1. Introduction
In traditional flood control management, probable rainfall is estimated by conducting statistical analysis of extreme rainfall data accumulated through rainfall observation over several decades. Extreme rainfall data can be divided into two types. An Annual Maximum Series is a statistical sample constructed of annual maximum rainfalls extracted from observed time series of rainfalls. A Peaks Over Threshold data set is a statistical sample constructed of extreme values exceeding a given threshold. Statistical analysis of such data is called hydrological frequency analysis [
1]. The mathematical part of these hydrological frequency analysis methods is based on extreme value theory, whose basis was constructed by Fisher and Tippet [
2]. They proved that the maximum values of any sample asymptotically approach one of three types of extreme value distribution. These three types of extreme value distribution are the Gumbel distribution, the Frechet distribution, and the negative Weibull distribution in the present. Gumbel [
3] also adopted a type I maximum asymptotic distribution for expressing the probability distribution of flood discharge. This research of Gumbel’s pioneered hydrological frequency analysis in the context of extreme value theory. Later, Gnedenko [
4] proved a necessary and sufficient condition in order for probability distributions to belong to a domain of attraction of extreme value distribution. In addition, von Mises [
5] and Jenkinson [
6] proposed a generalized extreme value distribution, which can express each of the three types of extreme value distribution noted above. Gumbel’s “Statistics of Extremes” [
7] summarized the main research results of extreme value theory of that era. Coles [
8] and de Haan [
9] illustrated subsequent developments of extreme value theory. Based on this previous research, modern hydrological frequency analysis is conducted as follows. First, several probability distributions are selected as candidates for frequency analysis. Second, probability distributions selected as candidates in the first step are applied to extreme hydrological data such as extreme rainfall or extreme river discharge, and parameters of these probability distributions are estimated. Third, estimated probability distributions are evaluated in a comparative framework based on goodness-of-fit criteria and stability [
10]. Through this procedure, a single probability distribution is adopted for frequency analysis. Finally, a
T-year hydrological quantity is estimated based on the adopted probability distribution. Although this procedure is solidly established, statistical estimation in hydrological frequency analysis involves substantial uncertainty because the total number of observed extreme rainfall data are limited, ranging from about several tens to 200. This shortage of extreme rainfall data makes it difficult to evaluate torrential heavy rainfalls. Takara [
11] pointed out that the observed data for torrential rainfalls deviate strongly from adopted probability distributions in river planning. In addition, the return period for these observed data calculated by the adopted probability distribution is thousands of years to tens of thousands of years, which can be orders of the magnitude longer than the observation data set length. For an example of this difficulty,
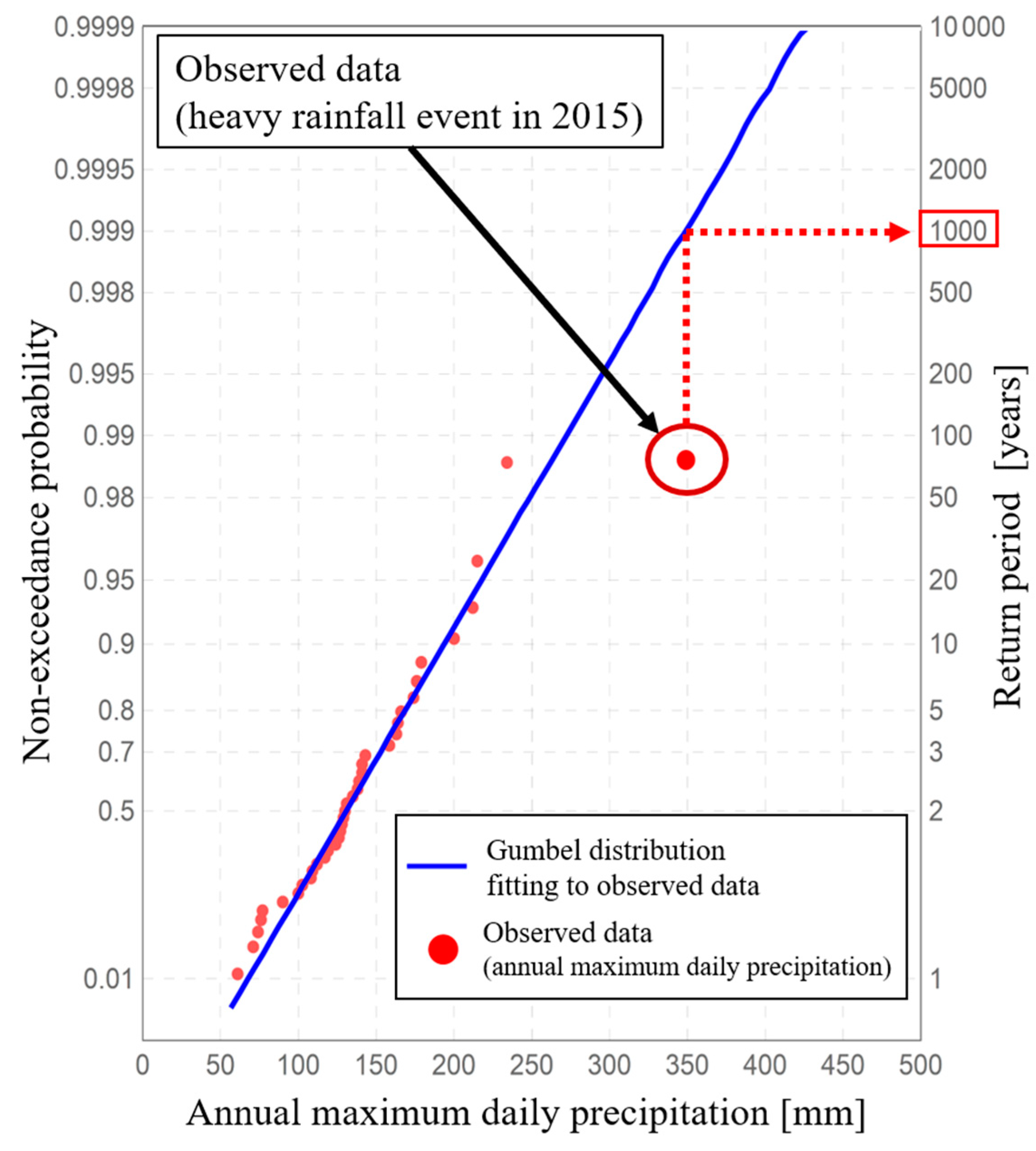
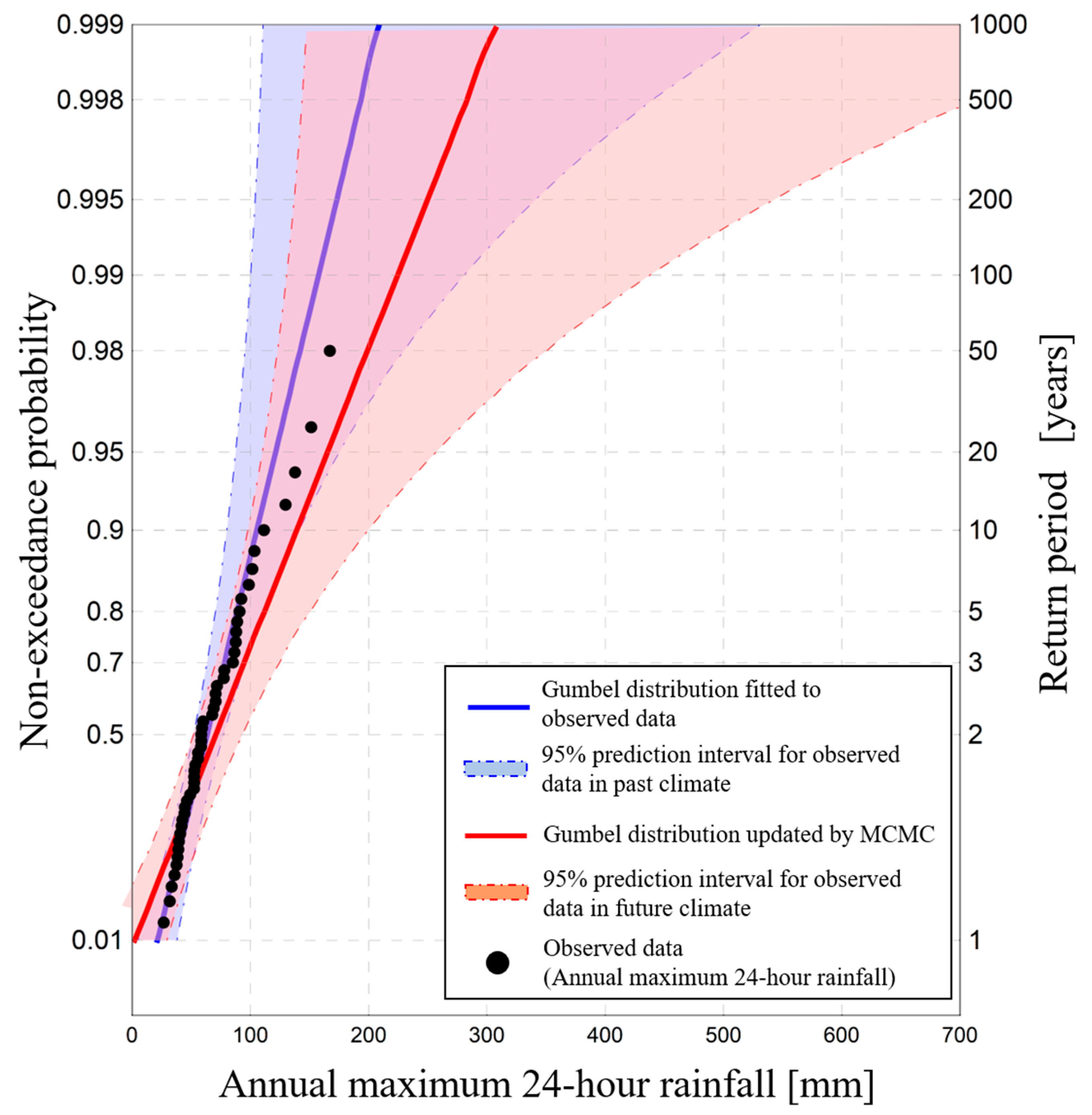
Figure 1 shows observed data for the annual maximum daily rainfall for 36 years at Ikari observatory in the Tone river basin of Japan, along with a Gumbel distribution fitted to these observed data and an observed datum for a heavy rainfall event in 2015. Based on this figure, the observed datum of heavy rainfall event deviates strongly from the adopted Gumbel distribution, and the return period for this datum is 1000 years. Observed data with such a return period are often treated as outliers [
12], because major river planning in Japan is designed based on hydrological values with return periods of about 100 to 200 years [
11]. Design return periods in major river basins of various countries are shown in
Table 1 [
13,
14,
15,
16,
17,
18]. These data make clear that each case of river planning involves difficulty in managing extreme hydrological events with return periods of several thousands of years, especially in Japan. Furthermore, the estimation error increases by extrapolation of the probability distribution when estimating probable hydrological quantities corresponding to long-term return periods exceeding the observation period. Especially, the flood control management of The Netherlands uses the traditional concept of return period, considering the effects of climate change and economic development as global warming proceeds [
19]. Meanwhile, in recent years in Japan, rainfall events of heaviness exceeding recorded maximum have occurred frequently, causing severe damage to society. Therefore, it is necessary to formulate flood control management in the face of the intensification of heavy rainfall caused by climate change accompanied with global warming. Therefore, in this research, we propose evaluation method of uncertainty of design rainfall and prediction method for torrential rainfall. These methods are constructed by using the theory of probability limit method test [
20] which can theoretically estimate the range where observed data could realize (acceptance region), including outliers in traditional hydrological frequency analysis. In addition, an application of these methods to future climate by incorporation of ensemble climate projection data using Markov Chain Monte Carlo method is shown in this paper.
