Developing a Discharge Estimation Model for Ungauged Watershed Using CNN and Hydrological Image


Abstract
:1. Introduction
2. Materials and Methods
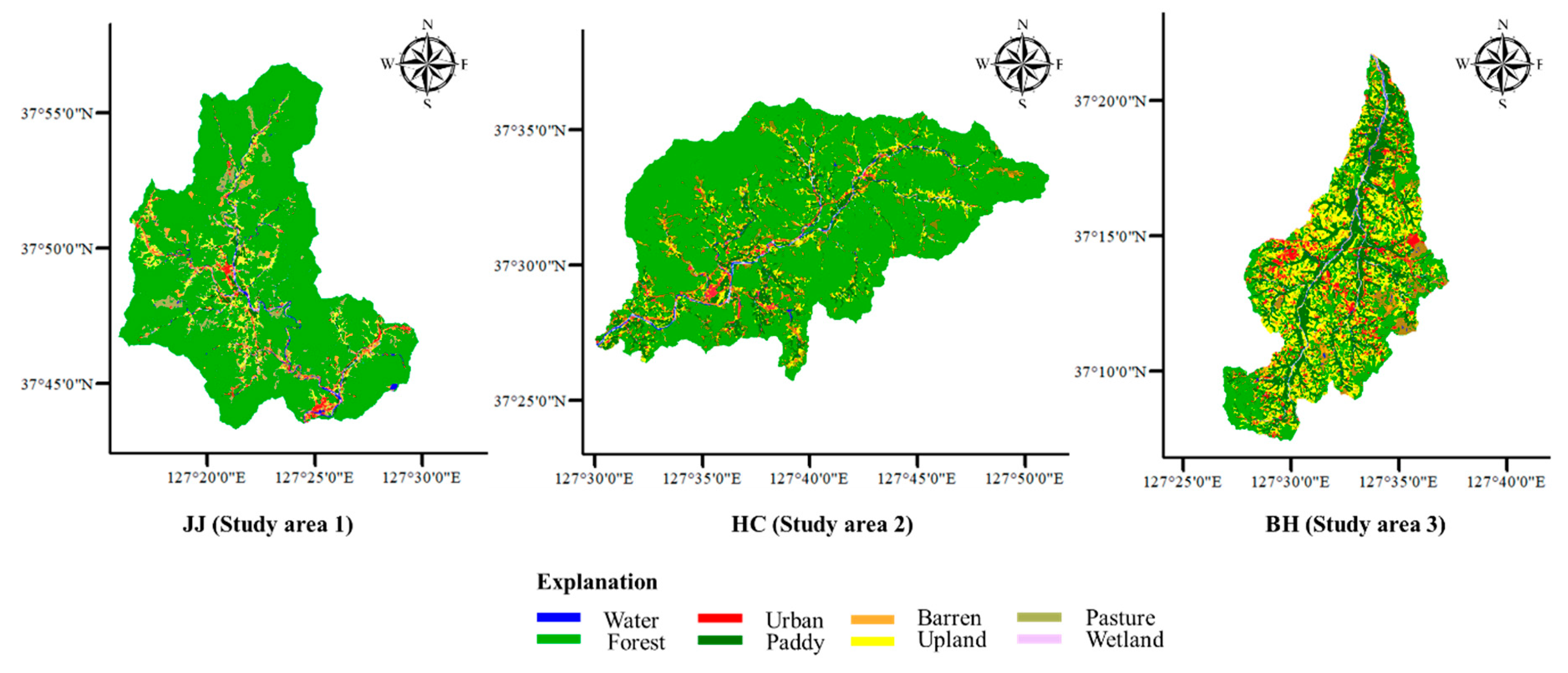
2.1. Study Area
2.2. Data Collection
2.3. Research Method
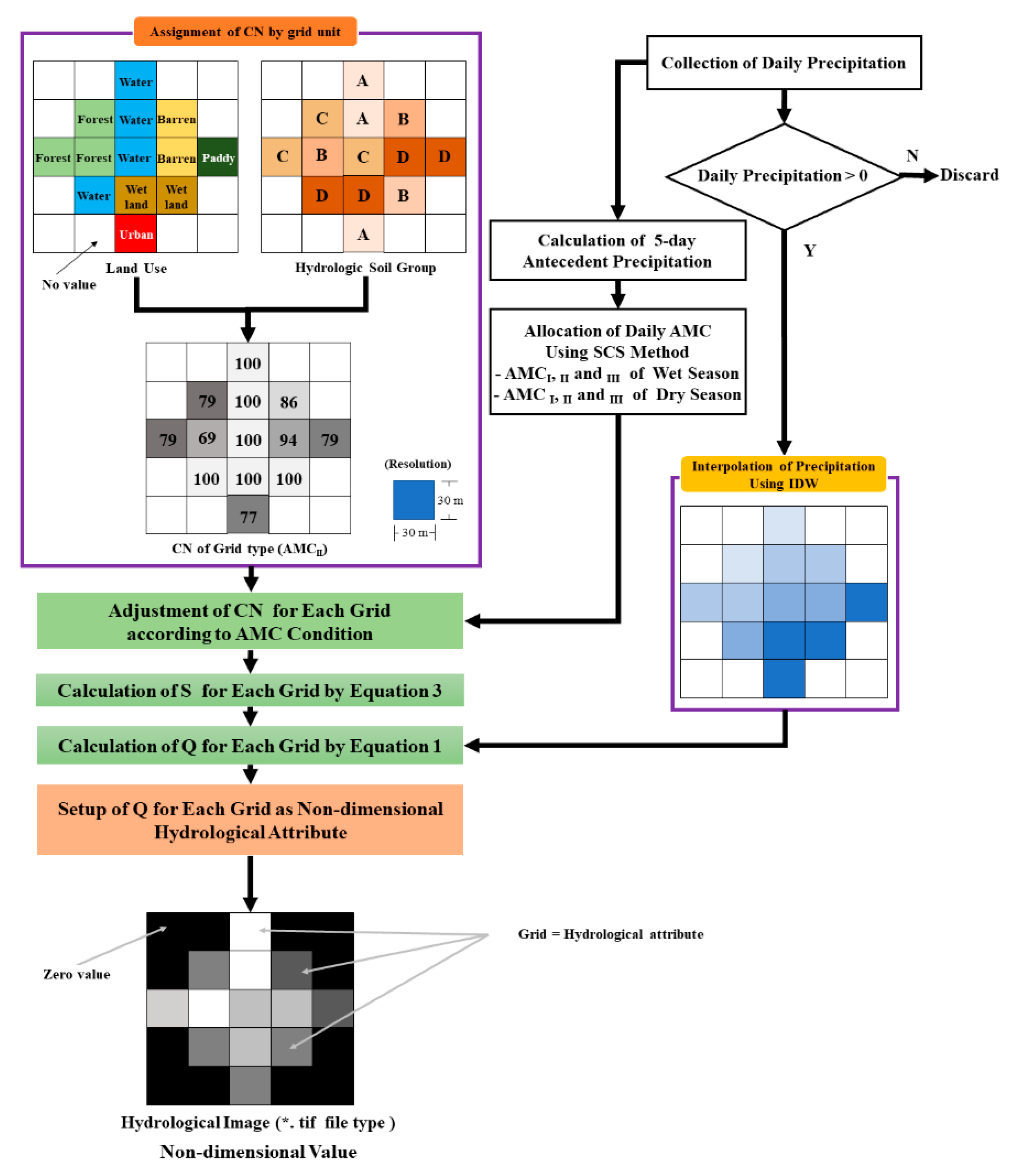
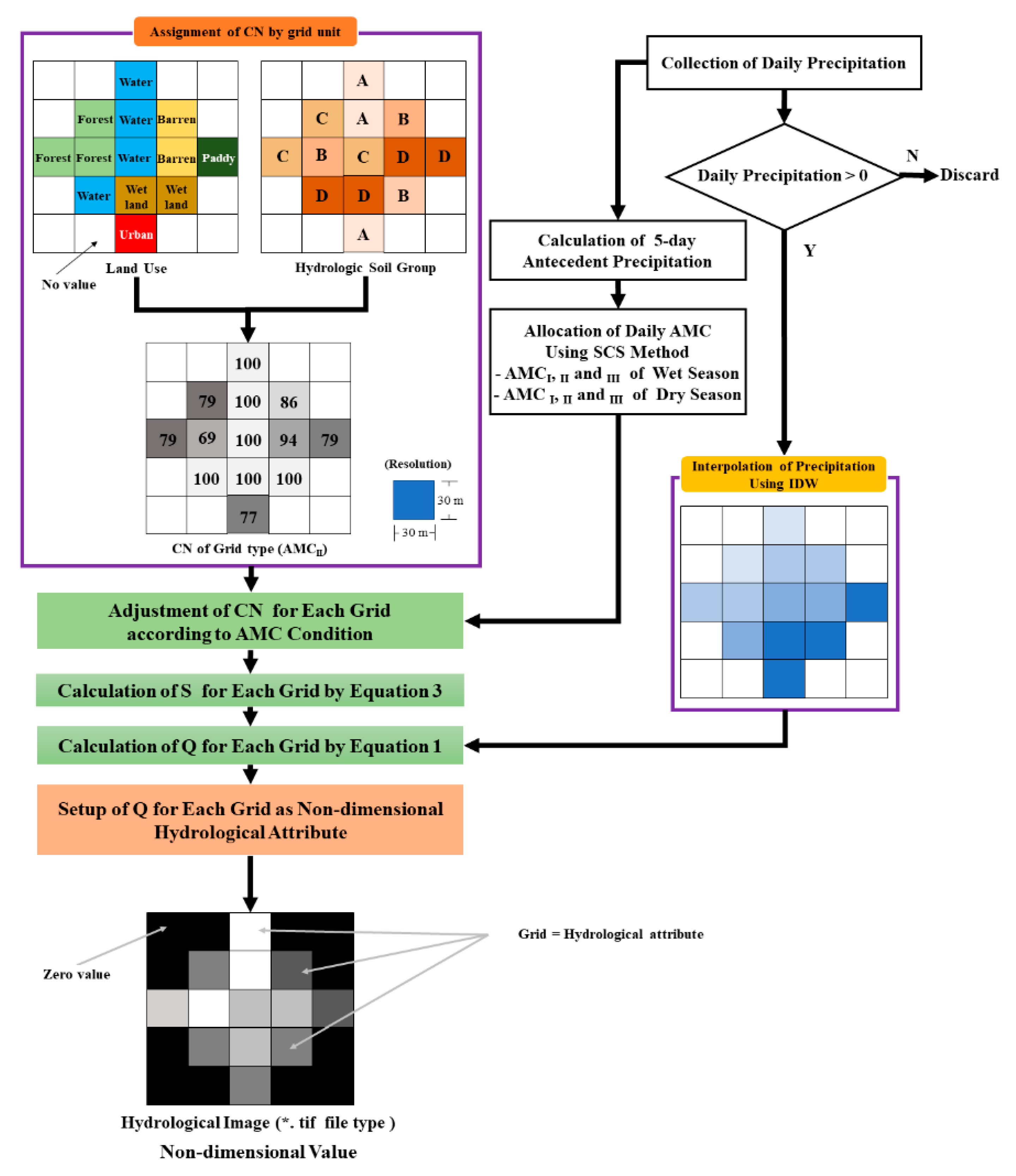
2.3.1. Building the Dataset for the CNN Model
- (1)
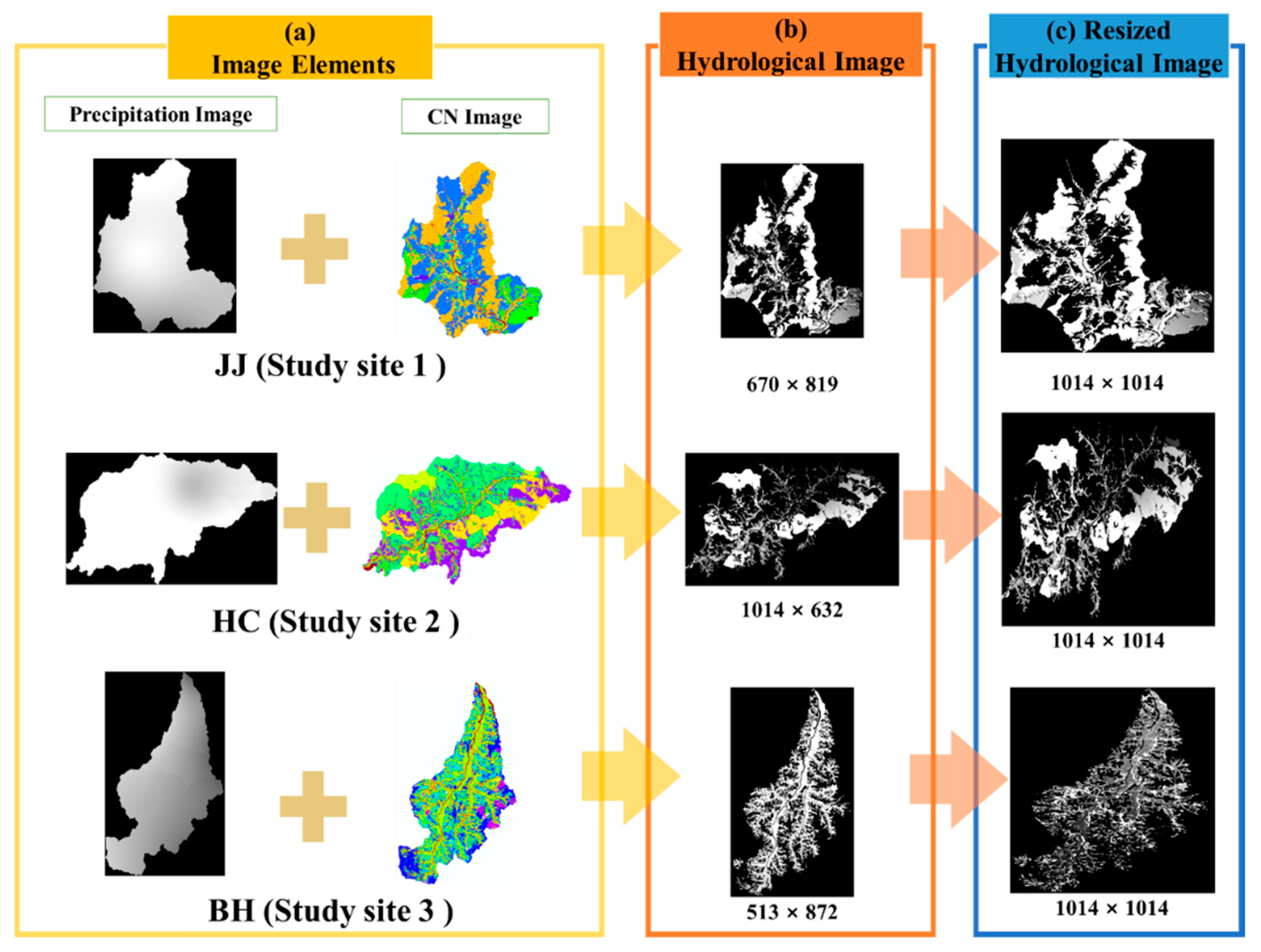
- Hydrological Image as a Feature
