1. Introduction
In multiple-criteria decision-making (MCDM) problems, fuzzy set theory, proposed by Zadeh, is an effective alternative to characterize uncertainty and complexity [
1]. Fuzzy set theory can systematically process linguistic information from decision-makers (DMs) or experts in decision-making problems [
2,
3]. In traditional MCDM, there exists a basic assumption that DMs are rational [
4,
5,
6,
7]. Nevertheless, DMs are usually not rational decision-makers, and real decision-making behavior often deviates from the prediction of expected utility. That is, DMs’ nonrational preferences have a critical impact on the associated decision-making results. To characterize DMs’ nonrational preferences, some non-expected utility functions have been proposed, such as prospect theory [
7], rank-dependent utility [
8], and loss aversion utility [
9]. The most striking of the non-expected utility functions is prospect theory. Prospect theory is the most influential theory of decision-making with uncertain information. Different from expected utility theory, prospect theory evaluates the outcomes with respect to some reference outcome, where gains or losses are called prospects. The value function in prospect theory characterizes the phenomenon that losses loom larger than gains. The probability weighting function describes the phenomenon that DMs overweight (or underweight) small (moderate to large) probabilities. The empirical works on psychological behavior justify prospect theory [
10]. That is, decisions made based on prospect theory are in line with real decision-making [
11,
12,
13,
14].
In addition, in MCDM problems, fuzzy set theory provides an effective mathematical method to process the uncertainty of DMs’ judgement. A DM’s mind can be highly modeled by the linguistic variables that are characterized by fuzzy numbers. For instance, “the car is good”, “the stability is high”, and so on. However, it fails to adequately describe a more complex situation involving hesitant and probabilistic information simultaneously. For example, the mobile phone is good at a probability of 0.7, and the mobile phone is “medium good” at a probability of 0.3, etc. For such situations, Dempster and Shafer proposed evidence theory [
15,
16]. As a reasoning method for uncertain information, a belief structure derived from evidence theory can adequately represent the uncertainty involving DMs’ judgement [
17,
18,
19], which apples to numerous fields, including pattern recognition [
20,
21], risk assessment [
22,
23], identification of influential nodes [
24,
25], etc. [
26,
27,
28]. By making use of belief structures, the various types of uncertainty in the decision-making process can be described adequately. This paper adopts belief structures to describe the decision-making situations involving hesitant and probabilistic information simultaneously.
By reviewing the above works on MCDM problems, it was found that there are some gaps in the extant literature. (1) Although the psychological preferences of DMs are considered in the extant MCDM works based on prospect theory, these works do not involve the various types of uncertainty, such as hesitant and probabilistic information. That is, the method based on prospect theory cannot deal with MCDM problems involving hesitant and probabilistic information simultaneously. (2) Evidence theory addresses the problems of the various types of uncertainty in the existing MCDM works, but the literature fails to consider the psychological preferences of DMs, except Nusrat and Yamada [
29]. However, Nusrat and Yamada only showed a descriptive decision-making model and ignored the various types of uncertainty in the decision-making process.
Consequently, a novel method is proposed in this paper. It takes into account the following two situations: (1) DMs show nonrational preferences that are taken into account based on prospect theory; (2) the experts’ subjective judgment of criteria involves hesitant and probabilistic information simultaneously. In this paper, we consider an MCDM problem with hesitant and probabilistic information, where DMs present behaviors of nonrational preferences. A novel method, called the evidential prospect theory framework, is developed based on evidence theory and prospect theory. Within the proposed framework, belief structures derived from evidence theory are applied to characterize the experts’ uncertainty about the subjective assessment of criteria for different alternatives, which involves hesitant and probabilistic information simultaneously. Prospect theory models DMs’ nonrational preferences. Then, by combining belief structures, the weighted average method is applied to estimate the final aggregated weighting factors of different alternatives. Furthermore, the expected prospect values of different alternatives are derived from the final aggregated weighting factors and prospect theory, which is applied to the ranking order of all alternatives.
Compared to the existing models that address MCDM problems, the evidential prospect theory framework has two advantages: First, the proposed framework characterizes decision-making situations involving hesitant and probabilistic information simultaneously. Second, the proposed framework considers DMs’ nonrational preferences. Since the extant works still have not referred to hesitant and probabilistic information and nonrational preferences simultaneously, the proposed framework fills the research gap involving hesitant and probabilistic information and nonrational preferences simultaneously in MCDM problems. In addition, the proposed framework in this paper can apply to green supplier selection in the field of sustainability. Although MCDM is an effective approach to green supplier evaluation, the existing MCDM models ignore either the various types of uncertainty in the decision-making process or DMs’ nonrational preferences [
30,
31]. The proposed framework considers not only the various types of uncertainty but also DMs’ nonrational preferences. Thus, the proposed framework in this paper is an effective method to select green suppliers, since the results derived by this framework are more in line with DMs’ real decision-making.
