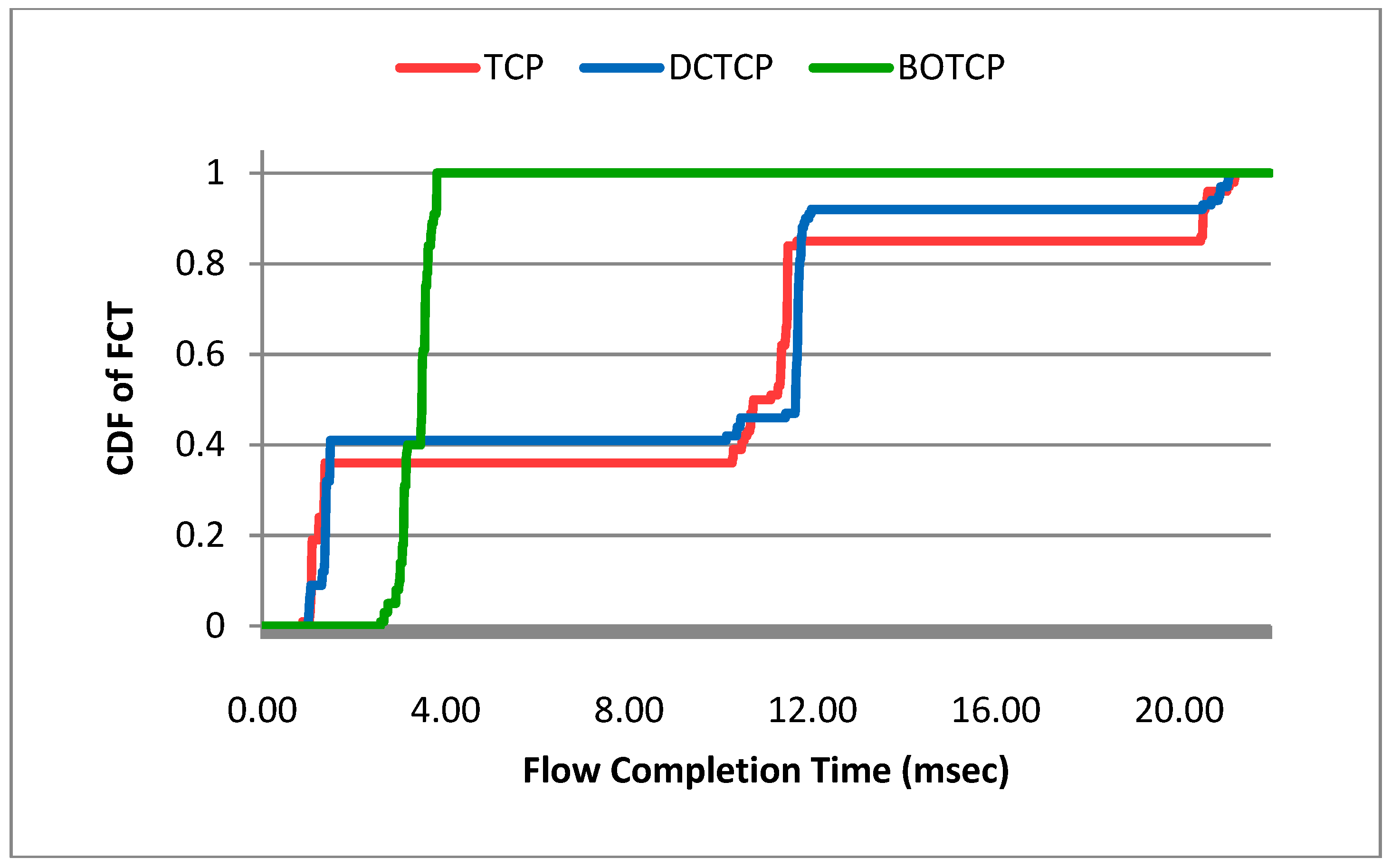
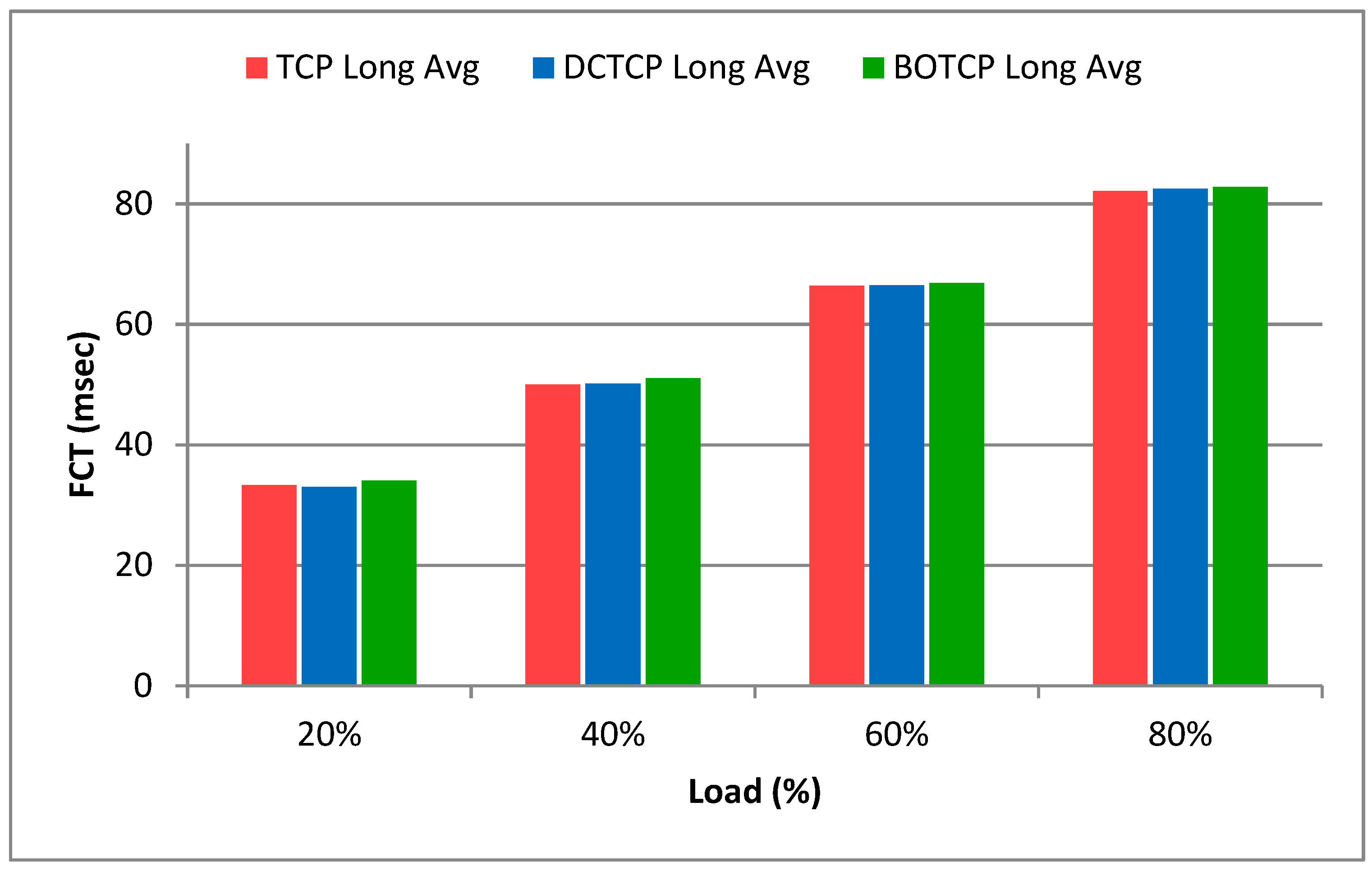
5.4. Flow Completion Time of Long Flows
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Xia, W.; Zhao, P.; Wen, Y.; Xie, H. A survey on data center networking (DCN): infrastructure and operations. IEEE Commun. Surv. Tutor. 2017, 19, 640–656. [Google Scholar] [CrossRef]
- Abts, D.; Felderman, B. A guided tour of data-center networking. Commun. ACM 2012, 55, 44–51. [Google Scholar] [CrossRef]
- Hu, J.; Huang, J.; Lv, W.; Zhou, Y.; Wang, J.; He, T. CAPS: Coding-based adaptive packet spraying to reduce flow completion time in data center. In Proceedings of the IEEE INFOCOM Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018. [Google Scholar]
- Liu, S.; Xu, H.; Liu, L.; Bai, W.; Chen, K.; Cai, Z. RepNet: Cutting latency with flow replication in data center networks. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- Ousterhout, J.; Agrawal, P.; Erickson, D.; Kozyrakis, C.; Leverich, J.; Mazières, D.; Rumble, S.M. The case for RAMClouds: Scalable high-performance storage entirely in DRAM. ACM SIGOPS. Oper. Sys. Rev. 2010, 43, 92–105. [Google Scholar] [CrossRef]
- Guo, C.; Wu, H.; Tan, K.; Shi, L.; Zhang, Y.; Lu, S. Dcell: A scalable and fault-tolerant network structure for data centers. ACM SIGCOMM Comput. Commu. Rev. 2008, 38, 75–86. [Google Scholar] [CrossRef]
- Zhang, Y.; Ansari, N. On architecture design, congestion notification, TCP incast and power consumption in data centers. IEEE Commun. Surv. Tutor 2013, 15, 39–64. [Google Scholar] [CrossRef]
- Al-Tarazi, M.; Chang, J.M. Performance-aware energy saving for data center networks. IEEE Trans. Netw. Serv. Manag. 2019, 16, 206–219. [Google Scholar] [CrossRef]
