
autoRA: An Algorithm to Automatically Delineate Reference Areas—A Case Study to Map Soil Classes in Bahia, Brazil

 ,
,  ,
,  ,
,  ,
,
Abstract
1. Introduction
2. Materials and Methods
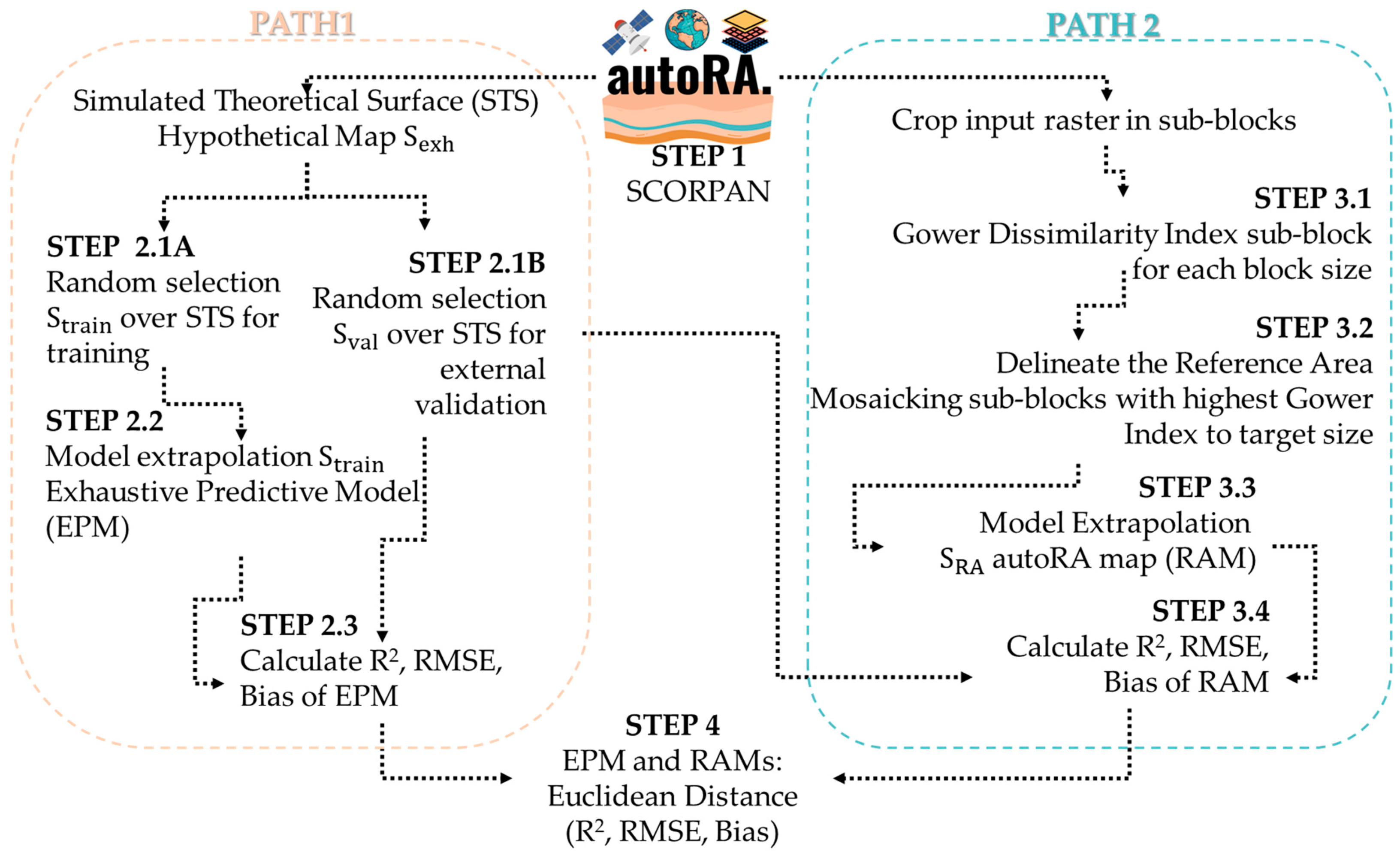
2.1. The autoRA Algorithm
2.2. autoRA Heterogeneous Coverage and Extrapolation Formalization
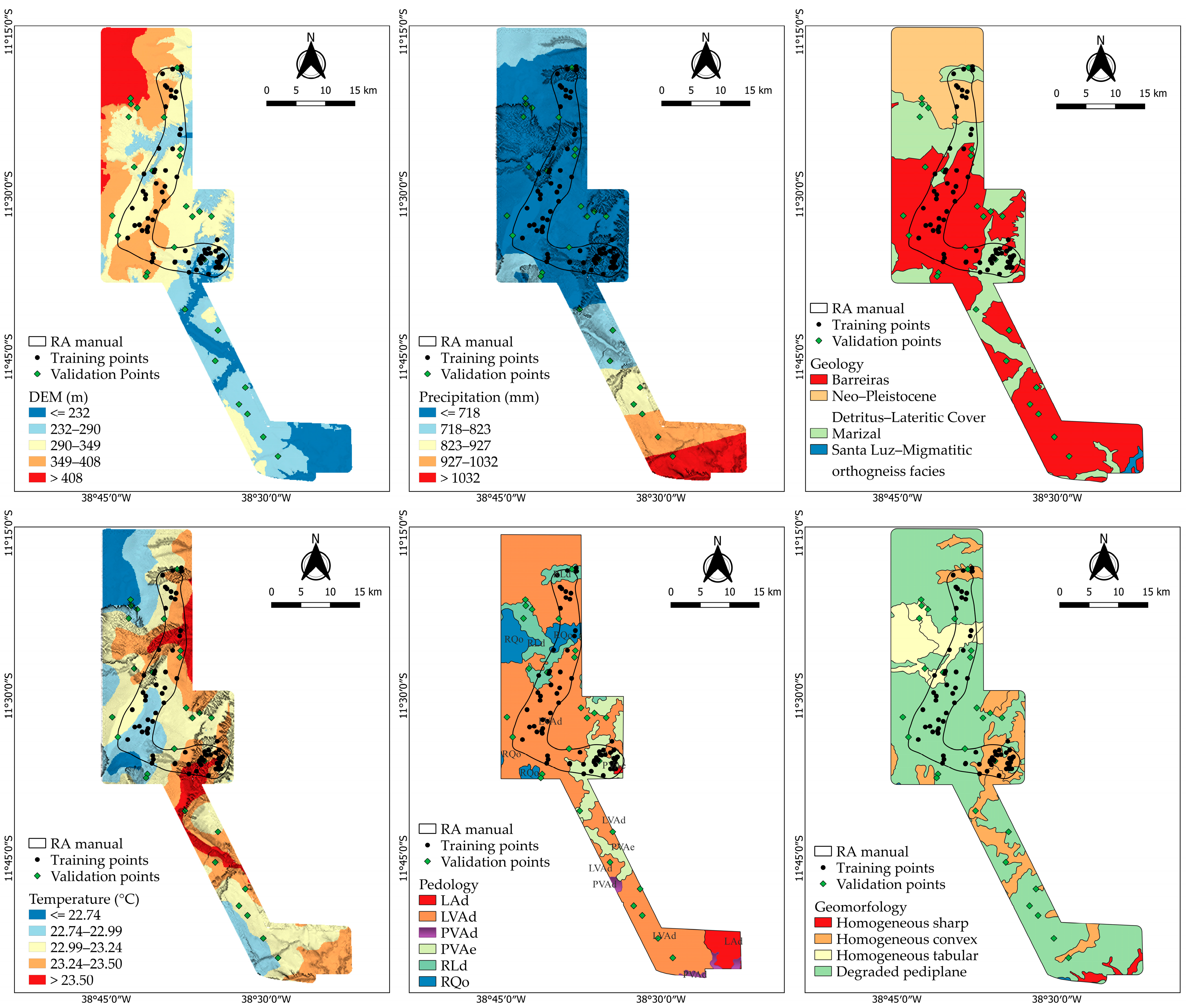
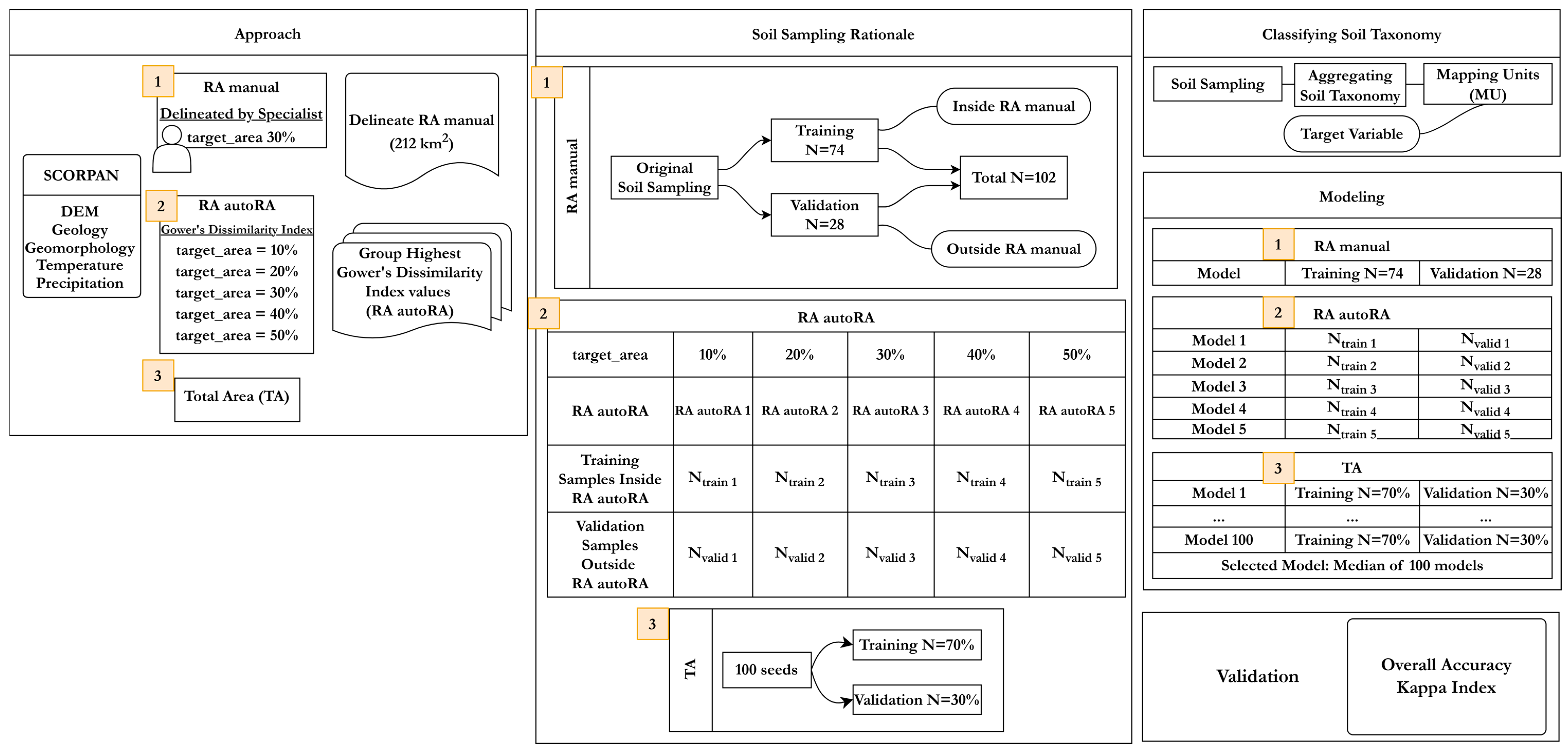
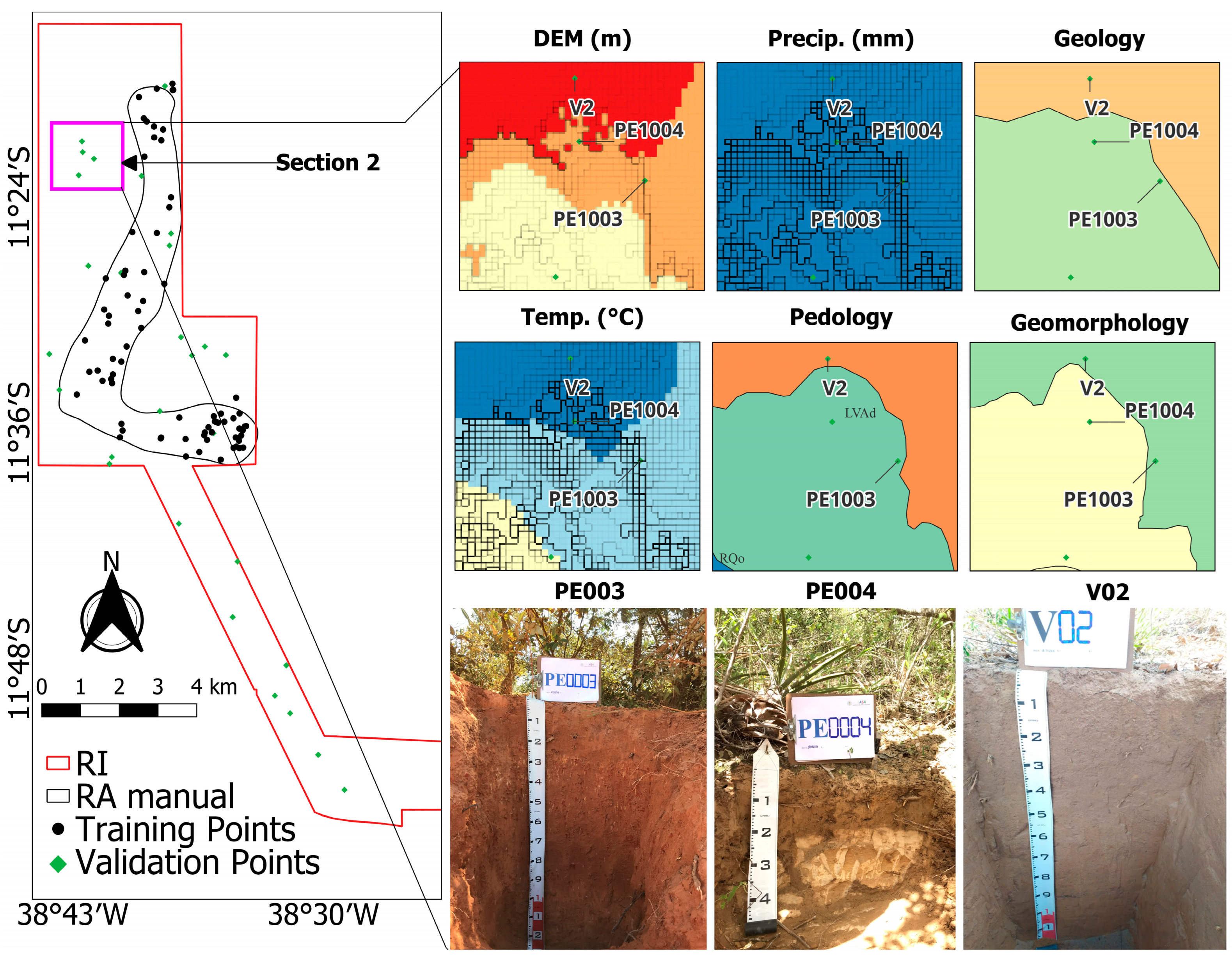
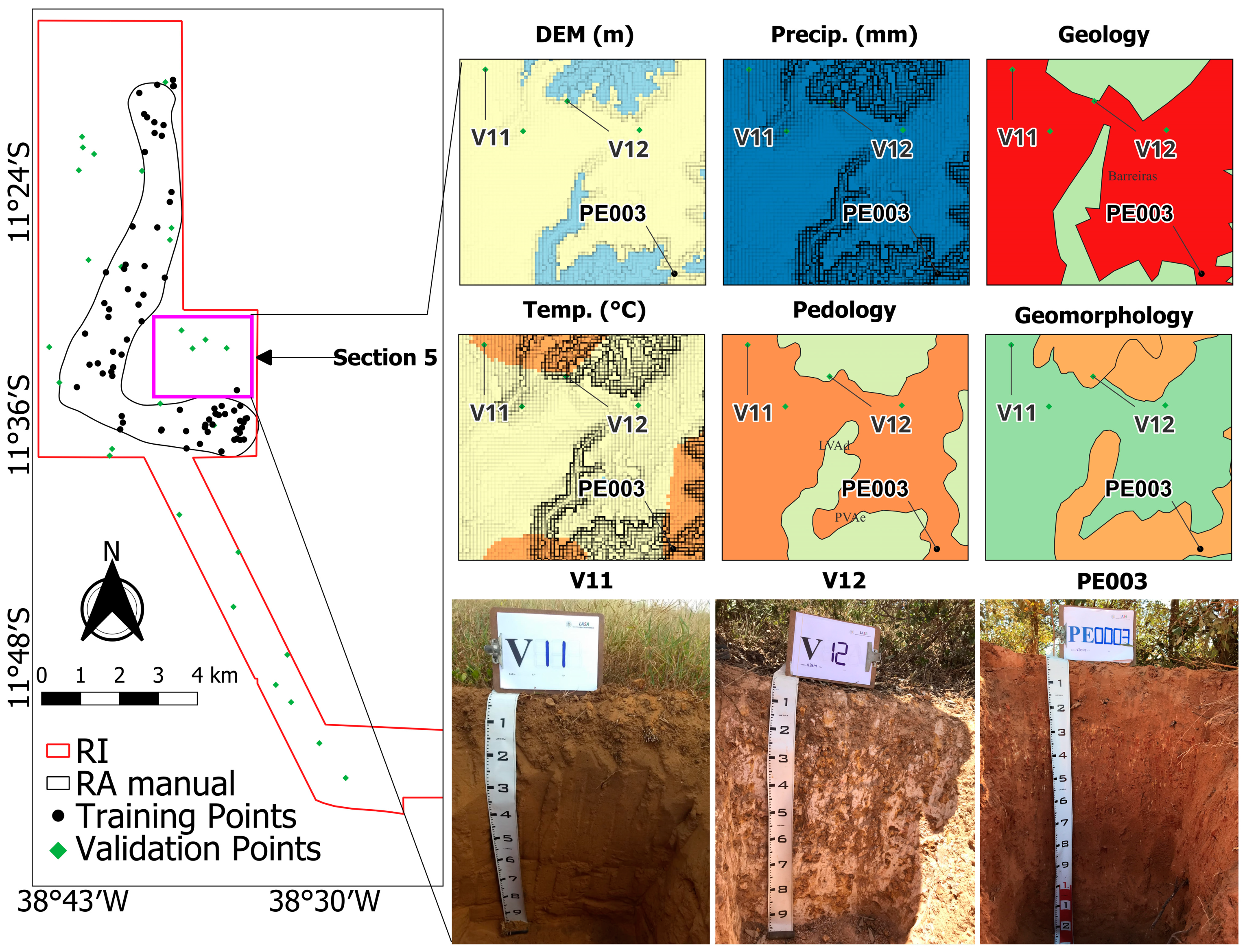
2.3. Study Area, Data Preparation, and Manual Delineation of Reference Area
2.4. Soil Sampling Regrouping and Spatial Prediction Using the Reference Area and the Total Area Dataset
2.5. Accuracy of the Mapping Unit Maps
3. Results and Discussion
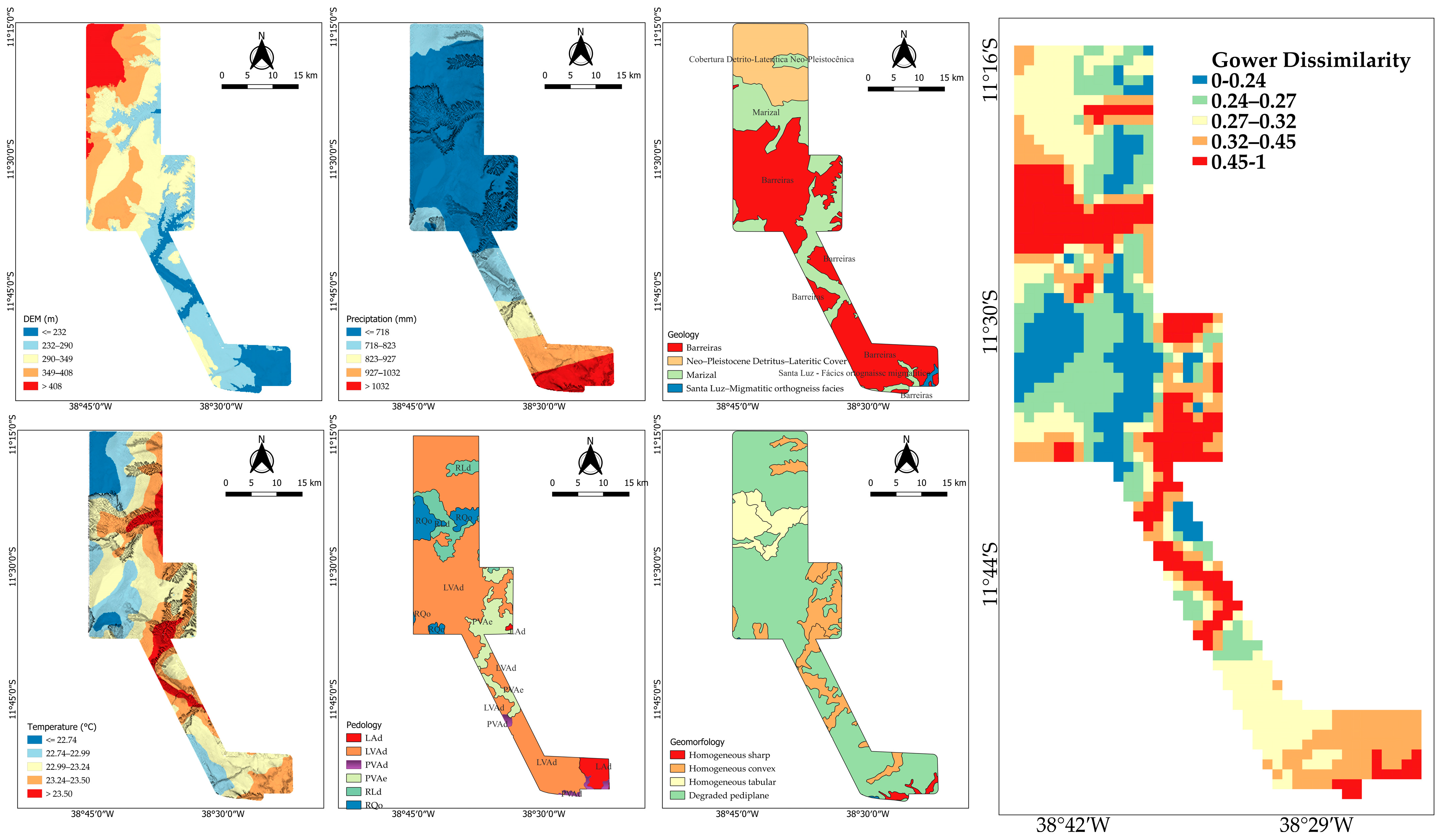
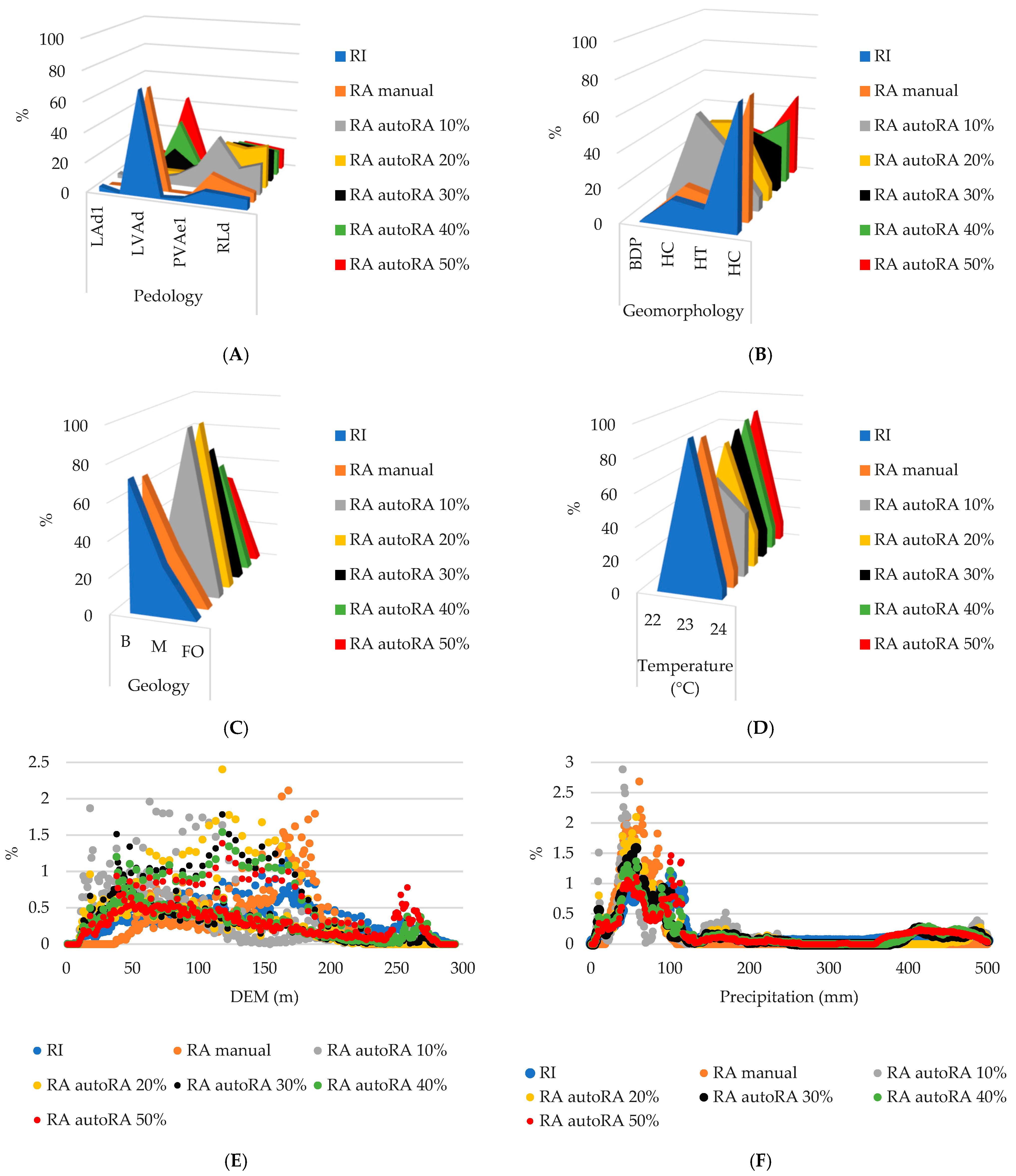
3.1. Soil Landscape Relationship and Spatial Distribution
3.2. The Gower Dissimilarity Index Map
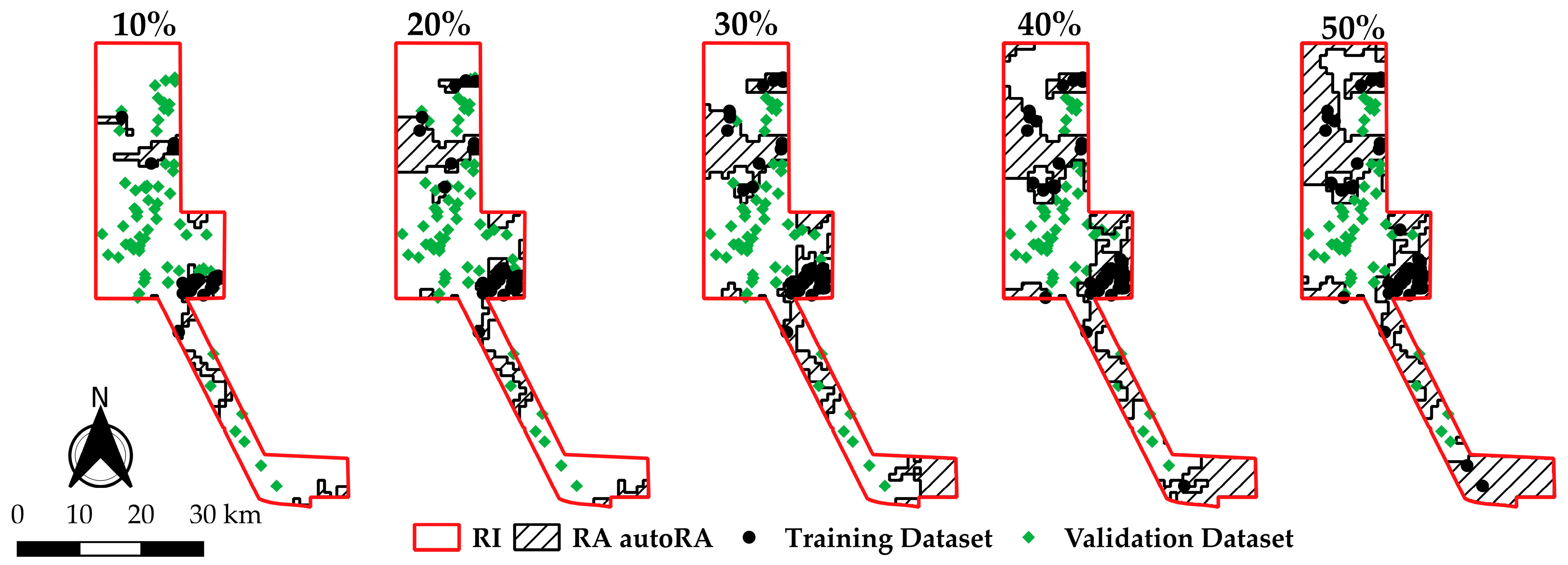
3.3. Reference Area Delineation Using autoRA and Associated Training and Validation Datasets
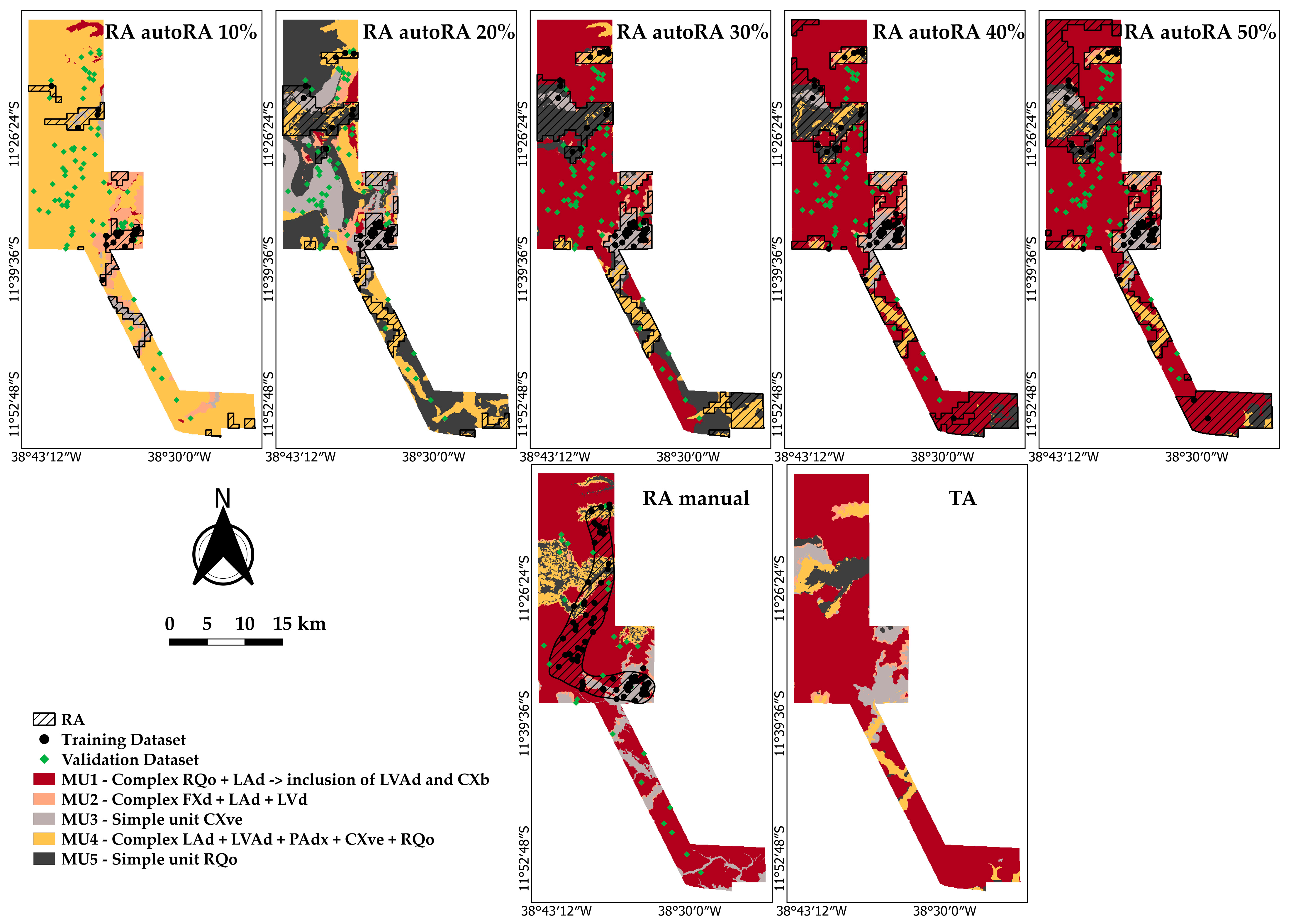
3.4. Soil Maps and Performance
3.5. Filling the Research Gap on Automatic Delineation of Reference Area in Digital Soil Mapping
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Biswas, A.; Zhang, Y. Sampling Designs for Validating Digital Soil Maps: A Review. Pedosphere 2018, 28, 1–15. [Google Scholar] [CrossRef]
- Brus, D.J. Statistical Sampling Approaches for Soil Monitoring. Eur. J. Soil Sci. 2014, 65, 779–791. [Google Scholar] [CrossRef]
- Brus, D.J.; Kempen, B.; Heuvelink, G.B.M. Sampling for Validation of Digital Soil Maps. Eur. J. Soil Sci. 2011, 62, 394–407. [Google Scholar] [CrossRef]
- Carter, M.R.; Gregorich, E.G. (Eds.) Soil Sampling and Methods of Analysis; CRC Press: Boca Raton, FL, USA, 2007; ISBN 978-0-429-12622-2. [Google Scholar]
- Khomutinin, Y.; Fesenko, S.; Levchuk, S.; Zhebrovska, K.; Kashparov, V. Optimising Sampling Strategies for Emergency Response: Soil Sampling. J. Environ. Radioact. 2020, 222, 106344. [Google Scholar] [CrossRef]
- Lagacherie, P.; Legros, J.P.; Burrough, P.A. A Soil Survey Procedure Using the Knowledge of Soil Pattern Established on a Previously Mapped Reference Area. Geoderma 1995, 65, 283–301. [Google Scholar] [CrossRef]
- Lagacherie, P.; Robbez-Masson, J.M.; Nguyen-The, N.; Barthès, J.P. Mapping of Reference Area Representativity Using a Mathematical Soilscape Distance. Geoderma 2001, 101, 105–118. [Google Scholar] [CrossRef]
- de Arruda, G.P.; Demattê, J.A.M.; Chagas, C.d.S.; Fiorio, P.R.; e Souza, A.B.; Fongaro, C.T. Digital Soil Mapping Using Reference Area and Artificial Neural Networks. Sci. Agric. 2016, 73, 266–273. [Google Scholar] [CrossRef]
- Mallavan, B.P.; Minasny, B.; McBratney, A.B. Homosoil, a Methodology for Quantitative Extrapolation of Soil Information Across the Globe. In Digital Soil Mapping; Boettinger, J.L., Howell, D.W., Moore, A.C., Hartemink, A.E., Kienast-Brown, S., Eds.; Springer: Dordrecht, The Netherlands, 2010; pp. 137–150. ISBN 978-90-481-8862-8. [Google Scholar]
