
Seasonal Prediction of Summer Precipitation in the Middle and Lower Reaches of the Yangtze River Valley: Comparison of Machine Learning and Climate Model Predictions



Abstract
:1. Introduction
2. Data and Prediction Methods
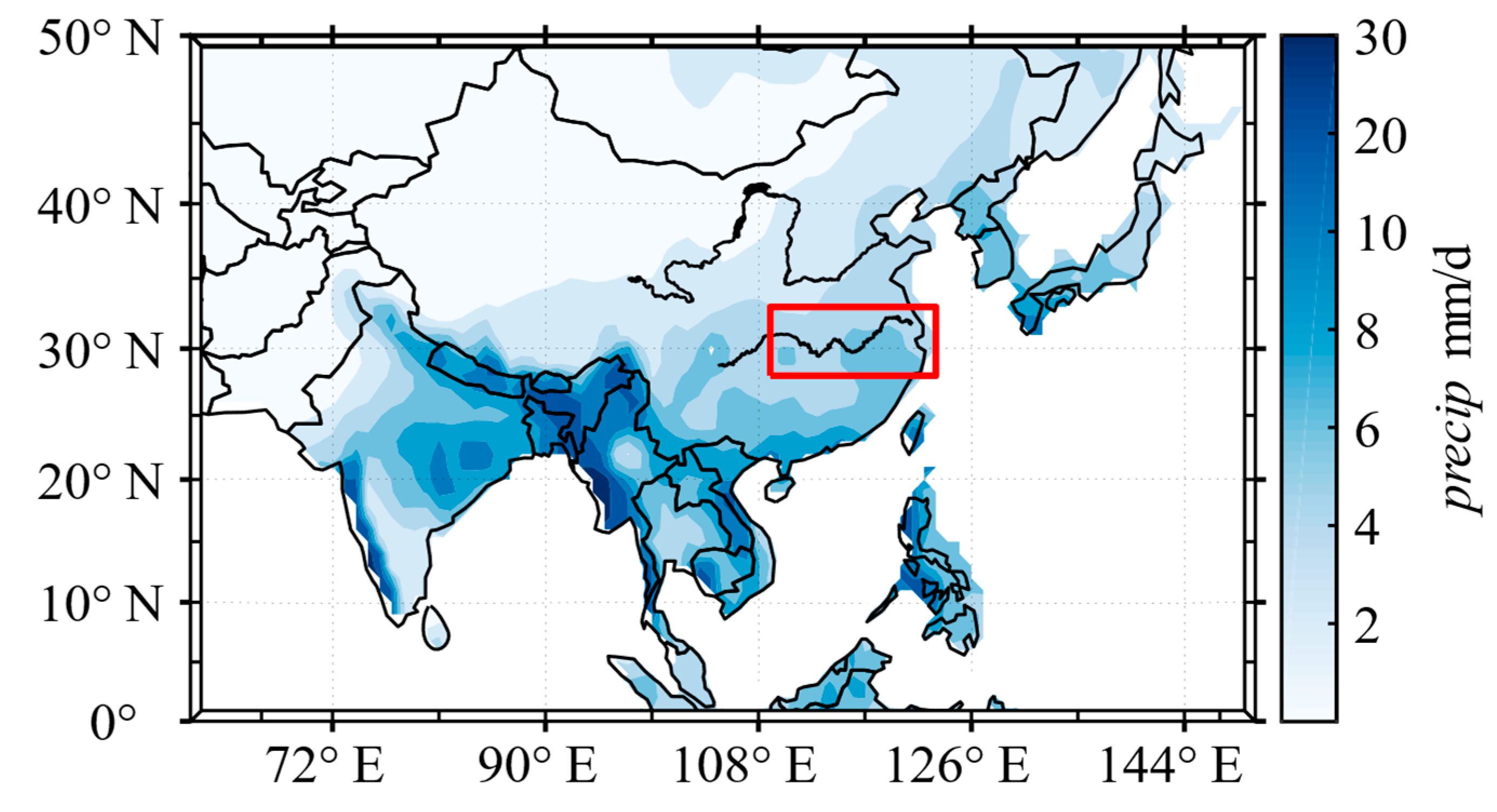
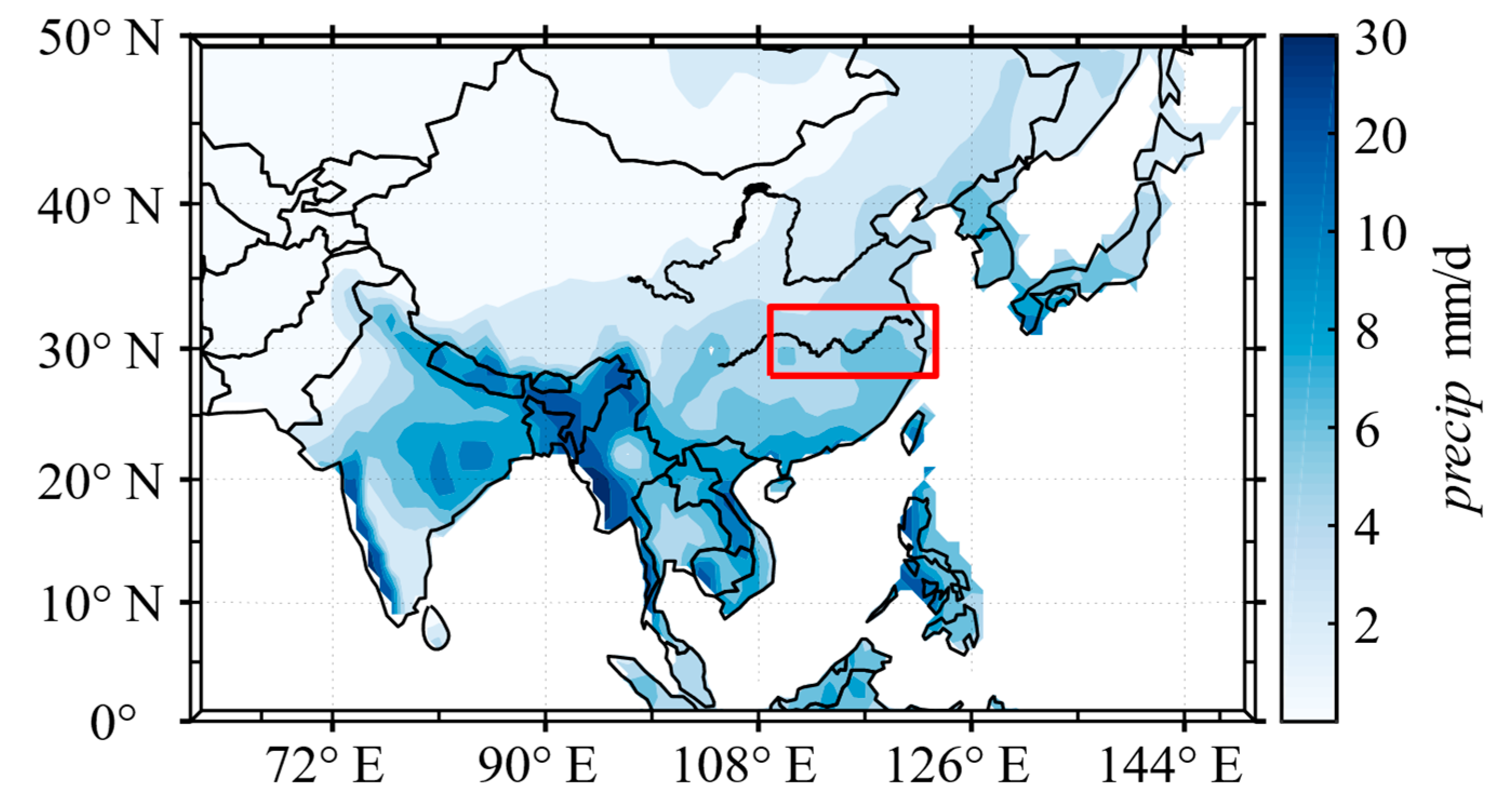
2.1. Precipitation Data
2.2. Predictor Data
2.3. Climate Model Prediction Data
2.4. Cross Validation of Prediction Results
2.5. Prediction Methods
2.5.1. Decision Tree (DT)
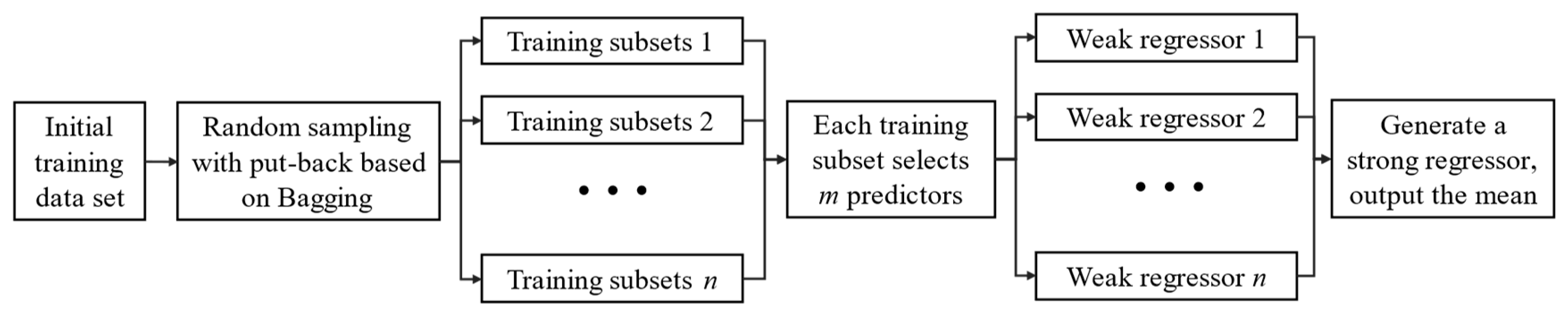
2.5.2. Random Forest (RF)
2.5.3. Backpropagation Neural Network (BPNN)
2.5.4. Convolutional Neural Network (CNN)
2.5.5. Multiple Linear Regression (MLR)
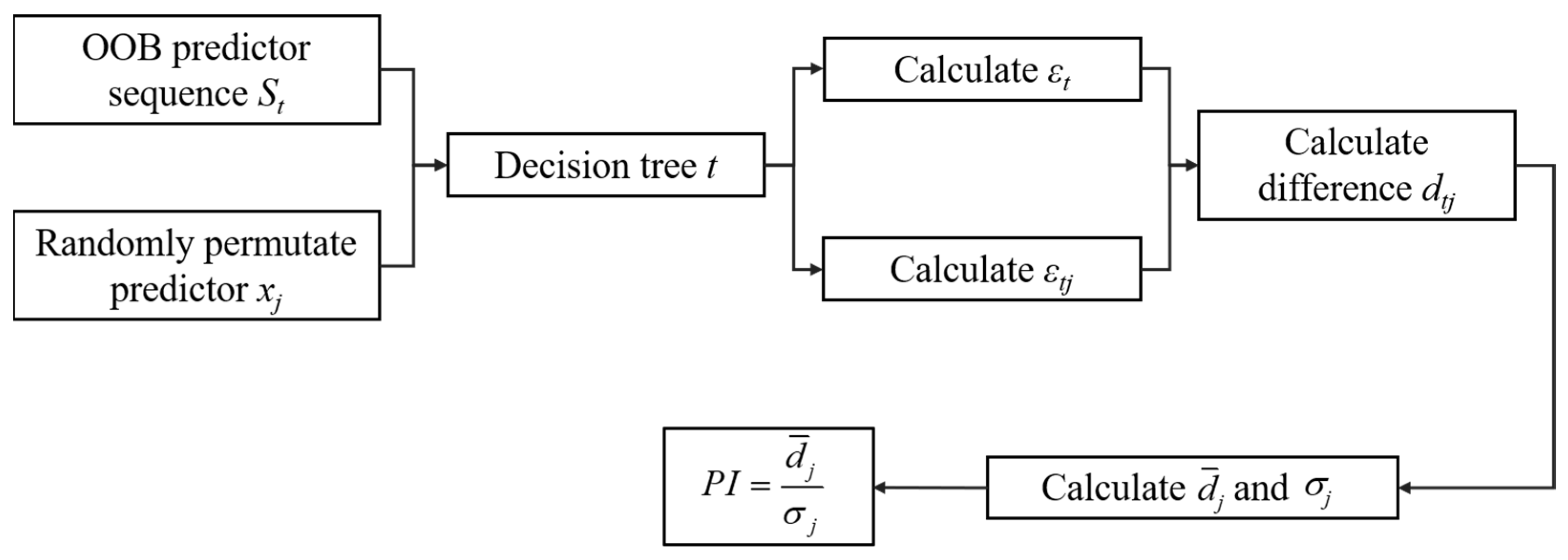
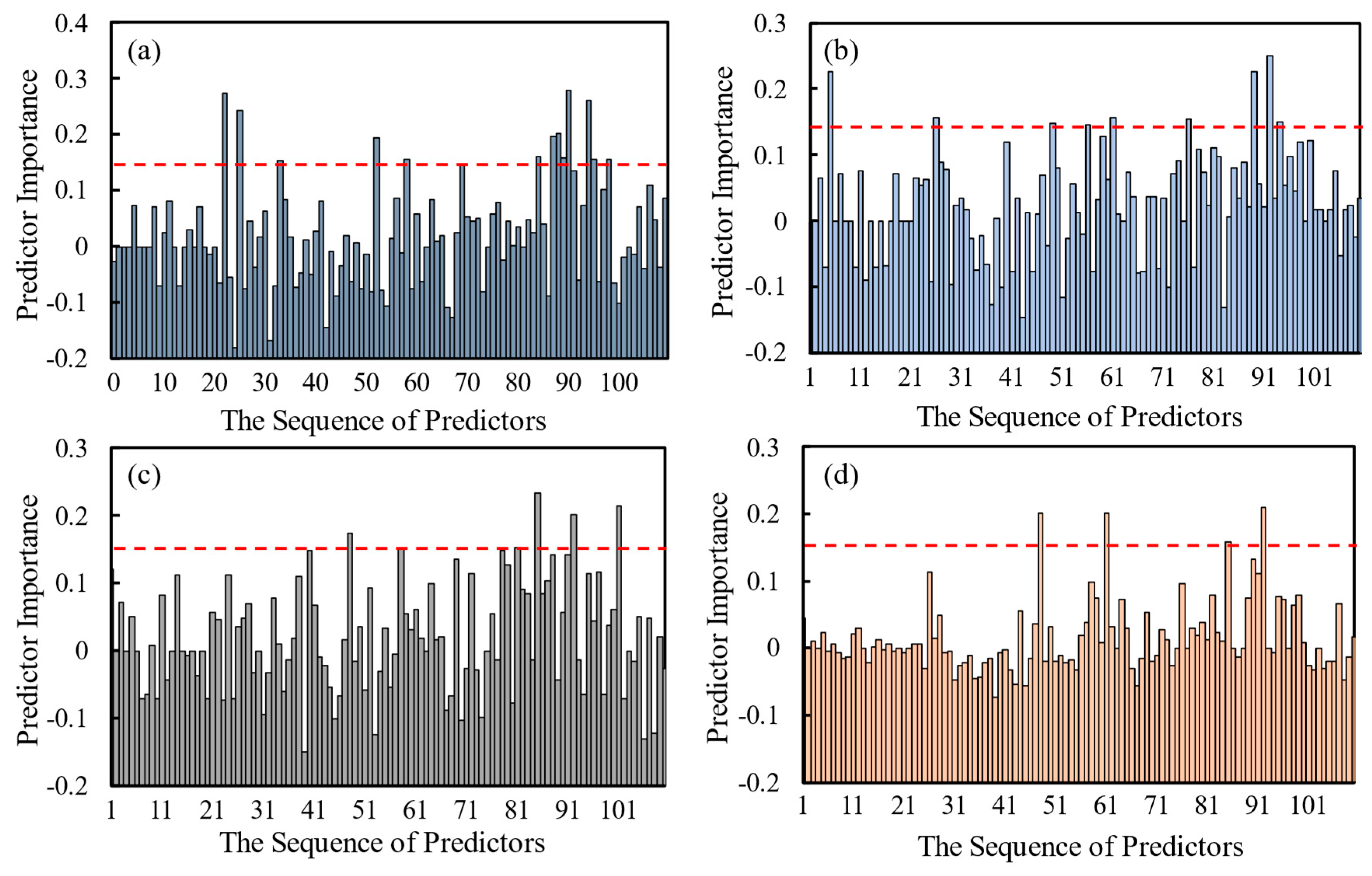
