
Prediction of Floor Failure Depth Based on Dividing Deep and Shallow Mining for Risk Assessment of Mine Water Inrush


Abstract
1. Introduction
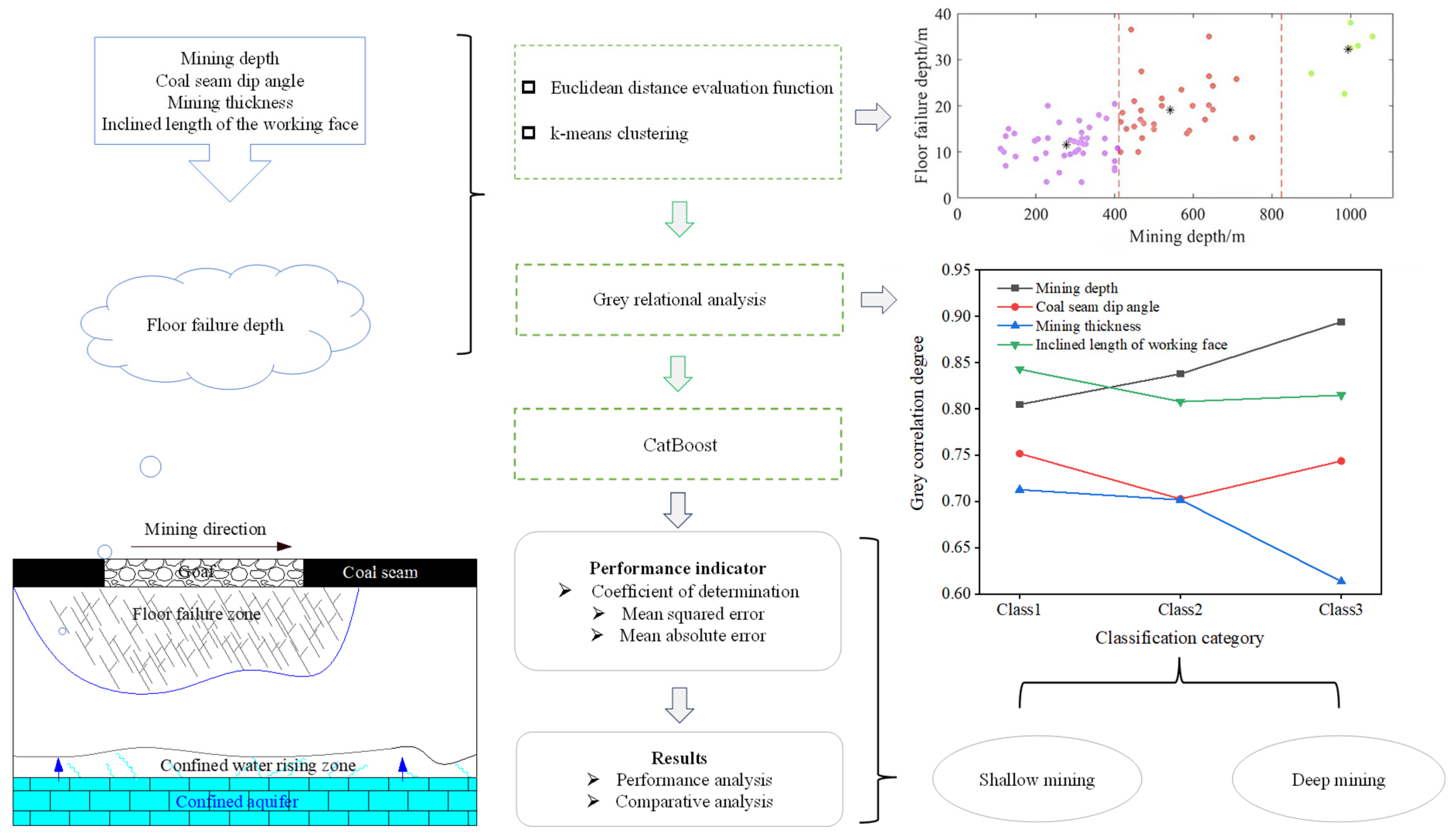
2. Basic Data on Coal Seam Floor Failure Depth
2.1. Analysis of the Main Controlling Factors
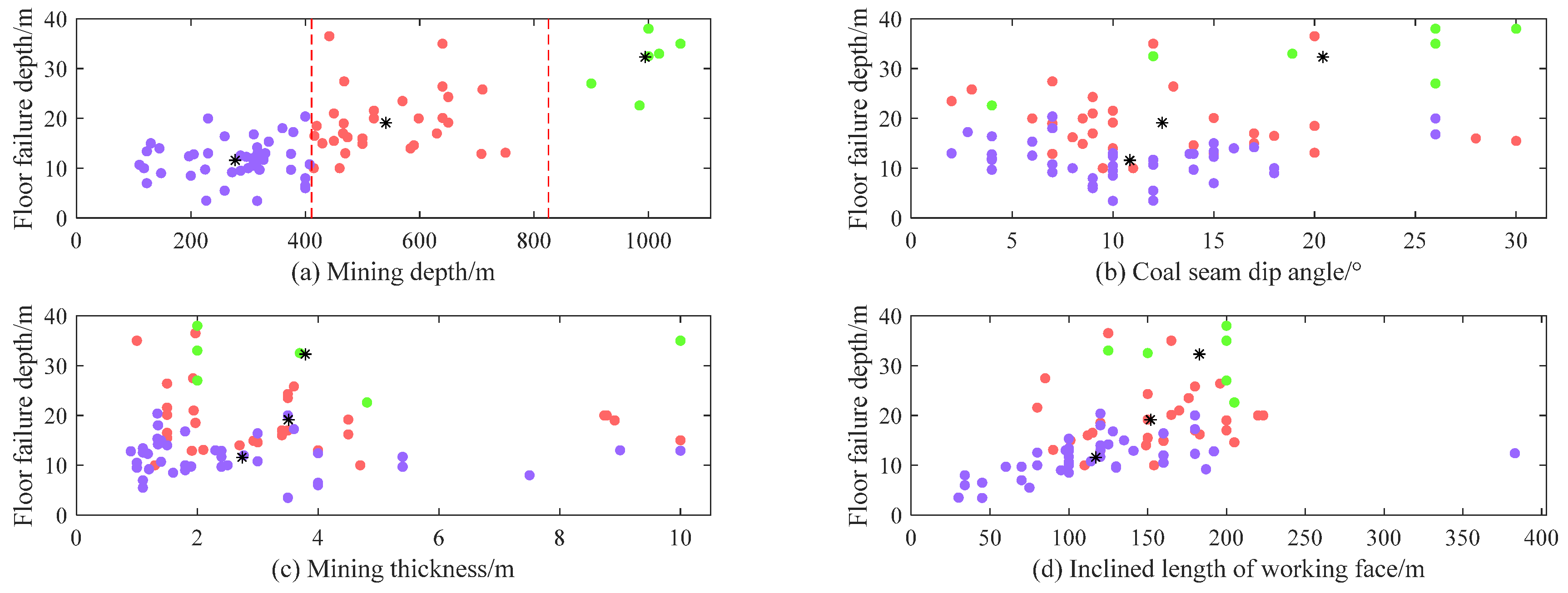
2.2. Statistical Analysis of Measured Data
3. Cluster Analysis of Measured Data Based on Different Mining Depths
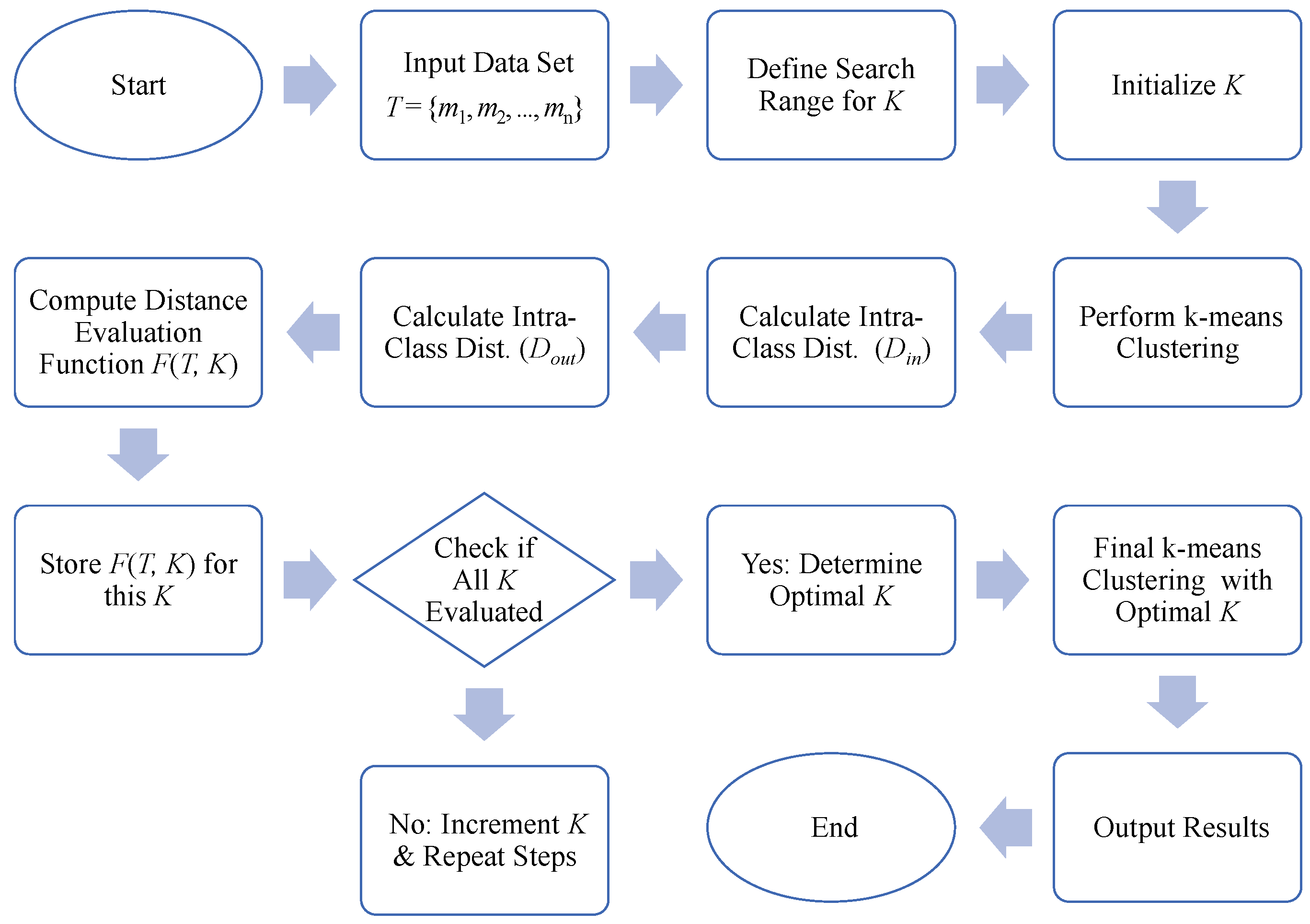
