4.1. Models’ Development Strategy
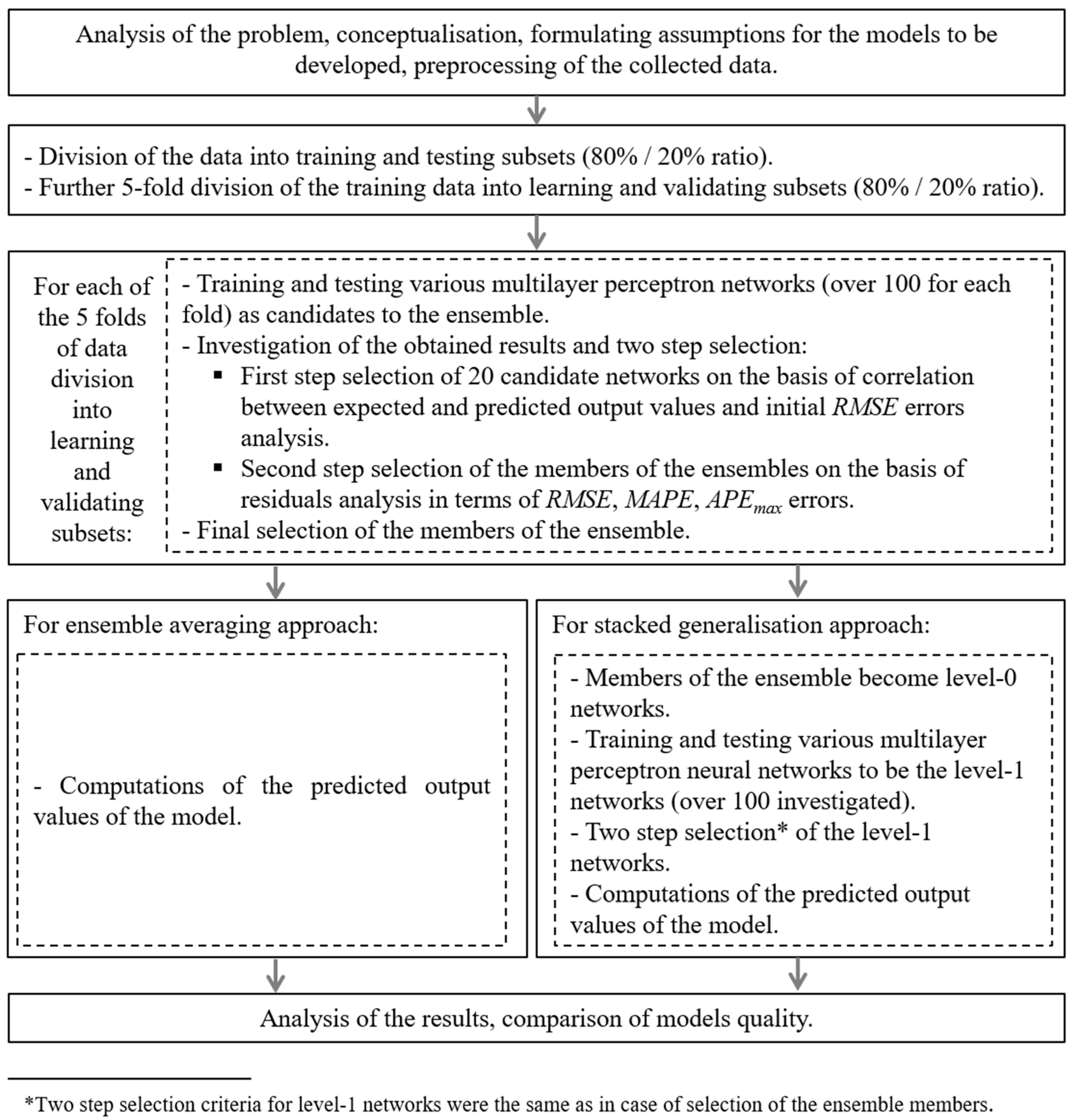
The strategy of the model development included conducting multiple training and testing of a number of different types of single ANNs as candidates to become members of the ensemble, forming the ensemble, and then investigating the two approaches discussed earlier. The strategy is presented schematically in the chart in
Figure 2 and then discussed in detail.
The whole set of collected data was divided into two main subsets used for training and testing purposes. The testing subset, later referred to as T, was selected carefully to be statistically representative for the whole data collection and included 20% of the samples from the whole set of collected data. The data belonging to this subset did not take part in the training of ANNs and was used for the purposes of examination of single ANNs, as well as the ensemble models built upon the ensemble averaging and stacked generalisation approaches. Samples belonging to the subset T play the role of new cases in prediction performance analysis as well.
The remaining data was used for training i.e., for supervised learning and validating of single ANNs candidates to become members of the ensemble. Later, these subsets are referred to as L and V, respectively, whilst the whole training subset is referred to as L&V. The strategy involved division of the remaining data in the relation L/V = 80%/20%, repeated five times, so the five folds of data were available for training purposes. Moreover, each of the samples belonging to the L&V subset took part in supervised learning in four folds and in validating in one fold, so the networks for each fold are trained with data which varies in terms of falling different samples either to the L or V subsets.
