Improving Object-Based Land Use/Cover Classification from Medium Resolution Imagery by Markov Chain Geostatistical Post-Classification



Abstract
1. Introduction
2. Materials
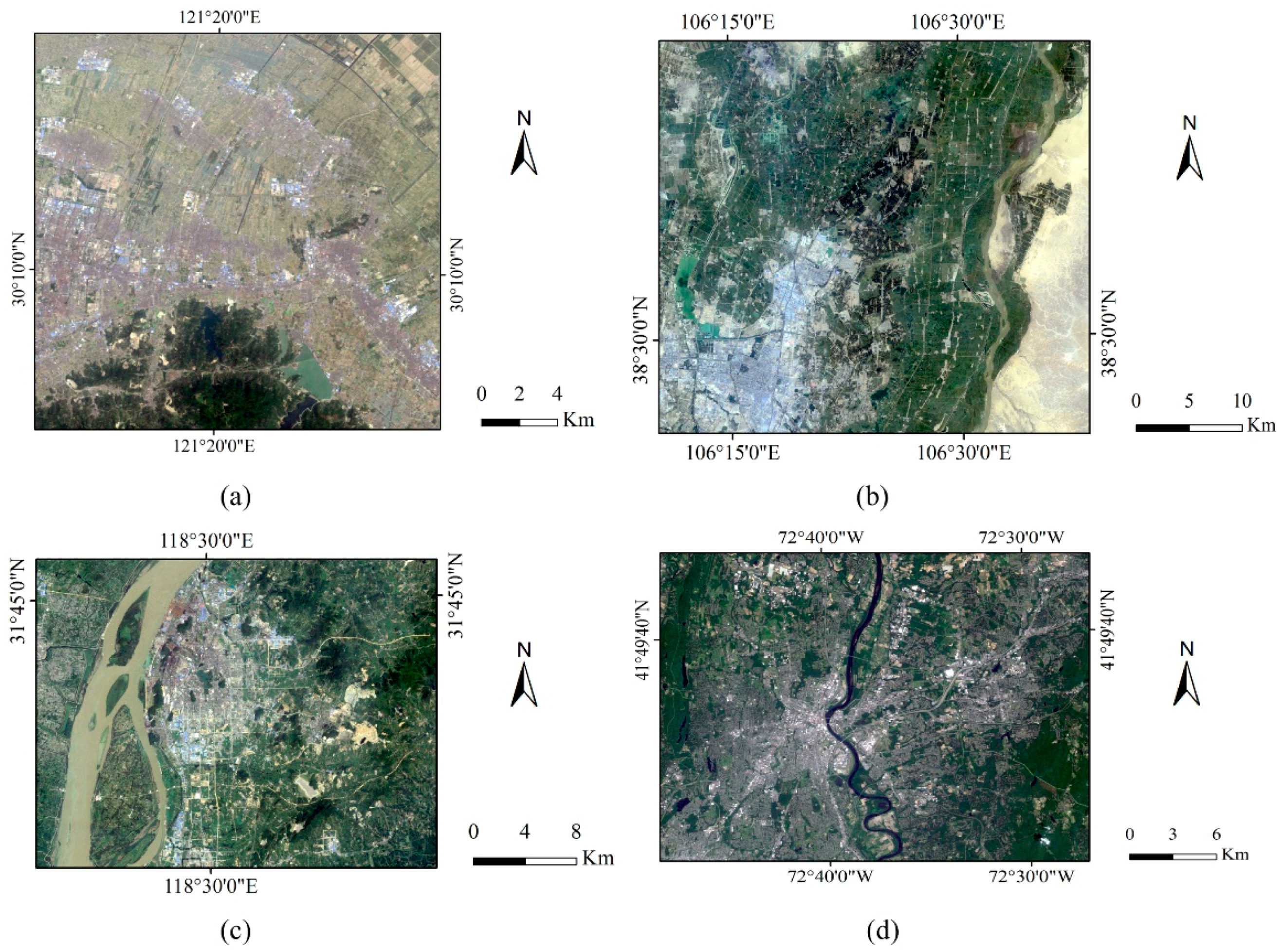
2.1. Remote Sensing Data
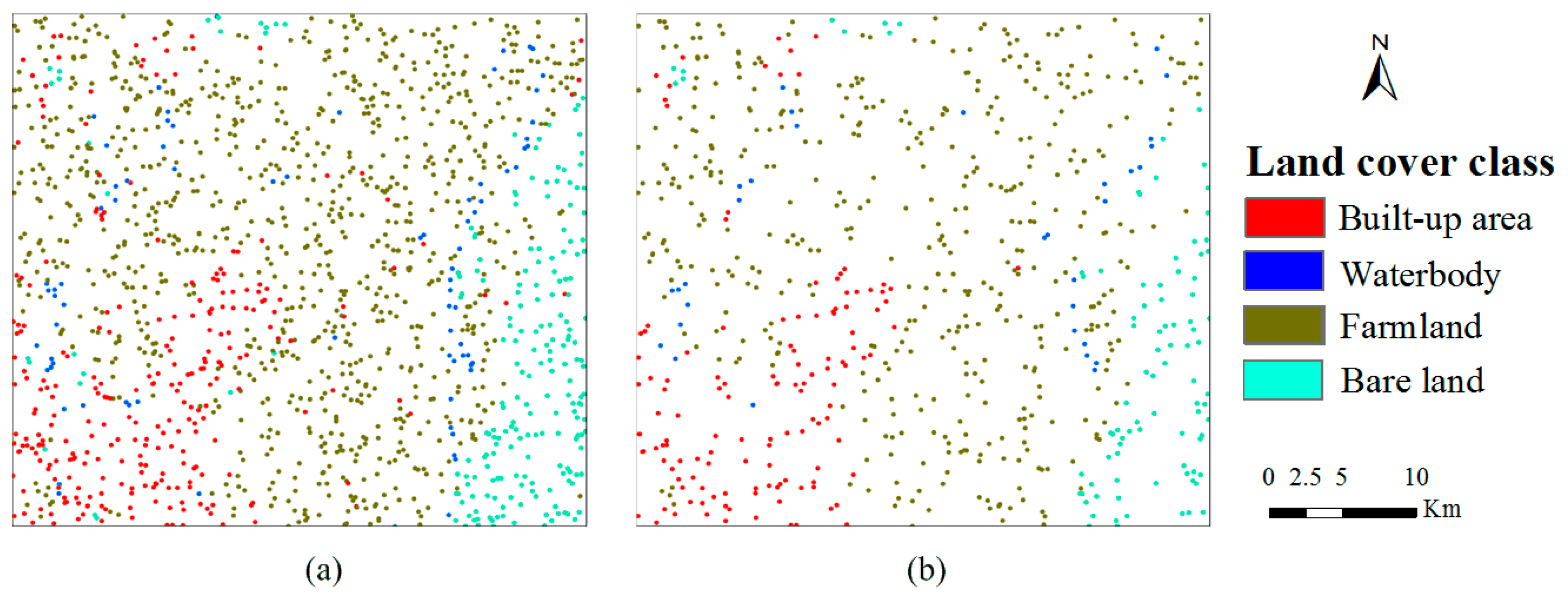
2.2. Expert-Interpreted Data
3. Methodology
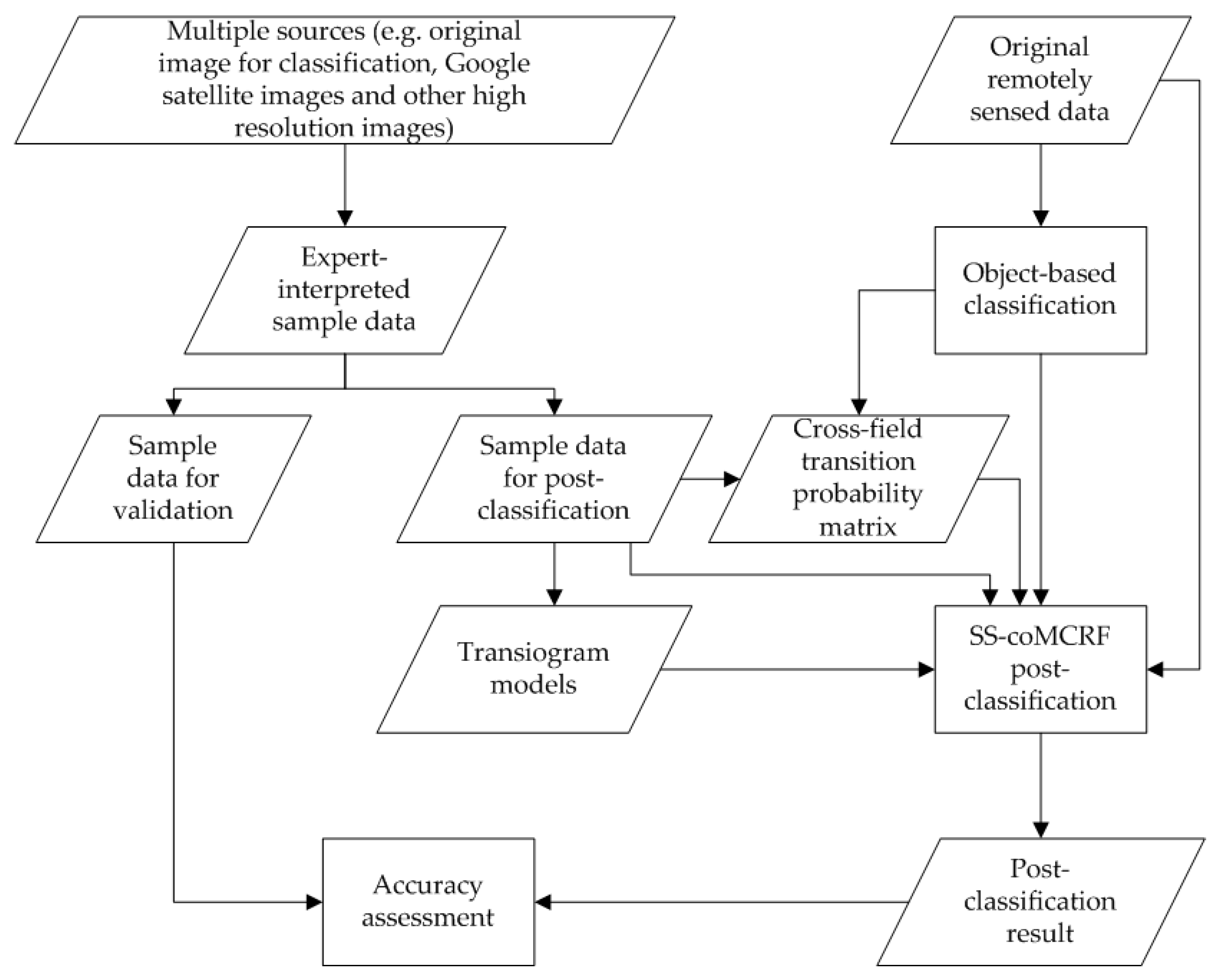
3.1. General Procedure
3.2. Spectral Similarity-Enhanced MCRF Co-Simulation Model
3.3. Inputs and Outputs for the SS-coMCRF Model
3.4. Object-Based Classification
4. Results and Discussions
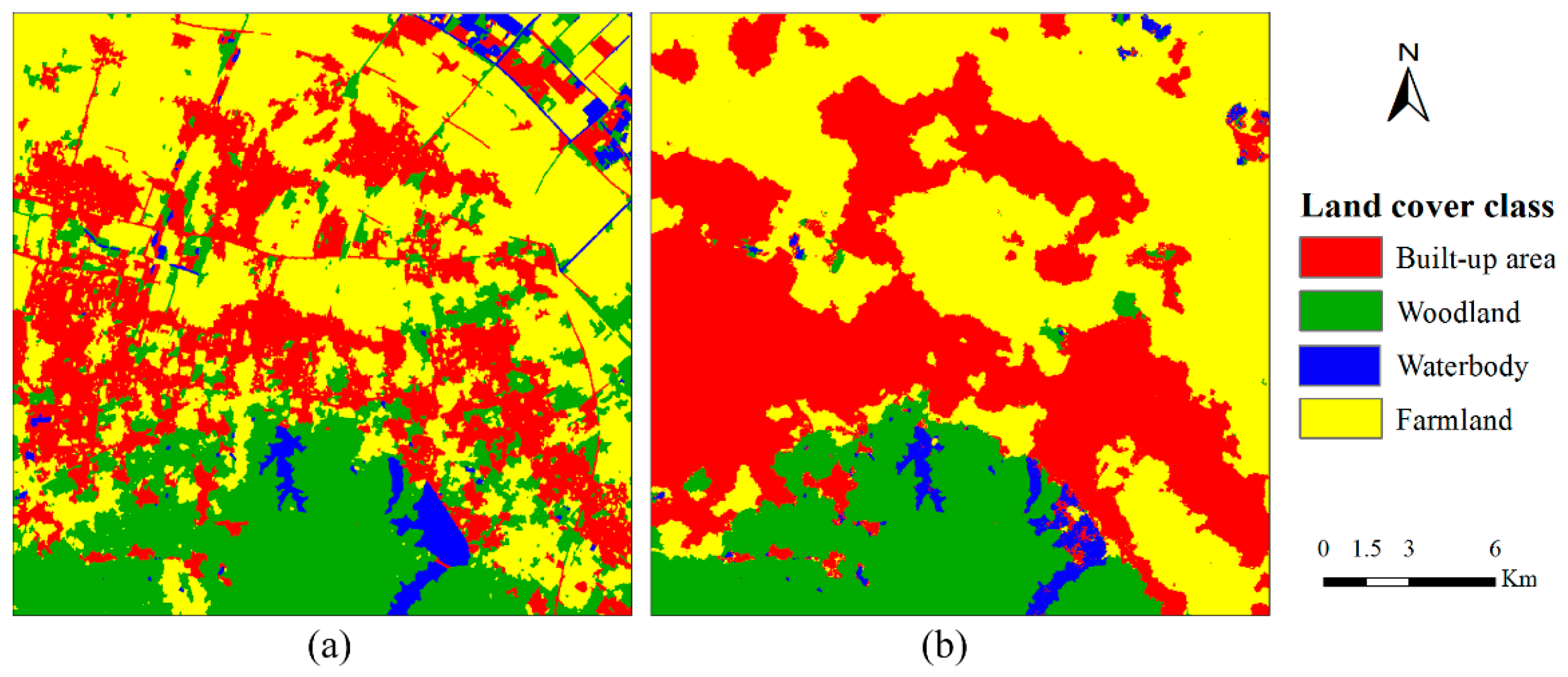
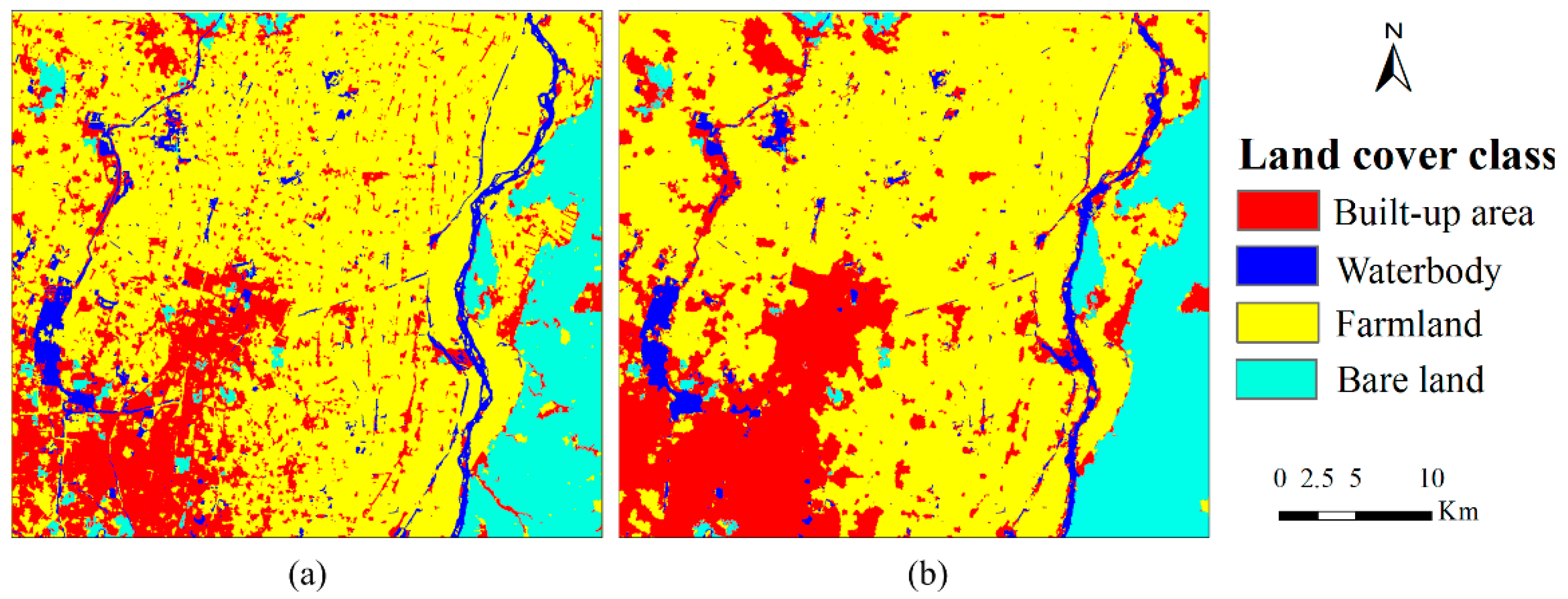
4.1. Case 1
4.2. Case 2
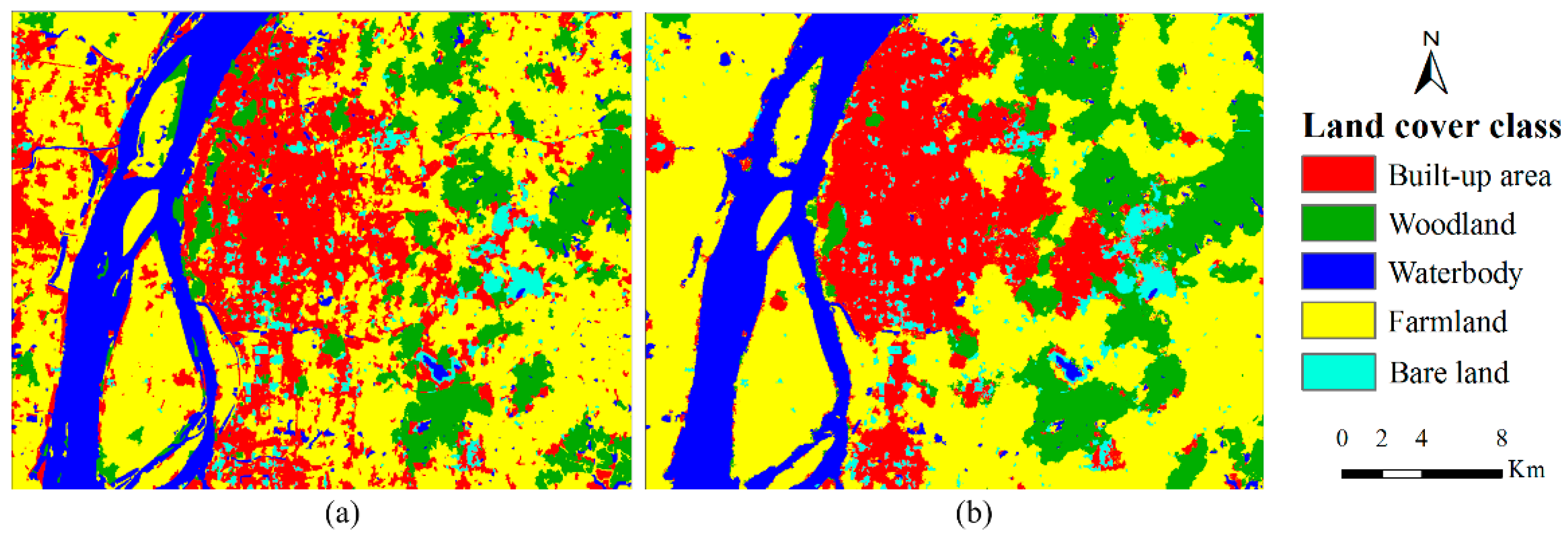
4.3. Case 3
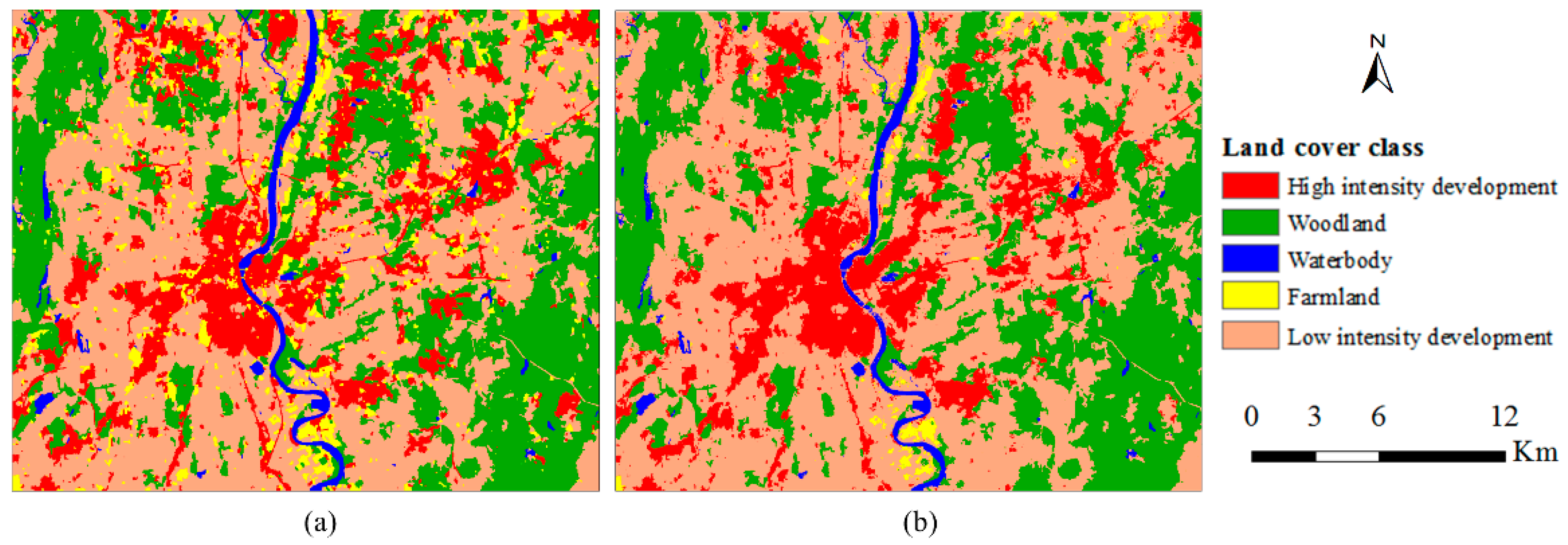
4.4. Case 4
4.5. Discussions
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Weng, Q. A remote sensing—GIS evaluation of urban expansion and its impact on surface temperature in the Zhujiang Delta, China. Int. J. Remote Sens. 2001, 22, 1999–2014. [Google Scholar] [CrossRef]
- Hassan, Z.; Shabbir, R.; Ahmad, S.S.; Malik, A.H.; Aziz, N.; Butt, A.; Erum, S. Dynamics of land use and land cover change (LULCC) using geospatial techniques: A case study of Islamabad Pakistan. SpringerPlus 2016, 5, 812. [Google Scholar] [CrossRef] [PubMed]
- Dwivedi, R.S.; Sreenivas, K.; Ramana, K.V. Cover: Land-use/land-cover change analysis in part of Ethiopia using Landsat Thematic Mapper data. Int. J. Remote Sens. 2005, 26, 1285–1287. [Google Scholar] [CrossRef]
- Erle, E.; Pontius, R. Land-Use and Land-Cover Change: The Encycl Earth; Cleveland, C.J., Ed.; Environmental Information Coalition, National Council for Science and the Environment: Washington, DC, USA, 2007; Available online: http://www.ecotope.org/people/ellis/papers/ellis_eoe_lulcc_2007.pdf (accessed on 29 May 2017).
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2407. [Google Scholar] [CrossRef]
- Chen, X.; Vierling, L.; Deering, D. A simple and effective radiometric correction method to improve landscape change detection across sensors and across time. Remote Sens. Environ. 2005, 98, 63–79. [Google Scholar] [CrossRef]
