
Regional Ecological Environment Quality Prediction Based on Multi-Model Fusion

Abstract
1. Introduction
2. Study Area and Dataset
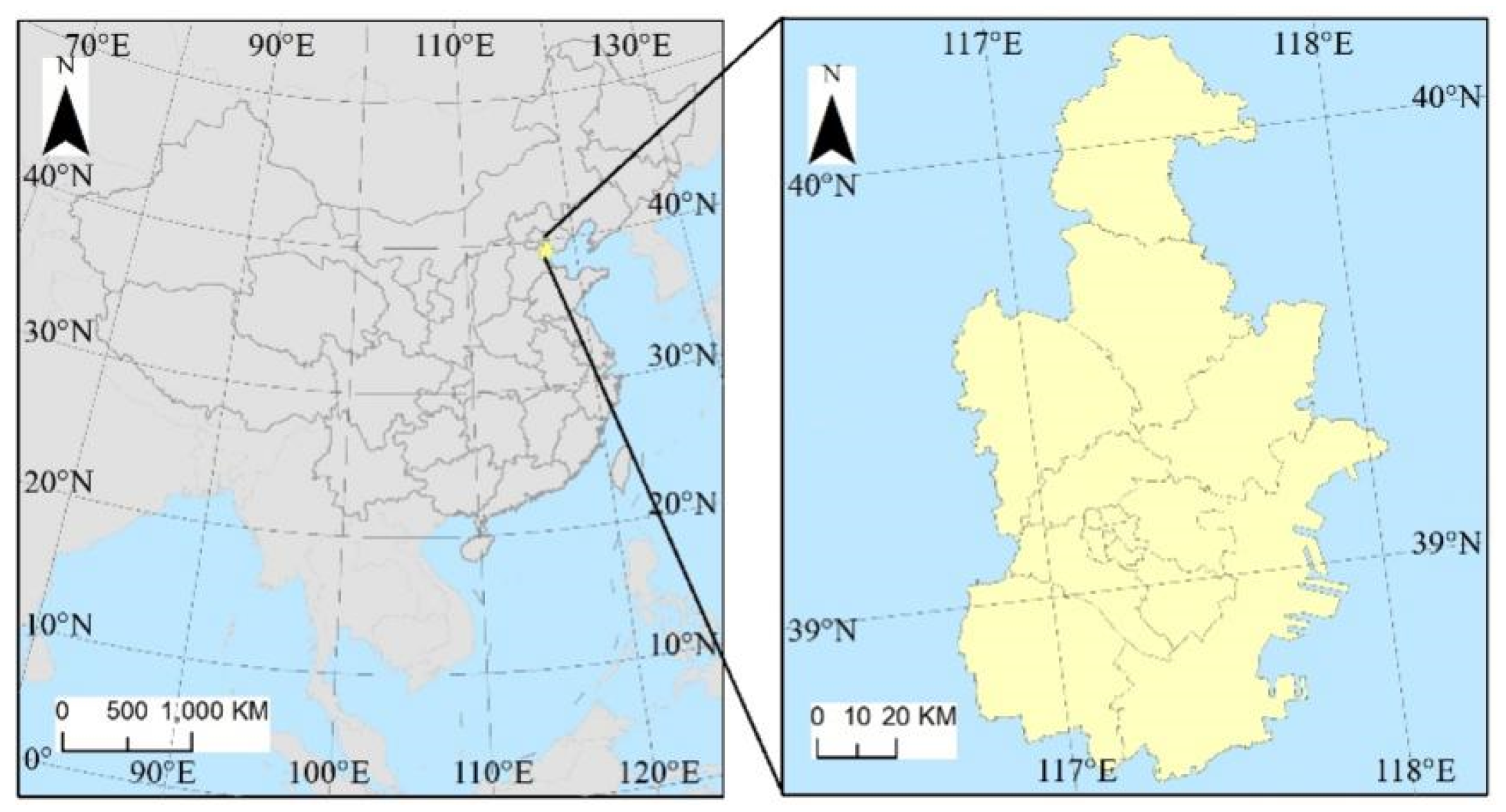
2.1. Study Area
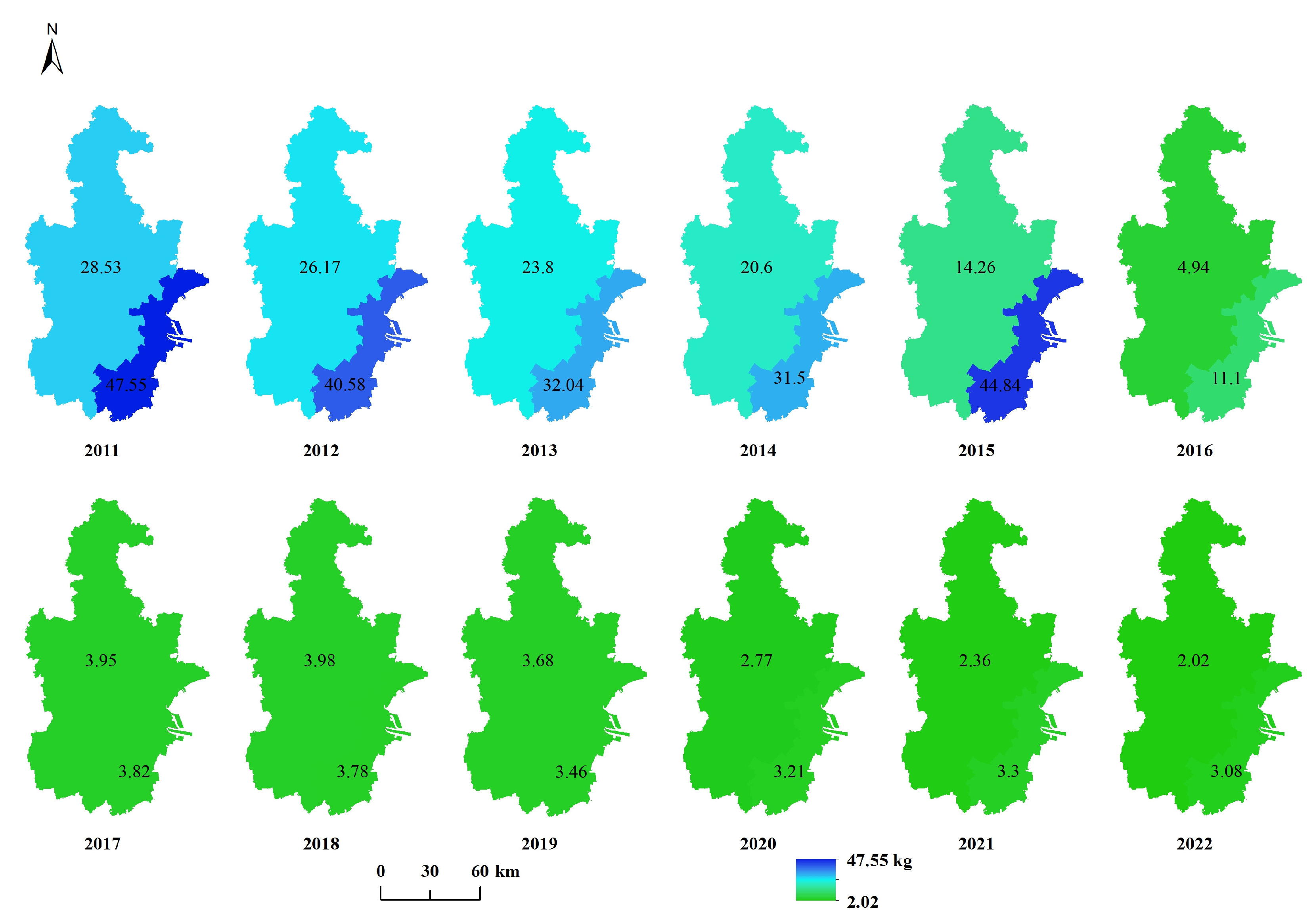
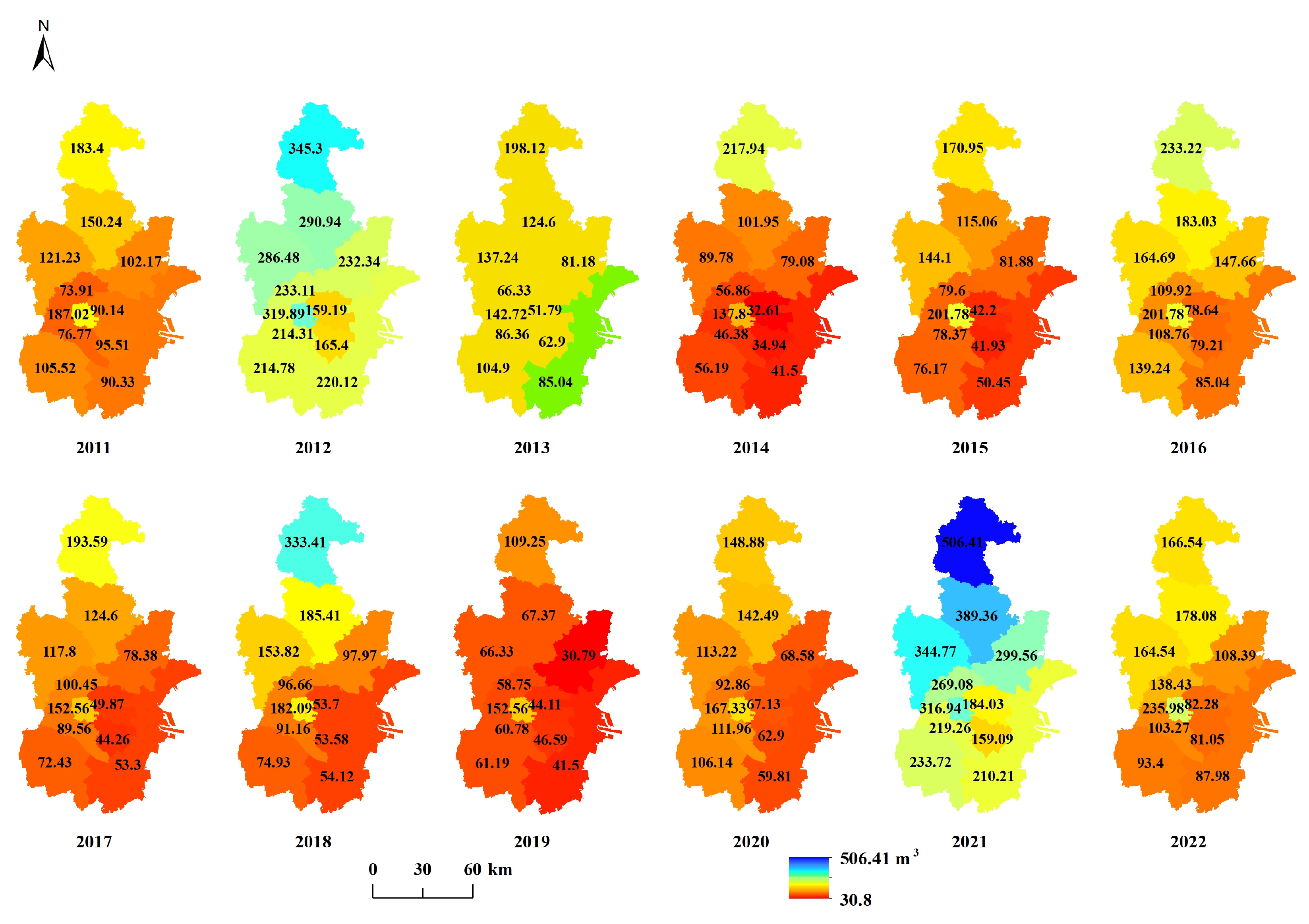
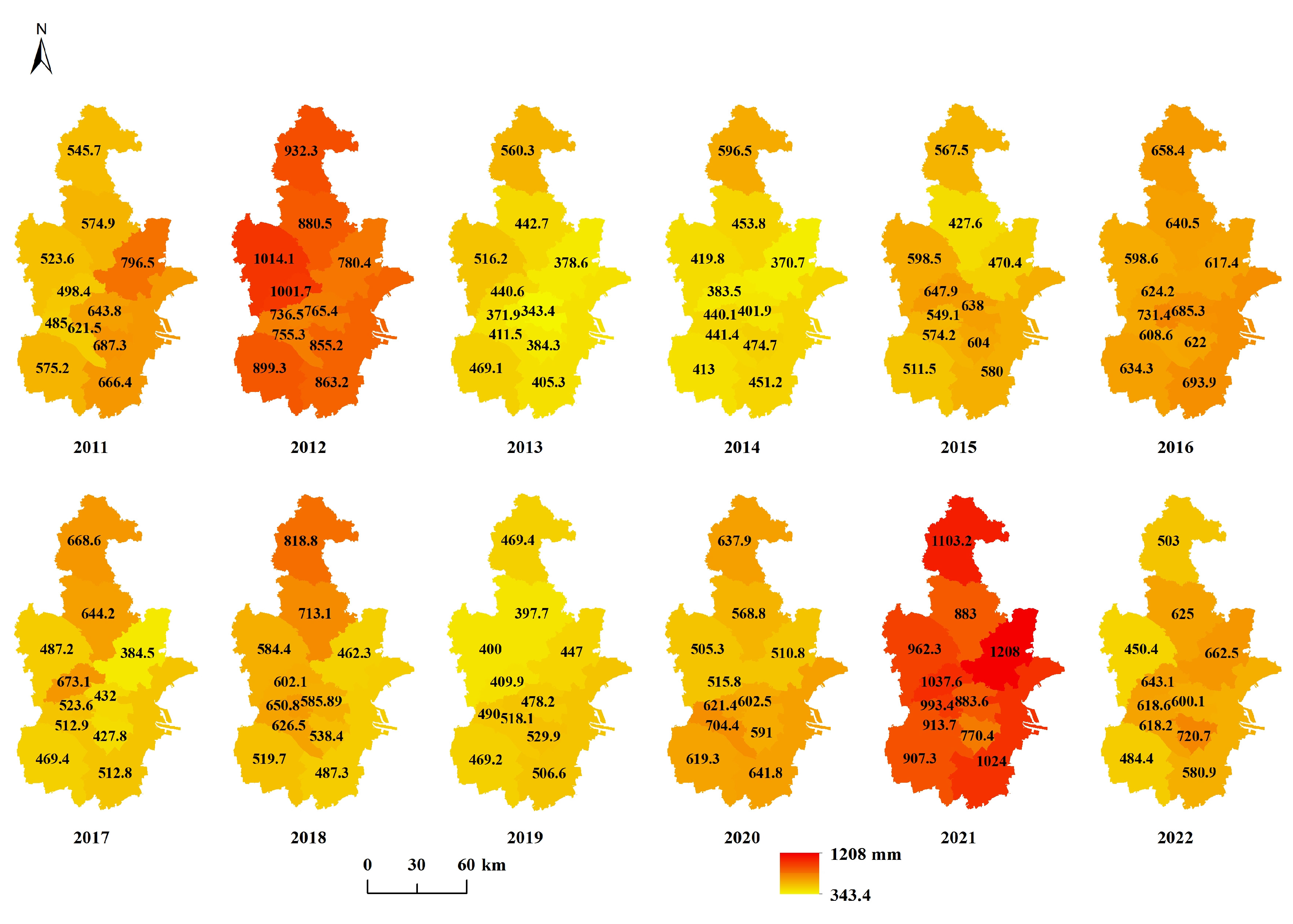
2.2. Dataset
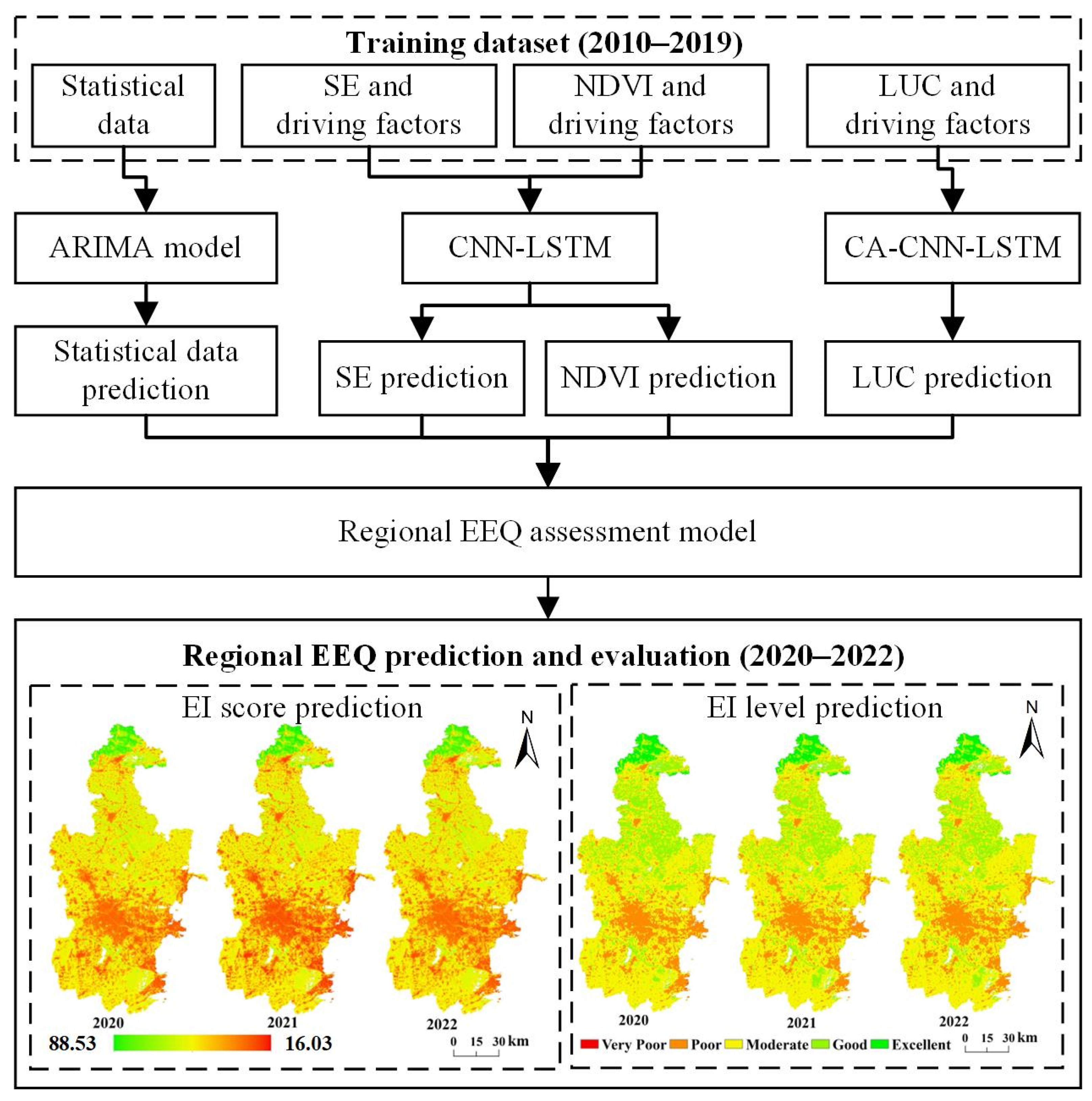
3. Methods
3.1. Regional EEQ Assessment with the EI Model
3.2. Regional EEQ Prediction and Evaluation
3.2.1. Statistical Data Prediction Using the ARIMA
3.2.2. NDVI and SE Prediction Using CNN and LSTM Models
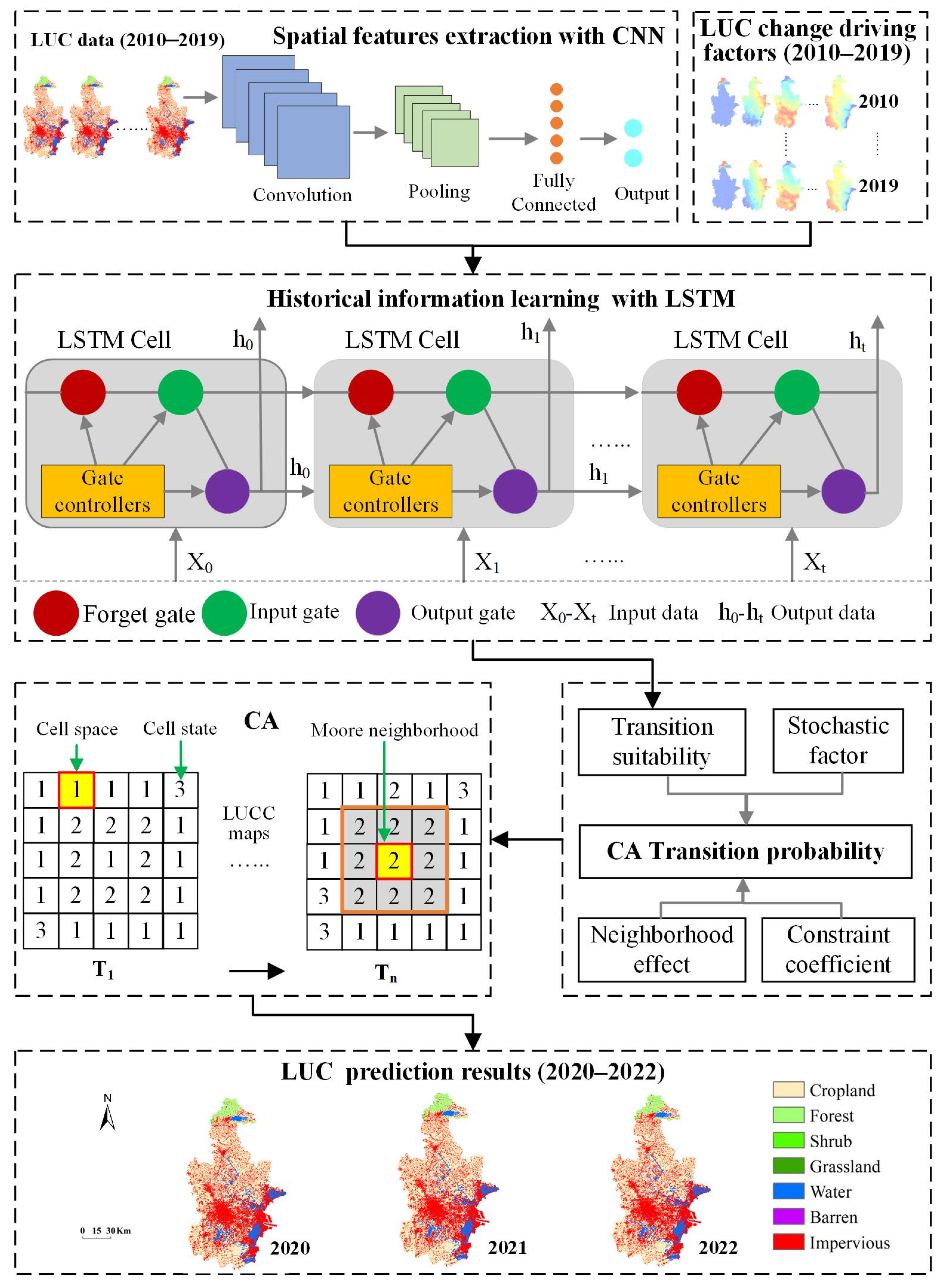
3.2.3. LUC Prediction Using a CA Model Coupled with CNN and LSTM Models
3.2.4. Evaluation Metrics
4. Model Implementation and Experimental Results
4.1. Model Implementation
4.2. Model Performance and Analysis
4.3. Exploring the Causes of EI Prediction Errors
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
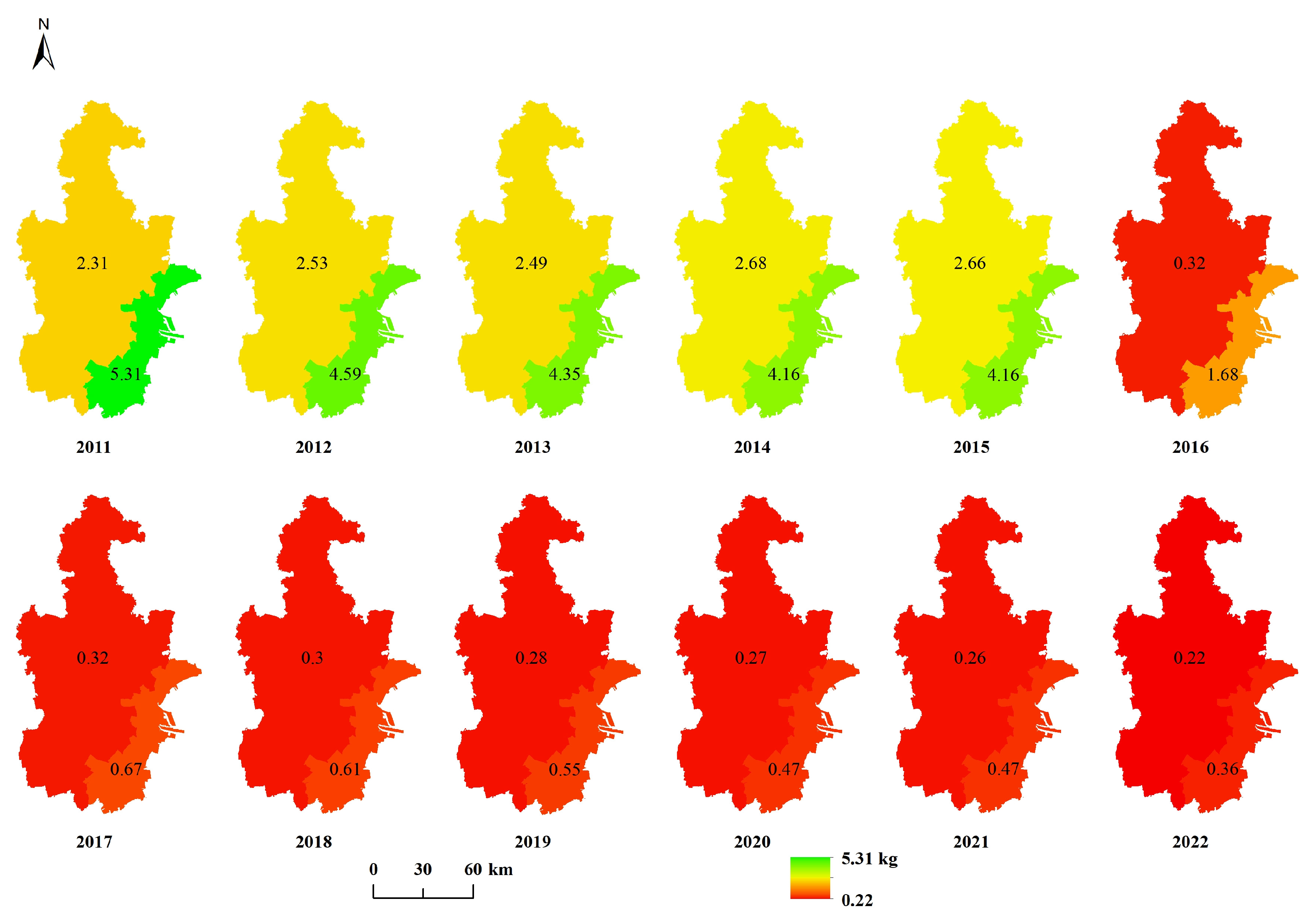
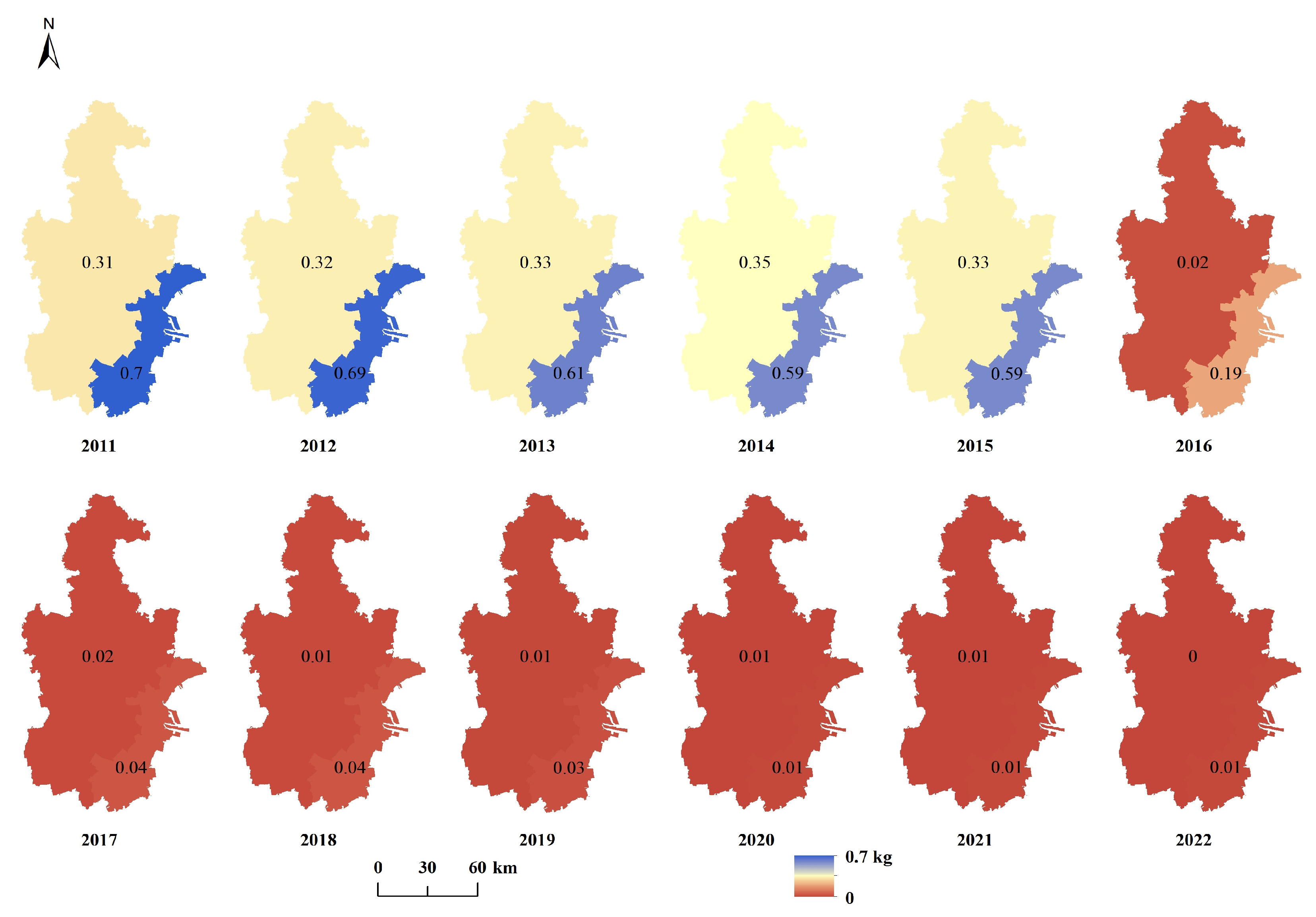
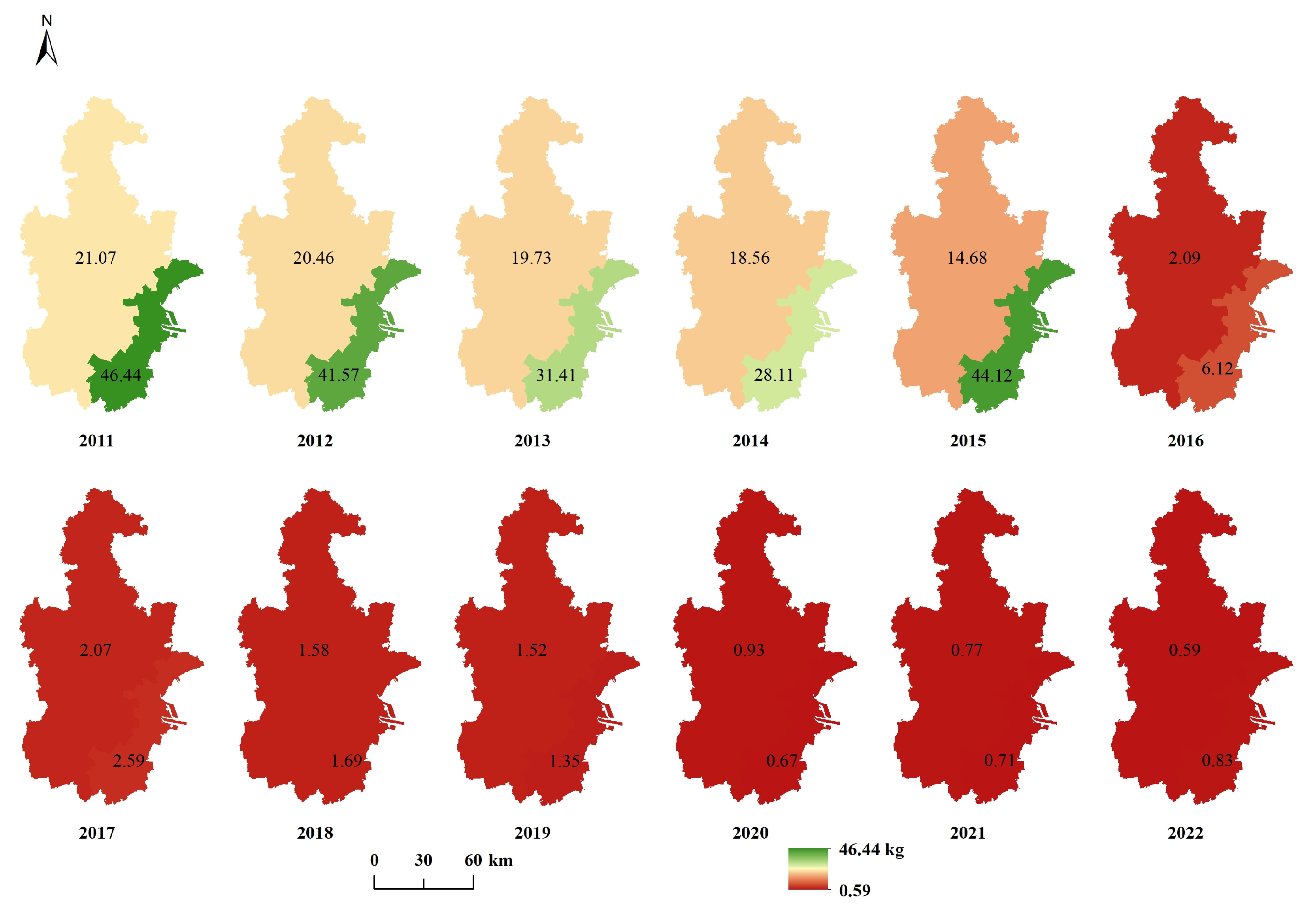
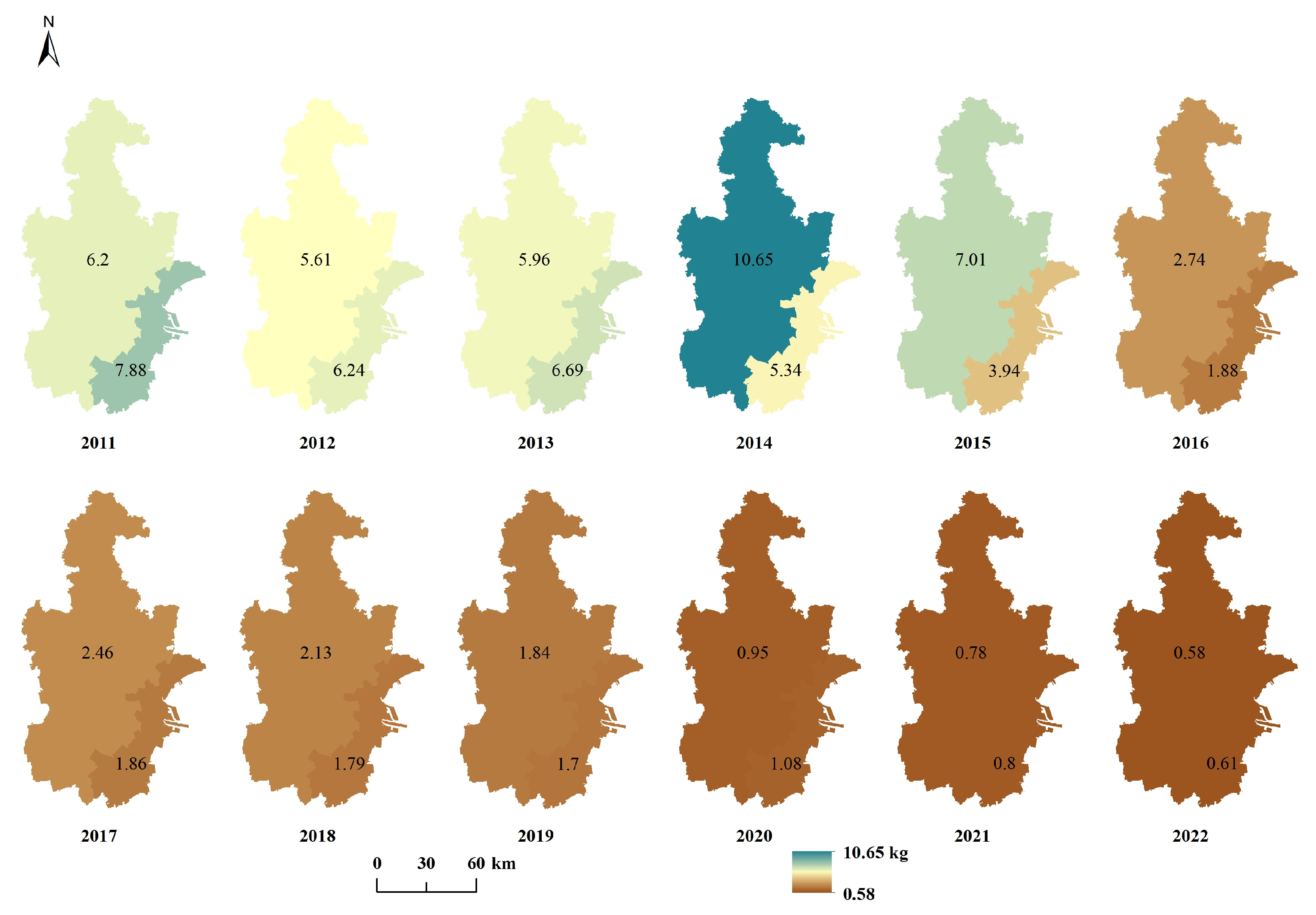
Appendix A
References
- Miao, C.-l.; Sun, L.-y.; Yang, L. The studies of ecological environmental quality assessment in Anhui Province based on ecological footprint. Ecol. Indic. 2016, 60, 879–883. [Google Scholar] [CrossRef]
- Yibo, Y.; Ziyuan, C.; Simayi, Z.; Haobo, Y.; Xiaodong, Y.; Shengtian, Y. Dynamic evaluation and prediction of the ecological environment quality of the urban agglomeration on the northern slope of Tianshan Mountains. Environ. Sci. Pollut. Res. 2023, 30, 25817–25835. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Qiao, J.; Li, M.; Dun, Y.; Zhu, X.; Ji, X. Spatiotemporal evolution of ecological environmental quality and its dynamic relationships with landscape pattern in the Zhengzhou Metropolitan Area: A perspective based on nonlinear effects and spatiotemporal heterogeneity. J. Clean. Prod. 2024, 480, 144102. