1. Introduction
Management of watershed resources depends on adequate understanding of nonpoint source pollutant sources and sinks and their complex relationship. In watershed systems, physical and chemical processes are influenced by anthropogenic and natural drivers causing them to vary in time and space. Physical processes controlling soil erosion, transport, and deposition by wind and surface water can impact associated processes locally or influence processes located further downstream in the watershed, and even beyond the watershed boundaries. The level of complexity of watershed systems poses a challenge for conservation agencies responsible for allocating limited resources and developing mitigation plans.
The development and evaluation of conservation strategies are often supported by watershed modeling technology. These tools feature advanced scientific understanding of watershed systems through detailed characterization and estimation of the complex integrated relationship between nonpoint source pollutants, farming practices, conservation measures, local physical characteristics, and weather conditions. In simulation tools, the watershed is subdivided into basic modeling units [
1]. Features and parameters within basic modeling units are assumed to be homogeneous and variations at scales smaller than the basic modeling unit scale are aggregated or averaged to represent the dominant process/feature [
2,
3]. The adoption of basic modeling units is required to abridge real world complexities, simplify input databases development, and reduce computational loads. However, incorrect adoption of basic modeling unit scales could invalidate homogeneity assumptions and, therefore, compromise modeling results. The effect of the watershed subdivision scale on modeling results has been studied [
4,
5,
6,
7,
8]. The level of watershed discretization can affect how daily water balance is calculated by models (evapotranspiration, percolation, soil moisture, and surface runoff) because variations in assigned soil and land cover type to modeling units often determine curve number (CN) values adoption [
7]. Greater variability has been estimated in annual sediment and nutrient loads when varying basic modeling unit scale and they were attributed to over generalization of slopes, land use/land cover, soil properties, and consequently CNs [
2,
5,
8]. Studies involving hydrological modeling to support natural resources conservation can be categorized into two groups based on scale: local (watershed) and regional (basin).
Studies of individual watersheds (or sub-watersheds) have been the most adopted method. Selected watersheds/sub-watersheds are characterized and modeled using detailed spatial-temporal site-specific information in studies designed to estimate hydrological patterns [
9,
10,
11], nonpoint source pollutions [
12], and placement and assessment of conservation practices [
13,
14,
15]. The utilization of watershed modeling technology at such fine scale can be time-consuming as it requires understanding of the model input requirements, data sources and their limitations, and efficient development of model input databases. Despite the level of detail describing the watershed’s features, these studies only provide local information on a few individual watersheds that often cannot be scaled up to describe the entire conservation region (state, province, or basin). Furthermore, individual studies are often performed by multiple stakeholders under uncoordinated efforts, using different modeling tools [
16,
17,
18,
19,
20], and based on varying assumptions of process characterization, input parameters, and time period. Comparison and/or aggregation of these uncoordinated efforts to generate information at the regional scale are not feasible.
Conversely, watershed modeling technology has also been used in studies designed to assess conditions at larger scales, such as at basin (HUC06) and sub-basin (HUC08) scales. In the study of Panagopoulos et al. [
21], the Upper Mississippi River Basin (~492,000 km
2) and the Ohio-Tennessee River Basin (528,000 km
2) were discretized into 5729 and 6350 sub-catchments, respectively, yielding an average basic modeling unit area of 8444.4 ha. Each sub-catchment was designed to represent US Geological Survey (USGS) “12-digits sub-watersheds” (HUC12). Watershed simulations using the Soil and Water Assessment Tool (SWAT) model [
22] suggested that increased discretization of such a large area from HUC08 scale (USGS 8-digit sub-basin terminology) into HUC12 sub-watersheds improved the characterization of climatic and physical conditions and yielded acceptable estimates of hydrology and water quality. Similarly, Daggupati et al. [
23] used the SWAT model to simulate hydrology and crop yield of the Missouri River Basin (~1,371,000 km
2) using HUC12 sub-watersheds as basic modeling units (13,465 HUC12s with average 9819.13 ha). In this work, the basin was subdivided into three sub-basins which were simulated individually but linked to provide flow from the upstream to the downstream sub-basin. Large-scale watershed simulations offer the capability of quantifying the impact of anthropogenic and natural drivers to hydrology, supporting water and nonpoint source pollutant management efforts at regional scales, such as basin scale [
24] and even continental scale [
25]. These large-scale studies are important and appropriate to provide a regional overview but at a cost of significant aggregation (lumping) of information within basic modeling units and, therefore, risking unrealistic homogeneity assumptions. Furthermore, analyses of results at scales smaller than basic modeling unit scales are not achievable.
Bridging the scale gap between local and regional hydrological modeling technology support efforts by municipal, state, and federal conservation agencies by providing integrated hydrological simulations covering large geographical areas but with detailed spatial characterization. Advances in computing technology now allow the development of technology to automate input database preparation to support fine-scale discretization of large areas, concurrent or parallel model execution, and novel storage for inputs and outputs. In this study, a multiscale and standardized procedure was developed to support conservationists with an Integrated Technology for Evaluation and Assessment of Multi-scale-hydrological Systems (ITEAMS) approach in characterizing water and nonpoint source pollution spatiotemporal dynamics at basin scales but through individual field-scale analyses. Specifically, the objectives of this study are: (1) to develop integrated technology for evaluation and assessment of multi-scale-hydrological systems, (2) to describe efforts to automate watershed modeling input database generation, model execution, and results summarization, and (3) to apply and assess the performance of the developed system to a real scenario at basin scale (USGS—HUC06).
2. Materials and Methods
2.1. Description of the AnnAGNPS Watershed Pollution Model
The Annualized Agricultural Non-Point Source (AnnAGNPS) watershed pollution model was developed by the U.S. Department of Agriculture as a tool to quantify the potential effects of agriculture practices on the generation and transport of nonpoint source pollutants in ungauged agricultural watersheds. The AnnAGNPS model was designed to assist decision-makers in identifying sources of pollutants, selection and spatial location of conservation practices, and quantifying the integrated effect of these in time and space. Detailed descriptions of the AnnAGNPS model’s general structure, watershed characterization requirements, key modules for daily water balance and sediment and nutrients erosion and transportation calculations have been provided in previous studies [
26,
27,
28,
29,
30,
31] and therefore, only a summary description of key components pertinent to this study is included.
The AnnAGNPS model includes components for daily time step long-term continuous simulation at watershed-scale, with capabilities of modeling and simulating surface runoff, sediment, nutrient (nitrogen, phosphorus, and organic carbon), and pesticide transport, primarily from agricultural watersheds [
32]. The watershed is divided into two basic modeling units representing concentrated flow, referred to as reaches, and sub-catchments, referred to as AnnAGNPS cells [
28]. AnnAGNPS cells and reaches are hierarchically connected representing routing of surface and shallow subsurface flow throughout the watershed.
Capabilities of the AnnAGNPS model for agricultural studies include tools to estimate the effect of crop growth, canopy cover, root mass, fall height, and soil disturbance by farming equipment based on detailed input parameters characterizing farming management schedule and operations in time and space. The AnnAGNPS model contains tools to estimate loads from ephemeral gully sources [
33,
34] and potential loads reduction due to conservation practices, such as riparian vegetation strips [
35] and sedimentation ponds [
9,
14].
2.2. Enhancement to the AnnAGNPS Model
In the AnnAGNPS model, the watershed is discretized into channels and upland/fields (sub-catchments) according to the two basic modeling units considered of reaches and AnnAGNPS cells. Even though this discretization can be performed manually, the most common approach is to use GIS-based tools to define reaches and AnnAGNPS cells based on topographic analysis and user-defined topographic threshold values. Each AnnAGNPS cell needs to be characterized by a set of parameters including, but not limited to, weather, topography, land use, farming management (schedule, operations, fertilization, irrigation, etc.), and soil databases. Parameters within AnnAGNPS cells (scales smaller than the AnnAGNPS cell) are assumed to be homogeneous [
28]. The GIS-based discretization of the watershed (
Figure 1a) is internally represented by a hierarchical tree-like structure used to define the order of AnnAGNPS cell daily calculations and corresponding flow routing sequence (
Figure 1b). In this schema, reaches receive flow from AnnAGNPS cells and/or from upstream reaches, and therefore, a proper calculation sequence is necessary to assure loads are being routed from field into streams and from upstream streams to downstream streams all the way to the watershed’s outlet.
