3.1. Motivation
Consider the example formula,
F, and the activities of variables before the restart shown in
Table 1.
Since the VSIDS decision strategy increased the activity of variable that was involved in the conflict analysis,
Table 2 shows the activities scores of variables after the restart and constant conflicts. From
Table 3, we obtained the resulting assignment trail before the restart; “
xi→xj” means that variable
xi is a decision variable, and variable
xj is an implied variable. Then, the conflict occurs when
x7 is propagated at level 5. Due to first-UIP scheme, we obtained the learnt clause, ¬
x2˅¬
x3˅¬
x7.
From
Table 1,
Table 2,
Table 3 we can easily conclude that (1) CDCL solvers will favor more frequent restarts, causing only a few clauses to be learned between two restarts, and, consequently, the activity scores of some variables will change slightly because of the frequent restarts; (2) these variables are repeatedly assigned in the new trail, which is ensured by the phase-saving heuristic used by most CDCL solvers. Let us compare the assignment trails before and after the restart. As shown in
Table 3, the first seven assigned variables in both trails remain the same, albeit in a different order, namely, {
x1,
x5,
x2,
x6,
x4,
x3,
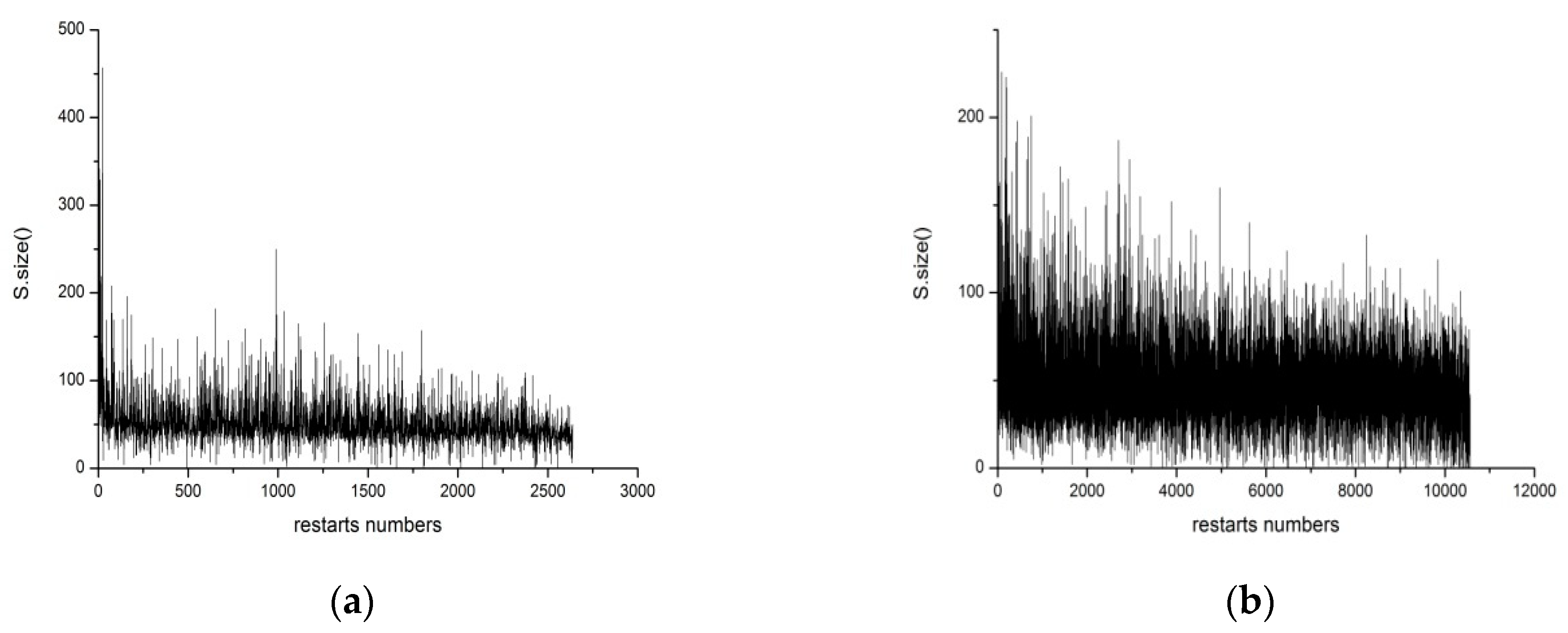
x8}. As previously mentioned, after restarting, the solver tends to reassign many of the assignment trails; that is to say, the assignment trail is duplicated. To clarify this phenomenon intuitively, we applied the solver, Glucose3.0, to solve an instance: Aaai10-planning-ipc5-pathways-13-step17.cnf, which has been randomly selected from the SAT Competition 2014 Application benchmark, by adopting the Luby restarts strategy and dynamic Glucose-restart strategy, respectively. From
Figure 1, the
x-axis represents the numbers of restarts, unlike restart schemes that generate different restart numbers. Meanwhile, the
y-axis represents the number of the duplicate assignment trails (the denotation of
S.size() will be discussed in