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, X.; He, S.; Niu, R. Eco-environmental assessment model of the mining area in Gongyi, China. Sci. Rep. 2021, 11, 17549. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Yu, Y.; Gao, Y.; He, J.; Yu, X.; Malik, I.; Wistuba, M.; Yu, R. Remote Sensing Monitoring and Evaluation of the Temporal and Spatial Changes in the Eco-Environment of a Typical Arid Land of the Tarim Basin in Western China. Land 2021, 10, 868. [Google Scholar] [CrossRef]
- Zhu, D.; Chen, T.; Wang, Z.; Niu, R. Detecting ecological spatial-temporal changes by Remote Sensing Ecological Index with local adaptability. J. Environ. Manag. 2021, 299, 113655. [Google Scholar] [CrossRef] [PubMed]
- Boori, M.S.; Choudhary, K.; Paringer, R.; Kupriyanov, A. Eco-environmental quality assessment based on pressure-state-response framework by remote sensing and GIS. Remote Sens. Appl. Soc. Environ. 2021, 23, 100530. [Google Scholar] [CrossRef]
- Standard. Technical Criterion for Ecosystem Status Evaluation; China Environmental Science Press: Beijing, China, 2015. [Google Scholar]
- Wang, Q.; Gao, M.; Zhang, H. Agroecological Efficiency Evaluation Based on Multi-Source Remote Sensing Data in a Typical County of the Tibetan Plateau. Land 2022, 11, 561. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, Q.O.; Shao, Y.; Sun, S.; Xiao, L.; Guo, J. Ecological environment assessment based on land use simulation: A case study in the Heihe River Basin. Sci. Total Environ. 2019, 697, 133928. [Google Scholar] [CrossRef] [PubMed]
- Clauset, A.; Larremore, D.B.; Sinatra, R. Data-driven predictions in the science of science. Science 2017, 355, 477–480. [Google Scholar] [CrossRef] [PubMed]
- Shumway, R.H.; Stoffer, D.S. ARIMA Models. In Time Series Analysis and Its Applications: With R Examples; Springer International Publishing: Cham, Switzerland, 2017; pp. 83–171. [Google Scholar]