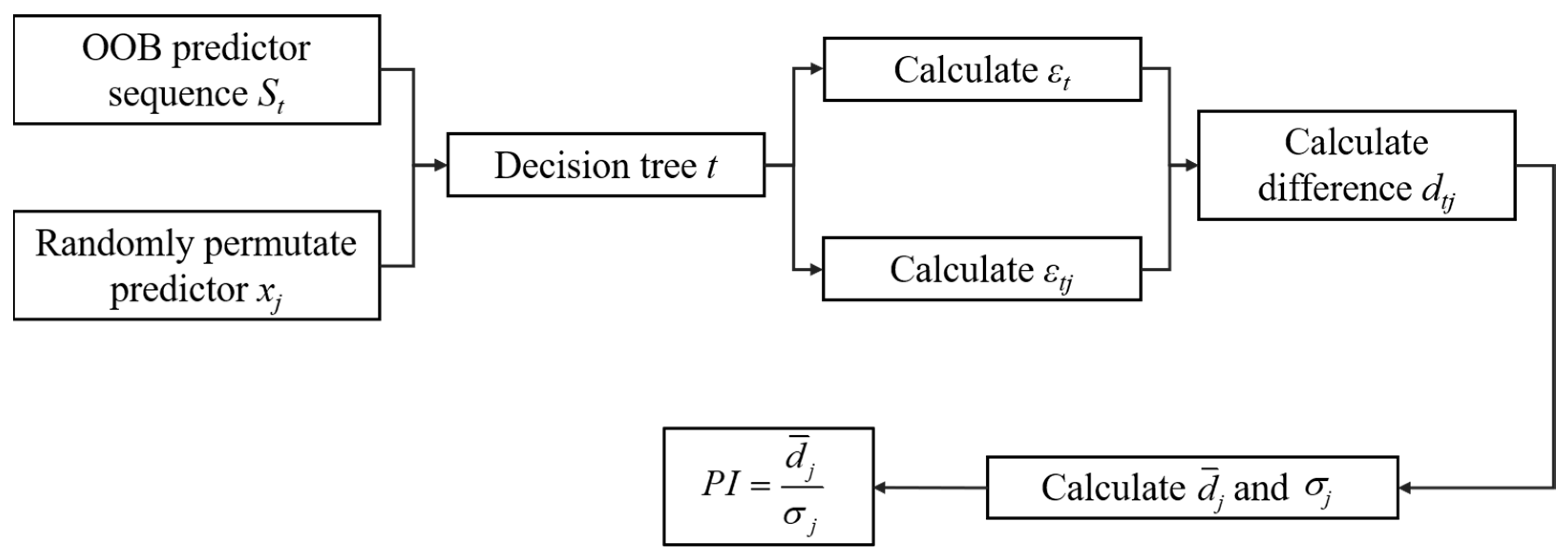
3. Predictor Importance Analysis Model (PIAM)
- For DT , where :
- (a)
- Determine the observation of OOB data (precipitation anomaly) and the value of the predictors. These OOB data sets will be input into the DT. Denote the sequence of predictors as ;
- (b)
- Calculate the root mean square error () of the OOB data;
- (c)
- For predictor , :
- Randomly permutate the observation of predictor ;
- Put the observation into the weak regressor and calculate the prediction error of the model;
- Calculate the difference between cases without or with permutation. If predictor has little impact on the prediction model, will be relatively small and its absolute value will be close to 0.