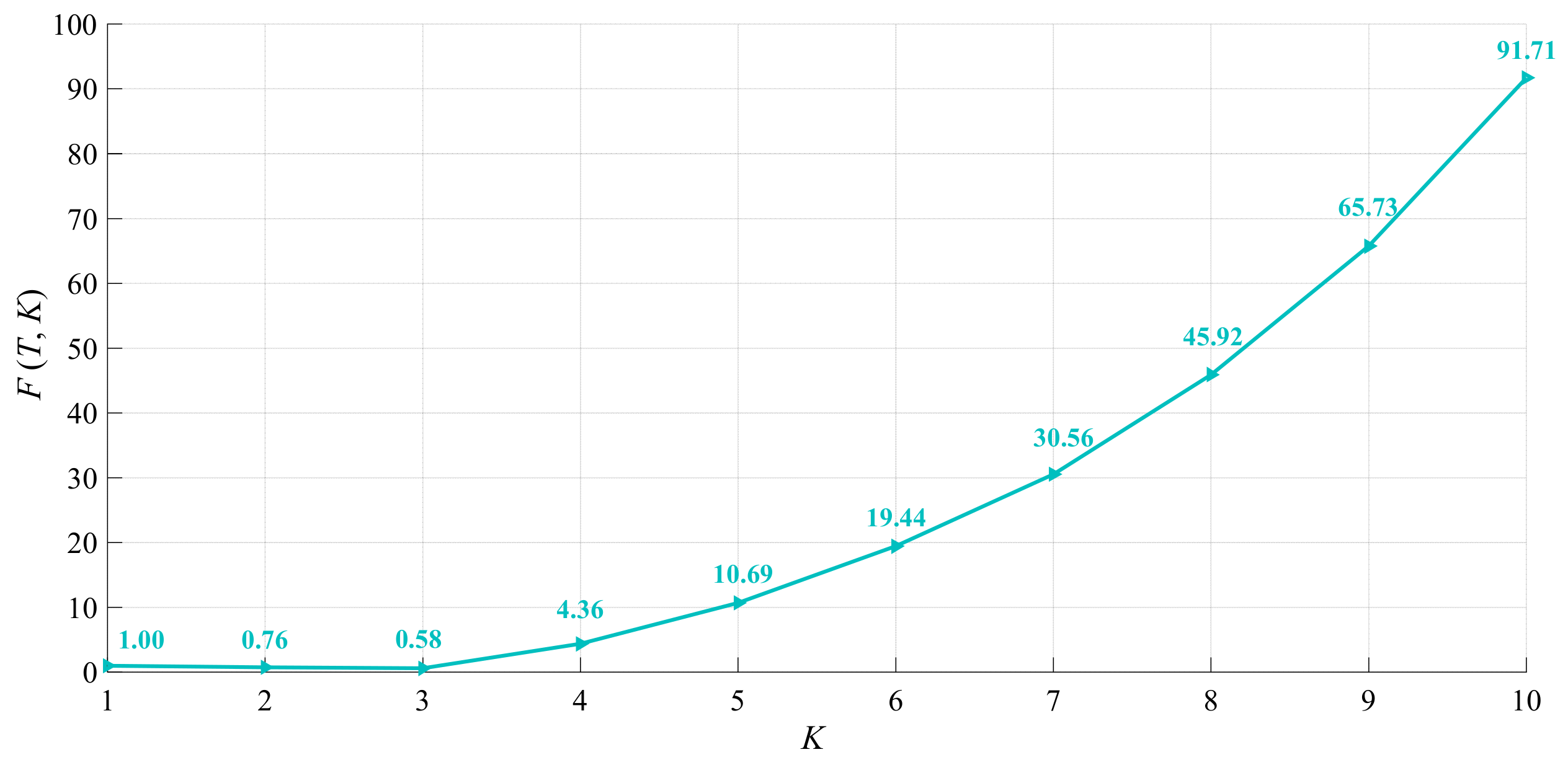
3.1. Selection of the Optimal Number of K Clusters
- (1)
- Consider I = {T, K} as the clustering space and define the inter-class distance as the summation of Euclidean distances from all cluster centers (the mean of samples within each class) to the center of the universe (the mean of all samples):where Dout is the distance between classes, m is the sample mean, and mi is the mean of all samples in class Ci.