- Nuñez, M.N.; Ciapessoni, H.H.; Rolla, A.; Kalnay, E.; Cai, M. Impact of land use and precipitation changes on surface temperature trends in Argentina. J. Geophys. Res. 2008, 113, D06111. [Google Scholar] [CrossRef]
- Rahman, A.; Kumar, S.; Fazal, S.; Siddiqui, M.A. Assessment of land use/land cover change in the North-West District of Delhi using remote sensing and GIS techniques. J. Indian Soc. Remote Sens. 2012, 40, 689–697. [Google Scholar] [CrossRef]
- Foody, G.M. Remote sensing of tropical forest environments: Towards the monitoring of environmental resources for sustainable development. Int. J. Remote Sens. 2003, 24, 4035–4046. [Google Scholar] [CrossRef]
- Herold, M.; Scepan, J.; Clarke, K.C. The use of remote sensing and landscape metrics to describe structures and changes in urban land uses. Environ. Plan. A 2002, 34, 1443–1458. [Google Scholar] [CrossRef]
- Yuan, F.; Sawaya, K.E.; Loeffelholz, B.C.; Bauer, M.E. Land cover classification and change analysis of the Twin Cities (Minnesota) Metropolitan Area by multitemporal Landsat remote sensing. Remote Sens. Environ. 2005, 98, 317–328. [Google Scholar] [CrossRef]
- Srivastava, P.K.; Han, D.; Rico-Ramirez, M.A.; Bray, M.; Islam, T. Selection of classification techniques for land use/land cover change investigation. Adv. Space Res. 2012, 50, 1250–1265. [Google Scholar] [CrossRef]
- Guneroglu, A. Coastal changes and land use alteration on Northeastern part of Turkey. Ocean. Coast. Manag. 2015, 118, 225–233. [Google Scholar] [CrossRef]
- El-Asmar, H.M.; Taha, M.M.N.; El-Sorogy, A.S. Morphodynamic changes as an impact of human intervention at the Ras El-Bar-Damietta Harbor coast, NW Damietta Promontory, Nile Delta, Egypt. J. Afr. Earth Sci. 2016, 124, 323–339. [Google Scholar] [CrossRef]
- Rundquist, D.C.; Narumalani, S.; Narayanan, R.M. A review of wetlands remote sensing and defining new considerations. Remote Sens. Rev. 2001, 20, 207–226. [Google Scholar] [CrossRef]
