1. Introduction
Access to groundwater is essential for sustaining life in West Texas. Without it, the region would become uninhabitable. The drinking water supply for Andrews, Martin, Ector, Midland, Crane, and Upton Counties comes from four aquifers: Edwards, Ogallala, Pecos, and Dockum Aquifers. With the population in the area continuing to grow due to economic stability, there will be an increased reliance on limited water resources [
1]. The Texas Water Development Board (TWDB) has conducted a comprehensive assessment of groundwater quality across the state. It is important to recognize that while the majority of groundwater sources adhere to state and federal safety standards, there are certain individuals residing in rural areas that rely on untreated private wells. Moreover, it should be noted that specific regions within the state possess elevated levels of Total Dissolved Solids, arsenic, radionuclides, and human-caused pollution, thereby rendering their water unable to meet state and federal regulations [
2,
3].
Total dissolved solids (TDS) is a parameter used to determine if water conforms to state and federal regulations, which is the focus of this study. Total Dissolved Solids (TDS) is a measure of the concentration of dissolved minerals in the water. It is typically reported in milligrams per liter (mg/L), and it serves as an indicator of the water’s salinity level. This measurement is particularly important in determining the quality of drinking water, as high TDS levels can indicate the presence of harmful contaminants. By monitoring TDS levels, we can ensure that our water supply is safe and free from harmful substances. TDS monitoring is carried out by the TWDB, which collects samples annually from 600 to 700 sites. These samples are then analyzed for major ions, trace elements (primarily metals), and nutrients. The results of the analysis are collected and stored in the TWDB Groundwater Database (GWDB), which is available to the public free of charge [
3,
4]. Please note that our study primarily focuses on the quality of aquifers. We are using the TDS reading from the GWDB and applying the standards set by the World Health Organization (WHO). The WHO index is used to categorize and determine the preferable TDS levels. As stated earlier, it is worth noting that the WHO categorization index for the study area is significantly affected by various environmental changes.
To be more specific, the region has undergone a recent economic boom thanks to the thriving oil and gas industry, which has unfortunately led to a water-stressed ecosystem. Furthermore, it is essential to highlight that the area has an arid climate and minimal natural recharge to the aquifers, exacerbating the existing water scarcity issue [
4]. A more detailed explanation of the significance of TDS in groundwater quality is essential because TDS serves as a key indicator of water purity, impacting its safety for human consumption as well as its suitability for agricultural and industrial use [
3,
4]. Understanding TDS levels helps identify potential health risks, trace pollution sources, and guide effective water treatment strategies, ultimately contributing to improved public health and water resource management. Additionally, understanding the impact of TDS on public health is crucial, as it highlights potential health risks associated with high TDS levels, such as gastrointestinal issues and the presence of harmful contaminants [
4]. This knowledge aids in assessing water safety, guiding regulatory standards, and ensuring the better protection of public health.
Previous research has assessed the groundwater quality within the study area. One such study identified the significant impact of human activities, particularly those related to agriculture and waste disposal, on groundwater quality [
5]. The study highlights that a variety of chemical species and salinity levels have been on the rise, with numerous measurements surpassing environmental thresholds. These findings emphasize the need for a comprehensive approach that considers aquifer depletion and groundwater contamination when developing sustainable crop production strategies and managing resources within the area [
5,
6,
7]. Chaudhuri and Ale [
6] aimed to better understand the interrelationships between various water quality parameters, evaluate the contributing factors to groundwater salinization, identify potential regional disparities, and outline the most significant influences on water quality at the regional level. The research concluded that the salinization of the Ogallala aquifer was caused by both natural and human-induced processes, including agricultural and domestic waste disposal and hydrocarbon exploration. Additionally, the study commented on the challenges related to data availability and consistency; this was also a challenge in the previous study.
There has been a considerable reduction in the number of available water quality observations over time, which has led to difficulties in establishing robust trends in salinization and changes in solute levels throughout time [
5,
7]. Another study by New Mexico Tech examined the intricate relationship between shale oil production, groundwater quality, and environmental risks. This study highlighted the potential dangers arising from the interaction between naturally occurring TDS constituents and those introduced during shale oil production. The findings underscored the possibility of the formation of new harmful compounds as a result of these interactions, which raises significant concerns about groundwater contamination. However, it is important to note that the study recognizes certain limitations arising from data availability and emphasizes the urgent need for more comprehensive and regular collections of groundwater quality data to ensure accurate assessments of the risks involved [
7].
It has been found that obtaining reliable information on the quality of groundwater can be challenging. In order to effectively evaluate the potential hazards of water quality, it is crucial to gather consistent and accurate data. To tackle this problem, we propose the use of machine learning algorithms to forecast outcomes. Shamsuddin et al. [
8] conducted research on water quality in the Langat River Basin. They used machine learning algorithms, such as Decision Trees, to predict the Water Quality Index (WQI). Three models were compared in the experiments, namely Neural Networks, Decision Trees, and Support Vector Machines (SVM). Although the Neural Networks model was more accurate in classifying water quality than the Decision Tree model, the SVM model was the best multiclass classifier for WQI classification, outperforming both Decision Trees and Neural Networks. However, in our study, the Decision Tree was also the most effective classifier, which could be attributed to our data using different parameters. The study recognized that the data were unbalanced and recommended larger datasets to improve the analysis [
8,
9,
10]. Xu et al. [
9] developed a framework that uses machine learning to predict total nitrogen concentrations in inland rivers and nearshore seawater temperature and salinity. They achieved this by analyzing available water variables and remote sensing data. The study found that the Random Forest model was the most effective in predicting total nitrogen concentrations in rivers, with an accuracy rate of 95.1%.
Machine learning is more cost-effective than traditional monitoring methods and can improve real-time water quality assessment for river management. The study also successfully applied the Random Forest model to predict seawater temperature and salinity with high accuracy using remote sensing data from the Google Earth Engine platform [
9]. Recently, a study conducted by Juna and their team [
10] looked into the issue of predicting water quality in the face of rapid population growth and its negative impact. The study found that current prediction methods often struggle with missing data, leading to a decrease in accuracy. To address this, the study proposed a nine-layer multilayer perceptron combined with a K-Nearest Neighbor (KNN) imputer to handle missing values. The results showed that the nine-layer MLP model achieved an impressive 99% accuracy for water quality prediction when using the KNN imputer. This outperformed other machine learning models, highlighting the importance of addressing missing data for more accurate water quality prediction. This has potential implications for water resource management and public health [
4,
10]. These Decision Tree, Random Forest, and K-Nearest Neighbors algorithms are widely used for organizing environmental data and managing water quality indices [
8,
9,
10].
By utilizing well-established models, we can gain a better comprehension of the underlying patterns and connections present in the existing data. This approach has the potential to unearth solutions for complicated problems or uncover previously undiscovered issues. We used machine learning algorithms to predict TDS categorization index by WHO. This index serves as a crucial starting point for our analysis, as it allows us to uncover patterns and correlations within our data. The purpose of our study is to achieve a comprehensive understanding of the data, eliminate any factors that hinder our efforts, predict water quality, and map it across the six counties. Therefore, we can effectively address the issue of incomplete or inadequate groundwater data and pave the way for more accurate and reliable forecasting in the future. It is important to mention that we only included complete data analysis for this study, and incomplete data analysis was excluded. This decision was made to identify patterns in the dataset and eliminate any unnecessary factors in future research.
