1. Introduction
The Sacramento–San Joaquin Delta (Delta) serves as California’s most crucial water hub, where the state’s two largest rivers, Sacramento River and San Joaquin River, converge to form a 2978-square-kilometer (1150-square-mile) inland Delta and estuary system [
1,
2]. This vital water resource supports approximately 27 million people, irrigates 1.21 million hectares of farmland, and maintains a diverse ecosystem of over 750 species [
3,
4]. Beyond water conveyance, the Delta generates significant economic value through recreation, recreational fishing, and transportation activities.
Water quality in the Delta, particularly the concentration levels of ion constituents including dissolved chloride, bromide, and sulfate, directly impacts multiple stakeholders and uses. For agricultural operations, elevated chloride levels can increase soil salinity and reduce crop yields. In urban water treatment, high bromide concentrations lead to the formation of harmful disinfection by-products (DBPs), requiring additional treatment steps to ensure public safety [
5,
6]. Agricultural runoff, urban development, and tidal influences continuously introduce various pollutants and ions into the system, making water quality monitoring and prediction essential for effective management [
7,
8,
9].
Managing these water quality challenges requires balancing diverse needs: agricultural productivity, drinking water safety, and ecosystem health [
10]. The complex interplay between these demands, combined with Delta’s dynamic hydrology, creates a pressing need for accurate and timely water quality monitoring and prediction tools [
11].
Physical sampling and laboratory analysis remain the gold standard for monitoring ion constituents in the Delta, providing highly accurate and reliable measurements of water quality parameters [
12]. This direct measurement approach ensures precise quantification of individual ion constituents and serves as the foundation for calibrating and validating other estimation methods.
However, traditional sampling methods present several limitations:
Time and cost constraints: laboratory analysis often requires days or weeks to complete, involving substantial personnel and equipment resources.
Limited coverage: physical sampling provides only point-in-time measurements at specific locations, lacking continuous temporal and spatial coverage.
Operational delays: the time lag between collecting samples in the field and receiving laboratory results can impede timely operational decisions for water management.
These limitations have driven the development of alternative approaches for estimating ion constituent levels, particularly through the use of Electrical Conductivity (EC) as a proxy measurement.
Due to the limitations of direct sampling, scientists have explored faster and more cost-effective methods for estimating ion constituent levels in the Delta. Electrical Conductivity (EC) has emerged as a valuable proxy measurement, due to its unique advantages in water quality monitoring. EC can be measured continuously through in situ sensors and simulated effectively through hydrodynamic models, providing real-time monitoring capabilities that are crucial for operational decision-making [
13]. Moreover, EC demonstrates strong correlations with various ion concentrations, making it a reliable indicator of the overall ionic content in water [
14]. These characteristics have made EC the foundation for most ion constituent estimation methods in the Delta, enabling more frequent and widespread simulation than would be possible through direct sampling alone.
The development of methods for estimating ion constituents from EC measurements spans several decades. Classical approaches primarily rely on parametric regression equations, assuming that the relationship between EC and ion concentrations follows specific mathematical patterns (linear, quadratic, etc.) under different conditions [
15,
16,
17]. These methods aim to simplify the conversion process from EC measurements to ion constituent levels.
The evolution of these approaches shows increasing sophistication over time. The pioneering work by [
18] established the foundation by developing linear regression equations between EC, chloride, and total dissolved solids (TDS). Throughout the 1990s and early 2000s, researchers significantly expanded upon this foundation. Jung [
19] investigated correlations between EC and various ions in Delta island return flows, while Suits [
20] developed linear relationships between EC, chloride, and bromide at Delta export locations. A significant advancement came with Denton’s comprehensive study, which provided multiple methodological approaches for estimating a broader suite of ions [
5].
The current state-of-the-art classical approach, developed by Hutton et al. [
21], represents the most comprehensive parametric regression method to date. This study introduced a novel decision tree framework that determines appropriate regression equations based on multiple factors, including the sub-region of the Delta, Water Year Type (WYT), Month, and Sacramento X2 location [
22], which is a key marker for salinity intrusion. Using these parameters, the method classifies conditions as seawater-dominated, San Joaquin River-dominated, or mixed, applying specific equations accordingly.
While the approach of Hutton et al. [
21] significantly improved upon previous methods, it faces several limitations. A fundamental challenge lies in the simplified source assumptions, where classical methods generally consider only two major sources of salinity—seawater and the San Joaquin River. Agricultural drainage, despite being a significant salinity source in the Delta, is often oversimplified or considered aligned with the San Joaquin River source. This simplification can lead to inaccuracies, since agricultural drainage has distinct ionic compositions and behavior patterns compared to river inflows.
The handling of mixed conditions presents another significant challenge. Classical models tend to oversimplify these conditions by assuming a dominant source or using a single equation for mixed conditions. However, the reality is more complex, since salinity in the Delta typically results from multiple simultaneous sources, with their relative influences varying over time. The same EC level can correspond to markedly different ionic compositions depending on the source: seawater-dominated water often contains higher proportions of chloride and bromide, whereas water influenced by agricultural drainage or river flows is generally richer in sulfate.
Perhaps the most challenging aspect is the dynamic nature of these mixed conditions. The Delta exists almost perpetually in a mixed state, with salinity levels influenced by multiple sources simultaneously. The relationship between EC and ion concentrations shifts dynamically based on the varying contributions from different sources, and current parametric approaches struggle to capture these relationships, particularly during periods of rapid hydrological changes.
These limitations highlight the need for more sophisticated approaches that can better capture the complex and dynamic relationships between EC and ion constituents in the Delta system. Machine learning methods, with their ability to identify and adapt to complex patterns in data, offer promising solutions to these challenges.
Recent developments in machine learning have opened new possibilities for addressing these challenges. Following established protocols for water and environmental modeling using machine learning in California [
23], our first study [
24] served as a proof of concept to evaluate whether machine learning models could outperform traditional regression equations in simulating ion constituents. This pioneering work focused on the South Delta region, using a relatively small dataset of approximately 200 samples collected from seven stations between 2018 and 2020. Using R (
https://www.r-project.org/, accessed on 1 June 2022) as the programming platform, we compared four machine learning approaches—Generalized Additive Model, Regression Trees, Random Forest, and Artificial Neural Networks—against conventional regression equations. The results demonstrated that machine learning models, particularly Random Forest, provided superior simulations of ion constituents compared to traditional regression equations. These improvements were especially notable for ions that exhibit pronounced non-linear relationships with EC. This study established the viability of machine learning approaches for simulating ion constituents in the Delta.
Building on these promising initial results, our subsequent research [
25] significantly expanded both the geographic and temporal scope of the analysis. Implemented in Python (
https://www.python.org/, accessed on 1 June 2022) this comprehensive study covered the entire Interior Delta and incorporated an extensive dataset spanning over 60 years, with sample sizes ranging from approximately 1000 to 2000 measurements for different ion constituents. This study developed and validated Artificial Neural Network (ANN) architectures specifically designed for ion constituent prediction, demonstrating remarkable improvements over the benchmark classical approach [
21]. The ANN model showed significant improvements in both accuracy metrics, with R
2 improvements ranging from 0% for well-modeled constituents like TDS, to 85% for more complex constituents like sulfate. More importantly, the ANN model reduced the Mean Absolute Error (MAE) across all constituents, with improvements of 24% for TDS, 33% for magnesium, 32% for sodium, 40% for calcium, 34% for chloride, 59% for sulfate, 25% for bromide, 26% for alkalinity, and 20% for potassium. Additionally, the study introduced an interactive web browser-based dashboard hosted on Microsoft Azure, making these sophisticated prediction tools accessible to users regardless of their programming expertise. This user-friendly interface allows stakeholders to simulate ion levels under various hydrological conditions, compare results across different machine learning models, and visualize outcomes for informed decision-making.
The current study builds on the two studies mentioned above [
24,
25] and extends them in several important directions. First, we focus on applying ML models to three strategically important drinking water intake locations, where water quality monitoring is crucial for operational decision-making. Second, we enhance the accessibility and utility of our modeling tools through three complementary dashboards: (a) a new publicly available dashboard for intake locations; (b) an improved version of our previous dashboard [
25] that incorporates Hutton et al.’s [
22] parametric regression equations for direct comparison with ML approaches for the Interior Delta; and (c) a novel Model Interpretability Dashboard that helps demystify the “black box” nature of ML models by visualizing how they respond to different predictors and operating conditions for the Interior Delta. This third dashboard is particularly innovative as it allows users to explore model behavior, assess sensitivity to input variables, and build trust in ML predictions by comparing them with traditional parametric approaches. Finally, to address key limitations of current ML approaches—specifically, their temporal and spatial distribution constraints and inability to simulate potential future scenarios—we develop a novel hybrid water quality model that combines hydrodynamic modeling with machine learning, supported by its own interactive dashboard for scenario exploration and analysis. Together, these advancements not only provide more accurate predictions, but also make complex ML models more transparent and interpretable for water resource managers, helping them to make more informed decisions about monitoring and managing ion constituents in the Delta.
This paper first presents our development of machine learning models for predicting ion constituents (chloride, bromide, and sulfate) at three critical water intake locations. We describe our methodology, including data characteristics and model optimization procedures, followed by performance analyses demonstrating significant improvements over existing approaches.
We then present three complementary web-based tools. The first is a new Intake Locations Dashboard specifically designed for water intake locations. The other two dashboards build upon the previous Interior Delta study of Namadi et al. [
25]: an Enhanced Comparison Dashboard that integrates classical methods with machine learning approaches, and a Model Interpretability Dashboard that helps users to understand model behavior across the Interior Delta.
To address spatial coverage limitations in the Interior Delta, we introduce a novel hybrid approach combining DSM2 hydrodynamic modeling with machine learning [
26]. This model enables continuous spatial prediction of ion constituents across 162 points throughout the Interior Delta.
Finally, we discuss implications of the current study for Delta water management, acknowledge current limitations, and suggest directions for future research.
