Efficient Vehicle Detection and Distance Estimation Based on Aggregated Channel Features and Inverse Perspective Mapping from a Single Camera


Abstract
:1. Introduction
1.1. Related Works
1.2. Definition of Problems
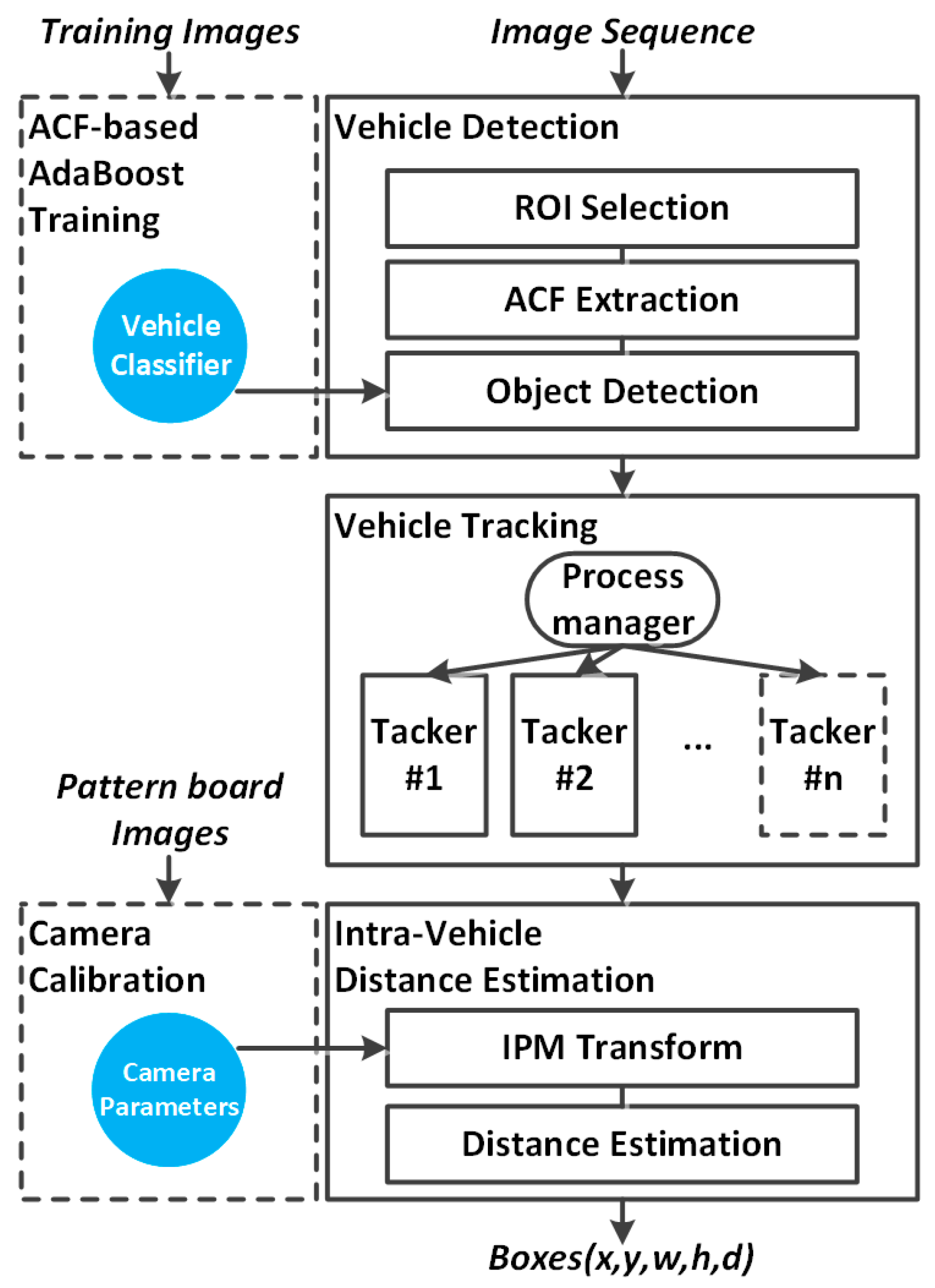
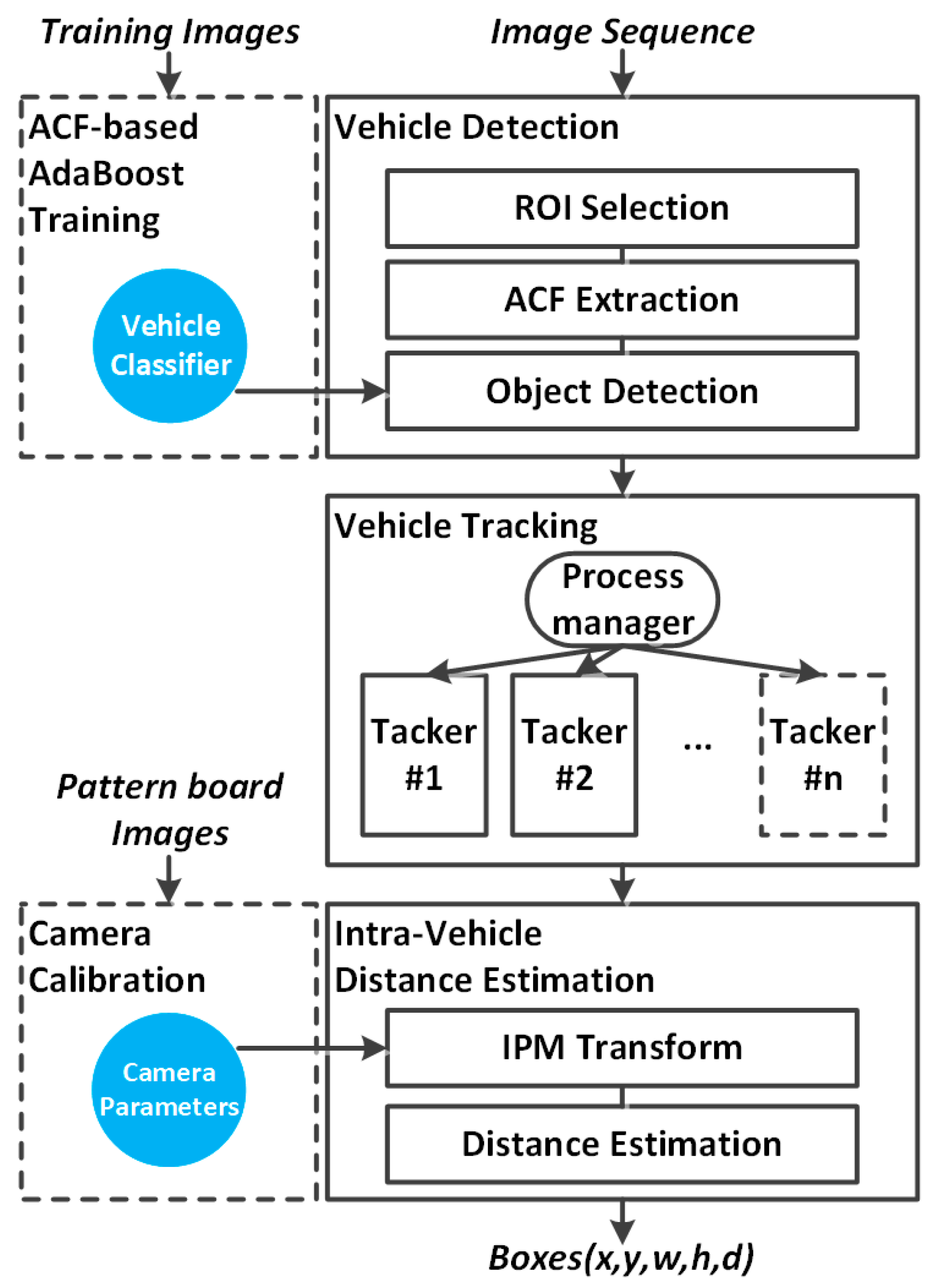
2. Proposed Methods
3. Vehicle Detection
3.1. ROI Selection
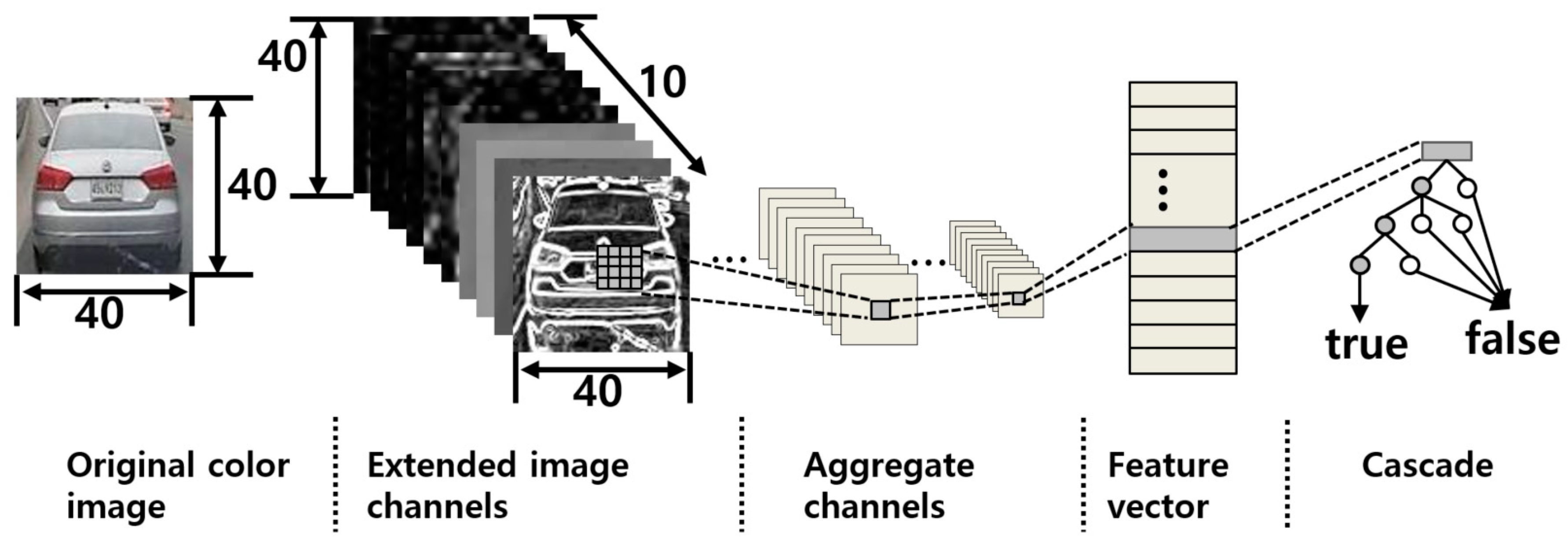
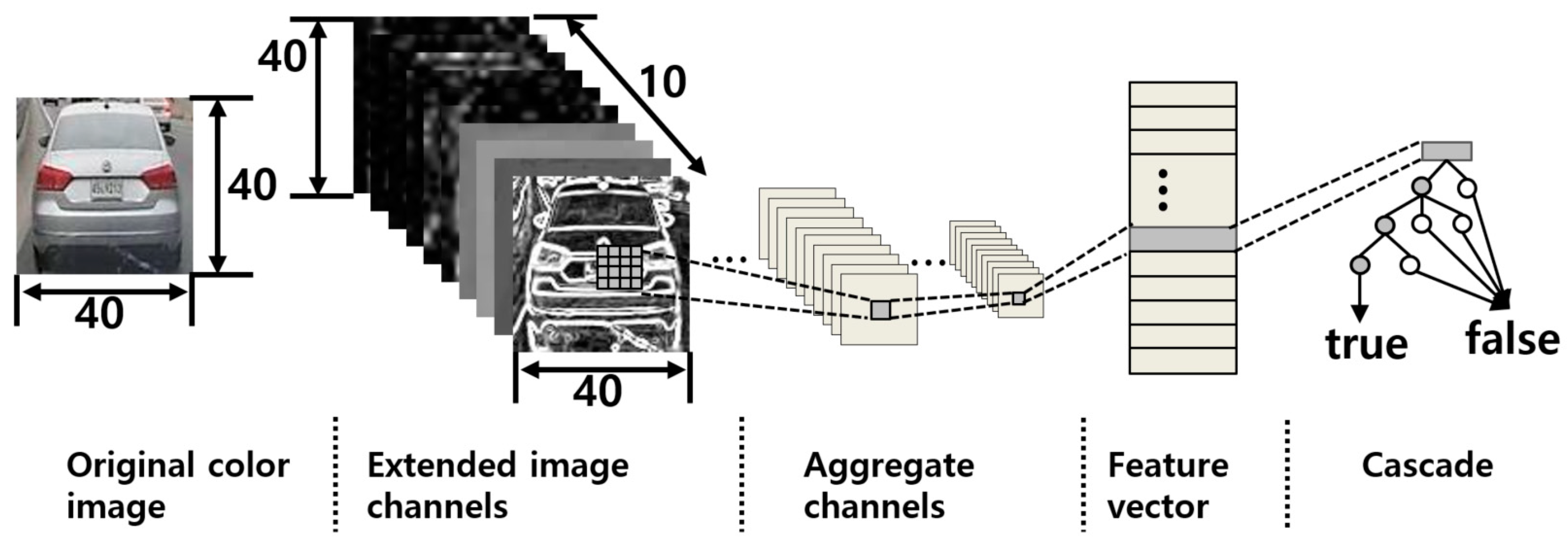
3.2. Extraction of Aggregated Channel Features
3.3. Object Detection
4. Vehicle Tracking
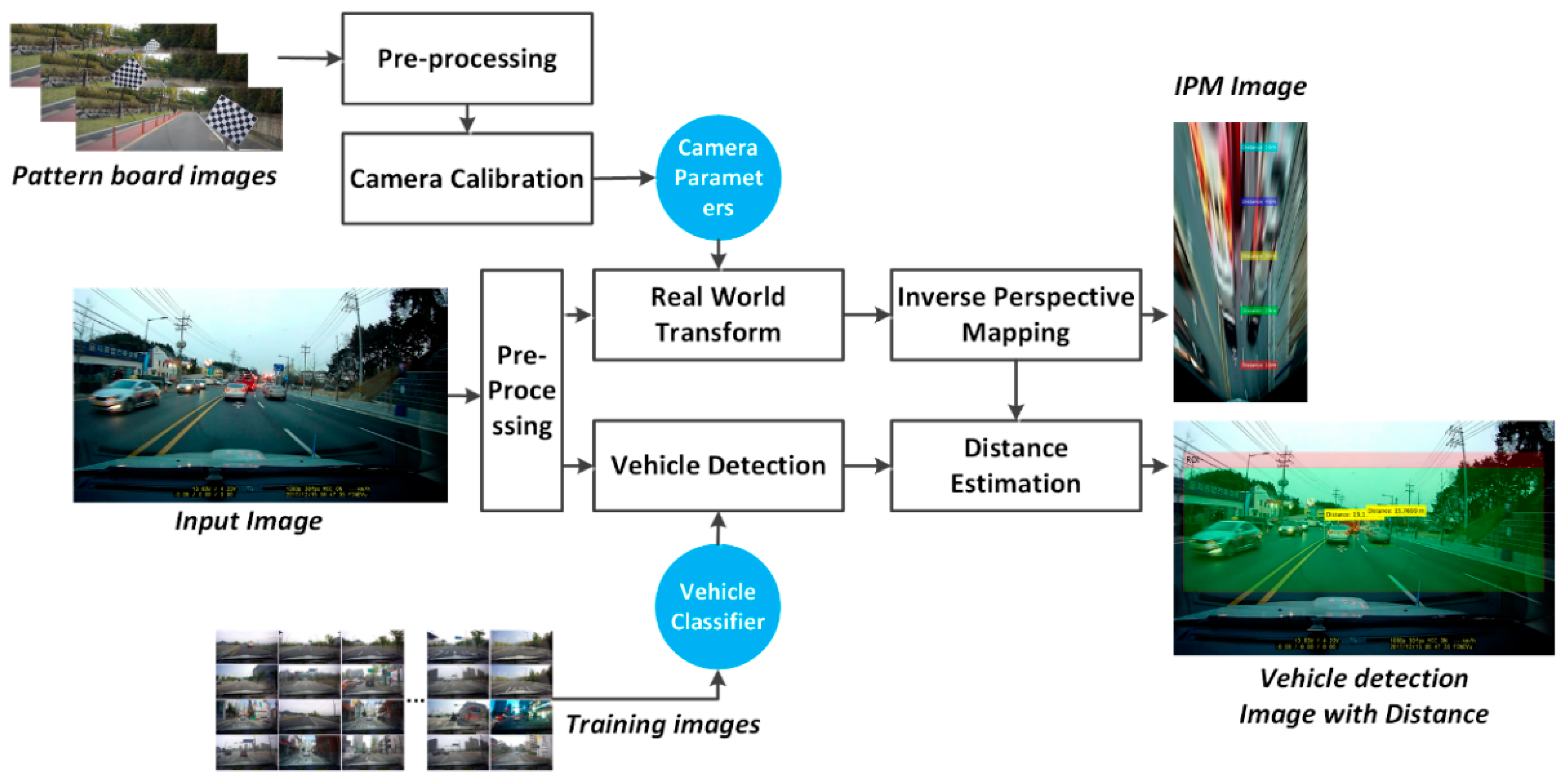
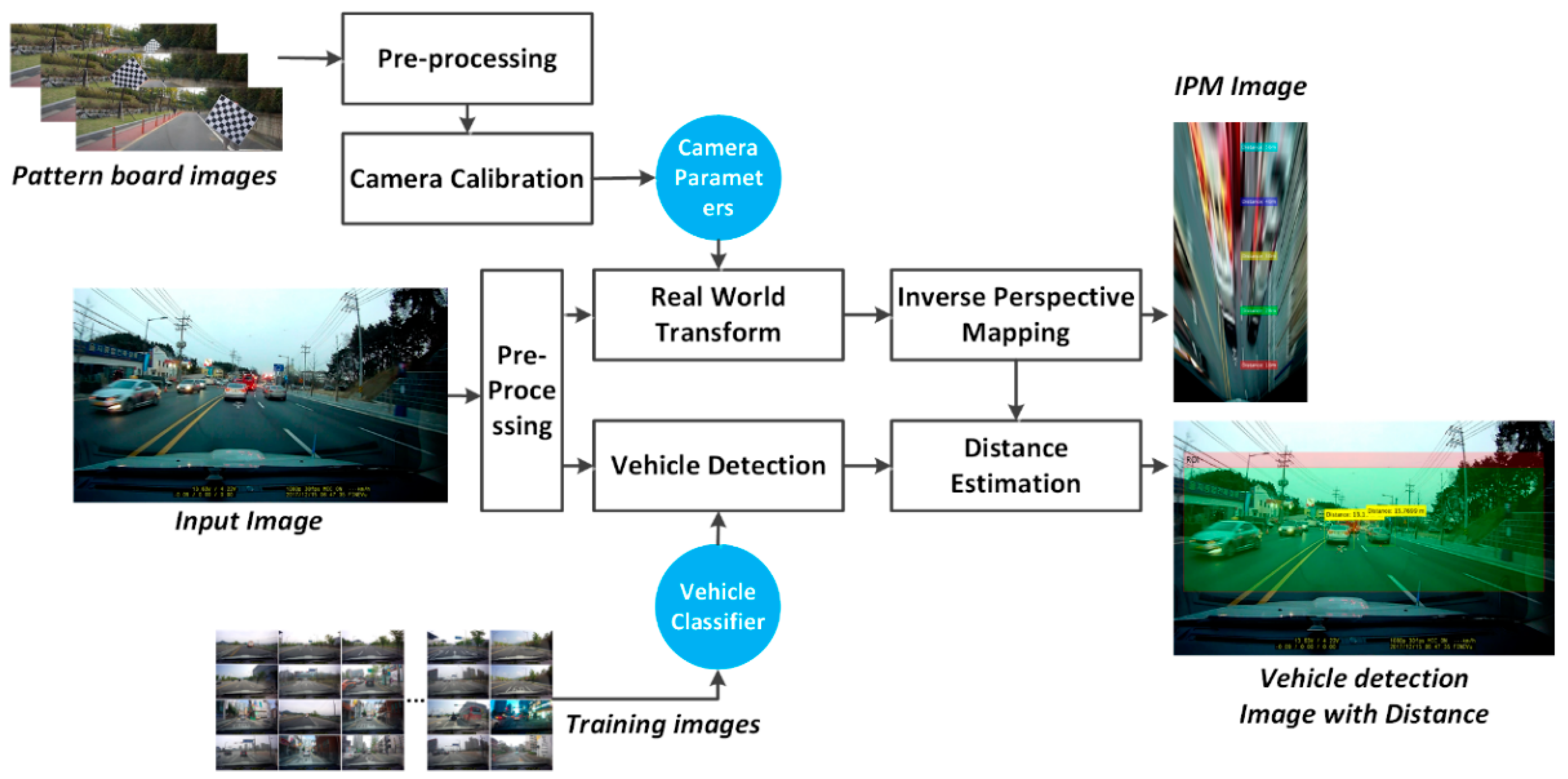
5. Vehicle Distance Estimation
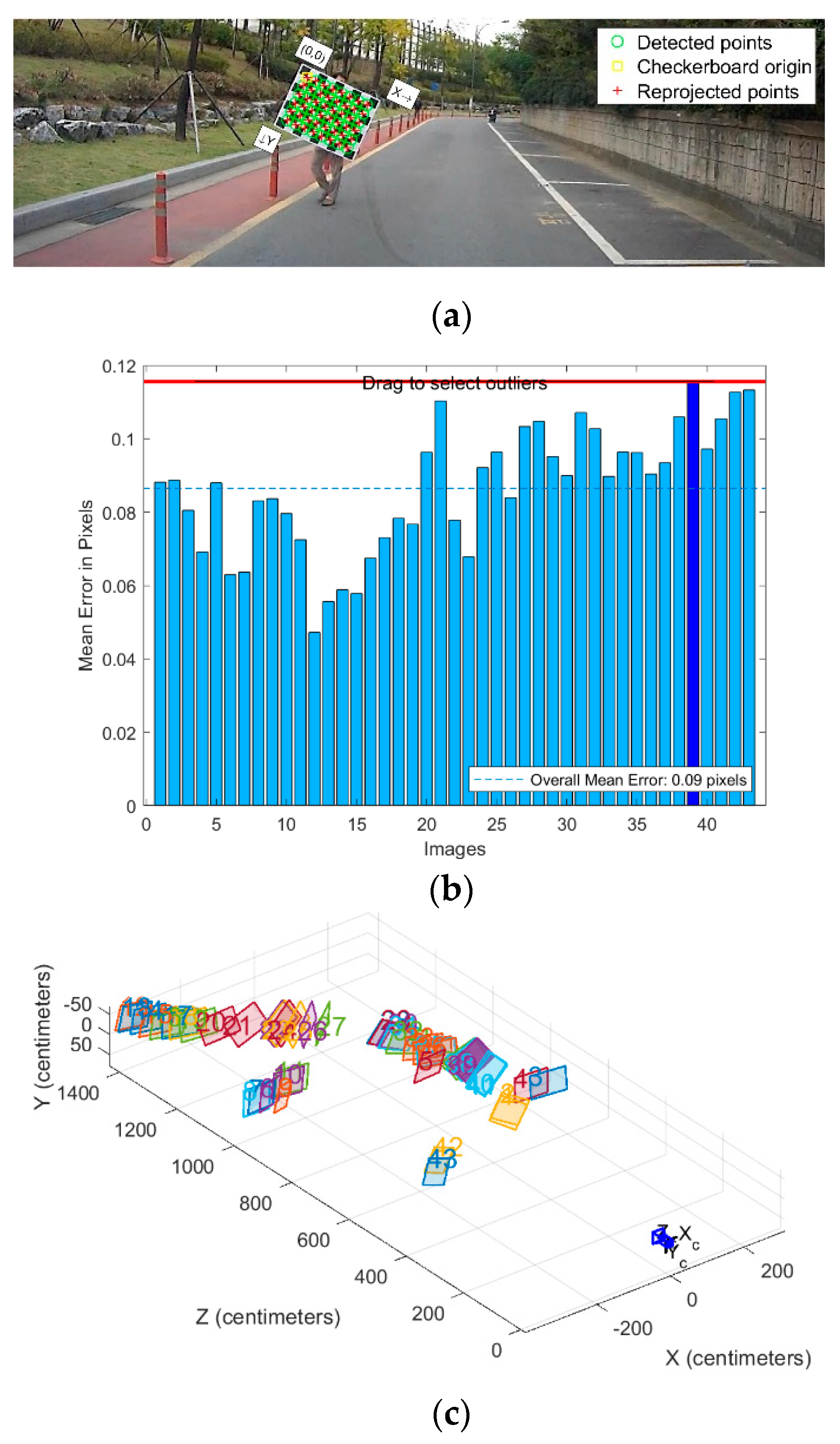
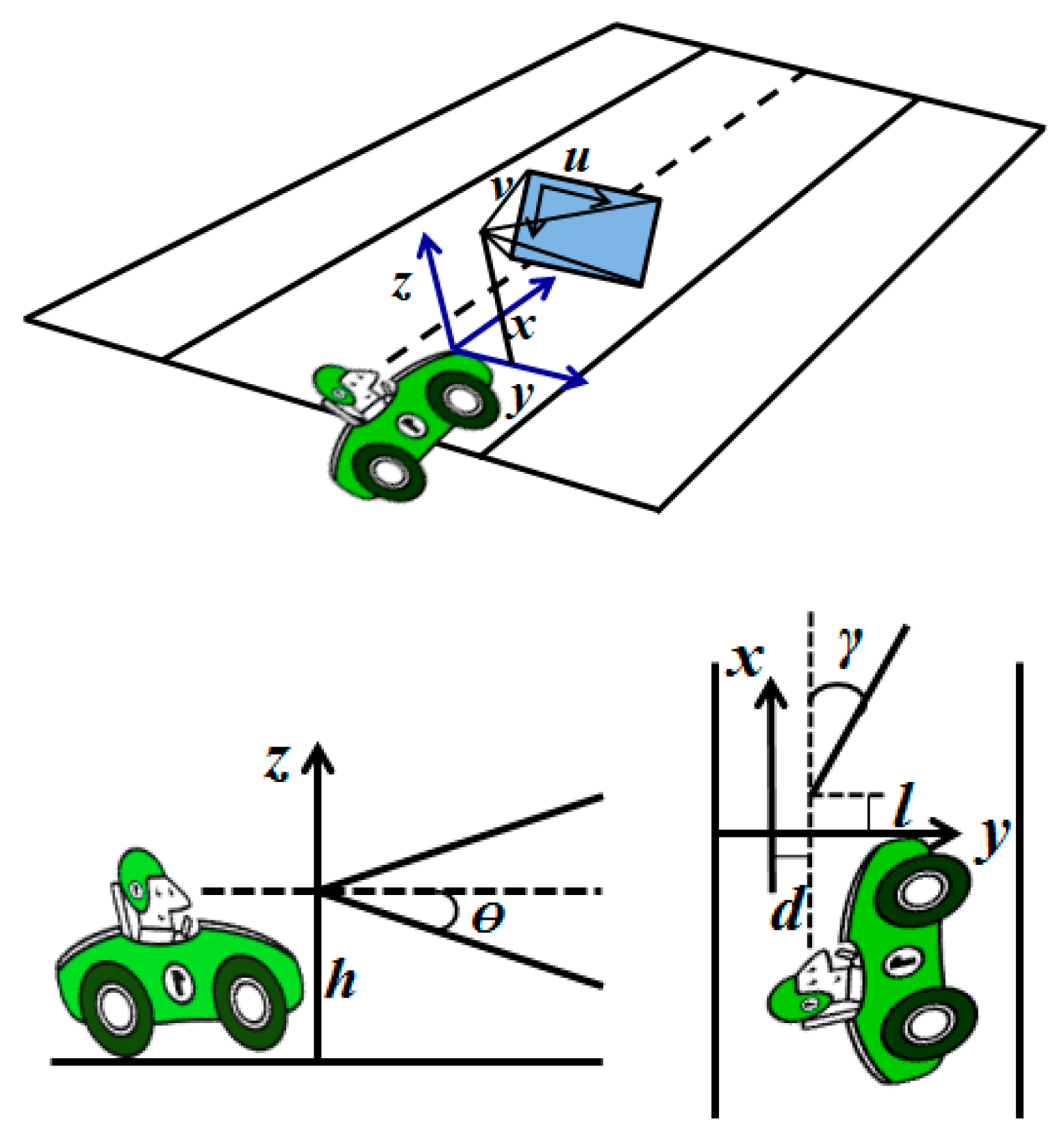
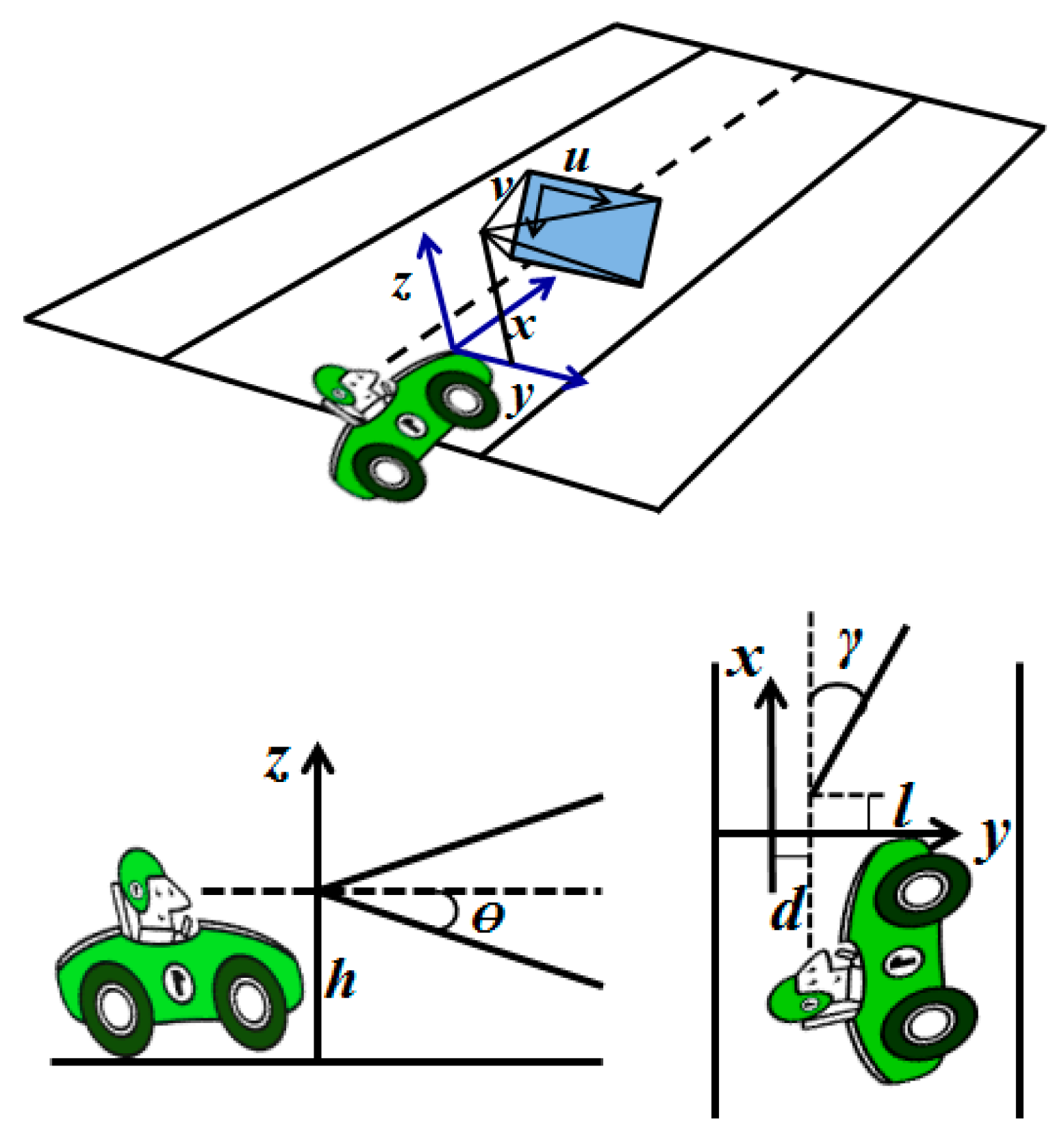
5.1. Camera Parameters Extraction
5.2. Inverse Perspective Transformation
6. Experimental Results
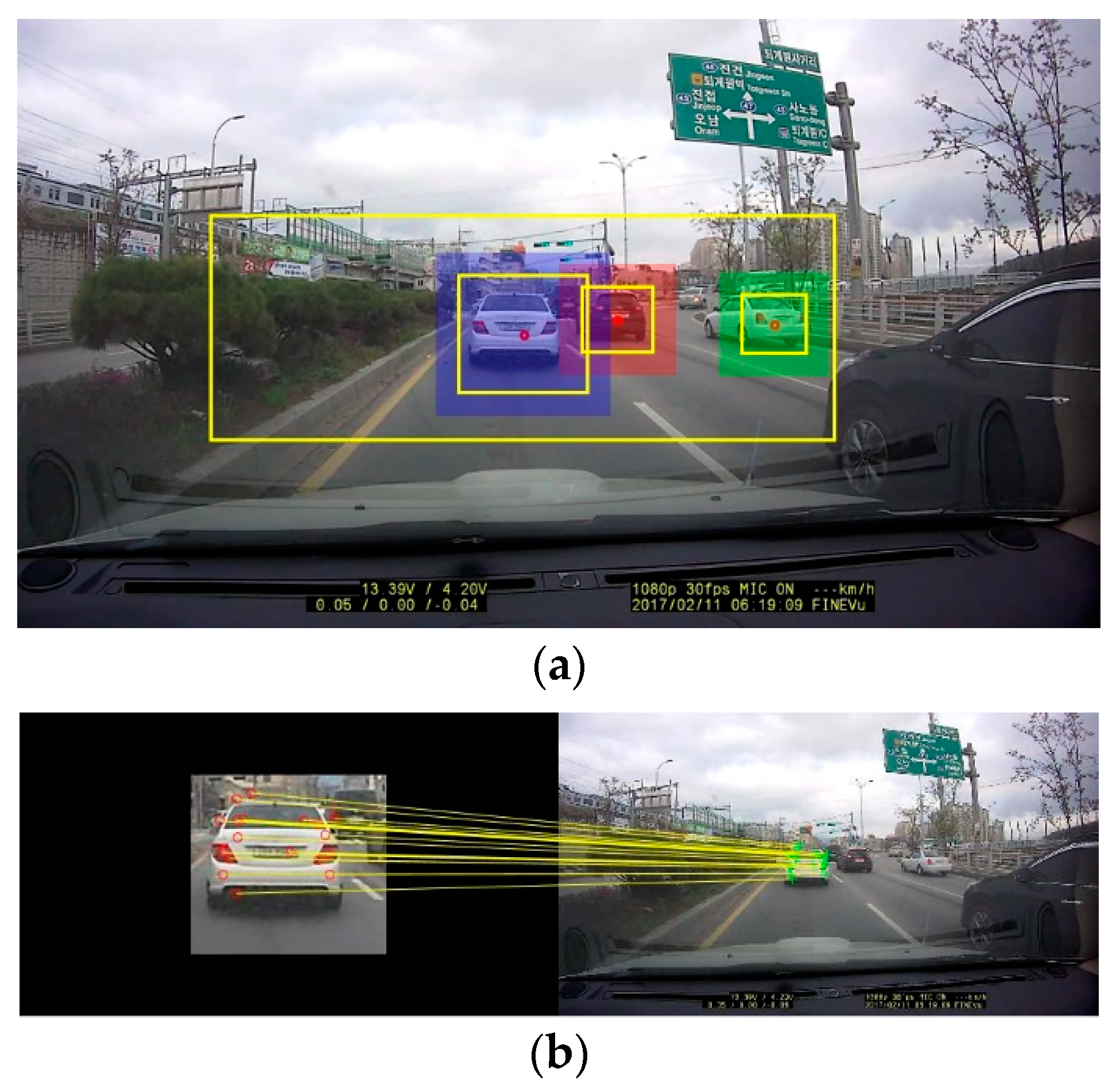
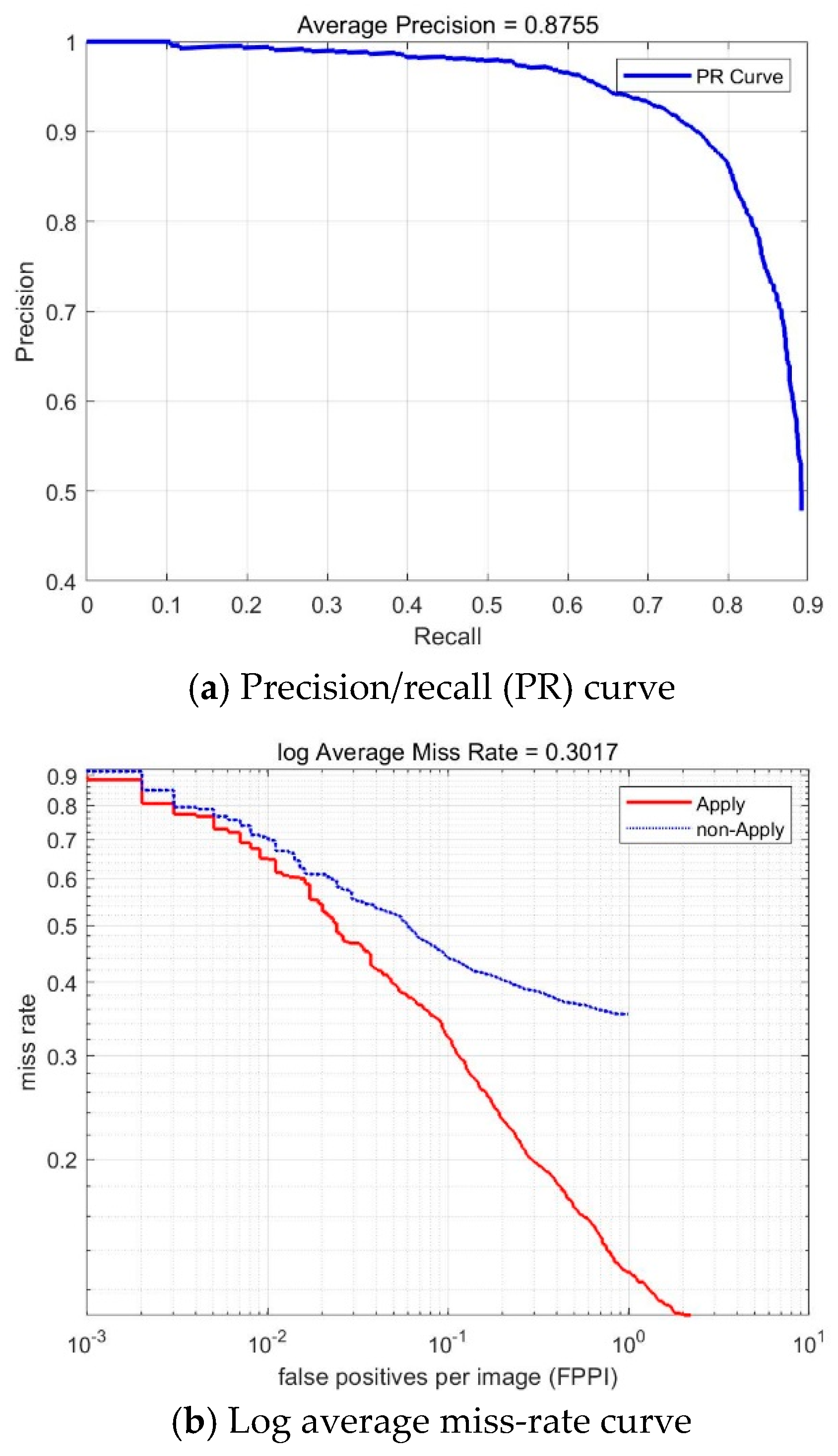
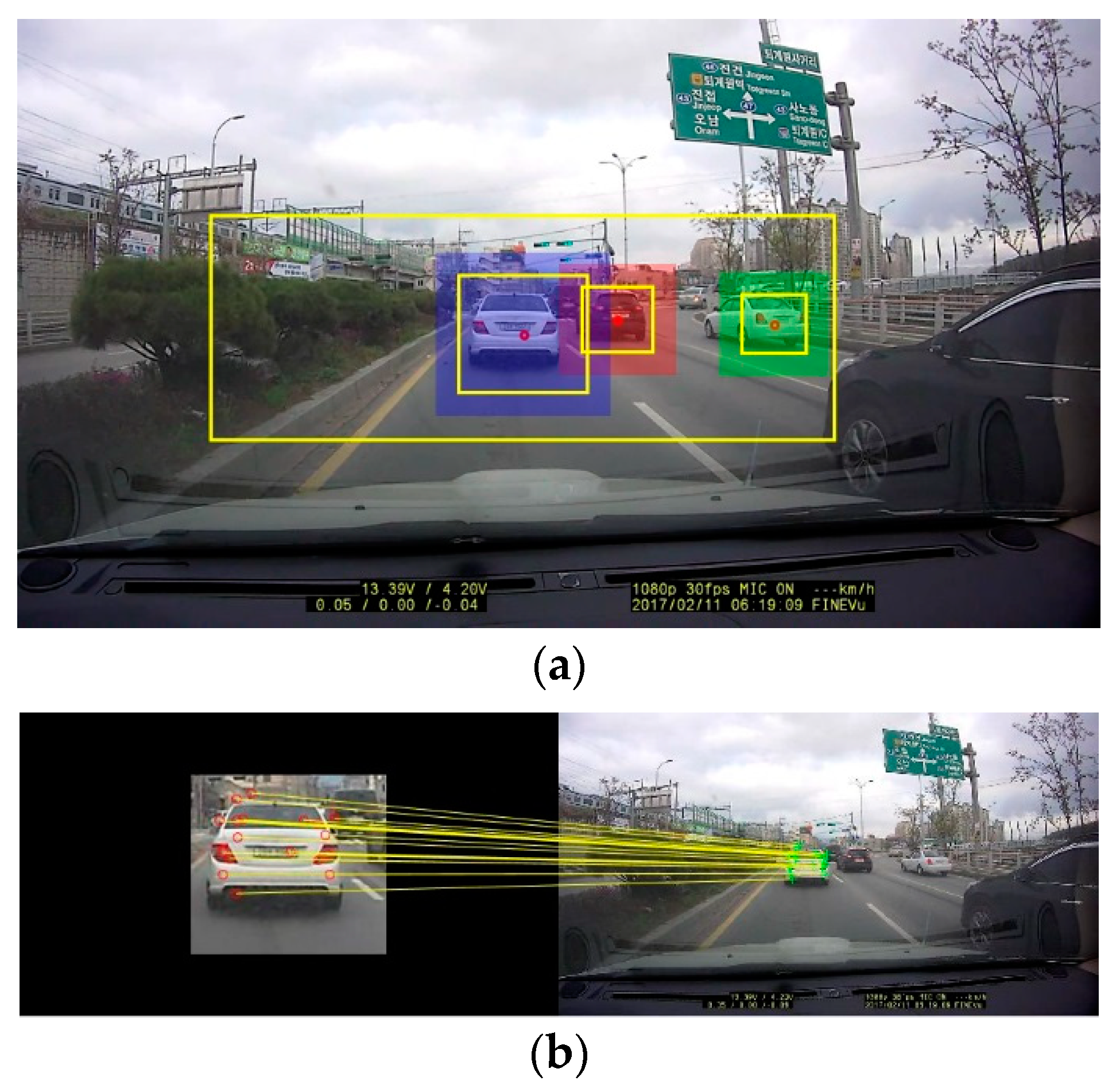
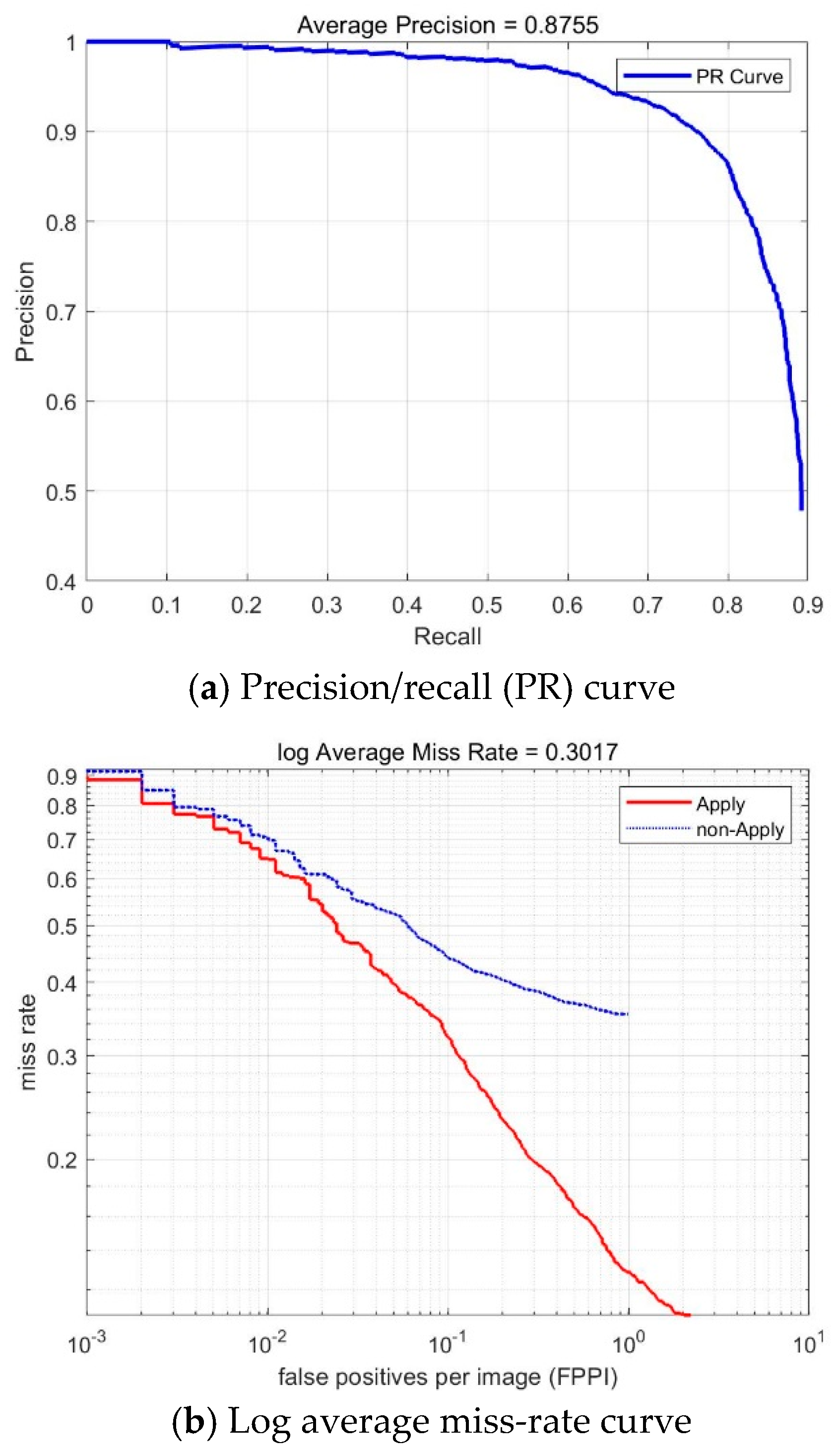
6.1. Results of Vehicle Detection
6.2. Results of Vehicle Distance Estimation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kukkala, V.K.; Tunnell, J.; Pasricha, S.; Bradley, T. Advanced driver-assistance systems-a path toward autonomous vehicles. IEEE Consum. Electron. Mag. 2018, 7, 18–25. [Google Scholar] [CrossRef]
- Khan, S.M.; Dey, K.C.; Chowdhury, M. Real-time traffic state estimation with connected vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1687–1699. [Google Scholar] [CrossRef]
- Eckelmann, S.; Trautmann, T.; Ußler, H.; Reichelt, B.; Michler, O. V2V-communication, LiDAR system and positioning sensors for future fusion algorithms in connected vehicles. Transp. Res. Procedia 2017, 27, 69–76. [Google Scholar] [CrossRef]