Section 3.2). It is visually obvious that the overwhelming majority of duplicate assignment trails are made by the solver, regardless of the restart strategy adopted by the solver.
3.2. Duplicate Trails
Referring to the example in
Section 3.1., the variable,
x1, which still has the highest VSIDS score after the restart, is chosen as the decision variable and is assigned as true again at level 1. Consequently, this will cause an implied literal
x5, and it is thus the same before and after the restart. Note that the second decision literal after the restart is
x2 and its implied literal is
x6, and it no longer matches the trail before the restart, where the decision literal is
x6 and the corresponding implied literal is
x2. In addition, the third decision literal and the fourth decision literal are also the same in both trails (between the two trails). Here, there are two literal assignment trails in the first four levels before and after the restart, that is
Sbefore = {
x1, ¬
x5,
x2,
x6,
x4,
x3,
x8} and
Safter = {
x1, ¬
x5,
x6,
x2,
x4,
x3,
x8,
x7}. The two search space, which is determined by the sequence,
Sbefore and
Safter, are the same since the search path according to
Sbefore is:
x1 = 1˄
x5 = 0˄
x2 = 1˄
x6 = 1˄
x4 = 1˄
x3 = 1˄
x8 = 1, equivalent to
x1 = 1˄
x5 = 0˄
x6 = 1˄
x2 = 1˄
x4 = 1˄
x3 = 1˄
x8 = 1, which is the search path of
Safter. Therefore, we define a sequence,
S, containing those variables (decision variables and propagation variables) that keeps the reduced formula the same before and after the restart, in the above example, as S = {
x1,
x5,
x2,
x6,
x4,
x3,
x8}. Consequently, we checked whether the assignment sequence,
S, is the same one as when each restart occurs. Noticeably,
S.size() stands for the number of duplicate assignment variables. In the above example,
S.size() = 7. The greater the value of
S.size(), the greater the number of matching variables. When the value of
S.size() remains large over a period of time, it indicates that the search path remains almost constant during this time. Aiming for this situation, the search path should be tuned by a dissimilar decision variable. Here is the sketch of the algorithm of the identification of duplicate trails.
