



Detection of Floating Objects on Water Surface Using YOLOv5s in an Edge Computing Environment

 ,
,  ,
,  and
and
Abstract
:1. Introduction
- An enhanced coordinate attention mechanism is incorporated into the YOLOv5 feature extraction network, and the FPN (Feature Pyramid Network, FPN) is refined to strengthen the fusion capability of feature extraction.
- The complex operators in the network are optimized for better adaptation to embedded platforms at the edge.
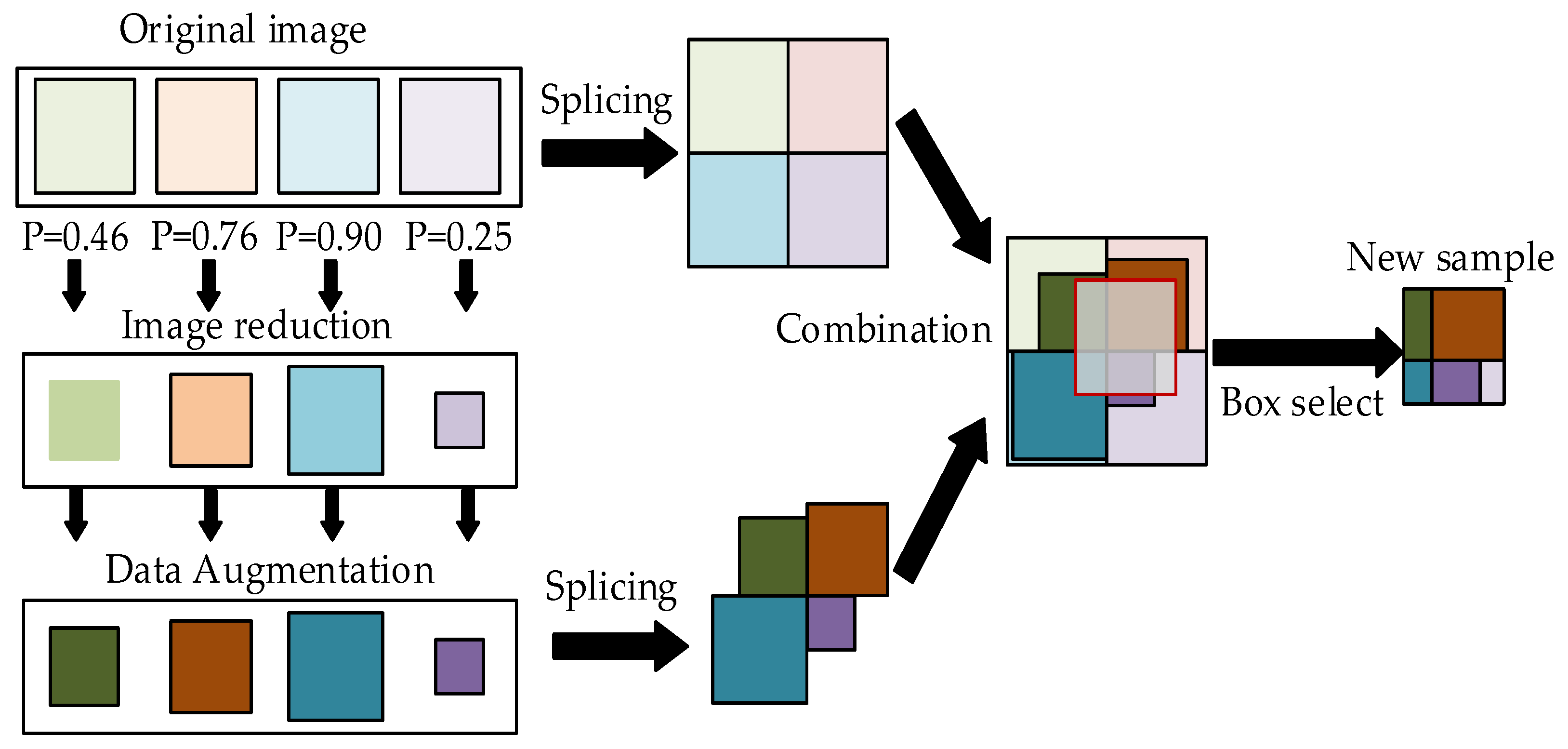
- A small target data augmentation method based on Mosaic is introduced to the model. The model’s robustness is improved by adding data samples containing more small targets.
- A channel-level pruning method is used to compress the model volume, which is then deployed in edge devices for testing.
- Ablation experiments were performed to verify the effectiveness of the improved model, as well as to compare and analyze the performances of different models in an edge environment.