- Zhang, J.; Ren, F.; Lin, C. Survey on transport control in data center networks. IEEE Netw. 2013, 27, 22–26. [Google Scholar] [CrossRef]
- Huang, J.; Lv, W.; Li, W.; Wang, J.; He, T. QDAPS: Queueing delay aware packet spraying for load balancing in data center. In Proceedings of the IEEE 26th International Conference on Network Protocols, Cambridge, UK, 24–27 September 2018. [Google Scholar]
- Sreekumari, P.; Jung, J. Transport protocols for data center networks: A survey of issues, solutions and challenges. Photonic Netw. Commun. 2016, 31, 112–128. [Google Scholar] [CrossRef]
- Kandula, S.; Sengupta, S.; Greenberg, A.; Patel, P.; Chaiken, R. The nature of data center traffic: Measurements & analysis. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009. [Google Scholar]
- Greenberg, A.; Hamilton, J.R.; Jain, N.; Kandula, S.; Kim, C.; Lahiri, P.; Sengupta, S. VL2: A scalable and flexible data center network. ACM SIGCOMM Comput. Commu. Rev. 2009, 39, 51–62. [Google Scholar] [CrossRef]
- Benson, T.; Anand, A.; Akella, A.; Zhang, M. Understanding data center traffic characteristics. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 92–99. [Google Scholar] [CrossRef]
- Ren, Y.; Zhao, Y.; Liu, P.; Dou, K.; Li, J. A survey on TCP Incast in data center networks. Int. J. Commun. Syst. 2014, 27, 1160–1172. [Google Scholar] [CrossRef]
- Zeng, G.; Bai, W.; Chen, G.; Chen, K.; Han, D.; Zhu, Y. Combining ECN and RTT for datacenter transport. In Proceedings of the First Asia-Pacific Workshop on Networking, Hong Kong, China, 3–4 August 2017. [Google Scholar]
