1. Introduction
With increasingly severe global climate change and environmental challenges [
1,
2], the need for understanding and predicting atmospheric processes and weather phenomena has become more urgent. Clouds, as an important component of the atmospheric system, exhibit significant differences in their characteristics with changes in altitude. This difference is not only reflected in the shape, density, and color of clouds, but also directly affects the dynamic evolution of clouds and the operation of weather systems [
3,
4,
5]. Therefore, accurately displaying the characteristics of cloud layers at different heights is crucial for improving the realism and accuracy of cloud modeling. In this context, the WRF model, with its excellent high resolution and nestability, demonstrates strong flexibility and scalability, and occupies an important position in the field of atmospheric science research [
6,
7]. Therefore, cloud 3D modeling technology based on WRF is gradually emerging. By using the data generated by WRF models for cloud 3D modeling, the spatial distribution and physical properties of clouds can be more accurately characterized, and the mechanism of cloud effects on weather systems and climate change can be further revealed, providing more solid scientific support for meteorological prediction and climate research [
8,
9].
Due to the high complexity of 3D cloud data, traditional mathematical models often struggle to quickly capture its essential features [
10]. Therefore, phenomenological modeling methods were widely used in the early stages of research due to their speed and simplicity, among which the most classic algorithms include the Metaball method [
11], fractal method [
12], texture method [
13], noise method [
14], and cloud image-driven method [
15]. However, these algorithms did not fully consider the physical nature of clouds, resulting in insufficient presentation of cloud features generated.
The physics cloud modeling method is based on principles of fluid mechanics and thermodynamics, and deeply explores the formation, evolution, and dissipation processes of clouds. This enables more accurate simulation of cloud morphology and dynamic characteristics, and to some extent solves the problem of insufficient presentation of cloud features. Here, Miyazaki et al. [
16] optimize cellular automata and have proposed the CELL method, which effectively simulates the motion and feature changes in clouds, but the resolution is insufficient. Goswami et al. [
10] use a Lagrangian model to compensate for the shortcomings of fluid mechanics and achieve rapid establishment of cloud models. Compared to phenomenological modeling methods, physics model methods improve cloud modeling accuracy and enhance their sense of physicality, but the cloud morphology still appears rough and lacks a sense of hierarchy.
The modeling method based on particle systems has become the mainstream due to its ability to accurately characterize cloud characteristics. This type of method simulates the motion and interaction of cloud particles, which can more realistically represent the morphological features of clouds. Among them, Reeves et al. [
17] use particle systems to simulate fuzzy or irregular objects, reflecting the characteristics by controlling the generation, movement, change, and disappearance of particles. However, when this method is applied to 3D cloud modeling, the density differences between cloud layers are ignored, resulting in insufficient representation of cloud layering. Xing et al. [
18] obtain the density texture of clouds by introducing the density field of clouds to simulate the density distribution of clouds. However, modeling methods based on density texture still have shortcomings in presenting the hierarchical aspect of clouds, especially when dealing with sparse-density cloud scenes. Unbscheiden et al. [
19] improve the particle system by replacing particles with textures to achieve real-time simulation of clouds. However, this method is limited by texture and generates a single cloud shape, making it difficult to display the differential characteristics of cloud layers at different heights. Zhang et al. [
20] use 3D texture technology to simulate cloud shapes, generated Perlin Worley noise textures by combining 3D Perlin noise and 3D Worley noise through a remapping function, and set the height distribution of cloud density using a height mask. However, when applying this method to cloud modeling, there is insufficient attention paid to the physical characteristics of clouds, resulting in the inability to accurately display the differential features of clouds at different heights. Bi et al. [
15] combine cellular automata with particle systems to improve cloud modeling efficiency, but the fixed nature of cellular automata leads to unnatural shape changes under different viewpoints. Zhang et al. [
21] proposed a detail-level particle system that improves modeling efficiency, but lacks correlation analysis based on cloud particle density, limiting performance in large-scale applications. Xie et al. [
22] improve cloud rendering efficiency via a WRF-based particle and LOD model, but oversimplified cloud structure and ignored multilayer and multiple scattering effects. Elhaddad et al. [
23] propose a computationally efficient cloud simulation method based on Lennard-Jones Potential, enabling real-time large-scale cloud animation but relying on simplified physical interactions.
The above particle system cloud modeling methods mainly focus on improving the realism of clouds and the efficiency of near-vision modeling. However, there are still shortcomings in the performance of cloud features at different heights, and the computational cost is too high for far-vision modeling. The objective of the research was to capture the microphysical differences in various cloud layers, enhance the authenticity of cloud structure modeling, and improve the computational efficiency in long-range vision scenes simultaneously. We propose a multi-level particle system modeling algorithm with WRF, which utilizes the cloud water mixing ratio and cloud ice mixing ratio from WRF data to adjust particle radii according to height. These two physical properties vary with altitude and reflect the phase and concentration of cloud particles. The main contributions are as follows:
To address the issue of insufficient presentation of cloud differentiation features in cloud modeling, we combine a weight mechanism and PID controller to achieve differentiated modeling of clouds at different heights. Based on the unique physical properties of cloud layers at different heights, the radius of cloud particles can be flexibly and accurately adjusted to achieve precise presentation of cloud characteristics at different heights. Meanwhile, the PID controller can quickly and accurately adjust the parameters of the particle system during dynamic processes based on real-time feedback, minimizing system errors and ensuring the accuracy and stability of modeling.