Modifications were performed to add a new basic modeling unit to the AnnAGNPS model, in addition to reaches and AnnAGNPS cells, to accommodate receiving of information from external sources. The new basic modeling unit, referred to as the “external cell-source”, was implemented to receive information on precipitation, irrigation, streamflow, suspended sediment by particle size, and chemicals from external sources. Those contributions are added as loads to a given point in the channel network—upstream of a selected reach (
Figure 1c). Additional modifications included sub-routines to read external gage station files and to revise the hierarchical tree-like structure to assure proper sequence of AnnAGNPS cells and reach calculations and flow routing subroutines. These modifications allow for integrated simulations in an ITEAMS approach where the output of one simulation can be used as input into another. Additionally, this new capability can be used in situations in which point-sources need to be simulated (like a dam release, pumping into streams, or drainage structures in urban areas).
Additionally, a new stand-alone AnnAGNPS component was developed, the AnnAGNPS Subset Tool for Independent Runs (ASTIR), to divide large functioning simulations automatically into smaller simulations and, if desired, execute them concurrently on the smaller simulations. This is an alternative to simulate large watershed systems with fine-scale characterization while reducing computational loads and execution time as the smaller simulations can be executed concurrently and are critical in developing an ITEAMS approach.
2.3. Evaluation of the AnnAGNPS ITEAMS Simulation Capabilities
The capabilities of ITEAMS were evaluated by comparing AnnAGNPS between single (standard method) and integrated (proposed method) simulations. The selected watershed is in Western Tennessee, U.S.A and contains a catchment area of 63,033 ha (
Figure 2). The watershed was discretized into 12,581 AnnAGNPS cells (sub-catchments) with average area of 5 ha and 5047 reaches with average length of 460 m. This discretization was performed by GIS analysis of topographic data using a hydrologically enforced DEM with 3-m spatial resolution and generated by a Light Detection and Ranging (LiDAR) sensor. The U.S. Geological Survey (USGS) classifies this watershed with hydrologic unit code 10 (HUC10) and further subdivides it into six sub-watersheds (six HUC12s in
Figure 2): North Fork Forked Deer River Upper (6), Cain Creek (5), Mud Creek (3), North Fork Forked Deer River Middle (4), Doakville Creek (1), North Fork Forked Deer River Lower (2).
Each of the AnnAGNPS cells was described in terms of topography, soil, daily parameters of weather and farming management schedules and operation between 1 January 2008 to 31 December 2018. Annual land use/land cover between 2008 and 2018, including crop type information, was obtained from the U.S. Department of Agriculture—National Agricultural Statistics Service Information—Crop Data Layer (CDL). Typical one-season farming management schedules and operations for dominant crops were integrated with annual sequences of crop type to generate a total of 4135 unique 11-year crop rotations (management schedules linked to farming operations). The main crop types were maize (corn), cotton, winter wheat/soybean, and soybean. The main non-crop types were forest, developed areas, grass/pasture, wetlands, and water bodies. These classes combined, crop and non-crop, represented more than 90% of the watershed.
Key AnnAGNPS reaches linking one HUC12 to another downstream of it were identified and used to split the AnnAGNPS simulation into six via both methods: manually (user-defined reach in the downstream simulation to receive information from upstream simulation) and using the ASTIR program (automated). The single simulation generated daily results of runoff and suspended sediment per five particle sizes at these selected reaches (2715, 4008, 1329, 3, and 1326) and at the outlet. Six linked simulations were performed in the following order (
Figure 2): three individual simulations of sub-watersheds 3, 5 and 6; two individual simulations of sub-watersheds 1 and 4 (in which sub-watershed 4 is linked with outputs from 3, 5, and 6); and sub-watershed 2 (linked with outputs from 1 and 4). This hierarchical subdivision allows for concurrent execution of sub-watershed simulations in three steps: first, three sub-watersheds (3, 5, and 6), followed by two (1 and 4), and then sub-watershed 2.
2.4. Application to Basin Scale
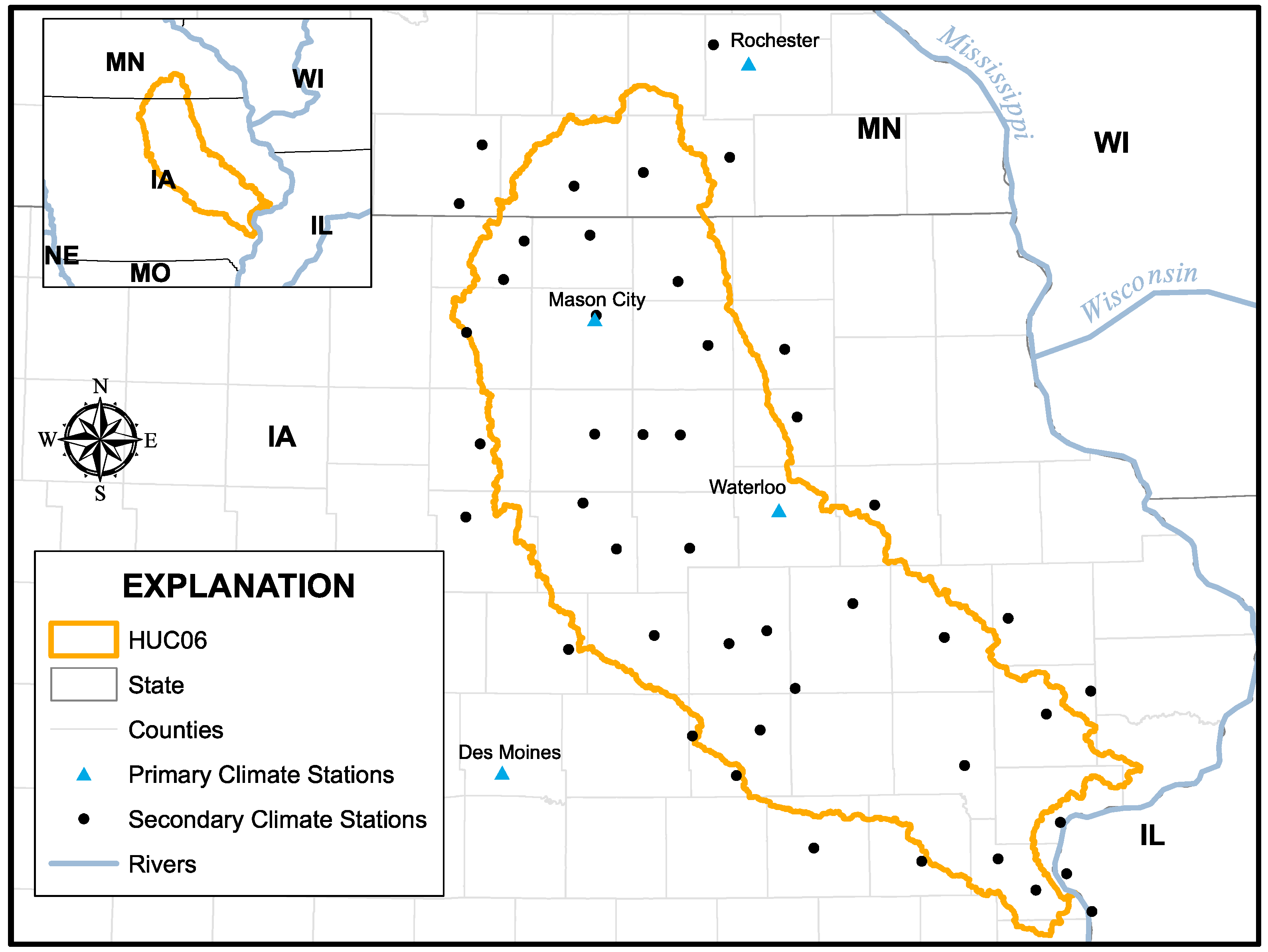
The ITEAMS modeling approach was applied to a USGS basin (HUC6) predominantly located in Iowa, U.S.A (
Figure 3). This basin covers an area of 3,268,691 ha (32,686.91 km
2) with land use/land cover predominantly agriculture. According to USDA-CDL information, between the years 2008 and 2018, the following land use/land cover represented more than 95% of the basin: corn, soybeans, grassland/pasture, deciduous forest, and developed/open space [
36].