In algorithm 2, suppose
xnext is the next assigned variable,
dl is the current decision level,
decisionLevel is the decision level before the restart, trail_order[] presents the variable assignment trail, and trail_order[
dl] presents the decision variable of the decision level,
dl. The assignment sequence is checked to ascertain whether it is the same after each restart or not; that is, deciding whether those variables, which are ahead of
xnext in the assignment sequence before the restart, are the same as those variables, which are ahead of
xnext in the assignment sequence after the restart. For another, those variables are sorted by activity in the assignment trail, so only the activity[trail_order[
dl]] value and activity[
xnext] value need to be judged. If the activity[
xnext] is greater than the activity[trail_order[
dl]], which shows existing repeated variables, then
S.size should be increased. When
S.size meets certain conditions, namely, MIN<=
S.size <= MAX, then the addition of counter
count is needed. If the value of
count is greater than a parameter
threshold, it indicates that the assignment sequence is always repeated, and the changeTrailOrder() function is used to change the activity value ordering of the variable; if not, the pickDecisionVar function continues to be used. However, the question is how to set the parameter values of the MIN, MAX, and
threshold for miscellaneous instances. Different parameters provide different behaviors. It is extremely tough to find a consistent ranking of solvers on the different sets of benchmarks. In the SAT community, experimental evidence is often required for any idea. We now show how we set the parameters of the MIN, MAX, and
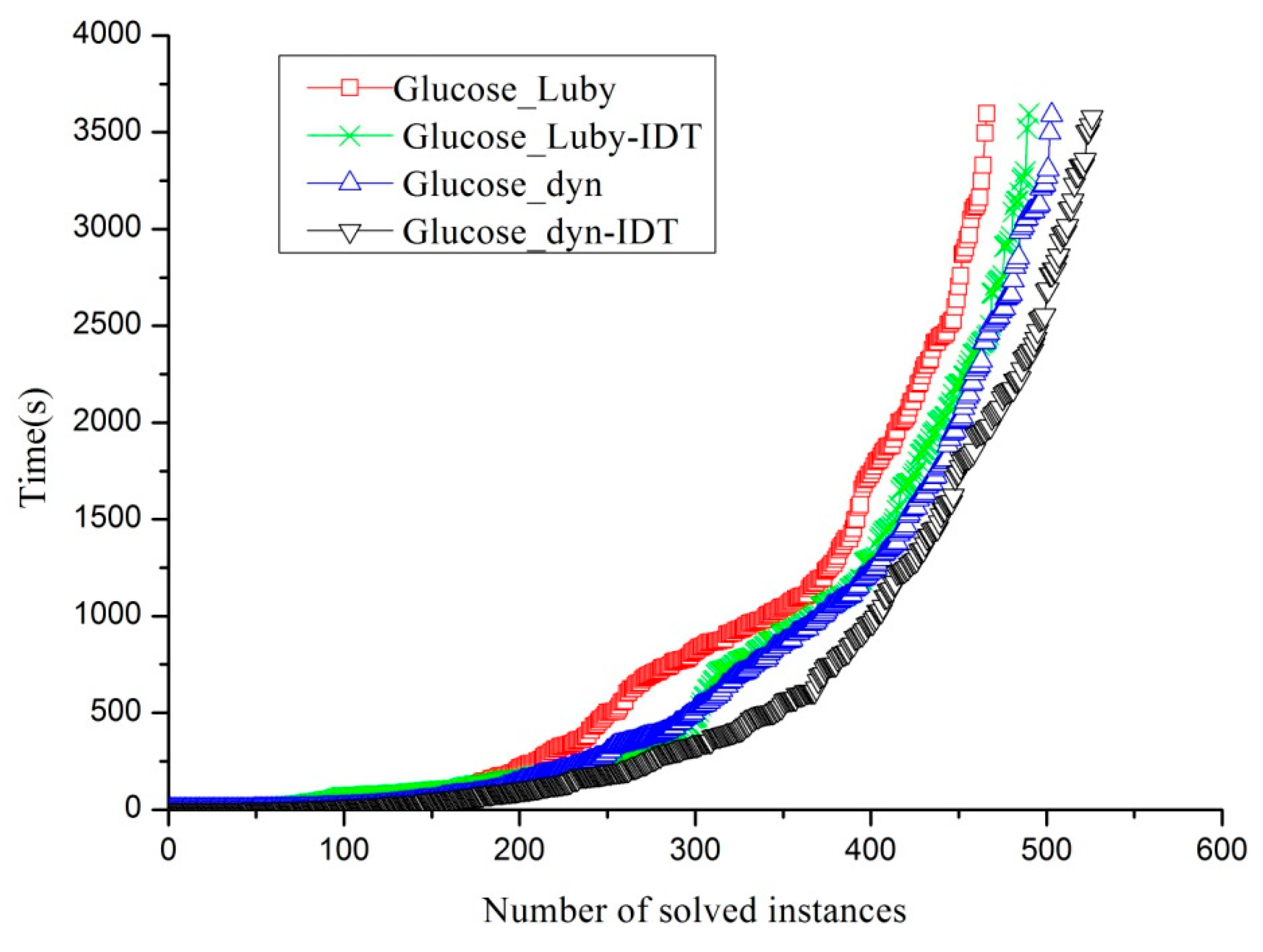
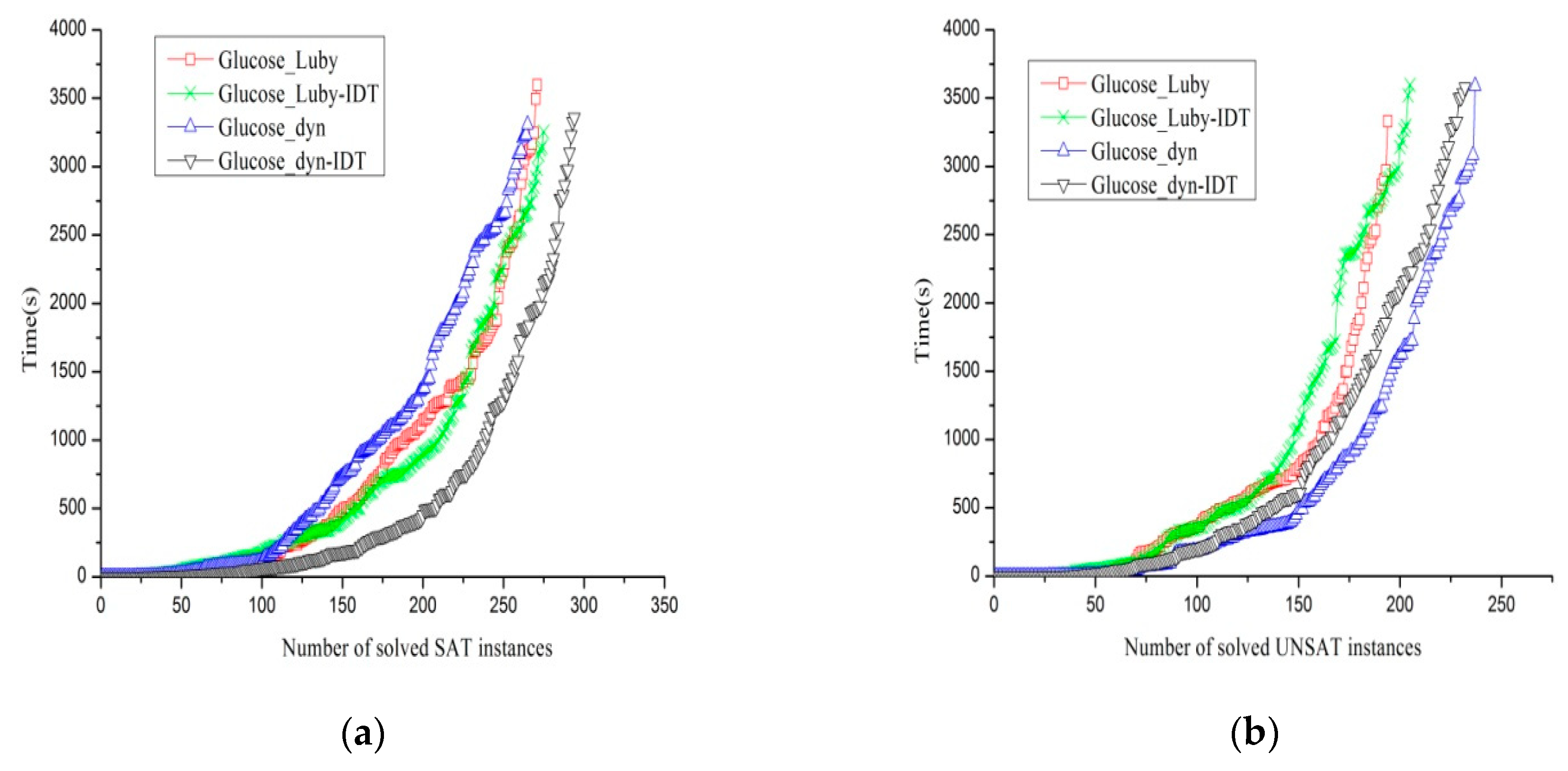
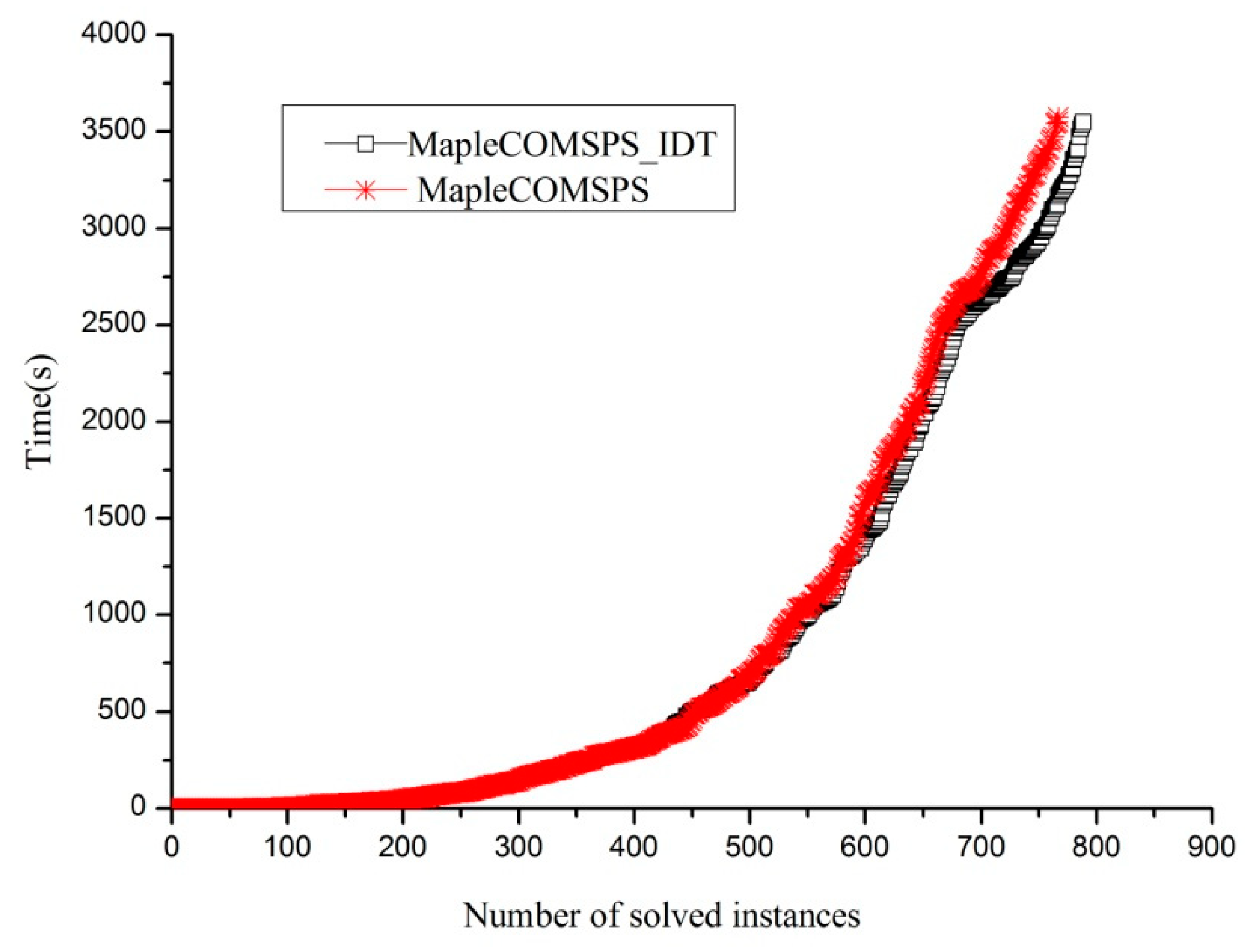
threshold by observing the performance of Glucose3.0 on the benchmarks, originally from the SAT 2015 Application benchmark only. Additionally, the CPU cutoff used was 1000 s. The Glucose3.0 solver is one of the award-winning SAT solvers in the corresponding competitive events since 2009.