- Brummelen, J.V.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part C Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Kim, J.B. Development of a robust traffic surveillance system using wavelet support vector machines and wavelet invariant moments. Inf. Int. Interdiscip. J. 2013, 16, 3787–3800. [Google Scholar]
- Kim, J.B. Detection of traffic signs based on eigen-color model and saliency model in driver assistance systems. Int. J. Automot. Technol. 2013, 14, 429–439. [Google Scholar] [CrossRef]
- Gargoum, S.A.; Karsten, L.; El-Basyouny, K.; Koch, J.C. Automated assessment of vertical clearance on highways scanned using mobile LiDAR technology. Autom. Constr. 2018, 95, 260–274. [Google Scholar] [CrossRef]
- Kang, C.; Heom, S.W. Intelligent safety information gathering system using a smart blackbox. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 8–10 January 2017; pp. 229–230. [Google Scholar]
- Kim, J.H.; Kim, S.K.; Lee, S.H.; Lee, T.M.; Lim, J. Lane recognition algorithm using lane shape and color features for vehicle black box. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–2. [Google Scholar]
- Rekha, S.; Hithaishi, B.S. Car surveillance and driver assistance using blackbox with the help of GSM and GPS technology. In Proceedings of the 2017 International Conference on Recent Advances in Electronics and Communication Technology (ICRAE), Bangalore, India, 16–17 March 2017; pp. 297–301. [Google Scholar]
