
A Hybrid Transformer-CNN Model for Interpolating Meteorological Data on the Tibetan Plateau



Abstract
1. Introduction
2. Materials and Methods
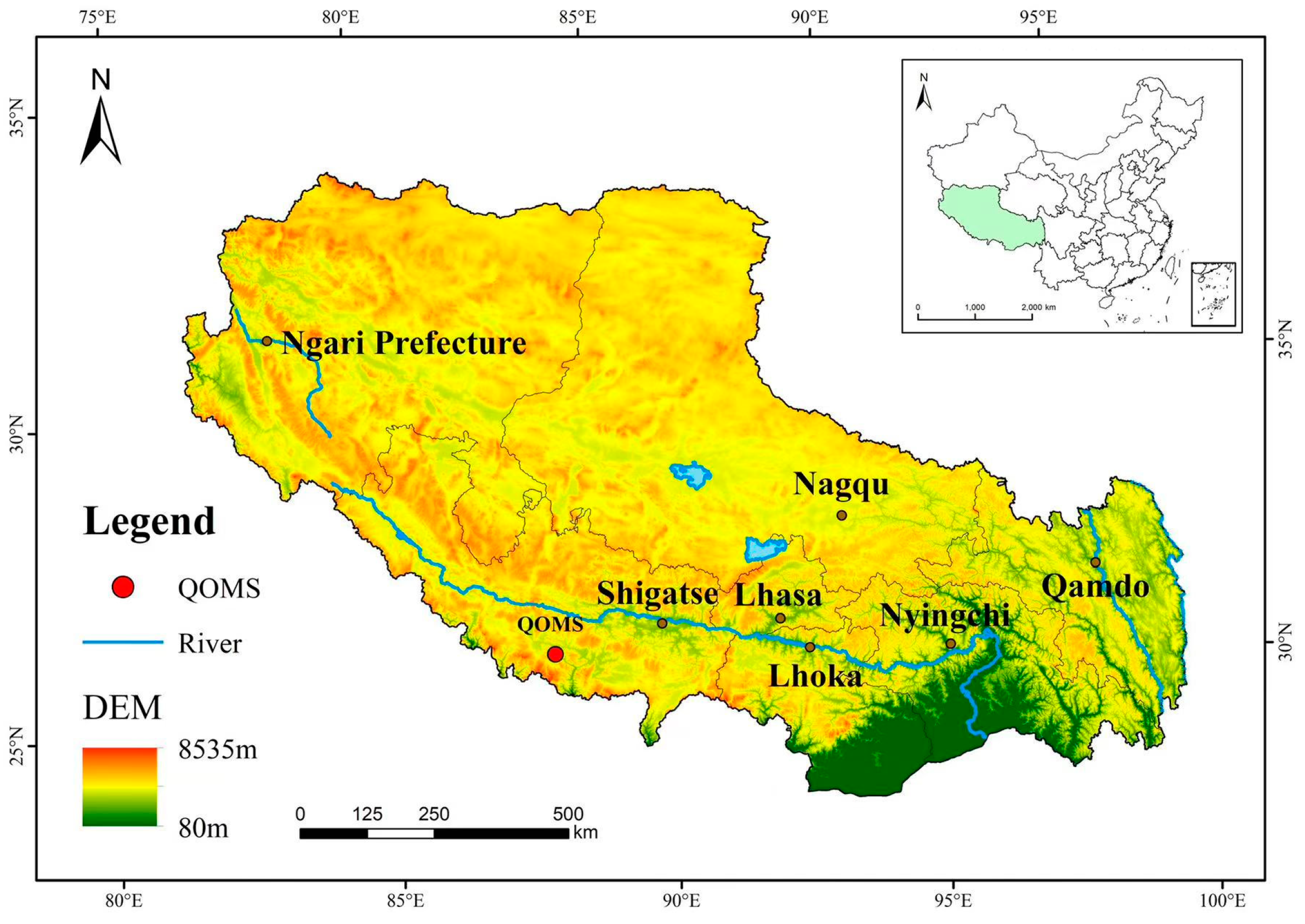
2.1. Study Area
2.2. Data
2.3. Data Processing
2.4. Experiments
2.4.1. OOB (Out-of-Bag)
2.4.2. Machine Learning Models
2.4.3. Deep Learning Models
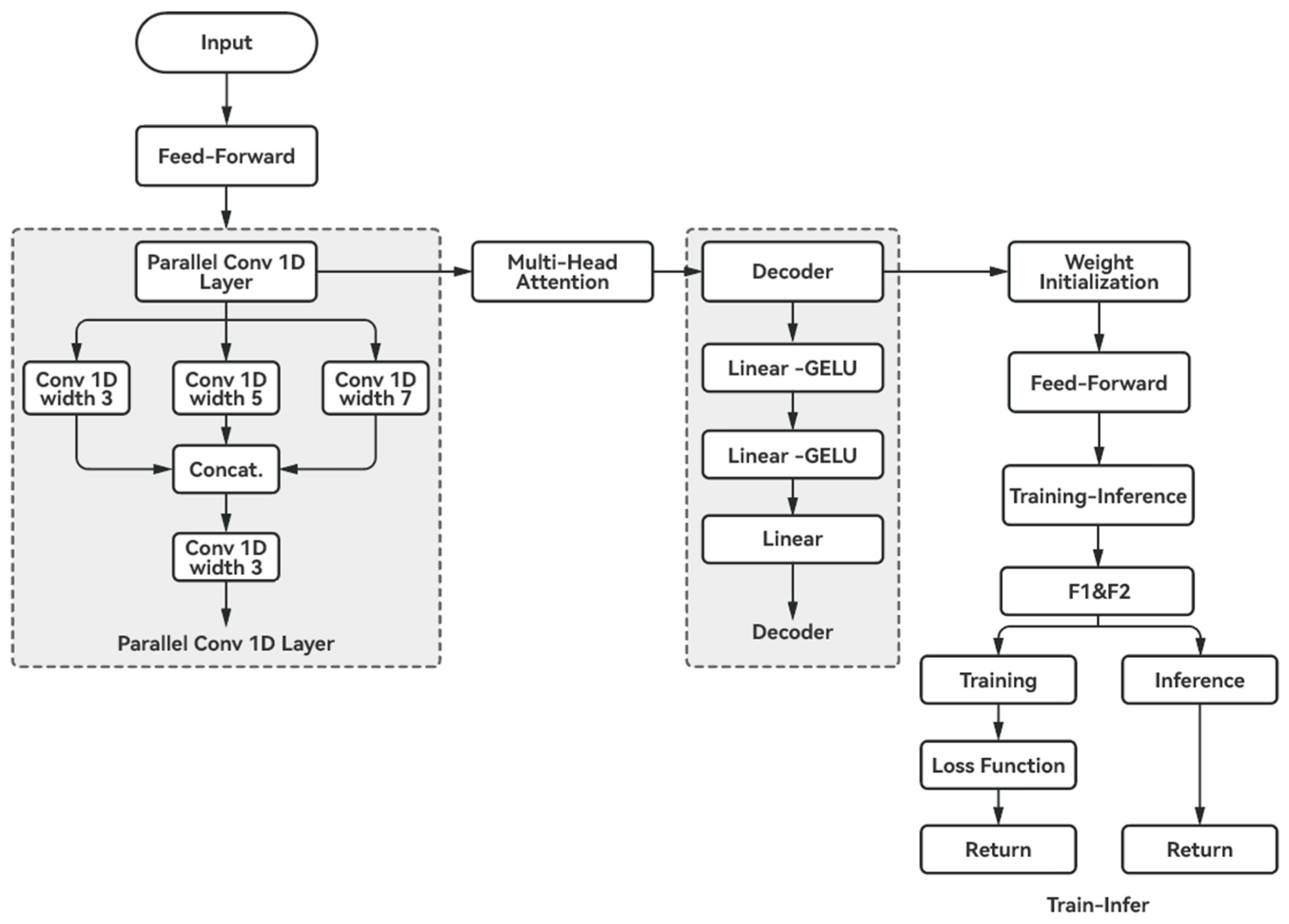
2.4.4. Transformer-CNN
2.4.5. Assessment of Model Performance
3. Results
3.1. Feature Importance and OOB Score
3.2. Inter-Comparison
