1. Introduction
There is only little doubt that eutrophication causes accelerated growth of harmful algal blooms, whether the nutrient enrichment comes from sewage or agricultural runoff [
1,
2,
3]. In a reaction to increasing concerns about water quality, the European Commission introduced Directive 2000/60/EC of the European Parliament and of the Council of 23 October 2000 establishing a framework for Community action in the field of water policy ([
4], abbreviated to WFD). The directive introduced a “good status” and required all water bodies to achieve it by 2015. The “good status” ensures that the water body departs only slightly from the biological community and hydrological and chemical characteristics that would be expected under conditions of minimal anthropogenic impact, as described in Annex V to the WFD. The “good status” consists of ecological status and chemical status in case of natural bodies or ecological potential and chemical status in heavily modified water bodies – each based on multiple criteria. The WFD applies the “one-out, all-out” principle in assessing the “good status”. Failing to satisfy just one of the indicators means the “good status” is not achieved. For this reason, the majority of European water bodies had not met the required standard by 2015. Based on [
5], only 40% of surface water bodies were in good ecological status or potential and only 38% of the bodies were in good chemical status. Excessive phosphorus inflow and eutrophication belong among the key reasons for not achieving the “good status”, especially in the case of water reservoirs. However, failing to achieve the “good status” may not mean violating the regulation. Water bodies may apply for an exemption if, e.g., costs of achieving the “good status” exceed generated benefits (the WFD does not state how large the gap needs to be). The application has to be supported by economic analysis of costs and benefits, which will inevitably be spatially distributed as discussed by [
6,
7]. If the exemption is approved, the deadline can be extended to 2021/2027 or a lower target can be set. The requirement of achieving the “good status” has a significant impact on management of water resources in the form of pollution modelling and planning of measures.
Numerous methodologies have been created in European countries to tackle cost proportionality of achieving the “good status” [
8,
9,
10,
11,
12,
13,
14]. These approaches use cost-benefit analysis (CBA) or criteria to assess cost proportionality of measure implementation. Martin-Ortega et al. [
15] use hydro-chemical models to simulate effectiveness of phosphorus mitigation measures, but most of the time effectiveness of measures is simply assumed. Designed measures are expected to reduce exactly the desired amount of the problematic substance. Robustness is often tested by sensitivity analysis of costs and benefits but testing of the abatement effect is rather scarce (e.g., Berbel et al. [
16] perform an analysis of uncertainty for both costs and efficiency of water-saving measures). Effectiveness of measures of a certain type is predetermined and constant, regardless of local conditions. This can hardly be true as not all measures have identical parameters and they are implemented under heterogeneous conditions. This means the reduction target might not be met and consequently, estimated benefits may be unrealistically high.
This paper aims to deal with uncertainty of measure effectiveness in the context of a proportionality analysis, which compares costs of measure implementation with benefits generated by achieving the “good status”. This is important under the WFD, because it allows a water body to not achieve the “good status” if the associated costs significantly outweigh the generated benefits. The approach to the proportionality analysis under the WFD is not unified, which is discussed, e.g., by [
7].
However, it is inappropriate to compare costs with benefits without knowing how likely the “good status” will be achieved with the selected measures. A deterministic analysis selects measures that are expected to meet the target without any further testing, possibly using ranges to account for uncertainty. The statistical approach of the Bayesian networks makes all the approaches based on CBA more accurate by providing such information. The idea is to apply the Bayesian networks prior to the economic analysis to determine whether the “good status” can be achieved using the selected measures. Unlike a standard CBA, Bayesian analysis does not automatically assume that the target will be met. Instead, Bayesian analysis reports the probability of achieving the target, which should precede the CBA. Knowledge of this probability is important as the generated benefits would undoubtedly be lower if the target was not met. This approach improves water quality management when it comes to measure implementation and may be used to make the CBA more precise. The main objective of this paper is to describe the Bayesian networks approach, which is demonstrated on a case study of Stanovice water reservoir.
Heckerman [
17] describes a Bayesian network as “a graphical model for probabilistic relationships among a set of variables”. These are an integral part of influence diagrams, which also include utility nodes and decision nodes. He provides rigorous derivation of the approach, including distribution analysis, inference, or a method for learning structure and parameters.