2. Materials and Methods
2.1. Study Area and Dataset Characteristics
Our research synthesizes and builds upon two complementary datasets from the Delta: the Interior Delta dataset from our previous work [
25] and a new focused dataset from strategic water intake locations. As shown in
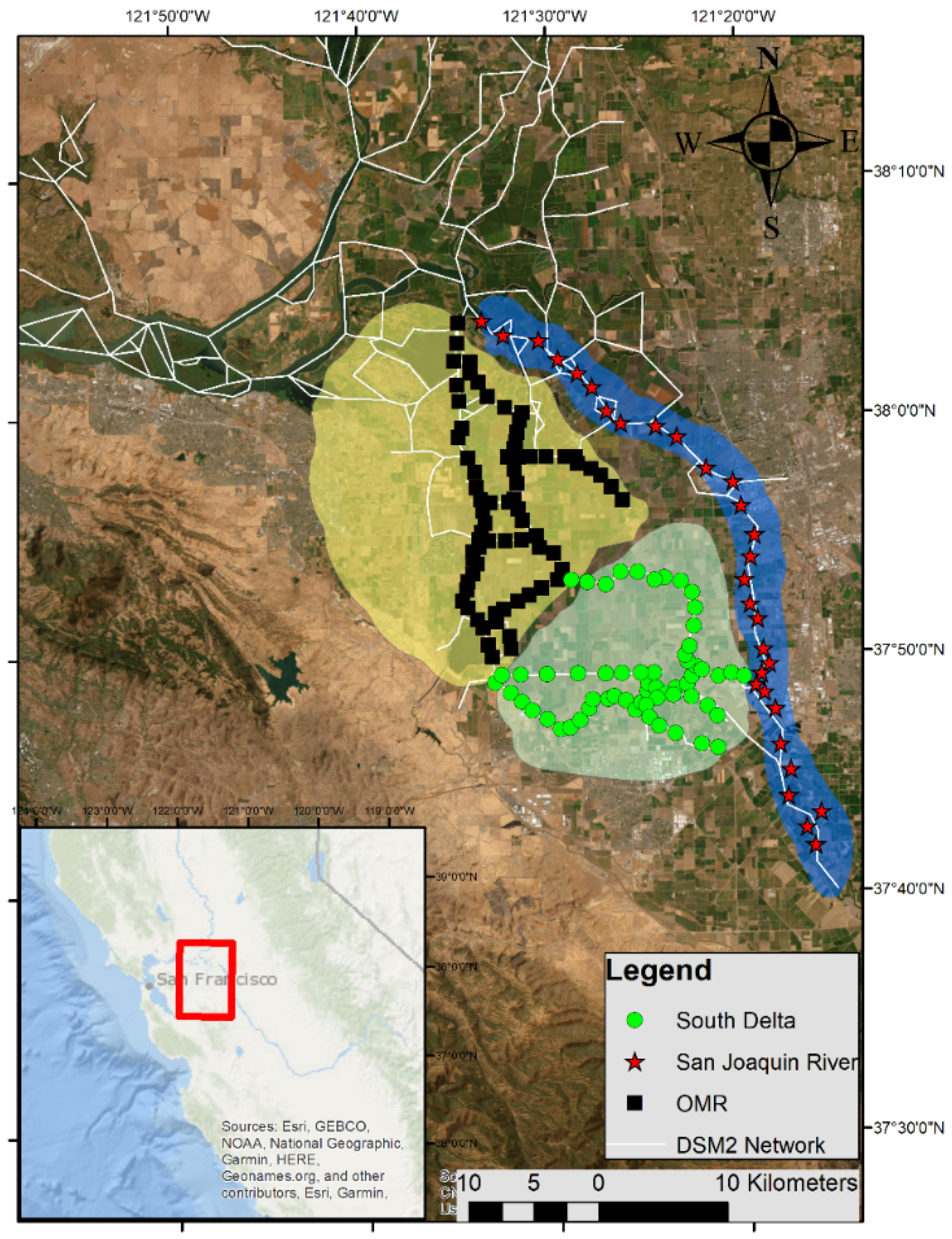
Figure 1, our study area encompasses both interior monitoring stations and critical water intake facilities. The Interior Delta monitoring network consists of three sub-regions: the Old and Middle River corridor (OMR, shown as red squares), the San Joaquin River corridor (SJRcorridor, marked by black triangles), and the South Delta region (represented by blue circles). The water intake locations, depicted as green stars, include three strategically important pumping plants: the Harvey O. Banks Pumping Plant (HRO; 37°47′53″ N, 121°37′23″ W), the Tracy Pumping Plant (TRP; 37°48′00″ N, 121°35′06″ W), and the O’Neill Forebay at the Gianelli Pumping Plant (ONG; 37°03′60″ N, 121°04′19″ W).
This study encompasses two complementary analyses. First, we expand upon our previous work that developed machine learning models for nine ion constituents (TDS, magnesium, sodium, calcium, chloride, sulfate, bromide, alkalinity, and potassium) across the Interior Delta monitoring stations, providing enhanced analysis and interpretation through our new dashboard tools. Second, we extend our modeling approach to water intake locations, where available monitoring data focus on three key ion constituents (chloride, bromide, and sulfate). These three constituents are particularly crucial for water quality management at pumping facilities, as they directly impact treatment processes and water supply operations.
The temporal and spatial coverage of these datasets reveals distinct characteristics that reflect their different roles in Delta water management. The Interior Delta dataset encompasses data from 1959 to 2022, though the temporal coverage varies by constituent and location. For detailed information about the Interior Delta monitoring timeline and data characteristics, readers are referred to our previous study [
25]. In contrast, our water intake locations feature more recent but substantially more intensive monitoring programs. The HRO and TRP data collection spans from 2019 to 2023, while ONG has a longer record, from 2012 to 2023. These locations are characterized by high-frequency sampling, resulting in robust sample sizes: ONG collected 2620–2783 samples, while HRO and TRP gathered 1214–1328 and 1181–1233 samples, respectively. This intensive monitoring reflects the operational importance of these facilities in California’s water supply infrastructure.
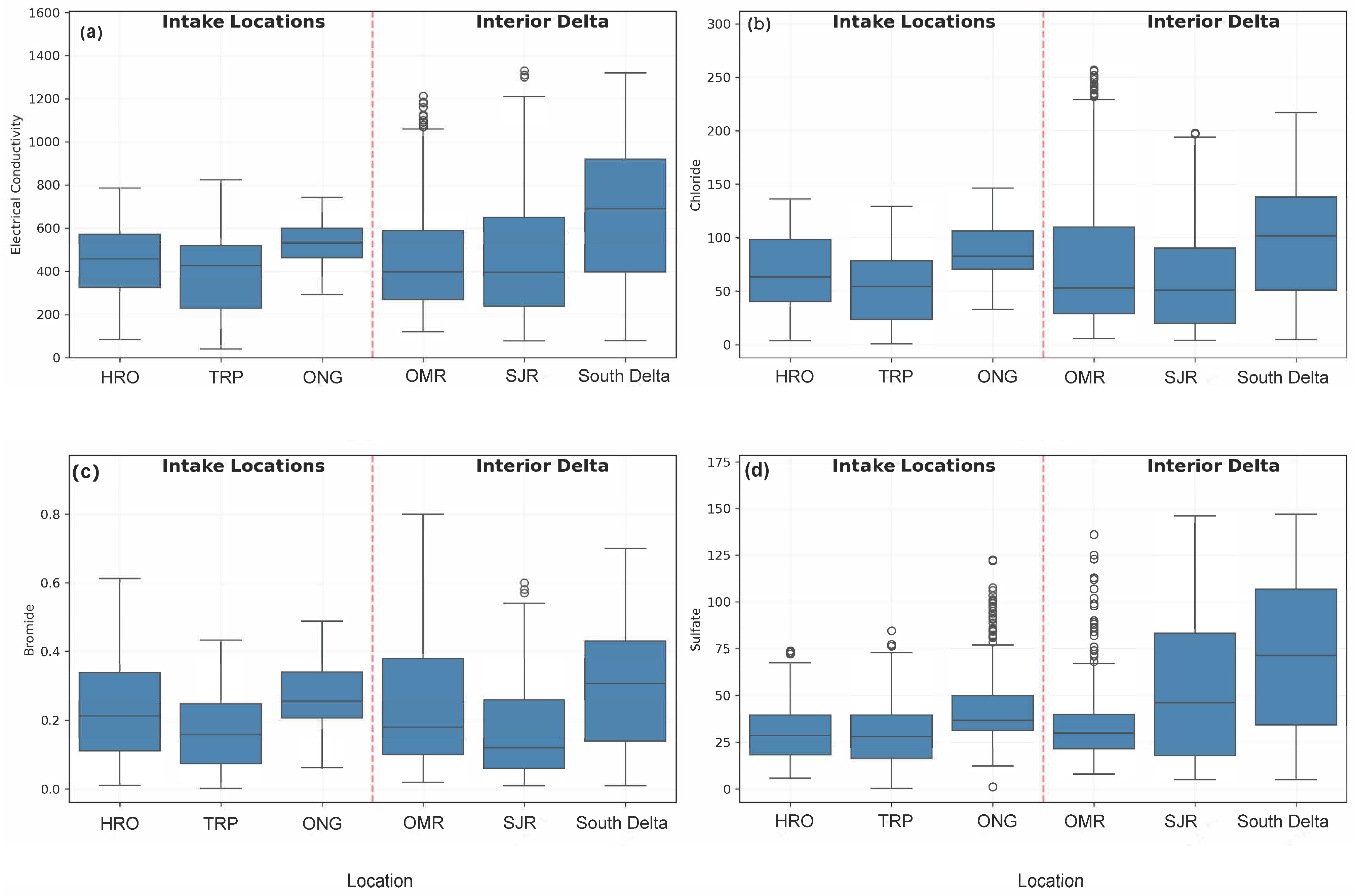
Analysis of constituent distributions, as illustrated in
Figure 2, reveals distinct patterns between the Interior Delta and the water intake locations. Interior Delta locations consistently show higher variability and maximum values across all the measured constituents. The South Delta region exhibits the highest median EC values and widest range, varying from approximately 200 to 1400 μS/cm, while intake locations maintain more consistent EC patterns between 300 and 800 μS/cm. Similar patterns emerge for chloride concentrations, where Interior Delta locations, particularly the South Delta and OMR, show notably higher maximum values and greater variability compared to the more stable concentrations at intake locations.
Bromide distributions follow comparable trends, with OMR exhibiting particularly high outliers and greater variability compared to the relatively consistent levels maintained at intake locations. Sulfate concentrations in the Interior Delta, especially in the South Delta and SJRcorridor, show higher median values and greater variability compared to intake locations, though ONG typically shows slightly higher median values among the intake locations, while still maintaining more stable concentrations overall.
These distinct patterns between the Interior Delta and the intake locations reflect their different roles in the Delta system. The Interior Delta locations capture the system’s natural variability and multiple water source influences, resulting in wider ranges of constituent concentrations. The more consistent patterns at intake locations reflect managed operations and water quality control measures, which are crucial for maintaining reliable water supply quality.
This comparison provides crucial context for our modeling approach and dashboard development. The stark differences between the Interior Delta and intake locations—particularly in sampling frequency (moderate vs. intensive) and constituent variability (wide-ranging vs. more consistent)—reveal fundamentally different water quality patterns at these locations. Due to these distinct characteristics, we developed separate simulation models specifically for water intake locations, rather than applying our Interior Delta models. This location-specific modeling approach ensures that predictions accurately reflect the unique water quality dynamics and operational patterns at each type of monitoring site.