2. Study Area
The study area is situated in West Texas’s Permian Basin, a renowned oil and gas-producing region globally. The basin covers a vast land area of 120,000 square miles (300,000 square kilometers), encompassing West Texas and southeast New Mexico. It stretches from the Matador Arch in the north to the Marathon fold belt of the Ouachita Trend in the south, and the Diablo Platform in the westbound basin [
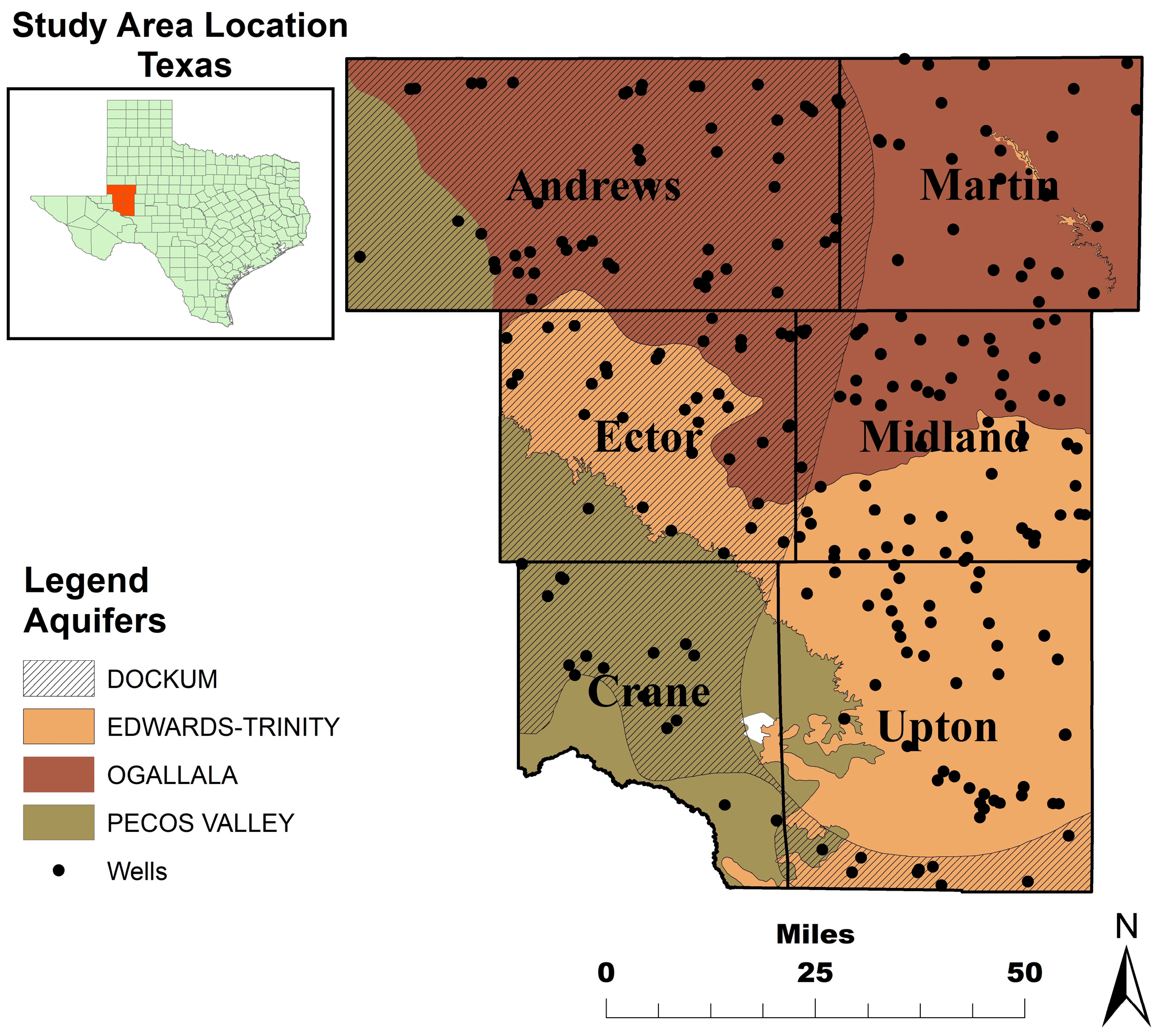
11]. Our focus lies on the central part of the basin, comprising counties such as Ector, Midland, Crane, Upton, Andrews, and Martin (
Figure 1). This specific location is distinguished by the existence of alluvial materials, including sand, silt, clay, and gravel, that were deposited by rivers during prehistoric times. The aquifer in this area was formed during the late Miocene to early Pliocene period as a result of the deposition of eastward-flowing streams that originated from the Rocky Mountains [
1]. This geological process created a unique environment for the formation of the aquifer, with distinct layers of sedimentary rocks and sandstone that have significant implications for water availability and quality. Overall, this region is an essential area for water resource management and is a critical component of the basin’s hydrological system [
1,
11]. Our study is centered on assessing the quality of aquifers in six counties through an analysis of laboratory reports, specifically focusing on the four aquifers: Ogallala, Pecos Valley, Dockum, and Edwards Trinity Plateau. We are primarily examining the TDS levels in these aquifers.
The Ogallala Formation is a notable geological formation, which is primarily composed of sediment derived from the Rocky Mountains. The formation comprises sand and gravel that were deposited in a braided stream pattern. As the sediment moved away from the mountains, it gradually became finer in texture. The vast majority of the Ogallala Formation is covered by the Blackwater Draw Formation, except for breaks and draws [
12]. The Ogallala Aquifer, a prominent feature of the region, spans an area of 36,300 square miles from the panhandle to Midland. It is part of the High Plains Aquifer System and consists of unconsolidated sediments that range from clay to gravel. The thickness of the Ogallala Aquifer varies from approximately 800 ft to regionally specific measurements. In the southern areas, it ranges from 150 ft to 300 ft. Notably, there exists hydraulic contact between the Ogallala and the Pecos Valley aquifer to the southwest, as well as the Edwards Trinity, Dockum, and Ria Banca Aquifers [
13]. The Pecos Valley aquifer is an extensive and significant underground water source that is composed of a variety of sediments, including alluvial, lacustrine, and eolian deposits. These sediments were deposited over millions of years during the Tertiary and Quaternary periods and are associated with the Ogallala Formation in the Pecos River Valley. The aquifer is situated in several structural basins, with the two largest being the Pecos Trough and Monument Draw Trough [
12]. Covering an area of 6800 square miles, the Pecos Valley Aquifer is mainly composed of alluvial and aeolian deposits that have accumulated over time. It boasts an average saturated thickness of 250 ft and a maximum thickness of 1500 ft, making it a significant and reliable source of water for the region. The aquifer’s vast size and composition make it an essential resource for agriculture, industry, and the local communities that depend on it for their daily needs. Its reliable and consistent supply of water has made it a vital resource for the region’s economic and social development [
12,
13].
The Dockum Aquifer, a relatively minor aquifer situated in the northwestern region of the state, is primarily composed of sandstones, conglomerates, mudstones, and siltstones. The Dockum Group, which stratigraphically defines this aquifer, is responsible for its formation. The Ogallala Aquifer overlies the Dockum Aquifer, except in the outcrop areas along the Canadian and Colorado Rivers, where the Ogallala has been eroded away. The no-flow lower boundary of the Dockum Aquifer is created by Permian red-bed shales. A portion of the Dockum Aquifer is in hydraulic communication with the Ogallala Aquifer and is considered a part of the High Plains Aquifer System. The Dockum Aquifer covers a vast area of 25,300 square miles, spanning 46 counties from the northwestern Panhandle to the south of Midland County. However, it has been reported that the water quality in this aquifer is poor. Nevertheless, some freshwater can be found in the north, and southeast outcrop areas and this groundwater is Late Triassic age. It consists of different stratigraphic components of the Dockum Group, including the Santa Rosa, Tecovas, Trujillo, and Copper Canyon formations. Understanding the composition and characteristics of the Dockum Aquifer is essential for ensuring the sustainable management of water resources in this region [
11,
13].
Lastly, the Edwards–Trinity Plateau Aquifer is a significant water source that covers the southwestern part of the state. The aquifer consists mainly of limestone and dolomite from the Edwards Group and sand from the Trinity Group. The freshwater layer of the aquifer has an average thickness of 433 feet. In general, the Aquifer’s thickness increases from less than 100 feet in the north to over 800 feet towards the south. The variation in the thickness of the aquifer is due to the terrain’s shape and the underlying Paleozoic depositional surface. The aquifer’s sediments are from the Trinity, Fredericksburg, and Lower Washita groups and belong to the Early Cretaceous period. The Trinity Group lies underneath the aquifer, while the Fredericksburg and Lower Washita Group sediments are above it. The Edwars-Trinity Plateau Aquifer sediments rest unevenly on the top of folded and faulted Paleozoic to Triassic-age sediments. The aquifer is mostly unconfined, but locally, the Trinity unit of the aquifer may be semi-confined where the overlying basal member of the Edwards Group has relatively impermeable sediments. The base of the aquifer slopes towards the south and southeast. Most of the rocks beneath the aquifer are less permeable than the aquifer and act as a barrier to groundwater flow. However, some rocks are permeable and connect hydraulically to the Edwards–Trinity Plateau Aquifer, increasing the thickness of the flow system [
13,
14].