The Bayesian view of probability differs significantly from the classical approach. Heckerman [
18] describes the frequentist approach as analyzing the probability “
P” of seeing specific data given a hypothesis—
P(D|H), where “D” stands for data and “H” for hypothesis. On the contrary, the Bayesian approach considers the probability of a hypothesis being true given the data—
P(H|D). While classical probability is a true state of the world and is set, Bayesian probability is much closer to one’s degree of belief. However, it still satisfies the rules of probability and is not necessarily subjective. As shown by [
19], the Bayesian approach based on empirical data is the same as the frequentist approach, which uses pooling of available data, and Bayesian analysis based on uninformative prior distribution is similar to frequentist analysis based on observed data. Only when expert opinion is used to form a prior, Bayesian analysis may be viewed as subjective.
Heckerman [
17] shows that we can learn about parameters after defining variables, assigning priors and using Bayes’ rule (1), which updates beliefs about the parameters of given data.
All the terms in the equation above also depend on our belief. P(H|belief) is called a prior, P(D|H, belief) a likelihood and P(H|D, belief) a posterior.
Bayesian networks are used heavily in different fields, e.g., software assistance [
20], medical diagnosis [
21] or manufacturing control [
22]. Bayesian networks are becoming increasingly popular in environmental sciences partly because of the introduction of the WFD. Hamilton et al. [
23] use them to confirm the relationship between nutrient levels and algal bloom initiation. They find that the probability goes up when nutrient inflows from land runoff and point sources increase. In water management, Bayesian networks can also be used to implement uncertainty about effectiveness of measures. Probability of achieving the selected target is obtained as a result of this analysis. Outputs of such an analysis are more robust and can be used by policy makers. Compared to a deterministic analysis, the results are probabilistic and do not provide a simple yes/no answer. Nevertheless, knowing whether the “good status” can be achieved with the selected measures is crucial in proportionality analysis.
Ames et al. [
24] provide a guideline for authors who plan to use Bayesian analysis in watershed management. They focus on defining the problem as a graphical structure, which includes identification of management endpoints, alternatives, data sources, variables and their discretization. They show how to build conditional probability tables (based on observed data, a simulation model or expert judgement) and demonstrate the approach on phosphorus management in the East Canyon watershed in Utah.
Different authors use networks of various complexity, ranging from a very simple model used by [
25] to a complex network consisting of 35 nodes used by [
26]. Some papers focus solely on satisfying a given limit, e.g., [
24], while others model sustainability of several coastal lake catchment systems [
27]. Studies also differ in input data as Bayesian networks are not limited to empirical inputs. These are prevalent, but they are often complemented by use of expert judgement, e.g., [
28], regression or process-based models, e.g., [
26], or dynamic models such as MyLake [
29]. Collected data are discretized in most of the papers, but [
30] develop a regression-oriented Tree Augmented Naive Bayes, which can work with continuous variables and allows for dependence among explanatory variables. The authors present risk maps of exceeding the nitrogen limit. Other examples of Bayesian network application in water management can be found in, e.g., [
31,
32,
33]. The paper is structured as follows. The next section introduces the area and local conditions of Stanovice reservoir. Other parts of
Section 2 demonstrate the methodological approach used and its application to the Stanovice water reservoir, where phosphorus abatement measures are to be implemented to satisfy the WFD requirement of the “good status”. The results are presented in a following section, and discussion and conclusions follow.
2. Materials and Methods
Stanovice reservoir is situated in the Czech Republic next to the city of Karlovy Vary in North-West Bohemia (
Figure 1). The catchment area covers 92 km
2. The main purpose of the Stanovice reservoir is to supply the Karlovy Vary area with drinking water. Its minor functions include fishery, flood protection and electricity generation.
