Abstract
Selecting the proper performance metric constitutes a key issue for most classification problems in the field of machine learning. Although the specialized literature has addressed several topics regarding these metrics, their symmetries have yet to be systematically studied. This research focuses on ten metrics based on a binary confusion matrix and their symmetric behaviour is formally defined under all types of transformations. Through simulated experiments, which cover the full range of datasets and classification results, the symmetric behaviour of these metrics is explored by exposing them to hundreds of simple or combined symmetric transformations. Cross-symmetries among the metrics and statistical symmetries are also explored. The results obtained show that, in all cases, three and only three types of symmetries arise: labelling inversion (between positive and negative classes); scoring inversion (concerning good and bad classifiers); and the combination of these two inversions. Additionally, certain metrics have been shown to be independent of the imbalance in the dataset and two cross-symmetries have been identified. The results regarding their symmetries reveal a deeper insight into the behaviour of various performance metrics and offer an indicator to properly interpret their values and a guide for their selection for certain specific applications.
1. Introduction
Symmetry has played and continues playing, a highly significant role in the way of how humans perceive the world [1]. In the scientific fields, symmetry plays a key role as it can be discovered in nature [2,3], society [4] and mathematics [5]. Moreover, symmetry also provides an intuitive way to attain faster and deeper insights into scientific problems.
In recent years, an increasing interest has arisen in detecting and taking advantage of symmetry in various aspects of theoretical and applied computing [6]. Several studies involving symmetry have been published in network technology [7], human interfaces [8], image processing [9], data hiding [10] and many other applications [11].
On the other hand, pattern recognition and machine learning procedures are becoming key aspects of modern science [12] and the hottest topics in the scientific literature on computing [13]. Furthermore, in this field, symmetry is playing an interesting role either as a subject of study, in the form of machine learning algorithms to discover symmetries [14] or as a means to improve the results obtained by automatic recognition systems [15]. Let us emphasize this point: not only can knowing the symmetry of a certain computer algorithm be intrinsically rewarding since it sheds light on the behaviour of the algorithm but it can also be very useful for its interpretation, its optimization or as a criterion for the selection among various competing algorithms. As an example, in recent research, we have employed a symmetric criterion to select the best feature-extraction procedures (Discrete Cosine Transform versus Discrete Fourier Transform) [16] in an application of the classification of sounds [17,18] effectively deployed in a Wireless Sensor Network as shown in Figure 1. Another examples of industrial applications using classification of sounds can be found in Refs. [19,20].

Figure 1.
Node of the Wireless Sensor Network where the symmetry of classification performance metrics has been primarily applied.
In the broad field of machine learning, the study of how to measure the performance of various classifiers has attracted continued attention [21,22,23]. Classification performance metrics play a key role in the assessment of the overall classification process in the test phase, in the selection from among various competing classifiers in the validation phase and are even sometimes used as the loss function to be optimized in the process of model construction during the classification training phase.
However, to the best of our knowledge, no systematic study into the symmetry of these metrics has yet been undertaken. By discovering their symmetries, we would reach a better understanding of their meaning, we could obtain useful insights into when their use would be more appropriate and we would also gain additional and meaningful indicators for the selection of the best performance metric.
Although several dozen performance metrics can be found in the literature, we will focus on those which are probably the most commonly used: the metrics based on the confusion matrix [24]. Accuracy, precision and recall (sensitivity) are undoubtedly some of the most popular metrics. On the other hand, our research will be focused on the cases where there are only two classes (binary classifiers). Although this is certainly a limitation, it does provide a solid ground base for further research. Moreover, multiclass performance metrics are usually obtained by decomposing the multiclass problem into several binary classification sub-problems [25].
2. Materials and Methods
2.1. Definitions
Let us first consider an original (baseline) experiment , defined by the duple composed of a set of classifiers, and a set of their corresponding datasets, . The elements in every dataset belong to either of two classes, and , which are called Positive () and Negative () classes, respectively. The -th classifier operates on the corresponding dataset, thereby obtaining a resulting classification which can be defined by its binary confusion matrix and hence . The set of confusion matrices are denominated . The baseline experiment can therefore be defined as the set of classifiers operating on the set of datasets to obtain a set of confusion matrices, .
This paper will explore the behaviour of binary classification performance metrics when the original experiment is subject to different types of transformations. Let us define the -th transformed experiment composed of a set of classifiers, and a set of their corresponding datasets, , whose result is a set of confusion matrices . Hence, , where , indicates the type of transformation. In the -th experiment, when the -th classifier operates on its corresponding dataset, the result is summarized in the binary confusion matrix defined as
where
- is the number of positive elements in correctly classified as positive;
- is the number of negative elements in correctly classified as negative;
- is the number of positive elements in incorrectly classified as negative; and
- is the number of negative elements in incorrectly classified as positive.
Let us call , the positive, negative and total number of elements in . Therefore , and . The confusion matrix can then be described as
Let us now define as the ratio of positive elements in correctly classified as positive; and as the ratio of negative elements in correctly classified as negative. That is,
The confusion matrix can therefore be rewritten as
On the other hand, a dataset is called imbalanced if it has a different number of positive and negative elements, that is, . Classification on the presence of imbalanced datasets is a challenging task requiring specific considerations [26]. To quantify the imbalance, several indicators have been proposed, such as the dominance [27,28], the proportion between positive and negative instances (formalized as ) [29] and the imbalance ratio () defined as [30], which is also called skew [31]. This value lies within the range and has a value in the balanced case. We prefer to use an indicator showing a value in the balanced case, a value when all the elements in the dataset are positive and if all the elements are negative. We define the imbalance coefficient , which is an indicator that has these characteristics, as
The imbalance coefficient is graphically shown in Figure 2 (solid blue cline) as a function of the proportion of positive elements in the dataset. For the sake of comparison, that figure also shows the imbalance ratio (dashed green line).
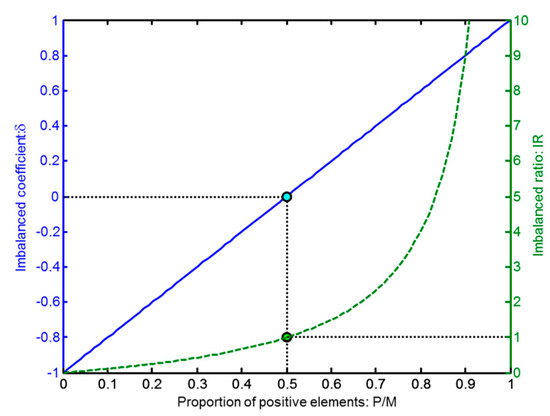
Figure 2.
Imbalance coefficient (solid blue line) and imbalance ratio (dashed green line) vs. the proportion of positive elements in the dataset.
Based on the imbalance coefficient, the number of positive and negative elements in the dataset can be rewritten as
By substituting these expressions into Equation (4), the confusion matrix becomes
where is the unitary confusion matrix defined as
It can be seen that is a function of 3 variables: the ratio of positive and negative correctly classified elements and the imbalance coefficient , that is, .
In order to measure the performance of the classification process, metrics are used. In this paper we focus on metrics that are based on the unitary confusion matrix and, for the sake of much easier comparison, all these metrics are converted within the range . Let us define as the -th of such metrics for the classifier operating on the dataset, where . Since it is based on the unitary confusion matrix, .
Let us now define as the set of the -th metric values corresponding to the -th experiment , that is, . Additionally, the sets , are also defined.
2.2. Representation of Metrics
With these definitions, it is clear that the metric and hence it is a 4-dimensional function since (one dimension) depends on (three independent dimensions). To depict their values, a first approach could involve a 3D representation space where each point is color-coded according to the value .
To show the different types of representations, let us define an arbitrary metric function
This function is only used as an example, corresponds to no specific classification metric and has been selected for its aesthetic results. Figure 3 depicts the 3D representation for said example function. The pairs of classifiers and datasets used in the experiment are selected in such a way that the space is covered with equally spaced points. The above figure may cause confusion, mainly when the number of points increases. An alternative is to slice the 3D graphic by a plane corresponding to a certain value of the imbalance coefficient. Figure 4a depicts such a slice in the 3D graphic for an arbitrary value and Figure 4b shows the slice on a 2D plane.
