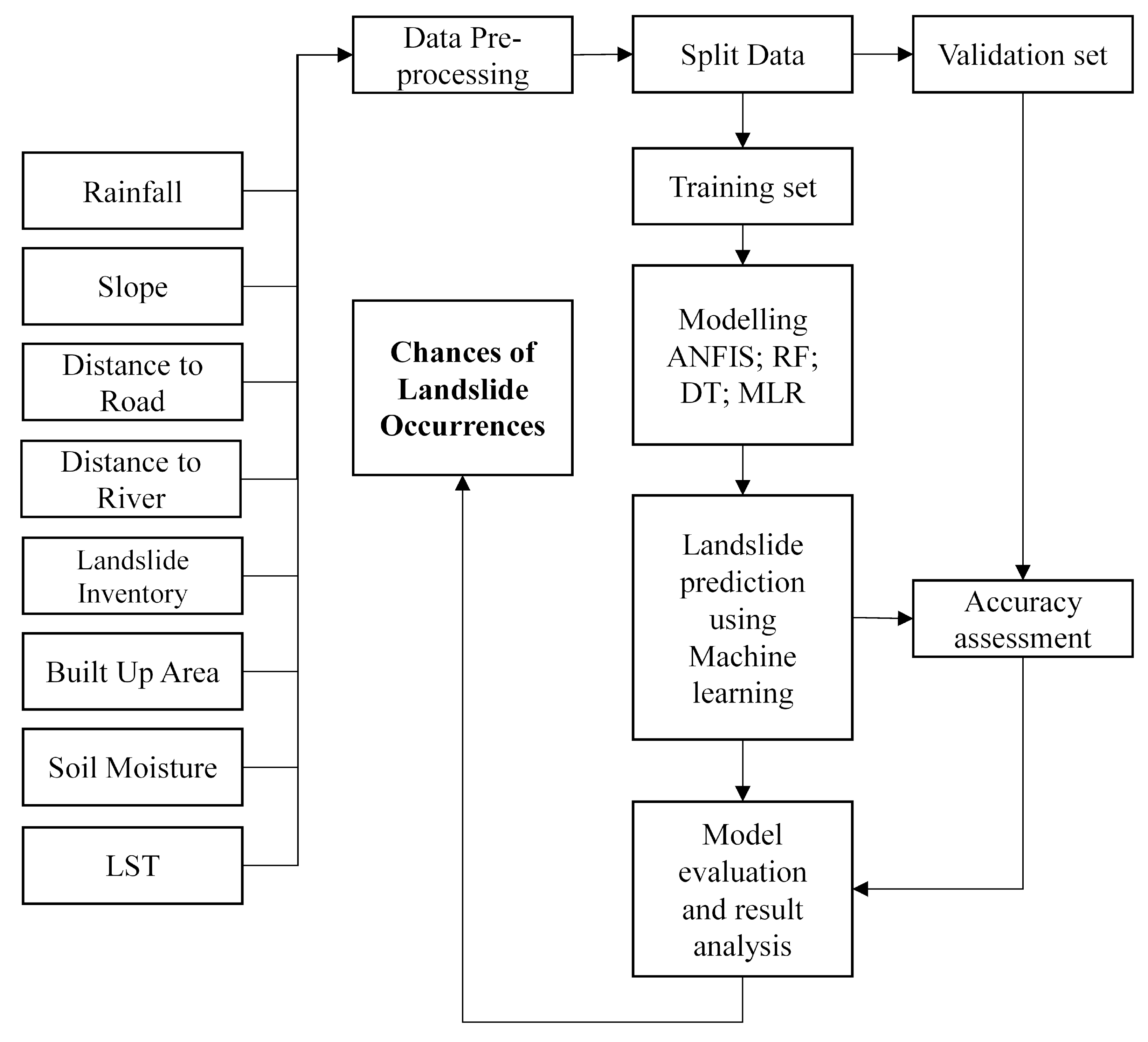
In this study, four machine learning models were used to predict landslides using both internal (geological and morphological) and external responsible (triggering) factors. The use of the two new significant responsible triggering factors (LST and BUA) resulted in improved model efficiency compared to when either one or both of these factors were not considered.