In existing studies, to evaluate heavy rainfalls treated as outliers or record-breaking rainfall, occurrence probabilities of these rainfalls are often analyzed. For example, Itokawa et al. [
21] calculated the distribution of the number of new records from each observatory in Japan and compared the derived distribution to the theoretical one, demonstrating a good accordance between the two distributions. Yamada et al. [
22] investigated the number of annual maxima for daily and 3-day total precipitation measurements in Japan, discussing the effects of climate change. In addition, to manage torrential rainfall in future climate, a flood risk evaluation method using an ensemble climate projection database has been proposed to deal with the intensification of heavy rainfall accompanied by climate change [
23,
24,
25,
26]. An ensemble climate projection database contains numerous calculated results for meteorological values for past and future climate. Such database can be interpreted as rainfall data possibly experienced in the past and to be experienced in the future. Yamada et al. [
23,
25,
26] conducted downscale calculations of the ensemble climate projection database d4PDF and constructed a horizontal, high-resolution database of resolution high enough to evaluate future rainfall characteristics. Ensemble downscaling calculations makes it possible to intercorporate actual observed data and simulation data to compensate for the shortage of observed data when considering flood control management. In traditional flood control management, the design rainfall is decided using only a sample of the observed data available. On the other hand, this horizontal, high-resolution database allows for rational quantification of the design rainfall’s uncertainty caused by the shortage of observed data. The range of this design rainfall uncertainty is defined as a confidence interval. As an example,
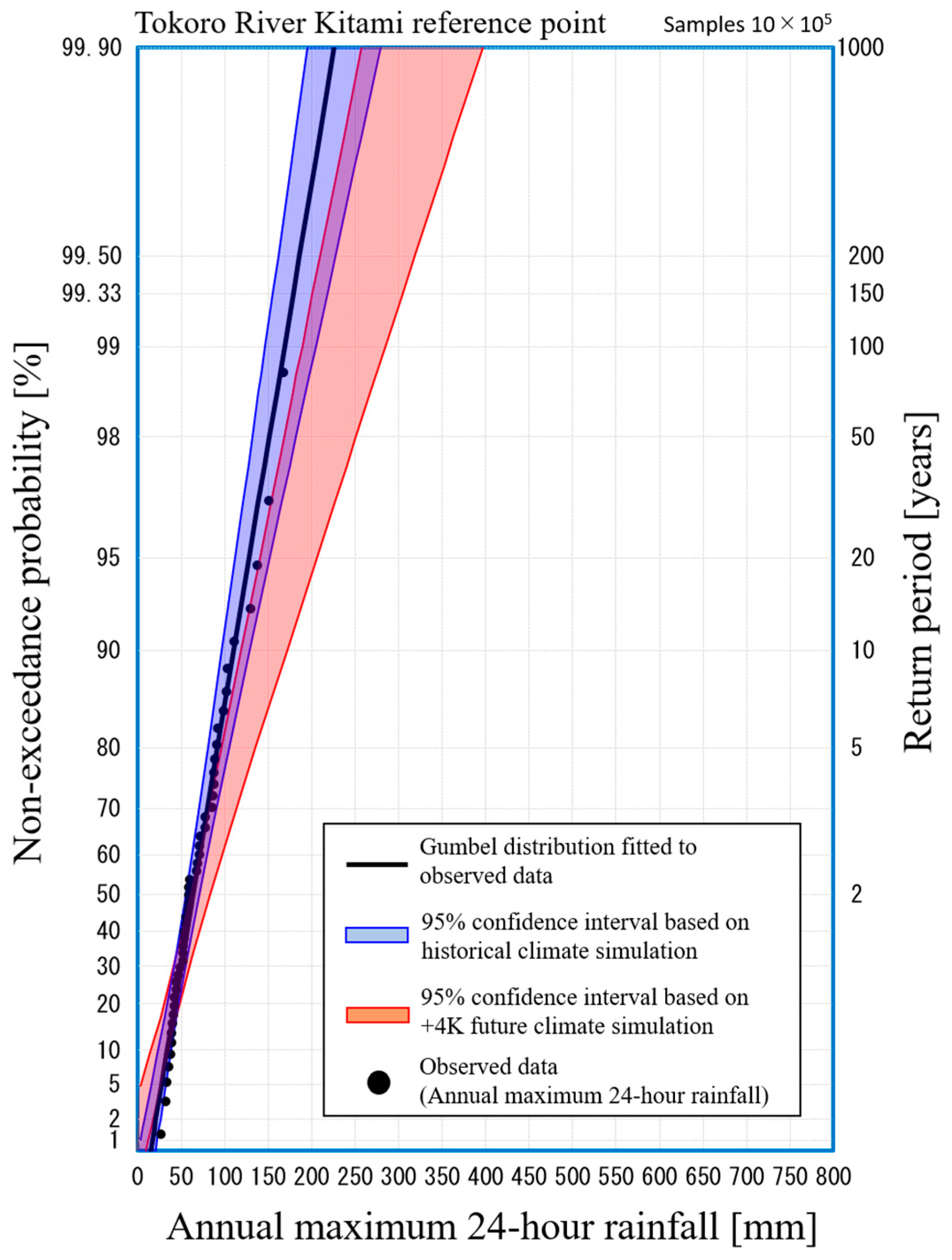
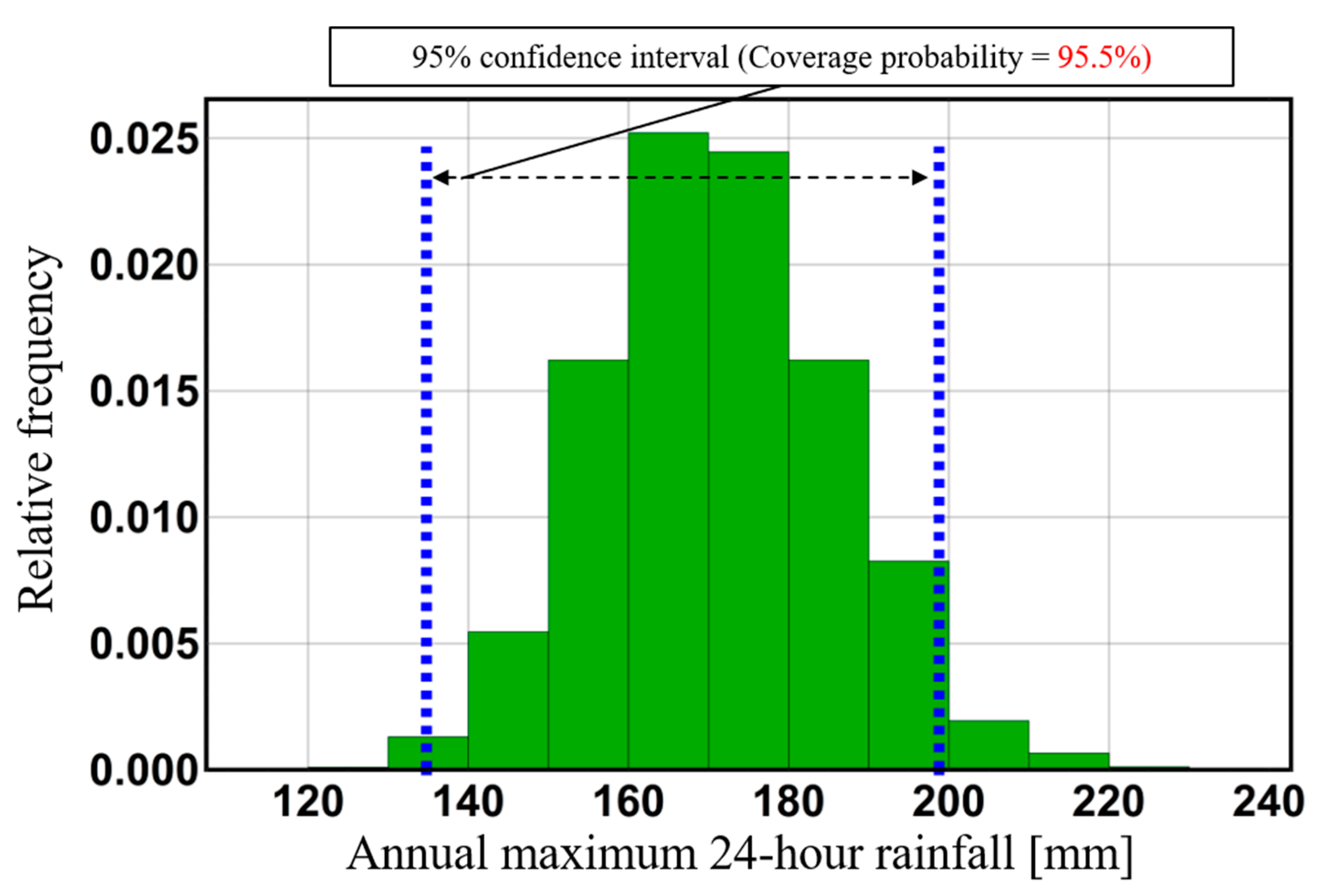
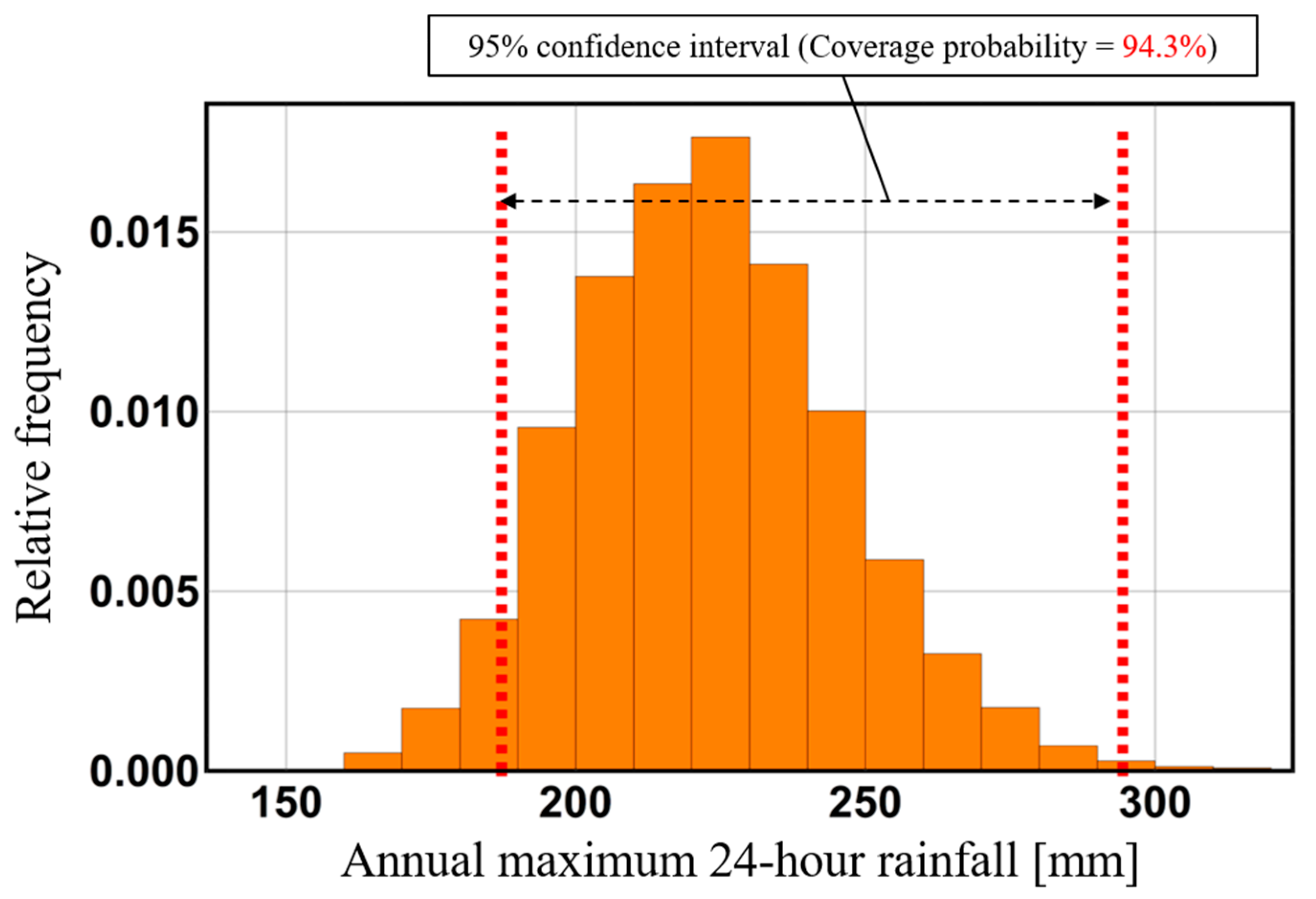
Figure 2 shows observed data of annual maximum 24-h rainfall in the Tokoro river basin (black points), a Gumbel distribution fitted to the observed data (solid black line), a 95% confidence interval on past climate (blue range), and a 95% confidence interval on future climate in which average global temperature increases by 4K from the era of industrial revolution [
23,
25,
26]. These confidence intervals can be derived from a physical Monte Carlo method using
Ensemble statistical samples from both the past and the +4K future of this horizontal, high-resolution database. In the field of conventional mathematical statistics or frequency analysis, confidence intervals are often expressed by numerical methods such as the jackknife or bootstrap method [
27]. Many of these conventional methods use an assumption of normality based on the central limit theorem to estimate statistics. However, it can be difficult to treat a distribution of probable rainfall as a normal distribution. It can also be problematic to assume a normal distribution for
T-year extreme rainfall given the limited extreme rainfall data available at present. Our proposed confidence interval does not use above mentioned assumptions. On the other, to handle unsteadiness caused by climate change, the nonstationary extreme value analysis is effective. Stationarity of rainfall is assumed in traditional hydrological frequency analysis but prevents consideration of unsteadiness caused by climate change [
27]. Therefore, in general, probability distributions that dominate hydrological systems, such as rainfall, as modeled in traditional analysis, do not reflect real-world change. In nonstationary analysis method, nonstationary extreme value distribution model whose parameter is function of time is generally used. By this time-varying parameter, detecting of unsteadiness of natural phenomenon and expressing time variation of
T-year extremes can be possible. However, increasing number of parameters concerning time might cause estimation error. Detailed explanation of theory and models in nonstational frequency analysis are shown by Coles [
8] and Khaliq [
28]. Recently, effectiveness of nonstationary analysis against climate change is shown in existing studies through derivation nonstational
T-year annual monthly temperature [
29] and future change of
T-year annual maximum rainfall [
30]. Moreover, large ensemble climate simulations enable estimation of design hydrological quantity by using thousands of samples to delete substantial uncertainty inherit estimated values. For example, Wiel et al. [
31] simulates 2000 years by using global climate model and global hydrological model for a present-day and 2 K warmer climate in the Paris climate agreements [
32] and evaluated
T-year discharge by empirical distribution and stational extreme value distribution constructed of simulated discharges to quantify future change of
T-year discharge. In addition, The Royal Netherlands Meteorological Institute [
33] in the Netherlands has conducted future projection for flood discharge in Rhine river and estimated
T-year discharge based on empirical distribution constructed of calculated discharge from large ensemble climate projections, according to global warming scenarios. Here, we assume there still exists uncertainty in estimation, because although ensemble climate projection data enable us to use thousands sample, initial conditions or boundary conditions are reflected on actual observed information. Therefore, it can be said that estimated values have uncertainty caused by finiteness of observed information. The frequency analysis based on probability limit method test we propose can express this kind of uncertainty as a form of acceptance region, for probability distribution constructed of a lot of data from ensemble climate projections. On the other hand, there is the effective concept of prediction interval which can evaluate observed data of torrential rainfall in future time. A prediction interval is defined as a range determined by observed data into which future data are expected to fall. Considering this definition, a prediction interval includes a distribution of a random variable expressing observed data for a future time with a given confidence coefficient. Many parts of the theoretical framework of prediction intervals are provided by Takeuchi [
34]. On the other hand, little previous research has focused on prediction intervals for extreme values. In previous research, prediction intervals for extreme values have been constructed using the assumption of a normal distribution, a
t-distribution, and so on, for extreme values. However, as Kitano [
35] pointed out, it may be preferable to adopt extreme value distributions for probability distributions of extreme values, rather than a normal distribution or a
t-distribution. Recently, a construction method for prediction intervals of extreme values was provided by Kitano [
35]. The method proposed is superior to previous methods from the perspective that it does not need an assumption of normality. Coles [
36] and Kitano [
37] proposed construction methods for prediction distributions for extreme values by constructing a prior distribution for parameters of the extreme value distribution and applying a Markov Chain Monte Carlo method to update more rational prediction for extremes. In their research, outliers are considered as realized values in right tail of prediction distribution or interval. Based on this concept, prediction possibility of outliers is shown through prediction distribution or prediction interval constructed by MCMC which evaluates outliers in prior information by incorporation of each obtainment of newly observed data. Considering these previous studies, we newly incorporate ensemble climate projection data in MCMC method to make rational estimation for heavy rainfall in future climate.