2.2. Model Development
2.2.1. Input Variable Selection
Our model development utilized a consistent set of predictor variables across both Interior Delta and water intake locations, maintaining methodological continuity with our previous work [
25]. The selected predictors capture key physical and operational factors influencing ion constituent concentrations:
1. Electrical Conductivity (EC): A real-time measurement obtained through in situ sensors that indicates the water’s ability to conduct an electrical current, serving as a proxy for total dissolved solids and overall salinity levels [
27]. EC measurements provide continuous monitoring capabilities, which are crucial for operational decision-making.
2. Sacramento X2: A key hydrodynamic indicator, measured as the distance (in kilometers) from the Golden Gate Bridge to the location where the tidally averaged near-bottom salinity is 2 practical salinity units (psu) [
28]. This metric effectively captures Delta outflow conditions and the extent of seawater intrusion from the Pacific Ocean into the Delta system [
29].
3. Water Year Type (WYT): California’s water year runs from October 1 to September 30, with types classified as Wet, Above-Normal, Below-Normal, Dry, or Critical, based on measured unimpaired runoff [
30]. This classification integrates various hydrological factors, including precipitation, snowmelt, and river flows, providing a comprehensive indicator of water availability and system conditions [
31].
4. Month: This is included to capture seasonal patterns in water quality, reflecting cyclical changes in precipitation, temperature, agricultural practices, and water management operations.
5. Location: A categorical variable distinguishing between monitoring sites. For water intake locations, this includes HRO, TRP, and ONG, while the Interior Delta locations are categorized into the OMR, SJRcorridor, and South Delta sub-regions.
These predictors were selected for their demonstrated relationships with ion constituent concentrations and their operational relevance in water management. The combination of continuous (EC, X2) and categorical (WYT, Location, and Month) variables enables our models to capture both direct relationships and complex interaction effects influencing water quality patterns.
While maintaining methodological consistency, our benchmark comparison uses performance metrics from existing approaches. Since no prior models exist for water intake locations, we compared our new models’ performance metrics against the documented performance of both ML and classical methods in the Interior Delta [
24,
25]. For example, if the Interior Delta ML model demonstrated a specific MAE for chloride predictions in that region, we used this as a benchmark to evaluate our new model’s MAE for chloride predictions at water intake locations. This comparison, while across different locations, provides context for assessing our models’ relative performance in predicting ion constituents.
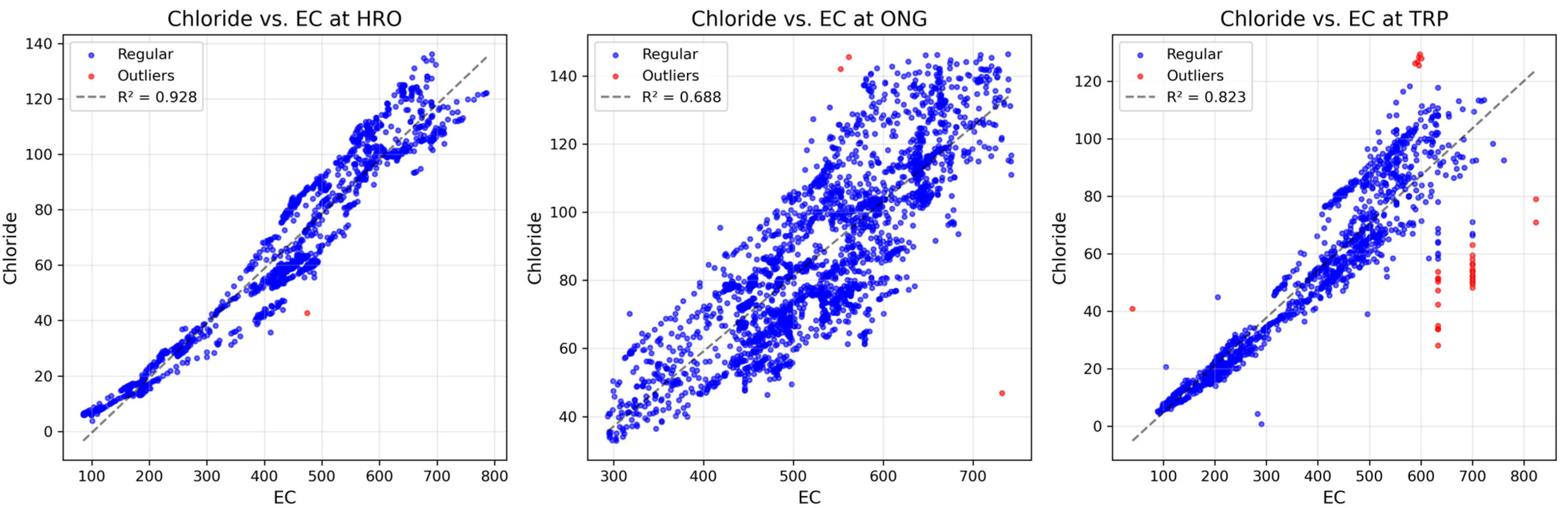
Data preprocessing and quality control were crucial steps to ensure model reliability. We implemented a regression-based outlier detection method focusing on the fundamental relationship between EC and ion constituents, where points exceeding three standard deviations from the regression line were flagged as potential outliers. This analysis revealed minimal outliers across locations, as detailed in
Table 1, with outlier percentages generally less than 3% across all constituents and locations. The strong coefficient of determination (R
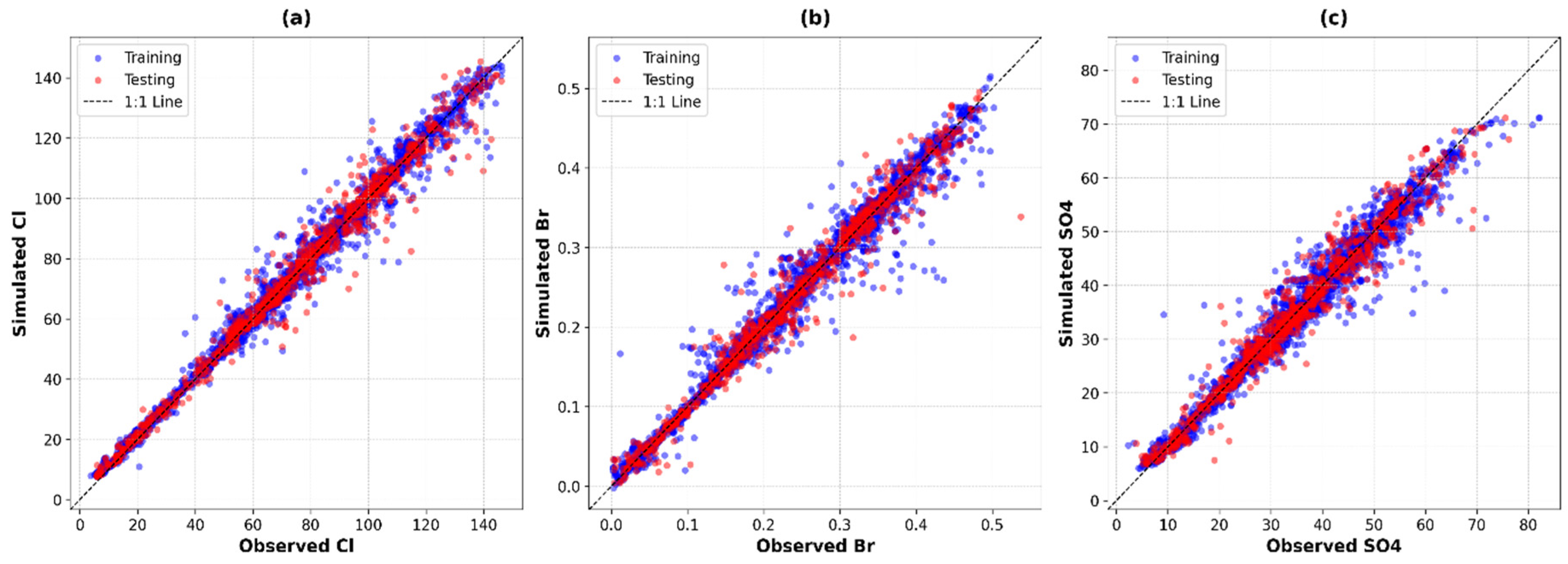
2) values, particularly for chloride (0.928 at HRO, 0.688 at ONG, and 0.823 at TRP), indicated high data quality and validated our outlier detection approach.
Figure 3 illustrates the relationship between EC and chloride concentrations at the three water intake locations, demonstrating both the effectiveness of our outlier detection method and the varying relationships at different locations.
Following outlier detection, we implemented a comprehensive feature preprocessing pipeline using Scikit-learn’s ColumnTransformer function to prepare the data for model training. Numerical predictors (EC and X2) were standardized using the StandardScaler function to transform them to zero mean and unit variance, ensuring consistent scale across features and preventing convergence issues during model training. Categorical variables (Location, WYT, Month) were transformed using one-hot encoding to convert them into binary features while avoiding multicollinearity. This preprocessing pipeline was saved using joblib to ensure consistent transformation of future data points. The standardization and encoding approach helps to prevent any single feature from dominating the model training process, ensures proper handling of categorical information, and facilitates stable model convergence during training.
2.2.2. Machine Learning Approaches
Machine learning, a subset of artificial intelligence, enables computers to learn patterns from data without explicit programming [
32]. In recent years, machine learning techniques have been increasingly applied to water quality modeling, due to their ability to capture complex, non-linear relationships in environmental systems. Numerous studies have demonstrated the effectiveness of machine learning in water quality applications, including the prediction of dissolved oxygen [
33], suspended sediment [
34], and salinity [
35,
36,
37,
38].
Artificial Neural Networks (ANNs) are particularly powerful machine learning models inspired by biological neural networks [
39]. Among the various ANN architectures, we employed the Multi-Layer Perceptron (MLP), a feedforward neural network architecture well suited for regression problems like ion constituent prediction. The MLP architecture consists of multiple layers of interconnected nodes (neurons), with each connection having an associated weight that is adjusted during training. Each neuron applies a non-linear activation function to the weighted sum of its inputs, enabling the network to learn complex patterns in the data. This architecture has proven effective in various water quality applications, including prediction of chemical oxygen demand and analysis of heavy metal content.
Building upon our previous comparative analysis of machine learning algorithms [
25], we employed ANNs for simulating ion constituent concentrations at water intake locations. The selection of ANNs was guided by their demonstrated superior performance in capturing non-linear relationships between environmental predictors and ion concentrations in the Delta system, particularly their ability to adapt to complex spatial and temporal patterns in water quality dynamics. We implemented an MLP architecture using TensorFlow [
40]. The model training utilized the Adam optimizer with the mean squared error (MSE) loss function, chosen for its effectiveness in regression tasks and adaptability to varying gradients.
