1. Introduction
As the National Institute of Standards and Technology (NIST) defines, cloud computing [
1] is a new paradigm that provides configurable resource pool by network access. Resources such as networks, servers and storage can be rapidly provided and released without service provider getting heavily involved. Since Cloud computing technologies offer scalability, are reliable and trustworthy, and offer high performance at relatively low cost, they have a variety of application domains [
2], such as virtual computing labs [
3], linguistic group decision-making [
4], three-dimensional reconstruction [
5], etc. In the Cloud model, services including Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS) are available to consumers with various demands. Among these three service models, IaaS has the capability to provide Virtual Machines (VMs) and enables customers to control the computational resources or networking components without caring about the location, maintenance or management of the physical devices. In general, IaaS can meet the requirement of performing complex tasks or large applications and measure the service according to the Cloud pricing schemes. However, the process of mapping tasks to VMs, namely task scheduling, becomes more complex due to the large number of physical servers, the complex Cloud environment, the variety of consumer requirements and different Service Level Agreements (SLA) compared with traditional distributed or heterogeneous computing environment.
The task Scheduling problem in Cloud, which is known to be NP-hard, is assigning different tasks to corresponding resource node under the Quality of Services (QoS) constraints. Cloud task scheduling is an NP-hard problem. For an NP-hard algorithm, it is generally believed that no algorithm exists that solves each instance in polynomial time [
6]. Some traditional task scheduling algorithms have been applied in heterogeneous computing environments such as Min-Min [
7], Max-Min [
8], etc. Min-Min algorithm allocates tasks with shortest completion time to the corresponding machine. By contrast, Max-Min algorithm prefers to choose larger tasks which can cause smaller task delays for long time. Although these algorithms are simple and can be easily transplanted to the Cloud environment, they may lead to lower efficiency when the number of tasks is very large.
In recent years, bio-inspired algorithms (also called swarm intelligence algorithms), such as Genetic Algorithm (GA), Particle Swarm Optimization (PSO), Simulated Annealing (SA), and Artificial Bee Colony (ABC), have proven able to solve NP problems effectively. These algorithms originate from the behavior of nature biological group or physical phenomena, and have features such as intelligence, self-organization, parallelism, etc. The nature group can perform complex intelligent behavior, even though the capacity of each individual is very limited. All the individuals can cooperate with each other without any centralized control and spontaneously move toward the optimal direction. For example, ants, bee or birds can always be efficient in finding food sources despite the limited ability of communication and intelligence. Inspired by group intelligence, swarm intelligence algorithms can provide solutions for those complex optimization problems which do not have priori knowledge or global model and have the following characteristics: (1) The ability of each individual in the system is relatively simple and their active period is short. (2) There are no special requirements on the problems to be optimized, such as continuity, linearity, constraint, etc. (3) Individuals have the chance to change the environment and the whole system is self-regulated. (4) Centralized control constraints so human interventions or adjustments are not necessary during the problem solving process. (5) Members in the group are independent and distributed, so they can deal with the problem in parallel. (6) Each individual can perceive the environment and cooperate with others, and the cost of increasing or decreasing the scale of population is low. (7) The complex behavior manifested by the group is acquired through the interaction process of simple individuals. Due to the merits of swarm intelligence algorithms mentioned, researchers have introduced many of them to obtain feasible solutions for non-linear, complex, strong constraint or large-scale problems.
Zhan et al. [
9] presented an improved Particle Swarm Optimization algorithm to solve the problem of cloud task scheduling. In the iterative process, PSO is combined with simulated annealing algorithm to achieve global fast convergence while avoiding running into local optimal. Zuo et al. [
10] proposed a resource allocation framework in which an IaaS provider can outsource its tasks to External Clouds (ECs) when its own resources are not sufficient to meet the demand. They focused on how to allocate users’ tasks to maximize the profit of IaaS provider while guaranteeing QoS. The task scheduling problem is formulated as an integer programming (IP) model, and solved by a self-adaptive learning particle swarm optimization (SLPSO)-based scheduling approach. Chen et al. [
11] presented a parallelized genetic ant colony system (PGACS), which consists of the genetic algorithm, including the new crossover operations and the hybrid mutation operations, and the ant colony systems with communication strategies. Tsai et al. [
12] proposed parallel cat swarm optimization method, and, in [
13], they used the enhanced parallel cat swarm optimization (EPCSO) to solve the numerical optimization and aircraft schedule recovery problem.
Wu et al. [
14] implemented genetic algorithm and Chemical Reaction Optimization (CRO) algorithm to optimize task scheduling problem in Cloud environment. They compared the performance the two algorithms in terms of makespan and energy consumption. Mahmood et al. [
15] proposed a greedy and a genetic algorithm with an adaptive selection of suitable crossover and mutation operations to allocate and schedule real-time tasks with precedence constraint on heterogamous virtual machines.
Artificial Bee Colony (ABC) [
16] algorithm is an optimization algorithm based on the intelligent behaviour of honey bee swarm, which has the ability to get out of a local minimum and can be efficiently used for multivariable, multimodal function optimization. Babu et al. [
17] presented a load balancing algorithm based on Artificial Bee Colony (ABC), in which tasks on overloaded virtual machines are selected and migrated to other VMs. Navimipour et al. [
18] applied ABC to the task scheduling problem in the cloud environment. A food source represents a feasible task scheduling scheme and is evaluated by the pre-defined fitness. The population is randomly generated in the initialization phase, after which employed, onlooker and scout bees are sent to mine the food sources until the iteration reach its max value.
Simulated annealing is a heuristic method that has been implemented to obtain good solutions of an objective function defined on a number of discrete optimization problems [
19]. It has proven to be a flexible local search method and can be successfully applied to many real-life problems. Mandal et al. [
20] implemented three meta-heuristic algorithms to solve Cloud task scheduling, including Simulated Annealing, Firefly Algorithm and Cuckoo Search Algorithm. The main goal of these algorithms is to minimize the overall processing time of the VMs which execute a set of tasks.
With the prevalence of Cloud Computing, more users have obtained benefits from Cloud Computing service. For example, one of the most promising cloud computing applications is online data sharing [
21], such as photo sharing in Online Social Networks among more than one billion users [
22], and online health record system [
23]. Massive data centers and high-speed networks enable processing multiple tasks in parallel, and there is a need to schedule or allocate those tasks to appropriate virtual machines efficiently. However, most of the works mentioned above were simulated or tested in a small scale. The number of tasks is up to decades in [
10,
17,
18,
20], hundreds in [
9,
15], or a little more than one thousand in [
14]. Those algorithms may not work effectively under high pressure in Cloud environment. Moreover, the pay-per-use payment method and sustainable development policy also have strong correlations with time consumption and the energy consumed. Therefore, there is a need to research on the task scheduling problem in large scale. Motivated by these considerations and the works mentioned above, we present an incremental genetic algorithm to task scheduling problem in Cloud environment. The main contributions of this paper include: (i) proposing an incremental genetic algorithm to tackle large scale task scheduling problem in Cloud environment; (ii) designing an adaptive mutation and crossover rate for the proposed algorithm; and (iii) experimental results obtained using the proposed method compared with the results of applying Min-Min, Max-Min, Standard GA, Min-Min, Max-Min, Simulated Annealing and Artificial Bee Colony Algorithm, showing that our approach can reduce the computation time. In this paper, we investigate some traditional and bio-inspired algorithms that can be applied in the distributed computing environments and propose an adaptive incremental Genetic Algorithm (AIGA) to address the Cloud task scheduling problem. We model the problem based on IaaS instance and set the minimum makespan as the objective.