For solution against uncertainty caused by finiteness of observed extreme rainfall data, prediction difficulty of torrential heavy rainfall in present and future situation, we used a probability limit method test [
20] to construct a new hydrological frequency analysis based on confidence intervals and prediction interval that does not require any parametric assumptions as possible. The introduction of confidence intervals allows risk in flood control management to be expressed by considering where a given rainfall datum lies within the confidence interval. In addition, this research, based the construction methods for prediction intervals on the theory of the probability limit method test, provides a theoretical framework for the estimation of scale and occurrence risk of heavy rainfall in future. However, analysis based on confidence intervals and prediction intervals still requires an assumption of stationarity, meaning that the probability characteristics of hydrological events do not change as time proceeds. Therefore, confidence intervals and prediction intervals reflecting the effects of climate change can be constructed by incorporating information from future projection data into the updating of these intervals. This paper presents a method for deriving confidence intervals and prediction intervals under a situation of progressive global warming by incorporating climate projection data into extreme value distributions derived from past observed extreme rainfall data currently available. Based on this update of confidence interval and prediction interval, uncertainty of design rainfall and the magnitude of torrential rainfall itself in future climate is estimated.
The organization of this paper is as follows.
Section 2 shows the mathematical theory of confidence interval and prediction interval.
Section 3 shows the detail of probability limit method test and construction method of confidence interval and prediction interval based on this hypothesis test theory.
Section 4 shows estimation methods to construct extreme value distribution in future climate, based on Markov Chain Monte Carlo method incorporating ensemble climate projection data.
Section 5 shows the results of validity evaluation of confidence interval based on the theory of probability limit method test and the acceptance region of the theory through comparison of ensemble climate projection data.
Section 6 summarizes the main results of this research.
3. Methodology
The probability limit method test [
20] is a hypothesis test theory that improves the weak power of the Kolmogorov–Smirnov test [
39,
40] at the tail of an assumed probability distribution. In addition, Anderson–Daring test [
41,
42] gives more weight to the tails than does Kolmogorov–Smirnov test. Kolmogorov–Smirnov test is a nonparametric test in the sense that the distribution of test statistics is theoretically decided, without setting assumption of parametric distribution to test statistics. Anderson–Darling test makes use of the specific distribution in calculating critical values [
43]. This has the advantage of allowing a more sensitive test and the disadvantage that critical values must be calculated for each distribution. In addition, probability limit method test has an advantage whose acceptance region can be constructed with no assumption of specific distribution concerning a variable in its region. The power of a test is the probability of rejecting a null hypothesis. The greater the power of the test of the adopted hypothesis, the narrower the confidence interval and prediction interval based on this test and the greater the accuracy of estimation and prediction. In the probability limit method test, a critical line of the probability limit method, called the probability limit line, is constructed on each side of an assumed probability representing function. Significant difference with the null hypothesis is found when observed data fall outside the interval defined by the limit lines. Here, the probability representing function is defined as the inverse function of the cumulative density function [
44].
In the following,
D(
X;
) represents an assumed probability distribution,
FX(
x) represents the cumulative density function of
D(
X;
), and
χX(
u) represents the probability representing function of
D(
X;
). As above,
X represents a random variable, while random variable
U (=
FX(
x)) represents the cumulative probability of
X. The forms of the cumulative density function (
FX(
x)) and the probability representing function
χX(
u) are respectively shown in Equations (4) and (5).
3.1. Kolmogorov–Smirnov Test
Kolmogorov [
39] proposed a maximum difference between the “cumulative density function of an assumed distribution” and the “empirical cumulative density function” as test statistics. Smirnov [
40] showed tables of realized values of the test statistics Kolmogorov proposed. Through these analyses, the theoretical framework of Kolmogorov–Smirnov test was developed. The Kolmogorov–Smirnov test is one of the hypothesis test theories for testing goodness-of-fit between an assumed cumulative density function
FX(
x) and an observed sample
X when a sample
X (= {
x1,
x2,…,
xn}) is treated as an independent sample from an unknown population which has continuous cumulative density function
FT(
x). In this context, null hypothesis
H0 and alternative hypothesis
H1 are described as follows.
The Kolmogorov–Smirnov test is a nonparametric goodness-of-fit test, so any continuous probability distribution can be assumed. In the Kolmogorov–Smirnov test, an empirical cumulative density function is constructed by order statistics derived from observed sample
X (= {
x1,
x2,…,
xn}) that follows continuous independent and identically distribution. Here, order statistics are defined as a statistical sample constructed of observed data in ascending order. The empirical cumulative density function (
Fn(
x)) is expressed as
where
n is sample size and
i is the ascending order of each datum in observed sample
X.
The Kolmogorov–Smirnov test statistic
dn in the case of a two-sided test expressed by Equation (9).
For a sufficiently large sample size
n, the limiting distribution of Kolmogorov–Smirnov test statistics is expressed by Equation (10) [
39,
40,
45].
In the following, the critical value
zn−1/2 is alternatively described as
εn. Massy [
46], Birnbaum [
47] and Miller [
48] showed tables of critical values
zn−1/2 for rejection probabilities
P(
dn ≤
zn−1/2) in the case that sample size
n is finite. When a Kolmogorov–Smirnov test with two-sided probability of
p is conducted, an acceptance region of
ith-order statistics
X(i) derived from the observed sample
X is expressed by Equation (11). In Equation (11), the critical value is expressed as
εn,(1−p). Here,
p is a significance level, and (1 −
p) is a confidence coefficient. In the Kolmogorov–Smirnov test, the hypothesis is rejected when observed order statistics
x(i) fall outside the range of this acceptance region.
Here, χX(u−εn,(1−p)) is the lower critical value, while χX(u + εn,(1−p)) is the upper critical value. By using plotting position formula, critical values can be plotted on both sides of an assumed probability distribution as critical points. Critical lines can be constructed by interpolating critical points for the lower and upper sides. This framing leads to a more concrete procedure for the Kolmogorov–Smirnov test: critical lines are constructed based on the significance level, and the hypothesis is rejected if observed data fall outside the range of the acceptance region.
We now explore the case of the Kolmogorov–Smirnov test for 5% two-sided probability. The critical value in the case of 5% two-sided probability is the 95%ile value of the Kolmogorov–Smirnov test statistic distribution. Here, Equation (12) embraces the critical value in the case of 5% probability, expressed as
εn,0.95. The critical value
εn,0.95 is expressed in turn by Equation (13) [
47]. Therefore, in this case, an adopted
X(i) region is defined by Equation (14).
Next, we detail the power of test characteristics of the Kolmogorov–Smirnov test.