Another key assumption was to select one ANN for each of the folds of
L and
V subsets to become the member of the ensemble. The selection was made on the basis of two-step ANNs’ performance analysis and assessment within the sets of networks trained with the use of each fold of
L and
V subsets. The rationale for such assumption was not only to choose the best networks but also to minimise the risk that the prediction of the model is biased due to the sampling of the
L and
V subsets. The employed error function and criteria of the trained networks assessment are presented in
Table 4. For the purposes of performance assessment and analysis of single ANNs, Pearson’s correlation coefficient (15) and error measures (16)–(20) were calculated for the
L,
V,
L&V, and
T subsets.
Selection of the ensemble members was preceded by an investigation of a number of various multilayer perceptron (MLP) ANNs with one hidden layer, whose structures included 11 neurons in the input layer, h neurons in the hidden layer, and 1 neuron in the output layer. The choice of the MLP networks relied on their applicability to regression problems (compare References [
29,
49]).
The networks varied in the number of neurons in the hidden layer (h ranged from 4 to 11), the types of employed activation functions—both in the neurons of the hidden and output layer (sigmoid, hyperbolic tangent, exponential, and linear function) and the initial weights of the neurons—at the beginning of the training process. The Broyden–Fletcher–Goldfarb–Shanno algorithm (BFGS) was used for training individual networks—the details about the algorithm can be found in the literature, e.g., Reference [
47]. The choice of the training algorithm was dictated by its availability in the software that were used for neural simulations. As one of the three available algorithms, BFGS offered the fastest performance and best convergence of training and testing processes for the investigated problem. A variety of different combinations of employed activation functions and numbers of neurons in hidden layers that made, altogether, over 100 networks were trained for each of the five folds of
L and
V subsets.
