
Safety Monitoring Method for the Uplift Pressure of Concrete Dams Based on Optimized Spatiotemporal Clustering and the Bayesian Panel Vector Autoregressive Model





Abstract
1. Introduction
2. Basic Theory and Methods
2.1. Time Series Similarity Measure
- (1)
- Cosine similarity [27]
- (2)
- Bilateral slope distance [28]
- (3)
- Dynamic Time Warping (DTW) [30]
- (1)
- Bounded condition:
- (2)
- Continuity:
- (3)
- Monotonicity:
2.2. Clustering and Evaluation
2.2.1. OPTICS Clustering Algorithm
2.2.2. Clustering Index Evaluation
- (1)
- Silhouette coefficient [31]
- (2)
- Calinski–Harabasz index [32]
2.3. BPVAR Model Theory
2.3.1. Unit Root Test for Panel Data
- (1)
- Difference method
- (2)
- Seasonal difference method
- (3)
- Sliding average method [38]
2.3.2. Test of Lag Order on Panel Data
2.3.3. Bayesian Estimation of PVAR
3. Building Method of the Concrete Dam Uplift Pressure Safety Monitoring Model
- (1)
- The uplift pressure monitoring data sample set D and the neighbourhood radius at each measuring point are input. The minimum number of points in the neighbourhood radius MinPts.
- (2)
- The distance matrix is calculated based on the DTW, cosine similarity, and bilateral slope distance.
- (3)
- Based on the matrix calculated in (2), the OPTICS algorithm is used for clustering.
- (4)
- Spatial clustering results for different distance matrices using the clustering index silhouette coefficient and variance ratio criterion and the results with the silhouette coefficient closest to one and the largest Calinski–Harabasz index were selected. This result was the optimal clustering result. The uplift pressure measuring points with similar heights were utilized to create panel data.
- (5)
- The stability of each type of uplift pressure measuring point’s panel data is assessed through the application of LLC, IPS, and ADF-Fisher methods.
- (6)
- If a series is nonstationary, the difference method is used to convert it to a stationary series.
- (7)
- According to Equations (22)–(24), the order of the model was determined by using the AIC, BIC, and HQIC, and the minimum information criterion was utilized to ascertain the optimal lag order of the model.
- (8)
- Whether there is monitoring data of exogenous variables in the data is determined. If so, the exogenous variables (water level, precipitation, temperature, and time) are entered to establish the model according to Equation (26); otherwise, the model is created according to Equation (25).
- (9)
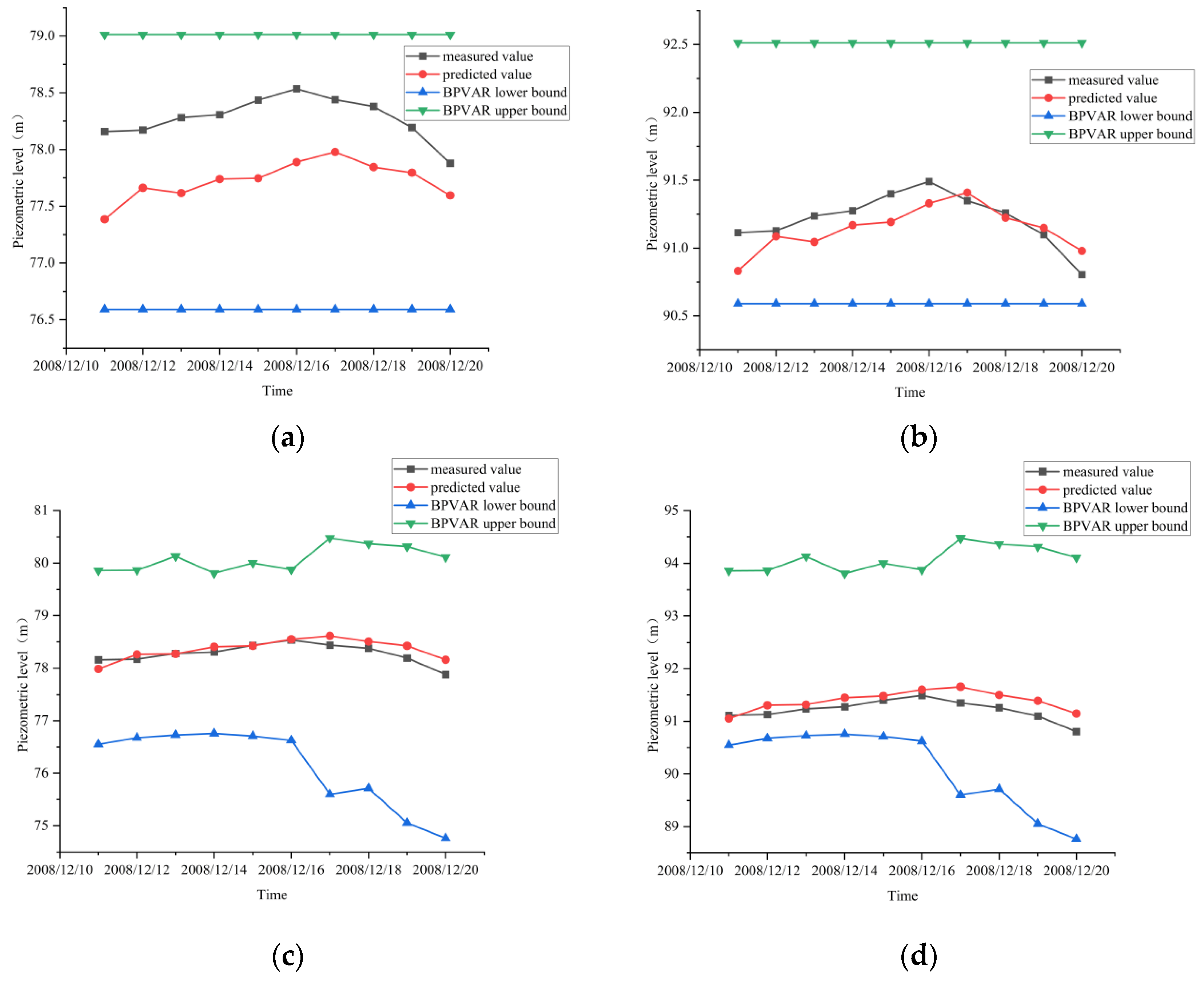
- By using the Gibbs sampling method to infer the posterior distribution of the model parameters, the fitting results of the uplift pressure monitoring data are obtained from the posterior probability distribution of the model parameters. The model uses one-step advance forecasting. For the case of no exogenous variables, the forecast result is calculated according to Equation (25), and it consists mainly of two parts: endogenous variables and the residual vector. The number of lag terms of endogenous variables is calculated by the optimal lag order determined. For the presence of exogenous variables, the forecast result is calculated according to Equation (26) and is composed of three parts: endogenous variables, exogenous variables, and residual vectors. The number of lag terms of endogenous variables is determined by the optimal lag order. The prediction interval of the BPVAR model represents a 95% confidence interval.