4.1. Establishing the Best Model for a Landslide Early Warning System (LEWS)
4.1.1. Multiple Linear Regression (MLR)
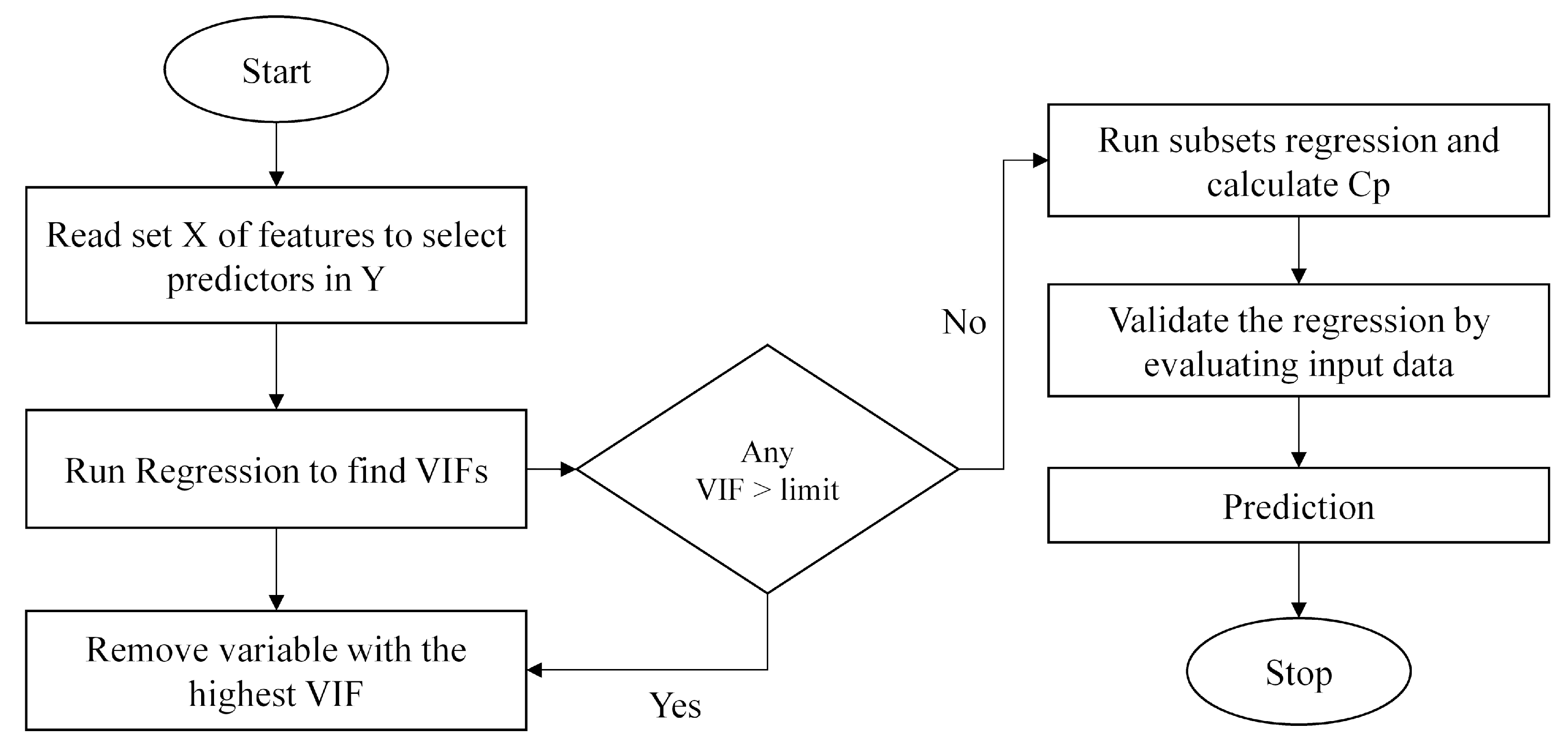
In the Multiple Linear Regression (MLR) model, the newly incorporated parameters were found to be highly significant and contributed to the overall model, as shown in
Table 4 above. The models were evaluated using various tests, e.g., AUC, RMSE, confusion matrix, sensitivity, specificity, and mean absolute error. These showed the overall testing statistics and accuracy of the various machine learning models used to predict landslides.
Figure 8 shows the algorithm flowchart used to perform the landslide chance estimation using the MLR model. At the end of the model run (stop), the results were generated.
The prediction precision of the model was calculated by finding the difference between the predicted and observed data values. Using the function ‘head (pred), head (testing)’ in RStudio, the difference between the two values was evaluated by generating head (top) values of both the predicted and observed values. Both were found to be highly identical with very little difference. Further, the accuracy of the MLR model was improved from 95.79% to 98.27% by including the new variables in the model (
Table 5).