- Voltz, M.; Lagacherie, P.; Louchart, X. Predicting Soil Properties over a Region Using Sample Information from a Mapped Reference Area. Eur. J. Soil Sci. 1997, 48, 19–30. [Google Scholar] [CrossRef]
- Ferreira, A.C.d.S.; Ceddia, M.B.; Costa, E.M.; Pinheiro, É.F.M.; do Nascimento, M.M.; Vasques, G.M. Use of Airborne Radar Images and Machine Learning Algorithms to Map Soil Clay, Silt, and Sand Contents in Remote Areas under the Amazon Rainforest. Remote Sens. 2022, 14, 5711. [Google Scholar] [CrossRef]
- Ferreira, A.C.S.; Pinheiro, É.F.M.; Costa, E.M.; Ceddia, M.B. Predicting Soil Carbon Stock in Remote Areas of the Central Amazon Region Using Machine Learning Techniques. Geoderma Reg. 2023, 32, e00614. [Google Scholar] [CrossRef]
- Lagacherie, P.; Voltz, M. Predicting Soil Properties over a Region Using Sample Information from a Mapped Reference Area and Digital Elevation Data: A Conditional Probability Approach. Geoderma 2000, 97, 187–208. [Google Scholar] [CrossRef]
- Lagacherie, P.; Ledreux, C.; Legros, J.-P. Modélisation de la connaissance d’un pédologue cartographe. Mappemonde 1993, 32, 12–13. [Google Scholar] [CrossRef]
- Yigini, Y.; Panagos, P. Reference Area Method for Mapping Soil Organic Carbon Content at Regional Scale. Procedia Earth Planet. Sci. 2014, 10, 330–338. [Google Scholar] [CrossRef]
- Gonçalves, T.G.; Pons, N.A.D.; Melloni, E.G.P.; Mancini, M.; Curi, N. Digital Soil Mapping: Predicting Soil Classes Distribution in Large Areas Based on Existing Soil Maps from Similar Small Areas. Ciênc. E Agrotecnologia 2021, 45, e007921. [Google Scholar] [CrossRef]
- Dornik, A.; Cheţan, M.A.; Drăguţ, L.; Dicu, D.D.; Iliuţă, A. Optimal Scaling of Predictors for Digital Mapping of Soil Properties. Geoderma 2022, 405, 115453. [Google Scholar] [CrossRef]
- Grunwald, S. Current State of Digital Soil Mapping and What Is Next. In Digital Soil Mapping: Bridging Research, Environmental Application, and Operation; Boettinger, J.L., Howell, D.W., Moore, A.C., Hartemink, A.E., Kienast-Brown, S., Eds.; Springer: Dordrecht, The Netherlands, 2010; pp. 3–12. ISBN 978-90-481-8863-5. [Google Scholar]
- Boettinger, J.L. (Ed.) Digital Soil Mapping: Bridging Research, Environmental Application, and Operation; Progress in soil science; Springer: Dordrecht, The Netherlands; London, UK, 2010; ISBN 978-90-481-8862-8. [Google Scholar]
- Horst-Heinen, T.Z.; Dalmolin, R.S.D.; ten Caten, A.; Moura-Bueno, J.M.; Grunwald, S.; Pedron, F.d.A.; Rodrigues, M.F.; Rosin, N.A.; da Silva-Sangoi, D.V. Soil Depth Prediction by Digital Soil Mapping and Its Impact in Pine Forestry Productivity in South Brazil. For. Ecol. Manag. 2021, 488, 118983. [Google Scholar] [CrossRef]
- Khaledian, Y.; Miller, B.A. Selecting Appropriate Machine Learning Methods for Digital Soil Mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Saurette, D.D.; Heck, R.J.; Gillespie, A.W.; Berg, A.A.; Biswas, A. Sample Size Optimization for Digital Soil Mapping: An Empirical Example. Land 2024, 13, 365. [Google Scholar] [CrossRef]