This study is centered around six counties that feature a diverse array of land cover types, including developed areas, barren land, forests, shrublands, herbaceous areas, and cultivated lands. The region has recently experienced a surge in employment opportunities, particularly in industries such as oil and gas extraction, mining support activities, heavy and civil engineering construction, and pipeline transportation. These occupations, in fact, are among the most common in the region [
15]. Over the past decade, the oil production industry has experienced an impressive and steady growth rate, with an average increase of 15.3 percent per year since 2010. As of April 2022, the Permian Basin, which is a vast oil-producing region spanning parts of Texas and New Mexico, has emerged as a dominant player in the U.S. oil market, accounting for a staggering 43.6 percent of the country’s oil output. This represents a significant rise from the 18.1 percent share it held in 2013. The Permian Basin’s success can largely be attributed to the use of advanced drilling technologies, which have allowed for the extraction of oil from previously inaccessible shale formations. In fact, in the fourth quarter of 2021 alone, Texas’s Permian Basin produced over 3.5 million barrels per day, further solidifying its position as a major contributor to the U.S. oil industry [
16,
17]. As a direct result of the surge in oil production within the vicinity, the demographic of the area has expanded significantly. Over the course of ten years, from 2010 to 2020, the region saw a notable increase of 13.2 percent in its population, with the counties of Andrews, Midland, and Ector boasting the most substantial gains at 25.9 percent, 24.2 percent, and 20.4 percent, respectively. These figures clearly indicate a surge in population density that can be attributed to the increase in oil production, which has inevitably led to a corresponding rise in economic activity and social development [
15].
The study area, which is situated in semi-arid regions, is characterized by a landscape dominated by native grasses and mesquite trees. Precipitation levels in the Permian Basin are relatively low, with an average annual rainfall ranging from 10 to 20 inches. The bulk of this rainfall is received during the spring and early summer months, primarily through thunderstorms. Interestingly, the region experiences extreme temperature fluctuations, with January being characterized by low temperatures that can plummet to as low as 28° F, while July experiences high temperatures that can soar to 95° F or even higher [
1,
18]. The area’s primary source of water is groundwater, which is considered a vital resource due to low precipitation levels. Despite population growth in the region, it is not contributing to the groundwater shortage, which is a positive development. In light of the rising temperatures and arid environmental conditions that West Texas is currently facing, it has become imperative to prioritize the preservation of the region’s drinking water quality. With the population on a steady incline, it is crucial to take necessary measures to address the declining state of the water system. Failing to do so could have devastating consequences for the advancing counties in the area. Therefore, it is of the utmost importance to act swiftly and decisively to safeguard the well-being of the local communities.
3. Data and Methods
The dataset was collected from the Texas Water Development Boards’ (TWDB) Groundwater Database (GWDB), a U.S. government website operated by the state of Texas [
14]. This division is responsible for all aspects of groundwater studies in the state. The TWDB-GWDB objective is to monitor groundwater levels and quality. By using the historical lab analysis and integrating it with a machine learning algorithm, we can predict the quality of taste based on TDS and correlate it with the other presented variables to obtain a better prediction and then evaluate the spatial distribution of the groundwater qualities based on TDS. In order to properly analyze the data collected from the TWDB-GWDB website, it was crucial first to clean the dataset. Initially, there were 1342 wells in the dataset, but unfortunately, there were also 10,118 null values present. These null values posed a potential problem for machine-learning algorithms, so we removed them along with duplicates. While this did result in missing data and gaps in the dataset, it was necessary to ensure the accuracy of our analysis. After the preprocessing step, we were left with 557 rows and 22 columns of data, along with 254 wells spread across six counties (see
Supplemental Table S1 at the end of paper for all well information). We created a quality index to determine the quality of water taste based on TDS (Total Dissolved Solids). This index utilized the preferable TDS levels established by the World Health Organization (WHO) to categorize the wells as excellent (300 mg/L), good (600 mg/L), fair (900 mg/L), poor (1200 mg/L), or unsuitable (>1200 mg/L).
TDS is typically measured using a TDS meter, which estimates the concentration of dissolved ions by measuring the water’s electrical conductivity [
13,
14]. For other water quality parameters, techniques such as pH measurement, turbidity assessment, and dissolved oxygen (DO) level measurement are commonly employed. For example, pH levels were determined using a digital pH meter with a resolution of ±0.01, ensuring high accuracy in both acidic and basic conditions. Turbidity was evaluated with a nephelometer, configured to measure in Nephelometric Turbidity Units (NTU), while DO was measured using an electrochemical DO meter, calibrated to 100% saturation and set to record in mg/L. These settings and equipment were chosen for their accuracy, reliability, and relevance to the specific water quality parameters under investigation [
14].
When trying to understand the relationship between two or more variables, the correlation analysis method is a useful statistical technique. This method uses Pearson’s correlation coefficient, which measures the degree of correlation between two variables at a fixed distance (Equations (1) and (2)). The correlation coefficient is represented by the symbol ‘r’ and ranges from −1 to +1. A positive ‘r’ value indicates a positive correlation, while a negative value indicates a negative correlation. The absolute value of ‘r’ indicates the strength of the correlation, but it does not establish a causal relationship [
19].
COV (
X,
Y) measures the co-variation between two variables. By using the t-statistic, we can test if two variables are correlated. The general correlation coefficient is 0, and if we find a correlation, we can establish its extent and direction [
20,
21].
where
3.1. Evaluation Metrics
To evaluate how well the models are performing, we rely on a range of metrics, including accuracy, precision, recall, F1-scores, and cross-validation. By analyzing these metrics, we can effectively compare and determine which machine-learning algorithms are superior to others. This method enables us to make informed decisions and continuously improve the quality of our models. Keep in mind that we are using classification and not regression in machine learning; classification can predict a continuous value if it is in the form of a class label probability. Calculating accuracy for machine learning models is made easy with the scikit-learn library’s accuracy score function. Furthermore, the classification report function provides a convenient way to obtain precision, recall, and F1-scores simultaneously. This can save valuable time and effort in evaluating the performance of different models. When faced with multi-class classification challenges, a commonly employed metric is the accuracy score. This approach involves calculating the accuracy of each class individually before finally deriving the average accuracy across all the classes. By utilizing this method, it becomes easier to gauge the effectiveness of the classification model in correctly identifying and categorizing different classes [
22].
The report that pertains to classification is based on data derived from the confusion matrix, which is a fundamental tool in determining the accuracy of a prediction. The classification report is composed of four essential categories: true negative (TN), true positive (TP), false negative (FN), and false positive (FP). TN occurs when an instance is predicted to be negative and is actually negative, while TP is when an instance is predicted to be positive and is indeed positive. FN is when an instance is predicted to be negative, but it is actually positive. FP, on the other hand, happens when an instance is predicted to be positive, but is, in reality, negative [
23]. To accurately calculate precision, which is the accuracy of positive predictions, true positives must be divided by the sum of true positives and false positives (refer to Equation (3)). Similarly, recall is determined by dividing true positive by the sum of true positive and false negative (refer to Equation (4)). In situations where precision and recall scores are not equal, the F1 score is a valuable tool as it is the harmonic mean of both recall and precision. This score is particularly useful in such situations (refer to Equation (5)).
For an optimal outcome, precision, recall, and F1 score values should be as close to 1.0 as possible. Lastly, accuracy is measured by identifying positive and negative values in the predicted data accurately (refer to Equation (6)). It is essential to note that precision and recall are both significant indicators of a model’s performance. Precisely put, precision measures the correctness of positive predictions, while recall measures the completeness of actual positives predicted. Therefore, it is crucial to strive for a balance between precision and recall for an optimal outcome [
24,
25].
To ensure precise and reliable predictions for future data analysis, we have employed a robust technique known as cross-validation classification (Equations (7) and (8)).
where
When analyzing qualitative data, the cross-validation technique can be an incredibly useful tool for classification processes. In order to evaluate the effectiveness of a model, the number of incorrectly classified observations is taken into consideration. To accomplish this, the data are divided into two separate groups: the training set and the testing set. This technique is particularly advantageous for classification models, as it allows for a subset of the dataset to be evaluated while the rest is used for training. By doing so, the model is able to learn from the majority of the data while still reserving a portion for testing purposes. In addition, the K-Fold technique can be utilized within the cross-validation method to explore all possible ways to split the data. This not only helps to prevent overfitting but also identifies the most suitable model for future testing. Overall, the cross-validation technique is a powerful tool that can greatly enhance the accuracy and efficiency of classification models [
26,
27].
