1. Introduction
The rank minimization (RM) problem aims to recover an unknown low-rank matrix from very limited information. It has gained am increasing amount of attention rapidly in recent years, since it has a range of applications in many computer vision and machine learning areas, such as collaborative filtering [
1], subspace segmentation [
2], non-rigid structure from motion [
3] and image inpainting [
4]. This paper deals with the following rank minimization problem:
where
is a linear map and the vector
is known. The matrix completion (MC) problem is a special case of the RM problem, where
is a sampling operator in the form of
,
is an index subset, and
is a vector formed by the entries of
X with indices in
.
Although Label (
1) is simple in form, directly solving it is an NP-hard problem due to the discrete nature of the rank function. One popular way is replacing the rank function with the nuclear norm, which is the sum of the singular values of a matrix. This technique is based on the fact that the nuclear norm minimization (NNM) is the tightest convex relaxation of the rank minimization problem [
5]. The obtained new problem is given by
where
denotes the nuclear norm. It has been shown that recovering a low-rank matrix can be achieved by solving Label (
2) [
1,
6].
In practical applications, the observed data may be corrupted with noise, namely
, where
e contains measurement errors dominated by certain normal distribution. In order to recover the low-rank matrix robustly, problem (
2) should be modified to the following inequality constrained problem:
where
is the
norm of vector and the constant
is the noise level. When
, problem (
3) reduces to the noiseless case (
2).
Alternatively, problems (
2) and (
3) can be rewritten as the nuclear norm regularized least-square (NNRLS) under some conditions:
where
is as given parameter.
The studies on the nuclear norm minimization problem are mainly along two directions. The first one is enhancing the precision of a low rank approximation via replacing the nuclear norm by a non-convex regularizer—for instance, the Schatten
p-norm [
7,
8], the truncated nuclear norm [
4,
9], the log or fraction function based norm [
10,
11], and so on. The second one is improving the efficiency of solving problems (
2), (
3) and (
4) and their variants. For instance, the authors in [
12] treated the problem (
2) as a standard linear semidefinite programming (SDP) problem, and proposed the solving algorithm from the dual problem. However, since the SDP solver uses second-order information, with the increase in the size of the matrix, the memory required to calculate the descending direction quickly becomes too large. Therefore, algorithms that use only first-order information are developed, such as the singular value thresholding (SVT) algorithm [
13], the fixed point continuation algorithm (FPCA) [
14], the accelerated proximal gradient Lagrangian (APGL) method [
15], the proximal point algorithm based on indicator function (PPA-IF) [
16], the augmented Lagrange multiplier (ALM) algorithm [
17] and the alternating direction methods (ADM) [
18,
19,
20,
21].
In particular, Chen et al. [
18] applied the ADM to solve the nuclear norm based matrix completion problem. Due to the simplicity of the linear mapping
, i.e.,
, all of the ADM subproblems of the matrix completion problem can be solved exactly by an explicit formula; see [
18] for details. Here, and hereafter
and
represent the adjoint of
and the identity operator. However, for a generic
with
, some of the resulting subproblems no longer have closed-form solutions. Thus, the efficiency of the ADM depends heavily on how to solve these harder subproblems.
To solve this difficulty, a common strategy is to introduce new auxiliary variables, e.g., in [
19], one auxiliary variable was introduced for solving Label (
2), while two auxiliary variables were introduced for Label (
3). However, with more variables and more constraints, more memory is required and the convergence of ADM also becomes slower. Moreover, to update auxiliary variables, whose subproblems are least square problems, expensive matrix inversions are often necessary. Even worse, the convergence of ADM with more than two variables is not guaranteed. To mitigate these problems, Yang and Yuan [
21] presented a linearized ADM to solve the NNRLS (
4) as well as problems (
2) and (
3), where each subproblems admit explicit solutions. Instead of the linearized technique, Xiao and Jin [
19] solve one least square subproblem iteratively by the Barzilai–Borwein (BB) gradient method [
22]. Unlike [
19], Jin et al. [
20] used the linear conjugate gradient (CG) algorithm rather than BB to solve the subproblem.