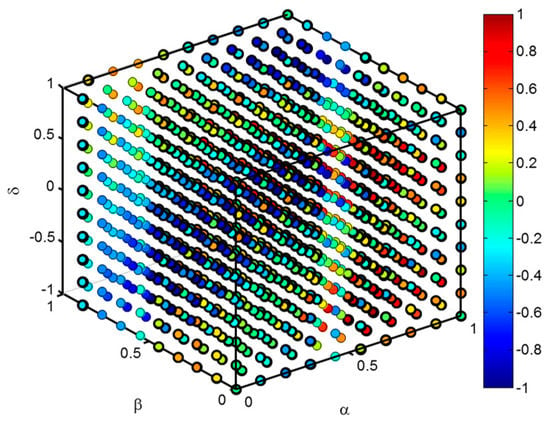
Figure 3.
3D representation of a 4-dimension metric value . The value of the metric is colour-coded for every point in the 3D space.
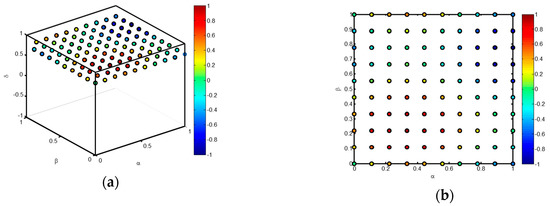
Figure 4.
Representation of a metric value for . (a) Slice of the 3D graphic by a plane corresponding to ; (b) 2D representation of the slice.
In the previous figure, the slice contains 100 values of the metric. However, to obtain a clearer understanding of the metric behaviour, a much larger number of points is recommended. For this purpose, the experiment is designed by selecting a set of virtual pairs of classifiers and datasets in such a way that the plane is fully covered. The result, as shown in Figure 5, appears as a heat map for a certain value of the imbalance coefficient ( in the example).
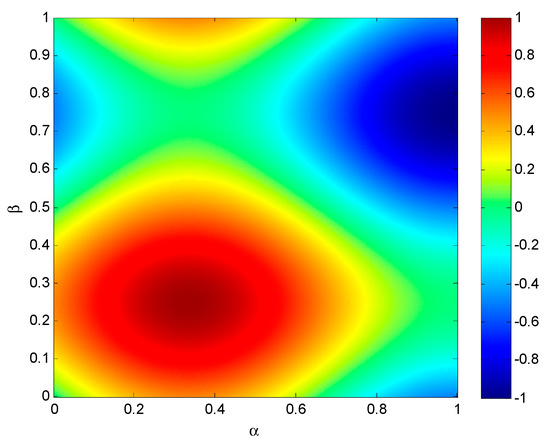
Figure 5.
Heat map of a metric value for .
In order to analyse the behaviour of the metric for different values of the imbalance coefficient, a panel of heat maps can be used, as depicted in Figure 6.
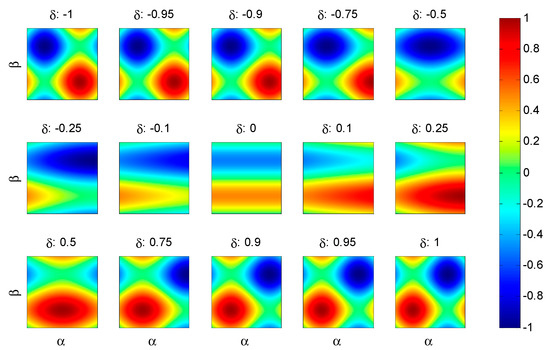
Figure 6.
Panel of heat maps representing the metric .
2.3. Transformations
The original baseline experiment is subject to various types of transformations. As a result of the -th transformation, the metrics related to the baseline experiment are transformed into , which can be written either as or as
It is said that the metric is symmetric under the transformation if . Conversely, is called antisymmetric under (or symmetric under the complementary transformation ) if Analogously, it is said that the metrics and are cross-symmetric under the transformation if . Conversely, and are called anti-cross-symmetric under (or cross-symmetric under the complementary transformation ) if
2.3.1. One-Dimensional Transformations
One-dimensional transformations is the name given to those mirror reflections with respect to a single (one and only one) dimension of the 4-dimensional performance metric. Type transformation implies that the -th transformed classifier shows a ratio of correctly classified positive elements which has the symmetric value of the ratio obtained by the baseline classifier . Since the values of such ratios lie within the range , the symmetry exists with respect to the hyperplane and can be stated as . An example of this transformation is depicted in Figure 7.
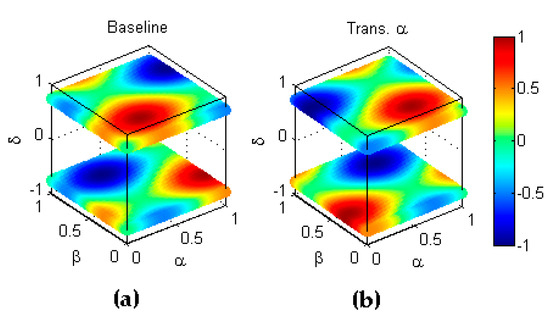
Figure 7.
Transformation type of a metric. (a) Baseline metric. (b) Reflection symmetry with respect to the hyperplane .
Analogously, type transformation implies that the -th transformed classifier shows a ratio of correctly classified negative elements which has the symmetric value of the ratio obtained by the baseline classifier . Since the value of such ratios also lie within the range , the symmetry exists with respect to the hyperplane and can be stated as . An example of this transformation is depicted in Figure 8.
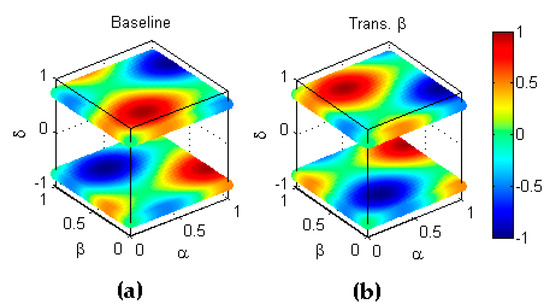
Figure 8.
Transformation type of a metric. (a) Baseline metric; (b) Reflection symmetry with respect to the hyperplane .
Conversely, type transformation, which, instead of operating on classifiers, operates on datasets, implies that the -th transformed dataset has an imbalance ratio which has the symmetric value of the imbalanced ratio in the baseline corresponding to dataset . Since the value of such imbalance ratios lie within the range , the symmetry exists with respect to the hyperplane and can be stated as . An example of this transformation is depicted in Figure 9.
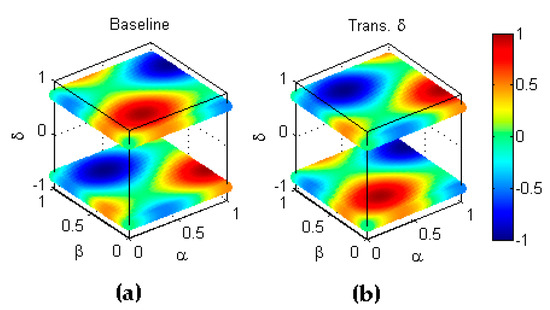
Figure 9.
Transformation type of a metric. (a) Baseline metric. (b) Reflection symmetry with respect to the hyperplane .
Finally, type transformation jointly operates on classifiers and datasets in such a way that the -th of performance metrics for the classifier operating on the dataset has the symmetric value of the performance metric in the baseline experiment . Since the value of such metrics lie within the range , the symmetry exists with respect to the hyperplane and can be stated as . An example of this transformation is depicted in Figure 10 where it should be noted that the dimension is shown by the colour code of each point. Therefore, an inversion in is shown as a colour inversion.
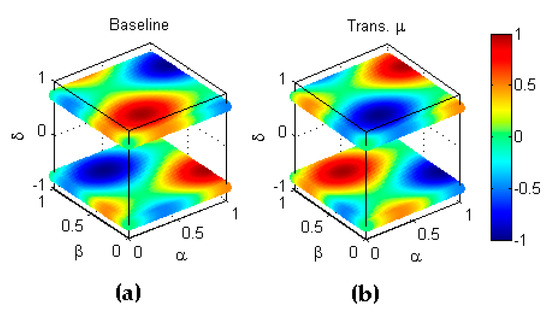
Figure 10.
