2.1. Atmospheric Dispersion Model
The modeling of air contaminant dispersion is the basis of the dispersion prediction. The Gaussian models are widely used in atmospheric dispersion. Requiring only a few input parameters, Gaussian models are simpler compared to some complex models like the Lagrangian model. Further, the results of Gaussian models are trustworthy for near-field dispersion cases. Consequently, the Gaussian models are suitable for the modeling of air contaminant dispersion in data assimilation, which requires fast computing of the dispersion model. In this paper, the Gaussian plume model is applied to model the continuous release of the point source in the chemical industry park. In this model, the air contaminant concentration of a given point (x, y, z) is expressed as follows:
where x, y, and z are the coordinates of downwind, crosswind, and vertical directions, respectively. Parameter of u is the wind velocity. H
e and q represent the effective height and release rate of the source, respectively. The effective height of the source (H
e) is calculated by:
, where H and Δh represent the physical height of the source and the height of plume rise. The plume rise height (
) is calculated by the formula in CALPUFF [
16]. The plume rise due to buoyancy and momentum during neutral or unstable conditions is:
where
is the momentum flux (
), F is the buoyancy flux (
),
is the source height wind speed (
),
is the downwind distance (
),
is the neutral entrainment parameter,
is the jet entrainment coefficient (
), and w is the source gas exit speed (m/s). In addition, considering the deposition velocity
, Equation (1) is rewritten as:
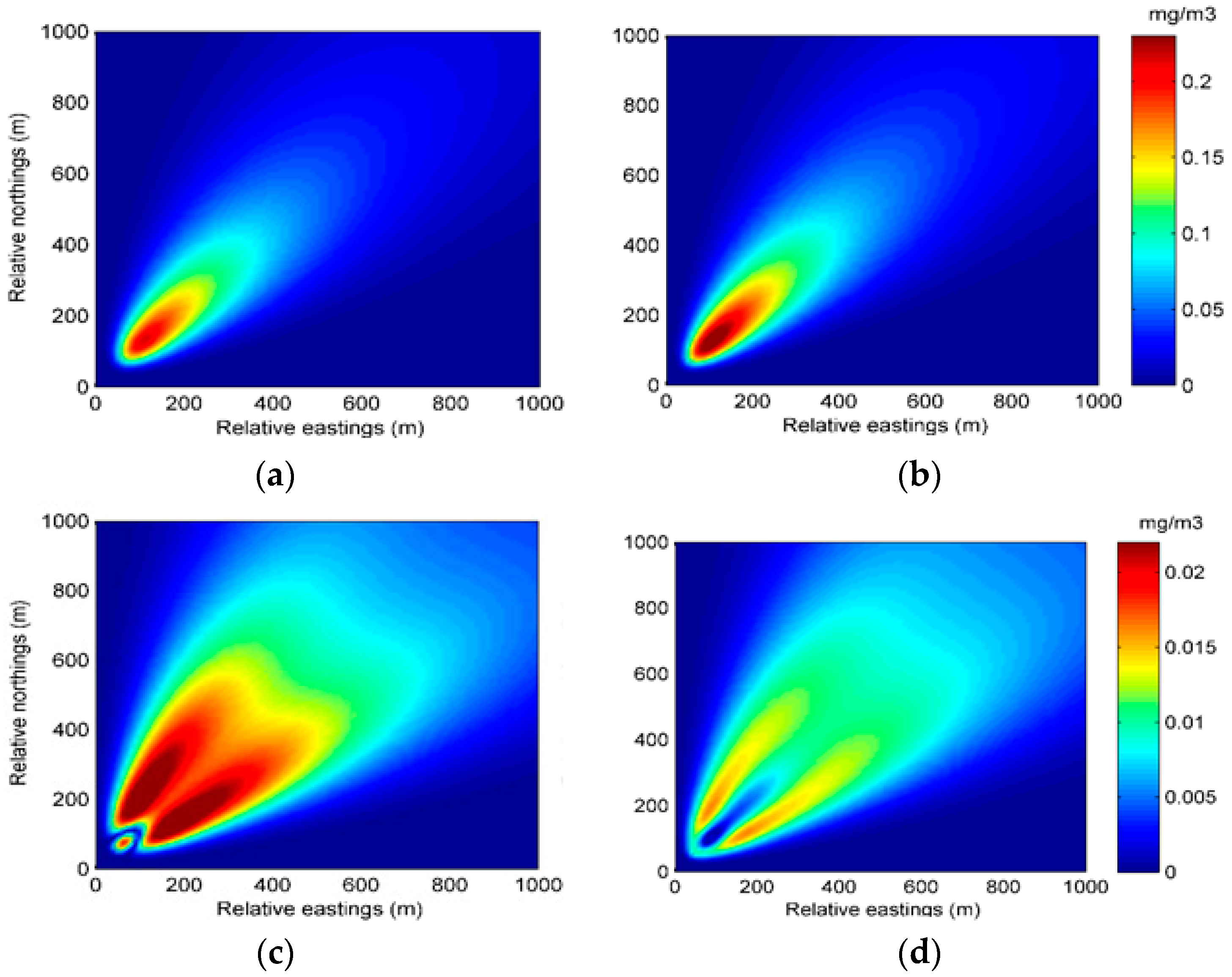
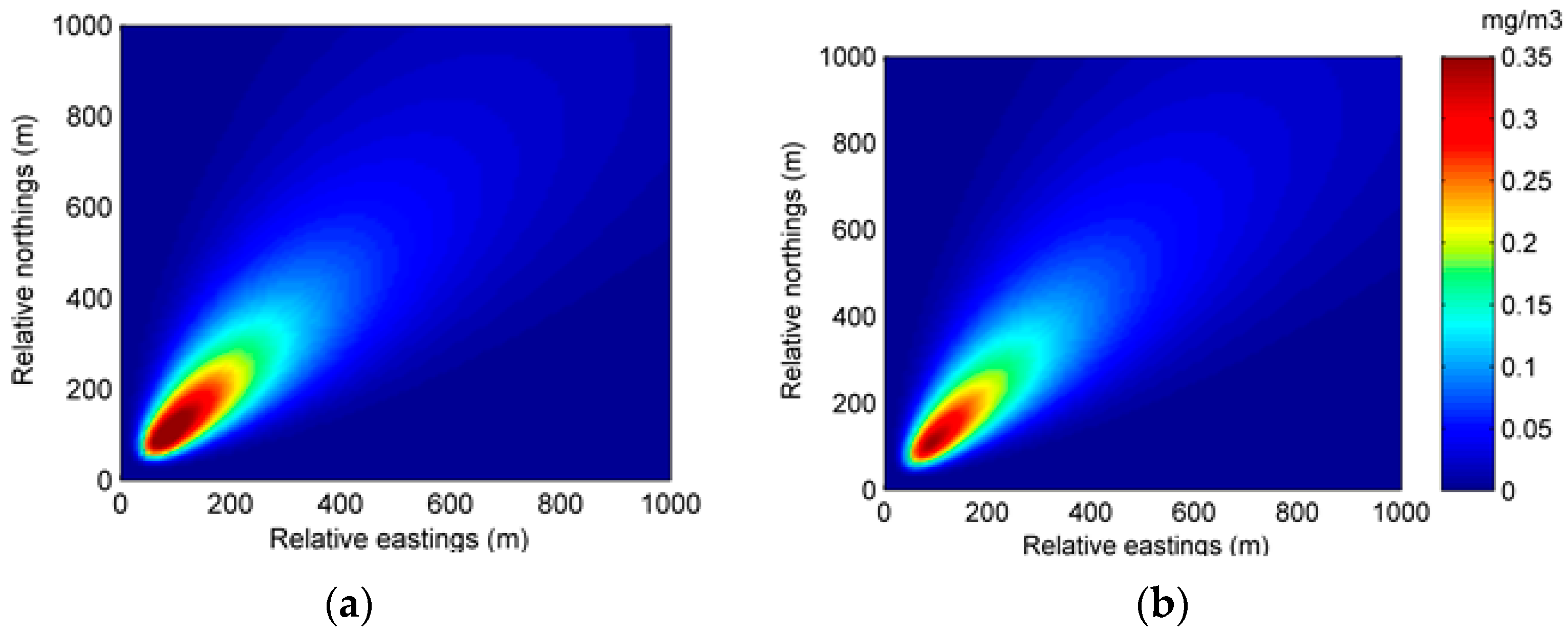
In the Gaussian plume model, the air contaminant concentration in axis y and z is considered to follow the Gaussian distribution. Therefore, the key parameters of the model are
and
, which represent the standard deviations that describe the crosswind and vertical mixing of air contaminants. The standard deviations can be described by empirical formulas:
where x represents the downwind distance. The parameters of a, b, c, and d are dispersion coefficients closely related to the environmental conditions, such as atmospheric stability and terrain. Several derivations of these dispersion coefficients exist where a popular approach is based on the Pasquill’s atmospheric stability class [
17]. The empirical formulas of
and
illustrate that the standard deviations increase with the downwind distance. The Gaussian plume model can be applied to model the continuous release of the point source in the chemical industry park. However, relying solely on this model may fail to make an accurate prediction, since these model parameters usually vary with the environmental conditions and are hard to measure precisely. For example, we can only obtain their empirical values of the four dispersion coefficients, but no accurate value is available. There is currently no perfect formula to calculate these coefficients from the atmospheric stability. As for the wind field parameters (i.e., wind direction and velocity), they are also difficult to precisely measure. Further, the release rate q is usually unknown during the contaminant gas leakage incident. Without accurate parameters in the conventional modeling of atmospheric dispersion, it is a common practice to bring imperfect estimations of these parameters into the model for calculation, which inevitably introduces errors into the model prediction. Thus, there is an urgent need to dynamically estimate these parameters to improve the accuracy of the model prediction.