The remainder of this paper is organized as follows. In
Section 2, we describe the task scheduling problem and optimization objective by mathematic model. We also represent two best-known heuristics, Min-Min and Max-Min algorithms, which are widely used to address task scheduling in many platforms.
Section 3 provides details of the proposed adaptive incremental genetic algorithm on IaaS. In
Section 4, we compare the performance of Min-Min, Max-Min, standard GA and the adaptive incremental GA and discuss the experimental result.
Section 5 concludes the paper.
2. Task Scheduling Problem
In a Cloud model, datacenter consists of many physical servers on which VMs are running and user tasks are bound to different types of VMs according to the specific demand. There are two scheduling problems based on different levels. One is deciding to which host the VM should be deployed. The VM scheduling method directly affects resource utilization, energy consumption and efficiency of datacenter in Cloud. Some scheduling algorithms, such as first-come-first-serve or greedy algorithm, may result in an increase in the number of active physical servers, especially when the virtual machine requests are greatly different. Another one is task scheduling problem that determines to which VM the task should be allocated. In the Cloud environment, large-scale tasks are firstly divided into several small tasks by Map/Reduce model, and then distributed to the appropriate Cloud servers in the resource pool. Based on the status of each virtual machine and the quality of service requirement, tasks should be assigned to appropriate VM. Task scheduling strategy affects task completion time and associated execution costs. It is important for both providers and users to improve efficiency and reduce costs by applying proper scheduling methods in Cloud computing.
Cloud Information Service (CIS) and datacenter broker are responsible for scheduling VM and tasks based on user requests and quality requirements. Users are concerned about the cost of services, while service providers expect to maximize efficiency, while minimizing energy consumption and costs. To some extent, these factors relate to the task execution time, so we consider makespan as the optimization objective in this paper. We model the task scheduling problem as follows.
Suppose that there are m tasks , and n virtual machines . It is a NP-complete problem which has ways to allocate these tasks to VMs.
In general, a VM can be described by CPU, memory bandwidth and storage. Some Cloud service providers such as Amazon use Compute Unit (CU) to describe the CPU capacities. One EC2 Compute Unit (ECU) provides the equivalent CPU capacity of a 1.0–1.2 GHz 2007 Opteron or 2007 Xeon processor [
24]. Since Cloud service is used on demand and paid according to the used hours, CU can be used to estimate the required execution time before applying for the cloud resources. When task
is bound to virtual machine
, the occupation time of
depends on the length of task and the CU of VM. The execution time for
on
is given by
,
where
,
,
represents the length of task
, and
denotes the CU of virtual machine
.
The occupation time for
can be calculated by,
where
represents the mapping relationship between a task and a virtual machine. When
,
is allocated on
.
It is relevant to point out that the execution time required to complete all the tasks equals the maximum value of all the virtual machines’ occupation time, because tasks are processing in parallel on VM. For the purpose of minimizing makespan, the objective function can be formulated as follows,
where
denotes the allocation status and
represents corresponding execution time.
3. Adaptive Incremental Genetic Algorithm
Genetic Algorithm (GA) is a bio-inspired algorithm which belongs to Evolutionary Algorithms (EA). Genetic algorithm is based on the idea of Darwin’s Theory of Evolution and Mendelian Genetics. Darwin’s Theory of Evolution indicates that, during the process of biological evolution, individuals who are more able to adapt to the environment have a higher probability of survival; Mendel’s genetic theory demonstrates that genes are kept by chromosome in the form of genes, and gene mutation or chromosome crossover can generate new features for individuals. Those genetic structures with high adaptability are easier to be retained.
The main operators of GA include selection, crossover and mutation. In GA, select operator imitates the natural selection. The purpose of selection is saving “good” individuals. The larger the fitness value is, the higher the probability that allows the individual to enter into the next generation. On the contrary, individuals with smaller fitness value will be less likely to be kept. Selection strategies affect the direction of evolution and convergence rate of the population. Crossover is the process of gene recombination. Ideally, the offspring produced by the crossover of two parents should inherit the excellent features of their parents. Mutation operation produces new individual by changing a few genes. It contributes to the diversity of population and also plays an important role in approaching the optimal solution.
When using GA to optimize different problems, each chromosome represents a candidate solution. Fitness is defined to evaluate the solution. A series of genetic operations (crossover, recombination, mutation, etc.) are used to generate new chromosomes, while select operators will choose better solution to retain. After a number of generations, the group converges to the individuals who are most adaptive to the environment, that is, the optimal solution.
To address task scheduling problem, the chromosome can be encoded with real number. The chromosome represents a feasible solution. Considering the complex cloud environment, the datacenter schedules a great number of tasks in the request list. Standard GA can cost a long time to search for the optimal solution because evaluation, crossover and mutation operators involve more computing. In this paper, an incremental method is proposed to tackle this problem. The tasks are divided into some independent sets, and then every time some tasks are chosen to schedule. Details about the proposed adaptive incremental GA are as follows.
3.1. Encoding
Encoding strategies such as binary encoding, real number encoding and symbol encoding have been applied on different problems. Binary coding maps solution space to a bit string, which is a simple and common encoding method. Similarly, a real-valued chromosome is represented by a real number in the decision space. In the task scheduling problem, the chromosome is encoded by real number. The length of a chromosome equals the number of tasks. The gene’s value represents to which VM the task is allocated.
3.2. Fitness Function
The fitness function is used to evaluate the quality of the candidate solution, which is an important index for selecting the best individual. Usually, the value of objective function can be directly used for fitness measurement, or define the fitness function according to the specific problem. As given in Equation (
3), the fitness is calculated by the makespan of a solution. The maximum finish time of among all the VMs is the fitness value.
3.3. Select
There are several selection strategies such as roulette, tournament and sorting selection. The roulette method firstly computes the probability of selection according to each individual’s fitness (the proportion of the individual’s fitness to the sum of all individual fitness value). Then, the disk is divided into N copies, each with a central angle which is proportional to the probability of selection. Choosing an individual depends on a randomly generated number falling into which region. Tournament selects a certain number of individuals, and the individual with highest fitness will be chosen. This process continues until the number of individuals to reach a pre-set size. Sorting selection firstly calculates each individual’s fitness value. After sorting by fitness, the solution will be assigned a probability of selection. Then, the selection is determined by the order of distribution.