- (2)
- Consider I = {T, K} as the clustering space. Intra-class distance is defined as the summation of internal distances within all classes. More specifically, intra-class distance is calculated as the sum of the Euclidean distances from all objects within each class to the respective class center:where Din is the intra-class distance, p is any spatial object, and mi is the mean of all samples in class Ci.
- (3)
- Consider I = {T, K} as the cluster space. When Dout is approximately equal to Din, this indicates that the number of clusters is optimal. Consequently, the distance evaluation function is defined as follows:
3.2. Determination of Cluster Category
- (1)
- Determine the number of clusters, K. Establish the optimal number for dividing the dataset. As per Section 3.1, the most suitable cluster number was K = 3.
- (2)
- Cluster center initialization: K data points are randomly chosen from the dataset to serve as the initial cluster centers:where represents the initial cluster center set and represents the initial j-th cluster center.
- (3)
- Assign data points to cluster centers:where Si denotes the index set of the cluster to which the i-th data point belongs, signifies the distance between the data point xi and the j-th cluster center , and represents the l-th cluster center at the t-th iteration.
- (4)
- Update the cluster centers:where represents the updated position of the j-th cluster center and represents the number of data points belonging to the j-th cluster.
- (5)
- Iterate through steps 3 and 4 until the cluster center positions remain unchanged or a predefined number of iterations is reached.
- (6)
- Upon completion of clustering, assign each data point to a cluster.
4. Grey Correlation Analysis of the Main Controlling Factors in Deep and Shallow Coal Seams
4.1. Grey Relational Degree Theory
4.2. Grey Relational Grade Calculation
- (1)
- Average dimensionless processing
- (2)
- Calculation of the correlation coefficient
- (3)
- Grey relational degree solution
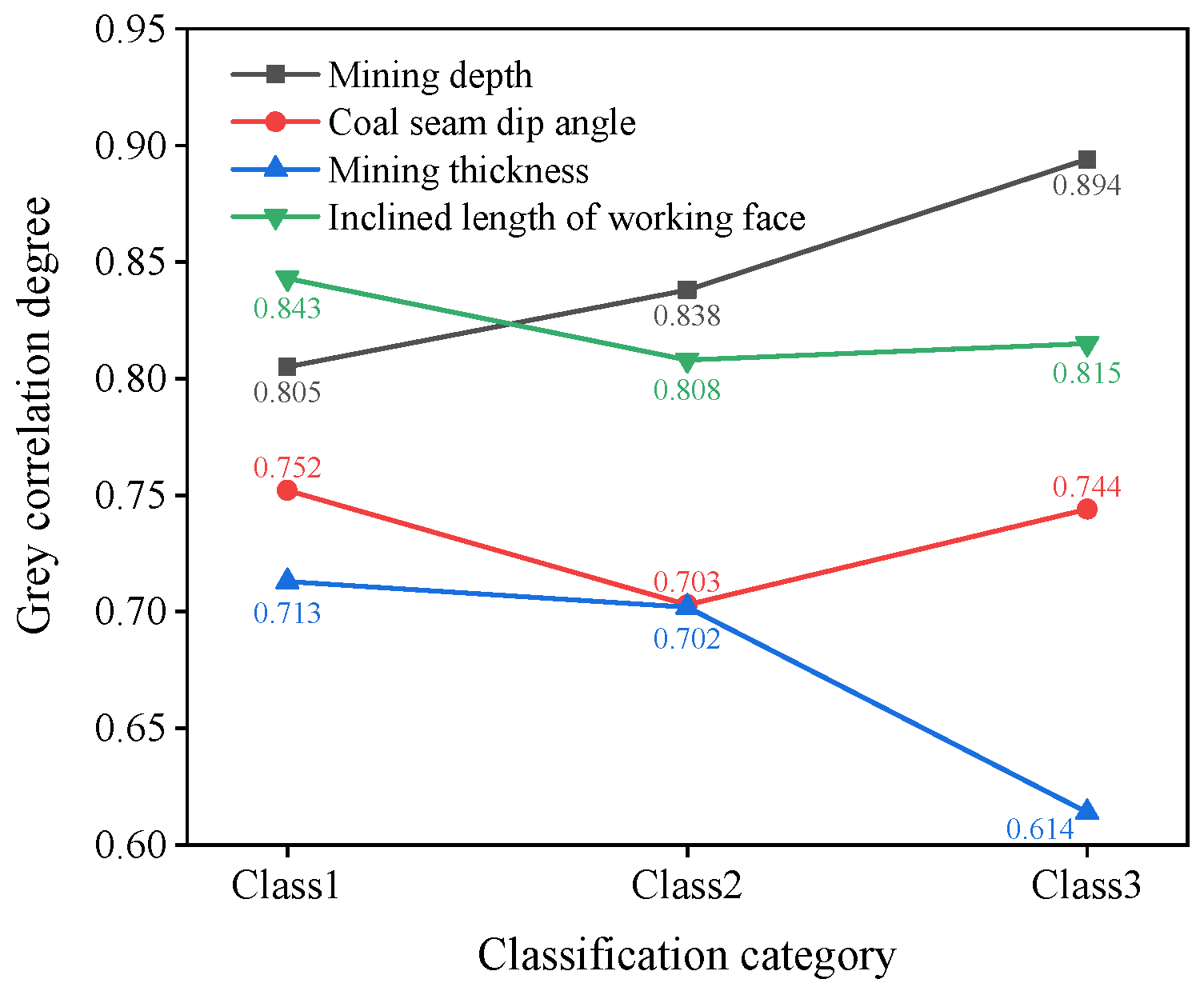