- (2)
- Target Data
- (3)
- Dataset Setting
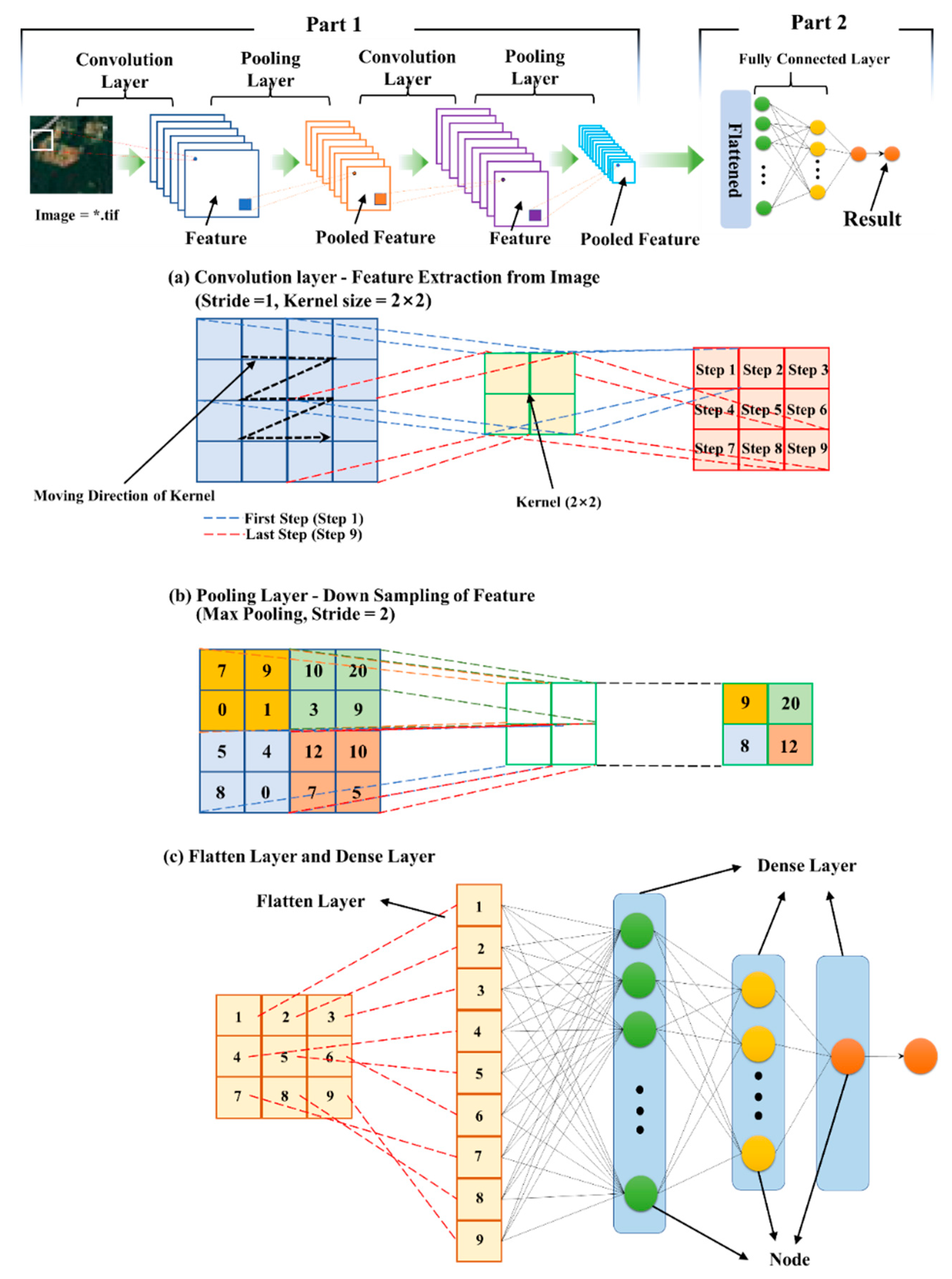
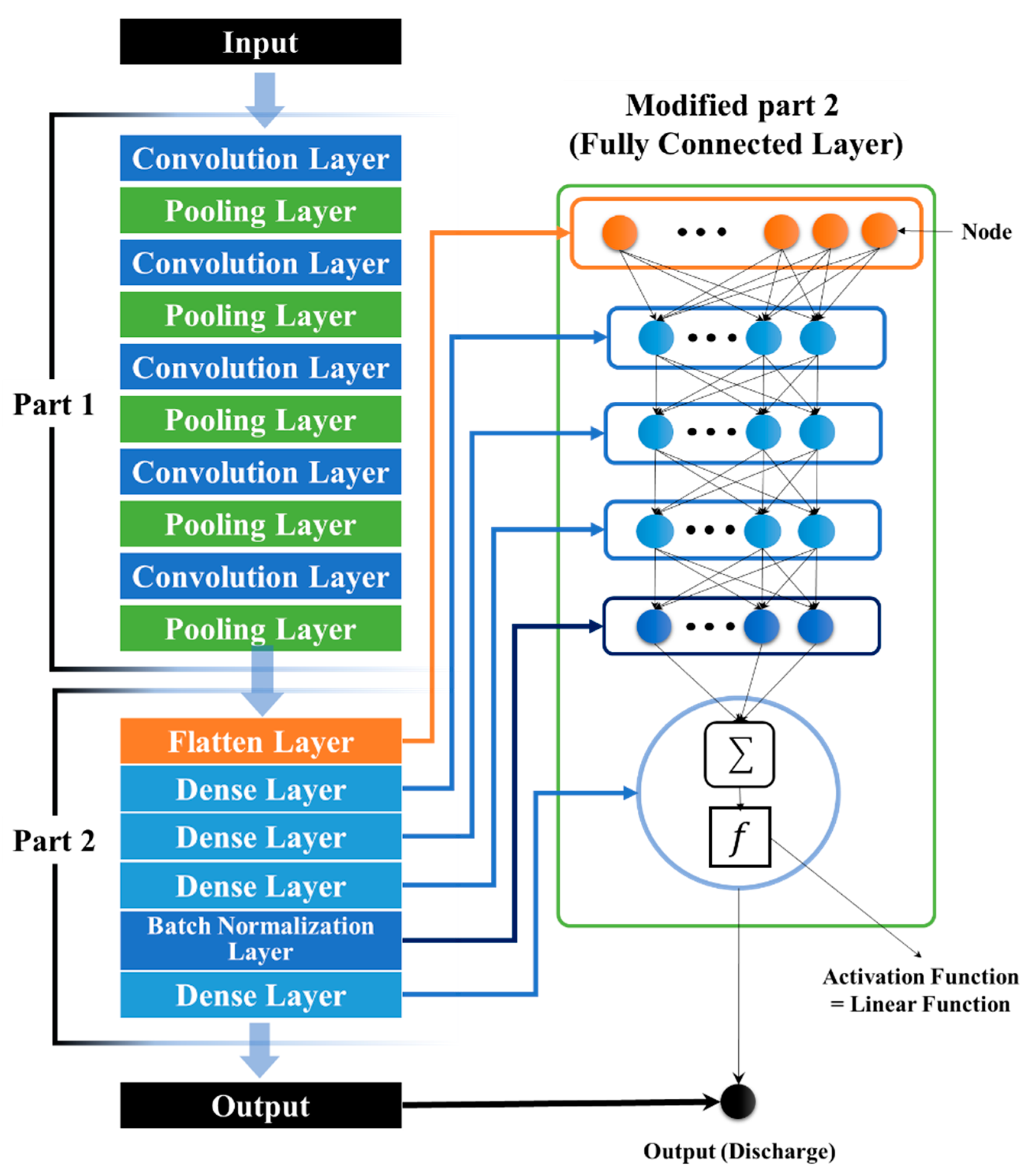
2.3.2. CNN Structure Configuration
2.3.3. Detailed Modified Configuration
2.4. Evaluation of Model
3. Result and Discussion
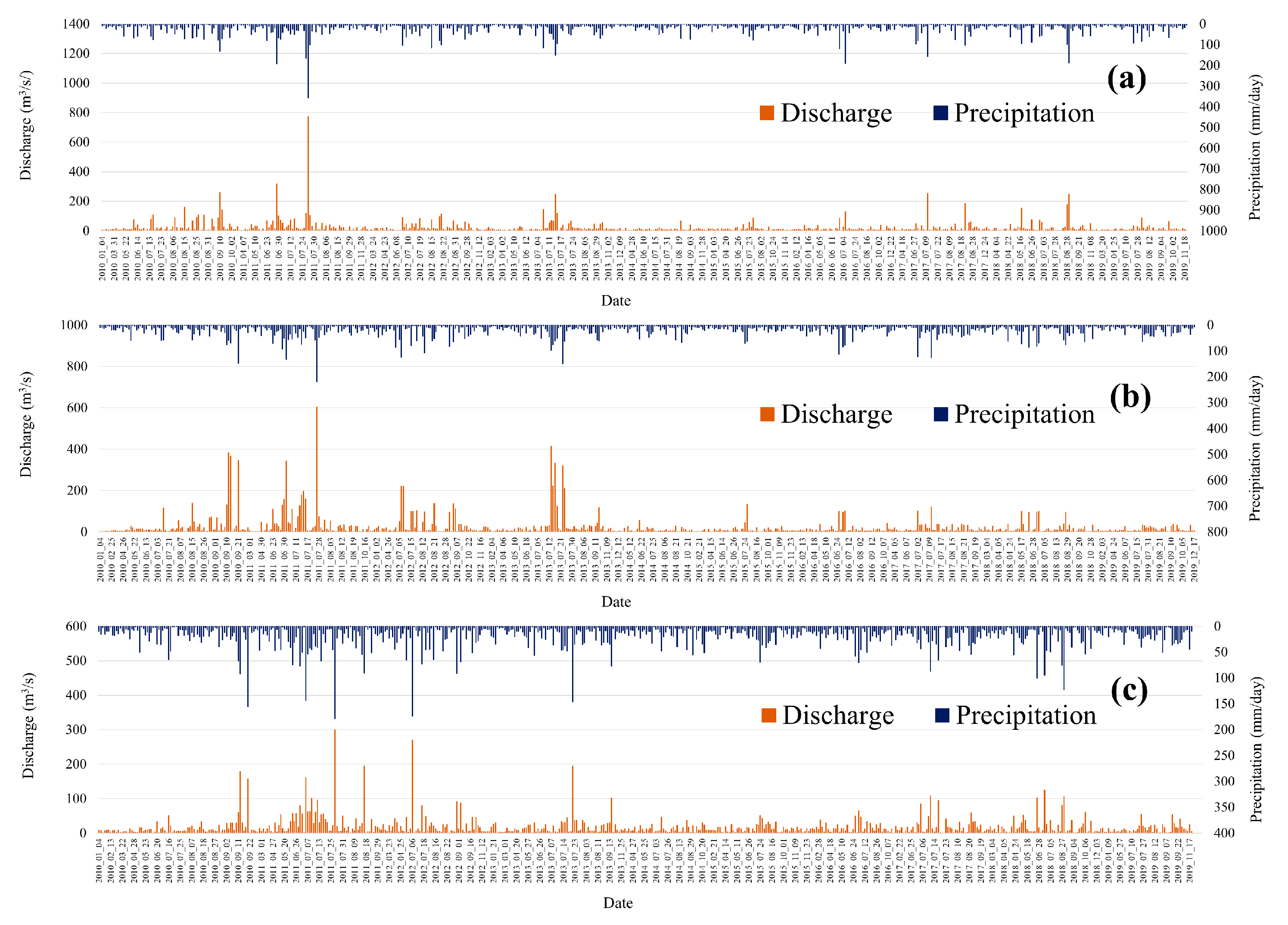
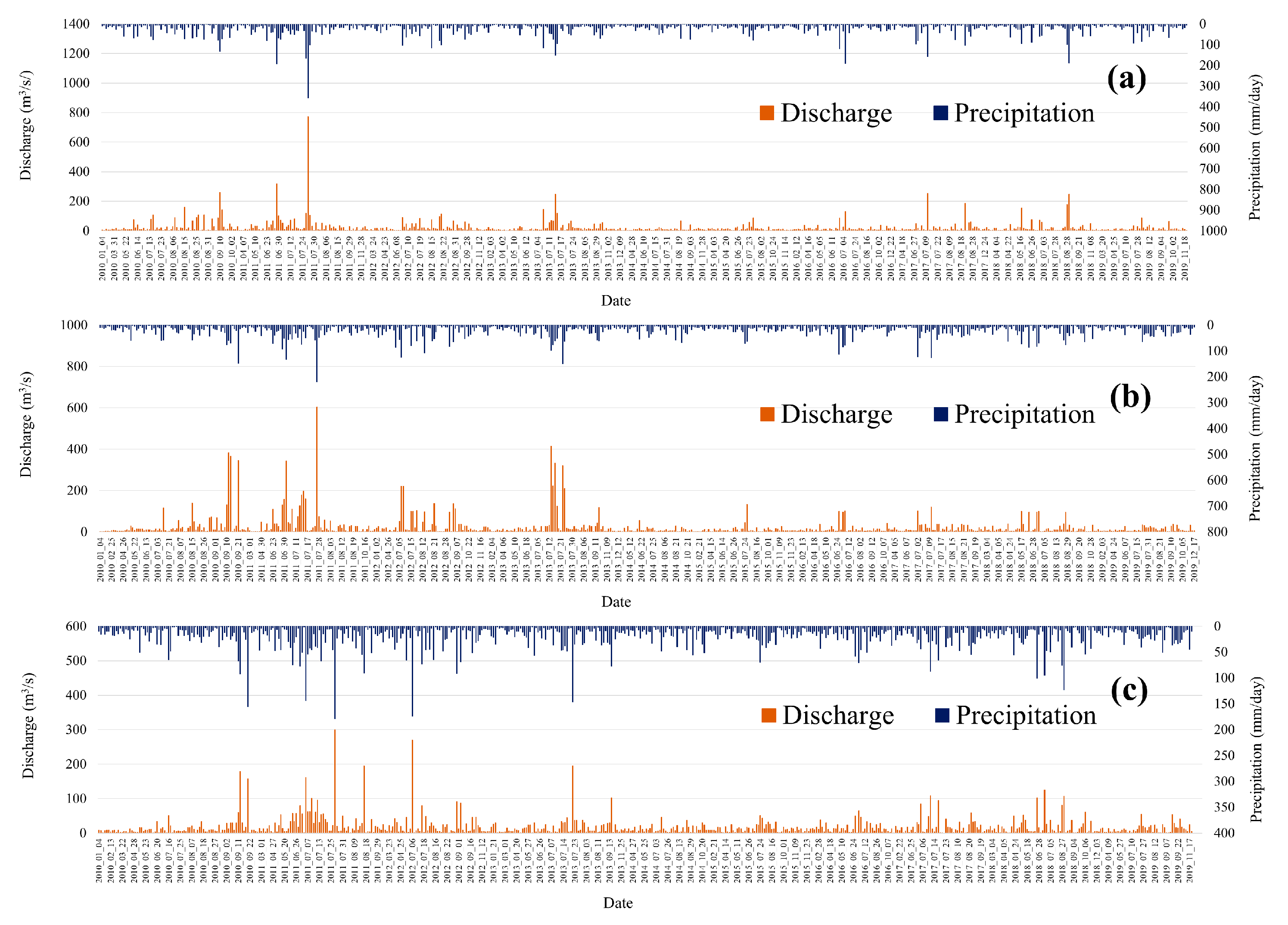
3.1. Precipitation and Discharge by Watershed
3.2. Result of Building the Hydrological Image
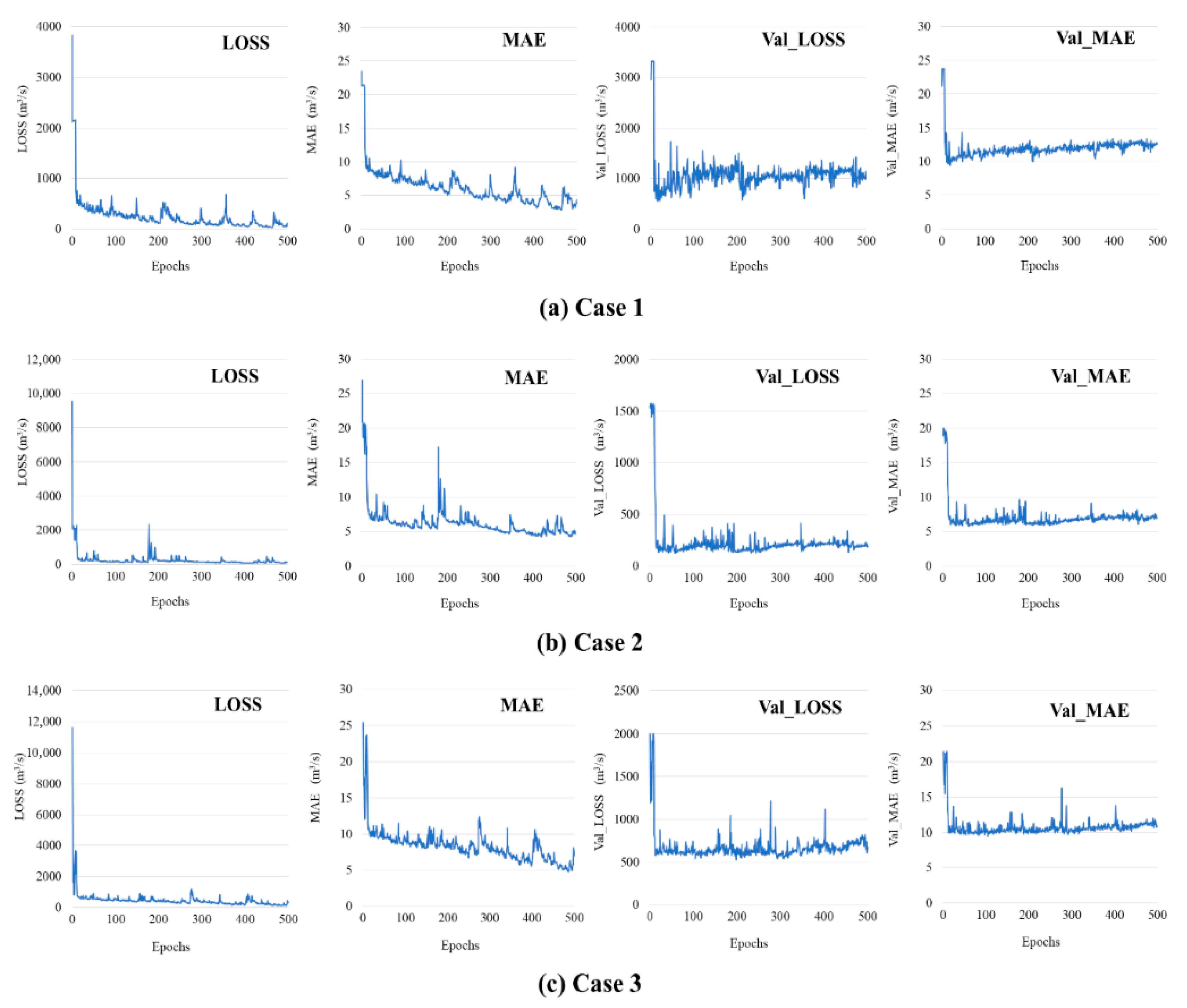