To solve insufficient cloud hierarchy characterization caused by inaccurate capture of cloud density distribution, we adopt multi-scale mean-shift clustering to accurately capture cloud clusters with a high density. By combining the Adaptive Kernel Density Estimation (AKDE) algorithm, we can more accurately distinguish between the dense and sparse regions of clouds. This not only enhances the hierarchical representation of cloud structures but also effectively improves the clustering speed. On this basis, we introduce a weighted computing mechanism based on particle correlation and Euclidean distance between particles, ensuring that the importance of each particle attribute is fully considered in the clustering process, and ensuring that the clustering results are more authentic and accurate.
To tackle high computational costs in modeling and achieve a comprehensive balance between the effectiveness and efficiency of long-range modeling, we propose an optimal control point selection mechanism based on the correlation between edge particle density and contour, and utilize the weight information of boundary particles for modeling optimization. We use the mean-shift clustering method to quickly select cluster edge regions, and conduct particle density and contour correlation analysis based on density features to obtain the optimal control points. On this basis, a cascaded Bezier curve is proposed to optimize cloud contours by integrating particle density weight information, which can effectively reduce modeling and computational costs while maintaining the visual effects of the model.
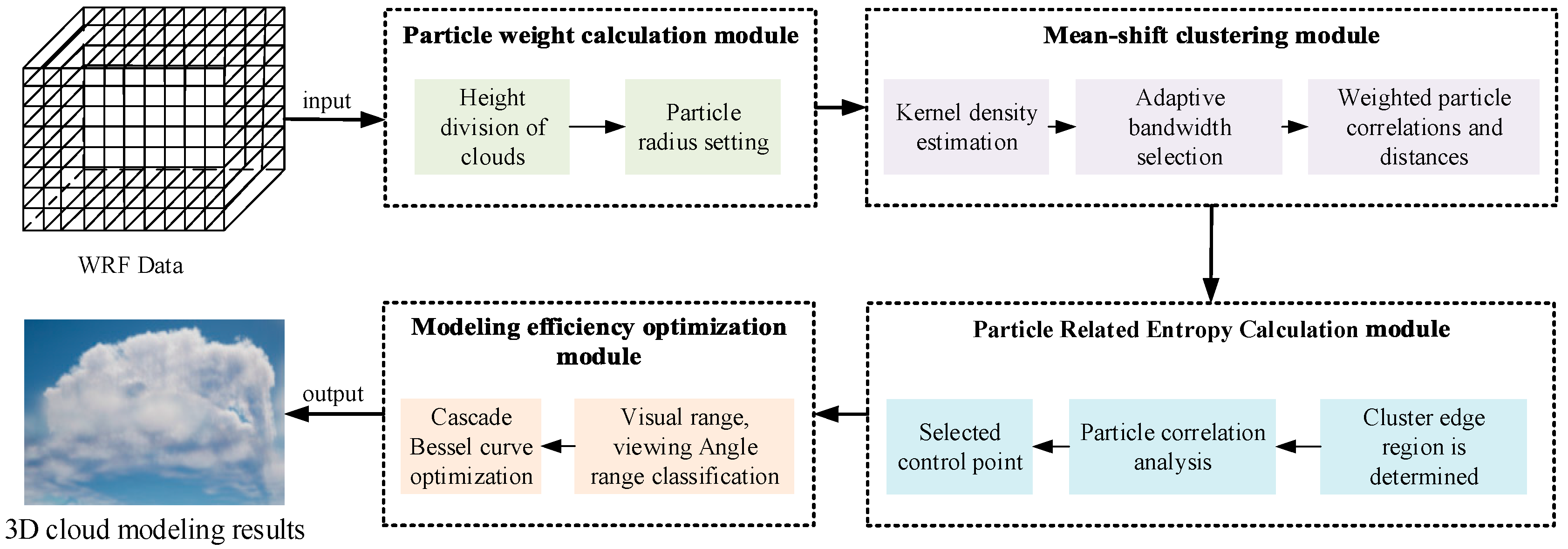
2. Method
To accurately display the characteristics of cloud layers at different heights and achieve efficient modeling at long distances, we propose a multi-level particle system cloud modeling algorithm based on WRF, which combines a weight mechanism and PID controller to extract differentiated features of cloud layers. Meanwhile, the multi-scale mean-shift clustering method is utilized to accurately characterize the contours of dense cloud clusters. On this basis, we designed an optimal control point selection mechanism and utilized cascaded Bezier curves to achieve realistic long-range modeling effects while considering computational costs. The algorithm mainly consists of several parts: a particle weight calculation module, clustering module, particle correlation entropy calculation module, and modeling optimization module based on cascaded Bessel functions. The overall process is shown in
Figure 1.
