


A Deep Learning Method for Improving Community Multiscale Air Quality Forecast: Bias Correction, Event Detection, and Temporal Pattern Alignment

 ,
, 
 ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Meteorology—Air Quality Data
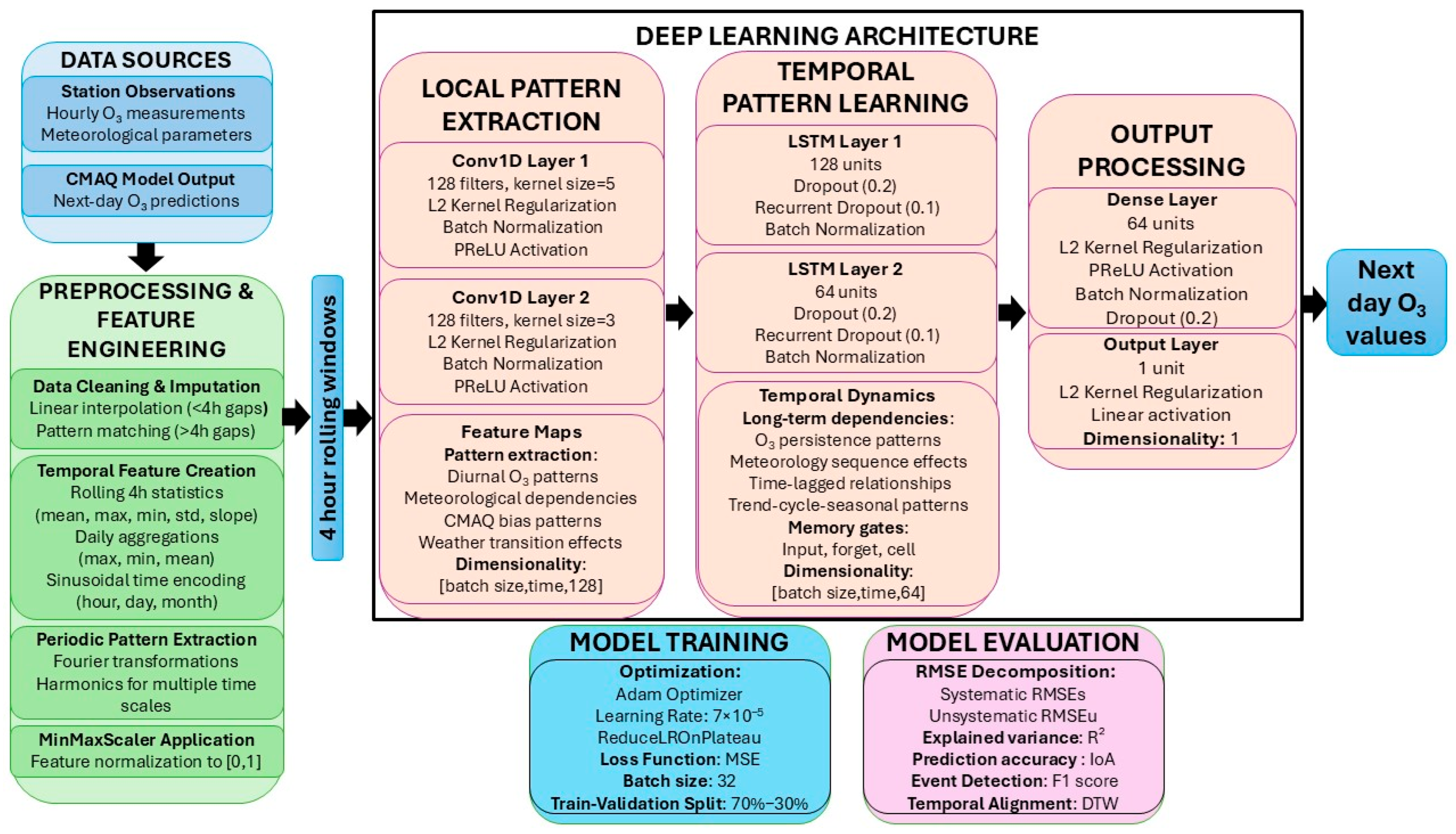
2.2. Data Preprocessing
2.2.1. Missing Data Handling
2.2.2. Feature Engineering
- –
- Fourier transformations: Fourier features were introduced to capture periodic fluctuations in the data over different temporal scales (daily, weekly, monthly, and yearly) using sine and cosine components for multiple harmonics of these periods to recognize recurring patterns;
- –
- Trigonometric time encoding: Hour, day, and month values were sinusoidally transformed to preserve temporal cyclicity;
- –
- Statistical aggregates: Daily max, min, mean of meteorological and air quality variables, such as temperature, wind speed, CMAQ O3 predictions, and past station measurements, to provide insights into broader trends;
- –
- Rolling window features: 4 h moving windows computed local means, extrema, standard deviation, and slope of stations’ measurements to detect sudden changes and emerging trends;
- –
- Sliding window statistics: The sliding window technique used in this DNN model is a crucial feature engineering method for handling sequential data, such as time series forecasting. By transforming the original dataset into overlapping sequences of fixed-length windows, the model can learn patterns and dependencies over past observations to make future predictions. Specifically, for each sample in the dataset, the input features (X) are structured into windows of size 4, capturing recent trends. This approach helps the model develop a temporal understanding of the data, improving its ability to generalize and make accurate predictions. By applying this technique to both the training and testing sets, the model ensures consistency in feature representation and maintains temporal structure, which is essential for forecasting tasks.
2.2.3. Normalization and Data Splitting
2.3. DNN Model Overview
- –
- Two 1D Convolutional (Conv1D) layers, each followed by batch normalization and Parametric Rectified Linear Unit (PReLU) activations, to extract localized temporal-spatial features from the multivariate input series;
- –
- Two LSTM layers, stacked sequentially to model long-range temporal dependencies. These are configured to return sequences to preserve timestep continuity and are regularized using dropout and recurrent dropout to mitigate overfitting;
- –
- A fully connected (dense) layer with L2 regularization and PReLU activation, which integrates high-level representations learned by the LSTM layers;
- –
- An output layer configured for regression, using the Mean Squared Error (MSE) as the loss function.