2.2. Data Assimilation Using Particle Filter
For the modeling of air contaminant dispersion, in order to diminish the errors of input parameters and produce an accurate prediction, a data assimilation model based on particle filter is developed. Particle filter, also called the Sequential Monte Carlo (SMC) method, is a sample-based method that uses Bayesian inference and stochastic sampling techniques to recursively estimate the state of the dynamic system from some given observations. The core idea of particle filter is using a series of weighted random sampling particles to approximate the posterior probability density function of the system state. A typical particle filter algorithm includes four steps (i.e., initialization, importance sampling, weight update, and resample) and goes through multiple iterations. In order to apply particle filter to the Gaussian plume model, the state space model of atmospheric dispersion needs to be developed. Usually, a dynamic system can be described and formulated as a discrete state space model:
where (6) and (7) represent the system state transition model and measurement model, respectively.
and
are system state variables and measurement variables at time step t, respectively. The function f describes the transition of the system states with time. The function g defines the relationship between state variables and measurement variables. The parameters of
and
are two independent random variables representing the state noise and the measurement noise, respectively.
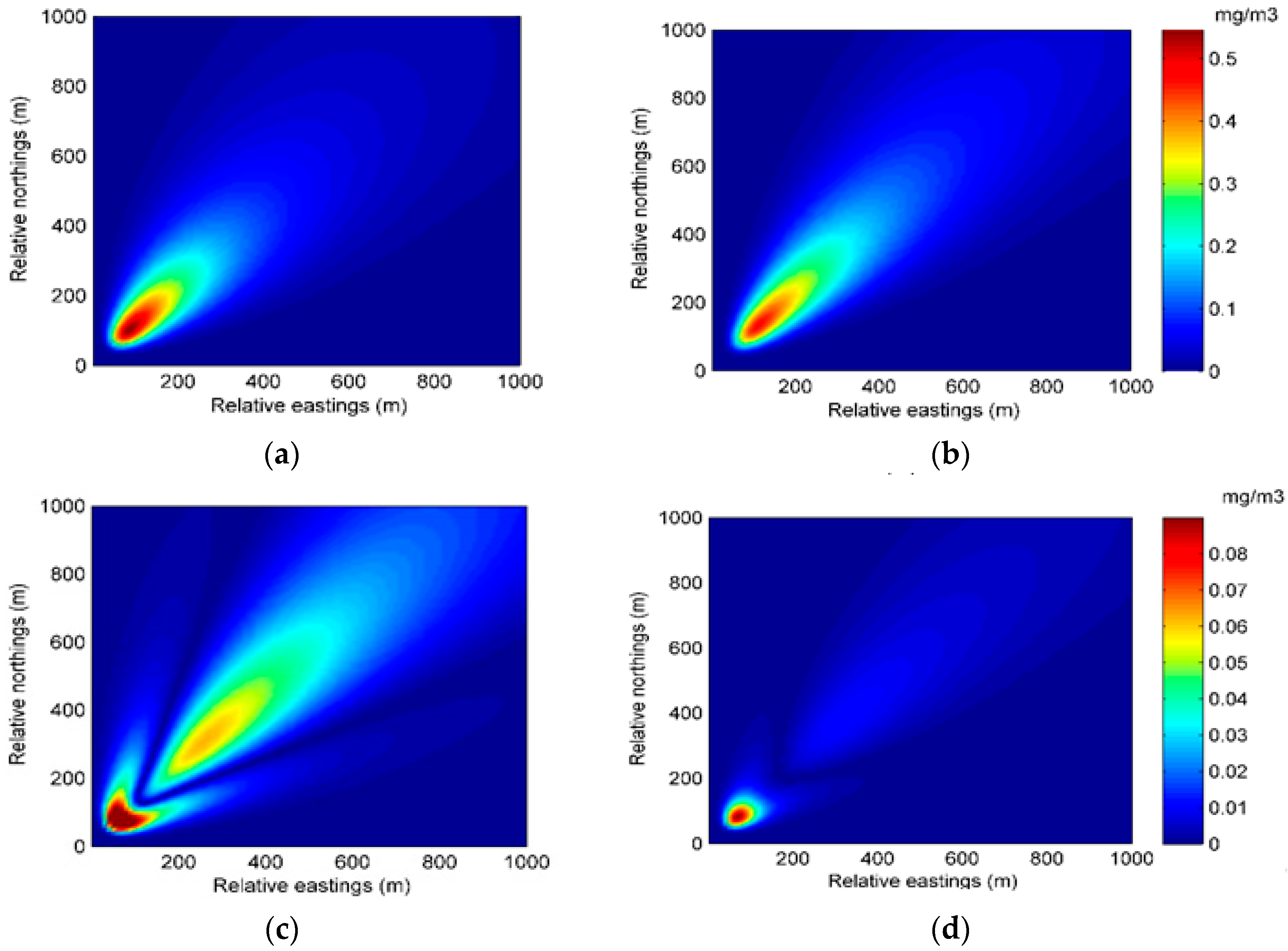
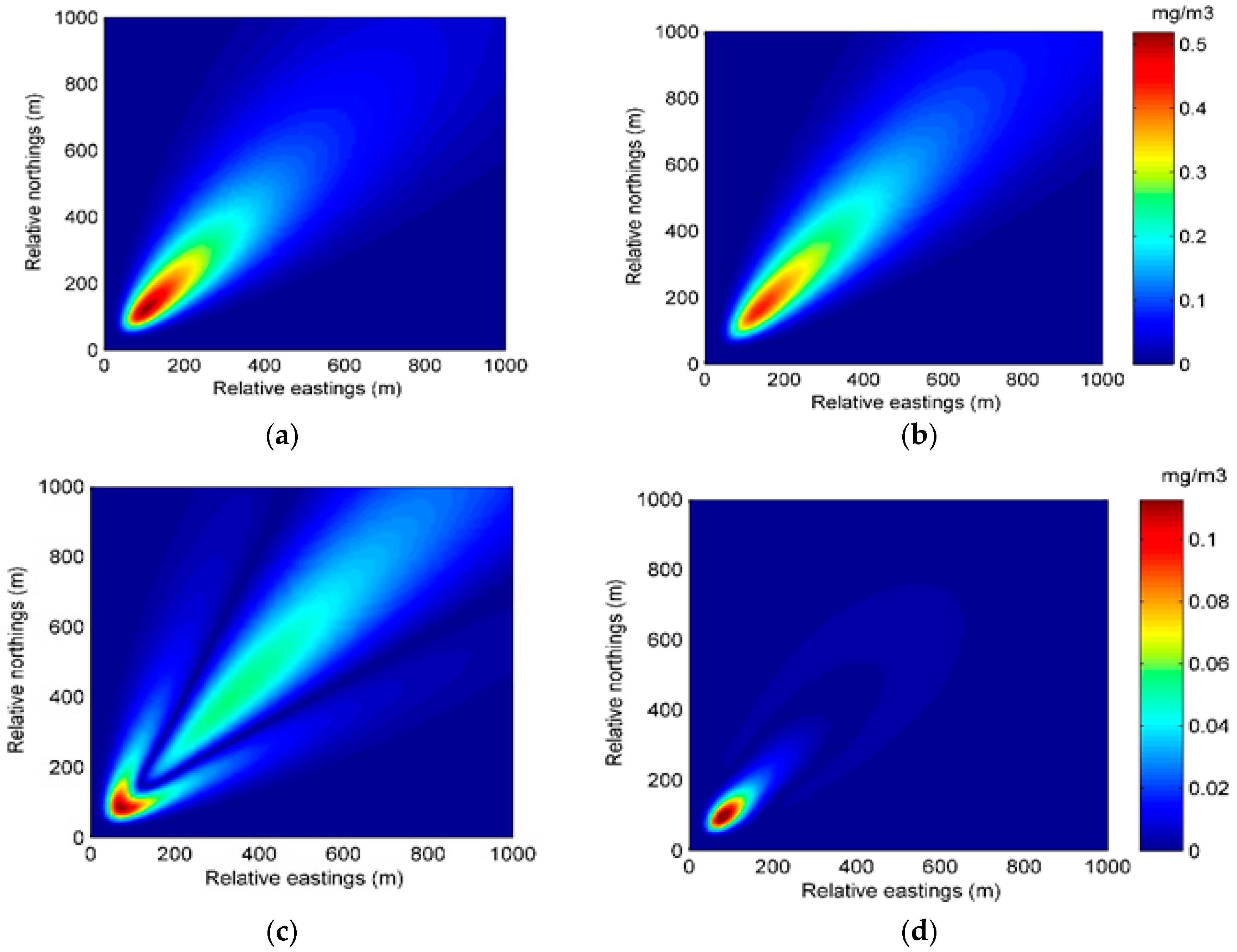
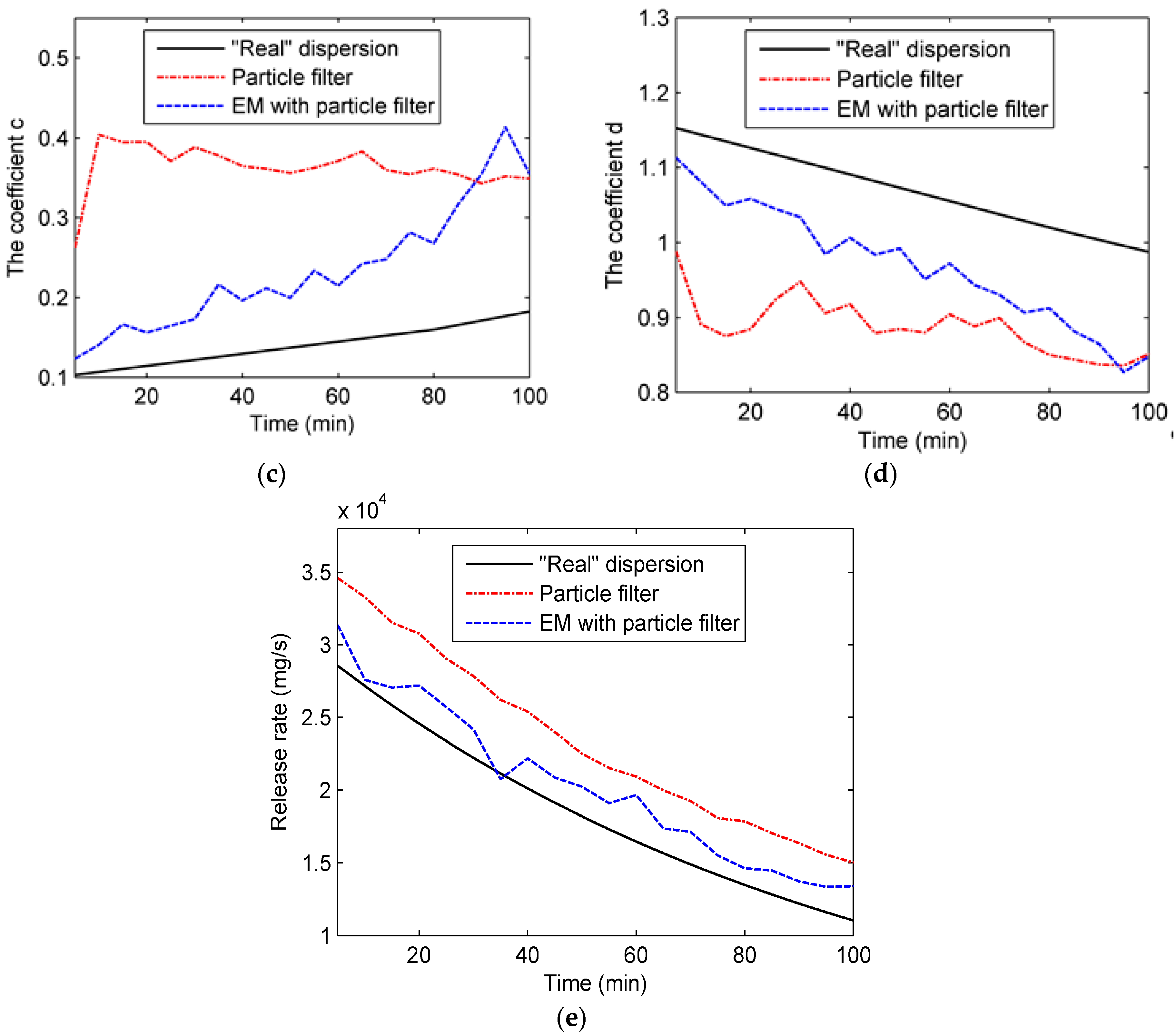
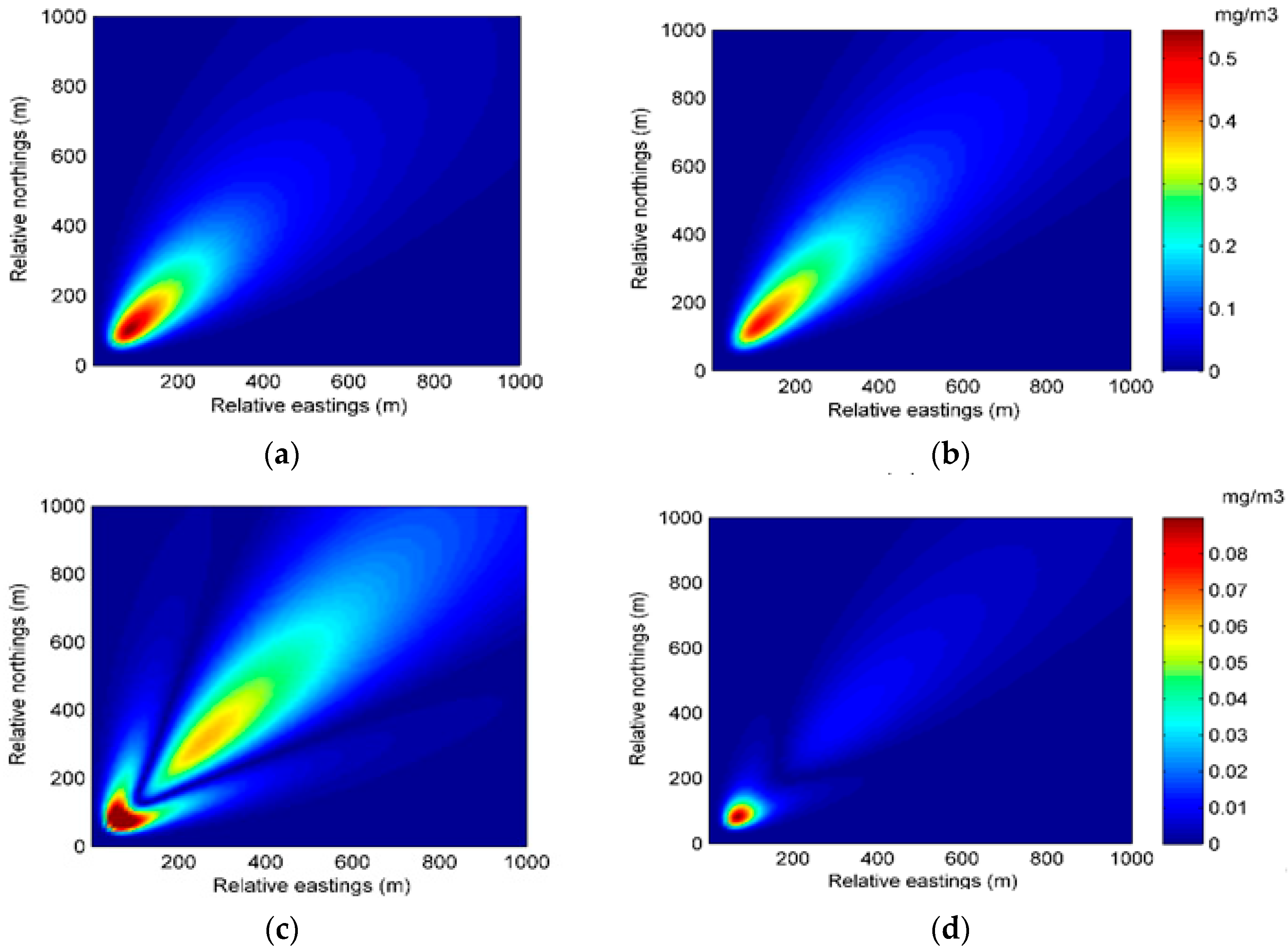
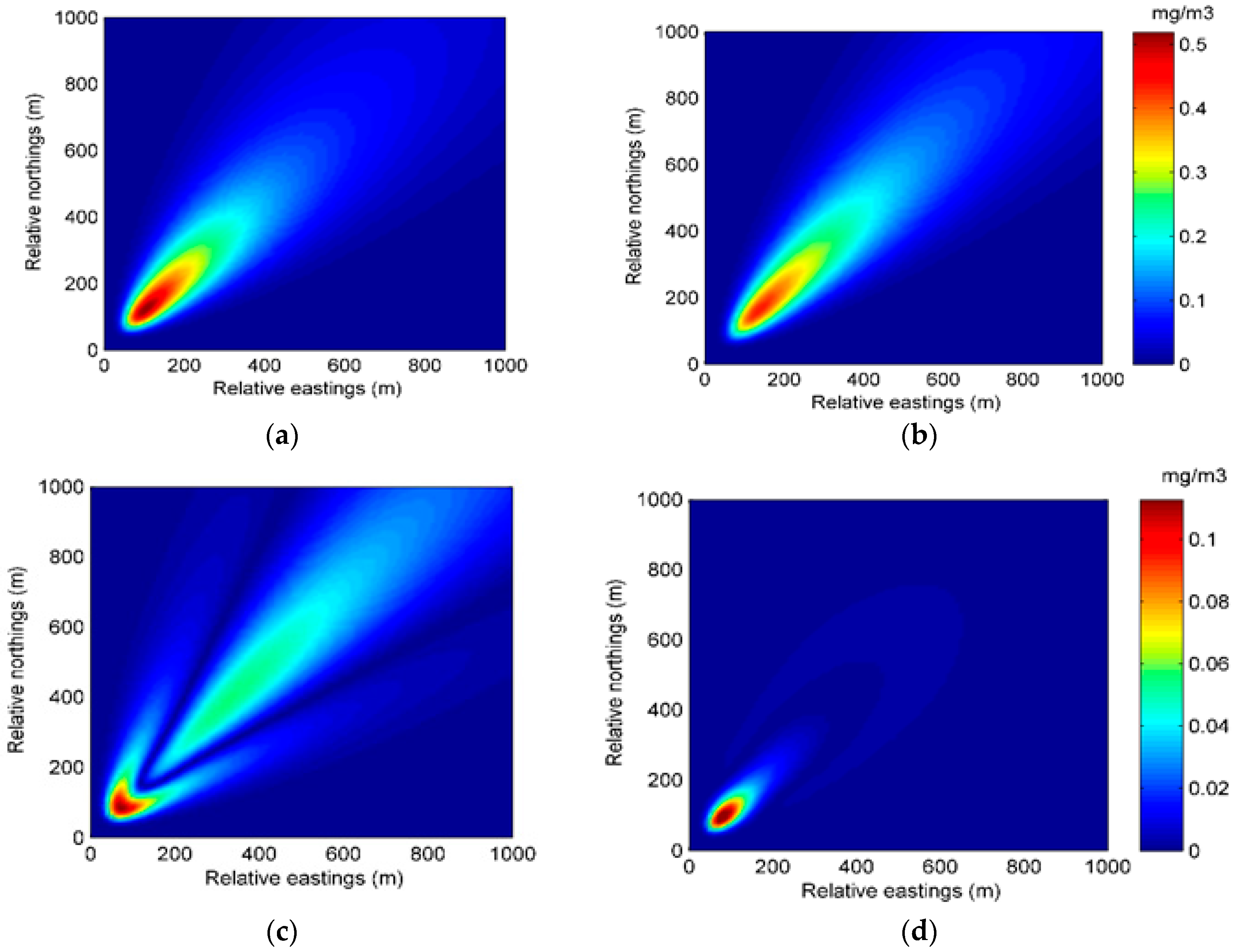
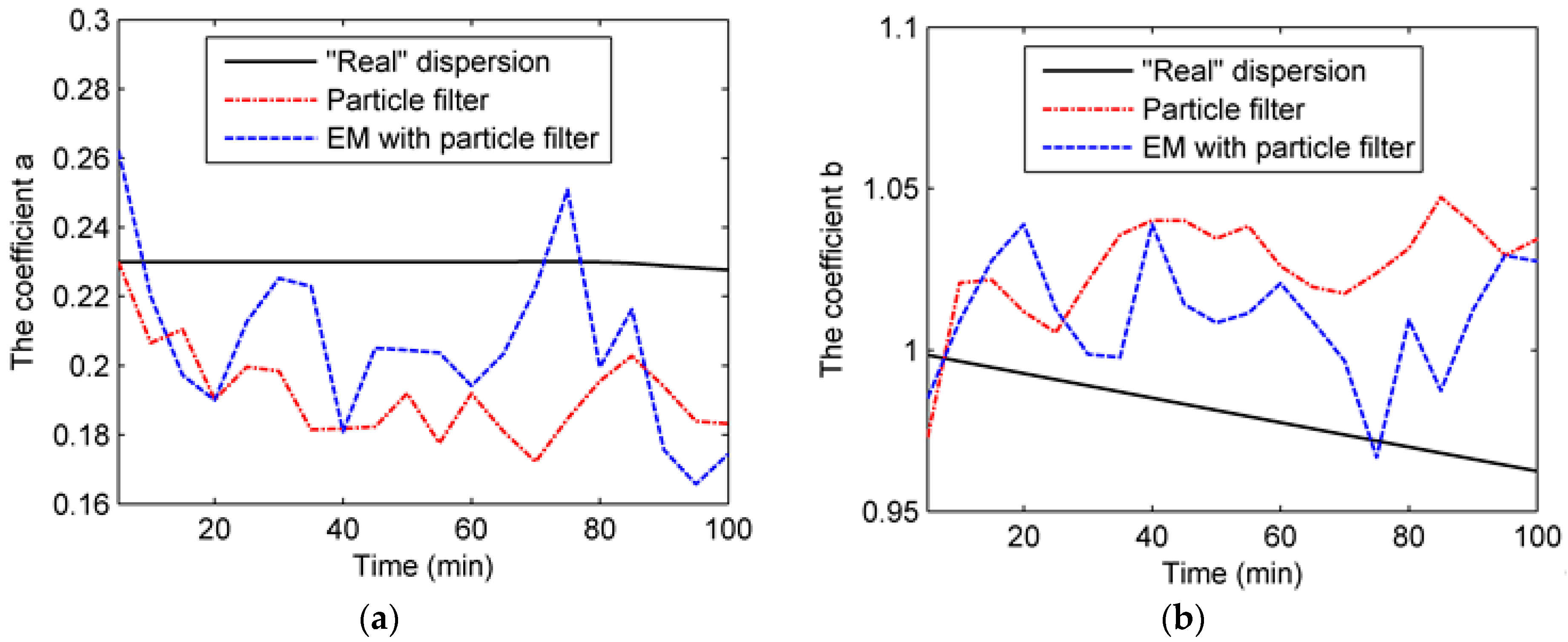
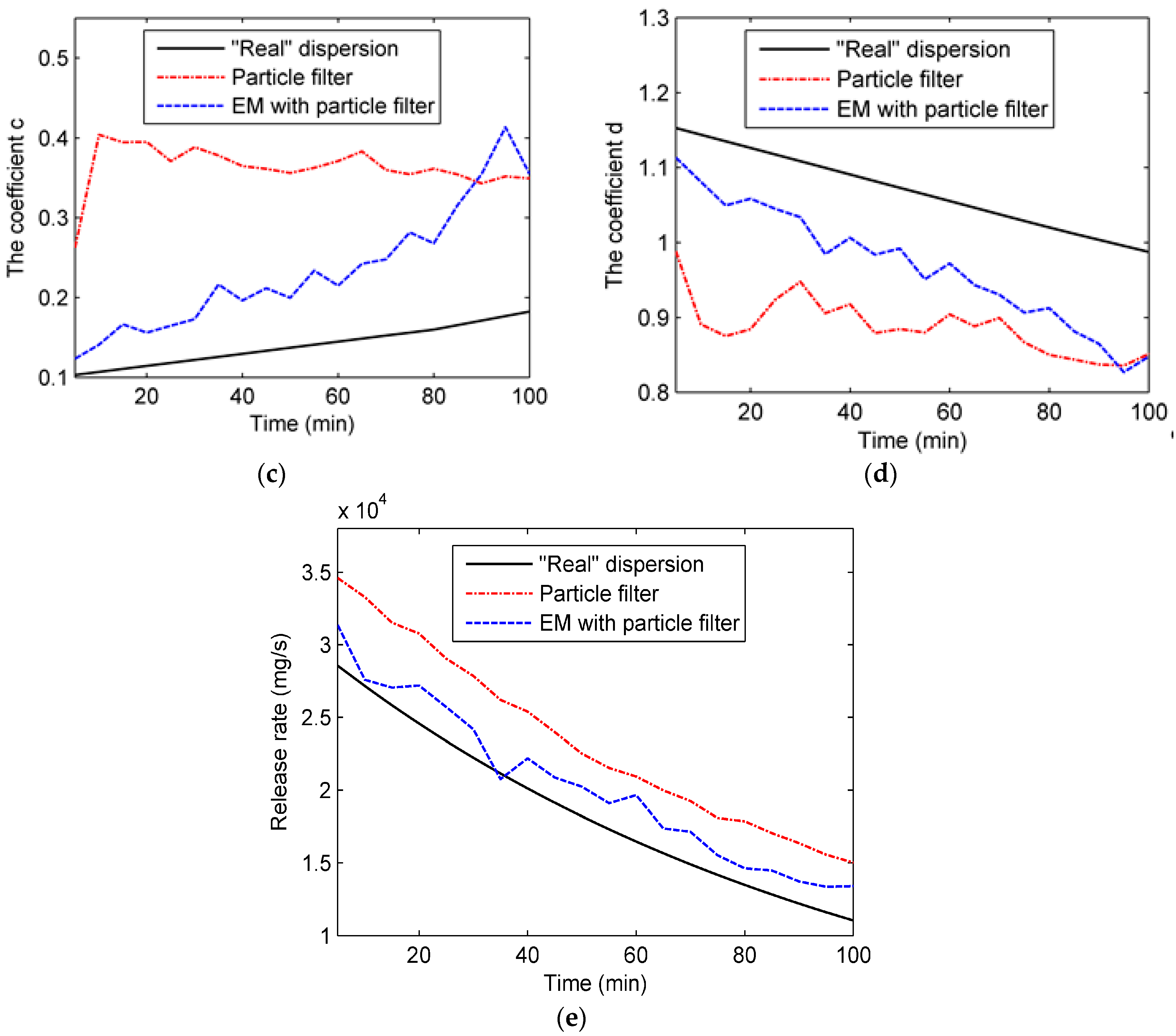
The state transition model is based on the state parameters. Therefore, the selection of the state parameters is key to the construction of the state transition model. For the Gaussian plume model, there are several choices of state parameters. One of the common practices is dividing the area of dispersion into numerous grids and choosing the concentrations