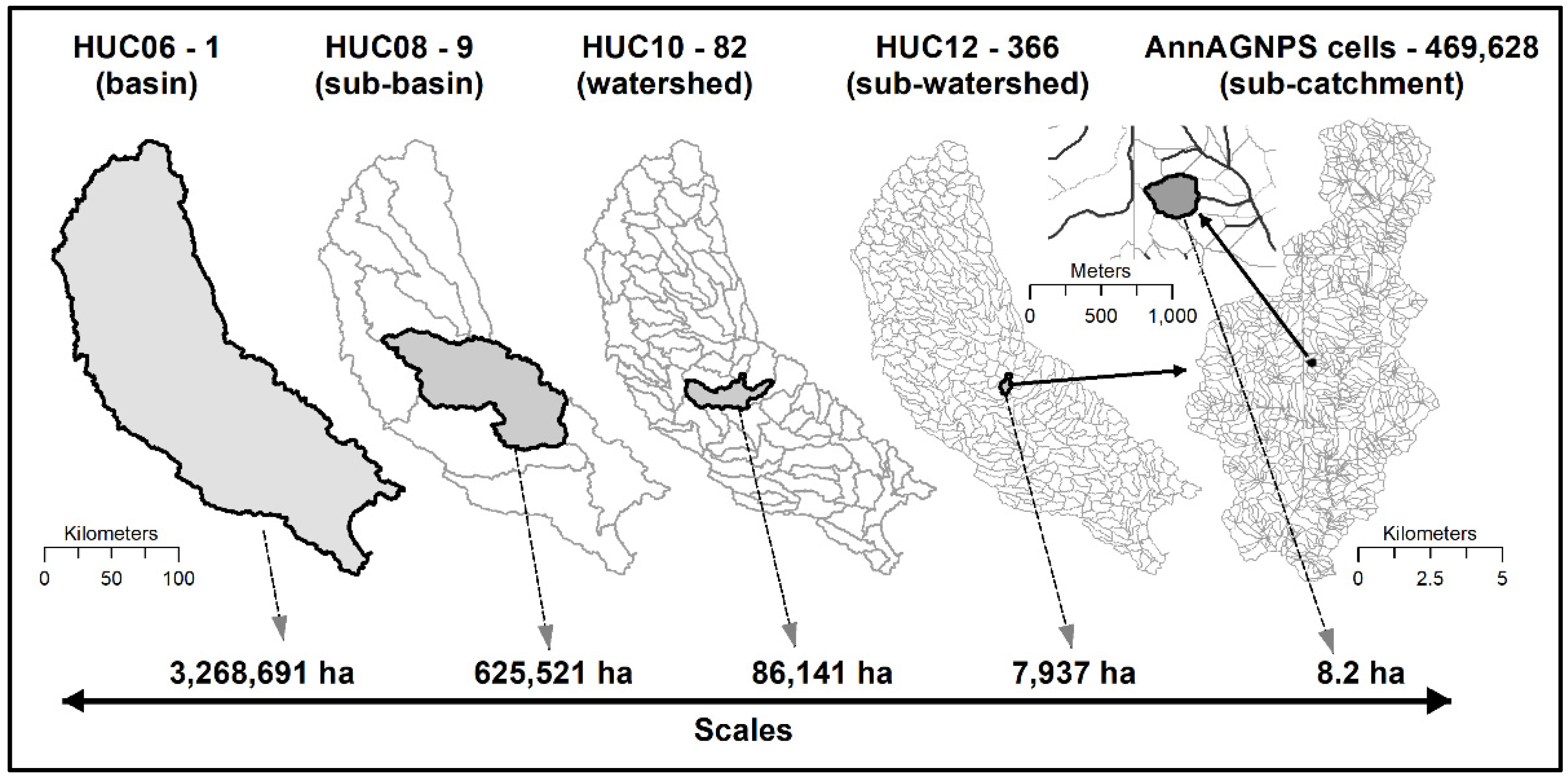
The selected basin is characterized by the U.S. Geological Survey into hydrological units. Hydrological units vary in size and are successively divided into smaller hydrologic units. Each hydrological unit is represented by a unique hydrologic unit code (HUC). The study site corresponds to HUC06–070802. This HUC06 is further subdivided into 9 HUC08s (sub-basins), 82 HUC10s (watersheds), and 366 HUC12s (sub-watersheds). Each HUC12 constituted an AnnAGNPS simulation and therefore, the 366 HUC12s were further subdivided into 469,628 AnnAGNPS cells, representing field/sub-catchment scale (
Figure 4). Results were calculated at sub-catchment scale and aggregated into sub-watershed, watershed, and sub-basin scale, demonstrating the multi-scale analysis potential of the ITEAMS simulation process (
Figure 4).
Given the large volume and sizes of datasets, it was not feasible to develop a single working AnnAGNPS simulation depicting the entire basin at the field-scale to automatically develop the ITEAMS approach using the ASTIR computer program. Therefore, multiple automated procedures were developed to process all these datasets and generate the necessary AnnAGNPS ITEAMS input databases for the 366 sub-watersheds (HUC12s) considered. Custom Python scripts were developed and integrated within the AnnAGNPS computer program and its accompanying tools. These analyses were carried out in a scientific workstation with a Linux operating system due to the high computational requirements of processing speed (CPU clock), concurrent runs (number of CPU cores) and overall available RAM memory.
2.4.1. Topographic Analysis and Sub-Watershed Characterization
Topographic information was obtained from DEMs generated from LiDAR surveys. Individual DEMs were provided per county (5 in Minnesota and 31 in Iowa) at 3-m spatial resolution and resampled to 9-m into a continuous virtual raster grid covering the entire study area. Provided USGS HUC12s boundaries were buffered by 500 m and their rectangular extent coordinates were used to clip the virtual raster grid, generating 366 new rectangular 9-m DEM raster grid files.
Each of these DEMs were preprocessed using the AnnAGNPS TOPAGNPS computer program three times [
37]. In the first processing step, the TOPAGNPS program was used to determine the sub-watershed outlets. The TOPAGNPS program was applied in reduced mode to perform standard GIS analysis of pit filling, flow direction, and flow accumulation calculations. The intersection of the original HUC12 boundary (vector) with the raster grid cell with the highest flow accumulation identified the outlet. Upon quality control inspection, this automated procedure identified the correct outlet location in most HUC12s, with a few exceptions in which manual outlet placement was required. In the second processing step, the TOPAGNPS computer program was used in full mode and the outlet locations were entered along with user-provided topographic thresholds of Critical Source Area (CSA) of 10ha and Minimum Source Channel Length (MSCL) of 250 m. This step yielded new sub-watershed boundaries, channel network (AnnAGNPS reaches), sub-watershed division into sub-catchments (AnnAGNPS cells), and generation of the AnnAGNPS input reach and cell data sections (
Figure 5a,b). Visual inspection of the results indicated the automated procedure worked in the majority of HUC12s and only a few HUCs required reprocessing using hydrological enforcement to assure human-made structures were not incorrectly blocking flow (bridges, culverts, etc.). In the third processing, sub-watershed boundaries of HUC12s that flow into the HUC12 being investigated were used to mask out parts of the DEM and force the TOPAGNPS program to re-generate outputs. This last step was needed to assure there is no overlap between sub-watersheds.
2.4.2. Meteorology
Daily observed and synthetic weather parameters for the time period between 1 January 2006 and 31 December 2018 were used. Observed climate measurements were gathered from the U.S. National Oceanic and Atmospheric Administration (NOAA)—Global Historical Climatology Network Daily [
38] within and around the selected basin (
Figure 3). A total of 45 weather stations were selected (black circles in
Figure 3), quality controlled, and defined as secondary climate stations within the AnnAGNPS modeling schema. These weather stations were assigned to individual AnnAGNPS cells based on GIS zonal analysis of the AnnAGNPS cell layer and the weather station Voronoi diagram layer. These stations provided daily temperature (min and max) and precipitation. Four additional stations were selected because they provided the long-term statistical parameters (blue triangles in
Figure 3) needed to generate synthetic estimates of minimum and maximum temperatures, precipitation, dew point, sky cover, wind speed, and solar radiation using the Generation of weather Elements for Multiple applications (GEM) model. The GEM climate model utilizes local historical climate data and long-term statistical parameters to produce continuous synthetic daily climate data [
39]. Synthetic estimates of temperature and precipitation were replaced with observed ones based on spatial proximity. These four sites were designated as primary weather stations because they contained continuous datasets (no gaps). Primary weather stations were assigned to sub-watersheds (HUC12s) using GIS zonal analysis of the HUC12 boundaries and the primary weather station Voronoi diagram layer. During individual AnnAGNPS simulations, weather input parameters were read from the secondary weather station by default, and in case of missing values, were then read from the primary weather station. This allowed for a continuous weather input parameter while, at the same time, accounting for spatial/temporal variations captured by the large number of observation stations.
