Analytic Loss Minimization: Theoretical Framework of a Second Order Optimization Method

Abstract
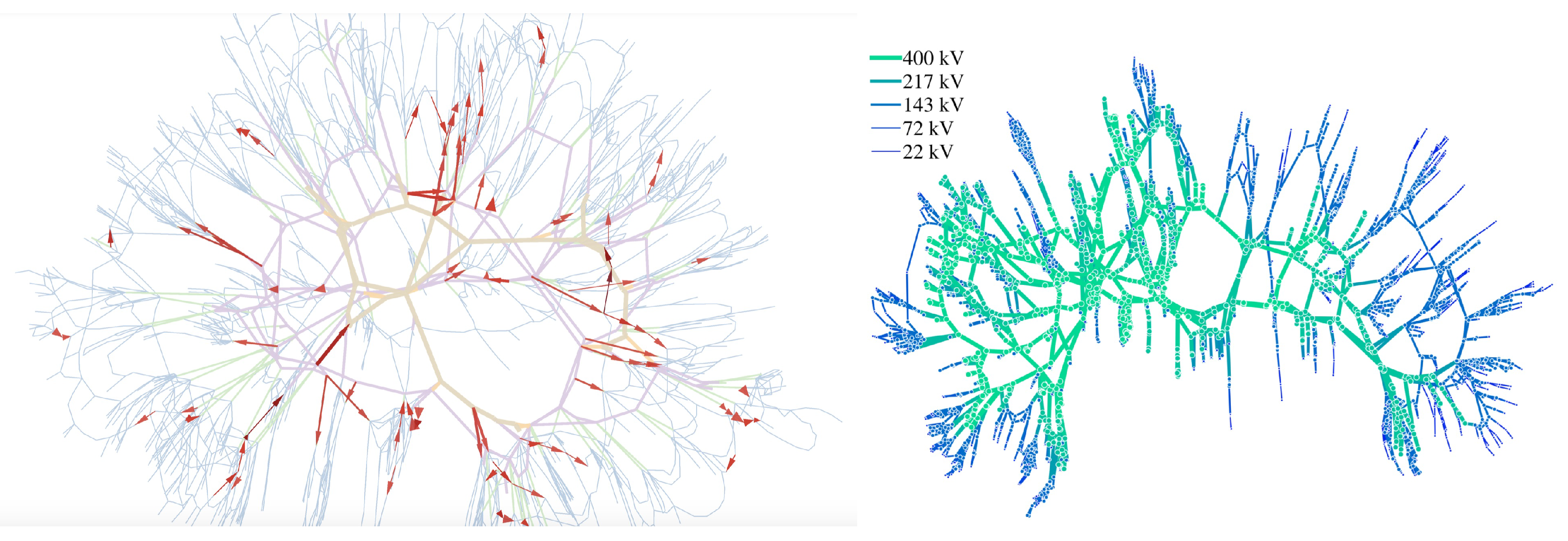
:1. Introduction
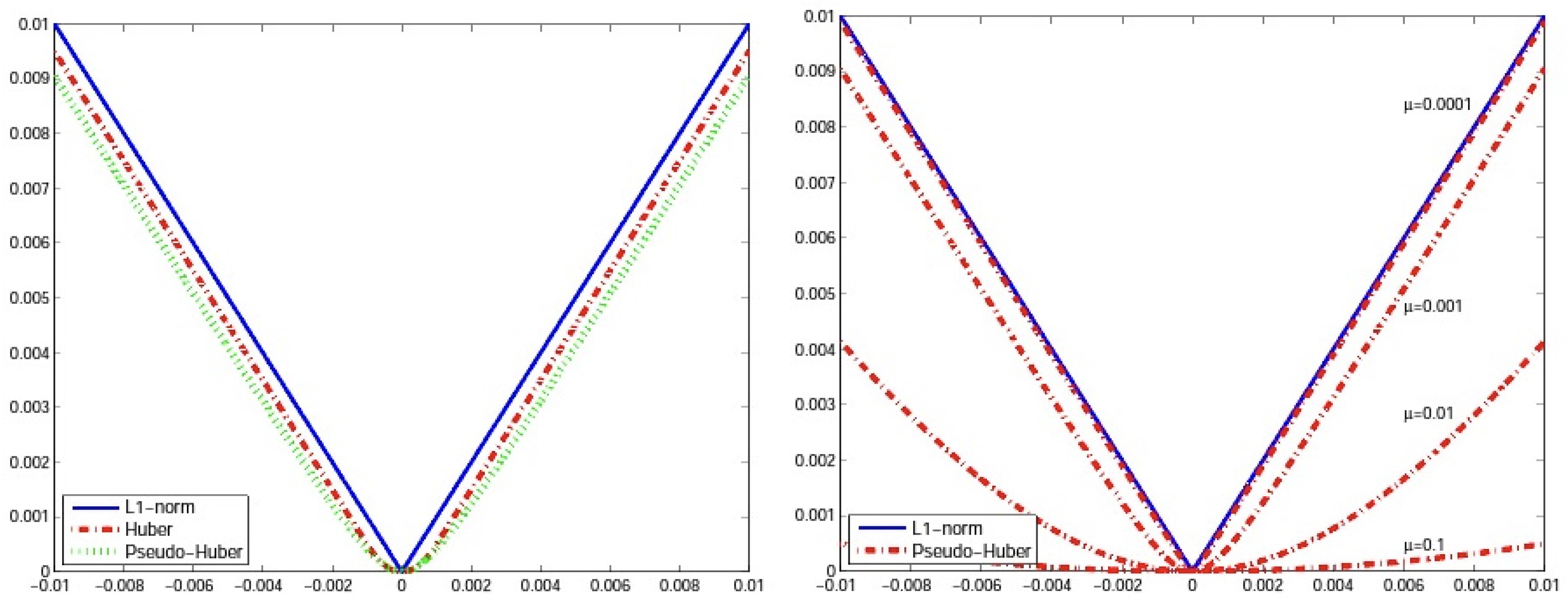
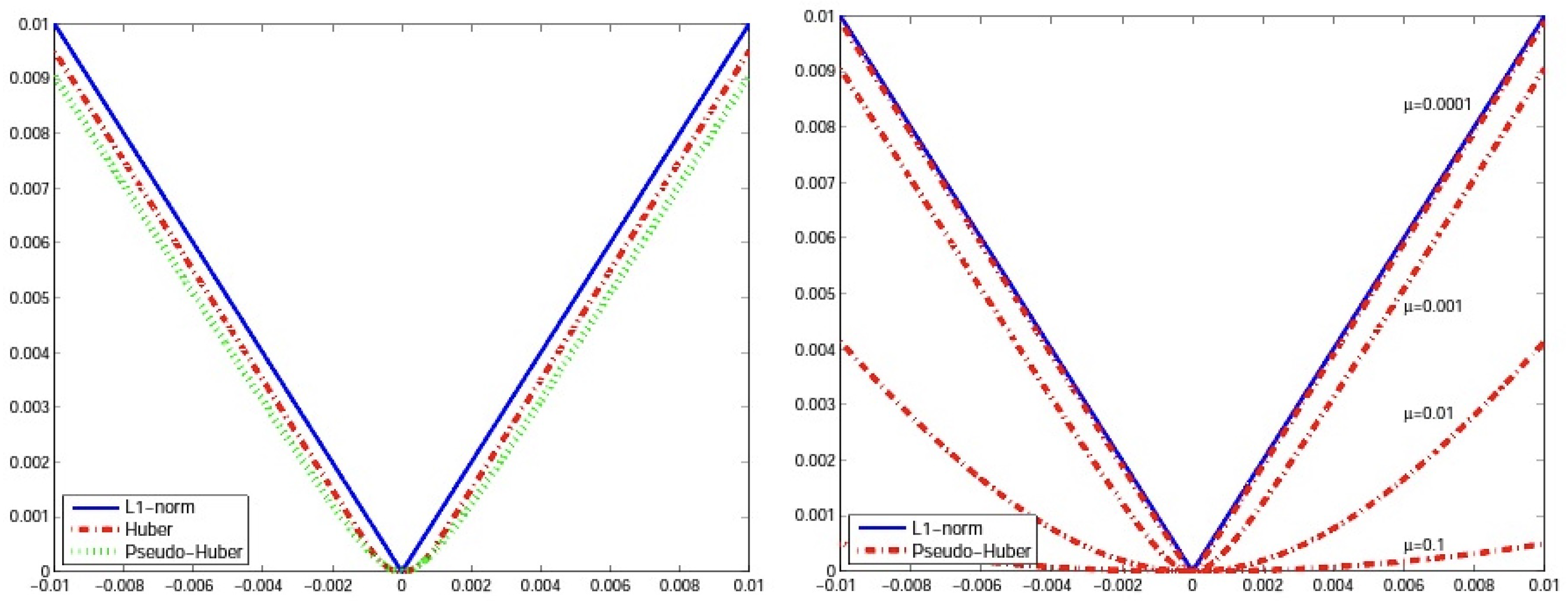
2. Mathematical Background
3. Main Results
4. Conclusions
Funding
Conflicts of Interest
References
- MD1: Structural and Dynamic Modelling of Integrated Energy Systems. Available online: https://esipp.ie/research/modelling (accessed on 26 January 2019).
