

An Improved ResNet-Based Algorithm for Crack Detection of Concrete Dams Using Dynamic Knowledge Distillation

Abstract
:1. Introduction
2. Methodology
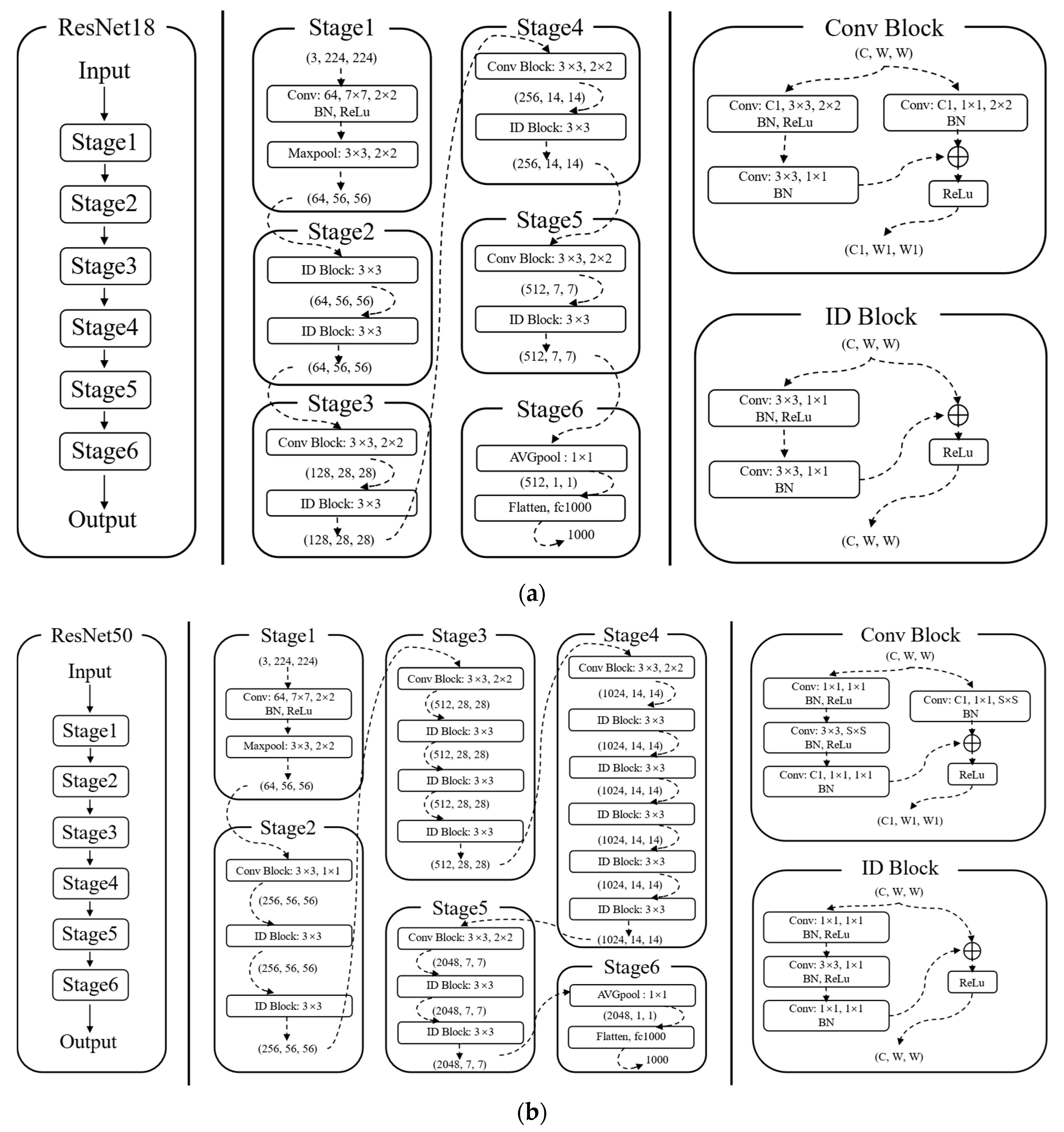
2.1. ResNet-Based Dynamic Knowledge Distillation Architecture
2.1.1. Selection of Appropriate Teacher and Student Models
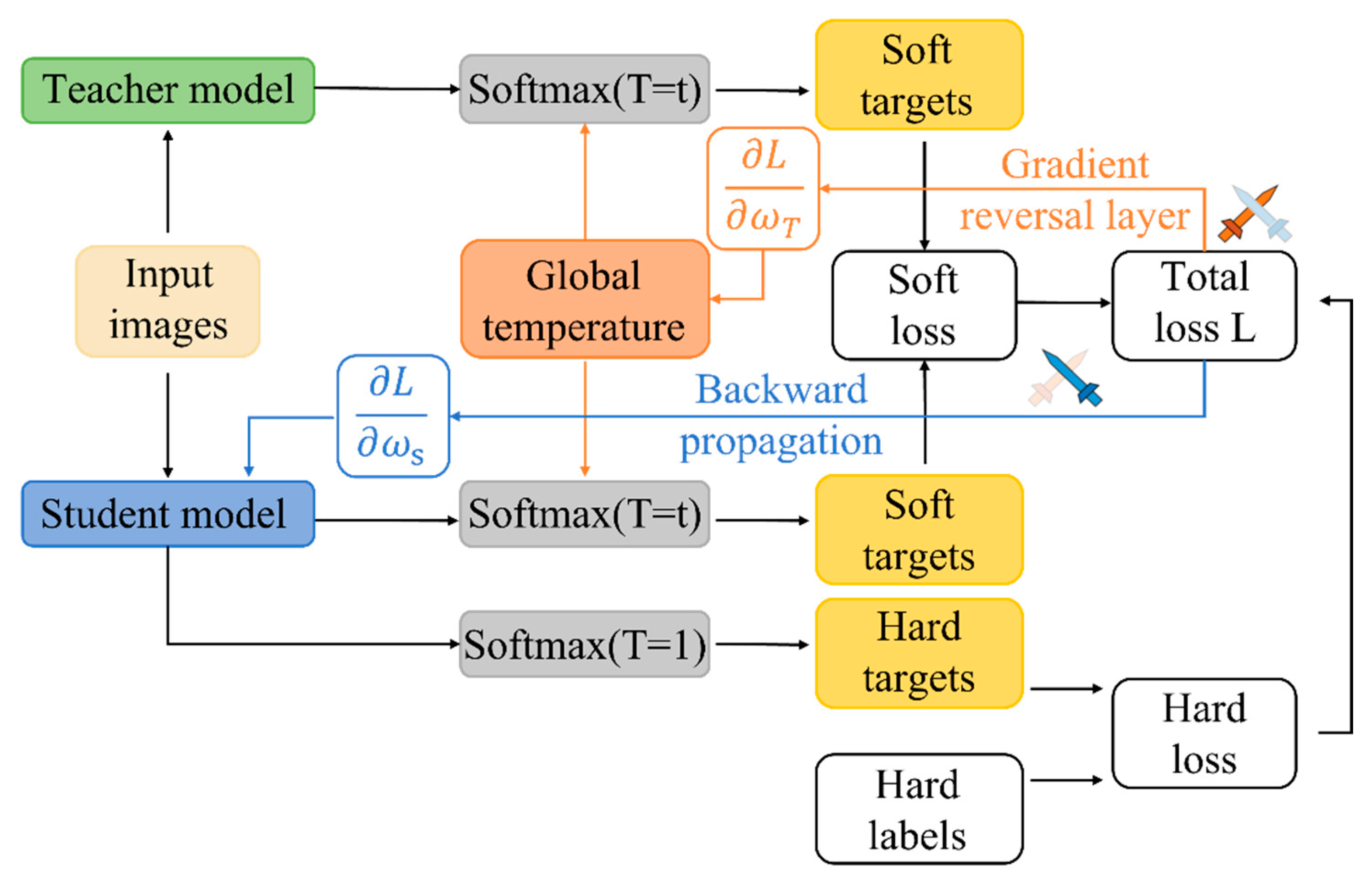
2.1.2. Distillation Loss Function
2.1.3. Dynamic Temperature for Knowledge Distillation
| Algorithm 1: Implementation of Dynamic Distillation |
| Input: Training dataset D; Total training epoch M; Pre-trained Teacher ; Learnable Temperature Module |
| Output: Distilled Student |
| Initialize: Epoch m = 1; Randomly initialize: , |
| while m ≤ M do |
| for batch x in D do |
| Forward propagation through and to obtain predictions |
| Obtain temperature T by |
| Calculate the loss L and update and by backward propagation |
| end for |
| m = m + 1; |
| end while |
2.2. Transfer Learning
3. Preliminary Experiments on Mini-ImageNet
3.1. Training Tricks
3.2. Some Findings
4. Experiments on Concrete Crack Detection
4.1. Concrete Crack Datasets
4.2. Results
5. Case Study
5.1. Case Description—HKC Dam
5.2. Application to HKC Dam
6. Discussion
- Preliminary experiments on mini-ImageNet prove soft targets can transfer a great deal of knowledge to the distilled model. If the smaller network is trained by adding the additional task of matching the soft targets produced by the large network at a higher temperature (T = 4), its accuracy will increase from 79.41% to 82.33%. We also find that knowledge distillation can improve generalization by narrowing the gap between training and validation accuracy compared to the original student model (from 14.03% to 10.16%) and even the teacher model (from 12.61% to 10.16%). In addition, the distillation effect is further improved with a dynamic temperature module (from 82.33% to 82.52%), compared with the results of distillation systems under fixed temperature parameters. The final distillation temperature approaches 3.95, which is different from the empiric value of 4, which confirms our previous conjecture.