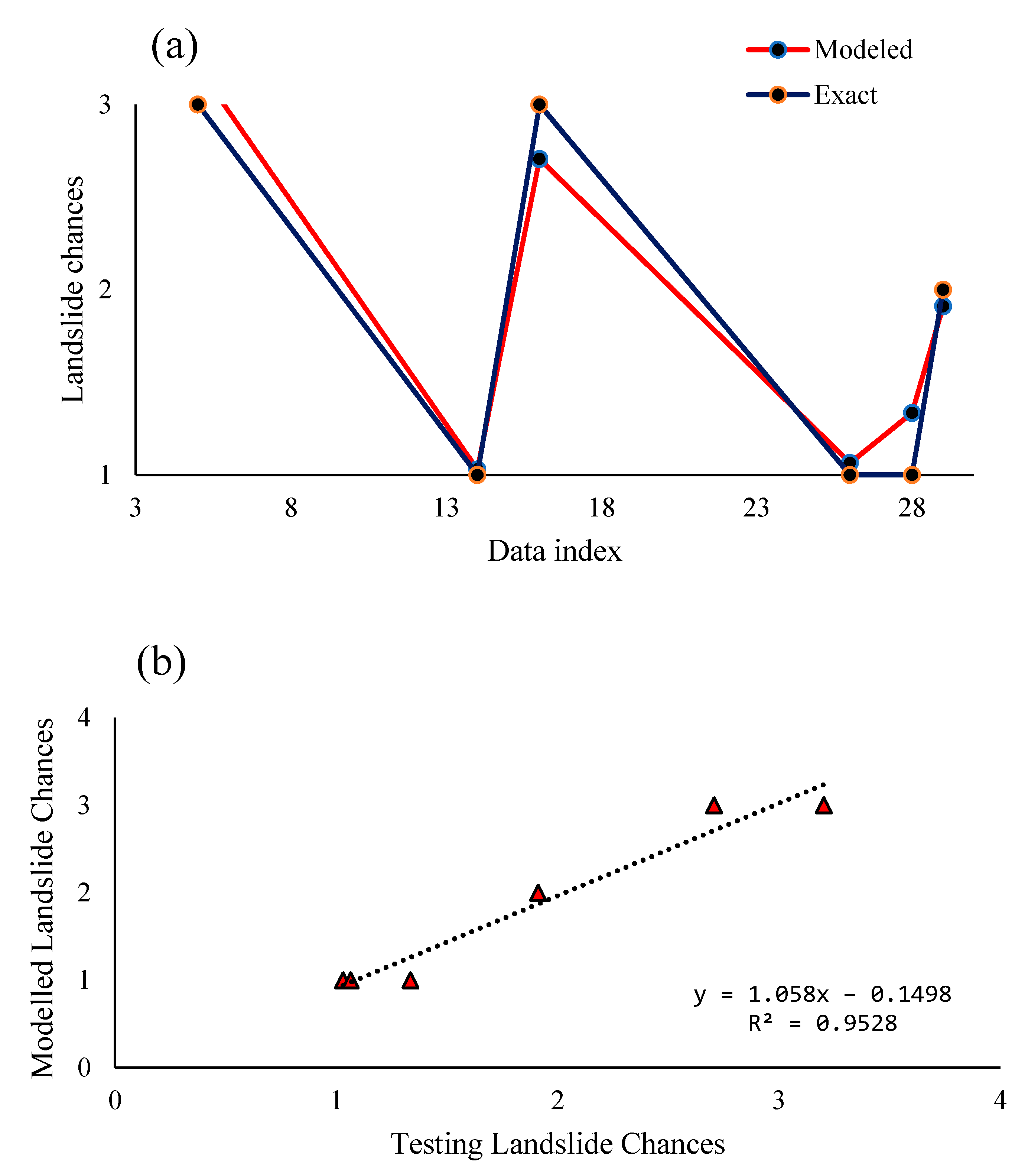
The predicted vs. observed data values are shown in
Table 6 and
Table 7, respectively, while the graph in
Figure 9a shows the predicted and observed data values graphically, which were highly identical and similar.
Figure 9b, shows the high R
2 between the modelled and predicted landslide chances using the MLR model.
As the method of experimentation, the model was tested by making some example predictions based on the different input data values provided to the model. The model predicted landslide chances as the upper limit, lower limit, and fit as shown in
Table 8. Thus, the predictions generated by the MLR model were reliable.
4.1.2. Decision Tree
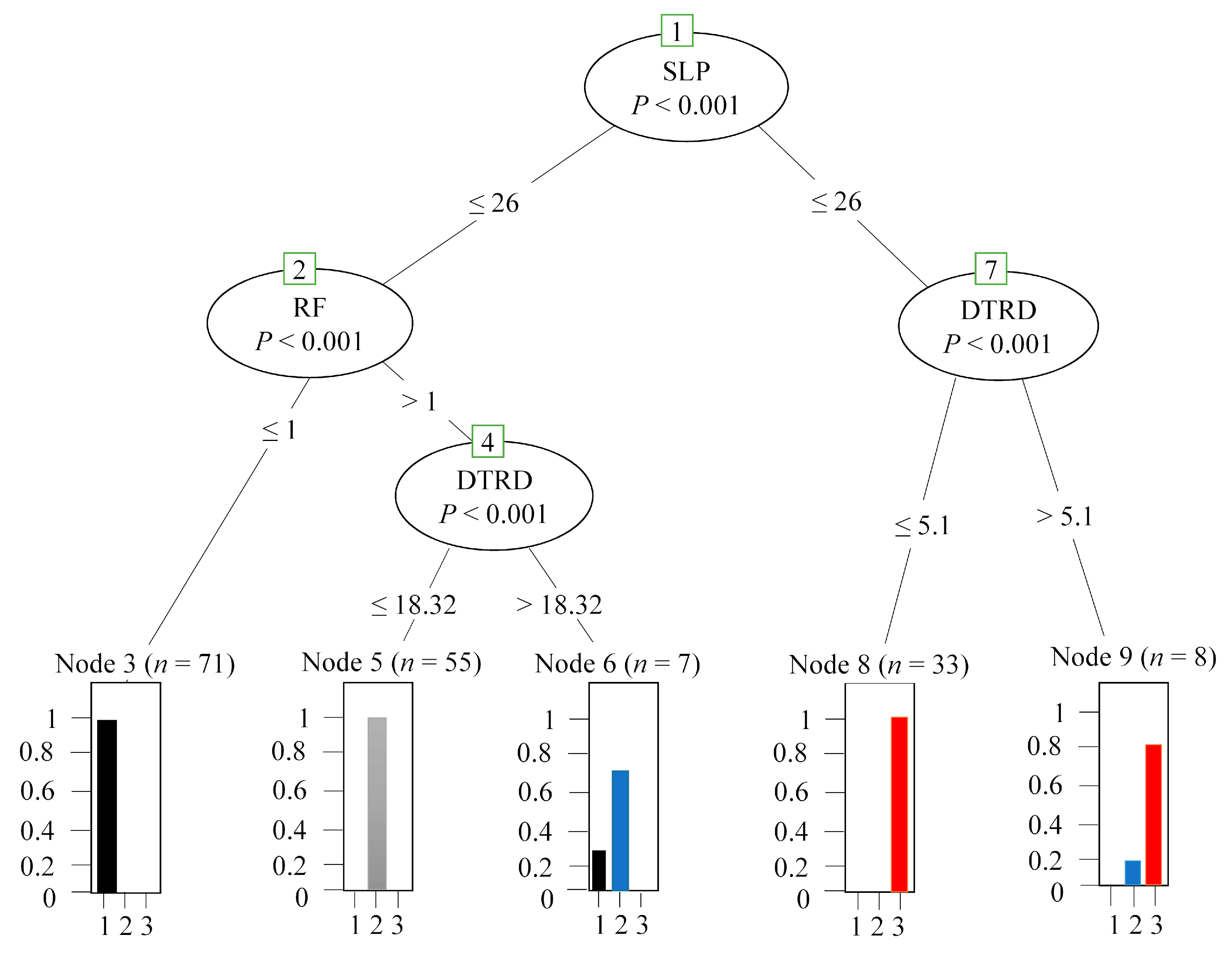
The Decision Tree Model classified the testing data into various classification branches, which help to predict the result easily and precisely [
60]. The model comprised five response nodes, seven input variables, and a single response variable (LC). A confusion matrix that provided a holistic view of the model was generated to calculate the model’s overall accuracy. The model showed an accuracy of 95.7% for the testing data and 98.3% for the training data. The confusion matrix for both the training and testing data is shown in
Table 9 and
Table 10, respectively.
Figure 10 shows the conceptual algorithm flowchart of this model.
The accuracy of the training data was calculated using Equation (8)
Likewise, the accuracy of the testing data was evaluated as:
Therefore, the training data showed 98.3% accuracy, while the testing data showed 95.5% accuracy. The sensitivity and specificity were also calculated, as shown in
Table 4, to find the significance and accuracy of the model.
The sensitivity or true positive rate (TPR) was calculated using Equation (9).
where
The specificity or the true negative rate (TNR) was calculated using Equation (10).
where
4.1.3. Adaptive Neuro-Fuzzy Inference System (ANFIS)