4.3. Grey Relational Analysis
5. Prediction of Floor Failure Depth in Deep and Shallow Coal Seams
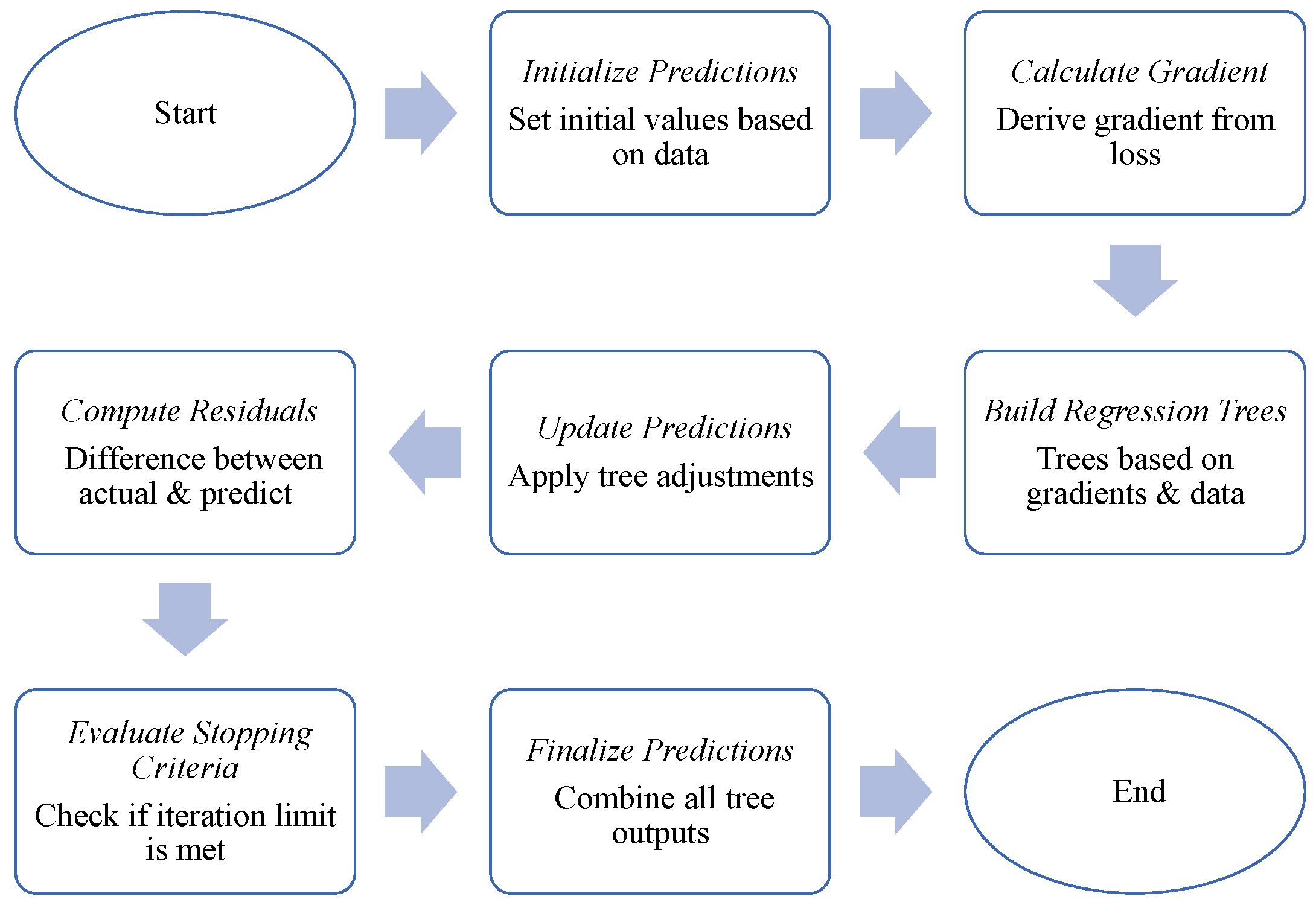
5.1. Principles of the Catboost Algorithm
- (1)
- Initialization: Specify the number of iterations (T) and the learning rate (η). Initialize the model’s predicted value (p), typically by using the average value of the training set. Assuming there are n samples in the training set, the initial prediction value iswhere yi represents the actual value of the i-th sample.
- (2)
- Calculate the gradient of the loss function: Compute the gradient of the loss function for each sample with respect to the current model’s predicted value. In the case of regression problems, the loss function employs the squared loss function (L2 loss):
- (3)
- Build regression trees: In each iteration, construct a regression tree based on the gradient of the loss function and the information gain of features. A regression tree is a decision tree designed for gradient boosting and is used to model regression problems.
- (4)
- Update the model’s prediction value: Adjust the model’s prediction value based on the currently constructed regression tree. For the t-th iteration (t = 1, 2, …, T), the updated predicted value iswhere ft(xi) represents the predicted value of the regression tree for the sample xi in the t-th round iteration.
- (5)
- Update residuals: Compute the difference between the current predicted value and the actual label to obtain the residual for the next iteration. For the t-th round of iteration, the calculated residual is
- (6)
- Check stopping criteria: Check whether the predefined number of iterations T has been reached or if other stopping criteria (e.g., error convergence) have been met. If the stop criterion is satisfied, the training process concludes; otherwise, it returns to step 3.
- (7)
- Conduct final prediction: Once the training is finished, use CatBoost to aggregate the prediction outputs from all regression trees to produce the final model prediction result.