2. Related Works
3. Methods
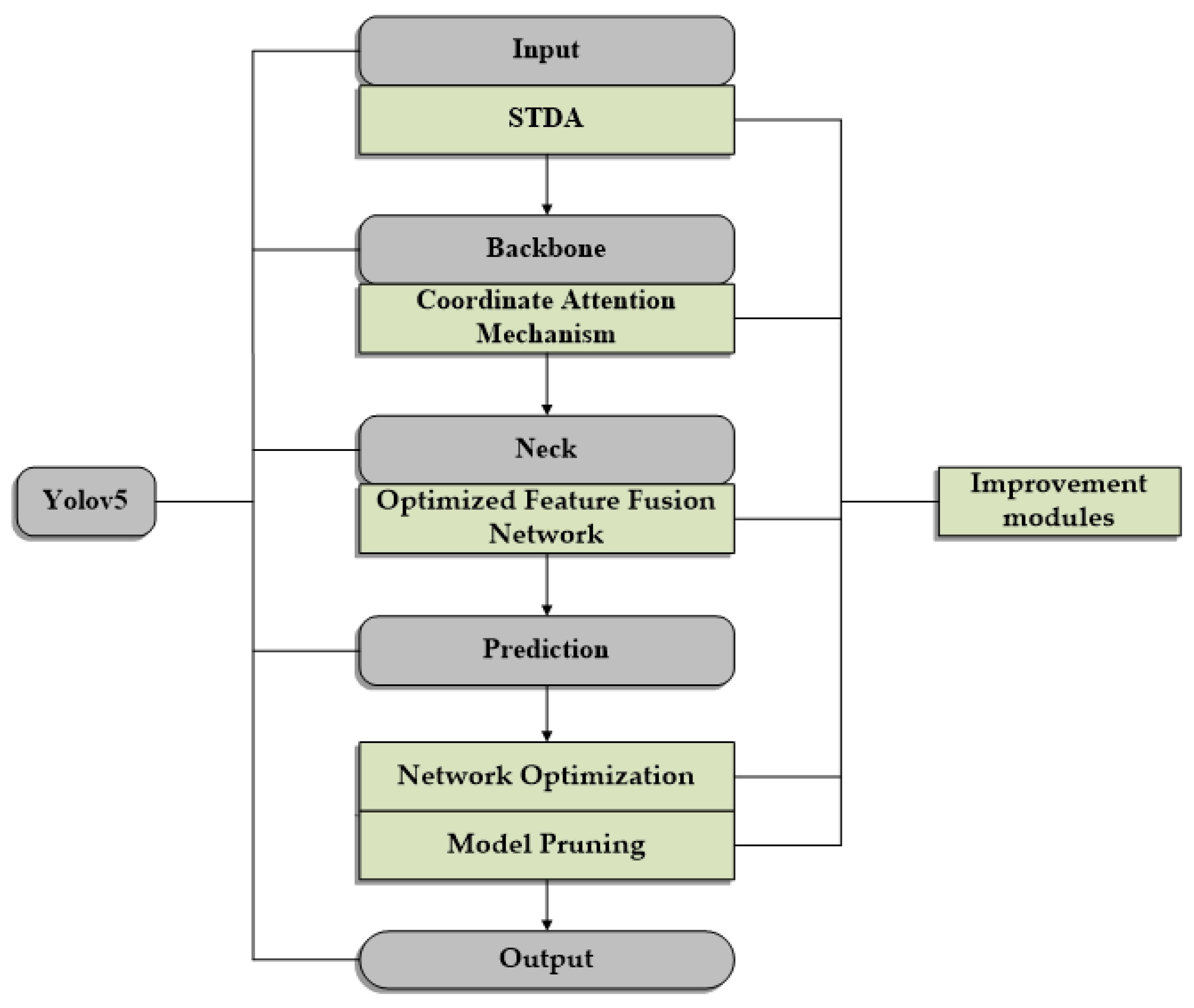
3.1. Yolov5 Network Structure
3.2. Improved YOLOv5 Network
3.2.1. Small Target Data Augmentation
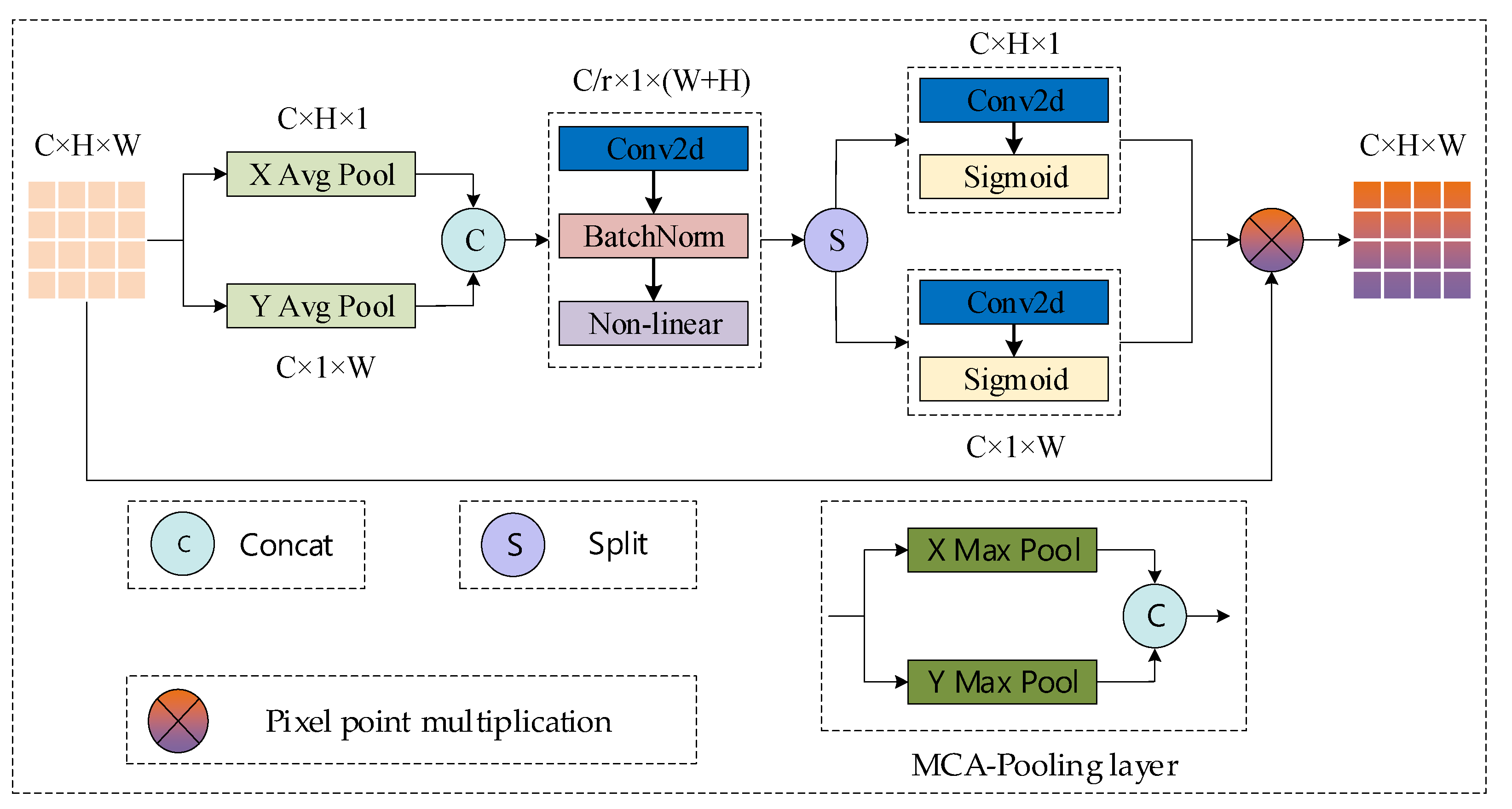
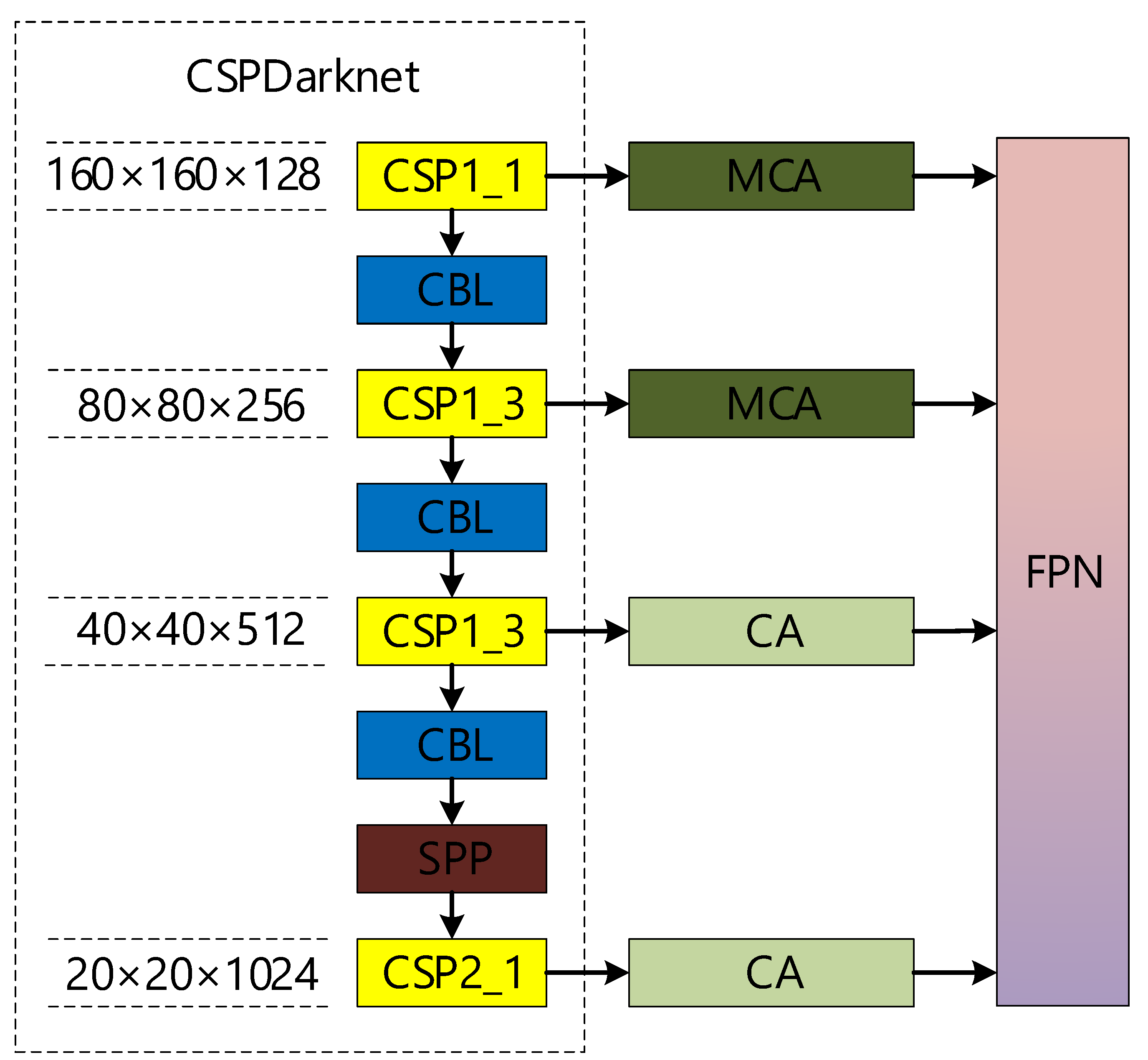
3.2.2. Feature Extraction Network Incorporating Coordinate Attention Mechanism
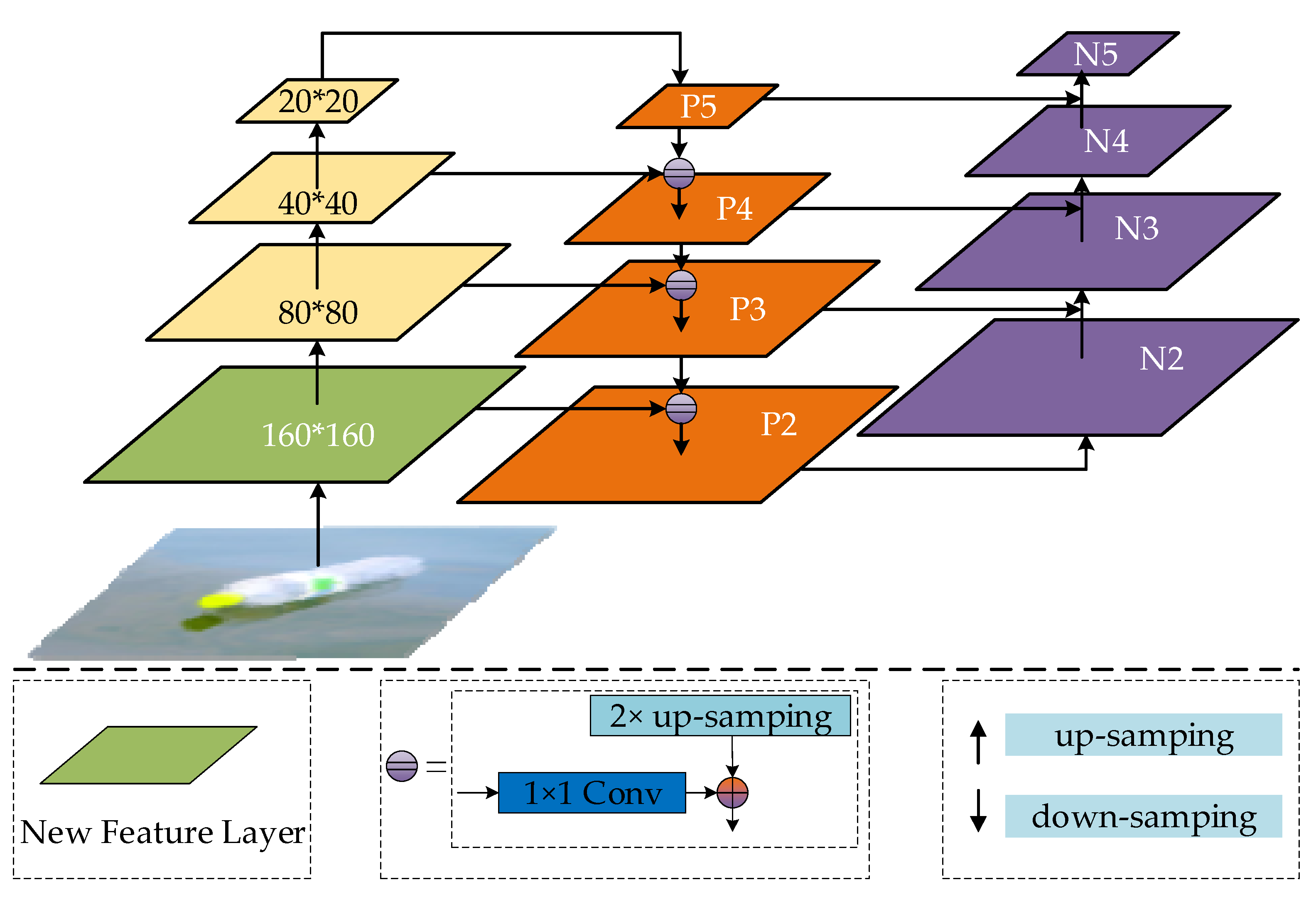
3.2.3. Optimized Feature Fusion Network
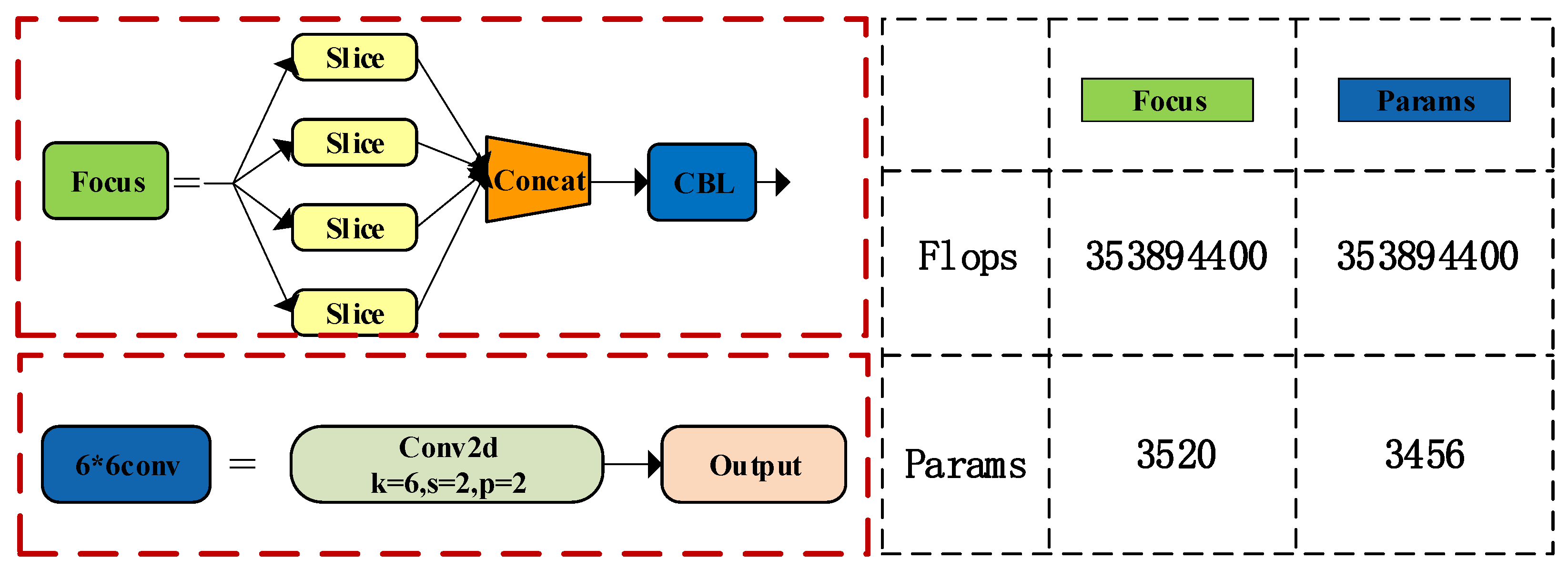
3.2.4. Network Optimization for Edge Devices
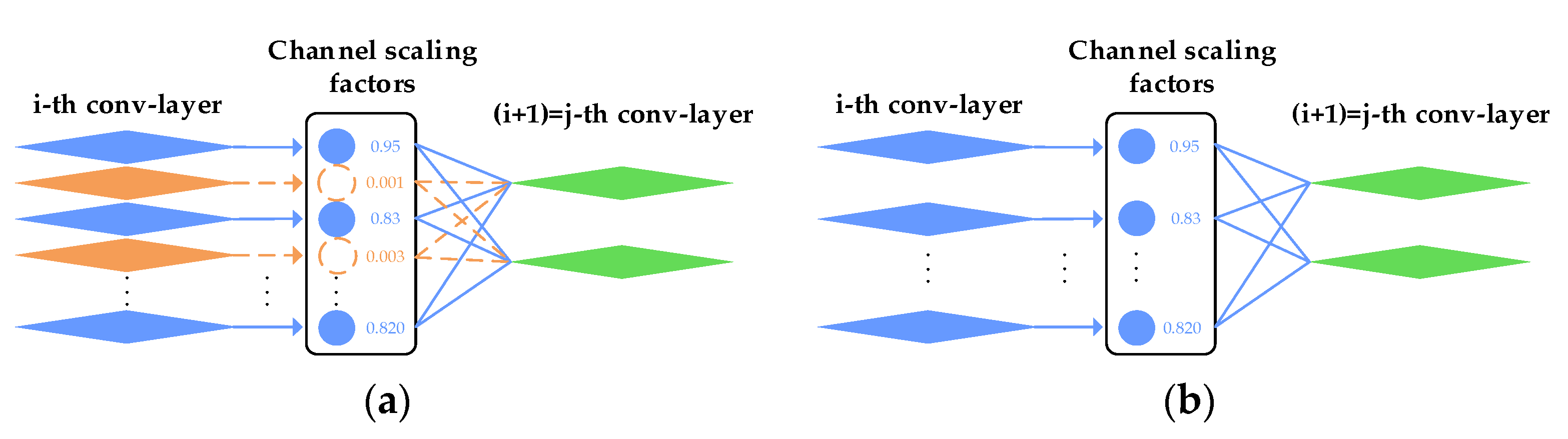
3.2.5. Model Pruning
4. Dataset and Experimental Environment
4.1. Datasets
4.2. Experimental Environment
5. Results and Discussion
5.1. Evaluation Metrics
5.2. Network Training
5.3. Experimentation and Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Paquin, M.; Cosgrove, C. The United Nations World Water Development Report 2016: Water and Jobs; UNESCO for UN-Water; United Nations Water: Geneva, Switzerland, 2016. [Google Scholar]
- Kilic, Z. Water pollution: Causes, negative effects and prevention methods. İstanbul Sabahattin Zaim Üniversitesi Fen Bilim. Enstitüsü Derg. 2021, 3, 129–132. [Google Scholar] [CrossRef]
- Schwarzenbach, R.P.; Egli, T.; Hofstetter, T.B.; Von Gunten, U.; Wehrli, B. Global water pollution and human health. Annu. Rev. Env. Resour. 2010, 35, 109–136. [Google Scholar] [CrossRef]
- Zamora-Ledezma, C.; Negrete-Bolagay, D.; Figueroa, F.; Zamora-Ledezma, E.; Ni, M.; Alexis, F.; Guerrero, V.H. Heavy metal water pollution: A fresh look about hazards, novel and conventional remediation methods. Environ. Technol. Inno. 2021, 22, 101504. [Google Scholar] [CrossRef]
- Porretti, M.; Arrigo, F.; Di Bella, G.; Faggio, C. Impact of pharmaceutical products on zebrafish: An effective tool to assess aquatic pollution. Comp. Biochem. Phys. C 2022, 261, 109439. [Google Scholar] [CrossRef] [PubMed]
