
IMGT® Nomenclature of Engineered IGHG Variants Involved in Antibody Effector Properties and Formats



Abstract
1. Introduction
2. An Ontology and a System to Bridge Genes, Sequences and Structures to Functions
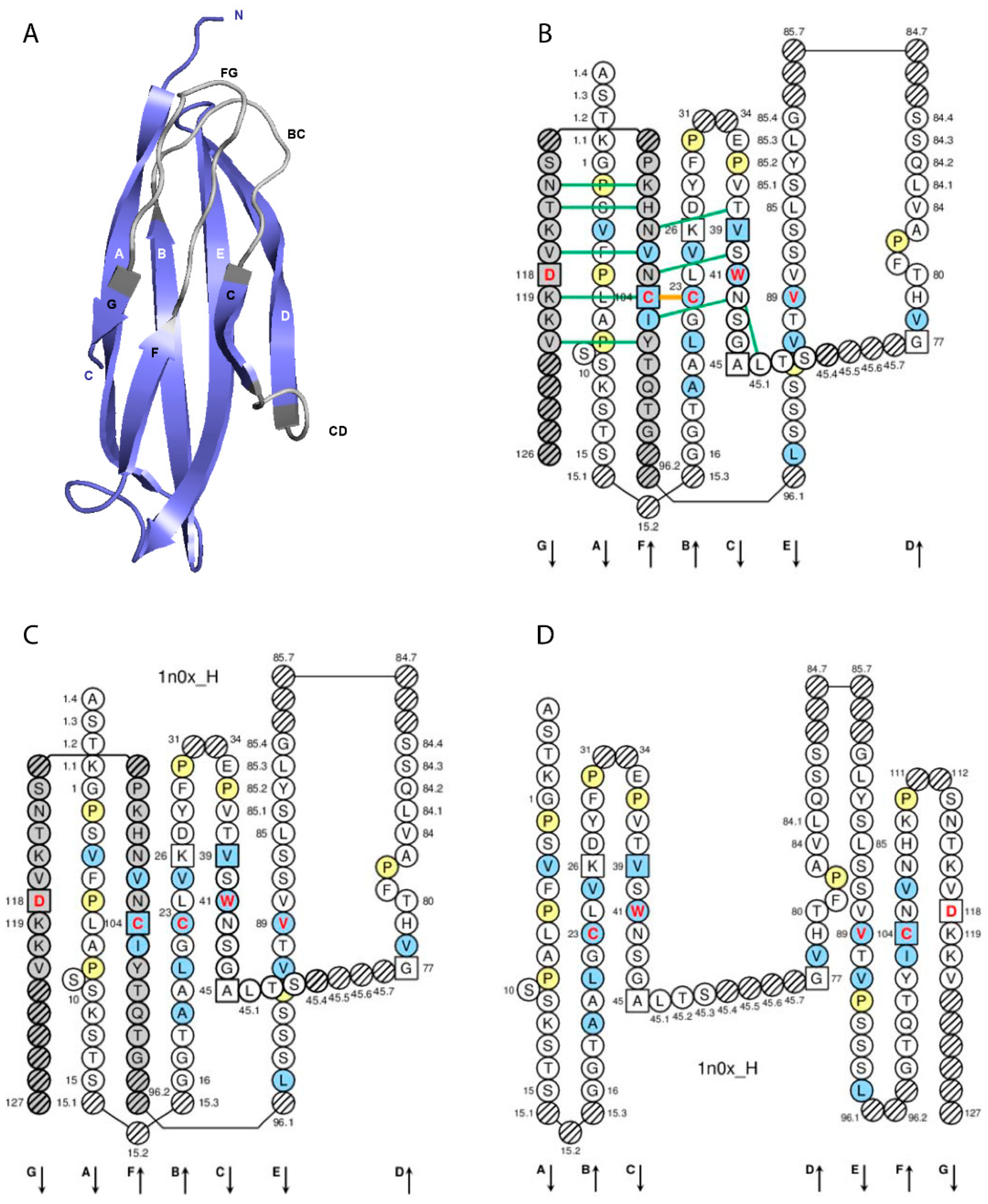
3. Immunoglobulin IgG Receptor, Chains, Domains and Amino Acids
4. IGHG, IGKC and IGLC2 Engineered Variants
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lefranc, M.-P. Immunoglobulin and T cell receptor genes: IMGT® and the birth and rise of immunoinformatics. Front Immunol. 2014, 5, 22. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. IMGT® Homo sapiens IG and TR loci, gene order, CNV and haplotypes: New concepts as a paradigm for jawed vertebrates genome assemblies. Biomolecules 2022, 12, 381. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Lefranc, G. The Immunoglobulin FactsBook; Academic Press: London, UK, 2001; pp. 1–457. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. Immunoglobulins or Antibodies: IMGT® Bridging Genes, Structures and Functions. Biomedicines 2020, 8, 319. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Lefranc, G. The T Cell Receptor FactsBook; Academic Press: London, UK, 2001; pp. 1–397. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. Antibody sequence and structure analyses using IMGT®: 30 years of immunoinformatics. In Computer Aided Antibody Design: Methods and Protocols; Tsumoto, K., Kuroda, D., Eds.; Methods in Molecular Biology; Springer: New York, NY, USA, 2022; in press. [Google Scholar]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin genes. In Current Protocols in Immunology; Coligan, J.E., Bierer, B.E., Margulies, D.E., Shevach, E.M., Strober, W., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2000; pp. A.1P.1–A.1P.37. [Google Scholar]
- Lefranc, M.-P. Nomenclature of the human T cell Receptor genes. In Current Protocols in Immunology; Coligan, J.E., Bierer, B.E., Margulies, D.E., Shevach, E.M., Strober, W., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2000; pp. A.1O.1–A.1O.23. [Google Scholar]
- Lefranc, M.-P. WHO-IUIS Nomenclature Subcommittee for Immunoglobulins and T cell receptors report. Immunogenetics 2007, 59, 899–902. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. WHO-IUIS Nomenclature Subcommittee for Immunoglobulins and T cell receptors report. Immunoglobulins and T cell receptors report August 2007, 13th International Congress of Immunology, Rio de Janeiro, Brazil. Dev. Comp. Immunol. 2008, 32, 461–463. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT, the international ImMunoGeneTics information system. In Immunoinformatics: Bioinformatic Strategies for Better Understanding of Immune Function; Bock, G., Goode, J., Eds.; Novartis Foundation Symposium; John Wiley and Sons: Chichester, UK, 2003; Volume 254, pp. 126, discussion 136–142, 216–222, 250–252. [Google Scholar]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Chaume, D. IMGT, the international ImMunoGeneTics information system: The reference in immunoinformatics. Stud. Health Technol. Inform. 2003, 95, 74–79. [Google Scholar] [PubMed]
- Lefranc, M.-P. IMGT, the International ImMunoGenetics Information System®. In Antibody Engineering Methods and Protocols, 2nd ed.; Lo, B.K.C., Ed.; Methods in Molecular Biology; Humana Press: Totowa, NJ, USA, 2004; Volume 248, pp. 27–49. [Google Scholar]
- Lefranc, M.-P. IMGT, the international ImMunoGeneTics information system: A standardized approach for immunogenetics and immunoinformatics. Immunome Res. 2005, 1, 3. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Lefranc, M.-P. IMGT®, the international ImMunoGeneTics information system® for immunoinformatics. Methods for querying IMGT® databases, tools and Web resources in the context of immunoinformatics. In Immunoinformatics: Predicting Immunogenicity in Silico; Flower, D.R., Ed.; Methods in Molecular Biology; Humana Press: Totowa, NJ, USA, 2007; Chapter 2; Volume 409, pp. 19–42. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Regnier, L.; Duroux, P. IMGT, a system and an ontology that bridge biological and computational spheres in bioinformatics. Brief. Bioinform. 2008, 9, 263–275. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT®, the international ImMunoGeneTics information system® for immunoinformatics. Methods for querying IMGT® databases, tools and Web resources in the context of immunoinformatics. Mol. Biotechnol. 2008, 40, 101–111. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Jabado-Michaloud, J.; Folch, G.; Bellahcene, F.; Wu, Y.; Gemrot, E.; Brochet, X.; Lane, J.; et al. IMGT®, the International ImMunoGeneTics Information System®. Nucleic Acids Res. 2009, 37, D1006–D1012. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT, the International ImMunoGeneTics Information System. Cold Spring Harb. Protoc. 2011, 6, 595–603. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT® information system. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 959–964. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Duroux, P.; Jabado-Michaloud, J.; Folch, G.; Aouinti, S.; Carillon, E.; Duvergey, H.; Houles, A.; Paysan-Lafosse, T.; et al. IMGT®, the International ImMunoGeneTics Information System® 25 Years on. Nucleic Acids Res. 2015, 43, D413–D422. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Immunoglobulin superfamily (IgSF). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. MH Superfamily (MhSF). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Busin, C.; Malik, A.; Mougenot, I.; Déhais, P.; Chaume, D. LIGM-DB/IMGT: An integrated database of Ig and TcR, part of the Immunogenetics database. Ann. N. Y. Acad. Sci. 1995, 764, 47–49. [Google Scholar] [CrossRef]
- Giudicelli, V.; Duroux, P.; Ginestoux, C.; Folch, G.; Jabado-Michaloud, J.; Chaume, D.; Lefranc, M.-P. IMGT/LIGM-DB, the IMGT® comprehensive database of immunoglobulin and T cell receptor nucleotide sequences. Nucleic Acids Res. 2006, 34, D781–D784. [Google Scholar] [CrossRef]
- Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/GENE-DB: A comprehensive database for human and mouse immunoglobulin and T cell receptor genes. Nucleic Acids Res. 2005, 33, D256–D261. [Google Scholar] [CrossRef]
- Kaas, Q.; Ruiz, M.; Lefranc, M.-P. IMGT/3Dstructure-DB and IMGT/StructuralQuery, a database and a tool for immunoglobulin, T cell receptor and MHC structural data. Nucleic Acids Res. 2004, 32, D208–D210. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Kaas, Q.; Lefranc, M.-P. IMGT/3Dstructure-DB and IMGT/DomainGapAlign: A Database and a Tool for Immunoglobulins or Antibodies, T Cell Receptors, MHC, IgSF and MhcSF. Nucleic Acids Res. 2010, 38, D301–D307. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/3Dstructure-DB: Querying the IMGT Database for 3D Structures in Immunology and Immunoinformatics (IG or Antibodies, TR, MH, RPI, and FPIA). Cold Spring Harb. Protoc. 2011, 6, 750–761. [Google Scholar] [CrossRef]
- Poiron, C.; Wu, Y.; Ginestoux, C.; Ehrenmann, F.; Duroux, P.; Lefranc, M.-P. IMGT/mAb-DB: The IMGT® database for therapeutic monoclonal antibodies. In Proceedings of the 11èmes Journées Ouvertes de Biologie, Informatique et Mathématiques (JOBIM), Montpellier, France, 7–9 September 2010. [Google Scholar]
- Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/V-QUEST, an Integrated Software for Immunoglobulin and T Cell Receptor V-J and V-D-J Rearrangement Analysis. Nucleic Acids Res. 2004, 32, W435–W440. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. Interactive IMGT on-line tools for the analysis of immunoglobulin and T cell receptor repertoires. In New Research on Immunology; Veskler, B.A., Ed.; Nova Science Publishers Inc.: New York, NY, USA, 2005; pp. 77–105. [Google Scholar]
- Brochet, X.; Lefranc, M.-P.; Giudicelli, V. IMGT/V-QUEST: The Highly Customized and Integrated System for IG and TR Standardized V-J and V-D-J Sequence Analysis. Nucleic Acids Res. 2008, 36, W503–W508. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. IMGT® standardized analysis of immunoglobulin rearranged sequences. In Immunoglobulin Gene Analysis in Chronic Lymphocytic Leukemia; Ghia, P., Rosenquist, R., Davi, F., Eds.; Wolters Kluwer Health Italy: Milano, Italy, 2008; Chapter 2; pp. 33–52. [Google Scholar]
- Giudicelli, V.; Brochet, X.; Lefranc, M.-P. IMGT/V-QUEST: IMGT standardized analysis of the immunoglobulin (IG) and T cell receptor (TR) nucleotide sequences. Cold Spring Harb. Protoc. 2011, 6, 695–715. [Google Scholar] [CrossRef]
- Alamyar, E.; Duroux, P.; Lefranc, M.-P.; Giudicelli, V. IMGT® tools for the nucleotide analysis of immunoglobulin (IG) and T cell receptor (TR) V-(D)-J repertoires, polymorphisms, and IG mutations: IMGT/V-QUEST and IMGT/HighV-QUEST for NGS. In Immunogenetics; Christiansen, F., Tait, B., Eds.; Methods in Molecular Biology; Humana Press: New York, NY, USA, 2012; Chapter 32; Volume 882, pp. 569–604. [Google Scholar] [CrossRef]
- Yousfi Monod, M.; Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/JunctionAnalysis: The first tool for the analysis of the immunoglobulin and T cell receptor complex V-J and V-D-J JUNCTIONs. Bioinformatics 2004, 20, i379–i385. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. IMGT/JunctionAnalysis: IMGT standardized analysis of the V-J and V-D-J Junctions of the rearranged immunoglobulins (IG) and T cell receptors (TR). Cold Spring Harb. Protoc. 2011, 6, 716–725. [Google Scholar] [CrossRef]
- Giudicelli, V.; Protat, C.; Lefranc, M.-P. The IMGT strategy for the automatic annotation of IG and TR cDNA sequences: IMGT/Automat. In Proceedings of the European Conference on Computational Biology (ECCB 2003), Data and Knowledge Bases, Institut National de Recherche en Informatique et en Automatique, Poster DKB_31, ECCB 2003, Paris, France, 27–30 September 2003; pp. 103–104. [Google Scholar]
