
Homogenization of the Probability Distribution of Climatic Time Series: A Novel Algorithm


Abstract
1. Introduction
2. State of the Art of the Homogenization of Probability Distribution
2.1. Nonlinearity of Inhomogeneity Biases
2.2. Quantile Matching
- (i)
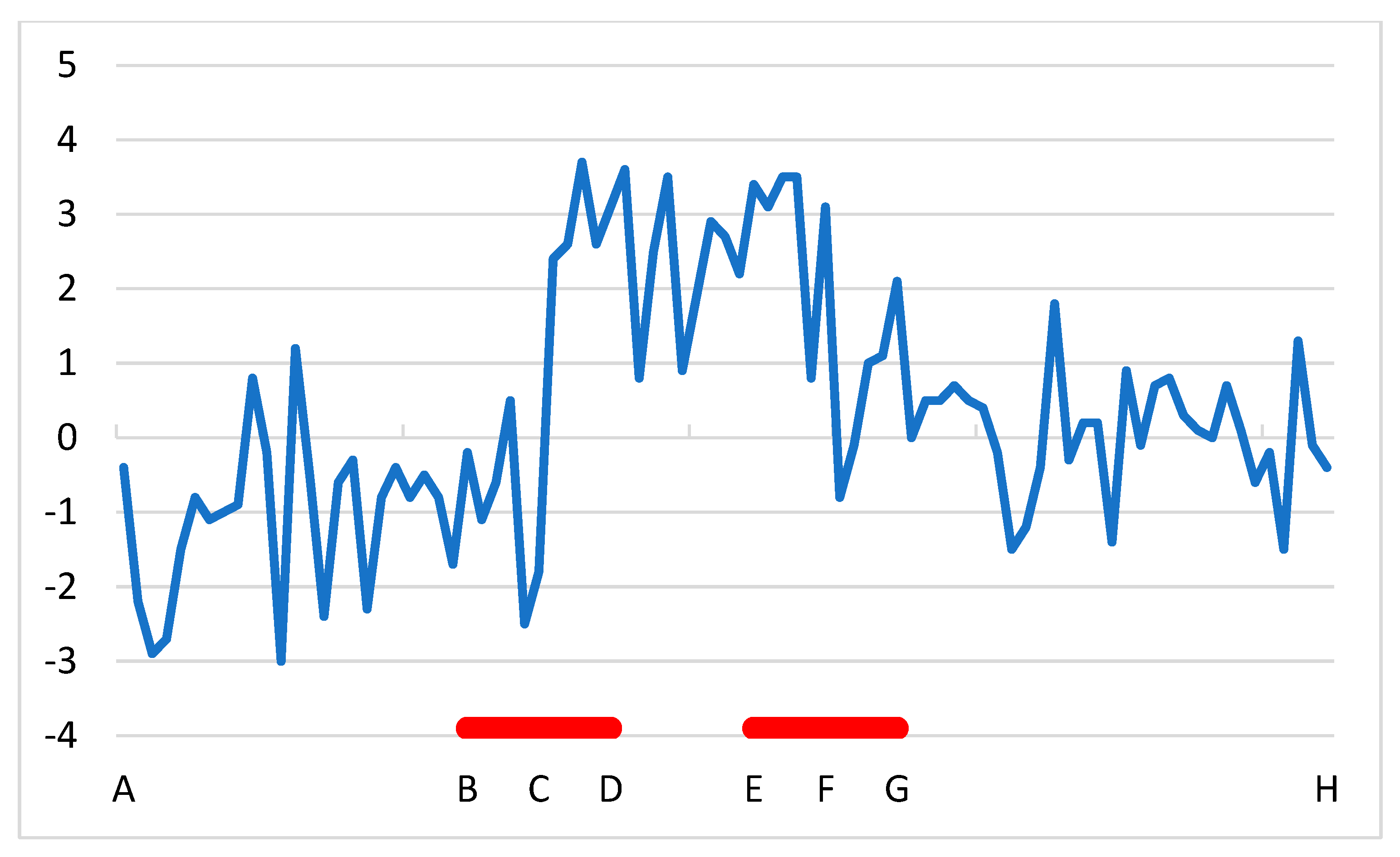
- Often only relatively short sections of the time series are used in QM (marked with red color in Figure 2, and referred to as red sections). This results in increased sampling errors. In addition, only neighbor series with no detected break in the red sections of the time series are used, which may reduce further the amount of data considered, and may increase further sampling errors.
- (ii)
- Given that only neighbor series with no break in the red sections are used in the QM procedure related to the matching detected break of the candidate series, the sets of neighbor series considered often differ for different breaks. For instance, in Figure 2, neighbor series with no detected break between B and D are used in the calculations for break C, while neighbor series with no detected break between E and G are used in the calculations for break F. However, the expected value of estimations varies according to neighbor series, and thus the change in the set of neighbor series acts as if an unconsidered break was between D and E, affecting the overall bias between A and H.