- MacLeod, M.; Arp, H.P.H.; Tekman, M.B.; Jahnke, A. The global threat from plastic pollution. Science 2021, 373, 61–65. [Google Scholar] [CrossRef] [PubMed]
- Lechthaler, S.; Waldschläger, K.; Sandhani, C.G.; Sannasiraj, S.A.; Sundar, V.; Schwarzbauer, J.; Schüttrumpf, H. Baseline Study on Microplastics in Indian Rivers under Different Anthropogenic Influences. Water 2021, 13, 1648. [Google Scholar] [CrossRef]
- Galloway, T.S.; Cole, M.; Lewis, C. Interactions of microplastic debris throughout the marine ecosystem. Nat. Ecol. Evol. 2017, 1, 0116. [Google Scholar] [CrossRef] [PubMed]
- Jambeck, J.R.; Geyer, R.; Wilcox, C.; Siegler, T.; Perryman, M.; Andrady, A.; Narayan, R.; Law, K.L. Plastic waste inputs from land into the ocean. Science 2015, 347, 768–771. [Google Scholar] [CrossRef] [PubMed]
- Lamb, J.B.; Willis, B.L.; Fiorenza, E.A.; Couch, C.S.; Howard, R.; Rader, D.N.; True, J.D.; Kelly, L.A.; Ahmad, A.; Jompa, J.; et al. Plastic waste associated with disease on coral reefs. Science 2018, 359, 460–462. [Google Scholar] [CrossRef]
- Syanya, F.J.; Litabas, J.A.; Mathia, W.M.; Ntakirutimana, R. Nutritional fish diseases in aquaculture: A human health hazard or mythical theory: An overview. Eur. J. Nutr. Food Saf. 2023, 15, 41–58. [Google Scholar] [CrossRef]
- Chaudhari, A.; Bhatt, C.; Krishna, A.; Travieso-González, C.M. Facial Emotion Recognition with Inter-Modality-Attention-Transformer-Based Self-Supervised Learning. Electronics 2023, 12, 288. [Google Scholar] [CrossRef]
- Zhang, K.Y.; Amineh, R.K.; Dong, Z.Q.; Nadler, D. Microwave Sensing of Water Quality. IEEE Access 2019, 7, 69481–69493. [Google Scholar] [CrossRef]
- Phung, K.A.; Nguyen, T.T.; Wangad, N.; Baraheem, S.; Vo, N.D.; Nguyen, K. Disease Recognition in X-ray Images with Doctor Consultation-Inspired Model. J. Imaging 2022, 8, 323. [Google Scholar] [CrossRef] [PubMed]