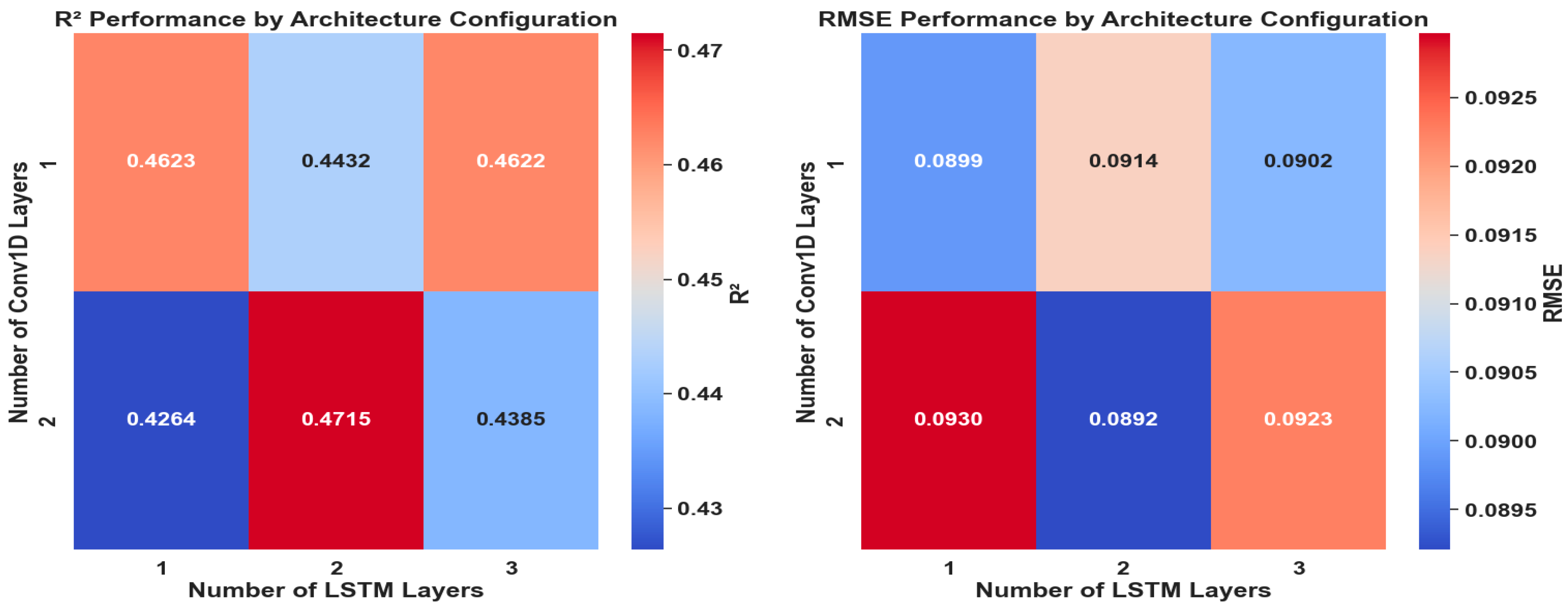
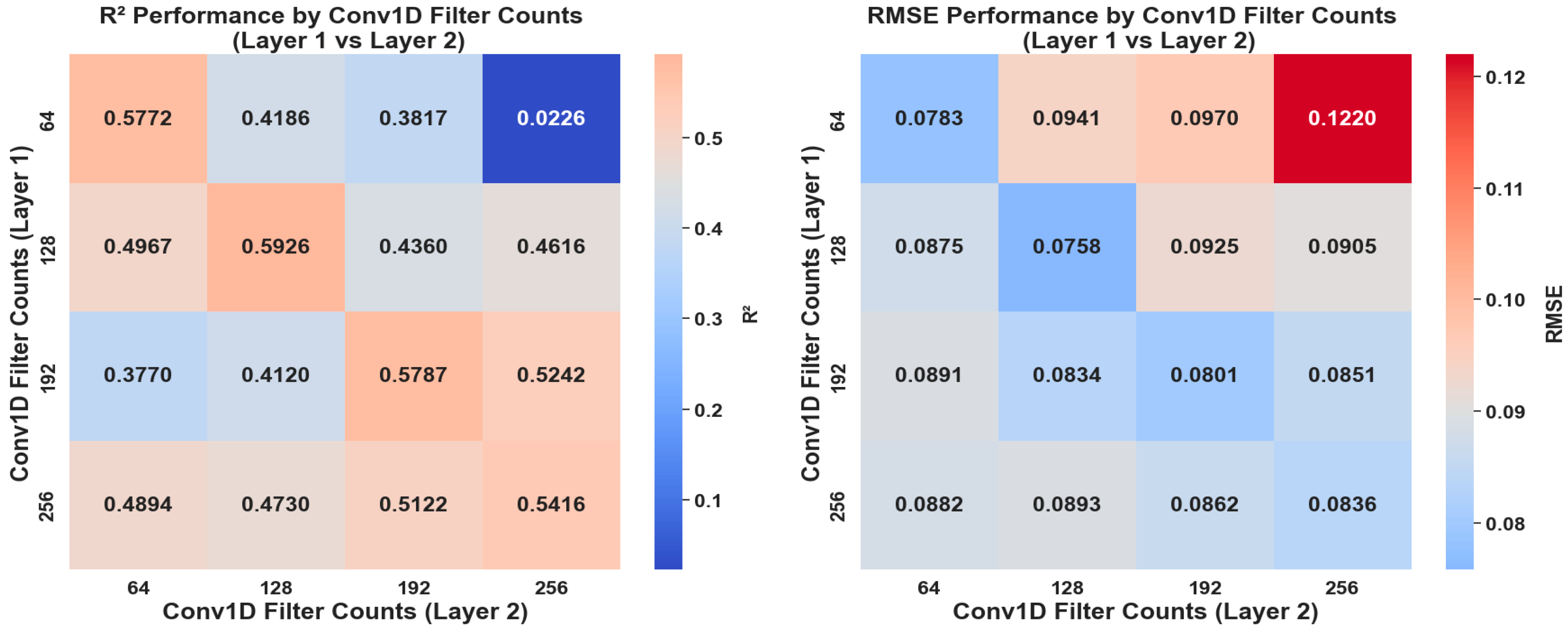
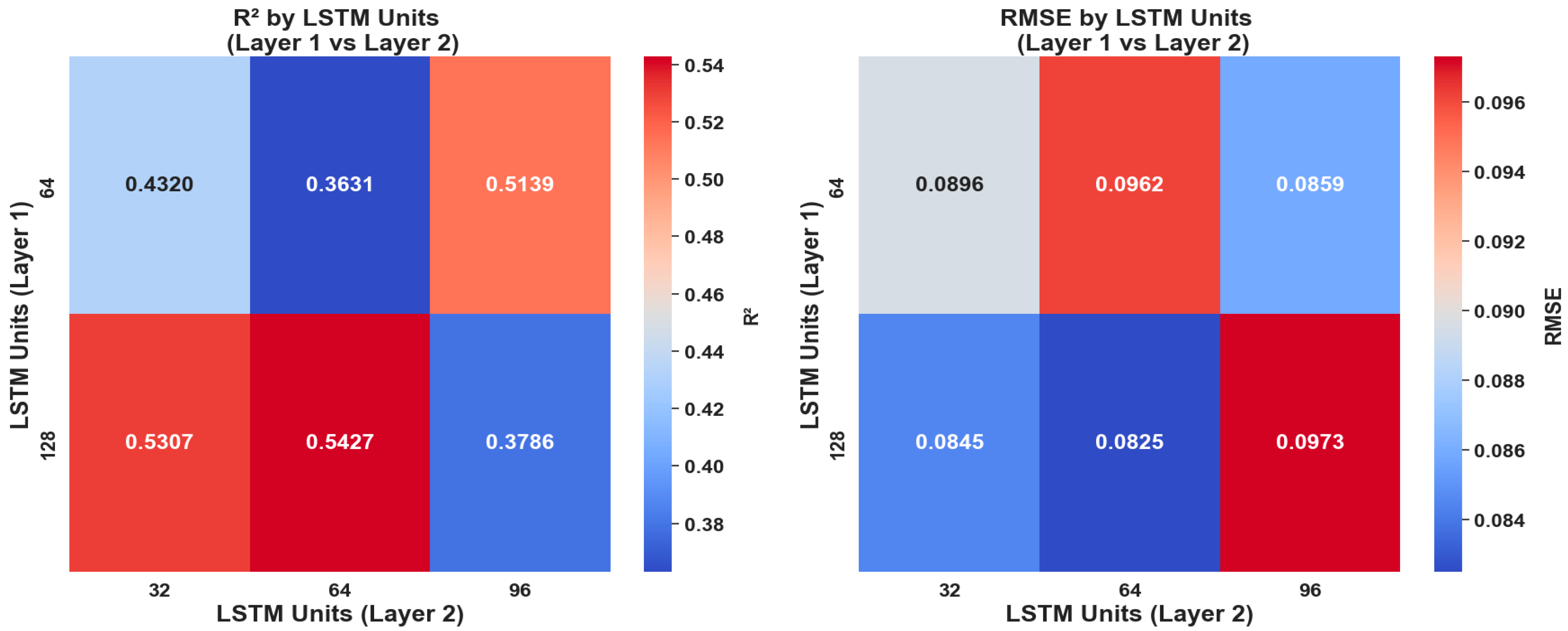
2.3.1. Model Optimization and Hyperparameter Tuning
- –
- The number of Conv1D and LSTM layers;
- –
- The number of filters per Conv1D layer;
- –
- The number of LSTM units per layer.