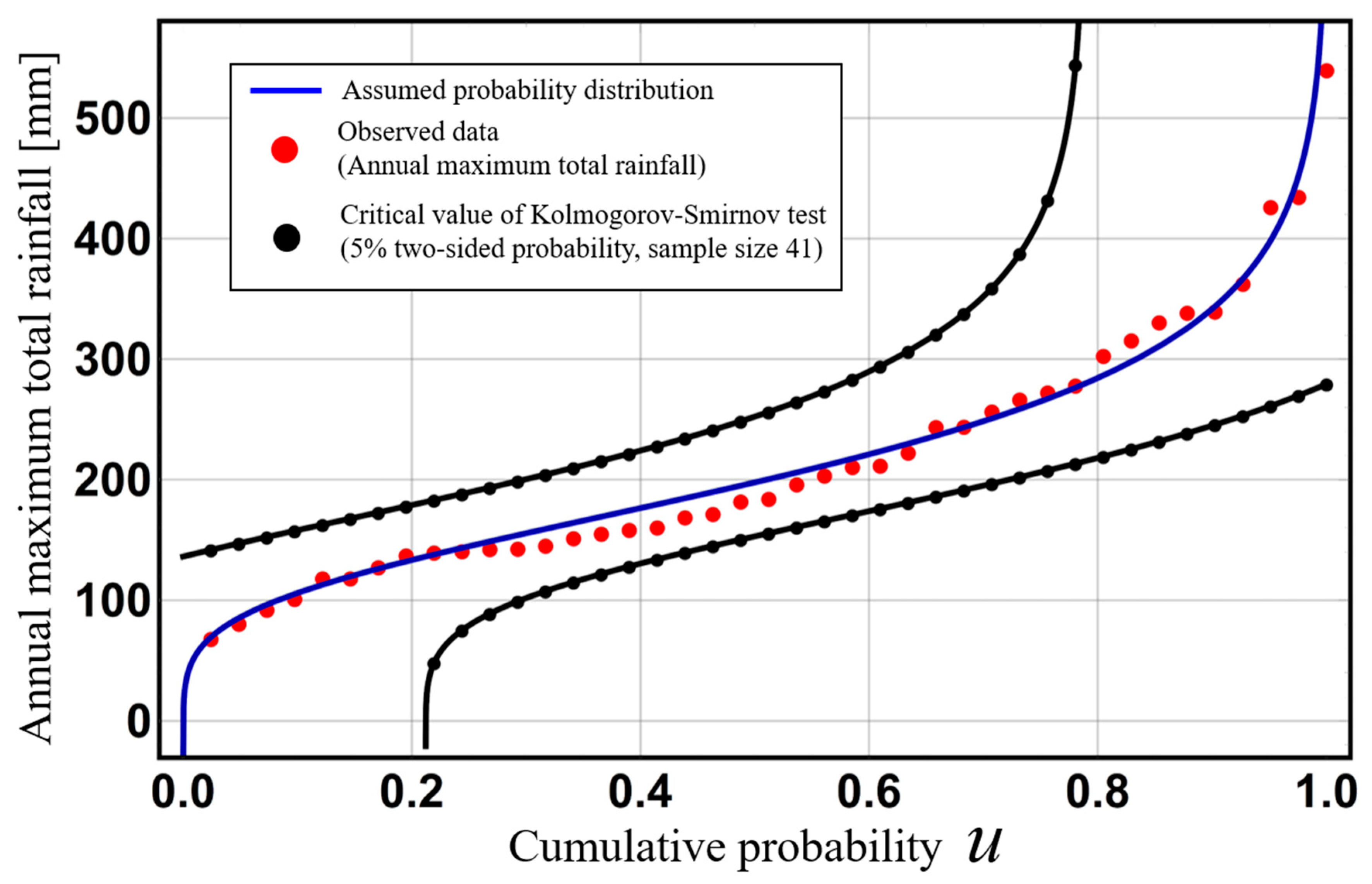
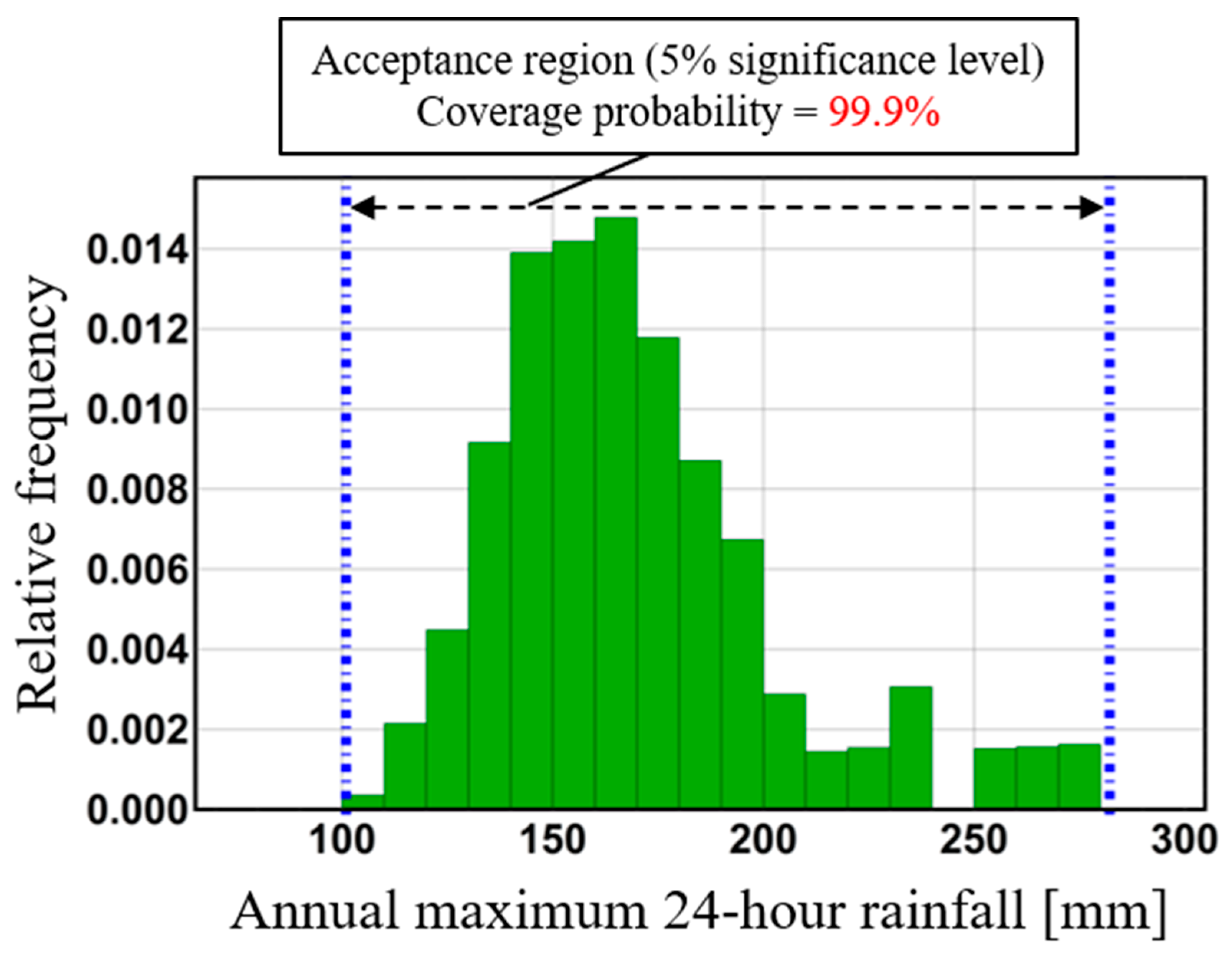
Figure 3 shows observed data for annual maximum total rainfall for 41 years from 1977 to 2018 in the Kusaki dam basin, a Gumbel distribution that these observed data are assumed to follow, and critical lines in the case of a 5% two-sided probability Kolmogorov–Smirnov test. Here these annual maximum total rainfalls are defined as total rainfall during a 72-h period. In this figure, the acceptance region is narrow in the central part of an assumed distribution. This result illustrates the strong power of the Kolmogorov–Smirnov test at the central part of an assumed probability distribution and its weak power at the tail of the distribution.
3.2. Probability Limit Method Test
This section provides a detailed outline of the probability limit method test. Here, cumulative probability
U (=
FX(
x)) follows a uniform distribution on interval [0,1]; this uniform distribution is also described as a standard uniform distribution or
U [0,1]. We also consider order statistics {
u(1),
u(2), …,
u(n)} constructed of realized values of random variable from
U [0,1]. The probability distribution of
ith-order statistics from standard uniform distribution becomes a beta distribution with parameter (
i,
n −
i + 1). In Equation (15),
FU(i) (
u) expresses the cumulative density function of
ith-order statistics
U(i),
Iu (
i,
n −
i + 1) representing the cumulative density function of the beta distribution with parameter (
i,
n −
i + 1):
Here, probability
α is defined as the probability used for derivation of probability limit values [
20]. The occurrence probability of an extreme
U(i) value is the probability that
U(i) falls in the tail of the beta distribution with parameter (
i,
n −
i + 1). Solution
u of equation
FU(i)(
u) =
α is defined as the lower probability limit value
zL(
i) under a standard uniform distribution, while solution
u of equation
FU(i)(
u) = 1 −
α is defined as the upper probability limit value
zU(
i) under a standard uniform distribution. Therefore,
zL(
i) is the 100
α%ile value of the beta distribution with parameter (
i,
n −
i + 1), and
zU(
i) is the 100(1 −
α)%ile value of the beta distribution with parameter (
i,
n −
i + 1). Probability
αmin is defined as
where
Iu(
i,
n −
i + 1)|
u = u(i) is the nonexceedance probability of
ith-order statistics
u(i), and
I1 − u (
n −
i + 1,
i)|
u= u(i) is the exceedance probability of
ith-order statistics
u(i), following the beta distribution with parameter of (
i,
n −
i + 1). Equation (16) expresses a mathematical process to derive probability
αmin. The nonexceedance probability and exceedance probability of the order statistics {
u(1),
u(2),
…,
u(n)} are compared, and the smaller of the two probabilities is extracted. As a result, a set of
n probabilities is obtained. Probability
αmin is the minimum value of these
n probabilities. Here, a set of
n probabilities is described as {
α’1,
α’2,
…, α’n}, so probability
αmin can be described as
αmin = Min{
α’1,
α’2,
…, α’n}.
Next, the construction method and distributional characteristics of probability
αmin are illustrated in detail. Firstly, a set of
n random values under the standard uniform distribution are generated, and ensemble sample
Uens. j = {
u j1,
u j2, …,
u jn} is constructed from these random values. This procedure is repeated
N times, obtaining
N sets of samples {
Uens. 1,
Uens. 2, …,
Uens. N}. Here,
j expresses the sample number (
j = 1, 2,…,
N). For a sample of
Uens. j, the
ith-order statistics
Uj(i) under the standard uniform distribution follow a beta distribution with parameter (
i,
n −
i + 1). In the below, the
u j(i) that occurs farthest down either tail of the beta distribution with parameter (
i,
n −
i + 1) in a sample of
Uens. j is described as
u j(i)’ to help clarify the explanation. When
u j(i)’ falls in the left tail of the beta distribution with parameter (
i,
n −
i + 1), the nonexceedance probability of
u j(i)’ is extracted, so this nonexceedance probability is defined as
αmin (
j). On the other hand, when
u j(i)’ falls in the right tail of beta distribution with parameter (
i,
n −
i + 1), the exceedance probability of
u j(i)’ is extracted, and this exceedance probability is defined as
αmin (
j). The mathematical procedure shown in Equation (16) is applied to the set of
N ensemble samples {
Uens. 1,
Uens. 2, …,
Uens. N}, obtaining a sample of
αmin values {
αmin(1),
αmin(2), …,
αmin(
N)}. Here, the order of
αmin is so small that
αmin is converted to a form of −log
10(2
αmin) for convenience. For example, the average order of
αmin is about 10
−2.