- For difference , calculate the average and the standard deviation .
- Finally, predictor importance can be calculated as .
4. Precipitation Prediction Based on Machine Learning
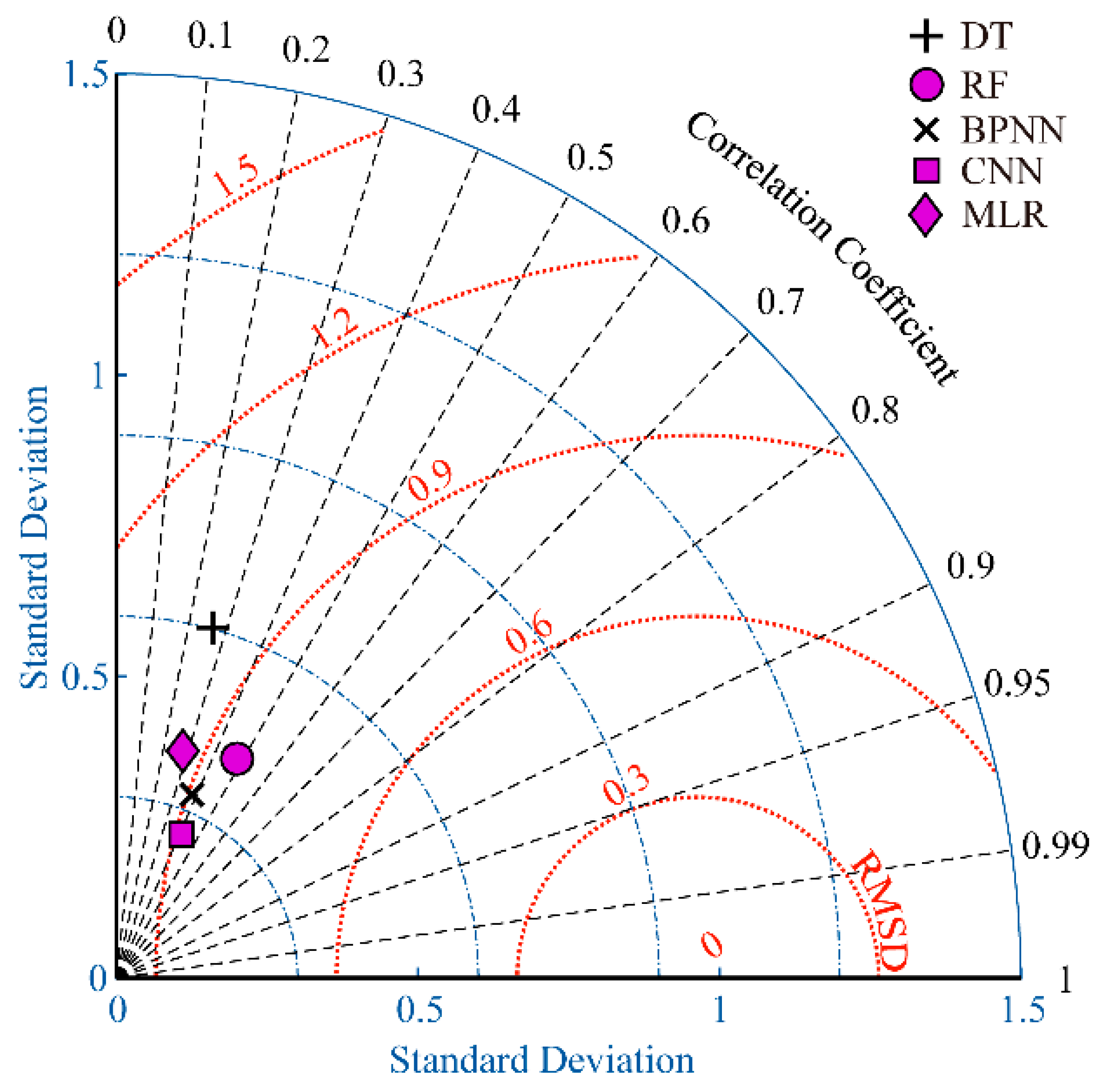
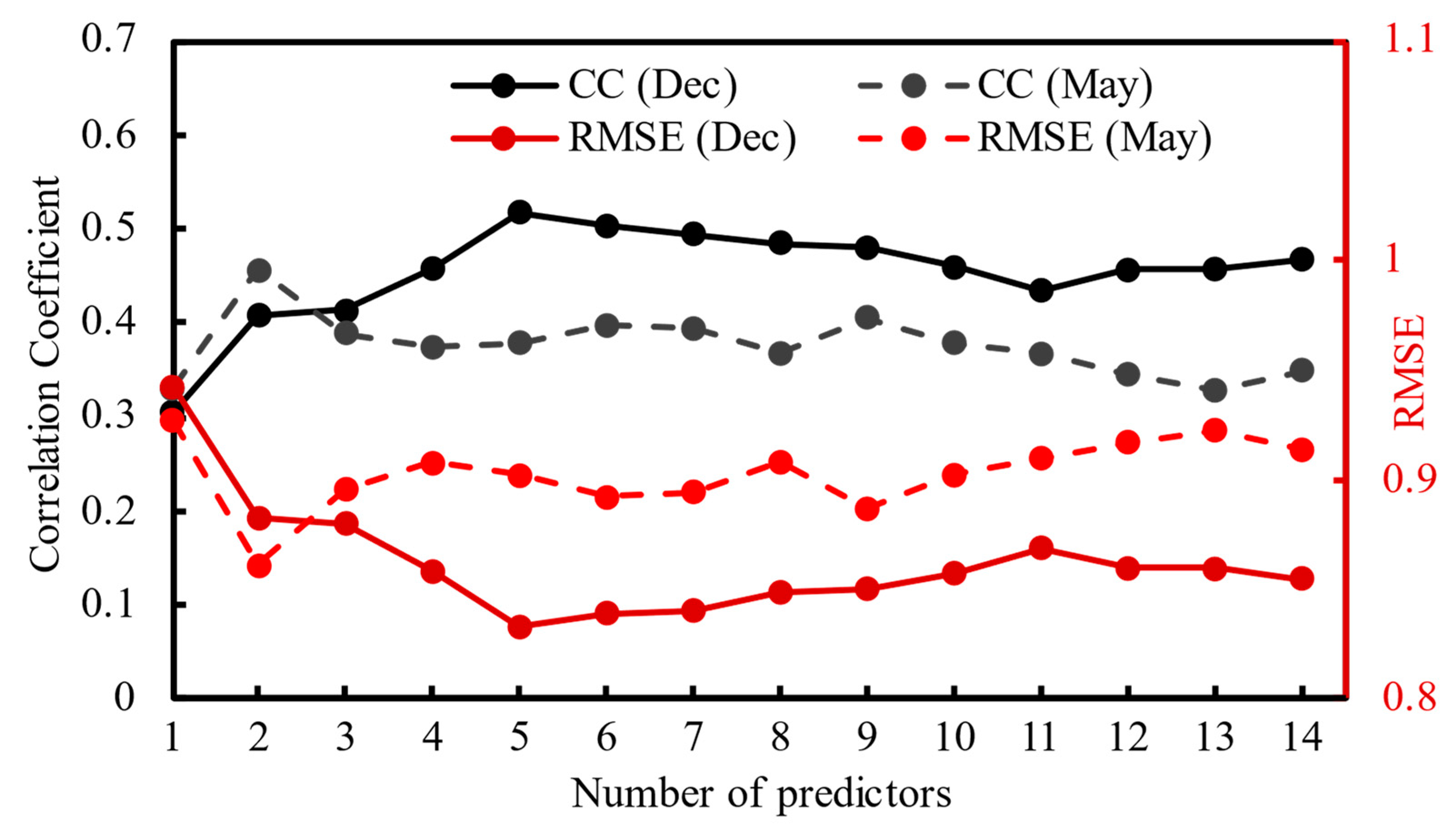
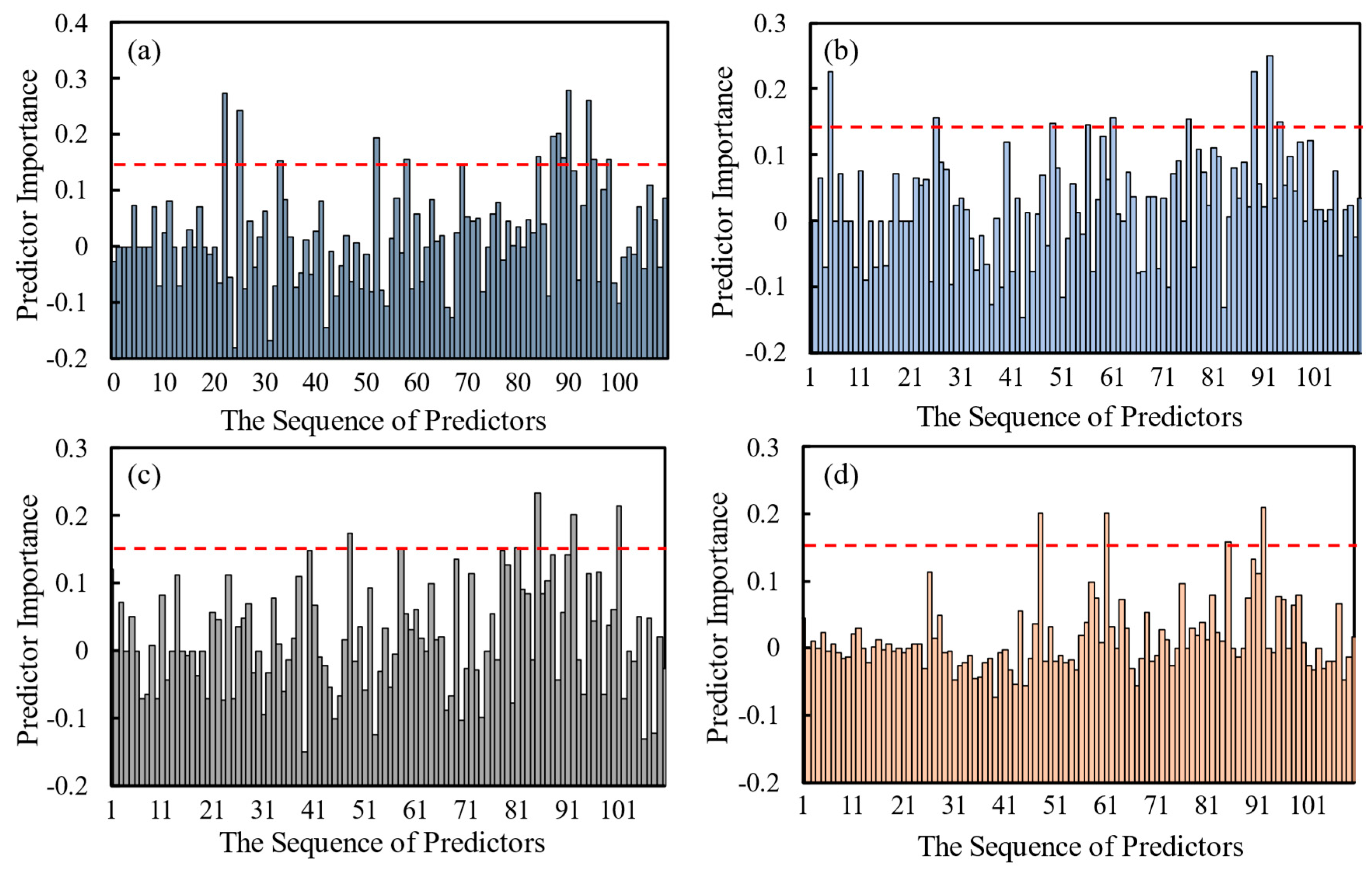
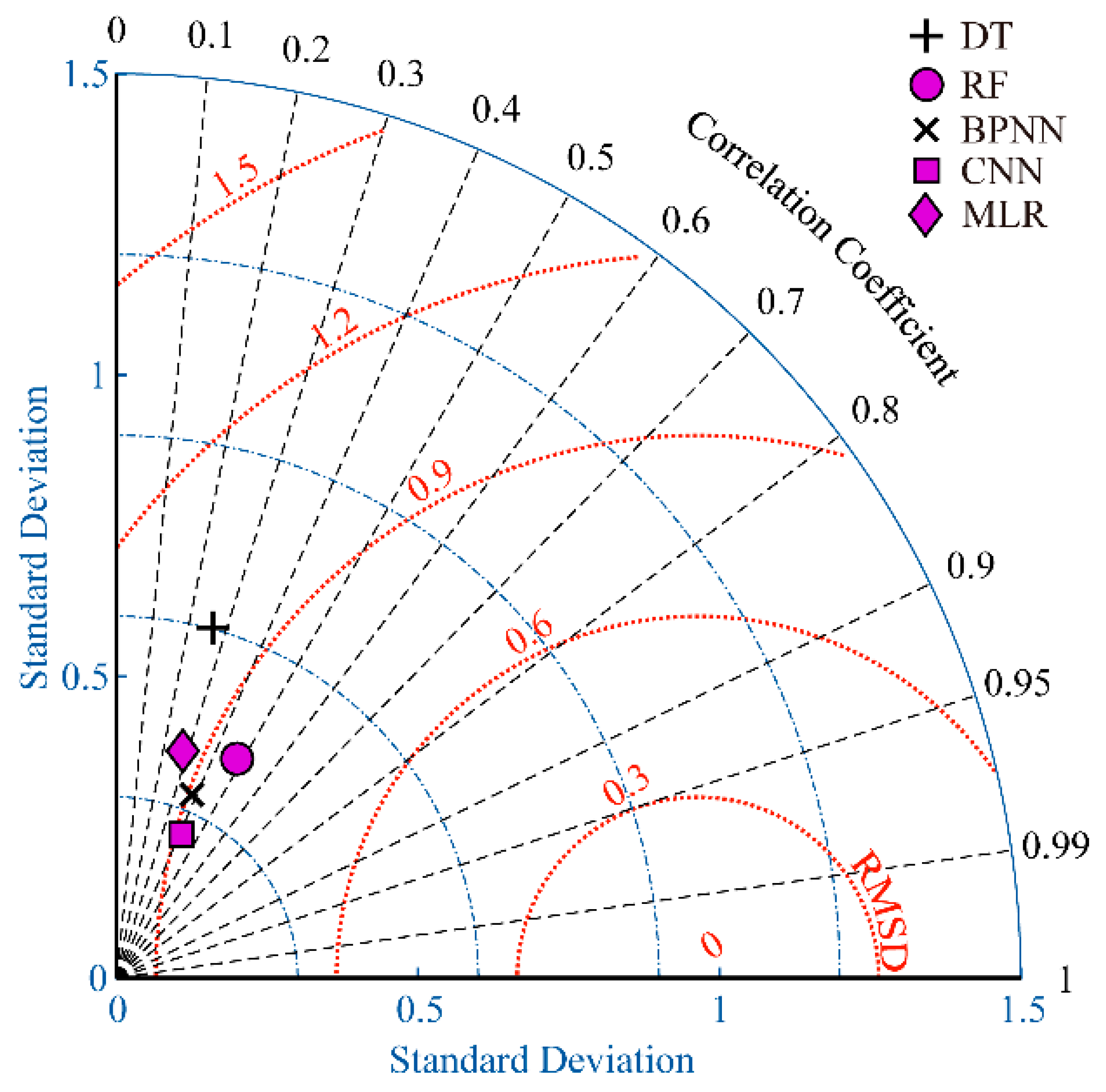
4.1. Comparison of Five Machine Learning Methods
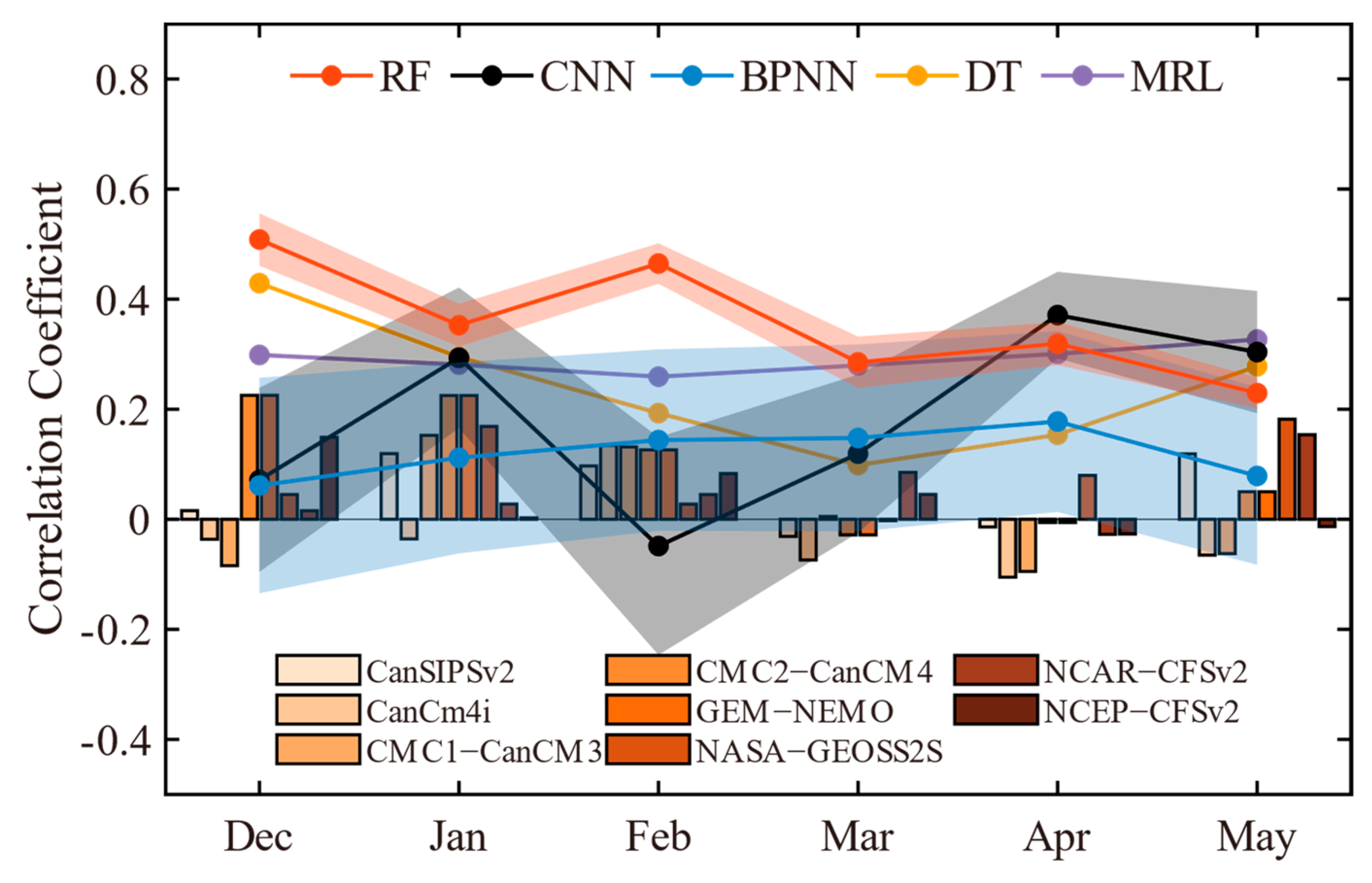
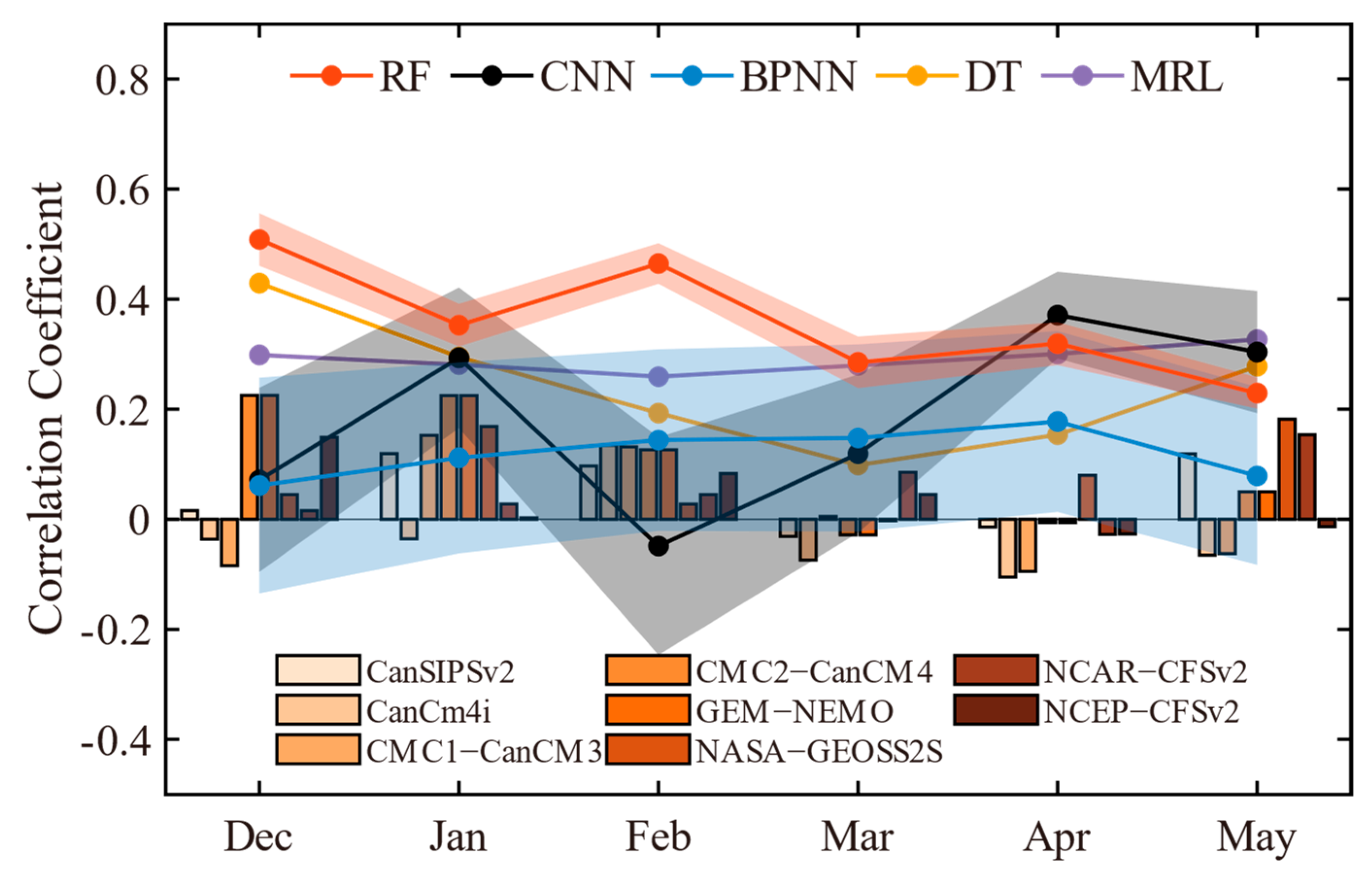
4.2. Comparison of Machine Learning Methods and Numerical Model Simulations
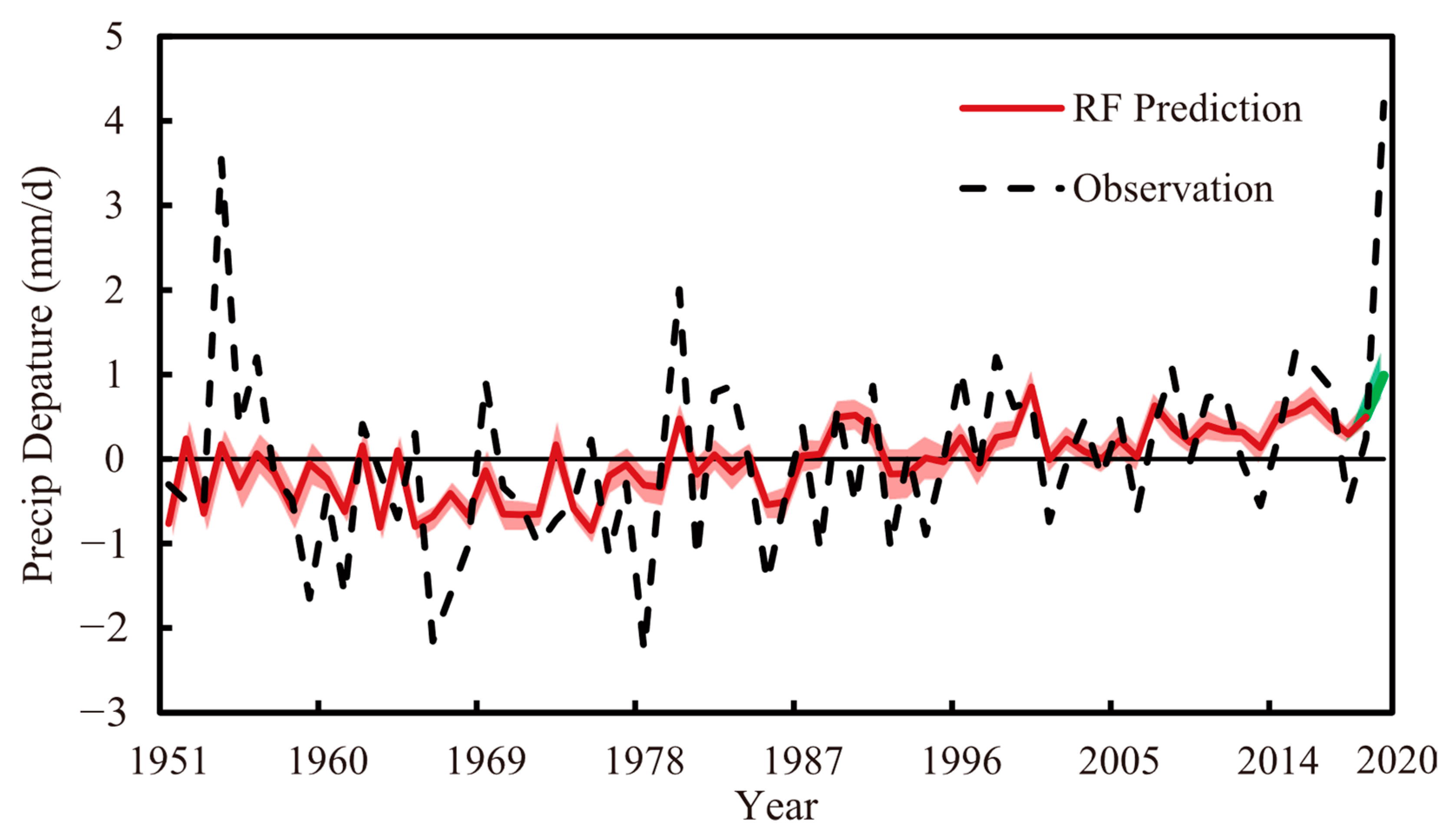
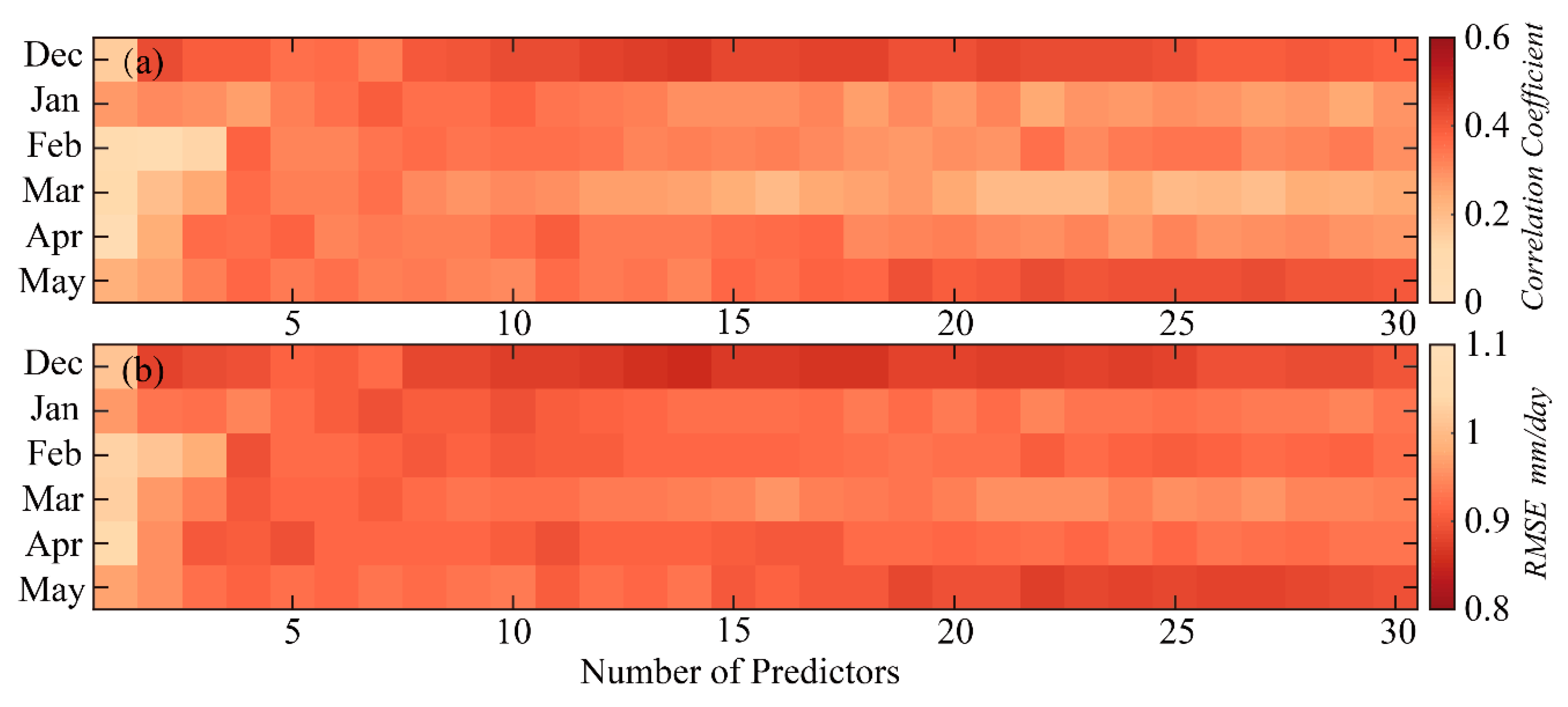
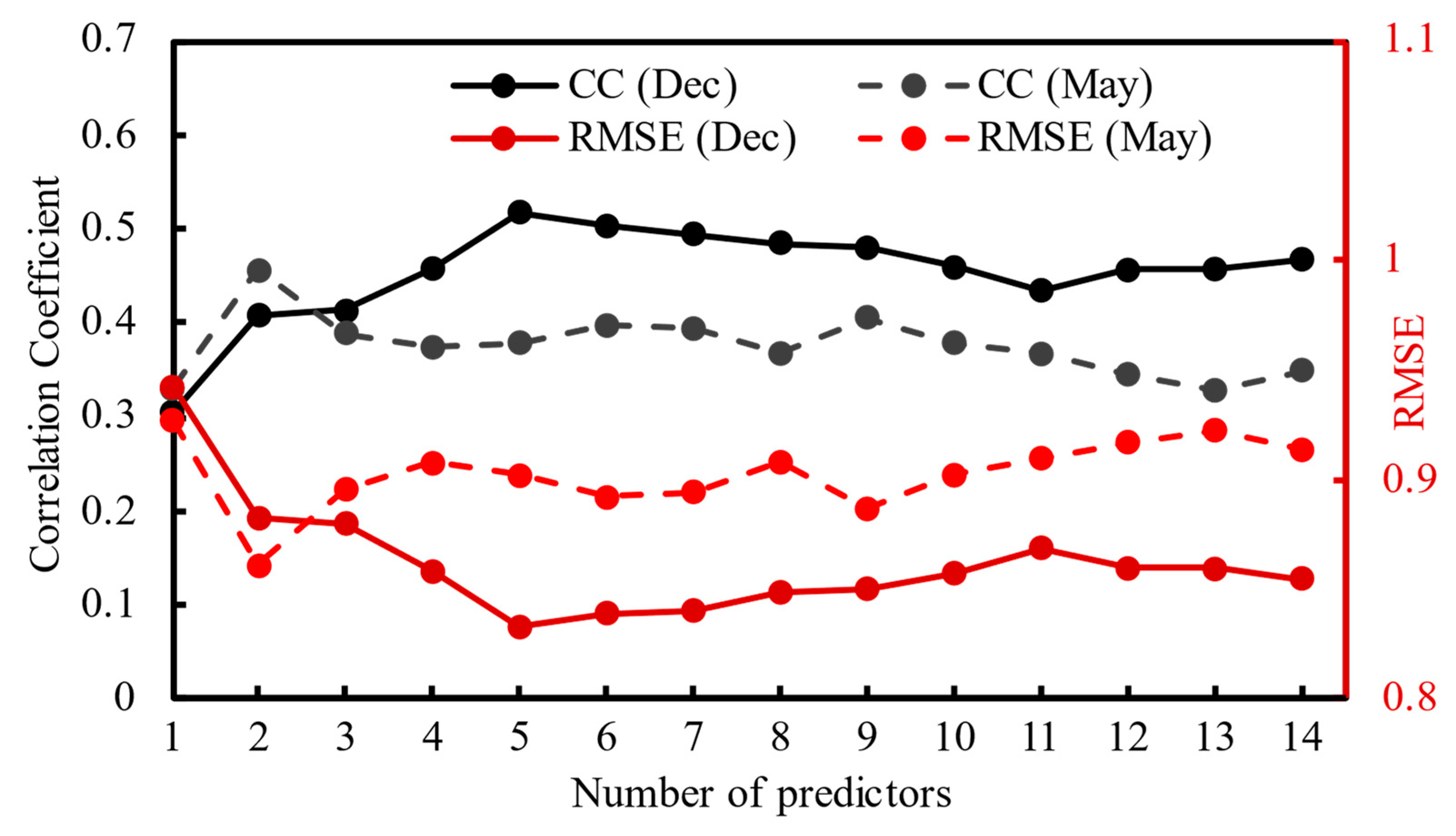
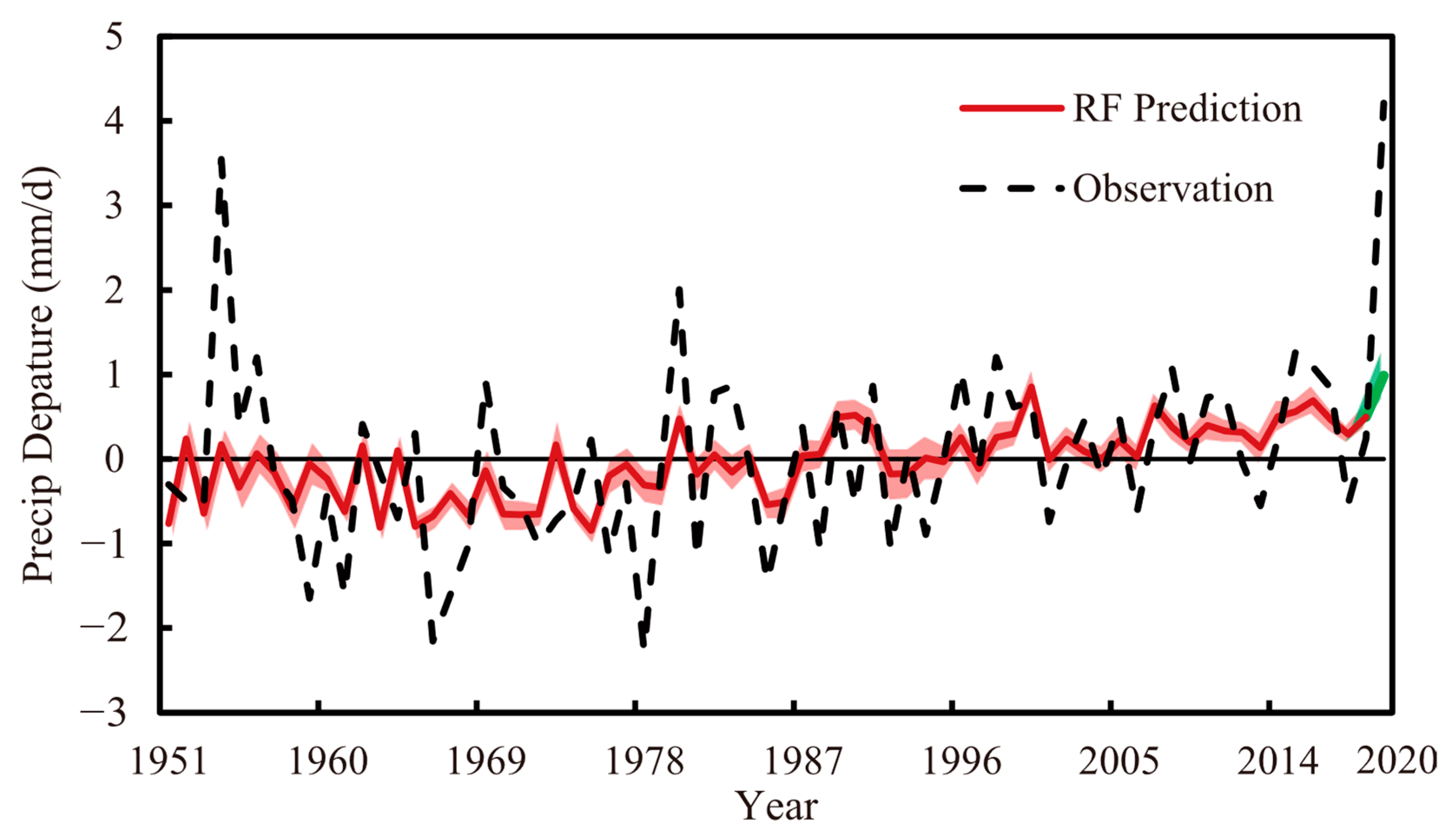
4.3. Cross Validation Prediction Results Analysis of Optimal Method
5. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ronghui, H.; Zhenzhou, Z.; Gang, H. Characteristics of the Water Vapor Transport in East Asian Monsoon Region and Its Difference from That in South Asian Monsoon Region in Summer. Sci. Atmos. Sin. 1998, 22, 76–85. (In Chinese) [Google Scholar]
- Wei, J.; Dirmeyer, P.A.; Bosilovich, M.G.; Wu, R. Water Vapor Sources for Yangtze River Valley Rainfall: Climatology, Variability, and Implications for Rainfall Forecasting. J. Geophys. Res. Atmos. 2012, 117, 1–11. [Google Scholar] [CrossRef]
- Ding, Y.; Sun, Y.; Wang, Z.; Zhu, Y.; Song, Y. Inter-Decadal Variation of the Summer Precipitation in China and Its Association with Decreasing Asian Summer Monsoon Part II: Possible Causes: Possible Causes for Inter-Decadal Variation in Summer Precipitation in China. Int. J. Climatol. 2009, 29, 1926–1944. [Google Scholar] [CrossRef]