The Adaptive Neuro-Fuzzy Inference System (ANFIS), a novel hybrid prediction algorithm blended with the learning abilities of neural network and transparent linguistic representation of the Fuzzy system, was used to generate a range of prediction responses to determine the degree of warnings for landslides that resolved the issue of the binary type of prediction classification used in various earlier studies. ANFIS is a hybrid intelligent system where both a neural network and a Fuzzy Inference System (FIS) are combined for better outcomes. The model followed a holdout data partitioning approach with 75% training and 25% test data for better predictions. The cross-validation technique was used to find the best model based on the prediction accuracy, execution time, and membership function. The best membership function was determined by using all membership functions.
Table 11 shows the results from the ANFIS model.
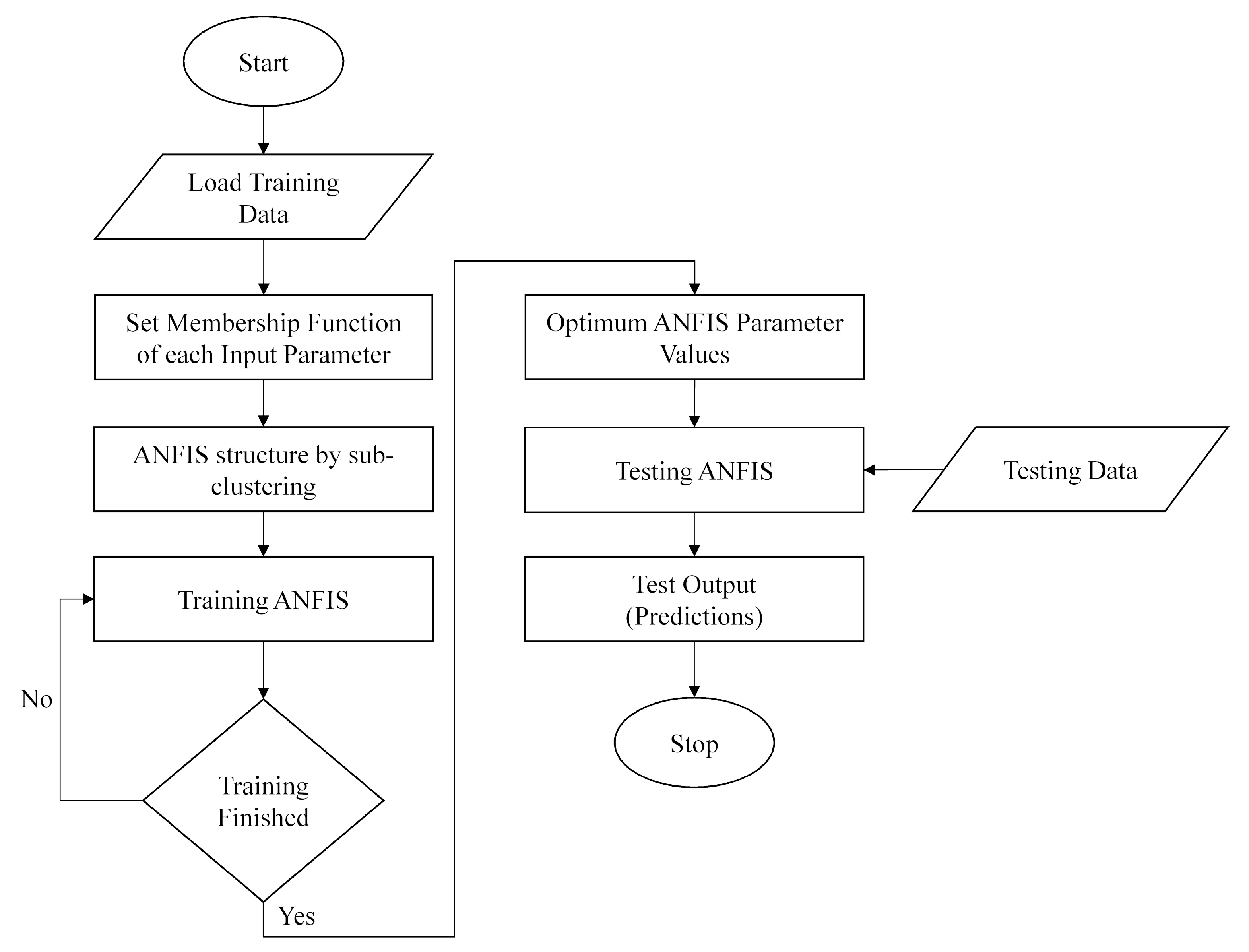
Figure 11 shows the algorithm flowchart used to perform the landslide chances estimation using the ANFIS. As can be seen from the flowchart, the testing was performed on the optimum variables once the training was finished during the early stages of the model run.
All the ANFIS simulations were conducted using the ANFIS, Fuzzy Logic toolbox of MATLAB v. 7.0. The ANFIS model was tested by running the model in the MATLAB environment. An example prediction was generated using the model. The prediction generated was found to be highly significant and accurate. The model showed a minimal training error RMSE = 0.000299 and an average testing error of 0.048609, which is very low; so, the model can be considered a best-fit model for landslide predictions. The MATLAB code used for the ANFIS model execution in Fuzzy Logic toolbox environment was as follows:
Details of the ANFIS model.
Number of nodes: 4426
Number of linear parameters = 2187