- Zhang, S.Q.; Zhang, S.K.; Zhang, J.Y. A study on wetland classification model of remote sensing in the Sangjiang Plain. Chin. Geogr. Sci. 2000, 10, 68–73. [Google Scholar] [CrossRef]
- Butt, A.; Shabbir, R.; Ahmad, S.S.; Aziz, N. Land use change mapping and analysis using Remote Sensing and GIS: A case study of Simly watershed, Islamabad, Pakistan. Egypt. J. Remote Sens. Space Sci. 2015, 18, 251–259. [Google Scholar] [CrossRef]
- Guo, Q.; Kelly, M.; Gong, P.; Liu, D. An object-based classification approach in mapping tree mortality using high spatial resolution imagery. GISci. Remote Sens. 2007, 44, 24–47. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with landsat thematic mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Mas, J.-F. Monitoring land-cover changes: A comparison of change detection techniques. Int. J. Remote Sens. 1999, 20, 139–152. [Google Scholar] [CrossRef]
- Yang, X. Satellite monitoring of urban spatial growth in the Atlanta metropolitan area. Photogramm. Eng. Remote Sens. 2002, 68, 725–734. [Google Scholar] [CrossRef]
- Zhou, W.; Troy, A.; Grove, M. Object-based land cover classification and change analysis in the Baltimore metropolitan area using multitemporal high resolution remote sensing data. Sensors 2008, 8, 1613–1636. [Google Scholar] [CrossRef] [PubMed]
- Jawak, S.D.; Devliyal, P.; Luis, A.J. A comprehensive review on pixel oriented and object oriented methods for information extraction from remotely sensed satellite images with a special emphasis on cryospheric applications. Adv. Remote Sens. 2015, 4, 177–195. [Google Scholar] [CrossRef]
- Blaschke, T.; Lang, S.; Lorup, E.; Strobl, J.; Zeil, P. Object-oriented image processing in an integrated GIS/remote sensing environment and perspectives for environmental applications. Environ. Inf. Plan. Politics Public 2000, 2, 555–570. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Myint, S.W.; Giri, C.P.; Wang, L.; Zhu, Z.; Gillette, S.C. Identifying mangrove species and their surrounding land use and land cover classes using an object-oriented approach with a lacunarity spatial measure. GISci. Remote Sens. 2008, 45, 188–208. [Google Scholar] [CrossRef]