- –
- 1–2 Conv1D layers for spatial pattern extraction;
- –
- 1–3 LSTM layers for capturing temporal dependencies;
- –
- Symmetric and asymmetric filter arrangements in the Conv1D layers (e.g., 64–64, 128–128);
- –
- Progressive reduction in LSTM units across layers to reflect hierarchical feature refinement.
2.3.2. Model Compilation and Training Strategy
2.4. Performance Metrics
3. Results and Discussion
3.1. Sensitivity Analysis of Model Architecture
3.2. Sensitivity Analysis of Loss Functions
3.3. Final Neural Network Architecture
- –
- Two Conv1D layers (128 filters each, PReLU activation, batch normalization, dropout rate = 0.2);
- –
- Two LSTM layers (128 and 64 units, both returning sequences, with batch normalization and recurrent dropout);
- –
- One dense layer (64 neurons, L2 regularization, PReLU, batch normalization, and dropout);
- –
- Output layer with MSE loss function.
3.4. Alternative Data Splits and Robustness Check
3.5. Performance Metrics Results
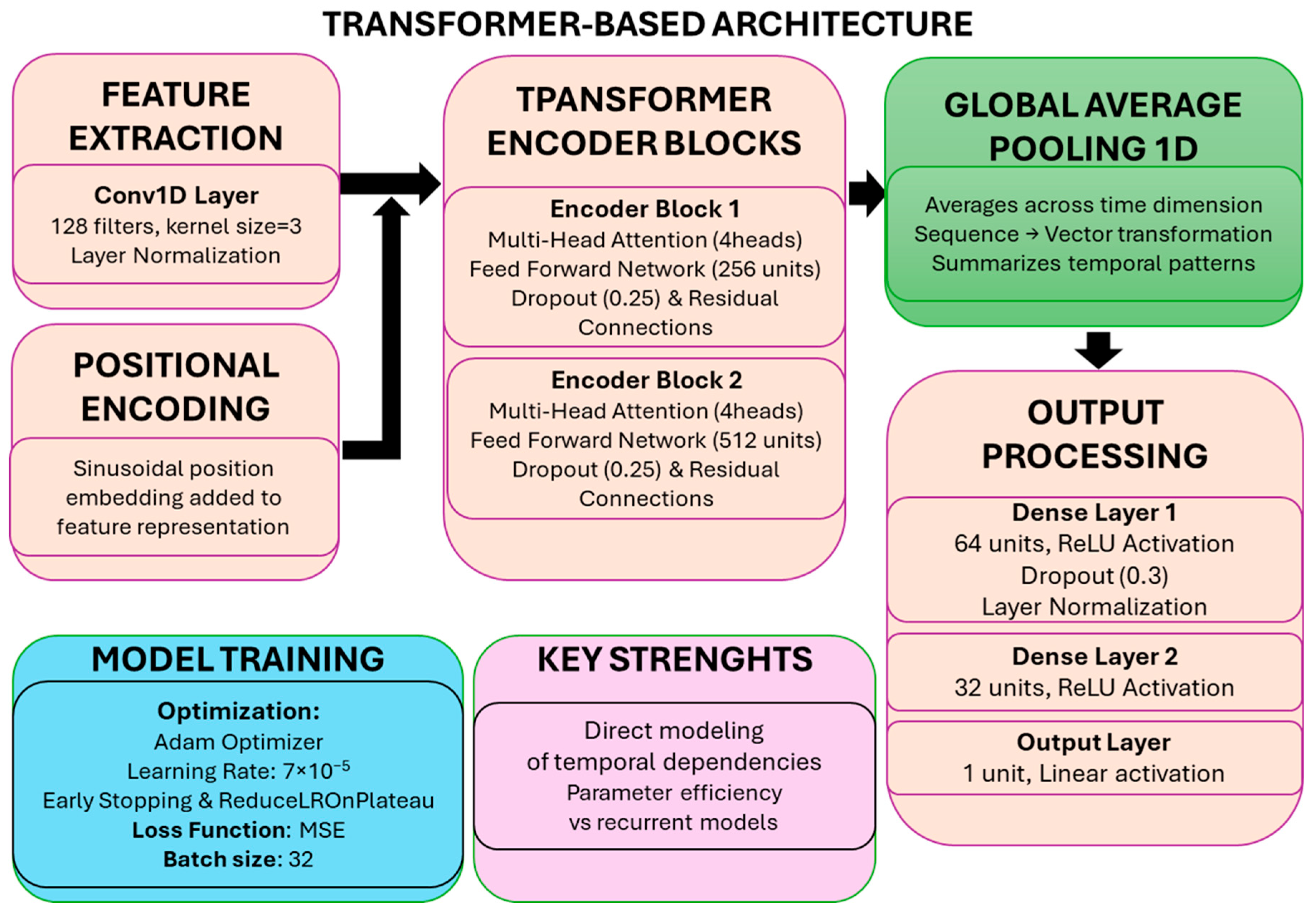
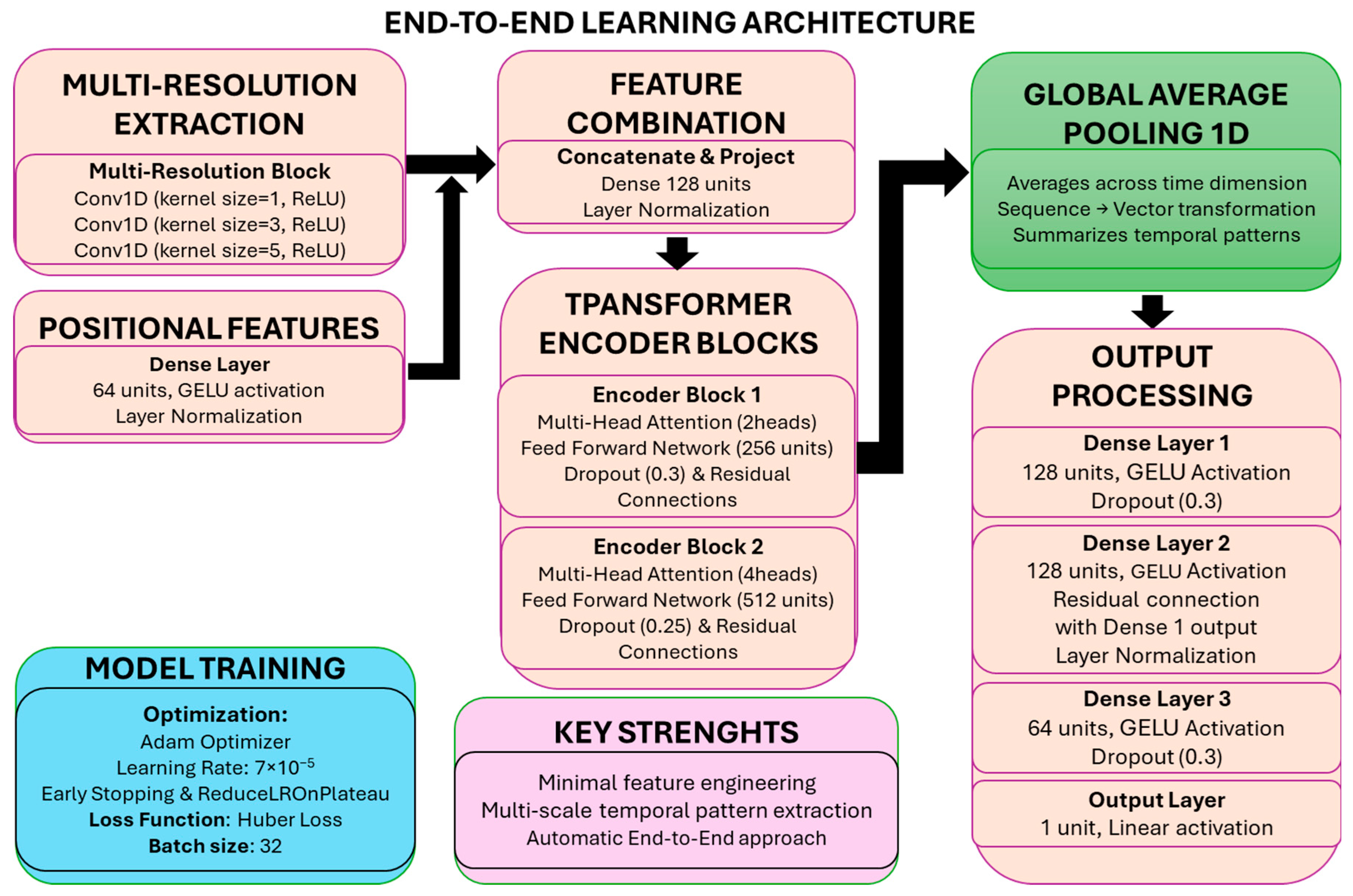
3.6. Attention-Based Enhancements and Model Intercomparison
- The ability to identify and prioritize the most relevant time steps for prediction;
- Improved handling of long-range dependencies in temporal data;
- Enhanced interpretability by providing insight into which inputs most influence the prediction.
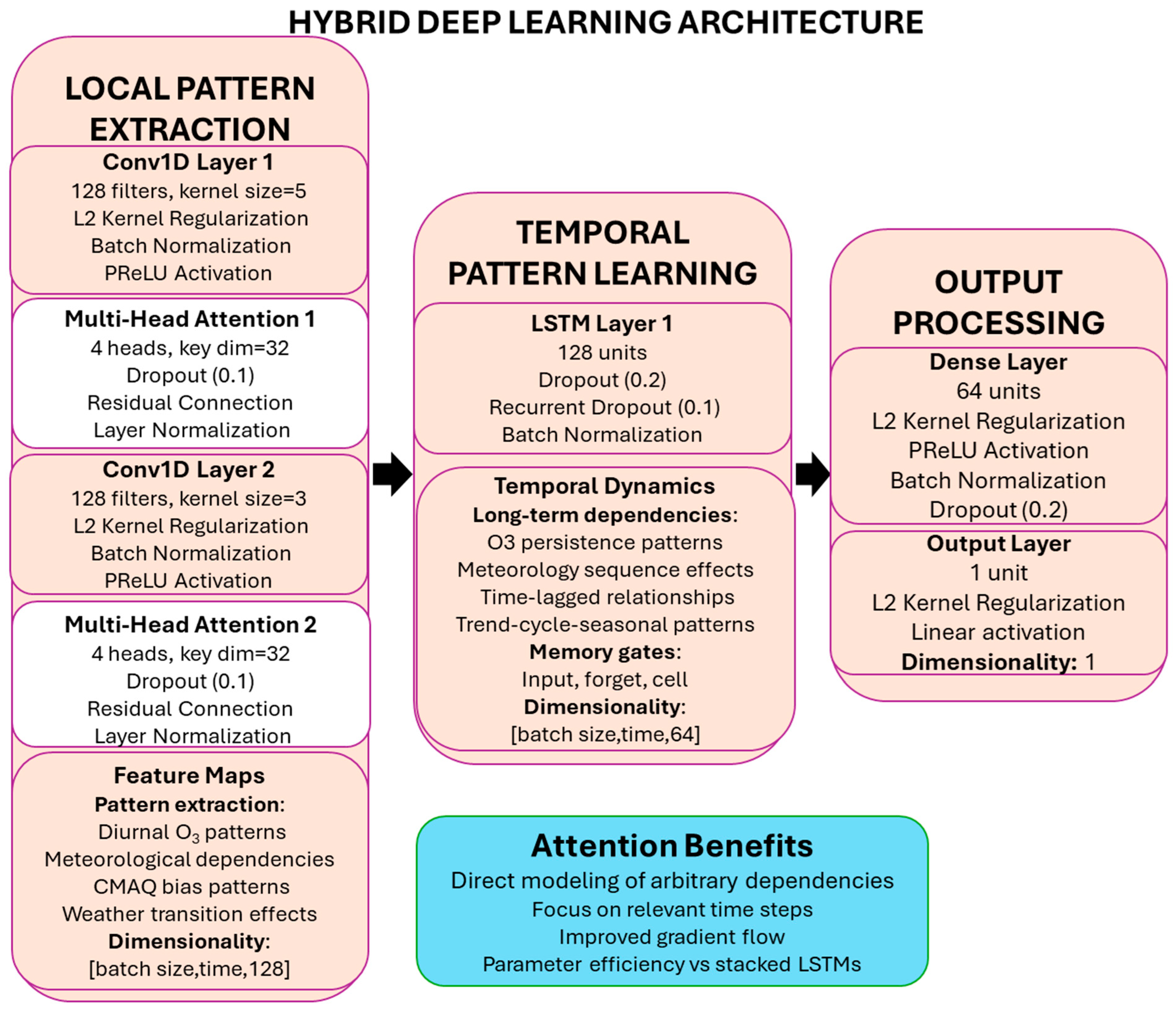
3.6.1. Hybrid CNN-LSTM with Attention Enhancement
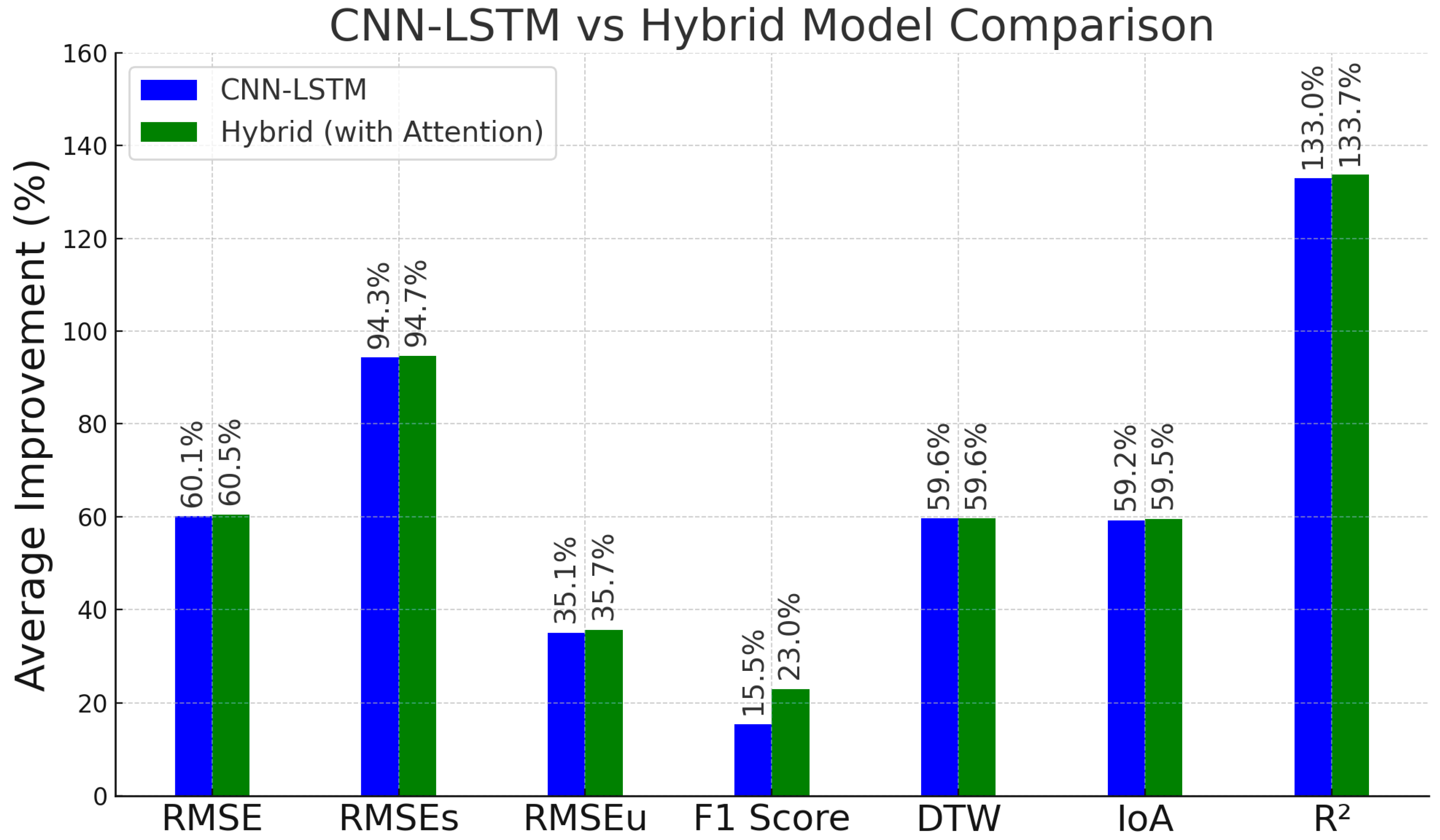
3.6.2. Comparison of Deep Learning Approaches for Air Quality Forecasting
4. Conclusions
- RMSE Decomposition: This study introduced the decomposition of RMSE into its systematic (RMSEs) and unsystematic (RMSEu) components to distinguish model bias from random variability;
- Error Reduction: RMSE was reduced by 34.11% to 71.63% across all monitoring stations;
- Systematic Bias Correction: RMSEs were reduced by up to 99.26%, effectively addressing persistent biases in CMAQ outputs;
- Variability Capture: RMSEu was reduced by up to 47.54%, improving model performance under fluctuating environmental conditions;
- Peak Detection: The F1 score showed significant improvement in peak pollution event detection, with gains of up to 37%, enhancing early warning capabilities for high pollution episodes;
- Temporal Alignment: Dynamic Time Warping (DTW) distance was reduced by up to 72.77%, indicating better alignment with observed temporal patterns;
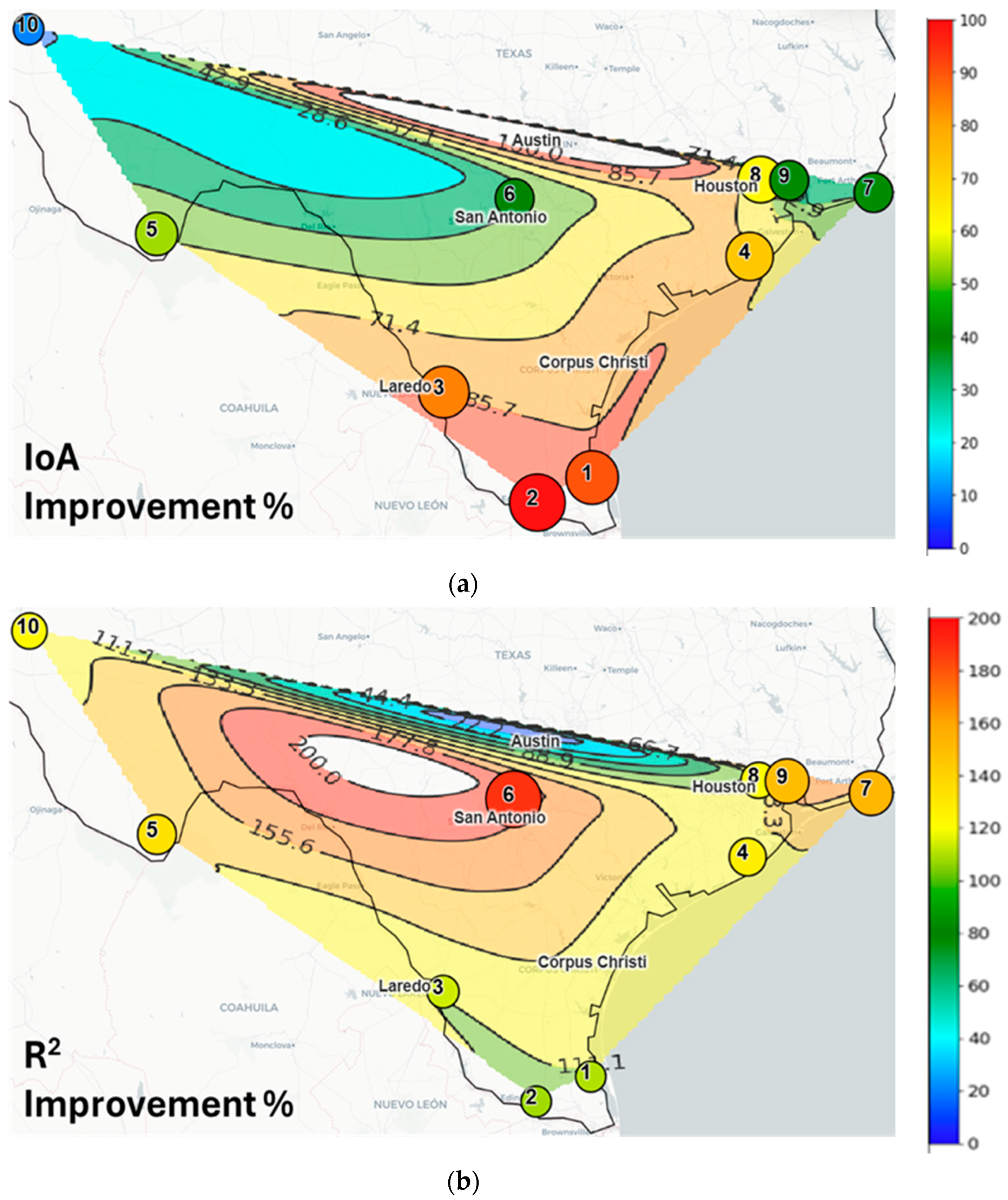
- Model Agreement: The Index of Agreement (IoA) improved by up to 90.09%, confirming better overall predictive accuracy;
- Explained Variance: The Coefficient of Determination (R2) increased by up to 188.80%, demonstrating a superior ability to capture variability in air quality data;
- Hybrid Architecture Efficiency: The addition of multi-head self-attention mechanisms allowed the removal of one LSTM layer, maintaining or improving performance while reducing training time and increasing parallelizability.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AMSE | Asymmetric Mean Squared Error |
| CMAQ | Community Multiscale Air Quality |
| CNNs | Convolutional Neural Networks |