- Shan, D.; Ren, F. Improving ECN marking scheme with micro-burst traffic in data center networks. In Proceedings of the IEEE INFOCOM Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Chen, Y.; Griffith, R.; Liu, J.; Katz, R.H.; Joseph, A.D. Understanding TCP incast throughput collapse in datacenter networks. In Proceedings of the 1st ACM Workshop on Research on Enterprise Networking, Barcelona, Spain, 21–21 August 2009. [Google Scholar]
- Shukla, S.; Chan, S.; Tam, A.S.-W.; Gupta, A.; Xu, A.; Chao, H.J. TCP PLATO: Packet labelling to alleviate time-out. IEEE J. Sel. Areas Commun. 2014, 32, 65–76. [Google Scholar] [CrossRef]
- Zhang, J.; Ren, F.; Yue, X.; Shu, R.; Lin, C. Sharing bandwidth by allocating switch buffer in data center networks. IEEE J. Sel. Areas Commun. 2014, 32, 39–51. [Google Scholar] [CrossRef]
- Zhang, J.; Ren, F.; Shu, R.; Cheng, P. TFC: Token flow control in data center networks. In Proceedings of the Eleventh European Conference on Computer Systems, London, UK, 18–21 April 2016. [Google Scholar]
- Pal, M.; Medhi, N. VolvoxDC: A new scalable data center network architecture. In Proceedings of the Conference on Information Networking, Chiang Mai, Thailand, 10–12 January 2018. [Google Scholar]
- Alvarez-Horcajo, J.; Lopez-Pajares, D.; Martinez-Yelmo, I.; Carral, J.A.; Arco, J.M. Improving Multipath Routing of TCP Flows by Network Exploration. IEEE Access 2019, 7, 13608–13621. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, F.R.; Wang, S.; Huang, T.; Liu, Z.; Liu, Y. Load balancing in data center networks: A survey. IEEE Commu. Surv. Tutor. 2018, 20, 2324–2352. [Google Scholar] [CrossRef]