2.4.3. Soil
Soil data were gathered from the USDA, Natural Resources Conservation Service, (NRCS) website [
40]. Two types of datasets were downloaded: a GIS layer with soil type and a tabular database describing soil composition, physical properties and individual soil layers (one set per county). The soil group ID was merged with the county ID so that unique soil IDs were generated. The GIS layer was mosaiced into a single file and rasterized at 9 m spatial resolution. Dominant soil type was assigned to each AnnAGNPS cell by GIS-based zonal analysis and this information was updated in the AnnAGNPS cell data section for each HUC12 representing an individual AnnAGNPS simulation (
Figure 5c). Tabular data were processed using the NASIS Import to the AnnAGNPS (NITA) computer program (distributed as part of the AnnAGNPS package). This software ingests tabular soil information downloaded from the USDA—National Soil Information Systems (NASIS) in its original file format, preprocesses the information to perform basic quality control, and generates two AnnAGNPS input database files: soil type and soil layers (
Figure S1). A total of 3440 unique soil types based on unique ID combining soil groups and county numbers were considered.
2.4.4. Land Use/Land Cover and Farming Management Database
Crop type and land use/land cover information was gathered from the CDL raster grid files at 30 m spatial resolution [
36]. Eleven GIS layers were downloaded representing individual years from 2008 to 2011. Similar to the soil assignment, a GIS zonal statistic operation was performed to assign the dominant crop type to each AnnAGNPS cell for each year considered (
Figure 5d). The result of this analysis was a 11-year sequence of crop/land use type for each AnnAGNPS cell. The 11-year sequence of crop type in combination with typical farming practices representing one season were entered in custom scripts to generate 11-year crop rotations describing individual AnnAGNPS cells (
Figure S2). Typical farming practices include management schedules as a temporal series of in-field operations. Each farm management schedule contains a continuous sequence of activities from all years considered in the simulation [
27].
2.4.5. Hierarchical Flow Network
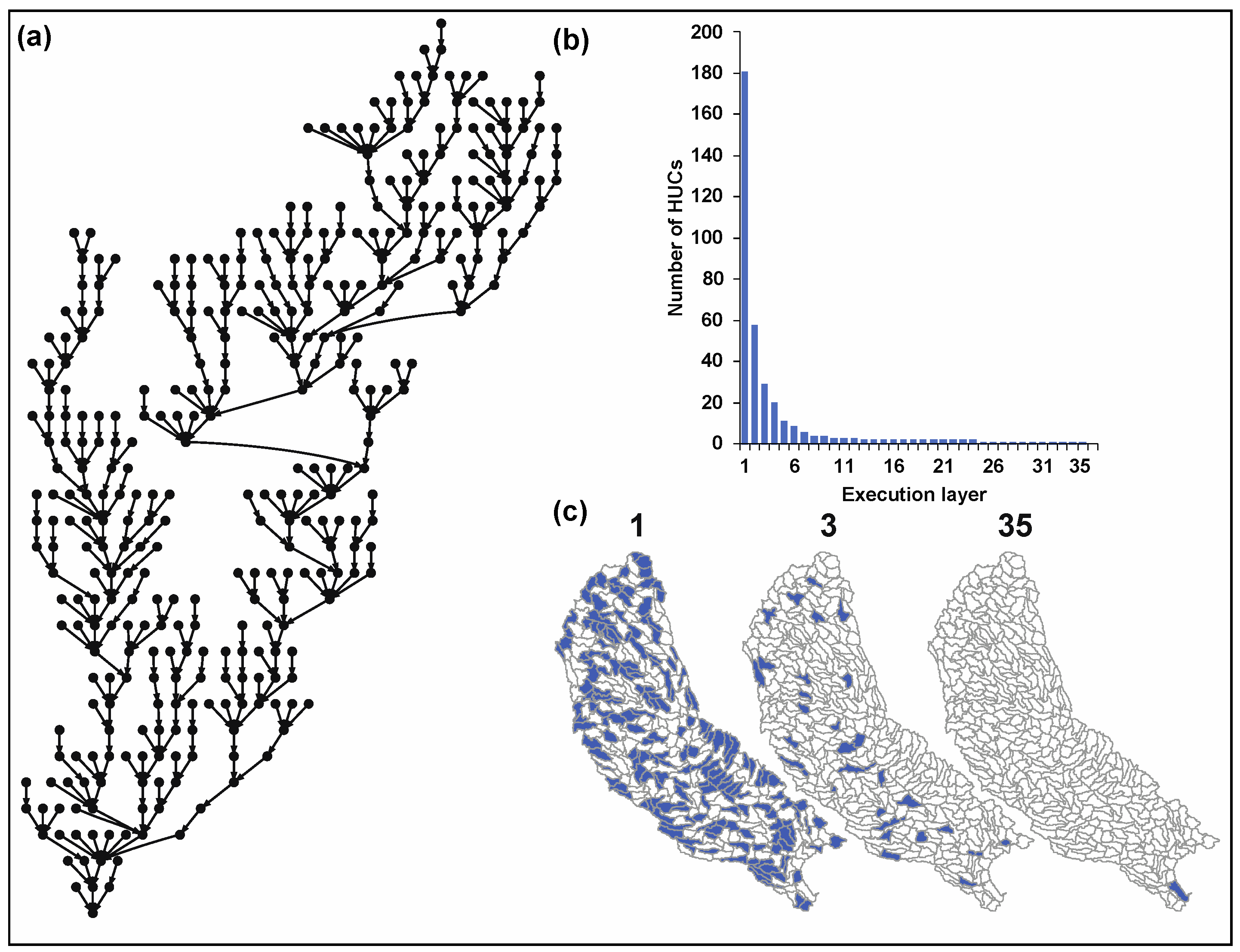
In the USGS framework, sub-watersheds (HUC12s) flow into another downstream sub-watershed. This hierarchical flow determines the sequence of execution of linked AnnAGNPS simulations. A hierarchical tree-like structure was created based on the USGS framework and it was used to define the sequence and connectivity between AnnAGNPS simulations (
Figure 6a). A total of 35 layers were obtained. Each layer in the hierarchical tree-like structure represented a step and consisted of a set of independent AnnAGNPS simulations that could be executed concurrently. For example, the first layer with 181 sub-watersheds constituted the most upstream sub-watersheds (sub-watersheds that did not receive flow from any other sub-watersheds), and therefore, could be executed concurrently (
Figure 6b). The second layer, with 58 sub-watersheds, could also be executed concurrently but only after all AnnAGNPS simulations listed in layer 1 had been completed, because HUC12s in the second layer receive flow from HUC12s in the first layer. Spatially, the lower layers were spread throughout the watershed and higher layers tend to be more concentrated in the downstream portion of the basin (HUC06) as they receive flow from several upstream HUC12s (
Figure 6c). Custom Python scripts were developed to generate linked simulations input databases, execute targeted simulations concurrently, and record outputs.
3. Results and Discussion
3.1. Evaluation of the ITEAMS Approach
Results from the ITEAMS simulations, assembled manually and using the ASTIR program, were compared to results from the single simulation, which was considered the reference. No difference was observed between the ITEAMS simulations generated using the ASTIR program and generated manually, and therefore, only the manually integrated results are reported. Analyses were performed using load estimates from the AnnAGNPS model at reaches 1326, 2715, and at the outlet. The largest differences were observed at the outlet and therefore, these results were selected to be presented.
Daily analysis between 2008 and 2018 of simulated runoff and suspended sediment (clay and silt) loads were carried out using standard statistical metrics of Pearson’s correlation coefficient, Nash–Sutcliffe, percent bias, and RMSE-observations standard deviation ratio (RSR) [
41]. Minimal differences in runoff between the two simulation methods were observed. Based on threshold metrics proposed by Moriasi et al. [
42], all metrics were within the very good category at daily time scale (
Table 1). Differences between these methods were mainly in suspended sediment loads represented by PBIAS values for clay and silt particle sizes (
Table 1).