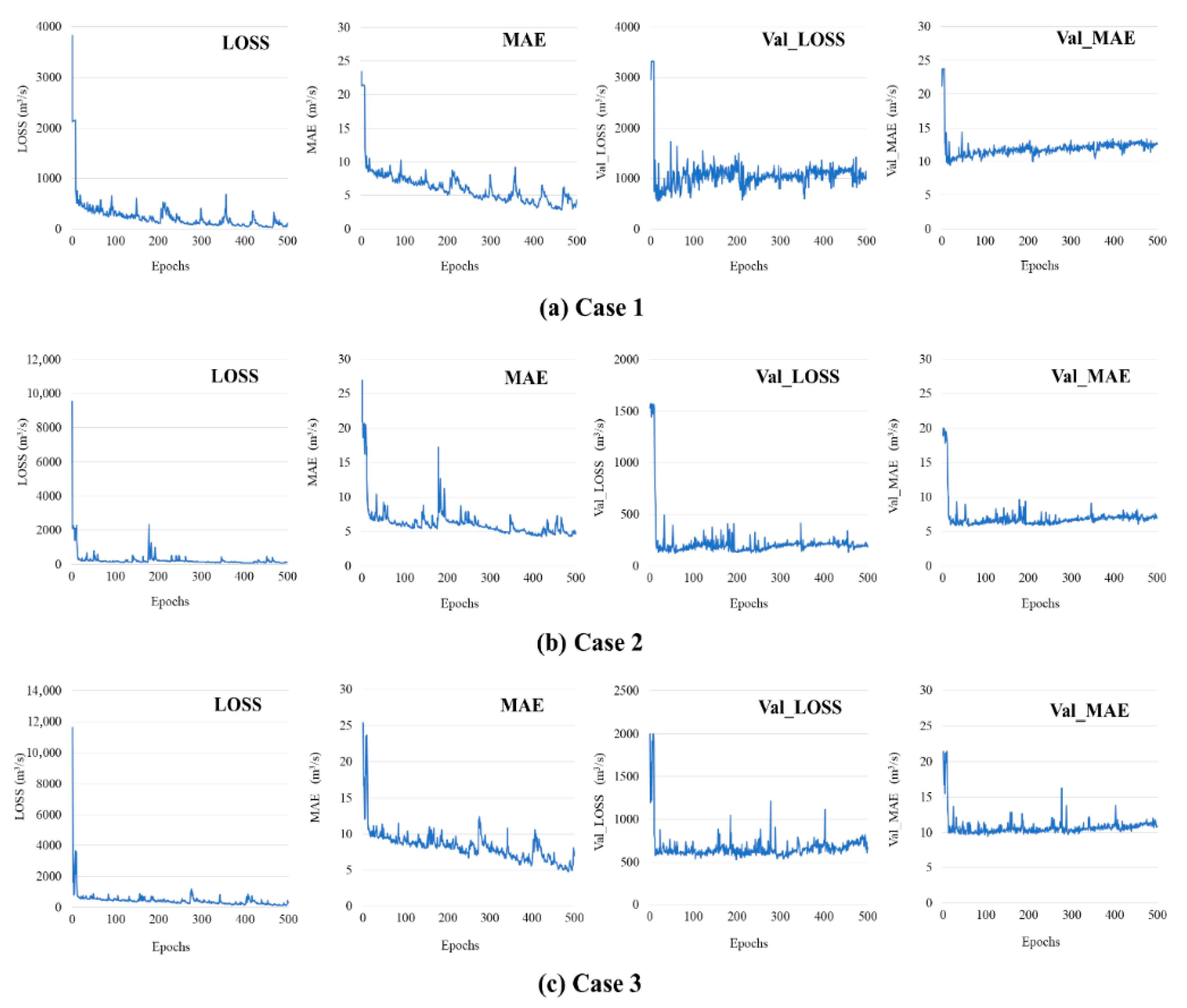
3.3. Model Structure and Training Results
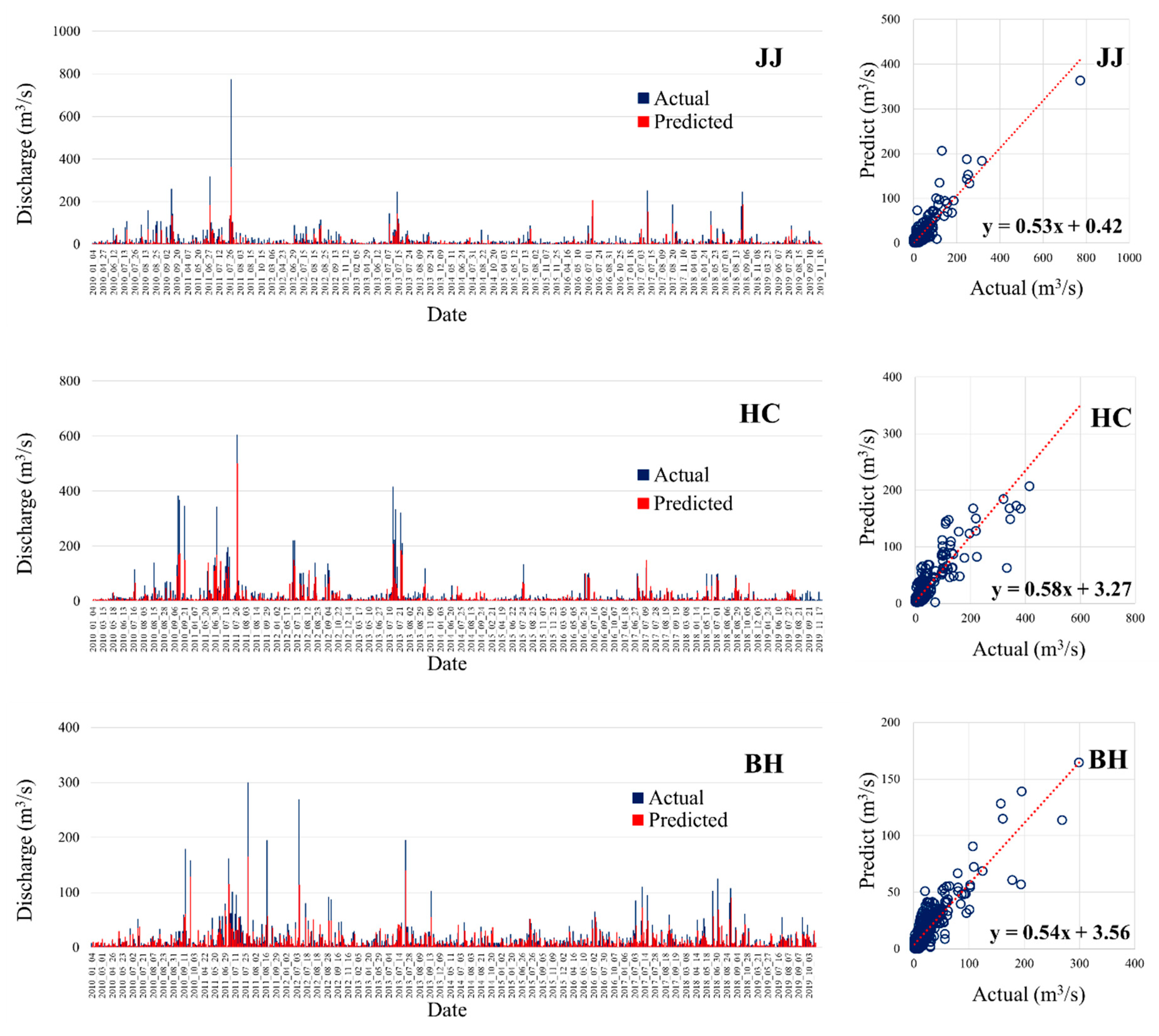
3.4. Model Prediction Results and Model Evaluation
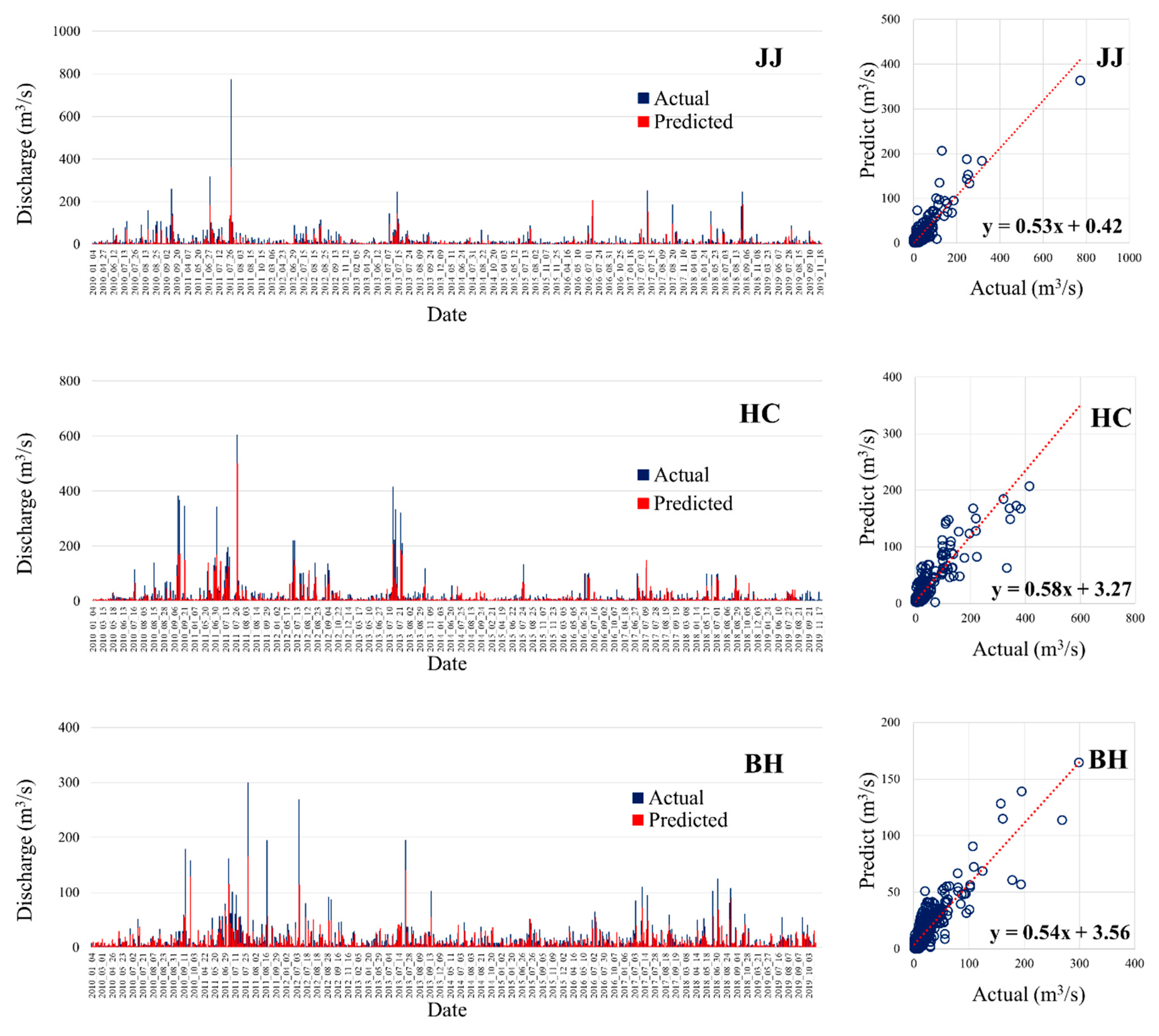
3.4.1. Model Prediction
3.4.2. Model Evaluation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Biswas, A.K. Integrated water resources management: A reassessment. Water Int. 2004, 29, 248–256. [Google Scholar] [CrossRef]