- Dassios, I.; Keane, A.; Cuffe, P. Calculating Nodal Voltages Using the Admittance Matrix Spectrum of an Electrical Network. Mathematics 2019, 7, 106. [Google Scholar] [CrossRef]
- Kessel, P.; Glavitsch, H. Estimating the voltage stability of a power system. IEEE Trans. Power Deliv. 1986, 1, 346–354. [Google Scholar] [CrossRef]
- Thukaram, D.; Vyjayanthi, C. Relative electrical distance concept for evaluation of network reactive power and loss contributions in a deregulated system. IET Gener. Transm. Distrib. 2009, 3, 1000–1019. [Google Scholar] [CrossRef]
- Visakha, K.; Thukaram, D.; Jenkins, L. Transmission charges of power contracts based on relative electrical distances in open access. Electr. Power Syst. Res. 2004, 70, 153–161. [Google Scholar] [CrossRef]
- Vyjayanthi, C.; Thukaram, D. Evaluation and improvement of generators reactive power margins in interconnected power systems. IET Gener. Transm. Distrib. 2011, 5, 504–518. [Google Scholar] [CrossRef]
- Yesuratnam, G.; Thukaram, D. Congestion management in open access based on relative electrical distances using voltage stability criteria. Electr. Power Syst. Res. 2007, 77, 1608–1618. [Google Scholar] [CrossRef]
- Merris, R. Laplacian matrices of graphs: A survey. Linear Algebra Appl. 1994, 197, 143–176. [Google Scholar] [CrossRef]
- Sanchez-Garcia, R.J.; Fennelly, M.; Norris, S.; Wright, N.; Niblo, G.; Brodzki, J.; Bialek, J.W. Hierarchical spectral clustering of power grids. IEEE Trans. Power Syst. 2014, 29, 2229–2237. [Google Scholar] [CrossRef]
- Cuffe, P.; Dassios, I.; Keane, A. Analytic Loss Minimization: A Proof. IEEE Trans. Power Syst. 2016, 31, 3322–3323. [Google Scholar] [CrossRef]
- Dassios, I.K.; Cuffe, P.; Keane, A. Visualizing voltage relationships using the unity row summation and real valued properties of the FLG matrix. Electr. Power Syst. Res. 2016, 140, 611–618. [Google Scholar] [CrossRef]
- Abdelkader, S.M.; Morrow, D.J.; Conejo, A.J. Network usage determination using a transformer analogy. IET Gener. Transm. Distrib. 2014, 8, 81–90. [Google Scholar] [CrossRef]
- Abdelkader, S.M.; Flynn, D. A new method for transmission loss allocation considering the circulating currents between generator. Eur. Trans. Electr. Power 2010, 20, 1177–1189. [Google Scholar] [CrossRef]
- Abdelkader, S.M. Characterization of transmission losses. IEEE Trans. Power Syst. 2011, 26, 392–400. [Google Scholar] [CrossRef]
- Dassios, I.; Fountoulakis, K.; Gondzio, J. A preconditioner for a primal-dual newton conjugate gradient method for compressed sensing problems. SIAM J. Sci. Comput. 2015, 37, A2783–A2812. [Google Scholar] [CrossRef]
- Dassios, I.; Baleanu, D. Optimal solutions for singular linear systems of Caputo fractional differential equations. Math. Methods Appl. Sci. 2018. [Google Scholar] [CrossRef]
{kind=link}
{kind=link}
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dassios, I.K. Analytic Loss Minimization: Theoretical Framework of a Second Order Optimization Method. Symmetry 2019, 11, 136. https://doi.org/10.3390/sym11020136
Dassios IK. Analytic Loss Minimization: Theoretical Framework of a Second Order Optimization Method. Symmetry. 2019; 11(2):136. https://doi.org/10.3390/sym11020136
Chicago/Turabian StyleDassios, Ioannis K. 2019. "Analytic Loss Minimization: Theoretical Framework of a Second Order Optimization Method" Symmetry 11, no. 2: 136. https://doi.org/10.3390/sym11020136
APA StyleDassios, I. K. (2019). Analytic Loss Minimization: Theoretical Framework of a Second Order Optimization Method. Symmetry, 11(2), 136. https://doi.org/10.3390/sym11020136