Hyperparameter optimization is a crucial step in developing neural networks, as these parameters significantly influence model performance, but cannot be learned directly from training data. Unlike model weights and biases that are updated during training, hyperparameters must be set before the training process begins. However, the complex interactions between different hyperparameters make it challenging to determine their optimal values theoretically, necessitating empirical optimization approaches.
MLPs have a number of hyperparameters, including network architecture (number of layers and neurons), activation functions, learning rate, batch size, optimizer settings, and regularization parameters. Optimizing all possible hyperparameters simultaneously would be computationally intensive and often impractical. For instance, considering just five options for ten hyperparameters would result in 510 (approximately 9.7 million) possible combinations. Therefore, researchers typically focus on optimizing a subset of hyperparameters that are known to have the most significant impact on model performance.
In this study, we focused on three critical hyperparameters:
Number of hidden layers (2 to 5 layers);
Number of neurons per layer (10, 20, 30, or 40);
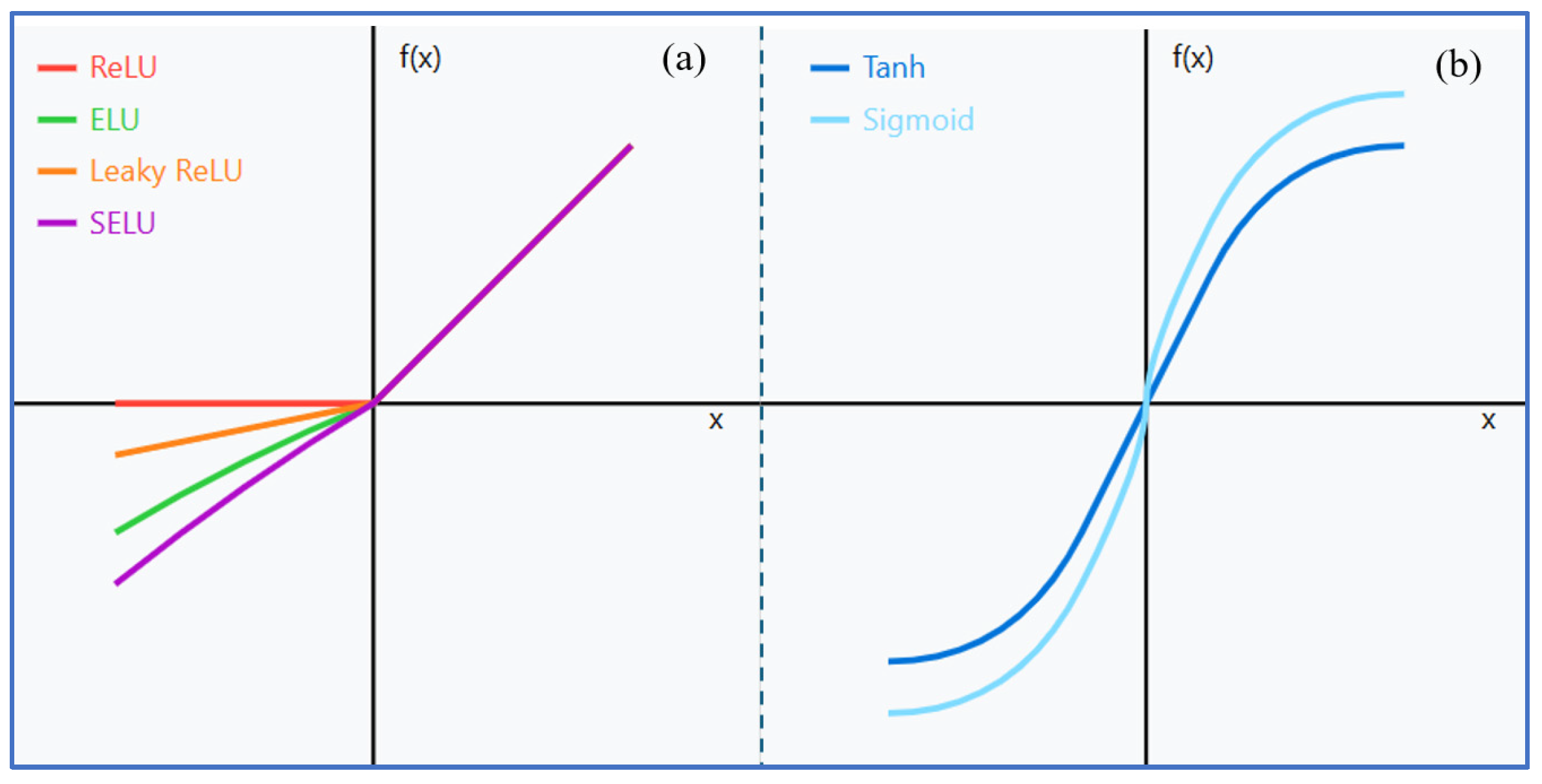
Activation functions (ReLU, tanh, ELU, SELU, Leaky ReLU, and sigmoid) (Equations (1)–(6)).
Figure 4 illustrates these activation functions, grouped into two families. The ReLU family (
Figure 4a) includes the following:
where α is a positive constant
where α is a small positive constant
where λ and α are learned parameters.
The sigmoid family (
Figure 4b) includes the following:
This approach differs from our previous study [
25] in several ways. In our earlier work, we fixed the number of hidden layers at 4, but allowed each layer to have different numbers of neurons (ranging from 20 to 44 in increments of 2) and different activation functions (choosing from ELU, ReLU, tanh, and sigmoid). This resulted in 13 possible neuron counts and 4 activation functions for each of the 4 layers, leading to (13 × 4)⁴ = 331,776 possible combinations. Given this large search space, we randomly sampled 100 combinations for evaluation.
In contrast, our current approach explores different network depths, while maintaining consistency across layers (same number of neurons and activation function for all hidden layers). We also expanded our activation function options by adding SELU and Leaky ReLU. This new approach results in 4 (layer options) × 4 (neuron options) × 6 (activation functions) = 96 possible combinations, allowing us to exhaustively evaluate all possibilities, rather than relying on random sampling.
We implemented a systematic grid search across these hyperparameters using TensorFlow. The model training utilized the Adam optimizer with the mean squared error (MSE) loss function, chosen for its effectiveness in regression tasks and adaptability to varying gradients. To prevent overfitting and ensure model generalization, we implemented early stopping with validation loss monitoring (patience = 50 epochs). The optimization process involved stratified data splitting (60% training, 20% validation, 20% testing), standardization of numerical features (EC, X2), and one-hot encoding of categorical variables (Location, WYT, Month). The preprocessing pipeline was preserved using joblib to ensure consistent transformation of future data points, which is crucial for model deployment and operational use.
2.2.3. Model Evaluation Metrics
Model evaluation in water quality prediction requires careful consideration of both prediction accuracy and generalization capability. We established an evaluation framework incorporating multiple complementary metrics and validation strategies to ensure robust assessment of model performance.
Our evaluation framework centered on three primary performance metrics, each capturing different aspects of model performance. The coefficient of determination (R2), defined in Equation (7), quantifies the proportion of variance in the observed data explained by the model. While higher values indicate a better model fit, R2 alone can be misleading, as it is sensitive to the range and distribution of the data. However, its widespread use in water quality modeling studies makes it valuable for comparing results across different research efforts and methodologies. The Mean Absolute Error (MAE, Equation (8)) provides a direct measure of prediction accuracy in the original units of measurement (mg/L), making it particularly valuable for operational applications. Unlike R2, the MAE is less sensitive to outliers and offers more interpretable results. The magnitude of acceptable MAE varies by constituent, considering its typical concentration range and operational requirements. The third metric, Percentage Bias (PBIAS, Equation (9)), reveals systematic over- or under-prediction tendencies in the model. Positive values indicate overestimation, while negative values suggest underestimation. In water quality applications, consistent bias could significantly impact treatment processes and management decisions, making PBIAS an essential metric for operational reliability assessment.
We implemented a multi-layered validation approach to ensure robust evaluation of model performance. The dataset was divided into three subsets through random stratified sampling: 60% for training, 20% for validation during model development, and 20% reserved as an independent test set. This split ensured unbiased evaluation of final model performance on previously unseen data, while maintaining similar statistical distributions across all sets. The comparison of performance metrics between training and test sets served as a crucial check for potential overfitting, where small differences indicate good generalization, while large discrepancies would suggest model reliability issues requiring refinement.
The performance metrics are defined as follows:
where
represents observed values,
represents predicted values, ȳ is the mean of observed values, and
is the number of observations.
To further assess model stability and generalization capabilities, we implemented a k-fold cross-validation analysis (k = 5). This approach systematically partitions the data into five equal folds, using four folds for training and one for testing, rotating through all possible combinations. We maintained consistent preprocessing across all folds using Scikit-learn’s ColumnTransformer, which included standardization of numerical features (EC, X2) and one-hot encoding of categorical variables (Location, WYT, Month). For each fold, we loaded the previously trained models and preprocessors for each ion constituent, then evaluated their performance using the three metrics mentioned above (R2, MAE, and PBIAS). This cross-validation implementation was performed independently for each ion constituent (chloride, bromide, and sulfate), allowing us to assess the stability of model performance across different subsets of data and different constituents. The analysis was automated using the TensorFlow and Scikit-learn libraries, ensuring consistent evaluation procedures across all folds and constituents. This systematic approach provides a more reliable estimate of model performance than single train-test splits, which was particularly important given the temporal and spatial variability in our water quality data.
2.3. Dashboard Development
Web-based dashboards offer significant advantages for water quality management tools, providing universal accessibility, real-time updates, and interactive visualizations without requiring local software installation. Our implementation leverages Microsoft Azure’s Web Apps service, a cloud computing platform that provides scalable hosting infrastructure [
41]. Azure Web Apps manage server maintenance, security updates, and load balancing, allowing the applications to efficiently handle multiple concurrent users. The system’s computational resources are adjustable based on usage demands—if additional processing power is needed to handle more users or complex calculations, the cloud computing capacity can be increased by upgrading the subscription level. During periods of lower demand, capacity can be scaled down to optimize costs.
The development infrastructure uses GitHub (
https://github.com/, accessed on 1 June 2022) as a version control and code hosting platform, integrated with Azure through continuous integration and deployment (CI/CD) pipelines. When code updates are pushed to GitHub, Azure automatically deploys these changes to the production environment after running automated tests, ensuring rapid updates while maintaining system stability. The cloud resources are configured based on anticipated computational needs and usage patterns, with subscription levels adjusted monthly to balance performance and cost.
All three dashboards share a common technical foundation, built using Python’s scientific computing stack [
42]. The visualization layer employs Panel for creating interactive web interfaces and HoloViews for generating dynamic plots [
43]. These libraries were chosen for their ability to create responsive, interactive visualizations, while efficiently handling large datasets [
30]. Bokeh serves as the underlying plotting library, enabling the creation of interactive plots that can be updated in real time as users adjust parameters [
44]. The dashboards use a consistent set of UI components, such as sliders, dropdown menus, and buttons, to provide a familiar user experience across applications.