3.3. Scatter Plot of Transformer-CNN
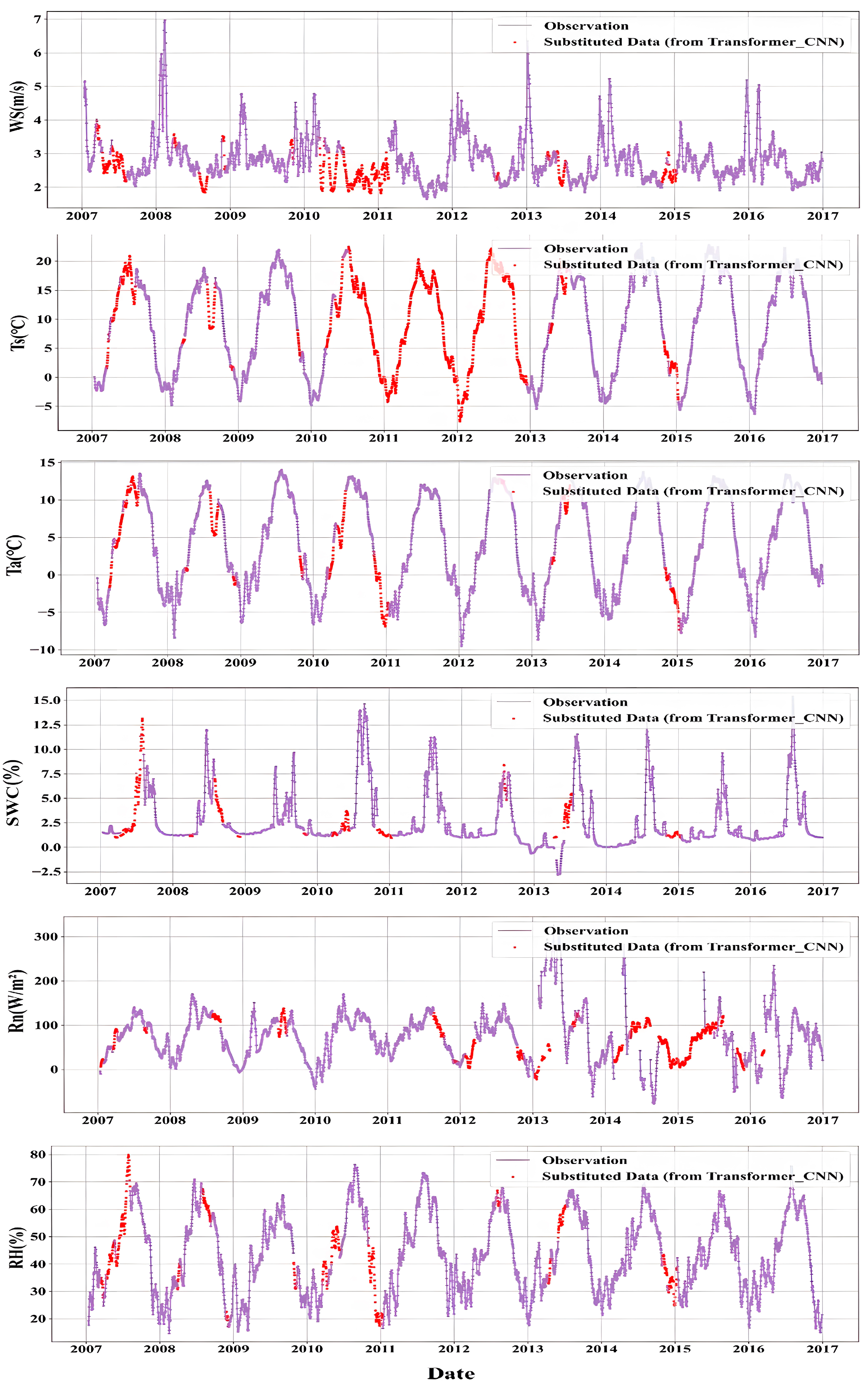
3.4. Complete Dataset
4. Discussion
4.1. Discussion on the Results of Transformer-CNN Model
4.2. Climate Change Trends
5. Conclusions
- Compared with seven traditional single machine learning methods, we found that the hybrid model significantly outperforms the single machine learning methods in meteorological data imputation, demonstrating the model’s superiority.
- The Transformer-CNN model performs best in simulating air temperature, relative humidity, wind speed, ground net radiation, and soil temperature. On the test dataset, the coefficients of determination for the interpolated results of Ta, RH, WS, SWC, Ts, and Rn were 0.97, 0.92, 0.97, 0.79, 0.93, and 0.98, respectively. These results underscore the model’s strong potential for meteorological data interpolation on the Qinghai-Tibet Plateau, though its effectiveness ultimately hinges on the complexity of the target elements and the quality and comprehensiveness of the input data.