- Xing, Y.; Lv, C.; Chen, L.; Wang, H.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.Y. Advances in vision-based lane detection: Algorithms, integration, assessment, and perspectives on ACP-based parallel vision. IEEE/CAA J. Autom. Sin. 2018, 5, 645–661. [Google Scholar] [CrossRef]
- Chen, Y.C.; Su, T.F.; Lai, S.H. Integrated vehicle and lane detection with distance estimation. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 473–485. [Google Scholar]
- Kim, G.; Cho, J.S. Vision-based vehicle detection and inter-vehicle distance estimation. J. IEEK 2012, 49SP, 1–9. [Google Scholar]
- Tram, V.T.B.; Yoo, M. Vehicle-to-vehicle distance estimation using a low-resolution camera based on visible light communications. IEEE Access 2018, 6, 4521–4527. [Google Scholar] [CrossRef]
- Liu, L.C.; Fang, C.Y.; Chen, S.W. A novel distance estimation method leading a forward collision avoidance assist system for vehicles on highways. IEEE Trans. Intell. Transp. Syst. 2017, 18, 937–949. [Google Scholar] [CrossRef]
- Rezaei, M.; Terauchi, M.; Klette, R. Robust vehicle detection and distance estimation under challenging lighting conditions. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2723–2743. [Google Scholar] [CrossRef]
- Huang, D.Y.; Chen, C.H.; Chen, T.Y.; Hu, W.C.; Feng, K.W. Vehicle detection and inter-vehicle distance estimation using single-lens video camera on urban/suburb roads. J. Vis. Commun. Image Represent. 2017, 46, 250–259. [Google Scholar] [CrossRef]
- Yang, Z.; Cheng, L.S.C.P. Vehicle detection in intelligent transportation systems and its applications under varying environments: A review. Image Vis. Comput. 2018, 69, 143–154. [Google Scholar] [CrossRef]