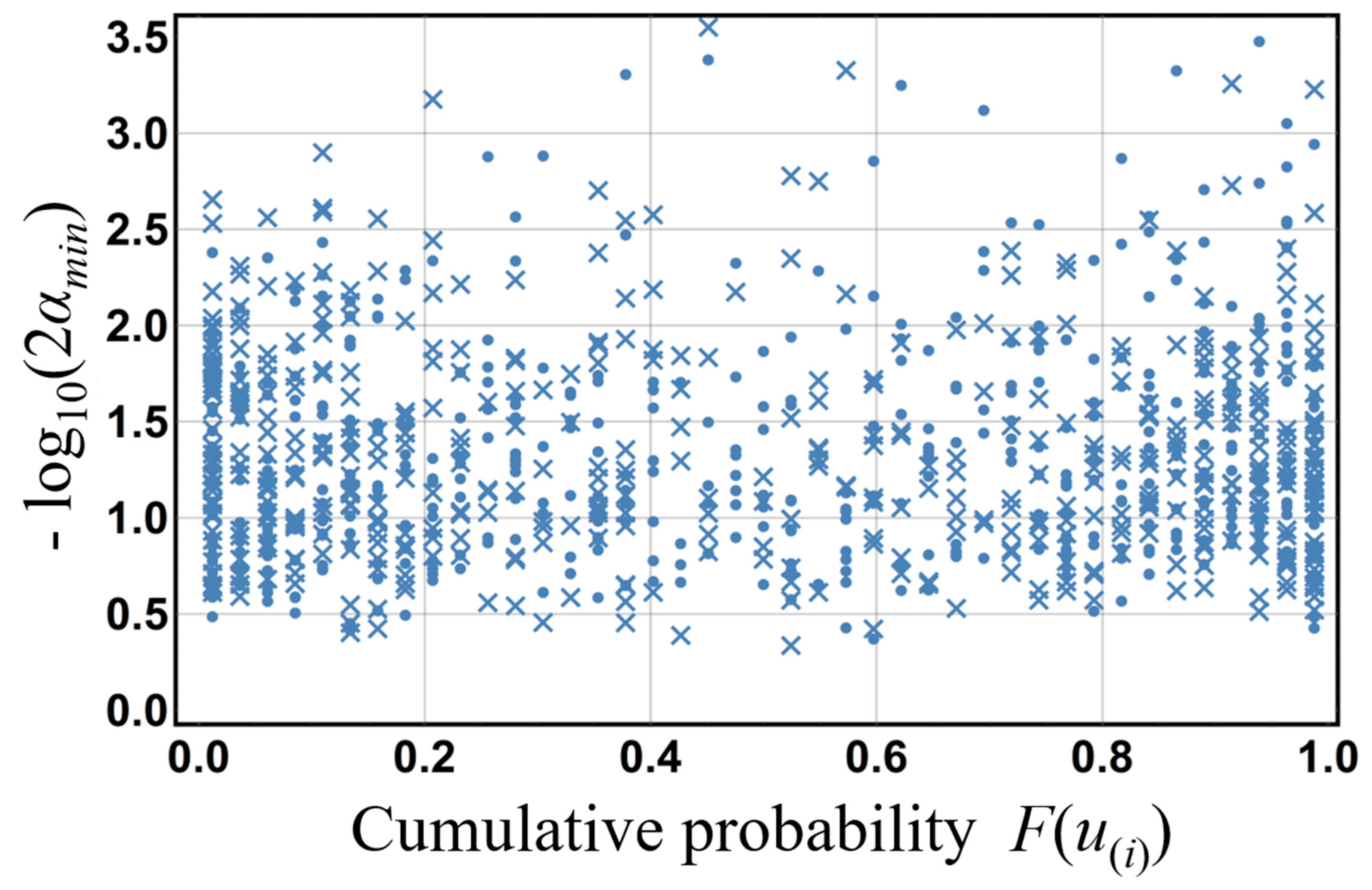
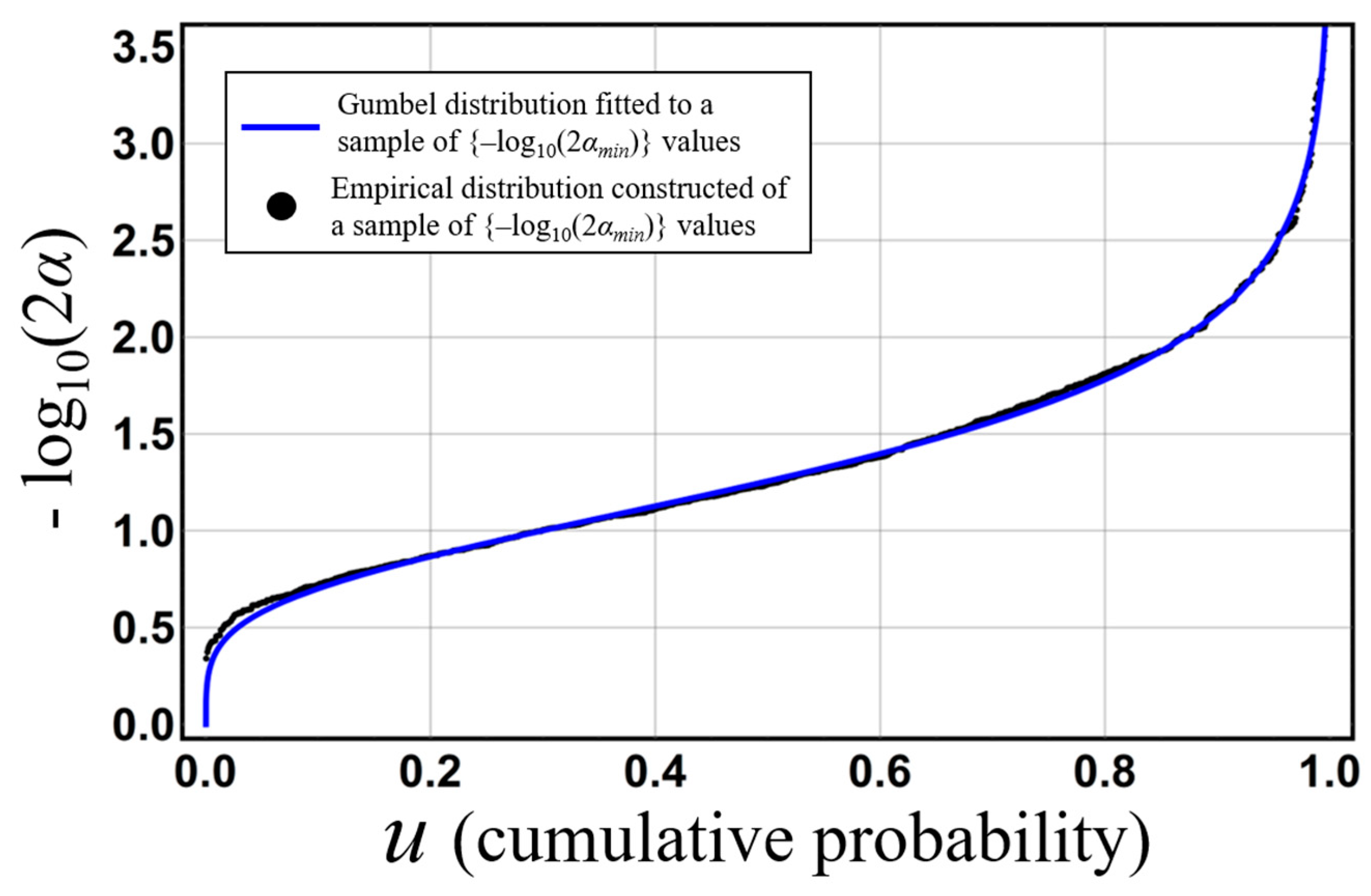
Figure 4 shows a 1000-member set of −log
10(2
αmin) values and the cumulative probability of
u(i) that gives
αmin (
F(
u(i)) ( =
i/
n)). In this figure,
αmin, which is given by
Iu(
i,
n−
i + 1) and the nonexceedance probability, is shown as [×];
αmin, which is given by
I1−u(
n−
i + 1,
i) and the exceedance probability, is shown as [O]. This figure makes clear that
αmin is distributed uniformly, and that
αmin takes on the value of the nonexceedance and exceedance probabilities with almost equal frequency. To describe probability
α corresponding to arbitrary significance levels, empirical representing function
χemp(
u), i.e., the probability representing function of the empirical distribution, is constructed using
N − log
10(2
αmin). An example of this empirical representing function
χemp(
u) for
N = 1000 is shown in
Figure 5. In the empirical representing function shown in
Figure 5, the probability
α near the cumulative probability of 1.0 represents the nonexceedance probability or exceedance probability, whichever
ith-order statistic occurs more farther down either tail of the beta distribution with parameter (
i,
n −
i + 1). Here, probability
α corresponds to a two-sided probability of
p representing the elimination of 100(
p/2)% from the smaller probability
αmin of the nonexceedance probability or exceedance probability, since
αmin takes on the value of the nonexceedance and exceedance probabilities with almost equal frequency.
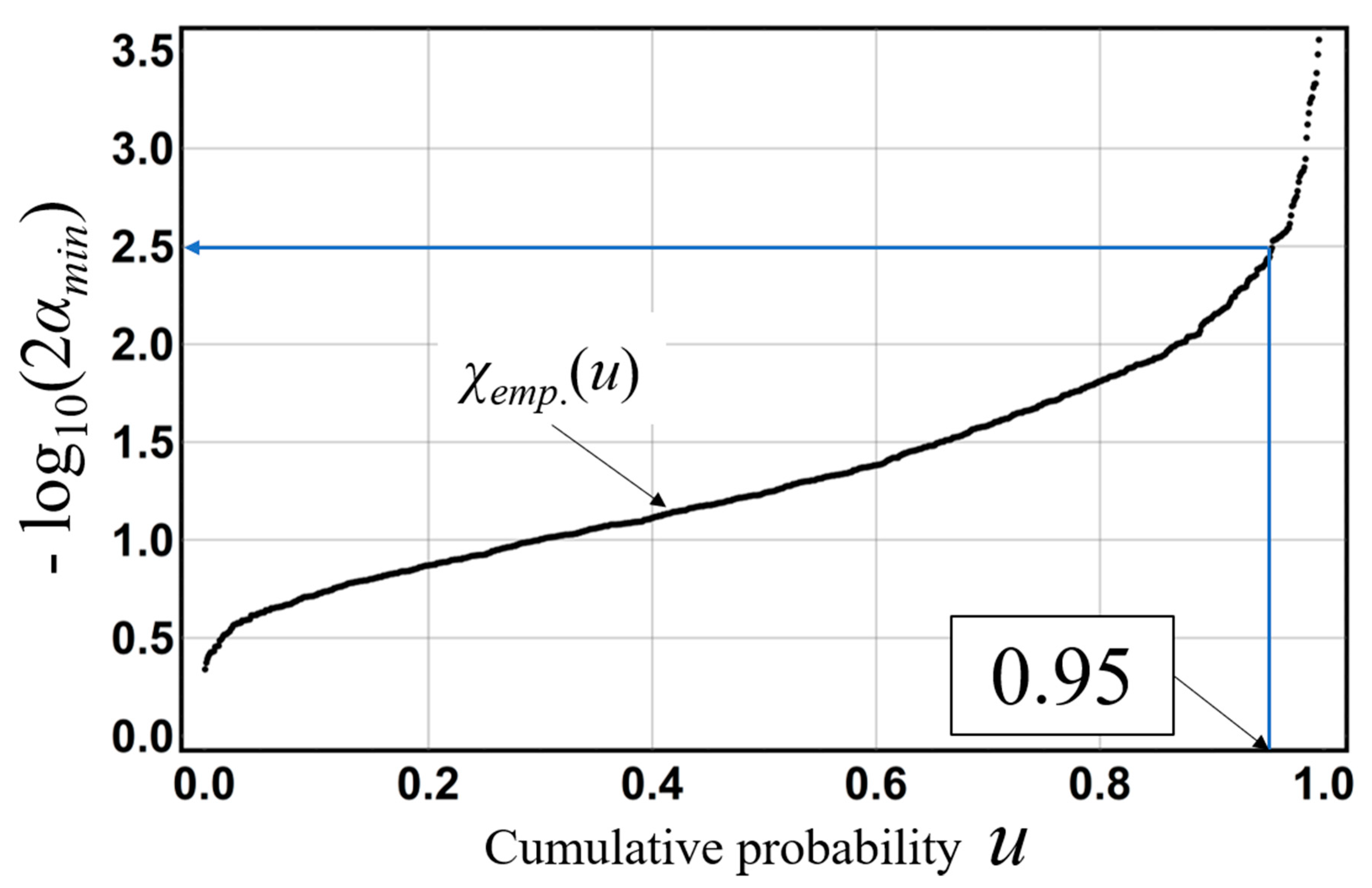
Next, we illustrate the derivation method of probability
α corresponding to a 5% two-sided probability in the probability limit method test. Probability
α corresponding to a 100(1−
α)% two-sided probability is obtained by solving equation
χemp. (
p) = −log
10(2
α) for
α. For example, probability
α corresponding to a 5% two-sided probability is derived by solving
χemp.(0.95) = −log
10(2
α) = 2.5, resulting in an
α value of about 1.5 × 10
−3 in
Figure 5.
The lower probability limit and upper probability limit values under a standard uniform distribution can be derived by using probability
α calculated by the method outlined above. Here, in Equation (15), the event (
U(i) ≤
u) means that a value less than
u occurs more than
i times. Therefore, Equation (17) provides an easier way to calculate the probability limit value in the probability limit method test:
The lower probability limit value corresponding to the two-sided probability of
p is the one eliminating the occurrence probability of the more extreme (i.e., smaller)
ith-order statistics in the beta distribution with parameter (
i,
n −
i + 1). Similarly, the upper probability limit value corresponding to the two-sided probability of
p is the one eliminating the occurrence probability of the more extreme (i.e., larger)
ith-order statistics in the beta distribution with parameter (
i,
n −
i + 1). Values derived by applying the precise cumulative probability
FU(
u(i)) to the probability limit value are defined as the lower probability limit point (
FU(
u(i)),
zL(
i)) and the upper probability limit value (
FU(
u(i)),
zU(
i)) under the standard uniform distribution. Here,
FU(
u(i)) is defined as
i/
n. In the standard uniform distribution, the lower probability limit line is defined as an interpolated line of lower probability limit points, while the upper probability limit line is defined as an interpolated line of upper probability limit points for
i = 1, 2, …,
n.
