

Optimal Regional Allocation of Future Population and Employment under Urban Boundary and Density Constraints: A Spatial Interaction Modeling Approach


Abstract
1. Introduction
1.1. Historical Overview of Urban Modeling
1.2. Spatial Interaction Modeling: Structure and Variables
1.3. Planning Optimization Models and Spatial Interaction Modeling
1.4. Sprawl versus Compact City: Cost Assessment
1.5. Summary and Research Goals
- Develop a new SIM for commuting trip distribution, based on Tobit regression estimation [49] and including spatial structure variables measured by competing destinations (CD) [5] and intervening opportunity (IO) [6] factors. It is expected that incorporating these factors will better represent commuting behavior and commuting costs.
- Using the Tobit commuting SIM, develop a new commuting cost minimization model that simultaneously allocates target increments in the population and employment to geographical units across a city or metropolitan area under various scenarios of (a) population and employment densities (land consumption per resident and per employee) and (b) land availability in each geographical unit, as determined by the growth boundaries and environmental constraints. The results of this optimization include a minimum commuting cost surface, which is then to be estimated by polynomial regression, with the densities as independent variables.
- Combining the polynomial commuting cost model with estimated land development cost models and synthetic congestion cost models, develop a total cost minimization model to determine the optimal densities under various growth boundary scenarios and various parametric assumptions for the congestion cost functions.
- Use data on a specific U.S. metropolitan area to test the feasibility of the above-methodological goals. This would be a proof-of-concept goal, but is not intended to provide an actual plan for the local authorities of this metropolitan area.
2. Data and Methods
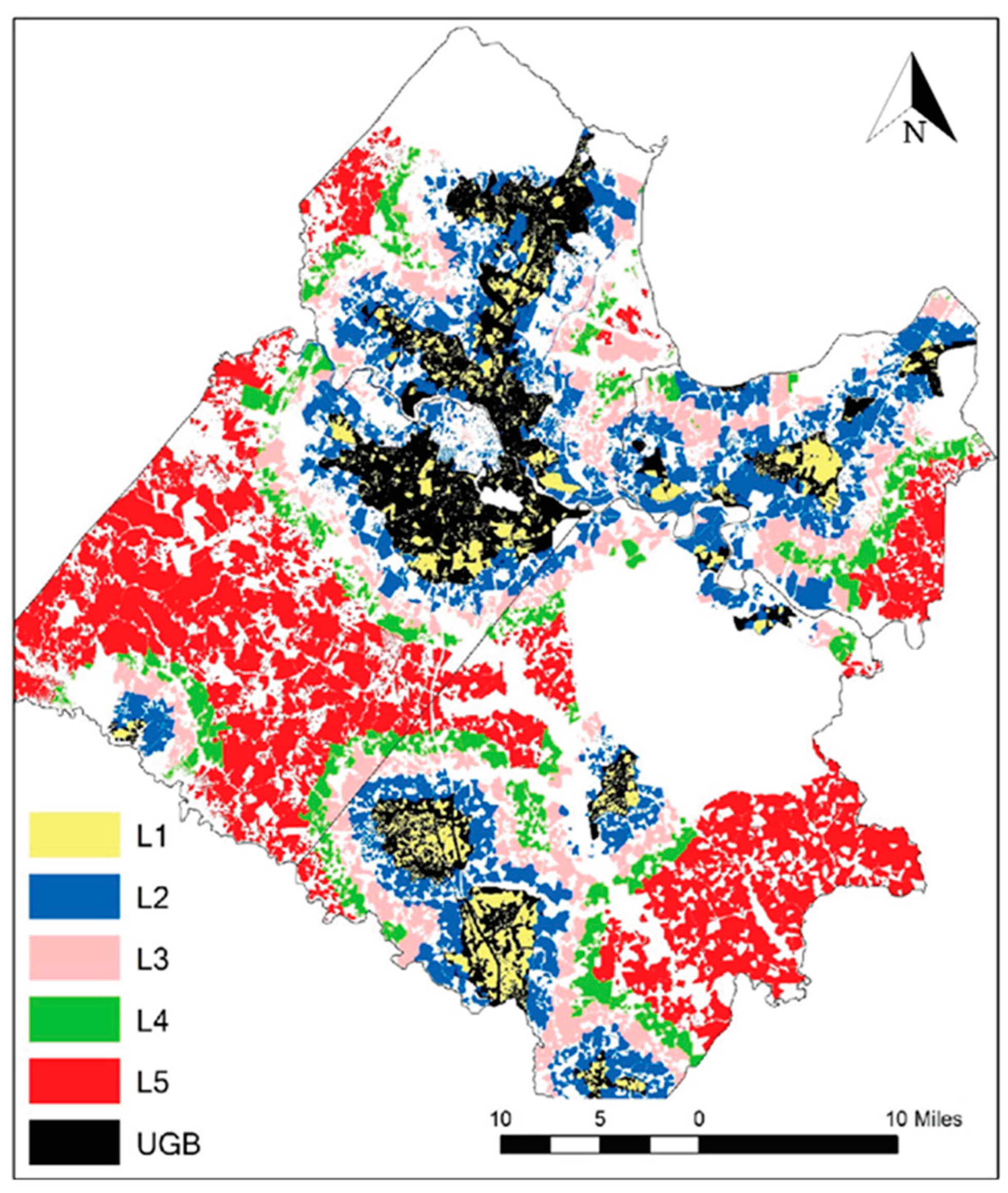
2.1. Overview of the Study Area
2.2. Data Sources
2.2.1. CTPP 2000
2.2.2. Property Data
- Real Estate Taxes|Fredericksburg, VA—Official Website (fredericksburgva.gov);
- Stafford County, VA (staffordcountyva.gov);
- Assessment Office, Spotsylvania County, VA; Real Estate, Caroline County, VA;
- Real Estate, King George County, VA (kinggeorgecountyva.gov).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Residential Property | Workplace Property | |||||||
|---|---|---|---|---|---|---|---|---|
| Jurisdiction | Average Size (Acre) | Average Property Value (USD) | Average Land Value (USD) | Average Building Value (USD) | Average Size (Acre) | Average Property Value (USD) | Average Land Value (USD) | Average Building Value (USD) |
| Caroline | 2.3658 | 220,462 | 47,598 | 162,618 | 5.3395 | 576,642 | 144,972 | 304,321 |
| Fredericksburg | 0.3525 | 260,831 | 53,914 | 178,740 | 1.2749 | 945,372 | 388,820 | 506,586 |
| King George | 3.2624 | 245,225 | 72,054 | 167,082 | 4.5400 | 517,810 | 196,227 | 271,619 |
| Spotsylvania | 1.3127 | 147,640 | 65,580 | 82,059 | 14.0769 | 3,717,248 | 3,330,981 | 386,267 |
| Stafford | 1.1375 | 372,153 | 102,621 | 269,531 | 3.3182 | 1,241,485 | 479,788 | 761,687 |
| FAMPO | 1.4254 | 247,782 | 77,390 | 167,696 | 8.3923 | 2,309,510 | 1,809,006 | 481,376 |
2.3. Variables
2.3.1. Dependent Variable
2.3.2. Independent Variables
Group A
- -
- Percentage of workers driving alone from their residence (P_DA_RES);
- -
- Percentage of workers carpooling from their residence (P_CP_RES);
- -
- Percentage of male workers driving alone from their residence (P_MDA_RES);
- -
- Percentage of male workers carpooling from their residence (P_MCP_RES).