- Giudicelli, V.; Chaume, D.; Jabado-Michaloud, J.; Lefranc, M.-P. Immunogenetics sequence Annotation: The strategy of IMGT based on IMGT-ONTOLOGY. Stud. Health Technol. Inform. 2005, 116, 3–8. [Google Scholar]
- Alamyar, E.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. IMGT/HighV-QUEST: A high-throughput system and web portal for the analysis of rearranged nucleotide sequences of antigen receptors—High-throughput version of IMGT/V-QUEST. In Proceedings of the 11èmes Journées Ouvertes de Biologie, Informatique et Mathématiques (JOBIM), Montpellier, France, 7–9 September 2010. [Google Scholar]
- Alamyar, E.; Giudicelli, V.; Li, S.; Duroux, P.; Lefranc, M.-P. IMGT/HighV-QUEST: The IMGT® web portal for immunoglobulin (IG) or antibody and T cell receptor (TR) analysis from NGS high throughput and deep sequencing. Immunome Res. 2012, 8, 26. [Google Scholar]
- Li, S.; Lefranc, M.-P.; Miles, J.J.; Alamyar, E.; Giudicelli, V.; Duroux, P.; Freeman, J.D.; Corbin, V.; Scheerlinck, J.-P.; Frohman, M.A.; et al. IMGT/HighV-QUEST paradigm for T cell receptor IMGT clonotype diversity and next generation repertoire immunoprofiling. Nat. Commun. 2013, 4, 2333. [Google Scholar] [CrossRef]
- Giudicelli, V.; Duroux, P.; Lavoie, A.; Aouinti, S.; Lefranc, M.-P.; Kossida, S. From IMGT-ONTOLOGY to IMGT/HighV-QUEST for NGS immunoglobulin (IG) and T cell receptor (TR) repertoires in autoimmune and infectious diseases. Autoimmun. Infect. Dis. 2015, 1, 1–15. [Google Scholar]
- Giudicelli, V.; Duroux, P.; Kossida, S.; Lefranc, M.-P. IG and TR single chain Fragment variable (scFv) sequence analysis: A new advanced functionality of IMGT/V-QUEST and IMGT/HighV-QUEST. BMC Immunol. 2017, 18, 35. [Google Scholar] [CrossRef]
- Aouinti, S.; Malouche, D.; Giudicelli, V.; Kossida, S.; Lefranc, M.-P. IMGT/HighV-QUEST statistical significance of IMGT clonotype (AA) diversity per gene for standardized comparisons of next generation sequencing immunoprofiles of immunoglobulins and T cell receptors. PLoS ONE 2015, 10, e0142353, https://doi.org/10.1371/journal.pone.0142353. eCollection 2015. Correction: PLoS ONE 2016, 11, e0146702. [Google Scholar] [CrossRef]
- Aouinti, S.; Giudicelli, V.; Duroux, P.; Malouche, D.; Kossida, S.; Lefranc, M.-P. IMGT/StatClonotype for pairwise evaluation and visualization of NGS IG and TR IMGT clonotype (AA) diversity or expression from IMGT/HighV-QUEST. Front. Immunol. 2016, 7, 339. [Google Scholar] [CrossRef]
- Lane, J.; Duroux, P.; Lefranc, M.-P. From IMGT-ONTOLOGY to IMGT/LIGMotif: The IMGT® standardized approach for immunoglobulin and T cell receptor gene identification and description in large genomic sequences. BMC Bioinform. 2010, 11, 223. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/DomainGapAlign: IMGT standardized analysis of amino acid sequences of Variable, Constant, and Groove domains (IG, TR, MH, IgSF, MhSF). Cold Spring Harb. Protoc. 2011, 6, 737–749. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/DomainGapAlign: The IMGT® tool for the analysis of IG, TR, MHC, IgSF and MhcSF domain amino acid polymorphism. In Immunogenetics; Christiansen, F., Tait, B., Eds.; Methods in Molecular Biology; Humana Press: New York, NY, USA, 2012; Chapter 33; Volume 882, pp. 605–633. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. IMGT/Collier de Perles: IMGT Standardized representation of Domains (IG, TR, and IgSF Variable and Constant Domains, MH and MhSF Groove Domains). Cold Spring Harb. Protoc. 2011, 6, 726–736. [Google Scholar] [CrossRef]
- Pommié, C.; Levadoux, S.; Sabatier, R.; Lefranc, G.; Lefranc, M.-P. IMGT standardized criteria for statistical analysis of immunoglobulin V-REGION amino acid properties. J. Mol. Recognit. 2004, 17, 17–32. [Google Scholar] [CrossRef]
- Lefranc, M.-P. From IMGT-ONTOLOGY IDENTIFICATION axiom to IMGT standardized keywords: For immunoglobulins (IG), T cell receptors (TR), and conventional genes. Cold Spring Harb. Protoc. 2011, 6, 604–613. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, IDENTIFICATION axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. From IMGT-ONTOLOGY DESCRIPTION axiom to IMGT standardized labels: For immunoglobulin (IG) and T cell receptor (TR) sequences and structures. Cold Spring Harb. Protoc. 2011, 6, 614–626. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, DESCRIPTION axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Complementarity Determining Region (CDR-IMGT). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Framework Region (FR-IMGT). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Jefferis, R.; Lefranc, M.-P. Human immunoglobulin allotypes: Possible implications for immunogenicity. mAbs 2009, 1, 332–338. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. Human Gm, Km and Am allotypes and their molecular characterization: A remarkable demonstration of polymorphism. In Immunogenetics; Christiansen, F., Tait, B., Eds.; Humana Press: New York, NY, USA, 2012; Chapter 34; Volume 882, pp. 635–680. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin heavy (IGH) genes. Exp. Clin. Immunogenet. 2001, 18, 100–116. [Google Scholar] [CrossRef]
- Lefranc, M.-P. From IMGT-ONTOLOGY CLASSIFICATION axiom to IMGT standardized gene and allele nomenclature: For immunoglobulins (IG) and T cell receptors (TR). Cold Spring Harb. Protoc. 2011, 6, 627–632. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, CLASSIFICATION Axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, NUMEROTATION axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Unique database numbering system for immunogenetic analysis. Immunol. Today 1997, 18, 509. [Google Scholar] [CrossRef]
- Lefranc, M.-P. The IMGT unique numbering for Immunoglobulins, T cell receptors and Ig-like domains. Immunology 1999, 7, 132–136. [Google Scholar]
- Lefranc, M.-P.; Pommié, C.; Ruiz, M.; Giudicelli, V.; Foulquier, E.; Truong, L.; Thouvenin-Contet, V.; Lefranc, G. IMGT unique numbering for immunoglobulin and T cell receptor variable domains and Ig superfamily V-like domains. Dev. Comp. Immunol. 2003, 27, 55–77. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Pommié, C.; Kaas, Q.; Duprat, E.; Bosc, N.; Guiraudou, D.; Jean, C.; Ruiz, M.; Da Piedade, I.; Rouard, M.; et al. IMGT unique numbering for immunoglobulin and T cell receptor constant domains and Ig superfamily C-like domains. Dev. Comp. Immunol. 2005, 29, 185–203. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Duprat, E.; Kaas, Q.; Tranne, M.; Thiriot, A.; Lefranc, G. IMGT unique numbering for MHC groove G-DOMAIN and MHC superfamily (MhcSF) G-LIKE-DOMAIN. Dev. Comp. Immunol. 2005, 29, 917–938. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT unique numbering for the Variable (V), Constant (C), and Groove (G) domains of IG, TR, MH, IgSF, and MhSF. Cold Spring Harb. Protoc. 2011, 6, 633–642. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT unique numbering. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 952–959. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Immunoinformatics of the V, C, and G domains: IMGT® definitive system for IG, TR and IgSF, MH, and MhSF. In Immunoinformatics: From Biology to Informatics, 2nd ed.; De, R.K., Tomar, N., Eds.; Methods in Molecular Biology; Humana Press: New Yor, NY, USA, 2014; Volume 1184, pp. 59–107. [Google Scholar] [CrossRef]
- Ruiz, M.; Lefranc, M.-P. IMGT gene identification and Colliers de Perles of human immunoglobulins with known 3D structures. Immunogenetics 2002, 53, 857–883. [Google Scholar]
- Kaas, Q.; Lefranc, M.-P. IMGT Colliers de Perles: Standardized sequence-structure representations of the IgSF and MhcSF superfamily domains. Curr. Bioinform. 2007, 2, 21–30. [Google Scholar] [CrossRef]
- Kaas, Q.; Ehrenmann, F.; Lefranc, M.-P. IG, TR and IgSf, MHC and MhcSF: What do we learn from the IMGT Colliers de Perles? Brief. Funct. Genom. Proteom. 2007, 6, 253–264. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT Collier de Perles for the Variable (V), Constant (C), and Groove (G) domains of IG, TR, MH, IgSF, and MhSF. Cold Spring Harb. Protoc. 2011, 6, 643–651. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT Collier de Perles. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 944–952. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. Ontology for Immunogenetics: IMGT-ONTOLOGY. Bioinformatics 1999, 15, 1047–1054. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY and IMGT databases, tools and web resources for immunogenetics and immunoinformatics. Mol. Immunol. 2004, 40, 647–660. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT-ONTOLOGY, IMGT® databases, tools and Web resources for Immunoinformatics. In Immunoinformatics; Schoenbach, C., Ranganathan, S., Brusic, V., Eds.; Immunomics Reviews, Series of Springer Science and Business Media LLC.; Springer: New York, NY, USA, 2008; Chapter 1; Volume 1, pp. 1–18. [Google Scholar]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY 2012. Frontiers in Bioinformatics and Computational Biology. Front. Genet. 2012, 3, 79. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 964–972. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. IMGT/3Dstructure-DB: T-cell Receptor TR Paratope and peptide/Major Histocompatibility pMH contact sites and epitope. Methods Mol. Biol. 2022, 2453, 533–570. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Antibody nomenclature: From IMGT-ONTOLOGY to INN definition. mAbs 2011, 3, 1–2. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. International Nonproprietary Names (INN) for Biological and Biotechnological Substances (a Review). WHO/EMP/RHT/TSN/2019.1. Available online: http://www.nihs.go.jp/dbcb/INN/BioReview2019.pdf (accessed on 14 August 2022).