- Yihui, D.; Chan, J.C.L. The East Asian Summer Monsoon: An Overview. Meteorol. Atmos. Phys. 2005, 89, 117–142. [Google Scholar] [CrossRef]
- Ke, F.; Jun, W.H.; Jean, C.Y. A Physically-Based Statistical Forecast Model for the Middle-Lower Reaches of the Yangtze River Valley Summer Rainfall. Chin. Sci. Bull. 2008, 53, 602–609. (In Chinese) [Google Scholar] [CrossRef]
- Dirmeyer, P.A.; Fennessy, M.J.; Marx, L. Low Skill in Dynamical Prediction of Boreal Summer Climate: Grounds for Looking beyond Sea Surface Temperature. J. Clim. 2003, 16, 995–1002. [Google Scholar] [CrossRef]
- Duan, W.; Wei, C. The ‘spring predictability barrier’ for ENSO predictions and its possible mechanism: Results from a fully coupled model. Int. J. Climatol. 2013, 33, 1280–1292. [Google Scholar] [CrossRef]
- Dickinson, R.E. How Coupling of the Atmosphere to Ocean and Land Helps Determine the Timescales of Interannual Variability of Climate. J. Geophys. Res. 2000, 105, 20115–20119. [Google Scholar] [CrossRef]
- Barnston, A.G.; Smith, T.M. Specification and Prediction of Global Surface Temperature and Precipitation from Global SST Using CCA. J. Clim. 1996, 9, 2660–2697. [Google Scholar] [CrossRef] [Green Version]
- Kirtman, B.P.; Min, D.; Infanti, J.M.; Kinter, J.L.; Paolino, D.A.; Zhang, Q.; Van Den Dool, H.; Saha, S.; Mendez, M.P.; Becker, E.; et al. The North American Multimodel Ensemble: Phase-1 Seasonal-to-Interannual Prediction; Phase-2 toward Developing Intraseasonal Prediction. Bull. Am. Meteorol. Soc. 2014, 95, 585–601. [Google Scholar] [CrossRef]
- Shukla, J.; Anderson, J.; Baumhefner, D.; Brankovic, C.; Chang, Y.; Kalnay, E.; Marx, L.; Palmer, T.; Paolino, D.; Ploshay, J.; et al. Dynamical Seasonal Prediction. Bull. Am. Meteorol. Soc. 2000, 81, 2593–2606. [Google Scholar] [CrossRef]