- Ahmad, M.W.; Reynolds, J.; Rezgui, Y. Predictive modelling for solar thermal energy systems: A comparison of support vector regression, random forest, extra trees and regression trees. J. Clean. Prod. 2018, 203, 810–821. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An Introductory Review of Deep Learning for Prediction Models with Big Data. Front. Artif. Intell. 2020, 3. [Google Scholar] [CrossRef] [PubMed]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Tong, X.; Feng, Y. A review of assessment methods for cellular automata models of land-use change and urban growth. Int. J. Geogr. Inf. Sci. 2020, 34, 866–898. [Google Scholar] [CrossRef]
- Liang, X.; Guan, Q.; Clarke, K.C.; Chen, G.; Guo, S.; Yao, Y. Mixed-cell cellular automata: A new approach for simulating the spatio-temporal dynamics of mixed land use structures. Landsc. Urban Plan. 2021, 205, 103960. [Google Scholar] [CrossRef]
- Zhou, Y.; Huang, C.; Wu, T.; Zhang, M. A novel spatio-temporal cellular automata model coupling partitioning with CNN-LSTM to urban land change simulation. Ecol. Model. 2023, 482, 110394. [Google Scholar] [CrossRef]
- Qin, W.; Ismail, M.H.; Ramli, M.F.; Deng, J.; Wu, N. Evaluation and Prediction of Ecological Quality Based on Remote Sensing Environmental Index and Cellular Automata-Markov. Sustainability 2025, 17, 3640. [Google Scholar] [CrossRef]
- Liang, L.; Song, Y.; Shao, Z.; Zheng, C.; Liu, X.; Li, Y. Exploring the causal relationships and pathways between ecological environmental quality and influencing Factors: A comprehensive analysis. Ecol. Indic. 2024, 165, 112192. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Q.; Chen, Y.; Zhou, H.; Xiang, Y.; Liu, Z.; Hou, Y. Vegetation Change and Eco-Environmental Quality Evaluation in the Loess Plateau of China from 2000 to 2020. Remote Sens. 2023, 15, 424. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; He, Y.; Cao, S.; Li, H.; Ran, L.; Ding, Y.; Filonchyk, M. LSTM time series NDVI prediction method incorporating climate elements: A case study of Yellow River Basin, China. J. Hydrol. 2024, 629, 130518. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, R.; Yang, Y.; Li, L.; Chen, L. Assessing the urban eco-environmental quality by the remote-sensing ecological index: Application to Tianjin, North China. ISPRS Int. J. Geo-Inf. 2021, 10, 475. [Google Scholar] [CrossRef]
- Han, H.; Guo, L.; Zhang, J.; Zhang, K.; Cui, N. Spatiotemporal analysis of the coordination of economic development, resource utilization, and environmental quality in the Beijing-Tianjin-Hebei urban agglomeration. Ecol. Indic. 2021, 127, 107724. [Google Scholar] [CrossRef]
- Yang, J.; Huang, X. 30 m annual land cover and its dynamics in China from 1990 to 2019. Earth Syst. Sci. Data Discuss. 2021, 2021, 1–29. [Google Scholar]
- Gao, J.; Shi, Y.; Zhang, H.; Chen, X.; Zhang, W.; Shen, W.; Xiao, T.; Zhang, Y. China Regional 250m Fractional Vegetation Cover Data Set (2000–2023); National Tibetan Plateau/Third Pole Environment Data Center: Beijing, China, 2024. [Google Scholar] [CrossRef]
- Yan, J.; Wang, S.; Feng, J.; He, H.; Wang, L.; Sun, Z.; Zheng, C. The 30 m Annual Soil Water Erosion Dataset in Chinese Mainland from 1990 to 2022; Science Data Bank: Beijing, China, 2024. [Google Scholar] [CrossRef]
- Abrams, M.; Yamaguchi, Y.; Crippen, R. ASTER GLOBAL DEM (GDEM) VERSION 3. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, XLIII-B4-2022, 593–598. [Google Scholar] [CrossRef]
- Peng, S. 1-km Monthly Mean Temperature Dataset for China (1901–2024); National Tibetan Plateau/Third Pole Environment Data Center: Beijing, China, 2024. [Google Scholar] [CrossRef]
- Peng, S. High-Spatial-Resolution Monthly Precipitation Dataset over China During 1901–2017; National Tibetan Plateau/Third Pole Environment Data Center: Beijing, China, 2019. [Google Scholar] [CrossRef]