- Guimaraes Koch, S.S.; Thorpe, R.; Kawasaki, N.; Lefranc, M.-P.; Malan, S.; Martin, A.C.R.; Mignot, G.; Plückthun, A.; Rizzi, M.; Shubat, S.; et al. International nonproprietary names for monoclonal antibodies: An evolving nomenclature system. mAbs 2022, 14, 2075078. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Antibody databases and tools: The IMGT® experience. In Therapeutic Monoclonal Antibodies: From Bench to Clinic; An, Z., Ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009; Chapter 4; pp. 91–114. ISBN 978-0-470-11791-0. [Google Scholar]
- Lefranc, M.-P. Antibody databases: IMGT®, a French platform of world-wide interest. Bases de données anticorps: IMGT®, une plate-forme française d’intérêt mondial “Anticorps monoclonaux en thérapeutique”. Méd./Sci. 2009, 25, 1020–1023. [Google Scholar] [CrossRef][Green Version]
- Lefranc, M.-P.; Ehrenmann, F.; Ginestoux, C.; Duroux, P.; Giudicelli, V. Use of IMGT® databases and tools for antibody engineering and humanization. In Antibody Engineering; Chames, P., Ed.; Methods in Molecular Biology; Humana Press: New York, NY, USA, 2012; Chapter 1; Volume 907, pp. 3–37. [Google Scholar]
- Lefranc, M.-P. How to use IMGT® for therapeutic antibody engineering. In Handbook of Therapeutic Antibodies, 2nd ed.; Dübel, S., Reichert, J., Eds.; Defining the Right Antibody Composition; Wiley: Hoboken, NJ, USA, 2014; Chapter 10; Volume 1, pp. 229–264. [Google Scholar]
- Lefranc, M.-P. IMGT® immunoglobulin repertoire analysis and antibody humanization. In Molecular Biology of B Cells, 2nd ed.; Alt, F.W., Honjo, T., Radbruch, A., Reth, M., Eds.; Academic Press: London, UK, 2014; Chapter 26; pp. 481–514. ISBN 978-0-12-397933-9. [Google Scholar]
- Shirai, H.; Prades, C.; Vita, R.; Marcatili, P.; Popovic, B.; Xu, J.; Overington, J.P.; Hirayama, K.; Soga, S.; Tsunoyama, K.; et al. Antibody informatics for drug discovery. Biochim. Biophys. Acta 2014, 1844, 2002–2015. [Google Scholar] [CrossRef] [PubMed]
- Alamyar, E.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. Antibody V and C domain sequence, structure and interaction analysis with special reference to IMGT®. In Monoclonal Antibodies: Methods and Protocols, 2nd ed.; Ossipow, V., Fischer, N., Eds.; Methods in Molecular Biology; Humana Press: New York, NY, USA, 2014; Volume 1131, pp. 337–381. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Immunoglobulins: 25 years of Immunoinformatics and IMGT-ONTOLOGY. Biomolecules 2014, 4, 1102–1139. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Antibody informatics: IMGT, the international ImMunoGeneTics information system. In Antibodies for Infectious Diseases; Crowe, J.E., Boraschi, D., Rappuoli, R., Eds.; ASM Press: Washington, DC, USA, 2015; pp. 363–379. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. IMGT® and 30 years of Immunoinformatics insight in antibody V and C domain structure and function. Antibodies 2019, 8, 29. [Google Scholar] [CrossRef]
- Edelman, G.M.; Cunningham, B.A.; Gall, W.E.; Gottlieb, P.D.; Rutishauser, U.; Waxdal, M.J. The covalent structure of an entire gammaG immunoglobulin molecule. Proc. Natl. Acad. Sci. USA 1969, 63, 78–85. [Google Scholar] [CrossRef]
- Kabat, E.A.; Wu, T.T.; Reid-Miller, M.; Perry, H.M.; Gottesman, K.S. Sequences of Proteins of Immunological Interest, 5th ed.; NIH publication n° 91-3242; US Department of Health and Human Services: Washington, DC, USA, 1991; pp. 662, 680, 689.
- Booth, B.J.; Ramakrishnan, B.; Narayan, K.; Wollacott, A.M.; Babcock, G.J.; Shriver, Z.; Viswanathan, K. Extending human IgG half-life using structure-guided design. mAbs 2018, 10, 1098–1110. [Google Scholar] [CrossRef]
- Liu, R.; Oldham, R.J.; Teal, E.; Beers, S.A.; Cragg, M.S. Fc-Engineering for Modulated Effector Functions-Improving Antibodies for Cancer Treatment. Antibodies 2020, 9, 64. [Google Scholar] [CrossRef] [PubMed]
- Chappel, M.S.; Isenman, D.E.; Everett, M.; Xu, Y.Y.; Dorrington, K.J.; Klein, M.H. Identification of the Fc gamma receptor class I binding site in human IgG through the use of recombinant IgG1/IgG2 hybrid and point-mutated antibodies. Proc. Natl. Acad. Sci. USA 1991, 88, 9036–9040. [Google Scholar] [CrossRef] [PubMed]
- Idusogie, E.E.; Wong, P.Y.; Presta, L.G.; Gazzano-Santoro, H.; Totpal, K.; Ultsch, M.; Mulkerrin, M.G. Engineered antibodies with increased activity to recruit complement. J. Immunol. 2001, 166, 2571–2575. [Google Scholar] [CrossRef] [PubMed]
- Brinkhaus, M.; Douwes, R.G.J.; Bentlage, A.E.H.; Temming, A.R.; de Taeye, S.W.; Tammes Buirs, M.; Gerritsen, J.; Mok, J.Y.; Brasser, G.; Ligthart, P.C.; et al. . Glycine 236 in the lower hinge region of human IgG1 differentiates FcγR from Complement effector function. J. Immunol. 2020, 205, 3456–3467. [Google Scholar] [CrossRef]
- Shields, R.L.; Namenuk, A.K.; Hong, K.; Meng, Y.G.; Rae, J.; Briggs, J.; Xie, D.; Lai, J.; Stadlen, A.; Li, B.; et al. High resolution mapping of the binding site on human IgG1 for Fc gamma RI, Fc gamma RII, Fc gamma RIII, and FcRn and design of IgG1 variants with improved binding to the Fc gamma R. J. Biol. Chem. 2001, 276, 6591–6604. [Google Scholar] [CrossRef]
- Lazar, G.A.; Dang, W.; Karki, S.; Vafa, O.; Peng, J.S.; Hyun, L.; Chan, C.; Chung, H.S.; Eivazi, A.; Yoder, S.C.; et al. Engineered antibody Fc variants with enhanced effector function. Proc. Natl. Acad. Sci. USA 2006, 103, 4005–4010. [Google Scholar] [CrossRef]
- Oganesyan, V.; Damschroder, M.M.; Leach, W.; Wu, H.; Dall’Acqua, W.F. Structural characterization of a mutated, ADCC-enhanced human Fc fragment. Mol. Immunol. 2008, 45, 1872–1882. [Google Scholar] [CrossRef]
- Stavenhagen, J.B.; Gorlatov, S.; Tuaillon, N.; Rankin, C.T.; Li, H.; Burke, S.; Huang, L.; Vijh, S.; Johnson, S.; Bonvini, E.; et al. Fc optimization of therapeutic antibodies enhances their ability to kill tumor cells in vitro and controls tumor expansion in vivo via low-affinity activating Fcgamma receptors. Cancer Res. 2007, 67, 8882–8890. [Google Scholar] [CrossRef]
- Mimoto, F.; Igawa, T.; Kuramochi, T.; Katada, H.; Kadono, S.; Kamikawa, T.; Shida-Kawazoe, M.; Hattori, K. Novel asymmetrically engineered antibody Fc variant with superior FcγR binding affinity and specificity compared with afucosylated Fc variant. mAbs 2013, 5, 229–236. [Google Scholar] [CrossRef]
- Duncan, A.R.; Woof, J.M.; Partridge, L.J.; Burton, D.R.; Winter, G. Localization of the binding site for the human high-affinity Fc receptor on IgG. Nature 1988, 332, 563–564. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.A.; Keremane, S.R.; Vielmetter, J.; Bjorkman, P.J. Structural characterization of GASDALIE Fc bound to the activating Fc receptor FcγRIIIa. J. Struct. Biol. 2016, 1, 78–89. [Google Scholar] [CrossRef] [PubMed]
- Richards, J.O.; Karki, S.; Lazar, G.A.; Chen, H.; Dang, W.; Desjarlais, J.R. Optimization of antibody binding to FcgammaRIIa enhances macrophage phagocytosis of tumor cells. Mol. Cancer Ther. 2008, 7, 2517–2527. [Google Scholar] [CrossRef] [PubMed]
- Moore, G.L.; Chen, H.; Karki, S.; Lazar, G.A. Engineered Fc variant antibodies with enhanced ability to recruit complement and mediate effector functions. mAbs 2010, 2, 181–189. [Google Scholar] [CrossRef]
- Diebolder, C.A.; Beurskens, F.J.; de Jong, R.N.; Koning, R.I.; Strumane, K.; Lindorfer, M.A.; Voorhorst, M.; Ugurlar, D.; Rosati, S.; Heck, A.J.; et al. Complement is activated by IgG hexamers assembled at the cell surface. Science 2014, 343, 1260–1263. [Google Scholar] [CrossRef] [PubMed]
- Smith, P.; DiLillo, D.J.; Bournazos, S.; Li, F.; Ravetch, J.V. Mouse model recapitulating human Fcγ receptor structural and functional diversity. Proc. Natl. Acad. Sci. USA 2012, 109, 6181–6186. [Google Scholar] [CrossRef]
- Natsume, A.; In, M.; Takamura, H.; Nakagawa, T.; Shiz, Y.; Kitajima, K.; Wakitani, M.; Ohta, S.; Satoh, M.; Shitara, K.; et al. Engineered antibodies of IgG1/IgG3 mixed isotype with enhanced cytotoxic activities. Cancer Res. 2008, 68, 3863–3872. [Google Scholar] [CrossRef]
- Tao, M.H.; Smith, R.I.; Morrison, S.L. Structural features of human immunoglobulin G that determine isotype-specific differences in complement activation. J. Exp. Med. 1993, 178, 661–667. [Google Scholar] [CrossRef]
- Idusogie, E.E.; Presta, L.G.; Gazzano-Santoro, H.; Totpal, K.; Wong, P.Y.; Ultsch, M.; Meng, Y.G.; Mulkerrin, M.G. Mapping of the C1q binding site on rituxan, a chimeric antibody with a human IgG1 Fc. J. Immunol. 2000, 164, 4178–4184. [Google Scholar] [CrossRef] [PubMed]