- Doblas-Reyes, F.J.; García-Serrano, J.; Lienert, F.; Biescas, A.P.; Rodrigues, L.R.L. Seasonal Climate Predictability and Forecasting: Status and Prospects. WIREs Clim. Chang. 2013, 4, 245–268. [Google Scholar] [CrossRef]
- Luo, L.; Wood, E.F.; Pan, M. Bayesian Merging of Multiple Climate Model Forecasts for Seasonal Hydrological Predictions: Bayesian seasonal hydrologic predictions. J. Geophys. Res. 2007, 112. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Babovic, V. Multi-Site Multivariate Downscaling of Global Climate Model Outputs: An Integrated Framework Combining Quantile Mapping, Stochastic Weather Generator and Empirical Copula Approaches. Clim. Dyn. 2019, 52, 5775–5799. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Rozos, E.; Dimitriadis, P.; Mazi, K.; Koussis, A.D. A Multilayer Perceptron Model for Stochastic Synthesis. Hydrology 2021, 8, 67. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Shalev, G.; Klambauer, G.; Hochreiter, S.; Nearing, G. Towards Learning Universal, Regional, and Local Hydrological Behaviors via Machine Learning Applied to Large-Sample Datasets. Hydrol. Earth Syst. Sci. 2019, 23, 5089–5110. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Schmitt, R.W.; Ummenhofer, C.C.; Karnauskas, K.B. Implications of North Atlantic Sea Surface Salinity for Summer Precipitation over the U.S. Midwest: Mechanisms and Predictive Value. J. Clim. 2016, 29, 3143–3159. [Google Scholar] [CrossRef] [Green Version]
- Pham, Q.; Yang, T.-C.; Kuo, C.-M.; Tseng, H.-W.; Yu, P.-S. Combing Random Forest and Least Square Support Vector Regression for Improving Extreme Rainfall Downscaling. Water 2019, 11, 451. [Google Scholar] [CrossRef] [Green Version]
