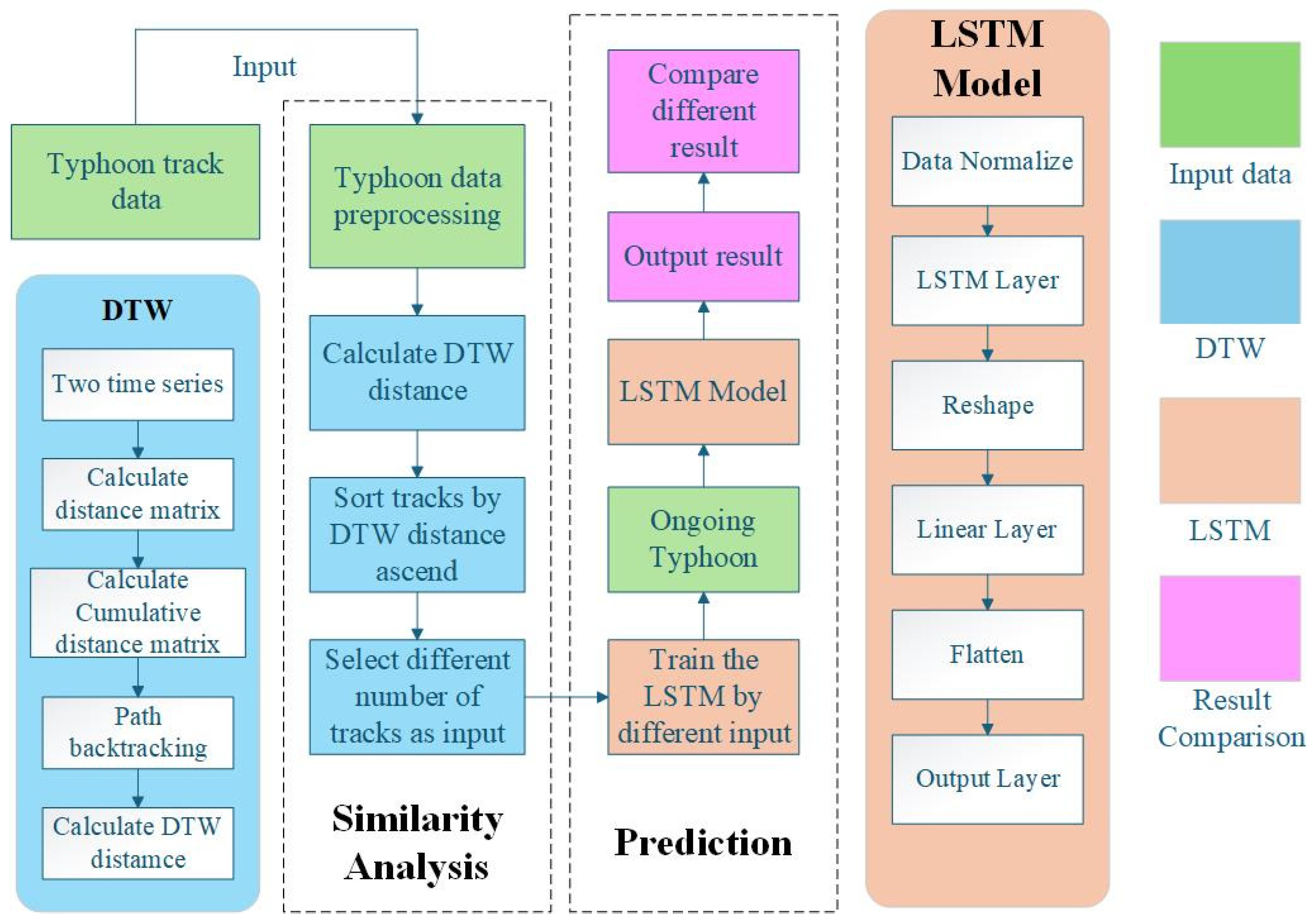
In this part, an LSTM deep learning model for processing and predicting typhoon tracks will be proposed. It learns the diverse input data provided by the similarity analysis model and predicts the real typhoon tracks in the future.
2.2.1. Long Short-Term Neural Network
A Long Short-Term Neural Network (LSTM) is a kind of Recurrent Neural Network (RNN) architecture designed to process a sequence of data and capable of learning long-term dependencies. Unlike standard RNNs, LSTMs are designed to avoid the vanishing gradient problem, which can limit the ability of conventional RNNs to learn long-term dependencies [
32]. These features make LSTM a good choice to handle predicting problems with long time series data.