- Wang, P.; Trimponias, G.; Xu, H.; Geng, Y. Luopan: Sampling-based load balancing in data center networks. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 133–145. [Google Scholar] [CrossRef]
- Ye, J.L.; Chen, C.; Chu, Y.H. A Weighted ECMP Load Balancing Scheme for Data Centers Using P4 Switches. In Proceedings of the IEEE 7th International Conference on Cloud Networking (CloudNet), Tokyo, Japan, 22–24 October 2018. [Google Scholar]
- Munir, A.; Qazi, I.A.; Uzmi, Z.A.; Mushtaq, A.; Ismail, S.N.; Iqbal, M.S.; Khan, B. Minimizing flow completion times in data centers. In Proceedings of the IEEE INFOCOM, Turin, Italy, 14–19 April 2013. [Google Scholar]
- Alizadeh, M.; Greenberg, A.; Maltz, D.A.; Padhye, J.; Patel, P.; Prabhakar, B.; Sridharan, M. Data center tcp (dctcp). ACM SIGCOMM Compu. Commu. Rev. 2011, 41, 63–74. [Google Scholar]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, H.; Arshad, M.J. Buffer Occupancy-Based Transport to Reduce Flow Completion Time of Short Flows in Data Center Networks. Symmetry 2019, 11, 646. https://doi.org/10.3390/sym11050646
Ahmed H, Arshad MJ. Buffer Occupancy-Based Transport to Reduce Flow Completion Time of Short Flows in Data Center Networks. Symmetry. 2019; 11(5):646. https://doi.org/10.3390/sym11050646
Chicago/Turabian StyleAhmed, Hasnain, and Muhammad Junaid Arshad. 2019. "Buffer Occupancy-Based Transport to Reduce Flow Completion Time of Short Flows in Data Center Networks" Symmetry 11, no. 5: 646. https://doi.org/10.3390/sym11050646
APA StyleAhmed, H., & Arshad, M. J. (2019). Buffer Occupancy-Based Transport to Reduce Flow Completion Time of Short Flows in Data Center Networks. Symmetry, 11(5), 646. https://doi.org/10.3390/sym11050646