Self-Supervised Contextual Data Augmentation for Natural Language Processing



Abstract
:1. Introduction
2. Related Work
2.1. Self-Supervised Learning
2.2. Data Augmentation
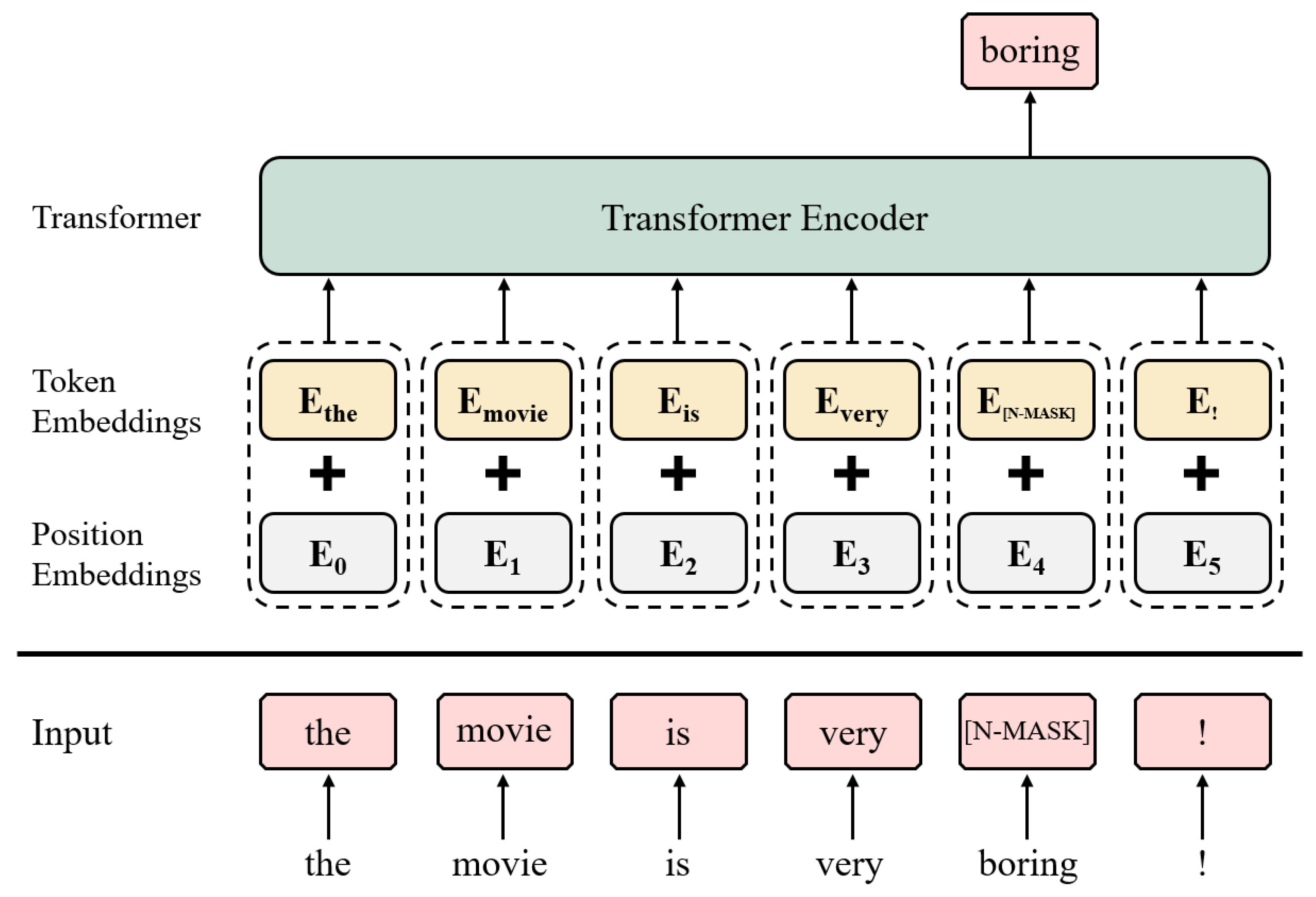
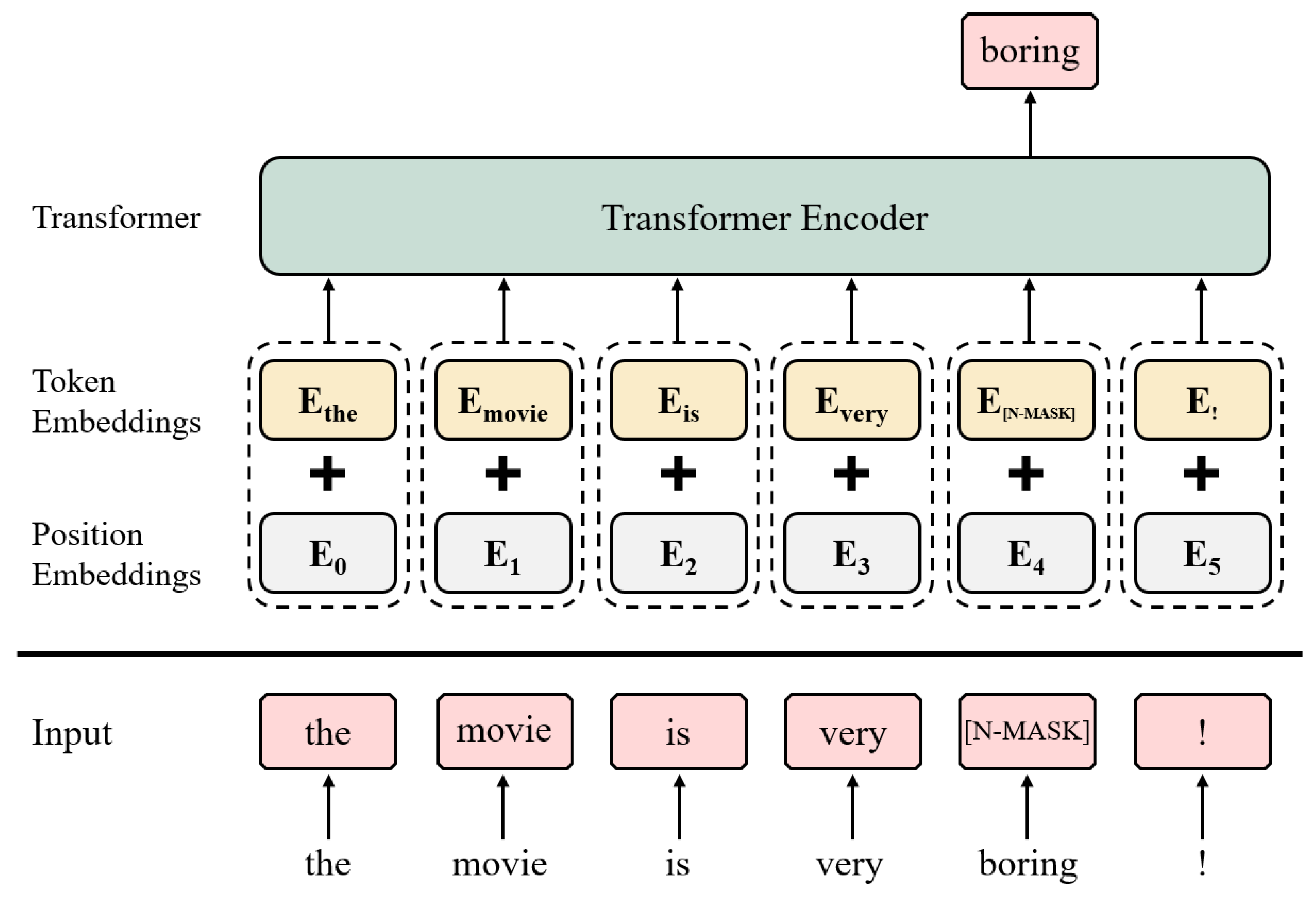
2.3. Transformer and Transformer Encoder
2.4. Masked Language Model
3. Proposed Method
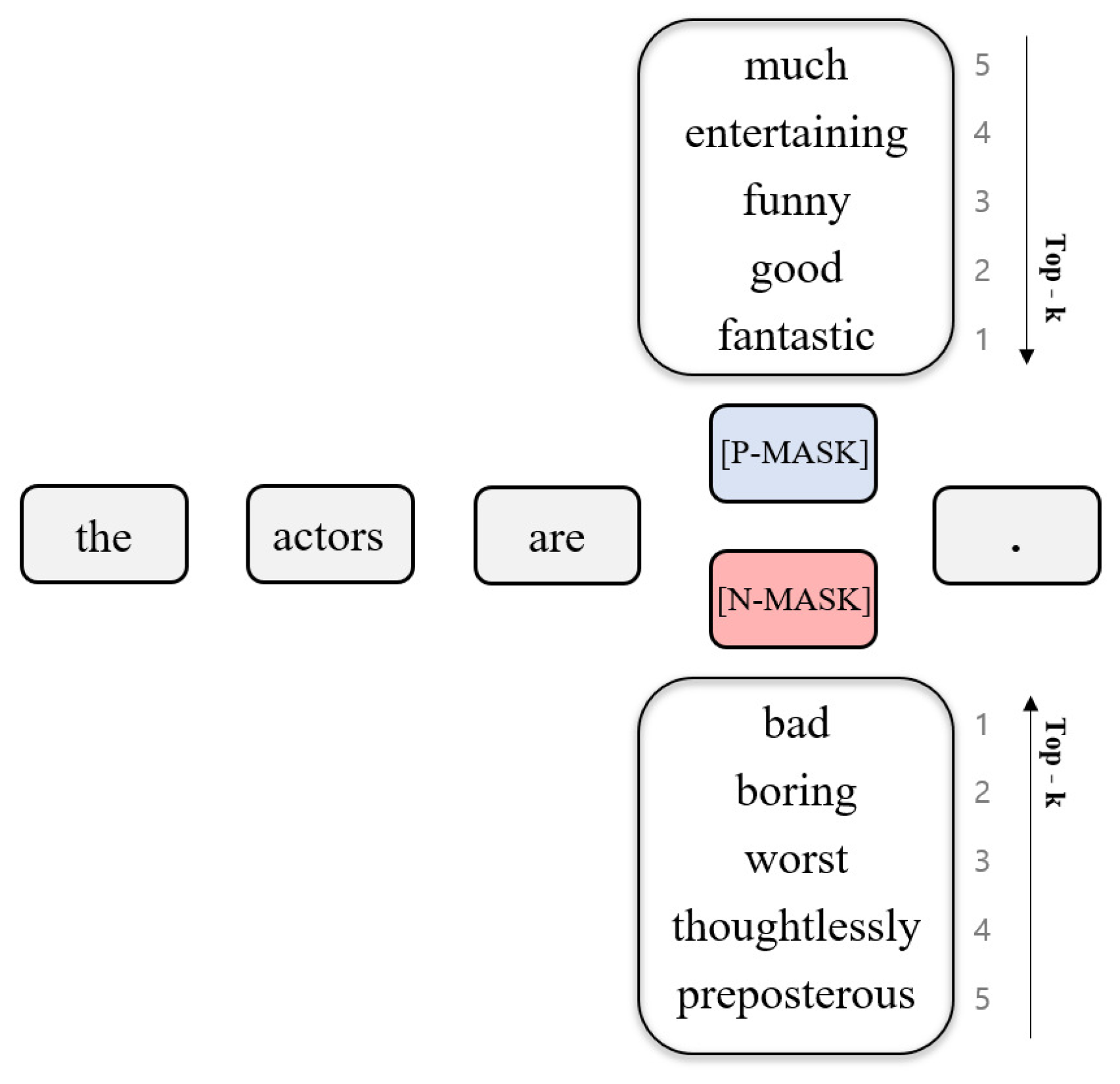
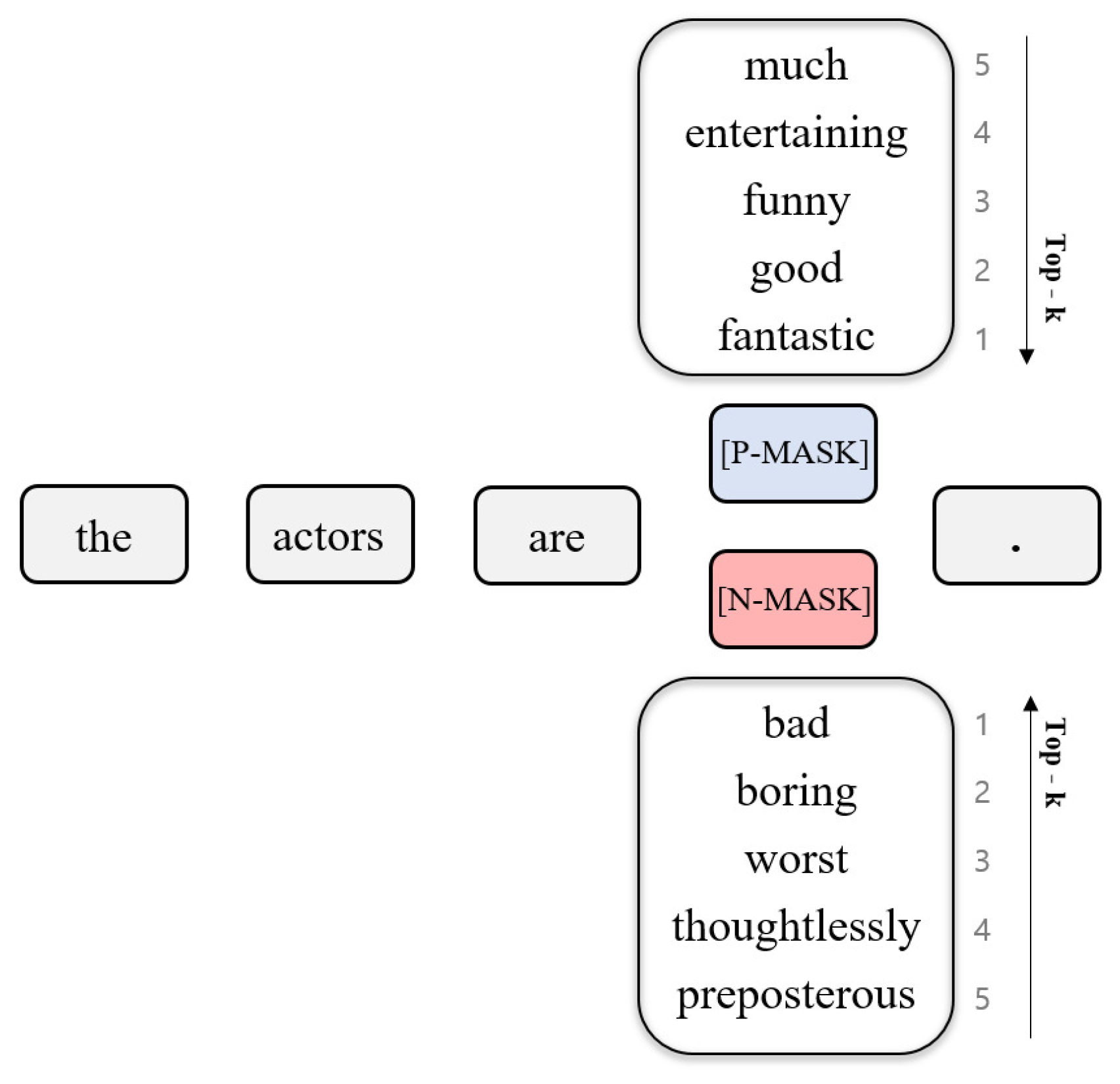
3.1. Label-Masked Language Model
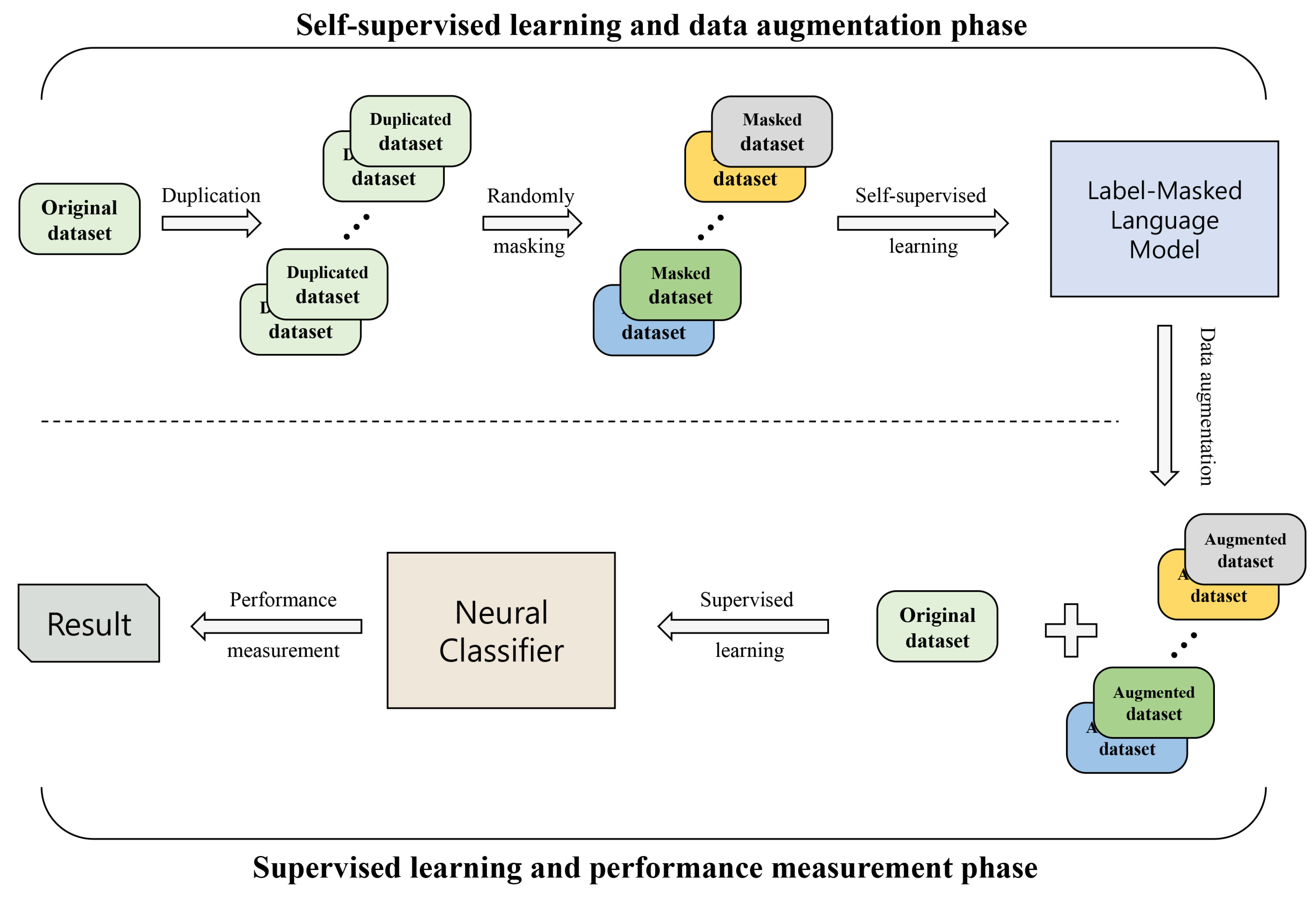
3.2. Self-Supervised Contextual Data Augmentation
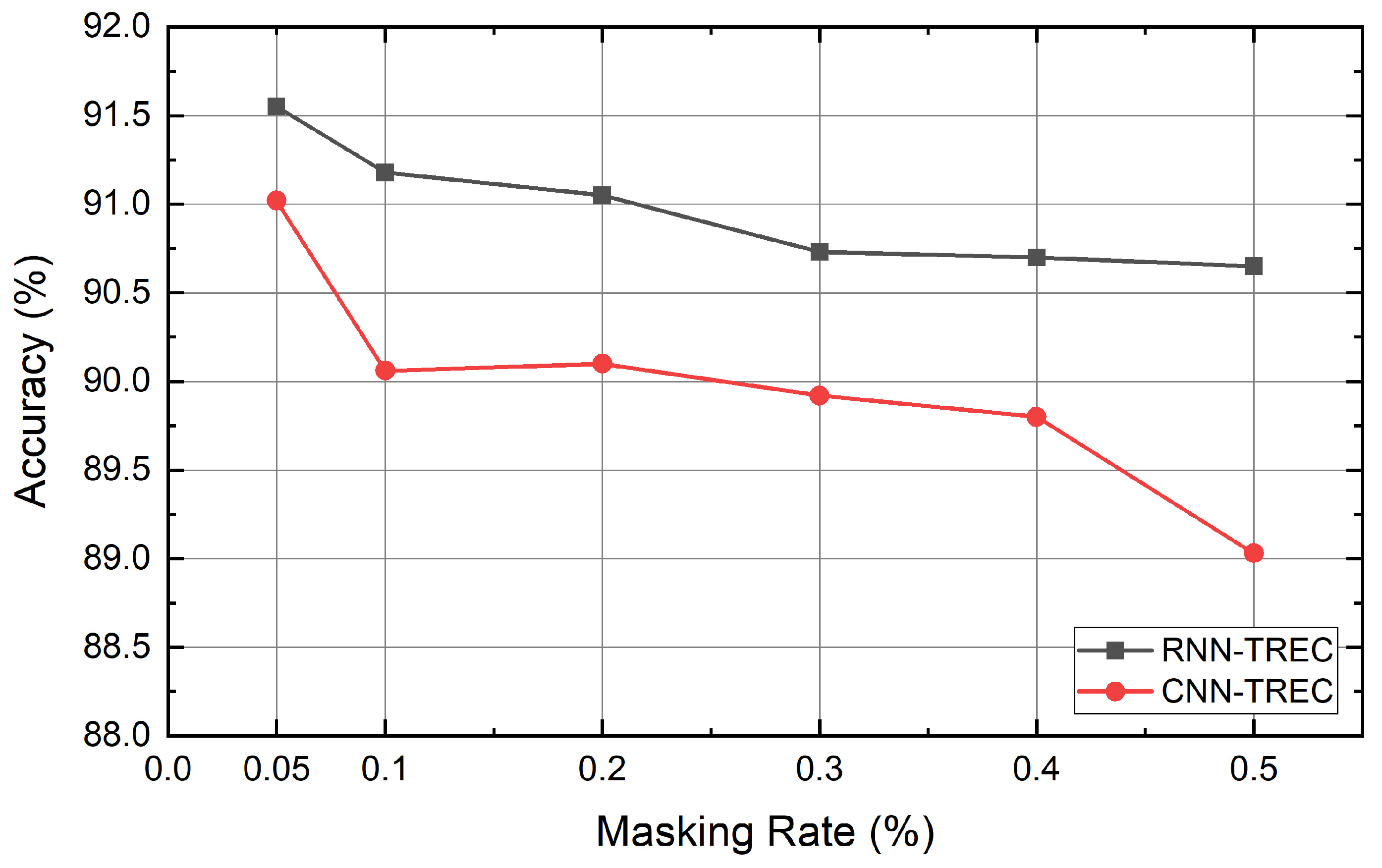