In this paper, we further investigate the efficiency of ADM in solving the nuclear norm minimization problems. We first reformulate the problems (
2), (
3) and (
4) into a unified form as follows:
where
and
. In this paper, we always fix
. When considering problems (
2) and (
3), we choose
, where
denotes the indicator function over
, i.e.,
When considering problem (
4), we choose
. As a result, for a general linear mapping
, we only need to solve such a problem whose objective function is a sum of two convex functions and one of them contains an affine transformation.
Motivated by the ADM algorithms above, we then present a unified proximity algorithm with adaptive penalty (PA-AP) to solve Label (
5). In particular, we employ the proximity idea to deal with the problems encountered by the present ADM, by adding a proximity term to one of the subproblems. We term the proposed algorithm as a proximity algorithm because we can rewrite it as a fixed-point equation system of proximity operators of
f and
g. By analyzing the fixed-point equations and applying the “Condition-M” [
23], the convergence of the algorithm is proved under some assumptions. Furthermore, to improve the efficiency, an adaptive tactic on the proximity parameters is put forward. This paper is closely related to the works [
23,
24,
25,
26]. However, this paper is motivated to improve ADM to solve the nuclear norm minimization problem with linear affine constraints.
The organization of this paper is as follows. In
Section 2, a review of ADM and its application on NNM are provided. In addition, the properties about subdifferentials and proximity operators are introduced. To improve ADM, a proximity algorithm with adaptive penalty is proposed, and convergence of the proposed algorithm is obtained in
Section 3.
Section 4 demonstrates the performance and effectiveness of the algorithm through numerical experiment. Finally, we will make a conclusion in
Section 5.
2. Preliminaries
In this section, we give a brief review on ADM and its applications to the NNM problem (
2) developed in [
19,
20]. In addition, some preliminaries on subdifferentials and proximity operators are given. Throughout this paper, linear maps are denoted with calligraphic letters (e.g.,
), while capital letters represent matrices (e.g., A), and boldface lowercase letters represent vectors (e.g.,
).
We begin with introducing the ADM. The basic idea of ADM goes back to the work of Gabay and Mercier [
27]. ADM is designed to solving the separable convex minimization problem:
where
,
are convex functions, and
,
and
. The corresponding augmented Lagrangian function is
where
is the Lagrangian multiplier and
is a penalty parameter. ADM is to minimize (
8) first with respect to
, then with respect to
, and finally update
iteratively, i.e.,
The main advantage of ADM is to make use of the separability structure of the objective function .
To solve (
2) based on ADM, the authors in [
19,
20] introduced an auxiliary variable
Y, and equivalently transformed the original model into
The augmented Lagrangian function to (
10) is
where
,
are Lagrangian multipliers,
are penalty parameters and
denotes the Frobenius inner product, i.e., the matrices are treated like vectors. Following the idea of ADM, given
, the next pair
is determined by alternating minimizing (
11),
Firstly,
can be updated by
which in fact corresponds to evaluating the proximal operator of
, i.e.,
which is defined below.
Secondly, given
,
can be updated by
which is a least square subproblem. Its solution can be found by solving a linear equation:
However, computing the matrix inverse
is too costly to implement. Though [
19,
20] adopted inverse-free methods, i.e., BB and CG, to solve (
14) iteratively, they are still inefficient, which will be shown in
Section 4.
Next, we review definitions of subdifferential and proximity operator, which play an important role in the algorithm and convergence analysis. The subdifferential of a convex function
at a point
is the set defined by
The conjugate function of
is denoted by
, which is defined by
For
,
, it holds that
where
denotes the domain of a function.
For a given positive definite matrix
, the weighted inner product is defined by
. Furthermore, the proximity operator of
at
with respect to
[
23] is defined by
If
, then
is reduced to
and
is short for
. A relation between subdifferentials and proximity operators is that
which is frequently used to construct fixed-point equations and prove convergence of the algorithm.