- Hoang, T.; Hoang, D.; Jo, K.H. Realtime Multi-Person Pose Estimation with RCNN and Depthwise Separable Convolution. In Proceedings of the 2020 RIVF International Conference on Computing and Communication Technologies (RIVF), Ho Chi Minh, Vietnam, 14–15 October 2020. [Google Scholar]
- Zhang, W.; Wang, S.H.; Sophanyouly, T.C.; Chen, J.Z.; Qian, Y.T. Deconv R-CNN for Small Object Detection on Remote Sensing Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Widiyanto, S.; Wardani, D.T.; Wisnu Pranata, S. Image-Based Tomato Maturity Classification and Detection Using Faster R-CNN Method. In Proceedings of the 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 21–23 October 2021. [Google Scholar]
- Zhang, X.; Cui, J.; Liu, H. Weed Identification in Soybean Seedling Stage Based on Optimized Faster R-CNN Algorithm. Agriculture 2023, 13, 2023. [Google Scholar] [CrossRef]
- Zhang, X.B.; Zhang, Y.; Hu, M.; Ju, X.M. Insulator defect detection based on YOLO and SPP-Net. In Proceedings of the 2020 International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Bangkok, Thailand, 30 October–1 November 2020. [Google Scholar]
- Zailan, N.A.; Mohd Khairuddin, A.S.; Khairuddin, U.; Taguchi, A. YOLO-based Network Fusion for Riverine Floating Debris Monitoring System. In Proceedings of the International Conference on Electrical, Communication, and Computer Engineering, Kuala Lumpur, Malaysia, 12–13 June 2021. [Google Scholar]
- Song, W.; Suand, S.A. TSR-YOLO: A Chinese Traffic Sign Recognition Algorithm for Intelligent Vehicles in Complex Scenes. Sensors 2023, 23, 749. [Google Scholar] [CrossRef] [PubMed]