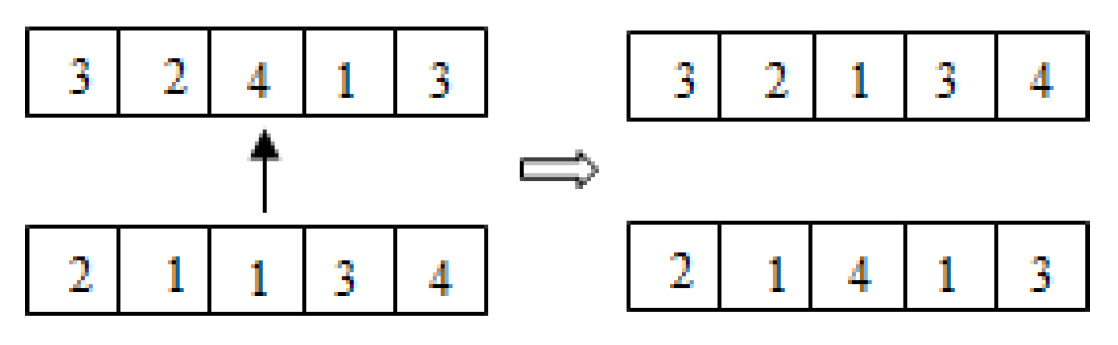
3.4. Crossover
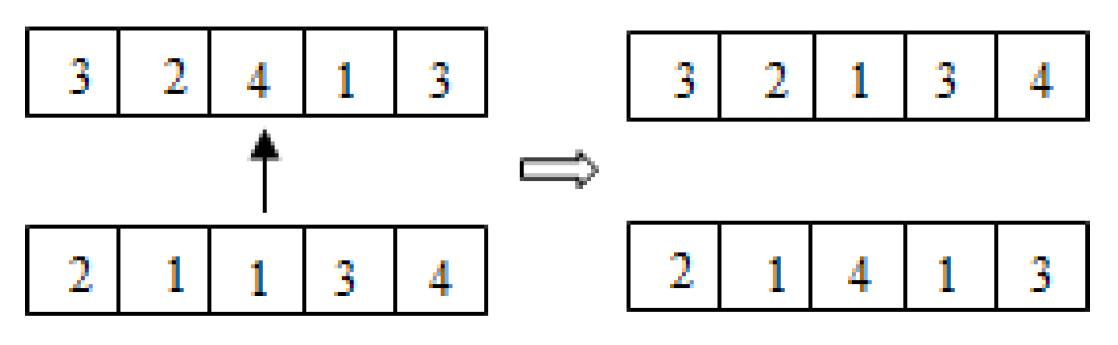
There are some crossover strategies such as single-point crossover, two-point crossover, uniform crossover and so on. An example of single-point crossover is shown in
Figure 1 .
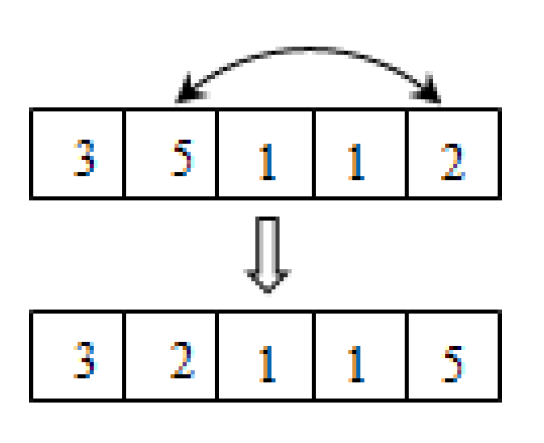
3.5. Mutation
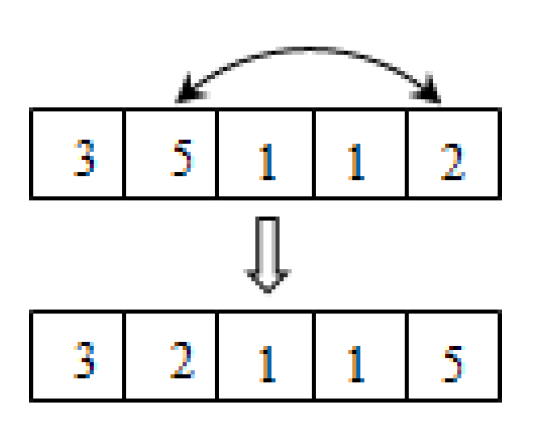
Mutation operators include uniform mutation, Gaussian mutation, etc. In this paper, we use a new mutation strategy state as follows. First, choose a mutation position, and then exchange its value with a randomly selected gene. The values of the two positions should not be the same, otherwise select another position. The mutation operator is shown in
Figure 2.
We define adaptive mutation and crossover operator as follows.
where
,
is the maximum iteration,
i is the current iteration, and
are the control parameters.
For each generation, sort the population by fitness in ascending order. For each individual, its mutation rate and crossover rate is calculated by,
where
,
is the position of individual
j in the population,
s is the population size,
is the fitness of local best solution in iteration
i,
l represents the evolutionary trend of the population, and
t is the threshold. The main steps of GA-based task scheduling include,
- (1)
Initialize GA parameters: Initialize the population size, crossover rate, mutation rate, max generation, etc.
- (2)
Initialize job list: Each job is a set of tasks and the number of tasks is equal to the predefined interval size. Define the maximum iteration as the value that max generation divided by the number of jobs (also other finite bound can be used).
- (3)
Optimization stage: For each job in the job list, use adaptive GA to optimize the scheduling problem. After randomly generating or initializing the population based on Max-Min, do select, crossover, mutation and record the best individual until the iteration reach the maximum value. Notice that, before handling the next job, the virtual machines’ occupation times should be updated by the optimal solution of the previous job.
The pseudo code of Adaptive Incremental Genetic Algorithm is shown in Algorithm 1.
| Algorithm 1 Incremental Genetic Algorithm |
Input: Population size , max iteration, objective function, control parameters, task list T, VM types, interval size;
Output: The global best solution;
1: Choose tasks from T, the number of tasks equals to the interval size;
2: Initialize the population P
3: Evaluate each individual in P
4: while iteration < max generation do
5: for each individual in P do
6: Calculate the to be chosen;
7: if then
8: Select the individual to the new population ;
9: end if
10: end for
11: Sort according to fitness
12: Calculate the mutation and crossover rate of each individual;
13: for each individual in do
14: if then
15: Perform crossover;
16: end if
17: if then
18: Perform mutation;
19: end if
20: end for
21: Update the global best solution; iteration++;
22: end while
23: Update the occupation time of each virtual machine |
4. Experimental Result
In this section, we give details about the experimental work. Experiments were set to compare the performance of the proposed Adaptive Incremental Genetic Algorithm (AIGA) with that of two traditional scheduling methods, Min-Min and Max-Min, and three meta-heuristic algorithms, Standard Genetic Algorithm (SGA) [
14], Artificial Bee Colony (ABC) [
18] and Simulated Annealing (SA) [
20] algorithm.
Min-Min is based on the idea that shortest unassigned tasks will be scheduled with highest priority to the machine which can complete the task in shortest time. Min-Min begins with a set of unallocated tasks in the waiting list. First, it computes the Minimum Completion Time (MCT) for all tasks on all available machines. Then, it selects the minimum MCT and allocates the task to the corresponding resource. After removing the task from the list, the available time of the machine should be updated. This process repeats until all the tasks in the waiting list have been scheduled. Max-Min is similar to the Min-Min algorithm. In the choosing stage, Max-Min selects the largest task first and allocates it to the machine which has the MCT.
The virtual machine (instance) specifications refer to the scheme of Amazon Elastic Compute Cloud [
25,
26] (
Table 1). The length of tasks is randomly generated ranging from 10 to 1000.
We first compare the performance of AIGA with that of two traditional scheduling methods, Min-Min and Max-Min. Suppose there are ten randomly generated tasks, the length of each tasks is in [814.0, 447.0, 610.0, 319.0, 876.0, 692.0, 663.0, 631.0, 626.0, 655.0]. Then, task execution time on each VM can be calculated as shown in
Table 2.