- Thiang, A.T.; Guntoro, R.L. Type of vehicle recognition using template matching method. In Proceedings of the International Conference on Electrical Electronics Communication and Information, Jakarta, Indonesia, 7–8 March 2001; pp. 1–5. [Google Scholar]
- Choi, J.; Lee, K.; Cha, K.; Kwon, J.; Kim, D.; Song, H. Vehicle tracking using template matching based on feature points. In Proceedings of the 2006 IEEE International Conference on Information Reuse & Integration, Waikoloa Village, HI, USA, 16–18 September 2006; pp. 573–577. [Google Scholar]
- Sharma, K. Feature-based efficient vehicle tracking for a traffic surveillance system. Comput. Electr. Eng. 2018, 70, 690–701. [Google Scholar] [CrossRef]
- Oren, M.; Papageorgiou, C.; Sinha, P.; Osuna, E.; Poggio, T. Pedestrian detection using wavelet templates. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 193–199. [Google Scholar]
- Daigavane, P.M.; Bajaj, P.R.; Daigavane, M.B. Vehicle detection and neural network application for vehicle classification. In Proceedings of the 2011 International Conference on Computational Intelligence and Communication Networks, Gwalior, India, 7–9 October 2011; pp. 758–762. [Google Scholar]
- Satzoda, R.K.; Trivedi, M.M. Multipart vehicle detection using symmetry-derived analysis and active learning. IEEE Trans. Intell. Transp. Syst. 2016, 17, 926–937. [Google Scholar] [CrossRef]
- Kim, J.B. Automatic vehicle license plate extraction using region-based convolutional neural networks and morphological operations. Symmetry 2019, 11, 882. [Google Scholar] [CrossRef]
- Wei, Y.; Tian, Q.; Guo, J.; Huang, W.; Cao, J. Multi-vehicle detection algorithm through combining Harr and HOG features. Math. Comput. Simul. 2019, 155, 130–145. [Google Scholar] [CrossRef]