- Niemeyer, I.; Canty, M.J. Pixel-based and object-oriented change detection analysis using high-resolution imagery. In Proceedings of the 25th Symposium on Safeguards and Nuclear Material Management, Stockholm, Sweden, 13–15 May 2003; pp. 2133–2136. [Google Scholar]
- Chen, G.; Hay, G.J.; Carvalho, L.M.T.; Wulder, M.A. Object-based change detection. Int. J. Remote Sens. 2012, 33, 4434–4457. [Google Scholar] [CrossRef]
- Qian, Y.; Zhang, K.; Qiu, F. Spatial contextual noise removal for post classification smoothing of remotely sensed images. In Proceedings of the 2005 ACM Symposium on Applied Computing, Santa Fe, New Mexico, 13–17 March 2005; pp. 524–528. [Google Scholar] [CrossRef]
- Gong, P.; Howarth, P.J. Frequency-based contextual classification and gray-level vector reduction for land-use identification. Photogramm. Eng. Remote Sens. 1992, 58, 423–437. [Google Scholar]
- Gallego, F.J. Remote sensing and land cover area estimation. Int. J. Remote Sens. 2004, 25, 3019–3047. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Manandhar, R.; Odeh, I.O.A.; Ancev, T. Improving the accuracy of land use and land cover classification of Landsat data using post-classification enhancement. Remote Sens. 2009, 1, 330–344. [Google Scholar] [CrossRef]
- Stow, D.A.; Collins, D.; McKinsey, D. Land use change detection based on multi-date imagery from different satellite sensor systems. Geocarto Int. 1990, 5, 3–12. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Wilkinson, G.G. Results and implications of a study of fifteen years of satellite image classification experiments. IEEE Trans. Geosci. Remote Sens. 2005, 43, 433–440. [Google Scholar] [CrossRef]
- Blaes, X.; Vanhalle, L.; Defourny, P. Efficiency of crop identification based on optical and SAR image time series. Remote Sens. Environ. 2005, 96, 352–365. [Google Scholar] [CrossRef]
