1. Introduction
One of the global problems is atmospheric pollution, which is one of the main risks to public health, being the most important cause of death worldwide [
1]. This is a global problem that affects both developed countries, especially in their large cities, and developing countries, so air pollution can have various adverse effects on the natural environment, highlighting in the first place, acid rain, smog, loss of biodiversity, climate change, and ozone layer depletion [
2].
Air pollution is a worldwide problem, where the main pollutants affecting the atmosphere are gases (CO, NO
2, SO
2, and Pb) and particulate matter PM
10 and PM
2.5 [
3,
4] These are generally released by anthropogenic and natural sources, where respiratory morbidity studies are implicated for certain types of air pollutants according to the World Health Organization (WHO), the main one being particulate matter, PM
2.5 [
5,
6]. PM
10 and PM
2.5 particles are those that generate a negative effect on health, as well as on the environment and ecosystems; these dangerous particles suspended in the air are composed of solid and liquid particles [
7,
8].
According to the WHO [
9], data indicate that nearly the entire global population breathes air exceeding the World Health Organization’s recommended limits, with significant pollutant concentrations. Air pollution in urban and rural areas worldwide contributes to approximately 2 million premature deaths annually.
The rise in urban air pollution in recent decades and its effects on public health exemplify ongoing environmental degradation linked to certain societal structures [
10]. In urban settings, pollution from fossil fuels used in energy production, vehicle emissions, and the burning of organic matter has been associated with increased respiratory illnesses and hospitalizations due to sulfur oxides (SOx), nitrogen oxides (NOx), and sulfur dioxide (SO
2) [
11].
Hazardous air pollutants [
12] known for their severe health impacts, have also been studied alongside climate change. While these pollutants have diverse origins, industrial emissions are particularly concerning due to their significant contribution to PM
10 and PM
2.5 particles, gases, and heavy metals. People living near industrial areas experience higher pollution exposure compared to those in less industrialized regions [
12,
13].