- Carvalho, W.D.; Pereira, N.R.; Fernandes, E.I.; Calderano, B.; Pinheiro, H.S.K.; Chagas, C.D.S.; Bhering, S.B.; Pereira, V.R.; Lawall, S. Sample Design Effects on Soil Unit Prediction with Machine: Randomness, Uncertainty, and Majority Map. Rev. Bras. Ciênc. Solo 2020, 44, e0190120. [Google Scholar] [CrossRef]
- Casa, R.; Castaldi, F.; Pascucci, S.; Basso, B.; Pignatti, S. Geophysical and Hyperspectral Data Fusion Techniques for In-Field Estimation of Soil Properties. Vadose Zone J. 2013, 12, 1–10. [Google Scholar] [CrossRef]
- Grunwald, S.; Vasques, G.M.; Rivero, R.G. Fusion of Soil and Remote Sensing Data to Model Soil Properties. In Advances in Agronomy; Elsevier: Amsterdam, The Netherlands, 2015; Volume 131, pp. 1–109. ISBN 978-0-12-802136-1. [Google Scholar]
- Ji, W.; Adamchuk, V.I.; Chen, S.; Mat Su, A.S.; Ismail, A.; Gan, Q.; Shi, Z.; Biswas, A. Simultaneous Measurement of Multiple Soil Properties through Proximal Sensor Data Fusion: A Case Study. Geoderma 2019, 341, 111–128. [Google Scholar] [CrossRef]
- Rodrigues, H.; Ceddia, M.B.; Tassinari, W.; Vasques, G.M.; Brandão, Z.N.; Morais, J.P.S.; Oliveira, R.P.; Neves, M.L.; Tavares, S.R.L. Remote and Proximal Sensors Data Fusion: Digital Twins in Irrigation Management Zoning. Sensors 2024, 24, 5742. [Google Scholar] [CrossRef] [PubMed]
- Minasny, B.; McBratney, A.B. A Conditioned Latin Hypercube Method for Sampling in the Presence of Ancillary Information. Comput. Geosci. 2006, 32, 1378–1388. [Google Scholar] [CrossRef]
- Malone, B.P.; Minansy, B.; Brungard, C. Some Methods to Improve the Utility of Conditioned Latin Hypercube Sampling. PeerJ 2019, 7, e6451. [Google Scholar] [CrossRef]
- Saurette, D.D.; Heck, R.J.; Gillespie, A.W.; Berg, A.A.; Biswas, A. Divergence Metrics for Determining Optimal Training Sample Size in Digital Soil Mapping. Geoderma 2023, 436, 116553. [Google Scholar] [CrossRef]
- de Carvalho Junior, W.; Saraiva Koenow Pinheiro, H.; Bacis Ceddia, M.; Souza Valladares, G. Pedometrics in Brazil; Springer: Cham, Switzerland, 2024; ISBN 978-3-031-64579-2. [Google Scholar]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On Digital Soil Mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- USDA/NRCS. Dynamic Soil Property Guide Version 3; USDA/NRCS: Washington, DC, USA, 2024. [Google Scholar]
- Gower, J.C. A General Coefficient of Similarity and Some of Its Properties. Biometrics 1971, 27, 857–871. [Google Scholar] [CrossRef]
- Gauld, D.B. Topological Properties of Manifolds. Am. Math. Mon. 1974, 81, 633–636. [Google Scholar] [CrossRef]
- Adams, R.A.; Fournier, J.J.F. (Eds.) 4-The Sobolev Imbedding Theorem. In Pure and Applied Mathematics; Sobolev Spaces; Elsevier: Amsterdam, The Netherlands, 2003; Volume 140, pp. 79–134. [Google Scholar]
- Ferry, S.; Weinberger, S. Quantitative Algebraic Topology and Lipschitz Homotopy. Proc. Natl. Acad. Sci. USA 2013, 110, 19246–19250. [Google Scholar] [CrossRef]
- Falconer, K.J.; Marsh, D.T. On the Lipschitz Equivalence of Cantor Sets. Mathematika 1992, 39, 223–233. [Google Scholar] [CrossRef]