| Conv1D | 1D Convolutional |
| CTMs | Chemical Transport Models |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DTW | Dynamic Time Warping |
| GNN-LSTM | Graph Neural Networks-Long Short-Term Memory |
| GNNs | Graph Neural Networks |
| IoA | Index of Agreement |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NGR | Nonhomogeneous Gaussian Regression |
| PINNs | Physics-Informed Deep Neural Networks |
| PReLU | Parametric Rectified Linear Unit |
| RMSE | Root Mean Square Error |
| RMSEs | Systematic Root Mean Square Error |
| RMSEu | Unsystematic Root Mean Square Error |
References
- Appel, K.W.; Bash, J.O.; Fahey, K.M.; Foley, K.M.; Gilliam, R.C.; Hogrefe, C.; Hutzell, W.T.; Kang, D.; Mathur, R.; Murphy, B.N.; et al. The Community Multiscale Air Quality (CMAQ) Model Versions 5.3 and 5.3.1: System Updates and Evaluation. Geosci. Model Dev. 2021, 14, 2867–2897. [Google Scholar] [CrossRef] [PubMed]
- Byun, D.; Schere, K.L. Review of the Governing Equations, Computational Algorithms, and Other Components of the Models-3 Community Multiscale Air Quality (CMAQ) Modeling System. Appl. Mech. Rev. 2006, 59, 51–77. [Google Scholar] [CrossRef]
- Chatani, S.; Morikawa, T.; Nakatsuka, S.; Matsunaga, S.; Minoura, H. Development of a Framework for a High-Resolution, Three-Dimensional Regional Air Quality Simulation and Its Application to Predicting Future Air Quality over Japan. Atmos. Environ. 2011, 45, 1383–1393. [Google Scholar] [CrossRef]
- Kitayama, K.; Morino, Y.; Yamaji, K.; Chatani, S. Uncertainties in O3 Concentrations Simulated by CMAQ over Japan Using Four Chemical Mechanisms. Atmos. Environ. 2019, 198, 448–462. [Google Scholar] [CrossRef]
- Morino, Y.; Chatani, S.; Hayami, H.; Sasaki, K.; Mori, Y.; Morikawa, T.; Ohara, T.; Hasegawa, S.; Kobayashi, S. Evaluation of Ensemble Approach for O3 and PM2.5 Simulation. Asian J. Atmos. Environ. 2010, 4, 150–156. [Google Scholar] [CrossRef]
- Trieu, T.T.N.; Goto, D.; Yashiro, H.; Murata, R.; Sudo, K.; Tomita, H.; Satoh, M.; Nakajima, T. Evaluation of Summertime Surface Ozone in Kanto Area of Japan Using a Semi-Regional Model and Observation. Atmos. Environ. 2017, 153, 163–181. [Google Scholar] [CrossRef]
- Bocquet, M.; Elbern, H.; Eskes, H.; Hirtl, M.; Žabkar, R.; Carmichael, G.R.; Flemming, J.; Inness, A.; Pagowski, M.; Pérez Camaño, J.L.; et al. Data Assimilation in Atmospheric Chemistry Models: Current Status and Future Prospects for Coupled Chemistry Meteorology Models. Atmos. Chem. Phys. 2015, 15, 5325–5358. [Google Scholar] [CrossRef]
- Huang, C.; Niu, T.; Wu, H.; Qu, Y.; Wang, T.; Li, M.; Li, R.; Liu, H. A Data Assimilation Method Combined with Machine Learning and Its Application to Anthropogenic Emission Adjustment in CMAQ. Remote Sens. 2023, 15, 1711. [Google Scholar] [CrossRef]
- Jung, J.; Souri, A.H.; Wong, D.C.; Lee, S.; Jeon, W.; Kim, J.; Choi, Y. The Impact of the Direct Effect of Aerosols on Meteorology and Air Quality Using Aerosol Optical Depth Assimilation During the KORUS-AQ Campaign. J. Geophys. Res. Atmos. 2019, 124, 8303–8319. [Google Scholar] [CrossRef]