4. Engineering Examples
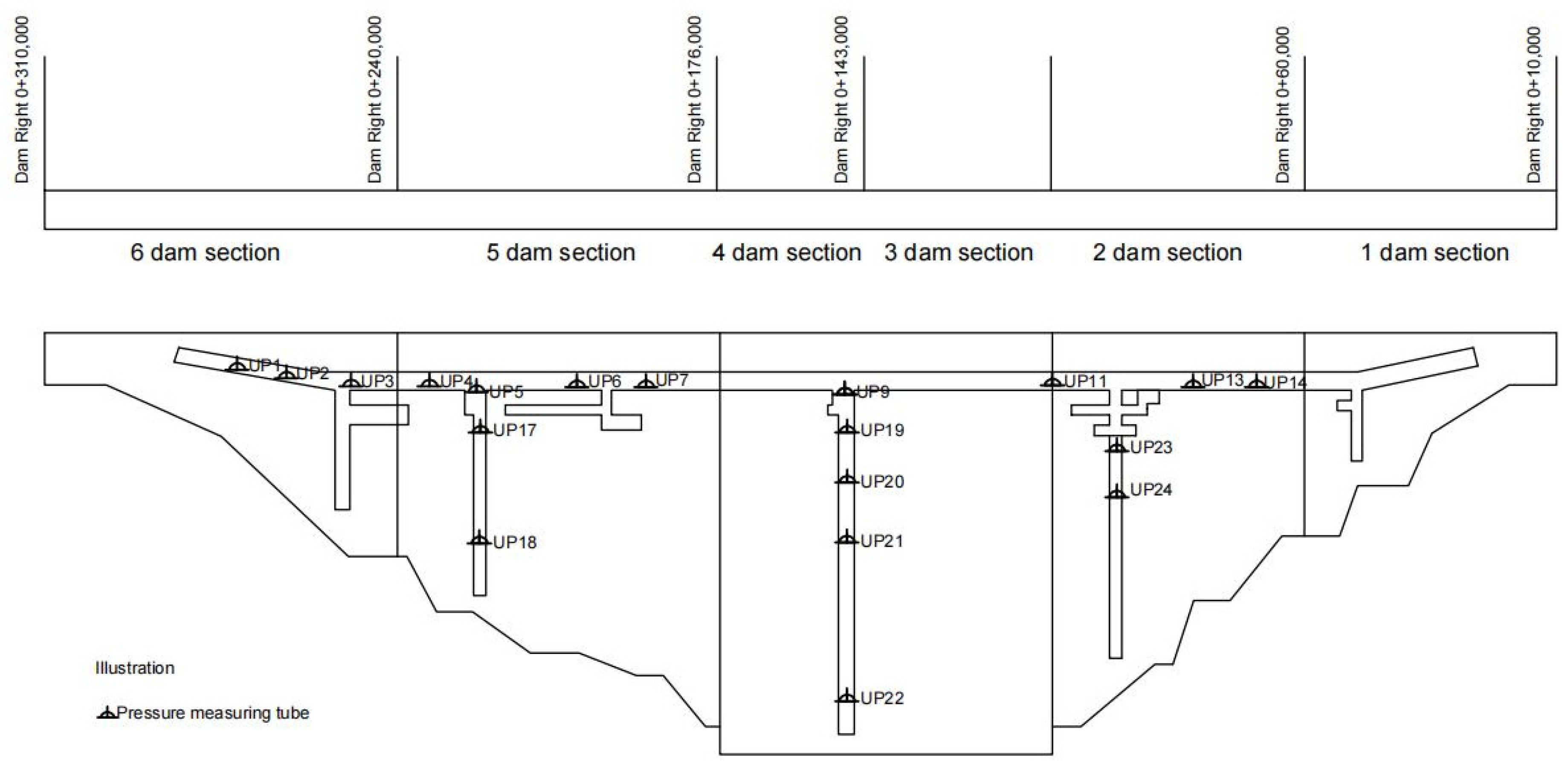
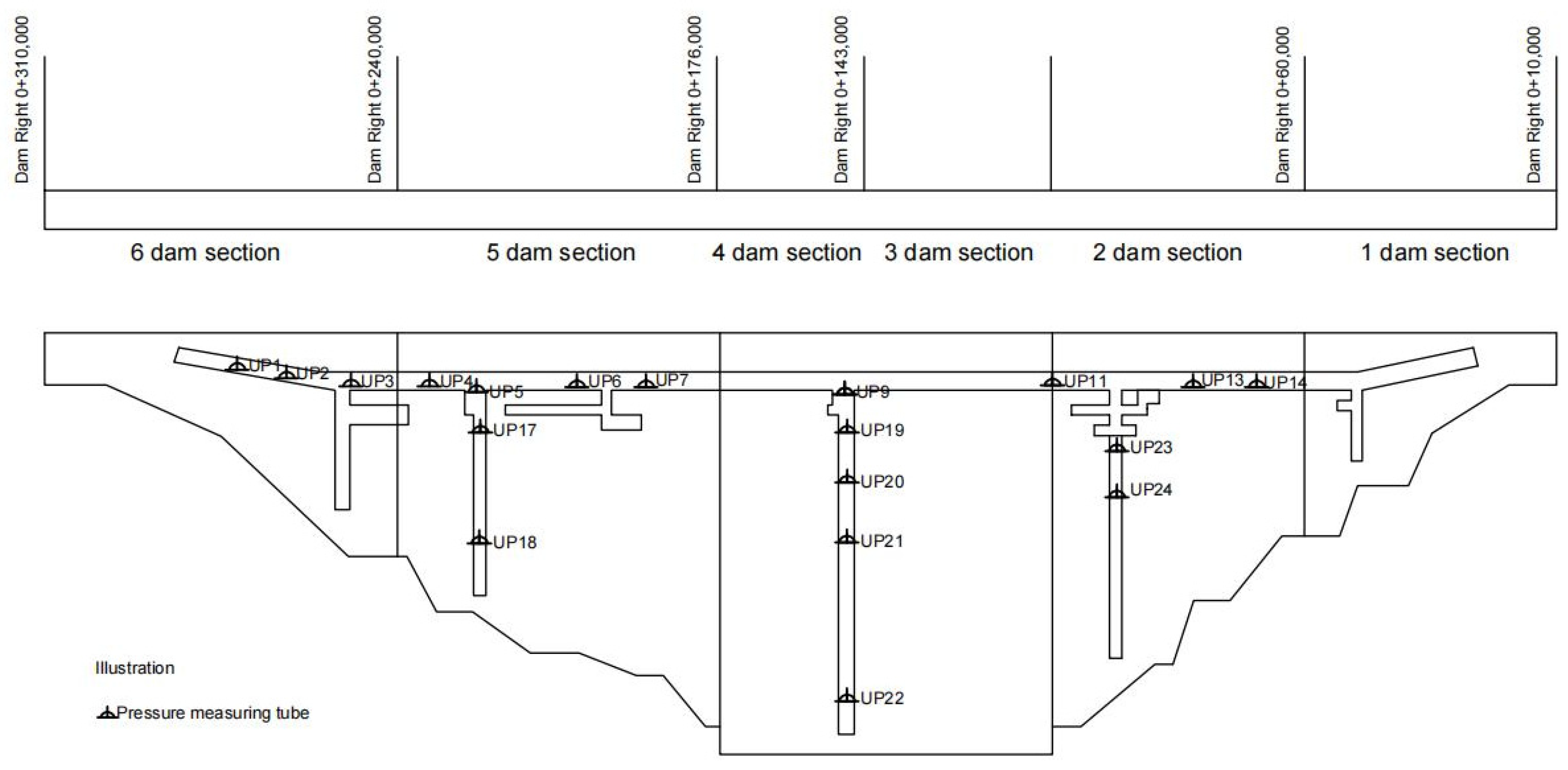
4.1. Project Overview
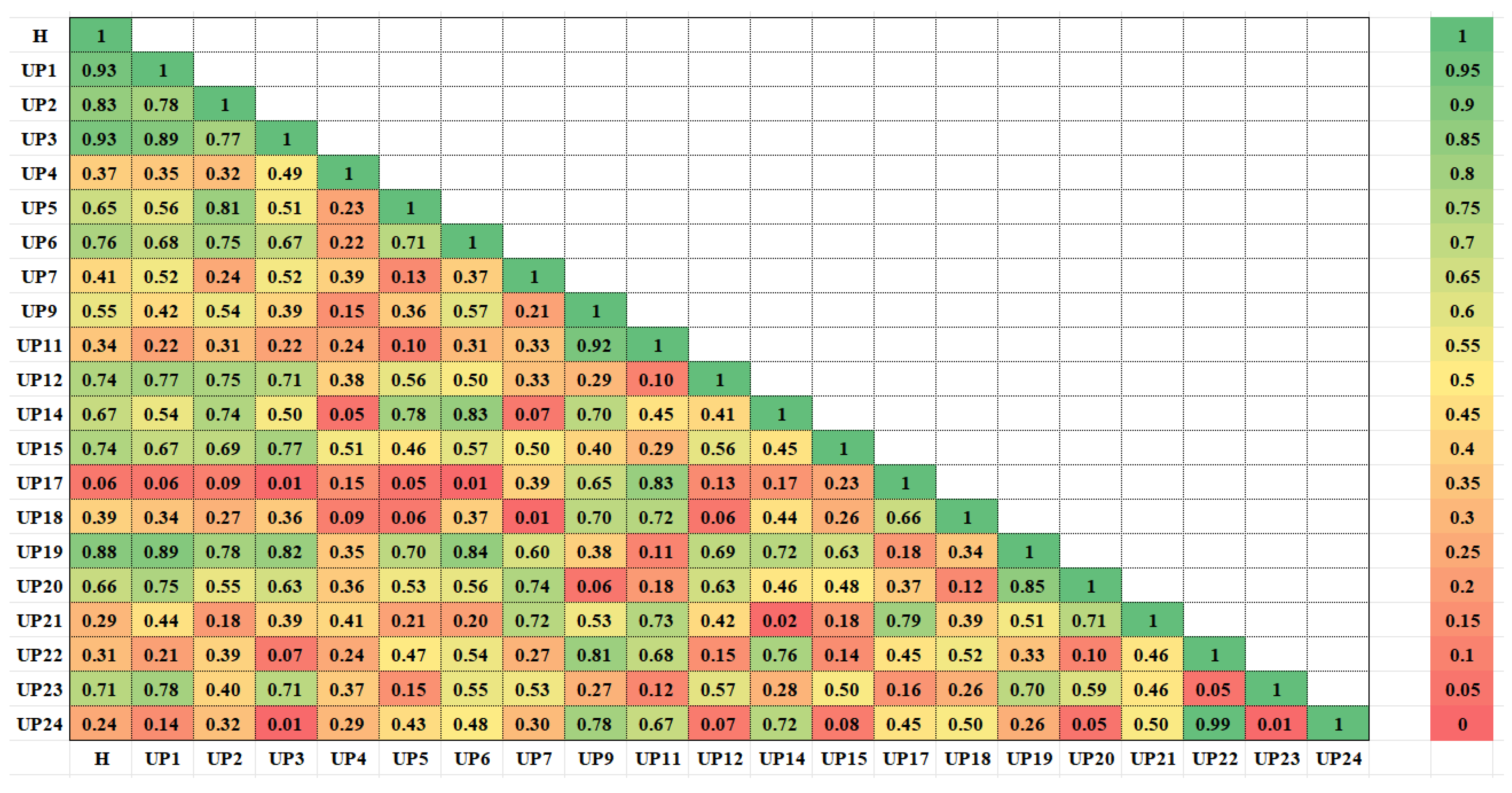
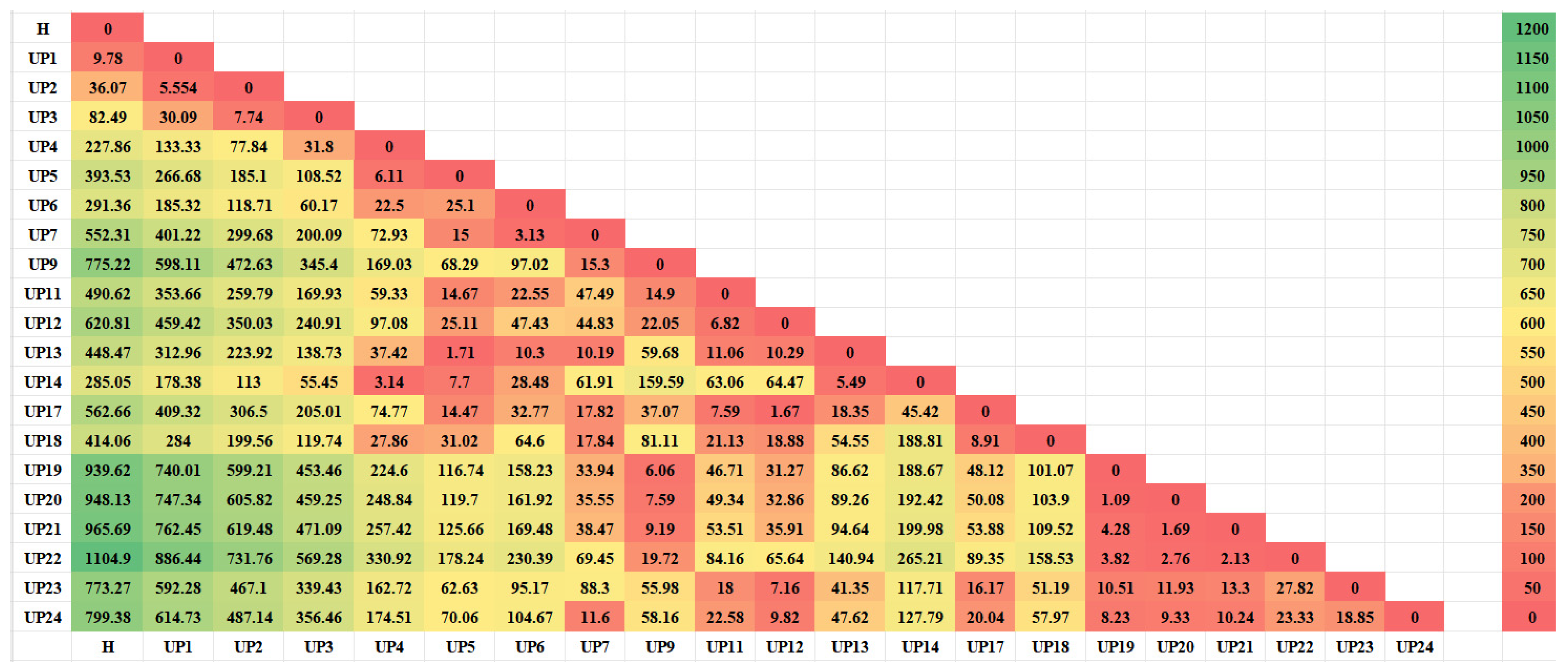
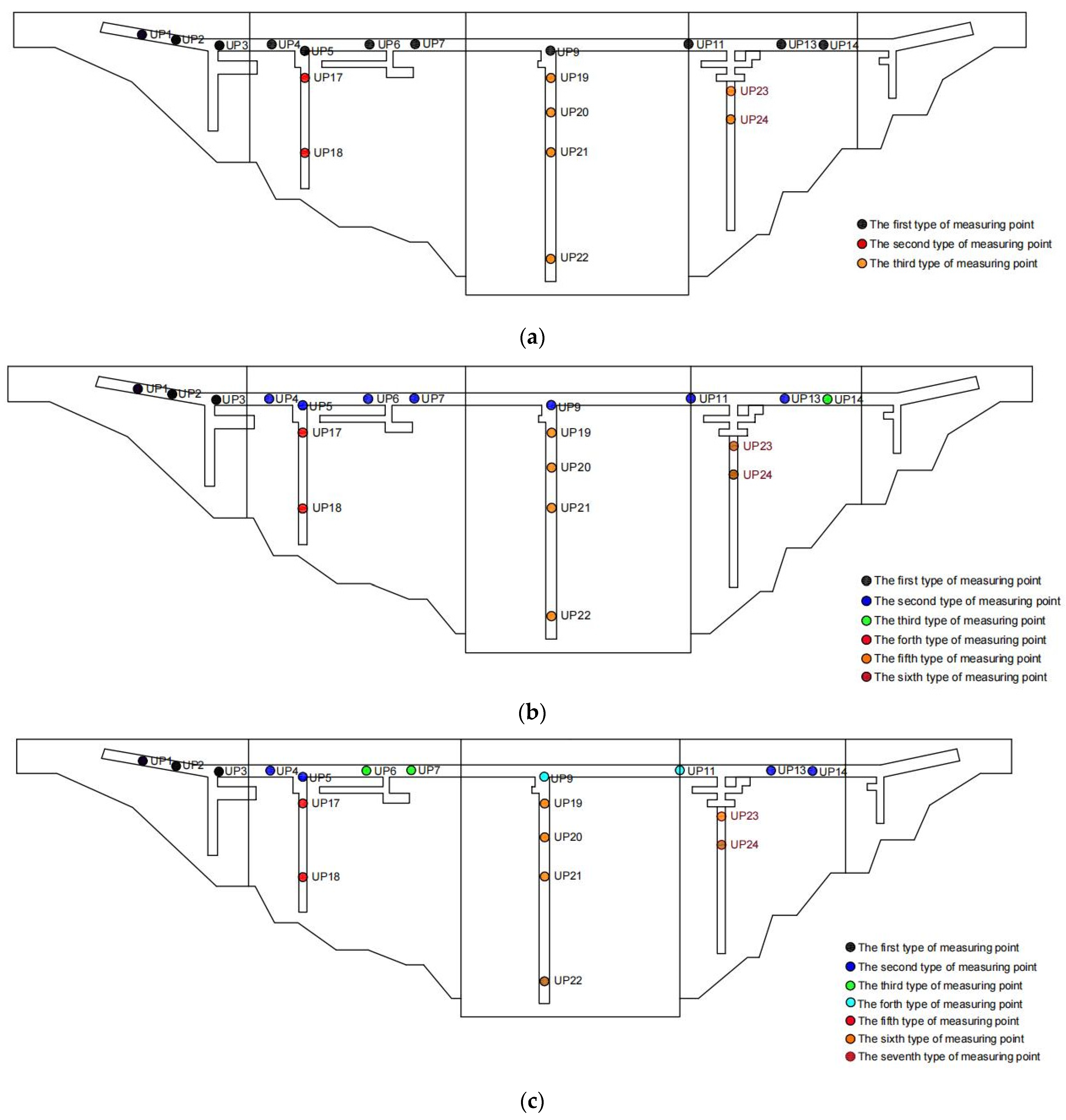