In
Figure 1, the particle weight calculation module mainly achieves differentiated modeling of clouds at different heights through weight and particle radius settings. The clustering module adopts an adaptive multi-scale mean-shift clustering algorithm, which integrates AKDE into the mean-shift algorithm to enable adaptive bandwidth selection and accurately delineate the hierarchical structure of clouds at different altitudes, significantly improving the sense of hierarchy between clouds. The particle correlation entropy calculation module mainly determines the importance of particles in the whole based on the correlation analysis experiment between particles, and selects the optimal control point to lay a foundation for the subsequent efficiency optimization. Finally, the modeling optimization module based on cascaded Bessel functions utilizes cascaded Bessel curve technology to effectively solve the problem of high computational costs in long-range modeling while maintaining the visual effects of the model.
2.1. Particle Weight Calculation
Clouds at different heights exhibit diverse forms and state characteristics. For example, the lower cloud layer below 2000 m is mainly dominated by cumulus clouds. Clouds in this height range are evenly distributed, usually presenting a pure white color, and have relatively high cloud water content; clouds between 2000 m and 7000 m are mainly high cumulus clouds, forming relatively thin cloud layers that exhibit layered, patchy, or feathery characteristics; clouds between 7000 m and 13,000 m are mainly high-level clouds, presenting a filamentous form.
To improve the modeling accuracy, it is necessary to conduct correlation analysis within each particle cluster and screen out particles with a higher importance as candidate control points. Additionally, height information can be added to the WRF data, thereby enhancing the representation accuracy of cloud structures. However, in general, the data output by WRF does not directly provide altitude information. To obtain true altitude information, we use the conversion equation between air pressure and altitude to convert the air pressure data in WRF data to the corresponding altitude. The conversion equation is as follows:
where
is the height of the poster,
is atmospheric pressure, and
is the current altitude pressure.
To better reflect the characteristics of cloud layers, we consider the differences in features between cloud layers at different heights and set a different particle radius for each height range. According to the height classification characteristics of cloud layers, particles with a radius range of less than 100 um are used for clouds below 2000 m to better simulate the microstructure of lower cloud layers. For clouds between 2000 and 7000 m, due to the more complex morphology and characteristics of cloud layers, particles with a radius range of 100–200 um can better simulate the particle distribution and structure of mid-level clouds. For high-level clouds above 7000 m, particles with a radius greater than 200 um are used because the clouds are often composed of larger ice crystals. Combining the cloud water mixture ratio and cloud ice mixture ratio in WRF data, the particle radius weights are set as follows:
where
and
are parameters that are adjusted according to height;
and
represent the cloud water mixing ratio and cloud ice mixing ratio, respectively.
The three-dimensional particle system processed by assigning particle weights may experience systematic errors in specific scenes, such as when a certain value of the cloud ice mixture ratio or cloud water mixture ratio is too large or too small. To solve this problem, this article uses a PID controller for error control. The PID controller mainly consists of three parts—a proportional term, integral term, and differential term—which can be used to quickly and accurately adjust the parameters of the particle system in the dynamic process of 3D cloud modeling, thereby minimizing system errors.
where
represents the result;
represents the proportional term, which reflects the degree of influence of the current error on the controller output;
represents the integral term, which is used to handle the system static error, that is, the error that the system cannot completely eliminate;
represents the differential term, which is used to suppress the system oscillation and improve the system response speed.
2.2. Mean-Shift Clustering
In the process of cloud modeling, cloud layers are typically composed of cloud patches with varying densities. The mean-shift clustering algorithm, being a non-parametric clustering algorithm based on density, aligns well with the requirements of cloud modeling, especially when capturing cloud clusters in regions of higher density. However, the existing mean-shift clustering algorithm performs poorly when it comes to modeling multi-level structures. To address the complex and variable multi-level structures of cloud layers, we extend mean-shift clustering to a multi-scale approach and integrate the AKDE method to achieve dynamic clustering, thus better accommodating the multi-level structures within cloud layers. Our algorithm effectively preserves the hierarchical features of cloud layers at different altitudes, ensuring both the visual stability and authenticity of clouds even in the scenes of long-range modeling. The iterative process of mean-shift clustering is illustrated in
Figure 2.
Given that WRF data are three-dimensional, in order to more accurately estimate local density, we use a three-dimensional kernel function for density estimation, as shown in (4).
where
is the number of samples,
represents bandwidth, and
is the three-dimensional Gaussian kernel function; the equation is shown in (5).
Employing a three-dimensional Gaussian kernel function offers a superior means of illustrating the spatial distribution features of three-dimensional data, precisely capturing the arrangement of points within the dataset in three-dimensional space. Equation (6) displays the gradient formula for kernel density estimation in three-dimensional Euclidean space, utilizing the mean-shift clustering algorithm.
where
is the normalization constant. According to (6), the vector of the mean-shift clustering algorithm can be represented as follows:
The centroid iteration position of the mean-shift clustering algorithm can be obtained by (7). For sample points in three-dimensional Euclidean space, the next centroid position is shown as (8).