Table 4 supplies the number of solved instances when changing the parameters. The parameters,
MIN = 20,
MAX = 50, and
threshold = 10, have the best performance compared to all the other parameters.
| Algorithm 2. Identification of duplicate trails |
| Input: variable score array activity[] |
| Output: call changeTrailOrder() or PickDecisionVar() |
| 1 count←0 |
| 2 for dl←1 to decisionLevel |
| 3 if activity[trail_order[dl]]< activity[xnext] |
| 4 then S.size++ |
| 5 end if |
| 6 end for |
| 7 if MIN<=S.size<=MAX |
| 8 then count++ |
| 9 end if |
| 10 if count>threshold |
| 11 then changeTrailOrder() |
| 12 else |
| 13 pickDecisionVar() |
| 14 end if |
The purpose of the changeTrailOrder() function is to change the sort order of variables in the trail, in essence, it is changing the activity of each variable. Certain branching heuristic strategies, which are adopted in modern CDCL solvers, increase the activity of those corresponding variables only by 1. The more the variable is associated with constructing the conflict, the larger its activity. In the subsequent process, variables with large activity values are preferred. Thus, it is believed that the easier it is to avoid conflicts that have occurred before, the easier it is to reduce the search space. However, due to restarts that are frequently used in modern SAT solvers leading to a similar learning process, this further leads to the similarity of a learnt clause and may cause the changing of activities of a few variables on this occasion, thus further generating the repeated assignment sequence. Therefore, to change the activity value of variable to a large extent, the additional bonus value is added according to the number of times that a variable is responsible for conflict analysis. If the number of times the variable participates in the conflict analysis is greater, the earlier the variable is selected for unit propagation, and the more likely the conflict will occur. Between the two restart intervals, the number of times each variable has participated in the conflict analysis process is counted, and the variable that has the maximum count value is recorded. When the changeTrailOrder() function is used, the activity of the variable that has the maximum count is increased by 100, with the purpose of tuning the sequence of the variables substantially.