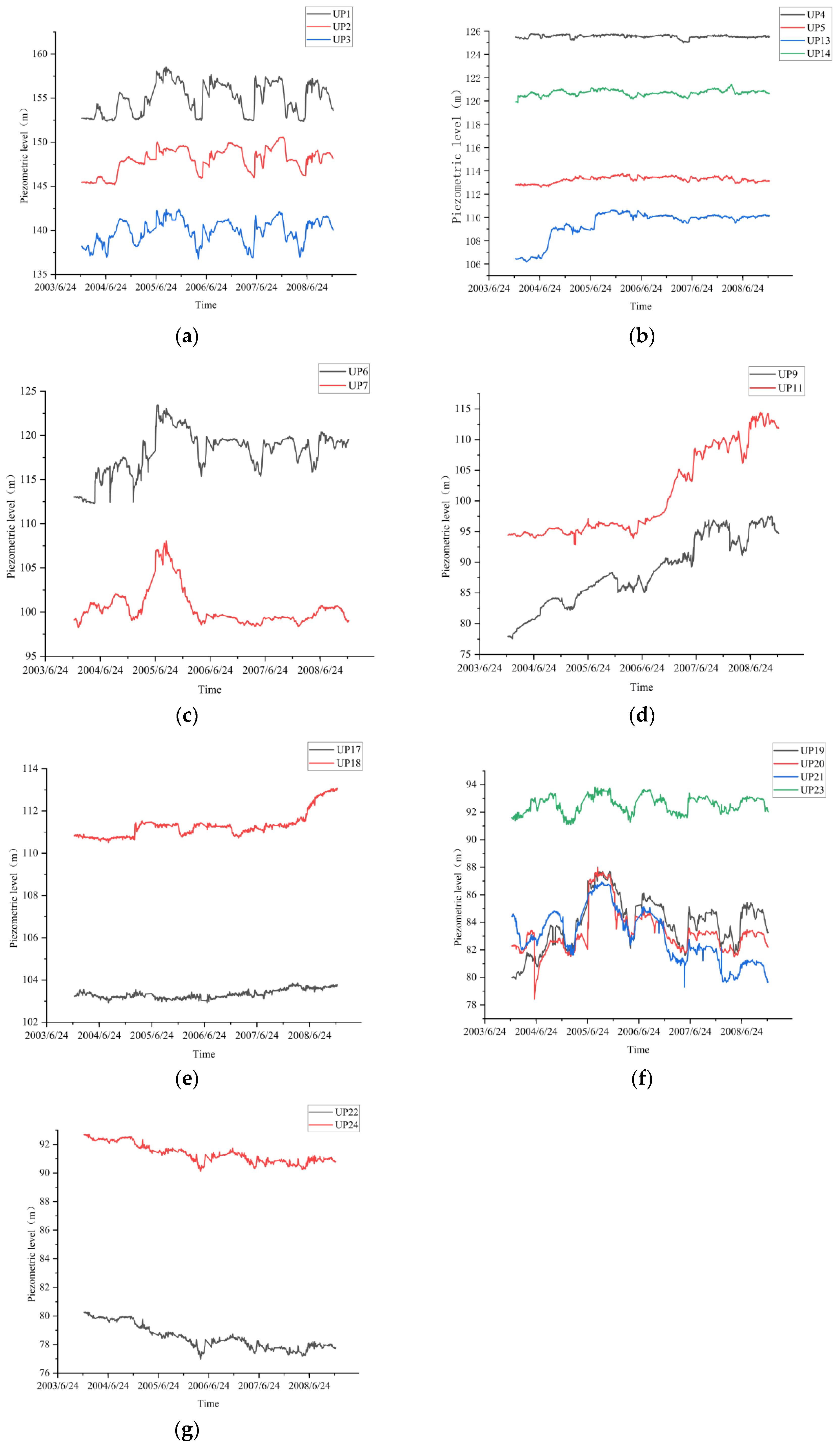
4.2. Spatial Cluster Analysis
4.3. BPVAR Model Construction
4.3.1. Stationary Test of Panel Data
4.3.2. Selection of the Optimal Lag Order
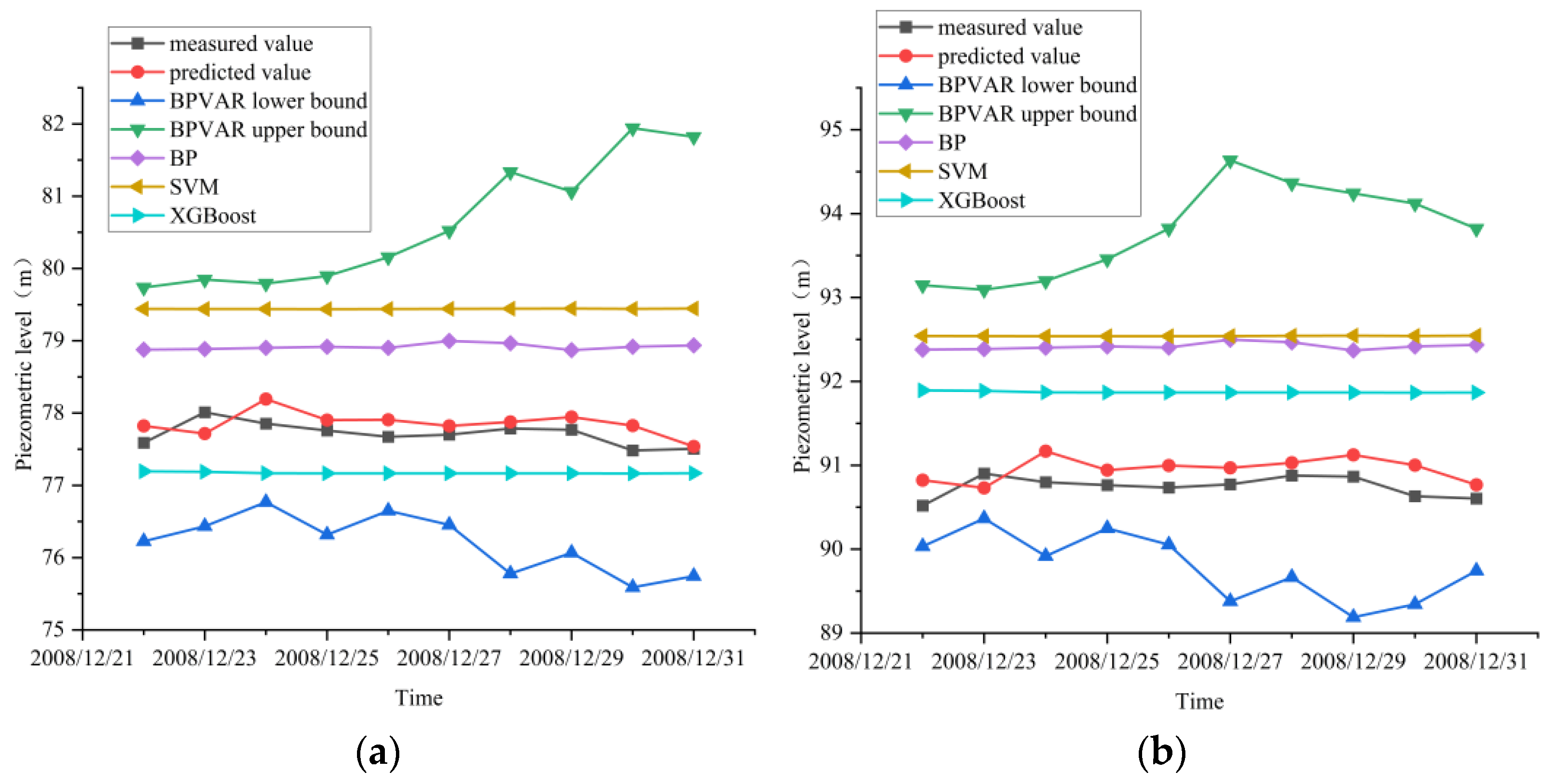
4.3.3. Model Adaptation and Forecasting Analysis
5. Conclusions
- (1)
- Through the calculation of the clustering evaluation index, the DTW-based clustering results among the OPTICS clustering results calculated by three different distance indicators were found to be consistent with the variation pattern of the uplift pressure monitoring value. Research on engineering applications has shown that the uplift pressure measuring points of a water conservancy project dam foundation can be divided into seven types, and the measuring points of the same type show similar variation in the law of uplift pressure.