5.2. Modeling
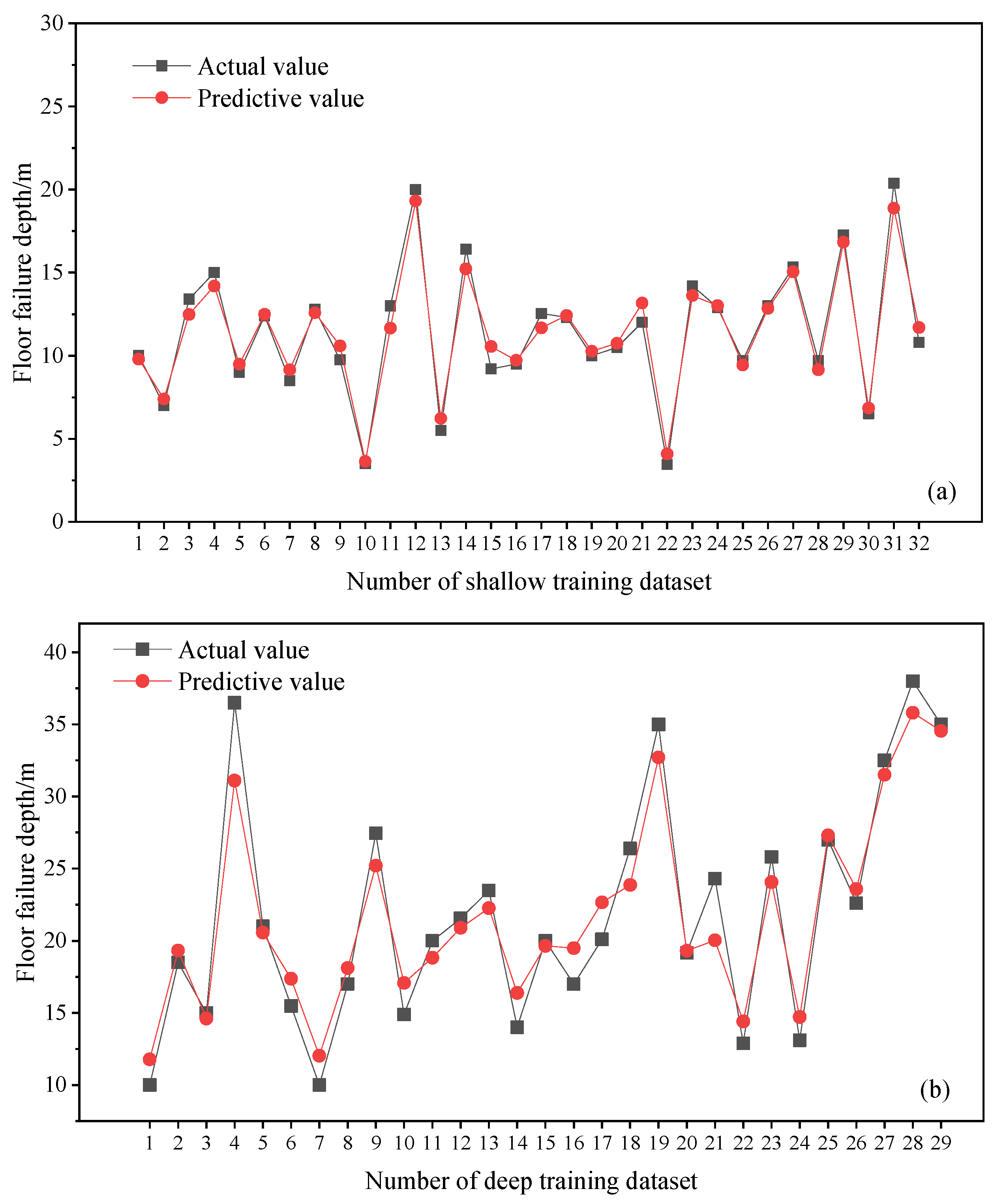
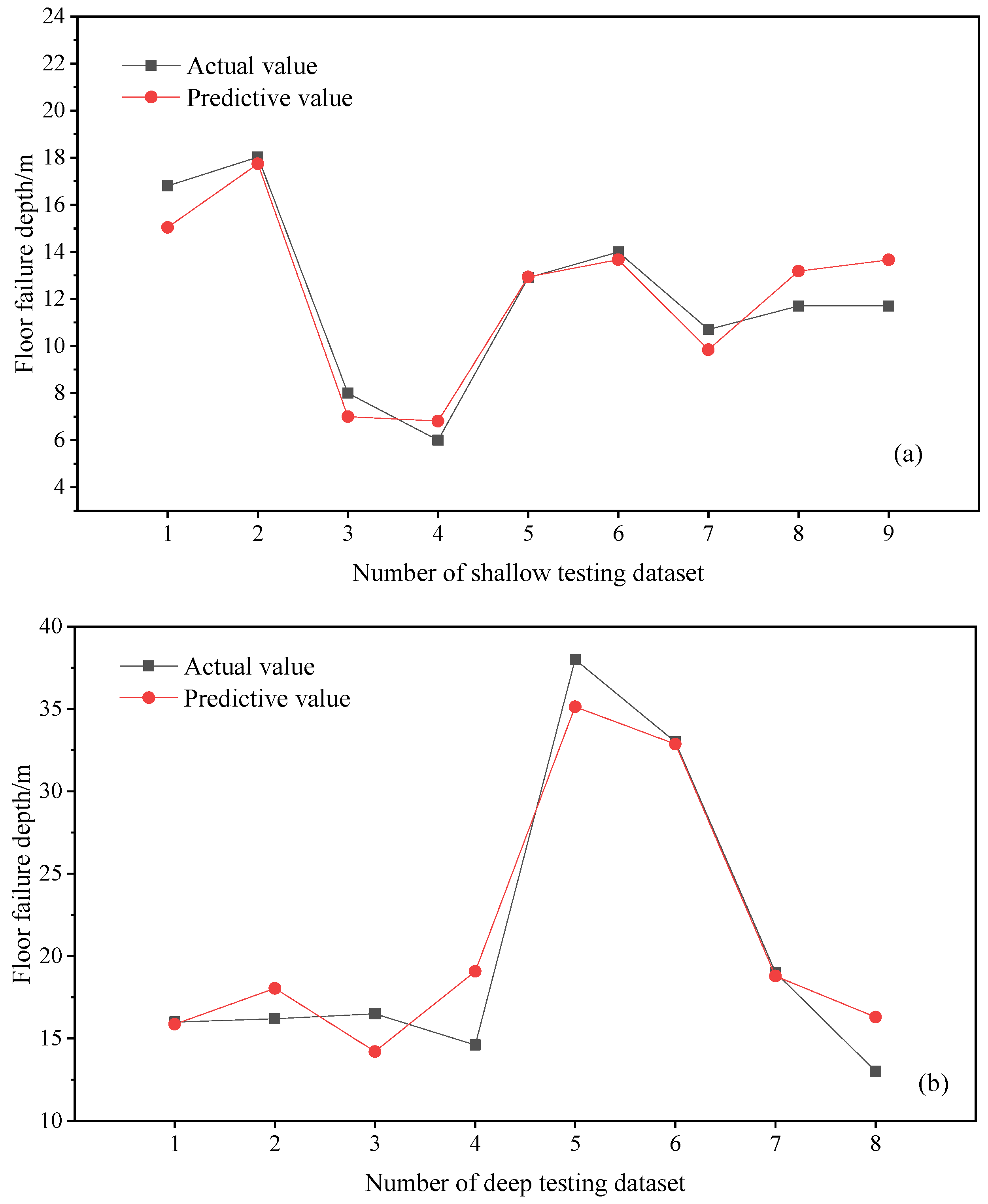
5.3. Model Evaluation
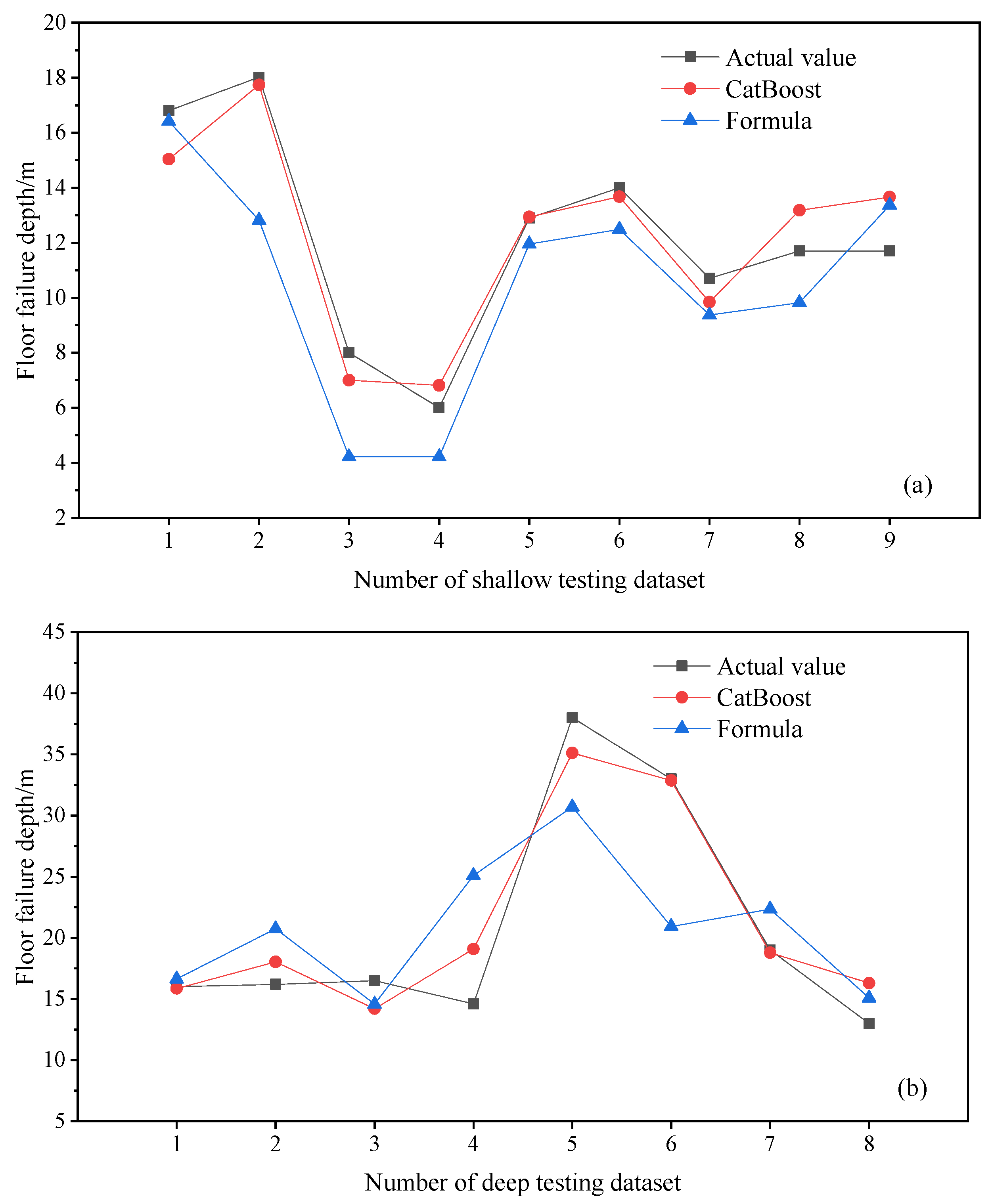
5.4. Comparative Analysis of Prediction Results
6. Discussion
7. Conclusions
- (1)
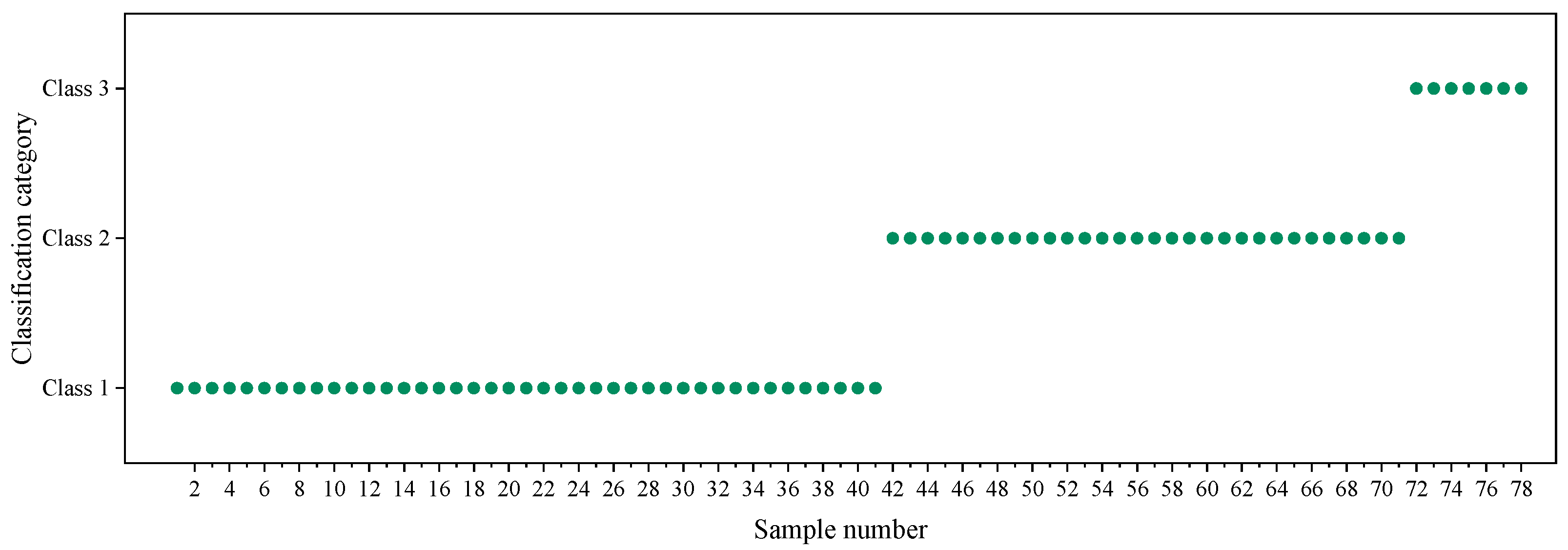
- First, using 78 sets of measured floor failure depth data and considering the differences in coal seam floor failure modes at different depths, a distance evaluation function based on Euclidean distance was formulated as a clustering effectiveness index. After employing this metric to identify the optimal number of clusters (K = 3), the K-means clustering algorithm was applied to categorize the data into three sample types. The D1 boundaries for these three sample types were within the range of 407.7 to 414.9 m and 750 to 900 m.
- (2)
- Subsequently, the grey correlation analysis method was used to calculate the correlation degree between the floor failure depth and its main controlling factors. The weight order for the first type of sample was as follows: D2 > D1 > D3 > D4. In the case of the second and third types of samples, D1 surpassed D2 and became the most influential factor. Therefore, taking the D1 range of 407.7 m to 414.9 m as the boundary, the first type of sample was categorized as shallow mining, while the second and third types were classified as deep mining. The determination of the mining boundaries of deep and shallow coal seams divided the measured data and provided basic data for the CatBoost prediction model for the depth of deep and shallow coal seam floor failure.