- (iii)
2.3. Climatol
2.4. MASHv4
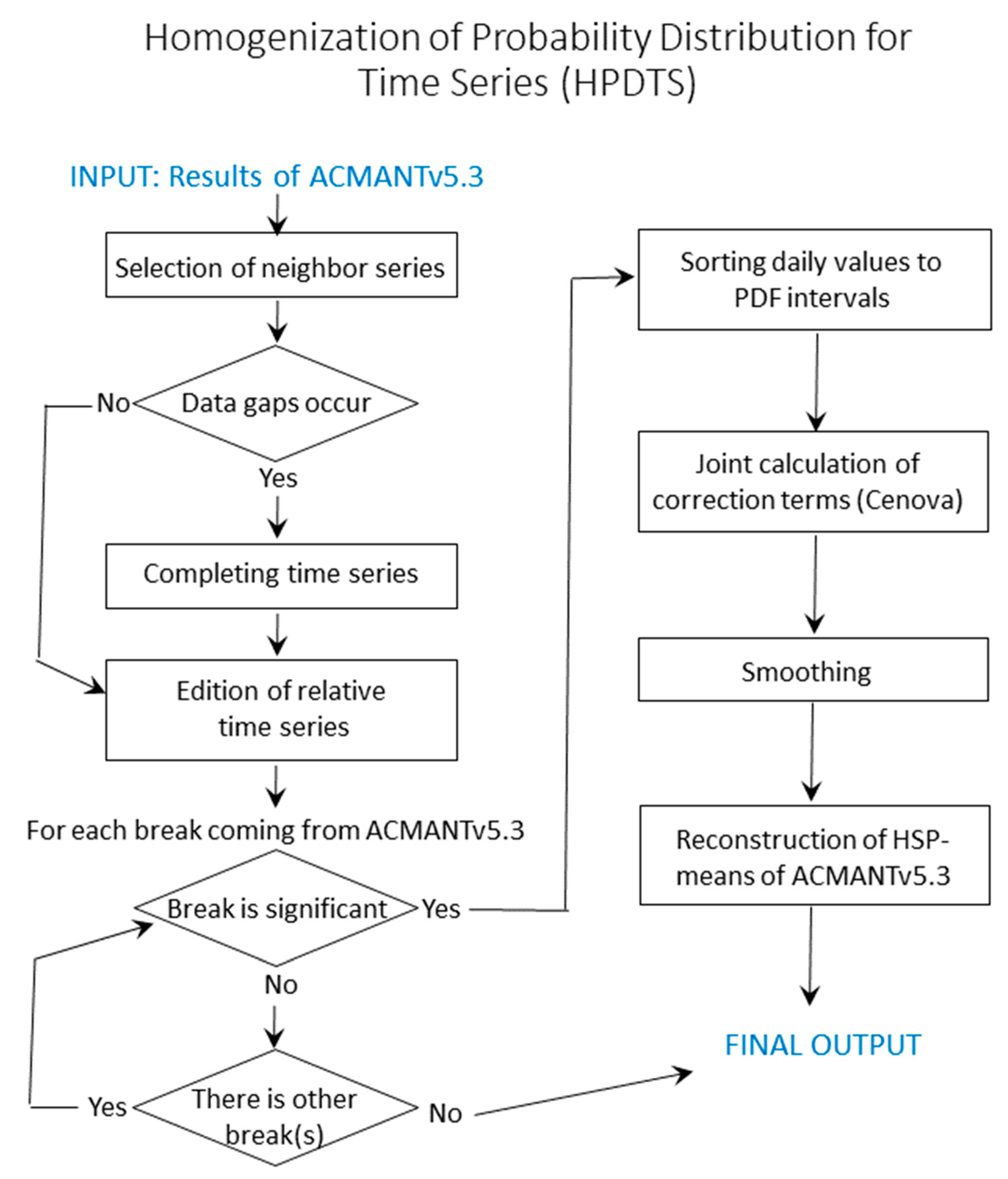
3. Homogenization of the Probability Distribution for Time Series (HPDTS)
3.1. Principles of the Development
- The input dataset of the procedure comprises the homogenized time series obtained by the ACMANTv5.3 procedure. The time series are divided into intervals similarly to QM. The way of the division is fixed for any given climate variable. During the operations, the arithmetical mean or extreme values of the observed daily values within a given PDF interval are used.
- The HPDTS procedure is applied separately to each candidate series of a studied dataset, but each candidate time series is examined together with a set of neighbor series.
- A statistical significance test is performed for each break of the candidate series detected by ACMANTv5.3, and breaks being insignificant for HPD are skipped.
- All pieces of the candidate series and neighbor series data are used in the calculations, and the combined effect of inhomogeneities are calculated by an equation system similar to Benova.
- Symmetric low pass filters and linear interpolation between adjacent quantiles are applied, while the use of any other function type is avoided.
- HPDTS does not alter HSP means, so that all HSP means calculated by ACMANTv5.3 are preserved.
- In the version presented here, seasonal changes in inhomogeneity biases are not considered either in the ACMANTv5.3 procedure (seasonality mode “flat” is selected) or during HPDTS.
3.2. Concepts and Definitions
- -
- Homogenized period: the period of the time series for which homogenization can be performed, i.e., it has sufficient amount of observed data, and the period can be compared to the data of a sufficient number of neighbor series. This term can be applied either before or after the homogenization is executed.
- -
- Relative time series: series of differences between a candidate series and its neighbor series. In HPDTS the candidate series is compared to one composite reference series.
- -
- Station effect: the summarized effect of station representativeness and inhomogeneity biases. The station representativeness is a station specific constant, while inhomogeneity biases are approached by step function.
- -
- Style of symbols: scalars are written by italics, while vectors and matrix are presented by bold capital letters.