3.2. Machine Learning Algorithms
In order to ensure that the Machine Learning algorithm functions with optimal accuracy, it is imperative to partition the data into distinct sets. This allows the model to be applied and tested on a specific portion of the dataset, which in turn, helps evaluate the performance of the trained model and provides a metric for measuring its overall accuracy. The partitioning of the data is typically into three sets: training, testing, and validation sets. The training set comprises 80% of the dataset and is used to train the model. The remaining 20% is allocated for testing and validation. This partitioning of data ensures that the model is tested on a different set of data than what was used for training purposes. Once the data is correctly partitioned, it can be fitted into the machine learning algorithm, and accurate predictions can be made [
26,
28].
A Decision Tree is a machine learning algorithm that can handle both categorical and numerical data for classification or regression tasks. This algorithm adopts a tree-like structure where each internal node represents a test condition, each branch represents the test result, and each leaf node represents a class label or a predicted value. Following the path from the root node to the appropriate leaf node based on the feature values allows you to create a node that makes decisions. One of the greatest strengths of the Decision Tree algorithm is its versatility in handling different data types. Unlike other classification or regression techniques, Decision Trees can accommodate both categorical and numerical data [
26]. When predicting the quality of a particular class, the forecast is determined by a mathematical tool known as the Gini index. This index is derived from Equation (9) and is used to calculate the overall variance within the class. Additionally, the Gini index measures the purity of a node, indicating the inequality in the sample. Essentially, this tool assigns a value ranging from zero to one, with zero representing a completely homogeneous sample where all elements are similar, and one representing maximum inequality among elements [
26,
29].
Random Forest is a highly effective algorithm that has garnered widespread acclaim for its ability to produce accurate predictions while simultaneously reducing the risk of overfitting. At its core, this algorithm is based on a clever combination of Decision Trees, with each tree being trained on a different portion of the dataset. To make a prediction, the algorithm uses the same equation Gini index as the Decision Tree (Equation (9)). This involves constructing a Decision Tree for each sample and generating a prediction for each tree [
26]. These predicted results are then put to a vote, with the most popular prediction becoming the final result. The key advantage is that it randomly selects a subset of features for each tree during training, making the model more resilient and less prone to errors and inaccuracies. Since each tree is trained on a different subset of features, the model is better able to capture non-linear relationships between variables. This is particularly useful when working with complex datasets containing various data points. This algorithm has the ability to estimate feature importance with a high degree of accuracy. This can be especially useful when working with large datasets, as it allows us to focus on the most important data points and disregard less relevant information [
26,
30].
The K-Nearest Neighbors classifier is a powerful tool that operates under the fundamental principle that objects or instances that share similar features are more likely to belong to the same class. In essence, this algorithm determines the class label of new data points by identifying the K nearest neighbors from the training dataset and assigning a label based on the majority vote of those neighbors. To find these K-Nearest samples, the technique calculates the Euclidean distance between the new sample and every sample in the training set known as “Minkowski”. This distance is calculated by finding the square root of the total squared differences between the values of the two samples, which measures their difference (Equations (10)).
Once the distances have been calculated, the method selects the K samples that are closest to the new sample. It is important to note that the value of K is a hyperparameter that has a significant impact on the model’s functionality, so it must be carefully chosen. Overall, the K-Nearest Neighbors classifier is an efficient and effective algorithm that can help identify and classify data points with remarkable accuracy [
31,
32].
4. Results and Discussion
We have classified the data into categories based on the WHO’s acceptable TDS limits, which are determined by the quality of taste. Once the dataset was categorized, we utilized machine learning algorithms to identify the classes and determine the split percentage of 80% for training and 20% for testing. In our study, the machine learning algorithms employed were Decision Tree, Random Forest, and K-Nearest Neighbors. We selected these top three machine learning algorithms, which are widely used to classify environmental data, evaluate water quality, and manage water resources [
8,
9,
26,
27]. These algorithms demonstrated the highest accuracy and were deemed the most promising for predicting taste quality. It is worth mentioning that the algorithms were not optimized. Therefore, fine-tuning the hyperparameters of the algorithms could lead to either higher or lower performance. Decision Trees use a hierarchical structure to split data based on features, with hyperparameters like maximum depth controlling overfitting. Random forests enhance prediction accuracy by combining multiple Decision Trees, with the number of trees being a key hyperparameter. K-Nearest Neighbors classifies data based on proximity, where the number of neighbors (k) affects the bias–variance tradeoff. Selecting the right hyperparameters is crucial for optimizing model performance and aligning the algorithms with research goals [
32].
4.1. Climate Change
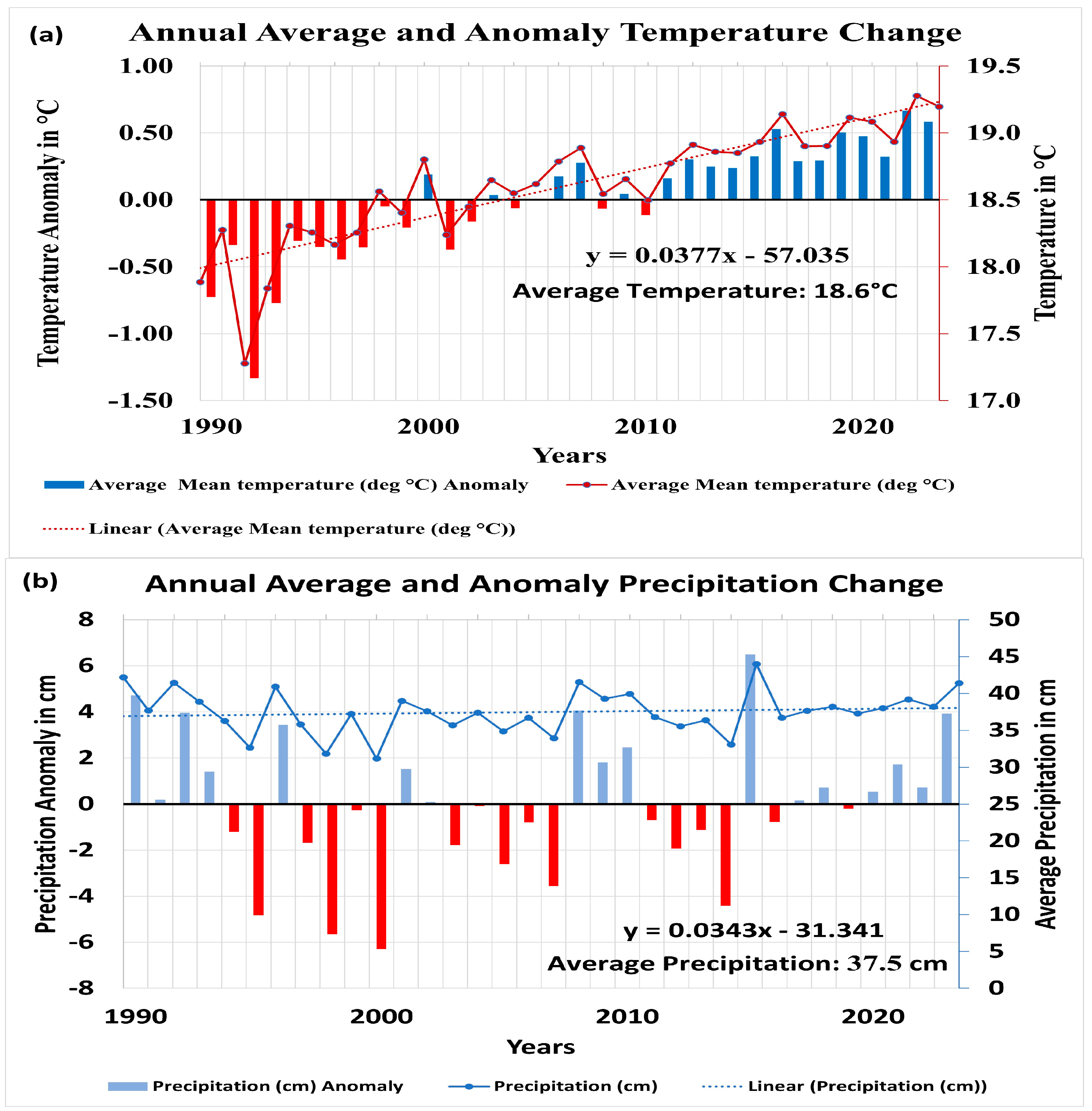
This report presents a thorough analysis of temperature and precipitation patterns in six counties between 1990 and 2023. Its goal is to provide a detailed overview of climate changes in the past. The graphs featured in this study show the average temperatures and precipitation levels for the representative concentration pathways (RCP) 4.5 in West Texas. These pathways are based on varying levels of greenhouse gas emissions, with RCP 4.5 predicting lower emissions. It is important to note that the precipitation and temperature data were provided by the U.S. Geological Survey [
33,
34]. Moreover,
Figure 2a shows a linear regression of the annual average temperature, revealing a slope of 0.0377. This means that the average temperature rose from 17.9 °C to 19.2 °C during the 1990 to 2023 period. These findings are significant as they offer valuable insight into the effects of climate change on weather patterns in this region.
