A Novel Orthogonal Extreme Learning Machine for Regression and Classification Problems


Abstract
:1. Introduction
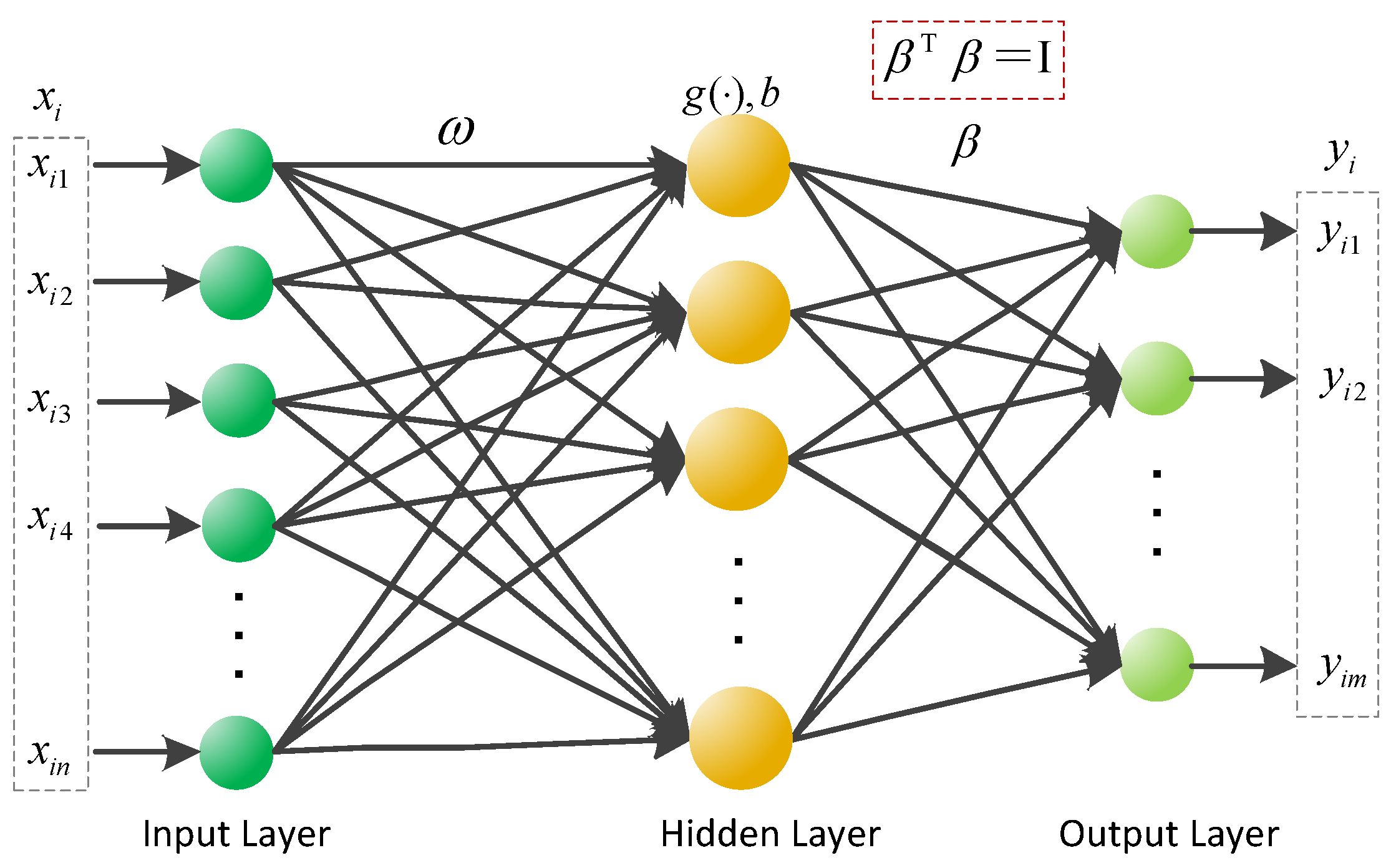
2. Extreme Learning Machine
3. Novel Orthogonal Extreme Learning Machine (NOELM)
| Algorithm 1: Optimization to objective problem (8) | |
| Basic Information: training samples | |
| Initialization: Set threshold and | |
| S1. | Generate the input weight layer and bas vector ; |
| S2. | Calculate the output matrix of the hidden layer based on Equation (3); |
| S3. | Calculate the orthogonal of span , and its orthogonal complement , then ; |
| S3. | While |
| S4. | Relax the column , from the matrix , separately, and fix the rest; |
| S5. | Set , then solve ; |
| S6. | Set , , then . By SVD, , so as to obtain and ; |
| S7. | Based on the Equation (21), ; |
| S8. | Calculate the vector , ; |
| S9. | Partition so as to obtain and , then replace of to obtain , and ; |
| End While | |
| S10. | Calculate , then if , terminate, otherwise, , is the new orthogonal complement of , go to step S3. |
4. Convergence and Complexity Analysis
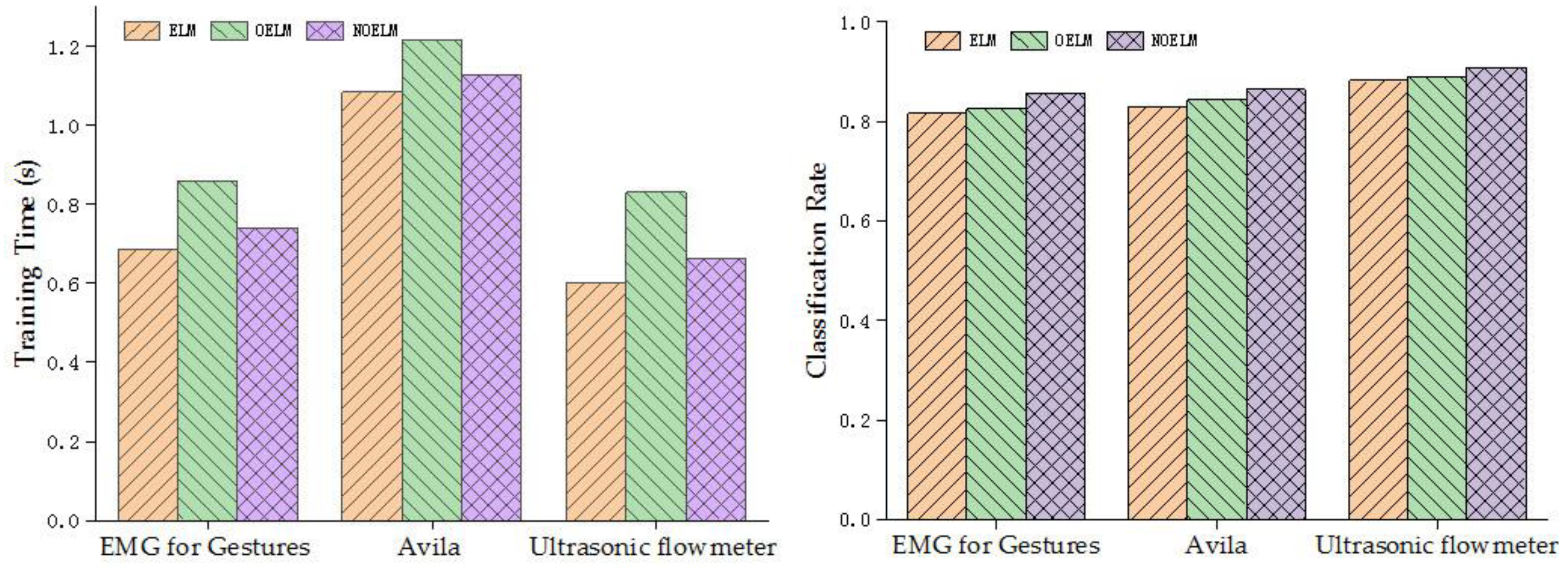
5. Performance Evaluation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the Artificial Neural Network model for prediction of monthly Standardized Precipitation and Evapotranspiration Index using hydrometeorological parameters and climate indices in eastern Australia. Atmos. Res. 2015, 161–162, 65–81. [Google Scholar] [CrossRef]
- Acharya, N.; Singh, A.; Mohanty, U.C.; Nair, A.; Chattopadhyay, S. Performance of general circulation models and their ensembles for the prediction of drought indices over India during summer monsoon. Nat. Hazards 2013, 66, 851–871. [Google Scholar] [CrossRef]
- Deo, R.C.; Tiwari, M.K.; Adamowski, J.F.; Quilty, J.M. Forecasting effective drought index using a wavelet extreme learning machine (W-ELM) model. Stoch. Environ. Res. Risk Assess. 2017, 31, 1211–1240. [Google Scholar] [CrossRef]
- Huang, G.-B.; Chen, L. Convex incremental extreme learning machine. Neurocomputing 2007, 70, 3056–3062. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, J.; Zhu, Z. Regularization incremental extreme learning machine with random reduced kernel for regression. Neurocomputing 2018, 321, 72–81. [Google Scholar] [CrossRef]