4. Numerical Experiments
In this section, we present some numerical experiments to show the effectiveness of the proposed algorithm (PA-AP). To this end, we test algorithms to solve the nuclear norm minimization problem, the noiseless matrix completion problem
, noisy matrix completion
and low-rank image recovery problem. We compare PA-AP against the ADM [
18], IADM-CG [
20] and IADM-BB [
19]. All experiments are performed under Windows 10 and MATLAB R2016 running on a Lenovo laptop with an Intel CORE i7 CPU at 2.7 GHz and 8 GB of memory. In the numerical experiments of the first two parts, we use randomly generated square matrices for simulations. We denote the true solution by
. We generate the rank-
r matrix
as a product of
, where
and
are independent
matrices with i.i.d. Gaussian entries. For each test, the stopping criterion is
where
. The algorithms are also forced to stop when the iteration number exceeds
.
Let
be the solution obtained by the algorithms. We use the relative error to measure the quality of
compared to the original matrix
, i.e.,
It is obvious that, in each iteration of computing
, PA-AP contains an SVD computation that computes all singular values and singular vectors. However, we actually only need the ones that are bigger than
. This causes the main computational load by using full SVD. Fortunately, this disadvantage can be smoothed by using the software PROPACK [
30], which is designed to compute the singular values bigger than a threshold and the corresponding vectors. Although PROPACK can calculate the first fixed number of singular values, it cannot automatically determine the number of singular values greater than
. Therefore, in order to perform a local SVD, we need to predict the number of singular values and vectors calculated in each iteration, which is expressed by
. We initialize
, and update it in each iteration as follows:
where
is the number of singular values in the
singular values that are bigger than
.
We use r and p to represent the rank of an matrix and the cardinality of the index set , i.e., , and use to represent the sampling rate. The “degree of freedom” of a matrix with rank r is defined by . For PA-AP, we set , , , , and . In all the experimental results, the boldface numbers always indicate the best results.
4.1. Nuclear Norm Minimization Problem
In this subsection, we use PA-AP to solve the three types of problems including (2)–(4). The linear map
is chosen as a partial discrete cosine transform (DCT) matrix. Specifically, in the noiseless model (2),
is generated by the following MATLAB scripts:
which shows that
maps
into
. In the noise model (
3), we further set
where
is the additive Gaussian noise of zero mean and standard deviation
. In (
3), the noise level
is chosen as
.
The results are listed in
Table 1, where the number of iterations (Iter) and CPU time in seconds (Time) besides RelErr are reported. To further illustrate the efficiency of PA-AP, we test problems with different matrix sizes and sampling rates (
). In
Table 2, we compare the PA-AP with IADM-CG and IADM-BB for solving the NNRLS problem (
4). It shows that our method is more efficient than the other two methods, and thus it is suitable for solving large-scale problems.
4.2. Matrix Completion
This subsection adopts the PA-AP method to solve the noiseless matrix completion problem (
2) and the noisy matrix completion problem (
3) to verify its validity. The mapping
is a linear projection operator defined as
, where
is a vector formed by the components of
with indices in
. The indicators of the selected elements are randomly arranged to form a column vector, and the index set of the first
is selected to form the set
. For noisy matrix completion problems, we take
.
In
Table 3, we report the numerical results of PA-AP for noiseless and noisy matrix completion problems, taking
and
. Only the rank of the original matrix is considered to be
and
. As can be seen from
Table 3, the PA-AP method can effectively solve these problems. Compared with the noiseless problem, PA-AP solves the noisy problems accuracy of the solution dropped. Moreover, the number of iterations and the running time decrease as
increases.
To further verify the validity of the PA-AP method, it is compared with ADM, IADM-CG and IADM-BB. When RelChg is lower than
, the algorithms are set to terminate. The numerical results of the four methods for solving the noiseless and noisy MC problem are recorded in
Table 4 and
Table 5, from which we can see that the calculation time of the PA-AP method is much less than IADM-BB and IADM-CG, and the number of iterations and calculation time of PA-AP and ADM are almost the same, while our method is relatively more accurate. From the limited experimental data, the PA-AP method is shown to be more effective than the ADM, IADM-BB and IADM-CG.