- Experiments on concrete crack detection prove the improved pre-trained network based on dynamic knowledge distillation has an improvement of 4.92% compared to the original student network without pretraining, with an accuracy of 99.85%. The accuracy is 1.05% higher than that of networks with CBAM. Compared with other DCNNs, such as AlexNet and VGG, the accuracy is improved by 2.83% and 4.92%, respectively. Experimental results demonstrate that the proposed dynamic distillation and transfer learning are highly beneficial for crack detection tasks and can satisfy the dual requirements of high accuracy and model compression. It is particularly true for tasks with insufficient samples, such as the application of HKC Dam.
- When common feature encoders obtained from concrete cracks with rich features were applied to crack detection in HKC Dam through transfer learning, its accuracy reached 98.39%, making it easy to draw sweeping conclusions: dynamic distillation and transfer learning can help networks improve the ability to extract common features such as texture and contour of cracks and alleviate the overfitting problem of datasets involving unrich samples.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rezaiee-Pajand, M.; Kazemiyan, M.S.; Aftabi Sani, A. A Literature Review on Dynamic Analysis of Concrete Gravity and Arch Dams. Arch. Comput. Methods Eng. 2021, 28, 4357–4372. [Google Scholar] [CrossRef]
- Lee, Y.-H.; Ryu, J.-H.; Heo, J.; Shim, J.-W.; Lee, D.-W. Stability Improvement Method for Embankment Dam with Respect to Conduit Cracks. Appl. Sci. 2022, 12, 567. [Google Scholar] [CrossRef]
- Ge, M.; Petkovšek, M.; Zhang, G.; Jacobs, D.; Coutier-Delgosha, O. Cavitation Dynamics and Thermodynamic Effects at Elevated Temperatures in a Small Venturi Channel. Int. J. Heat Mass Transf. 2021, 170, 120970. [Google Scholar] [CrossRef]
- Ge, M.; Sun, C.; Zhang, G.; Coutier-Delgosha, O.; Fan, D. Combined Suppression Effects on Hydrodynamic Cavitation Performance in Venturi-Type Reactor for Process Intensification. Ultrason. Sonochem. 2022, 86, 106035. [Google Scholar] [CrossRef]
- Ge, M.; Manikkam, P.; Ghossein, J.; Kumar Subramanian, R.; Coutier-Delgosha, O.; Zhang, G. Dynamic Mode Decomposition to Classify Cavitating Flow Regimes Induced by Thermodynamic Effects. Energy 2022, 254, 124426. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, H.; Wang, H.; Wang, S.; Li, Y. Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network. Sensors 2020, 20, 2069. [Google Scholar] [CrossRef] [Green Version]
- Mohan, A.; Poobal, S. Crack Detection Using Image Processing: A Critical Review and Analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Vanhoucke, V.; Senior, A.; Mao, M. Improving the Speed of Neural Networks on CPUs. 2011; pp. 1–8. Available online: https://www.semanticscholar.org/paper/Improving-the-speed-of-neural-networks-on-CPUs-Vanhoucke-Senior/fbeaa499e10e98515f7e1c4ad89165e8c0677427#citing-papers (accessed on 3 August 2023).