- Using the imputed data for linear regression and Mann-Kendall trend tests, air temperature and soil temperature shown an upward trend, while wind speed, soil moisture content, and ground net radiation show a downward trend against the backdrop of global warming. This finding provides more comprehensive and robust data support for the trend of climate change on the Tibetan Plateau in the context of global warming.
- This study only utilized QOMS station data for the interpolation analysis, which may not fully represent the diverse environmental conditions across the Qinghai-Tibet Plateau. To improve the generalizability of the results, future work will include the use of data from multiple stations throughout the plateau. This will allow for a more comprehensive analysis and provide a better representation of the spatial variability within the region. Additionally, the integration of remote sensing data and climate model outputs could further enhance the accuracy of the interpolated meteorological elements. Expanding the dataset and employing these additional resources will improve the robustness of the findings, providing more reliable insights into the climate dynamics of the Qinghai-Tibet Plateau.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Yang, K.; Prein, A.F. Added value of kilometer-scale modeling over the third pole region: A CORDEX-CPTP pilot study. Clim. Dynam. 2021, 57, 1673–1687. [Google Scholar]
- Qiu, J. The third pole. Nature 2008, 454, 393–396. [Google Scholar] [PubMed]
- Duan, A.M.; Wu, G.X. Role of the Tibetan Plateau thermal forcing in the summer climate patterns over subtropical Asia. Clim. Dyn. 2005, 24, 793–807. [Google Scholar]
- Haylock, M.R.; Hofstra, N.; Klein Tank, A.M.G.; Klok, E.J.; Jones, P.D.; New, M. A European Daily High-Resolution Gridded Data Set of Surface Temperature and Precipitation for 1950–2006. J. Geophys. Res. Atmos. 2008, 113, D20119. [Google Scholar]
- Kang, S.; Xu, Y.; You, Q.; Flügel, W.A.; Pepin, N.; Yao, T. Review of climate and cryospheric change in the Tibetan Plateau. Environ. Res. Lett. 2022, 5, 015101. [Google Scholar]
- Li, Z.; Yang, K.; Wang, W.; Guo, X.; Chen, Y. Method for Estimating Missing Meteorological Data over the Tibetan Plateau. J. Geophys. Res. Atmos. 2014, 119, 11509–11525. [Google Scholar]
- Sun, S.; Chen, Y.; Li, W.; Liu, M.; Li, Q. Spatial Interpolation of Meteorological Data Based on Thin Plate Spline Method in the Tibetan Plateau. Atmos. Ocean. Sci. Lett. 2016, 9, 133–138. [Google Scholar]
- Vekuri, H.; Tuovinen, J.-P.; Kulmala, L.; Papale, D.; Kolari, P.; Aurela, M.; Laurila, T.; Liski, J.; Lohila, A. A widely-used eddy covariance gap-filling method creates systematic bias in carbon balance estimates. Sci. Rep. 2023, 13, 1720. [Google Scholar]
- Zhu, S.; McCalmont, J.; Cardenas, L.M.; Cunliffe, A.M.; Olde, L.; Signori-Müller, C.; Litvak, M.E.; Hill, T. Gap-filling carbon dioxide, water, energy, and methane fluxes in challenging ecosystems: Comparing between methods, drivers, and gap-lengths. Agric. For. Meteorol. 2023, 332, 109365. [Google Scholar]
- Afrifa-Yamoah, E.; Mueller, U.A.; Taylor, S.M.; Fisher, A.J. Missing Data Imputation of High-Resolution Temporal Climate Time Series Data. Meteorol. Appl. 2020, 27, e1873. [Google Scholar]