- Bessagnet, B.; Menut, L.; Couvidat, F.; Meleux, F.; Siour, G.; Mailler, S. What Can We Expect from Data Assimilation for Air Quality Forecast? Part II: Analysis with a Semi-Real Case. J. Atmos. Ocean. Technol. 2019, 36, 1433–1448. [Google Scholar] [CrossRef]
- Menut, L.; Bessagnet, B. What Can We Expect from Data Assimilation for Air Quality Forecast? Part I: Quantification with Academic Test Cases. J. Atmos. Ocean. Technol. 2019, 36, 269–279. [Google Scholar] [CrossRef]
- Rao, S.T.; Luo, H.; Astitha, M.; Hogrefe, C.; Garcia, V.; Mathur, R. On the Limit to the Accuracy of Regional-Scale Air Quality Models. Atmos. Chem. Phys. 2020, 20, 1627–1639. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.; Souri, A.H. Chemical Condition and Surface Ozone in Large Cities of Texas during the Last Decade: Observational Evidence from OMI, CAMS, and Model Analysis. Remote Sens. Environ. 2015, 168, 90–101. [Google Scholar] [CrossRef]
- Li, X.; Choi, Y.; Czader, B.; Roy, A.; Kim, H.; Lefer, B.; Pan, S. The Impact of Observation Nudging on Simulated Meteorology and Ozone Concentrations during DISCOVER-AQ 2013 Texas Campaign. Atmos. Chem. Phys. 2016, 16, 3127–3144. [Google Scholar] [CrossRef]
- Martin, R.V.; Fiore, A.M.; Van Donkelaar, A. Space-Based Diagnosis of Surface Ozone Sensitivity to Anthropogenic Emissions. Geophys. Res. Lett. 2004, 31, L06120. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive Neural Network Model for Analysis and Forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Díaz-Robles, L.A.; Ortega, J.C.; Fu, J.S.; Reed, G.D.; Chow, J.C.; Watson, J.G.; Moncada-Herrera, J.A. A Hybrid ARIMA and Artificial Neural Networks Model to Forecast Particulate Matter in Urban Areas: The Case of Temuco, Chile. Atmos. Environ. 2008, 42, 8331–8340. [Google Scholar] [CrossRef]
- Eslami, E.; Choi, Y.; Lops, Y.; Sayeed, A. A Real-Time Hourly Ozone Prediction System Using Deep Convolutional Neural Network. Neural Comput. Appl. 2020, 32, 8783–8797. [Google Scholar] [CrossRef]
- Eslami, E.; Salman, A.K.; Choi, Y.; Sayeed, A.; Lops, Y. A Data Ensemble Approach for Real-Time Air Quality Forecasting Using Extremely Randomized Trees and Deep Neural Networks. Neural Comput. Appl. 2020, 32, 7563–7579. [Google Scholar] [CrossRef]
- Lops, Y.; Choi, Y.; Eslami, E.; Sayeed, A. Real-Time 7-Day Forecast of Pollen Counts Using a Deep Convolutional Neural Network. Neural Comput. Appl. 2020, 32, 11827–11836. [Google Scholar] [CrossRef]
- Sayeed, A. Integrating Deep Neural Network with Numerical Models to Have Better Weather and Air Quality Forecast Both Spatially and Temporally. Ph.D. Thesis, Department of Earth and Atmospheric Sciences, College of Natural Sciences and Mathematics, University of Houston, Houston, TX, USA, 2021. [Google Scholar]
- Yuan, W.; Wang, K.; Bo, X.; Tang, L.; Wu, J. A Novel Multi-Factor & Multi-Scale Method for PM2.5 Concentration Forecasting. Environ. Pollut. 2019, 255, 113187. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Du, P.; Hao, Y.; Ma, X.; Niu, T.; Yang, W. An Innovative Hybrid Model Based on Outlier Detection and Correction Algorithm and Heuristic Intelligent Optimization Algorithm for Daily Air Quality Index Forecasting. J. Environ. Manag. 2020, 255, 109855. [Google Scholar] [CrossRef]