- Environmental Protection Agency (US-EPA). Guidelines for Reviewing TMDLs under Existing Regulations; US-EPA: Washington, DC, USA, 2002. Available online: https://www.epa.gov/sites/production/files/2015-10/documents/2002_06_04_tmdl_guidance_final52002.pdf (accessed on 5 November 2019).
- Duan, Q.; Sorooshian, S.; Gupta, V.K. Optimal use of the SCE-UA global optimization method for calibrating watershed models. J. Hydrol. 1994, 158, 265–284. [Google Scholar] [CrossRef]
- United States Department of Agriculture, Soil Conservation Service (USDA-SCS). Chapter 10: Estimation of Direct Runoff from Storm Rainfall. In National Engineering Handbook Hydrology Chapters; USDA-SCS: Washington, DC, USA, 2004. [Google Scholar]
- Sivapalan, M.; Takeuchi, K.; Franks, S.W.; Gupta, V.K.; Karambiri, H.; Lakshmi, V.; Liang, X.; McDonnell, J.J.; Mendiondo, E.M.; O’Connell, P.E.; et al. IAHS decade on Predictions in Ungauged Basins (PUB), 2003–2012: Shaping an exciting future for the hydrological sciences. Hydrol. Sci. J. 2003, 48, 857–880. [Google Scholar] [CrossRef] [Green Version]
- US Army Corps of Engineers Hydrologic Engineering Center. HEC-RAS 2D Modeling User’s Manual; USACE: Davis, CA, USA, 2016; Available online: https://www.hec.usace.army.mil/software/hec-ras/documentation/HEC-RAS%205.0%202D%20Modeling%20Users%20Manual.pdf (accessed on 5 February 2020).