Based on [
34], Stanovice fails to achieve the “good status” mainly because of anthropogenic effects in the surrounding area such as agriculture and population. The whole area suffers from cyanobacterial growths in summer as a result of excessive inflows of dissolved phosphorus. Based on an analysis of [
35,
36], the main sources of phosphorus are wastewater, especially from small villages without wastewater treatment, and agriculture due to water erosion from fields into watercourses. This fact lowers the recreational benefits and makes the drinking water treatment more expensive (although the water body does not achieve the “good status”, it can still be used as a water reservoir. The “good status” depends on chemical status and ecological potential defined in the WFD, which are not directly related to suitability for drinking. The water is drinkable after receiving proper treatment). Point sources and diffuse sources contribute evenly to the total inflows. T. G. Masaryk Water Research Institute estimated that 60–200 kg of dissolved phosphorus needs to be reduced annually to achieve the “good status”. The upper bound was used in the analysis.
Dostál & Krása and Ansorge & Drozd [
35,
36] identified several groups of measures on both point sources (construction and renovation of wastewater treatment plants, sewerage systems, dead-end and accumulation cesspits, retention wetlands, biological reservoirs, domestic wastewater treatment plants, intensification of the treatment process in wastewater treatment plants) and agricultural land (e.g., broad-base terraces, building ditches, grassing, afforestation, contour farming, leaving crop residue, wetland establishment) as viable options for reducing phosphorus inflows. Within these groups, many individual measures of the same type were identified and specific locations in the Stanovice catchment were found where these measures can be implemented. However, not all the measures are necessary to improve the reservoir status. Therefore, an economic approach was used to identify the most cost-efficient ones [
7]. The five most common and theoretically the most efficient groups of agricultural measures were selected and used together with the measures on point sources in the analysis (broad-base terraces (BBT), vegetated filter strips (VFS), changes in crop rotation (CCR), leaving crop residue (LCR), no-tillage methods (NTM), (re)construction of wastewater treatment plants (WWTP) and sewerage systems (SW), cleaning of biological ponds). In total, that represents a pool of 244 specific measures that have a potential to reduce 344.6 kg of dissolved phosphorus a year. However, that is more than the required threshold of 200 kg a year. Annualized costs and phosphorus amounts reduced were also estimated for each specific measure by [
35,
36], and the measures were ranked based on their cost-effectiveness (costs per kg reduced). To assess economic efficiency, the authors use a dynamic cost-effectiveness analysis [
37].
Table 1 presents an overview of the selection process. The measure types in italics were included in the final analysis.
The desired threshold of 200 kg a year can be reached by implementation of 99 measures with the total annualized costs of EUR 43,233. Five of the selected measures are on point sources (especially construction of WWTPs). Despite the small number of measures on point sources, they contribute 62% to the total reduction.
2.1. Methodology
The approach used in this paper is illustrated in
Figure 2. The analysis begins with the construction of a Bayesian network. It is important to decide what variables are used as inputs to the model and to define causalities among them. This is followed by data collection. Most importantly, it is necessary to determine how effective the groups of measures are in reality. Therefore, it is necessary to obtain information about what percentage of the existing amount of phosphorus a given measure can reduce. Such information may come from empirical data if a similar measure has already been used elsewhere or from literature if such a measure has been tested under laboratory/field conditions. Since no two measures in the same group will be completely identical, the resulting effectiveness will differ for most of the individual measures. Therefore, one cannot use a single number to determine the effectiveness of a group of measures and it is more appropriate to use the collected data to estimate probability distributions for each group of measures instead. If the dataset is large enough, it is possible to skip this step and go straight to discretization. Ames et al. [
24] use historical records to form probability distributions of streamflow and phosphorus concentration. However, this requires hundreds of observations, which were not available for our case study. Alternatively, it is possible to use the data described above to estimate a probability distribution for each group of measures and simulate a large number of values, which are then discretized into intervals (e.g., [
33] use simulation models to learn about conditional probabilities and dependencies). This method is not as demanding on data and only dozens of observations are needed. It is more preferable to use a small number of intervals, which may represent a degree to which a given group of measures reduces the present amount of phosphorus. Yu et al. [
38] concluded that more than two intervals should be used. Based on that, 4 intervals of levels of phosphorus reduction effectiveness (minimum, low, medium, high) were defined. Based on the number of observations in each interval, a probability of measure effectiveness falling into that specific interval is determined using (2) for each group of measures.