The graph in
Figure 2a also illustrates the anomaly detected in the yearly average temperature, which serves as the standard temperature for the specific region. This standard temperature is calculated by averaging the temperature data for 30 or more years. A negative anomaly in this context indicates cooler weather conditions that fall below the historical temperature standard, while a positive anomaly suggests warmer weather conditions that exceed the historical temperature standard [
35]. Between 2011 and 2023, the study area did not experience any negative anomalies, which means that the region is currently experiencing warmer weather conditions [
34].
The provided information presents an overview of the annual mean precipitation in cases with minimal emissions. As demonstrated in
Figure 2b, these conditions exhibit a gradual increase with a slope of 0.0343, while the average rainfall remains at around 37.5 cm. In
Figure 2b, we can observe the average annual precipitation anomaly, which is akin to the average annual temperature anomaly represented in
Figure 2a. On the graph, the negative values indicate a decrease in rainfall, whereas positive values signify an increase in precipitation. According to the data, if the emissions continue to remain high, there is a possibility of a reduction in rainfall in the six counties [
34]. However, if we take steps to keep the emissions low, there is a likelihood of receiving slightly more rainfall in the area.
Upon careful analysis of the visual data, it has been determined that the area under consideration is prone to witness a noteworthy surge in temperature and a noticeable decline in precipitation, provided the emissions persistently remain high. The increase in temperature from 17.9 °C to 19.2 °C between 1990 and 2023, with a slope of 0.0377, indicates a warming trend that could intensify evaporation rates. This increase may lead to higher concentrations of TDS in groundwater, as less water infiltrates to dilute these solids [
33,
34]. Precipitation shows a slight increase with a slope of 0.0343 in the study area; however, the presence of negative values suggests periods of reduced precipitation. If these reductions persist due to ongoing high emissions, decreased rainfall could reduce the recharge of groundwater systems, exacerbating the concentration of TDS [
35]. This combination of higher temperatures and potentially lower rainfall could lead to deteriorating groundwater quality, posing challenges for water management and requiring targeted strategies to mitigate these impacts.
This conclusion implies that our region is gradually transforming into a drier terrain [
4,
34]. Nevertheless, it is worth noting that the available models are not adequate enough to offer a comprehensive understanding of the interrelationship between temperature, precipitation, groundwater recharge, and TDS quality. Recent studies have revealed that with the progression of climate change and recurring droughts, the soil has the potential to become water-repellent, resulting in the formation of Soil Water Repellency (SWR). This phenomenon can considerably decrease or slow down the absorption of water into the soil. Consequently, SWR can lead to ecological imbalances, such as amplified surface runoff and a higher risk of erosion. Additionally, it can lead to the contamination of groundwater through preferential flow [
36,
37]. Further investigations are necessary to determine if SWR has any impact on the area of study.
4.2. Land-Cover Changes
The region under examination has undergone considerable alterations in land utilization, mainly due to the oil and gas industry and overall development. To better understand these changes, maps
Figure 3a,b have been referenced, which display the National Land Cover Database (NLCD) for the years 1991 and 2019, respectively. These maps have been sourced from the Texas Natural Resources Information System [
14]. While these modifications have brought with them economic benefits and noticeable population growth, they have also had an impact on the local hydrology system, leading to significant changes in its elements [
1,
38]. A summary of these alterations can be found in
Table 1.
Table 1 presents comprehensive information on land area coverage for 1991 and 2019 in square kilometers (km
2). To help with understanding, the same data are also shown as percentages. The table shows the change in the region over time in percentages. Notably, there has been an increase in Water, Developed, Shrubland, and Planted/Cultivated (Crops), as seen in the Changes column. However, Barren and Herbaceous (Grass) have decreased, and Forest has remained neutral. It is important to note that negative numbers indicate a decrease in distinguishing features. The region has undergone a 4.69% growth in developed land, primarily due to the oil and gas industry, which includes well sites and production pads scattered throughout West Texas. This increase in developed land can have significant environmental consequences, including increased runoff due to the impervious area, resulting in a decrease in evaporation, transpiration, and infiltration [
1,
38].
The utilization of land for crops and livestock grazing has been shown to have a significant impact on rainfall recharge, particularly in Hebaceous and Planted/Cultivated areas. The displacement of native vegetation with shallow-rooted crops can lead to a reduction in rainfall recharge, as the deeper roots of native vegetation play a critical role in this process. Moreover, grazing practices have the potential to alter soil structure, reduce vegetation cover density, and potentially affect infiltration. This observation was made by Han, Currell, Cao, and Hall in 2017, highlighting the importance of sustainable land management practices in maintaining healthy ecosystems [
39,
40,
41]. All of these alterations can significantly impact the local groundwater systems.
The changes in land cover between 1991 and 2019 have significant implications for Total Dissolved Solids (TDS) levels in groundwater systems, as shown in
Table 1. The most notable changes include a substantial increase in developed land, which expanded by 759.47 km
2 (from 1.32% to 6.01% of the total area). This increase in developed land is likely to contribute to higher TDS levels due to increased runoff from impervious surfaces, which reduces infiltration and carries more pollutants into groundwater systems [
40,
41]. The overall reduction in herbaceous land by 5037.90 km
2 (from 34.96% to 3.84%) might decrease the soil’s natural filtration capacity, potentially increasing TDS levels. These land cover changes underscore the complexity of their impact on TDS levels, requiring careful consideration in environmental management strategies [
41].
4.3. Water Quality
The dataset in question has not undergone normalization, a statistical technique that adjusts and rescales data points. However, normalization can lead to a loss of data context, resulting in data being split into multiple tables that require extra joins to retrieve. This can make it difficult to understand the relationships between different data points. Additionally, since this dataset pertains to water laboratory analysis, modifying one variable or element could alter the balance of elements, rendering the TDS readings invalid. For example, one well in the dataset had a low pH of 6.07, indicating it was a weak acid and able to dissolve more solids. If this data point were normalized, it would change to a pH of 7, which is neutral, and the TDS should read lower than the initial reading. However, the data have not been normalized, and no changes have been made.