3.3. HPDTS Algorithm
4. Efficiency of HPDTS
4.1. Test Dataset
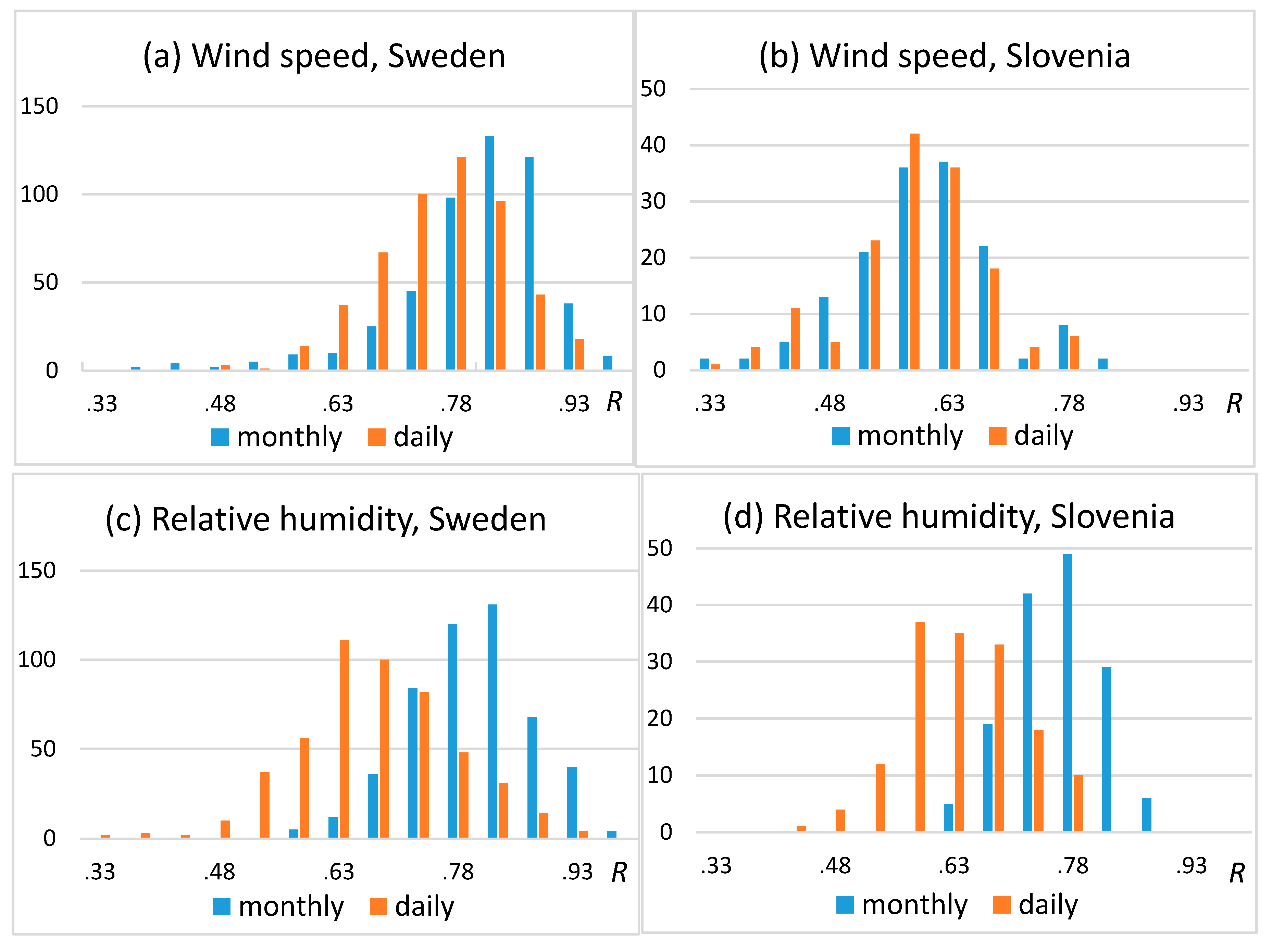
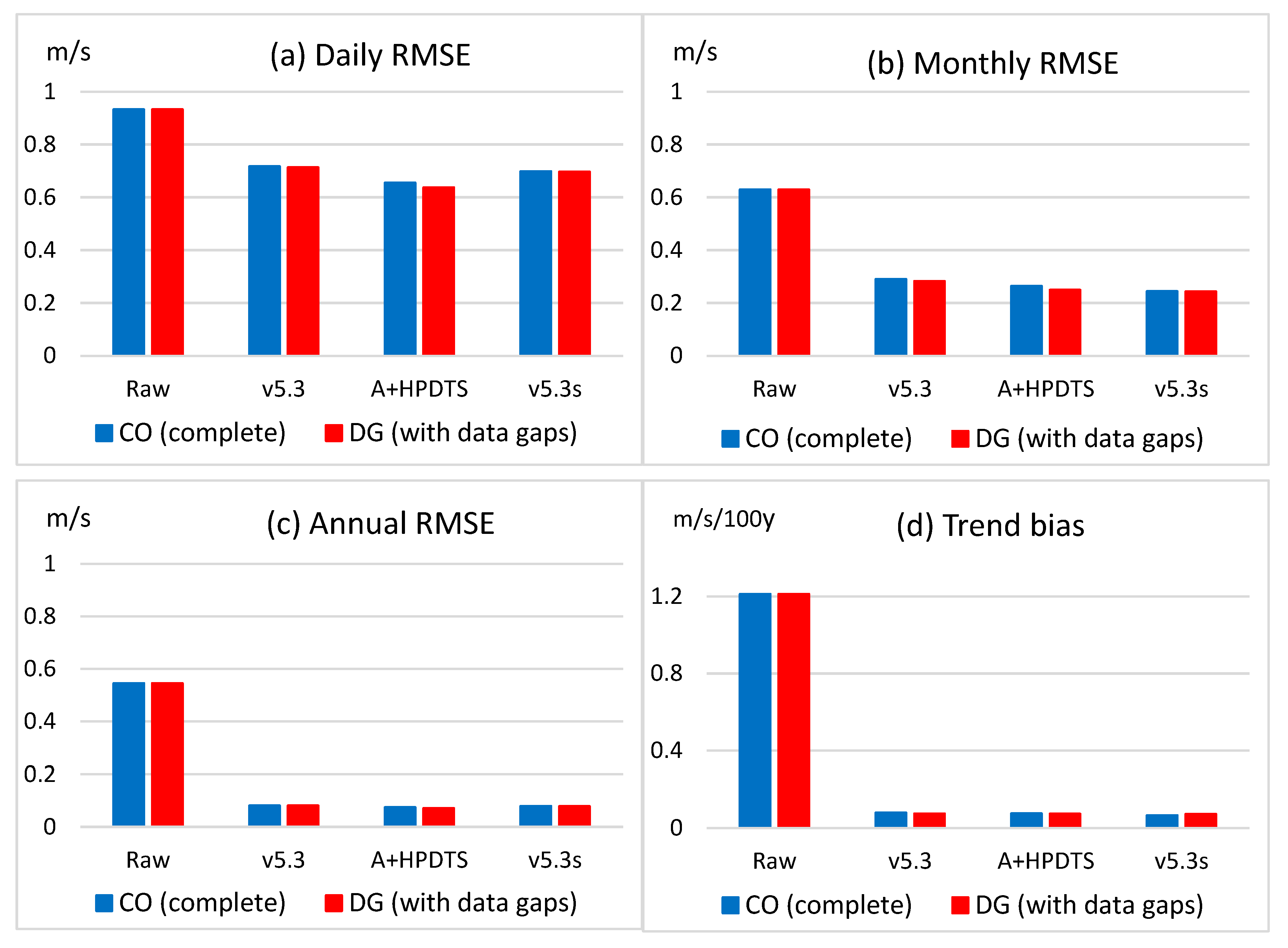
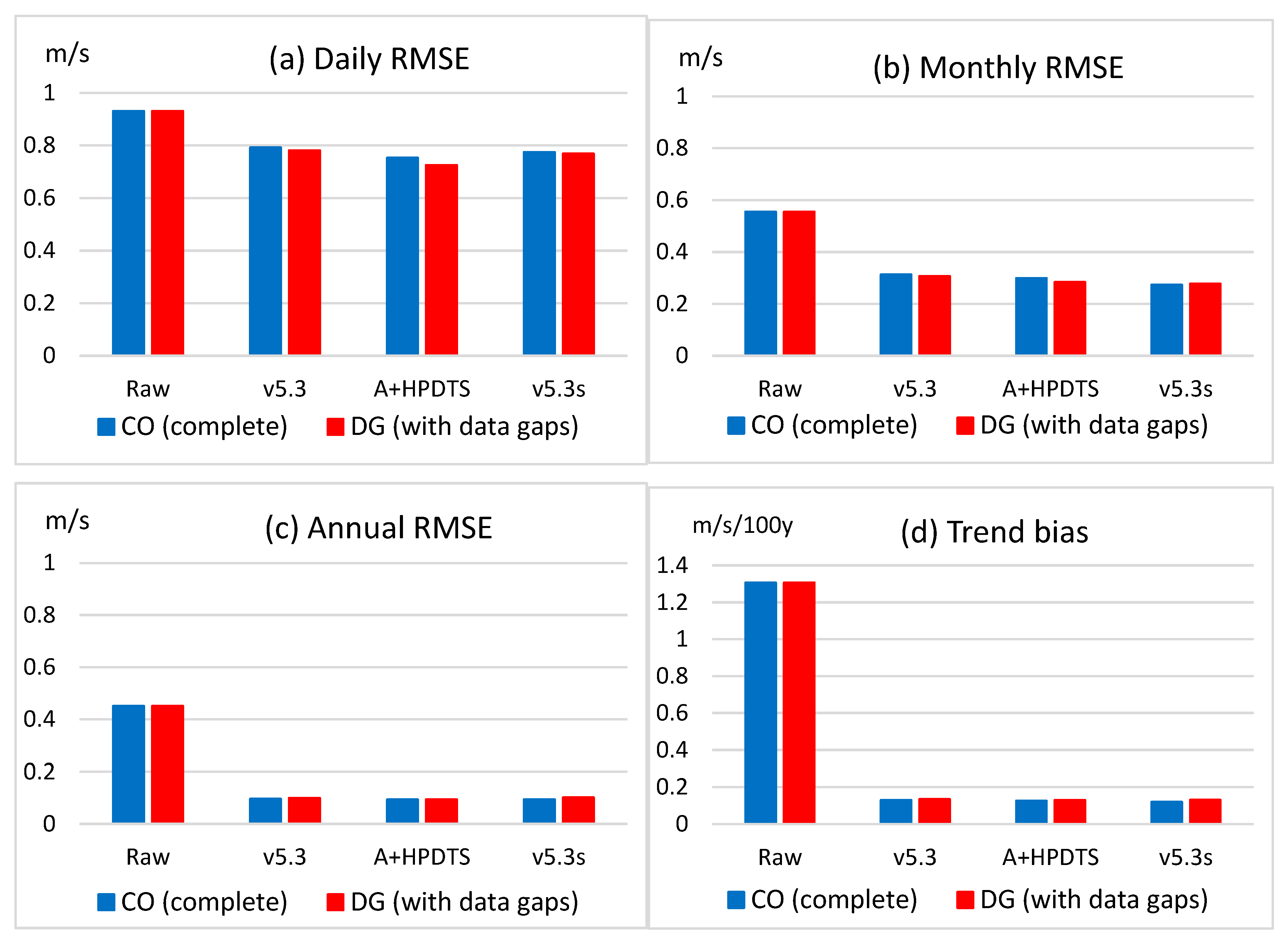
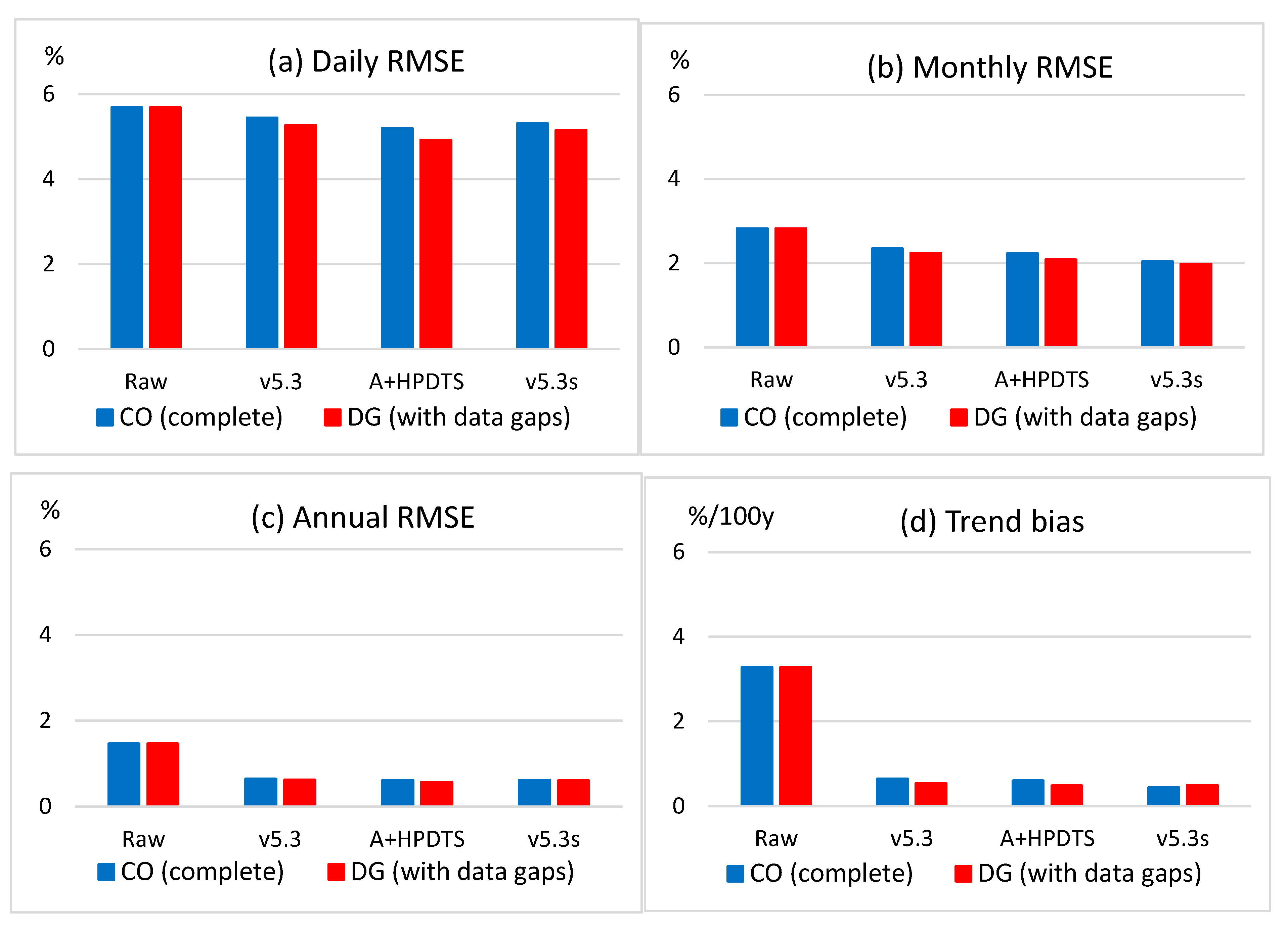
4.2. Test Results I: RMSE for All Data
4.3. Test Results: RMSE for Extreme Values
5. Discussion
6. Conclusions
- HPDTS is applied on datasets for which the section mean biases have been removed by a previous homogenization procedure.
- HPDTS considers the joint effect of inhomogeneity biases by calculating all adjustment terms with an equation system (Cenova) summarizing the climate signal and station effects within a given network. Using this method, the accuracy of daily and monthly data are improved, and the positive features of the previous homogenization results are preserved.
- HPDTS applies adjustments only for breaks which cause significant quantile dependent inhomogeneity biases.
- The present version of the method does not consider seasonal variations in inhomogeneity biases.
- HPDTS has been tested on some sections of the European project INDECIS benchmark dataset, and the test results are favorable. HPDTS resulted in 4 to 12% RMSE reduction in wind speed and relative humidity test data in all temporal scales. The results for the extreme tails of the PDF were more varied, but the notable accuracy improvement of high wind speed data is highlighted here for the great practical importance of this type of climatic extremes.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| A + HPDTS | Merged ACMANTv5.3 + HPDTS procedure |
| CO | Dataset with complete time series |
| DG | Datasets including data gaps |
| FF | Wind speed |
| HH | Relative humidity |
| HPD | Homogenization of probability distribution |
| HPDTS | Homogenization of Probability Distribution for Time Series |
| HSP | Homogeneous sub-period |
| HSP* | Sections between two consecutive separating points |
| MA | Moving average |
| Probability distribution function | |
| QM | Homogenization with quantile matching method |
| RMSE | Root mean squared error |
| Sl | Slovenia |
| Sw | Sweden |
| v5.3 | ACMANTv5.3 without seasonal changes in inhomogeneity biases |
| v5.3s | ACMANTv5.3 with seasonal changes in inhomogeneity biases |