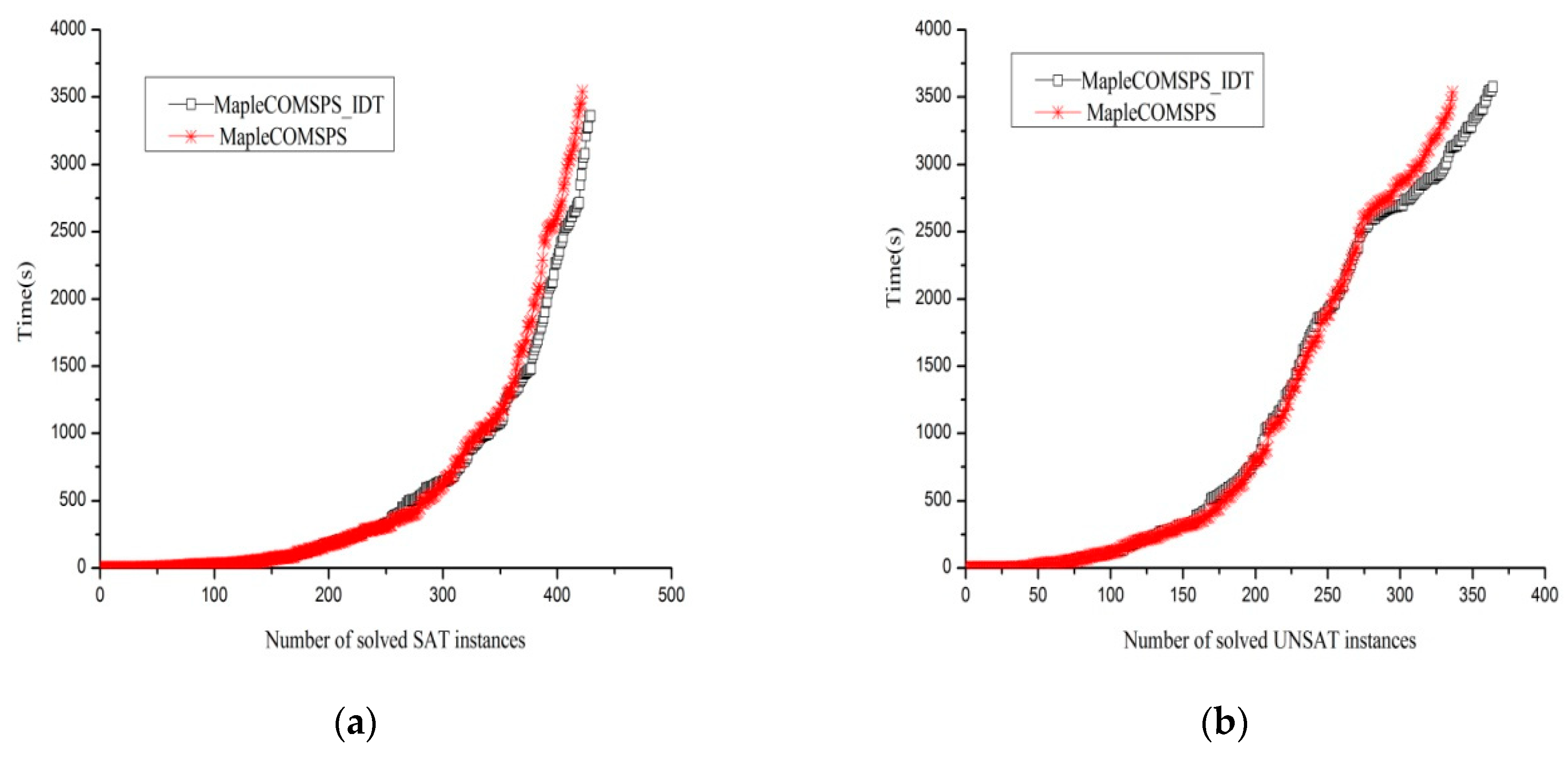
We conducted a comparison experiment by implementing the proposed algorithm 2 as the part of Glucose3.0, using two kinds of different restart policies for each to solve the aaai10-planning-ipc5-pathways-13-step17.cnf instance.
From
Figure 2, it is evident that plenty of S.size() = 0 exists. Apparently, S.size() is equal to zero, which shows that the assignment trail did not contain a repeated variable and searched from a diverse path, hence it reveals that changing the order of the variables has a role in choosing a different path, and further illustrates the effectiveness of this algorithm. Additionally, from
Figure 1b, we can see that the value of S.size() is approximately between 20 and 80. Meanwhile, after utilizing the proposed method, it is shown that the value of S.size() is between 0 and 20. This kind of phenomenon, on the one hand, means that the reduction of the value of S.size() implies that the number of duplicate assignment trails is decreasing. On the other hand, it further indicates that the proposed strategy is workable, due to the fact that it dynamically tunes decision variables and hence explores different branches.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}