Abstract
Variability or dispersion plays an important role in any process and provides insight into the spread of data from some central point, usually the mean. A process with less spread is preferred over a process in which values differ greatly from the mean. Various methods are available to estimate the process dispersion by using information on the variable of interest. Certain additional variables provide good insight to estimate the process dispersion. In this paper, we propose an efficient method for the estimation of process variability by using the exponential method. The properties of the proposed method were studied. We conducted simulation and empirical studies to compare the proposed method with some existing methods of estimation of variability. The results of the numerical study show that our proposed method is better than the other methods used in the study.
1. Introduction
The variability or dispersion is an important aspect of a process, as well as of any statistical study. It provides information about spread of data from some central point. In most cases, that central point is the mean of the data; hence, the variance provides insight into the spread. For example, we may be interested to see the spread in the length of some electrical components from a certain pre-assigned target value. It is always required to use methods or to design procedures which produce smaller spread. The dispersion of estimators in any process or in any sample survey is of utmost importance, as the estimators or processes which provide smaller variability are more efficient and, hence, preferred. The dispersion of the process or estimator depends on the variable under study, method of estimation, and information of certain additional variables that can control the dispersion of the process. The information of additional variables can be efficiently utilized to propose the methods which reduce variation of the process or of the estimator. In survey sampling, the estimation of dispersion can be done using different methods which range from simple to complex. Some of these methods utilize the information of additional variables and some do not. The popular methods which utilize the information of additional variables to estimate dispersion are based on the ratio of the study variable to an additional variable and on the linear regression of the study variable to the additional variable. In some cases, the transformation of additional variables plays a useful role in decreasing the variability of the estimators; hence, certain methods are based on the transformed additional variables.
Several authors proposed various methods to estimate the process variation using the information of an additional or auxiliary variable. The method of using the information of an additional variable characterizes a certain estimation method and is very useful in decreasing the variance of estimation.
Several studies were conducted by many researchers to estimate the variability of a process, known as the population variance of the study variable . The simplest estimator of population variance is the sample variance , which was proposed by Reference [1]. Some other estimators of variance were proposed in References [2,3,4,5,6,7] and are based on certain information of one or more auxiliary variables (X). The method of using auxiliary information is very useful in proposing efficient estimates of the population variance. Some methods which are useful in the estimation of population variance are given in the following section.
2. Materials and Methods
Suppose we have a finite process which can produce N units; let the value of the characteristic of interest be . Suppose that the variability of the process is to be estimated on the basis of a sample of size n. Let Y represent the variable of interest and X represent the auxiliary variable. Also, let and be the mean and variance of the variable of interest, and let and be the mean and variance of the auxiliary variable for the whole process. The corresponding sample measures are , and , respectively. When information on two variables is available, then the strength of interdependence (correlation coefficient) between these variables is of importance and is denoted by . Also, let and be the coefficients of kurtosis of the study and auxiliary variables, and let be the squared coefficient of skewness of the auxiliary variable. Some additional notations that are useful in studying the properties of various estimators of population variance are given below.
.
We also use and in practice, such that , , and , with .
We will now discuss some available estimators for process variability (the population variance).
The usual unbiased estimator of population variance is with the mean-square error (MSE) given as
The estimator given above is based on the information of the study variable only. An estimator of variance which utilizes the information of an auxiliary variable was proposed by Reference [1] as
The MSE of up to the first order is
Two exponential-type estimators of variance were proposed by Reference [8] as
and
The MSE of the estimators in Equations (4) and (5) are, respectively,
and
An exponential-type estimator of variance, proposed by Reference [7], is
with MSE as
where is the coefficient of variation of the auxiliary variable X. An estimator of variance, based on the coefficient of variations, was proposed by Reference [2] as
with MSE as
A general procedure for estimating population variance was proposed by Reference [9] as
with MSE as
Various authors have used certain transformations of the auxiliary variable to propose different estimators of variance. The popular transformation used by various authors is , where ; under this transformation, is an unbiased estimator for . Following the same transformation, Reference [6] proposed a dual ratio-type estimator for population variance as
with MSE given as
The use of a transformed auxiliary variable provides more efficient estimators of population variance; see, for example, References [6,7,8,9,10,11].