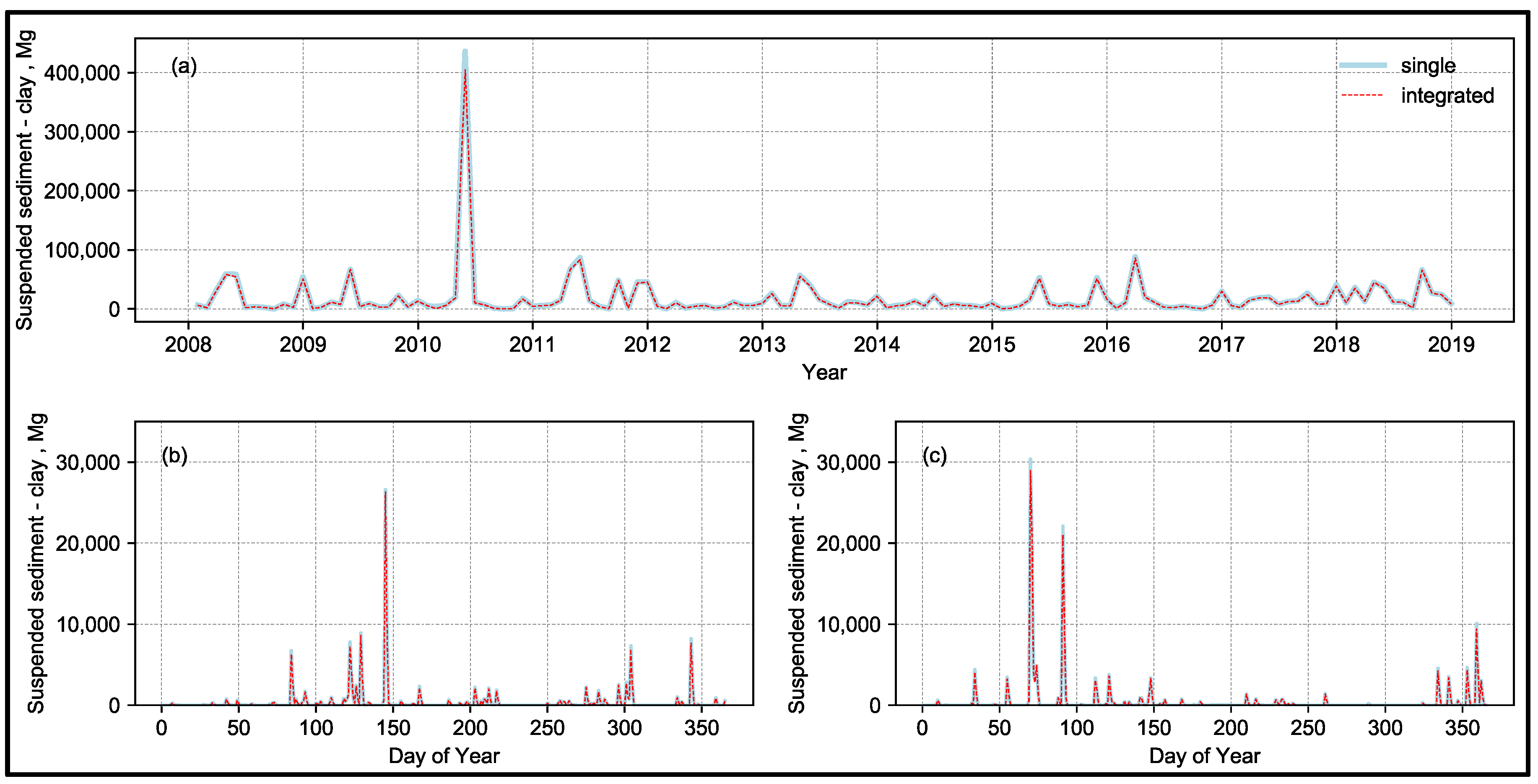
Upon close inspection, suspended sediment estimates are underestimated by the AnnAGNPS ITEAMS simulations during high-intensity events (
Figure 7). When considering the entire simulation period at a monthly time scale, the main difference between the two methods is in May 2010, during a 1000-year event (
Figure 7a). At the daily time scale, a similar pattern was observed, but at a smaller intensity (
Figure 7b,c). Based on these metrics, it was perceived that the developed ITEAMS simulation technology generates runoff similarly to the single simulation, even at daily time scale. Suspended sediment was slightly underestimated during high intensity events, especially at daily time steps, but this underestimation was smoothed out at monthly and annual time scales.
3.2. Application to Basin Scale
3.2.1. Automated Input Database Generation
Significant time and resources were devoted to gathering, processing, and developing AnnAGNPS input databases. Characterization of all 469,628 AnnAGNPS cells regarding topography, weather, soil, and farming management schedules and operations was the foundation for the subsequent hydrological modeling efforts. Utilization of semi-automated procedures to pre-process, analyze, and generate the necessary input for AnnAGNPS simulation yielded a large database describing each sub-catchment (field scale).
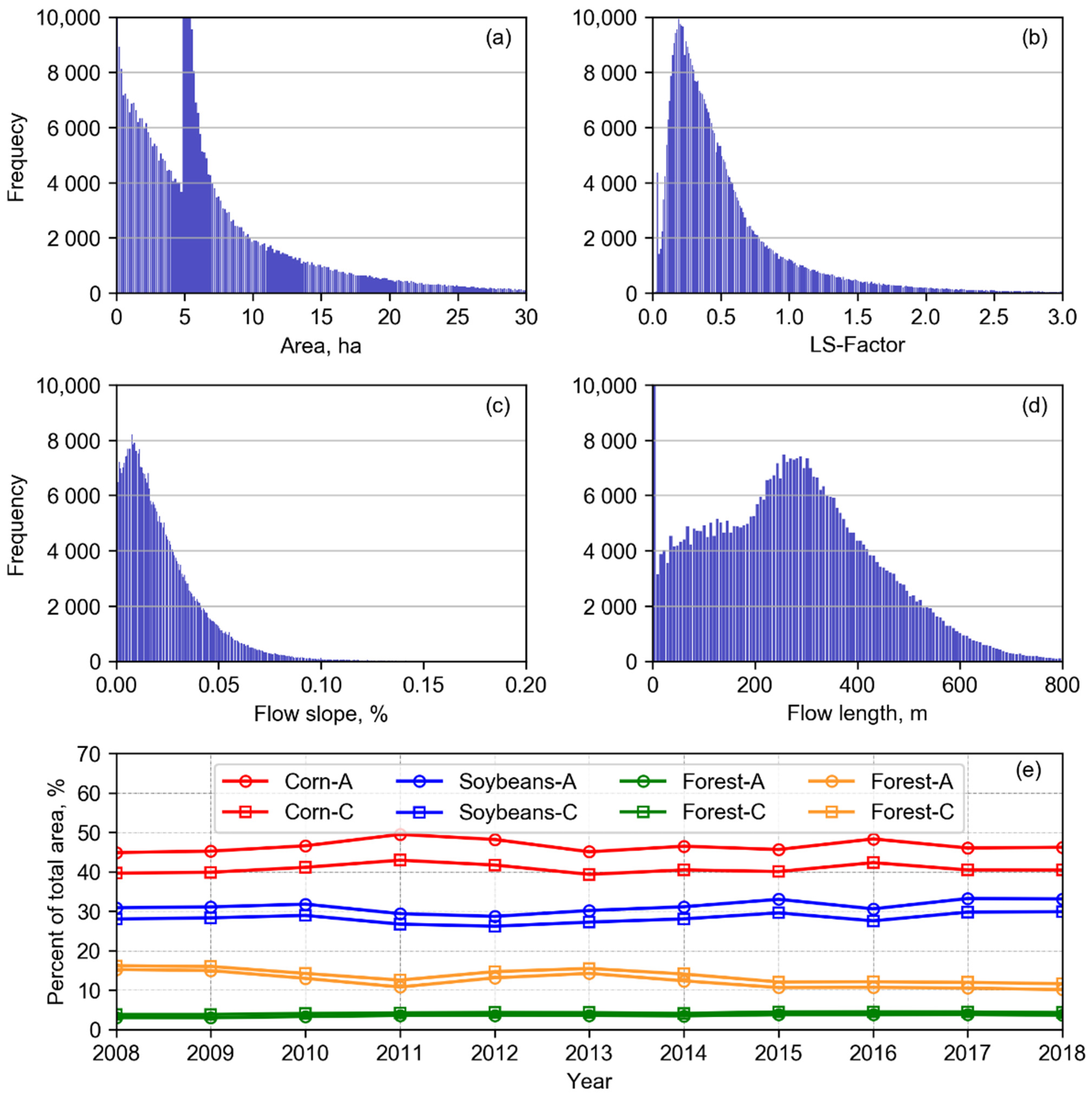
For instance, the topographic characterization of each AnnAGNPS cell determines how hillslopes will be internally considered when using the Revised Universal Soil Loss Equation (RUSLE) algorithm [
28,
43]. The definition of AnnAGNPS cells and reaches was performed using the TOPAGNPS GIS software package based on user-defined input parameters of MSCL and CSA and combined with custom scripts. The mean AnnAGNPS cell (sub-catchment) area was 6.8 ha with a standard deviation of 6.6 ha (
Figure 8a). The peak in the area histogram is due to AnnAGNPS cells flowing to the upstream end of streams (cell C1 in
Figure 1a) which were defined by the MSCL. AnnAGNPS cells flowing downstream of streams are defined by CSA (cells C2-5 in
Figure 1a). In the TOPAGNPS computer program, the RUSLE LS-factor is calculated for all raster grid cells (DEM spatial resolution) and the RUSLE LS-factor for an AnnAGNPS cell is calculated by a weighted average of all raster grid cells within it. In this study, the topographic characterization of these AnnAGNPS cells yielded a mean of 0.04 and standard deviation of 0.05 (
Figure 8b). Within each AnnAGNPS cell, the slope (
Figure 8c) and length (
Figure 8d) of the dominant flow was also recorded.