- Lompar, M.; Lalić, B.; Dekić, L.; Petrić, M. Filling Gaps in Hourly Air Temperature Data Using Debiased ERA5 Data. Atmosphere 2019, 10, 13. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Ren, Z.H. Application of Standard Sequence Method in Interpolation of Missing Daily Average Temperature Data. In Proceedings of the 8th National Symposium on Outstanding Young Meteorological Scientists, Yixing, China, 28 October–1 November 2014; p. 11. (In Chinese). [Google Scholar]
- Li, Z.N.; Zheng, J.; Qin, F.Q. Research on Interpolation Methods for Missing Wind Field Data. J. Nat. Disasters 2014, 23, 58–65. [Google Scholar]
- Sun, Y.; Wang, H.J.; Zhou, Y.H. Applicability of Three Interpolation Methods for Daily Temperature Missing Data at Regional Automatic Weather Stations. Torrential. Rain. Disasters 2023, 42, 97–104. (In Chinese) [Google Scholar]
- Gandin, L.S.; Kagan, R.L. Statistical Methods for Interpretation of Meteorological Data; Gidrometeoizdat: Leningrad, Russia, 1976. [Google Scholar]
- Yan, L.L.; Wen, S.Y.; Gao, W.J. Research and Preliminary Application of Interpolation Methods for Missing Hourly Temperature Data. Technol. Seism. Disaster Prev. 2019, 14, 446–455. [Google Scholar]
- Yu, W. Construction of Meteorological Similarity Network and Interpolation of Missing Meteorological Elements Data. Master’s Thesis, Southwest University, Chongqing, China, 2015. (In Chinese). [Google Scholar]
- Chen, X.; Xu, C.-Y.; Guo, S. Comparison and Evaluation of Multiple Data-Driven Methods for Interpolating Monthly Mean Precipitation in China. J. Hydrol. 2016, 542, 711–727. [Google Scholar]
- Krasnopolsky, V.M.; Fox-Rabinovitz, M.S. Complex Hybrid Models Combining Neural Networks and Other Components for Atmospheric Applications. Neural Netw. 2006, 19, 122–134. [Google Scholar] [CrossRef]
- Di Piazza, A.; Lo Conti, F.; Noto, L.V.; Viola, F.; La Loggia, G. Comparative Analysis of Different Techniques for Spatial Interpolation of Rainfall Data to Create Rainfall Maps at the Regional Scale. J. Hydrol. 2011, 409, 118–133. [Google Scholar]
- Khan, M.S.; Coulibaly, P.; Dibike, Y. Uncertainty Analysis of Statistical Downscaling Methods. J. Hydrol. 2006, 319, 357–382. [Google Scholar] [CrossRef]
- Samal, K.K.R.; Panda, A.K.; Babu, K.S.; Rao, D.R.K. An Improved Pollution Forecasting Model with Meteorological Impact Using Multiple Imputation and Fine-Tuning Approach. Sustain. Cities Soc. 2021, 70, 102923. [Google Scholar] [CrossRef]
- Sun, W.; Yu, Z.; Wei, Y.; Sun, L. Statistical Downscaling of Meteorological Variables for Climate Change Impact Assessment in an Alpine Region. Stoch. Environ. Res. Risk Assess. 2016, 30, 131–146. [Google Scholar]
- Sattari, M.T.; Rezazadeh-Joudi, A.; Kusiak, A. Assessment of Different Methods for Estimation of Missing Data in Precipitation Studies. Hydrol. Res. 2017, 48, 1032–1044. [Google Scholar]
- Han, E.H.; Wen, X.L.; Wang, B.B. Application of Meteorological Reanalysis Data in Interpolation of Missing Data from Wind Measurement Towers in Complex Mountainous Wind Farms. Jiangxi Sci. 2017, 35, 200–205+234. (In Chinese) [Google Scholar]
- Tang, H.Q.; Li, Q.Y.; Liu, Z.J. Research on Meteorological Data Interpolation Method Based on Rough RBF Neural Network. Comput. Eng. Des. 2014, 35, 282–286. [Google Scholar]