- IBGE. Mapeamento de Recurso Naturais do Brasil Escala 1:250.000; Documentação Técnica Geral; Diretoria de Geociências, Coordenação de Recursos Naturais e Estudos Ambientais: Rio de Janeiro, Brazil, 2018. [Google Scholar]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-Km Spatial Resolution Climate Surfaces for Global Land Areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L.; et al. The Shuttle Radar Topography Mission. Rev. Geophys. 2007, 45, RG2004. [Google Scholar] [CrossRef]
- Bornand, M.; Favrot, J.C. Cartographie des sols et gestion de l’eau, depuis l’échelle régionale jusqu’a l’échelon parcellaire: L’exemple en France du Languedoc-Roussillon. Bull. Reseau Eros. 1998, 18, 405–418. [Google Scholar]
- Favrot, J.C. Pour Une Approche Raisoneé Du Drainage Agricole En France. La Méthode Des Secteurs de Référence. CR Académie Agric. Fr. 1981, 67, 716–723. [Google Scholar]
- Favrot, J.-C.; Lagacherie, P. La cartographie automatisee des sols: Une aide a la gestion ecologique des paysages ruraux. Comptes Rendus De L’académie D’agriculture De Fr. 1993, 79, 61–76. [Google Scholar]
- Roudier, P.; Hewitt, A.E.; Beaudette, D.E. A Conditioned Latin Hypercube Sampling Algorithm Incorporating Operational Constraints. In Digital Soil Assessments and Beyond; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Ellili, Y.; Walter, C.; Michot, D.; Pichelin, P.; Lemercier, B. Mapping Soil Organic Carbon Stock Change by Soil Monitoring and Digital Soil Mapping at the Landscape Scale. Geoderma 2019, 351, 1–8. [Google Scholar] [CrossRef]
- Keskin, H.; Grunwald, S.; Harris, W.G. Digital Mapping of Soil Carbon Fractions with Machine Learning. Geoderma 2019, 339, 40–58. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using Deep Learning for Digital Soil Mapping. SOIL 2019, 5, 79–89. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024. [Google Scholar]
- Costa, E.M.; Ceddia, M.B.; dos Santos, F.N.; Silva, L.d.O.; de Rezende, I.P.T.; Fernandes, D.A.C. Training Pedologist for Soil Mapping: Contextualizing Methods and Its Accuracy Using the Project Pedagogy Approach. Rev. Bras. Ciênc. Solo 2021, 45, 33. [Google Scholar] [CrossRef]
- Cheng, X.; Luo, Y.; Xu, X.; Sherry, R.; Zhang, Q. Soil Organic Matter Dynamics in a North America Tallgrass Prairie after 9 Yr of Experimental Warming. Biogeosciences 2011, 8, 1487–1498. [Google Scholar] [CrossRef]
- Owens, P.R.; Rutledge, E.M. MORPHOLOGY. In Encyclopedia of Soils in the Environment; Hillel, D., Ed.; Elsevier: Oxford, UK, 2005; pp. 511–520. ISBN 978-0-12-348530-4. [Google Scholar]
- Clothier, B.E.; Pollok, J.A.; Scotter, D.R. Mottling in Soil Profiles Containing a Coarse-Textured Horizon. Soil Sci. Soc. Am. J. 1978, 42, 761–763. [Google Scholar] [CrossRef]
- Ceddia, M.B.; Villela, A.L.O.; Pinheiro, É.F.M.; Wendroth, O. Spatial Variability of Soil Carbon Stock in the Urucu River Basin, Central Amazon-Brazil. Sci. Total Environ. 2015, 526, 58–69. [Google Scholar] [CrossRef]