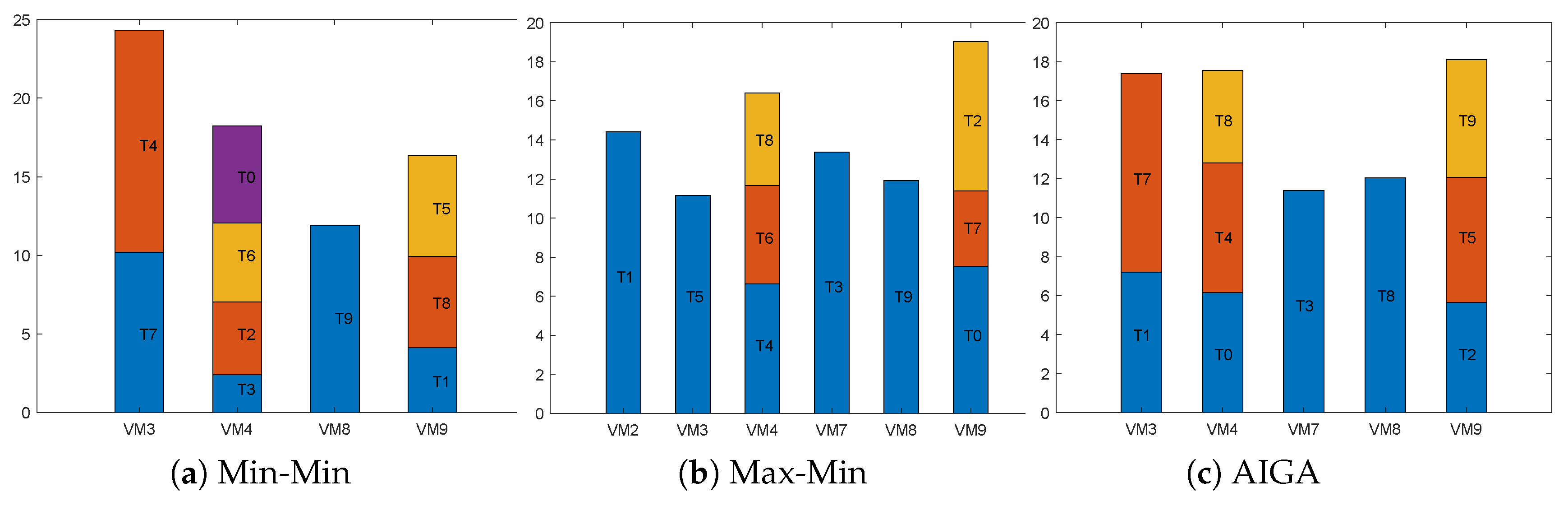
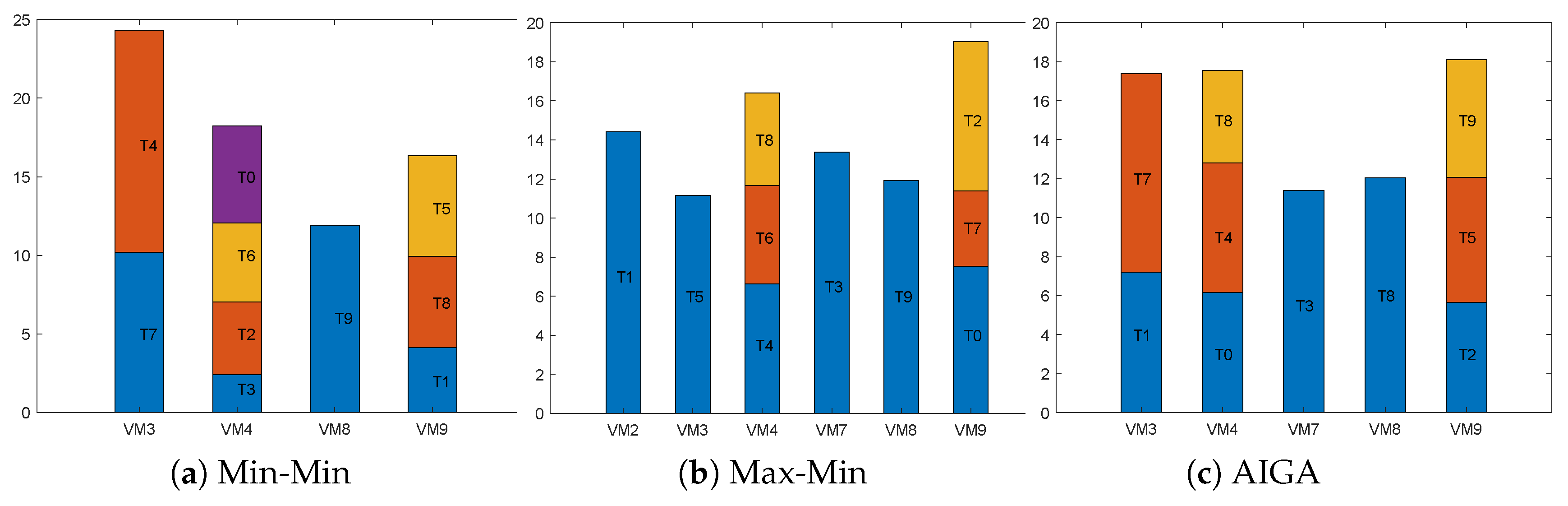
Figure 3 represents the makespan and assignment of tasks by Min-Min, Max-Min and AIGA. Note that AIGA can achieve different result as random factors are involved, so
Figure 3c shows only one possible solution of AIGA. Min-Min and Max-Min allocate the tasks in the order [3, 1, 2, 8, 7, 9, 6, 5, 0, 4] and [4, 0, 5, 6, 9, 7, 8, 2, 1, 3], respectively. As makespan is the maximum execution time among all the VMs after all the tasks are scheduled, the makespan obtained by each algorithm is 24.31, 19.5 and 18.12, respectively. AIGA has the minimum fitness of optimal solution.