Membership function type = Trimf
Number of membership functions = 3
Total number of parameters = 2250
Number of nonlinear parameters = 63
Number of fuzzy rules = 2187
Number of training data pairs = 158
Model Execution.
g= readfis (‘T335.fis’);
r = input (‘RF (Rainfall in mm (1-4)) =’);
a = input (‘LST (Land Surface Temperature (284-306)) =‘);
b = input (‘SM (Soil Moisture (283-305)) =‘);
c = input (‘SLP (Slope (6-66)) =‘);
d = input (‘DTRD (Distance to Road (1-45)) =‘);
e = input (‘DTR (Distance to River (10-298)) =‘);
f = input (‘BUA (Built-up area near Prone Site (1-29965)) =‘);
g = evalfis ([r a b c d e f], g);
disp ([‘Chances of Landslide:’, num2str(h)]);
%h = output (‘Chances of Landslide is:’);
%xlswrite (‘RPredict’,h);
Response and output result of the model.
Input Variables and Input Values
RF (Rainfall in mm (1-4)) = 2
LST (Land Surface Temperature (284-306)) =290
SM (Soil Moisture (283-305)) =292
SLP (Slope (6-66)) = 14
DTRD (Distance to Road (1-45)) = 41
DTR (Distance to River (10-298)) = 290
BUA (Built-up area near Prone Site (1-29965)) = 500
Result: Chances of Landslide: 0.99562
The model generated an output ‘Result’ as Chances of Landslides = 0.99562, nearly equal to ‘1’. Therefore, it meant that the model generated a ‘Low’ level warning for the input data provided. The warning output generated by the model was found to be highly accurate with a low RMSE and misclassification.
4.1.4. Random Forest (RF)
Random Forest, a machine learning algorithm known for its deep learning, classification, and prediction capabilities, was used to classify and predict the chances of landslides. Training data were provided as an input to the model, which classified it into various classes based on the variable importance and its significance to the overall model. The model tried different numbers of trees and variables at each split to find the best combination for superlative classification and precise predictions.