- Hezareh, M.; Hessell, A.J.; Jensen, R.C.; van de Winkel, J.G.; Parren, P.W. Effector function activities of a panel of mutants of a broadly neutralizing antibody against human immunodeficiency virus type 1. J. Virol. 2001, 75, 12161–12168. [Google Scholar] [CrossRef]
- Duncan, A.R.; Winter, G. The binding site for C1q on IgG. Nature 1988, 332, 738–740. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Alegre, M.L.; Varga, S.S.; Rothermel, A.L.; Collins, A.M.; Pulito, V.L.; Hanna, L.S.; Dolan, K.P.; Parren, P.W.; Bluestone, J.A.; et al. In vitro characterization of five humanized OKT3 effector function variant antibodies. Cell Immunol. 2000, 200, 16–26. [Google Scholar] [CrossRef] [PubMed]
- Schlothauer, T.; Herter, S.; Koller, C.F.; Grau-Richards, S.; Steinhart, V.; Spick, C.; Kubbies, M.; Klein, C.; Umaña, P.; Mössner, E. Novel human IgG1 and IgG4 Fc-engineered antibodies with completely abolished immune effector functions. Protein Eng. Des. Sel. 2016, 29, 457–466. [Google Scholar] [CrossRef] [PubMed]
- Alegre, M.L.; Collins, A.M.; Pulito, V.L.; Brosius, R.A.; Olson, W.C.; Zivin, R.A.; Knowles, R.; Thistlethwaite, J.R.; Jolliffe, L.K.; Bluestone, J.A. Effect of a single amino acid mutation on the activating and immunosuppressive properties of a “humanized” OKT3 monoclonal antibody. J. Immunol. 1992, 148, 3461–3468. [Google Scholar]
- Shang, L.; Daubeuf, B.; Triantafilou, M.; Olden, R.; Dépis, F.; Raby, A.C.; Herren, S.; Dos Santos, A.; Malinge, P.; Dunn-Siegrist, I.; et al. Selective antibody intervention of Toll-like receptor 4 activation through Fc γ receptor tethering. J. Biol. Chem. 2014, 289, 15309–15318. [Google Scholar] [CrossRef]
- Vafa, O.; Gilliland, G.L.; Brezski, R.J.; Strake, B.; Wilkinson, T.; Lacy, E.R.; Scallon, B.; Teplyakov, A.; Malia, T.J.; Strohl, W.R. An engineered Fc variant of an IgG eliminates all immune effector functions via structural perturbations. Methods 2014, 65, 114–126. [Google Scholar] [CrossRef]
- Borrok, M.J.; Mody, N.; Lu, X.; Kuhn, M.L.; Wu, H.; Dall’Acqua, W.F.; Tsui, P. An “Fc-Silenced” IgG1 format with extended half-life designed for improved stability. J. Pharm. Sci. 2017, 106, 1008–1017. [Google Scholar] [CrossRef]
- Wilkinson, I.; Anderson, S.; Fry, J.; Julien, L.A.; Neville, D.; Qureshi, O.; Watts, G.; Hale, G. Fc-engineered antibodies with immune effector functions completely abolished. PLoS ONE 2021, 16, e0260954. [Google Scholar] [CrossRef]
- An, Z.; Forrest, G.; Moore, R.; Cukan, M.; Haytko, P.; Huang, L.; Vitelli, S.; Zhao, J.Z.; Lu, P.; Hua, J.; et al. IgG2m4, an engineered antibody isotype with reduced Fc function. mAbs 2009, 1, 572–579. [Google Scholar] [CrossRef]
- Rother, R.P.; Rollins, S.A.; Mojcik, C.F.; Brodsky, R.A.; Bell, L. Discovery and development of the complement inhibitor eculizumab for the treatment of paroxysmal nocturnal hemoglobinuria. Nat. Biotechnol. 2007, 25, 1256–1264. [Google Scholar] [CrossRef]
- Labrijn, A.F.; Buijsse, A.O.; van den Bremer, E.T.; Verwilligen, A.Y.; Bleeker, W.K.; Thorpe, S.J.; Killestein, J.; Polman, C.H.; Aalberse, R.C.; Schuurman, J.; et al. Therapeutic IgG4 antibodies engage in Fab-arm exchange with endogenous human IgG4 in vivo. Nat. Biotechnol. 2009, 27, 767–771. [Google Scholar] [CrossRef] [PubMed]
- Chu, S.Y.; Vostiar, I.; Karki, S.; Moore, G.L.; Lazar, G.A.; Pong, E.; Joyce, P.F.; Szymkowski, D.E.; Desjarlais, J.R. Inhibition of B cell receptor-mediated activation of primary human B cells by coengagement of CD19 and FcgammaRIIb with Fc-engineered antibodies. Mol. Immunol. 2008, 45, 3926–3933. [Google Scholar] [CrossRef] [PubMed]
- Szili, D.; Cserhalmi, M.; Bankó, Z.; Nagy, G.; Szymkowski, D.E.; Sármay, G. Suppression of innate and adaptive B cell activation pathways by antibody coengagement of FcγRIIb and CD19. mAbs 2014, 6, 991–999. [Google Scholar] [CrossRef]
- Leabman, M.K.; Meng, Y.G.; Kelley, R.F.; DeForge, L.E.; Cowan, K.J.; Iyer, S. Effects of altered FcγR binding on antibody pharmacokinetics in cynomolgus monkeys. mAbs 2013, 5, 896–903. [Google Scholar] [CrossRef] [PubMed]
- Robbie, G.J.; Criste, R.; Dall’acqua, W.F.; Jensen, K.; Patel, N.K.; Losonsky, G.A.; Griffin, M.P. A novel investigational Fc-modified humanized monoclonal antibody, motavizumab-YTE, has an extended half-life in healthy adults. Antimicrob. Agents Chemother. 2013, 57, 6147–6153. [Google Scholar] [CrossRef] [PubMed]
- Dall’Acqua, W.F.; Woods, R.M.; Ward, E.S.; Palaszynski, S.R.; Patel, N.K.; Brewah, Y.A.; Wu, H.; Kiener, P.A.; Langermann, S. Increasing the affinity of a human IgG1 for the neonatal Fc receptor: Biological consequences. J. Immunol. 2002, 169, 5171–5180. [Google Scholar] [CrossRef]
- Zalevsky, J.; Chamberlain, A.K.; Horton, H.M.; Karki, S.; Leung, I.W.; Sproule, T.J.; Lazar, G.A.; Roopenian, D.C.; Desjarlais, J.R. Enhanced antibody half-life improves in vivo activity. Nat. Biotechnol. 2010, 28, 157–159. [Google Scholar] [CrossRef]
- Hinton, P.R.; Johlfs, M.G.; Xiong, J.M.; Hanestad, K.; Ong, K.C.; Bullock, C.; Keller, S.; Tang, M.T.; Tso, J.Y.; Vásquez, M.; et al. Engineered human IgG antibodies with longer serum half-lives in primates. J. Biol. Chem. 2004, 279, 6213–6216. [Google Scholar] [CrossRef]
- Oganesyan, V.; Damschroder, M.M.; Cook, K.E.; Li, Q.; Gao, C.; Wu, H.; Dall’Acqua, W.F. Structural insights into neonatal Fc receptor-based recycling mechanisms. J. Biol. Chem. 2014, 289, 7812–7824. [Google Scholar] [CrossRef]
- Stapleton, N.M.; Andersen, J.T.; Stemerding, A.M.; Bjarnarson, S.P.; Verheul, R.C.; Gerritsen, J.; Zhao, Y.; Kleijer, M.; Sandlie, I.; de Haas, M.; et al. Competition for FcRn-mediated transport gives rise to short half-life of human IgG3 and offers therapeutic potential. Nat. Commun. 2011, 2, 599. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, Y.; Xi, G.; Zhang, F. HX008: A humanized PD-1 blocking antibody with potent antitumor activity and superior pharmacologic properties. mAbs 2020, 12, 1724751. [Google Scholar] [CrossRef] [PubMed]
- Dall’Acqua, W.F.; Kiener, P.A.; Wu, H. Properties of human IgG1s engineered for enhanced binding to the neonatal Fc receptor (FcRn). J. Biol. Chem. 2006, 281, 23514–23524. [Google Scholar] [CrossRef] [PubMed]
- Labrijn, A.F.; Rispens, T.; Meesters, J.; Rose, R.J.; den Bleker, T.H.; Loverix, S.; van den Bremer, E.T.; Neijssen, J.; Vink, T.; Lasters, I.; et al. Species-specific determinants in the IgG CH3 domain enable Fab-arm exchange by affecting the noncovalent CH3-CH3 interaction strength. J. Immunol. 2011, 187, 3238–3246. [Google Scholar] [CrossRef]
- Ridgway, J.B.; Presta, L.G.; Carter, P. ‘Knobs-into-holes’ engineering of antibody CH3 domains for heavy chain heterodimerization. Protein Eng. 1996, 9, 617–621. [Google Scholar] [CrossRef]
- Saito, S.; Namisaki, H.; Hiraishi, K.; Takahashi, N.; Iida, S. Engineering a human IgG2 antibody stable at low pH. Protein Sci. 2020, 29, 1186–1195. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IMGT Databases | IMGT Tools | IMGT Web Resources ‘The IMGT Marie-Paule Page’ | |
|---|---|---|---|
| Sequences | IMGT/LIGM-DB [24,25] IMGT/PRIMER-DB IMGT/CLL-DB | IMGT/V-QUEST [31,32,33,34,35,36] IMGT/JunctionAnalysis [37,38] IMGT/Automat [39,40] IMGT/HighV-QUEST [36,41,42,43,44,45] IMGT/StatClonotype [46,47] IMGT/PhyloGene IMGT/Allele-Align | Standardized keywords and labels [53,54] Standardized labels [55,56,57,58] IMGT Repertoire (IG and TR, MH, RPI Alignments of alleles Protein displays Tables of alleles CDR-IMGT lengths Allotypes [59,60] Isotypes, etc. |
| Genes | IMGT/GENE-DB [26] | IMGT/LIGMotif [48] IMGT/LocusView IMGT/GeneView IMGT/GeneSearch IMGT/CloneSearch IMGT/GeneInfo | Gene and allele nomenclature [1,2,3,4,5,7,8,9,10,61,62,63] Chromosomal localizations Locus representations Locus description Gene exon/intron splicing sites Gene tables Potential germline repertoires Lists of genes Correspondence between nomenclatures. |
| Structures | IMGT/2Dstructure-DB IMGT/3Dstructure-DB [27,28,29] IMGT/mAb-DB [30] | IMGT/DomainGapAlign [28,49,50] IMGT/DomainDisplay IMGT/StructuralQuery IMGT/Collier-de-Perles [51] | IMGT unique numbering per domain [64,65,66,67,68,69,70,71,72] 2D Colliers de Perles (IG and TR, MH, RPI) [51,73,74,75,76,77] IMGT classes for amino acid physicochemical properties [52] IMGT Colliers de Perles reference profiles [52] 3D representations. |
| IMGT-ONTOLOGY Axioms and Concepts | IMGT Scientific Chart Rules | |
|---|---|---|
| IDENTIFICATION [54] | Concepts of identification [53] | Standardized keywords [53,54] (e.g., clonotype, paratope, epitope, variant, Fc receptor, FcR) (1). |