| WMA | Weighted moving average |
References
- Auer, I.; Böhm, R.; Jurkovic, A.; Orlik, A.; Potzmann, R.; Schöner, W.; Ungersböck, M.; Brunetti, M.; Nanni, T.; Maugeri, M.; et al. A new instrumental precipitation dataset for the Greater Alpine Region for the period 1800–2002. Int. J. Climatol. 2005, 25, 139–166. [Google Scholar] [CrossRef]
- Venema, V.; Trewin, B.; Wang, X.L.; Szentimrey, T.; Lakatos, M.; Aguilar, E.; Auer, I.; Guijarro, J.; Menne, M.; Oria, C.; et al. Guidelines on Homogenization; WMO-No. 1245; World Meteorological Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Trewin, B. A daily homogenized temperature data set for Australia. Int. J. Climatol. 2013, 33, 1510–1529. [Google Scholar] [CrossRef]
- Brunet, M.; Asin, J.; Sigró, J.; Bañon, M.; García, F.; Aguilar, E.; Palenzuela, J.E.; Peterson, T.C.; Jones, P. The minimization of the screen bias from ancient Western Mediterranean air temperature records: An exploratory statistical analysis. Int. J. Climatol. 2011, 31, 1879–1895. [Google Scholar] [CrossRef]
- Hannak, L.; Friedrich, K.; Imbery, F.; Kaspar, F. Analyzing the impact of automatization using parallel daily mean temperature series including breakpoint detection and homogenization. Int. J. Climatol. 2020, 40, 6544–6559. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I.; García-Vera, M.A.; Stepanek, P. A complete daily precipitation database for northeast Spain: Reconstruction, quality control, and homogeneity. Int. J. Climatol. 2010, 30, 1146–1163. [Google Scholar] [CrossRef]
- Domonkos, P.; Tóth, R.; Nyitrai, L. Climate Observations: Data Quality Control and Time Series Homogenization; Elsevier: Amsterdam, The Netherlands, 2022; 302p. [Google Scholar]
- Domonkos, P. Relative homogenization of climatic time series. Atmosphere 2024, 15, 957. [Google Scholar] [CrossRef]
- Menne, M.J.; Williams, C.N.; Vose, R.S. The U.S. Historical Climatology Network Monthly Temperature Data, Version 2. Bull. Am. Meteor. Soc. 2009, 90, 993–1008. [Google Scholar] [CrossRef]
- Venema, V.; Mestre, O.; Aguilar, E.; Auer, I.; Guijarro, J.A.; Domonkos, P.; Vertacnik, G.; Szentimrey, T.; Štěpánek, P.; Zahradníček, P.; et al. Benchmarking monthly homogenization algorithms. Clim. Past 2012, 8, 89–115. [Google Scholar] [CrossRef]