The paper proceeds as follows. In
Section 2, evidence theory, prospect theory, and hesitant fuzzy sets are reviewed. In
Section 3, a novel score function is introduced. In
Section 4, the evidential prospect theory framework is developed. In
Section 5, a case involving a parabolic trough concentrating solar power plant (PTCSPP) is shown to illustrate the application of the proposed method. Conclusions are drawn in
Section 6.
3. A Novel Score Function
Ranking fuzzy information plays a critical role in decision-making problems involving imprecise information; existing ranking methods were introduced based on score functions, which map fuzzy information into the real numbers. First, several existing score functions for HFEs are reviewed. Then, a novel score function is proposed.
Definition 2 [
36]
. Let an HFE be denoted by , is called the score function, where l(h) is the number of elements in the HFE. For two HFEs h1 and h2, if S(h1) > S(h2), then , i.e., h1 is superior to h2. If S(h1) = S(h2), then , i.e., h1 is indifferent to h2. An interesting observation is that is not reasonable in some cases when S(h1) = S(h2), since S(h) is the average value of all elements in h.
Definition 3 [
38]
. Let be an HFE, where l(h) is the number of elements in h. A score function iswhere β(τ) (τ = 1, 2, …, l(h)) is increasing with τ and β(τ) > 0. For two HFEs h1 and h2, if S′(h1) > S′(h2), then , which means that h1 is superior to h2. If S′(h1) = S′(h2), then , which means that h1 is indifferent to h2. From Definition 3, it follows that a higher element in h has a greater weight value β(τ). For instance, β(τ) =τ/[10 l(h)], so DMs not only overweight small probabilities but also underweight moderate to large probabilities. Thus, a novel score function is proposed by using the probability weighting function shown in Equation (2).
Definition 4. Let be an HFE, where l(h) is the number of elements in h. A score function is defined as follows:where , β(τ) (τ = 1, 2, …, l(h)) is increasing with τ and β(τ) > 0. From Definition 4, it follows that the comparison laws are as follows.
Definition 5. For two HFEs h1 and h2, if S″(h1) > S″(h2), then
, i.e., h1 is superior to h2. If S″(h1) = S″(h2), then , i.e., h1 is indifferent to h2.
Proposition 1. The score function S″(h) lies in [0, 1] for any HFE h.
Proof. Let
,
and
; since
γτ ∈[0, 1] for
τ = 1, 2, …,
l(
h),
and
Obviously, 0 ≤ S″(h) ≤ 1, i.e., S″(h)∈[0, 1]. □
Example 1. Let h1 = {0.3, 0.5}, h2 = {0.4}, and h1 = {0.2, 0.4, 0.6} be three HFEs. It follows from Definition 2 that S(h1) = S(h2) = S(h3) = 0.4, which means . By applying Definition 3, we can obtain S′(h1) = 0.383, S′(h2) = 0.4, and S′(h3) = 0.467, which means . By applying the proposed score function, we have S″(h1) = 0.1719, S″(h2) = 0.4, and S″(h3) = 0.1837, which means .
In Example 1, the ranking order of HFEs derived from Definition 4 is not consistent with those obtained by Definitions 2 and 3, since Definition 2 only considers the average value of all elements in the HFEs, while Definition 3 ignores the nonrational behavior of DMs. The novel score function proposed in this paper considers the nonrational behavior of DMs, where DMs not only overweight small probabilities but also underweight moderate to large probabilities. This implies that the ranking order derived from Definition 4 is more consistent with human behavior.
4. The Evidential Prospect Theory Framework
4.1. Evidential Decision-Making Problems
Let
A denote a decision matrix, the factors of which consist of finite alternatives
Ai and finite criteria
Cj, where
i = 1, 2, 3,…,
t and
j = 1, 2, 3, …,
n.
xij is used to measure the rating of the alternative Ai based on the criterion Cj. is a weight vector on the criteria satisfying and .
To compare these alternatives, a group of linguistic terms is defined, including seven assessment grades ranging from “very poor” to “very good”. These are shown in
Table 1.