- -
- Percentage of residents in sales or service occupations (P_OCC1_RES);
- -
- Percentage of residents in clerical or administrative support occupations (P_OCC2_RES);
- -
- Percentage of residents in manufacturing, construction, or maintenance occupations (P_OCC3_RES);
- -
- Percentage of residents in professional, managerial, or technical occupations (P_OCC4_RES);
- -
- Percentage of male residents in sales or service occupations (P_MOCC1_RES);
- -
- Percentage of male residents in clerical or administrative support occupations (P_MOCC2_RES);
- -
- Percentage of male residents in manufacturing, construction, or maintenance occupations (P_MOCC3_RES);
- -
- Percentage of male residents in professional, managerial, or technical occupations (P_MOCC4_RES).
- -
- Percentage of Hispanic or Latino residents (P_HIS_RES);
- -
- Percentage of White residents (P_WHT_RES);
- -
- Percentage of Black or African American residents (P_BLK_RES).
- -
- Percentage of resident households with an income of USD 75,000 or more in 1999 (P_HINC_RES);
- -
- Median resident household income (MHI_RES);
- -
- Percentage of resident workers with high earnings (USD 50,000+) in 1999 (P_HERN_RES);
- -
- Percentage of resident workers below the poverty level in 1999 (P_POV_RES);
- -
- Percentage of households with self-owned housing (P_OWNSELF_RES);
- -
- Percentage of households with owned housing with and without a mortgage (P_OWN_RES).
Group B
- -
- Percentage of employees below the poverty level (P_BlwPov_EMP);
- -
- Mean travel time (MTT_EMP);
- -
- Percentage of workers with low earnings (P_LERN_EMP);
- -
- Percentage of workers that carpool (P_CarPool_EMP).
- -
- Percentage of workers in manufacturing (P_Mfg_EMP);
- -
- Percentage of workers in wholesale trade (P_WhlTrd_EMP);
- -
- Percentage of workers in retail trade (P_RetTrd_EMP);
- -
- Percentage of workers in service industries (P_serv_EMP);
- -
- Percentage of workers in public administration (P_Pub_EMP).
Group C
Group D
2.4. Statistical and Optimization Methodology
| TOTAL COST = commuting cost (TCOM) |
| + land development cost (LDC) |
| + congestion cost (TCON) |
3. Results
3.1. Tobit Regression
3.2. Minimizing Commuting Costs in the Allocation of Population and Employment
3.2.1. Scenarios
- ULP: (0.10–0.50) by 0.05 increments
- ULE: (0.05–0.25) by 0.025 increments
3.2.2. Model Formulation
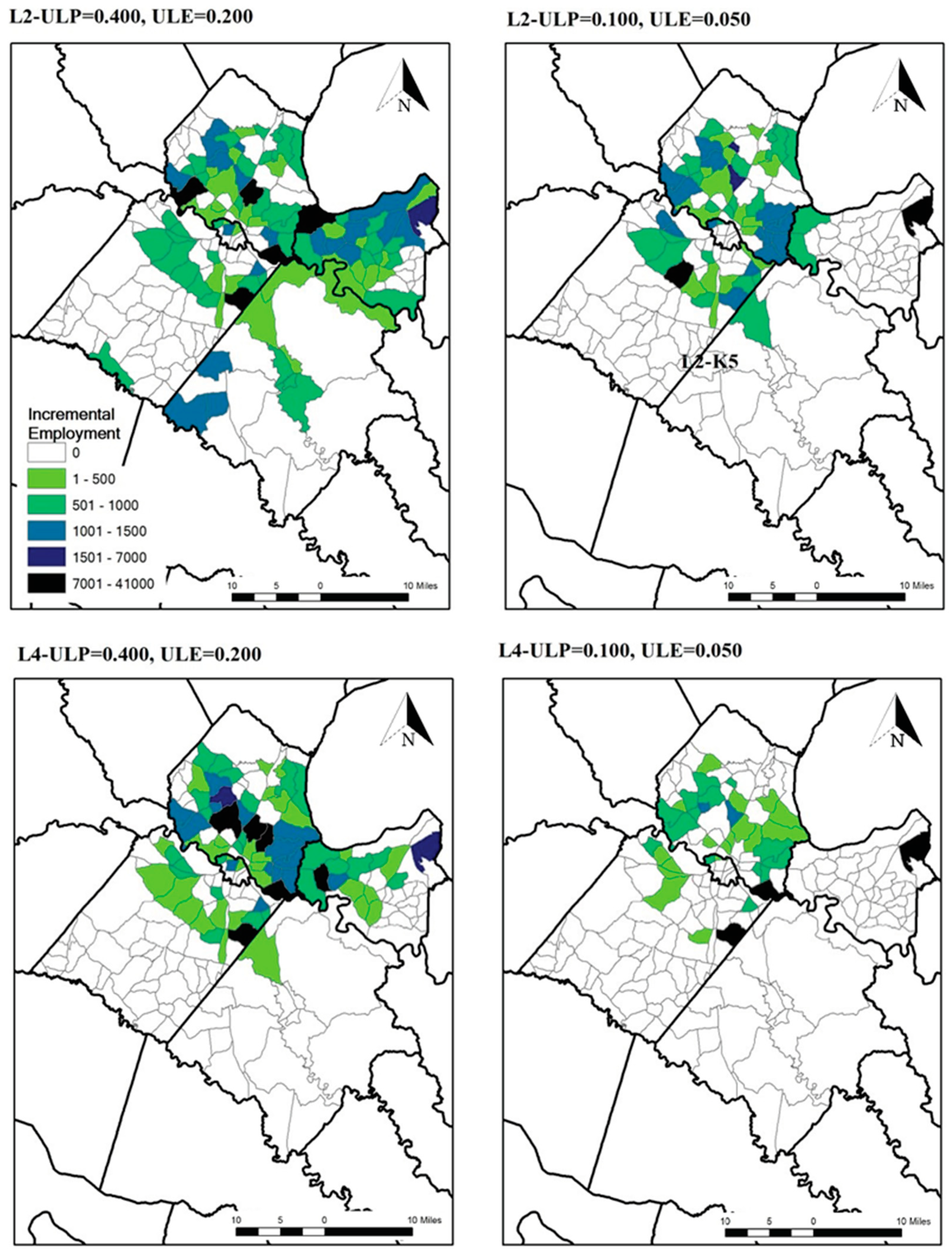
3.2.3. Optimization Results
3.3. Minimizing All Costs in the Allocation of Population and Employment
3.3.1. Overview of Costs
3.3.2. Estimation of the Commuting Cost Surface
3.3.3. Estimation of Land Development Costs
acreage; employees)
- IR = average mortgage interest rate over 1997~2006 = 6.71% = 0.0671
- N = number of periods = 30 years (normal mortgage payment period)
3.3.4. Congestion Cost Synthetic Functions
3.3.5. Total Development Cost Minimization
- K1 = 0.1, 0.3, 0.5;
- K2 = 0.1, 0.3, 0.5;
- b = 1.0, 3.0, 5.0;
- d = 1.0, 3.0, 5.0.