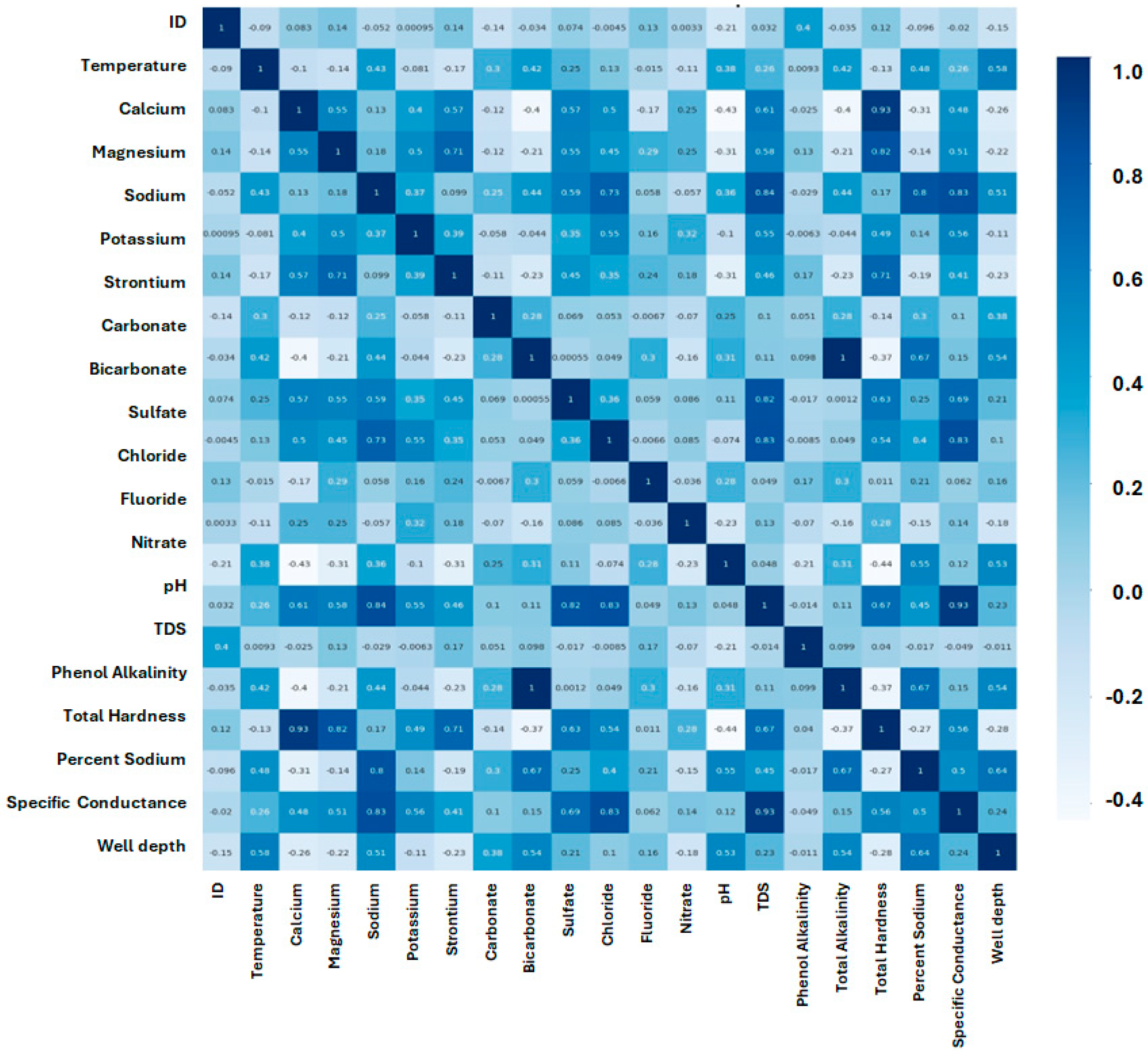
The objective of cross-validation classification is to evaluate the model’s performance and generalizability by systematically partitioning the data into training and validation sets. This process helps in identifying the most reliable model by minimizing overfitting and ensuring that the model performs well on unseen data. The importance of a correlation map is to understand the relationships between variables; highly correlated features can lead to multicollinearity, which distorts model predictions. Addressing correlation is crucial to improving the accuracy and interpretability of the classification model. Our research involved the application of a correlation heat map to visually represent numerical data, which can be found in
Figure 4. This tool is highly valuable when it comes to interpreting and analyzing large volumes of information, as it employs a color scheme to indicate the value of each data point. To represent correlation values, we utilized a blue color scheme, with darker blues denoting high-value correlation points and lighter blues representing low-value points. The use of this color scheme enabled us to effectively convey patterns and trends in the data sets, making it significantly more convenient to analyze and interpret the information in a timely manner.
In adherence to the Data and Methods section, Pearson’s correlation coefficient was utilized to assess the intensity and direction of correlation between variables. The coefficient, ranging from −1 to +1, is indicative of either a negative correlation or a positive correlation, respectively. In summary, this coefficient serves as a valuable tool to quantify the level of correlation between two variables, and, thus, aids in drawing accurate conclusions and making informed decisions based on the obtained results. The objective of the TDS correlation result is to evaluate the relationship between TDS levels and various groundwater quality parameters.
Table 2 is important for identifying the primary contributors to TDS in groundwater sources, which can guide effective groundwater quality management and treatment strategies. The highest correlations are with Specific Conductance (0.8811), Sulfate (0.8472), and Chloride (0.813), indicating these factors are strongly associated with TDS levels. Other significant correlations include Sodium (0.8085) and Total Hardness (0.7007). Some parameters like pH (0.0297) and Carbonate (0.0931) exhibit weak correlations with TDS. They have minimal impact on TDS concentrations. By understanding which parameters are most strongly correlated with TDS, interventions can be more precisely targeted to improve groundwater quality.
With the help of
Table 2, which is generated from the heatmap, we can identify variables that are interdependent and even estimate the values of difficult variables by using easily accessible parameters. This approach is highly versatile and has been adopted in various fields, including finance, marketing, and science. It is particularly useful when we aim to comprehend the relationship between variables and predict outcomes based on that relationship. Correlation analysis is a crucial aspect of statistics, and it is gaining significance in a growing number of industries and fields. Out of the total wells, there were 4 that were categorized as excellent, 70 as good, 102 as fair, 87 as poor, and 294 as unsuitable. This categorization system proved to be an effective method for evaluating the water taste quality of the wells in question.
The following information and visuals provide a comprehensive depiction of the water quality in West Texas from 1990 to 2023.
Figure 5 illustrates the average readings of TDS (Total Dissolved Solids) for each sample year and classifies them according to water quality. It is worth noting that over the years, some TDS levels have been higher, indicating a decline in water quality for specific wells. Consequently, the graph may display bars of different sizes due to the method we use to present our data and quality cutoffs, as previously discussed. Furthermore, some data had to be removed due to null values, resulting in gaps in the graph. Additionally, certain wells may have been deactivated during this period, and not all water samples were subjected to laboratory analysis. Incomplete analyses were also excluded from the data set for machine learning purposes, which may lead to a skewed representation of the water quality figures. To gain a better understanding of the situation, we have mapped out the wells with TDS values in
Figure 6a,b.
To gain greater insight into the quality of groundwater, maps can prove to be a valuable resource. Specifically,
Figure 6a,b provide an overview of groundwater quality during two distinct periods: the 1990s and the 2020s. Both maps utilize a color gradient to represent TDS values, with red hues indicating elevated readings. A thorough analysis of these maps can yield important information regarding water quality trends over time. It is clearly evident that groundwater quality has declined. Previous studies from 1992 to 2019 analyzed a subset of the well we examined and indicated that most of the area may have inadequate water quality [
41,
42]. Upon reviewing TDS measurements and maps, it is clear that all the tested wells surpass the recommended threshold of 300 mg/L for excellent-quality water. Our results show significant correlations between TDS and various water quality parameters. Specifically, TDS exhibits a strong positive correlation with Specific Conductance (0.8811), Sulfate (0.8472), Chloride (0.813), and Sodium (0.8085). These high correlation values suggest that these parameters are key contributors to TDS levels in groundwater [
41]. The strong correlations indicate that increases in Specific Conductance, Sulfate, Chloride, and Sodium levels lead to higher TDS levels, which could signify deteriorating groundwater quality [
42]. This could have potential implications for water use, as elevated TDS levels are often associated with poor taste, hardness, and potentially harmful chemical concentrations. This finding is concerning and warrants further exploration to determine the root cause of this decline.
4.4. Machine Learning Applications
TDS is a critical parameter in water quality analysis, reflecting the concentration of dissolved substances that influence environmental health and human consumption safety. In the context of machine learning optimization, accurately predicting TDS levels is essential for assessing water quality. The optimization process, including the selection of appropriate algorithms and the fine-tuning of hyperparameters, ensures that the predictive model is robust and reliable, minimizing errors and improving the accuracy of TDS predictions. This not only enhances the model’s performance but also provides a scientifically sound basis for decision-making in environmental management [
25]. For this purpose, we employed three different machine learning algorithms: Decision Tree, Random Forest, and K-Nearest Neighbors. After analyzing the results, we found that these three algorithms have the highest accuracy in predicting taste quality. However, it should be noted that we did not optimize these algorithms, and fine-tuning them may lead to better or worse performance. The machine learning algorithms employed in this study were Decision Tree, Random Forest, and K-Nearest Neighbors. As a side note, other machine learning algorithms were used in this study. However, we are presenting the top three performers that show the best accuracy. The top three algorithms had the highest accuracy rating and were deemed to be the most promising for predicting quality of taste.