The resulting probabilities enter the previously designed Bayesian network. Netica software (available at
https://www.norsys.com/download.html) is then used to simulate the case study. It is a tool for working with belief networks and it allows definition of relationships between variables as probabilities. Using algorithms and known probabilities, Netica estimates the probabilities that are unknown. In this case, the software also knows the maximum amount of phosphorus that a given group of measures can reduce from
Table 1. Therefore, it is possible to define each interval in terms of kilograms reduced. Using this information, probabilities of all intervals and dependencies among variables, Netica simulates many different scenarios and gives an outcome in terms of a probability that a scenario reduces at least the desired amount of phosphorus. The final step is to interpret the results, which is not trivial due to their probabilistic nature. It is important to consider how close to 100% one wants to get. Overall, the analysis is quite straightforward as no attempt was made to model the whole ecosystem and all indicators of the “good status”, but only reduction of the phosphorus from the identified load pathways was considered.
2.2. Data
As stated above, a considerable number of observations is required, because the analysis estimates a probability of achieving a certain goal based on information about previously implemented measures. However, no data about agricultural measures that would compare the situation prior to and after measure implementation are available in the Czech Republic. Therefore, results of empirical experiments from literature were used to collect as many observations as possible to estimate the probability distributions. See
Supplementary Materials for more details. Despite using the available literature, our samples for changes in crop rotation and broad-base terraces remain unsatisfactory and are not included in the analysis. As for WWTPs, municipalities where a WWTP had recently been built or intensified were addressed. Although the municipalities often differ in size from the ones where the measures will be applied, it still gives a decent idea about their effectiveness and whether they comply with their respective limits. Stricter limits are enforced in larger cities, but what is important for the analysis is how the real effectiveness compares with the concentration limits for which a given WWTP was designed. A similar approach was used for WWTP and sewerage system construction. Data on recently built WWTPs (last 6 years) were collected to get a satisfactory dataset (the sample consists of more than 100 sewerage and WWTP construction projects, including renovation and intensification). Unfortunately, the last measure on point sources (biological ponds) is quite unique in the Czech Republic and no data about its effectiveness exist. In such cases, expert judgement may be used to form a triangular distribution as suggested by [
28], or a uniform distribution can be used if the parameters cannot be estimated. However, the authors want to keep this case study as empirical as possible and this measure was discarded. Therefore, only five of the measures listed in
Table 1 enter the analysis (the ones in italics: VFS, LCR, NTM, WWTP, WWTP+SW).
The analysis begins with converting the collected data on effectiveness in percentage terms to absolute values in terms of phosphorus reduced. For agricultural measures, each observation (effectiveness) was multiplied by the total amount of phosphorus inflows from the area where corresponding measures from the same group are to be applied. That is the amount of phosphorus that ends up in the catchment area each year without any measures implemented. In the case of WWTPs, data on targeted phosphorus concentration and real inflow and outflow concentrations were used to determine WWTP effectiveness. The targeted concentrations correspond to the respective concentration limits, which differ based on the WWTP technology and legislative requirements. These limits are often stricter than what the legislation requires. The concentrations are measured just before and after the treatment process. Higher (lower) amounts of phosphorus than expected can be reduced using each group of measures. For agricultural measures, the real effectiveness needs to exceed (fall short of) the expected one indicated in
Table 1. For WWTPs, phosphorus concentration in outflow water needs to be lower (higher) than the target. This computation results in absolute values in terms of kilograms reduced for each observation. To avoid problems with overrepresentation of one WWTP in the sample especially from larger municipalities, ten observations for each WWTP with over ten data points were chosen randomly. This issue is still present in the case of agricultural measures but is less of a problem. Many more agricultural measures are planned, and they will be implemented under slightly heterogeneous conditions. Moreover, the dataset is still rather sparse in some cases (NTM, LCR).
2.3. Analysis
The dataset was tested for outliers, which were excluded from the analysis. Using the remaining observations, a probability distribution of effectiveness was estimated for each group of measures. It is necessary to be careful as there are insufficient numbers of observations for two groups of measures.