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lowry, I.S. A Model of Metropolis; Rand Corporation: Santa Monica, CA, USA, 1964. [Google Scholar]
- Anas, A. Discrete choice theory, information theory and the multinomial logit and gravity models. Transp. Res. Part B Methodol. 1983, 17, 13–23. [Google Scholar] [CrossRef]
- Sen, A.; Smith, T. Gravity Models of Spatial Interaction Behaviour; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Nijkamp, P.; Ratajczak, W. Gravitational Analysis in Regional Science and Spatial Economics: A Vector Gradient Approach to Trade. Int. Reg. Sci. Rev. 2020, 44, 400–431. [Google Scholar] [CrossRef]
- Fotheringham, A.S. A new set of spatial-interaction models: The theory of competing destinations. Environ. Plan. A 1983, 15, 15–36. [Google Scholar] [CrossRef]
- Stouffer, S.A. Intervening opportunities and competing migrants. J. Reg. Sci. 1960, 2, 1–26. [Google Scholar] [CrossRef]
- Gitlesen, J.P.; Thorsen, I. A Competing Destinations Approach to Modeling Commuting Flows: A Theoretical Interpretation and An Empirical Application of the Model. Environ. Plan. A Econ. Space 2000, 32, 2057–2074. [Google Scholar] [CrossRef]
- Sirmans, C.F. Determinants of journey to work flows: Some empirical evidence. Ann. Reg. Sci. 1977, 11, 98–108. [Google Scholar] [CrossRef]
- Sandow, E. Commuting behaviour in sparsely populated areas: Evidence from northern Sweden. J. Transp. Geogr. 2008, 16, 14–27. [Google Scholar] [CrossRef]
- Sermons, M.; Koppelman, F.S. Representing the differences between female and male commute behavior in residential location choice models. J. Transp. Geogr. 2001, 9, 101–110. [Google Scholar] [CrossRef]
- Prashker, J.; Shiftan, Y.; Hershkovitch-Sarusi, P. Residential choice location, gender and the commute trip to work in Tel Aviv. J. Transp. Geogr. 2008, 16, 332–341. [Google Scholar] [CrossRef]
- O’Kelly, M.E.; Niedzielski, M.A.; Gleeson, J. Spatial interaction models from Irish commuting data: Variations in trip length by occupation and gender. J. Geogr. Syst. 2012, 14, 357–387. [Google Scholar] [CrossRef]
- Lin, D.; Allan, A.; Cui, J. The impacts of urban spatial structure and socio-economic factors on patterns of commuting: A review. Int. J. Urban Sci. 2015, 19, 238–255. [Google Scholar] [CrossRef]
- So, K.S.; Orazem, P.F.; Otto, D.M. The effects of housing prices, wages, and commuting time on joint residential and job location choices. Am. J. Agric. Econ. 2001, 83, 1036–1048. [Google Scholar] [CrossRef]
- Wu, K.-L. Employment and Housing Development and Their Impacts on Metropolitan Commuting: An Empirical Study of the Development of the Silicon Valley Region of the San Francisco Bay Area. Ph.D. Thesis, City and Regional Planning. University of California at Berkeley, Berkeley, CA, USA, 1997. [Google Scholar]
- Glenn, P.T.I.; Ubøe, J. Wage payoffs and distance deterrence in the journey to work. Transp. Res. Part B 2004, 38, 853–867. [Google Scholar] [CrossRef]
- Ahrens, A.; Lyons, S. Do rising rents lead to longer commutes? A gravity model of commuting flows in Ireland. Urban Stud. 2020, 58, 264–279. [Google Scholar] [CrossRef]
- Sohn, J. Are commuting patterns a good indicator of urban spatial structure? J. Transp. Geogr. 2005, 13, 306–317. [Google Scholar] [CrossRef]
- Wilson, A.G.; Coelho, J.D.; Macgill, S.M.; Williams, H.C.W.L. Optimization in Locational and Transport Analysis; John Wiley: New York, NY, USA, 1981. [Google Scholar]
- Kim, T.J. Alternative transportation modes in an urban land use model: A general equilibrium approach. J. Urban Econ. 1979, 6, 197–215. [Google Scholar] [CrossRef]
- Boyce, D.E.; Lundqvist, L. Network equilibrium models of urban location and travel choices: Alternative formulations for the stockholm region. Pap. Reg. Sci. 2005, 61, 93–104. [Google Scholar] [CrossRef]
- Kim, T.J. Integrated Urban System modeling: Theory and Practice; Martinus Nijhoff: Norwell, MA, USA, 1989. [Google Scholar]
- Prastacos, P. An integrated land-use-transportation model for the San Francisco Region: 1. Design and mathematical structure. Environ. Plan. A 1986, 18, 307–322. [Google Scholar] [CrossRef]
- Prastacos, P. An integrated land-use-transportation model for the San Francisco Region: 2. Empirical estimation and results. Environ. Plan. A 1986, 18, 511–528. [Google Scholar] [CrossRef]