- Štěpánek, P.; Zahradnicek, P.; Farda, A. Experiences with data quality control and homogenisation of daily records of various meteorological elements in the Czech Republic in the period 1961–2010. Időjárás 2013, 117, 123–141. [Google Scholar]
- Lindau, R.; Venema, V.K.C. The uncertainty of break positions detected by homogenization algorithms in climate records. Int. J. Climatol. 2016, 36, 576–589. [Google Scholar] [CrossRef]
- O’Neill, P.; Connolly, R.; Connolly, M.; Soon, W.; Chimani, B.; Crok, M.; de Vos, R.; Harde, H.; Kajaba, P.; Nojarov, P.; et al. Evaluation of the homogenization adjustments applied to European temperature records in the Global Historical Climatology Network Dataset. Atmosphere 2022, 13, 285. [Google Scholar] [CrossRef]
- Szentimrey, T. Multiple Analysis of Series for Homogenization (MASH). In Second Seminar for Homogenization of Surface Climatological Data; Szalai, S., Szentimrey, T., Szinell, C., Eds.; WCDMP-41; WMO: Geneva, Switzerland, 1999; pp. 27–46. [Google Scholar]
- Szentimrey, T. Methodological questions of series comparison. In Sixth Seminar for Homogenization and Quality Control in Climatological Databases; Lakatos, M., Szentimrey, T., Bihari, Z., Szalai, S., Eds.; WCDMP-76; WMO: Geneva, Switzerland, 2010; pp. 1–7. [Google Scholar]
- Caussinus, H.; Mestre, O. Detection and correction of artificial shifts in climate series. J. R. Stat. Soc. Ser. C Appl. Stat. 2004, 53, 405–425. [Google Scholar] [CrossRef]
- Mestre, O.; Domonkos, P.; Picard, F.; Auer, I.; Robin, S.; Lebarbier, E.; Böhm, R.; Aguilar, E.; Guijarro, J.; Vertacnik, G.; et al. HOMER: Homogenization software in R—Methods and applications. Időjárás 2013, 117, 47–67. [Google Scholar]
- Menne, M.J.; Williams Jr, C.N. Homogenization of temperature series via pairwise comparisons. J. Clim. 2009, 22, 1700–1717. [Google Scholar] [CrossRef]
- Lindau, R.; Venema, V.K.C. On the reduction of trend errors by the ANOVA joint correction scheme used in homogenization of climate station records. Int. J. Climatol. 2018, 38, 5255–5271. [Google Scholar] [CrossRef]
- Domonkos, P.; Joelsson, L.M.T. ANOVA (Benova) correction in relative homogenization: Why it is indispensable. Int. J. Climatol. 2024, 44, 4515–4528. [Google Scholar] [CrossRef]