- Recio, J.; Hermosilla, T.; Ruiz, L.; Fdez-Sarría, A. Analysis of the addition of qualitative ancillary data on parcel-based image classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2009, 38, 1–4. [Google Scholar]
- Lawrence, R.L.; Wrlght, A. Rule-based classification systems using classification and regression tree (CART) analysis. Photogramm. Eng. Remote Sens. 2001, 67, 1137–1142. [Google Scholar] [CrossRef]
- Li, W.; Zhang, C.; Willig, M.R.; Dey, D.K.; Wang, G.; You, L. Bayesian Markov chain random field cosimulation for improving land cover classification accuracy. Math. Geosci. 2015, 47, 123–148. [Google Scholar] [CrossRef]
- Zhang, W.; Li, W.; Zhang, C. Land cover post-classifications by Markov chain geostatistical cosimulation based on pre-classifications by different conventional classifiers. Int. J. Remote Sens. 2016, 37, 926–949. [Google Scholar] [CrossRef]
- Zhang, W.; Li, W.; Zhang, C.; Li, X. Incorporating spectral similarity into Markov chain geostatistical cosimulation for reducing smoothing effect in land cover postclassification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1082–1095. [Google Scholar] [CrossRef]
- Li, W. Markov chain random fields for estimation of categorical variables. Math. Geol. 2007, 39, 321–335. [Google Scholar] [CrossRef]
- Bayes, M.; Price, M. An essay towards solving a problem in the doctrine of chances. By the Late Rev. Mr. Bayes, F. R. S. Communicated by Mr. Price, in a Letter to John Canton, A. M. F. R. S. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418. [Google Scholar] [CrossRef]
- Jaffray, J. Bayesian updating and belief functions. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; Volume 219, pp. 555–576. [Google Scholar]
- Li, W.; Zhang, C. A single-chain-based multidimensional Markov chain model for subsurface characterization. Environ. Ecol. Stat. 2008, 15, 157–174. [Google Scholar] [CrossRef]
- Li, W. Transiograms for characterizing spatial variability of soil classes. Soil Sci. Soc. Am. J. 2007, 71, 881–893. [Google Scholar] [CrossRef][Green Version]