LSTM has three gates, which control different parts of the LSTM cell. They are forget gate
, input gate
and output gate
. The candidate memory cell, represented as
is crucial in determining how the LSTM’s internal memory will evolve over time, serving as a ‘proposed update’ to the cell state. The data that is utilized to inform the decisions made by the LSTM gates and to compute the candidate memory cell comprises two primary components: the input data at the current time step
and the hidden state from the previous time step
. These two pieces of information work in tandem to shape the flow of data through the LSTM network and contribute to its ability to capture and retain long-term dependencies in sequential data. In this paper, we build a unidirectional LSTM network [
33] for typhoon track prediction.
In the LSTM cell, the Input Gate plays a role in determining which new information from the current input and previous hidden state should be added to the cell state, ensuring that only relevant and significant data are incorporated. The Forget Gate decides what information from the previous cell state is no longer needed and should be discarded, helping the network forget irrelevant details and focus on important features. In the last, the Output Gate regulates the output of the LSTM cell, controlling which parts of the cell state should be revealed based on the current context, thus providing the network with the ability to output information that is relevant for the next step in the sequence.
The hidden states in an LSTM cell are illustrated as follows:
where
is the batch size.
and
are the number of hidden units and features.
is a sigmoid activation function that ranges between 0 and 1, and the
function is a hyperbolic tangent activation function that squashes input values to a range between −1 and 1.
indicates element-wise multiplication.
and
are weight parameters and
are biased parameters.
2.2.2. Using an LSTM Model for Future Prediction