- Jazayeri, A.; Cai, H.; Zheng, J.Y.; Tuceryan, M. Vehicle detection and tracking in car video based on motion model. IEEE Trans. Intell. Transp. Syst. 2011, 12, 583–595. [Google Scholar] [CrossRef]
- Chen, S.H.; Chen, R.S. Vision-based distance estimation for multiple vehicles using single optical camera. In Proceedings of the 2011 Second International Conference on Innovations in Bio-inspired Computing and Applications, Shenzhen, China, 16–18 December 2011; pp. 9–12. [Google Scholar]
- Bertozz, M.; Broggi, A.; Fascioli, A. Stereo inverse perspective mapping: Theory and applications. Image Vis. Comput. 1998, 16, 585–590. [Google Scholar] [CrossRef]
- Dollar, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Aggregate channel features for multi-view face detection. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 194–201. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Song, G.; Lee, K.; Lee, J. Vehicle detection using edge analysis and AdaBoost algorithm. Trans. KSAE 2009, 17, 1–11. [Google Scholar]
- Zhuang, L.; Xu, Y.; Ni, B. Pedestrian detection using ACF based fast R-CNN. In Digital TV and Wireless Multimedia Communications; Springer: Singapore, 2017; pp. 172–181. [Google Scholar]
- Kim, J.B. Detection of direction indicators on road surfaces using inverse perspective mapping and NN. J. Inf. Process. Korean 2015, 4, 201–208. [Google Scholar]
- Yang, W.; Fang, B.; Tang, Y.Y. Fast and accurate vanishing point detection and its application in inverse perspective mapping of structured road. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 755–766. [Google Scholar] [CrossRef]
- Jeong, S.H.; Kim, J.K. A study on detection and distance estimation of forward vehicle for FCWS (Forward Collision Warning System). Proc. IEEK 2013, 1, 597–600. [Google Scholar]