Transformation type of a metric. (a) Baseline metric. (b) Reflection symmetry with respect to the hyperplane .
2.3.2. Multidimensional Transformations
Let us now consider transformations that exchange two or more dimensions of the 4-dimensional performance metric. Firstly, let us define type transformation as that which exchanges and dimensions. This implies that the -th transformed classifier/dataset pair shows a ratio of correctly classified positive elements which has the same value as the ratio of correctly classified negative elements obtained by the baseline classifier/dataset pair . This exchange can be seen as the symmetry with respect to the hyperplane (main diagonal of the plane) and can be stated as . An example of this transformation is depicted in Figure 11.
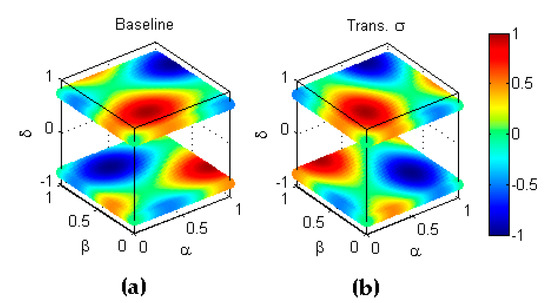
Figure 11.
Transformation type of a metric. (a) Baseline metric; (b) Reflection symmetry with respect to the hyperplane .
Although the four axes in these plots remain dimensionless, not all of them have the same meaning. So, and are both ratios of correctly classified elements. It would be nonsensical, for instance, to rescale without also rescaling . However, has a completely different meaning and its scale can and in fact does, differ from and . The same reasons can be applied to the axes . Therefore, all the exchanges of multidimensional axes are meaningless, except the interchange of and . All the other remaining exchanges are dismissed in our study.
The one- and two-dimensional transformations described above are called basic transformations and are summarized in Table 1.

Table 1.
Summary of basic transformations.
2.3.3. Combined Transformations.
More complex transformations can be obtained by concatenating basic transformations. For instance, applying basic transformation () and then basic transformation () produces a new combined transformation featured by . As each of the one-dimensional transformations operates on an independent axis, they have the commutative and associative properties, that is, given 3 one-dimensional transformations, , it is true that and that that .
However, bi-dimensional type transformation operates on the same axis as and . In this case, the order of transformation matters, as they do not have the commutative property. For instance, On the other hand, . Therefore, it is clear that .
Having 5 basic transformations and not initially considering their order, any combined transformation can be binary coded in terms of the presence/absence of each basic component. Therefore combinations are possible; only 31 if the identity transformation (coded 00000) is dismissed. In order to code a combined transformation, the order is used where transformation indicates the Most Significant Bit (MSB) and the transformation specifies the Least Significant Bit (LSB). An example of this code is shown in Table 2. With this selection, codes greater than 15 contain a transformation type , that is, they are useful in exploring antisymmetric behaviour. In the cases where the order of transformations matters, and ( or ), then their corresponding codes refer to various different combined transformations.
Table 2.
Example of the coding of combined transformations.
A first example of combined transformations is that of the inverse labelling of classes. As stated above, the elements in every dataset belong to either of two classes, and , which are called Positive () and Negative () classes, respectively. The inverse labelling transformation () explores the classification metric behaviour when the labelling of the classes is inverted, that is, when is called the Positive class and the Negative class. Let us consider the -th classifier operating on its corresponding dataset. In the baseline experiment, the ratio of correctly classified positive elements () refers to class conversely () refers to class . In the transformed experiment, the ratio of correctly classified positive elements () refers to class conversely () refers to class , which means that and . That is, the first step of this transformation implies interchanging the axes and which is equivalent to reflection symmetry with respect to the main diagonal, formerly defined as the basic transformation of type (Figure 12b).
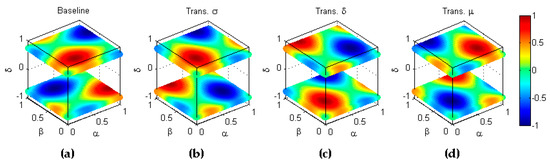
Figure 12.
Transformation by inverse labelling of classes (). (a) Baseline metric; (b) Reflection symmetry with respect to the main diagonal (); (c) Reflection symmetry with respect to the plane (; (d) Reflection symmetry with respect to the plane (colour inversion, ).
Additionally, in the baseline experiment, the number of positive elements () refers to class while in the transformed experiment, the number of positive elements () refers to class , which means that and , while the total number of elements remains unaltered: . Therefore, by recalling Equation (5),
Hence, the second step of this transformation also implies reflection symmetry with respect to the hyperplane , previously defined as the basic transformation of type (Figure 12c).
Finally, the complementary transformation involves a third and final step of inverting the sign of the metric, which is equivalent to reflection symmetry with respect to the hyperplane , formerly defined as the basic transformation of type (Figure 12d).
Therefore, the inverse labelling transformation can be defined as and its complementary as , where
A second example of combined transformations is given by the inverse-scoring transformation () which explores classification metric behaviour when the scoring of the classification results are inverted. In the baseline experiment, let us consider the -th classifier operating on its corresponding dataset, thereby obtaining a ratio of correctly classified positive elements and a ratio in the negative case. The -th metric assigns a score of . High values of the score usually correspond to high ratios . In the inverted score transformation (), the -th classifier operating on its corresponding dataset obtains a ratio of correctly classified positive elements which is equal to the ratio of positive elements incorrectly classified in the baseline experiment, that is, which implies a type transformation. Analogously, for the negative class, which implies a type transformation. If have high values, then will have low values and, to be consistent, the result should be marked with a low score. For that reason, the inverse scoring transform also implies a transformation type , that is, it uses the symmetric value of the metric . Therefore, the inverse labelling transformation can be defined as where
The results are depicted in Figure 13.
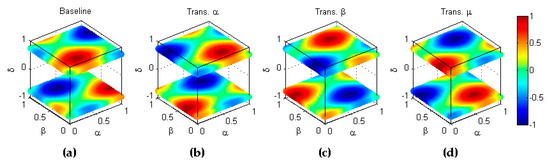
Figure 13.
Transformation by inverse scoring (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (; (d) Reflection symmetry with respect to the plane (colour inversion, ).
A third example is that of the full inversion (), which explores the classification metric behaviour when both the labelling () and the scores () are inverted. This transformation can be featured by the concatenation of their two components, which can be written as
The results are depicted in Figure 14.
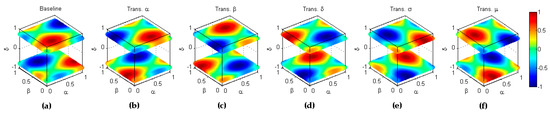
Figure 14.
Transformation by full inversion scoring (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (. (c) Reflection symmetry with respect to the main diagonal (); (d) Reflection symmetry with respect to the plane (. (e) Reflection symmetry with respect to the plane (colour inversion, ).
Finally let us consider the transformation
that is, . Analogously, it can be shown that .
2.4. Performance Metrics
Based on the binary confusion matrix, numerous performance metrics have been proposed [32,33,34,35,36]. For our study, the focus is placed on 10 of these metrics, which are summarized in Table 3. The terms used in that table are taken from the elements of a generic confusion matrix which can be stated as
Table 3.
Definition of classification performance metrics.
The last three metrics (, and ) take values within the range, while the ranges for the first seven lie within the interval. For comparison purposes, these metrics are used herein in their normalized version ( interval). By naming a metric defined within the interval as , it can be normalized within the range by the expression
It can easily be shown that all these metrics can be expressed as a function .
Although only performance metrics based on the confusion matrix are considered, a marginal approach to Receiver Operating Characteristics (ROC) analysis [37] can also be carried out. In this analysis, the Area Under Curve () is commonly used as a performance metric. However, for classifiers offering only a label (and not a set of scores for each label) or when a single threshold is used on scores, the value of and are the same [38]. Therefore, in the forthcoming sections, whenever is mentioned it could also be understood as .