- Alqaysi, H.; Fedorov, I.; Qureshi, F.Z.; O’Nils, M. A Temporal Boosted YOLO-Based Model for Birds Detection around Wind Farms. J. Imaging 2021, 7, 227. [Google Scholar] [CrossRef]
- Liu, Z.P.; Fang, W.; Sun, J. SSD small object detection algorithm based on feature enhancement and sample selection. In Proceedings of the 2021 20th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES), Nanning, China, 10–12 December 2021. [Google Scholar]
- Liu, S.C.; Shi, H.J.; Guo, Z. Remote sensing image object detection based on improved SSD. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022. [Google Scholar]
- Zhang, L.L.; Wei, Y.X.; Wang, H.B.; Shao, Y.H.; Shen, J. Real-Time Detection of River Surface Floating Object Based on Improved RefineDet. IEEE Access 2021, 9, 81147–81160. [Google Scholar] [CrossRef]
- Dai, M.; Dorjoy, M.M.H.; Miao, H.; Zhang, S. A New Pest Detection Method Based on Improved YOLOv5m. Insects 2023, 14, 54. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.J.; Liu, B.J. Target Recognition Algorithm Based on YOLOv5 Network and Depth Camera for 2D Interference Elimination. In Proceedings of the 2022 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 20–22 May 2022. [Google Scholar]
- Kim, Y.; Yi, S.; Ahn, H.; Hong, C.H. Accurate Crack Detection Based on Distributed Deep Learning for IoT Environment. Sensors 2023, 23, 858. [Google Scholar] [CrossRef]
- Donno, M.D.; Tange, K.; Dragoni, N. Foundations and Evolution of Modern Computing Paradigms: Cloud, IoT, Edge, and Fog. IEEE Access 2019, 7, 150936–150948. [Google Scholar] [CrossRef]
- Sun, X.; Deng, H.; Liu, G.; Deng, X. Combination of Spatial and Frequency Domains for Floating Object Detection on Complex Water Surfaces. Appl. Sci 2019, 9, 5220. [Google Scholar] [CrossRef]
- Zhang, R.B.; Xiao, Y.F.; Zheng, Y.N. Detection of Floating Objects on Water Surface Based on Fusion of Lidar and Vision. Appl. Laser 2021, 41, 619–628. [Google Scholar]