- Caindec, E.K.; Prastacos, P. A Description of POLIS. The Projective Optimization Land Use Information System; Working Paper 95-1; Association of Bay Area Governments: Oakland, CA, USA, 1995. [Google Scholar]
- Barber, G.M. Urban population distribution planning. Ann. Assoc. Am. Geogr. 1977, 67, 239–245. [Google Scholar] [CrossRef]
- Garin, R. A matrix formulation of the lowry model for intrametropolitan activity allocation. J. Am. Inst. Plan. 1966, 32, 361–364. [Google Scholar] [CrossRef]
- Barber, G.M. Locating employment growth in urban areas to minimize travel time. Prof. Geogr. 1978, 30, 149–155. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, Y.; Sun, C. Optimization and Application of Integrated Land Use and Transportation Model in Small- and Medium-Sized Cities in China. Sustainability 2019, 11, 2555. [Google Scholar] [CrossRef]
- Samani, A.R.; Mishra, S.; Lee, D.J.-H.; Golias, M.M.; Everett, J. A new approach to develop large-scale land-use models using publicly available data. Environ. Plan. B Urban Anal. City Sci. 2021, 49, 169–187. [Google Scholar] [CrossRef]
- Putnam, S.H. Integrated Urban Models: Policy Analysis of Transportation and Land Use; Pion Limited: London, UK, 1983. [Google Scholar]
- Wu, J.; Yi, T.; Wang, H.; Wang, H.; Fu, J.; Zhao, Y. Evaluation of Medical Carrying Capacity for Megacities from a Traffic Analysis Zone View: A Case Study in Shenzhen, China. Land 2022, 11, 888. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, C.; Sun, D.; Qian, Y. The influence of the spatial pattern of urban road networks on the quality of business environments: The case of Dalian City. Environ. Dev. Sustain. 2021, 24, 9429–9446. [Google Scholar] [CrossRef]
- Yuan, M.; Liu, Y.; He, J.; Liu, D. Regional land-use allocation using a coupled MAS and GA model: From local simulation to global optimization, a case study in Caidian District, Wuhan, China. Cartogr. Geogr. Inf. Sci. 2014, 41, 363–378. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, Y.; Wang, X.; Lin, Q.; Li, L. A new approach to land use optimization and simulation considering urban development sustainability: A case study of Bortala, China. Sustain. Cities Soc. 2022, 87, 104135. [Google Scholar] [CrossRef]
- Clark, W.V.W.; Wang, W. Job access and commuting patterns: Balancing work and residence in Los Angeles. Urban Geogr. 2005, 26, 610–626. [Google Scholar] [CrossRef]
- Ewing, R.; Pendall, R.; Chen, D. Measuring Sprawl and Its Transportation Impacts. Transp. Res. Rec. J. Transp. Res. Board 2003, 1831, 175–183. [Google Scholar] [CrossRef]
- Weber, J.; Sultana, S. Employment Sprawl, Race and the Journey to Work in Birmingham, Alabama. Southeast. Geogr. 2008, 48, 53–74. [Google Scholar] [CrossRef]
- Sultana, S. Racial variation in males commuting time: What does the evidence suggest? Prof. Geogr. 2005, 57, 66–82. [Google Scholar] [CrossRef]
- Dunphy, T.; Fisher, K. Transportation, Congestion, and Density: New Insights. Transp. Res. Rec. 1996, 1552, 89–96. [Google Scholar] [CrossRef]
- Levinson, D.M.; Kumar, A. Density and the Journey to Work. Growth Change 1997, 28, 147–172. [Google Scholar] [CrossRef] [PubMed]
- O’Toole, R. The Myth of the Compact City: Why Compact Development Is Not the Way to Reduce Carbon Dioxide Emissions. Cato Inst. Policy Anal. 2009, 653. Available online: https://ssrn.com/abstract=1543980 (accessed on 18 January 2023). [CrossRef]
- Cambridge Systematics, Inc. Moving Cooler: An Analysis of Transportation Strategies for Reducing Greenhouse Gas Emissions; Urban Land Institute: Washington, DC, USA, 2009. [Google Scholar]
- Stevens, M.R. Does compact development make people drive less? J. Am. Plan. Assoc. 2017, 83, 7–18. [Google Scholar] [CrossRef]
- Emrath, P.; Liu, F. Vehicle carbon dioxide emissions and the compactness of residential development. Cityscape A J. Policy Dev. Res. 2008, 10, 185–202. [Google Scholar]
- Stone, B., Jr. Urban sprawl and air quality in large US cities. J. Environ. Manag. 2008, 86, 688–698. [Google Scholar] [CrossRef]
- Schindler, M.; Caruso, G. Urban compactness and the trade-off between air pollution emission and exposure: Lessons from a spatially explicit theoretical model. Comput. Environ. Urban Syst. 2014, 45, 13–23. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, C.; He, B.-J. Spatial and temporal heterogeneity of urban land area and PM2.5 concentration in China. Urban Clim. 2022, 45, 101268. [Google Scholar] [CrossRef]