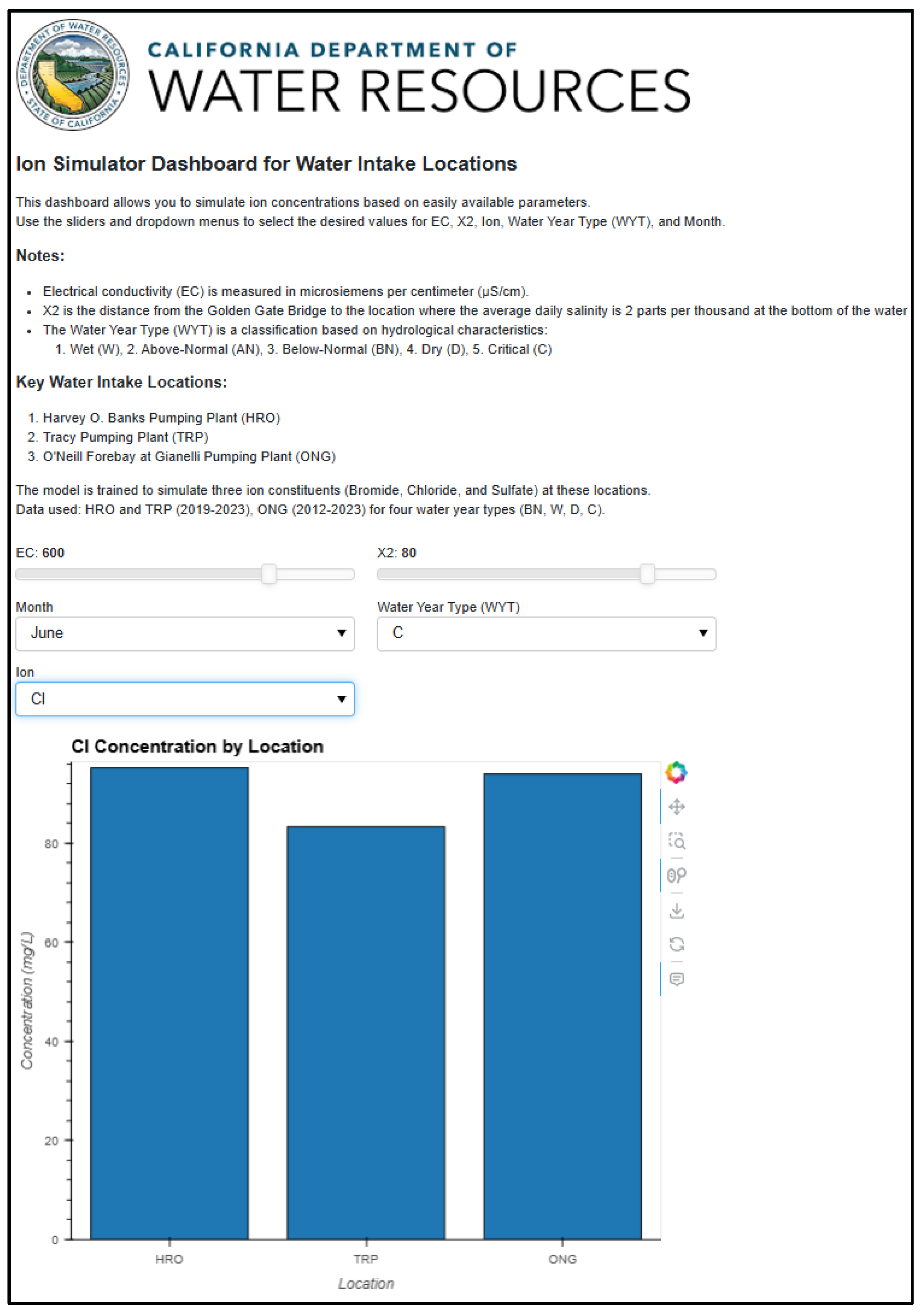
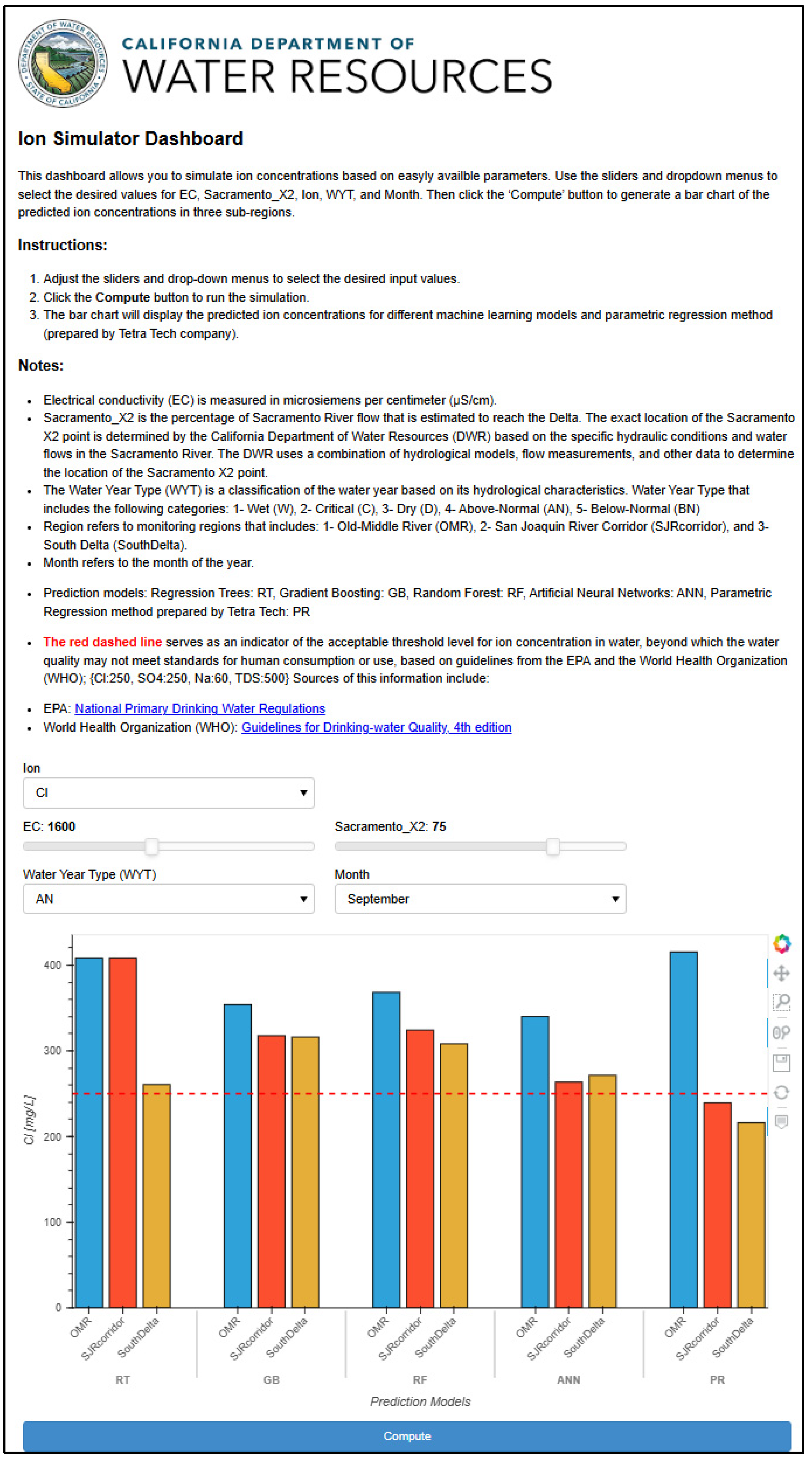
The Water Intake Locations Dashboard focuses on water intake locations, providing real-time predictions of ion concentrations based on user-specified parameters. Users can adjust parameters like EC, Sacramento X2, Water Year Type, and Month, with results displayed through interactive bar charts that compare different model predictions. By relying on pre-trained models, this dashboard delivers fast predictions without requiring the computational overhead of training models on-the-fly.
The Enhanced Interior Delta Dashboard extends our previous Interior Delta dashboard [
25] by integrating Hutton et al.’s parametric regression equations alongside machine learning predictions [
21]. This integration enables direct comparisons between four machine learning approaches—Regression Trees (RTs), Gradient Boosting (GB), Random Forest (RF), and Artificial Neural Networks (ANNs)—and the classical parametric method across three sub-regions. The dashboard also includes horizontal threshold lines for key ion constituents (chloride: 250 mg/L, sulfate: 250 mg/L, sodium: 60 mg/L, and total dissolved solids: 500 mg/L), allowing users to quickly identify when predicted concentrations exceed acceptable water quality standards [
45].