- Lee, H.S.; Oh, S.; Jo, D.; Kang, B.Y. Estimation of driver’s danger level when accessing the center console for safe driving. Sensors 2018, 18, 3392. [Google Scholar] [CrossRef] [PubMed]
- Yin, J.L.; Chen, B.H.; Lai, K.-H.R.; Li, Y. Automatic dangerous driving intensity analysis for advanced driver assistance systems from multimodal driving signals. IEEE Sens. J. 2018, 18, 4785–4794. [Google Scholar] [CrossRef]
- Choudhury, S.; Chattopadhyay, S.P.; Hazra, T.K. Vehicle detection and counting using haar feature-based classifier. In Proceedings of the 2017 8th Annual Industrial Automation and Electromechanical Engineering Conference (IEMECON), Bangkok, Thailand, 16–18 August 2017; pp. 106–109. [Google Scholar]
- Arunmozhi, A.; Park, J. Comparison of HOG, LBP and Haar-like features for on-road vehicle detection. In Proceedings of the 2018 IEEE International Conference on Electro/Information Technology (EIT), Rochester, MI, USA, 3–5 May 2018; pp. 362–367. [Google Scholar]
- Zheng, Y.; Guo, B.; Li, C.; Yan, Y. A Weighted Fourier and Wavelet-Like Shape Descriptor Based on IDSC for Object Recognition. Symmetry 2019, 11, 693. [Google Scholar] [CrossRef]
- Gong, L.; Hong, W.; Wang, J. Pedestrian detection algorithm based on integral channel features. In Proceedings of the IEEE Chinese Control and Decision Conference, Shenyang, China, 9–11 June 2018; pp. 941–946. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards Reaching Human Performance in Pedestrian Detection. IEEE Trans. PAMI 2018, 40, 973–986. [Google Scholar] [CrossRef]