The first step of selection included an assessment of correlation coefficient between the expected and predicted output and root mean squared error (RMSE) values. From the set networks, which fulfilled the conditions of RL > 0.90, RV > 0.90, RL&V > 0.90, and RT > 0.90, the authors initially selected 20 networks for which the differences between RMSEL, RMSEV, RMSEL&V, and RMSET were the smallest.
The second step of the selection relied on a thorough review of the initially selected networks for each of the five folds of
L and
V subsets. The authors carried out a residual analysis, in terms of both measures presented in
Table 4, and distributions, dispersions, and values of errors for the samples belonging to the training and testing subsets.
4.2. Results and Discussion
A review and comparison of the network’s performance, based on the methodical analysis, allowed for finally choosing five networks—one for each fold of
L and
V subsets. The five selected networks—later referred to as ANN1, ANN2, ANN3, ANN4, and ANN5—are presented in
Table 5.
Table 6 presents the results of training and testing of the five selected networks acting separately. The results in the Table are given according to the criteria presented in
Table 4. The results in
Table 6 are satisfying, however one can easily see that there are some differences between the performances of the five networks.
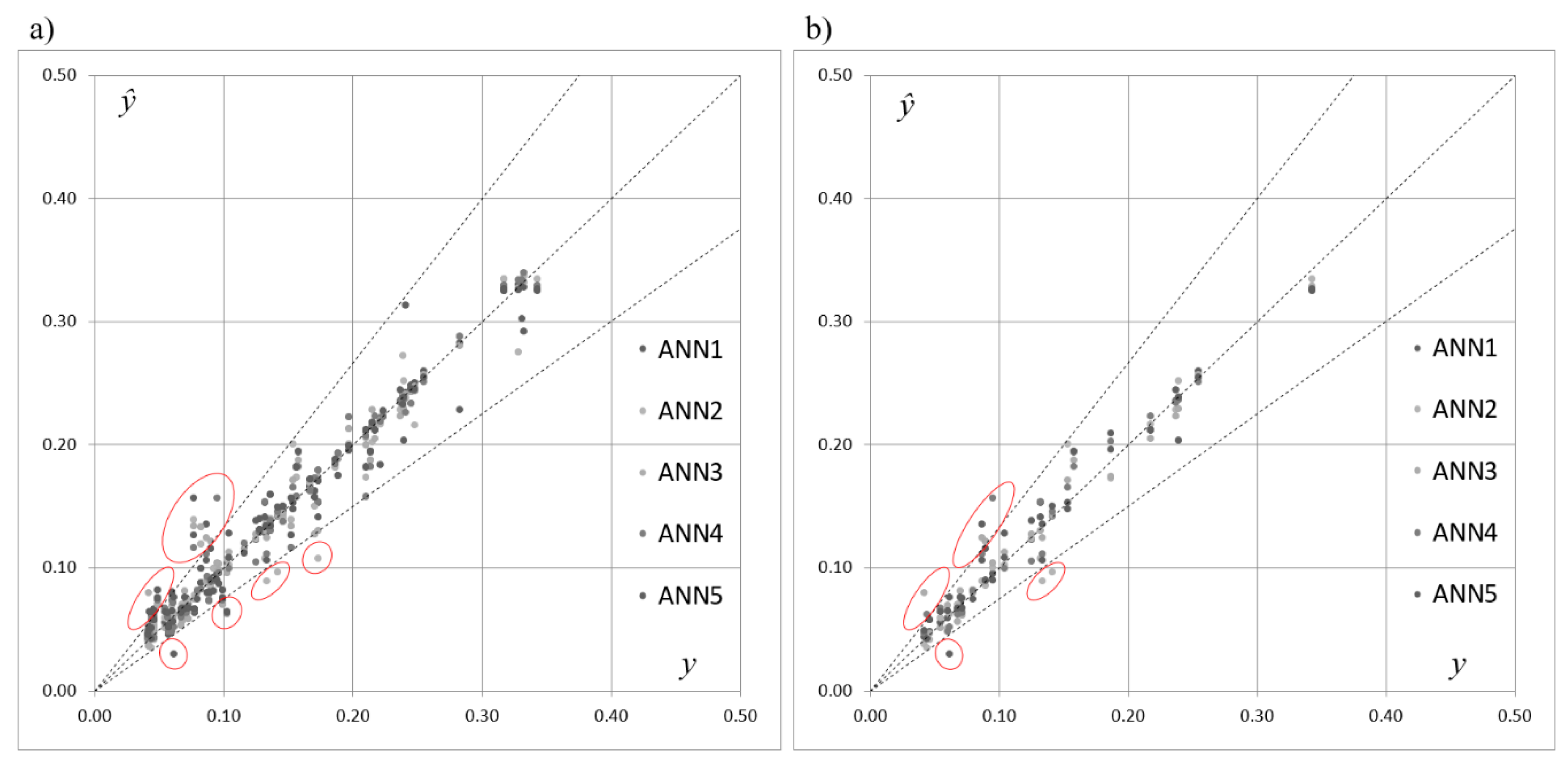
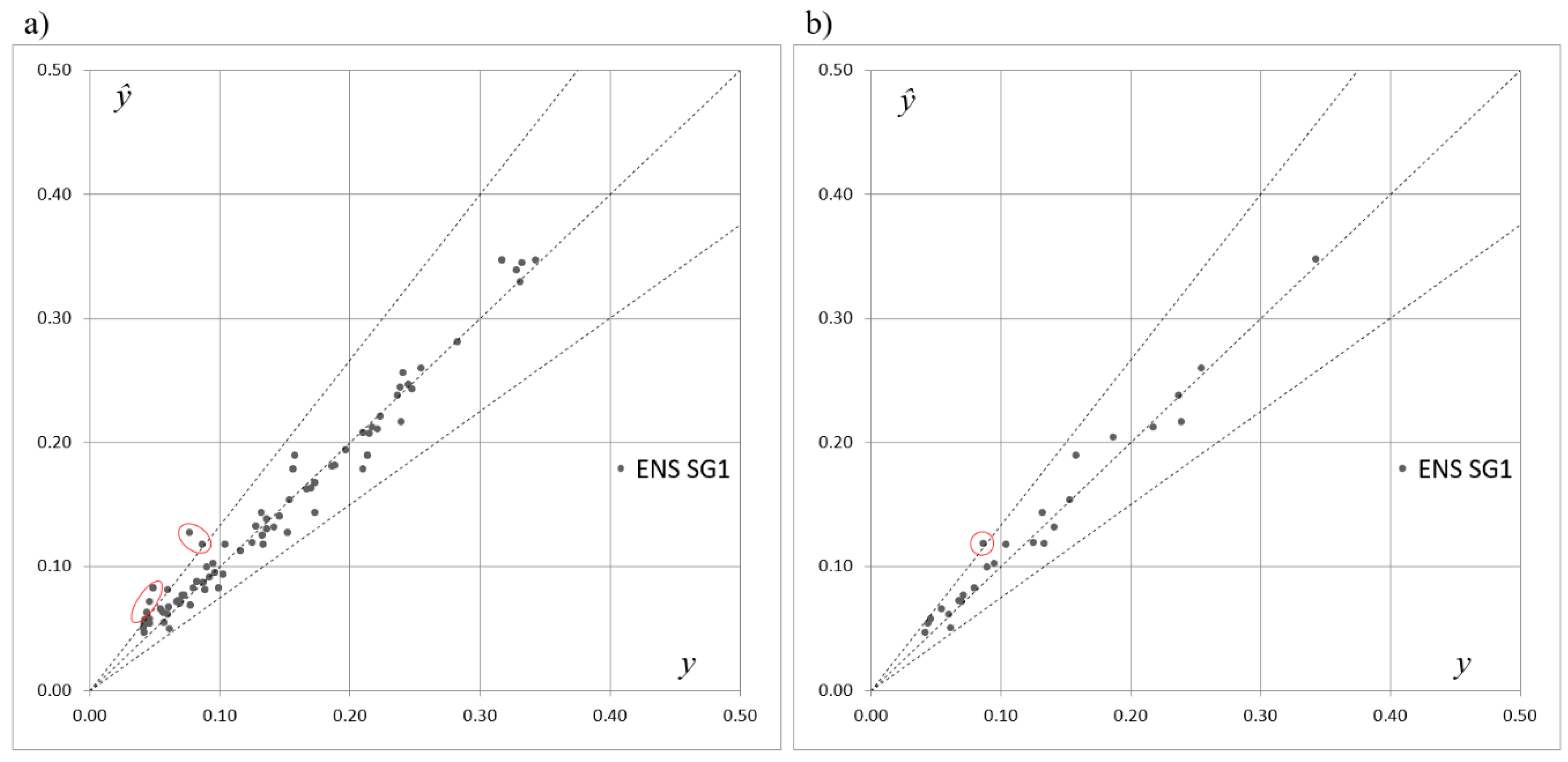
Figure 3 presents the scatterplot of the expected and predicted values of
SOCind, points of coordinates (
yp,
ŷp), for the training and testing subsets drawn for the five selected networks acting individually. One can see that, in terms of the criteria shown in
Table 4 and according to the results presented in
Table 5, the performance of the three networks acting individually was similar and the errors were comparable. However,
Figure 3a,b and the analysis of the location and the distribution of the points in the graphs reveal that the predictions for will depended strongly on the choice of a single network acting separately. Although most of the points were distributed along the line of a perfect fit, some points (marked with the ellipses) were placed outside of the cone delimited by percentage errors equal to +25% and −25%.