- Wang, D.; Wang, P.; Shi, J. A fast and efficient conformal regressor with regularized extreme learning machine. Neurocomputing 2018, 304, 1–11. [Google Scholar] [CrossRef]
- Yin, Y.; Zhao, Y.; Zhang, B.; Li, C.; Guo, S. Enhancing ELM by Markov Boundary based feature selection. Neurocomputing 2017, 261, 57–69. [Google Scholar] [CrossRef]
- Ding, X.-J.; Lan, Y.; Zhang, Z.-F.; Xu, X. Optimization extreme learning machine with ν regularization. Neurocomputing 2017, 261, 11–19. [Google Scholar]
- Yildirim, H.; Özkale, M.R. The performance of ELM based ridge regression via the regularization parameters. Expert Syst. Appl. 2019, 134, 225–233. [Google Scholar] [CrossRef]
- Inaba, F.K.; Salles, E.O.T.; Perron, S.; Caporossi, G. DGR-ELM–Distributed Generalized Regularized ELM for classification. Neurocomputing 2018, 275, 1522–1530. [Google Scholar] [CrossRef]
- Miche, Y.; Akusok, A.; Veganzones, D.; Björk, K.-M.; Séverin, E.; du Jardin, P.; Termenon, M.; Lendasse, A. SOM-ELM—Self-Organized Clustering using ELM. Neurocomputing 2015, 165, 238–254. [Google Scholar] [CrossRef]
- Ming, Y.; Zhu, E.; Wang, M.; Ye, Y.; Liu, X.; Yin, J. DMP-ELMs: Data and model parallel extreme learning machines for large-scale learning tasks. Neurocomputing 2018, 320, 85–97. [Google Scholar] [CrossRef]
- Krishnan, G.S.; S., S.K. A novel GA-ELM model for patient-specific mortality prediction over large-scale lab event data. Appl. Soft Comput. 2019, 80, 525–533. [Google Scholar] [CrossRef]
- Nayak, D.R.; Zhang, Y.; Das, D.S.; Panda, S. MJaya-ELM: A Jaya algorithm with mutation and extreme learning machine based approach for sensorineural hearing loss detection. Appl. Soft Comput. 2019, 83, 105626. [Google Scholar] [CrossRef]
- Peng, Y.; Kong, W.; Yang, B. Orthogonal extreme learning machine for image classification. Neurocomputing 2017, 266, 458–464. [Google Scholar] [CrossRef]
- Peng, Y.; Lu, B.-L. Discriminative manifold extreme learning machine and applications to image and EEG signal classification. Neurocomputing 2016, 174, 265–277. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, S.; Long, X.; Lu, B.-L. Discriminative graph regularized extreme learning machine and its application to face recognition. Neurocomputing 2015, 149, 340–353. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, Z.; Nie, F. Orthogonal least squares regression for feature extraction. Neurocomputing 2016, 216, 200–207. [Google Scholar] [CrossRef]