2.5. Exploring Symmetries
In order to determine the existence of any symmetric or cross-symmetric behaviour on the 10 classification performance metrics described in the previous section, we should explore whether, for each metric (or pair of metrics), its baseline and any of the 31 combinations of transformations obtain the same result as that of the baseline of the same metric (symmetry) or any other metric (cross-symmetry). Moreover, many of these combined transformations must take the order into account. Therefore, several thousands of different analyses have to be undertaken. Although performing this task using analytical derivations is not an impossible assignment (preferably using some kind of symbolic computation), it is certainly arduous.
An alternative approach is to identify the distance of two metrics. More formally, for the -th transformation, let us consider the -th combination of classifier operating on the dataset. The classification result is measured using the -th metric, . Similarly, for the -th transform and the -th combination of classifier operating on the dataset, let us measure its performance using the -th metric, . The distance between these measures is defined as . The distance between the -th metric and the -th metric can then be defined as
Therefore, symmetric or cross-symmetric behaviour can be identified by a distance equal to zero.
It should be noted that if the -th metric is symmetric under the -th transformation, that is, and also under the -th transformations, , it will also be symmetric under the concatenation of the two transformations. In effect,
Conversely, this is not true for cross-symmetries. If the -th and -th metric are cross-symmetric under the -th transformation, that is, and also under the -th transformations, , they are not necessarily cross-symmetric under the concatenation of the two transformations. In effect,
2.6. Statistical Symmetries
The symmetries of the performance metrics can also be explored from a statistical point of view. Let us recall that is the -th dataset in the -th experiment with an imbalance described by its imbalance coefficient . The elements in are processed by the classifier in order to obtain a ratio of correctly classified positive and negative elements. The -th metric is based on these values and hence . Let us also recall that the set of all these values for , are denoted , , and and therefore .
Let us now suppose that the elements in the experiments are randomly selected in such a way that , are uniformly distributed within their respective ranges. Therefore, becomes a random variable, which can be statistically described.
First of all, the probability density function (pdf) of : is obtained and its symmetry (or lack thereof) is ascertained. A more precise assessment of the statistical symmetry can be obtained by computing the skewness, which is defined as
where is the mean of and is its variance.
3. Results
3.1. Identifying Symmetries
The symmetric behaviour of the 10 metrics is first determined by means of computing the distance between the baseline and each of the 31 possible transformations, in accordance with Equation (20). The results are depicted in Figure 15. Each row shows the symmetries of a metric. In the columns are the 31 different transformations. Any given metric-transformation pair (small rectangles in the graphic) is shown in yellow if it has zero-distance with the metric baseline. The right-hand-side of the plot (whose code is greater than or equal to 16) corresponds to a combined transformation where the axis has been inverted, that is, where the transformation type is present. This is therefore the area for antisymmetric behaviour.
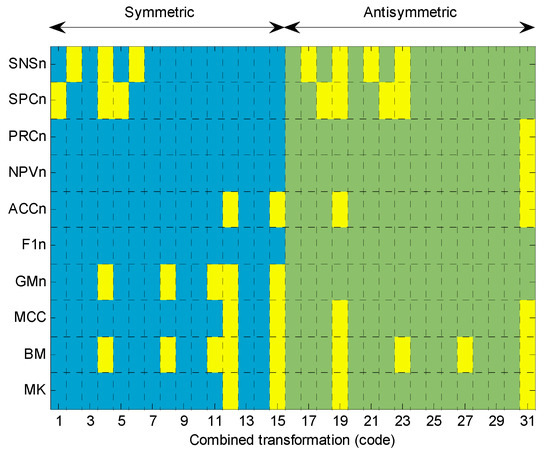
Figure 15.
Symmetric behaviour of performance metrics for any combined transformation.
Let us first analyse each metric in terms of the accuracy (), the Matthews correlation coefficient () and the markedness (). These three metrics present a symmetric behaviour for the combined transformations shown in Table 4. For instance, the first row indicates that the three metrics are symmetric for a combination of the transformations and taken in any order ( or ), which corresponds to the code 12 (01100) for a coding scheme () where represents the Most Significant Bit and represents the Least Significant Bit.
Table 4.
Symmetric transformations of , and .
The first case (code 12) corresponds to the transformation or, in other words, to the inverse labelling transformation which can be formulated for accuracy as
The results are depicted in Figure 16.
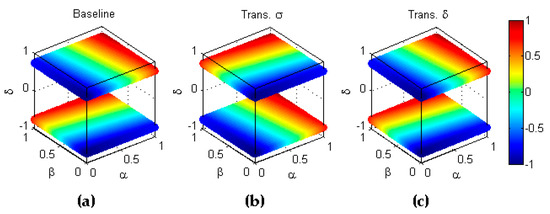
Figure 16.
Symmetry of accuracy with respect to inverse labelling (). (a) Baseline metric; (b) Reflection symmetry with respect to the main diagonal (); (c) Reflection symmetry with respect to the plane (.
The second case (code 15) corresponds to 4 transformations ordered in two different ways. In the first ordering, we have . Recalling Equation (17), . It can therefore be written that , that is, it is equivalent to the inverse labelling transformation. The same result is obtained for . Hence, code 15 is the same case as code 12.
The third case (code 19) corresponds to the transformation or, in other words, to the inverse scoring transformation which can be formulated for accuracy as
The results are depicted in Figure 17.
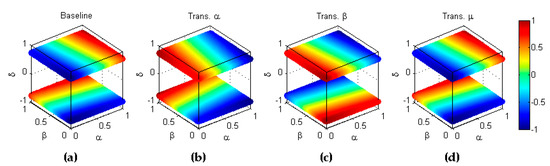
Figure 17.
Symmetry of accuracy with respect to the inverse scoring (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (; (d) Reflection symmetry with respect to the plane (colour inversion, ).
Finally, code 31 corresponds to 5 transformations ordered in 4 different ways. In the first ordering we have but, by considering that the order of and are not relevant, it can also be written as , that is, it is equivalent to the full transformation. The same result is obtained for the 3 remaining orderings which can be formulated for accuracy as
The results are depicted in Figure 18.
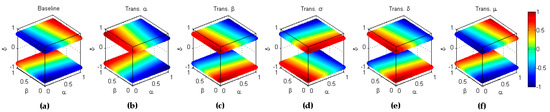
Figure 18.
Symmetry of accuracy with respect to the full inversion (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (; (d) Reflection symmetry with respect to the main diagonal (); (e) Reflection symmetry with respect to the plane (; (f) Reflection symmetry with respect to the plane (colour inversion, ).
Let us now focus on precision () and the negative prediction value (). These two metrics present a symmetric behaviour for the combined transformations shown in Table 5.
Table 5.
Symmetric transformations of and .
These two metrics present symmetric behaviour for only the combined transformations code 31 () which, in any of its ordering, is equivalent to the full inversion and can be formulated for precision as
In other words, precision is symmetric with respect to the concatenation of inverse labelling and the inverse scoring transformations. The results are depicted in Figure 19.
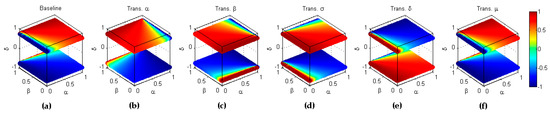
Figure 19.
Symmetry of precision with respect to the full inversion (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (; (d) Reflection symmetry with respect to the main diagonal (); (e) Reflection symmetry with respect to the plane (; (f) Reflection symmetry with respect to the plane (colour inversion, ).
Let us now analyse the geometric mean (), which presents symmetric behaviour for the combined transformations shown in Table 6.
Table 6.
Symmetric transformations of .
In first place, code 4 corresponds to . In fact, this metric is not only symmetric with respect to but also independent of , as it can be seen in Table 3. Secondly, combined transformations coded as 8 and 11 are equivalent to the transformation, that is, is symmetric with respect to the diagonal in the plane. This can be formulated as
Finally, codes 12 and 15 imply concatenating to but as the metric is independent of , it is again equivalent to , that is, . These results are depicted in Figure 20.