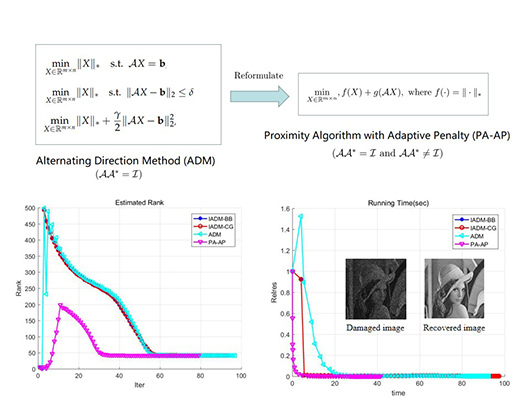
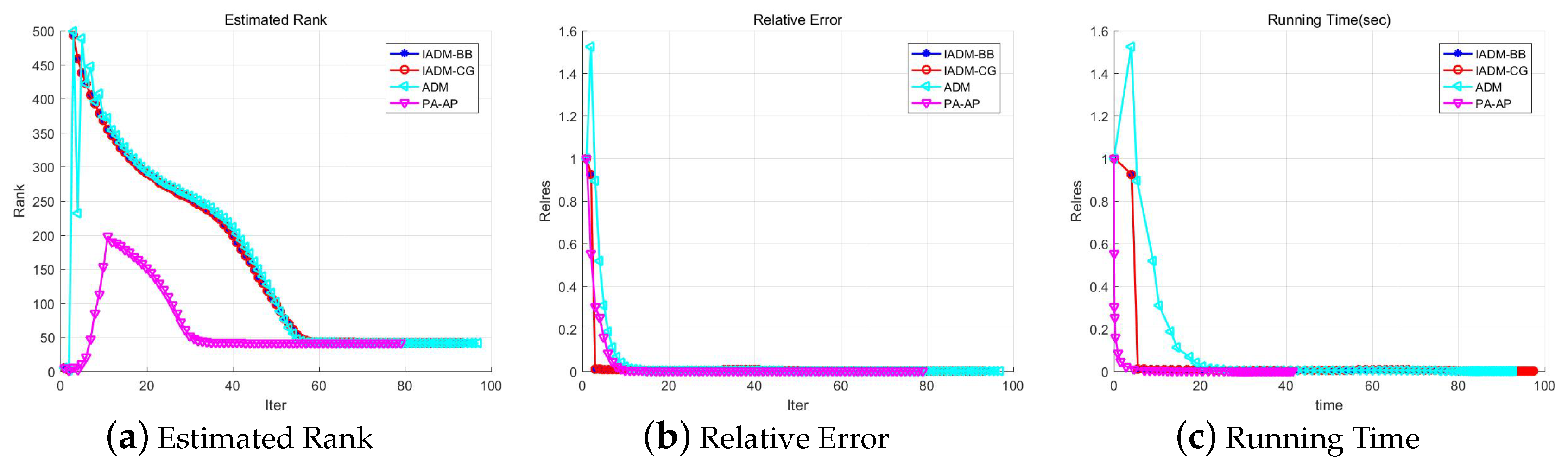
4.3. Low-Rank Image Recovery
In the section, we turn to solve problem (
2) for low-rank image recovery. The effectiveness of the PA-AP method is verified by testing three
grayscale images. First, the original images are transformed into low-rank images with rank 40. Then, we lose some elements from the low rank matrix to get the damaged image, and restore them by using the PA-AP, ADM, IADM-BB and IADM-CG, respectively. The iteration process is stopped when RelChg falls below
. The original images, the corresponding low-rank images, the damaged images, and the restored images by the PA-AP are depicted in
Figure 1. Observing the figure, we clearly see that our algorithm performs well.
To evaluate the recovery performance, we employ the Peak Signal-to-Noise Ratio (PSNR), which is defined as
where
is the infinity norm of
, defined as the maximum absolute value of the elements in
. From the definition, higher PSNR indicates a better recovery result.
Table 6 shows the cost time, relative error and PSNR of recovery image by different methods. From
Table 6, we can note that the PA-AP method is able to obtain higher PSNR as
increases. Moreover, the running time of PA-AP is always much less than the other methods with different settings.
Figure 2 shows the executing process of the different methods. From
Figure 2, it is clear that our method can estimate the rank exactly after 30 iterations, and runs much less time before termination than other methods.





{kind=link}
{kind=link}
{kind=link}