- da Silva Freitas, L.C.; Cavalcanti, L.C.S.; Neto, J.J.F. Geoenvironmental Diagnosis of the Protected Areas of the Spix’s Macaw, Bahia. Rev. Bras. Geogr. Fis. 2024, 17, 3416–3449. [Google Scholar] [CrossRef]
- Silva, M.D.S.D.; Barreto-Garcia, P.A.B.; Monroe, P.H.M.; Pereira, M.G.; Pinto, L.A.D.S.R.; Nunes, M.R. Physically Protected Carbon Stocks in a Brazilian Oxisol under Homogeneous Forest Systems. Geoderma Reg. 2025, 40, e00915. [Google Scholar] [CrossRef]
- Junior, P.R.P.R.; Nascimento, F.R.D. Environment, geology-geomorphology and water availability in the Guandu river basin/Rio de Janeiro. William Morris Davis-Rev. Geomorfol. 2022, 3, 1–20. [Google Scholar] [CrossRef]
- Gonçalves, R.V.S.; Cardoso, J.C.F.; Oliveira, P.E.; Raymundo, D.; de Oliveira, D.C. The Role of Topography, Climate, Soil and the Surrounding Matrix in the Distribution of Veredas Wetlands in Central Brazil. Wetl. Ecol. Manag. 2022, 30, 1261–1279. [Google Scholar] [CrossRef]
- Momoli, R.S.; Cooper, M. Water Erosion on Cultivated Soil and Soil under Riparian Forest. Pesqui. Agropecu. Bras. 2016, 51, 1295–1305. [Google Scholar] [CrossRef]
- van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial Data for Landslide Susceptibility, Hazard, and Vulnerability Assessment: An Overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Fernandes, K.; Júnior, J.M.; Ribon, A.A.; de Almeida, G.M.; Moitinho, M.R.; de Lima Dias Delarica, D.; Bahia, A.S.R.d.S.; da Silva Oliveira, D.M. Characterization and Detailed Mapping of C by Spectral Sensor for Soils of the Western Plateau of São Paulo. Sci. Rep. 2024, 14, 17311. [Google Scholar] [CrossRef]
- Pereira, M.G.; Anjos, L.H.C. Formas extraíveis de ferro em solos do estado do Rio de Janeiro. Rev. Bras. Ciênc. Solo 1999, 23, 371–382. [Google Scholar] [CrossRef]
- Costa, E.M.; Rodrigues, H.M.; Ferreira, A.C.D.S.; Ceddia, M.B.; Fernandes, D.A.C. Using Legacy Soil Data to Plan New Data Collection: Study Case of Rio de Janeiro State: Brazil. In Pedometrics in Brazil; De Carvalho Junior, W., Saraiva Koenow Pinheiro, H., Bacis Ceddia, M., Souza Valladares, G., Eds.; Progress in Soil Science; Springer Nature: Cham, Switzerland, 2024; pp. 101–113. ISBN 978-3-031-64578-5. [Google Scholar]
- Neyestani, M.; Sarmadian, F.; Jafari, A.; Keshavarzi, A.; Sharififar, A. Digital Mapping of Soil Classes Using Spatial Extrapolation with Imbalanced Data. Geoderma Reg. 2021, 26, e00422. [Google Scholar] [CrossRef]
- Baruck, J.; Nestroy, O.; Sartori, G.; Baize, D.; Traidl, R.; Vrščaj, B.; Bräm, E.; Gruber, F.E.; Heinrich, K.; Geitner, C. Soil Classification and Mapping in the Alps: The Current State and Future Challenges. Geoderma 2016, 264, 312–331. [Google Scholar] [CrossRef]
- Odgers, N.P.; McBratney, A.B.; Carré, F. Soil Profile Classes. In Pedometrics; McBratney, A.B., Minasny, B., Stockmann, U., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 265–288. ISBN 978-3-319-63439-5. [Google Scholar]