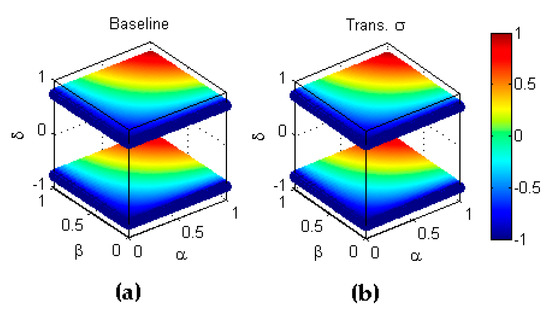
Figure 20.
Symmetry of geometric mean with respect to . (a) Baseline metric; (b) Reflection symmetry with respect to the main diagonal ().
In the case of bookmaker informedness (), the symmetric behaviour is obtained for the combined transformations shown in Table 7.
Table 7.
Symmetric transformations of .
Again code 4 corresponds to as a consequence that this metric is independent of (see Table 3). Secondly, combined transformations coded as 8 and 11 are equivalent to the transformation, that is, is symmetric with respect to the diagonal in the plane. This can be formulated as
Additionally, codes 12 and 15 imply concatenating to but since the metric is independent of , it is again equivalent to , that is, . These results are depicted in Figure 21.
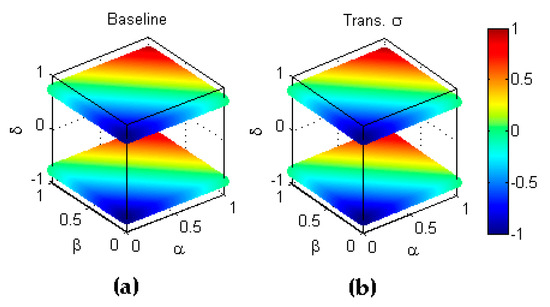
Figure 21.
Symmetry of bookmaker informedness with respect to . (a) Baseline metric; (b) Reflection symmetry with respect to the main diagonal ().
Code 19 and also code 23 since the metric does not depend on , correspond to the transformation or, in other words, to the inverse scoring transformation , which can be formulated for bookmaker informedness as
The results are depicted in Figure 22.
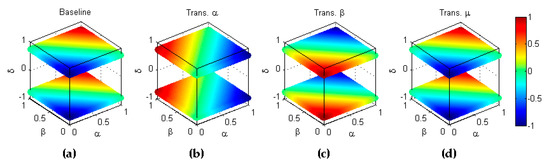
Figure 22.
Symmetry of bookmaker informedness with respect to the inverse scoring (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (; (d) Reflection symmetry with respect to the plane (colour inversion, ).
In other words, the bookmaker informedness is symmetric with respect to the inverse labelling and to the inverse scoring transformations. This implies that it is also symmetric with respect to the concatenations of these two transforms, which occurs in codes 27 and 31 (recall that the latter is independent of ) corresponding to the full inversion which can be formulated as
The results are depicted in Figure 23.
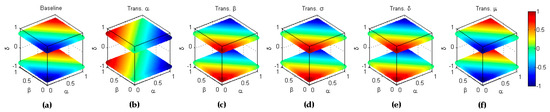
Figure 23.
Symmetry of bookmaker informedness with respect to the full inversion (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (; (c) Reflection symmetry with respect to the main diagonal (); (d) Reflection symmetry with respect to the plane (; (e) Reflection symmetry with respect to the plane (colour inversion, ).
In the case of sensitivity (), the symmetric behaviour is found for the combined transformations shown in Table 8.
Table 8.
Symmetric transformations of sensitivity.
Codes 2 and 4 correspond to and as a consequence of this metric being independent of and (see Table 3). Code 19 (and also codes 17, 21 and 23 since the metric does not depend on nor ) corresponds to the transformation or, in other words, to the inverse scoring transformation , which can be formulated as
This result is depicted in Figure 24.
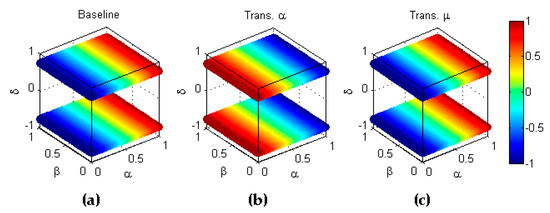
Figure 24.
Symmetry of sensitivity with respect to the combined transformation (). (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (colour inversion, ).
On considering the specificity (), its symmetric behaviour is shown in Table 9.
Table 9.
Symmetric transformations of specificity.
Codes 1 and 4 corresponds to and as a consequence of this metric being independent of and (see Table 3). Code 19 (and also codes 18, 22 and 23 as the metric depends neither on nor on ) corresponds to the transformation , that is, to the inverse scoring transformation , which can be formulated as
This result is depicted in Figure 25.
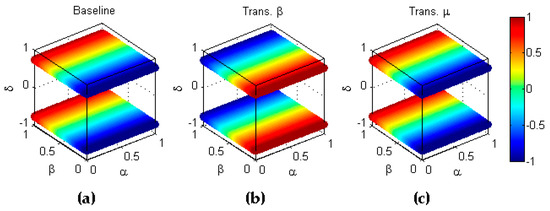
Figure 25.
Symmetry of specificity with respect to the combined transformation () (a) Baseline metric; (b) Reflection symmetry with respect to the plane (); (c) Reflection symmetry with respect to the plane (colour inversion, ).
Finally, it can be observed that the score metric is not symmetric under any transformation. The results for each metric are summarized in Table 10.
Table 10.
Summary of symmetries.
3.2. Identifying Cross-Symmetries
In order to explore whether any cross-symmetry can be identified among the 10 metrics, we have computed the distance (using Equation (20)) of the baseline of each metric (and its 31 possible transformations), to the remaining baseline metrics. The results are depicted in Figure 26. Each row corresponds to the baseline of a metric and each column to the baseline and its 31 transformations of the other metric. Any given metric-metric pair (small squares in the graphic) is shown in yellow if it has zero-distance for any possible transformation.
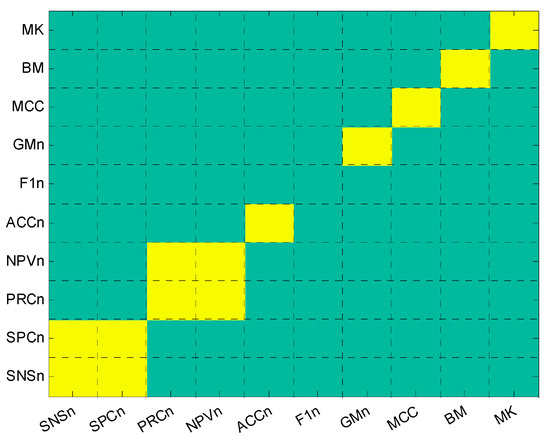
Figure 26.
Cross-symmetric behaviour of performance metrics for any combined transformation.
The diagonal presents a summary of the results explored in the previous section, that is, every metric, except for the score, presents some kind of symmetry under some transformation. The cases of cross-symmetries appear in the elements off diagonal. Two cross-symmetries arise: the and the .
In order to attain a deeper insight into these cross-symmetries, let us consider, for each of the two pairs, the distances between the baseline of the first metric in the pair and the full set of transformations (including the baseline) of the second metric. The results are depicted in Figure 27. Each row shows the cross-symmetries of a pair of metrics. In the columns are the 32 different transformations (including the baseline) of the second metric in the pair. Any given (second-metric transformation) pair (small squares in the graphic) is shown in yellow if it has zero-distance with the first metric baseline. As in Figure 15, the right-hand-side of the plot (with code greater than or equal to 16) corresponds to combined transformation where the axis has been inverted, that is, where the transformation type is present. This is therefore the area for antisymmetric behaviour.
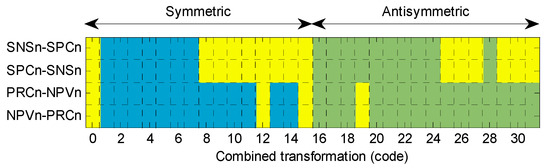
Figure 27.
Cross-symmetric behaviour for any combined transformation.
Let us first analyse each pair of metrics in terms of the or pair, which present cross-symmetric behaviour for the combined transformations shown in Table 11.
Table 11.
Cross-symmetric transformations of the pair.