Table 7 presents the maximal values of absolute percentage errors (20) calculated for the five selected ANNs. The values in
Table 7 reveal significant errors of predictions, which also justify employment of ensembles of neural networks in the problem.
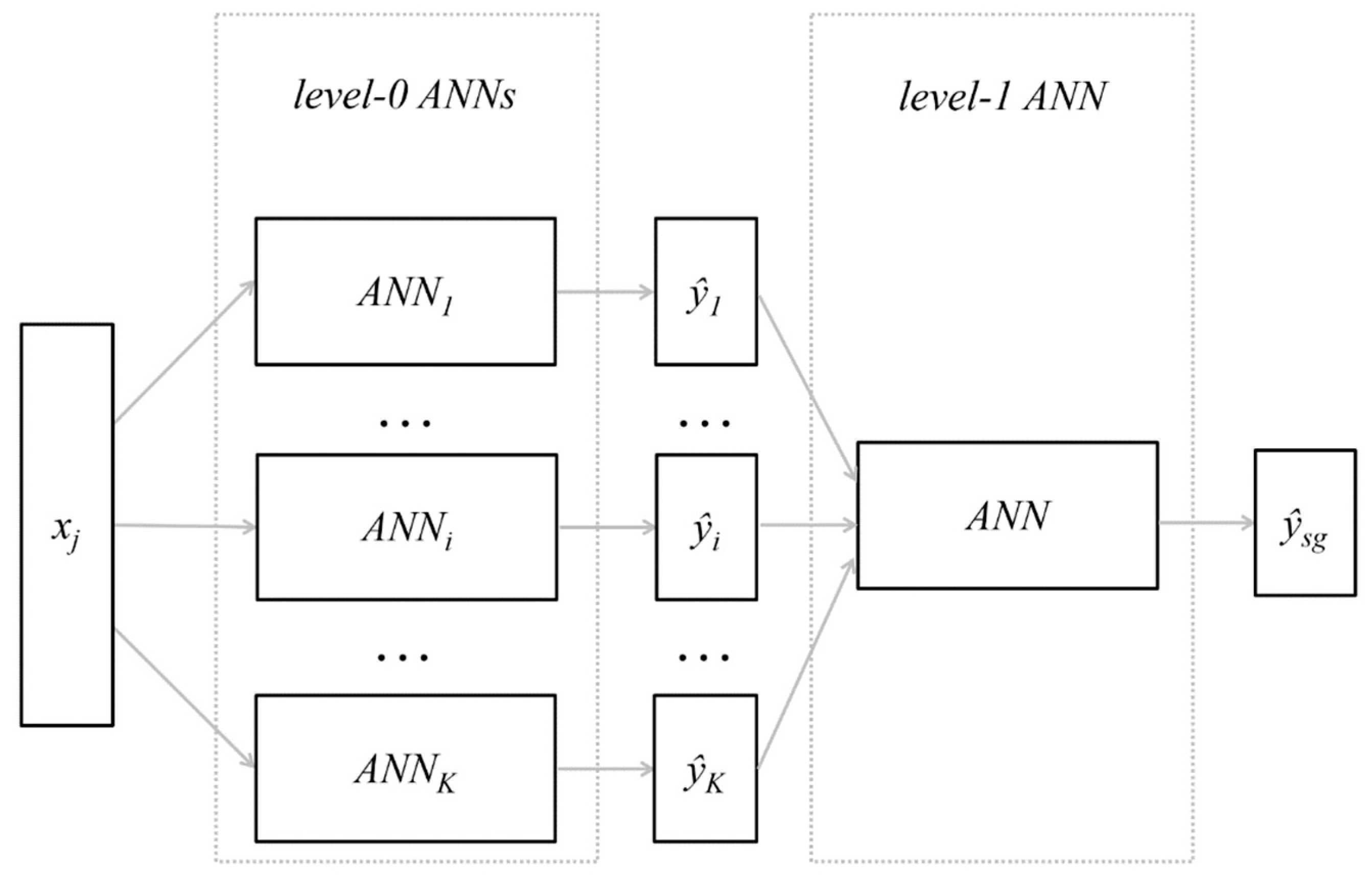
The five chosen networks were combined to form the ensemble. The rules presented earlier—Equations (10) and (11)—were employed for implementation of the ensemble averaging approach and the outputs of the model were computed as well as the errors and error measures. This model is later called ENS AV.