- Mastin, M.C.; Thanh, L. User’s Guide to SSARRMENU.; US Geological Survey: Tacoma, WA, USA, 2002. Available online: https://pubs.usgs.gov/of/2001/ofr01439/pdf/ofr01-439.pdf (accessed on 5 February 2020).
- Lewis, A.R. Storm Water Management Model. User’s Manual; Water Supply and Water Resources Division National Risk Management Research Laboratory: Cincinnati, OH, USA, 2004. Available online: https://www.epa.gov/sites/production/files/2019-02/documents/epaswmm5_1_manual_master_8-2-15.pdf (accessed on 12 September 2020).
- Nourani, V.; Komasi, M.; Alami, M.T.; Aalami, M.T. Hybrid wavelet-genetic programming approach to optimize ANN modeling of rainfall-runoff process. J. Hydrol. Eng. 2012, 17, 724–741. [Google Scholar] [CrossRef]
- Duan, Q.; Sorooshian, S.; Gupta, V. Effective and efficient global optimization for conceptual rainfall-runoff models. Water Resour. Res. 1992, 28, 1015–1031. [Google Scholar] [CrossRef]
- Cheng, C.; Ou, C.; Chau, K. Combining a fuzzy optimal model with a genetic algorithm to solve multi-objective rainfall–runoff model calibration. J. Hydrol. 2002, 268, 72–86. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Li, J.; Xu, H. Improving flood forecasting capability of physically based distributed hydrological models by parameter optimization. Hydrol. Earth Syst. Sci. 2016, 20, 375–392. [Google Scholar] [CrossRef] [Green Version]
- Huo, J.; Zhang, Y.; Luo, L.; Long, Y.; He, Z.; Liu, L. Model parameter optimization method research in heihe river open modeling environment (HOME). Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1759017. [Google Scholar] [CrossRef]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Patel, A.B.; Joshi, G.S. Modeling of rainfall-runoff correlations using artificial neural network—A case study of Dharoi watershed of a Sabarmati River Basin, India. Civ. Eng. J. 2017, 3, 78–87. [Google Scholar] [CrossRef]
- Salas, F.R.; Somos-Valenzuela, M.A.; Dugger, A.; Maidment, D.R.; Gochis, D.J.; David, C.; Yu, W.; Ding, D.; Clark, E.P.; Noman, N. Towards real-time continental scale streamflow simulation in continuous and discrete space. J. Am. Water Resour. Assoc. 2018, 54, 7–27. [Google Scholar] [CrossRef]
- Akhtar, M.K.; Corzo, G.A.; Van Andel, S.J.; Jonoski, A. River flow forecasting with artificial neural networks using satellite observed precipitation pre-processed with flow length and travel time information: Case study of the Ganges river basin. Hydrol. Earth Syst. Sci. 2009, 13, 1607–1618. [Google Scholar] [CrossRef] [Green Version]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2013; pp. 8609–8613. [Google Scholar]
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2013; pp. 8599–8603. [Google Scholar]
- Seckin, N. Modeling flood discharge at ungauged sites across Turkey using neuro-fuzzy and neural networks. J. Hydroinformatics 2010, 13, 842–849. [Google Scholar] [CrossRef]
- Maca, P.; Pech, P.; Pavlásek, J. Comparing the selected transfer functions and local optimization methods for neural network flood runoff forecast. Math. Probl. Eng. 2014, 2014, 782351. [Google Scholar] [CrossRef] [Green Version]
- Kumar, P.; Praveen, T.V.; Prasad, M.A. Artificial neural network model for rainfall-runoff-A case study. Int. J. Hybrid. Inf. Technol. 2016, 9, 263–272. [Google Scholar] [CrossRef]
- Kashani, M.H.; Ghorbani, M.A.; Dinpashoh, Y.; Shahmorad, S. Integration of Volterra model with artificial neural networks for rainfall-runoff simulation in forested catchment of northern Iran. J. Hydrol. 2016, 540, 340–354. [Google Scholar] [CrossRef]
- Kimura, N.; Yoshinaga, I.; Sekijima, K.; Azechi, I.; Baba, D. Convolutional neural network coupled with a transfer-learning approach for time-series flood predictions. Water 2019, 12, 96. [Google Scholar] [CrossRef] [Green Version]
- KMA: Korea Meteorological Administration. Available online: https://www.kma.go.kr (accessed on 3 January 2020).
- WAMIS: Water Management Information System, National Institute of Environmental Research. Available online: https://www.water.nier.go.kr (accessed on 1 March 2019).
- EGIS: Environmental Geographic Information Service. Available online: https://www.egis.me.go.kr (accessed on 9 January 2019).
- Song, C.M. Hydrological image building using curve number and prediction and evaluation of runoff through convolution neural network. Water 2020, 12, 2292. [Google Scholar] [CrossRef]
- Natural Resources Conservation Service (NRCS). Urban. Hydrology for Small Watersheds; United States Department of Agriculture, Conservation Engineering Division, Natural Resources Conservation Service: Washington, DC, USA, 1986. Available online: https://www.nrcs.usda.gov/Internet/FSE_DOCUMENTS/stelprdb1044171.pdf (accessed on 20 May 2020).
- Li, C.; Liu, M.; Hu, Y.; Shi, T.; Zong, M.; Walter, T. Assessing the impact of urbanization on direct runoff using improved composite CN method in a large urban area. Int. J. Environ. Res. Public Health 2018, 15, 775. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Chen, Y. Identifying key hydrological processes in highly urbanized watersheds for flood forecasting with a distributed hydrological model. Water 2019, 11, 1641. [Google Scholar] [CrossRef] [Green Version]
- Ministry of Land, Infrastructure and Transport, South Korea. Design Flood Estimation Techniques; Ministry of Land Transport and Maritime Affairs: Seoul, Korea, 2012. (In Korean)
- Schumann, A.H. Thiessen polygon. In Encyclopedia of Hydrology and Lakes. Encyclopedia of Earth Science; Springer: Dordrecht, Germany, 1998; pp. 648–649. Available online: https://doi.org/10.1007/1-4020-4497-6_220 (accessed on 11 March 2020).
- Miller, H. Tobler’s First Law and Spatial Analysis. Ann. Assoc. Am. Geogr. 2004, 94, 284–289. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Taravat, A.; Del Frate, F.; Cornaro, C.; Vergari, S. Neural networks and support vector machine algorithms for automatic cloud classification of whole-sky ground-based images. IEEE Geosci. Remote. Sens. Lett. 2014, 12, 666–670. [Google Scholar] [CrossRef]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Li, Q.; Cai, W.; Wang, X.; Zhou, Y.; Feng, D.D.; Chen, M. Medical image classification with convolutional neural network. In Proceedings of the 2014 13th International Conference on Control Automation Robotics & Vision (ICARCV), Singapore, 10–12 December 2014; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2014; pp. 844–848. [Google Scholar]
- Hussain, M.; Bird, J.J.; Faria, D.R. A Study on CNN Transfer Learning for Image Classification. In Advances in Intelligent Systems and Computing; Springer Science and Business Media LLC: Berlin, Germany, 2019; pp. 191–202. [Google Scholar]
- Medina, E.; Petraglia, M.R.; Gomes, J.G.R.C.; Petraglia, A. Comparison of CNN and MLP classifiers for algae detection in underwater pipelines. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 November–1 December 2017; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2017; pp. 1–6. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision-ECCV 2020; Springer Science and Business Media LLC: Berlin, Germany, 2014; Volume 8689, pp. 818–833. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 1, pp. 448–456. [Google Scholar]
- Keras: The Python Deep Learning API. Available online: https://keras.io/ (accessed on 27 August 2020).
- TensorFlow. An End-to-End Open Source Machine Learning Platform. Available online: https://www.tensorflow.org/ (accessed on 27 August 2020).