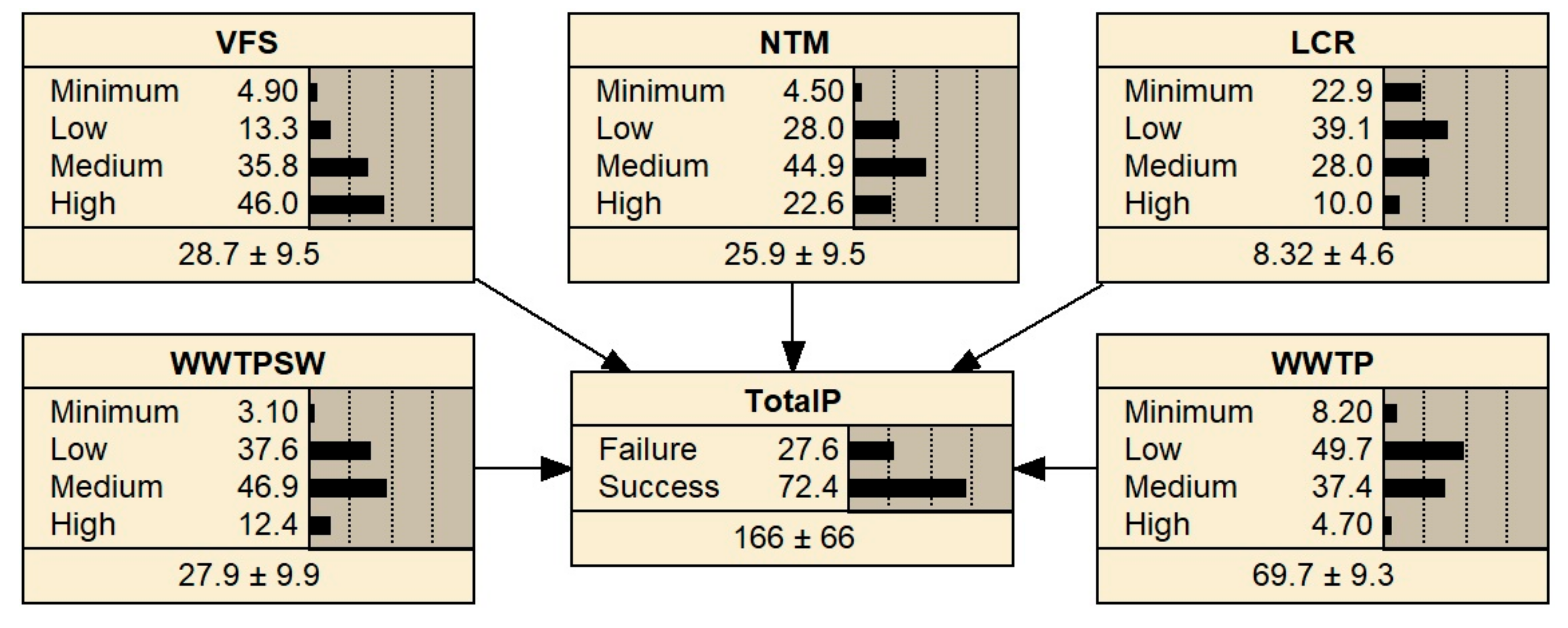
Table 2 summarizes the process, where abbreviations represent the different measure types (VFS: vegetated filter strips; NTM: no-tillage method; LCR: leaving crop residue; WWTP: wastewater treatment plant; SW: sewerage system). While LCR, NTM, WWTP and WWTP + SW follow a normal distribution, VFS did not fit in any common distribution family and had to be transformed to follow a normal distribution. Based on their attributes, 1000 observations from respective distributions were simulated for each group of measures. As it is unlikely that any measure would lead to a worsening of the current state, all negative values were replaced with zeros. Similarly, if any observation suggested a reduction of more than the maximum amount of phosphorus from a given load pathway, the maximum possible value was used instead. Descriptive statistics for the simulated values are also captured in
Table 2.