The LSTM model is built for processing typhoon data, because the track data are kind of sequence data. Also, LSTM is commonly used in future locations of moving objects, which means it has the ability to perform space-time prediction [
34]. In this paper, the deep learning model is a kind of multi-task LSTM model, which uses a network model to simultaneously predict the longitude and latitude [
35].
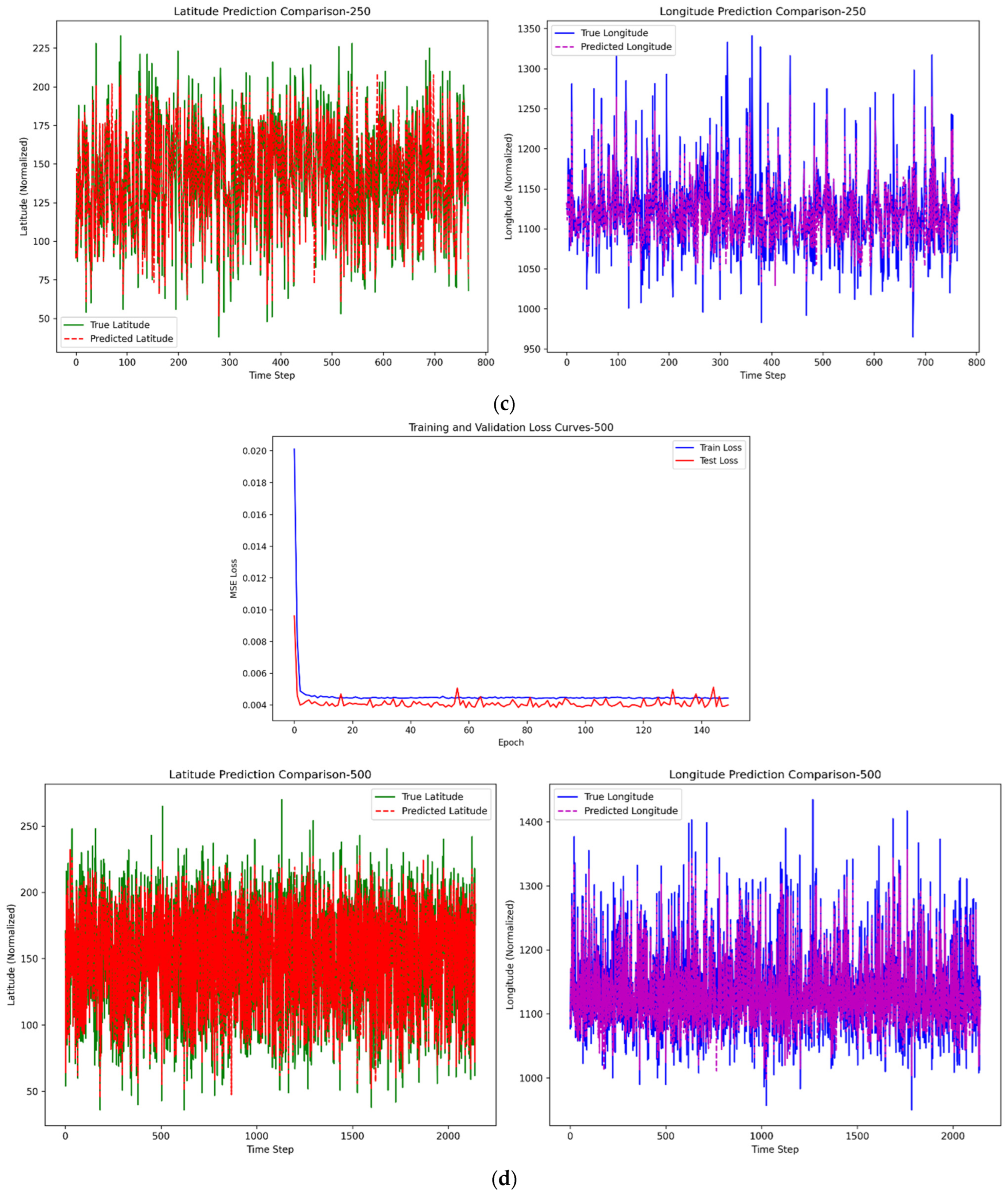
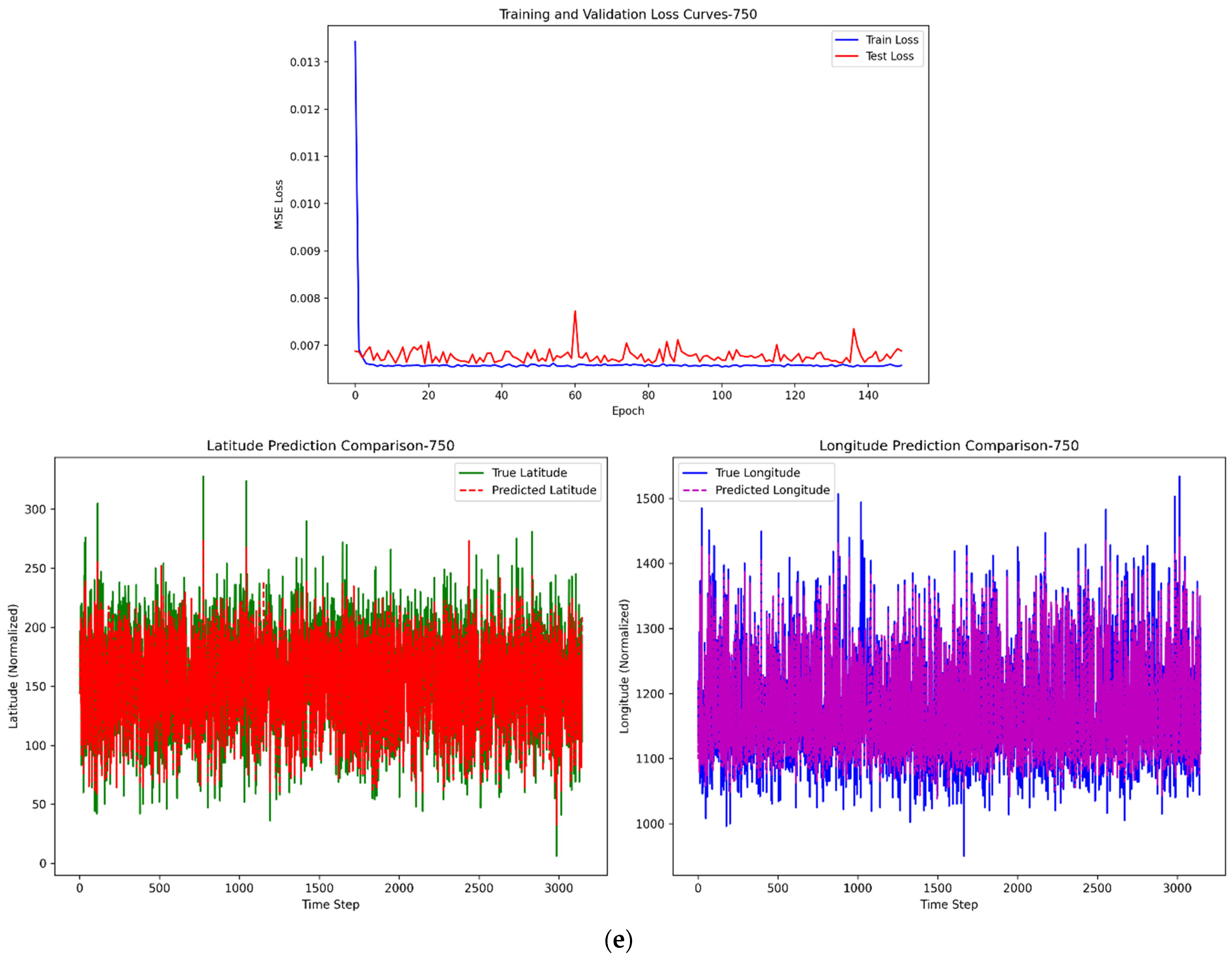
The input data to the model comprise four dimensions: typhoon intensity, central latitude, central longitude, and central pressure, which were retained during the data preprocessing phase. These variables collectively contribute to the computations within the LSTM layers, jointly determining the parameters of the hidden states and enhancing the predictive accuracy of the model. The optimal paths obtained using the DTW algorithm, comprising 50, 100, 250, 500, and 750 paths, are sequentially input into the LSTM model for training. The performance of the model is evaluated based on the results from the test set to determine the optimal number of paths. This approach allows for a systematic comparison of the model’s predictive accuracy across different path quantities, ultimately identifying the configuration that yields the highest performance in terms of typhoon trajectory prediction.
Before the data were input into the model, these numerical data, such as longitude, latitudes, can be normalized to [0,1] with the function below:
where
represents the original value and
represents the normalized value.
In this research, we design a sequence-to-sequence LSTM model that processes typhoon trajectory data and outputs predictions for each time step in the input sequence. This architecture preserves temporal resolution throughout the network, making it particularly suitable for real-time trajectory updating applications.
The model accepts 3D tensors with shape (sequence length, batch size, input size), where input size is set as 4 for latitude, longitude, pressure, wind speed, and the sequence length is set as 1.