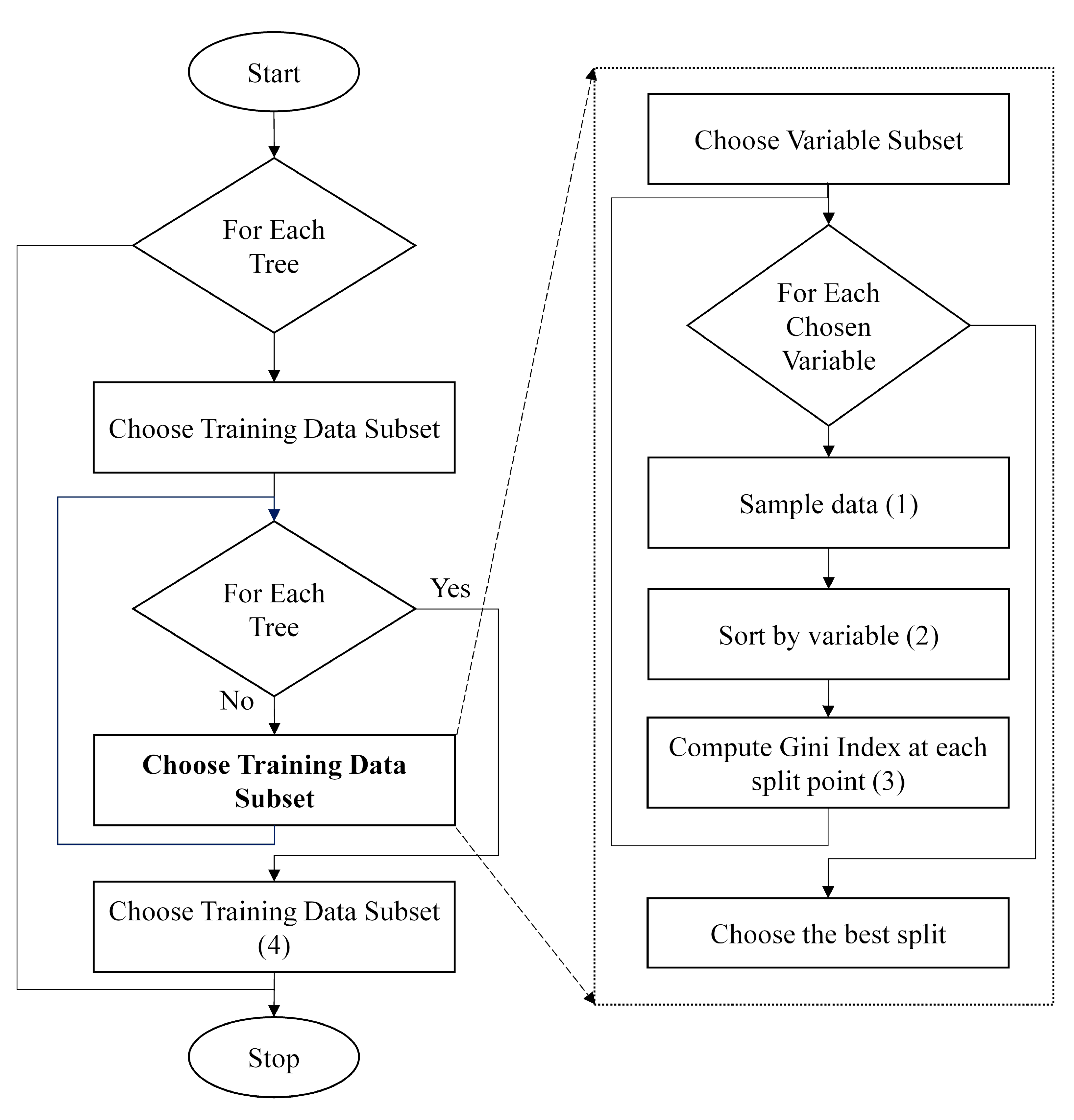
Figure 12 shows the algorithm flowchart used to perform the landslide chances estimation using the random forest model; it can be seen that this model uses extensive processes and loops for calculating the training dataset. This is the reason for its very high precision and accuracy in any machine learning-based land system process modelling.