Due to the significant impact of bandwidth on the performance of mean-shift clustering, dynamically selecting bandwidth to achieve optimal performance during the mean-shift clustering process is an urgent problem. To solve this problem, our algorithm combines mean-shift clustering with AKDE, enabling the mean-shift algorithm to achieve adaptive bandwidth selection based on local density changes in the cloud. Specifically, considering the bandwidth value as a representation correlated with cloud density, adaptive bandwidth adjustment is achieved by locally estimating the density of each grid point and mapping the density to the bandwidth using a linear function. The AKDE formula is shown in (9).
where
and
represent data points, and
represents the local density at the point
. With the local density data of all grid data points obtained, the mapping function equation is shown in (10).
where
is the adaptive bandwidth of the current cluster,
represents the local density value at the centroid of the cluster, and
represents the linear function mapping the local density value to the bandwidth value, and the linear function equation is represented as follows:
where
and
respectively represent the maximum and minimum local density values within the current data range. This strategy can more flexibly adapt to the data characteristics of different density regions, enabling more accurate reflection of local density changes when simulating cloud layers, and thus capturing the density distribution inside the cloud layer more finely.
Due to the excessive reliance on local distance information and the lack of consideration for the correlation between particle attributes in the AKDE algorithm, this paper introduces a mechanism for weighted calculation of particle correlation and Euclidean distance between particles in the clustering process. This mechanism ensures that the importance of each particle attribute is fully considered during the clustering process, while using Euclidean distance weighting to compensate for the shortcomings of the AKDE algorithm in dealing with distant particles, ensuring that the clustering results are more authentic and accurate. The weighting equation between
and
is shown in (12).
where
is the total number of particles,
and
represent the value of each particle for the
-th attribute, and
represents the weight of the
-th attribute. The coefficient selection for weighted calculation is determined by the influence of the attributes themselves on the cloud formation process. For example, attributes such as particle size and color have a greater impact on cloud modeling, while particle velocity has a smaller impact. Therefore, the weighting coefficient of the former is greater than that of the latter.
The mean-shift algorithm finds the maximum value of local density by iterating, so it may be severely affected by algorithm efficiency when processing large-scale 3D data. To address this issue, we adopt a strategy of reducing the computation of particles with high similarity to minimize the number of iterations. Firstly, assuming that the number of particles in each cluster is the same, the modeling can be achieved by finding the minimum number of available particles required in all clusters. Therefore, the probability of finding at least one available particle in each cluster is shown in (13).
where
represents that there are
clusters in the dataset, and
represents the minimum number of available particles required to find all clusters. Therefore, when
, all clusters can be found. In the actual modeling process, adjusting the number of clusters according to the size of the dataset and finding the minimum number of available particles required for all clusters can achieve efficient clustering.
2.3. Particle-Related Entropy Calculation
In the actual modeling process, changes in LoS have a significant impact on modeling accuracy and efficiency. Especially when the LoS becomes farther, the use of traditional particle modeling methods often leads to excessive consumption of computational resources. This is because the modeling method of using a fixed particle number and radius is difficult to adapt to changing observation conditions. In addition, changes in observation angles also lead to dynamic changes in particle importance information, further exacerbating the complexity of modeling. Therefore, we refine the calculation of particle-related entropy into two levels: intra-cluster and inter-cluster, aiming to reduce unnecessary particle calculations and optimize the calculation process. When implementing particle-related entropy calculation within a cluster, the focus is on particles near the cloud edge contour, while optimizing other particles within the cluster using a linear dilution strategy. This processing method ensures that when the LoS changes, the contour of the cloud can be optimized based on the edge contour particle information, and the integrity of the internal structure of the cloud can be ensured based on the density within the cluster, thereby ensuring modeling accuracy and improving computational efficiency.