- Tobin, J. Estimation of relationships for limited dependent variables. Econom. J. Econom. Soc. 1958, 26, 24–36. [Google Scholar] [CrossRef]
- Guldmann, J.-M. Competing destinations and intervening opportunities interaction models of inter-city telecommunication flows. Pap. Reg. Sci. 1999, 78, 179–194. [Google Scholar] [CrossRef]
- Veall, M.R.; Zimmermann, K.F. Pseudo-R2 measures for some common limited dependent variable models. J. Econ. Surv. 1996, 10, 241–259. [Google Scholar] [CrossRef]
- He, F.; Yang, J.; Zhang, Y.; Sun, D.; Wang, L.; Xiao, X.; Xia, J. Offshore Island Connection Line: A new perspective of coastal urban development boundary simulation and multi-scenario prediction. GIScience Remote Sens. 2022, 59, 801–821. [Google Scholar] [CrossRef]
- Li, J.; Gong, J.; Guldmann, J.-M.; Yang, J. Assessment of Urban Ecological Quality and Spatial Heterogeneity Based on Remote Sensing: A Case Study of the Rapid Urbanization of Wuhan City. Remote Sens. 2021, 13, 4440. [Google Scholar] [CrossRef]
- Gulmann, J.-M. Urban Land Use Allocation and Environmental Pollution Control: An Intertemporal Optimization Approach. Socio-Econ. Plan. Sci. 1979, 13, 71–86. [Google Scholar] [CrossRef]










| Jurisdiction | Population | % | Employment | % |
|---|---|---|---|---|
| Caroline | 22,120 | 9.2% | 1945 | 2.3% |
| Fredericksburg | 19,275 | 8.0% | 19,760 | 23.2% |
| King George | 16,805 | 7.0% | 9912 | 11.6% |
| Spotsylvania | 90,405 | 37.5% | 26,521 | 31.1% |
| Stafford | 92,460 | 38.4% | 27,059 | 31.8% |
| Total | 241,065 | 100.0% | 85,197 | 100.0% |
| Flow | % | |||
|---|---|---|---|---|
| FAMPO | Internal | 7125 | 10.61 | |
| TAZ-to-TAZ | 60,023 | 89.39 | ||
| Jurisdiction | Caroline | Internal | 1261 | 1.88 |
| Jurisdiction-to-Jurisdiction | 203 | 0.30 | ||
| Fredericksburg | Internal | 4056 | 6.04 | |
| Jurisdiction-to-Jurisdiction | 12,699 | 18.91 | ||
| King George | Internal | 4314 | 6.42 | |
| Jurisdiction-to-Jurisdiction | 3173 | 4.73 | ||
| Spotsylvania | Internal | 15,863 | 23.62 | |
| Jurisdiction-to-Jurisdiction | 6377 | 9.50 | ||
| Stafford | Internal | 11,469 | 17.08 | |
| Jurisdiction-to-Jurisdiction | 7733 | 11.52 | ||
| Total Flow | 67,148 | 100% | ||
| Variable | N | Mean | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|---|
| F: flow | 3469 | 19.35 | 34.17 | 4.00 | 990.00 |
| P: population | 3469 | 2332.27 | 2659.69 | 15.00 | 15,730.00 |
| E: employees | 3469 | 1683.79 | 1687.31 | 4.00 | 6415.00 |
| D: distance | 3469 | 10.51 | 6.97 | 0.42 | 41.07 |
| Variable | N | Mean | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|---|
| F: flow | 31875 | 0 | 0 | 0 | 0 |
| P: population | 31875 | 1167.99 | 1765.41 | 0 | 15,730.00 |
| E: employees | 31875 | 319.25 | 734.31 | 0 | 6415.00 |
| D: distance | 31875 | 18.76 | 9.25 | 0.70 | 50.53 |
| Variable | N | Mean | Median | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|---|---|
| P | 188 | 1282.26 | 625.00 | 1903.91 | 0.0 | 15,730.0 |
| P_DA_RES | 188 | 0.7601 | 0.7782 | 0.1498 | 0.0 | 1.000 |
| P_BLK_RES | 188 | 0.1525 | 0.1165 | 0.1421 | 0.0 | 0.674 |
| P_OCC1_RES | 188 | 0.1618 | 0.1627 | 0.0844 | 0.0 | 0.600 |
| P_OCC2_RES | 188 | 0.1858 | 0.1920 | 0.0914 | 0.0 | 0.455 |
| P_OCC3_RES | 188 | 0.2150 | 0.2000 | 0.1140 | 0.0 | 0.580 |
| P_OCC4_RES | 188 | 0.1769 | 0.1700 | 0.1002 | 0.0 | 0.495 |
| P_M_RES | 188 | 0.4981 | 0.4912 | 0.0918 | 0.0 | 0.984 |
| P_UNEMP_RES | 188 | 0.0214 | 0.0165 | 0.0256 | 0.0 | 0.150 |
| P_MUNEMP_RES | 188 | 0.0189 | 0.0000 | 0.0305 | 0.0 | 0.200 |
| P_CP_RES | 188 | 0.1480 | 0.1334 | 0.1031 | 0.0 | 0.700 |
| P_MDA_RES | 188 | 0.7538 | 0.7802 | 0.1866 | 0.0 | 1.000 |
| P_MCP_RES | 188 | 0.1517 | 0.1303 | 0.1305 | 0.0 | 1.000 |
| P_MOCC1_RES | 188 | 0.1232 | 0.1172 | 0.1031 | 0.0 | 0.667 |
| P_MOCC2_RES | 188 | 0.0837 | 0.0817 | 0.0696 | 0.0 | 0.400 |
| P_MOCC3_RES | 188 | 0.3279 | 0.3094 | 0.1731 | 0.0 | 1.000 |
| P_MOCC4_RES | 188 | 0.2047 | 0.2000 | 0.1375 | 0.0 | 0.695 |
| P_HIS_RES | 188 | 0.0185 | 0.0000 | 0.0309 | 0.0 | 0.192 |
| P_WHT_RES | 188 | 0.7876 | 0.8220 | 0.1699 | 0.0 | 1.000 |
| P_DIS_RES | 188 | 0.1429 | 0.1250 | 0.1028 | 0.0 | 0.600 |
| P_HINC_RES | 188 | 0.4013 | 0.4006 | 0.2163 | 0.0 | 1.000 |