- Peng, S. 1-km Monthly Potential Evapotranspiration Dataset for China (1901–2024); National Earth System Science Date Center: Beijing, China, 2024. [Google Scholar] [CrossRef]
- Mooney, P.; Minghini, M. A review of OpenStreetMap data. In Mapping and the Citizen Sensor; Ubiquity Press: London, UK, 2017; pp. 37–59. [Google Scholar]
- Lebakula, V.; Sims, K.; Reith, A.; Rose, A.; McKee, J.; Coleman, P.; Kaufman, J.; Urban, M.; Jochem, C.; Whitlock, C.; et al. LandScan Global 30 Arcsecond Annual Global Gridded Population Datasets from 2000 to 2022. Sci. Data 2025, 12, 495. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Pang, B.; Nijkamp, E.; Wu, Y.N. Deep Learning with TensorFlow: A Review. J. Educ. Behav. Stat. 2020, 45, 227–248. [Google Scholar] [CrossRef]
- Whang, S.E.; Roh, Y.; Song, H.; Lee, J.-G. Data collection and quality challenges in deep learning: A data-centric ai perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
- Ji, Z.; Wan, Y. A novel method for socioeconomic data spatialization. Spat. Stat. 2021, 43, 100501. [Google Scholar] [CrossRef]
- Ladosz, P.; Weng, L.; Kim, M.; Oh, H. Exploration in deep reinforcement learning: A survey. Inf. Fusion 2022, 85, 1–22. [Google Scholar] [CrossRef]
- Corso, G.; Stark, H.; Jegelka, S.; Jaakkola, T.; Barzilay, R. Graph neural networks. Nat. Rev. Methods Primers 2024, 4, 17. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Variable | Description | Resolution |
|---|---|---|---|
| LUC | LUC | LUC change data. | 30 m |
| NDVI | NDVI | Annual NDVI calculated as the average of maximum NDVI values from May to September. | 250 m |
| Soil erosion | SE | Soil water erosion data in t/(hm2 a) | 30 m |
| Climate | TEM | Annual mean temperature expressed with 0.1 °C units. | 1 km |
| PRE | Annual mean precipitation in mm. | 1 km | |