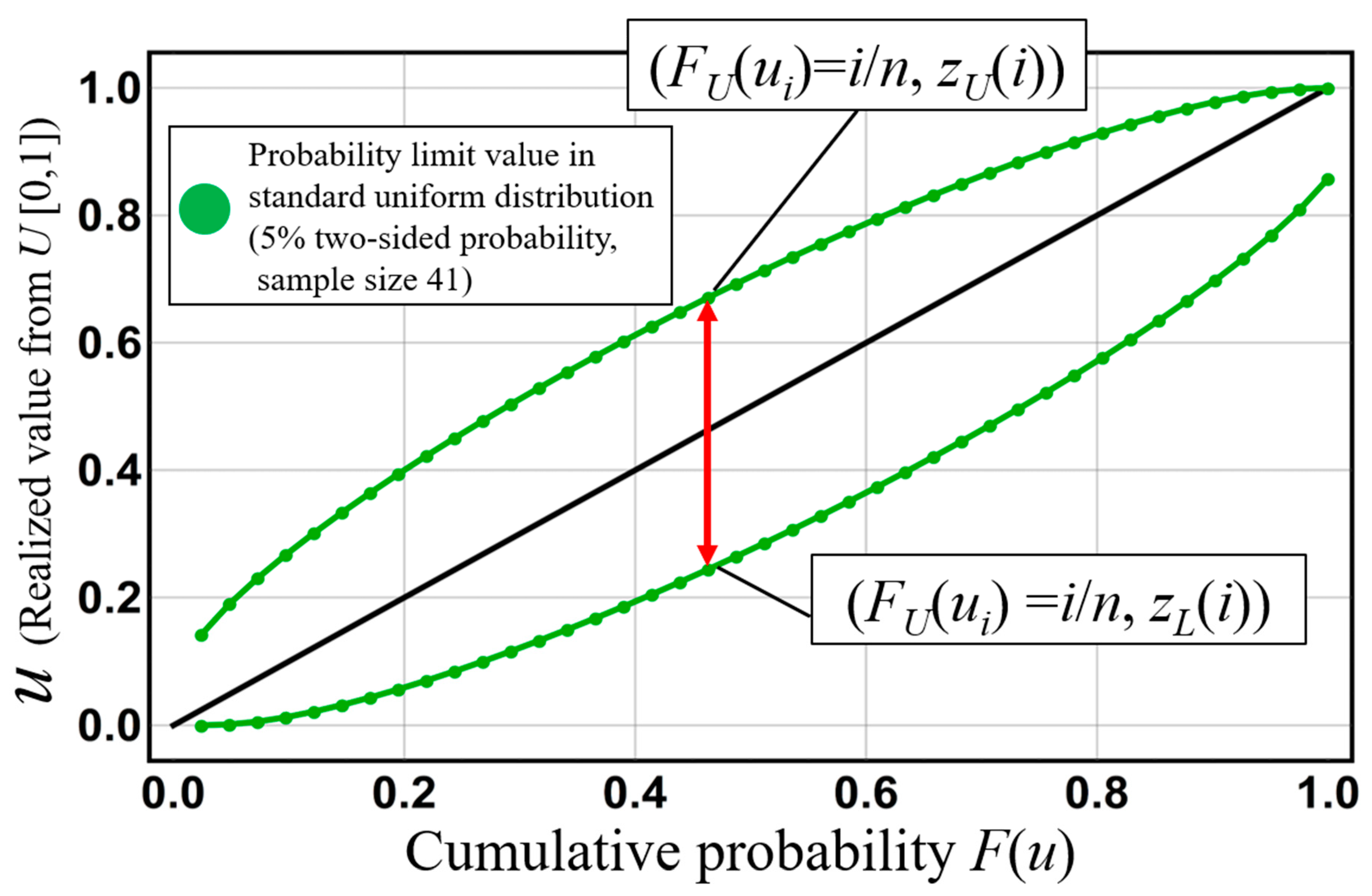
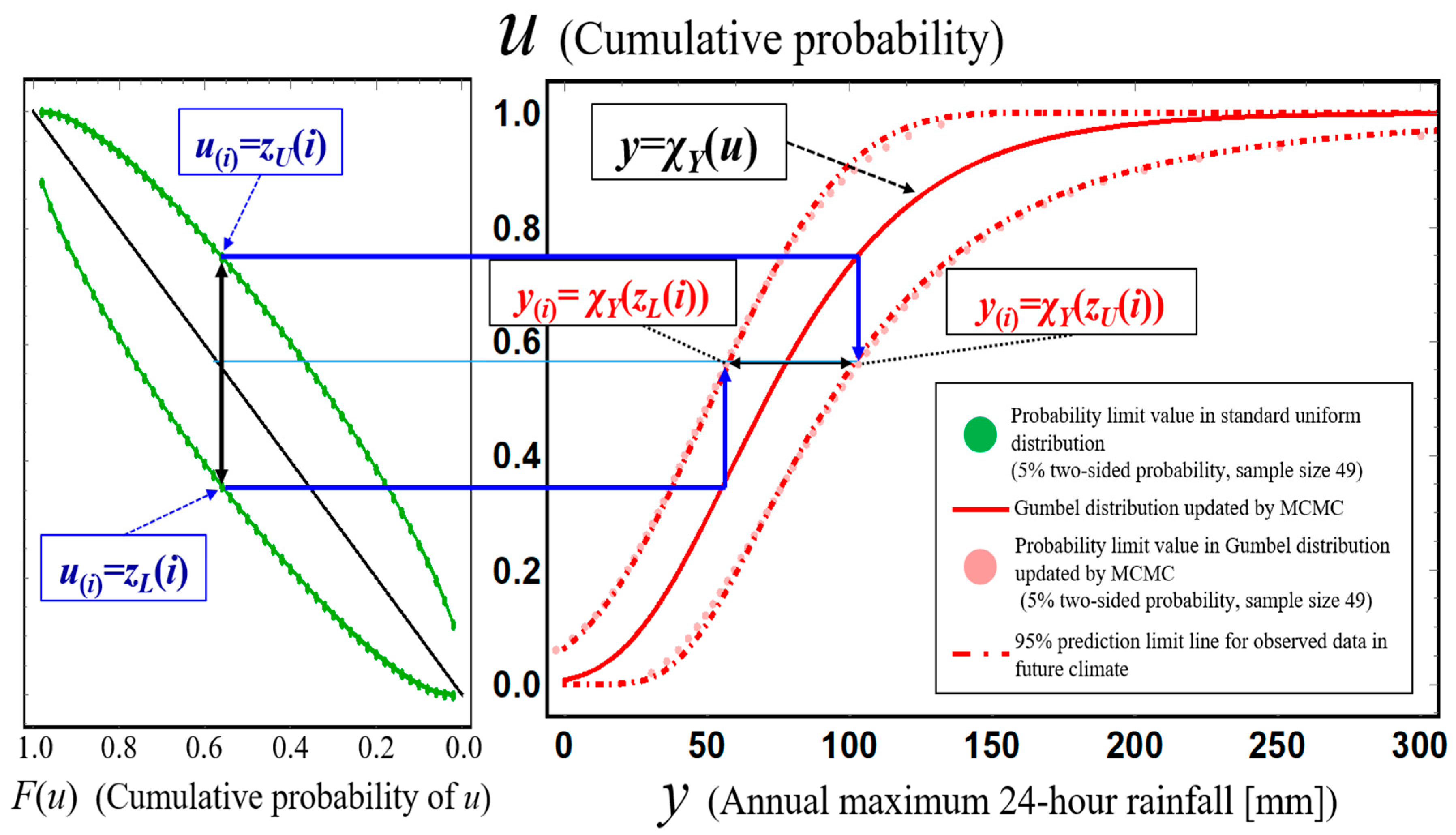
Figure 6 shows probability limit lines for a standard uniform distribution for a 5% two-sided probability and a sample size of 41. This figure shows the range that the
ith-order cumulative probability
U(i)(=
FX(
X(i))) can take.
Next, we provide a derivation procedure for the probability limit values of the assumed probability distribution
D(
X;
).
U follows a standard uniform distribution, and probability limit values are treated as cumulative probability. Therefore, the lower probability limit value in the assumed probability distribution is described by
χX(
zL(
i)), while the upper probability limit in assumed probability distribution is described by
χX(
zU(
i)).
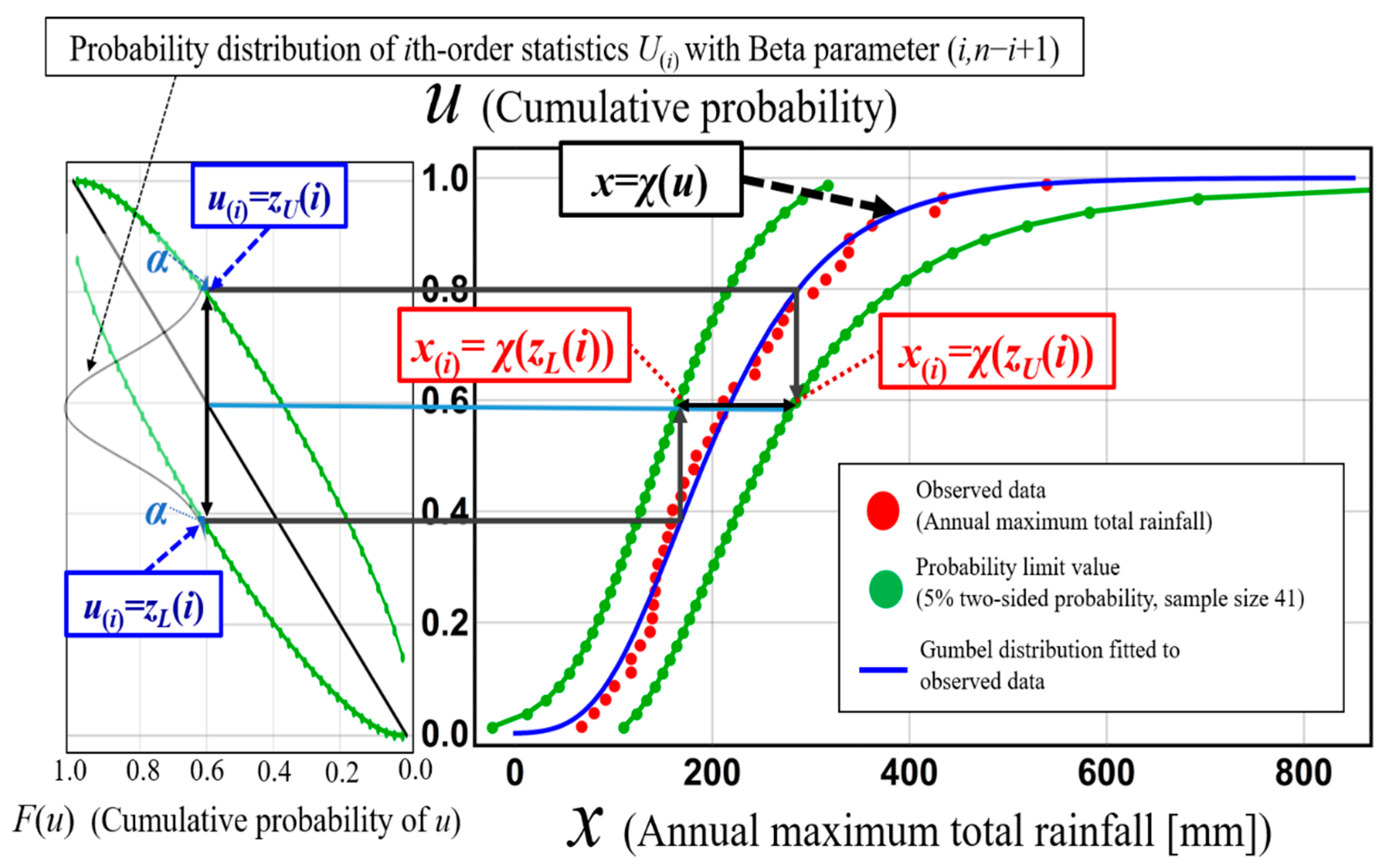
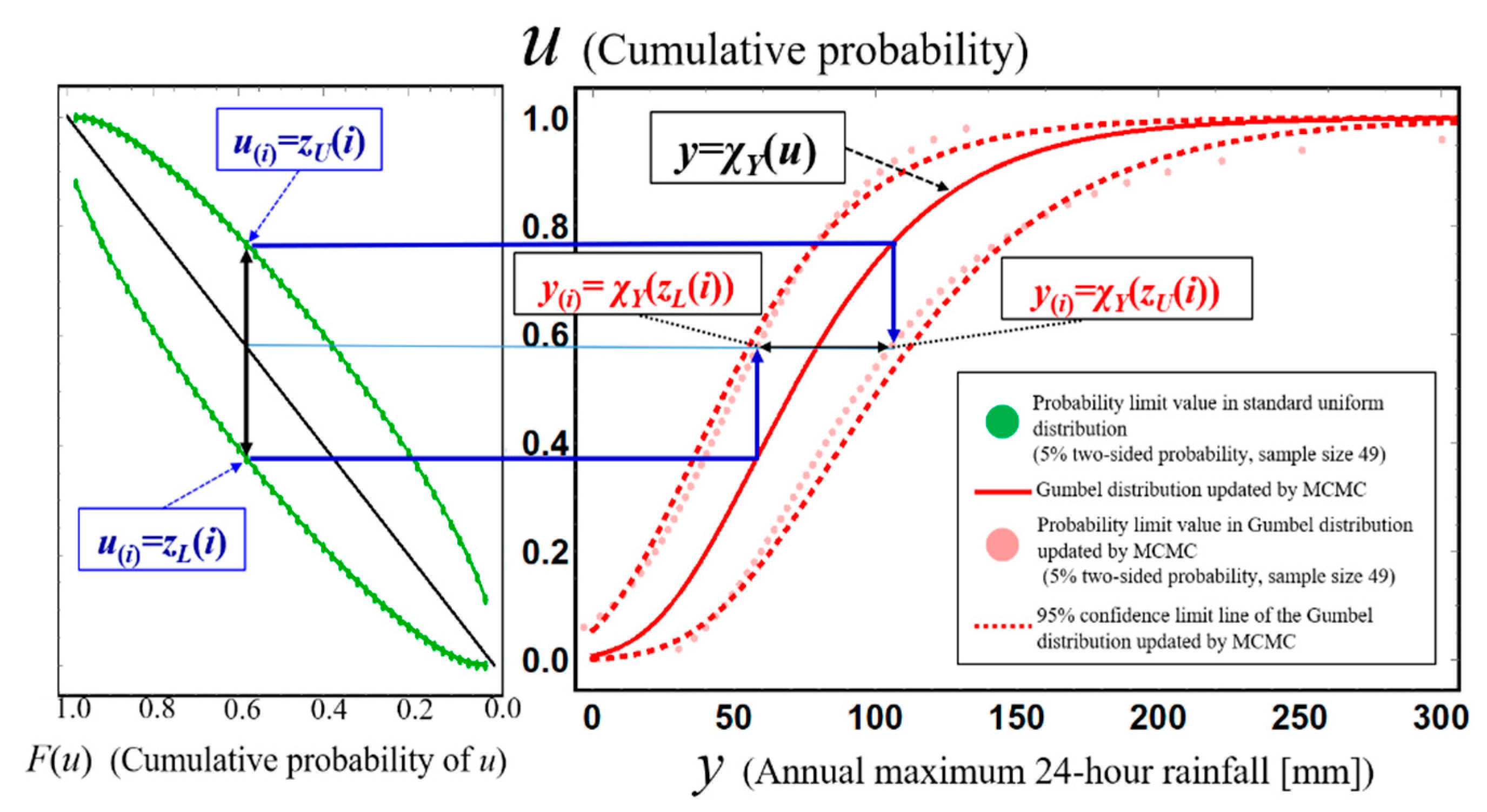
Figure 7 shows the construction process of the probability limit line for a 5% two-sided probability for an assumed Gumbel distribution of annual maximum total rainfall for 41 years from 1977 to 2018 in the Kusaki dam basin, Japan. This figure shows that acceptance regions [z
L(
i), z
U(
i)] for the
ith cumulative probability are converted to acceptance regions [
χX(
zL(
i)),
χX(
zU(
i))] for
ith-order annual maximum total rainfall
X(i) itself through the representing function of an assumed probability distribution.