The model generates one-step predictions through a modified output layer, producing a tensor of shape (batch size, 1, output size), where output size is set as 2, representing latitude and longitude coordinates at each future time step. In the four-step prediction, we change the shape of the tensor to (batch size, 4, output size) to directly output 4 steps ahead predictions by jointly learning from historical path sequences.
The architecture employs a two-layer stacked LSTM with hidden size, enabling hierarchical feature extraction from raw input sequences. Dropout is applied between LSTM layers to mitigate overfitting.
Then, a fully connected layer transforms the final LSTM hidden state into a flattened vector of length , which is then reshaped to (steps, output size) to explicitly represent multi-step predictions. In one-step prediction, “steps” is set as 1 and 4 in the four-step prediction.
To balance the learning, we choose Mean Square Error (MSE) as the loss function. The loss function is shown below:
where
represents the real path trajectory’s latitude or longitude, and
represents the predicted path trajectory’s latitude or longitude. These two losses will be added with the same weight. The Adam optimizer [
36] is proposed in this research to utilize for gradient adjustment in LSTM models. In Adam optimizer, a weight decay regularization term was implemented to counteract overfitting in the neural network architecture.
In the context of hyperparameter optimization, we have opted for the Bayesian optimization approach. Bayesian optimization is a method designed to efficiently explore and optimize black-box functions. It achieves this by constructing a probabilistic surrogate model, typically a Gaussian Process, to approximate the unknown function and guide the search toward its global optimum [
37]. The utilization of Bayesian optimization for hyperparameter tuning not only enhances the predictive accuracy of the model but also significantly curtails the temporal expenditure associated with the optimization process.