| DESCRIPTION [56] | Concepts of description [55] | Standardized labels and annotations [55,56,57,58] (e.g., CDR-IMGT [57], FR-IMGT [58], antibody description [84]) |
| CLASSIFICATION [63] | Concepts of classification [62] | Reference sequences Standardized IG and TR gene nomenclature (group, subgroup, gene, allele) [1,2,3,4,5,7,8,9,10,61,62,63] (1). |
| NUMEROTATION [64] | Concepts of numerotation [65,66,67,68,69,70,71,72] | IMGT unique numbering for V- and V-LIKE domains [65,66,67] C- and C-LIKE domains [68] G- and G-LIKE domains [69] IMGT Colliers de Perles [73,74,75,76,77] |
| ORIENTATION | Concepts of orientation | Chromosome orientation Locus orientation Gene orientation DNA strand orientation Domain beta-strand orientation |
| OBTENTION | Standardized origin Standardized methodology | |
| IG Structure Labels (IMGT/3Dstructure-DB [27,28,29]) | Sequence Labels (IMGT/LIGM-DB [24,25]) | |||
|---|---|---|---|---|
| Receptor | Chain | Domain Type | Domain | Region 1 |
| IG-GAMMA-1_KAPPA | H-GAMMA-1 | V | VH | V-D-J-REGION |
| C | CH1 | C-REGION 2 | ||
| C | CH2 | |||
| C | CH3 | |||
| L-KAPPA | V | V-KAPPA | V-J-REGION | |
| C | C-KAPPA | C-REGION | ||
| C Domain Strands, Turns and Loops a | IMGT Position b | Lengths c | Characteristic IMGT Residue@Position d |
|---|---|---|---|
| A-STRAND | 1–c15 | 15 (14 if gap at 10) | |
| AB-TURN | 15.1–15.3 | 0-3 | |
| B-STRAND | 16–26 | 11 | 1st-CYS 23 |
| BC-LOOP | 27–31 34–38 | 10 (or less) | |
| C-STRAND | 39–45 | 7 | CONSERVED-TRP 41 |
| CD-STRAND | 45.1–45.9 | 0–9 | |
| D-STRAND | 77–84 | 8 (or 7 if gap at 82) | |
| DE-TURN | 84.1–84.7 85.1–85.7 | 0–14 | |
| E-STRAND | 85–96 | 12 | hydrophobic 89 |
| EF-TURN | 96.1–96.2 | 0–2 | |
| F-STRAND | 97–104 | 8 | 2nd-CYS 104 |
| FG-LOOP | 105–117 | 13 (or less, or more) | |
| G-STRAND | 118–128 | 11 (or less) |
| IMGT Engineered Fc Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes With the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | 1. Property and Function | 2. Property and Function |
|---|---|---|---|---|---|---|
| G1v1 | CH2 P1.4 | CH2 E1.4 > P (233) | E233P | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APPLLGGPS | ADCC reduction. Prevents FcγRI binding [101] | |
| G1v2 | CH2 V1.3 | CH2 L1.3 > V (234) | L234V | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEVLGGPS | ADCC reduction Decreases FcγRI binding [101] | |
| G1v3 | CH2 A1.2 | CH2 L1.2 > A (235) | L235A | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELAGGPS | ADCC reduction. Prevents FcγRI binding [101] | |
| G1v5 | CH2 W109 | CH2 K109 > W (326) | K326W | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNWA..LPAPI | ADCC reduction [102] | CDC enhancement. Increases C1q binding [102] |
| G1v47 | CH2 delG1.1 | CH2 G1.1 > del (326) | G236del | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLGPS | ADCC reduction. Eliminates binding to FcγRI, FcγRIIA, FcγRIIIA [103] | |
| G1v50 | CH2 P1.4 V1.3 A1.2 delG1.1 | CH2 E1.4 > P (233), L1.3 > V (234), L1.2 > A (235), G1.1 > del (236) | E233P, L234V, L235A, G236del | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APPVA-GPS | ADCC reduction. Decreases FcgammaR binding (G2-like motif). [Combines G1v1, v2, v3 and v47] | |
| G1v52 | CH2 R1.1, R113 | CH2 G1.1 > R (231) L113 > R (328) | G236R, L328R GRLR | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLRGPS IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..RPAPI | ADCC reduction. Abrogates FcgammaR binding | |
| G1v66 | CH2 A27 | CH2 D27 > A | D265A | IGHG1 CH2 23–31 (261–269) CVVVDVSHE > CVVVAVSHE | ADCC reduction. Reduces FcγR binding. | |
| G1v67 | CH2 S27 | CH2 D27 > S | D265S | IGHG1 CH2 23–31 (261–269) CVVVDVSHE > CVVVSVSHE | ADCC reduction. Reduces FcγR binding. |
| IMGT Engineered Fc Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | 1. Property and Function | 2. Property and Function | 3D |
|---|---|---|---|---|---|---|---|
| G1v6 | CH2 A85.4, A118, A119 | CH2 S85.4 > A(298), E118 > A (333), K119 > A (334) | S298A, E333A, K334A | IGHG1 CH2 84.1–85.1 (294–301) EQYNSTYR > EQYNATYR FG 105–117,118,119 (322–334) KVSNKA..LPAPIEK > KVSNKA..LPAPIAA | ADCC enhancement. Increases FcγRIIIa binding [104] | ||
| G1v7 | CH2 D3, E117 | CH2 S3 > D (239), I117 > E (332) | S239D, I332E DE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLGGPD FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPAPE | ADCC enhancement. Increases FcγRIIIA binding [105] | ||
| G1v8 | CH2 D3, L115, E117 | CH2 S3> D (239), A115 > L (330), I117 > E (332) | S239D, A330L, I332E DLE, 3M | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLGGPD FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPLPE | ADCC enhancement. Increases FcRIIIA binding [105] | Decreases FcγRIIB binding [105] | 3D [106] |
| G1v9 | CH2 L7, P83, L85.2, I88. CH3 L83 | CH2 F7 > L (243), R83 > P (292), Y85.2 > L (300), V88 > I (305) CH3 P83 > L (396) | F243L, R292P, Y300L, V305I, P396l LPLIL | IGHG1 CH2 6–10 (242–246) LFPPK > LLPPK 83–88 (292–305) REEQYNSTYRVVSV > PEEQYNSTLRVVSI CH3 83–84.4 (396–401) PVLDSD > IVLDSD | ADCC enhancement. 100% increase. [107] | ||
| G1v10 | CH2 Y1.3, Q1.2, W1.1, M3, D30, E34, A85.4 | CH2 L1.3 > Y (234), L1.2 > Q (235), G1.1 > W (236), S3 > M (239), H30 > D (268), D34 > E (270), S85.4 > A (298) | L234Y, L235Q, G236W, S239M, H268D, D270E, S298A | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEYQWGPM 27–31,34 (265–270) DVSHED > DVSDEE 84.1–85.1 (294–301) EQYNSTYR > EQYNATYR | ADCC enhancement. Increases FcγIIIA binding [108] >2000-fold (F158), >1000-fold (V158) in the association of G1v10 and G1v11 [108] | ||
| G1v11 | CH2 E34, D109, M115, E119 | CH2 D34 > E (270), K109 > D (326), A115 > M (330) K119 > E (334) | D270E, K326D, A330M, K334E |
IGHG1 CH2 27–31,34 (265–270) DVSHED > DVSHEE FG 105–117,118,119 (322–334) KVSNKA..LPAPIEK > KVSNDA..LPMPIEE | ADCC enhancement. Increases FcγIIIA binding [108] >2000-fold (F158), >1000-fold (V158) in the association of G1v10 and G1v11 [108] | ||
| G2v1 | CH2 L1.3, L1.2, G1.1 | CH2 V1.2 > LL(234,235) A1.1 > G(236) | V235LL, A236G | IGHG2 CH2 1.6–3 (231–239) AP.PVAGPS > APPLLGGPS | ADCC enhancement. Confers FcγRI binding (WT does not show any binding capacity) [101] | ||
| G4v1 | CH2 L1.3 | CH2 F1.3 > L (234) | F234L | IGHG4 CH2 1.6–3 (231–239) APEFLGGPS > APELLGGPS | ADCC enhancement. Increases FcγRI affinity [101] | ||
| Mus musculus G2Bv1 | CH2 L1.2 | CH2 E1.2 > L (235) | E235L | IGHG2B CH2 1.6–3 (231–239) APNLEGGPS > APNLLGGPS | ADCC enhancement. Increases FcγRI affinity [109] |
| IMGT Engineered Fc Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | 1. Property and Function | 2. Property and Function | 3D |
|---|---|---|---|---|---|---|---|
| G1v12 | CH2 A1.1, D3, L115, E117 | CH2 G1.1 > A (236), S3 > D (239), A115 > L (330), I117 > E (332) | G236A, S239D, A330L, I332E GASDALIE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLAGPD FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPLPE | ADCC enhancement. Increases FcγRIIIA binding [110] | ADCP enhancement. NK cell activation. Increases FcγRIIA binding [110] | 5d4q, 5d6d |
| G1v13 | CH2 A1.1, D3, E117 | CH2 G1.1 > A (236), S3 > D (239), I117 > E (332) | G236A, S239D, I332E GASDIE, ADE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLAGPD FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPAPE | ADCC enhancement. Increases FcγIIIA binding [111] | ADCP enhancement. NK cell activation. Increases FcγRIIA binding (70>fold)Increases FcγRIIA/FcγRIIB binding ratio (15-fold) [111] | |
| G1v45 | CH2 A1.1, L115, E117 | CH2 G1.1 > A (236), A115 > L (330), I117 > E(332) | G236A, A330L, I332E GAALIE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLAGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPLPE | ADCC enhancement Increases FcγIIIA binding | ADCP enhancement NK cell activation |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | 1. Property and Function | 2. Property and Function |
|---|---|---|---|---|---|---|
| G1v5 | CH2 W109 | CH2 K109 > W (326) | K326W | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNWA..LPAPI | CDC enhancement. Increases C1q binding [102] | ADCC reduction [102]. |
| G1v15 | CH2 S118 | CH2 E118 > S (333) | E333S | IGHG1 CH2 FG 105–117,118 (322–333) KVSNKA..LPAPIE > KVSNKA..LPAPIS | CDC enhancement. Increases C1q binding [102] | |
| G1v16 | CH2 W109, S118 | CH2 K109 > W (326), E118 > S (333) | K326W, E333S | IGHG1 CH2 FG 105–117,118 (322–333) KVSNKA..LPAPIE > KVSNWA..LPAPIS | CDC enhancement. Increases C1q binding [102] | |