- Pritam, D.; Dewan, J.H. Detection of fire using image processing techniques with LUV color space. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 1158–1162. [Google Scholar]
- Lee, Y.H.; Ko, J.Y.; Yoon, S.H.; Roh, T.M.; Shim, J.C. Bike detection on the road using correlation coefficient based on Adaboost classification. J. Adv. Inf. Tech. Convers. 2011, 9, 195–203. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Newman, W.M.; Sproull, R.F. Principles of Interactive Computer Graphics; McGraw-Hill: Tokyo, Japan, 1981. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step 1. Define learning data: m objects of interest (+1) and n non-objects of interest (−1): |
| Step 2. Initialization of the weight value of i-th weak classifier (h): |
| Step 3. Training step (repeat for t = 1, …, C, t++) |
| (1) Normalization of the weight value of the i-th learning sample of the t-th weak classifier: |
| (2) Calculation of error rate () of t-th weak classifier: |
| (3) Selection of a weak classifier (h) with a minimum error rate. |
| (4) Updating weight values: |
| Step 4. Creation of a strong classifier (H(x)) as a linear combination of weak classifiers (h): |
| Criteria | Method |
|---|---|
| position (x, y, width, height) | position = [25, 101, 846, 267] |
| aspect ratio (width/height) | 0.6939 <= ratio <= 13.1700 |
| brightness Ratio (avrIntensity) | 0.3563 <= avrIntensity <= 3.7889 |
| vehicle template |  template >= 0.7 template >= 0.7 |
| Measures | Average Precision | Log Average Error Rate | Training Time (s) | |
|---|---|---|---|---|
| Parameters | ||||
| T = 2, S = 2 | 0.7847 | 0.4917 | 283.57 | |
| T = 2, S = 4 | 0.5791 | 0.6387 | 432.47 | |
| T = 4, S = 2 | 0.8755 | 0.3017 | 592.30 | |