- Zheng, X.T.; Bian, T.T.; Zhang, D.Q.; He, W. Interpolation of Long Time Missing Values of Temperature Based on Deep Learning. Comput. Syst. Appl. 2022, 31, 221–228. (In Chinese) [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep Learning and Process Understanding for Data-Driven Earth System Science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Ma, Y.; Ma, W.; Hu, Z.; Su, Z. Application of Deep Learning for the Prediction of Rainfall in the Tibetan Plateau. Atmos. Res. 2018, 200, 50–60. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model. Adv. Neural Inf. Process. Syst. 2017, 30, 5617–5627. [Google Scholar]
- Ma, Y.; Xie, Z.; Ma, W.; Han, C.; Sun, F.; Sun, G.; Liu, L.; Lai, Y.; Wang, B.; Liu, X.; et al. A Comprehensive Observation Station for Climate Change Research on the Top of Earth. Bull. Am. Meteorol. Soc. 2023, 104, E563–E584. [Google Scholar] [CrossRef]
- Cheng, G.; Li, H.; Liu, S. Data Quality Control in Meteorological Research: Case Studies from Tibetan Plateau Observations. Int. J. Climatol. 2017, 37, 103–115. [Google Scholar]
- Gao, Z.; Bian, L.; Zhou, X. Measurements of turbulent transfer in the near-surface layer over a rice paddy in China. J. Geophys. Res. 2003, 108, 4535. [Google Scholar]
- Wang, S.; Zhang, Y.; Lü, S.; Shang, L.; Liu, H. Estimation of Turbulent Fluxes Using the Flux-Variance Method over an Alpine Meadow Surface in the Eastern Tibetan Plateau. Adv. Atmos. Sci. 2009, 26, 717–726. [Google Scholar]
- Troyanskaya, O.; Cantor, M.; Sherlock, G.; Brown, P.; Hastie, T.; Tibshirani, R.; Botstein, D.; Altman, R.B. Missing Value Estimation Methods for DNA Microarrays. Bioinformatics 2001, 17, 520–525. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Monard, M.C. A Study of K-Nearest Neighbour as an Imputation Method. Front. Artif. Intell. Appl. 2002, 87, 251–260. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE T Inform. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Wu, R.; Liang, Y.; Lin, L.; Zhang, Z. Spatiotemporal Multivariate Weather Prediction Network Based on CNN-Transformer. Sensors 2024, 24, 7837. [Google Scholar] [CrossRef]
- Zhang, Y.; Long, M.; Chen, K.; Xing, L.; Jin, R.; Jordan, M.I.; Wang, J. Skilful Nowcasting of Extreme Precipitation with NowcastNet. Nature 2023, 619, 526–532. [Google Scholar] [CrossRef] [PubMed]
- Alerskans, E.; Nyborg, J.; Birk, M.; Kaas, E. A Transformer Neural Network for Predicting Near-Surface Temperature. Meteorol. Appl. 2022, 29, e2098. [Google Scholar] [CrossRef]
- Chen, R.; Wang, X.; Zhang, W.; Zhu, X.; Li, A.; Yang, C. A Hybrid CNN-LSTM Model for Typhoon Formation Forecasting. GeoInformatica 2019, 23, 375–396. [Google Scholar] [CrossRef]
- Dehghani, A.; Moazam, H.M.Z.H.; Mortazavizadeh, F.; Ranjbar, V.; Mirzaei, M.; Mortezavi, S.; Ng, J.L.; Dehghani, A. Comparative Evaluation of LSTM, CNN, and ConvLSTM for Hourly Short-Term Streamflow Forecasting Using Deep Learning Approaches. Ecol. Inform. 2023, 75, 102119. [Google Scholar] [CrossRef]
- Liu, S.; Liu, K.; Wang, Z.; Liu, Y.; Bai, B.; Zhao, R. Investigation of a Transformer-Based Hybrid Artificial Neural Network for Climate Data Prediction and Analysis. Front. Environ. Sci. 2025, 12, 1464241. [Google Scholar] [CrossRef]
- Charlton-Perez, A.J.; Dacre, H.F.; Driscoll, S.; Gray, S.L.; Harvey, B.; Harvey, N.J.; Hunt, K.M.; Lee, R.W.; Swaminathan, R.; Vandaele, R.; et al. Do AI Models Produce Better Weather Forecasts Than Physics-Based Models? A Quantitative Evaluation Case Study of Storm Ciarán. NPJ Clim. Atmos. Sci. 2024, 7, 93. [Google Scholar] [CrossRef]