- Domonkos, P. ACMANTv4: Scientific Content and Operation of the Software. 2020, 71p. Available online: https://github.com/dpeterfree/ACMANT/blob/ACMANTv4.4/ACMANTv4_description.pdf (accessed on 6 April 2024).
- Domonkos, P. Combination of using pairwise comparisons and composite reference series: A new approach in the homogenization of climatic time series with ACMANT. Atmosphere 2021, 12, 1134. [Google Scholar] [CrossRef]
- Joelsson, L.M.T.; Sturm, C.; Södling, J.; Engström, E.; Kjellström, E. Automation and evaluation of the interactive homogenization tool HOMER. Int. J. Climatol. 2022, 42, 2861–2880. [Google Scholar] [CrossRef]
- Bock, O.; Collilieux, X.; Guillamon, F.; Lebarbier, E.; Pascal, C. A breakpoint detection in the mean model with heterogeneous variance on fixed time-intervals. Stat. Comput. 2020, 30, 195–207. [Google Scholar] [CrossRef]
- Domonkos, P.; Guijarro, J.A.; Venema, V.; Brunet, M.; Sigró, J. Efficiency of time series homogenization: Method comparison with 12 monthly temperature test datasets. J. Clim. 2021, 34, 2877–2891. [Google Scholar] [CrossRef]
- Guijarro, J.A.; López, J.A.; Aguilar, E.; Domonkos, P.; Venema, V.K.C.; Sigró, J.; Brunet, M. Homogenization of monthly series of temperature and precipitation: Benchmarking results of the MULTITEST project. Int. J. Climatol. 2023, 43, 3994–4012. [Google Scholar] [CrossRef]
- Killick, R.E. Benchmarking the Performance of Homogenisation Algorithms on Daily Temperature Data. Ph.D. Thesis, University of Exeter, Exeter, UK, 2016. Available online: https://ore.exeter.ac.uk/repository/handle/10871/23095 (accessed on 16 May 2025).
- Guijarro, J.A. Recommended Homogenization Techniques Based on Benchmarking Results. WP-3 Report of INDECIS Project. 2019. Available online: http://www.indecis.eu/docs/Deliverables/Deliverable_3.2.b.pdf (accessed on 6 April 2024).
- INDECIS-WP3 Benchmarking Results. 2019. Available online: https://github.com/dpeterfree/INDECIS/blob/main/INDECIS-WP3_benchmarking_results.pdf. (accessed on 23 March 2025).
- Guijarro, J.A. Homogenization of Climatic Series with Climatol. 2018. Available online: https://www.climatol.eu (accessed on 6 April 2024).