Another example is the description of crop type/land cover by assignment of the dominant class to each AnnAGNPS cell. The original CDL dataset is provided as a raster grid at 30 m spatial resolution. A comparison of the percent of the total basin area for the four dominant crop type/land cover (95% of the basin) calculated based on the CDL raster grid layer (count of 30 × 30 m raster grid cells) and calculated based on dominant crop type assigned to AnnAGNPS cells (accumulated AnnAGNPS cell area) indicates a great correspondence between the two datasets (
Figure 8e). Annual trends are represented adequately by the AnnAGNPS cells and therefore, improve confidence in the simulation results. The highest difference is 6.5 percentage points for maize/corn in 2011. The daily time step combined with the utilization of modeling units at small scales captures spatial-temporal variations of natural and anthropogenic parameters at field scale.
3.2.2. Sediment Yield
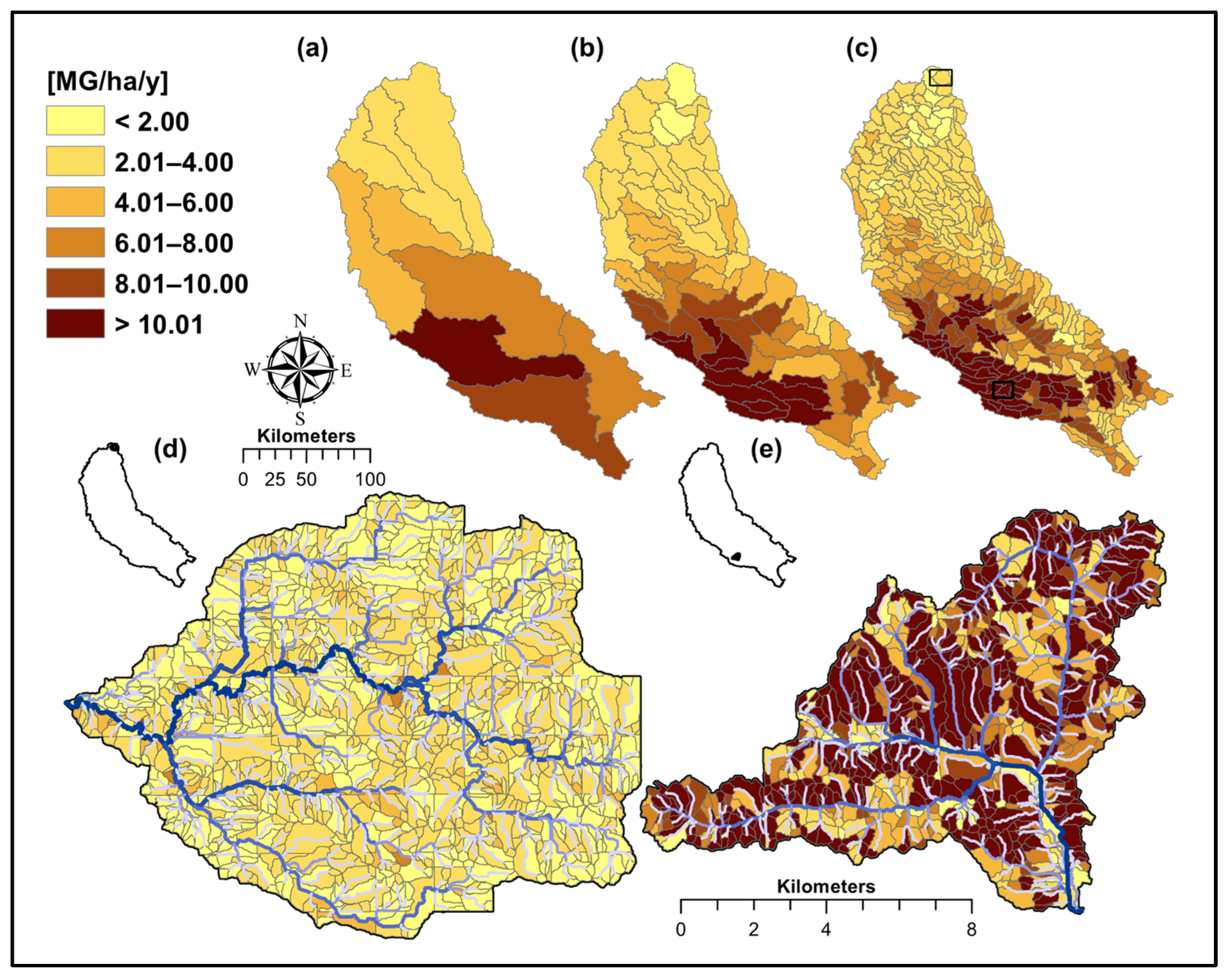
The term sediment yield refers to sediment detached and transported out of the hillslope; i.e., eroded from the field and transported to streams after accounting for deposition. Within the AnnAGNPS model, this information is calculated at the daily time step for surface flow, suspended sediment, and chemicals. Results can be reported for all AnnAGNPS cells daily, but in this study, sediment yield at different particle sizes was recorded as annual average per unit of area for all AnnAGNPS cells (
Figure 9). Estimates for individual AnnAGNPS cells were aggregated to sub-watershed (HUC12), watershed (HUC10), and sub-basin (HUC08) scales. The calculation of all hillslopes within a sub-watershed and the corresponding aggregation of these results to larger scales provided a standard procedure to estimate sediment erosion at regional scales.
Information regarding calculations of sheet and rill erosion using the RUSLE algorithm can be outputted per individual AnnAGNPS cell for improved understanding of sediment erosion/yield estimates (
Figure 10a,b). In addition to reporting suspended sediment results as annual average per unit of area (
Figure 9), outputs can be generated for different particle sizes (
Figure 10c) or as ranked ratio (
Figure 10d). For example, the 100 AnnAGNPS cells highlighted in
Figure 10d correspond to 11% of the sub-watershed total area but they contribute, on average, 31% of the total clay leaving fields and flowing into streams. This plethora of information at such high-resolution support the development of conservation alternatives for individual sub-watersheds but with the option to be scaled up for region assessment.