- Liu, F.; Wang, X.; Sun, F.; Wang, H.; Wu, L.; Zhang, X.; Liu, W.; Che, H. Correction of Overestimation in Observed Land Surface Temperatures Based on Machine Learning Models. J. Clim. 2022, 35, 5359–5377. [Google Scholar] [CrossRef]
- Taheri, M.; Schreiner, H.K.; Mohammadian, A.; Shirkhani, H.; Payeur, P.; Imanian, H.; Cobo, J.H. A Review of Machine Learning Approaches to Soil Temperature Estimation. Sustainability 2023, 15, 7677. [Google Scholar] [CrossRef]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of Machine Learning Approaches for Biomass and Soil Moisture Retrievals from Remote Sensing Data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef]
- Feng, Y.; Cui, N.; Hao, W.; Gao, L.; Gong, D. Estimation of Soil Temperature from Meteorological Data Using Different Machine Learning Models. Geoderma 2019, 338, 67–77. [Google Scholar] [CrossRef]
- Zare Abyaneh, H.; Bayat Varkeshi, M.; Golmohammadi, G.; Mohammadi, K. Soil Temperature Estimation Using an Artificial Neural Network and Co-Active Neuro-Fuzzy Inference System in Two Different Climates. Arab. J. Geosci. 2016, 9, 377. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, G. Estimation of Soil Moisture from Optical and Thermal Remote Sensing: A Review. Sensors 2016, 16, 1308. [Google Scholar] [CrossRef]
- Li, P.; Zha, Y.; Shi, L.; Tso, C.-H.M.; Zhang, Y.; Zeng, W. Comparison of the Use of a Physical-Based Model with Data Assimilation and Machine Learning Methods for Simulating Soil Water Dynamics. J. Hydrol. 2020, 584, 124692. [Google Scholar] [CrossRef]
- Breen, K.H.; James, S.C.; White, J.D.; Allen, P.M.; Arnold, J.G. A Hybrid Artificial Neural Network to Estimate Soil Moisture Using SWAT+ and SMAP Data. Mach. Learn. Knowl. Extr. 2020, 2, 16. [Google Scholar] [CrossRef]
- Phuong, D.N.D.; Tram, V.N.Q.; Nhat, T.T.; Ly, T.D.; Loi, N.K. Hydro-meteorological trend analysis using the Mann-Kendall and innovative-Şen methodologies: A case study. Int. J. Glob. Warm. 2020, 20, 145–164. [Google Scholar] [CrossRef]
- Zhao, L.; Wu, T.; Marchenko, S.S.; Sharkhuu, N. Thermal state of permafrost and active layer in Central Asia during the international polar year. Permafrost. Periglac. 2010, 21, 198–207. [Google Scholar] [CrossRef]
- Yang, K.; Wu, H.; Qin, J.; Lin, C.; Tang, W.; Chen, Y. Recent climate changes over the Tibetan Plateau and their impacts on energy and water cycle: A review. Global. Planet. Chang. 2014, 112, 79–91. [Google Scholar] [CrossRef]
- Yang, K.; Guo, X.; Wu, B. Recent trends in surface wind speed over the Tibetan Plateau. J. Clim. 2011, 24, 6540–6552. [Google Scholar]
- Li, Y.; Ma, Y.; Wu, R.; Sun, G.; Hu, Z. Decline in wind speed explains more than 60% of the decrease in potential evaporation across the Tibetan Plateau during 1980–2015. J. Hydrol. 2019, 580, 124235. [Google Scholar]
- Wang, W.; Ma, Y.; Li, M.; Zhang, M.; Hu, Z.; Wang, Y. Characteristics of the surface radiation balance in the northeastern Tibetan Plateau. J. Geophys. Res.-Atmos. 2016, 121, 11018–11034. [Google Scholar]
- Liang, S.; Wang, D.; He, T.; Yu, Y. Remote sensing of earth’s energy budget: Synthesis and review. Int. J. Digit. Earth 2019, 12, 737–780. [Google Scholar]
- Duan, A.; Xiao, Z. Does the climate warming hiatus exist over the Tibetan Plateau? Sci. Rep. 2015, 5, 13711. [Google Scholar]