- Li, L.; Girguis, M.; Lurmann, F.; Wu, J.; Urman, R.; Rappaport, E.; Ritz, B.; Franklin, M.; Breton, C.; Gilliland, F.; et al. Cluster-Based Bagging of Constrained Mixed-Effects Models for High Spatiotemporal Resolution Nitrogen Oxides Prediction over Large Regions. Environ. Int. 2019, 128, 310–323. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yang, W.; Wang, J. Air Quality Early-Warning System for Cities in China. Atmos. Environ. 2017, 148, 239–257. [Google Scholar] [CrossRef]
- Kim, H.S.; Han, K.M.; Yu, J.; Kim, J.; Kim, K.; Kim, H. Development of a CNN+LSTM Hybrid Neural Network for Daily PM2.5 Prediction. Atmosphere 2022, 13, 2124. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A Novel Spatiotemporal Convolutional Long Short-Term Neural Network for Air Pollution Prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Yang, M.; Fan, H.; Zhao, K. PM2.5 Prediction with a Novel Multi-Step-Ahead Forecasting Model Based on Dynamic Wind Field Distance. Int. J. Environ. Res. Public Health 2019, 16, 4482. [Google Scholar] [CrossRef]
- Borrego, C.; Monteiro, A.; Pay, M.T.; Ribeiro, I.; Miranda, A.I.; Basart, S.; Baldasano, J.M. How Bias-Correction Can Improve Air Quality Forecasts over Portugal. Atmos. Environ. 2011, 45, 6629–6641. [Google Scholar] [CrossRef]
- June, N.; Vaughan, J.; Lee, Y.; Lamb, B.K. Operational Bias Correction for PM2.5 Using the AIRPACT Air Quality Forecast System in the Pacific Northwest. J. Air Waste Manag. Assoc. 2021, 71, 515–527. [Google Scholar] [CrossRef]
- Huang, J.; McQueen, J.; Wilczak, J.; Djalalova, I.; Stajner, I.; Shafran, P.; Allured, D.; Lee, P.; Pan, L.; Tong, D.; et al. Improving NOAA NAQFC PM2.5 Predictions with a Bias Correction Approach. Weather. Forecast. 2017, 32, 407–421. [Google Scholar] [CrossRef]
- Fei, H.; Wu, X.; Luo, C. A Model-Driven and Data-Driven Fusion Framework for Accurate Air Quality Prediction. arXiv 2019, arXiv:1912.07367. [Google Scholar] [CrossRef]
- Sayeed, A.; Lops, Y.; Choi, Y.; Jung, J.; Salman, A.K. Bias Correcting and Extending the PM Forecast by CMAQ up to 7 Days Using Deep Convolutional Neural Networks. Atmos. Environ. 2021, 253, 118376. [Google Scholar] [CrossRef]
- Sayeed, A.; Choi, Y.; Eslami, E.; Jung, J.; Lops, Y.; Salman, A.K.; Lee, J.-B.; Park, H.-J.; Choi, M.-H. A Novel CMAQ-CNN Hybrid Model to Forecast Hourly Surface-Ozone Concentrations 14 Days in Advance. Sci. Rep. 2021, 11, 10891. [Google Scholar] [CrossRef]
- Koo, Y.-S.; Choi, Y.; Ho, C. Air Quality Forecasting Using Big Data and Machine Learning Algorithms. Asia-Pac. J. Atmos. Sci. 2023, 59, 529–530. [Google Scholar] [CrossRef]
- Bessagnet, B.; Beauchamp, M.; Menut, L.; Fablet, R.; Pisoni, E.; Thunis, P. Deep Learning Techniques Applied to Super-Resolution Chemistry Transport Modeling for Operational Uses. Environ. Res. Commun. 2021, 3, 085001. [Google Scholar] [CrossRef]
- Fang, L.; Jin, J.; Segers, A.; Liao, H.; Li, K.; Xu, B.; Han, W.; Pang, M.; Lin, H.X. A Gridded Air Quality Forecast through Fusing Site-Available Machine Learning Predictions from RFSML v1.0 and Chemical Transport Model Results from GEOS-Chem V13.1.0 Using the Ensemble Kalman Filter. Geosci. Model Dev. 2023, 16, 4867–4882. [Google Scholar] [CrossRef]