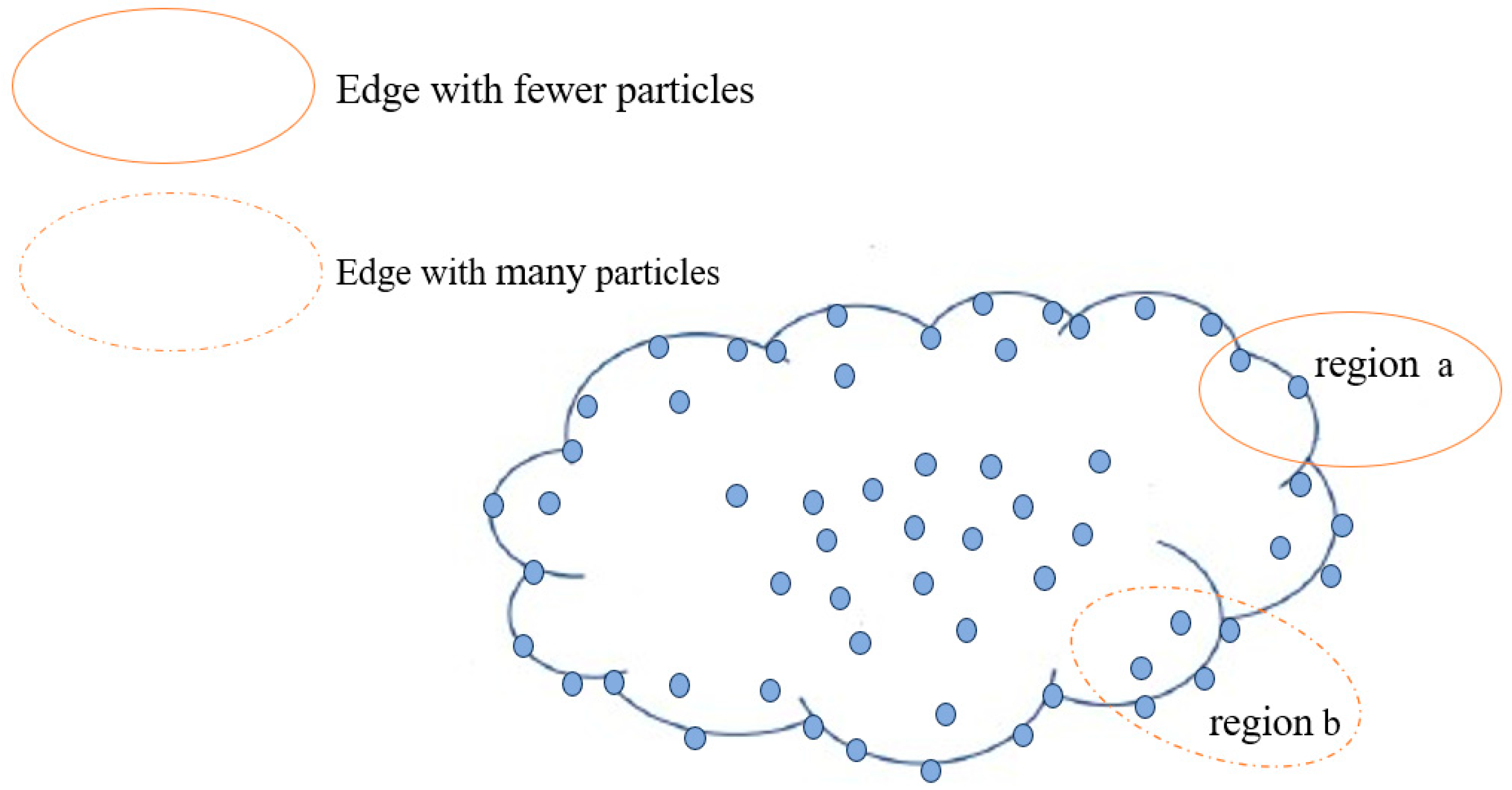
When calculating particle-related entropy within a cluster, the primary focus is on accurately identifying particles within the cluster boundary to reduce the computational complexity of unnecessary particles. Therefore, we utilize the density-based mean-shift clustering algorithm to define edge regions by identifying areas with a low density or significant density gradients, where edge particles are often distributed. In
Figure 3, all particles in the edge region of the cloud are shown, while only a portion of particles in the center region are displayed, mainly highlighting the contour-related features of particles in the edge region.
There is a significant difference in the complexity of line segments and the number of control points between region a and region b, which makes their roles in cloud optimization different. Region b has more contour control points, which are more important for cloud contour. To ensure uniform selection of cloud edge control points, the number of control points should be positively correlated with the density of the edge region. For example, in region b, which has higher density, more control points should be selected than in region a.
In 3D cloud modeling, the importance of cloud particles lies in their correlation with the overall cloud, that is, to what extent cloud particles can represent the information of the cloud as a whole. In the evaluation of the importance of cloud particles to the overall cloud, most existing methods directly perform inter-particle correlation analysis. Considering the multitude of particle attributes, this process is extremely cumbersome. Therefore, we introduce the concept of particle correlation entropy, which maps the multidimensional attributes of cloud particles to a one-dimensional array in the form of a linked list, thereby simplifying the computational complexity of inter-particle correlation. This process collects time series data, including key attributes such as position, velocity, color, and particle radius, and normalizes them to ensure data consistency and comparability.
In order to accurately analyze the importance of cloud particles in the overall cloud, it is necessary to perform relevant entropy calculations. Considering the advantages of a low computational complexity, high robustness, and powerful linear and nonlinear data processing capabilities of the Maximum Information Coefficient (MIC), we choose the MIC algorithm for correlation analysis and conduct correlation entropy calculation within the cluster. As mentioned earlier, edge particles play an important role in cloud contour characterization. Therefore, in this paper, edge particles are extracted one by one, and their importance in the overall cloud is evaluated by calculating the average entropy of each edge particle and other edge particles. The average correlation entropy is calculated as follows:
where
represents the correlation coefficient between
and
, and
is the total number of particles. After obtaining the average correlation entropy of each important particle, the setting of the correlation entropy mean threshold is the key to determining the classification of particle importance. Therefore, we conduct error experiments on different threshold settings for high-level cloud regions, and uses cloud modeling error calculation to quantitatively evaluate and analyze the rationality of the threshold value range. The error equation for cloud modeling is shown in (15):
where
represents the error for cloud modeling,
represents the number of particles greater than the threshold,
is the total number of particles, and
represents the local density of the particle. By calculating the ratio between the total density of particles exceeding the threshold and the overall density, we can determine the size of the error, as demonstrated in the correlation analysis experiment in
Section 3.2.1.