3.2.3. Load
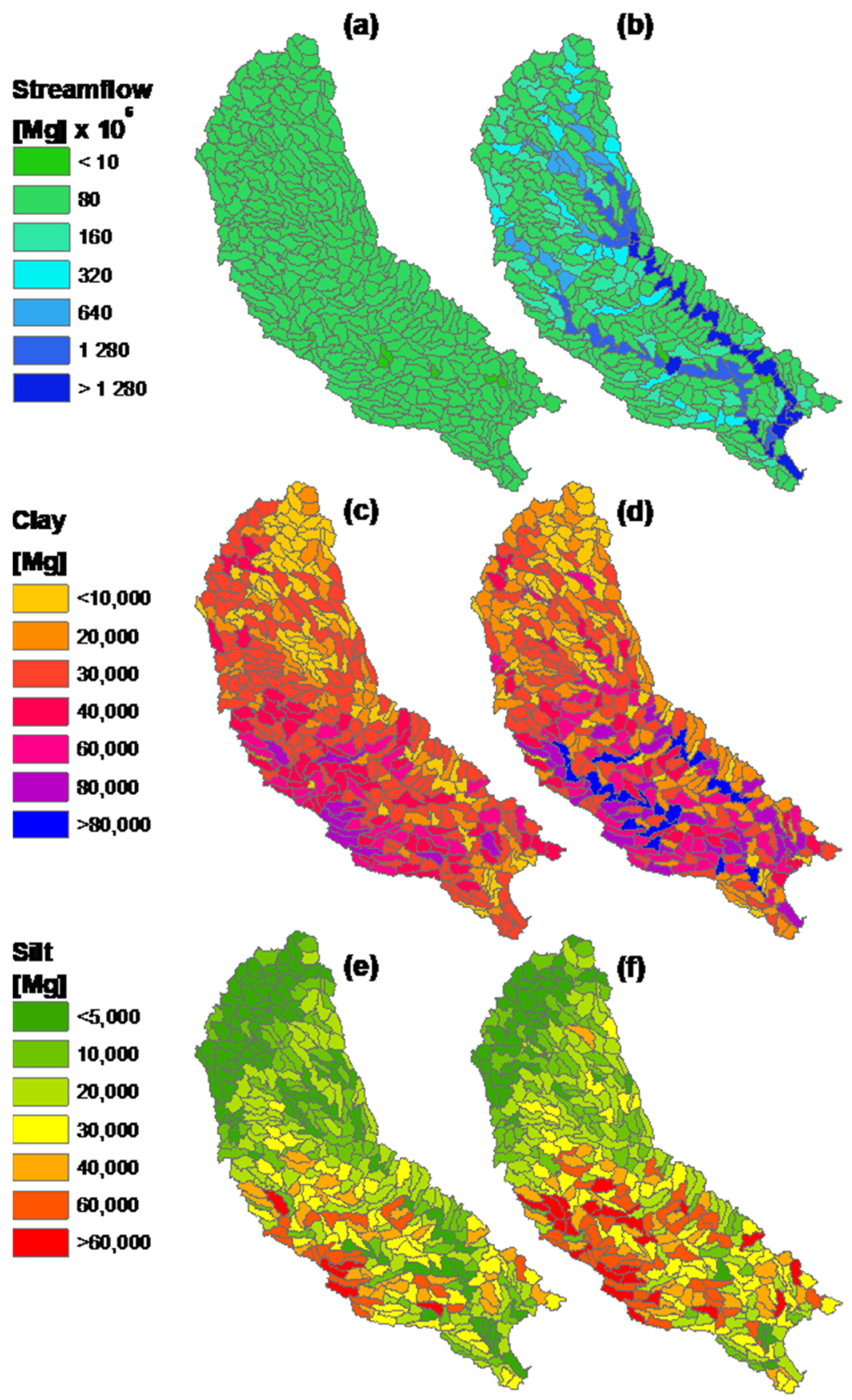
Load is defined as the amount of runoff, sediment, or nutrients reaching the sub-watershed outlet and is calculated by routing flow throughout the study site and by accounting for the integrated effect of channel and upland processes. Contrasting 366 single with AnnAGNPS ITEAMS simulations demonstrates how loads are transferred from one sub-watershed to another (
Figure 11). In the ITEAMS approach, loads increase from upstream to downstream along the main river and streams, as expected. However, unlike streamflow, suspended sediments of clay and silt particle sizes vary in space, indicating the model’s capability to depict changes in transport capacity and streamflow volumes (
Figure 11).
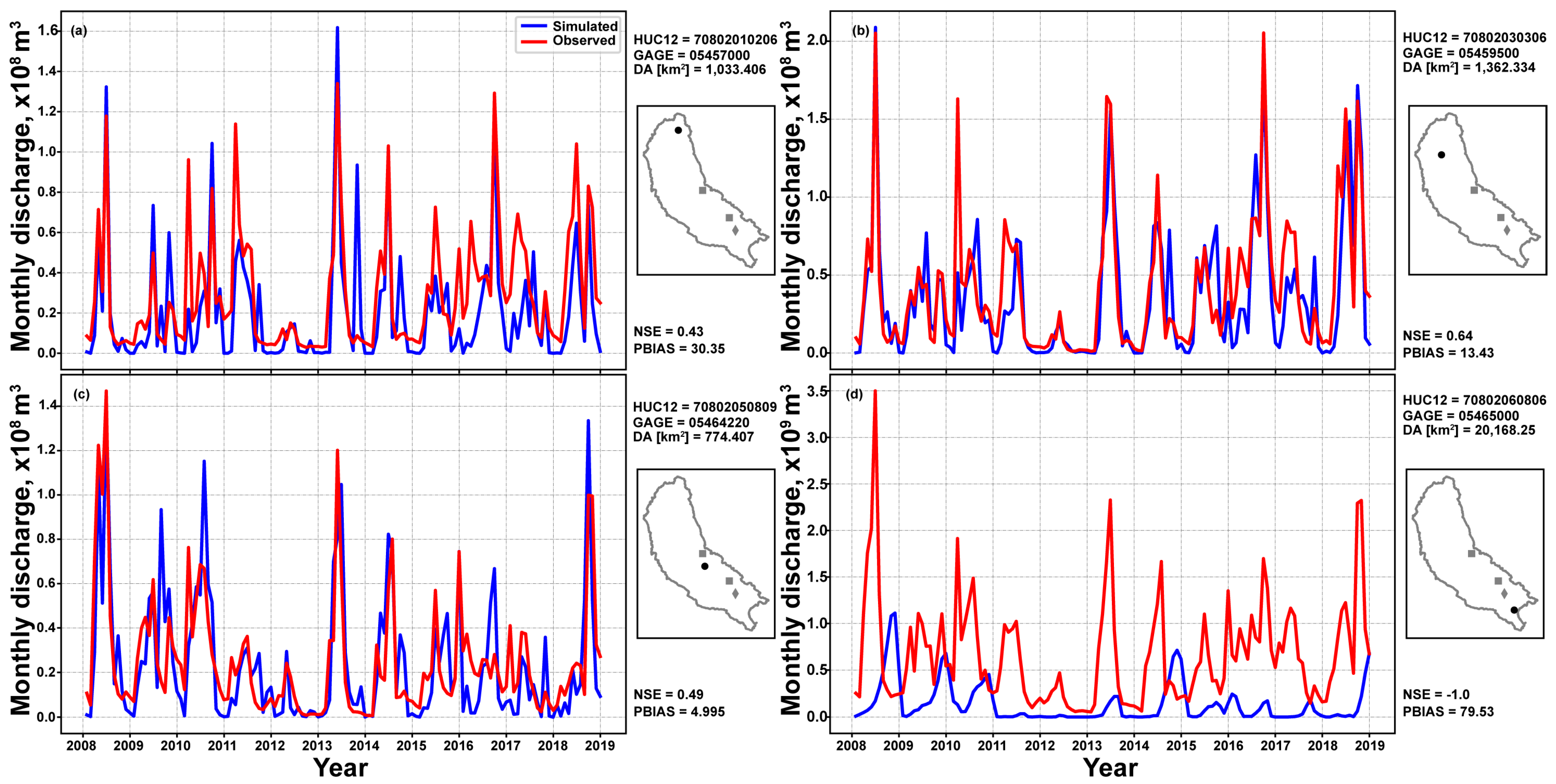
Comparison between simulated and observed streamflow at monthly time scale was performed (
Figure 12). These analyses were not intended to quantify the accuracy of these simulations, but rather demonstrate the potential effect of anthropogenic factors to hydrology in general and specifically to the ITEAMS approach. It is important to note that no calibration was performed and that the AnnAGNPS model does not simulate groundwater flow into nor from streams, limiting baseflow estimation. Two metrics of NSE and PBIAS as proposed by Moriasi et al. [
41,
42] were used to assess agreement between the two datasets. Overall, there was a very good agreement between parts of the basin located in rural areas and not being influenced by constructed structures (
Figure 12a–c). NSE values of 0.43, 0.64, and 0.49 demonstrate a good agreement between the two datasets indicating proper description of flow timing even when transferred from one simulation to another. However, PBIAS values from 4.9% to 30.3% indicate an average underestimation of monthly flow which could be attributed to differences in baseflow contribution to streamflow between simulated and observed. It is estimated that streamflow in the observed dataset (red line in
Figure 12) is composed of surface flow (from local sub-watershed and from all upstream sub-watersheds) combined with potential contributions from groundwater flow, while streamflow from simulated streamflow is composed only of surface flow (compounded flow from increased time of concentration as result from multiple contributing sub-watersheds). Comparisons further downstream (
Figure 12d) yield statistical values that are less desirable. Not only the amplitude but also the timing of events does not match. This can be attributed to the fact that this stream gage is located downstream of two cities (squares in
Figure 12) and a large dam (diamonds in
Figure 12). Managed flow represents a challenge in any hydrological modeling study, including an ITEAMS approach, in which municipalities and dams withdraw/release and affect the hydrology and deserve special attention.
3.3. Limitations
Although the entire procedure of preprocessing, GIS analysis, AnnAGNPS input database preparation, AnnAGNPS hierarchical execution, and results summarizing can be automated, the process is not without challenges. There were steps in which the fully automated procedure had to be quality controlled and revised manually. Soil databases were preprocessed using the NITA program to remove duplicated entries and address minor rounding errors; there were still inconsistencies in the database that needed to be identified and quality controlled.