| PET | Annual mean potential evapotranspiration in mm. | 1 km | |
| Topography | ELEV | Elevation in m. | 30 m |
| ASP | Aspect in degrees. | 30 m | |
| SLP | Slope in degrees. | 30 m | |
| TRI | Terrain ruggedness index in m. | 30 m | |
| Spatial distance | D2RW | Euclidean distance from railway in m. | - |
| D2RD | Euclidean distance from road network in m. | - | |
| D2RV | Euclidean distance from river network in m. | - | |
| Population | PD | Population density in terms of persons per pixel. | 1 km |
| Statistical data | COD | COD emission in ton. | - |
| NH3 | Ammonia nitrogen emission in ton. | - | |
| SO2 | SO2 emission in ton. | - | |
| YFC | Smoke (dust) emission in ton. | - | |
| NOX | Nitrogen oxide emission in ton. | - | |
| SOL | Solid waste disposal in ton. | - | |
| WR | Water resources in 100 million m3. | - | |
| TAP | Region’s total annual precipitation in mm. | - | |
| GDP/capita | Per capita GDP in CNY. | - | |
| Tertiary GDP | GDP of the tertiary industry in 100 million CNY. | - | |
| EFE | Education financing expenditure in million CNY. | - | |
| STFE | Scientific and technological financing expenditure in million CNY. | - | |
| EPFE | Environmental protection financing expenditure in million CNY. | - |
| Index | Calculation Formula | Data Used |
|---|---|---|
| EI | - | |
| HQI | LUC | |
| VCI | NDVI | |
| WDI | | LUC, Statistical data (WR) |
| LDI | LUC, SE | |
| PLI | Statistical data (COD, NH3, SO2, YFC, NOX SOL, TAP) |
| Indicator | Calculation Method | Meaning | |
|---|---|---|---|
| RMSE | represents the actual value, represents the predicted value, represents the mean of the actual values, and represents the number of grids. | Measures the average squared difference between the predicted and actual values. Smaller values indicate better accuracy, while larger values suggest higher errors. | |