| MHI_RES | 188 | 54,720.88 | 52,675.00 | 18,921 | 0 | 109,770 |
| P_HERN_RES | 188 | 0.2071 | 0.2032 | 0.1140 | 0.0 | 0.5052 |
| P_POV_RES | 188 | 0.0218 | 0.0112 | 0.0331 | 0.0 | 0.250 |
| P_OWNSELF_RES | 188 | 0.1881 | 0.1667 | 0.1385 | 0.0 | 1.000 |
| P_OWN_RES | 188 | 0.7895 | 0.8546 | 0.2137 | 0.0 | 1.125 |
| P_3VEH_RES | 188 | 0.3406 | 0.3354 | 0.1614 | 0.0 | 0.769 |
| P_OCCU_RES | 188 | 0.9131 | 0.9486 | 0.1428 | 0.0 | 1.000 |
| HEDU_RES | 188 | 0.0384 | 0.0341 | 0.0381 | 0.0 | 0.388 |
| Variable | N | Mean | Median | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|---|---|
| EMP | 188 | 453.1755 | 75.0000 | 964.605 | 0.0000 | 6415.0 |
| P_Full_EMP | 188 | 0.3321 | 0.3099 | 0.2435 | 0.0000 | 1.0000 |
| P_Veh2Plus_EMP | 188 | 0.7334 | 0.8265 | 0.2895 | 0.0000 | 1.0000 |
| P_BlwPov_EMP | 188 | 0.0364 | 0.0108 | 0.0698 | 0.0000 | 0.6667 |
| MTT_EMP | 188 | 24.712 | 25.000 | 15.369 | 0.0000 | 102.3 |
| P_LERN_EMP | 188 | 0.3681 | 0.3631 | 0.2498 | 0.0000 | 1.0000 |
| P_CarPool_EMP | 188 | 0.0883 | 0.0809 | 0.0923 | 0.0000 | 0.4000 |
| P_Mfg_EMP | 188 | 0.0379 | 0.0000 | 0.0948 | 0.0000 | 0.7500 |
| P_WhlTrd_EMP | 188 | 0.0192 | 0.0000 | 0.0480 | 0.0000 | 0.4000 |
| P_RetTrd_EMP | 188 | 0.0864 | 0.0106 | 0.1413 | 0.0000 | 1.0000 |
| P_serv_EMP | 188 | 0.3687 | 0.3637 | 0.3014 | 0.0000 | 1.0000 |
| P_Pub_EMP | 188 | 0.0327 | 0.0000 | 0.0777 | 0.0000 | 0.4427 |
| P_Finan_EMP | 188 | 0.0561 | 0.0000 | 0.1341 | 0.0000 | 1.0000 |
| Variable | N | Mean | Median | Standard Deviation | Minimum | Maximum |
|---|---|---|---|---|---|---|
| D | 35,344 | 17.947 | 17.380 | 9.379 | 0.420 | 50.530 |
| Parameter | Estimate | Standard Error | t-Value | Approx Pr > |t| |
|---|---|---|---|---|
| Intercept | −80.267754 | 4.532873 | −17.71 | <0.0001 |
| P | 0.011133 | 0.000426 | 26.13 | <0.0001 |
| EMP | 0.027680 | 0.001218 | 22.73 | <0.0001 |
| D | −3.966485 | 0.158067 | −25.09 | <0.0001 |
| IO_E | −0.000324 | 0.000024329 | −13.33 | <0.0001 |
| CD_E | 0.000160 | 0.000035343 | 4.53 | <0.0001 |
| P_DA_RES | 28.859800 | 3.679491 | 7.84 | <0.0001 |
| P_BLK_RES | 9.602796 | 3.023634 | 3.18 | 0.0015 |
| P_OCC1_RES | 23.840650 | 6.515631 | 3.66 | 0.0003 |
| P_OCC2_RES | 12.881209 | 5.595655 | 2.30 | 0.0213 |
| P_OCC3_RES | 16.725051 | 4.991596 | 3.35 | 0.0008 |
| P_OCC4_RES | 17.346662 | 5.671378 | 3.06 | 0.0022 |
| P_Mfg_EMP | 36.628397 | 4.083194 | 8.97 | <0.0001 |
| P_WhlTrd_EMP | 53.338335 | 7.888539 | 6.76 | <0.0001 |
| P_RetTrd_EMP | 22.840645 | 3.075172 | 7.43 | <0.0001 |
| P_Pub_EMP | 43.681025 | 5.569463 | 7.84 | <0.0001 |
| P_Serv_EMP | 19.602157 | 1.794940 | 10.92 | <0.0001 |
| P_Finan_EMP | 21.147896 | 2.754040 | 7.68 | <0.0001 |
| P2 | −0.000000662 | 3.1856992 × 10−8 | −20.78 | <0.0001 |
| E2 | −0.000002661 | 0.000000158 | −16.87 | <0.0001 |
| D2 | 0.048005 | 0.004843 | 9.91 | <0.0001 |
| POPEMP | 0.000002331 | 0.000000113 | 20.68 | <0.0001 |
| EMPCD | −0.000000109 | 1.807805 × 10−8 | −6.03 | <0.0001 |
| R-square | 0.4657 | |||
| Pseudo-R2 | 0.2394 | |||
| Log-likelihood | −20,466 |
| Jurisdiction | 2035 | ||
|---|---|---|---|
| Employment | Population | ||
| Caroline County | 14,216 | 47,007 | |
| Fredericksburg | 43,679 | 29,852 | |
| King George County | 17,821 | 40,744 | |
| Spotsylvania County | 62,551 | 236,885 | |
| Stafford County | 69,574 | 238,208 | |
| Total GWRC (PD 16) | 207,841 | 592,696 | |
| 2000 (Existing) | Increments | ||
| Employment | Population | ΔE | ΔP |
| 85,197 | 241,065 | 122,644 | 351,631 |
| Scenario L2 | To | |||||
|---|---|---|---|---|---|---|
| ULP = 0.400 | ULE = 0.200 | CR | FR | KG | SF | SP |
| From | CR | 1000 | 3830 | 4849 | 7395 | 4223 |
| FR | 0 | 961 | 33 | 528 | 802 | |
| KG | 9 | 2205 | 5531 | 2891 | 2369 | |
| SF | 0 | 4481 | 1575 | 10,991 | 3796 | |
| SP | 40 | 5855 | 1545 | 6215 | 10,695 | |
| Scenario L2 | To | |||||
| ULP = 0.100 | ULE = 0.050 | CR | FR | KG | SF | SP |
| From | CR | 29 | 1582 | 382 | 967 | 1463 |
| FR | 0 | 812 | 0 | 341 | 562 | |
| KG | 0 | 350 | 92 | 20 | 282 | |
| SF | 0 | 2016 | 0 | 3251 | 1322 | |
| SP | 0 | 2848 | 0 | 1417 | 3936 | |
| Scenario L4 | To | |||||
| ULP = 0.400 | ULE = 0.200 | CR | FR | KG | SF | SP |
| From | CR | 136 | 288 | 1349 | 2304 | 1415 |
| FR | 0 | 780 | 48 | 472 | 592 | |
| KG | 0 | 813 | 1057 | 1405 | 919 | |
| SF | 0 | 3836 | 1146 | 9045 | 2751 | |
| SP | 0 | 4886 | 1544 | 5245 | 8266 | |