To complete the process of model development based on the stacked generalisation approach, the authors investigated a number of artificial neural-network candidates to become the level-1 networks. The investigated networks’ structures included five neurons in the input layer (as a consequence of the selection of five ensemble member networks), h neurons in the hidden layer, and one neuron in the output layer. The number of neurons in hidden layer h ranged from one to three, as the structure of the level-1 network was supposed to be simple (compare
Section 2.2). The types of employed activation functions and training algorithm were the same as in the case of the training ensemble candidate networks (as presented previously in
Section 3). Training patterns that included outputs of the five ensemble member networks as the inputs of level-1 networks, and the accompanying real-life values of
SOCind as the expected outputs, were divided randomly for each investigated network into the learning and validating subset in the proportion L/V = 60%/40%. The investigated networks varied also in the initial weights of the neurons at the beginning of the training process. Altogether, around 100 networks were trained and examined. For the purposes of testing, the authors used the T subset, which was selected in the initial stage of the research (as presented previously in
Section 3). The criteria of two-step selection of the level-1 networks were similar as in the case of ensemble candidate networks (as presented previously in
Section 3). The final choice of two level-1 networks, namely MLP 5-2-1 and MLP 5-3-1, allowed for the introduction of two alternatively stacked generalisation-based models. The final choice of the two above-mentioned level-1 networks, and further discussion of two alternative models based on stacked generalisation, was due to the comparable quality of these models. These models are later called ENS SG1 and ENS SG2, respectively. The details of the selected level-1 networks are presented in
Table 8.
All three proposed models based on the ensemble of networks, namely ENS AV, ENS SG1, and ENS SG2, were assessed in terms of performance and prediction quality. The overall results appear together in
Table 9. For the purposes of performance assessment and analysis of ensemble averaging and stacked generalisation-based models, Pearson’s correlation coefficient (16) and error measures (17), (18), (19), and (20) were calculated for
L&V and
T subsets.
When the values in
Table 9 are collated with values in
Table 5 and
Table 6, the improvements in error measures can be seen easily. The performance of all three models based on the ensembles of networks is better when compared with the performance of the networks acting in isolation. The most evident improvement is achieved for
APEmax.
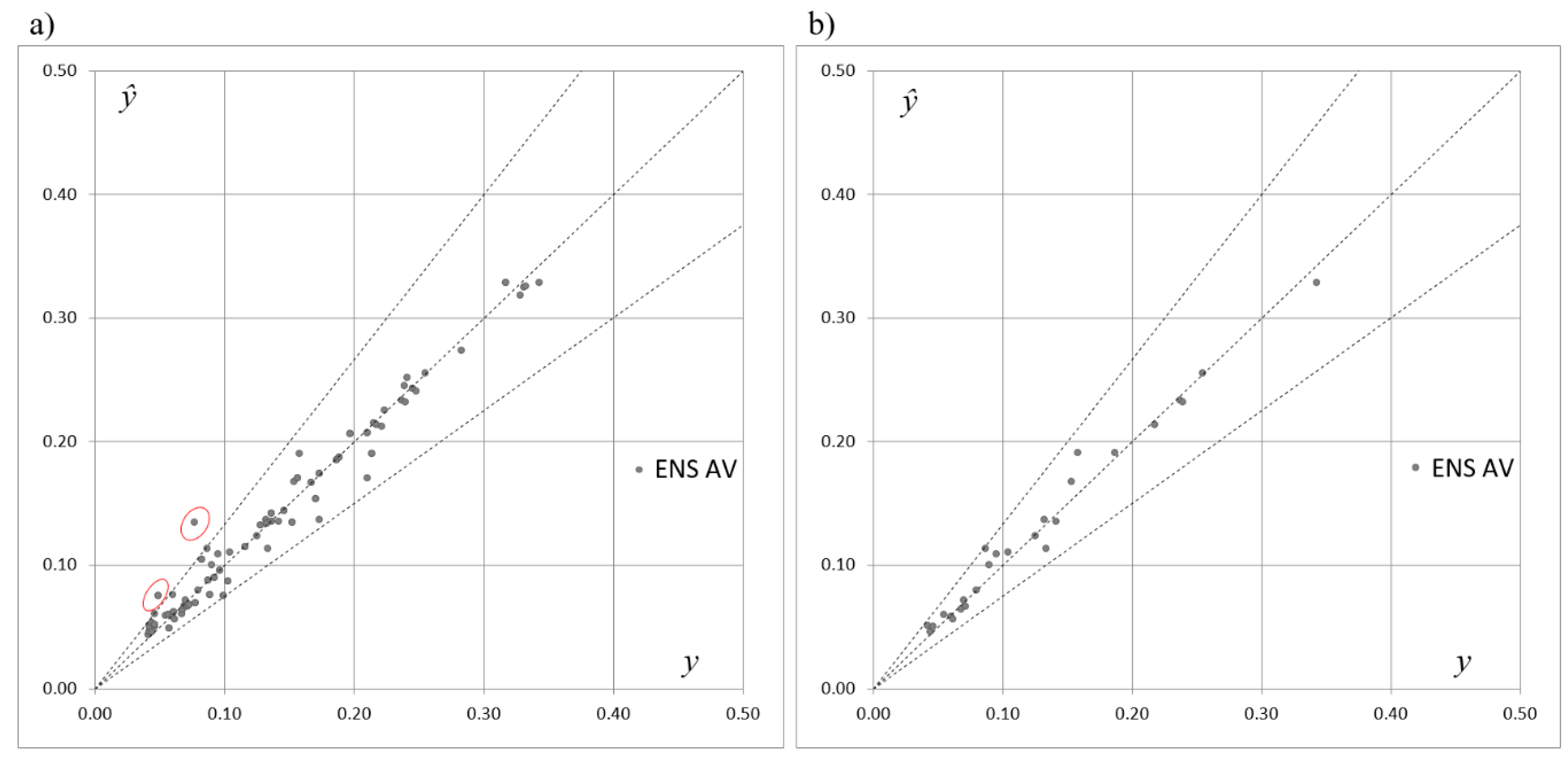
Figure 4,
Figure 5 and
Figure 6 depict scatterplots of the expected and predicted values of
SOCind for the ENS AV, ENS SG1, and ENS SG2 models.