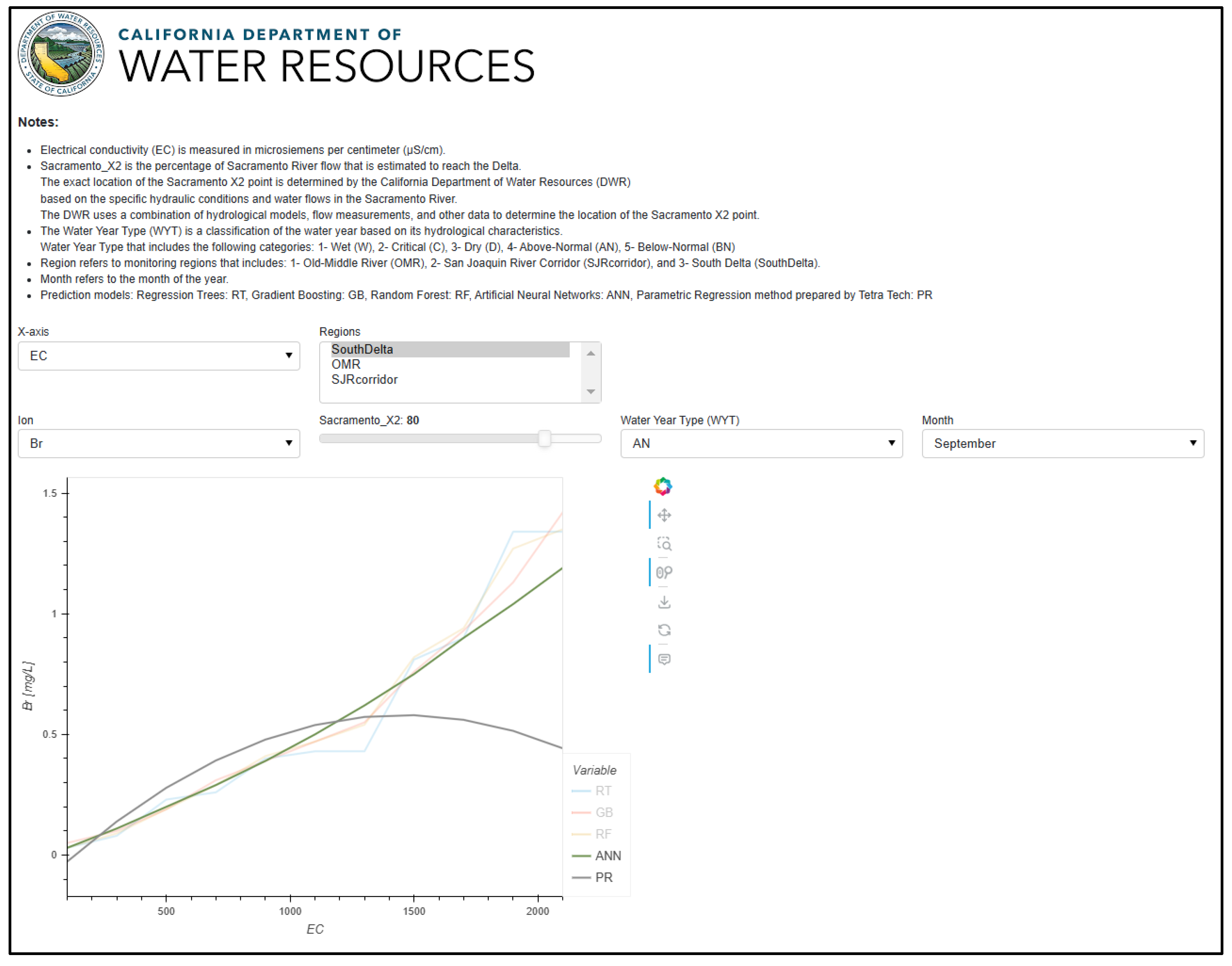
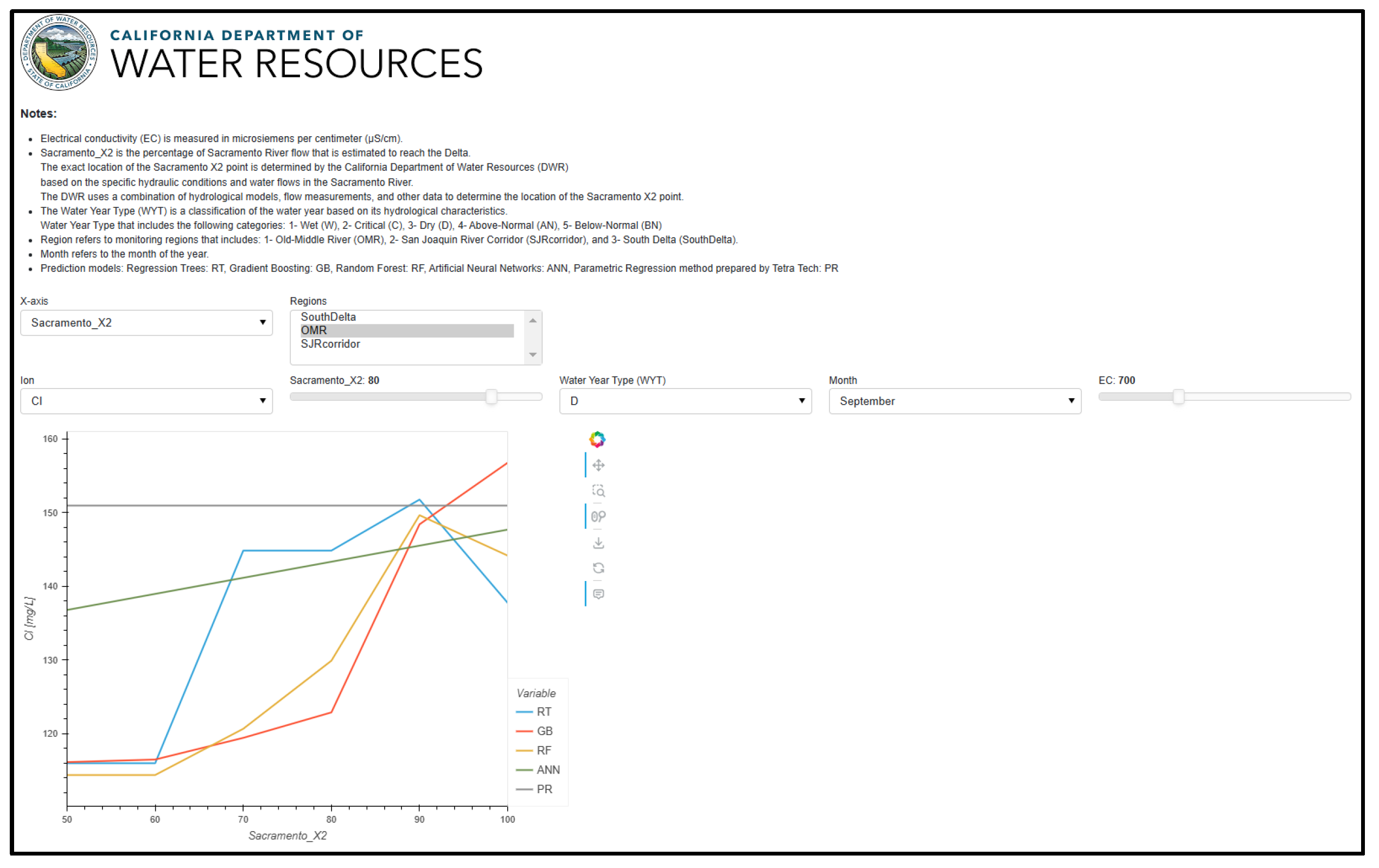
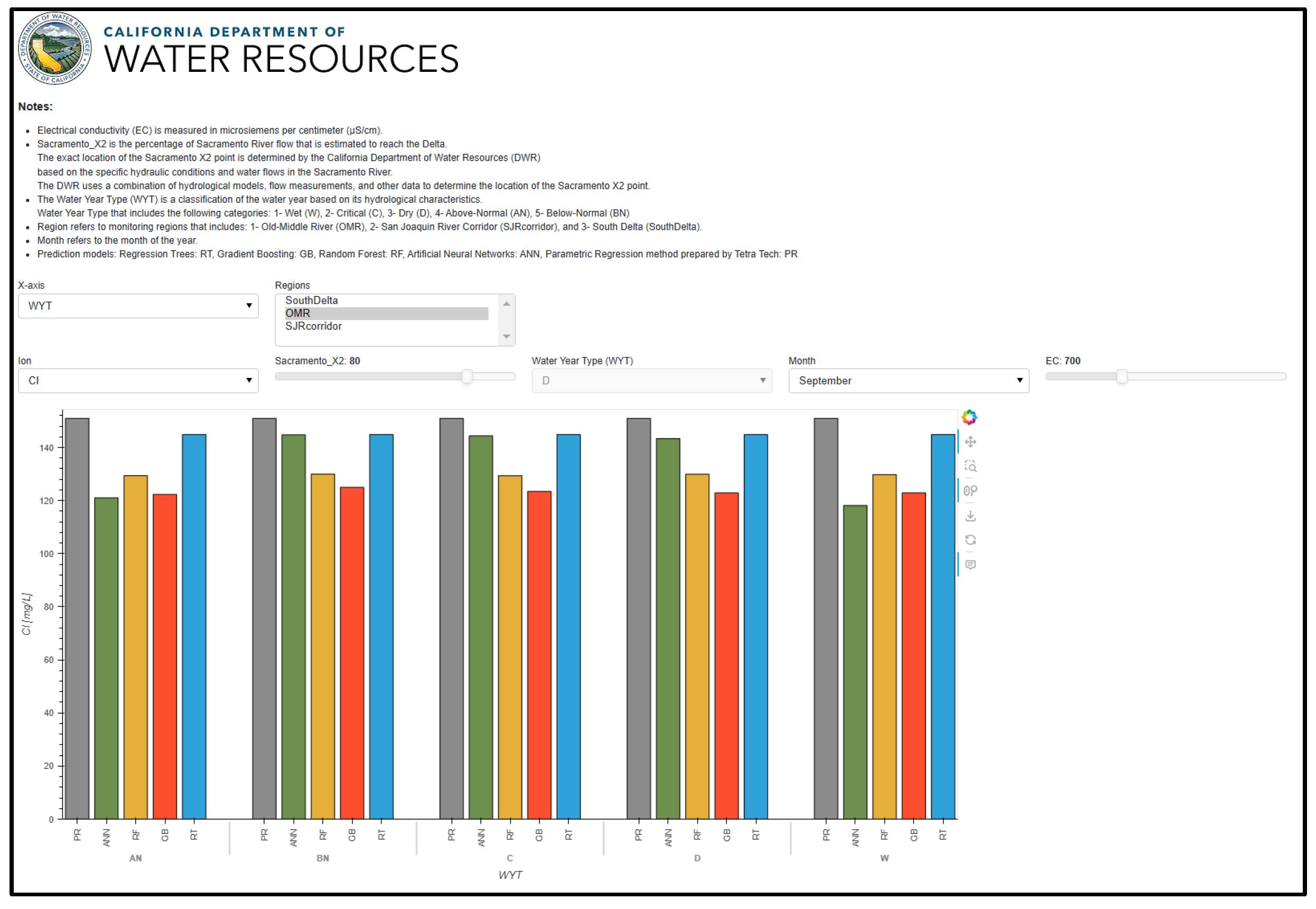
The Model Interpretability Dashboard serves as an analytical tool to help users understand how different parameters influence ion predictions. Users can select any input parameter—such as EC, Sacramento X2, Water Year Type, or Month—as the x-axis to observe changes in ion concentrations across its full range, while keeping other variables constant. This functionality allows users to perform the following:
Analyze the sensitivity of predictions to different input variables.
Compare how different regions respond to parameter changes.
Understand model behavior under various conditions.
Assess model stability across different parameter ranges.
Compare predictions from different modeling approaches (ML vs. classical methods).
The dashboard uses a cache-based system to optimize performance. For first-time parameter combinations, comprehensive calculations are performed, which may take a few seconds. However, these results are cached, enabling instant response times for subsequent queries with the same parameters. This caching mechanism is especially valuable for sensitivity analyses, where users often explore similar scenarios. The visualizations include interactive line plots for continuous variables and bar charts for categorical parameters, with options to display multiple regions and prediction methods simultaneously [
43].
Each dashboard maintains its own logging system to track usage patterns and performance metrics, which informs future optimizations and resource allocation. Error handling and input validation are implemented to ensure robustness, and responsive design principles are applied to ensure usability across different devices and screen sizes.
2.4. Addressing Model Limitations Through a Hybrid Approach
While both machine learning and classical approaches have demonstrated strong predictive capabilities for ion constituents, they share two fundamental limitations. First, predictions are constrained to specific monitoring locations, lacking continuous spatial coverage across the Delta. Second, neither approach can independently evaluate potential future scenarios, limiting their utility for long-term planning and climate change impact assessment.