| G1v17 | CH2 E29, F30, T107 | CH2 S29 > E (267), H30 > F(268), S107 > T (324) | S267E, H268F, S324T EFT | IGHG1 CH2 27–31 (265–269) DVSHE > DVEFE FG 105–117 (322–332) KVSNKA..LPAPI > KVTNKA..LPAPI | CDC enhancement Increases C1q binding [112] | |
| G1v18 | CH3 R1, G109, Y120 | CH3 E1 > R (345), E109 > G (430), S120 > Y (440) | E345R, E430G, S440Y | IGHG1 CH3 1.4–2 (341–346) GQPREP > GQPRRP 105–110 (426–431) SVMHEA > SVMHGA 118–125 (438–445) QKSLSLSP > QKYLSLSP | CDC enhancement. Increases C1q binding [113]. The triple mutant IgG1-005-RGY (IGHG1v18) form IgG1 hexamers [113] | Favors IgG1 hexamerization. |
| G1v35 | CH2 E29 | CH2 S29 > E (267) | S267E SE | IGHG1 CH2 27–31 (265–269) DVSHE > DVEHE | CDC enhancement. Increases C1q binding [112] | Binds to FCGRT and FcγRIIB, but not to other FcγR in a mouse model [114]. |
| G1G3v1 | CH2 Q38, K40, F85.2 | CH2 K38 > Q (274), N40 > K (276), Y85.2 > F (300) | K274Q, N276K, Y300F chimere G1–G3 (1) | IGHG1 CH2 34–41 (270–277) DPEVKFNW > DPEVQFKW 84.1–85.1 (294–301) EQYNSTYR > EQYNSTFR | CDC enhancement. Increases C1q binding [115]. | |
| G4v2 | CH2 P116 | CH2 S116 > P(331) | S331P | IGHG4 CH2 FG 105–117 (322–332) KVSNKG..LPSSI > KVSNKG..LPSPI | CDC enhancement [116]. (G1-, G2-, G3-like). |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v8 | CH2 D3, L115, E117 | CH2 S3 > D (239), A115 > L (330), I117 > E (332) | S239D, A330L, I332E DLE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLGGPD FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPLPE | CDC reduction. Ablates CDC [105] |
| G1v19 | CH2 A34 | CH2 D34 > A (270) | D270A | IGHG1 CH2 34–41 (270–277) DPEVKFNW > APEVKFNW | CDC reduction. Reduces C1q binding [117] |
| G1v20 | CH2 A105 | CH2 K105 > A (322) | K322A | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > AVSNKA..LPAPI | CDC reduction. Reduces C1q binding [117,118] |
| Mus musculus G2Bv2 | CH2 A101 | CH2 E101 > A(318) | E318A (2) | IGHG2B CH2 100–110 KEFKCKVNNKD > KAFKCKVNNKD | CDC reduction. Reduces C1q binding [119] |
| Mus musculus G2Bv3 | CH2 A103 | CH2 K103 > A(320) | K320A (2) | IGHG2B CH2 100–110 KEFKCKVNNKD > KEFACKVNNKD | CDC reduction. Reduces C1q binding [119] |
| Mus musculus G2Bv4 | CH2 A105 | CH2 K105 > A(322) | K322A (2) | IGHG2B CH2 100–110 KEFKCKVNNKD > KEFKCAVNNKD | CDC reduction. Reduces C1q binding [119] |
| IMGT Engineered Fc Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | 1. Property and Function | 2. Property and Function | 3. 3D and Property and Function |
|---|---|---|---|---|---|---|---|
| G1v4 | CH2 A114 | CH2 P114 > A (329) | P329A) | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LAAPI | ADCC reduction. Reduces FcγR binding [117] | CDC reduction. Reduces C1q binding [117] | |
| G1v14 | CH2 A1.3, A1.2 | CH2 L1.3 > A (234), L1.2 > A (235) | L234A, L235A LALA | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGGPS | ADCC reduction. Reduces FcγR binding [118,120] | CDC reduction. Reduces C1q binding [118,120] | |
| G1v14-1 | CH2 A1.3, A1.2, A1 | CH2 L1.3 > A (234), L1.2 > A (235), G1 > A (237) | L234A, L235A, G237A | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGAPS | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v14-4 | CH2 A1.3, A1.2, A114 | CH2 L1.3 > A (234), L1.2 > A (235), P114 > A (329) | L234A, L235A, P329A | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LAAPI | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v14-48 | CH2 A1.3, A1.2, R113 | CH2 L1.3 > A (234), L1.2 > A (235), L113 > R (328) | L234A, L235A, L328R | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..RPAPI | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v14-49 | CH2 A1.3, A1.2, G114 | CH2 L1.3 > A (234), L1.2 > A (235), P114 > G (329) | L234A, L235A, P329G LALAPG | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LGAPI | ADCC reduction. Reduces FcγR binding [121] | CDC reduction. Reduces C1q binding [121] | |
| G1v14-67 | CH2 A1.3, A1.2, S27 | CH2 L1.3 > A (234), L1.2 > A(235), D27 > S (265) | L234A, L235A, D265S | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGGPS 23–31 (261–269) CVVVDVSHE > CVVVSVSHE | ADCC reduction. Reduces FcγR binding [121]. | CDC reduction. Reduces C1q binding [121]. | Combines Homsap G1v14 and G1v67 (G1 CH2 S27). |
| G1v23 | CH2 E1.2 | CH2 L1.2 > E(235) | L235E | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELEGGPS | ADCC reduction. Reduces FcγR binding [122] | CDC reduction. Reduces C1q binding [122] | |
| G1v38 | CH2 S108, F113 | CH2 N108 > S (325), L113 > F (328) | N325S, L328F | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSSKA..FPAPI | ADCC reduction. Abrogates FcγRIII binding, increases FcγRII binding, retains FcγRI high affinity binding [123] | CDC reduction. Abrogates C1q binding. | |
| G1v39 | CH2 F1.3, E1.2, S116 | CH2 L1.3 > F (234), L1.2 > E (235), P116 > S (331) | L234F, L235E, P331S FES, TM | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEFEGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPASI | ADCC reduction Reduces FcγR effector properties [124] (2) | CDC reduction. Reduces C1q binding [122] | 3D 3c2s |
| G1v40 | CH2 A1.3, A1.2, S116 | CH2 L1.3 > A (234), L1.2 > A (235), P116 > S (331) | L234A, L235A, P331S | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAAGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LPASI | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v41 | CH2 F1.3, E1.2 | CH2 L1.3 > F (234), L1.2 > E (235) | L234F, L235E FE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEFEGGPS | ADCC reduction. Reduces FcγR binding [124] | CDC reduction. Reduces C1q binding [122] | |
| G1v43 | CH2 A1.3, E1.2, A1 | CH2 L1.3 > A (234), L1.2 > E (235), G1 > A (237) | L234A, L235E, G237A | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEAEGAPS | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding | |
| G1v48 | CH2 R113 | CH2 L113 > R (328) | L328R | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..RPAPI | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding | |
| G1v49 | CH2 G114 | CH2 P114 > G (329) | P329G | IGHG1 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LGAPI | ADCC reduction. Reduces FcγR binding [121] | CDC reduction. Reduces C1q binding [121] | |
| G1v51 | CH2 K29 | CH2 S29 > K (267) | S267K | IGHG1 CH2 27–31 (265–269) DVSHE > DVKHE | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding | |
| G1v53 | CH2 F1.3, Q1.2, Q105 | CH2 L1.3 > F (234) L1.2 > Q (235) K105 > Q (322) | L234F, L235Q, K322Q, FQQ | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEFQGGPS FG 105–117 (322–332) KVSNKA..LPAPI > QVSNKA..LPAPI | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding | |
| G1v53, G1v21 | CH2 F1.3, Q1.2, Q105 Y15.1, T16, E18 | CH2 L1.3 > F (234), L1.2 > Q (235), K105 > Q (322) M15.1 > Y (252), S16 > T (254), T18 > E (256) | L234F, L235Q, K322Q, M252Y, S254T, T256E FQQ–YTE | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APEFQGGPS 15–18 (251–256) LMI.SRT > LYITRE FG 105–117 (322–332) KVSNKA..LPAPI > QVSNKA..LPAPI | ADCC reduction. Reduces FcγR binding [125] (G1v53) | CDC reduction. Reduces C1q binding [125] (G1v53) | Extends half-life [125] (G1v21). |
| G1v59 | CH2 S1.3 T1.2 R1.1 | CH2 L1.3 > S(234) L1.2 > T (235) G1.1 > R (236) | L234S L235T G236R | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APESTRGPS | ADCC undetectable. Abrogates FcγR binding [126] | CDC undetectable. Abrogates C1q binding [126] | |
| G1v60 | CH2 S115, S116 | CH2 A115 > S(330) P116 > S (331) | A330S P331S | FG 105–117 (322–332) KVSNKA..LPAPI > QVSNKA..LPSSI | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v63 | CH2 S2 | CH2 P2 > S | P238S | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLGGSS | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v65 | CH2 delE1.4, delL1.3, delL1.2 | CH2 E1.4 > del, L1.3 > del, L1.2 > del | E233del, L234del, L235del | IGHG1 CH2 1.6–3 (231–239) APELLGGPS > AP- - -GGPS | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | |
| G1v70 | h S5, S11, S14, CH2 S2 | h C5 > S(220), C11 > S (226) C14 > S(226) CH2 P2 > S | C220S C226S C229S P238S | IGHG1 h 1–15 (216–230) EPKSCDKTHTCPPCP > EPKSSDKTHTSPPSP IGHG1 CH2 1.6–3 (231–239) APELLGGPS > APELLGGSS | ADCC reduction. Reduces FcγR binding. | CDC reduction. Reduces C1q binding. | Combines G1v63 with G1v37 (no H-L), G1v61 (no H-H h11) and G1v62 (no H-H h14). |
| G2v2 | CH2 Q30, L92, S115, S116 | CH2 H30 > Q(268), V92 > L(309), A115 > S(330), P116 > S(331) | H268Q, V309L, A330S, P331S IgG2m4 | IGHG2 CH2 27–38 (265–274) DVSHEDPEVQ > DVSQEDPEVQ 89–96 (306–313) LTVVHQDW > LTVLHQDW FG 105–117 (322–332) KVSNKG..LPAPI > KVSNKA..LPSSI | ADCC reduction. Reduces FcγR binding [127] | CDC reduction. Reduces C1q binding [127] | |