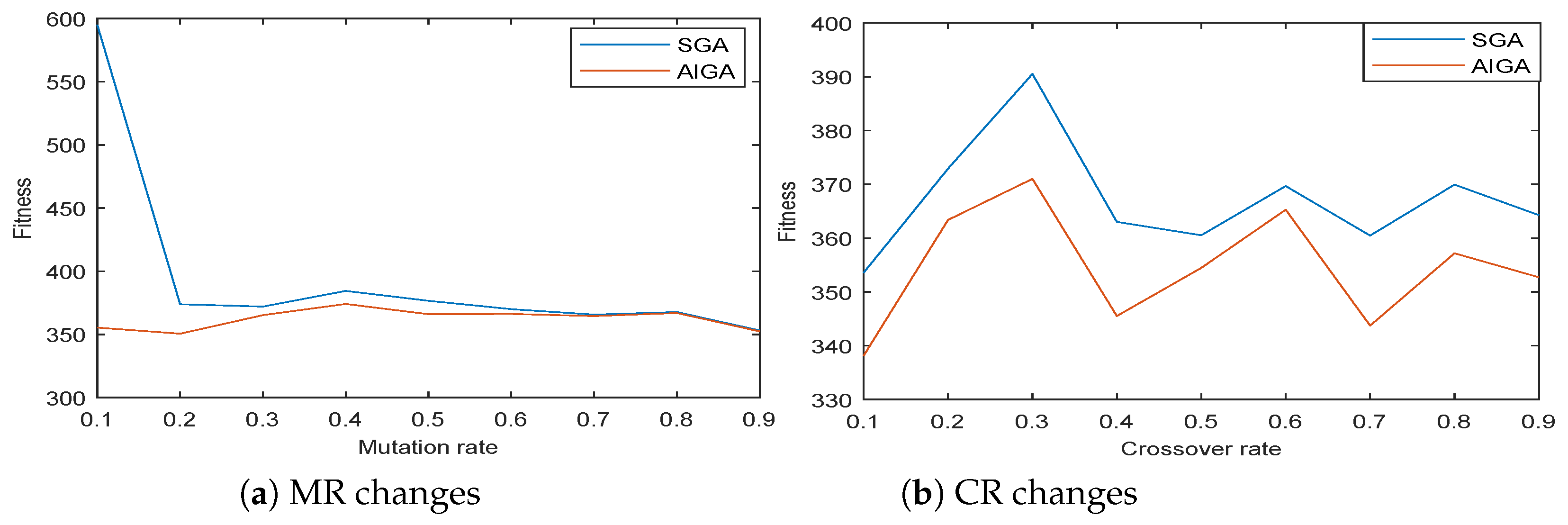
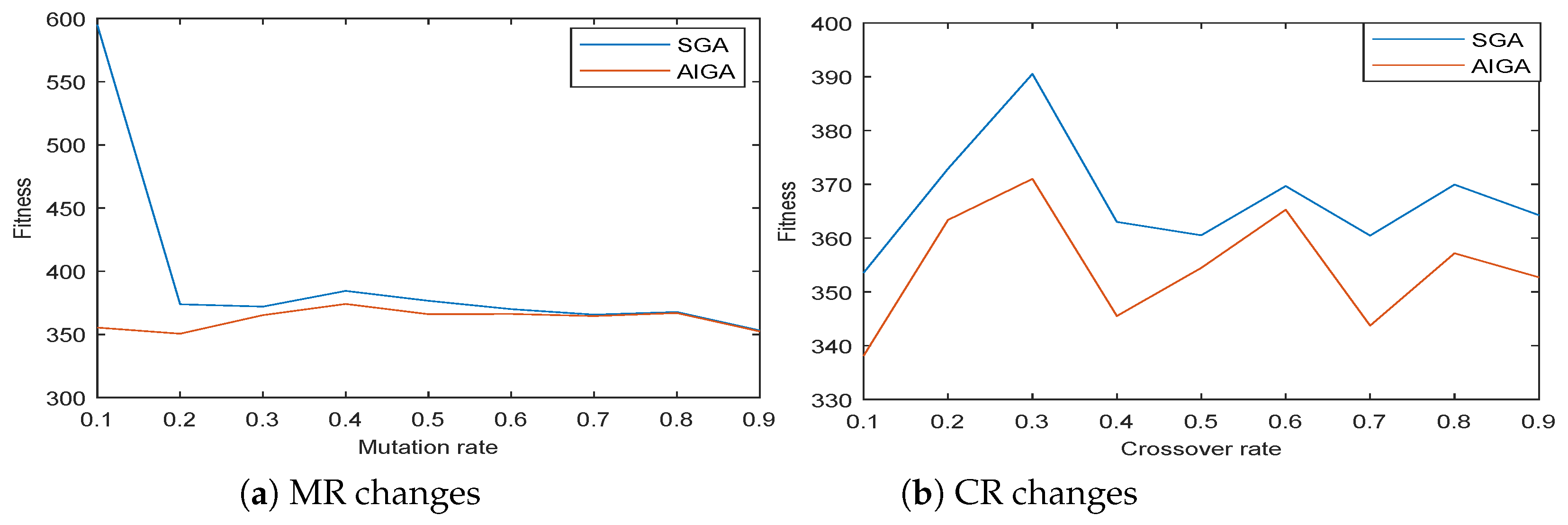
Then, we mainly evaluate the flexibility of SGA and AIGA according to different parameters. It has been long known that crossover rate and mutation rate have an important impact on the performance of GA. Typical values of crossover rate are in the range 0.5–1.0, and mutation rate is chosen in range 0.005–0.05 [
27]. Actually, features of the optimization problem should be considered when deciding these parameters. We set up two groups of experiments, one changes mutation rate (MR) and the other alters crossover rate (CR). Both set the number of tasks as 300. Each condition was run 10 times, giving the average fitness value.
Table 3 shows the result when the mutation rate ranges from 0.1 to 0.9 (crossover rate is 0.6). Overall, the fitness of global best solution obtained by AIGA is better than that of SGA;
Table 4 shows the result when the crossover rate ranges from 0.1 to 0.9 (mutation rate is 0.3). The fitness of global best solution obtained by AIGA also outperforms that of SGA.
Figure 4a,b gives the makespan chart according to different MR and CR. When mutation rate is low, SGA converges slowly which may run into local optimal. On the other hand, AIGA steadily outmatches SGA in the experiments.
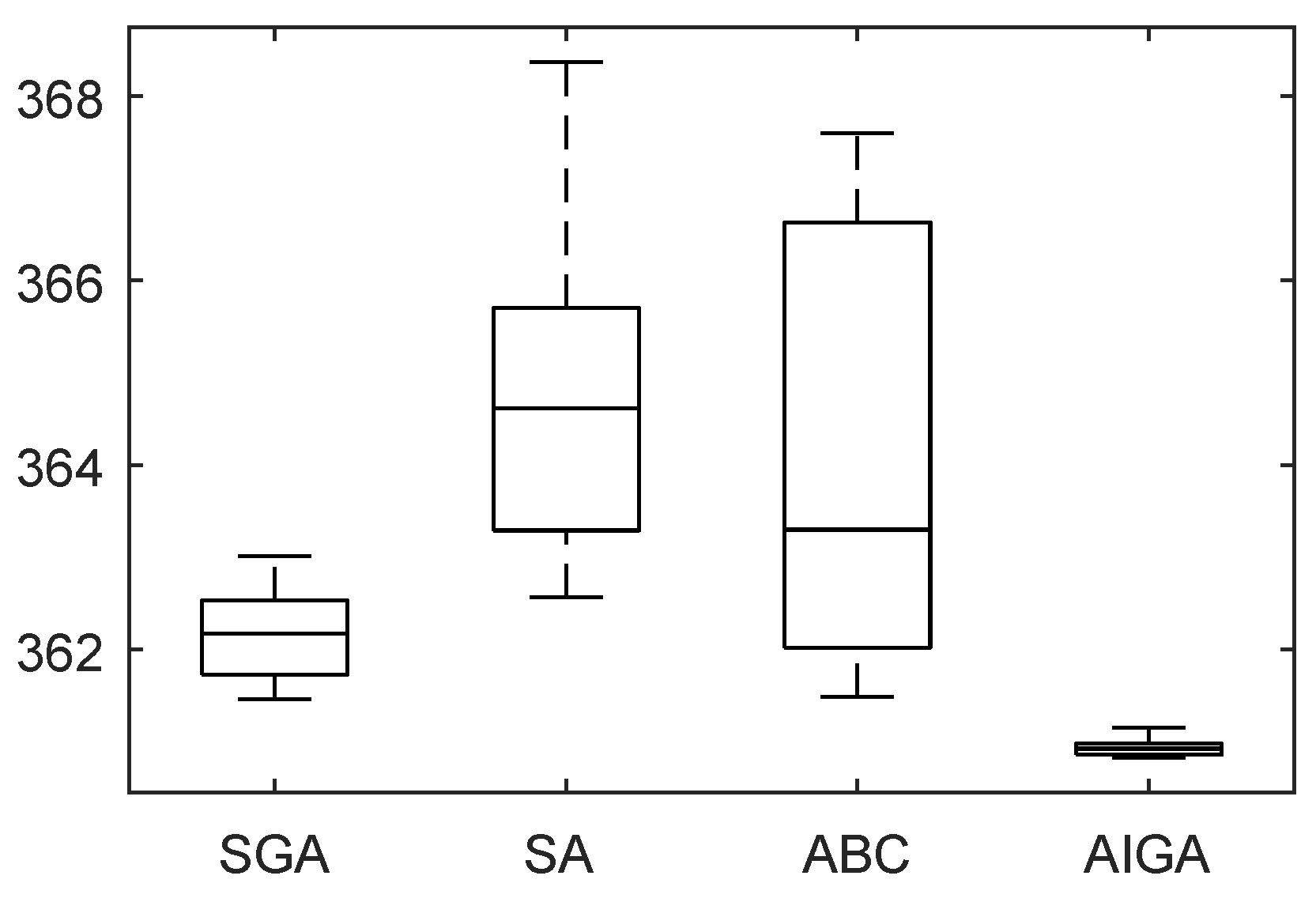
We also compare AIGA with Simulated Annealing (SA) and Artificial Bee Colony (ABC) algorithm in the task scheduling problem. As mentioned above, SGA may not find the optimal solution when mutation rate is too small, so we set MR 0.3 and CR 0.8. Then, 300 tasks were generate and each algorithm was run 10 times.