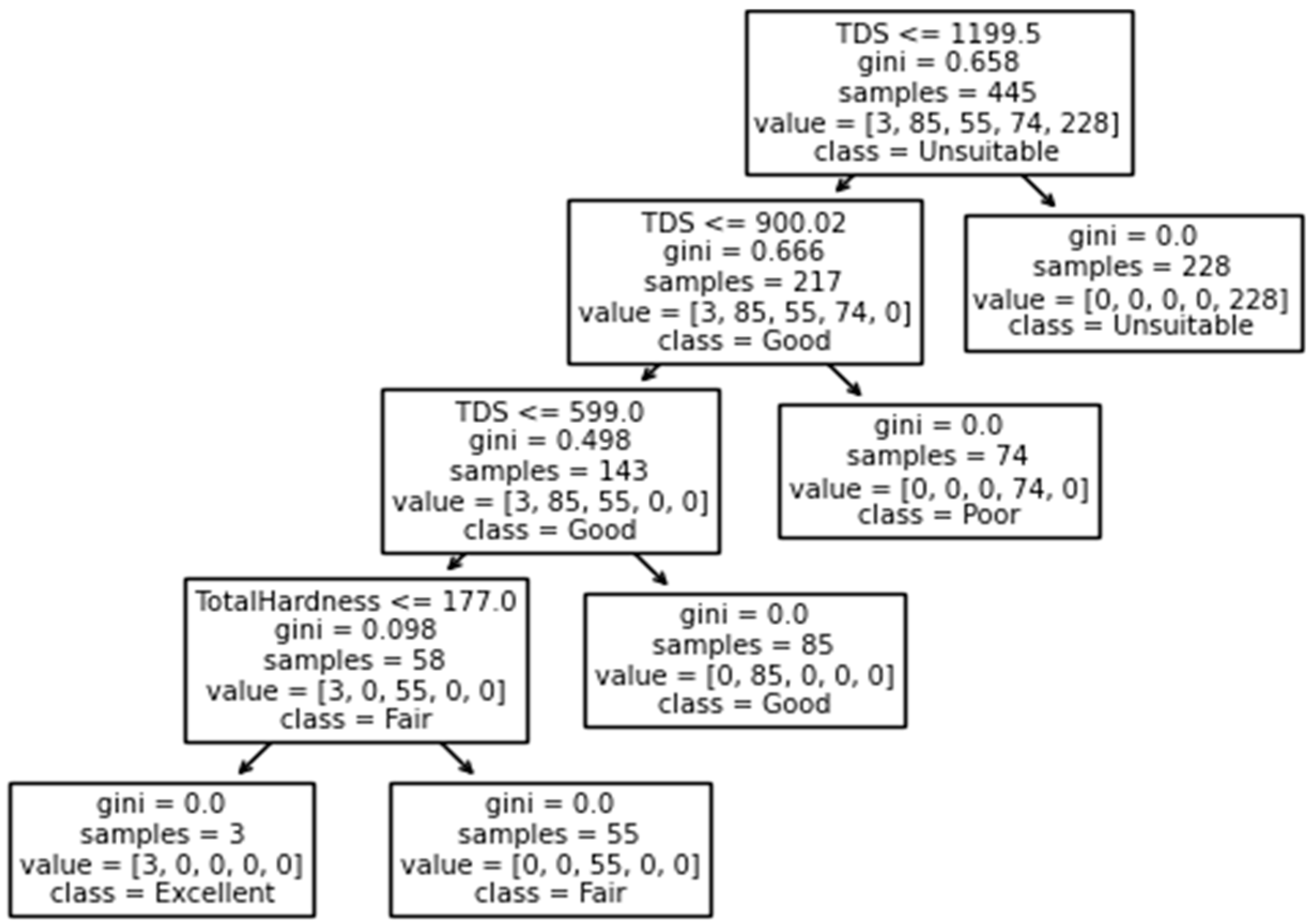
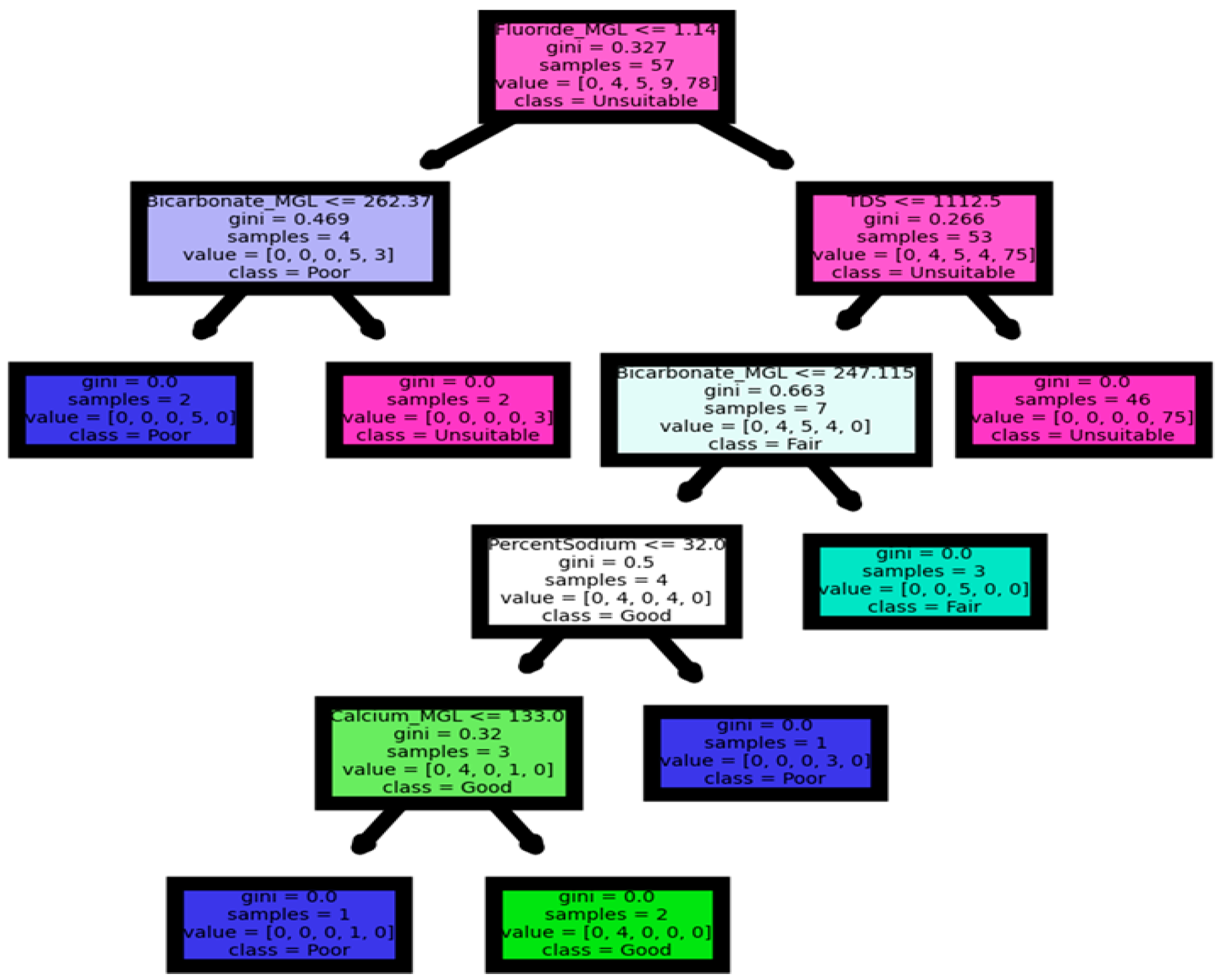
4.4.1. Decision Tree
Figure 7 presents the breakdown of water quality using a Decision Tree. The top of the figure shows the root node, which provides various information. Depending on the answer, the tree follows either the true or false path. The Gini index is then shown, which measures the purity of the node/leaf. A score of zero means that the node is pure, indicating that only one sample class exists within it. In the results presented, the score is greater than zero, indicating that the root node belongs to a different class. The “samples” value provides information about where the data came from, helping to double-check the results. The “value” list shows the number of samples in each category for that node, with the first element having a value of 3, representing the number of samples in the excellent group, followed by 85 for good, 55 for fair, 74 for poor, and 228 for unsuitable. Lastly, the “class” value displays the prediction that a given node will make, which can be determined from the “value” list [
26,
42]. Our analysis has produced a highly impressive accuracy score of 100%. The cross-validation mean score of 99.8% highlights the exceptional precision and consistency of the results.
4.4.2. Random Forest
The next machine learning algorithm is the Random Forest (
Figure 8), which is similar to the Decision Tree algorithm. However, the key difference and advantage of Random Forest is that it randomly selects a subset of features for each tree during training. This approach makes the model more robust and less likely to make errors or inaccuracies. In essence, Random Forest is a group of Decision Trees that are combined to generate a final result [
26,
42]. The diagram of the Random Forest analysis, as presented in
Figure 8, illustrates the outcome of our in-depth examination. The accuracy score we achieved is quite remarkable, reaching 100%. Moreover, the mean score of cross-validation was 99.4%, with a standard deviation of 0.72%. These statistics demonstrate the stability and accuracy of our findings, highlighting the validity of our analysis.