- Nie, F.; Xiang, S.; Liu, Y.; Hou, C.; Zhang, C. Orthogonal vs. uncorrelated least squares discriminant analysis for feature extraction. Pattern Recognit. Lett. 2012, 33, 485–491. [Google Scholar] [CrossRef]
- Zhang, Z.; Du, K. Successive projection method for solving the unbalanced Procrustes problem. Sci. China Ser. A 2006, 49, 971–986. [Google Scholar] [CrossRef]
- Bache, K.; Lichman, M. UCI Machine Learning Repository. University of California, School of Information and Computer Sciences: Irvine, CA, USA, 2013. Available online: http://archive.ics.uci.edu/ml (accessed on 11 October 2019).
- Xu, Z.; Yao, M.; Wu, Z.; Dai, W. Incremental Regularized Extreme Learning Machine and It’s Enhancement. Neurocomputing 2015, 174, 134–142. [Google Scholar] [CrossRef]
- Huang, G.-B.; Chen, L.; Siew, C.-K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Ying, L. Orthogonal incremental extreme learning machine for regression and multiclass classification. Neural Comput. Appl. 2016, 27, 111–120. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Datasets | Training | Testing | Attributes | Class |
|---|---|---|---|---|
| Avila | 5000 | 2000 | 10 | 12 |
| Electro-Myo-Graphic data (EMG) for Gestures | 10000 | 2000 | 6 | 8 |
| Ultrasonic Flowmeter | 112 | 69 | 33 | 4 |
| Stock | 450 | 500 | 9 | - |
| Abalone | 2000 | 1177 | 8 | - |
| Auto price | 80 | 79 | 14 | - |
| Auto-Miles Per Gallon (MPG) | 320 | 78 | 8 | - |
| Breast cancer | 100 | 94 | 32 | - |
| Buston housing | 250 | 256 | 13 | - |
| California housing | 8000 | 12640 | 8 | - |
| Census house (8L) | 10000 | 12784 | 8 | - |
| ELM | OELM | I_ELM | NOELM | |||||
|---|---|---|---|---|---|---|---|---|
| Nodes | Time(s) | Nodes | Time(s) | Nodes | Time(s) | Nodes | Time(s) | |
| Auto price | 42 | 0.0325 | 42 | 0.0677 | 50 | 0.0374 | 42 | 0.0241 |
| Breast cancer | 96 | 1.0217 | 96 | 2.1285 | 66 | 0.2324 | 96 | 0.7568 |
| Buston housing | 39 | 0.0453 | 39 | 0.0944 | 100 | 0.5672 | 39 | 0.0336 |
| Auto-MPG | 24 | 0.8835 | 24 | 1.8406 | 76 | 0.8173 | 24 | 0.6544 |
| Stock | 27 | 0.6392 | 27 | 1.3317 | 97 | 0.8039 | 27 | 0.4735 |
| Abalone | 24 | 0.4836 | 24 | 1.0075 | 40 | 0.3237 | 24 | 0.3582 |
| California housing | 24 | 0.4547 | 24 | 0.9473 | 69 | 6.0856 | 24 | 0.3368 |
| Census house (8L) | 24 | 0.7667 | 24 | 1.5973 | 57 | 5.2479 | 24 | 0.5679 |