- Jin, X.L.; Niu, P.W.; Liu, L.F. A GMM-Based Segmentation Method for the Detection of Water Surface Floats. IEEE Access 2019, 7, 119018–119025. [Google Scholar] [CrossRef]
- He, X.Q.; Wang, J.C.; Chen, C.B.; Yang, X.Q. Detection of the floating objects on the water surface based on improved YOLOv5. In Proceedings of the IEEE 2nd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA 2021), Chongqing, China, 17–19 December 2021. [Google Scholar]
- Lin, F.; Hou, T.; Jin, Q.; You, A. Improved YOLO Based Detection Algorithm for Floating Debris in Waterway. Entropy 2021, 23, 1111. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Xiao, W.; Ni, T. Efficient object detection method based on improved YOLOv3 network for remote sensing images. In Proceedings of the IEEE 3rd International Conference on Artificial Intelligence and Big Data (ICAIBD 2020), Chengdu, China, 28–31 May 2020. [Google Scholar]
- Li, G.J.; Yao, D.Y.; Ai, J.Y. Floating objects detection based on improved YOLOv3. J. Guangxi Univ. Nat. Sci. Ed. 2021, 46, 1569–1578. [Google Scholar]
- Tharani, M.; Amin, A.W.; Maaz, M.; Taj, M. Attention neural network for trash detection on water channels. arXiv 2020, arXiv:2007.04639. [Google Scholar]
- Li, H.; Yang, S.P.; Liu, J.J.; Fang, H.; Fu, Z.M.; Zhang, R.; Jia, H.M.; Lv, L.M. A method for detecting floating objects on water based on edge computing. In Proceedings of the IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB 2023), Beijing, China, 14–16 June 2023. [Google Scholar]
- Walawalkar, D.; Shen, Z.Q.; Liu, Z.C.; Savvides, M. Attentive Cutmix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Wang, C.L.; Zhou, Z.R.; Chen, Z.M. An Enhanced YOLOv4 Model with Self-Dependent Attentive Fusion and Component Randomized Mosaic Augmentation for Metal Surface Defect Detection. IEEE Access 2022, 10, 97758–97766. [Google Scholar] [CrossRef]