Each measure type was discretized into four intervals which represent levels of effectiveness of the given group of measures as done by e.g., [
24,
39]. Specifically, the intervals used stand for minimum, low, medium and high levels of effectiveness. Intervals of identical size were used within each group of measures. In the cases of WWTP and WWTP+SW there was one outlier, which was included in the analysis, but was ignored for interval selection as it would distort the final gaps. It should be noted that discretization inevitably leads to information loss, because the software treats the observations within each interval as uniformly distributed. Looking at histograms of the simulated data, most of the measures seem to be slightly more effective on average than previously expected. This holds especially for VFS and
WWTP, but it may not be apparent from the summary of discretized variables shown in
Table 3 because the intervals were not created in accordance with the expected effectiveness.
As mentioned previously, not enough data are available to evaluate the impact of broad-base terraces, changes in crop rotation and cleaning of biological ponds. It is still possible to test the probability of achieving the “good status” (annual 200 kg reduction) without these groups of measures; however, such analysis makes little sense. As indicated in
Table 1, 51.22 kg of phosphorus are expected to be reduced by BBT, CCR and cleaning of biological ponds. Therefore, the probability of success will inevitably be low when the groups of measures in question are not part of the analysis (the probability of success indeed drops to almost zero). Alternatively, one can use the groups of measures with available data and evaluate how effective these measures would be compared to the expectations. To do so, the target needs to be changed to consider only phosphorus that is expected to be reduced by the groups of measures entering the analysis. Subtracting 51.22 from the original threshold of 200 kg establishes an “adjusted good status” at 148.82 kg a year.
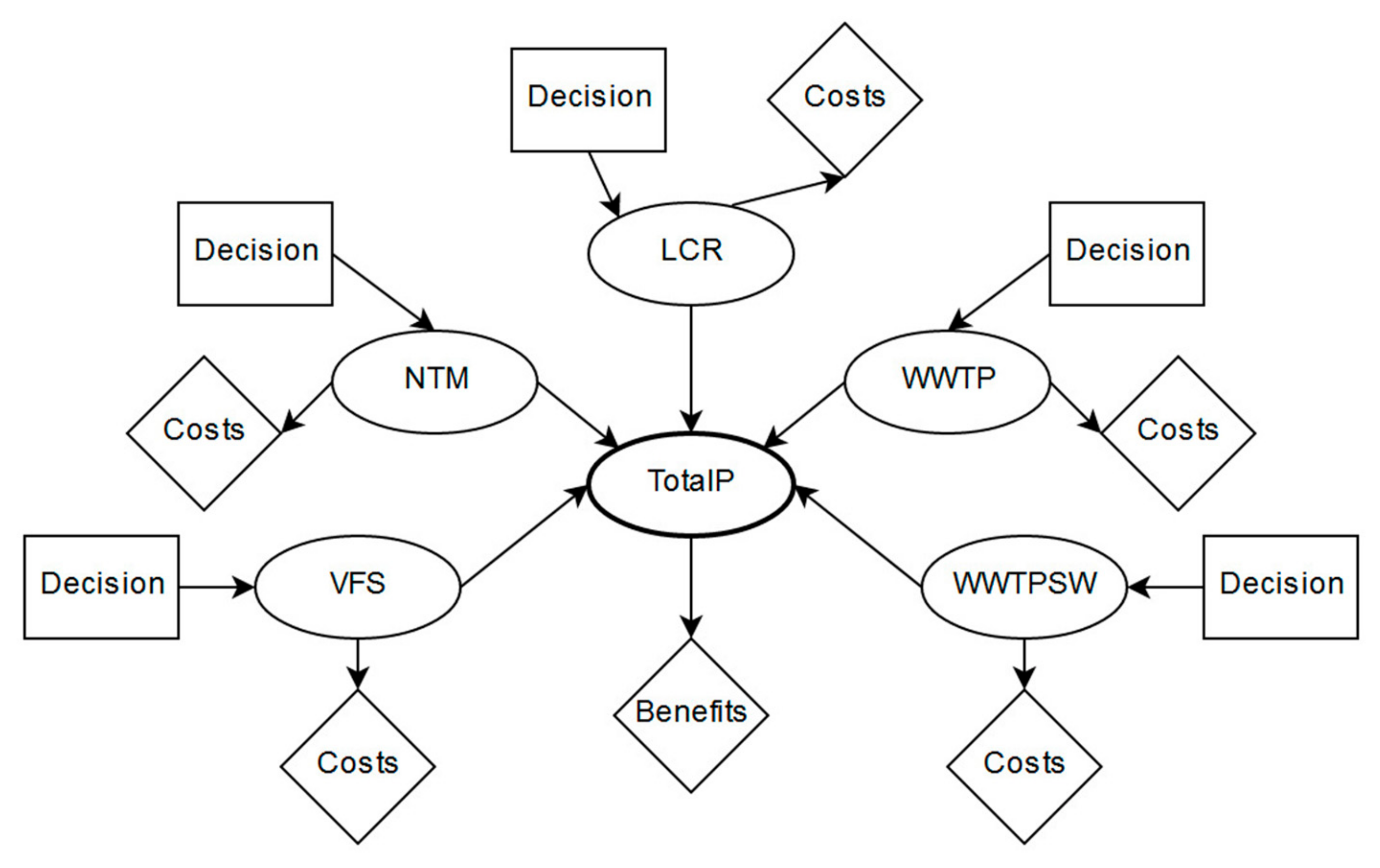
An influence diagram including the Bayesian network for the phosphorus abatement was designed based on dependencies among the variables.