- (3)
- Finally, the CatBoost prediction model was trained and tested using the measured data of divided deep and shallow coal seam floor failure depths. For the training set of the shallow coal seam CatBoost prediction model, the MSE was 0.50, MAE was 0.58, and R2 was 0.97; for the testing set, the MSE was 1.30, MAE was 0.95, and R2 was 0.90. The training set of the deep coal seam CatBoost prediction model had MSE = 4.09, MAE = 1.66, and R2 = 0.93; the testing set had MSE = 6.00, MAE = 1.91, and R2 = 0.92. This shows that whether in the training set or the testing set, the predicted values generated by the CatBoost model were basically consistent with the actual values. In addition, through a comparative analysis between the CatBoost prediction models for deep and shallow parts and the empirical formula, it was found that the prediction accuracy of the CatBoost prediction models was better. For the shallow coal seam testing set, the empirical formula yielded MSE = 6.23, MAE = 2.06, and R2 = 0.52, while for the deep coal seam testing set, the empirical formula yielded MSE = 43.68, MAE = 5.30, and R2 = 0.43. In contrast, the CatBoost model for the shallow coal seam achieved MSE = 1.30, MAE = 0.95, and R2 = 0.90 and, for the deep coal seam, the CatBoost model yielded MSE = 6.00, MAE = 1.91, and R2 = 0.92. This comparison indicates that the CatBoost models for both deep and shallow parts were more accurate and effective in predicting the depth of floor failure.
8. Limitations and Recommendations
- (1)
- Due to the limited measured data collected, the D1 boundary divided by deep and shallow mining fell within a range. Therefore, more data need to be collected to enrich the dataset and narrow down the boundaries of subsequent deep and shallow mining.
- (2)
- Only four main controlling factors were considered, but, in the actual production process, there may be many factors that affect the depth of floor failure. In future studies, we hope to improve the model by taking into account as many factors as possible, such as the hard rock coefficient.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, P.; Tian, R.; Xue, C.; Wu, J. Progress, opportunities, and key fields for groundwater quality research under the impacts of human activities in China with a special focus on western China. Environ. Sci. Pollut. Res. 2017, 24, 13224–13234. [Google Scholar] [CrossRef]
- Zhou, J.; Jiang, Z.; Qin, X.; Zhang, L. Heavy metal distribution and health risk assessment in groundwater and surface water of karst lead–Zinc Mine. Water 2024, 16, 2179. [Google Scholar] [CrossRef]
- Yin, D.; Lu, Z.; Li, Z.; Wang, C.; Li, X.; Hu, H. Effects of chloride ion transport characteristics and water pressure on mechanical properties of cemented coal gangue-fly ash backfill. Geomech. Eng. 2024, 38, 125–127. [Google Scholar] [CrossRef]
- Zipper, C.; Donovan, P.; Jones, J.; Li, J.; Price, J.; Stewart, R. Spatial and temporal relationships among watershed mining, water quality, and freshwater mussel status in an eastern USA river. Sci. Total Environ. 2016, 541, 603–615. [Google Scholar] [CrossRef] [PubMed]
- Moye, J.; Picard-Lesteven, T.; Zouhri, L.; El Amari, K.; Hibti, M.; Benkaddour, A. Groundwater assessment and environmental impact in the abandoned mine of Kettara (Morocco). Environ. Pollut. 2017, 231, 899–907. [Google Scholar] [CrossRef] [PubMed]
- Ren, Z.; Zhang, C.; Wang, Y.; Lan, S.; Liu, S. Stability analysis and grouting treatment of inclined shaft lining structure in water-rich strata: A case study. Geohaz. Mech. 2023, 1, 308–318. [Google Scholar] [CrossRef]
- Zhang, Z.; Xie, H.; Zhang, R.; Zhang, Z.; Gao, M.; Jia, Z.; Xie, J. Deformation damage and energy evolution characteristics of coal at different depths. Rock Mech. Rock Eng. 2019, 52, 1491–1503. [Google Scholar] [CrossRef]
- Xie, H.; Gao, F.; Ju, Y.; Gao, M.; Xie, L. Quantitative definition and investigation of deep mining. J. China Coal Soc. 2015, 40, 1–10. [Google Scholar]
- Xie, H.; Zhou, H.; Xue, D.; Wang, H.; Zhang, R.; Gao, F. Research and consideration on deep coal mining and critical mining depth. J. China Coal Soc. 2012, 37, 535–542. [Google Scholar]
- Qian, Q. The characteristic scientific phenomena of engineering response to deep rock mass and the implication of deepness. J. East China Inst. Technol. 2004, 27, 1–5. [Google Scholar]
- He, M. Conception system and evaluation indexes for deep engineering. Chin. J. Rock Mech. Eng. 2005, 24, 2854–2858. [Google Scholar]
- He, M.; Xie, H.; Peng, S.; Jiang, Y. Study on rock mechanics in deep mining engineering. Chin. J. Rock Mech. Eng. 2005, 24, 2803–2813. [Google Scholar]
- Zhang, J.; Li, Q.; Zhang, Y.; Cao, Z.; Wang, X. Definition of deep coal mining and response analysis. J. China Coal Soc. 2019, 44, 1314–1325. [Google Scholar]
- Xu, Y.; Yang, Y. Applicability analysis on statistical formula for failure depth of coal seam floor in deep mine. Coal Sci. Technol. 2013, 41, 129–132. [Google Scholar]
- Liu, W.; Mu, D.; Xie, X.; Yang, L.; Wang, D. Sensitivity analysis of the main factors controlling floor failure depth and a risk evaluation of floor water inrush for an inclined coal seam. Mine Water Environ. 2018, 37, 636–648. [Google Scholar] [CrossRef]
- Dong, S.; Wang, H.; Zhang, W. Judgement criteria with utilization and grouting reconstruction of top Ordovician limestone and floor damage depth in North China coal field. J. China Coal Soc. 2018, 44, 2216–2226. [Google Scholar]
- Hu, Y.; Li, W.; Liu, S.; Wang, Q. Prediction of floor failure depth in deep coal mines by regression analysis of the multi-factor influence index. Mine Water Environ. 2021, 40, 497–509. [Google Scholar] [CrossRef]
- Zhao, S. Resource exploitation and underground engineering under deep high stress--Summary of the 175th Xiangshan Conference. Adv. Earth Sci. 2002, 17, 295–298. [Google Scholar]
- Davoodi, S.; Mehrad, M.; Wood, D.; Rukavishnikov, V.; Bajolvand, M. Predicting uniaxial compressive strength from drilling variables aided by hybrid machine learning. Int. J. Rock Mech. Min. Sci. 2023, 170, 105546. [Google Scholar] [CrossRef]