| G2v3 | CH2 A1.2, A1, S2, A30, L92, S115, S116 | CH2 V1.2 > A (235), G1 > A (237), P2 > S(238), H30 > A(268), V92 > L(309), A115 > S(330), P116 > S(331) | V235A, G237A, P238S, H268A, V309L, A330S, P331S G2sigma | IGHG2 CH2 1.6–3 (231–239) AP.PVAGPS > AP.PAAASS 27–38 (265–274) DVSHEDPEVQ > DVSAEDPEVQ 89–96 (306–313) LTVVHQDW > LTVLHQDW FG 105–117 (322–332) KVSNKG..LPAPI > KVSNKA..LPSSI | ADCC reduction. Reduces FcγR binding [124]. Undetectable ADCC andV1 ADCP [124] | CDC reduction. Reduces C1q binding [124]. Undetectable CDC [124] | |
| G2G4v1 (1) | CH2 E1.4 > del P1.3, V1.2, A1.1 | CH2 E1.4 > del(233), F1.3 > P(234), L1.2 > V(235), G1.1 > A(236) | E233del, F234P, L235V, G236A | IGHG4 CH2 1.6–3 (231–239) APEFLGGPS > AP.PVAGPS | ADCC reduction. Reduces FcγR binding [128] | CDC reduction. Reduces C1q binding [128] | |
| G4v3 | CH2 E1.2 |
CH2 L1.2 > E(235) | L235E LE | IGHG4 CH2 1.6–3 (231–239) APEFLGGPS > APEFEGGPS | ADCC reduction. Reduces FcγR binding [122] | CDC reduction. Reduces C1q binding [122] | |
| G4v3 G4v5 | h P10, CH2 E1.2 |
h S10 > P(228) CH2 L1.2 > E(235) | S228P, L235E SPLE | IGHG4 h 1–12 (216–230) ESKYGPPCPSCP > ESKYGPPCPPCP CH2 1.6–3 (231–239) APEFLGGPS > APEFEGGPS | ADCC reduction. Reduces FcγR binding [122] (G4v3) | CDC reduction. Reduces C1q binding [122] (G4v3) | Prevents IgG4 half-IG exchange [129] (G4v5) |
| G4v3-49 | CH2 E1.2 G114 | CH2 L1.2 > E(235) P114 > G (329) | L235E P329G LEPG | IGHG4 CH2 1.6–3 (231–239) APEFLGGPS > APEFEGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LGAPI | ADCC reduction. Reduces FcγR binding [121] | CDC reduction. Reduces C1q binding [121] | |
| G4v3-49 G4v5 | h P10, CH2 E1.2 G114 | h S10 > P(228) CH2 L1.2 > E(235) P114 > G (329) | S228P, L235E P329G SPLEPG | IGHG4 h 1–12 (216–230) ESKYGPPCPSCP ESKYGPPCPPCP CH2 1.6–3 (231–239) APEFLGGPS > APEFEGGPS FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LGAPI | ADCC reduction. Reduces FcγR binding [121] (G4v3-49) | CDC reduction. Reduces C1q binding [121] (G4v3-49) | Prevents IgG4 half-IG exchange [129] (G4v5). |
| G4v4 | CH2 A1.3, A1.2 |
CH2 F1.3 > A (234), L1.2 > A (235) | F234A L235A FALA | IGHG4 CH2 1.6–3 (231–239) APEFLGGPS > APEAAGGPS | ADCC reduction. Reduces FcγR binding [120]. | CDC reduction. Reduces C1q binding [120]. | |
| G4v4 G4v5 | h P10, CH2 A1.3, A1.2 | h S10 > P(228) CH2 F1.3 > A (234) L1.2 > A (235) | S228P, F234A, L235A IgG4 ProAlaAla | IGHG4 h 1–12 (216–230) ESKYGPPCPSCP > ESKYGPPCPPCP CH2 1.6–3 (231–239) APEFLGGPS > APEAAGGPS | ADCC reduction. Reduces FcγR binding [124] (G4v4) | CDC reduction. Reduces C1q binding [120] (G4v4) | Prevents IgG4 half-IG exchange [129] (G4v5). |
| G4v7 | CH2 delE1.4, P1.3, V1.2, A1.1 | CH2 E1.4 > del (233) F1.3 > P (234), L1.2 > V (235), G1.1 > A (236), | E233del, F234P, L235V, G236A | IGHG4 CH2 1.6–3 (231–239) APEFLGGPS> AP-PVAGPS (G2-like) | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding | |
| G4v49 | CH2 G114 | CH2 P114 > G (329) | P329G | IGHG4 CH2 FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..LGAPI | ADCC reduction. Reduces FcγR binding [121] | CDC reduction. Reduces C1q binding [121] | |
| Canis lupus familiaris G2v1 | CH2 A1.3, A1.2, A1 | CH2 M1.3 > A (234), L1.2 > A (235), G1 > A (237). | M234A, L235A, G237A | IGHG2 CH2 1.6–3 (231–239) APEMLGGPS > APEAAGAPS | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding | |
| Canis lupus familiaris G2v2 | CH2 A1.3, A1.2, G114 | CH2 M1.3 > A (234), L1.2 > A(235) P114 > G(329) | M234A, L235A, P329G | IGHG2 CH2 1.6–3 (231–239) APEMLGGPS > APEAAGGPS IGHG1 CH2 FG 105–117 (322–332) KVNNKA..LPSPI > KVNNKA..LGSPI | ADCC reduction. Reduces FcγR binding | CDC reduction. Reduces C1q binding |
| IMGT Engineered Fc Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v25 | CH2 E29, F113 | CH2 S29 > E (267), L113 > F (328) | S267E, L328F | IGHG1 CH2 27–31 (265–269) DVSHE > DVEHE FG 105–117 (322–332) KVSNKA..LPAPI > KVSNKA..FPAPI | Increases FcγRIIB binding (400-fold) [130] Inhibits by downstream ITIM signaling in B cells [131] |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v29 | CH2 A84.4 | CH2 N84.4 > A (297) | N297A | IGHG1 CH2 83–86 REEQYNSTYRVV > REEQYASTYRVV | ADCC reduction. Reduces FcγR binding [132] |
| G1v30 | CH2 G84.4 | CH2 N84.4 > G(297) | N297G | IGHG1 CH2 83–86 REEQYNSTYRVV > REEQYGSTYRVV | ADCC reduction. Reduces FcγR binding [132] |
| G1v36 | CH2 Q84.4 | CH2 N84.4 > Q (297) | N297Q | IGHG1 CH2 83–86 REEQYNSTYRVV > REEQYQSTYRVV | ADCC reduction. Reduces FcγR binding |
| G4v36 | CH2 Q84.4 | CH2 N84.4 > Q (297) | N297Q | IGHG4 CH2 83–86 REEQFNSTYRVV > REEQFQSTYRVV | ADCC reduction. Reduces FcγR binding |
| Canis lupus familiaris G2v29 | CH2 A84.4 | CH2 N84.4 > A (297) | N297A | IGHG1 CH2 83–86 REEQFNGTYRVV > REEQFAGTYRVV | ADCC reduction. Reduces FcγR binding |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v21 | CH2 Y15.1, T16, E18 | CH2 M15.1 > Y (252), S16 > T (254), T18 > E (256) | M252Y, S254T, T256E YTE | IGHG1 CH2 13–18 (249–256) DTLMISRT > DTLYITRE | Half-life increase Enhances FCGRT binding at pH 6.0 [133,134] (1) |
| G1v22 | CH2 Y15.1, T16, E18, CH3 K113, F114, H116 | CH2 M15.1 > Y (252) S16 > T (254) T18 > E (256) CH3 H113 > K (433) N114 > F (434) Y116 > H (436) | M252Y S254T T256E H433K N434F Y436H | IGHG1 CH2 13–18 (249–256) DTLMISRT > DTLYITRE CH3 FG 105–117 (426–437) SVMHEA.LHNHYT > SVMHEA.LKFHHT | Half-life increase Enhances FCGRT binding at pH 6.0 [134] |
| G1v24 | CH3 L107, S114 | CH3 M107 > L (428), N114 > S (434) | M428L, N434S | GHG1 CH3- FG 105–117 (426–437) SVMHEA.LHNHYT > SVLHEA.LHSHYT | Half-life increase Enhances FCGRT binding at pH 6.0 (11-fold increase in affinity) [135] (2) |
| G1v42 | CH2 Q14, CH3 L107 | CH2 T14 > Q (250) CH3 M107 > L (428) | T250Q M428L | IGHG1 CH2 13–18 (249–256) DTLMISRT > DQLMISRT CH3- FG 105–117 (426–437) SVMHEA.LHNHYT > SVLHEA.LHNHYT | Half-life increase Enhances FCGRT binding at pH 6.0 [134] |
| G1v46 | CH3 K113, F114 | CH3 H113 > K (433), N114 > F(434) | H433K, N434F | IGHG1 CH3- FG 105–117 (426–437) SVMHEA.LHNHYT > SVMHEA.LKFHYT | Half-life increase Enhances FCGRT binding at pH 6.0. |
| G2v4 | CH2 Q14 | CH2 T14 > Q (250) | T250Q | IGHG2 CH2 13–18 (249–256) DTLMISRT > DQLMISRT | Half-life increase Enhances FCGRT binding at pH 6.0 [136] |
| G2v5 | CH3 L107 | CH3 M107 > L (428) | M428L | IGHG2 CH3 FG 105–117 (426–437) SVMHEA.LHNHYT > SVLHEA.LHNHYT | Half-life increase Enhances FCGRT binding at pH 6.0 [136] |
| G2v6 | CH2 Q14, CH3 L107 | CH2 T14 > Q (250) CH3 M107 > L(428) | T250Q M428L | IGHG2 CH2 13–18 (249–256) DTLMISRT > DQLMISRT CH3 FG 105–117 (426–437) SVMHEA.LHNHYT > SVLHEA.LHNHYT | Half-life increase Enhances FCGRT binding at pH 6.0 [136] |
| G2v8-1 | CH2 A93 | CH2 H93 > A (310) | H310A | IGHG2 CH2 89–96 (306–313) LTVVHQDW > LTVVAQDW | Abrogates FCGRT binding at pH 6.0 (G2v8 any amino acid replacement of H93 except cystein) [137]. Number 1 of G2v8-1 is for A |
| G3v1 | CH3 H115 | CH3 R115 > H(435) | R435H | IGHG3 CH3 FG 105–117 (426–437) SVMHEA.LHNRFT > SVMHEA.LHNHFT | Half-life increase Extends half-life [138] |
| G4v21 | CH2 Y15.1, T16, E18 | CH2 M15.1 > Y (252), S16 > T (254), T18 > E (256) | M252Y, S254T, T256E YTE | IGHG4 CH2 13–18 (249–256) DTLMISRT > DTLYITRE | Half-life increase Enhances FCGRT binding at pH 6.0 [134] |
| G4v22 | CH2 T16, P91, CH3 A114 | CH2 S16 > T(254), V91 > P (308) CH3 N114 > A (434) | S254T, V308P N434A | IGHG4 CH2 13–18 (249–256) DTLMISRT > DTLYITRE CH3 FG 105–117 (426–437) SVMHEA.LHNHYT > SVMHEA.LHAHYT | Half-life increase Enhances FCGRT binding at pH 6.0 [139] |
| G4v24 | CH3 L107 S114 | CH3 M107 > L (428) N114 > S(434) | M428L, N434A | CH3 FG 105–117 (426–437) SVMHEA.LHNHYT > SVLHEA.LHSHYT | Half-life increase Enhances FCGRT binding at pH 6.0 |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino acid changes on IGHG CH domain (Eu numbering between parentheses) | Amino acid changes with the Eu positions | Motif identifiable in gene and domain with positions according to the IMGT unique numbering and with Eu positions between parentheses | Property and function |
|---|---|---|---|---|---|
| G4v8 | CH3 R115, F116, P125 | CH3 H115 > R (435), Y116 > F (436), L125 > P (445) | H435R, Y436F, L445P | IGHG4 CH3- FG 105–117 (426–437) SVMHEA.LHNHYT > SVMHEA.LHNRFT 118–125 (438–445) QKSLSLSL > QKSLSLSP | Abrogates binding to Protein A |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v54 | CH2 C83, C85 | CH2 R83 > C (292), V85 > C (302) | R292C, V302C | IGHG1 CH2 83–86 REEQYNSTYRVV > CEEQYASTYRCV (v29) CEEQYGSTYRCV (v30) CEEQYQSTYRCV (v36) | Stabilizes CH2 in the absence of N84.4 (297) glycosylation |