- Skrynyk, O.; Aguilar, E.; Guijarro, J.; Randriamarolaza, L.Y.A.; Bubin, S. Uncertainty evaluation of Climatol’s adjustment algorithm applied to daily air temperature time series. Int. J. Climatol. 2021, 41, E2395–E2419. [Google Scholar] [CrossRef]
- Yosef, Y.; Aguilar, E.; Alpert, P. Changes in extreme temperature and precipitation indices: Using an innovative daily homogenized database in Israel. Int. J. Climatol. 2019, 39, 5022–5045. [Google Scholar] [CrossRef]
- Fioravanti, G.; Piervitali, E.; Desiato, F. A new homogenized daily data set for temperature variability assessment in Italy. Int. J. Climatol. 2019, 39, 5635–5654. [Google Scholar] [CrossRef]
- Adeyeri, O.E.; Laux, P.; Ishola, K.A.; Zhou, W.; Balogun, I.A.; Adeyewa, Z.D.; Kunstmann, H. Homogenising meteorological variables: Impact on trends and associated climate indices. J. Hydrol. 2022, 607, 127585. [Google Scholar] [CrossRef]
- Chimani, B.; Bochníček, O.; Brunetti, M.; Ganekind, M.; Holec, J.; Izsák, B.; Lakatos, M.; Tadić, M.P.; Manara, V.; Maugeri, M.; et al. Revisiting HISTALP precipitation dataset. Int. J. Climatol. 2023, 43, 7381–7411. [Google Scholar] [CrossRef]
- Prohom, M.; Domonkos, P.; Cunillera, J.; Barrera-Escoda, A.; Busto, M.; Herrero-Anaya, M.; Aparicio, A.; Reynés, J. CADTEP: A new daily quality-controlled and homogenized climate database for Catalonia (1950–2021). Int. J. Climatol. 2023, 43, 4771–4789. [Google Scholar] [CrossRef]
- Molina-Carpio, J.; Rivera, I.A.; Espinoza-Romero, D.; Cerón, W.L.; Espinoza, J.-C.; Ronchail, J. Regionalization of rainfall in the upper Madeira basin based on interannual and decadal variability: A multi-seasonal approach. Int. J. Climatol. 2023, 43, 6402–6419. [Google Scholar] [CrossRef]
- Casas-Castillo, M.d.C.; Llabrés-Brustenga, A.; Rodríguez-Solà, R.; Rius, A.; Redaño, À. Scaling properties of rainfall as a basis for intensity–duration–frequency relationships and their spatial distribution in Catalunya, NE Spain. Climate 2025, 13, 37. [Google Scholar] [CrossRef]
- Trewin, B.C.; Trevitt, A.C.F. The development of composite temperature records. Int. J. Climatol. 1996, 16, 1227–1242. [Google Scholar] [CrossRef]
- Nordli, P.O.; Alexandersson, H.; Frich, P.; Forland, E.J.; Heino, R.; Jonsson, T.; Tuomenvirta, H.; Tveito, O.E. The effect of radiation screens on Nordic time series of mean temperature. Int. J. Climatol. 1997, 17, 1667–1681. [Google Scholar] [CrossRef]
- Della-Marta, P.M.; Wanner, H. A method of homogenizing the extremes and mean of daily temperature measurements. J. Clim. 2006, 19, 4179–4197. [Google Scholar] [CrossRef]
- Squintu, A.A.; van der Schrier, G.; Brugnara, Y.; Klein Tank, A. Homogenization of daily temperature series in the European Climate Assessment & Dataset. Int. J. Climatol. 2019, 39, 1243–1261. [Google Scholar] [CrossRef]
- Squintu, A.A.; van der Schrier, G.; Štěpánek, P.; Zahradníček, P.; Klein Tank, A. Comparison of homogenization methods for daily temperature series against an observation-based benchmark dataset. Theor. Appl. Climatol. 2020, 140, 285–301. [Google Scholar] [CrossRef]
- Mestre, O.; Gruber, C.; Prieur, C.; Caussinus, H.; Jourdain, S. SPLIDHOM: A method for homogenization of daily temperature observations. J. Appl. Meteorol. Climatol. 2011, 50, 2343–2358. [Google Scholar] [CrossRef]
- Alexandersson, H. A homogeneity test applied to precipitation data. J. Climatol. 1986, 6, 661–675. [Google Scholar] [CrossRef]
- Easterling, D.R.; Peterson, T.C. A new method for detecting undocumented discontinuities in climatological time series. Int. J. Climatol. 1995, 15, 369–377. [Google Scholar] [CrossRef]
- Randriamarolaza, L.Y.A.; Aguilar, E.; Skrynyk, O.; Vicente-Serrano, S.M.; Domínguez-Castro, F. Indices for daily temperature and precipitation in Madagascar, based on quality-controlled and homogenized data, 1950–2018. Int. J. Climatol. 2022, 42, 265–288. [Google Scholar] [CrossRef]
- Montero-Martínez, M.J.; Andrade-Velázquez, M. Effects of urbanization on extreme climate indices in the valley of Mexico Basin. Atmosphere 2022, 13, 785. [Google Scholar] [CrossRef]
- Kessabi, R.; Hanchane, M.; Guijarro, J.A.; Krakauer, N.Y.; Addou, R.; Sadiki, A.; Belmahi, M. Homogenization and trends analysis of monthly precipitation series in the Fez-Meknes region, Morocco. Climate 2022, 10, 64. [Google Scholar] [CrossRef]
- Skrynyk, O.; Sidenko, V.; Aguilar, E.; Guijarro, J.; Skrynyk, O.; Palamarchuk, L.; Oshurok, D.; Osypov, V.; Osadchyi, V. Data quality control and homogenization of daily precipitation and air temperature (mean, max and min) time series of Ukraine. Int. J. Climatol. 2023, 43, 4166–4182. [Google Scholar] [CrossRef]