| Scenario L4 | To | |||||
| ULP = 0.100 | ULE = 0.050 | CR | FR | KG | SF | SP |
| From | CR | 2 | 7 | 0 | 0 | 23 |
| FR | 0 | 763 | 0 | 357 | 549 | |
| KG | 0 | 0 | 17 | 0 | 0 | |
| SF | 0 | 1787 | 0 | 4030 | 1170 | |
| SP | 16 | 4038 | 0 | 2075 | 3837 | |
| Land Scenario | Density Scenario | ||
|---|---|---|---|
| ULP = 0.400 | ULP = 0.100 | ||
| ULE = 0.200 | ULE = 0.050 | ||
| L2 | Objective function | 838,777 | 113,647 |
| Total flows | 81,819 | 21,671 | |
| Average commuting distance | 10.25 | 5.24 | |
| L4 | Objective function | 473,283 | 106,347 |
| Total flows | 48,294 | 18,671 | |
| Average commuting distance | 9.80 | 5.70 | |
| Normalized | ||||||||||
| Land Scenario L2 | ULE | |||||||||
| 0.050 | 0.075 | 0.100 | 0.125 | 0.150 | 0.175 | 0.200 | 0.225 | 0.250 | ||
| ULP | 0.10 | 12.21 | 15.05 | 17.09 | 17.17 | 17.23 | 19.56 | 20.26 | 21.67 | 22.12 |
| 0.15 | 15.06 | 16.24 | 17.56 | 18.32 | 20.61 | 22.26 | 22.99 | 23.18 | 23.44 | |
| 0.20 | 26.31 | 27.15 | 28.03 | 28.16 | 28.42 | 28.92 | 29.06 | 29.15 | 29.55 | |
| 0.25 | 33.14 | 39.99 | 40.34 | 41.25 | 41.32 | 42.06 | 44.21 | 45.06 | 45.30 | |
| 0.30 | 40.62 | 46.95 | 53.61 | 57.55 | 59.47 | 61.18 | 62.55 | 64.59 | 66.17 | |
| 0.35 | 48.17 | 60.51 | 66.65 | 71.39 | 79.09 | 81.80 | 85.00 | 87.99 | 91.40 | |
| 0.40 | 53.13 | 64.22 | 70.87 | 78.52 | 80.79 | 85.27 | 90.12 | 100.00 | ||
| 0.45 | 63.43 | 76.50 | 80.40 | |||||||
| 0.50 | ||||||||||
| Normalized | ||||||||||
| Land Scenario L4 | ULE | |||||||||
| 0.050 | 0.075 | 0.100 | 0.125 | 0.150 | 0.175 | 0.200 | 0.225 | 0.250 | ||
| ULP | 0.10 | 18.96 | 20.82 | 21.69 | 25.55 | 26.88 | 27.71 | 28.01 | 28.72 | 29.08 |
| 0.15 | 23.10 | 23.41 | 26.63 | 29.99 | 32.82 | 36.03 | 36.15 | 36.26 | 36.39 | |
| 0.20 | 31.63 | 35.46 | 38.57 | 39.61 | 39.90 | 40.13 | 40.33 | 40.50 | 40.73 | |
| 0.25 | 39.40 | 40.17 | 41.09 | 41.72 | 42.26 | 42.71 | 43.14 | 43.56 | 43.97 | |
| 0.30 | 44.12 | 46.64 | 51.31 | 53.13 | 53.93 | 54.71 | 55.55 | 56.36 | 57.20 | |
| 0.35 | 48.18 | 51.69 | 56.12 | 65.54 | 69.32 | 71.19 | 71.22 | 72.31 | 73.40 | |
| 0.40 | 49.13 | 56.64 | 64.89 | 71.43 | 80.24 | 83.10 | 84.40 | 85.64 | 87.05 | |
| 0.45 | 51.15 | 59.24 | 65.18 | 74.43 | 81.43 | 83.41 | 85.23 | 86.67 | 88.28 | |
| 0.50 | 55.52 | 63.55 | 72.26 | 80.09 | 88.76 | 92.80 | 95.45 | 97.63 | 100.00 | |
| Variables | Land Development Strategy | |
|---|---|---|
| L2 | L4 | |
| Intercept | 188,109 (1.71) * | 100,497 (2.16) * |
| ULP | −3,410,307 (−3.34) ** | −377,350 (−1.07) |
| ULE | 2,816,147 (1.89) * | 117,457 (0.17) |
| ULP × ULP | 19,994,468 (5.65) ** | 3,921,962 (3.54) ** |
| ULE × ULE | −14,772,237 (−1.68) * | 2,136,213 (0.48) |
| ULP × ULE | −4,477,808 (−0.93) | 878,521 (0.52) |
| ULP × ULP × ULP | −26,345,984 (−6.61) ** | −5,919,163 (−5.02) ** |
| ULE × ULE × ULE | 31,053,141 (1.72) * | −3,265,161 (−0.35) |
| ULP × ULP × ULE | 24,799,246 (3.94) ** | 9,630,043 (4.90) ** |
| ULP × ULE × ULE | −6,222,188 (−0.62) | −13,204,059 (−3.36) * |
| R2 | 0.987 | 0.983 |
| Land Development Cost (Residential) | Land Development Cost (Employment) | ||||||
|---|---|---|---|---|---|---|---|
| Intercept | 11.218 | 262.90 (<0.0001) | R2 0.85 | Intercept | 10.810 | 93.39 (<0.0001) | R2 0.78 |
| LN(P_2006) | 1.000 | Infty (<0.0001) | LN(E_2006) | 1.000 | Infty (<0.0001) | ||
| LN(ULP) | 0.014 | 0.34 (0.7311) | LN(ULE) | 0.502 | 10.40 (<0.0001) | ||
| RESTRICT | 16.899 | 2.37 (0.0173) | RESTRICT | 98.442 | 5.01 (<0.0001) | ||
| K1 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.3 | 0.5 | ||||||
| K2 | b | d | ULP | ULE | ULP | ULE | ULP | ULE |
| 0.1 | 1.0 | 1.0 | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L |
| 3.0 | 0.1000 L | 0.0805 | 0.1000 L | 0.0805 | 0.1000 L | 0.0805 | ||
| 5.0 | 0.1000 L | 0.2211 | 0.1000 L | 0.2211 | 0.1000 L | 0.2211 | ||
| 3.0 | 1.0 | 0.1447 | 0.0500 L | 0.1930 | 0.0500 L | 0.2206 | 0.0500 L | |
| 3.0 | 0.1443 | 0.0805 | 0.1917 | 0.0803 | 0.2186 | 0.0801 | ||
| 5.0 | 0.1435 | 0.2213 | 0.1876 | 0.2212 | 0.2121 | 0.2209 | ||
| 5.0 | 1.0 | 0.3135 | 0.0500 L | 0.5000 U | 0.0500 L | 0.5000 U | 0.0500 L | |
| 3.0 | 0.3089 | 0.0793 | 0.5000 U | 0.0763 | 0.5000 U | 0.0763 | ||
| 5.0 | 0.2952 | 0.2194 | 0.3594 | 0.2174 | 0.3989 | 0.2160 | ||
| 0.3 | 1.0 | 1.0 | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L |