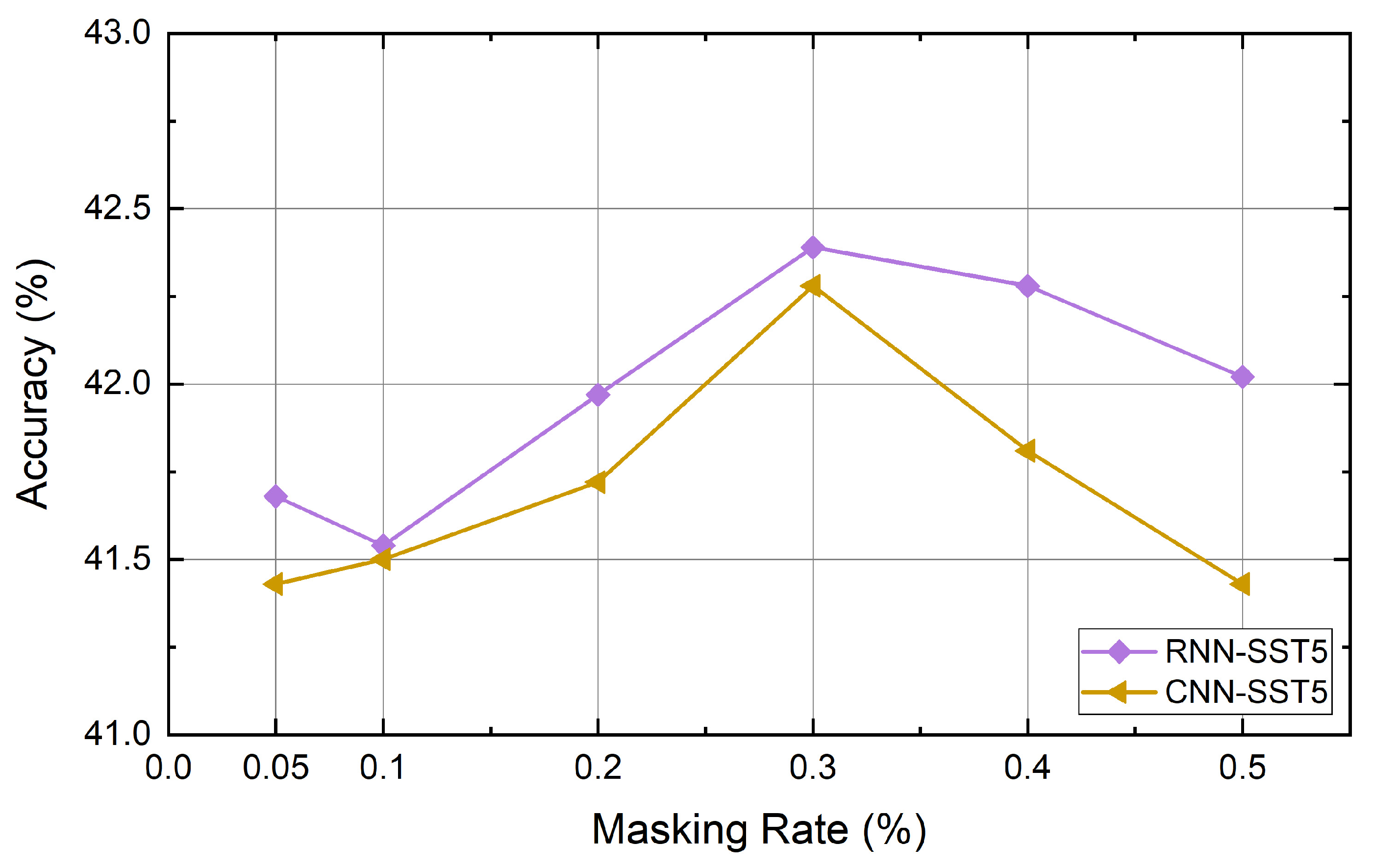
4. Experiment and Results
4.1. Experiments Setup
4.2. Datasets
- SST5: The Stanford Sentiment Treebank-5 is data for emotion classification tasks, which contains movie reviews with five labels (very positive, positive, neutral, negative, and very negative) [46].
- SST2: The Stanford Sentiment Treebank-2 is the same as SST5 but eliminates neutral reviews and has binary labels (positive and negative) [46].
- Subj: The subjectivity dataset is data for sentence classification tasks used to classify sentences with annotations based on whether they are subjective or objective [47].
- MPQA: The Multi-Perspective Question Answering dataset is an opinion polarity detection dataset consisting of short phrases. It has binary labels with positive and negative. [48].
- MR: Another Movie Reviews sentiment classification task dataset with binary labels (positive and negative) [49].
- TREC: The Text Retrieval Conference dataset consists of six question types and classifies the questions into different categories (abbreviation, entity, description, human, location, and numerical value) [50].