| ELM | OELM | I_ELM | NOELM | |||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |
| Auto price | 0.1283 | 0.1297 | 0.1141 | 0.1212 | 0.0997 | 0.1089 | 0.1056 | 0.1161 |
| Breast cancer | 0.13182 | 0.1499 | 0.1163 | 0.1340 | 0.1132 | 0.1219 | 0.1070 | 0.1245 |
| Buston housing | 0.1695 | 0.1708 | 0.14122 | 0.1502 | 0.1403 | 0.1353 | 0.1243 | 0.1379 |
| Auto-MPG | 0.1513 | 0.1584 | 0.1291 | 0.1394 | 0.1321 | 0.1363 | 0.1159 | 0.1279 |
| Stock | 0.1380 | 0.1423 | 0.1195 | 0.1245 | 0.1197 | 0.1227 | 0.1084 | 0.1138 |
| Abalone | 0.1327 | 0.1339 | 0.1171 | 0.1179 | 0.1109 | 0.1125 | 0.1077 | 0.1082 |
| California housing | 0.2555 | 0.2574 | 0.2265 | 0.2280 | 0.1993 | 0.2035 | 0.2092 | 0.2103 |
| Census house (8L) | 0.1439 | 0.1489 | 0.1254 | 0.1286 | 0.1017 | 0.1023 | 0.1143 | 0.1164 |
| ELM | OELM | I_ELM | NOELM | |||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |
| Auto price | 0.0033 | 0.0234 | 0.0024 | 0.0215 | 0.0031 | 0.0196 | 0.0018 | 0.0204 |
| Breast cancer | 0.0099 | 0.0209 | 0.0088 | 0.0188 | 0.0085 | 0.0167 | 0.0082 | 0.0176 |
| Buston housing | 0.0130 | 0.0183 | 0.0085 | 0.0148 | 0.0126 | 0.0135 | 0.0059 | 0.0126 |
| Auto-MPG | 0.0142 | 0.0179 | 0.0101 | 0.0141 | 0.0134 | 0.0162 | 0.0077 | 0.0118 |
| Stock | 0.0161 | 0.0172 | 0.0125 | 0.0131 | 0.0147 | 0.0158 | 0.0103 | 0.0106 |
| Abalone | 0.0058 | 0.0066 | 0.0053 | 0.0059 | 0.0049 | 0.0056 | 0.0050 | 0.0054 |
| California housing | 0.0047 | 0.0061 | 0.0068 | 0.0082 | 0.0027 | 0.0038 | 0.0080 | 0.0094 |
| Census house (8L) | 0.0034 | 0.0038 | 0.0026 | 0.0043 | 0.0006 | 0.0028 | 0.0033 | 0.0046 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, L.; Zhai, H.; Lin, H. A Novel Orthogonal Extreme Learning Machine for Regression and Classification Problems. Symmetry 2019, 11, 1284. https://doi.org/10.3390/sym11101284
Cui L, Zhai H, Lin H. A Novel Orthogonal Extreme Learning Machine for Regression and Classification Problems. Symmetry. 2019; 11(10):1284. https://doi.org/10.3390/sym11101284
Chicago/Turabian StyleCui, Licheng, Huawei Zhai, and Hongfei Lin. 2019. "A Novel Orthogonal Extreme Learning Machine for Regression and Classification Problems" Symmetry 11, no. 10: 1284. https://doi.org/10.3390/sym11101284
APA StyleCui, L., Zhai, H., & Lin, H. (2019). A Novel Orthogonal Extreme Learning Machine for Regression and Classification Problems. Symmetry, 11(10), 1284. https://doi.org/10.3390/sym11101284