4.4.3. K-Nearest Neighbors (KNN)
The KNN algorithm is a highly effective tool for determining the class of an unseen observation. This technique utilizes a voting mechanism to identify the class of a data point based on the majority-voted classes of the five closest points. To measure the distance between data points, Euclidean distance is used. This method identifies which points are close to each other. After sorting the distances, selecting the top k entries, and labeling the point based on the majority-voted classes, the accuracy score of the model can be determined [
42,
43]. Upon conducting analysis of the KNN, it was discovered that the accuracy score falls slightly below par at 92.9%. However, the cross-validation mean score is 93.7%, which indicates that the model is still highly reliable. The standard deviation obtained was 3.74%, which falls within an acceptable range. Overall, while there is always room for improvement, the KNN algorithm appears to be performing reasonably well. Its power lies in its ability to recognize the class of an observation using a voting mechanism, making it a valuable tool in various applications.
For a concise summary of the top three algorithms’ predictive capabilities, refer to
Table 3. This table offers a comprehensive breakdown of each algorithm’s performance metrics, including precision, recall, F1-scores, and accuracy.
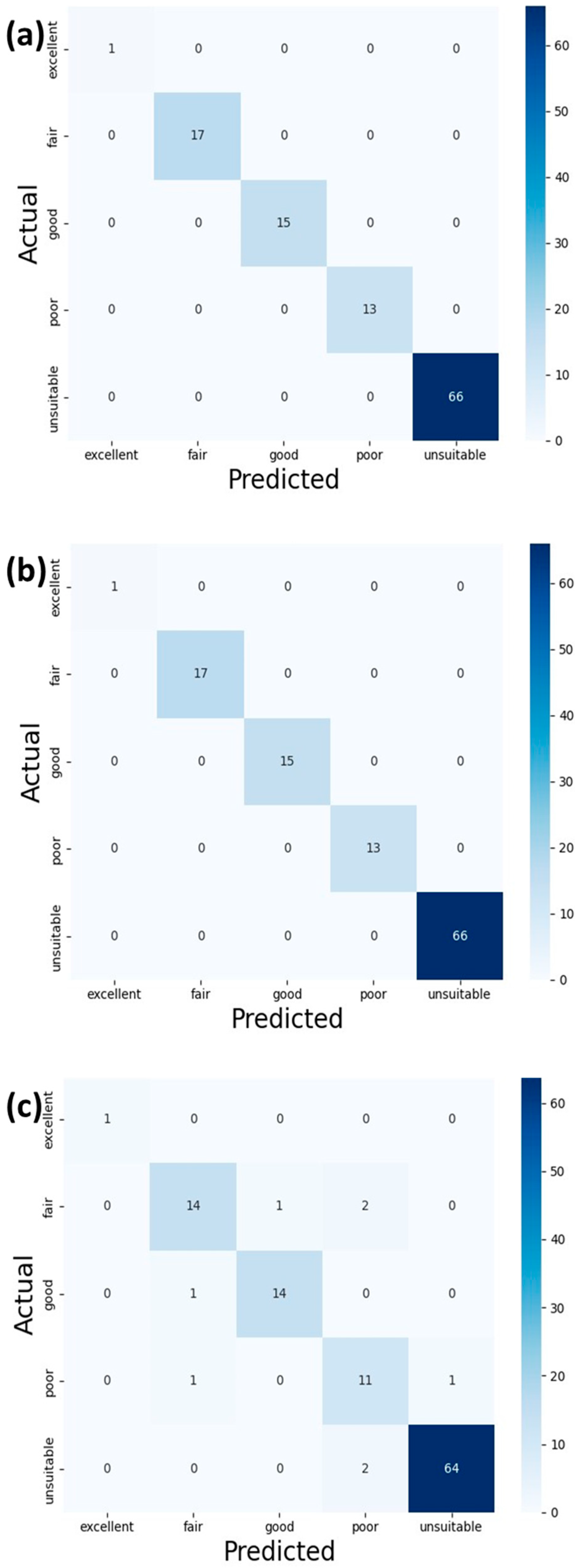
Figure 9 displays the confusion matrix, where the diagonal elements indicate the number of points for which the predicted label matches the true label (represented by darker blue colors). The off-diagonal elements represent mislabeled points by the classifier. It is an invaluable tool for comparing and selecting the optimal option. Additionally,
Table 4 provides cross-validation assessments for all models, presenting the mean score and standard deviation. This information is crucial for gauging the algorithms’ reliability and consistency.
The Decision Tree and Random Forest algorithms outperformed KNN across all metrics, achieving perfect precision, recall, and F1-scores (100%) in every water quality category (
Table 3). KNN exhibited lower performance, particularly in the “Fair” and “Poor” categories, where its precision, recall, and F1-scores dropped to as low as 73%.
Figure 9 presents that Random Forest, in particular, benefits from its ensemble nature, which enhances robustness and reduces the risk of overfitting. Based on
Table 4, the Decision Tree and Random Forest algorithms outperformed KNN in terms of cross-validation mean scores, with the Decision Tree achieving 99.80% and Random Forest 99.40%, compared with KNN’s 93.70%. The lower performance of KNN, coupled with its higher standard deviation of 3.74%, suggests that KNN is less consistent and more sensitive to variations in the dataset. The Decision Tree and Random Forest models exhibit not only higher accuracy but also greater stability, as reflected by their lower standard deviations (0.36% for Decision Tree and 0.72% for Random Forest). These factors contribute to the superior accuracy and consistency observed in the Decision Tree and Random Forest models [
41,
43].
Future research should address the limitations observed in the performance consistency of the KNN algorithm, which exhibited a lower mean score of 93.70% and a higher standard deviation of 3.74%. Further studies could explore methods to enhance the cross-validation assessments or investigate alternative algorithms that could perform more consistently in groundwater quality assessments. Addressing these areas could significantly advance the accuracy of groundwater quality assessments and contribute to more effective environmental monitoring and management practices. Additionally, further research for the long-term effects of increased urban development on TDS levels is recommended. Additional investigation into the specific impacts of the 759.47 km
2 increase in developed land and the 5037.90 km
2 reduction in herbaceous land on groundwater quality is necessary. Studies focusing on the interaction between different land cover types and their collective impact on TDS levels would also be valuable. Addressing these areas could provide more comprehensive insights into the complex dynamics of land cover changes and their implications for groundwater quality, leading to more effective environmental management strategies [
41,
43].
The confusion matrix is an important tool in evaluating the performance of classification models. It provides a detailed breakdown of the model’s predictions, showing the number of correct and incorrect predictions for each class. This allows for a more comprehensive assessment of a model’s accuracy, precision, and overall effectiveness in classifying data.
Figure 9 presents the confusion matrices for Decision Tree, Random Forest, and KNN. Both Decision Tree and Random Forest achieved perfect accuracy scores of 1.00, indicating that they correctly classified all data points, including labeling the total data as ‘excellent’. However, KNN achieved an accuracy of 0.93, indicating a few misclassifications. These results emphasize the superior performance of Decision Tree and Random Forest in this context, while KNN, although slightly less accurate, still performs well.
5. Conclusions
Water quality is a crucial issue in West Texas, where recent environmental developments have resulted in low-quality water that adversely impacts human life. In this study, we examined the use of machine learning algorithms for multiclass classification to assess water quality in the region. We analyzed a set of laboratory reports spanning from 1990 to 2023, using three different algorithms: Decision Tree, Random Forest, and K-Nearest Neighbors (KNN). Twenty-one water quality parameters were used as input for the models, and six water quality class labels were used as target output. This study aimed to evaluate the performance of different machine learning models in predicting water quality. We compared the Decision Tree, Random Forest, and KNN algorithms and found that both Decision Tree and Random Forest algorithms achieved higher accuracy in predicting water quality compared with the KNN algorithm. However, it is important to note that KNN is still a viable option for future research. With some alterations to the hyperparameters, it can potentially perform equally well.
This study’s findings have significant implications for improving groundwater quality management. By providing data mining approaches and machine learning techniques that offer a range of classification and forecasting methods, this study can contribute to addressing the specific needs of policymakers, environmental experts, and the general public. This can lead to more informed decision-making and the better management of water resources. Overall, this study highlights the potential of machine learning in predicting water quality and its impact on water management. To gain a better understanding of the environmental factors affecting water quality, we also used land cover maps to identify specific changes in the environment that impacted on groundwater quality in the Permian Basin, Texas. We mapped the groundwater quality to determine the extent of the problem. Therefore, our study provides valuable insights into the use of machine learning approaches for water quality assessment and highlights the environmental factors affecting water quality in Texas. By better understanding the impact of human activities on the environment, we can take steps to mitigate the risks and ensure the provision of safe and clean water for all.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}