- Li, W.; Zhang, C. Linear interpolation and joint model fitting of experimental transiograms for Markov chain simulation of categorical spatial variables. Int. J. Geogr. Inf. Sci. 2010, 24, 821–839. [Google Scholar] [CrossRef]
- De Kok, R.; Schneider, T.; Baatz, M. Object based image analysis of high resolution data in the alpine forest area. In Proceedings of the Joint Workshop for ISPRS WG I/1, I/3 AND IV/4, Sensors and Mappinhg from Space, Hanover, Germany, 27–30 September 1999; pp. 27–30. [Google Scholar]
- Yan, G.; Mas, J.-F.; Maathuis, B.H.P.; Xiangmin, Z.; Van Dijk, P.M. Comparison of pixel-based and object-oriented image classification approaches—A case study in a coal fire area, Wuda, Inner Mongolia, China. Int. J. Remote Sens. 2006, 27, 4039–4055. [Google Scholar] [CrossRef]
- Wolf, R. Redefining the concept of insulation. Tech. Text. Int. 1996, 5, 18–20. [Google Scholar] [CrossRef]
- Bhaskaran, S.; Paramananda, S.; Ramnarayan, M. Per-pixel and object-oriented classification methods for mapping urban features using Ikonos satellite data. Appl. Geogr. 2010, 30, 650–665. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cixi City | Expert-Interpreted Sample Data (Pixels) | Validation Data (Pixels) | Yinchuan City | Expert-Interpreted Sample Data (Pixels) | Validation Data (Pixels) |
| Built-up area | 512 | 147 | Built-up area | 338 | 121 |
| Woodland | 150 | 71 | Farmland | 882 | 324 |
| Waterbody | 31 | 14 | Waterbody | 59 | 20 |
| Farmland | 616 | 193 | Bare land | 149 | 53 |
| Total | 1309 | 425 | Total | 1428 | 518 |
| Maanshan City | Expert-Interpreted Sample Data (Pixels) | Validation Data (Pixels) | Hartford City | Expert-Interpreted Sample Data (Pixels) | Validation Data (Pixels) |
| Built-up area | 347 | 134 | High intensity development | 299 | 94 |
| Woodland | 208 | 80 | Farmland | 429 | 167 |
| Waterbody | 80 | 67 | Waterbody | 36 | 14 |
| Farmland | 699 | 269 | Bare land | 114 | 30 |
| Bare land | 67 | 26 | Low intensity development | 622 | 277 |
| Total | 1401 | 576 | Total | 1500 | 582 |
| Cross-Field Transition Probability | |||||