- Li, L.; Wang, J.; Franklin, M.; Yin, Q.; Wu, J.; Camps-Valls, G.; Zhu, Z.; Wang, C.; Ge, Y.; Reichstein, M. Improving Air Quality Assessment Using Physics-Inspired Deep Graph Learning. npj Clim. Atmos. Sci. 2023, 6, 152. [Google Scholar] [CrossRef]
- Sharma, H.; Shrivastava, M.; Singh, B. Physics Informed Deep Neural Network Embedded in a Chemical Transport Model for the Amazon Rainforest. npj Clim. Atmos. Sci. 2023, 6, 28. [Google Scholar] [CrossRef]
- Huang, L.; Liu, S.; Yang, Z.; Xing, J.; Zhang, J.; Bian, J.; Li, S.; Sahu, S.K.; Wang, S.; Liu, T.-Y. Exploring Deep Learning for Air Pollutant Emission Estimation. Geosci. Model Dev. 2021, 14, 4641–4654. [Google Scholar] [CrossRef]
- Vlasenko, A.; Matthias, V.; Callies, U. Simulation of Chemical Transport Model Estimates by Means of a Neural Network Using Meteorological Data. Atmos. Environ. 2021, 254, 118236. [Google Scholar] [CrossRef]
- Kow, P.-Y.; Chang, L.-C.; Lin, C.-Y.; Chou, C.C.-K.; Chang, F.-J. Deep Neural Networks for Spatiotemporal PM2.5 Forecasts Based on Atmospheric Chemical Transport Model Output and Monitoring Data. Environ. Pollut. 2022, 306, 119348. [Google Scholar] [CrossRef] [PubMed]
- Sayeed, A.; Eslami, E.; Lops, Y.; Choi, Y. CMAQ-CNN: A New-Generation of Post-Processing Techniques for Chemical Transport Models Using Deep Neural Networks. Atmos. Environ. 2022, 273, 118961. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B.; Dudhia, J.; Gill, D.O.; Barker, D.M.; Duda, M.G.; Huang, X.-Y.; Wang, W.; Powers, J.G. A Description of the Advanced Research WRF Version 4; National Center for Atmospheric Research (NCAR): Boulder, CO, USA, 2019. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 31 July–1 August 1994; pp. 359–370. [Google Scholar]
- Vaughan, N.; Gabrys, B. Comparing and Combining Time Series Trajectories Using Dynamic Time Warping. Procedia Comput. Sci. 2016, 96, 465–474. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 6000–6010, ISBN 978-1-5108-6096-4. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Lat, Lon | Mean O3 (ppb) | Max O3 (ppb) | Std O3 (ppb) | Mean T (°C) | Max T (°C) | Std T (°C) | Mean Wind Speed (m/s) | Std Wind Speed (m/s) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 26.54, −97.53 | 24.3 | 68.0 | 12.2 | 23.0 | 37.2 | 6.7 | 3.3 | 1.7 |
| 2 | 26.26, −98.24 | 23.0 | 69.0 | 11.3 | 23.0 | 40.6 | 7.4 | 3.1 | 1.4 |
| 3 | 27.51, −99.46 | 23.0 | 93.0 | 13.2 | 23.1 | 42.0 | 8.2 | 3.1 | 1.6 |
| 4 | 29.02, −95,47 | 23.9 | 91.0 | 14.5 | 20.3 | 37.2 | 7.6 | 2.4 | 1.5 |
| 5 | 29.28, −103.20 | 40.8 | 71.0 | 9.9 | 20.2 | 39.4 | 8.6 | 3.4 | 1.8 |
| 6 | 29.67, −98.54 | 29.1 | 95.0 | 16.9 | 18.8 | 39.0 | 9.2 | 2.4 | 1.4 |
| 7 | 29.74, −93.85 | 21.3 | 94.5 | 15.6 | 20.0 | 39.3 | 8.1 | 2.0 | 1.4 |
| 8 | 29.88, −95.33 | 25.1 | 79.0 | 12.7 | 20.2 | 36.7 | 7.8 | 3.2 | 1.7 |
| 9 | 29.87, −94.96 | 23.0 | 101.0 | 15.1 | 19.9 | 39.4 | 8.6 | 2.2 | 1.5 |
| 10 | 31.52, −104.88 | 32.3 | 97.0 | 15.0 | 17.5 | 39.5 | 10.1 | 3.5 | 1.8 |
| Station | RMSE | RMSES | RMSEU | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | CMAQ | Improvement | Model | CMAQ | Improvement | Model | CMAQ | Improvement | |