Model Details
Number of trees = 55
OOB estimate of error rate = 0%
ROC Area = 1 (100%)
Mean absolute error = 0.0186
Relative absolute error = 4.2596%
No. of variables tried at each split = 2
Correctly Classified Instances = 66 (100%)
Root mean squared error = 0.0684
Incorrectly Classified Instances = 0 (0%)
Root relative squared error = 14.5608%
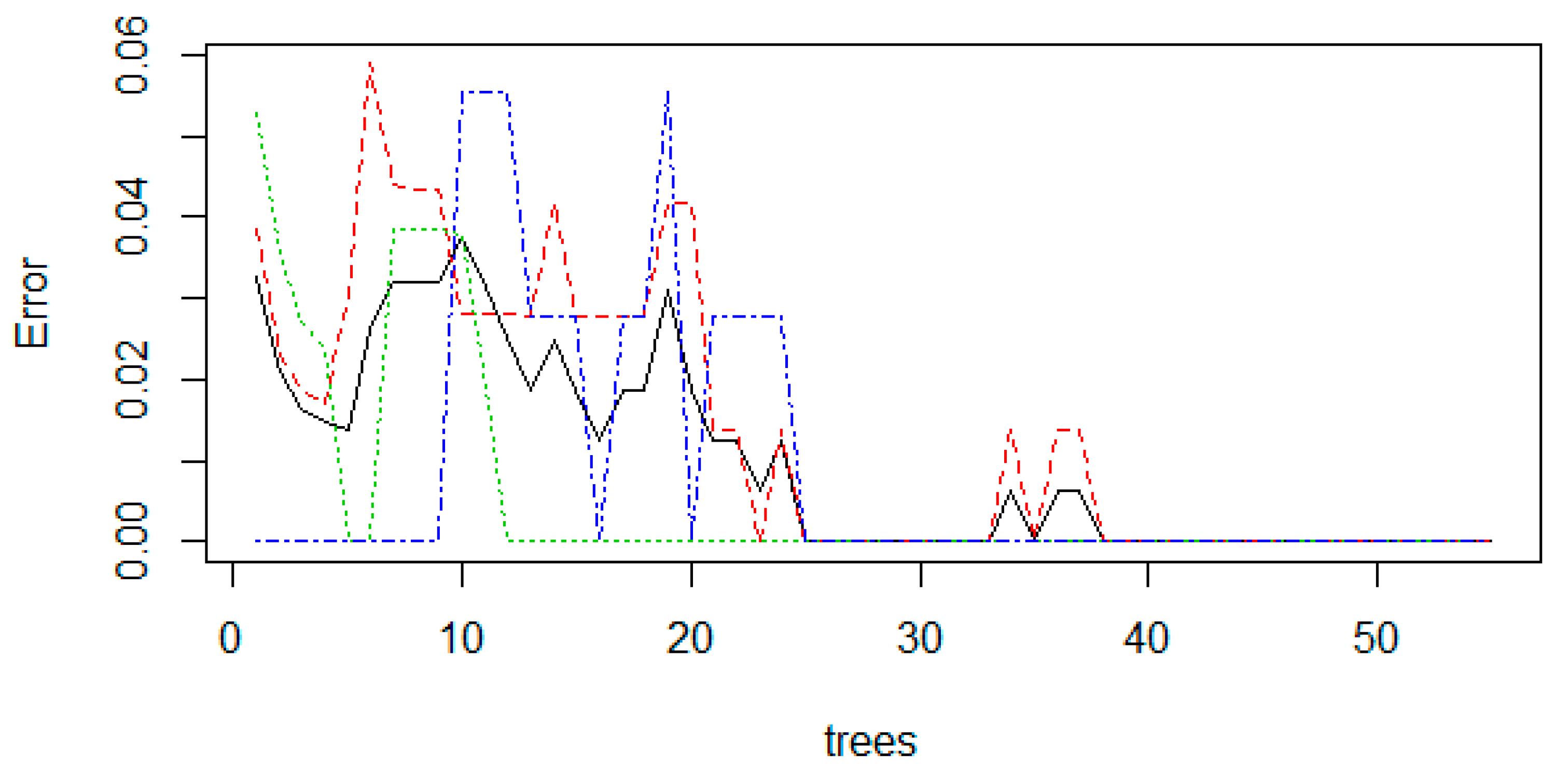
The model showed nearly about 99–100% accuracy, with 100% correctly classified instances. The model’s error rate was initially around 0.276 at ntree = 20 and mtry =2, which dropped to zero at ntree = 55 and mtry = 2 as shown in (
Figure 6). The prediction accuracy of the model was analysed by comparing and calculating the difference between the predicted and observed data (testing data) values, which was as follows:
The model showed approx. 100% accuracy when matched with the data that the particular tree had not seen (testing data). So, the model can be considered as a best-fit model for the classification and prediction of landslides.
4.2. Landslide Early Warning System (LEWS) and Land System Processes in the Rugged Himalayan Mountains
We performed multiple experiments that showed that ANFIS and RF outperformed the other proposed methods for establishing a landslide early warning system for the stretch of national highway between Chanderkote and Jawahar tunnel in J and K, India. All the independent variables used in both models were found to be significant. At the same time, the newly added variables LST and BUA (Built-up Area near the prone site) were also highly influential in increasing the accuracy of the model results, which until now have not been used to predict the chances of landslides. The evaluated P-values (significance of variables) showed that both variables were highly significant and contributed to the models. The overall prediction accuracy improved from 95% to 99% in ANFIS and the Random Forest algorithm. From these results, it is proposed that along the studied stretch of the national highway, at all vulnerable sites, sensors that provide information about the real-time ambient soil moisture and rainfall measurements should be installed. This can be used in the proposed LEWS system to provide real-time information about the chances of occurrences of landslide events using other satellite-derived variables.
The main factor contributing to the high landslides in the study area is the slope. In other words, surface topography is one such landscape characteristic that helps understand why some places are comparatively more vulnerable to landslides than others [
61,
62,
63,
64]. The topography has a significant effect on landslide kinematics [
65]. The region’s topography includes incised engraved valleys and rugged mountains with narrow gorges and very steep slopes having no or very little vegetation over the slopes [
66]. To understand the higher vulnerability of the area to landslides, we created a buffer of 5 km around the studied stretch of the national highway (
Figure 13). It can be observed that within this area, the elevation ranges from 605 m to 3666 m, which ascribes the study area with a higher relief and slope (
Figure 13a). The other manifestation of the elevation is slope and contours, helping to visualize surface topography more intuitively. The slope angle formed one of the essential inputs to all the models. As shown in
Figure 13b, the percent slope rise in the study area within the 5 km radius is exceptionally high, ranging from 0.00 to 160.28. Such areas with extremely high slope rises are typical of Himalayan landscapes. It provides the landslides with the required gravitational force to occur [
67]. According to many studies, it is a key factor causing slope instabilities [
68,
69]. The slope angle governs the retention of moisture and vegetation on the slopes, affecting its stability and soil strength. Slope angle affects the amount of rainfall falling on the slope due to the impact of wind on the slope, diverse slope aspects, and curvature [
70].