Figure 4,
Figure 5 and
Figure 6 present the points of coordinates (
yp,
) for the training and testing subsets separately. When compared to
Figure 3, these graphs show that combining the five selected ANNs allowed for the compensation of errors made by the ANNs acting in isolation in the case of the ENS AV as well as the ENS SG1 and ENS SG2 models. Although an improvement has been achieved in the case of all three introduced models, one can see that the best performance is provided by ENS SG2, where all of the points are distributed within the cone of acceptable errors. In the case of ENS AV and ENS SG1, there are single points located outside of the cone.
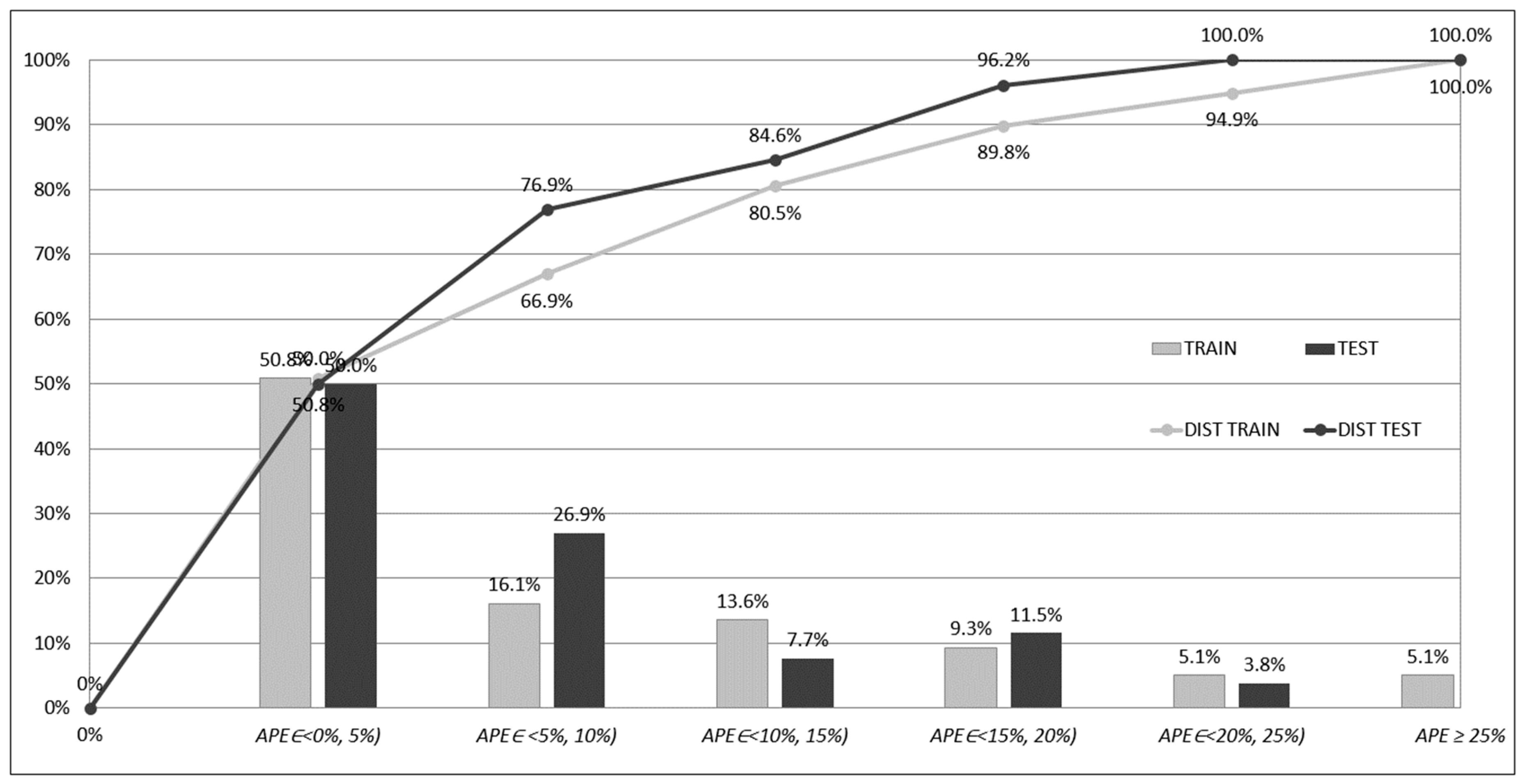
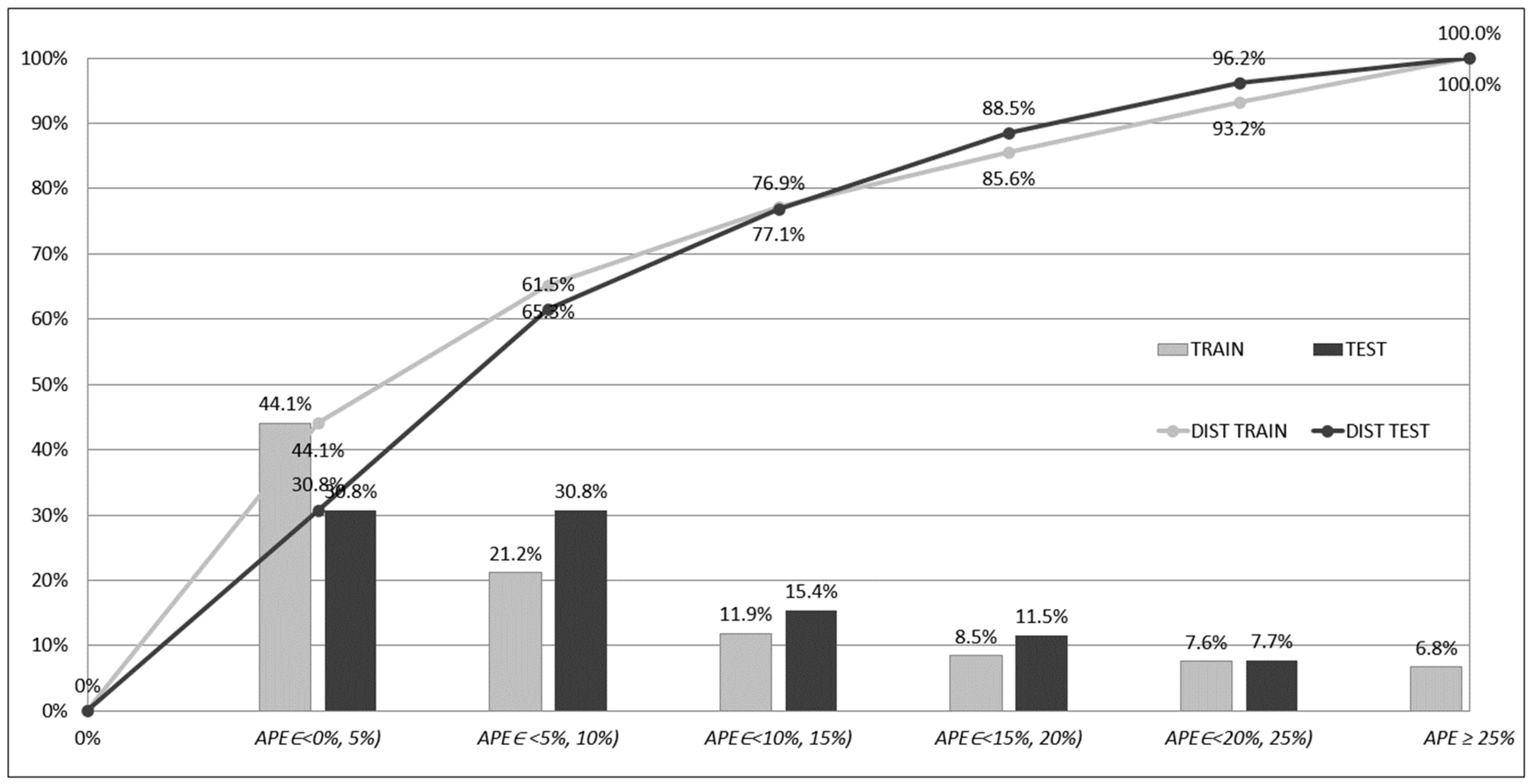
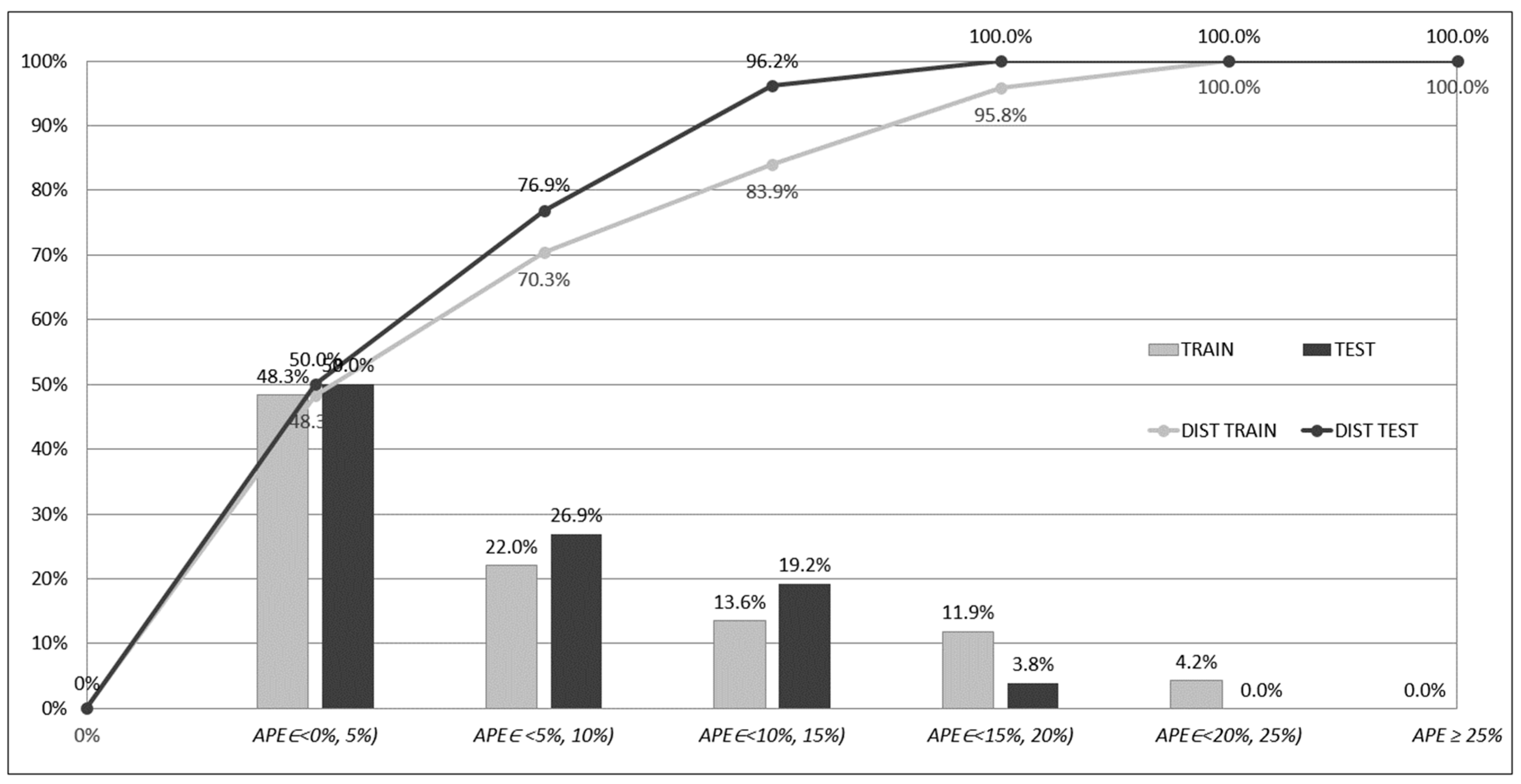
Figure 7,
Figure 8 and
Figure 9 depict frequencies and distributions of
APEp errors computed for the training and testing subsets for models based on ensembles of networks. The errors have been accumulated and counted in five intervals, whose ranges equalled 5%; one interval accumulated errors greater than 25%:
interval 1: 0% ≤ APEp < 5%,
interval 2: 5% ≤ APEp < 10%,
interval 3: 10% ≤ APEp < 15%,
interval 4: 15% ≤ APEp < 20%,
interval 5: 20% ≤ APEp < 25%,
interval 6: APEp ≥ 25%.
The columns in the
Figure 7,
Figure 8 and