| MAE | Measures the average absolute difference between the predicted and actual values. Smaller values indicate higher accuracy, while larger values suggest more errors. | ||
| MAPE | Measures the average absolute percentage difference between the predicted and actual values. Smaller values indicate higher accuracy, while larger values suggest greater errors. | ||
| R2 | Measures the fit between the predicted and actual values, ranging from 0 to 1. Values closer to 1 indicate better predictions, while values closer to 0 suggest poor degrees of fit. | ||
| OA | TP denotes correctly transformed grids, TN represents correctly unchanged grids, FP signifies incorrectly transformed grids, and FN denotes incorrectly unchanged grids. | The proportion of correct predictions, with values closer to 1 indicating higher accuracy and values closer to 0 indicating lower performance. | |
| Kappa | P0 is the proportion of correctly predicted grids, while Pk represents the accuracy expected from performing random classification based on the grid distribution. | Measures accuracy by comparing the category distributions between the predicted and observed data, with values ranging from −1 to 1. Higher values indicate better accuracy. | |
| COD | NH3 | SO2 | YFC | NOX | TAP | WR | |
|---|---|---|---|---|---|---|---|
| RMSE | 304.89 | 8.77 | 945.14 | 475.91 | 1662.92 | 191.89 | 1.46 |
| MAE | 269.81 | 4.02 | 774.29 | 422.72 | 1438.92 | 137.87 | 1.03 |
| MAPE | 17.68 | 28.3 | 23.7 | 8.61 | 9.18 | 15.9 | 33.68 |
| Year | NDVI | SE | |||||
|---|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | R2 | RMSE | MAE | R2 | |
| 2020 | 0.05 | 0.04 | 10.56 | 0.87 | 0.69 | 0.22 | 0.83 |
| 2021 | 0.06 | 0.04 | 15.81 | 0.83 | 1.64 | 0.37 | 0.8 |
| 2022 | 0.07 | 0.05 | 24.3 | 0.82 | 0.68 | 0.39 | 0.77 |
| Year | Kappa | OA |
|---|---|---|
| 2020 | 0.96 | 0.98 |
| 2021 | 0.96 | 0.97 |
| 2022 | 0.94 | 0.96 |
| Year | EI Score | EI Level | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | R2 | Kappa | OA | |