Codes 12 and 15 correspond to the transformation or, in other words, to the inverse labelling transformation which can be formulated as
The results are depicted in Figure 28.
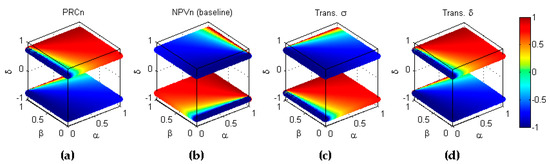
Figure 28.
Cross-symmetry of the pair with respect to the inverse labelling (). (a) Baseline metric; (b) Baseline metric; (c) Reflection symmetry of with respect to the main diagonal (); (d) Reflection symmetry of with respect to the plane (.
Code 19 corresponds to the transformation or, in other words, to the inverse scoring transformation , which can be formulated as
The results are depicted in Figure 29.
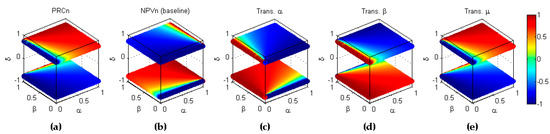
Figure 29.
Cross-symmetry of the pair with respect to the inverse scoring (). (a) Baseline metric; (b) Baseline metric. (c) Reflection symmetry of with respect to the plane (); (d) Reflection symmetry of with respect to the plane (; (e) Reflection symmetry of with respect to the plane (colour inversion, ).
Although the pair is cross-symmetric with respect to the inverse labelling and to the inverse scoring transformations, this does not imply that it is also cross-symmetric with respect to the concatenations of these two transforms (see Equation (22)). This is the reason why code 31 (corresponding to the full inversion is not present in Table 11.
The results for the pair are exactly the same. Therefore,
Let us now consider the pair of metrics and its cross-symmetric behaviour, which is found for the combined transformations shown in Table 12.
Table 12.
Cross-symmetric transformations of the pair.
Since specificity remains independent from (see Table 3), codes 25, 11, 12 and 15 correspond to , that is, to the inverse labelling which can be formulated as
Additionally, since specificity is also independent of , then codes 9 () and 13 () are equivalent to . Moreover, after a transformation, the resulting metric has no dependence on (due to the axis inversion) and hence codes 10 () and 14 () are also equivalent to . These results are depicted in Figure 30.
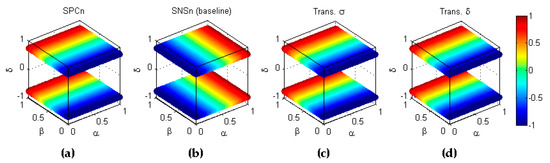
Figure 30.
Cross-symmetry of the pair with respect to the inverse labelling (). (a) Baseline metric; (b) Baseline metric; (c) Reflection symmetry of with respect to the main diagonal (); (d) Reflection symmetry of with respect to the plane (.
On the other hand, code 31 corresponds to full inversion transformation which can be formulated as
It can be shown that the remaining codes (25, 26, 27, 29 and 30) are also equivalent to . Moreover, after a transformation, the resulting metric does not depend on (due to the axis inversion) and hence codes 10 () and 14 () are also equivalent to . These results are depicted in Figure 31.

Figure 31.
Cross-symmetry of the pair with respect to the full inversion (). (a) Baseline metric. (b) Baseline metric. (c) Reflection symmetry of with respect to the main diagonal (). (d) Reflection symmetry of with respect to the plane (. (e) Reflection symmetry with respect to the plane (). (f) Reflection symmetry with respect to the plane (. (g) Reflection symmetry with respect to the plane (colour inversion, ).
The results for the pair are exactly the same, so
The results for every pair of cross-symmetric metrics are summarized in Table 13.
Table 13.
Summary of cross-symmetries.
3.3. Skewness of the Statistical Descriptions of the Metrics
In order to explore the symmetric behaviour of the statistical descriptions of the metrics, let us recall that, for the baseline experiment, can be considered a statistical variable. First of all, let us select a subset of the corresponding to a certain value of the imbalance coefficient, that is, and obtain its probability density function (pdf) which will be called local pdf (since it is obtained solely for a value of ). The results for every metric with are shown in Figure 32.
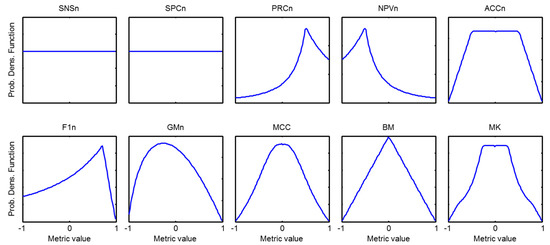
Figure 32.
Local probability density function of every metric and .
This result can be generalized for various values of the imbalance coefficient by obtaining the depicted in Figure 33 as a set of heatmap plots. In every plot, the horizontal axis represents the imbalance coefficient while the value of the metric is drawn in the vertical axis. The value of the is colour-coded.
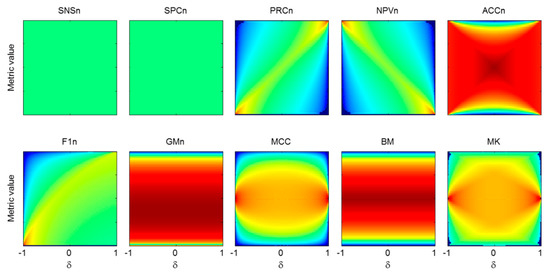
Figure 33.
Local probability density function of every metric as a function of . The value of pdf is colour coded.
In Figure 32 and Figure 33, the symmetry of the statistical descriptions of the metrics can easily be observed. However, in order to achieve a more precise insight, the local skewness of every is obtained in accordance with Equation (23) and its value is shown in Figure 34 for every metric. It can be observed that 6 metrics (, , , ,) have a symmetric ; one metric () has a slightly asymmetric but its asymmetry does not depend on ; 2 metrics ( and ) have a clearly asymmetric but their skewness is symmetric with respect to the origin; and finally, the metric has a and a skewness that are both asymmetric.
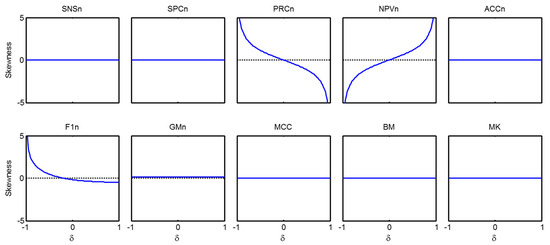
Figure 34.
Skewness of the statistical description for every metric as a function of .
Let us now examine the for all the values of the imbalance coefficient , that is, and obtain its probability density function (pdf) which will be called global pdf (as it is obtained for every ). The resulting is shown in Figure 35 for every metric.
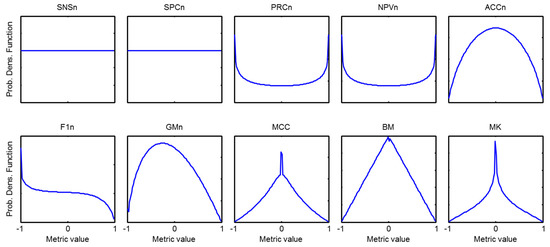
Figure 35.
Global probability density function of every metric and .
It can be observed that all the metrics show a symmetric except for and . The global pdf for maintains the slight asymmetry of local pdf (global skewness of 0.18) since does not depend on . In the cases of and the symmetry of the local skewness compensates for their values and hence they show a symmetric global pdf. Finally, the positive values of local skewness partially compensate for its negative values (see Figure 34), which results in an almost uniform global pdf except for their extreme values (global skewness of 0.14). These results are summarized in Table 14.
Table 14.
Summary of statistical symmetry.
4. Discussion
From the previous results, summarized in Table 10, Table 13 and Table 14, it can be seen that although several thousands of combined transformations have been tested, the performance metrics only present three types of symmetries: under labelling inversion; under scoring inversion; and under full inversion (the sequence of labelling and scoring inversion).
For a certain performance metric to be symmetric under labelling inversion means that it pays attention to or focuses on, positive and negative classes with the same intensity and therefore classes can be exchanged without affecting the value of the metric. These metrics should be used in applications where the cost of misclassification is the same for each class. This is the case for 5 out of the 10 metrics tested: , , , .