To overcome these limitations, we developed a hybrid water quality model that integrates the Delta Simulation Model 2 (DSM2) with our machine learning framework. DSM2 is a well-established hydrodynamic and water quality model used extensively for simulating water conditions in the Delta [
45]. DSM2 can simulate EC across an extensive network of nodes throughout the Delta, providing spatial and temporal detail that can be leveraged to enhance prediction capabilities.
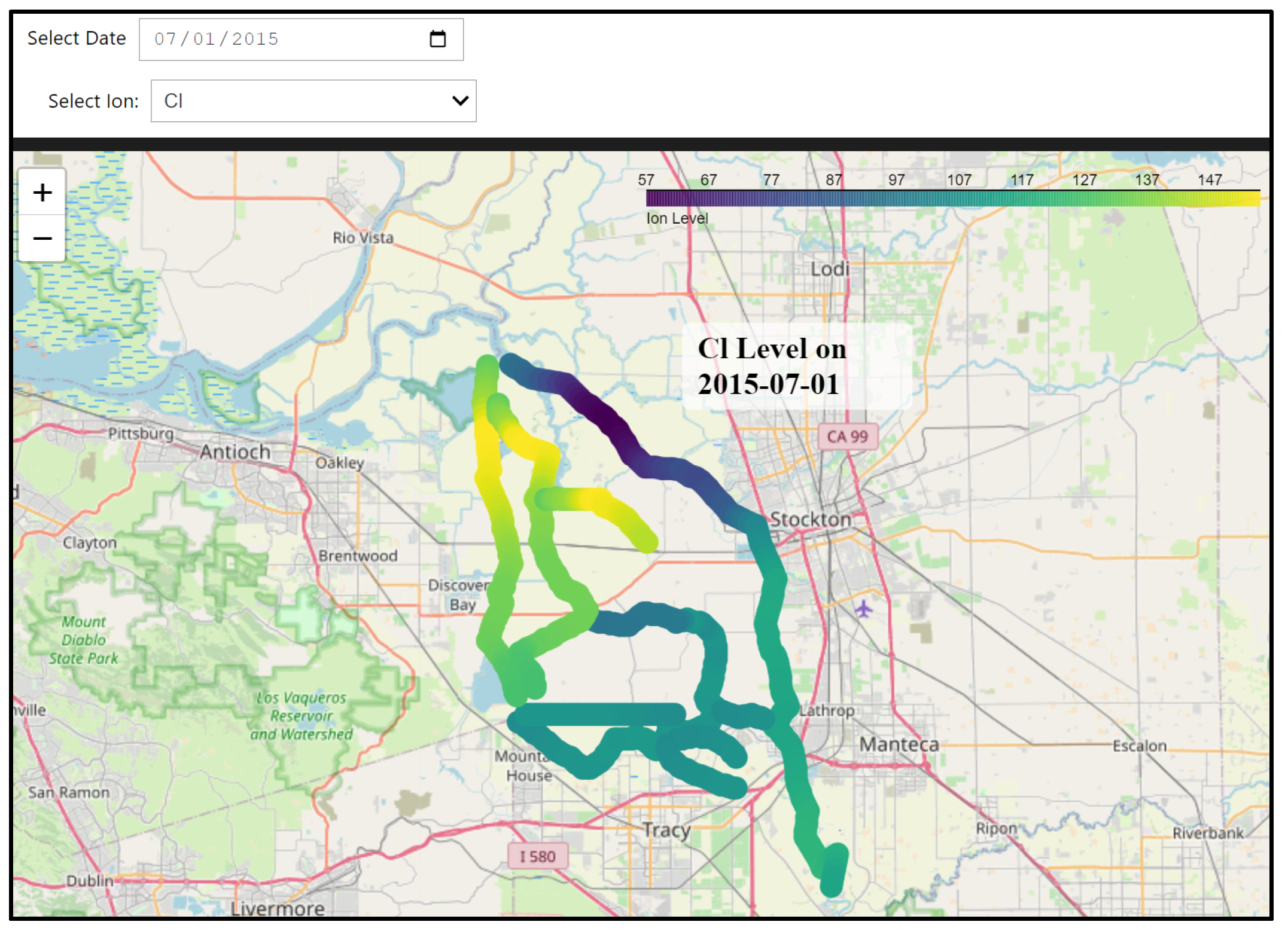
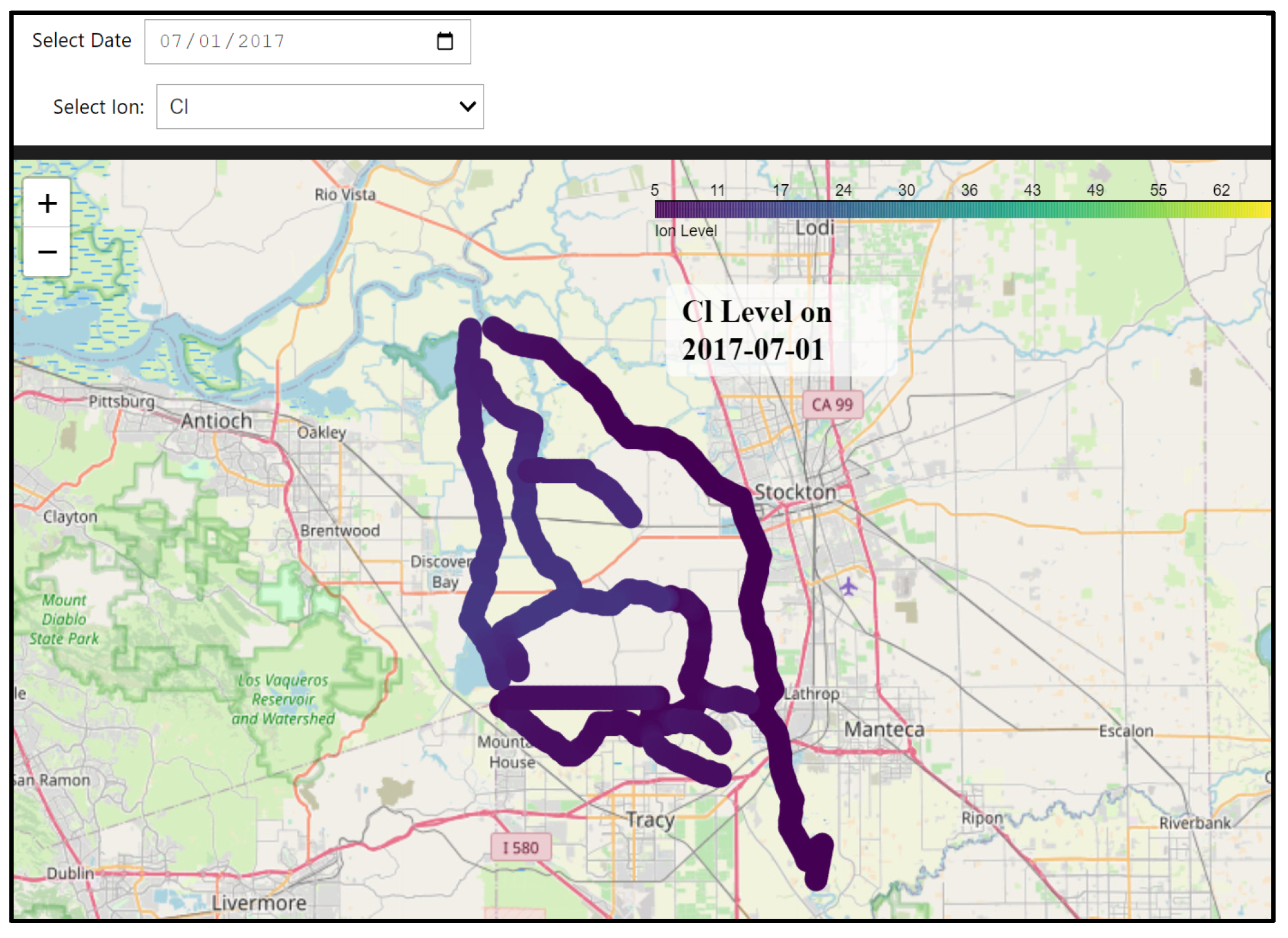
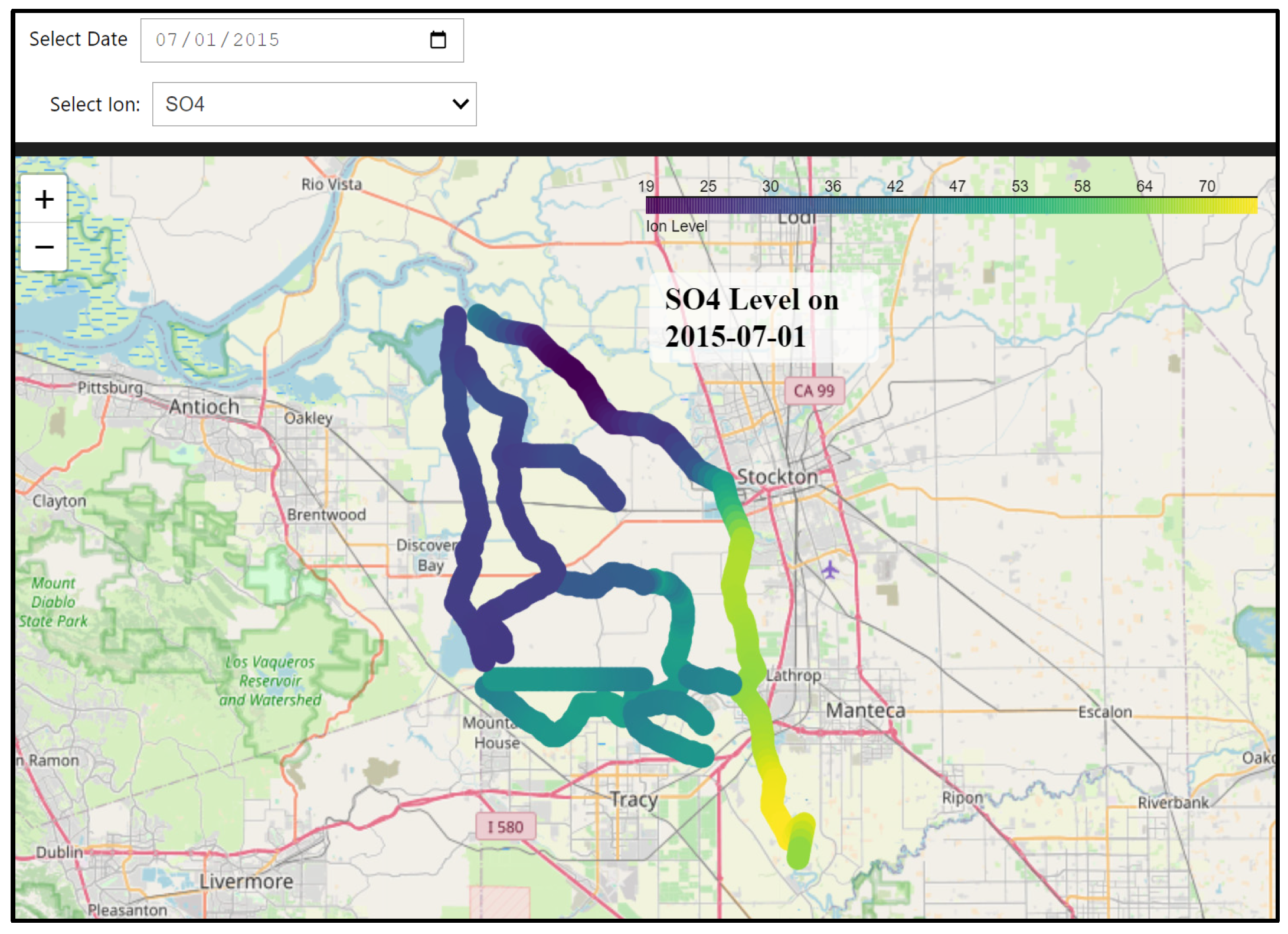
For this hybrid approach, we selected 162 points across three key sub-regions: 60 in the South Delta (green circles), 30 along the San Joaquin River corridor (red stars), and 72 in the Old–Middle River corridor (black squares), as illustrated in
Figure 5. These points were carefully positioned to capture key water quality gradients and hydrodynamic features across the Delta system while maintaining computational efficiency. This strategic distribution ensures comprehensive coverage of critical areas and enables effective spatial interpolation between monitoring locations. The hybrid model operates in two stages:
DSM2 simulation: DSM2 is used to generate EC values at all 162 points, ensuring extensive spatial and temporal coverage.