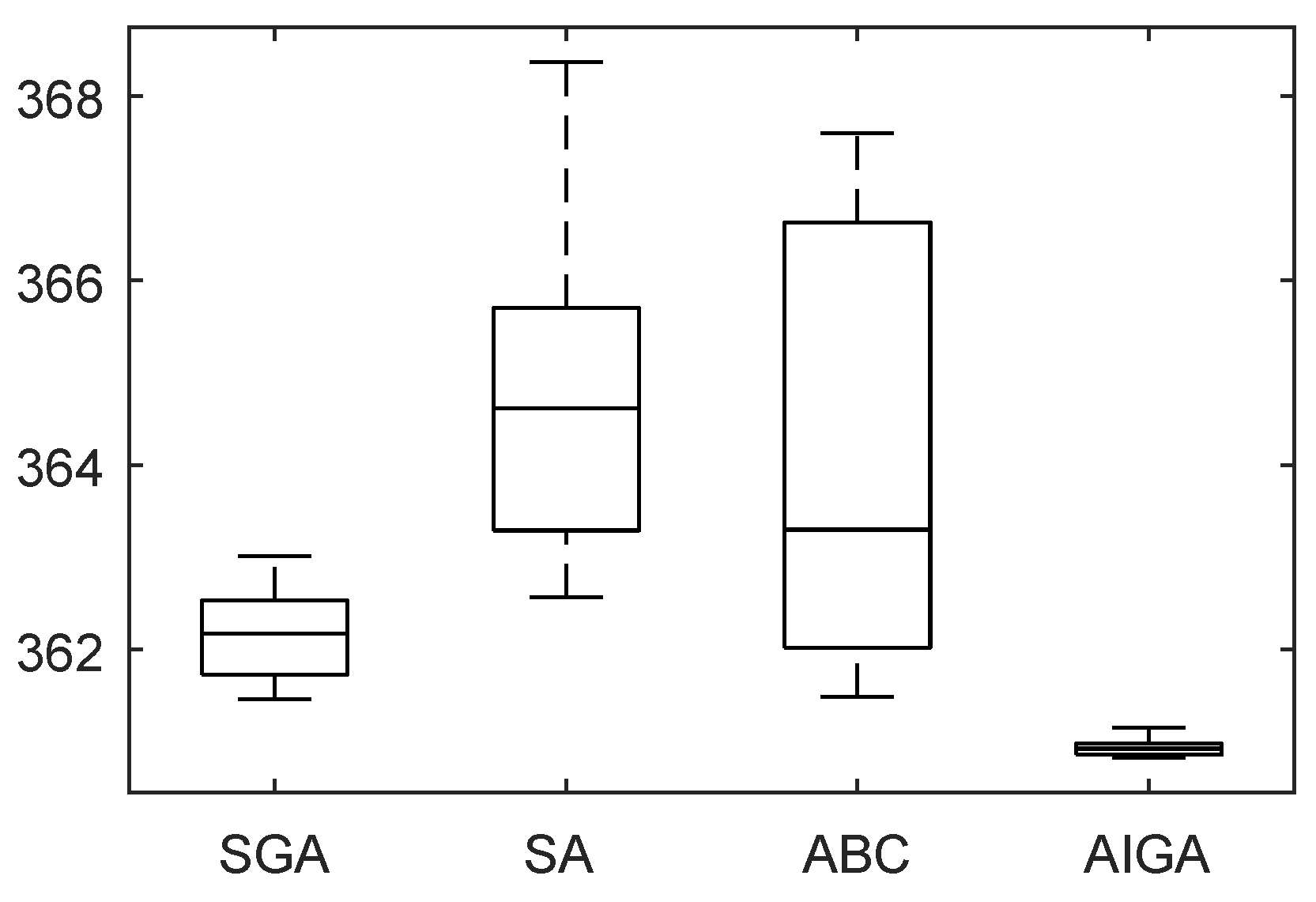
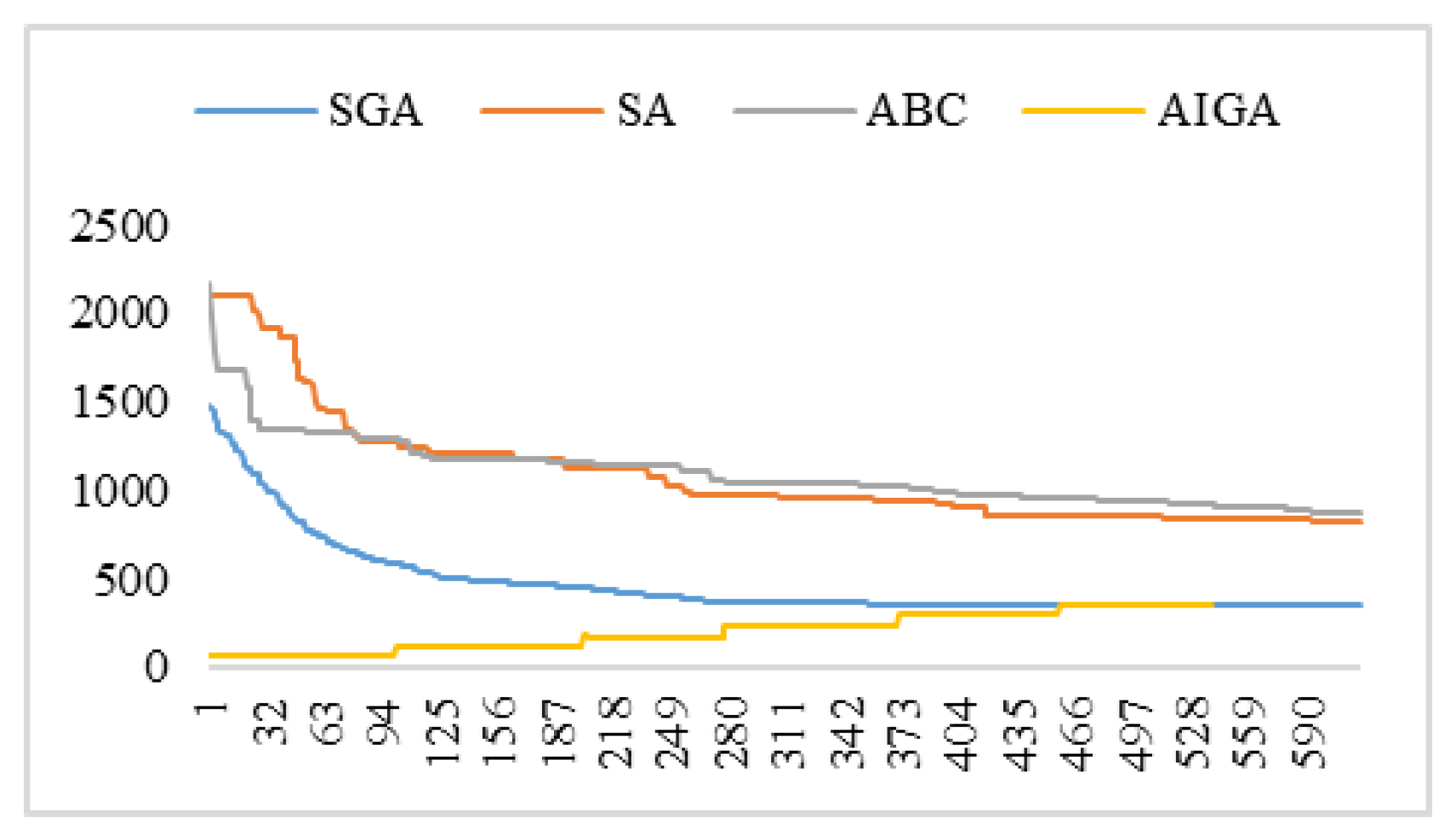
Figure 5 shows the boxplot of optimal fitness obtained by SA, ABC, SGA and AIGA. The distribution of fitness acquired by AIGA is more concentrated in a small range in comparison with others.