- Devine, S.M.; Steenwerth, K.L.; O’Geen, A.T. A Regional Soil Classification Framework to Improve Soil Health Diagnosis and Management. Soil Sci. Soc. Am. J. 2021, 85, 361–378. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, A.-X.; Liu, J.; Ma, T.; Yang, L.; Zhou, C. An Adaptive Uncertainty-Guided Sampling Method for Geospatial Prediction and Its Application in Digital Soil Mapping. Int. J. Geogr. Inf. Sci. 2023, 37, 476–498. [Google Scholar] [CrossRef]
- Henrys, P.A.; Mondain-Monval, T.O.; Jarvis, S.G. Adaptive Sampling in Ecology: Key Challenges and Future Opportunities. Methods Ecol. Evol. 2024, 15, 1483–1496. [Google Scholar] [CrossRef]
- Huang, J.; McBratney, A.B.; Minasny, B.; Triantafilis, J. Monitoring and Modelling Soil Water Dynamics Using Electromagnetic Conductivity Imaging and the Ensemble Kalman Filter. Geoderma 2017, 285, 76–93. [Google Scholar] [CrossRef]
- Gomes, L.C.; Beucher, A.M.; Møller, A.B.; Iversen, B.V.; Børgesen, C.D.; Adetsu, D.V.; Sechu, G.L.; Heckrath, G.J.; Koch, J.; Adhikari, K.; et al. Soil Assessment in Denmark: Towards Soil Functional Mapping and Beyond. Front. Soil Sci. 2023, 3, 1090145. [Google Scholar] [CrossRef]
- Zhang, Y.; Saurette, D.D.; Easher, T.H.; Ji, W.; Adamchuk, V.I.; Biswas, A. Comparison of Sampling Designs for Calibrating Digital Soil Maps at Multiple Depths. Pedosphere 2022, 32, 588–601. [Google Scholar] [CrossRef]
- Abdulraheem, M.I.; Zhang, W.; Li, S.; Moshayedi, A.J.; Farooque, A.A.; Hu, J. Advancement of Remote Sensing for Soil Measurements and Applications: A Comprehensive Review. Sustainability 2023, 15, 15444. [Google Scholar] [CrossRef]
- Zhou, Y.; Biswas, A.; Hong, Y.; Chen, S.; Hu, B.; Shi, Z.; Li, S. Enhancing Soil Profile Analysis with Soil Spectral Libraries and Laboratory Hyperspectral Imaging. Geoderma 2024, 450, 117036. [Google Scholar] [CrossRef]
- Khosravani, P.; Baghernejad, M.; Taghizadeh-Mehrjardi, R.; Mousavi, S.R.; Moosavi, A.A.; Fallah Shamsi, S.R.; Shokati, H.; Kebonye, N.M.; Scholten, T. Assessing the Role of Environmental Covariates and Pixel Size in Soil Property Prediction: A Comparative Study of Various Areas in Southwest Iran. Land 2024, 13, 1309. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
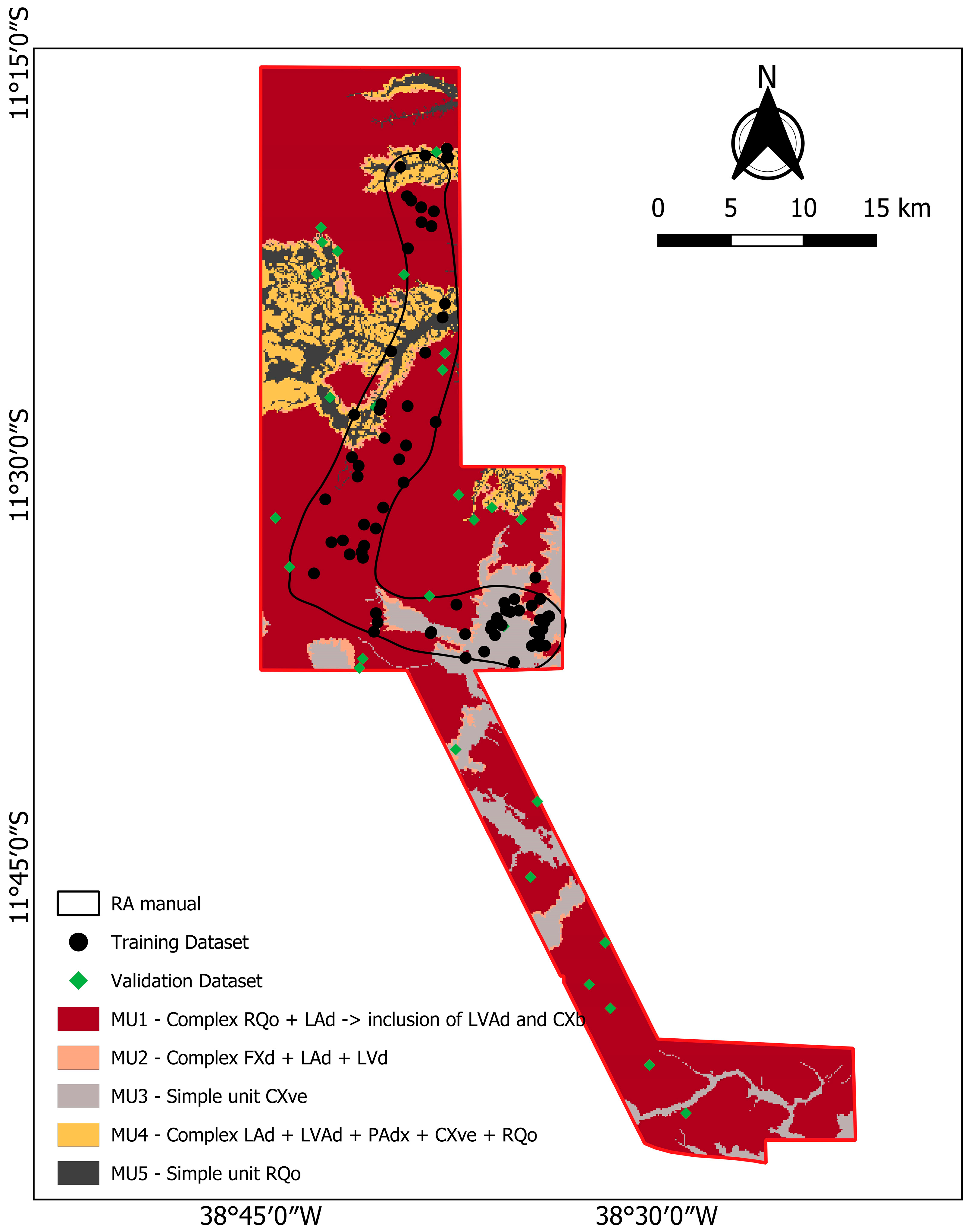
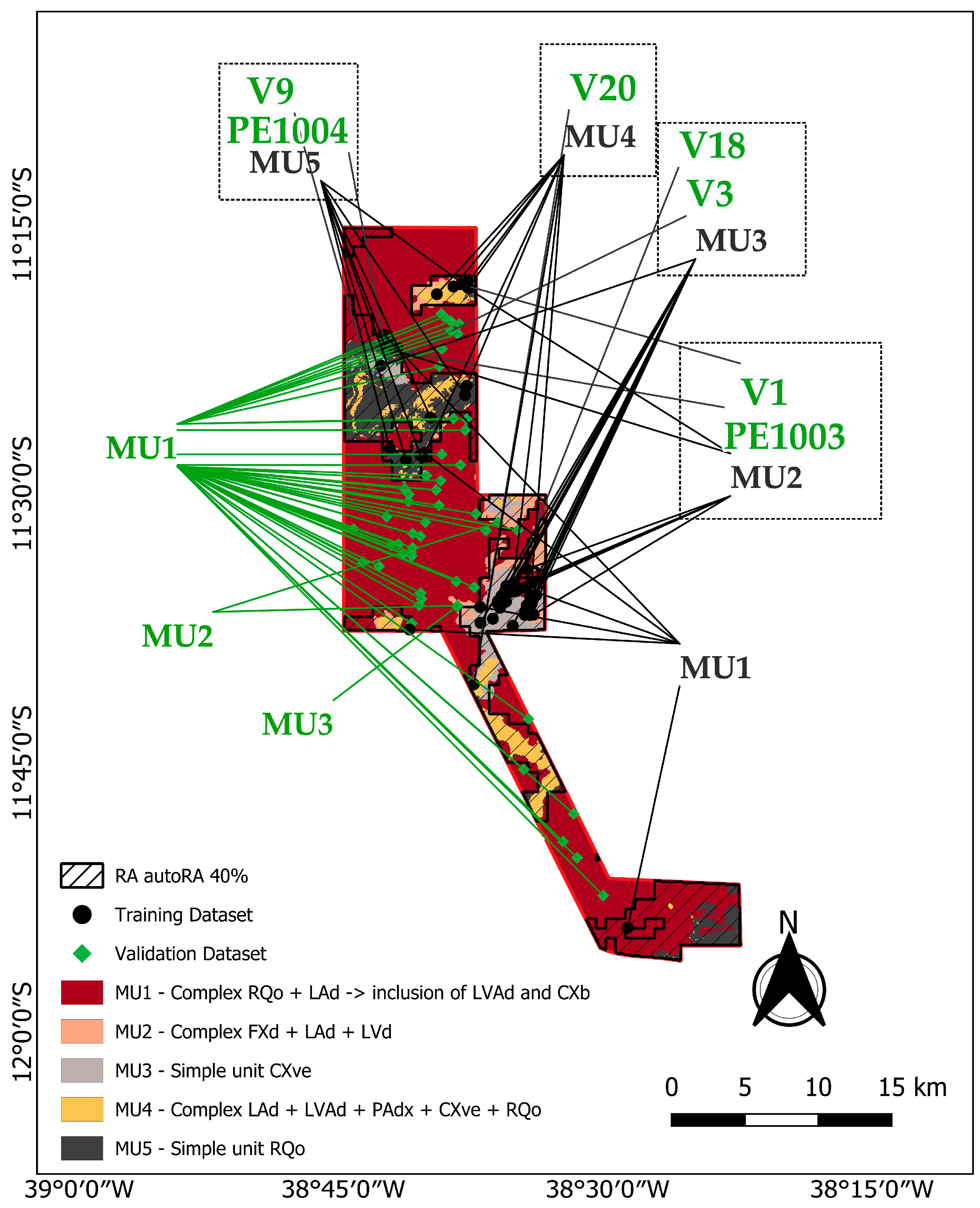
| MU | Description | Environment | Area (km2) | % | Brazilian Soil Classification System | USDA Soil Taxonomy Correspondence |
|---|---|---|---|---|---|---|
| MU1 | Complex RQo + LAd + CXbd | Plateau, flat to gently undulating relief | 636.92 | 71 | NEOSSOLO QUARTZARÊNICO Órtico típico, LATOSSOLO AMARELO Distrófico textura média, CAMBISSOLO HÁPLICO Tb Distrófico, textura média-arenosa, A moderado | RQo: Entisols (Typic Quartzipsamments); LAd: Oxisols (Typic Hapludox); CXbd: Inceptisols (Typic Dystrudepts) |
| MU2 | Complex FXd + LAd + LVd | Upper and middle slopes of plateaus | 28.49 | 3 | PLINTOSSOLO HÁPLICO Distrófico petroplíntico, LATOSSOLO AMARELO Distrófico petroplíntico, A moderado, fase epipedregoso, Inclusão de LATOSSOLO VERMELHO Distrófico textura média | FXd: Inceptisols (Aquic Dystrudepts); LAd: Oxisols (Petroplinthic Haplustox); LVd: Oxisols (Typic Hapludox) |