The main purpose of this paper is to propose a generalized exponential estimator for population variance by utilizing transformed auxiliary information. The estimator is proposed in Section 3.
3. Proposed Estimator
Using the concept of Reference [6], we propose two general exponential-type estimators, known as the exponential ratio and exponential product estimators of population variance, by utilizing transformed auxiliary information x. The proposed estimators are as follows:
and
where . The MSE of the proposed estimators, up to the first order, are
and
We have also proposed another estimator, following Reference [11] as
or
Using and , and using a Taylor series expansion of Equation (21), we have
The bias of the proposed estimator, up to the first order, is given as
The MSE of the estimator in Equation (21) is
The optimum value of ai is obtained by minimizing Equation (23) and is given as
Using the optimum value of in Equation (23), the minimum value of MSE is
3.1. Special Cases
The special cases of the proposed estimator are obtained using different values of the constants involved and are given in Table 1.

Table 1.
Special cases of the proposed estimator.
We now compare the proposed estimator with some popular available estimators of population variance. The efficiency comparison is given in Section 3.2.
3.2. Efficiency Comparison of the Generalized Exponential Estimator
The comparison of the proposed estimator was done by comparing the mean-square error of the proposed estimator with that of some available estimators. We compared our proposed estimator with , , , and given in Section 2. The mean-square errors of these estimators are given in Equations (1), (3), (6), and (15), respectively.
Now, the comparison of the proposed estimator with shows that
The comparison of with shows that
Again, the comparison of with shows that
The comparison of with shows that
We now give numerical examples for the application of the proposed estimator.
4. Results
In this section, we present the numerical studies for the application of the proposed generalized estimator of population variance. The numerical study is twofold. We firstly provide 10 real examples by considering 10 real populations; later, we provide a simulation study to see the performance of the proposed generalized estimator of variance. The results of these studies are given in the sections below.
4.1. Numerical Study
In this section, we present a numerical study to see the performance of the proposed estimator in estimating the variability of processes. These studies were conducted using 10 real populations which were previously used by various authors to see the performance of their proposed estimators. The description of these populations can be found in the source given.
The summary measures for these 10 populations are given in Table 2. The summary measures of two populations indicate that the study variable and auxiliary variable are highly correlated. This is generally an underlying requirement for ratio- and exponential-type estimators for the estimation of population characteristics.
Table 2.
Summary measures for populations.
We computed the mean-square error of various estimators using the data of above populations. After computing the mean-square error, we computed the percent relative efficiency (PRE) of various estimators, relative to , using Equation (26).
The efficiency provides information about the sample size required to achieve a desired result, using an estimator that is provided by the base estimator with a sample of size 100. This, therefore, means that a smaller value of PRE indicates that the estimator is more efficient. The results are given in Table 3.
Table 3.
Percent relative efficiency (PRE) of various estimators.
We can see, from Table 3, that the proposed estimator is the most efficient estimator, as this estimator requires the least number of observations to obtain a desired result as obtained by with a sample of size 100. We then conducted a regression analysis to see the effect of the correlation coefficient and coefficient of skewness of the auxiliary variable on the efficiency of the estimator. The regression model that we built is as follows:
The regression summary alongside the result of the test of significance for each estimator is given in Table 4.
Table 4.
Regression summary for various estimators.
From the above table, we can see that the average efficiency of our proposed estimator, , is the lowest, as for this estimator has the smallest value. We can also see that the correlation coefficient has a significant effect on the efficiency of , and the regression model for this estimator is significant at 5%. The value of for our proposed estimator is the second lowest, which indicates that this estimator is the second best estimator for the estimation of population variance. The regression coefficient is significant at 10% for this estimator, which indicates that the correlation coefficient between the study and auxiliary variables will provide useful information to predict the efficiency of estimator . The other significant regression model is for ; for this estimator, the coefficient of is significant. This indicates that the coefficient of kurtosis of the auxiliary variable has a significant effect on the efficiency of this estimator. We can also see from Table 4 that the estimator showed the worst performance in this study, as coefficient for this estimator has the highest value.