by grid as the state parameters. This choice directly describes the atmospheric dispersion. However, the vast region of the chemical industry park means a high dimension of the state parameters, which results in a high computation cost. In this paper, the dispersion coefficients a, b, c, and d in (4) and (5), as well as the release rate q, are selected as the state parameters in the second case, while the state parameters in the first case only include four dispersion coefficients. Selected as the state parameters, the four dispersion coefficients play important roles in the Gaussian plume model. The standard deviations
and
, which are derived from the four dispersion coefficients, describe the crosswind and vertical mixing of air contaminants. Further, correlated closely with various environmental conditions, these coefficients are hard to measure precisely. As for the release rate, it is difficult to identify for the sake of safety during the contaminant gas leakage incident. Therefore, the coefficients and release rate need dynamic updates by data assimilation. Additionally, the wind field, which is hard to measure precisely, is assumed to be known for simplicity. In the following construction of the data assimilation model, only the second case is discussed because the data assimilation model in the first case is similar to that in the second case. The system state vector and state transition model can be described as follows:
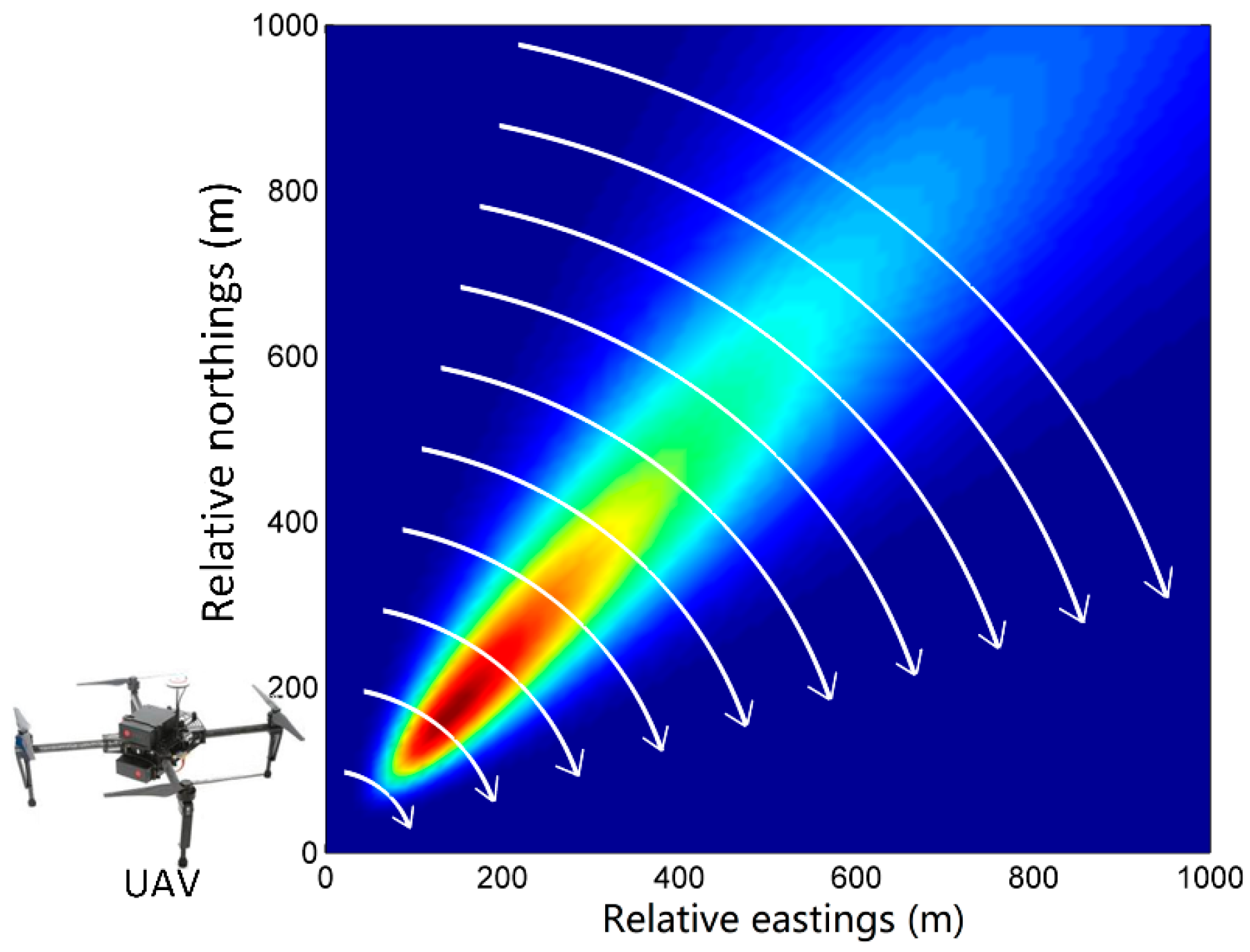
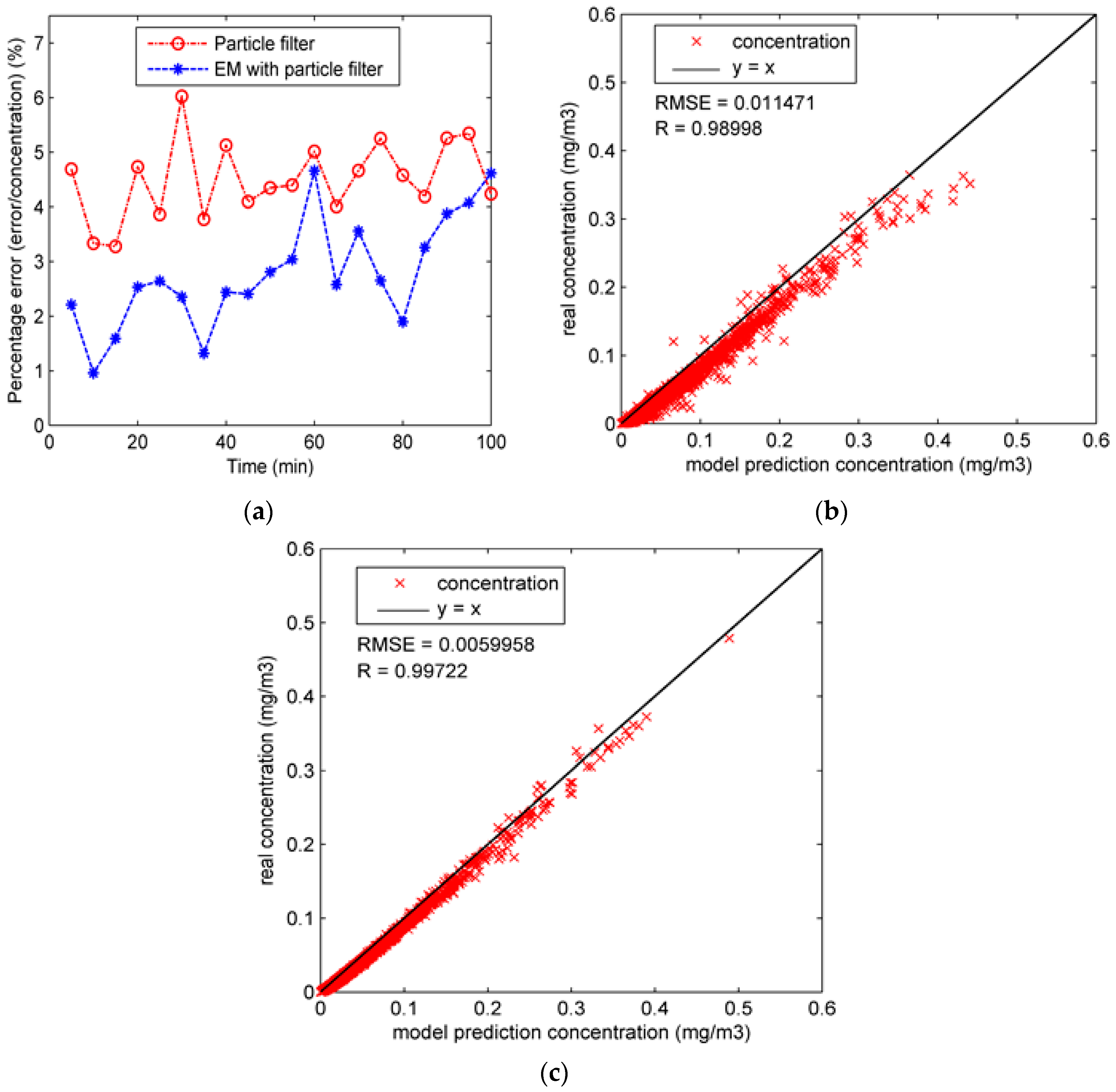
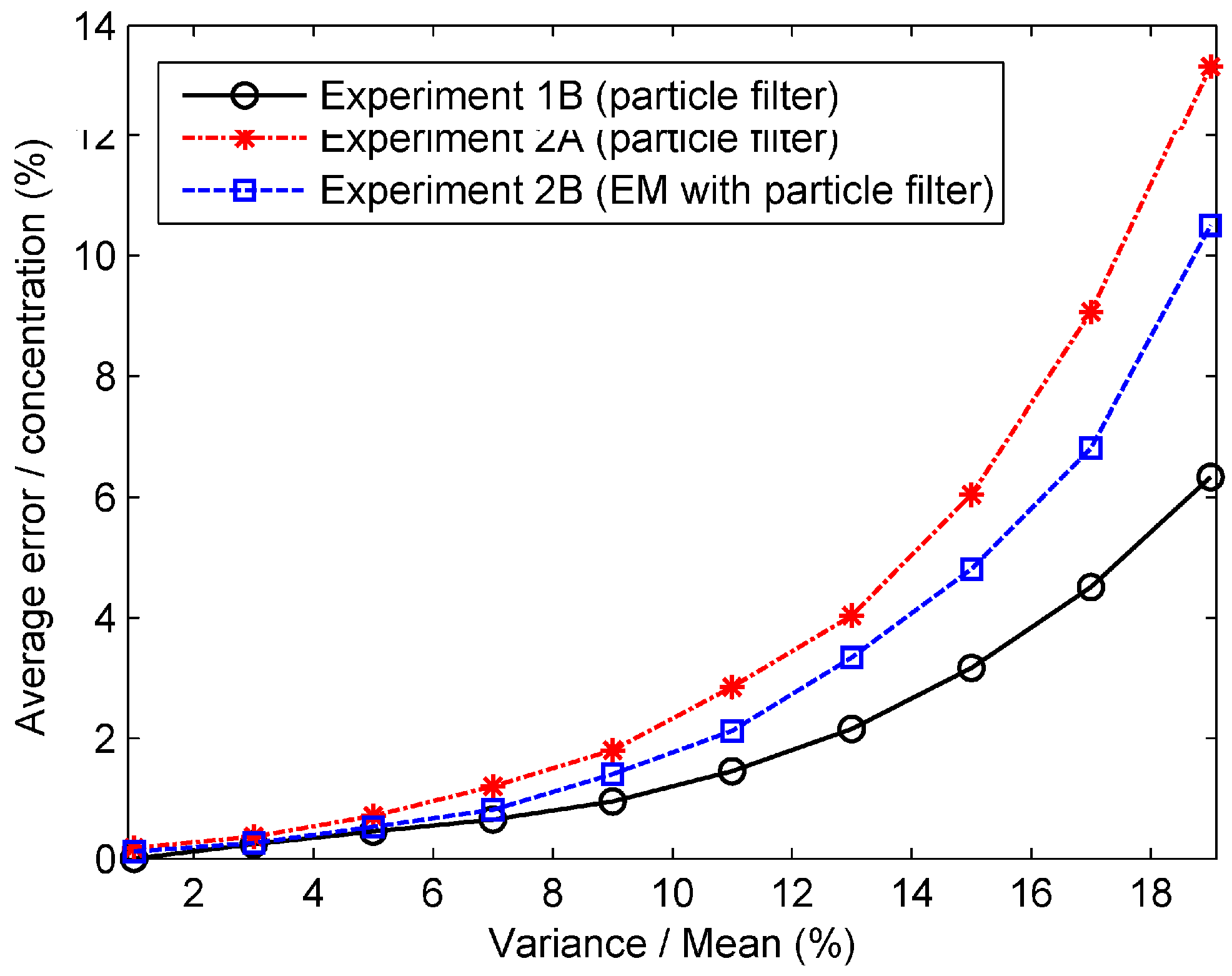
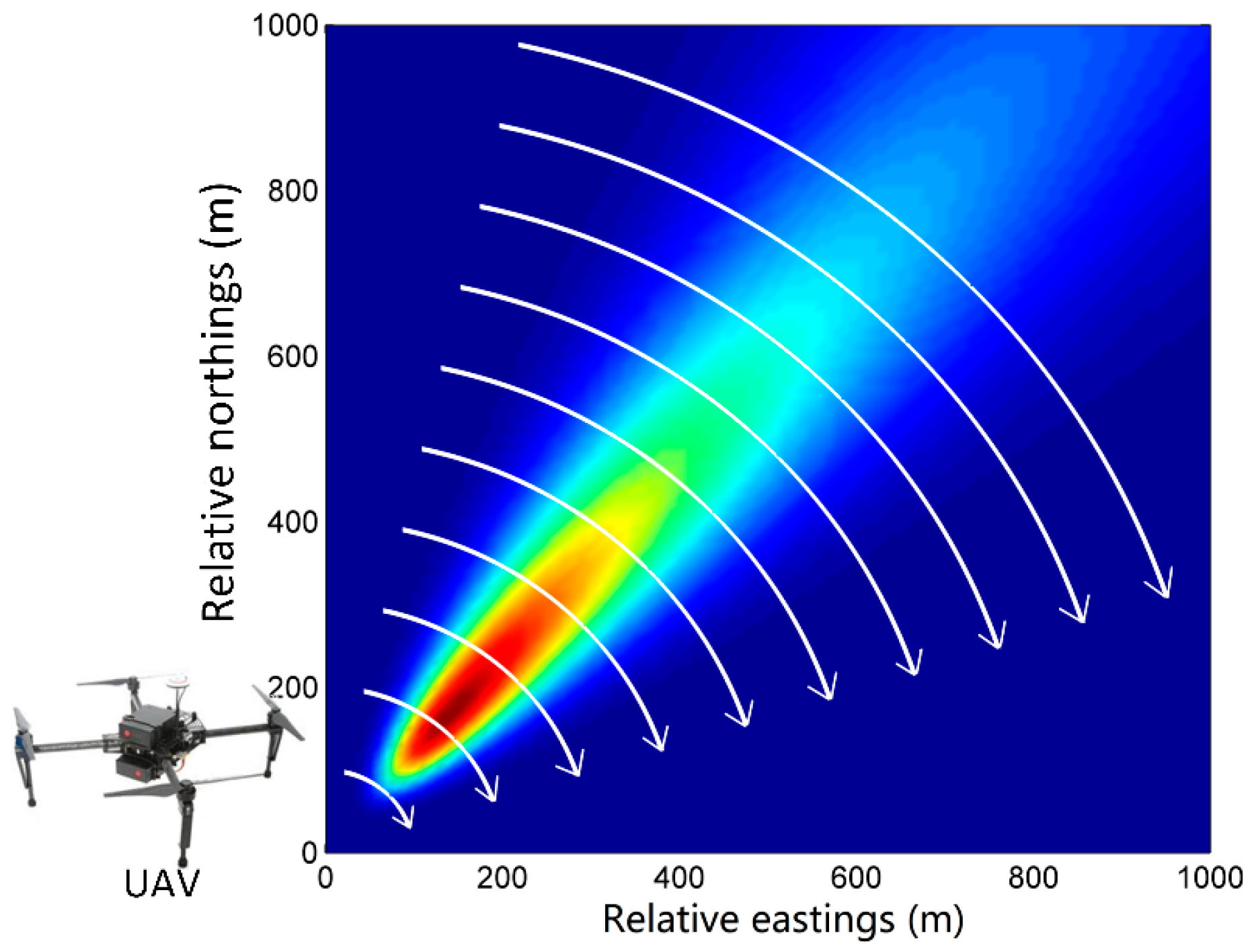
Due to the short duration of each time step in our experiments (only 1 min), the meteorological condition of the chemical industry park changes slightly. Therefore, the dispersion coefficients derived from the meteorological condition remain almost stable during each time step. In terms of the release rate, it is also stable within a time step. Therefore, the state transition function is defined as an identically equal function. The variation of the state vector is provided by , which is considered to be a Gaussian white noise vector of which all