| MU3 | Simple unit CXve | Hills with lower elevation than plateaus (Center of Sátiro Dias) | 95.45 | 11 | CAMBISSOLO HÁPLICO Ta Eutrófico típico, textura média-argilosa, Inclusões: LUVISSOLO HÁPLICO Pálico típico, VERTISSOLO HÁPLICO Sódico | CXve: Inceptisols (Typic Eutrudepts); Luvisolo: Alfisols (Typic Haplustalfs); Vertissolo: Vertisols (Typic Haplusterts) |
| MU4 | Complex LAd + LVAd + PAdx + CXve + RQo | Hill regions within canyons | 78.04 | 8 | LATOSSOLO AMARELO Distrófico textura média, LATOSSOLO VERMELHO-AMARELO Distrófico textura média, ARGISSOLO AMARELO Distrófico petroplíntico, CAMBISSOLO HÁPLICO Ta Eutrófico típico, textura média-argilosa, NEOSSOLO QUARTZARÊNICO Órtico típico | LAd: Oxisols (Typic Haplustox); LVAd: Oxisols (Typic Kandiudox); PAdx: Alfisols (Plinthic Kandiustalfs); CXve: Inceptisols (Typic Eutrudepts); RQo: Entisols (Typic Quartzipsamments) |
| MU5 | Simple unit RQo | Lowlands within canyons (north of Sátiro Dias) | 61.82 | 7 | NEOSSOLO QUARTZARÊNICO Órtico típico, textura muito arenosa, A fraco | RQo: Entisols (Typic Quartzipsamments) |
| TOTAL | - | - | 900.72 | 100 | - | - |
| N Training | N Validation | Accuracy | Kappa | |
|---|---|---|---|---|
| RA manual | 74 | 28 | 0.75 | 0.50 |
| RA autoRA 10% | 22 | 72 | 0.14 | 0.06 |
| RA autoRA 20% | 38 | 64 | 0.11 | 0.01 |
| RA autoRA 30% | 43 | 59 | 0.85 | 0.42 |
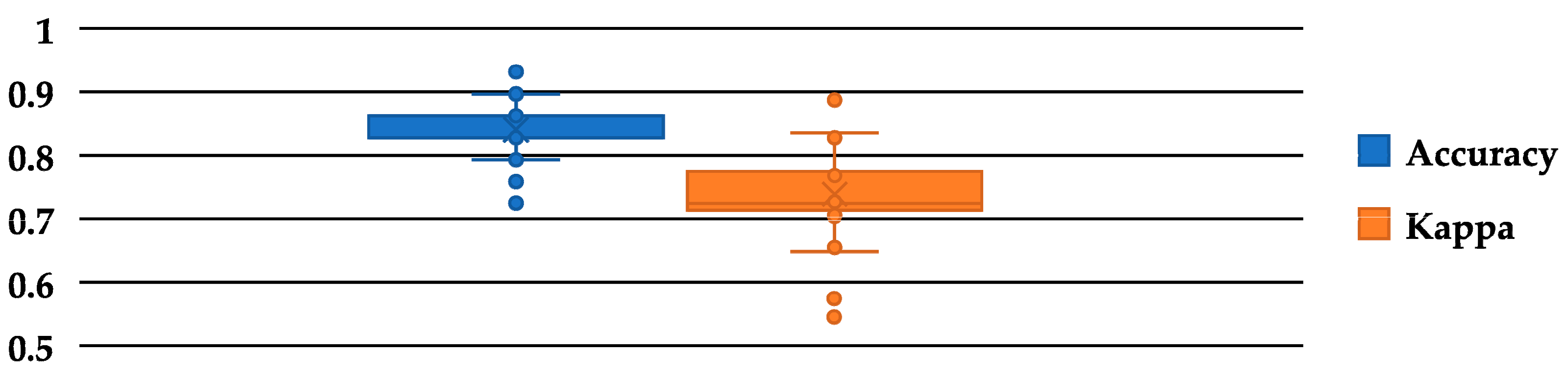
| RA autoRA 40% | 51 | 51 | 0.96 | 0.65 |
| RA autoRA 50% | 53 | 49 | 0.96 | 0.49 |
| TA | 74 | 28 | 0.84 | 0.74 |
| RA manual | ||||||||||
| Reference | MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI |
| MU1 | 19 | 0 | 0 | 0 | 1 | 20 | 0.95 | 636.96 | 0.71 | 0.00 |
| MU2 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 28.6 | ||
| MU3 | 0 | 0 | 1 | 1 | 0 | 2 | 0.5 | 95.29 | ||
| MU4 | 0 | 2 | 1 | * | 2 | 5 | --- | 78.1 | ||
| MU5 | 0 | 0 | 0 | 0 | * | 0 | --- | 62.12 | ||
| Total | 19 | 3 | 2 | 1 | 3 | 28 | --- | |||
| Producer’s Accuracy | 1 | 0.33 | 0.5 | 0 | 0 | --- | --- | |||
| AR autoRA 10% | ||||||||||
| Reference | MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI |
| MU1 | * | 0 | 0 | 0 | 53 | 53 | * | 14.89 | 0.76 | 0.00 |
| MU2 | 0 | * | 0 | 0 | 0 | 0 | * | 96.42 | ||
| MU3 | 0 | 0 | 7 | 0 | 1 | 8 | 0.95 | 29.79 | ||
| MU4 | 1 | 0 | 2 | * | 4 | 7 | * | 746.44 | ||
| MU5 | 1 | 0 | 0 | 0 | 3 | 4 | 0.95 | 0 | ||
| Total | 2 | 0 | 9 | 0 | 61 | 72 | --- | |||
| Producer’s Accuracy | * | * | 0.78 | * | 0.05 | --- | --- | |||
| AR autoRA 20% | ||||||||||
| Reference | MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI |
| MU1 | 4 | 4 | 18 | 13 | 14 | 53 | 0.08 | 26.55 | 0.03 | 0.59 |
| MU2 | 1 | * | 2 | 1 | 1 | 5 | * | 33.58 | ||
| MU3 | 0 | 2 | * | 0 | 0 | 2 | * | 193.41 | ||
| MU4 | 0 | 0 | 0 | 1 | 1 | 2 | 0.5 | 228.04 | ||
| MU5 | 0 | 0 | 0 | 0 | 2 | 2 | 1 | 405.96 | ||
| Total | 5 | 6 | 20 | 15 | 18 | 64 | --- | |||
| Producer’s Accuracy | 0.95 | * | * | 0.07 | 0.11 | --- | --- | |||
| AR autoRA 30% | ||||||||||