- Li, H.; Yang, S.P.; Liu, J.J.; Yang, Y.; Kadoch, M.; Liu, T.Y. A Framework and Method for Surface Floating Object Detection Based on 6G Networks. Electronics 2022, 11, 2939. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Fan, R.X.; Qiu, Z.P. Improved YOLOv5 Algorithm Based on CBAM Attention Mechanism. In Proceedings of the 2022 International Conference on Frontiers of Artificial Intelligence and Machine Learning (FAIML), Hangzhou, China, 19–21 June 2022. [Google Scholar]
- Chang, C.C.; Huang, C.H.; Chu, Y.S. A hardware-friendly pruning approach by exploiting local statistical pruning and fine grain pruning techniques. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Yeosu, Korea, 26–28 October 2022. [Google Scholar]
- Liu, Z.; Li, J.G.; Shen, Z.Q. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 24–27 October 2017. [Google Scholar]
- Song, S.J.; Jing, J.F.; Huang, Y.Q.; Shi, M.Y. EfficientDet for fabric defect detection based on edge computing. J. Eng. Fibers Fabr. 2021, 16, 15589250211008346. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Training Set | Validation Set | Test Set |
|---|---|---|---|
| Bottles | 3280 | 410 | 410 |
| Plastic bags | 2560 | 320 | 320 |
| Planktonic algae | 1200 | 150 | 150 |
| Dead fishes | 1040 | 130 | 130 |
| Environment | System and Hardware | Version and Hardware Model |
|---|---|---|
| Training environment | Systems | Ubuntu18.04 |
| Graphics card | GeForce RTX 3090 | |
| Framework | Pytorch | |
| Edge test environment | Data collection equipment | 2 Megapixel 1/1.8” CMOS Smart Capture Camera |
| Embedded chips | Hi3519AV100 |
| CA | MCA | Error Detection/pc | Error Detection Rate/% | Model Size/MB |
|---|---|---|---|---|