Air pollution has become a major challenge for global environmental protection and urban development, impacting both human health and ecosystems. Climate change has intensified awareness of this issue among scholars and policymakers [
14]. In Latin America, over 100 million people are exposed to air pollution levels surpassing WHO recommendations [
15]. At-risk groups such as children, the elderly, individuals with health conditions, and those from lower socioeconomic backgrounds face increased risks from poor air quality.
According to Cordova [
16,
17], Metropolitan Lima (LIM) frequently experiences high PM
10 and PM
2.5 levels due to rapid industrialization and economic expansion. This area also accounts for 29% of Peru’s population of 34,105,243. Weather stations and other environmental measurement devices generate a large amount of data that is difficult to process manually, and machine learning algorithms help process it efficiently to identify patterns and relationships between PM
2.5 and meteorological variables [
18] so machine learning algorithms can adequately process large amounts of data and identify patterns and relationships between PM
2.5 and meteorological variables. Variables in the air environment can change rapidly based on external factors such as changes in weather conditions or human activity [
19].
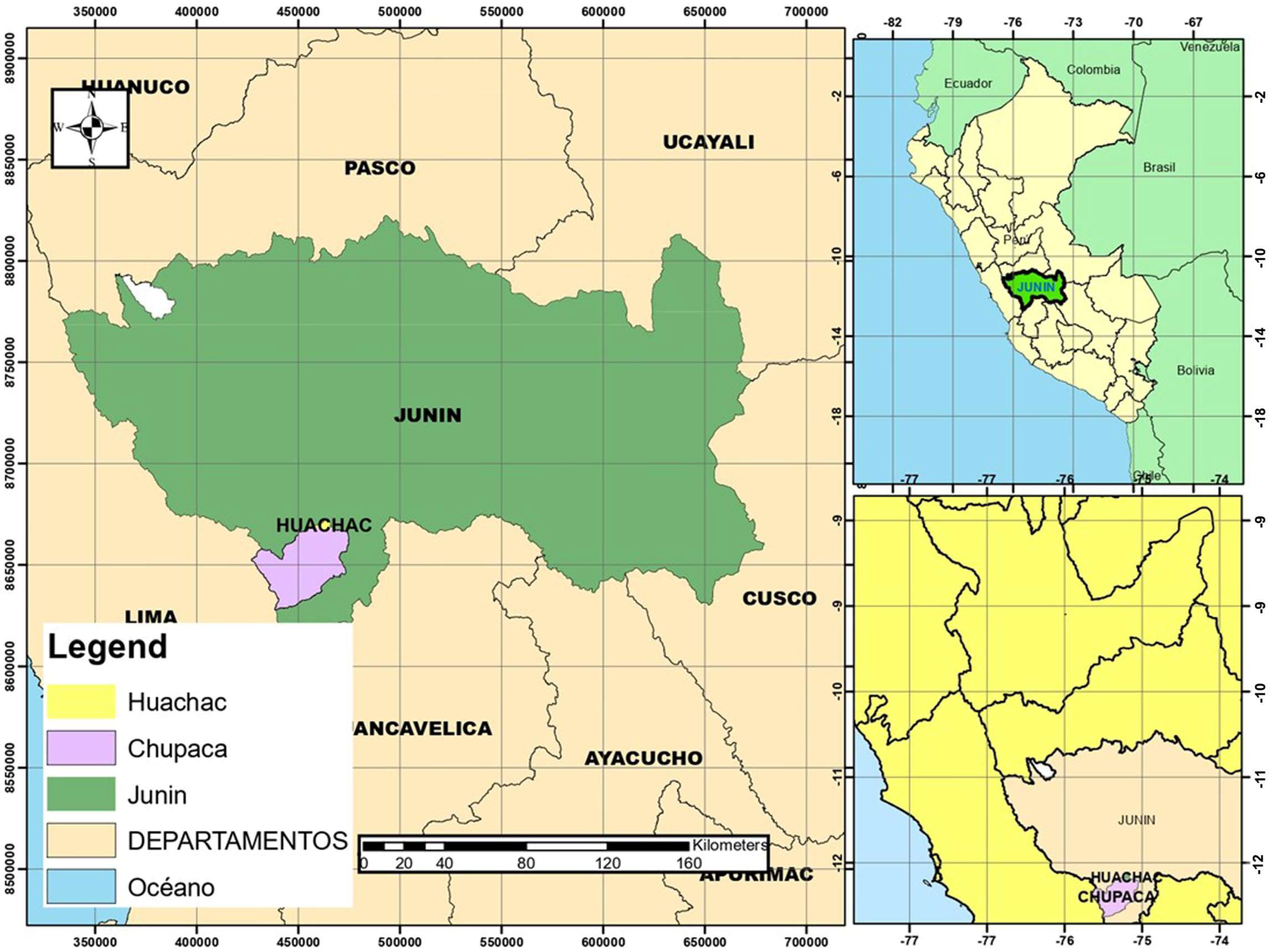
In Peru, due to increased industrialization and the extensive use of hydrocarbons, an increase in the concentration of PM
2.5 particles in the air has been visualized [
20], which generates a problem in terms of public health and the environment, so the research aims to optimize predictive machine learning models with data from the Huachac astronomical station, Chupaca, Junín, to analyze and predict the concentration of PM
2.5.
In Huachac, Junín, air pollution, especially PM 2.5 particulate matter, represents a significant health and environmental risk. However, there is limited capacity to predict and manage this pollutant due to the lack of accurate predictive models that integrate relevant environmental variables. This hinders the implementation of effective pollution control and mitigation policies. Therefore, it is necessary to develop a predictive model based on Machine Learning techniques to anticipate PM 2.5 levels and optimize environmental management in the region.