- Pauca-Tanco, G.A.; Arias-Enríquez, J.F.; Quispe-Turpo, J.d.P. High-resolution bioclimatic surfaces for Southern Peru: An approach to climate reality for biological conservation. Climate 2023, 11, 96. [Google Scholar] [CrossRef]
- Jupin, J.L.J.; Garcia-López, A.A.; Briceño-Zuluaga, F.J.; Sifeddine, A.; Ruiz-Fernández, A.C.; Sanchez-Cabeza, J.-A.; Cardoso-Mohedano, J.G. Precipitation homogenization and trends in the Usumacinta River Basin (Mexico-Guatemala) over the period 1959–2018. Int. J. Climatol. 2024, 44, 108–125. [Google Scholar] [CrossRef]
- Bozzoli, M.; Crespi, A.; Matiu, M.; Majone, B.; Giovannini, L.; Zardi, D.; Brugnara, Y.; Bozzo, A.; Berro, D.C.; Mercalli, L.; et al. Long-term snowfall trends and variability in the Alps. Int. J. Climatol. 2024, 44, 4571–4591. [Google Scholar] [CrossRef]
- Szentimrey, T. Overview of mathematical background of homogenization, summary of method MASH and comments on benchmark validation. Int. J. Climatol. 2023, 43, 6314–6329. [Google Scholar] [CrossRef]
- Ilona, J.; Bartók, B.; Dumitrescu, A.; Cheval, S.; Gandhi, A.; Tordai, Á.V.; Weidinger, T. Using long-term historical meteorological data for climate change analysis in the Carpathian region. Atmosphere 2022, 13, 1751. [Google Scholar] [CrossRef]
- Li, Z.; Shi, Y.; Argiriou, A.A.; Ioannidis, P.; Mamara, A.; Yan, Z. A comparative analysis of changes in temperature and precipitation extremes since 1960 between China and Greece. Atmosphere 2022, 13, 1824. [Google Scholar] [CrossRef]
- Szentes, O.; Lakatos, M.; Pongrácz, R. New homogenized precipitation database for Hungary from 1901. Int. J. Climatol. 2023, 43, 4457–4471. [Google Scholar] [CrossRef]
- Dumitrescu, A.; Amihaesei, V.-A.; Cheval, S. RoCliB–bias-corrected CORDEX RCMdataset over Romania. Geosci. Data J. 2023, 10, 262–275. [Google Scholar] [CrossRef]
- Collins, W.J.; Bellouin, N.; Doutriaux-Boucher, M.; Gedney, N.; Hinton, T.; Jones, C.D.; Liddicoat, S.; Martin, G.; O’Connor, F.; Rae, J.; et al. Evaluation of the HadGEM2 Model; Hadley Centre Technical Note 74; Met Office: Exeter, UK, 2008; 47p. [Google Scholar]
- Alexandersson, H.; Moberg, A. Homogenization of Swedish temperature data. Part I: Homogeneity test for linear trends. Int. J. Climatol. 1997, 17, 25–34. [Google Scholar] [CrossRef]
- Toreti, A.; Kuglitsch, F.G.; Xoplaki, E.; Luterbacher, J. A novel approach for the detection of inhomogeneities affecting climate time series. J. Appl. Meteorol. Climatol. 2012, 51, 317–326. [Google Scholar] [CrossRef]
- Leeper, R.D.; Rennie, J.; Palecki, M.A. Observational Perspectives from U.S. Climate Reference Network (USCRN) and Cooperative Observer Program (COOP) Network: Temperature and Precipitation Comparison. J. Atmos. Ocean. Technol. 2015, 32, 703–721. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Daily RMSE | Monthly RMSE | Annual RMSE | Trend Bias | |||||
|---|---|---|---|---|---|---|---|---|
| CO | DG | CO | DG | CO | DG | CO | DG | |
| FF_Sw | 8.7 | 10.6 | 8.9 | 11.4 | 9.3 | 12.0 | 4.8 | 0.9 |
| FF_Sl | 4.9 | 7.2 | 4.6 | 7.3 | 3.9 | 5.2 | 2.9 | 3.4 |
| HH_Sw | 4.6 | 6.5 | 4.8 | 7.0 | 5.0 | 8.5 | 6.9 | 9.8 |
| HH_Sl | 5.0 | 10.1 | 5.1 | 9.6 | 5.0 | 7.5 | –0.6 | –0.7 |
| Sweden | Slovenia | |||||||
|---|---|---|---|---|---|---|---|---|
| f < 0.05 | f > 0.95 | f < 0.05 | f > 0.95 | |||||
| CO | DG | CO | DG | CO | DG | CO | DG | |
| FF RMSE (m/s) | 0.6 | 0.6 | 0.9 | 1.0 | 0.5 | 0.6 | 1.3 | 1.3 |
| FF red. by HPDTS (%) | 1.5 | –0.8 | 8.5 | 9.1 | 1.5 | –1.5 | 4.2 | 3.9 |
| FF error reduction total | 13.5 | 5.6 | 31.0 | 29.9 | –4.2 | –11.7 | 18.2 | 18.2 |
| HH RMSE (%) | 7.5 | 7.1 | 2.9 | 3.0 | 10.3 | 9.8 | 3.6 | 3.7 |
| HH red. by HPDTS (%) | 3.7 | 4.5 | 0.3 | –1.1 | 3.9 | 4.6 | –1.3 | –4.0 |
| HH error reduction total | 7.6 | 12.0 | 0.2 | –4.6 | 10.4 | 14.9 | 1.4 | –1.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Domonkos, P. Homogenization of the Probability Distribution of Climatic Time Series: A Novel Algorithm. Atmosphere 2025, 16, 616. https://doi.org/10.3390/atmos16050616
Domonkos P. Homogenization of the Probability Distribution of Climatic Time Series: A Novel Algorithm. Atmosphere. 2025; 16(5):616. https://doi.org/10.3390/atmos16050616
Chicago/Turabian StyleDomonkos, Peter. 2025. "Homogenization of the Probability Distribution of Climatic Time Series: A Novel Algorithm" Atmosphere 16, no. 5: 616. https://doi.org/10.3390/atmos16050616
APA StyleDomonkos, P. (2025). Homogenization of the Probability Distribution of Climatic Time Series: A Novel Algorithm. Atmosphere, 16(5), 616. https://doi.org/10.3390/atmos16050616