| T = 4, S = 4 | 0.8422 | 0.2947 | 680.04 | |
| T = 5, S = 2 | 0.8428 | 0.2901 | 751.25 | |
| T = 5, S = 4 | 0.8433 | 0.2908 | 821.34 | |
| T = 6, S = 2 | 0.8292 | 0.3161 | 1257.56 | |
| T = 6, S = 4 | 0.8375 | 0.2906 | 1503.33 | |
| Measures | Average Precision | Recall (R) | Average Processing Time, (s) | |
|---|---|---|---|---|
| Features | ||||
| Haar | 0.7310 | 0.4941 | 0.135 | |
| LBP | 0.7641 | 0.5634 | 0.126 | |
| HOG | 0.8375 | 0.4775 | 0.149 | |
| Our methods | 0.8755 | 0.3017 | 0.121 | |
| Measure | Average Distance Estimation (m) | Accuracy (%) | |
|---|---|---|---|
| Distance | |||
| 10 m | 9.8 | 98.0 | |
| 20 m | 21.7 | 92.2 | |
| 30 m | 32.7 | 91.7 | |
| 40 m | 43.8 | 91.3 | |
| 50 m | 54.8 | 91.2 | |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.B. Efficient Vehicle Detection and Distance Estimation Based on Aggregated Channel Features and Inverse Perspective Mapping from a Single Camera. Symmetry 2019, 11, 1205. https://doi.org/10.3390/sym11101205
Kim JB. Efficient Vehicle Detection and Distance Estimation Based on Aggregated Channel Features and Inverse Perspective Mapping from a Single Camera. Symmetry. 2019; 11(10):1205. https://doi.org/10.3390/sym11101205
Chicago/Turabian StyleKim, Jong Bae. 2019. "Efficient Vehicle Detection and Distance Estimation Based on Aggregated Channel Features and Inverse Perspective Mapping from a Single Camera" Symmetry 11, no. 10: 1205. https://doi.org/10.3390/sym11101205
APA StyleKim, J. B. (2019). Efficient Vehicle Detection and Distance Estimation Based on Aggregated Channel Features and Inverse Perspective Mapping from a Single Camera. Symmetry, 11(10), 1205. https://doi.org/10.3390/sym11101205