We also show the efficiencies of various estimators in Figure 1, where estimators are numbered from 1 to 7 in the order in which they appear in Table 4. This means that estimator is numbered 1 and estimator is numbered 7. The graph also shows that our proposed estimator is the most efficient estimator in this study.
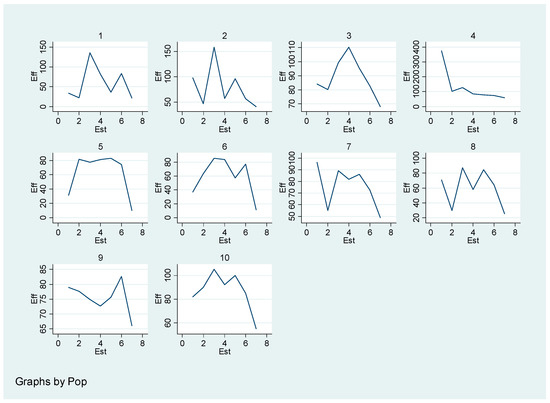
Figure 1.
Population wise efficiency comparison.
We now present the results of the simulation study in Section 4.2.
4.2. Simulation Results
In this section, we give the results of the simulation study to see the performance of our proposed estimator. The simulation study was conducted by generating populations of size 500 having a specific correlation structure between the study and auxiliary variables. For each of the populations with a specific correlation coefficient, various estimators were computed. The process was repeated 20,000 times, and we then computed the mean0square error of each estimator alongside the percent relative efficiency as defined in Equation (26). The results of this simulation study are given in Table 5.
Table 5.
Percentage relative efficiency (PRE) of existing estimators.
The results of the simulation study clearly indicate that our proposed estimator outperformed other estimators used in the study; hence, we can say that our proposed estimator will estimate process variability with the least error. The efficiency of various estimators is given in Figure 2 below
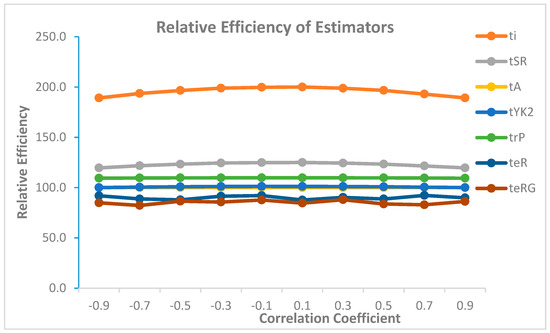
Figure 2.
Efficiency comparison with respect to correlation coefficient.
From above figure we can see that our proposed estimator is most efficient for all values of correlation coefficient.
5. Conclusions and Recommendations
In this paper, we proposed a new method for the estimation of process dispersion when the information on a variable of interest and an auxiliary variable is available. We see that the proposed estimator can provide certain other estimators as a special case. We obtained the mean-square error of the proposed estimator and found that the mean-square error of our proposed estimator was less than the mean-square error of other available estimators of variability. We conducted numerical and simulation studies to see the performance of our proposed estimator, and we found that our proposed estimator estimates process variability with the least error. We can, therefore, conclude that our proposed estimator can be used for the estimation of process variability in various areas, including quality control and engineering.
Author Contributions
Conceptualization, M.I. and M.Q.S.; methodology, M.Q.S.; software, T.A. and M.I.; validation, T.A., M.I. and M.Q.S.; formal analysis, T.A.; investigation, T.A.; resources, T.A.; data curation, M.I.; writing—original draft preparation, T.A.; writing—review and editing, M.I. and M.Q.S.; visualization, T.A.; supervision, M.I. and M.Q.S.; project administration, M.I. and M.Q.S.