4.3. Neural Classifier Architecture
4.4. Hyperparameters
4.5. Baselines
- RNN / CNN Without data augmentation method.
- w/synonym A method of substituting random words with synonyms using WordNet [52].
- w/context A method of contextual augmentation for each word using bidirectional LM proposed by Kobayashi [29].
- w/context+label A method that adds a label condition to w/context [29].
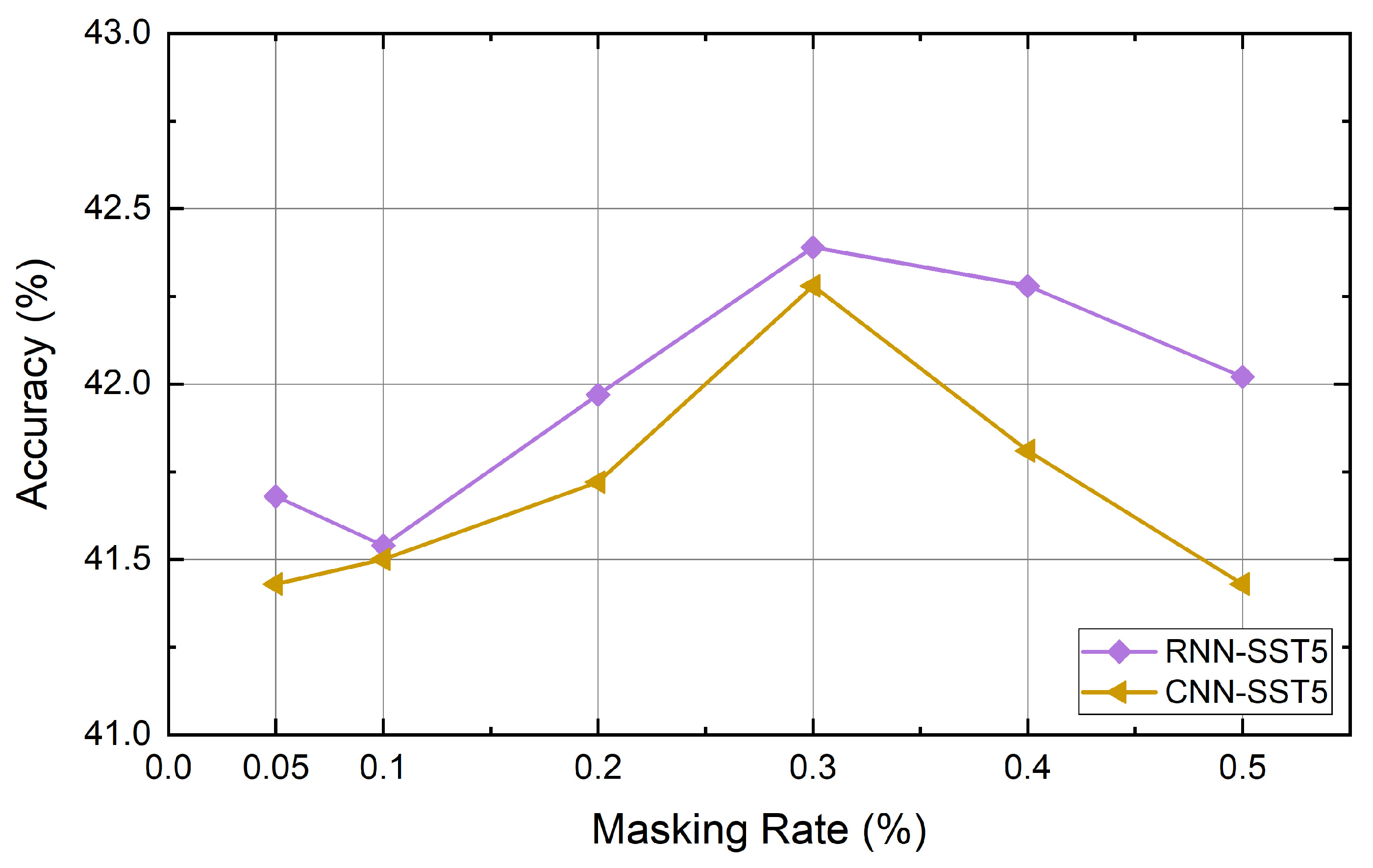