| 1 | 7.75 | 22.87 | 66.11% | 0.548 | 19.42 | 97.18% | 7.73 | 12.09 | 36.06% |
| 2 | 7.15 | 25.20 | 71.63% | 0.80 | 21.25 | 96.23% | 7.10 | 13.54 | 47.54% |
| 3 | 7.97 | 26.67 | 70.11% | 0.68 | 22.90 | 97.02% | 7.94 | 13.66 | 41.88% |
| 4 | 8.67 | 23.93 | 63.91% | 0.42 | 19.67 | 97.88% | 8.63 | 13.63 | 36.70% |
| 5 | 6.38 | 14.41 | 55.72% | 0.374 | 10.22 | 96.34% | 6.37 | 10.16 | 37.29% |
| 6 | 9.75 | 21.61 | 54.86% | 1.17 | 16.90 | 93.07% | 9.68 | 13.47 | 28.09% |
| 7 | 8.75 | 21.95 | 60.13% | 2.23 | 17.92 | 87.54% | 8.46 | 12.69 | 33.29% |
| 8 | 8.05 | 22.64 | 64.46% | 0.26 | 18.83 | 98.64% | 8.04 | 12.58 | 36.07% |
| 9 | 8.55 | 21.15 | 59.55% | 0.13 | 16.99 | 99.26% | 8.55 | 12.59 | 32.06% |
| 10 | 8.43 | 12.79 | 34.11% | 1.45 | 7.08 | 79.56% | 8.30 | 10.66 | 22.07% |
| Station | F1 Score | DTW | IoA | R2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | CMAQ | Improvement (%) | Model | CMAQ | Improvement (%) | Model | CMAQ | Improvement (%) | Model | CMAQ | Improvement (%) | |
| 1 | 0.61 | 0.45 | 35.30 | 2.98 | 8.15 | 63.47 | 0.81 | 0.43 | 90.09 | 0.42 | −4.09 | 110.16 |
| 2 | 0.59 | 0.43 | 37.38 | 2.68 | 9.84 | 72.77 | 0.84 | 0.42 | 99.76 | 0.47 | −5.61 | 108.34 |
| 3 | 0.70 | 0.60 | 16.37 | 3.31 | 10.36 | 68.05 | 0.87 | 0.47 | 84.60 | 0.56 | −3.96 | 114.05 |
| 4 | 0.51 | 0.48 | 5.91 | 3.59 | 8.82 | 59.31 | 0.88 | 0.51 | 72.68 | 0.59 | −2.14 | 127.60 |
| 5 | 0.63 | 0.56 | 14.56 | 2.13 | 5.12 | 58.34 | 0.83 | 0.54 | 54.28 | 0.51 | −1.51 | 133.62 |
| 6 | 0.80 | 0.70 | 13.60 | 4.31 | 10.40 | 58.58 | 0.91 | 0.65 | 39.31 | 0.65 | −0.70 | 188.80 |
| 7 | 0.68 | 0.67 | 0.79 | 3.69 | 9.14 | 59.59 | 0.91 | 0.66 | 38.20 | 0.65 | −1.22 | 152.84 |
| 8 | 0.65 | 0.52 | 25.82 | 3.31 | 8.24 | 59.76 | 0.86 | 0.53 | 61.64 | 0.56 | −2.51 | 122.13 |
| 9 | 0.65 | 0.63 | 2.67 | 3.52 | 9.67 | 63.60 | 0.90 | 0.64 | 41.63 | 0.63 | −1.26 | 149.94 |
| 10 | 0.80 | 0.78 | 2.34 | 3.63 | 5.38 | 32.62 | 0.92 | 0.84 | 10.04 | 0.70 | 0.32 | 122.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stergiou, I.; Traka, N.; Melas, D.; Tagaris, E.; Sotiropoulou, R.-E.P. A Deep Learning Method for Improving Community Multiscale Air Quality Forecast: Bias Correction, Event Detection, and Temporal Pattern Alignment. Atmosphere 2025, 16, 739. https://doi.org/10.3390/atmos16060739
Stergiou I, Traka N, Melas D, Tagaris E, Sotiropoulou R-EP. A Deep Learning Method for Improving Community Multiscale Air Quality Forecast: Bias Correction, Event Detection, and Temporal Pattern Alignment. Atmosphere. 2025; 16(6):739. https://doi.org/10.3390/atmos16060739
Chicago/Turabian StyleStergiou, Ioannis, Nektaria Traka, Dimitrios Melas, Efthimios Tagaris, and Rafaella-Eleni P. Sotiropoulou. 2025. "A Deep Learning Method for Improving Community Multiscale Air Quality Forecast: Bias Correction, Event Detection, and Temporal Pattern Alignment" Atmosphere 16, no. 6: 739. https://doi.org/10.3390/atmos16060739
APA StyleStergiou, I., Traka, N., Melas, D., Tagaris, E., & Sotiropoulou, R.-E. P. (2025). A Deep Learning Method for Improving Community Multiscale Air Quality Forecast: Bias Correction, Event Detection, and Temporal Pattern Alignment. Atmosphere, 16(6), 739. https://doi.org/10.3390/atmos16060739