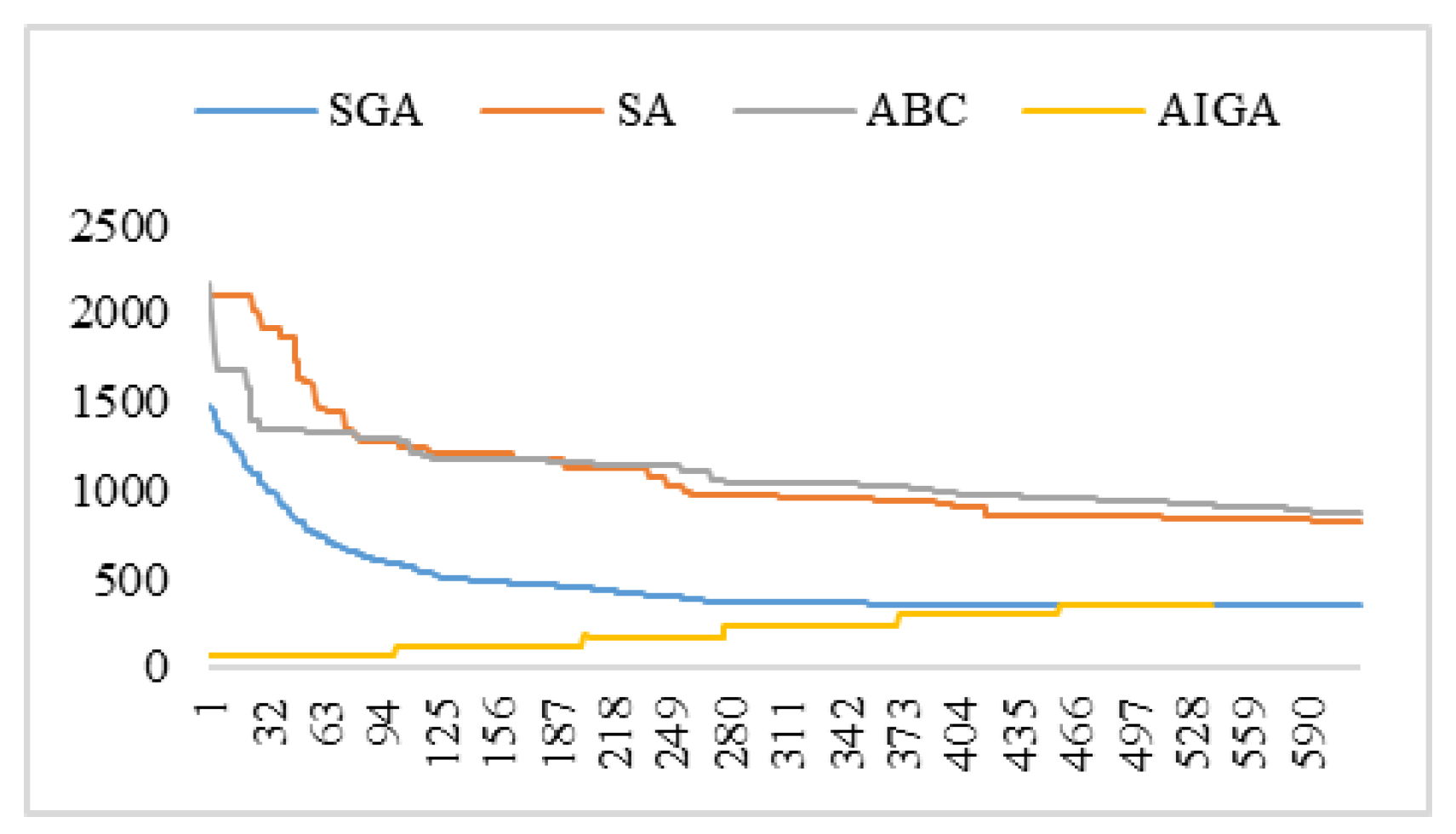
Figure 6 gives convergence curve of the four algorithms. SA and ABC converge relatively slowly compared to SGA and AIGA. AIGA starts from lowest point and gradually increases until to it meets the stop criteria. The optimal fitness of SGA and AIGA are quite close at the end of iteration.
Table 5 gives the optimal fitness when the number of tasks increases from 100 to 90,000 (mutation rate is 0.5 and crossover rate is 0.8).