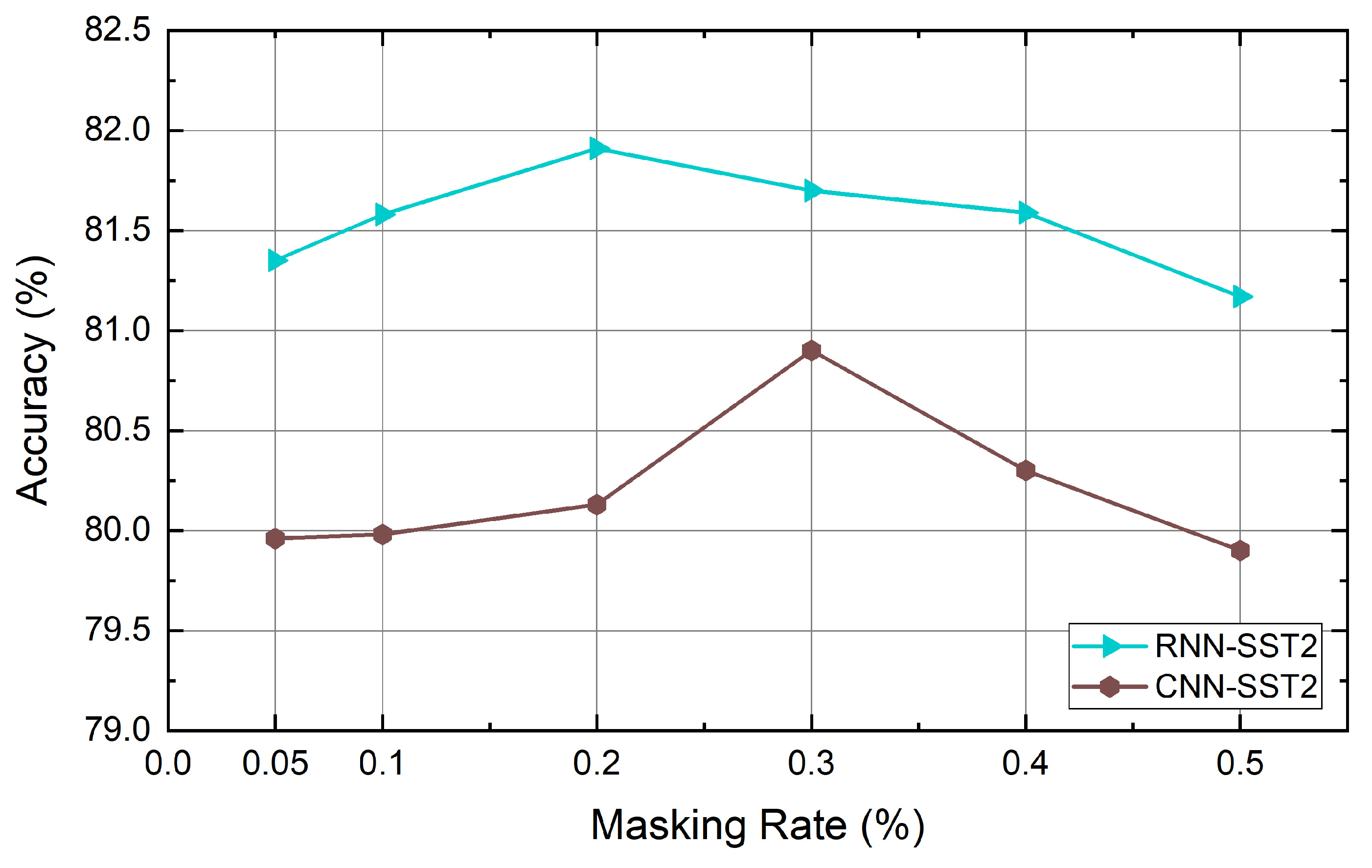
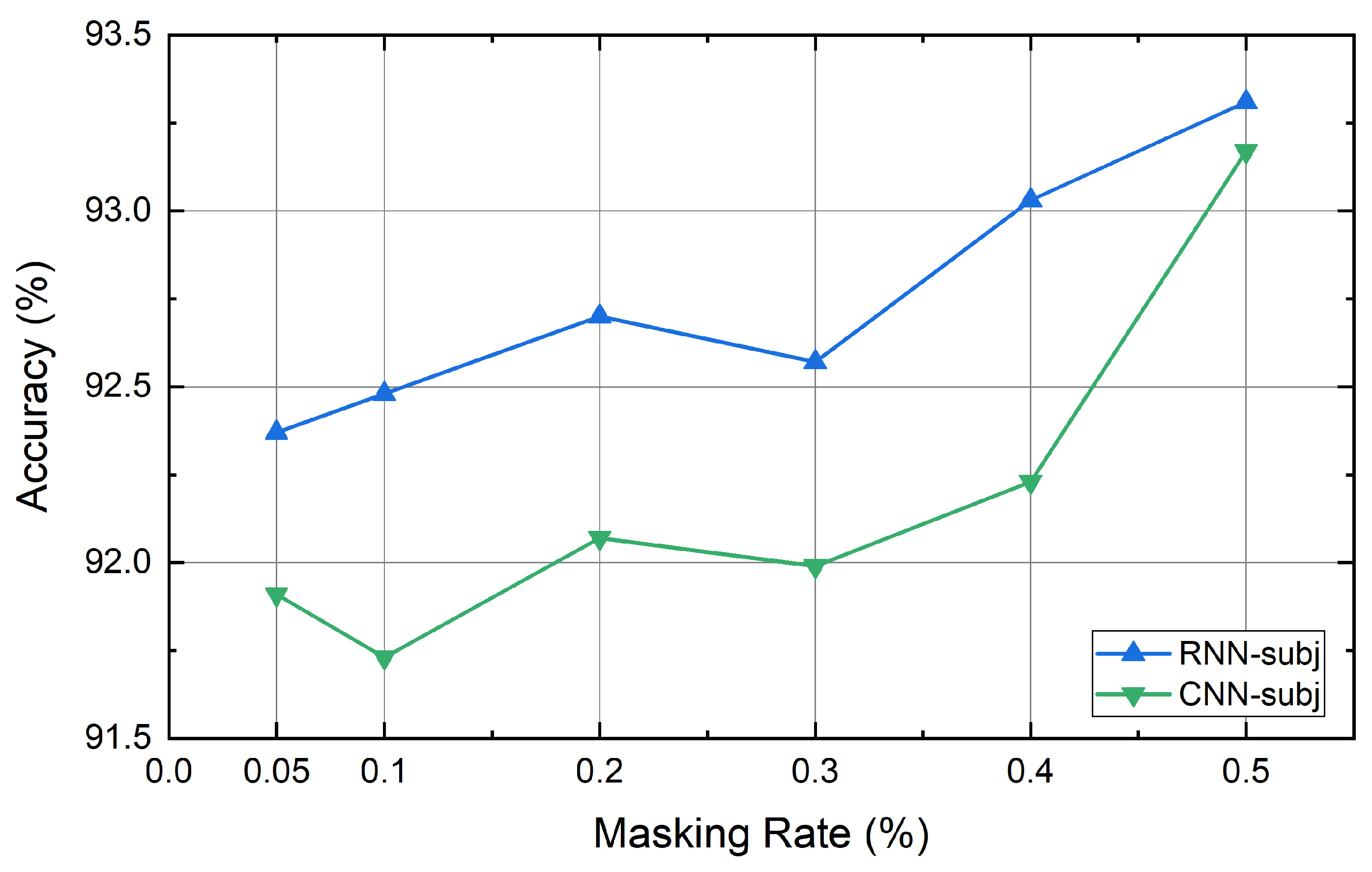
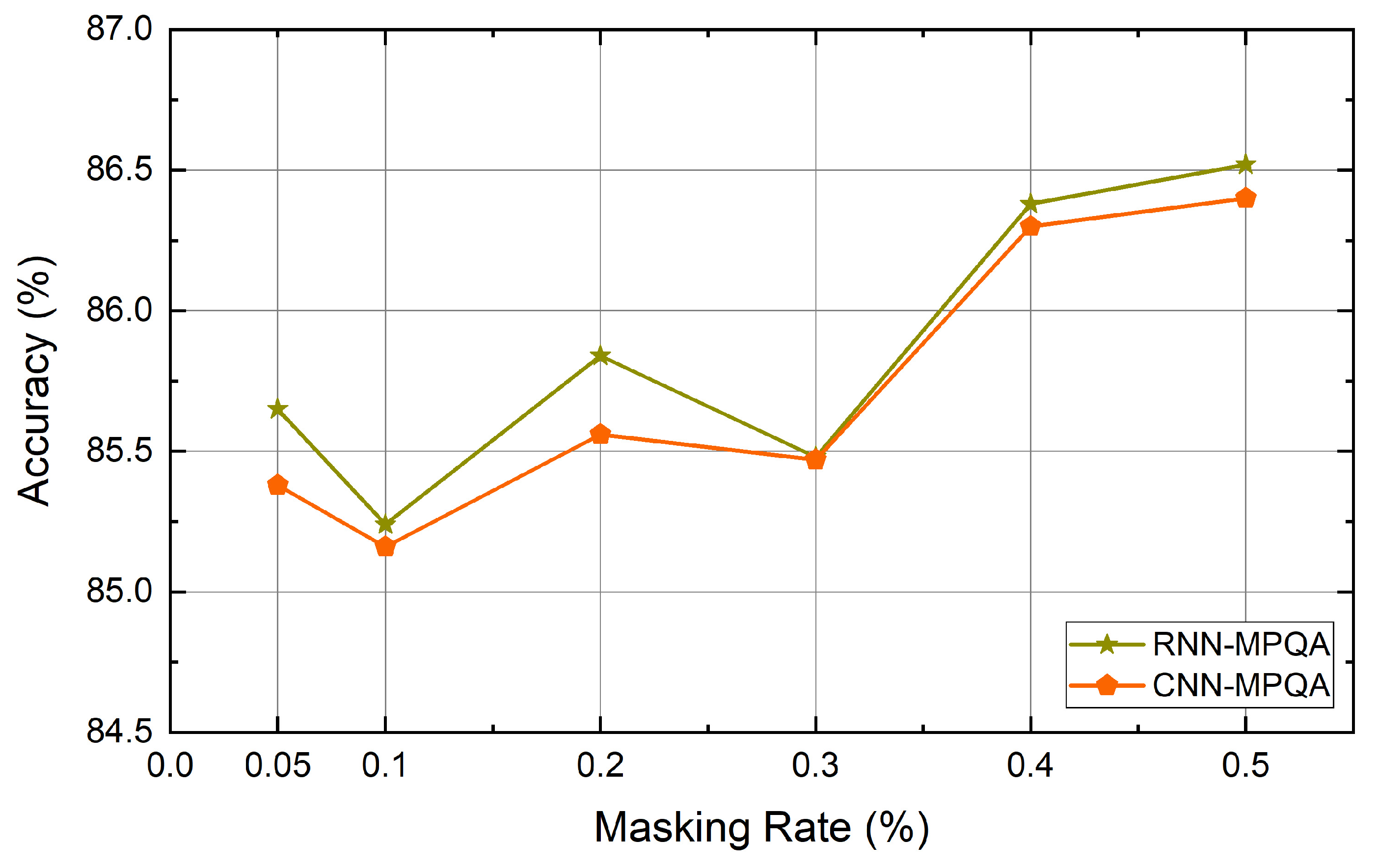
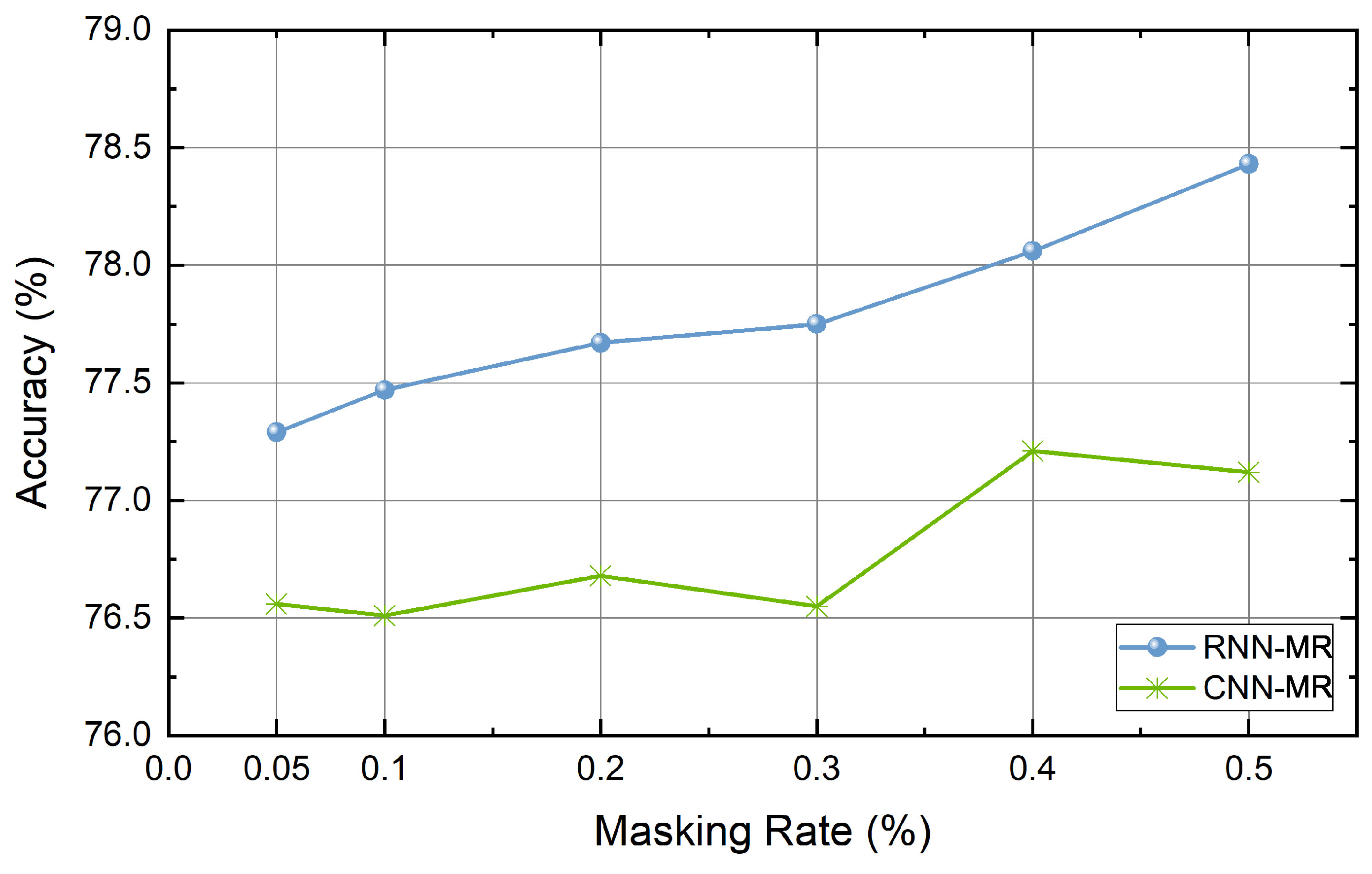
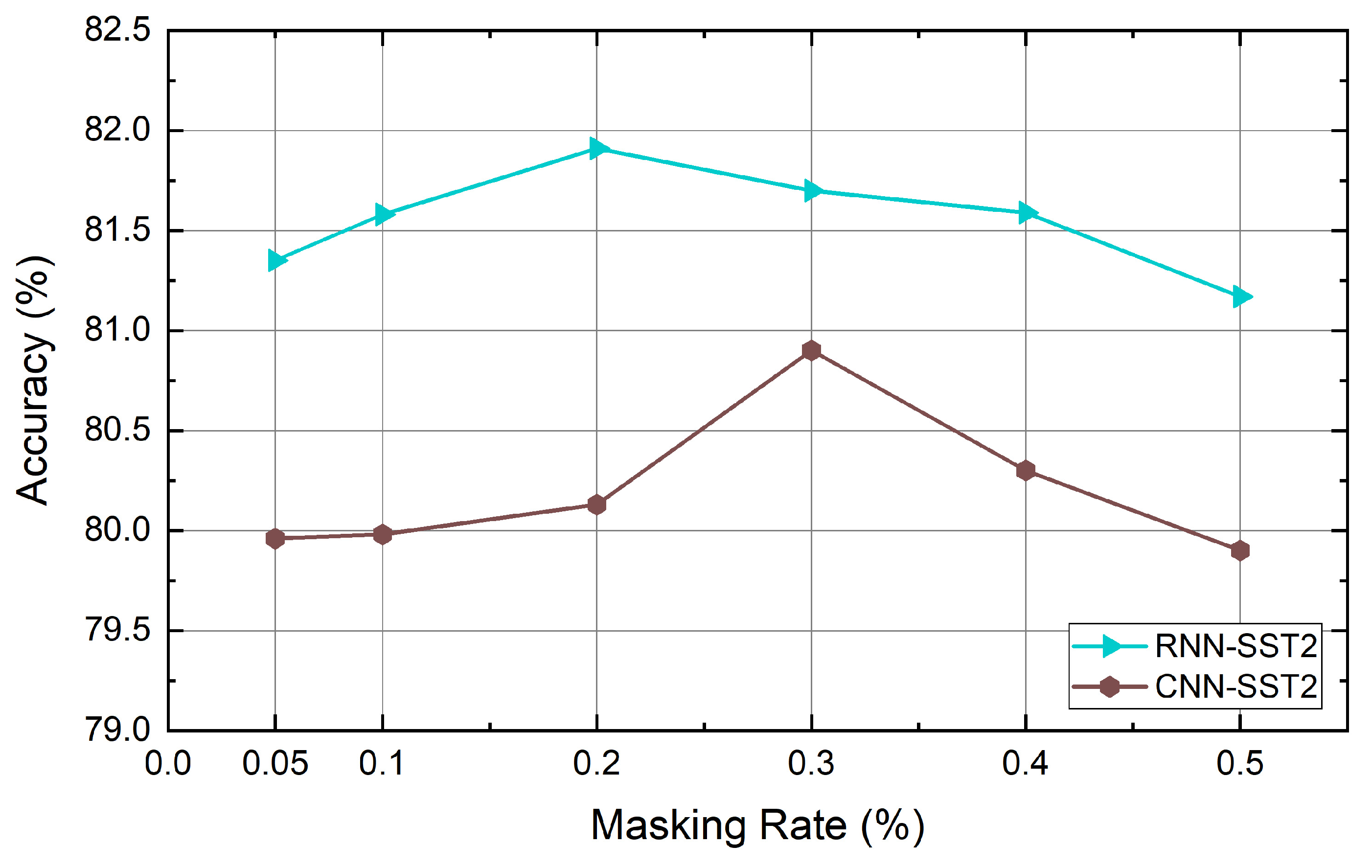
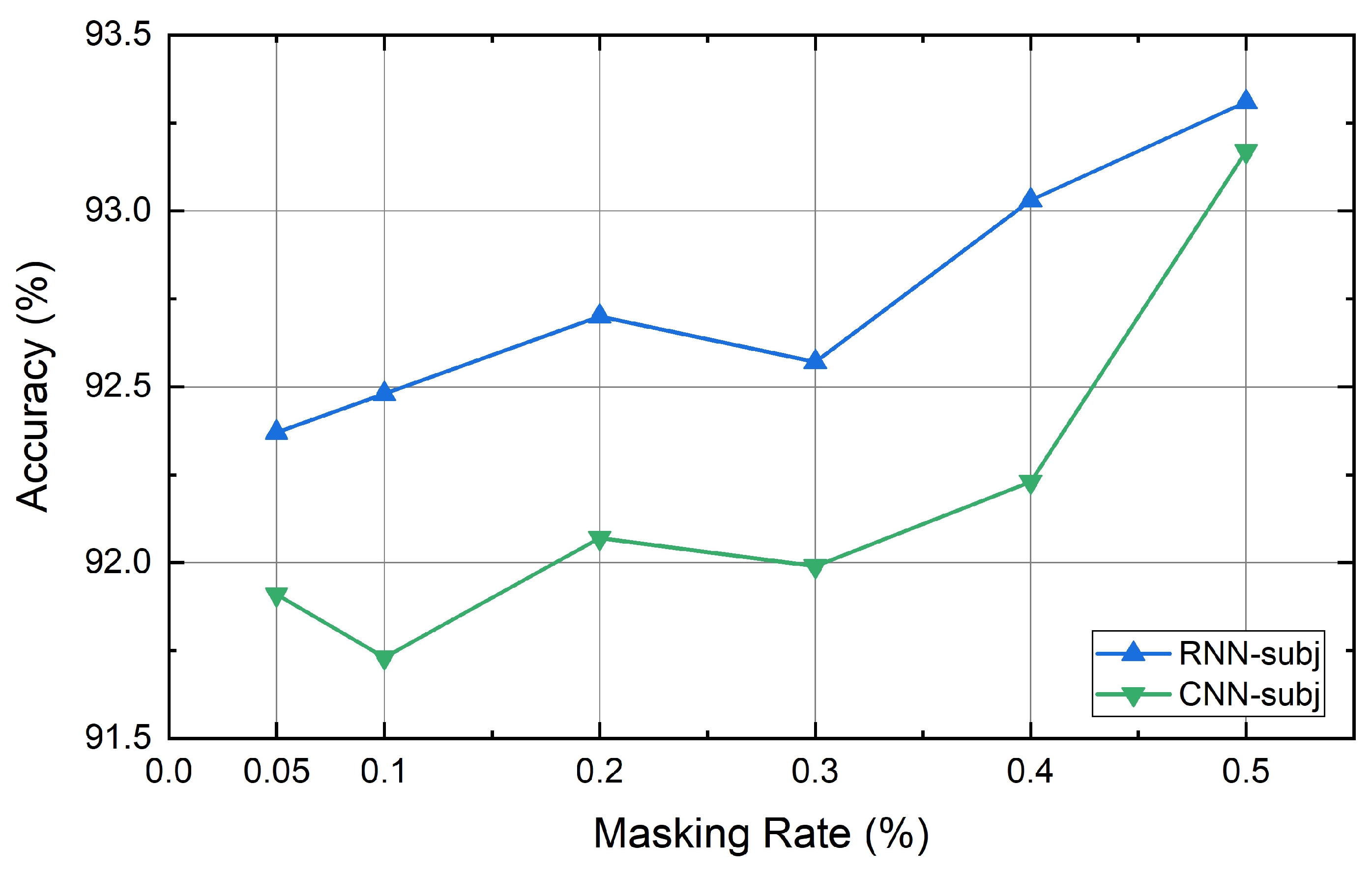
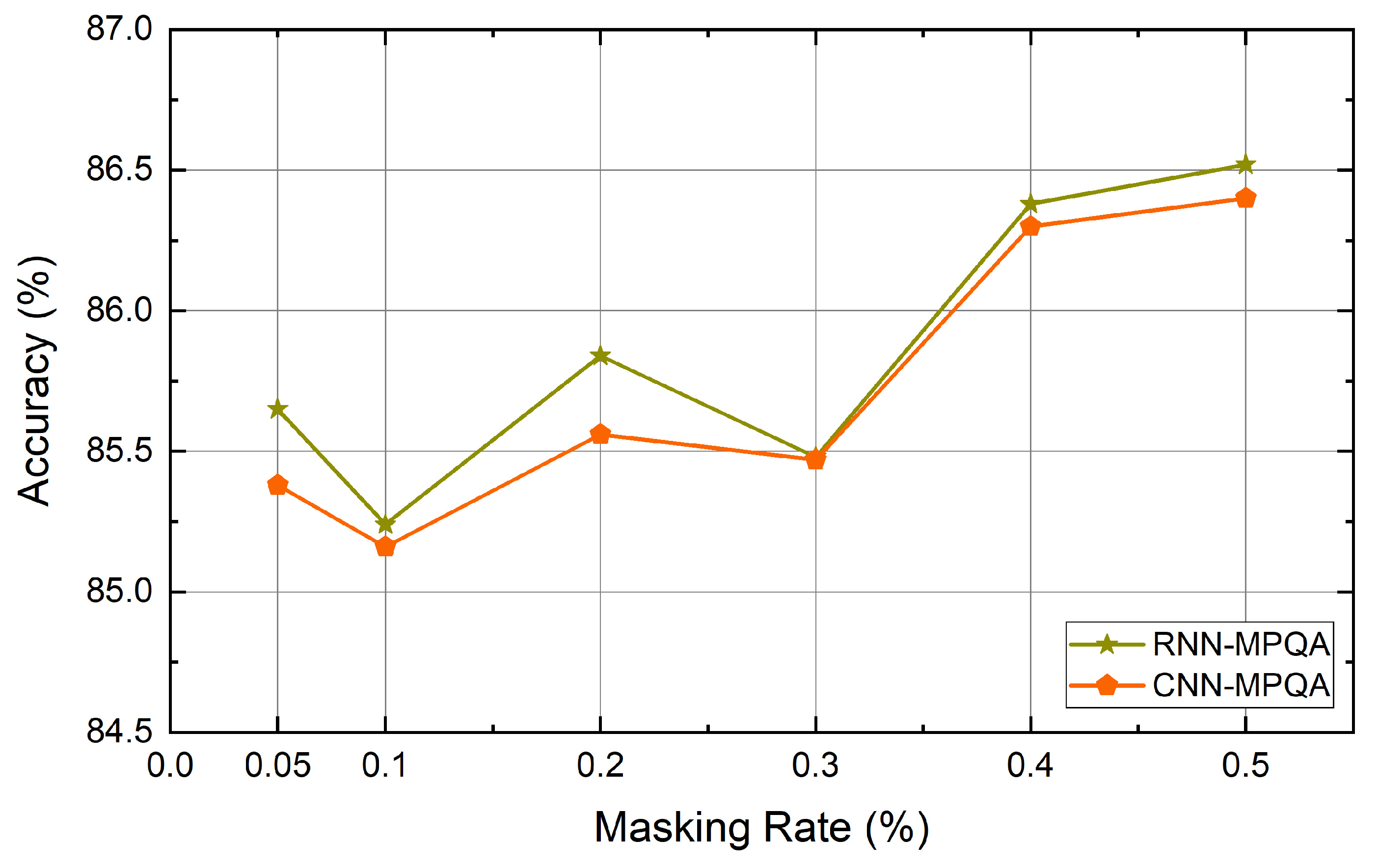
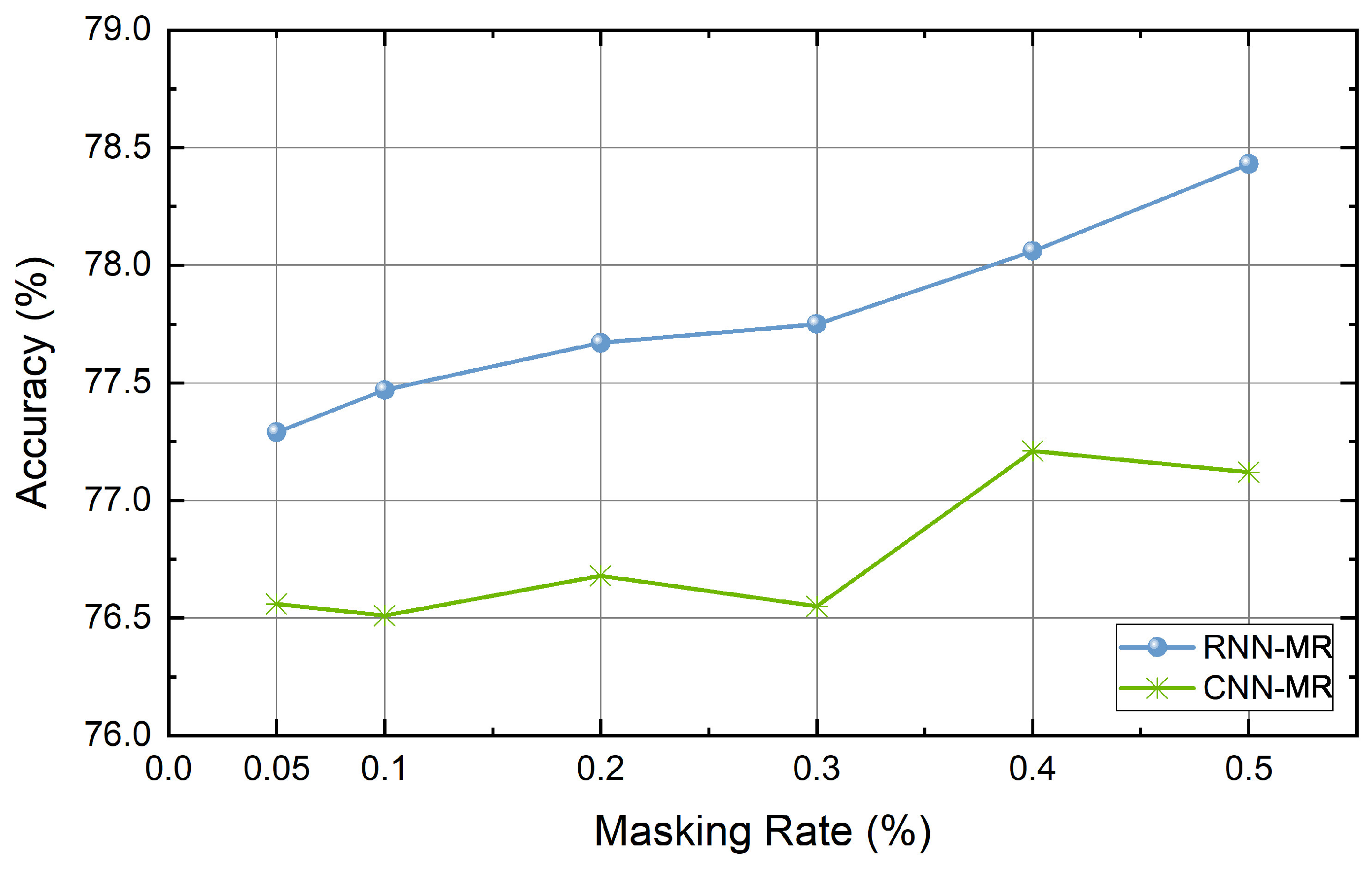
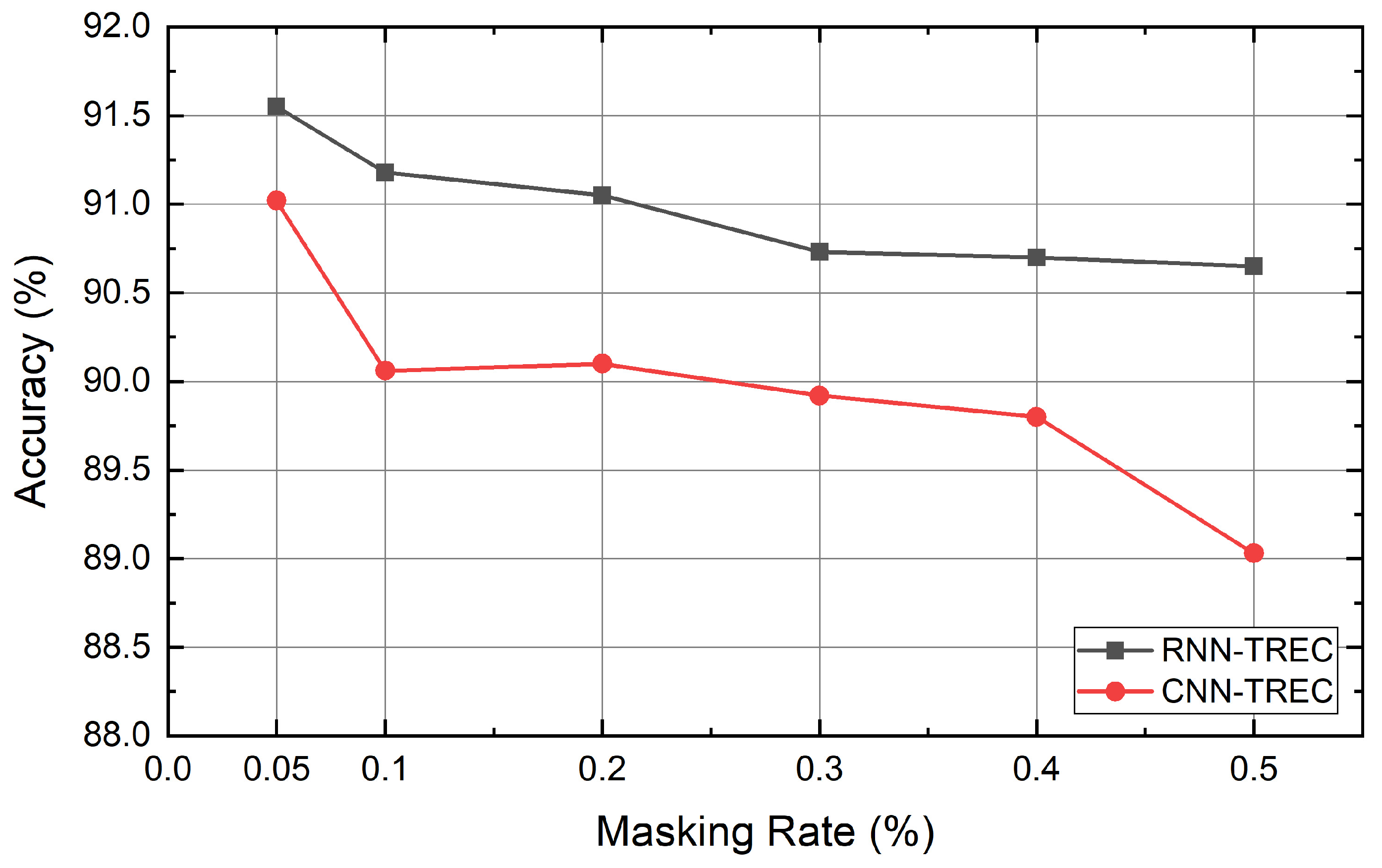
4.6. Experiment Results
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MLM | Masked language model |
| CV | Computer vision |
| NLP | Natural language processing |
| LM | Language model |
| RNN | Recurrent neural network |
| CNN | Convolutional neural network |
| LSTM | Long short-term memory |
| ReLU | Rectified linear unit |
References
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. 2019. Available online: https://openai.com/blog/sparse-transformers (accessed on 10 November 2019).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- He, K.; Girshick, R.; Dollár, P. Rethinking imagenet pre-training. arXiv 2018, arXiv:1811.08883. [Google Scholar]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding Back-Translation at Scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 489–500. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. 2019. Available online: https://openai.com/blog/better-language-models/ (accessed on 10 November 2019).