- (2)
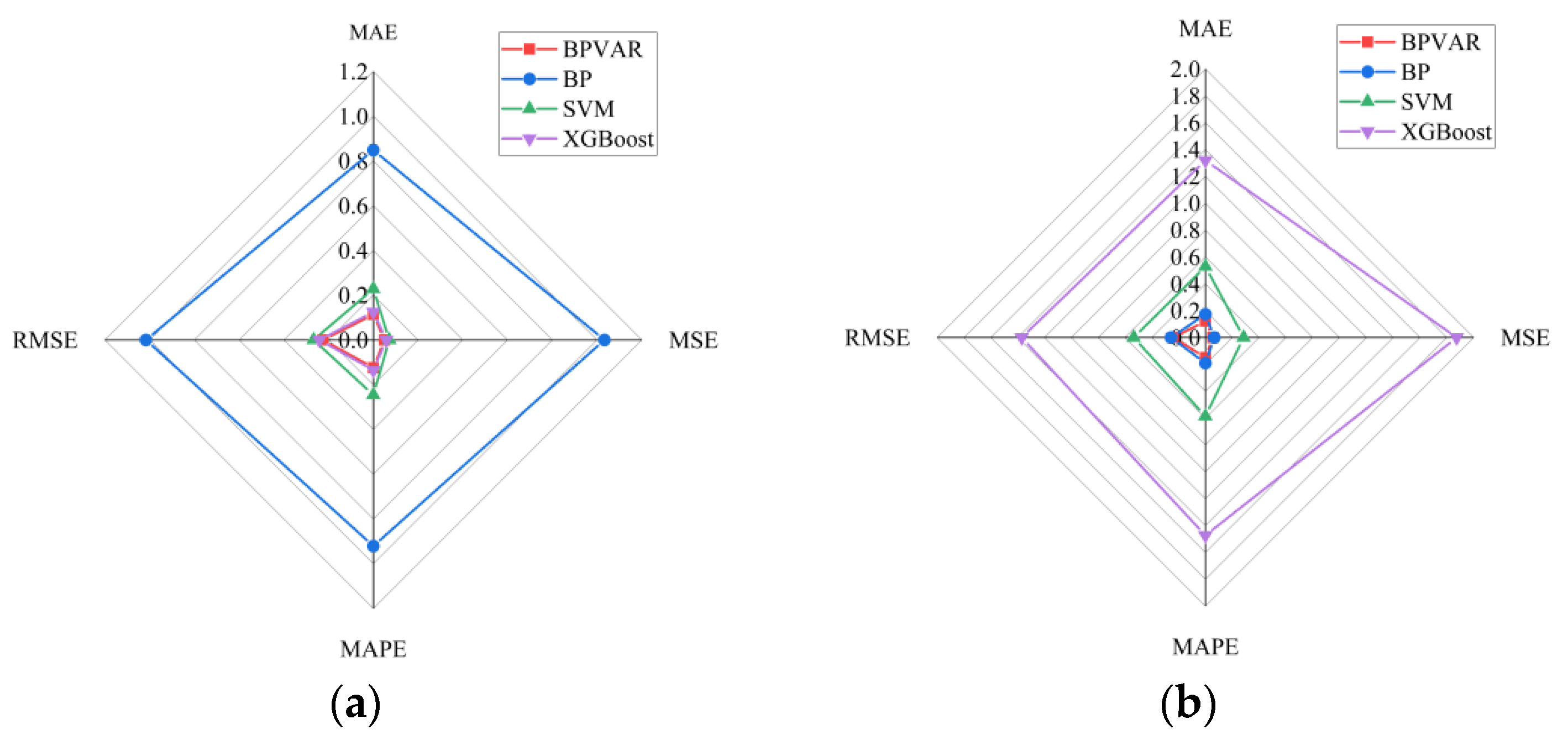
- After adding exogenous variables to the BPVAR model, the multiple correlation coefficients between the fitted values and the measured values of the training set and the test set data exceeded 0.80, indicating that the modeling effect of the model was good, and the predicted uplift pressure fell within the 95% confidence interval, indicating that the BPVAR model performed well in interval prediction. The MAE, MAPE, MSE, and RMSE predicted by the BPVAR model were smaller than those of the BP model, the SVM model, and the XGBoost model.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Z.R. Safety Monitoring Theory of Hydraulic Structures and Its Application; Higher Education Press: Beijing, China, 2003. [Google Scholar]
- Warren, T. Roller-compacted concrete dams: A brief history and their advantages. Dams Reserv. 2012, 22, 87–90. [Google Scholar] [CrossRef]
- Zhong, D.H.; Wang, F.; Wu, B.P.; Cui, B.; Liu, Y.X. From digital dam to smart dam. J. Hydroelectr. Power 2015, 34, 1–13. [Google Scholar]
- Bukenya, P.; Moyo, P.; Beushausen, H.; Oosthuizen, C. Health monitoring of concrete dams: A literature review. J. Civ. Struct. Health Monit. 2014, 4, 235–244. [Google Scholar] [CrossRef]
- Fang, C.H.; Duan, Y.H. Statistical analysis of dam—Break incidents and its cautions. Yangtze River 2010, 41, 96–101. [Google Scholar]
- Habib, P. The Malpasset dam failure. Eng. Geol. 1987, 24, 331–338. [Google Scholar] [CrossRef]
- Si, C.D.; Lian, J.J. Genetic support vector machine method for seepage safety monitoring of earth-rock dams. J. Hydraul. Eng. 2007, 38, 1341–1346. [Google Scholar]
- Li, F.Q.; Qian, J.L. Application of characteristic polynomial roots of auto regression time series model in analysis of dam observation data. J. Zhejiang Univ. Eng. Sci. 2009, 43, 193–196. [Google Scholar]
- Gu, C.; Fu, X.; Shao, C.; Shi, Z.; Su, H. Application of spatiotemporal hybrid model of deformation in safety monitoring of high arch dams: A case study. Int. J. Environ. Res. Public Health 2020, 17, 319. [Google Scholar] [CrossRef] [PubMed]
- Wei, B.; Liu, B.; Yuan, D.; Mao, Y.; Yao, S. Spatiotemporal hybrid model for concrete arch dam deformation monitoring considering chaotic effect of residual series. Eng. Struct. 2021, 228, 111488. [Google Scholar] [CrossRef]
- Cheng, L.; Zheng, D. Two online dam safety monitoring models based on the process of extracting environmental effect. Adv. Eng. Softw. 2013, 57, 48–56. [Google Scholar] [CrossRef]
- Popescu, T.D.; Alexandru, A. Blind source separation: A preprocessing tool for monitoring of structures. In Proceedings of the IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR), Cluj-Napoca, Romania, 24–26 May 2018. [Google Scholar]
- Zhu, W.B.; Zhao, J.H. Application of BLS-SVM to dam safety monitoring data validation. Hydropower Autom. Dam Monit. 2009, 33, 46–50. [Google Scholar]
- Xu, C. Research on Machine Learning Models for Health Diagnosis of Spatial Deformation Behavior of Super-High Arch Dams. Ph.D. Thesis, Changzhou University, Changzhou, China, 2020. [Google Scholar]
- Hu, J.; Ma, F. Zoned deformation prediction model for super high arch dams using hierarchical clustering and panel data. Eng. Comput. 2020, 37, 2999–3021. [Google Scholar] [CrossRef]
- Hu, T.Y. Spatial and temporal clustering model of concrete arch dam deformation data based on panel data analysis method. J. Yangtze River Sci. Res. Inst. 2021, 38, 39–45. [Google Scholar]
- Wang, S.; Xu, C.; Liu, Y.; Wu, B. Mixed-coefficient panel model for evaluating the overall deformation behavior of high arch dams using the spatial clustering. Struct. Control. Health Monit. 2021, 28, e2809. [Google Scholar] [CrossRef]
- Liu, C. Research review on vector autoregressive model for panel data. Stat. Decis. 2021, 37, 25–29. [Google Scholar]
- Canova, F.; Ciccarelli, M. Panel vector autoregressive models: A survey. Adv. Econom. 2013, 32, 205–246. [Google Scholar]
- Lee, S.; Karim, Z.; Khalid, N.; Zaidi, M. The spillover effects of chinese shocks on the belt and road initiative economies: New evidence using panel vector autoregression. Mathematics 2022, 10, 2414. [Google Scholar] [CrossRef]