- Ide, H.; Kurita, T. Improvement of learning for CNN with ReLU activation by sparse regularization. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, Alaska, 14–19 May 2017; pp. 2684–2691. [Google Scholar] [CrossRef]
- Chen, Z.; Ho, P.-H. Global-connected network with generalized ReLU activation. Pattern Recognit. 2019, 96, 106961. [Google Scholar] [CrossRef]
- Bureau of Justice Assistance. Compstat: Its origins, evolution, and future in law enforcement agencies. In Proceedings of the COMPSTAT’ 2010, Paris, France, 22–27 August 2010; Springer Science and Business Media LLC: Berlin, Germany, 2010; Volume 16, pp. 177–186.
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Nesterov, Y. A method for unconstrained convex minimization problem with the rate of convergence. Dokl. USSR 1983, 269, 543–547. Available online: https://www.semanticscholar.org/paper/A-method-for-unconstrained-convex-minimization-with-Nesterov/ed910d96802212c9e45d956adaa27d915f5d7469 (accessed on 18 April 2020).
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam; ICLR Workshop, (1), 2013–2016, 2016. Available online: https://openreview.net/pdf/OM0jvwB8jIp57ZJjtNEZ.pdf (accessed on 21 April 2020).
- Zeiler, M.D. ADADELTA: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701v1. [Google Scholar]
- Hinton, G.; Tieleman, T. RMSprop Gradient Optimization; Lecture 6e of His Coursera Class. 2014. Available online: https://www.cs.toronto.edu/~{}tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 10 February 2019).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn. and Tensor Flow: Concepts, Tools, and Techniques to Build. Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Pillow. Available online: https://www.python-pillow.org (accessed on 10 February 2020).
- Lee, K.; Choi, C.; Shin, D.H.; Kim, H.S. Prediction of heavy rain damage using deep learning. Water 2020, 12, 1942. [Google Scholar] [CrossRef]
- Alsumaiei, A.A. Utility of artificial neural networks in modeling pan evaporation in hyper-arid climates. Water 2020, 12, 1508. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.-G.; Lee, J.E.; Kim, N.W.; Kim, H.-J. Medium-term rainfall forecasts using artificial neural networks with Monte-Carlo cross-validation and aggregation for the Han river basin, Korea. Water 2020, 12, 1743. [Google Scholar] [CrossRef]
- Mulualem, G.M.; Liou, Y.-A. Application of artificial neural networks in forecasting a standardized precipitation evapotranspiration index for the Upper Blue Nile basin. Water 2020, 12, 643. [Google Scholar] [CrossRef] [Green Version]
- Dancey, C.; Reidy, J. Statistics without Maths for Psychology, 5th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2011; p. 620. [Google Scholar]
- Lipiwattanakarn, S.; Saengsawang, S. Performance comparison of a conceptual hydrological model and a back-propagation neural network model in rainfall-runoff modeling. Eng. J. Res. Dev. 2005, 16, 35–42. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Areas | Land Cover | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Water | Urban | Barren | Pasture | Forest | Paddy | Upland | Wetland | Total | ||
| JJ (Study area 1) | Area (km2) | 2.6 | 5.8 | 5.2 | 19.2 | 207.5 | 4.4 | 13.5 | 2.4 | 260.6 |
| Proportion (%) | 1.0 | 2.2 | 2.0 | 7.4 | 79.6 | 1.7 | 5.2 | 0.9 | 100.0 | |
| HC (Study area 2) | Area (km2) | 2.3 | 6.5 | 2.9 | 22.5 | 235.8 | 20.8 | 19.6 | 3.7 | 314.1 |
| Proportion (%) | 0.7 | 2.1 | 0.9 | 7.2 | 75.1 | 6.6 | 6.2 | 1.2 | 100.0 | |
| BH (Study area 3) | Area (km2) | 1.6 | 11.7 | 4.0 | 18.2 | 41.6 | 50.9 | 49.7 | 3.5 | 181.1 |
| Proportion (%) | 0.9 | 6.5 | 2.2 | 10.1 | 23.0 | 28.1 | 27.4 | 1.9 | 100.0 | |
| Antecedent Soil Moisture Condition (AMC) | Sum Pi (mm) | |
|---|---|---|
| Dry Season | Wet Season | |
| AMC I (Dry condition) | P5 < 12.7 | P5 < 35.6 |
| AMC II (Normal condition) | 12.7 ≤ P5 ≤ 27.9 | 35.6 ≤ P5 ≤ 53.3 |
| AMC III (Wet condition) | P5 > 27.9 | P5 > 53.3 |
| Model | Watershed | Dataset Classification |
|---|---|---|
| Case 1 | JJ, HC | Input dataset (training dataset, validation dataset) |
| BH | Test data | |
| Case 2 | JJ, BH | Input dataset (training dataset, validation dataset) |
| HC | Test data | |
| Case 3 | HC, BH | Input dataset (training dataset, validation dataset) |
| JJ | Test data |
| Model | Dataset | Number of Data | Remark | |
|---|---|---|---|---|
| Case 1 | Input dataset | Training dataset | 735 | HC–BH |
| Validation dataset | 402 | HC–BH | ||
| Test dataset | Test date set | 554 | JJ (whole study period) | |
| Case 2 | Input dataset | Training dataset | 724 | JJ–BH |
| Validation dataset | 396 | JJ–BH | ||
| Test dataset | Test date set | 571 | HC (whole study period) | |
| Case 3 | Input dataset | Training dataset | 719 | HC–JJ |
| Validation dataset | 406 | HC–JJ | ||
| Test dataset | Test date set | 566 | BH (whole study period) | |
| Convolution Layer | Output Shape (Row_Size, Column_Size, Image_Channel) | Parameter | Activation Function |
|---|---|---|---|
| Conv2D 1 | 507, 507, 32 | 320 | ReLu |
| MaxPooling 1 | 253, 253, 32 | 0 | |
| Conv2D 2 | 127, 127, 64 | 18,496 | ReLu |
| MaxPooling 2 | 63, 63, 64 | 0 | |
| Conv2D 3 | 63, 63, 128 | 73,856 | ReLu |
| MaxPooling 3 | 31, 31, 128 | 0 | |
| Conv2D 4 | 31, 31, 256 | 295,168 | ReLu |
| MaxPooling 4 | 15, 15, 256 | 0 | |
| Conv2D 5 | 15, 15, 512 | 1,180,160 | ReLu |
| MaxPooling_5 | 7, 7, 512 | 0 | |
| Fully connected layer | (Number of nodes) | ||
| Flatten layer | 25,088 | 0 | |
| Dense layer 1 | 1024 | 25,691,136 | ReLu |
| Dense layer 2 | 512 | 524,800 | ReLu |
| Dense layer 3 | 128 | 65,664 | ReLu |
| Batch normalization layer | 128 | 512 | ReLu |
| Dense layer 4 | 1 | 129 | Liner |
| Total parameters: 27,850,241 | |||
| Trainable parameters: 27,849,985 | |||
| Nontrainable parameters: 256 | |||
| Contents | Predicted Study Area | r | NSE | RMSE (m3/s) |
|---|---|---|---|---|
| Case 1 | JJ (study area 1) | 0.9 | 0.7 | 27.0 |
| Case 2 | HC (study area 1) | 0.9 | 0.7 | 28.5 |
| Case 3 | BH (study area 1) | 0.9 | 0.7 | 16.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.Y.; Song, C.M. Developing a Discharge Estimation Model for Ungauged Watershed Using CNN and Hydrological Image. Water 2020, 12, 3534. https://doi.org/10.3390/w12123534
Kim DY, Song CM. Developing a Discharge Estimation Model for Ungauged Watershed Using CNN and Hydrological Image. Water. 2020; 12(12):3534. https://doi.org/10.3390/w12123534
Chicago/Turabian StyleKim, Da Ye, and Chul Min Song. 2020. "Developing a Discharge Estimation Model for Ungauged Watershed Using CNN and Hydrological Image" Water 12, no. 12: 3534. https://doi.org/10.3390/w12123534