- Gentine, P.; Pritchard, M.; Rasp, S.; Reinaudi, G.; Yacalis, G. Could Machine Learning Break the Convection Parameterization Deadlock? Geophys. Res. Lett. 2018, 45, 5742–5751. [Google Scholar] [CrossRef]
- Ham, Y.G.; Kim, J.H.; Luo, J.J. Deep Learning for Multi-Year ENSO Forecasts. Nature 2019, 573, 568–572. [Google Scholar] [CrossRef]
- Yiwei, Z.; Min, H.; Baohong, L.; Jian, Z.; Huan, L. Research of Medium and Long Term Precipitation Forecasting Model Based on Random Forest. Water Resour. Power 2015, 33, 6–10. (In Chinese) [Google Scholar]
- Chen, M.; Xie, P.; Janowiak, J.E. Global Land Precipitation: A 50-Yr Monthly Analysis Based on Gauge Observations. J. Hydrometeorol. 2002, 3, 249–266. [Google Scholar] [CrossRef]
- Browne, M.W. Cross-Validation Methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees. Int. Biom. Soc. 1983, 40, 874. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T. Receptive Fields, Binocular Interaction and Functional Architecture in the Cat’s Visual Cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Yongling, Z.; Shengan, W.; Yuguo, D.; Tong, H.; Quanzhou, G. Forecast of Summer Precipitation Based on SVD Iteration Model. Acta Meteorol. Sin. 2006, 64, 121–127. (In Chinese) [Google Scholar]
- Tang, S.; Luo, J.J.; He, J.; Wu, J.; Zhou, Y.; Ying, W. Toward Understanding the Extreme Floods over Yangtze River Valley in June–July 2020: Role of Tropical Oceans. Adv. Atmos. Sci. 2021, 38, 2023–2039. [Google Scholar] [CrossRef]
- Yunyun, L.; Yihui, D. Characteristics and Possible Causes for the Extreme Meiyu in 2020. Meteorol. Mon. 2020, 46, 1393–1404. (In Chinese) [Google Scholar] [CrossRef]