2.4. Modeling Optimization Based on Cascaded Bessel Functions
To fully utilize the importance information of boundary particles, we propose a cascaded Bezier curve based on the Bezier curve, selecting 2° and 30 px as thresholds for changes in viewing angle and LoS. We select the number of edge control points within each LoS range based on particle density, to achieve a cloud contour representation under different LoSs and viewing angles. Moreover, in long-range scenes, sparse processing of particles within cloud layers significantly reduces computational burden. This method can solve the problem of wasted computing resources at different viewing distances while ensuring the realism of 3D clouds.
Firstly, the visual range is divided into 100–150 px, 400–450 px, and 600–650 px, representing three observation levels: near, medium, and far. Each observation level has different requirements for the specific shape of clouds, such as requiring more cloud details for close range observation, while focusing more on the overall shape of clouds for long-range observation. Therefore, appropriate polynomial fitting methods are determined based on different observation levels to obtain the relationship between particle position and attribute information. Here, we use the least squares method to construct a fitting formula, as shown in (16):
where
is the fitted curve,
represents the order, and the minimum residual sum of squares can be obtained using the following equation:
where
represents the length of the dataset, and
represents the particle correlation information. The coefficient solution of the least squares method can be achieved through matrix operations, and its coefficient matrix is the Vandermonde matrix, as shown in (18):
where
represents the order, and m represents the length of the dataset. The coefficient vector is
a and the observation vector is
. The solution of the least squares method is obtained by solving the linear equation system
, where
is the Vandermonde matrix,
is the coefficient vector, and
is the observation vector. According to the experimental results, it was found that using
,
, and
for polynomial fitting is the best for the three LoS ranges of 100–150 px, 400–450 px, and 600–650 px, respectively.
After establishing the intrinsic correlation between particle position and its attribute information, the next focus of research is on how to adaptively determine the number of control points in the cloud edge region within each LoS range. Therefore, we adjust the number of control points based on the cloud density distribution and particle importance information at different LoSs, so that the larger the LoS, the fewer the control points. Subsequently, based on the adjusted number of control points, the order of the Bezier curve is adjusted accordingly to optimize the modeling efficiency. Specifically, this algorithm uses linear interpolation to configure control points, to achieve a centralized allocation of computing resources in high-density areas. The linear interpolation is shown in (19):
where
and
are the density of known points and distributed at both ends of the current point,
and
are the number of control points for
and
, respectively,
is the density of the current point, and
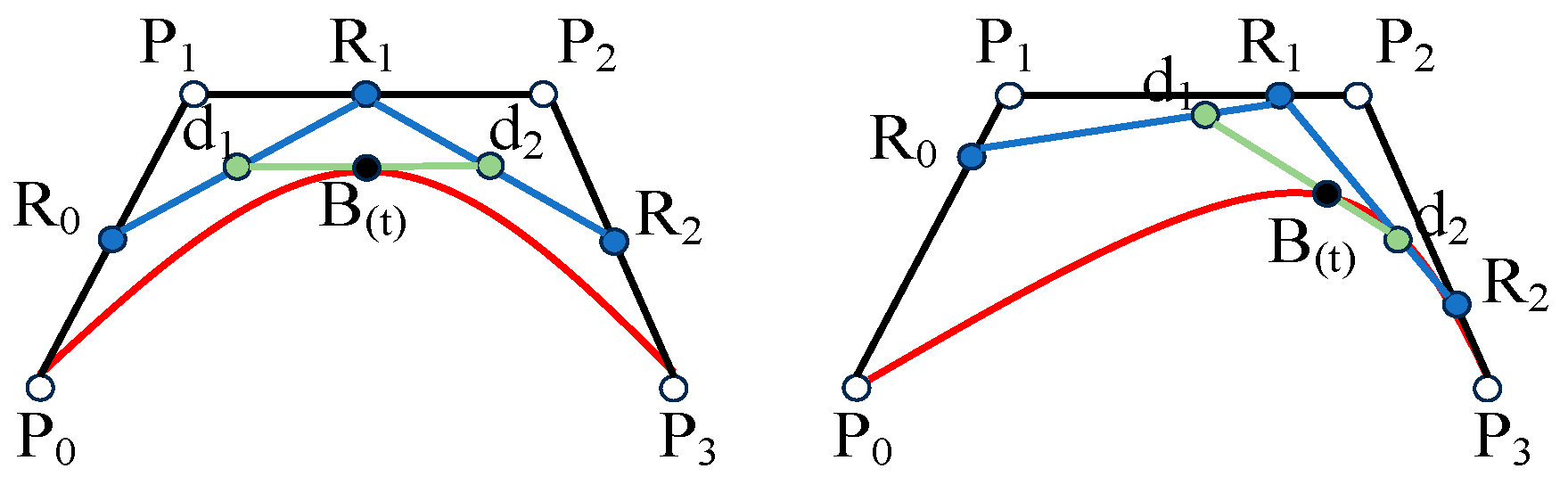
is the number of new control points obtained, and the position of the control points is adjusted. The number of control points in the local space determines the order of the Bezier curve. For example, when there are four control points, a third-order Bezier curve is used for optimization. The third-order Bezier curve is shown in
Figure 4.
where
represents the order of the Bezier curve,
represents a point on the curve,
represents a control point, and
represents a Bernstein polynomial; the Bernstein polynomial is shown in (21):
where
is a Bernstein polynomial with
. By utilizing the unique characteristics of Bezier curves, it is possible to significantly reduce computational costs while preserving the contour of the curve.