Multiple domain experts produce estimates of each criterion for each alternative, which are characterized by belief structures. Let a belief structure
proposed by expert
k be the evaluation value with respect to criterion
Cj for alternative
Ai, where the focal element
given by expert
k is a set of linguistic terms with respect to
Cj for
Ai. Evaluation values of the criteria for all alternatives given by all experts are shown in
Table 2.
Now, the utility function for each linguistic term is defined; this is characterized by an HFS, as shown in
Table 3.
4.2. Combining Belief structures
A weighted average method, introduced in
Section 2, was adopted to calculate the final belief structure. Specifically, the Jousselme distance between two belief structures
and
is
where
.
The similarity degree between
and
is given by
A larger similarity degree between
and
leads to a larger support degree. Note that the support degree is a degree supported by other evidence, and the support degree is
For a piece of evidence, the higher the support degree, the higher the credibility degree with respect to it would be. The credibility degree for belief structure
, also called the weighting factor, is
Thus, the average belief structure can be obtained by
where
.
The final belief structure combining
is
where
.
Since the
weight vector of the criteria is
, the average belief structure for alternative
Ai is
The final aggregated belief structure for each alternative can be calculated by
where
.
4.3. Applying Prospect Theory
Before using prospect theory, according to Definition 4, the utility values with respect to the assessment grades are defuzzified by applying the novel score function. Defuzzifying the utility value on different linguistic terms is denoted by S(*), where * = {VP, P, MP, M, MG, G, VG}.
After combining belief structures and defuzzifying the utility values of the assessment grades, we introduce prospect theory into the model. First, the associated parameters in prospect theory are determined. As described in
Section 2.2, the risk aversion coefficients are
α =
β = 0.88, the loss aversion coefficient is
λ = 2.25 and
r = 0.65. The final aggregated belief structure is regarded as the probability function. The next step is the selection of a reference point, which is very important in MCDM based on prospect theory. Outcomes below (above) a reference point are regarded as losses (gains). The linguistic term “
M” is regarded as the reference point, since such an assessment grade means that with probability 0.5 a criterion is good or bad.
The value function is calculated by
Then, the probability weighting function is
where
is the final aggregated belief structure with respect to the assessment grade for alternative
AiThe expected prospect value of each alternative is
Obviously, a larger leads to a better Ai. Thus, from the increasing order of with respect to the alternative Ai, the ranking order of all alternatives is shown. Suitable alternatives can be chosen according to the ranking order.
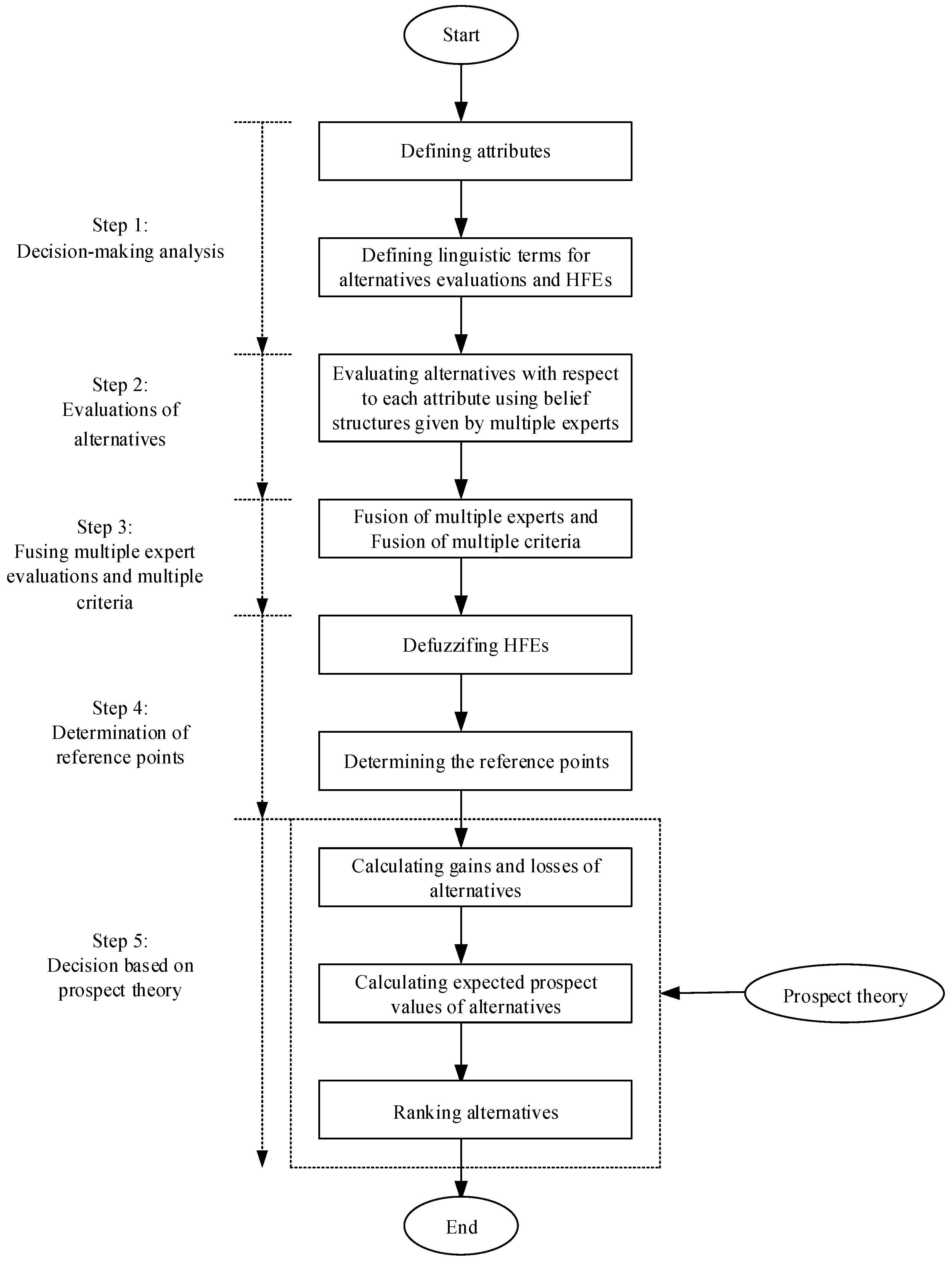
Here, a flow diagram with respect to the evidential prospect theory framework is shown in
Figure 1. Specifically, the flow of the evidential prospect theory framework consists of five steps, i.e., decision-making analysis, evaluation of alternatives, fusion of evaluations, determination of reference points, and making the decision based on prospect theory, respectively.