Another example was the automated determination of the sub-watershed outlets, sub-watershed boundaries, and channel network. No comprehensive hydrological enforcement procedure was applied to the DEMs. Similarly, the automated procedure to match outlets from upstream sub-watersheds with reaches in downstream sub-watershed had to be inspected and, in a few cases, revised. Due to the large size of the study area, it was not feasible to generate a single functioning AnnAGNPS simulation which could be automatically partitioned using the ASTIR computer program. Utilizing a script to perform the “manual” assembling of the ITEAMS simulations poses some challenges. Both automated procedures were applied and, based on visual inspection, a few HUC12s needed to be reprocessed with basic hydrological enforcement to account for large human-made structures being interpreted as dams and artificially affecting surface flow. It is expected that the quality and spatial resolution of the DEM affect the determination of surface flow and subsequent derived products.
The AnnAGNPS watershed pollution model contains algorithms to account for daily water balance yielding surface and shallow subsurface flow at sub-catchment scale. The AnnAGNPS model currently does not account for ground water movement and therefore, the generation of baseflow. Applying the ITEAMS approach to large systems poses the challenge of baseflow separation when comparing with observed values. Downstream sub-watershed streamflow includes contributions from surface flow and baseflow locally and also from the entire upstream system. Therefore, this limitation adds uncertainty when comparing simulated with observed estimates in large systems.
3.4. Implications for Hydrological Processes Understanding
The quality of the hydrological studies depends on how well they represent existing conditions in the study area. In studies covering large areas, it is required to describe different hydrological drivers, anthropogenic and natural, varying in time and space. The development of multiple integrated hydrological simulations at high spatial resolution (basic modeling units <10 ha) offers the capability to customize individual simulations to local conditions that are still accounted for when considering the overall hydrology of the study region. Examples of local hydrological conditions include, but are not limited to, multiple sources entering the system at punctual locations such as dam releases, urban releases/withdraw, irrigation sources from ground water and ditches, sediment retention ponds, implementation of field-scale conservation structures, capture of unique farming practices, and others. This level of description offers a unique platform for quantifying daily water balance to support water quantity and quality studies that capture local characteristics but provide regional information.
Furthermore, the developed system using the AnnAGNPS watershed pollution model offers the capability of integration with other hydrological/erosion models. For enhanced modeling of channel hydraulics, sediment transport and bed adjustment processes, and streambank erosion, the AnnAGNPS model already has the necessary components for linkage with the Conservation Channel Evolution and Pollutant Transport System (CONCEPTS) model and the Stream Network Watershed Scale Model (CCHE1D) [
44,
45,
46]. The AnnAGNPS model can also be linked with the Revised Universal Soil Loss Equation, Version 2 (RUSLE2) for estimation of sheet and rill erosion using more complex hillslope profiles [
28].
The developed set of 366 integrated AnnAGNPS ITEAMS simulations (input databases and respective output results) can serve as a template to be used by researchers with expertise in different hydrologic components to enhance it and build a more comprehensive hydrological representation of the system that assures all the processes are accounted for and integrated.
3.5. Implications for Resource Management
Technological improvements in computing, storage, and overall data management can now be leveraged to generate computer simulations of larger natural systems at higher resolution, represented by enhanced discretization, characterization, and calculations at field scales but, at the same time, capable of accounting for the complex individual field’s contribution to the entire hydrological system. Technology like the proposed in this study could support the development of nonpoint source pollution trade markets and targeted mitigation at field scale that would support efforts of reducing sediment/chemical loads at basin-scale (and larger) water bodies.
The proposed methodology could be expanded to the entire U.S. Midwest or even the agricultural continental U.S. to enhance estimates of soil loss due to agricultural activities while, at the same time, capturing local drivers impacting soil erosion and their impact on ecosystems. This system could be integrated with punctual monitoring sites and long-term experimental watersheds not only to quantify the accuracy of estimates but also to provide feedback into the simulations.
Furthermore, the utilization of computer modeling technology is often not adopted by conservation action agencies due to the challenges in data collection, preprocessing, and database input generation or lack of technical personnel dedicated to this task. Action agencies sometimes rely on partners to develop hydrological simulations for selected sub-watersheds, but these solutions are site-specific and often do not scale up to the entire region. Application of a standard and integrated multi-scale approach covering the entire region offers the opportunity to generate GIS layers with precalculated results covering different farming practices and/or conservation alternatives, thus facilitating their adoption by action agencies. Sharing of input databases and respective output results describing individual AnnAGNPS cells could support action agencies in developing and implementing target conservation practices. Alternatively, they could be used by action agencies as a starting point for future studies to incorporate custom local farming practices and account for their impact on the entire region. Furthermore, scale often dictates jurisdictions for management of natural resources [
47]. Having a multi-scale approach has the potential to promote collaboration between multiple stakeholders through the utilization of a more comprehensive and shared approach given that complex relations between nonpoint source and ecology are not constrained by political or hydrological unit boundaries [
47].
3.6. Future Developments
Future studies will include the development and evaluation of methods to account for anthropogenic factors controlling water quantity such as irrigation practices, urban center withdraw/releases, and release by large dam structures. Further characterization and understanding of these hydrological drivers will support efforts for a more holistic representation of the system’s hydrology.
Further enhancements will include the characterization and estimation of additional sources and sinks. One important source of sediment erosion and transport is ephemeral gully. The AnnAGNPS watershed pollution model already contains modules to estimate the contribution of ephemeral gullies [
33] and this source is considered an important, but yet not addressed, source of nonpoint source pollution in the U.S. Midwest region. Similarly, the impact of existing conservation structures, such as riparian vegetation strips and sediment retention ponds, will be implemented. Although the AnnAGNPS watershed pollution model already contains tools to estimate these sources and sinks, new automated/semi-automated technology needs to be developed to identify and describe existing structures at field scale but in such large areas—for example, automated extraction of information from publicly available geospatial datasets for mapping of natural and constructed riparian field strips, grassed waterways, and tillage practices.
Finally, sheet and rill estimations will be enhanced through performing calculations at scales smaller than the basic modeling units (AnnAGNPS cells) by integrating the AnnAGNPS model with a two-dimensional raster grid-based version of the Revised Universal Soil Loss Equation, Version 2 (RUSLE2) erosion model [
48]. This will allow for detailed estimation of sheet and rill erosion at sub-field scale while, at the same time, routing field sediment/chemical yield within and beyond the sub-watershed, and generating spatially continuous estimates at the basin scale.
4. Conclusions
Advances in computing capabilities now offer scientists the opportunity to develop comprehensive, multi-scale, and integrated systems for improved management of natural resources impacted by agriculture. Computing power can be used for expedited distributed calculations of high-resolution hydrological models covering very large areas. This concept was evaluated in this study.
The AnnAGNPS watershed pollution model was enhanced with new components designed to allow the integration of individual simulations into an ITEAMS component. Quantitative assessment of stream flow and suspended sediment estimates between the standard single simulation and distributed integrated simulations indicated no difference in stream flow and small underestimation (<5.5%) of suspended sediments, mainly during high-intensity rainfall events. These findings assured agreement between both methods.
The AnnAGNPS ITEAMS approach was applied to a basin with a total area of 3,268,691 ha which was discretized into 469,628 sub-catchments with an average size of 6.8 ha. Discretizing and describing topography, weather, soil, farming management schedule and operations for such a large number of sub-catchments required the development of automated/semi-automated procedures. The resulting 366 linked AnnAGNPS simulations were executed hierarchically, generating estimates of water and suspended sediment yield (leaving fields) and loads (reaching outlets). Despite challenges on original data inconsistencies and quality control, this pilot study revealed the multi-scale ITEAMS approach is a viable alternative for bridging the gap between local and regional hydrologic studies. Findings demonstrate the feasibility of modeling and simulating large areas, in which (a) all sub-watersheds within the basin are described, (b) detailed characterization at field scale is used, (c) simulations are performed using a single modeling tool (AnnAGNPS) under standard assumptions, and (d) aggregation of results at lower resolutions is possible. It demonstrates the potential to expand this work to incorporate coordinated efforts of research and action agencies to develop a comprehensive Spatial Decision Support Tool (SDST) specifically designed to evaluate the hydrological and agricultural impact on nonpoint source generation and mitigation. This SDST would help evaluate the effectiveness of conservation practices locally and, more importantly, the aggregated effect of multiple spatially distributed conservation practices to the entire region (basin or continent). Furthermore, such SDST would support evaluation and preparation of future changes in agricultural practices, requirements in conservation adoption, and climate variability.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}