|---|---|---|---|---|---|
| Pre-Classification Data | |||||
| Class ** | C1 | C2 | C3 | C4 | |
| Expert-interpreted sample data | C1 | 0.602 | 0.077 | 0.005 | 0.317 |
| C2 | 0 | 0.932 | 0 | 0.068 | |
| C3 | 0.231 | 0.231 | 0.538 | 0 | |
| C4 | 0.086 | 0.126 | 0.007 | 0.781 | |
| Object-Based Pre-Classification | MCRF Post-Classification | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class ** | C1 | C2 | C3 | C4 | Total | User’s Accuracy (%) | C1 | C2 | C3 | C4 | Total | User’s Accuracy (%) |
| C1 | 96 | 2 | 1 | 22 | 121 | 79 | 128 | 2 | 1 | 22 | 153 | 84 |
| C2 | 12 | 58 | 2 | 31 | 109 | 56 | 2 | 63 | 0 | 9 | 80 | 85 |
| C3 | 0 | 0 | 8 | 2 | 10 | 80 | 0 | 0 | 7 | 0 | 7 | 100 |
| C4 | 39 | 11 | 3 | 138 | 185 | 72 | 17 | 6 | 6 | 162 | 185 | 85 |
| Total | 147 | 71 | 14 | 193 | 425 | 147 | 71 | 14 | 193 | 425 | ||
| Producer’s accuracy (%) | 65 | 82 | 57 | 71 | 70.6 | 87 | 89 | 50 | 84 | 84.7 | ||
| Object-Based Classification | MCRF Post-Classification | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class ** | C1 | C2 | C3 | C4 | Total | User’s Accuracy (%) | C1 | C2 | C3 | C4 | Total | User’s Accuracy (%) |
| C1 | 83 | 33 | 0 | 11 | 128 | 65 | 97 | 26 | 0 | 9 | 132 | 73 |
| C2 | 32 | 287 | 5 | 6 | 330 | 87 | 21 | 294 | 3 | 5 | 323 | 91 |
| C3 | 0 | 2 | 15 | 0 | 17 | 88 | 0 | 2 | 17 | 0 | 19 | 89 |
| C4 | 6 | 2 | 0 | 36 | 44 | 82 | 3 | 2 | 0 | 39 | 44 | 89 |
| Total | 121 | 324 | 20 | 53 | 518 | 121 | 324 | 20 | 53 | 518 | ||
| Producer’s accuracy (%) | 69 | 89 | 75 | 68 | 81.3 | 80 | 91 | 85 | 74 | 86.3 | ||
| Object-Based Pre-Classification | MCRF Post-Classification | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class ** | C1 | C2 | C3 | C4 | C5 | Total | User’s Accuracy (%) | C1 | C2 | C3 | C4 | C5 | Total | User’s Accuracy (%) |
| C1 | 101 | 9 | 0 | 51 | 7 | 168 | 60 | 112 | 2 | 0 | 23 | 4 | 141 | 79 |
| C2 | 4 | 50 | 5 | 23 | 0 | 82 | 61 | 1 | 61 | 3 | 16 | 1 | 82 | 74 |
| C3 | 0 | 3 | 57 | 0 | 2 | 66 | 92 | 0 | 2 | 62 | 1 | 0 | 65 | 95 |
| C4 | 28 | 18 | 4 | 187 | 2 | 235 | 78 | 19 | 15 | 1 | 223 | 1 | 259 | 86 |