| Reference | MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI |
| MU1 | 48 | 0 | 0 | 0 | 4 | 52 | 0.92 | 506.48 | 0.59 | 0.46 |
| MU2 | 1 | 1 | 0 | 0 | 1 | 3 | 0.33 | 33.18 | ||
| MU3 | 0 | 2 | * | 0 | 0 | 2 | * | 60.05 | ||
| MU4 | 0 | 0 | 0 | * | 1 | 1 | * | 96.09 | ||
| MU5 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 191.74 | ||
| Total | 49 | 3 | 0 | 0 | 7 | 59 | --- | |||
| Producer’s Accuracy | 0.98 | 0.33 | * | * | 0.14 | --- | --- | |||
| AR autoRA 40% | ||||||||||
| Reference | MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI |
| MU1 | 48 | 0 | 0 | 0 | 0 | 48 | 1 | 637.68 | 0.76 | 0.22 |
| MU2 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 39.57 | ||
| MU3 | 0 | 2 | * | 0 | 0 | 2 | * | 58.23 | ||
| MU4 | 0 | 0 | 0 | * | 0 | 0 | * | 56.95 | ||
| MU5 | 0 | 0 | 0 | 0 | * | 0 | * | 95.11 | ||
| Total | 48 | 3 | 0 | 0 | 0 | 49 | --- | |||
| Producer’s Accuracy | 1 | 0.33 | * | * | * | --- | --- | |||
| AR autoRA 50% | ||||||||||
| Reference | MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI |
| MU1 | 47 | 0 | 0 | 0 | 0 | 47 | 1 | 631.64 | 0.76 | 0.00 |
| MU2 | 0 | * | 0 | 0 | 0 | 0 | * | 43.36 | ||
| MU3 | 0 | 2 | * | 0 | 0 | 2 | * | 58.95 | ||
| MU4 | 0 | 0 | 0 | * | 0 | 0 | * | 78.35 | ||
| MU5 | 0 | 0 | 0 | 0 | * | 0 | * | 75.24 | ||
| Total | 47 | 2 | 0 | 0 | 0 | 49 | --- | |||
| Producer’s Accuracy | 1 | * | * | * | * | --- | --- | |||
| Total Area | ||||||||||
| MU1 | MU2 | MU3 | MU4 | MU5 | Total | User’s Accuracy | Area (km2) | WPAI | WUAI | |
| MU1 | 16 | 0 | 0 | 0 | 0 | 16 | 1 | 652.88 | 0.84 | 0.00 |
| MU2 | 0 | * | 0 | 0 | 0 | 0 | * | 27.19 | ||
| MU3 | 0 | 2 | 7 | 0 | 1 | 10 | 0.70 | 80.9 | ||
| MU4 | 0 | 0 | 0 | 1 | 1 | 2 | 0.5 | 69.96 | ||
| MU5 | 0 | 0 | 0 | 1 | * | 1 | * | 56.61 | ||
| Total | 16 | 2 | 7 | 2 | 2 | 29 | --- | |||
| Producer’s Accuracy | 1 | * | 1 | 0.5 | * | --- | --- | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodrigues, H.; Ceddia, M.B.; Vasques, G.M.; Grunwald, S.; Babaeian, E.; Villela, A.L.O. autoRA: An Algorithm to Automatically Delineate Reference Areas—A Case Study to Map Soil Classes in Bahia, Brazil. Land 2025, 14, 604. https://doi.org/10.3390/land14030604
Rodrigues H, Ceddia MB, Vasques GM, Grunwald S, Babaeian E, Villela ALO. autoRA: An Algorithm to Automatically Delineate Reference Areas—A Case Study to Map Soil Classes in Bahia, Brazil. Land. 2025; 14(3):604. https://doi.org/10.3390/land14030604
Chicago/Turabian StyleRodrigues, Hugo, Marcos Bacis Ceddia, Gustavo Mattos Vasques, Sabine Grunwald, Ebrahim Babaeian, and André Luis Oliveira Villela. 2025. "autoRA: An Algorithm to Automatically Delineate Reference Areas—A Case Study to Map Soil Classes in Bahia, Brazil" Land 14, no. 3: 604. https://doi.org/10.3390/land14030604
APA StyleRodrigues, H., Ceddia, M. B., Vasques, G. M., Grunwald, S., Babaeian, E., & Villela, A. L. O. (2025). autoRA: An Algorithm to Automatically Delineate Reference Areas—A Case Study to Map Soil Classes in Bahia, Brazil. Land, 14(3), 604. https://doi.org/10.3390/land14030604