- Zhaobo, S. Short-Term Climate Prediction; China Meteorological Press: Beijing, China, 2010; pp. 223–255. (In Chinese) [Google Scholar]
- Lei, W.; Renhe, Z.; Jiayou, H. Diagnostic Analyses and Hindcast Experiments of Spring Sst on Summer Precipitation in China. Acta Meteorol. Sin. 2004, 62, 851–859. (In Chinese) [Google Scholar]
- Webster, P.J.; Yang, S. Monsoon and Enso: Selectively Interactive Systems. Q. J. R. Meteorol. Soc. 1992, 118, 877–926. [Google Scholar] [CrossRef]
- Budikova, D. Role of Arctic Sea Ice in Global Atmospheric Circulation: A Review. Glob. Planet. Chang. 2009, 68, 149–163. [Google Scholar] [CrossRef]
- Koster, R.D.; Mahanama, S.P.P.; Yamada, T.J.; Balsamo, G.; Berg, A.A.; Boisserie, M.; Dirmeyer, P.A.; Doblas-Reyes, F.J.; Drewitt, G.; Gordon, C.T.; et al. The Second Phase of the Global Land-Atmosphere Coupling Experiment: Soil Moisture Contributions to Subseasonal Forecast Skill. J. Hydrometeorol. 2011, 12, 805–822. [Google Scholar] [CrossRef]
- Lin, P.; Yang, Z.L.; Wei, J.; Dickinson, R.E.; Zhang, Y.; Zhao, L. Assimilating Multi-Satellite Snow Data in Ungauged Eurasia Improves the Simulation Accuracy of Asian Monsoon Seasonal Anomalies. Environ. Res. Lett. 2020, 15. [Google Scholar] [CrossRef]
- Pielke, R.A.; Liston, G.E.; Eastman, J.L.; Lu, L.; Coughenour, M. Seasonal Weather Prediction as an Initial Value Problem. J. Geophys. Res. Atmos. 1999, 104, 19463–19479. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Parameters | |
|---|---|---|---|
| Linear Model | Multiple Linear regression | 1. Predictors: 4. | |
| 2. Start time: May. | |||
| Nonlinear Model | Tree Model | Decision Tree | 1. Predictors: 7. |
| 2. Start time: December. | |||
| 3. Decision tree: 138. | |||
| Random Forest | 1. Predictors: 14. | ||