elements follow the Gaussian distribution . The measurement model describes the relationship between the state variables and observations. In this paper, the observations are air contaminant concentrations collected by the UAV at the trajectory points p (), where X, Y, Z are coordinate vectors. Therefore, the measurement function is defined as the Gaussian plume function (Equation (1)). In addition, the measurement noise in Equation (7) is assumed to be Gaussian white noise following the distribution that describes measurement errors. The measurement error originates from the observation device (i.e., UAV in this paper).
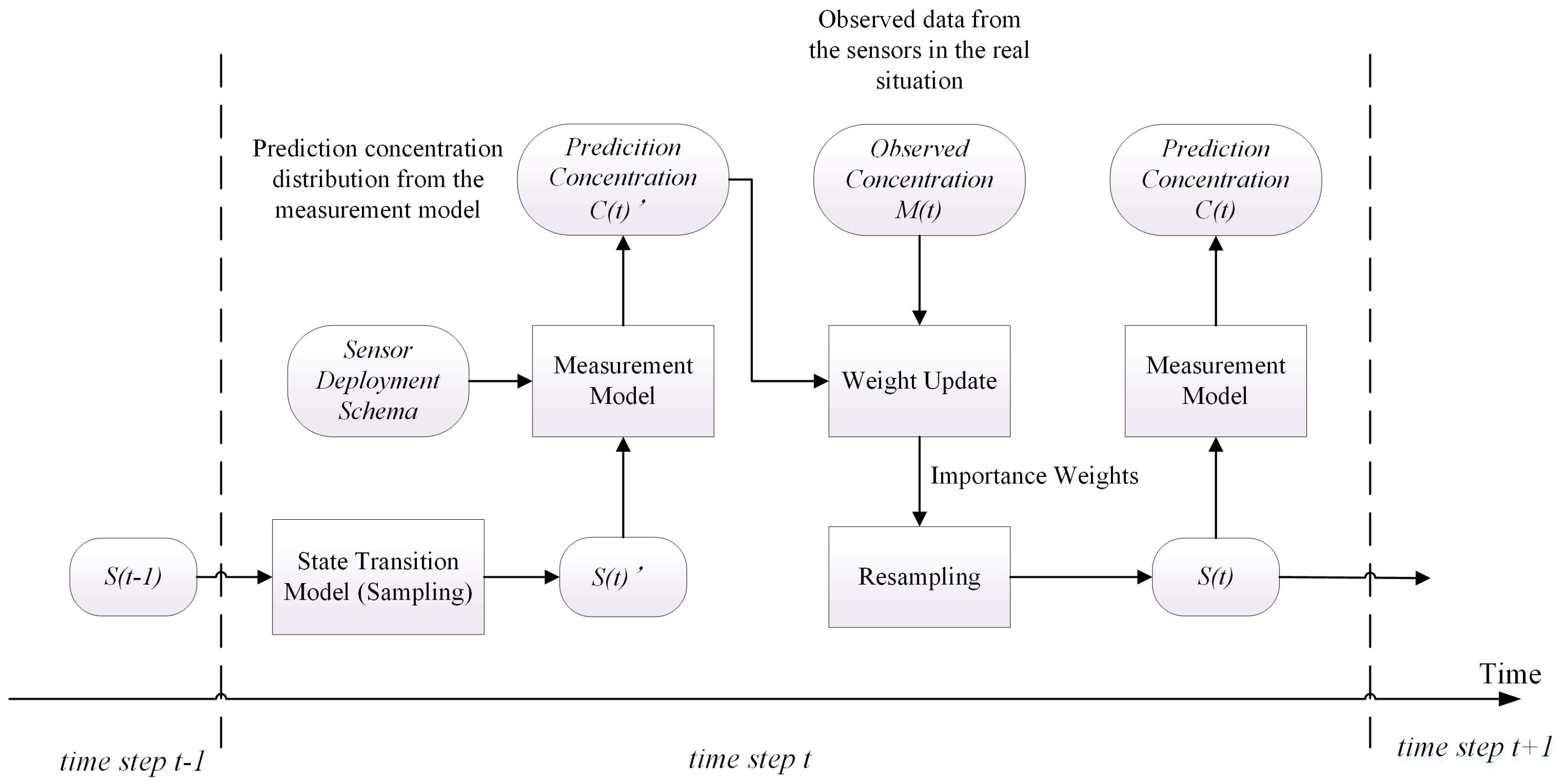
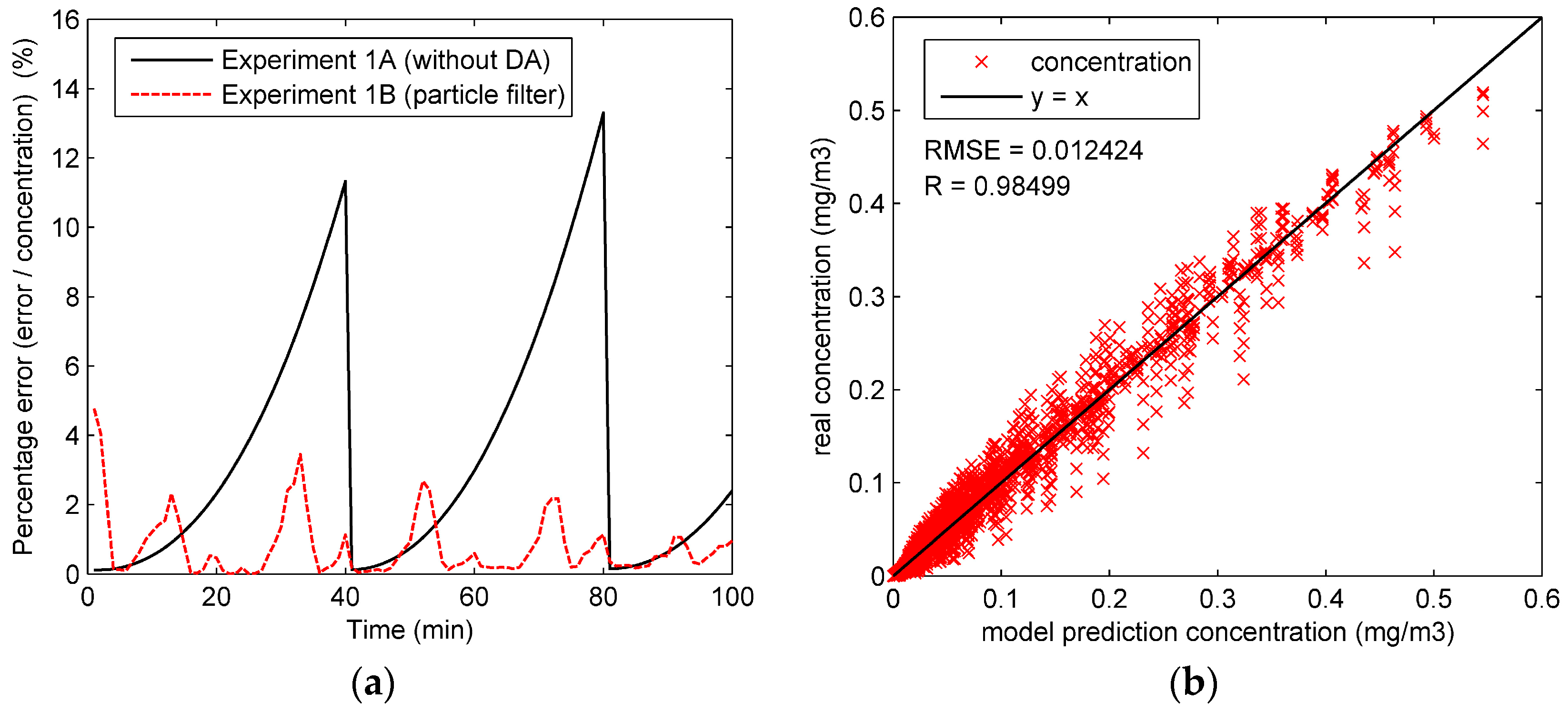
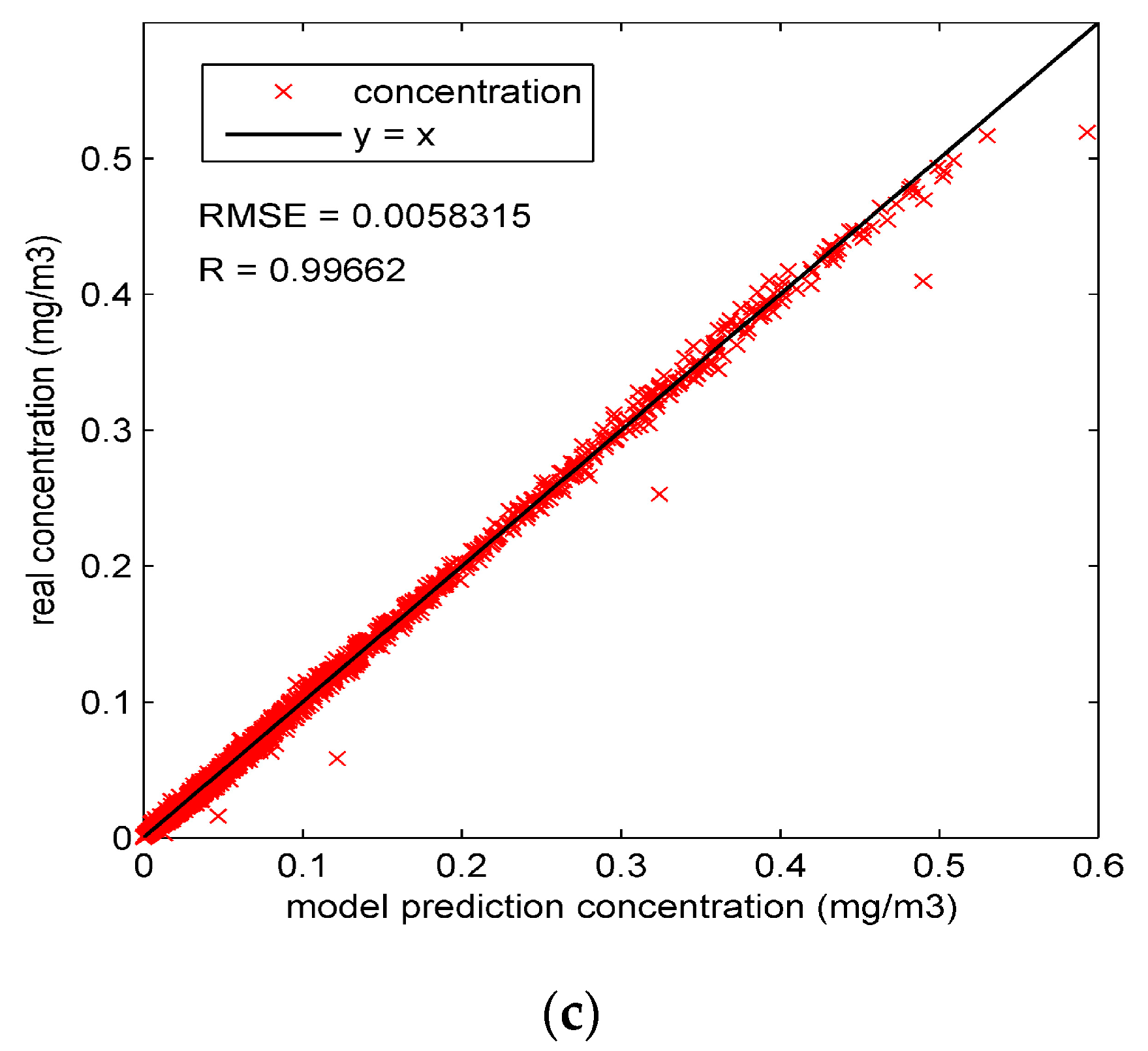
Figure 1 shows the structure of particle filter and the procedure of data assimilation. In this figure, the rectangle boxes represent the major components in one step of the algorithm. The rounded rectangles represent the data or variables. The data assimilation runs in a stepwise fashion. At time step t, the system states in time step