- Silva, F.; Sáfadi, T.; Muniz, J.; Rosa, G.; Aquino, L.; Mourão, G.; Silva, C. Bayesian analysis of autoregressive panel data model: Application in genetic evaluation of beef cattle. Sci. Agric. 2011, 68, 237–245. [Google Scholar] [CrossRef]
- Pesaran, M. Estimation and inference in large heterogeneous panels with a multifactor error structure. Econometrica 2006, 74, 967–1012. [Google Scholar] [CrossRef]
- Zellner, A. The Bayesian method of moments (Bmom). Adv. Econom. 1997, 12, 85–105. [Google Scholar]
- Canova, F.; Ciccarelli, M. Forecasting and turning point predictions in a Bayesian panel VAR model. J. Econom. 2004, 120, 327–359. [Google Scholar] [CrossRef]
- Koop, G.; Korobilis, D. Model uncertainty in panel vector autoregressive models. Eur. Econ. Rev. 2015, 81, 115–131. [Google Scholar] [CrossRef]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM SIGMOD Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Ye, Y.J.; Du, J. Consistency loss between classification and localization based on cosine similarity. Electron. Opt. Control 2023, 30, 41–48. [Google Scholar]
- Chen, H.D.; Chen, X.D.; Guan, J.Y.; Zhang, X.; Guo, J.J.; Yang, G.; Xu, B. A combination model for evaluating deformation regional characteristics of arch dams using time series clustering and residual correction. Mech. Syst. Signal Process. 2022, 179, 109397. [Google Scholar] [CrossRef]
- Kamalzadeh, H.; Ahmadi, A.; Mansour, S. Clustering Time-Series by a Novel Slope-Based Similarity Measure Considering Particle Swarm Optimization. Appl. Soft Comput. 2020, 96, 106701. [Google Scholar] [CrossRef]
- Song, K.Y.; Wang, N.B.; Wang, H.B. A Metric Learning-Based Univariate Time Series Classification Method. Information 2020, 11, 288. [Google Scholar] [CrossRef]
- Chen, Z.; Li, H.; Zhang, X.; Sun, G.; Li, H. Risk analysis of subsea control system integration test based on K-means. China Offshore Platf. 2024, 39, 45–50. [Google Scholar]
- He, Z.H.; Qin, W.D.; Duan, C.P. Chemical composition analysis of ancient glass products based on decision tree. In Proceedings of the 2023 International Conference on Mathematical Modeling, Algorithm and Computer Simulation (MMACS 2023), Seoul, Republic of Korea, 25–26 February 2023; Wuhan Zhicheng Times Cultural Development Co., Ltd.: Wuhan, China, 2023; Volume 9. [Google Scholar]
- Chen, Q. Advanced Econometrics and Stata Applications; Higher Education Press: Beijing, China, 2014. [Google Scholar]
- Levin, A.; Lin, C.; Chu, C. Unit root tests in panel data: Asymptotic and finite-sample properties. J. Econom. 2002, 108, 1–24. [Google Scholar] [CrossRef]
- Im, K.; Pesaran, M.; Shin, Y. Testing for unit roots in heterogeneous panels. J. Econom. 2003, 115, 53–74. [Google Scholar] [CrossRef]
- Wang, Z.; Nie, X. Unit root test and growth convergence of panel data. Stat. Decis. 2006, 2006, 19–22. [Google Scholar]
- Choi, I. Unit root tests for panel data. J. Int. Money Financ. 2001, 20, 249–272. [Google Scholar] [CrossRef]
- Li, J.; Ma, Z.Y.; Chen, B.F.; Li, X.J.; Zhou, F. Effect analysis of 2 m temperature correction in Xinyu city by moving average method. Meteorol. Hydrol. Mar. Instrum. 2022, 39, 43–46. [Google Scholar]
- Akaike, H. A New Look at Statistical Model Identification. IEEE Trans. Autom. Control. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Hannan, E.; Quin, G. The determination of the order of an autoregression. J. R. Stat. Soc. 1979, 41, 190–195. [Google Scholar] [CrossRef]
- Zellner, A.; Hong, C. Forecasting international growth rates using Bayesian shrinkage and other procedures. J. Econom. 1989, 40, 183–202. [Google Scholar] [CrossRef]
- Jarocinski, M. Responses to monetary policy shocks in the east and the west of Europe: A comparison. J. Appl. Econom. 2010, 25, 833–868. [Google Scholar] [CrossRef]
- Cui, J. Research on Structural Damage Identification Based on Sparse Bayesian Learning and GIBBS Sampling; Harbin Institute of Technology: Harbin, China, 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Indicators | Cosine Similarity | Bilateral Slope Distance | DTW |