Figure 9 show the percentage frequencies of the errors that have fallen into one of the intervals. The polylines show the distribution of the errors (cumulative frequencies according to the accepted order of intervals). In
Figure 7,
Figure 8 and
Figure 9, one can see that, in the case of the ENS AV and ENS SG1, only a few
APEp errors (19) are greater than 25%, and in the case of ENS SG2, none of them fall into this range. On the contrary, for networks acting separately, the significant number of errors is greater than 25%. These results can be explained through the analysis of the
APEp errors for the networks acting separately. For the networks acting separately (ANN1, ANN2, ANN3, ANN4, ANN5), many of the errors
APEp belonging to the interval 1 were relatively small and close to 0%. On the other hand, these small errors were accompanied by a significant number of errors
APEp ≥ 25%, and high values of
APEmax (compare
Table 7). In the case of the ensemble-based models, these errors have been compensated due to the ensemble averaging (ENS AV) or stacked generalisation (ENS SG1, ENS SG2).
The compensation resulted in the collection of most of the prediction errors in the first five intervals. One cost of this compensation is the decrease of the number of small errors, close to 0, in the first interval. The benefit of the compensation, however, is the improvement of the overall prediction performance and better knowledge generalisation. As mentioned previously, one can easily see that the best performance is offered by the ENS SG2 model as there were no errors APEp ≥ 25%.
The analysis of the research results leads to the conclusion that the employment of only one of the five selected networks (as presented in
Table 5) to support the prediction of
SOCind would burden the predictions with the choice of a network—this is confirmed by the distribution of points that represent expected and predicted values (
yp,
) in
Figure 3.
On the other hand, combining these five networks to form an ensemble compromises the strengths and weaknesses of the five ANNs—for some data, certain single-acting networks offered good predictions, whilst for others, there were weak predictions. Combining these networks into an ensemble allows for synergy. The decrease in APEmax, as well as more stable predictions, are the most beneficial from employment of the ensembles in the models. Furthermore, a risk of errors exceeding the critical level of 25%, in terms of percentage errors is reduced. These benefits have been achieved at some cost, mainly due to compensation of very small and very high errors offered by certain networks acting separately for certain training and testing patterns. However, the compensation of the errors from the ensemble-based models reduces the unwanted oversensitivity of the networks acting separately to certain training patterns.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}