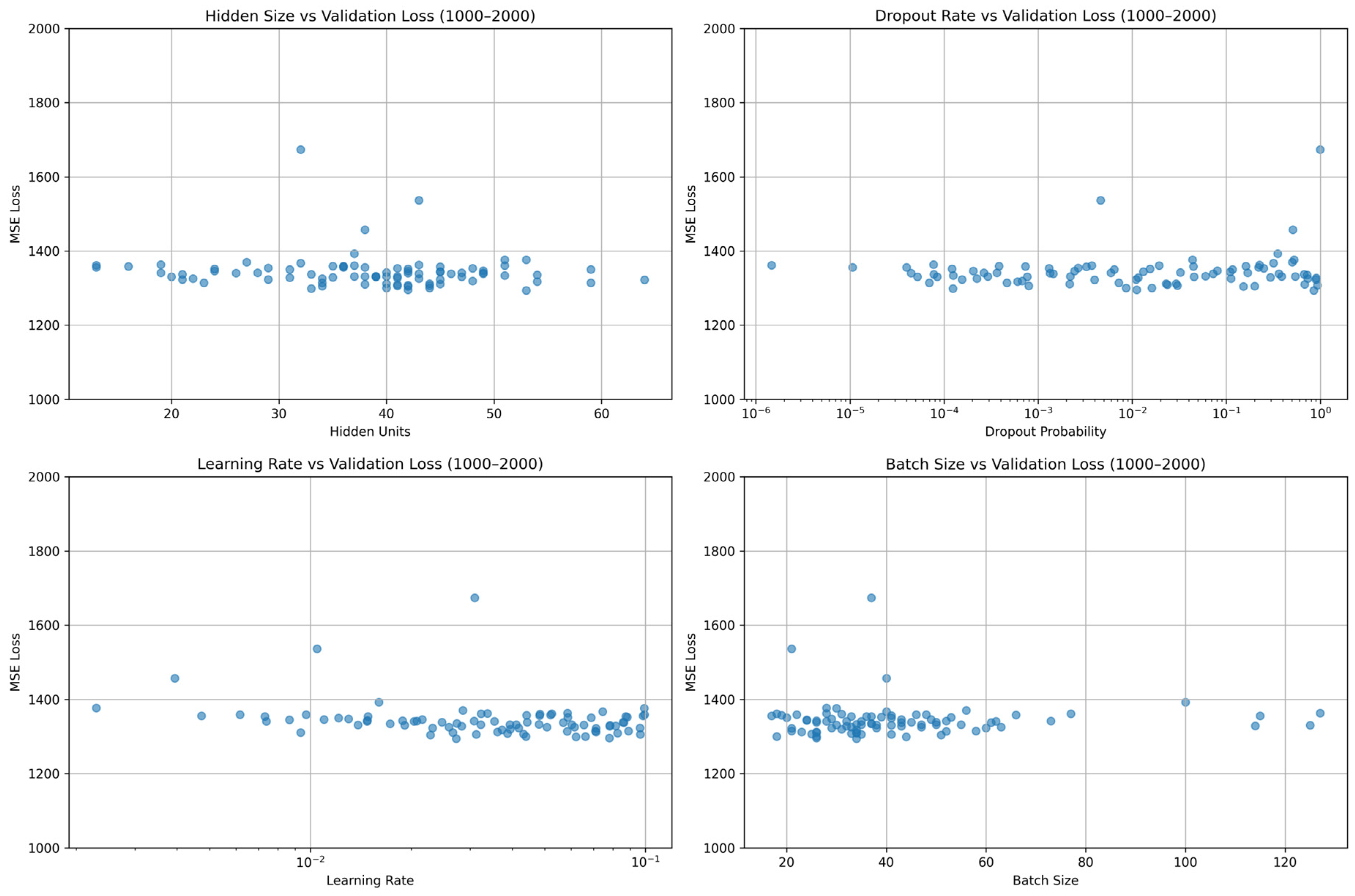
In the optimization, we allocated 70% of the dataset for training and reserved 30% for validation purposes during hyperparameter tuning. We conducted a systematic hyperparameter tuning process involving 1000 experimental trials to identify the optimal parameter configuration that minimizes the MSE on the validation dataset. The following key parameters were optimized: batch size, tested across a range of values to balance computational efficiency and gradient estimation quality. Network architecture parameters, like the number of hidden units and LSTM layers. Regularization parameters, like dropout and weight decay. In
Figure 2, 100 results of the batch size, dropout, learning rate, and number of hidden units are shown, but the visualization of these results lacks controlled variable analysis, potentially obscuring the individual effects of each hyperparameter on model performance.