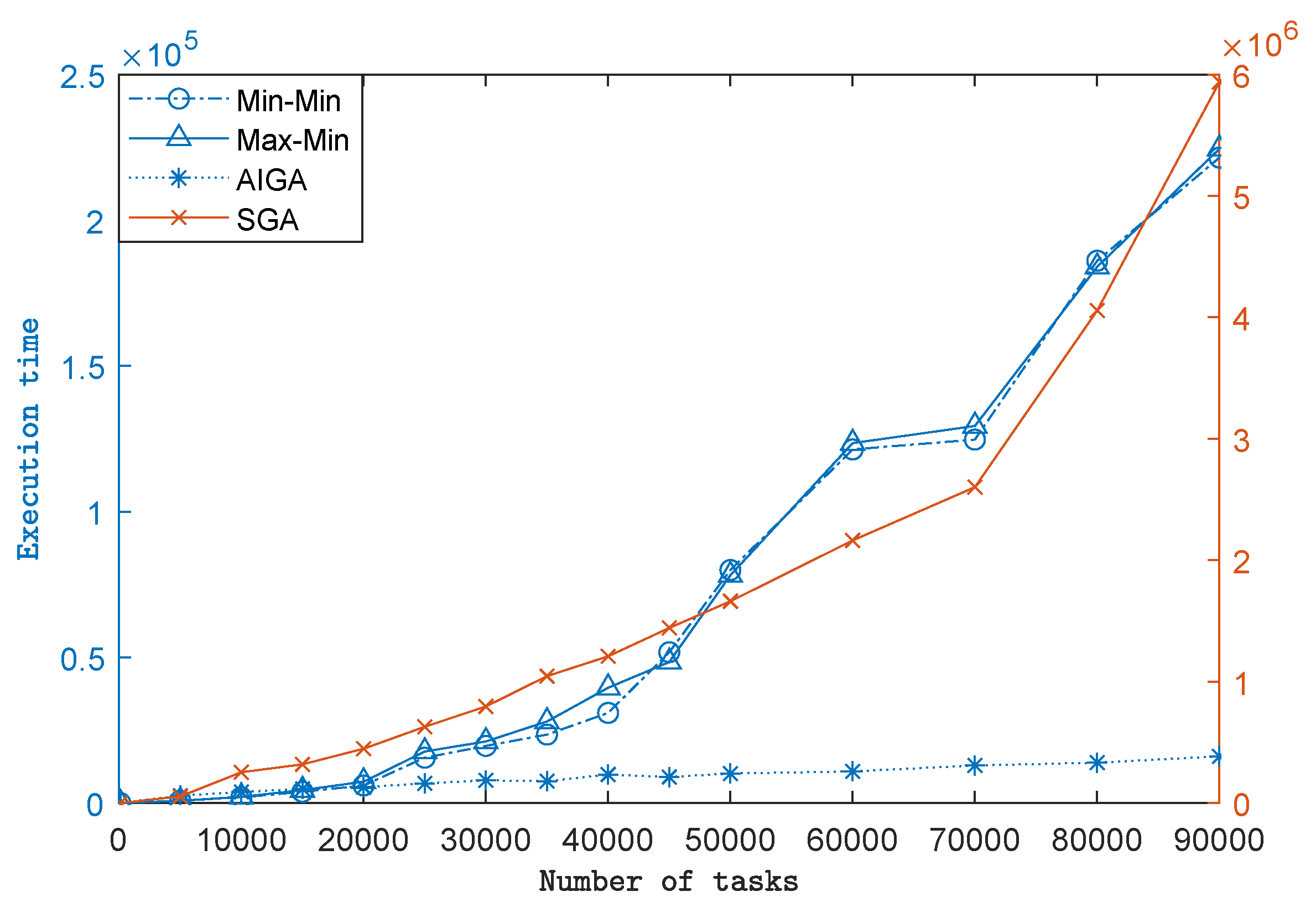
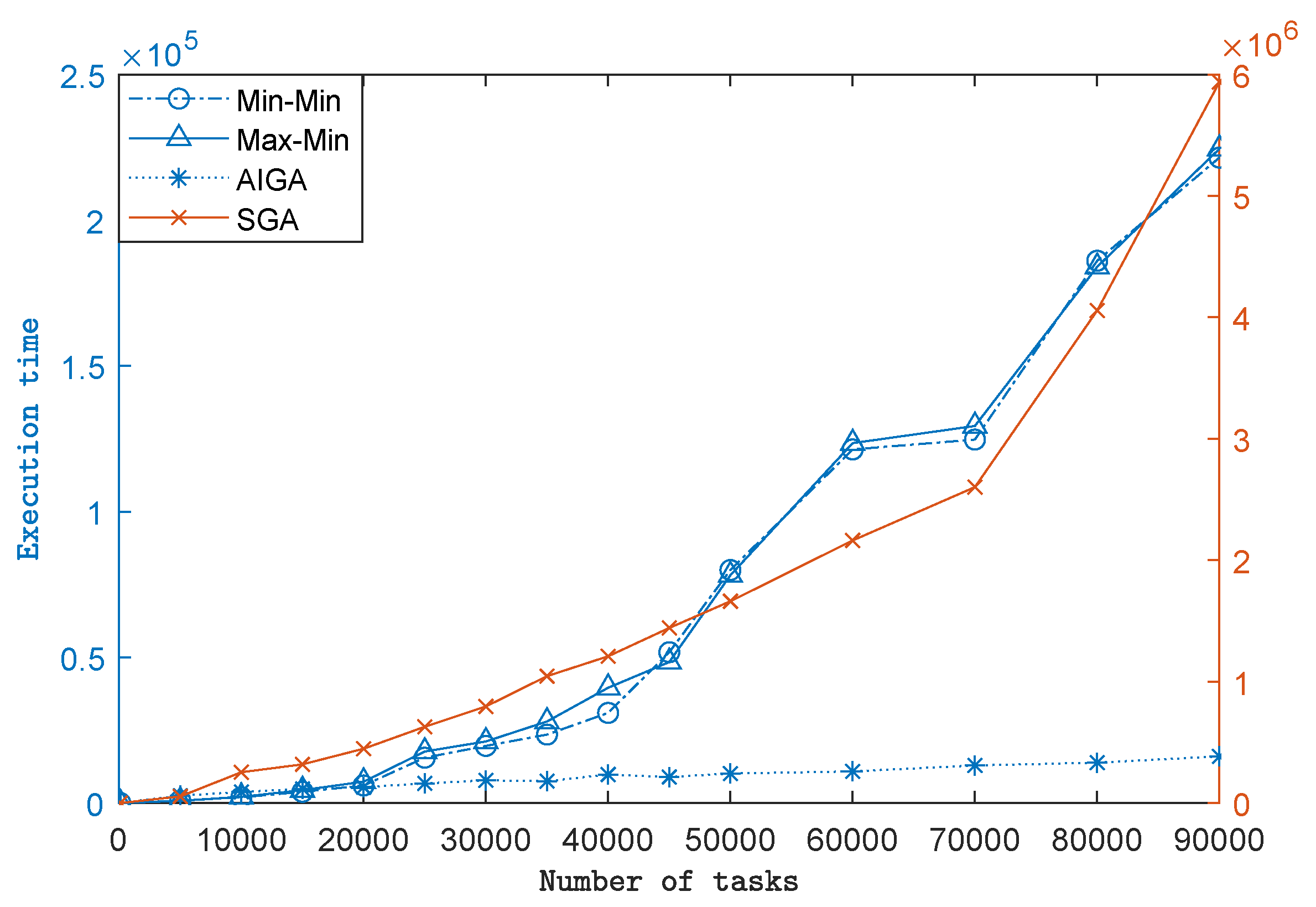
Figure 7 depicts the execution time of SGA, Min-Min, Max-Min and AIGA. Overall, AIGA has the minimum value of makespan. The execution time of these algorithms extend as the number of tasks increases. When there is a small number of tasks, Min-Min and Max-Min perform more efficiently. When the number of tasks exceeds 20,000, AIGA costs least computation time.
5. Conclusions and Future Work
For the task scheduling problem in Cloud environment, the time consumption has impact on the users’ payment and the energy consumed. It is important to optimize allocation of resources to reduce the makespan of processing a batch of tasks. Although GA or other bio-inspired algorithms are effective to solve NP-complete problems, it converges slowly when high-dimensional data are involved. To optimize large-scale task scheduling problem in Cloud environment with less makespan and computation time, we proposed an adaptive incremental Genetic algorithm. Our method called AIGA based on genetic algorithm which has adaptive probability of mutation rate and crossover rate can provide feasible solutions for the allocation of large numbers of tasks with less computation time.
We model the task scheduling as an objective optimization problem where the number of tasks corresponds to the dimensions of the problem. Extensive experiments had been designed to evaluate the performance of AIGA. Compared with two traditional scheduling methods, Min-Min and Max-Min, AIGA can find better solutions and costs less computation time as the number of tasks is very large. We also contrast different parameters of Standard GA by changing the mutation rate and crossover rate. AIGA steadily outperforms SGA in optimizing makespan despite the various control parameters. Two other meta-heuristic algorithms, Simulated Annealing (SA) and Artificial Bee Colony (ABC) algorithm, had been implemented. Experimental results show that the proposed AIGA performs best in terms of minimum objective function value, and has faster convergence speed than SA and ABC.
As part of our future work, we intend to establish a sophisticated mathematical model to describe the task scheduling problem on IaaS, such as introducing data or control dependences between tasks. Furthermore, we will consider evaluating AIGA for other objective functions such as energy consumption, resource utilization or optimize multiple objectives simultaneously.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}