Funding
This research received no external funding.
Acknowledgments
The authors thank the Department of Statistics, COMSATS University Islamabad, Lahore Campus, Pakistan for supporting this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Isaki, C.T. Variance Estimation Using Auxiliary Information. J. Am. Stat. Assoc. 1983, 78, 117–123. [Google Scholar] [CrossRef]
- Das, A.K.; Tripathi, T. Use of Auxiliary Information in Estimating the Finite Population Variance. Sankhya 1978, 40, 139–148. [Google Scholar]
- Upadhyaya, L.; Singh, H. An Estimator for Population Variance That Utilizes the Kurtosis of an Auxiliary Variable in Sample Surveys. Vikram Math. J. 1999, 19, 14–17. [Google Scholar]
- Kadilar, C.; Cingi, H. Ratio Estimators for the Population Variance in Simple and Stratified Random Sampling. Appl. Math. Comput. 2006, 173, 1047–1059. [Google Scholar] [CrossRef]
- Upadhyaya, L.N.; Singh, H.P.; Chatterjee, S.; Yadav, R. A Generalized Family of Transformed Ratio-Product Estimators in Sample Surveys. Model Assist. Stati. Appl. 2011, 6, 137–150. [Google Scholar] [CrossRef]
- Yadav, S.K.; Kadilar, C. A Class of Ratio-Cum-Dual to Ratio Estimator of Population Variance. J. Reliab. Stat. Stud. 2013, 6, 29–34. [Google Scholar]
- Asghar, A.; Sanaullah, A.; Hanif, M. Generalized Exponential Type Estimator for Population Variance in Survey Sampling. Revista Colombiana de Estadística 2014, 37, 213–224. [Google Scholar] [CrossRef]
- Singh, R.; Chauhan, P.; Sawan, N.; Smarandache, F. Improved Exponential Estimator for Population Variance Using Two Auxiliary Variables. arXiv Preprint, 2009; arXiv:0902.0126. [Google Scholar]
- Yadav, R.; Upadhyaya, L.N.; Singh, H.P.; Chatterjee, S. A Generalized Family of Transformed Ratio-Product Estimators for Variance in Sample Surveys. Commun. Stat.-Theory Methods 2013, 42, 1839–1850. [Google Scholar] [CrossRef]
- Sharma, B.; Tailor, R. A New Ratio-Cum-Dual to Ratio Estimator of Finite Population Mean in Simple Random Sampling. Glob. J. Sci. Front. Res. 2010, 10, 27–31. [Google Scholar]
- Sanaullah, A.; Ali, H.A.; ul Amin, M.N.; Hanif, M. Generalized Exponential Chain Ratio Estimators under Stratified Two-Phase Random Sampling. Appl. Math. Comput. 2014, 226, 541–547. [Google Scholar] [CrossRef]
- Das, A.K. Contributions to the Theory of Sampling Strategies Based on Auxiliary Information. Unpublished. Ph.D. Thesis, B.C.K.V., West Bengal, India, 1980. [Google Scholar]
- Murthy, M. Sampling Theory and Methods; Calcutta Statistical Publishing Society: Kolkatta, India, 1967. [Google Scholar]
- Available online: https://www.statcrunch.com/app/index.php?dataid=285946 (accessed on 26 January 2019).
- Gujarati, D.N.; Porter, D.C. Basic Econometrics, 5th ed.; McGraw Hill: New York, NY, USA, 2011; p. 189. [Google Scholar]
- Cochran, W.G. Sampling Technique; John Wiley: New York, NY, USA, 1977. [Google Scholar]
- Singh, R.K.; Chaudhary, B.D. Biometrical Method in Quantitative Genetics Analysis; Kalyani Publishers: New Delhi, India, 1987. [Google Scholar]
- Mukhopadhyay, P. Theory and Methods of Survey Sampling; Prentice Hall: New Delhi, India, 1998. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).