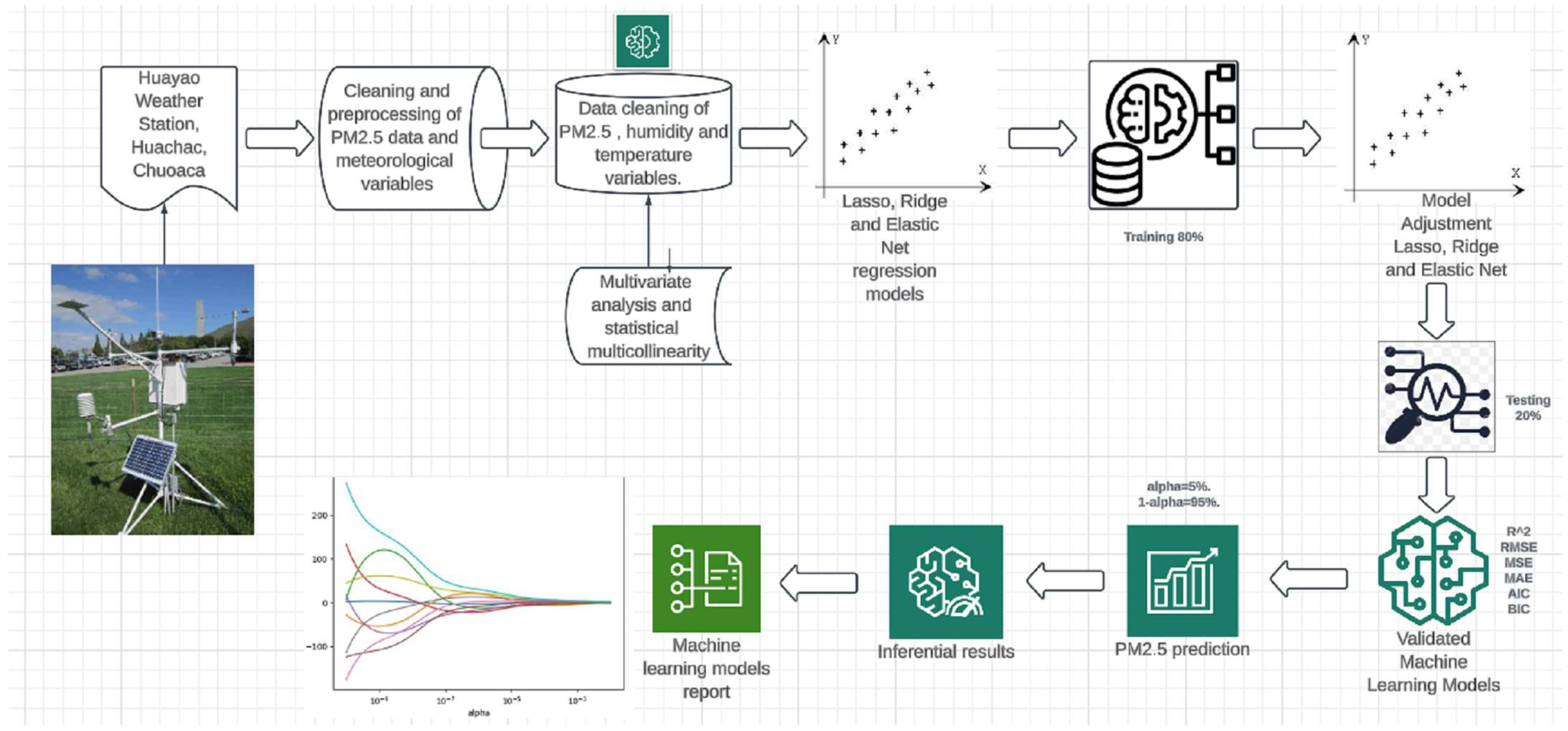
This study was conducted in the district of Huachac, province of Chupaca, department of Junín, Peru, where data were collected from the HUAYAO monitoring station using geolocation tools and software with Python 3.11 libraries. A sample of 16,543 records was conditioned and normalized using the EDA methodology.
The problem is atmospheric pollution by particulate matter in the environment, and this article aims to predict the behavior of PM2.5 particulate matter, applying machine learning methodology in order to make decisions for the benefit of the surrounding population.
This study provides a predictive machine learning model of PM2.5, which contributes to the predictive understanding of the behavior of environmental variables in the study areas, which will allow international bodies to use it as a model for analysis.
3. Results
A total of 16,543 records were analyzed for the variables under study, as shown in
Table 1, where PM
2.5AQI shows a data density with a trend to the left and a tail to the right due to the outliers on some days of the year but in general shows a mean of 33.1, with a standard deviation of PM
2.5 and a maximum value of 208, which represents an outlier and poses a risk to the health of the population. Absolute humidity showed a normal distribution since it had a mean of 4.72% with a median of 4.8 and a standard deviation of 0.987, indicating a relatively stable humidity over time. Likewise, the temperature showed an average of 10.8 °C with a median of 9 and a standard deviation of 0.23, with a temperature ranging between −6 and 28.