3.3. Power Comparison between Kolmogorov–Smirnov Test and Probability Limit Method Test
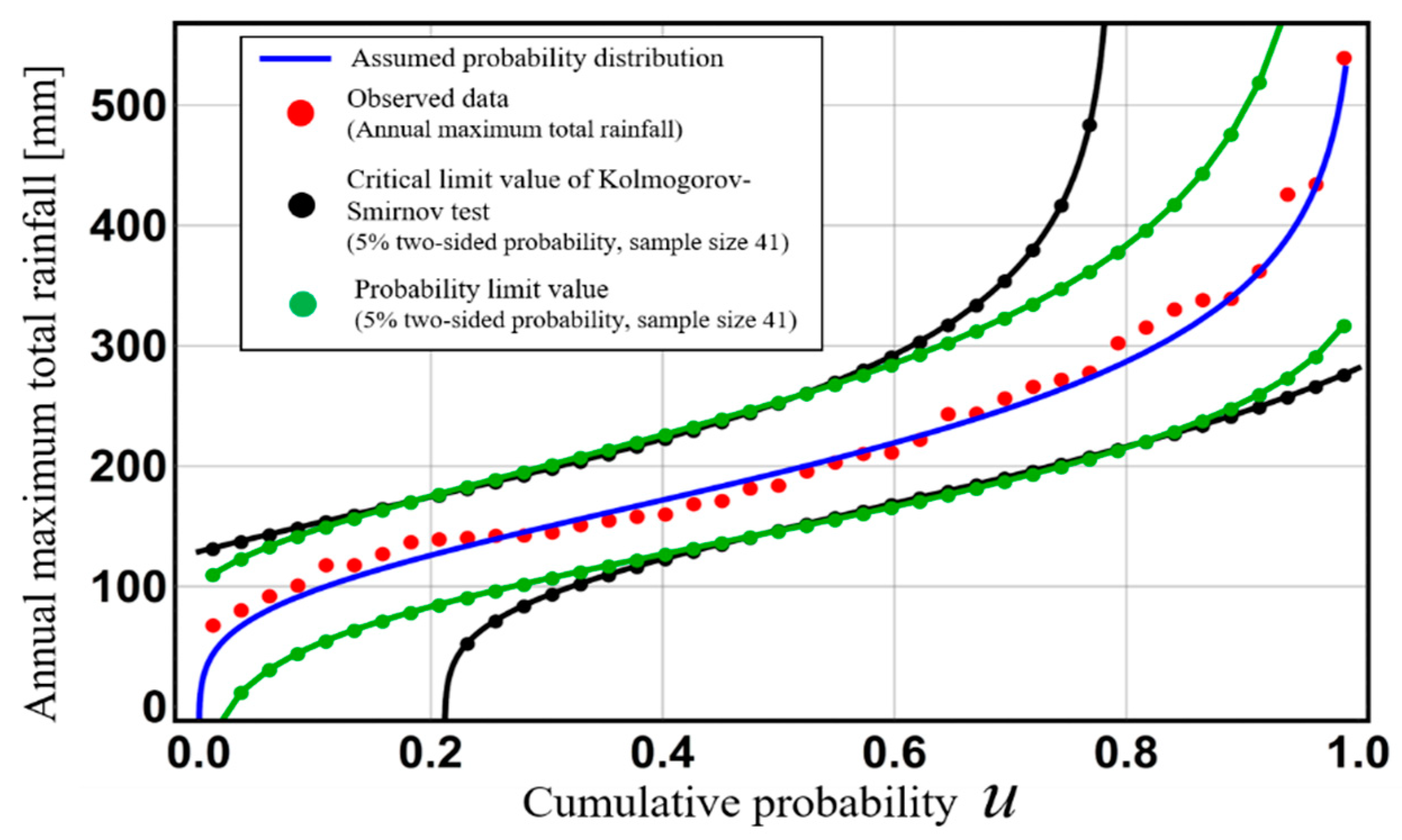
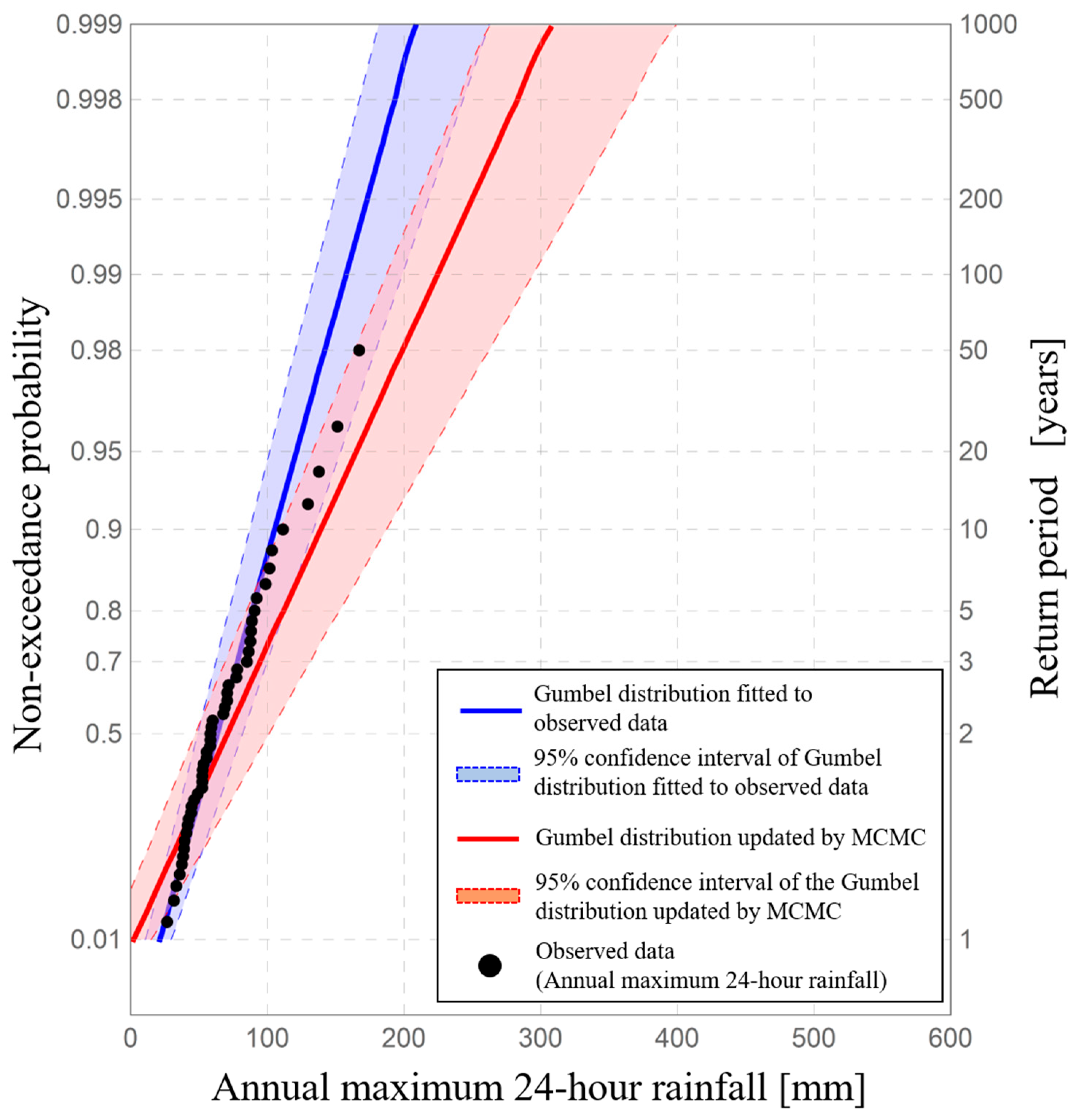
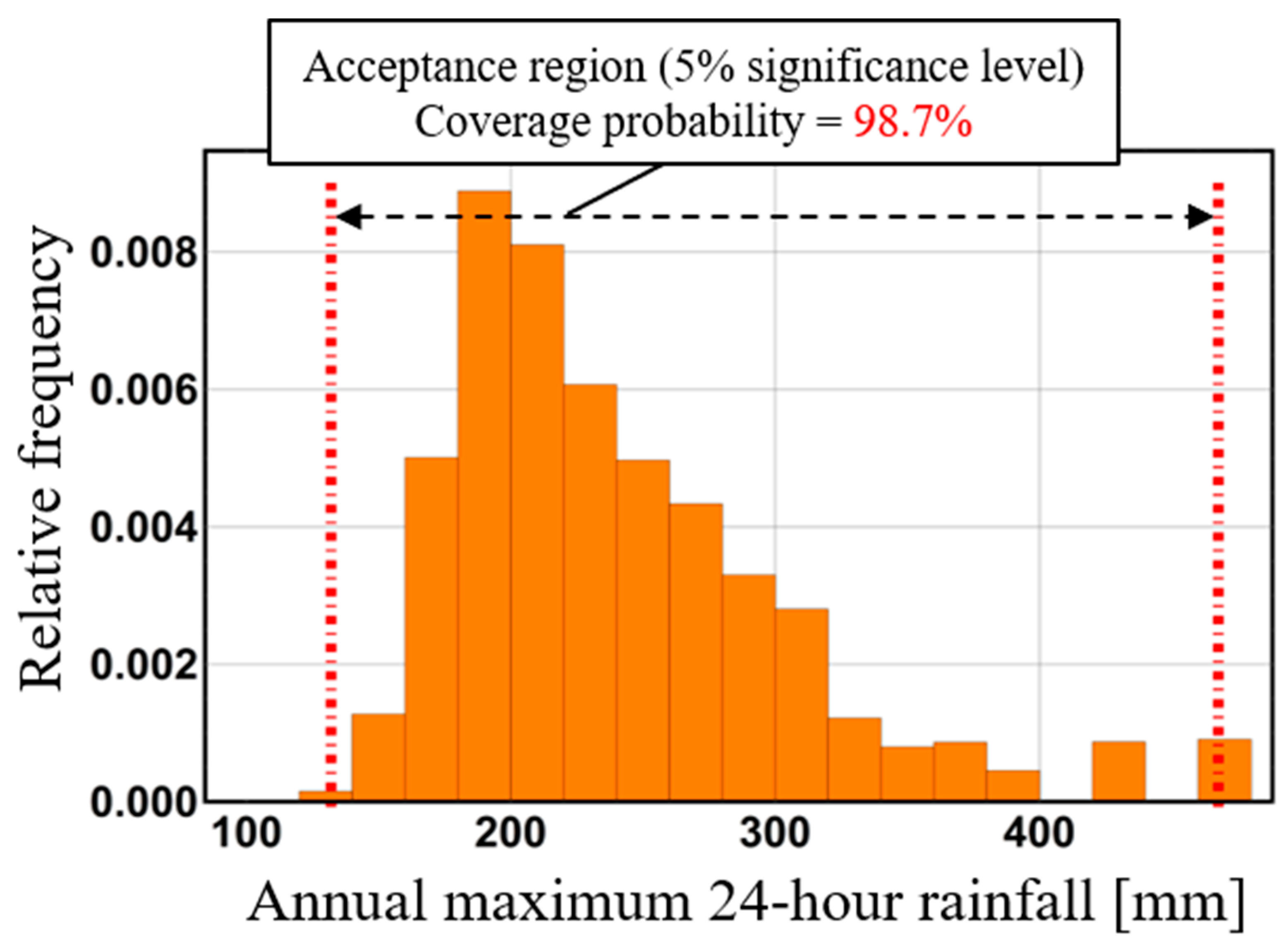
Figure 8 shows the critical lines of the Kolmogorov–Smirnov test and probability limit method tests for 5% two-sided probability using the same data. An acceptance region, i.e., the area between the limit lines, expresses how broadly the data are distributed under the adopted hypothesis-testing theory. Based on this figure, the range of the Kolmogorov–Smirnov test’s acceptance region is infinite at the tail of the assumed probability distribution. This means that infinite values of rainfall or river discharge are allowed under Kolmogorov–Smirnov test. The existence of infinite values of rainfall or river discharge does not accord with the real world. On the other hand, the acceptance region in the probability limit method test narrows at the tail of an assumed probability distribution. This means that extreme values corresponding to the tail of an assumed probability distribution can be estimated as an acceptance region with high accuracy. Thus, the power, confidence interval, and prediction interval are interrelated. In general, the greater power the adopted hypothesis-testing theory has, the more precise the confidence and prediction intervals based on the adopted hypothesis-testing theory. The design level for a given hydrological quantity fluctuates dramatically depending on the tail of the adopted distribution. Therefore, since the probability limit method test shows high accuracy at the distribution tails, confidence intervals and prediction intervals in this research are constructed based on probability limit method test to evaluate uncertainties in hydrological statistics.