| C5 | 1 | 0 | 1 | 8 | 15 | 25 | 60 | 2 | 0 | 1 | 6 | 20 | 29 | 69 |
| Total | 134 | 80 | 67 | 269 | 26 | 576 | 134 | 80 | 67 | 269 | 26 | 576 | ||
| Producer’s accuracy (%) | 75 | 63 | 85 | 70 | 58 | 71.2 | 84 | 76 | 92 | 83 | 77 | 83.0 | ||
| Object-Based Pre-Classification | MCRF Post-Classification | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class ** | C1 | C2 | C3 | C4 | C5 | Total | User’s Accuracy (%) | C1 | C2 | C3 | C4 | C5 | Total | User’s Accuracy (%) |
| C1 | 65 | 17 | 0 | 2 | 43 | 127 | 51 | 74 | 12 | 0 | 1 | 33 | 120 | 62 |
| C2 | 6 | 140 | 0 | 3 | 31 | 180 | 78 | 5 | 147 | 0 | 3 | 27 | 182 | 81 |
| C3 | 0 | 0 | 12 | 0 | 0 | 12 | 100 | 0 | 0 | 12 | 0 | 0 | 12 | 100 |
| C4 | 11 | 6 | 0 | 21 | 7 | 45 | 46 | 5 | 4 | 0 | 22 | 5 | 36 | 61 |
| C5 | 12 | 4 | 2 | 4 | 196 | 218 | 90 | 10 | 4 | 2 | 4 | 212 | 232 | 91 |
| Total | 94 | 167 | 14 | 30 | 277 | 582 | 94 | 167 | 14 | 30 | 277 | 582 | ||
| Producer’s accuracy (%) | 69 | 84 | 86 | 70 | 71 | 74.6 | 79 | 88 | 86 | 73 | 77 | 80.2 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Li, W.; Zhang, C.; Zhang, W. Improving Object-Based Land Use/Cover Classification from Medium Resolution Imagery by Markov Chain Geostatistical Post-Classification. Land 2018, 7, 31. https://doi.org/10.3390/land7010031
Wang W, Li W, Zhang C, Zhang W. Improving Object-Based Land Use/Cover Classification from Medium Resolution Imagery by Markov Chain Geostatistical Post-Classification. Land. 2018; 7(1):31. https://doi.org/10.3390/land7010031
Chicago/Turabian StyleWang, Wenjie, Weidong Li, Chuanrong Zhang, and Weixing Zhang. 2018. "Improving Object-Based Land Use/Cover Classification from Medium Resolution Imagery by Markov Chain Geostatistical Post-Classification" Land 7, no. 1: 31. https://doi.org/10.3390/land7010031
APA StyleWang, W., Li, W., Zhang, C., & Zhang, W. (2018). Improving Object-Based Land Use/Cover Classification from Medium Resolution Imagery by Markov Chain Geostatistical Post-Classification. Land, 7(1), 31. https://doi.org/10.3390/land7010031