| 3.0 | 0.1000 L | 0.1108 | 0.1000 L | 0.1108 | 0.1000 L | 0.1108 | ||
| 5.0 | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | ||
| 3.0 | 1.0 | 0.1447 | 0.0500 L | 0.1930 | 0.0500 L | 0.2206 | 0.0500 L | |
| 3.0 | 0.1439 | 0.1108 | 0.1905 | 0.1105 | 0.2168 | 0.1103 | ||
| 5.0 | 0.1435 | 0.2500 U | 0.1872 | 0.2500 U | 0.2113 | 0.2500 U | ||
| 5.0 | 1.0 | 0.3135 | 0.0500 L | 0.5000 U | 0.0500 L | 0.5000 U | 0.0500 L | |
| 3.0 | 0.3051 | 0.1090 | 0.5000 U | 0.1042 | 0.5000 U | 0.1042 | ||
| 5.0 | 0.2932 | 0.2500 U | 0.3551 | 0.2500 U | 0.3917 | 0.2500 U | ||
| 0.5 | 1.0 | 1.0 | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L |
| 3.0 | 0.1000 L | 0.1285 | 0.1000 L | 0.1285 | 0.1000 L | 0.1285 | ||
| 5.0 | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | ||
| 3.0 | 1.0 | 0.1447 | 0.0500 L | 0.1930 | 0.0500 L | 0.2206 | 0.0500 L | |
| 3.0 | 0.1438 | 0.1285 | 0.1899 | 0.1283 | 0.2158 | 0.1280 | ||
| 5.0 | 0.1435 | 0.2500 U | 0.1872 | 0.2500 U | 0.2113 | 0.2500 U | ||
| 5.0 | 1.0 | 0.3135 | 0.0500 L | 0.5000 U | 0.0500 L | 0.5000 U | 0.0500 L | |
| 3.0 | 0.3031 | 0.1265 | 0.5000 U | 0.1205 | 0.5000 U | 0.1205 | ||
| 5.0 | 0.2932 | 0.2500 U | 0.3551 | 0.2500 U | 0.3917 | 0.2500 U | ||
| K1 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.3 | 0.5 | ||||||
| K2 | b | d | ULP | ULE | ULP | ULE | ULP | ULE |
| 0.1 | 1.0 | 1.0 | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L |
| 3.0 | 0.1000 L | 0.0810 | 0.1000 L | 0.0810 | 0.1000 L | 0.0810 | ||
| 5.0 | 0.1000 L | 0.2218 | 0.1000 L | 0.2218 | 0.1000 L | 0.2218 | ||
| 3.0 | 1.0 | 0.1476 | 0.0500 L | 0.2064 | 0.0500 L | 0.2412 | 0.0500 L | |
| 3.0 | 0.1470 | 0.0809 | 0.2048 | 0.0807 | 0.2387 | 0.0806 | ||
| 5.0 | 0.1474 | 0.2223 | 0.2030 | 0.2227 | 0.2346 | 0.2228 | ||
| 5.0 | 1.0 | 0.3399 | 0.0500 L | 0.4456 | 0.0500 L | 0.5000 U | 0.0500 L | |
| 3.0 | 0.3351 | 0.0801 | 0.4273 | 0.0794 | 0.5000 U | 0.0787 | ||
| 5.0 | 0.3248 | 0.2226 | 0.3991 | 0.2220 | 0.4423 | 0.2215 | ||
| 0.3 | 1.0 | 1.0 | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L |
| 3.0 | 0.1000 L | 0.1108 | 0.1000 L | 0.1108 | 0.1000 L | 0.1108 | ||
| 5.0 | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | ||
| 3.0 | 1.0 | 0.1476 | 0.0500 L | 0.2064 | 0.0500 L | 0.2412 | 0.0500 L | |
| 3.0 | 0.1466 | 0.1107 | 0.2037 | 0.1106 | 0.2368 | 0.1104 | ||
| 5.0 | 0.1480 | 0.2500 U | 0.2036 | 0.2500 U | 0.2351 | 0.2500 U | ||
| 5.0 | 1.0 | 0.3399 | 0.0500 L | 0.4456 | 0.0500 L | 0.5000 U | 0.0500 L | |
| 3.0 | 0.3316 | 0.1097 | 0.4170 | 0.1089 | 0.4783 | 0.1081 | ||
| 5.0 | 0.3243 | 0.2500 U | 0.3973 | 0.2500 U | 0.4391 | 0.2500 U | ||
| 0.5 | 1.0 | 1.0 | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L | 0.1000 L | 0.0500 L |
| 3.0 | 0.1000 L | 0.1281 | 0.1000 L | 0.1281 | 0.1000 L | 0.1281 | ||
| 5.0 | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | 0.1000 L | 0.2500 U | ||
| 3.0 | 1.0 | 0.1476 | 0.0500 L | 0.2064 | 0.0500 L | 0.2412 | 0.0500 L | |
| 3.0 | 0.1465 | 0.1281 | 0.2032 | 0.1280 | 0.2360 | 0.1279 | ||
| 5.0 | 0.1480 | 0.2500 U | 0.2036 | 0.2500 U | 0.2351 | 0.2500 U | ||
| 5.0 | 1.0 | 0.3399 | 0.0500 L | 0.4456 | 0.0500 L | 0.5000 U | 0.0500 L | |
| 3.0 | 0.3299 | 0.1272 | 0.4126 | 0.1262 | 0.4676 | 0.1254 | ||
| 5.0 | 0.3243 | 0.2500 U | 0.3973 | 0.2500 U | 0.4391 | 0.2500 U | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.J.-H.; Guldmann, J.-M. Optimal Regional Allocation of Future Population and Employment under Urban Boundary and Density Constraints: A Spatial Interaction Modeling Approach. Land 2023, 12, 433. https://doi.org/10.3390/land12020433
Lee DJ-H, Guldmann J-M. Optimal Regional Allocation of Future Population and Employment under Urban Boundary and Density Constraints: A Spatial Interaction Modeling Approach. Land. 2023; 12(2):433. https://doi.org/10.3390/land12020433
Chicago/Turabian StyleLee, David Jung-Hwi, and Jean-Michel Guldmann. 2023. "Optimal Regional Allocation of Future Population and Employment under Urban Boundary and Density Constraints: A Spatial Interaction Modeling Approach" Land 12, no. 2: 433. https://doi.org/10.3390/land12020433
APA StyleLee, D. J.-H., & Guldmann, J.-M. (2023). Optimal Regional Allocation of Future Population and Employment under Urban Boundary and Density Constraints: A Spatial Interaction Modeling Approach. Land, 12(2), 433. https://doi.org/10.3390/land12020433