Various studies in the Himalayan regions have carried out landslide assessments. Studies have evaluated the impact of landslides by assessing their velocity, damaged area, and the distance of their runouts. Guo et al., (2022) carried out an in-depth analysis of the causes of the landslides and determined the deposit patterns using finite difference and numerical methods. Similar to the present study, this study evaluated the accuracy of the model using three new variables, friction coefficient, critical velocity, and steady friction coefficient. Studies have concluded that landslides are governed by regional geomorphic, geological, and climatic conditions, and thus any assessment requires an evaluation of all the contributing factors [
71]. In addition, erratic rainfall is also one of the important triggering factors.
The slopes along NH 44 national highway have suffered huge deformations due to heavy vehicular traffic, road widening, construction along the highway, and tectonic movements [
68,
69,
70]. The area from ‘Nachlana’ to ‘Seri’ is highly prone to landslides, with many active landslides present in the area. Most of the landslides on the National Highway were reported and identified in the same region. Therefore, this area can be considered a highly prone and vulnerable area to landslides. The landslide occurrences resulting from various other parameters in this area are strongly increased due to heavy traffic on this highway. Studies have shown how traffic intensity affects the frequency of landslide occurrence on this highway [
66,
68,
69]. The vibrations due to heavy transport, which includes the most significant proportion of heavy motor vehicles, is possibly the force influencing the mass movements in this area. Road construction along the mountainous region is often simultaneously accompanied by mining, and the slopes become unstable and result in landslides after a spell of rainfall. Moreover, the consequences become disastrous when the conditions are as on the NH 44 highway. Studies have been carried out that have evaluated the impact of rainfall on rock deformations. While assessing such a relationship, Li et al., (2022) concluded that the water content of the land mass movement has a direct relationship, and it is the result of rainfall variability that induces the failure of the soil interlayers and results in landslides. Such studies aimed to provide landslide prediction using real-time information about rainfall and soil moisture condition, similar to what has been achieved in the present study [
72].
We have also shown the 300 m contours of the study area (
Figure 13b). The contours of the study area range from 495 m to 4510 m, with very steep slopes that can highly influence the landslides and rockfalls over the area. Contour lines are important for landslide investigation and analysis because they allow us to investigate the overall topography of the landmass. In recent years, many studies have been carried out on the effect of topography on landslides. Different terrain mechanisms were explored with the help of various indoor model experiments [
73,
74,
75], and the landslide masses’ mechanical properties were explored with varying levels of moisture and terrain structures. All the parameters used in this study contributed to the landslides’ occurrence. According to various studies, moisture (precipitation) and topographical properties play a significant role in triggering landslides [
76,
77,
78,
79]. The excessive moisture in the soil increases the pore pressure, which decreases the shear strength of the soil and leads to slope failure [
78].
Based on the previous research [
68], and the current analysis, the key factors responsible for landslides on the Jammu Srinagar National Highway assessed were intensive rainfall events, anthropogenic activities, slope morphology, heavy traffic, vegetation density, changes in ground and surface water, land surface temperature (LST), and ongoing climate change, which has exacerbated their frequency of occurrences [
80,
81,
82,
83,
84,
85,
86]. Rainfall is a common factor triggering landslides. Intense or prolonged rainfall events decrease the shear strength and internal friction between the soil particles and cause the soil to slide downward, causing often fatal landslides [
87,
88]. There are also increases in the extreme precipitation events over the study area (Jammu and Kashmir), which have the potential to increase the frequency of natural hazards such as floods, landslides, snow avalanches, floods, GLOF, and LLOF [
89,
90]. Further, the soil profile on the slopes of this area is loose naturally; hence, a low intensive rainfall event is enough to trigger a landslide [
68]. This is mainly because the mountain characteristics near the study area, which is dominated by weak metamorphic rocks such as lithosole, sedimentary rocks, and semi-consolidated to consolidated sandstones and siltstones, show active weathering processes and liquefaction properties during prolonged precipitation events (Siwalik Himalayan Belt) [
91,
92,
93,
94,
95]. The weathering and liquefaction properties of the stones deposit a layer of clay and silt material on the slopes [
96,
97,
98,
99]. At the same time, the sandstones are transformed into small and fine-grained rock pieces and granules, which make slopes highly unstable and prone to failure [
100]. Most of the land failures in the study area are covered with thick colluvium material, claystone, mudstone, and siltstone [
68]. In contrast, others are covered with sedimentary rocks and sandstone granules, making these sites highly prone to rainfall-induced land failure [
68]. All these factors make the region highly susceptible and prone to landslides [
68,
89,
100,
101,
102].


 ,
, 



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}