3.4. Construction of Confidence Intervals and Prediction Intervals Based on Probability Limit Method Test
In this section, the construction method for confidence intervals and prediction intervals based on probability limit method tests is illustrated in detail [
49]. In this research, probability
α is derived from the extreme value distribution fitted to
N − log
10(2
αmin). We note that probability
α as used herein differs from that of Moriguti [
20]. The reason to adopt an extreme value distribution for a sample of −log
10(2
αmin) is as follows. Suppose that a sample {
α’1,
α’2,
…, α’n} is converted to a sample {−log
10(2
α’1), −log
10(2
α’2), …, − log
10(2
α’n)}. In this case, the following relation holds: −log
10(2
αmin)
= Max{−log
10(2
α’1) −log
10(2
α’2)
…, − log
10(2
α’n)}. Then −log
10(2
αmin) is the maximum value of any sample of the form {−log
10(2
α’1) − log
10(2
α’2)
…, −log
10(2
α’n)}. Maxima of a sample approximately follow an extreme value distribution as sample size increases. Therefore, it is rational to adopt an extreme value distribution for fitting of a sample of −log
10(2
αmin) values.
Figure 9 shows the probability representing function
χα(
u) fitted with a 1000-member set of −log
10(2
αmin) values. As seen in this figure,
χα(
u) and
χemp.(
u) almost coincide. Therefore, by deriving
χα(
u), confidence intervals can be constructed for arbitrary significance levels. For example, In the case of 5% two-sided probability, probability
α for construction of a 95% confidence interval can be obtained by solving
χα(0.95) = −log
10(2
α) = 2.5, resulting in an
α value of about 1.5 × 10
−3.
The interval [zL(i), zU(i)] is the mathematical range that the cumulative probability of the ith-order statistics derived from random variable series {X1, X2, …, Xn} takes. By substituting probability limit values under a standard uniform distribution into the probability representing function χX(u), the acceptance region of X (i) can be constructed in the form [χX (zL(i)), χX (zU(i))]. Therefore, χX (zL(i)) and χX (zU(i)) are the lower and upper probability limit values, respectively, of X(i), following an adopted probability distribution.
The construction procedure of the 100(1-
p)% confidence limit line is as follows. The function form of the adopted probability distribution
D(
X;
) is applied to “sample
XL = {
χX(
zL(1)),
χX(
zL(2)), …,
χX(
zL(
n))}, constructed of lower probability limit values” and “sample
XU = {
χX(
zU(1)),
χX(
zU(2)), …,
χX(
zU(
n))}, constructed of upper probability limit values.” This procedure allows parameter
to be estimated. Considering parameter
derived from sample
XL and parameter
derived from sample
XU, the probability distribution
D(
X;
) derived from these estimated values is established as the lower confidence limit of
D(
X;
), and
D(
X;
) is established as the upper confidence limit of
D(
X;
). Therefore, in this research,
D(
X;
) is defined as the 100(1 −
p)% lower confidence limit line, and
D(
X;
) is defined as the 100(1 −
p)% upper confidence limit line. In addition, the interval between these limit lines is defined as the 100(1 −
p)% confidence interval of
D(
X;
). In traditional hydrological frequency analysis, the confidence interval is derived from profile likelihood, parametric method, etc. The profile likelihood method assumes that statistics constructed of profile log-likelihood follow a chi-square distribution [
50]. Our proposed confidence intervals based on probability limit tests have the advantage of not requiring any assumption, relying instead on analytical construction as much as possible. In addition, hydrological frequency analysis using confidence intervals can be applied to runoff analysis regarding infiltration on a slope [
51,
52,
53].
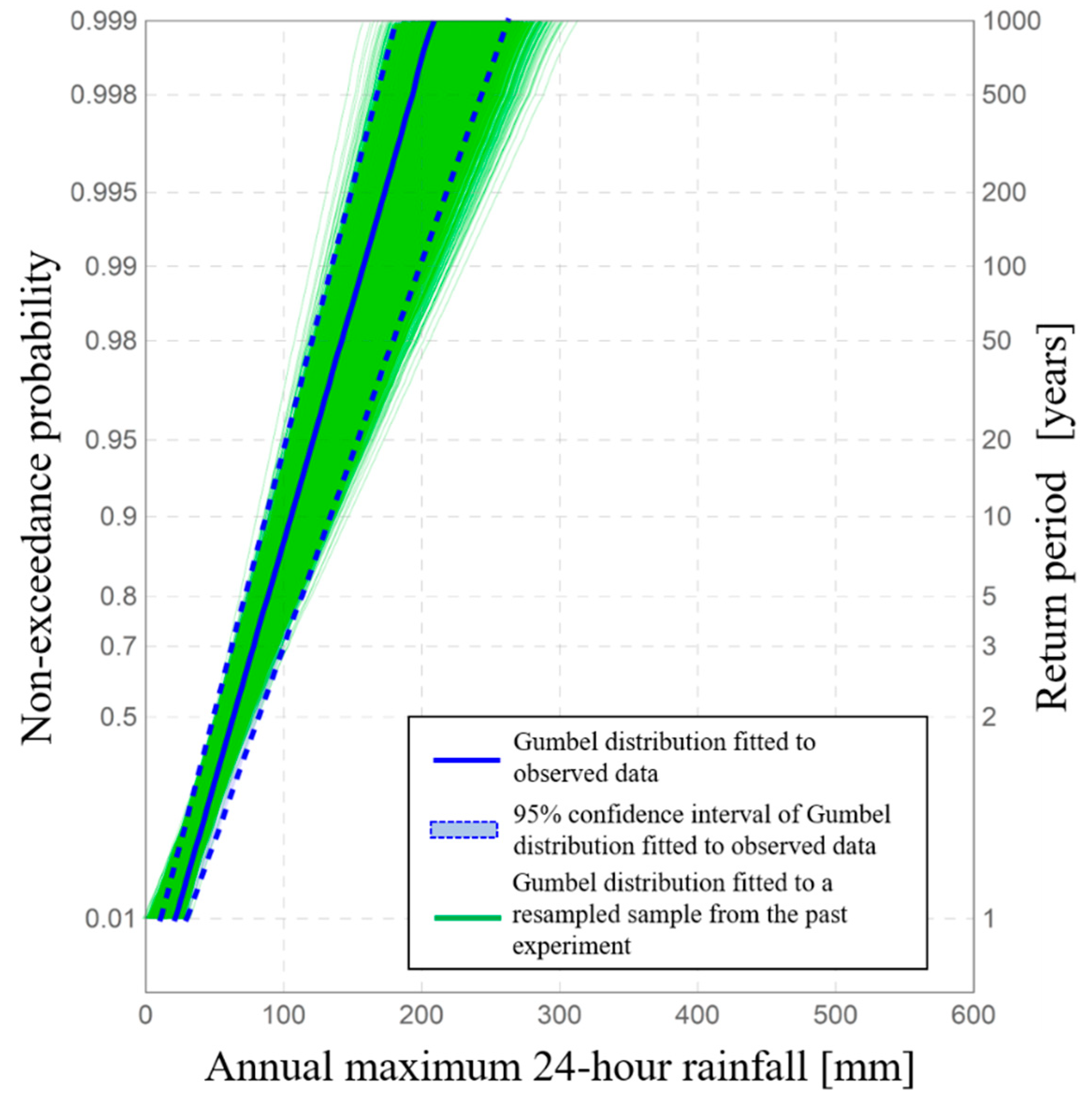
We next show the construction method for prediction intervals for probability distributions [
54]. The acceptance region of the probability limit method test estimates with high accuracy the range of extreme rainfall that could possibly be experienced. Probability limit values can be interpreted as limit values of extreme rainfall at a given significance level. Therefore, when a probability distribution fitted with the greatest number of probability limit values is selected, this probability distribution gives the limiting range of observed data. In addition, it is possible to use this probability distribution to obtain the limit of data as a form of the extrapolated value. This use expresses the prediction of the limit of observed data in future observations, beyond the limits of past concrete observations. Therefore, the probability distribution with the highest goodness-of-fit to probability limit values is defined as the prediction limit line. When the value of the confidence coefficient is near 1.0, the exceedance probability of the upper probability limit value is approximated as
p/2 [
53]. Because prediction limit values are extrapolated values of probability limit values, it can be assumed that the exceedance probability of the upper prediction limit is almost
p/2. Therefore, introducing the risk calculated by the above framework, it is possible to compare the occurrence risk of heavy rainfall to risk in some other fields. In addition, the occurrence risk of a heavy rainfall event can be quantified using the prediction interval. The risk is expressed as a product of the targeted return period and the one-sided probability of the prediction interval [
54]. Here, Knight [
55] defined risk as the phenomenon whose uncertainty is quantified as a form of the probability distribution. Considering this definition, risk is expressed as the occurrence risk of heavy rainfall that falls near any part of the upper prediction limit line with a high confidence coefficient and is evaluated as a phenomenon corresponding to the tail distribution of probable rainfall itself, which can be estimated using the prediction interval.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}