Step 1: The task of evaluating alternatives is translated to an MCDM. Firstly, the weights of the criteria are defined. Then, for each criterion, the linguistic terms are presented.
Step 2: Evaluations of criteria for the alternatives are given by multiple domain experts. The evaluation results with respect to each criterion are characterized as a belief structure.
Step 3: In the fusion of the multiple expert evaluations, the evaluations with respect to each criterion for each alternative are combined according to the weighted average method, where the weighting factor for each evaluation is given by Equation (6). The final aggregated evaluation values for the alternatives are calculated by Equations (9) and (10).
Step 4: The HFEs are defuzzified and the reference points are determined.
Step 5: It follows from Equation (12) that the expected prospect value of each alternative will be obtained. The ranking order is presented according to the expected prospect values. That is, the most suitable alternative is chosen.
6. Conclusions
Uncertain information and DMs’ nonrational behavior have received extensive attention in MCDM problems. In this paper, the evidential prospect theory framework was proposed to address MCDM problems involving hesitant and probabilistic information and nonrational behavior simultaneously. Within the proposed framework, belief structures are applied to characterize the subjective evaluations by experts of criteria for alternatives. Belief structures are fused by using a weighted average method such that the final aggregated weighting factor is determined. By combining prospect theory with belief structures, the ranking order of alternatives is determined, which can identify the most desirable alternative. The evidential prospect theory framework provides a simple and general method for MCDM problems involving hesitant and probabilistic information and nonrational behavior simultaneously. The evidential prospect theory framework proposed in this paper has two advantages: First, it makes use of evidence theory to model the various types of uncertainty in the decision-making process. Here, belief structures are applied to characterize experts’ subjective assessments of criteria for alternatives, which involve hesitant and probabilistic information simultaneously. Second, the application of prospect theory takes into account DMs’ nonrational behavior in the MCDM problems, so the decision-making results are more reasonable.
Although the evidential prospect theory framework proposed in this paper can address MCDM problems involving hesitant and probabilistic information and nonrational behavior simultaneously, the proposed framework still has its limitations. In particular, the evidential prospect theory framework was proposed under the assumption that the behaviors of DMs are not influenced by others. It is very likely that this assumption is violated, since it is inevitable that each person may be influenced by others’ behaviors in the real world. Thus, solving the interaction between decision-makers in MCDM problems will be a valuable future research topic.





{kind=link}
{kind=link}