Figure 3 shows the final diagram structure. Ovals represent chance nodes, rectangles stand for decision nodes and rhombi for utility nodes. Arrows indicate causality between two variables.
TotalP represents the variable of interest (probability of reducing the targeted amount of phosphorus).
4. Discussion
In the context of the WFD, [
25] argue that Bayesian networks are not suitable for environmental data, but they admit that the method corresponds with WFD logic as we are interested in whether the limits are satisfied, not by how much. On the other hand, Bayesian networks provide a robust way of determining whether the “good status” will be achieved in a specific water body. They also represent current knowledge of the system more realistically and can be updated without distorting the rest of the model thanks to conditional independencies [
26]. There are both advantages and drawbacks to this approach (see [
28] for a thorough discussion). First, one never gets a clear yes/no answer as the results are always probabilistic. The only way to be certain about the result is to aim for a 100% probability of success or zero. However, this is not desirable as that would mean the goal is achieved even when all the groups of measures are the least effective. The target would be met even if the effectiveness of all the groups of measures fell into the least effective section of the “minimum” interval, which is by itself very unlikely. If the target is met in such a situation, resources would be wasted in any other case. When the groups of measures are more effective, a smaller amount of the measures is required to achieve the “good status” at considerably lower costs. Therefore, careful consideration is needed when it comes to evaluating the results. Based on this, we see 72.4% of the 148.82 kg reduction as a reasonable number as the WFD requirements are broken in roughly a quarter of the cases and trying to achieve 100% is wasteful.
Computation of costs and benefits is quite unique in the case of achieving the “good status”. The costs are associated with implementation of the measures, meaning that the final number stays the same as in the case of deterministic analysis. However, information about the probability of achieving the “good status” is now available, which influences the calculation of benefits. It is very unlikely that the benefits grow linearly with a steady improvement in the water body status or in individual indicators that determine the status. It is more likely that some of the benefits are generated only when the “good status” is achieved. However, a significant amount of benefits is generated by visitors, and it is unlikely that a huge increase in benefits will occur once the water body already in a decent shape meets the last indicator and achieves the “good status”. Ideally, benefits associated with various levels of improvement should be estimated to make the comparison possible. This, however, is extremely difficult and time-consuming. It is not too problematic in the Stanovice case study. Macháč & Brabec [
7] estimated that benefits of achieving the “good status” (EUR 289,136) are significantly larger than the costs of measure implementation (EUR 43,233). However, if the results of the CBA are closer, the benefits need to be revaluated. It should be noted that while complicated, this computation leads to more precise results. The deterministic CBA gives a clear answer but assumes that the implemented measures reduce exactly the targeted amount of phosphorus representing an unrealistic 100% probability of success. This is hardly true in reality and the Bayesian analysis presented in this paper confirms that. Therefore, benefits must be adjusted accordingly, but discussion of proper evaluation of benefits is not the subject of this paper.