| G1v54-29 | CH2 C83, A84.4, C85 | CH2 R83 > C (292), N84.4 > A(297) V85 > C (302) | R292C, N297A V302C | IGHG1 CH2 83–86 REEQYNSTYRVV > CEEQYASTYRCV | Stabilizes CH2 in the absence of N84.4 (297) glycosylation |
| G1v54-30 | CH2 C83, G84.4, C85 | CH2 R83 > C (292), N84.4 > G (297) V85 > C (302) | R292C, N297G V302C | IGHG1 CH2 83–86 REEQYNSTYRVV > CEEQYGSTYRCV | Stabilizes CH2 in the absence of N84.4 (297) glycosylation |
| G1v54-36 | CH2 C83, Q84.4, C85 | CH2 R83 > C (292), N84.4 > Q (297) V85 > C (302) | R292C, N297Q V302C | IGHG1 CH2 83–86 REEQYNSTYRVV > CEEQYQSTYRCV | Stabilizes CH2 in the absence of N84.4 (297) glycosylation |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G4v5 | h P10 | h S10 > P(228) | S228P | IGHG4 h 1–12 (216–230) ESKYGPPCPSCP > ESKYGPPCPPCP (G1-like) | Prevents in vivo and in vitro IgG4 half-IG exchange [129] |
| G4v6 | CH3 K88 | CH3 R88 > K | R409K | IGHG1 CH3 85.4–89 (404–410) GSFFLYSRL > GSFFLYSKL | Reduces IgG4 half-IG exchange [141] |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v34 | CH3 G109 | CH3 E109 > G (430) | E430G | IGHG1 CH3- FG 105–117 (426–437) SVMHEA.LHNHYT > SVMHGA.LHNHYT | Favors IgG1 hexamerisation by increased intermolecular Fc-Fc interactions after antigen binding on the cell surface |
| IMGT Engineered Variant Name | IMGT Engineered Variant Definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | Property and Function |
|---|---|---|---|---|---|
| G1v26 | CH3 Y22 | CH3 T22 > Y (366) | T366Y | IGHG1 CH3 20–26 (364–370) SLTCLVK > SLYCLVK | Knob of knobs-into-holes G1v26 knob/G1v31 hole interactions between the CH3 of the two different gamma1 chains [142] |
| G1v31 | CH3 T86 | CH3 Y86 > T (407) | Y407T | IGHG1 CH3 85.4–89 (404–410) GSFFLYSKL > GSFFLTSKL | Hole of knobs-into-holes G1v26 knob/G1v31 hole interactions between the CH3 of the two different gamma1 chains [142] (G1v26 knob/G1v31 hole) |
| G1v32 | CH3 W22 | CH3 T22 > W (366) | T366W | IGHG1 CH3 20–26 (364–370) SLTCLVK > SLWCLVK | Knob of knobs-into-holes G1v32 knob/G1v33 hole interactions between the CH3 of the two different gamma1 chains |
| G1v33 | CH3 S22, A24, V86 | CH3 T22 > S (366), L24 > A (368), Y86 > V(407) | T366S, L368A, Y407V | IGHG1 CH3 20–26 (364–370) SLTCLVK > SLSCAVK 85.4–89 (404–410) GSFFLYSKL> GSFFLVSKL | Hole of knobs-into-holes G1v32 knob/G1v33 hole interactions between the CH3 of the two different gamma1 chains |
| G1v68 | CH3 V6, L22, L79, W81 | CH3 T6 > V (350) T22 > L (366) K79 > L (392) T81 > W (394) | T350V T366L K392L T394W | IGHG1 CH3 3–9 (347–353) QVYTLPP > QVYVLPP 20–26 (364–370) SLTCLVK > SLLCLVK 77–83 (390–396) NYKTTPP > NYLTWPP | Enhances, with G1v69, the heteropairing H-H of bispecific antibodies |
| G1v69 | CH3 V6, Y7, A85.1, V86 | CH3 T6 > V (350) L7 > Y (351) F85.1 > A (405) Y86 > V (407) | T350V L351Y F405A Y407V | IGHG1 CH3 3–9 (347–353) QVYTLPP > QVYVYPP IGHG1 CH3 85.4–89 (404–410) GSFFLYSKL > GSFALVSKL | Enhances, with G1v68, the heteropairing H-H of bispecific antibodies |
| IMGT Variant Name | IMGT Variant Description | IMGT Amino Acid Changes on IGHG CH Domain with Eu Numbering between Parentheses | Eu Numbering Variant | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering | Property and Function |
|---|---|---|---|---|---|
| G1v37 | h S5 | h C5 > S (220) | C220S | IGHG1 h 1–15 (216–230) EPKSCDKTHTCPPCP > EPKSSDKTHTCPPCP | No disulfide bridge inter H-L |
| G1v61 | h S11 | h C11 > S (226) | C226S | IGHG1 h 1–15 (216–230) EPKSCDKTHTCPPCP > EPKSCDKTHTSPPCP | No disulfide bridge inter H-H h 11 |
| G1v62 | h S14 | h C14 > S (229) | C229S | IGHG1 h 1–15 (216–230) EPKSCDKTHTCPPCP > EPKSCDKTHTCPPSP | No disulfide bridge inter H-H h 14 |
| IMGT Variant Name | IMGT Variant Description | IMGT Amino Acid Changes on IGHG CH Domain with Eu Numbering between Parentheses | Eu Numbering Variant | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering | Property and Function |
|---|---|---|---|---|---|
| G1v27 | CH2 C3 | CH2 S3 > C(329) | S239C | IGHG1 CH2 1.6–4 (231–240) APELLGGPSV > APELLGGPCV | Site-specific drug attachment engineered cysteine |
| G1v28 | CH2 C(3^4) | CH2 (3^4)C(239^240) | C(239^240) | IGHG1 CH2 1.6–4 (231–240) APELLGGPSV > APELLGGPSCV | Site-specific drug attachment engineered cysteine |
| G1v44 | CH3 C122 | CH3 S122 > C (442) | S442C | IGHG1 CH3 118–125 (438–445) QKSLSLSP > QKSLCLSP | Site-specific drug attachment engineered cysteine |
| G1v55 | CH3 C123 | CH3 L123 > C (443) | L443C | IGHG1 CH3 118–125 (438–445) QKSLSLSP > QKSLSCSP | Site-specific drug attachment engineered cysteine |
| G1v56 | CH2 F85.2 CH3 F85.2 | CH2 Y85.2 > F (pAMF) CH3 F85.2 > F (pAMF) | Y300F F404F | IGHG1 CH2 84.1–85.1 (294–301) EQYNSTYR > EQYNSTFR CH3 84.1–85.1 (398–405) LDSDGSFF LDSDGSFF | Modified phenylalanine for conjugation (produced in Escherichia coli, non glycosylated) |
| G1v64 | CH2 C36 | CH2 E36 > C | E272C | IGHG1 CH2 34–41 (270–277) DPEVKFNW > DPCVKFNW | Conjugation site-specific engineered cysteine |
| IMGT Variant Name | IMGT Variant Description | IMGT Amino Acid Changes on IGHG CH Domain with Eu Numbering between Parentheses | Eu Numbering Variant | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering | Property and Function |
|---|---|---|---|---|---|
| G1v57 | CH1 E26, E119 | CH1 K26 > E (147), K119 > E(213) | K147E, K213E | IGHG1 CH1 23–26 (144–147) CLVK > CLVE 118–121 (212–215) DKKV > DEKV | Enhances, with KCv57, the hetero pairing H-L of bispecific antibodies |
| KCv57 | IGKC R12, K13 | IGKC E12 > R, Q13 > K | E123R, Q124K | IGKC 10–15 (121–126) SDEQLK > SDRKLK | Enhances, with G1v57, the hetero pairing H-L of bispecific antibodies |
| G1v58 | CH1 C5, h V5 | CH1 F5 > C (126), h C5 > V (220) | F126C, C220V | IGHG1 CH1 1.4–15 (118–136) ASTKGPSVFPLAPSSKSTS > ASTKGPSVCPLAPSSKSTS IGHG1 h 1–15 (216–230) EPKSCDKTHTCPPCP > EPKSVDKTHTCPPCP | Alternative interchain cysteine mutations to enhance, with LC2v58, heteropairing of bispecific antibodies |
| LC2v58 | LC2 C10, V126 | IGLC S10 > C (121), C126 > V (214) | S121C, C214V | IGLC2 1.5–15 (107A–126) GQPKAAPSVTLFPPSSEELQ > GQPKAAPSVTLFPPCSEELQ IGLC2 118–127 (206–215) EKTVAPTECS > EKTVAPTEVS | Alternative interchain cysteine mutations to enhance, with G1v58, heteropairing of bispecific antibodies |
| IMGT Variant Name | IMGT Variant Description | IMGT Amino Acid Changes on IGHG CH Domain with Eu Numbering between Parentheses | Eu Numbering Variant | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering | Property and Function |
|---|---|---|---|---|---|
| G4v10 | CH3 L85.1, K88 | CH3 F85.1 > L(405), R88 > K (409) | F405L, R409K | IGHG1 CH3 85.4–92 (402–413) GSFFLYSRLTVD > GSFLLYSKLTVD | Control of half-IG exchange of bispecific IgG4 |
| IMGT Engineered Fc Variant Name | IMGT Engineered Variant definition | IMGT Amino Acid Changes on IGHG CH Domain (Eu Numbering between Parentheses) | Amino Acid Changes with the Eu Positions | Motif Identifiable in Gene and Domain with Positions According to the IMGT Unique Numbering and with Eu Positions between Parentheses | 1. Property and Function | 2. Property and Function | 3. Property and Function |
|---|---|---|---|---|---|---|---|
| G2v7 | CH2 Y85.2, L92, A339 | CH2 F85.2 > Y(300) V92 > L(309) T339 > A(339) | F300Y V309L T339A | IGHG2 CH2 85.4–92 (300–309) STFRVVSVLTVV > STYRVVSVLTVL 118–125 (333–340) EKTISKTK > EKTISKAK | Reduces acid-induced aggregation [143] | Low ADCC Low FcγR binding [143] | Low CDC Low C1q binding [143] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lefranc, M.-P.; Lefranc, G. IMGT® Nomenclature of Engineered IGHG Variants Involved in Antibody Effector Properties and Formats. Antibodies 2022, 11, 65. https://doi.org/10.3390/antib11040065
Lefranc M-P, Lefranc G. IMGT® Nomenclature of Engineered IGHG Variants Involved in Antibody Effector Properties and Formats. Antibodies. 2022; 11(4):65. https://doi.org/10.3390/antib11040065
Chicago/Turabian StyleLefranc, Marie-Paule, and Gérard Lefranc. 2022. "IMGT® Nomenclature of Engineered IGHG Variants Involved in Antibody Effector Properties and Formats" Antibodies 11, no. 4: 65. https://doi.org/10.3390/antib11040065
APA StyleLefranc, M.-P., & Lefranc, G. (2022). IMGT® Nomenclature of Engineered IGHG Variants Involved in Antibody Effector Properties and Formats. Antibodies, 11(4), 65. https://doi.org/10.3390/antib11040065