- Venkatesh, G.; Nurvitadhi, E.; Marr, D. Accelerating Deep Convolutional Networks Using Low-Precision and Sparsity. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2861–2865. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model Compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 535–541. [Google Scholar]
- Hong, Y.-W.; Leu, J.-S.; Faisal, M.; Prakosa, S.W. Analysis of Model Compression Using Knowledge Distillation. IEEE Access 2022, 10, 85095–85105. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Mishra, A.; Marr, D. Apprentice: Using Knowledge Distillation Techniques to Improve Low-Precision Network Accuracy. arXiv 2017, arXiv:1711.05852. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sarfraz, F.; Arani, E.; Zonooz, B. Knowledge Distillation Beyond Model Compression. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6136–6143. [Google Scholar]
- Wang, J.; Bao, W.; Sun, L.; Zhu, X.; Cao, B.; Yu, P.S. Private Model Compression via Knowledge Distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1190–1197. [Google Scholar] [CrossRef] [Green Version]
- Jafari, A.; Rezagholizadeh, M.; Sharma, P.; Ghodsi, A. Annealing Knowledge Distillation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 2493–2504. [Google Scholar]
- Walawalkar, D.; Shen, Z.; Savvides, M. Online Ensemble Model Compression Using Knowledge Distillation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 18–35. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient Knowledge Distillation for BERT Model Compression. arXiv 2019, arXiv:1908.09355. [Google Scholar]
- Allen-Zhu, Z.; Li, Y.; Liang, Y. Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers. arXiv 2018, arXiv:1811.04918. [Google Scholar]
- Arora, S.; Cohen, N.; Hazan, E. On the Optimization of Deep Networks: Implicit Acceleration by Overparameterization. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Brutzkus, A.; Globerson, A. Why Do Larger Models Generalize Better? A Theoretical Perspective via the XOR Problem. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Tu, Z.; He, F.; Tao, D. Understanding Generalization in Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 March 2020. [Google Scholar]
- Ba, L.J.; Caruana, R. Do Deep Nets Really Need to Be Deep? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Urban, G.; Geras, K.J.; Kahou, S.E.; Aslan, O.; Wang, S.; Caruana, R.; Mohamed, A.; Philipose, M.; Richardson, M. Do Deep Convolutional Nets Really Need to Be Deep and Convolutional? arXiv 2016, arXiv:1603.05691. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, Z.; Li, X.; Yang, L.; Zhao, B.; Song, R.; Luo, L.; Li, J.; Yang, J. Curriculum Temperature for Knowledge Distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7130–7138. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Goyal, P.; Dollar, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Özgenel, Ç.; Sorguc, A. Performance Comparison of Pretrained Convolutional Neural Networks on Crack Detection in Buildings. In Proceedings of the International Symposium on Automation and Robotics in Construction, Berlin, Germany, 20–25 July 2018. [Google Scholar]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Özgenel, Ç.F. Concrete Crack Images for Classification; Mendeley Data, V2; 2019. Available online: https://data.mendeley.com/datasets/5y9wdsg2zt/2 (accessed on 3 August 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | T | Epoch 1 | Train Acc 2 (%) | Hard Loss (%) | Best Acc 2 (%) | Val 3 Loss (%) |
|---|---|---|---|---|---|---|
| Student ResNet18 | - | 96 | 93.44 | 0.26 | 79.41 | 0.86 |
| Teacher ResNet50 | - | 99 | 94.40 | 0.22 | 81.79 | 0.76 |
| KD 4 | 2 | 97 | 93.05 | 0.10 | 81.61 | 0.79 |
| KD | 3 | 93 | 92.53 | 0.11 | 81.95 | 0.78 |
| KD | 4 | 97 | 92.49 | 0.11 | 82.33 | 0.78 |
| KD | 5 | 94 | 91.99 | 0.12 | 82.04 | 0.77 |
| KD(DT 5) | - | 99 | 92.34 | 0.11 | 82.52 | 0.77 |
| Model | ResNet18 * | ResNet50 * | KD | CBAM | AlexNet | VGG-Net | ||
|---|---|---|---|---|---|---|---|---|
| Best Acc | 94.93 | 96.07 | 95.56 | 98.62 | 99.85 | 98.80 | 97.02 | 94.93 |
| (+1.14) | (+0.63) | (+3.69) | (+4.92) | (+3.87) | (+2.09) | (+0.00) | ||
| (−0.51) | (+2.55) | (+3.78) | (+2.73) | (+0.95) | (−1.14) | |||
| Original Images | Original Feature Maps | Segmented Images | Detection Results |
|---|---|---|---|
 |  |  | positive |
 |  |  | positive |
 |  |  | positive |
 | 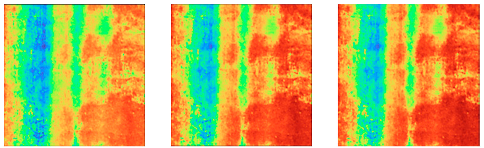 |  | negative |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Bao, T. An Improved ResNet-Based Algorithm for Crack Detection of Concrete Dams Using Dynamic Knowledge Distillation. Water 2023, 15, 2839. https://doi.org/10.3390/w15152839
Zhang J, Bao T. An Improved ResNet-Based Algorithm for Crack Detection of Concrete Dams Using Dynamic Knowledge Distillation. Water. 2023; 15(15):2839. https://doi.org/10.3390/w15152839
Chicago/Turabian StyleZhang, Jingying, and Tengfei Bao. 2023. "An Improved ResNet-Based Algorithm for Crack Detection of Concrete Dams Using Dynamic Knowledge Distillation" Water 15, no. 15: 2839. https://doi.org/10.3390/w15152839
APA StyleZhang, J., & Bao, T. (2023). An Improved ResNet-Based Algorithm for Crack Detection of Concrete Dams Using Dynamic Knowledge Distillation. Water, 15(15), 2839. https://doi.org/10.3390/w15152839