(denoted as
in
Figure 1) are fed into the system state transition model. Then, this model performs the transition function in Equation (9) to produce a sample for each particle in
. The resulting system state set of the transition model is denoted as
. To compute the importance weights of the particles, the concentration vector (denoted as
corresponding to each particle is computed according to the measurement model (Equation (7)). The locations corresponding to the concentration vectors
depend on the sensor deployment schema. In this paper, the sensor deployment schema is the trajectory of the virtual UAV, which will be introduced in
Section 3.1. Then, the importance weights of particles are calculated according to the likelihood between
and the observed concentrations M(t). After normalizing the weights of all particles, a resampling algorithm is applied to generate
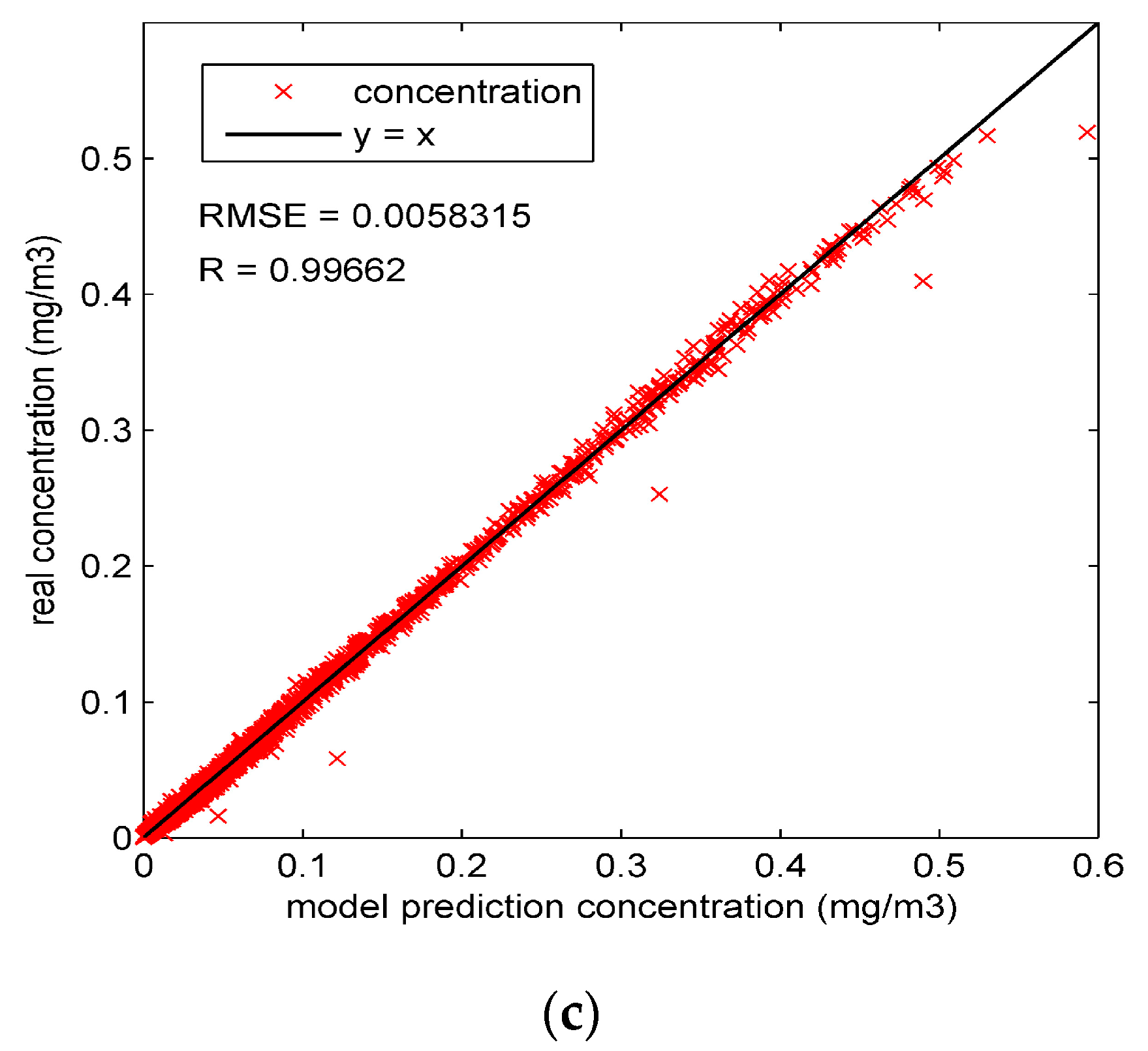
, which is the input for the next step. To observe the performance of model prediction, the prediction concentration
can be calculated from
by the measurement model.