After Bayesian optimization, the optimal hyperparameter combination we found is as follows: the batch size is set to 26, the number of hidden units is 42, the number of LSTM layers remains at 2, the learning rate is set to 0.007, the dropout rate is set to 0.09, and the weight decay is set to 0.0004. When hyperparameters are not set to their optimal values, they can significantly impact the performance and behavior of an LSTM model. Taking the learning rate as an example, when the learning rate is either too large or too small, the longitude–direction errors in the final prediction results are substantially large. A too high learning rate can cause the optimizer to overshoot optimal minima, leading to divergent training or oscillating convergence around the minimum, resulting in suboptimal final weights. A too low learning rate, however, slows down training drastically, potentially getting stuck in flat local minima or taking impractical time to converge, and might prematurely halt at a suboptimal solution due to limited training epochs. In the realm of forecasting future data, the methodology is bifurcated into one-step prediction and four-step prediction. One-step prediction and four-step prediction both use the latest data, according to the parameters in the LSTM model, to predict for a single future time step and for four consecutive future time steps. The whole process of one-step and four-step prediction will be proposed in
Section 3.







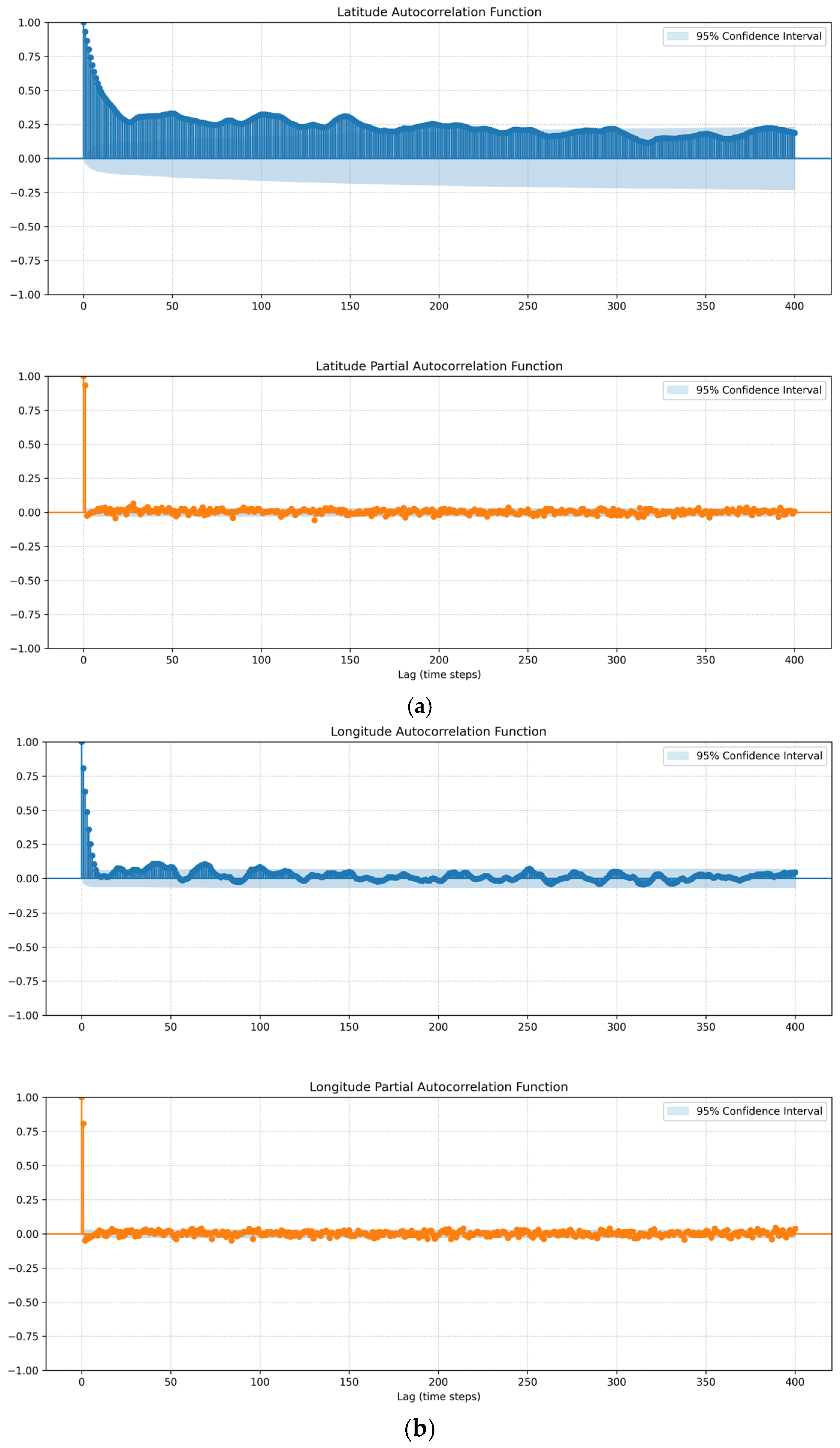



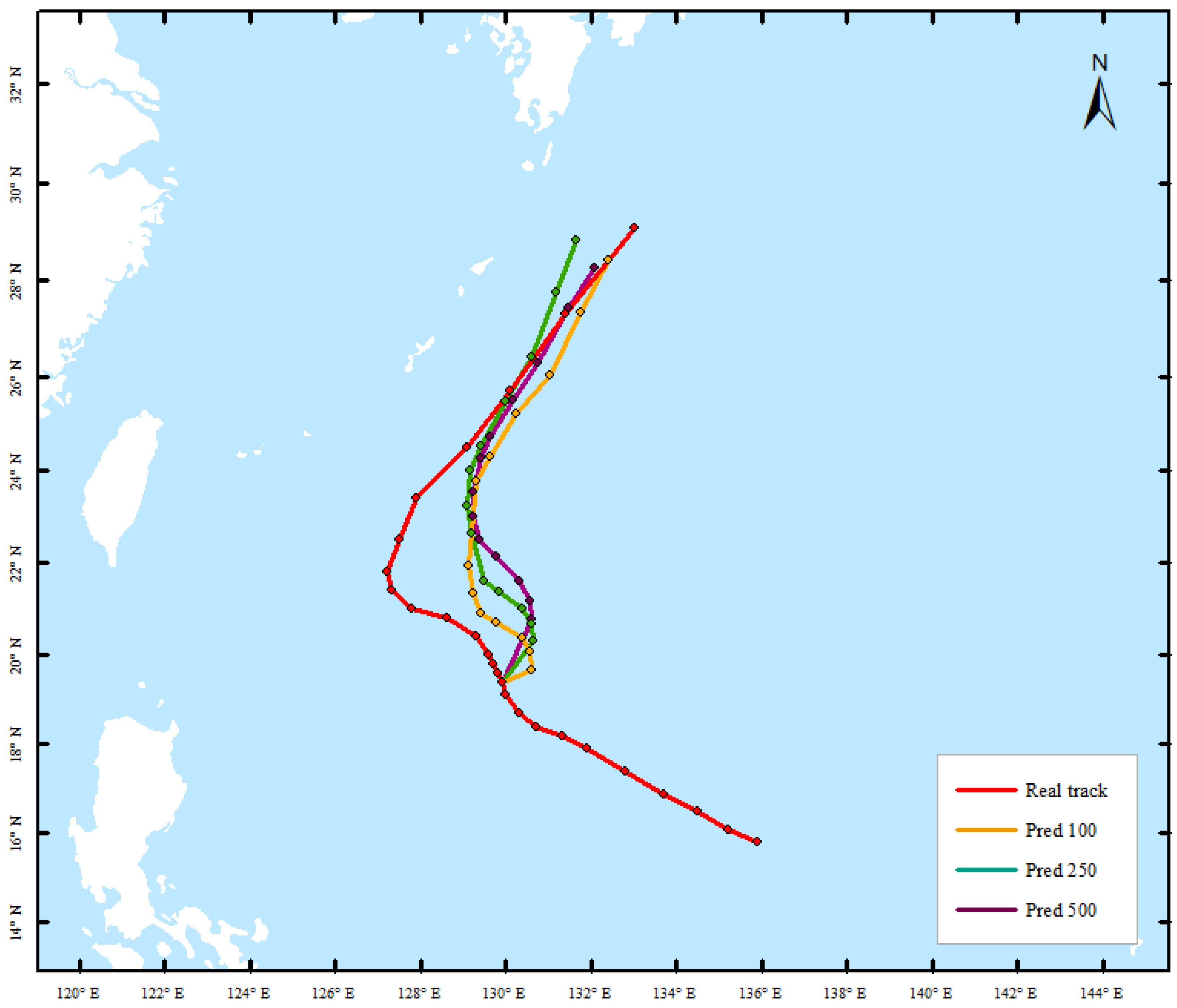

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}