The Bayesian approach is also more demanding on data availability. While the deterministic approach uses a fixed effectiveness for each measure within the same group (often based solely on expert judgement), the Bayesian method requires more empirical observations as a large sample is necessary for (ideally) representative discretization or at least probability distribution estimation. Allowing effectiveness within the group of measures to vary means that the analysis is closer to reality. It is confirmed by the collected data that similar measures do not always yield comparable results. First, not all the suggested measures in one group have the same parameters and are therefore likely to have different effectiveness. Moreover, local conditions also affect measure effectiveness and the fixed effectiveness cannot cover this variance. Expert judgement may also be used to substitute real data when the number of observations is unsatisfactory; see, e.g., [
24]. This solution is not preferred but is possibly less distortive than using just a few observations as standard error is inversely related to sample size.
As indicated above, Bayesian networks may be used to test the “what if” type of questions [
33]. In this case, the question is how much a particular group of measures contributes to achieving the target while maintaining the robustness. This could prove useful for measure selection. In the case study, the probability of meeting the respective target increases when NTM are dropped and their expected reduction is subtracted from the target. This indicates that NTM are less effective than other measures. Therefore, it may be efficient to go through the measure selection process again and handicap the ineffective measures. That means the expected effectiveness in
Table 1 would be lowered for measures in the NTM group but increased for measures such as WWTP. This method is more time-consuming, just like the whole Bayesian approach, but may be economically desirable as fewer measures may be needed in the end. We recommend adjusting the selection process based on the results of the Bayesian analysis. Using the true effectiveness of measures may prevent wasting of resources on measures that might not be essential for achieving the target.
Bayesian networks are useful in assessing measure effectiveness, but they may be used to test uncertainty about costs and benefits as well. It might not make too much sense for costs of implementation as they are mostly dependent on market prices and the uncertainty is problematic mainly for large long-term investments (interest rate), but it can be useful for evaluation of benefits and for planning of measures in general. As Lansford & Jones [
40] show, the largest part of benefits in water management (aesthetic, recreational, etc.) are not traded on markets and other techniques need to be used to estimate them correctly. Integrating the evaluation of benefits into the analysis should lead to accurate results, although they will again be probabilistic.
5. Conclusions
This paper applies the concept of Bayesian networks to decision making in water management. It helps to determine whether the “good status” required by the WFD can be achieved with a set of selected measures. Bayesian networks represent an effective way of assessing uncertainty of effectiveness of implemented measures, which can also be extended to costs and benefits and thus to proportionality analysis. The approach is presented on the case of the Stanovice water reservoir. Results of the case study show that the chosen measures eliminate the expected amount of phosphorus with a probability of 72.4%. Barton et al. [
28] find that the phosphorus limits will be met with a probability of 56% in their case study on the Morsa catchment in Norway. That number is not dramatically different from the result presented here. However, they also find that agricultural measures dominate the model, which is contrary to our conclusions. On the other hand, most of the other authors predict that it will be hard to achieve the “good status” in the water bodies they studied, e.g., [
29,
33]. A straight comparison of the results is complicated, because each region and catchment area represents specific conditions. For example, the main source of phosphorus in the Morsa catchment is agriculture [
28], which is contrary to the Stanovice case. Changes in the selection process might be desirable as some of the groups of measures exceed the original expectations about their effectiveness while other groups of measures fall short.
It is appropriate to incorporate the Bayesian approach into a proportionality analysis, which needs to be carried out if the water body applies for an exemption from achieving the “good status”. The approach should be used before conducting a CBA, because generated benefits heavily depend on achieving the “good status”. If the probability of breaking the regulation is high, more measures should be implemented and the whole process should be repeated until a higher probability is achieved. Thus, the economic assessment becomes more complex based on relevant biophysical aspects (effectiveness of measures) and the number of measures that lead to achieving the “good status”.
Bayesian networks are still used rather sparsely as they are demanding on data and not straightforward to interpret (especially in relation to the WFD). However, we believe this approach is informative and should be used more widely in water management. This paper offers an additional source of information for stakeholders who seek a more reliable way of assessing abatement measures in water management and planning and implementation of measures in catchments.







{kind=link}
{kind=link}
{kind=link}
{kind=link}