| ○ | ○ | 18 | 0.035 | 14.10 |
| ● | ○ | 5 | 0.009 | 14.82 |
| ● | ● | 3 | 0.006 | 14.82 |
| No. | CA + MCA | New FPN | STDA | Precision | mAP@0.5:0.95 | Recall |
|---|---|---|---|---|---|---|
| 1 | ○ | ○ | ○ | 0.8104 | 0.5213 | 0.8251 |
| 2 | ● | ○ | ○ | 0.8513 | 0.5767 | 0.8259 |
| 3 | ○ | ● | ○ | 0.8298 | 0.5260 | 0.8301 |
| 4 | ○ | ○ | ● | 0.8368 | 0.5391 | 0.7914 |
| 5 | ● | ● | ○ | 0.8730 | 0.5669 | 0.8509 |
| 6 | ● | ○ | ● | 0.8797 | 0.5772 | 0.8760 |
| 7 | ○ | ● | ● | 0.8414 | 0.5405 | 0.8590 |
| 8 | ● | ● | ● | 0.9376 | 0.5962 | 0.9081 |
| Algorithms | Precision | FPS | Model Size/MB |
|---|---|---|---|
| YOLOv5s | 0.8059 | 13 | 14.10 |
| SSD300 | 0.8002 | 2 | 90.06 |
| Faster R-CNN | 0.8490 | 0.62 | 165.80 |
| EfficientDet [46] | 0.7801 | 6.4 | 16.22 |
| Our Method | 0.9201 | 33 | 4.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Yang, S.; Zhang, R.; Yu, P.; Fu, Z.; Wang, X.; Kadoch, M.; Yang, Y. Detection of Floating Objects on Water Surface Using YOLOv5s in an Edge Computing Environment. Water 2024, 16, 86. https://doi.org/10.3390/w16010086
Li H, Yang S, Zhang R, Yu P, Fu Z, Wang X, Kadoch M, Yang Y. Detection of Floating Objects on Water Surface Using YOLOv5s in an Edge Computing Environment. Water. 2024; 16(1):86. https://doi.org/10.3390/w16010086
Chicago/Turabian StyleLi, He, Shuaipeng Yang, Rui Zhang, Peng Yu, Zhumu Fu, Xiangyang Wang, Michel Kadoch, and Yang Yang. 2024. "Detection of Floating Objects on Water Surface Using YOLOv5s in an Edge Computing Environment" Water 16, no. 1: 86. https://doi.org/10.3390/w16010086
APA StyleLi, H., Yang, S., Zhang, R., Yu, P., Fu, Z., Wang, X., Kadoch, M., & Yang, Y. (2024). Detection of Floating Objects on Water Surface Using YOLOv5s in an Edge Computing Environment. Water, 16(1), 86. https://doi.org/10.3390/w16010086