- Yang, M.; Nelson, F.E.; Shiklomanov, N.I.; Guo, D.; Wan, G. Permafrost degradation and its environmental effects on the Tibetan Plateau: A review of recent research. Earth-Sci. Rev. 2010, 103, 31–44. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Element | Sensor Model | Manufacturer | Height/Depth | Unit |
|---|---|---|---|---|---|
| Ta | Air temperature | HMP45C-GM | Vaisala | 1.5 m | °C |
| WS | Wind speed | 034B | MetOne | 1.5 m | m/s |
| WD | Wind direction | ° | |||
| RH | Humidity | HMP45C-GM | Vaisala | 1.5 m | % |
| P | Pressure | PTB220A | Vaisala | - | hPa |
| Rn | Radiations | CNR1 | Kipp & Zonen | - | W/m2 |
| Prec | Precipitation | RG13H | Vaisala | - | mm |
| Ts | Soil temperature | Model107 | Campbell | 0 cm | °C |
| SWC | Soil water content | CS616 | Campbell | 0 cm | v/v% |
| G0 | Soil heat flux | HFP01 | Hukseflflux | 0.05 m | W/m2 |
| H | Sensible heat flux | CSAT3 | Campbell | 3.25 m | W/m2 |
| LE | Latent heat flux | LI-7500 | Li-COR |
| Element | WS | Ta | RH | Rn | Ts | SWC |
|---|---|---|---|---|---|---|
| gap_value | 13% | 10.35% | 11.37% | 30.17% | 29.56% | 14.35% |
| Sets | Ta | RH | WS | SWC | Ts | Rn | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMES | R2 | |
| SVR | 2.73 | 0.90 | 12.20 | 0.78 | 1.28 | 0.66 | 2.67 | 061 | 5.71 | 0.83 | 101.18 | 0.82 |
| KNN | 3.70 | 0.83 | 14.13 | 0.74 | 1.35 | 0.65 | 2.56 | 0.60 | 5.04 | 0.87 | 112.75 | 0.78 |
| XGBoost | 3.19 | 0.87 | 12.79 | 0.76 | 1.26 | 0.68 | 2.59 | 0.59 | 5.15 | 0.86 | 105.51 | 0.81 |
| RF | 2.96 | 0.89 | 11.36 | 0.80 | 1.08 | 0.82 | 4.89 | 0.51 | 5.02 | 0.87 | 116.54 | 0.81 |
| LSTM | 2.94 | 0.90 | 14.36 | 0.71 | 1.14 | 0.74 | 4.44 | 0.52 | 5.46 | 0.85 | 126.53 | 0.77 |
| GRU | 2.75 | 0.91 | 12.94 | 0.77 | 0.99 | 0.76 | 3.12 | 0.56 | 4.98 | 0.87 | 108.64 | 0.80 |
| Transformer | 2.47 | 0.92 | 11.28 | 0.81 | 0.89 | 0.79 | 2.26 | 0.69 | 4.80 | 0.88 | 99.94 | 0.83 |
| Transformer-CNN | 1.50 | 0.97 | 7.48 | 0.92 | 0.35 | 0.97 | 1.85 | 0.79 | 3.67 | 0.93 | 35.44 | 0.98 |
| Indicator | MK Statistic | p-Value | Fitting Equation | Trend |
|---|---|---|---|---|
| Ta | 2.30 | 0.022 | Y = 1.95 × 10−4X + 3.70 | Increasing |
| RH | / | / | / | No trend |
| Ts | 4.34 | 1.37 × 10−5 | Y = 5.08 × 10−5X + 8.1123 | Increasing |
| WS | −7.11 | 1.18 × 10−12 | Y = −9.5 × 10−6X +2.945 | Decreasing |
| SWC | −20.56 | 0 | Y = 3.23 × 10−4X + 3.18 | Decreasing |
| Rn | −4.44 | 8.81 × 10−6 | Y = −2.44 × 10−3X + 78.47 | Decreasing |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Q.; Gao, Z.; Lu, M.; Yu, Y. A Hybrid Transformer-CNN Model for Interpolating Meteorological Data on the Tibetan Plateau. Atmosphere 2025, 16, 431. https://doi.org/10.3390/atmos16040431
Hou Q, Gao Z, Lu M, Yu Y. A Hybrid Transformer-CNN Model for Interpolating Meteorological Data on the Tibetan Plateau. Atmosphere. 2025; 16(4):431. https://doi.org/10.3390/atmos16040431
Chicago/Turabian StyleHou, Quanzhe, Zhiqiu Gao, Mingxinyu Lu, and Yinxin Yu. 2025. "A Hybrid Transformer-CNN Model for Interpolating Meteorological Data on the Tibetan Plateau" Atmosphere 16, no. 4: 431. https://doi.org/10.3390/atmos16040431
APA StyleHou, Q., Gao, Z., Lu, M., & Yu, Y. (2025). A Hybrid Transformer-CNN Model for Interpolating Meteorological Data on the Tibetan Plateau. Atmosphere, 16(4), 431. https://doi.org/10.3390/atmos16040431