The workflow of the particle filter is given in ALGORITHM. In this algorithm, the set of dispersion states is represented by a set of particles. The algorithm starts by initializing N particles representing the initial dispersion states. Each particle’s weight is initialized to 1/N. Then, the algorithm goes through stages of sampling, weight updating, and resampling iteratively. At the sampling stage, all the particles run according to the state transition model (Equation (9)), so each particle is replaced with a sampled dispersion state
. During the weight updating stage, the weights of the sampled dispersion states are updated as follows:
where
and
represent the weights of the
ith particle at time t − 1 and t, respectively. The
represents the likelihood function of
, which is calculated by the error between the predicted concentrations based on the
and observations. These weights are then normalized. Finally, the resampling stage selects the particles based on their normalized weights to form a new set of particles. In the resampling algorithm, the cumulative sums of the normalized weight of N particles
are calculated first, where
. Then, N ordered random numbers
are generated, where
. Next,
copies of the
ith particle are generated, where
is the number of
. Finally, these particles are assigned a new weight of 1/N and used in the next iteration of the Algorithm 1.
| Algorithm 1: Particle filter of data assimilation for a time step. |
Input: The dispersion states and the corresponding importance weights at time step t − 1 , and the measurement at time step t (mt).
Output: The dispersion states and the corresponding importance weights at time step t .
Sampling (System state transition) For each dispersion state in , draw a sample using the system state transition model (Equation (9)). Weight updating
For each dispersion state in , update the weight using Equation (10); Calculate the normalized weights: .
Resampling
Draw N particles from and according to the resampling algorithm; Set the weights: .
|
2.3. Particle Filter Combining EM Algorithm in the Second Case
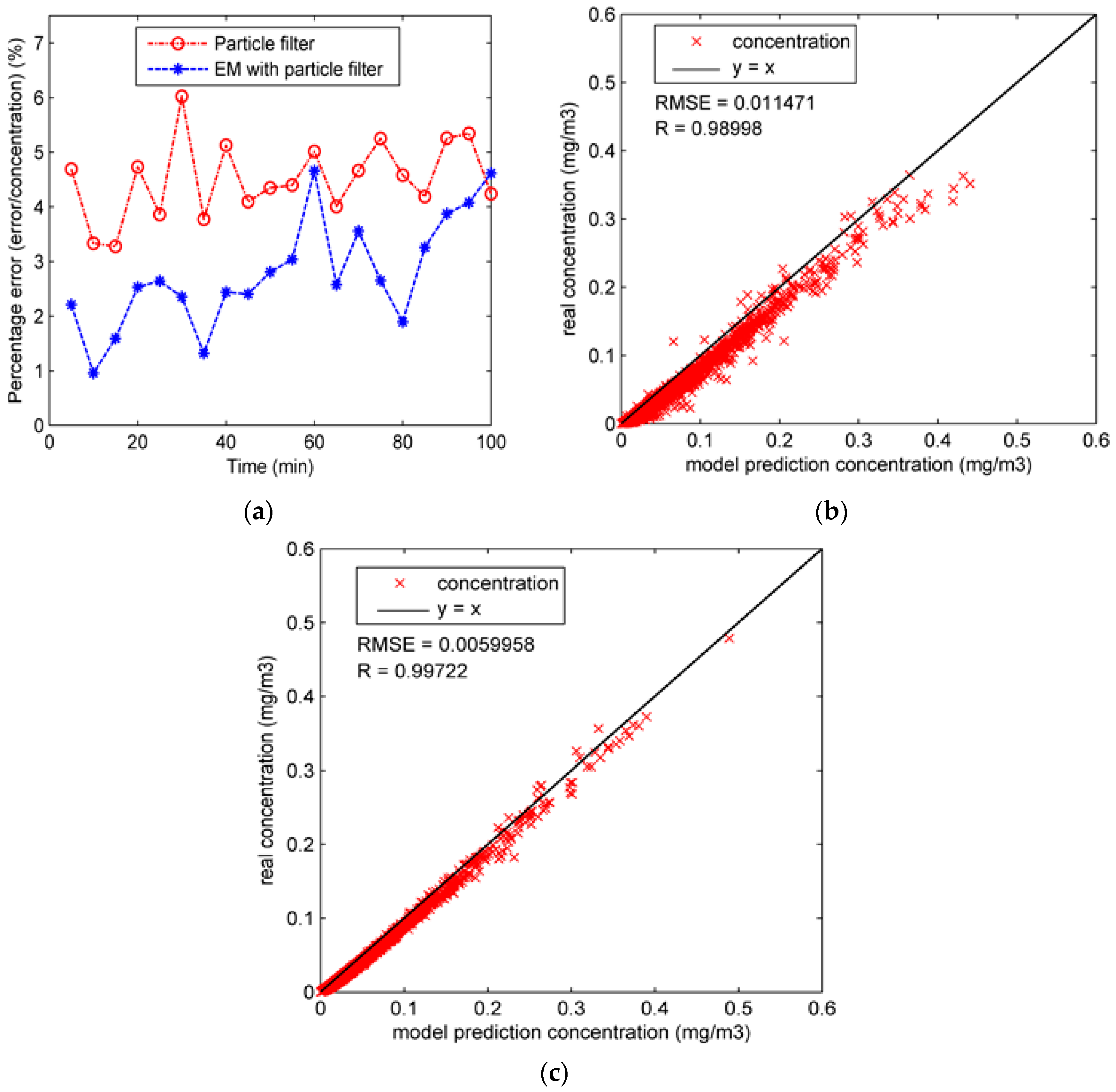
In the last section, the particle filter is applied to estimate the release rate and four dispersion coefficients in the second case. However, due to the higher dimension of the state vector and the complexity of the atmospheric dispersion, the particle distribution might not converge to a satisfactory result during the process of particle filter. In order to enhance the accuracy of the estimation, the particle filter is combined with the EM algorithm to iteratively estimate these parameters (i.e., the release rate and four dispersion coefficients). The EM algorithm is a generic method for computing the Maximum Likelihood Estimation (MLE) of parameter in an incomplete-data problem. In the incomplete-data problem, the estimation of the unknown parameter depends on the hidden variable , so is hard to estimate directly. To deal with the problem, the EM algorithm divides the estimation process of and into two steps (i.e., the Expectation Step (E-step) and the Maximization Step (M-step)) and runs iteratively. Specifically, in the E-step, the posterior probability of the hidden variable, which can also be considered as their expectation, is calculated from initial values of the parameters or the model parameters in the last iteration. Further, the expectation is regarded as the estimation of the hidden variable. Based on the estimation of the hidden variable, the MLE of is calculated by maximizing the likelihood function in the M-step. Therefore, by reducing the complexity of the parameter estimation, the EM algorithm exhibits an excellent performance in the incomplete-data problem.
However, there seems to be no apparent hidden variable or incomplete-data in the parameter estimation of the Gaussian plume model because the release rate and four dispersion coefficients are all included in the parameters
. In order to apply the EM algorithm to this parameter estimation problem, the problem is adjusted to an incomplete-data one. The four dispersion coefficients and the release rate at time step t are regarded as the hidden variables
and parameter
, respectively. Therefore, four dispersion coefficients and the release rate are estimated in the E-step and M-step, respectively. In the E-step, the hidden variables are estimated by calculating the posterior probability density function
, which can be approximated by particle filter with observations
. In the M-step, the MLE of the release rate is calculated by maximizing the likelihood function through Particle Swarm Optimization (PSO). The method of particle filter combining the EM algorithm can be expressed as follows. At time step
, the MLE of the release rate
depends on the hidden variables
,
. The likelihood of
and
is:
Then,
and
are estimated in the two steps, respectively. In the E-step, the posterior probability (expectation) of
is calculated using particle filter with the assumption that the
is known:
where
is the number of particles which represent the system states
. The
is the weight of the
particle, and
is the Dirac delta function. The observations are assimilated into the dispersion model by the particle filter in the E-step. Then, in the M-step, based on the estimation of
in the E-step, the MLE of
is computed by maximizing the likelihood using PSO:
The E- and M-steps are alternated repeatedly until convergence, which is determined by a stopping rule:
Using the method of particle filter combining the EM algorithm, both of the hidden variables and parameter are iteratively estimated in each time step.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}