- De Gouveia, S.; de Abreu Correa, L.; Teles, D.; Oliveira, M.; Clarke, T. Emergency shutdown valve damage classification by machine learning using synthetic data. Eng. Fail. Anal. 2024, 156, 107819. [Google Scholar] [CrossRef]
- Ge, Q.; Wang, J.; Liu, C.; Wang, X.; Deng, Y.; Li, J. Integrating feature selection with machine learning for accurate reservoir landslide displacement prediction. Water 2024, 16, 2152. [Google Scholar] [CrossRef]
- Asante-Okyere, S.; Shen, C.B.; Ziggah, Y.Y.; Rulegeya, M.M.; Zhu, X.F. A novel hybrid technique of integrating gradient-boosted machine and clustering algorithms for lithology classification. Nat. Resour. Res. 2020, 29, 2257–2273. [Google Scholar] [CrossRef]
- Egbueri, J. Prediction modeling of potentially toxic elements’ hydrogeopollution using an integrated Q-mode HCs and ANNs machine learning approach in SE Nigeria. Environ. Sci. Pollut. Res. 2021, 28, 40938–40956. [Google Scholar] [CrossRef] [PubMed]
- Egbueri, J.; Agbasi, J. Combining data-intelligent algorithms for the assessment and predictive modeling of groundwater resources quality in parts of southeastern Nigeria. Environ. Sci. Pollut. Res. 2022, 29, 57147–57171. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Sui, W.; Chen, D.; Liang, Y.; Li, R.; Li, X.; Chen, G. A new technique of grouting to prevent water–sand mixture inrush inside the mine panel—A case study. Water 2024, 16, 2071. [Google Scholar] [CrossRef]
- Yu, X.; Liu, Y.; Fan, H. Influence of coal seam floor damage on floor damage depth. Environ. Earth Sci. 2022, 81, 182. [Google Scholar] [CrossRef]
- Lu, Y.; Bai, L.; Chen, J.; Tong, W.; Jiang, Z. Development and application of a floor failure depth prediction system based on the WEKA platform. Geomech. Eng. 2020, 23, 51–59. [Google Scholar] [CrossRef]
- Hu, B.; Zhang, H.; Shen, B. Guide to Coal Pillar Setting and Coal Pressing Mining for Buildings, Water Bodies, Railways, and Main Roadways; China Coal Industry Publishing House: Beijing, China, 2017. [Google Scholar]
- Zhang, F.; Shen, B. Failure characteristics analysis of deep coal seam floor. J. Min. Saf. Eng. 2019, 36, 44–50. [Google Scholar]
- Liu, W.; Song, W.; Mu, D.; Zhao, J. Section observation system on floor mining damage zone and its application. J. Cent. South Univ. (Sci. Technol.) 2017, 48, 2808–2816. [Google Scholar]
- Shi, L.; Xu, D.; Qiu, M.; Jing, X.; Sun, H. Improved on the formula about the depth of damaged floor in working area. J. China Coal Soc. 2013, 38, 299–303. [Google Scholar]
- Zhang, W.; Zhao, K.; Zhang, G.; Dong, Y. Prediction of floor failure depth based on grey correlation analysis theory. J. China Coal Soc. 2015, 40, 53–59. [Google Scholar]
- Li, X.; Meng, X.; Ji, X.; Zhou, J.; Pan, C.; Gao, N. Zoning technology for the management of ecological and clean small-watersheds via k-means clustering and entropy-weighted TOPSIS: A case study in Beijing. J. Clean. Prod. 2024, 397, 136449. [Google Scholar] [CrossRef]
- Wu, L.; Li, B. MATLAB Data Analysis Methods; China Machine Press: Beijing, China, 2017. [Google Scholar]
- Yang, Y.; Tan, W.; Li, T.; Ruan, D. Consensus clustering based on constrained self-organizing map and improved Cop-Kmeans ensemble in intelligent decision support systems. Knowl. Based Syst. 2012, 32, 101–115. [Google Scholar] [CrossRef]
- Jiang, Q.; Liu, W.; Wu, S. Analysis on factors affecting moisture stability of steel slag asphalt concrete using grey correlation method. J. Clean. Prod. 2024, 397, 136490. [Google Scholar] [CrossRef]
- Sun, G.; Guan, X.; Yi, X.; Zhou, Z. Grey relational analysis between hesitant fuzzy sets with applications to pattern recognition. Expert Syst. Appl. 2018, 92, 521–532. [Google Scholar] [CrossRef]
- Xie, H.; Gao, F.; Ju, Y. Research and development of rock mechanics in deep ground engineering. Chin. J. Rock Mech. Eng. 2015, 34, 2161–2178. [Google Scholar]
- Liu, S.; Liu, W.; Shen, J. Stress evolution law and failure characteristics of mining floor rock mass above confined water. KSCE J. Civ. Eng. 2017, 21, 2665–2672. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big Data. 2020, 7, 94. [Google Scholar] [CrossRef]
- Ahmed, N.; Aldaw, M.; Ahmed, R.; Teodoriu, C. Modeling of necking area reduction of carbon steel in hydrogen environment using machine learning approach. Eng. Fail. Anal. 2024, 156, 107864. [Google Scholar] [CrossRef]
- Safaei, N.; Safaei, B.; Seyedekrami, S.; Talafidaryani, M.; Masoud, A.; Wang, S.; Moqri, L. E-CatBoost: An efficient machine learning framework for predicting ICU mortality using the eICU Collaborative Research Database. PLoS ONE 2022, 17, 0262895. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z. Machine Learning; Tsinghua University Press: Beijing, China, 2016. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Min. | Max. | Unit |
|---|---|---|---|
| Mining depth (D1) | 110.00 | 1056.00 | m |
| Inclined length of working face (D2) | 30.00 | 383.00 | m |
| Coal seam dip angle (D3) | 2.00 | 30.00 | ° |
| Mining thickness (D4) | 0.90 | 10.00 | m |
| Floor failure depth | 3.45 | 38.00 | m |
| Performance Indicators | CatBoost Model | Empirical Formula | ||
|---|---|---|---|---|
| Shallow Mining | Deep Mining | Shallow Mining | Deep Mining | |
| R2 | 0.90 | 0.92 | 0.52 | 0.43 |
| MSE | 1.30 | 6.00 | 6.23 | 43.68 |
| MAE | 0.95 | 1.91 | 2.06 | 5.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Han, M.; Zhao, J. Prediction of Floor Failure Depth Based on Dividing Deep and Shallow Mining for Risk Assessment of Mine Water Inrush. Water 2024, 16, 2786. https://doi.org/10.3390/w16192786
Liu W, Han M, Zhao J. Prediction of Floor Failure Depth Based on Dividing Deep and Shallow Mining for Risk Assessment of Mine Water Inrush. Water. 2024; 16(19):2786. https://doi.org/10.3390/w16192786
Chicago/Turabian StyleLiu, Weitao, Mengke Han, and Jiyuan Zhao. 2024. "Prediction of Floor Failure Depth Based on Dividing Deep and Shallow Mining for Risk Assessment of Mine Water Inrush" Water 16, no. 19: 2786. https://doi.org/10.3390/w16192786
APA StyleLiu, W., Han, M., & Zhao, J. (2024). Prediction of Floor Failure Depth Based on Dividing Deep and Shallow Mining for Risk Assessment of Mine Water Inrush. Water, 16(19), 2786. https://doi.org/10.3390/w16192786