ANN predictions: the simulated EC values are then used as inputs for our ANN model to predict ion concentrations at these points.
This hybrid model offers several advantages:
Continuous spatial coverage: the use of DSM2 provides simulated EC values across much of the Delta’s channel network, enabling spatial interpolation between the selected points to create a more continuous ion concentration map.
Temporal flexibility: DSM2 can generate EC data for any desired time period, from historical conditions to future projections (for example in this project: 2000–2023), providing complete temporal coverage.
Scenario analysis: the model’s capability to modify DSM2 input parameters allows for evaluation of future scenarios, such as changes in climate, hydrology, or operational practices.
Combining physics-based and data-driven insights: by integrating DSM2, a process-based model, with the ANN, a data-driven model, the hybrid system benefits from both detailed physical simulation and the flexibility of machine learning.
To make this hybrid model accessible, we developed a dedicated dashboard that visualizes spatial distributions of ion concentrations throughout the Delta. Users can select specific dates and ion constituents to view the spatial patterns on an interactive map. Due to the computational intensity of these calculations, particularly involving spatial interpolation, this dashboard is designed for local deployment, rather than cloud hosting. The full codebase is available through our GitHub repository, allowing users to conduct their analyses on local machines with their own computational resources.
This hybrid approach bridges the gap between localized predictions and broader spatial–temporal analysis, enabling scenario planning and improving water quality management throughout the Delta. The ability to produce continuous spatial distributions of ion concentrations represents a significant step forward in our capacity to understand and manage the complex dynamics of the Delta ecosystem.
4. Discussion
The development and implementation of machine learning approaches for ion constituent prediction in the Sacramento–San Joaquin Delta represents a significant advancement in water quality monitoring and management. Our results demonstrate both the technical advantages of these new methods and their practical utility for operational decision-making. This discussion examines the implications of our findings across several key dimensions: model performance and reliability, operational utility, and broader implications for water quality management.
4.1. Model Performance and Reliability
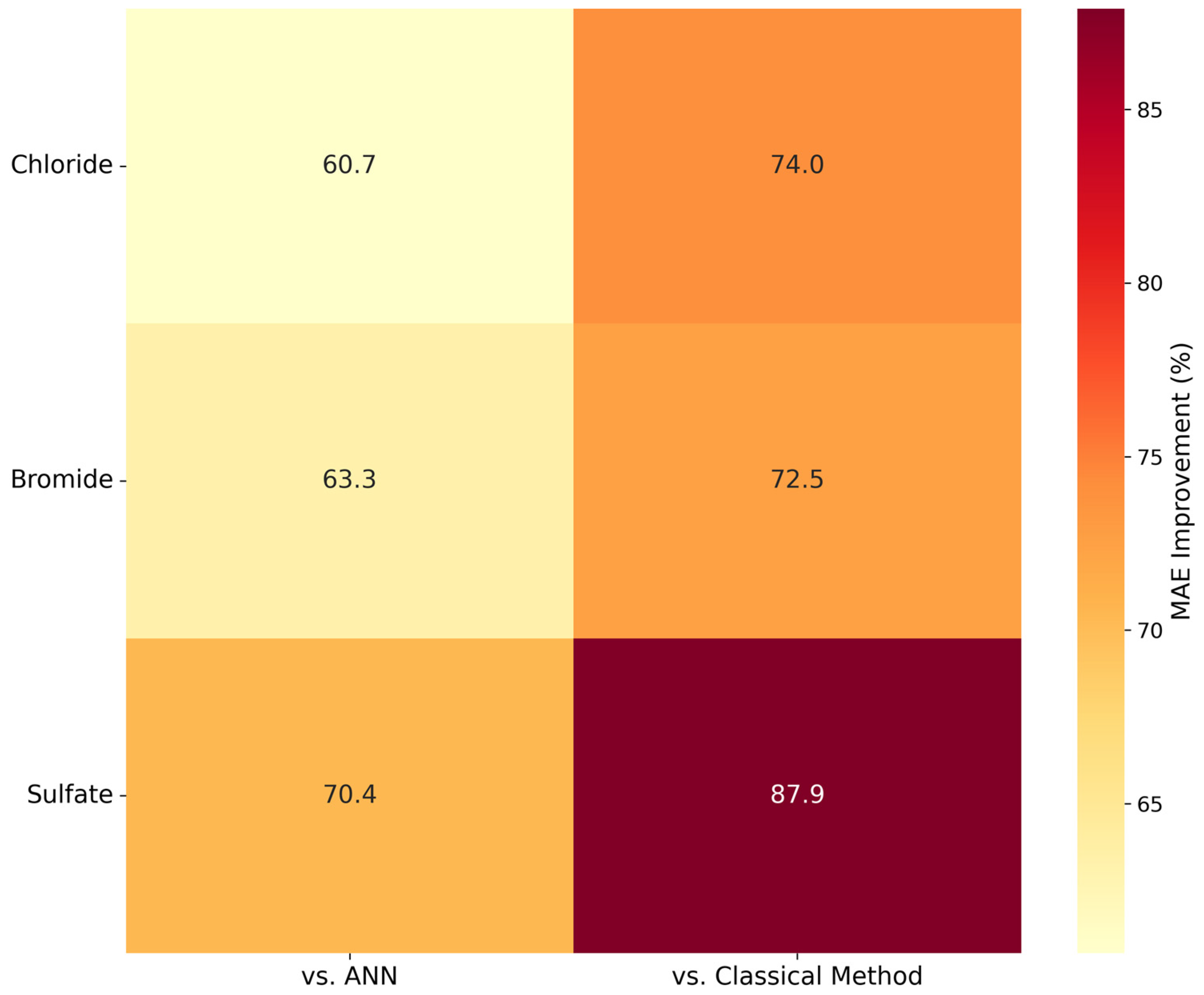
The superior performance of our location-specific ANN models compared to both the Interior Delta ML model and classical methods highlights several important considerations in water quality modeling. The substantial improvements in Mean Absolute Error (MAE)—ranging from 24% for TDS to 59% for sulfate—demonstrate that tailoring models to specific monitoring locations can significantly enhance prediction accuracy. This improvement likely stems from the models’ ability to capture location-specific relationships between Electrical Conductivity and ion constituents, which vary considerably across the Delta system.
The cross-validation results, showing remarkably low standard deviations across all metrics (e.g., R2 variations ≤ 0.006), confirm the robust generalization capabilities of our models. This stability is particularly noteworthy given the complex and dynamic nature of the Delta system, where multiple factors influence water quality simultaneously. The consistent performance across different data partitions suggests that the models have successfully captured underlying physical relationships, rather than simply fitting to training data patterns.
However, it is important to acknowledge certain limitations in our approach. The relatively short data record for some locations (2019–2023 for HRO and TRP) means that the models have not been exposed to the full range of possible hydrological conditions. While performance metrics remain strong, continued validation against new data will be crucial for ensuring long-term reliability. Additionally, the current exclusion of Above-Normal Water Year Types from some location-specific models represents a gap that should be addressed as more data become available.
4.2. Operational Utility and Dashboard Implementation
The Water Intake Locations Dashboard’s (DD3) focus on critical infrastructure points demonstrates how location-specific optimization can enhance operational relevance. The real-time visualization capabilities and mobile accessibility through QR codes reflect a practical understanding of how these tools will be used in the field. However, the dashboard’s current limitations regarding Water Year Types highlight the ongoing need for data collection and model refinement.
The development of three complementary dashboards, each serving different user needs, represents a significant step forward in making complex modeling tools accessible to water managers. The Enhanced Interior Delta Dashboard’s (DD1) integration of classical methods alongside machine learning predictions provides a valuable bridge between traditional and modern approaches, helping to build user confidence through direct comparison. The addition of regulatory threshold indicators directly addresses operational needs by providing immediate visual feedback on water quality compliance.
The Model Interpretability Dashboard addresses (DD2) a crucial challenge in the adoption of machine learning methods: the perceived “black box” nature of these models. By enabling users to visualize how models respond to different predictors and operating conditions, this tool helps to build trust in ML predictions. The smooth response curves demonstrated by the ANN model, particularly in comparison to other ML approaches, suggest that it has captured physically meaningful relationships, rather than arbitrary patterns in the training data.
Our hybrid approach, combining DSM2 hydrodynamic modeling with ANN predictions, represents a significant advancement in addressing spatial coverage limitations inherent in point-based monitoring systems. The ability to generate continuous spatial distributions of ion concentrations provides water managers with unprecedented insight into water quality dynamics across the Delta. This capability is particularly valuable for understanding how different operational decisions might affect water quality throughout the system, not just at monitoring locations.
The dashboard implementation strategy, using both cloud-hosted and locally deployed solutions, balances accessibility with computational requirements. The Azure-hosted dashboards provide widespread access to essential prediction tools, while the GitHub-hosted hybrid model enables more intensive analyses when needed. This dual approach ensures that different stakeholder needs can be met effectively, while managing computational resources efficiently.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}