| 2020 | 2.08 | 1.39 | 3.23 | 0.97 | 0.85 | 0.91 |
| 2021 | 2.34 | 1.69 | 3.73 | 0.96 | 0.79 | 0.87 |
| 2022 | 2.64 | 1.94 | 4.29 | 0.96 | 0.76 | 0.85 |
| Index | 2020 | 2021 | 2022 | |||
|---|---|---|---|---|---|---|
| AE_Value | DI_Count | AE_Value | DI_Count | AE_Value | DI_Count | |
| EI | 60,354.22 | / | 72,791.62 | / | 83,528.46 | / |
| HQI | 10,757.07 | 1467 | 11,965.79 | 1353 | 14,948.97 | 1875 |
| VCI | 44,414.13 | 22,492 | 55,472.64 | 23,362 | 56,005.5 | 21,613 |
| WDI | 15,128.86 | 1227 | 36,231.22 | 16,454 | 27,194.2 | 4351 |
| LDI | 6090.285 | 1035 | 10,727.17 | 1686 | 11,649.44 | 1811 |
| PLI | 26,610.41 | 16,634 | 4946.03 | 0 | 35,360.97 | 13,205 |
| Index | 2020 | 2021 | 2022 | |||
|---|---|---|---|---|---|---|
| AE_Value | DI_Count | AE_Value | DI_Count | AE_Value | DI_Count | |
| EI | 3532.11 | / | 3576.59 | / | 4564.23 | / |
| HQI | 2132.05 | 164 | 2021.32 | 155 | 2019.57 | 145 |
| VCI | 743.18 | 31 | 615.02 | 21 | 816.49 | 28 |
| WDI | 124.97 | 0 | 208 | 0 | 231.05 | 0 |
| LDI | 1020.31 | 65 | 1132.61 | 71 | 1880.84 | 140 |
| PLI | 91.37 | 0 | 63.43 | 0 | 233.76 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Li, Z.; Wei, B. Regional Ecological Environment Quality Prediction Based on Multi-Model Fusion. Land 2025, 14, 1486. https://doi.org/10.3390/land14071486
Song Y, Li Z, Wei B. Regional Ecological Environment Quality Prediction Based on Multi-Model Fusion. Land. 2025; 14(7):1486. https://doi.org/10.3390/land14071486
Chicago/Turabian StyleSong, Yiquan, Zhengwei Li, and Baoquan Wei. 2025. "Regional Ecological Environment Quality Prediction Based on Multi-Model Fusion" Land 14, no. 7: 1486. https://doi.org/10.3390/land14071486
APA StyleSong, Y., Li, Z., & Wei, B. (2025). Regional Ecological Environment Quality Prediction Based on Multi-Model Fusion. Land, 14(7), 1486. https://doi.org/10.3390/land14071486