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Florence, Italy, 28 July–2 August 2019; pp. 4171–4186. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 Setember 2010. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; The MIT Press: Long Beach, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Balaji, A.; Allen, A. Benchmarking Automatic Machine Learning Frameworks. arXiv 2018, arXiv:1808.06492. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. arXiv 2017, arXiv:1708.04896. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Advances in Neural Information Processing Systems; Palais des Congrès de Montréal: Montréal, QC, Canada, 2015; pp. 649–657. [Google Scholar]
- Wang, W.Y.; Yang, D. That’s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using# petpeeve tweets. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2557–2563. [Google Scholar]
- Kafle, K.; Yousefhussien, M.; Kanan, C. Data augmentation for visual question answering. In Proceedings of the 10th International Conference on Natural Language Generation, Santiago de Compostela, Spain, 4–7 September 2017; pp. 198–202. [Google Scholar]
- Wu, X.; Lv, S.; Zang, L.; Han, J.; Hu, S. Conditional BERT Contextual Augmentation. In International Conference on Computational Science; Springer: Seoul, Korea, 2019; pp. 84–95. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.T.; Le, Q.V. Unsupervised data augmentation. arXiv 2019, arXiv:1904.12848. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Gao, F.; Zhu, J.; Wu, L.; Xia, Y.; Qin, T.; Cheng, X.; Zhou, W.; Liu, T.Y. Soft Contextual Data Augmentation for Neural Machine Translation. In Proceedings of the 57th Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5539–5544. [Google Scholar]
- Kobayashi, S. Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Melbourne, Australia, 19 July 2018; pp. 452–457. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Aytar, Y.; Pfaff, T.; Budden, D.; Paine, T.; Wang, Z.; de Freitas, N. Playing hard exploration games by watching youtube. In Advances in Neural Information Processing Systems; Palais des Congrès de Montréal: Montréal, QC, Canda, 2018; pp. 2930–2941. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven exploration by self-supervised prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 16–17. [Google Scholar]
- Kahn, G.; Villaflor, A.; Ding, B.; Abbeel, P.; Levine, S. Self-supervised deep reinforcement learning with generalized computation graphs for robot navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Kolesnikov, A.; Zhai, X.; Beyer, L. Revisiting Self-Supervised Visual Representation Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1920–1929. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised Representation Learning by Predicting Image Rotations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–2 May 2018. [Google Scholar]
- Kim, D.; Cho, D.; Yoo, D.; Kweon, I.S. Learning Image Representations by Completing Damaged Jigsaw Puzzles. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 15 March 2018; pp. 793–802. [Google Scholar] [CrossRef]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2536–2544. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Fadaee, M.; Bisazza, A.; Monz, C. Data Augmentation for Low-Resource Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 567–573. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Mallidi, S.H.; Hermansky, H. Novel neural network based fusion for multistream ASR. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5680–5684. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Taylor, W.L. “Cloze procedure”: A new tool for measuring readability. J. Bull. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Wiebe, J.; Wilson, T.; Cardie, C. Annotating expressions of opinions and emotions in language. Lang. Resour. Eval. 2005, 39, 165–210. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, University of Michigan, Ann Arbor, MI, USA, 25–30 June 2005; pp. 115–124. [Google Scholar]
- Li, X.; Roth, D. Learning question classifiers. In Proceedings of the 19th International Conference on Computational linguistics—Volume 1; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 1–7. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Tokui, S.; Oono, K.; Hido, S.; Clayton, J. Chainer: A next-generation open source framework for deep learning. In Proceedings of the Workshop on Machine Learning Systems (LearningSys) in the Twenty-Ninth Annual Conference on Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 8–13 December 2015; Volume 5, pp. 1–6. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Length | Dataset Size | Vocabulary Size | Testset Size |
|---|---|---|---|---|---|
| SST5 | 5 | 18 | 11,855 | 17,836 | 2210 |
| SST2 | 2 | 19 | 9613 | 16,185 | 1821 |
| Subj | 2 | 23 | 10,000 | 21,323 | cross-validation |
| MPQA | 2 | 3 | 10,606 | 6246 | cross-validation |
| MR | 2 | 20 | 10,662 | 18,765 | cross-validation |
| TREC | 6 | 10 | 5952 | 9592 | 500 |
| Hyperparameters | Value |
|---|---|
| Learning rate | 0.0001 |
| Embedding dimension | 512 |
| Number of the head (h) | 4 |
| Hidden dimension () | 128 |
| Feed forward dimension () | 2048 |
| Dropout rate | 0.1 |
| Hyperparameters | Value |
|---|---|
| Learning rate | [0.001, 0.0003, 0.0001] |
| Embedding dimension | [300] |
| Hidden (filters) unit | [256, 512] |
| Dropout rate | [0.1, 0.2, 0.3, 0.4, 0.5] |
| Models | SST5 | SST2 | Subj | MPQA | MR | TREC | Avg. |
|---|---|---|---|---|---|---|---|
| RNN | 40.2 | 80.3 | 92.4 | 86.0 | 76.7 | 89.0 | 77.43 |
| w/ synonym | 40.5 | 80.2 | 92.8 | 86.4 | 76.6 | 87.9 | 77.40 |
| w/ context | 40.9 | 79.3 | 92.8 | 86.4 | 77.0 | 89.3 | 77.62 |
| + label | 41.1 | 80.1 | 92.8 | 86.4 | 77.4 | 89.2 | 77.83 |
| Ours (Small) | 42.0 (0.2) | 81.5 (0.2) | 93.0 (0.5) | 86.1 (0.5) | 78.3 (0.5) | 91.1 (0.1) | 78.67 |
| Ours (Big) | 42.4 (0.3) | 81.9 (0.2) | 93.3 (0.5) | 86.5 (0.5) | 78.4 (0.5) | 91.6 (0.05) | 79.02 |
| CNN | 41.3 | 79.5 | 92.4 | 86.1 | 75.9 | 90.0 | 77.53 |
| w/ synonym | 40.7 | 80.0 | 92.4 | 86.3 | 76.0 | 89.6 | 77.50 |
| w/ context | 41.9 | 80.9 | 92.7 | 86.7 | 75.9 | 90.0 | 78.02 |
| + label | 42.1 | 80.8 | 93.0 | 86.7 | 76.1 | 90.5 | 78.20 |
| Ours (Small) | 41.7 (0.2) | 79.9 (0.1) | 92.5 (0.5) | 86.2 (0.5) | 76.9 (0.5) | 90.9 (0.2) | 78.02 |
| Ours (Big) | 42.3 (0.3) | 80.9 (0.3) | 93.2 (0.5) | 86.4 (0.5) | 77.2 (0.4) | 91.0 (0.05) | 78.50 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, D.; Ahn, C.W. Self-Supervised Contextual Data Augmentation for Natural Language Processing. Symmetry 2019, 11, 1393. https://doi.org/10.3390/sym11111393
Park D, Ahn CW. Self-Supervised Contextual Data Augmentation for Natural Language Processing. Symmetry. 2019; 11(11):1393. https://doi.org/10.3390/sym11111393
Chicago/Turabian StylePark, Dongju, and Chang Wook Ahn. 2019. "Self-Supervised Contextual Data Augmentation for Natural Language Processing" Symmetry 11, no. 11: 1393. https://doi.org/10.3390/sym11111393
APA StylePark, D., & Ahn, C. W. (2019). Self-Supervised Contextual Data Augmentation for Natural Language Processing. Symmetry, 11(11), 1393. https://doi.org/10.3390/sym11111393