|---|---|---|---|
| Silhouette coefficient | 0.51 | 0.55 | 0.58 |
| Variance ratio criterion | 2684 | 2848 | 2850 |
| Category | Instrument ID Number | Similar Reasons |
|---|---|---|
| Category I | UP1, UP2, UP3 | The measuring point is located in front of the grouting curtain in the same dam section (dam Section 6). |
| Category II | UP4, UP5, UP13, UP14 | The measuring point is adjacent to and arranged behind the grouting curtain. |
| Category Ⅲ | UP6, UP7 | The measuring point is located in the same dam section (dam Section 5) and near the right bank. |
| Category IV | UP9, UP11 | The measuring point is located in the middle section of the dam and close to the riverbed. |
| Category V | UP17, UP18 | The measuring points are located in the same lateral corridor (5 dam sections). |
| Category VI | UP19, UP20, UP21, UP23 | The measuring point is located in the lateral corridor and near the upstream water level. |
| Category VII | UP22, UP24 | The measuring point is located in the lateral corridor and near downstream, which is greatly affected by the downstream water level. |
| Type of Measuring Point | LLC | IPS | ADF-Fisher |
|---|---|---|---|
| Category I | 0.01 | 0.01 | 0.02 |
| Category II | 0.02 | 0.01 | 0.00 |
| Category Ⅲ | 0.03 | 0.02 | 0.03 |
| Category IV | 0.00 | 0.00 | 0.05 |
| Category Ⅴ | 0.02 | 0.01 | 0.09 |
| Category VI | 0.00 | 0.00 | 0.01 |
| Category Ⅶ | 0.06 | 0.04 | 0.09 |
| Type of Measuring Point | Lag Order | AIC | BIC | HQIC |
|---|---|---|---|---|
| Category I | 1 | −5.26 | −5.25 | −5.22 |
| 2 | −6.15 | −6.12 | −6.08 | |
| 3 | −6.22 | −6.18 | −6.12 * | |
| 4 | −6.25 * | −6.20 * | −6.11 | |
| Category II | 1 | −17.09 | −17.06 | −17.02 |
| 2 | −17.21 | −17.16 | −17.08 * | |
| 3 | −17.25 * | −17.19 * | −17.07 | |
| 4 | −17.25 | −17.16 | −17.01 | |
| Category Ⅲ | 1 | −5.00 | −4.96 | −4.89 |
| 2 | −5.25 | −5.18 * | −5.06 * | |
| 3 | −5.26 * | −5.15 | −4.98 | |
| 4 | −5.26 | −5.12 | −4.89 | |
| Category IV | 1 | −7.93 | −7.93 | −7.91 |
| 2 | −8.32 | −8.31 | −8.29 | |
| 3 | −8.35 | −8.33 * | −8.30 * | |
| 4 | −8.36 * | −8.33 | −8.29 | |
| Category V | 1 | −6.75 | −6.72 | −6.68 |
| 2 | −7.08 | −7.04 | −6.96 * | |
| 3 | −7.11 | −7.04 * | −6.93 | |
| 4 | −7.13 * | −7.04 | −6.89 | |
| Category VI | 1 | −4.71 | −4.70 | −4.69 |
| 2 | −4.77 | −4.76 | −4.74 | |
| 3 | −4.79 | −4.77 | −4.74 | |
| 4 | −4.81 * | −4.79 * | −4.75 * | |
| Category Ⅶ | 1 | −3.88 | −3.81 | −3.80 |
| 2 | −3.87 | −3.86 * | −3.84 * | |
| 3 | −3.87 | −3.86 | −3.83 | |
| 4 | −3.86 * | −3.85 | −3.81 |
| Monitoring Point | Assessment Metrics | BPVAR | BP | SVM | XGBoost |
|---|---|---|---|---|---|
| UP22 | MAE | 0.114 | 0.848 | 0.228 | 0.125 |
| MSE | 0.05 | 1.033 | 0.071 | 0.058 | |
| MAPE | 0.124 | 0.921 | 0.246 | 0.135 | |
| RMSE | 0.224 | 1.017 | 0.267 | 0.241 | |
| UP24 | MAE | 0.121 | 0.173 | 0.529 | 1.319 |
| MSE | 0.056 | 0.066 | 0.285 | 1.873 | |
| MAPE | 0.149 | 0.191 | 0.586 | 1.473 | |
| RMSE | 0.237 | 0.257 | 0.534 | 1.369 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, L.; Han, J.; Ma, C.; Yang, J. Safety Monitoring Method for the Uplift Pressure of Concrete Dams Based on Optimized Spatiotemporal Clustering and the Bayesian Panel Vector Autoregressive Model. Water 2024, 16, 1190. https://doi.org/10.3390/w16081190
Cheng L, Han J, Ma C, Yang J. Safety Monitoring Method for the Uplift Pressure of Concrete Dams Based on Optimized Spatiotemporal Clustering and the Bayesian Panel Vector Autoregressive Model. Water. 2024; 16(8):1190. https://doi.org/10.3390/w16081190
Chicago/Turabian StyleCheng, Lin, Jiaxun Han, Chunhui Ma, and Jie Yang. 2024. "Safety Monitoring Method for the Uplift Pressure of Concrete Dams Based on Optimized Spatiotemporal Clustering and the Bayesian Panel Vector Autoregressive Model" Water 16, no. 8: 1190. https://doi.org/10.3390/w16081190
APA StyleCheng, L., Han, J., Ma, C., & Yang, J. (2024). Safety Monitoring Method for the Uplift Pressure of Concrete Dams Based on Optimized Spatiotemporal Clustering and the Bayesian Panel Vector Autoregressive Model. Water, 16(8), 1190. https://doi.org/10.3390/w16081190