| 2. Start time: December. | |||
| 3. Weak regressor: 180. | |||
| 4. Minimum leaf node: 8. | |||
| Neural Network | BP Neural Network | 1. Predictors: 8. | |
| 2. Start time: December. | |||
| 3. Hidden layer: 3. | |||
| 4. Number of neurons in each hidden layer: 50, 7 and 3. | |||
| Convolutional Neural Network | 1. Predictors: 11. | ||
| 2. Start time: April. | |||
| 3. Small batch: 200. | |||
| 4. Learning rate: 0.005. | |||
| 5. Number of neurons per layer: 50. | |||
| 6. Number of convolution layers and pooling layers: 5. | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.; Wei, J.; Song, Y.; Luo, J.-J. Seasonal Prediction of Summer Precipitation in the Middle and Lower Reaches of the Yangtze River Valley: Comparison of Machine Learning and Climate Model Predictions. Water 2021, 13, 3294. https://doi.org/10.3390/w13223294
He C, Wei J, Song Y, Luo J-J. Seasonal Prediction of Summer Precipitation in the Middle and Lower Reaches of the Yangtze River Valley: Comparison of Machine Learning and Climate Model Predictions. Water. 2021; 13(22):3294. https://doi.org/10.3390/w13223294
Chicago/Turabian StyleHe, Chentao, Jiangfeng Wei, Yuanyuan Song, and Jing-Jia Luo. 2021. "Seasonal Prediction of Summer Precipitation in the Middle and Lower Reaches of the Yangtze River Valley: Comparison of Machine Learning and Climate Model Predictions" Water 13, no. 22: 3294. https://doi.org/10.3390/w13223294
APA StyleHe, C., Wei, J., Song, Y., & Luo, J.-J. (2021). Seasonal Prediction of Summer Precipitation in the Middle and Lower Reaches of the Yangtze River Valley: Comparison of Machine Learning and Climate Model Predictions. Water, 13(22), 3294. https://doi.org/10.3390/w13223294