4. Conclusions
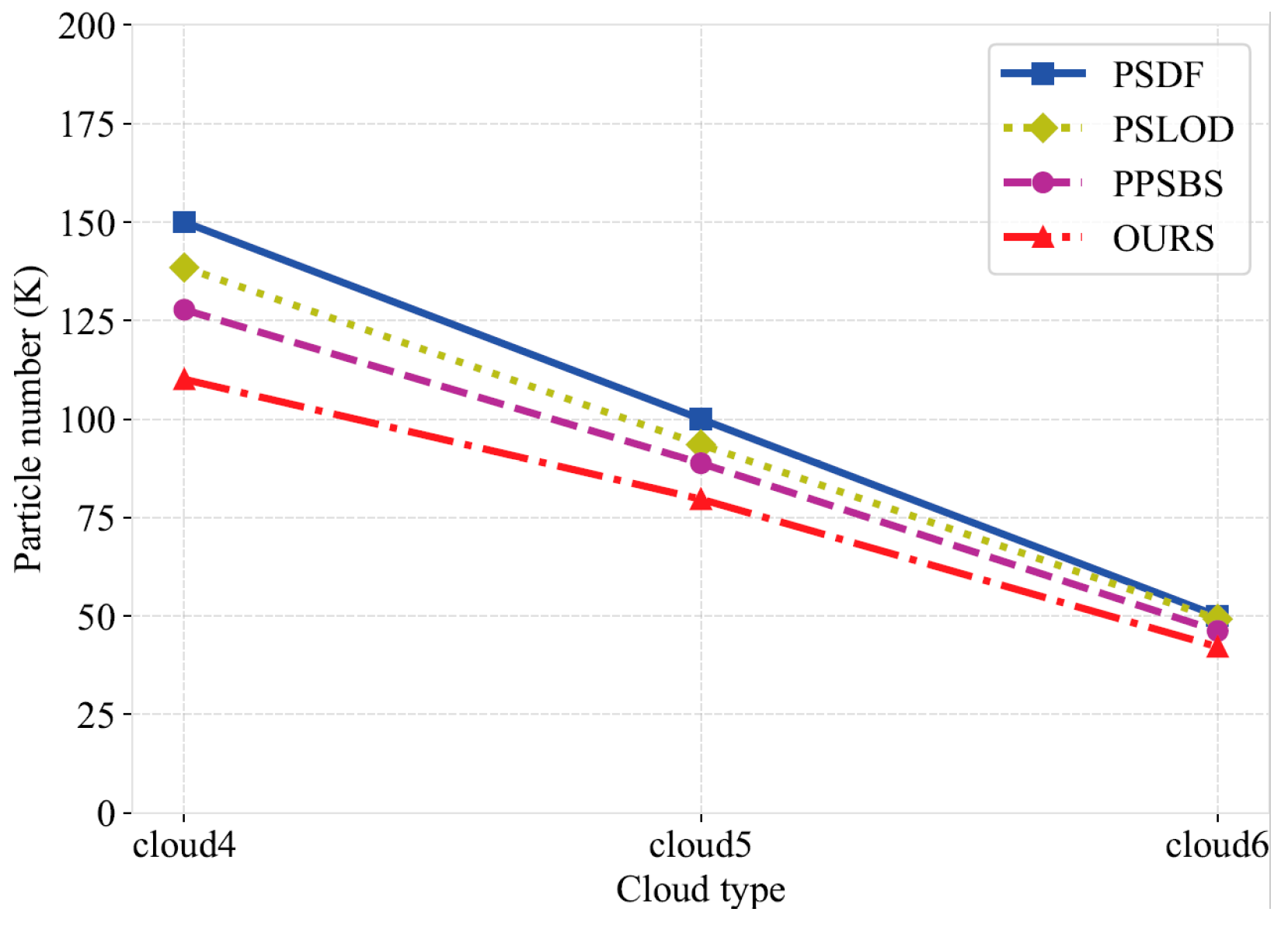
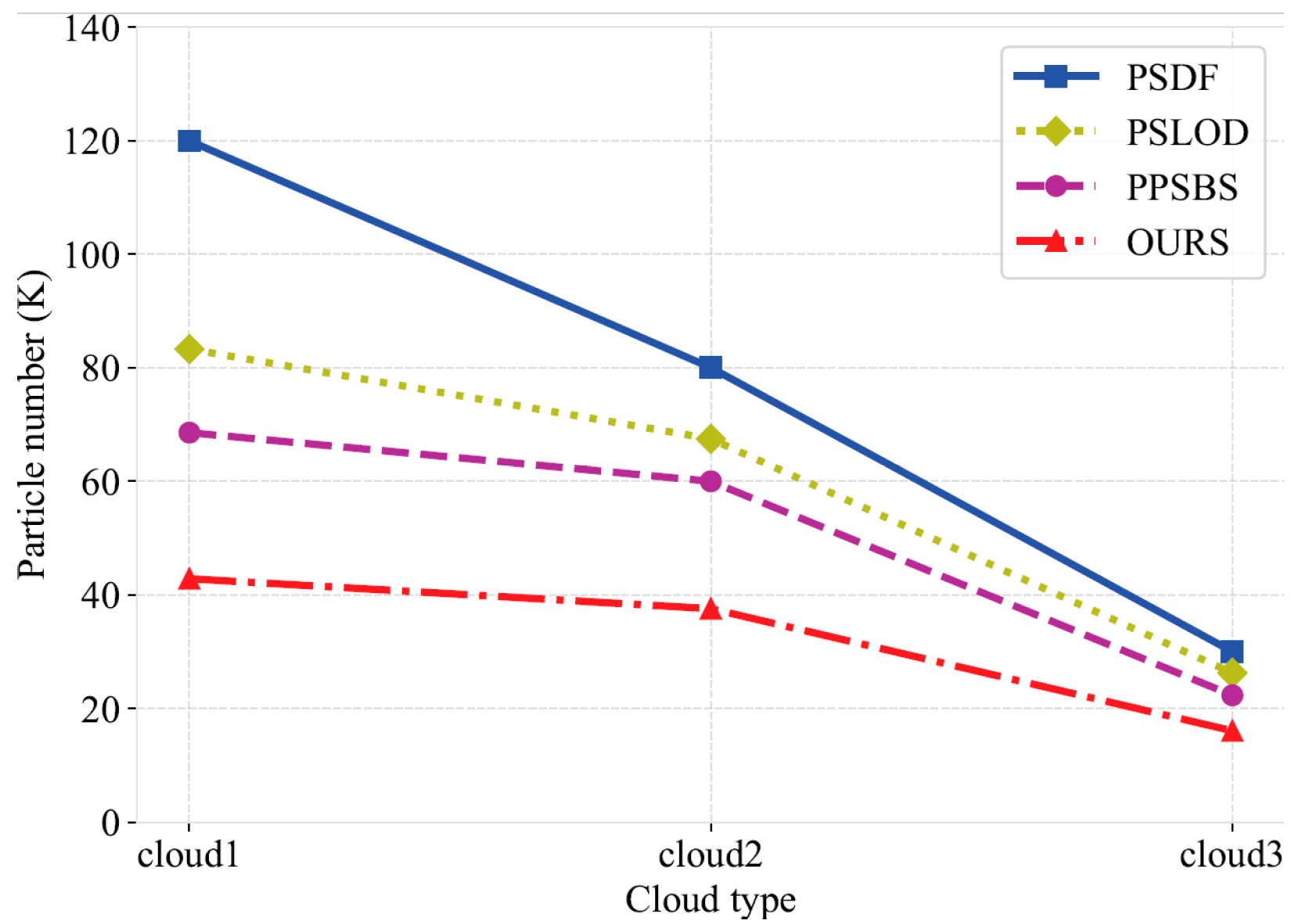
In this work, we propose a multi-level particle system 3D cloud modeling algorithm based on a WRF model to address the problem of current cloud modeling methods generally ignoring the differences in cloud characteristics at different heights and the high computational cost of remote modeling. First, we proposed a particle radius weight adjustment mechanism and a PID feedback mechanism based on the microphysical properties of clouds to enhance the differences in cloud structures at different altitudes. Secondly, based on the mean-shift algorithm, we introduced AKDE and designed a particle weighting and clustering strategy with an adaptive bandwidth to accurately capture the cloud density distribution and improve the hierarchical modeling performance. Finally, based on the correlation between the particle density in the edge region and the cloud contour, we carefully selected the optimal control points, and further improved the modeling efficiency through the cascade Bezier curve optimization under different viewing distances. The experimental results show that compared with similar algorithms, the running time of our algorithm is smaller by up to 60.1% at most and by an average of 37.5%, indicating enhanced computational efficiency and real-time capability. The number of particles is smaller by up to 64.3% at most and by an average of 30.1%, effectively reducing the calculation cost for long-range scenes. However, it should be noted that the module developed in this study has only been tested under specific meteorological phenomena, namely tropical cyclones and sea fog conditions, as these represent typical and complex weather scenarios that pose significant challenges for cloud modeling and visualization. We are also aware that when dealing with small-scale scenes, the improvement in the modeling efficiency of our algorithm is not significant, which to some extent limits its wide application in the field of cloud scene modeling. Therefore, future research will focus on improving the performance of the algorithm in small-scale scenes, further verifying it under a wider range of weather scenes, and actively exploring other potential modeling optimization strategies, with a view to further improving and expanding the application scope of this algorithm.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}