Other metrics, however, are more focused on the classification results obtained for the positive class. This is the case of 3 metrics: , which only depends on ; which measures the ratio of success on the elements classified as positive; and the score, which is a combination of and . These metrics found their main applications when the cost of misclassifying the positive class is higher than the cost of misclassifying the negative class, for instance, in the case of disease detection in medical diagnostics. Finally, other metrics are more focused on the classification results obtained for the negative class. This is the case of 2 metrics: which only depends on ; and which measures the ratio of success on the elements classified as negative. These 2 metrics are mainly applied if the most important issue is the misclassification of negative classes, for instance, in the case of identification of non-reliable clients in granting loans.
On the other hand, if a metric shows symmetric behaviour under scoring inversion it means that the good classifiers are positively scored to the same extent as bad classifiers are negatively scored. For instance, let us consider a first classifier which correctly classifies 80% of positive elements and also 70% of negative elements. Additionally, a second classifier obtains a ratio of 20% for positive and 30% for negative elements. A scoring-inversion symmetric-performance metric would have a value of, for example, +0.5 for the first classifier and a value of −0.5 for the second classifier. Therefore, the scoring symmetry indicates the relative importance assigned by the metric to the good and bad classifiers. This is the case for 6 out of the 10 metrics tested: , , , , , . Conversely, is more demanding as regards scoring good results than scoring bad results. This feature can be useful if the objective of the classification is focused on obtaining excellent results (and not just good results). Finally, on 3 of the metrics tested (, ), awarding good results differs from scoring bad results in that it depends on the relative values of the parameters (, and ).
Additionally, it can be seen that metrics showing both labelling and scoring symmetries also show symmetry for the full inversion (concatenation of the two symmetries). This is the case for 4 out of the 10 metrics tested: , , . An interesting result is that for and , although they have no labelling nor scoring symmetry, they do have full inversion symmetry. This fact means that swapping the positive and negative class labels also inverts how the good and bad classifiers are scored. An example of all these symmetries can be found in Table 15.
Table 15.
Examples of symmetric behaviour of metrics under several transformations (for balanced classes). Numbers in bold represent cases of asymmetric behaviour.
A particular degenerate case of symmetry arises when a metric depends on none of the variables. For example, from the results obtained in this research, several metrics have shown themselves to be independent of the imbalance coefficient . This is the case for 4 out of the 10 metrics tested: , , and . This is a particularly interesting result, since these metrics have no kind of bias if the classes are imbalanced. Conversely, the interpretation of classification metrics which do depend on should be carefully considered since they can be misleading as to what a good classifier is.
Additionally, some other metrics appear to be independent from the classification success ratios: which only depends on ; and which only depends on . This can be interpreted as a sort of one-dimensionality of these metrics, that is, is only focused on the positive class, while is only concerned about the negative class.
On the other hand, the two pairs of cross-symmetries found can be straightforwardly interpreted: when the labelling of classes are inverted, becomes and becomes . Moreover, by exchanging the scoring procedure of good and bad classifiers, becomes .
Let us now focus on the interpretation of the results of statistical symmetries. Statistical local symmetry means that, for a certain dataset, that is, for a certain value of the imbalance coefficient, the probability that a random classifier obtains a good score is the same as the probability that it obtains a bad score. This is the case for 6 out of the 10 metrics tested: , , , , , . They coincide with the metrics in that they have scoring symmetry, which shows that both concepts are closely related. Conversely, has a greater probability of having a bad result than a good result, which is consistent with the fact that it is more demanding on obtaining excellent results (and not just good results). Additionally, obtains good results with a higher probability (lower probability in the case of ) if the positive class is the majority class and vice versa if it is the minority class. Awarding good results differs from scoring bad ones in a way that depends on the relative values of the parameters (, ). Finally, in the case of balanced classes, the probability of obtaining good scores is greater than obtaining bad scores for, which shows some sort of indulgent judgment. However, the detailed behaviour of scores for different values of is more complex.
On the other hand, statistical global symmetry means that the probability that a random classifier operating on a random dataset obtains a good score is the same as obtaining a bad score. This is the case for 8 out of the 10 metrics tested: , , , , , , , and . Conversely, and are more likely to have a bad result than a good result, which can be interpreted as meaning that they are slightly tough judges.
On considering all these results and their meanings, the ten metrics can be organized into 5 clusters that show the features described in Table 16.
Table 16.
Summary of symmetric behaviour.
In Table 16, the identification of clusters has been carried out by means of informal reasoning. To formalize these analyses, every metric has been described with a set of features corresponding to the columns in Table 16. Most of the columns are binary valued (yes or no), while others admit several values. For instance, labelling symmetry value can be yes, no, cross-symmetry or cross-symmetry. In these cases, a one-hot coding mechanism (also called 1-of-K scheme) is employed [39]. The result is that each metric is defined using a set of 14 features. Although regular or advanced clustering techniques can be used [40,41,42,43], the reduced number of elements in the dataset (10 performance metrics) invites to address the problem using more intuitive methods. Using Principal Component Analysis (PCA) [44], the problem can be reduced to a bi-dimensional plane and its result is depicted in Figure 36. The 5 clusters mentioned in this section clearly appear therein.
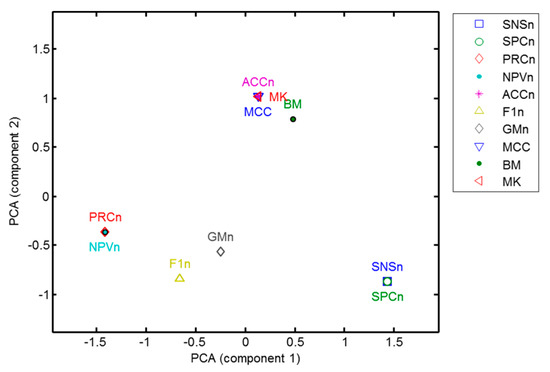
Figure 36.
Bi-dimensional representation of performance metrics according to their symmetries.
Another way to represent how performance metrics are grouped according to their symmetries is by drawing a dendrogram [45]. To this end, the 14 features are employed to characterize each performance metric. The distances between the metrics are then computed in the space of the features. These distances are employed to gauge how much the metrics are separated, as shown in Figure 37. Once again, this result is consistent with the 5 previously identified clusters.
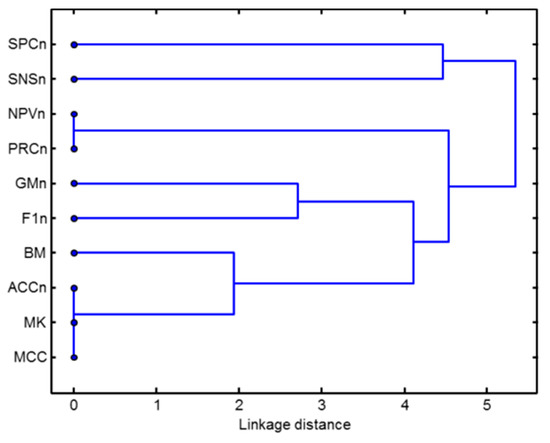
Figure 37.
Dendrogram of performance metrics according to their symmetries.
5. Conclusions
Based on the results obtained in our analysis, it can be stated that the majority of the most commonly used classification performance metrics present some type of symmetry. We have identified 3 and only 3 types of symmetric behaviour: labelling inversion, scoring inversion and the combination of the two inversions. Additionally, several metrics have been revealed as being robust under imbalanced datasets, while others do not show this important feature. Finally two metrics has been identified as one-dimensional, in that they focus exclusively on the positive (sensitivity) or on the negative class (specificity). The metrics have been grouped into 5 clusters according to their symmetries.
Selecting one performance metric or another is mainly a matter of its application, depending on issues such as whether the dataset is balanced, misclassification has the same cost in either class and whether good scores should only be reserved for very good classification ratios. None of the studied metrics can be universally applied. However, according to their symmetries, two of these metrics appear especially worthy in general-purpose applications: the Bookmaker Informedness () and the Geometric Mean (). Both of these metrics are robust under imbalanced datasets and treat both classes in the same way (labelling symmetry). The former metric () also has scoring symmetry while the latter () is slightly more demanding in terms of scoring good results over bad results.
In future research, the methodology for the analysis of symmetry developed in this paper can be extended to other classification performance metrics, such as those derived from multiclass confusion matrix or some ranking metrics (i.e. Receiver Operating Characteristic curve).
Author Contributions
A.L. conceived and designed the experiments; A.L., A.C., A.M. and J.R.L. performed the experiments, analysed the data and wrote the paper.
Funding
This research was funded by the Telefónica Chair “Intelligence in Networks” of the University of Seville.
Conflicts of Interest
The authors declare there to be no conflict of interest. The founding sponsors played no role: in the design of the study; in the collection, analyses or interpretation of data; in the writing of the manuscript; and in the decision to publish the results.
References
- Speiser, A. Symmetry in science and art. Daedalus 1960, 89, 191–198. [Google Scholar]
- Wigner, E. The Unreasonable Effectiveness of Mathematics. In Natural Sciences–Communications in Pure and Applied Mathematics; Interscience Publishers Inc.: New York, NY, USA, 1960; Volume 13, p. 1. [Google Scholar]
- Islami, A. A match not made in heaven: On the applicability of mathematics in physics. Synthese 2017, 194, 4839–4861. [Google Scholar] [CrossRef]
- Siegrist, J. Symmetry in social exchange and health. Eur. Rev. 2005, 13, 145–155. [Google Scholar] [CrossRef]
- Varadarajan, V.S. Symmetry in mathematics. Comput. Math. Appl. 1992, 24, 37–44. [Google Scholar] [CrossRef]
- Garrido, A. Symmetry and Asymmetry Level Measures. Symmetry 2010, 2, 707–721. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Wu, W.T.; Wang, H.; Xiong, M.; Wang, W. Symmetry-based structure entropy of complex networks. Phys. A Stat. Mech. Appl. 2008, 387, 2611–2619. [Google Scholar] [CrossRef]
- Magee, J.J.; Betke, M.; Gips, J.; Scott, M.R.; Waber, B.N. A human–computer interface using symmetry between eyes to detect gaze direction. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 1248–1261. [Google Scholar] [CrossRef]
- Liu, Y.; Hel-Or, H.; Kaplan, C.S.; Van Gool, L. Computational symmetry in computer vision and computer graphics. Found. Trends Comput. Gr. Vis. 2010, 5, 1–195. [Google Scholar] [CrossRef]
- Tai, W.L.; Chang, Y.F. Separable Reversible Data Hiding in Encrypted Signals with Public Key Cryptography. Symmetry 2018, 10, 23. [Google Scholar] [CrossRef]
- Graham, J.H.; Whitesell, M.J.; II, M.F.; Hel-Or, H.; Nevo, E.; Raz, S. Fluctuating asymmetry of plant leaves: Batch processing with LAMINA and continuous symmetry measures. Symmetry 2015, 7, 255–268. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2006. [Google Scholar]
- Top 10 Technology Trends for 2018: IEEE Computer Society Predicts the Future of Tech. Available online: https://www.computer.org/web/pressroom/top-technology-trends-2018 (accessed on 18 October 2018).
- Brachmann, A.; Redies, C. Using convolutional neural network filters to measure left-right mirror symmetry in images. Symmetry 2016, 8, 144. [Google Scholar] [CrossRef]
- Zhang, P.; Shen, H.; Zhai, H. Machine learning topological invariants with neural networks. Phys. Rev. Lett. 2018, 120, 066401. [Google Scholar] [CrossRef] [PubMed]
- Luque, A.; Gómez-Bellido, J.; Carrasco, A.; Barbancho, J. Optimal Representation of Anuran Call Spectrum in Environmental Monitoring Systems Using Wireless Sensor Networks. Sensors 2018, 18, 1803. [Google Scholar] [CrossRef]
- Romero, J.; Luque, A.; Carrasco, A. Anuran sound classification using MPEG-7 frame descriptors. In Proceedings of the XVII Conferencia de la Asociación Española para la Inteligencia Artificial (CAEPIA), Granada, Spain, 23–26 October 2016. [Google Scholar]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Non-sequential automatic classification of anuran sounds for the estimation of climate-change indicators. Exp. Syst. Appl. 2018, 95, 248–260. [Google Scholar] [CrossRef]
- Glowacz, A. Fault diagnosis of single-phase induction motor based on acoustic signals. Mech. Syst. Signal Process. 2019, 117, 65–80. [Google Scholar] [CrossRef]
- Glowacz, A. Acoustic-Based Fault Diagnosis of Commutator Motor. Electronics 2018, 7, 299. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. Data mining in metric space: An empirical analysis of supervised learning performance criteria. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Ferri, C.; Hernández-Orallo, J.; Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Ting, K.M. Confusion matrix. In Encyclopedia of Machine Learning and Data Mining; Springer: Boston, MA, USA, 2017; p. 260. [Google Scholar]
- Aly, M. Survey on multiclass classification methods. Neural Netw. 2005, 19, 1–9. [Google Scholar]
- Tsai, M.F.; Yu, S.S. Distance metric based oversampling method for bioinformatics and performance evaluation. J. Med. Syst. 2016, 40, 159. [Google Scholar] [CrossRef]
- García, V.; Mollineda, R.A.; Sánchez, J.S. Index of balanced accuracy: A performance measure for skewed class distributions. In Iberian Conference on Pattern Recognition and Image Analysis; Springer: Berlin/Heidelberg, Germany, 2009; pp. 441–448. [Google Scholar]
- López, V.; Fernández, A.; García, S.; Palade, V.; Herrera, F. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 2013, 250, 113–141. [Google Scholar] [CrossRef]
- Daskalaki, S.; Kopanas, I.; Avouris, N. Evaluation of classifiers for an uneven class distribution problem. Appl. Artif. Intell. 2006, 20, 381–417. [Google Scholar] [CrossRef]
- Amin, A.; Anwar, S.; Adnan, A.; Nawaz, M.; Howard, N.; Qadir, J.; Hussain, A. Comparing oversampling techniques to handle the class imbalance problem: A customer churn prediction case study. IEEE Access 2016, 4, 7940–7957. [Google Scholar] [CrossRef]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing imbalanced data--recommendations for the use of performance metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013. [Google Scholar]
- Powers, D.M. Evaluation: From Precision, Recall and F-measure to ROC, Informedness, Markedness and Correlation; Technical Report SIE-07-001; School of Informatics and Engineering, Flinders University: Adelaide, Australia, 2011. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Jurman, G.; Riccadonna, S.; Furlanello, C. A comparison of MCC and CEN error measures in multi-class prediction. PLoS ONE 2012, 7, e41882. [Google Scholar] [CrossRef] [PubMed]
- Gorodkin, J. Comparing two K-category assignments by a K-category correlation coefficient. Comput. Biol. Chem. 2004, 28, 367–374. [Google Scholar] [CrossRef] [PubMed]
- Flach, P.A. The geometry of ROC space: Understanding machine learning metrics through ROC isometrics. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Australasian Joint Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1015–1021. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Chakraborty, S.; Das, S. k—Means clustering with a new divergence-based distance metric: Convergence and performance analysis. Pattern Recognit. Lett. 2017, 100, 67–73. [Google Scholar] [CrossRef]
- Wang, Y.; Lin, X.; Wu, L.; Zhang, W.; Zhang, Q.; Huang, X. Robust subspace clustering for multi-view data by exploiting correlation consensus. IEEE Trans. Image Process. 2015, 24, 3939–3949. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Wu, L.; Lin, X.; Zhao, X. Unsupervised metric fusion over multiview data by graph random walk-based cross-view diffusion. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 57–70. [Google Scholar] [CrossRef]
- Wu, L.; Wang, Y.; Shao, L. Cycle-Consistent Deep Generative Hashing for Cross-Modal Retrieval. IEEE Trans. Image Process. 2019, 28, 1602–1612. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I. Principal component analysis. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1094–1096. [Google Scholar]
- Earle, D.; Hurley, C.B. Advances in dendrogram seriation for application to visualization. J. Comput. Gr. Stat. 2015, 24, 1–25. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).