Figure 3 shows the PM
2.5AQI, with the highest concentration in winter with an average of 52.6 g/m
3, in second place in spring with an average of 36.9 g/m
3, in third place in autumn with an average of 27.4 g/m
3 and finally in summer with an average of 15.6 g/m
3.
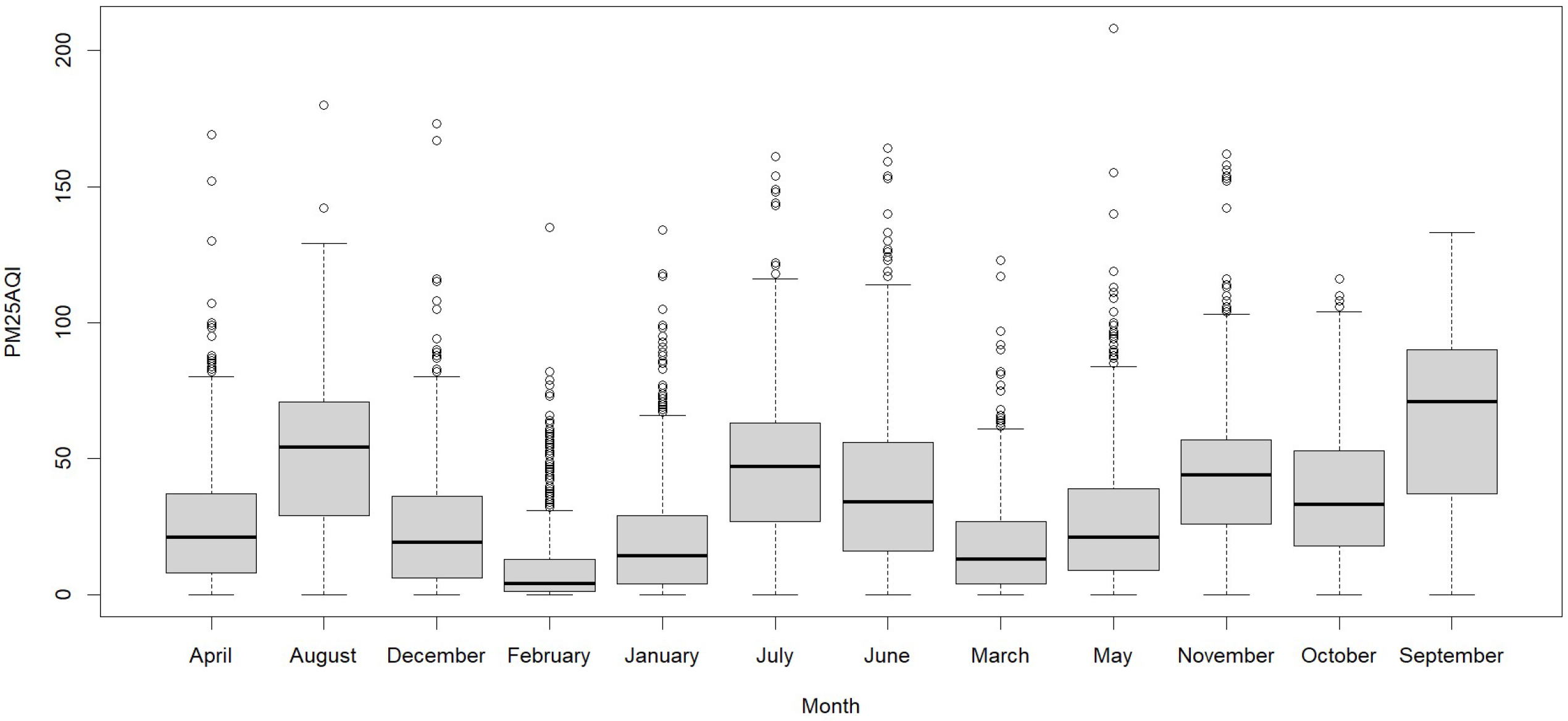
In
Figure 4, we observe the PM
2.5AQI by month for the year analyzed. In September, the index was 64.9, followed by August in second place with 51.7, July in third place with 46.0, and November in fourth place with 43.10. The remaining months had indices lower than 38.7.
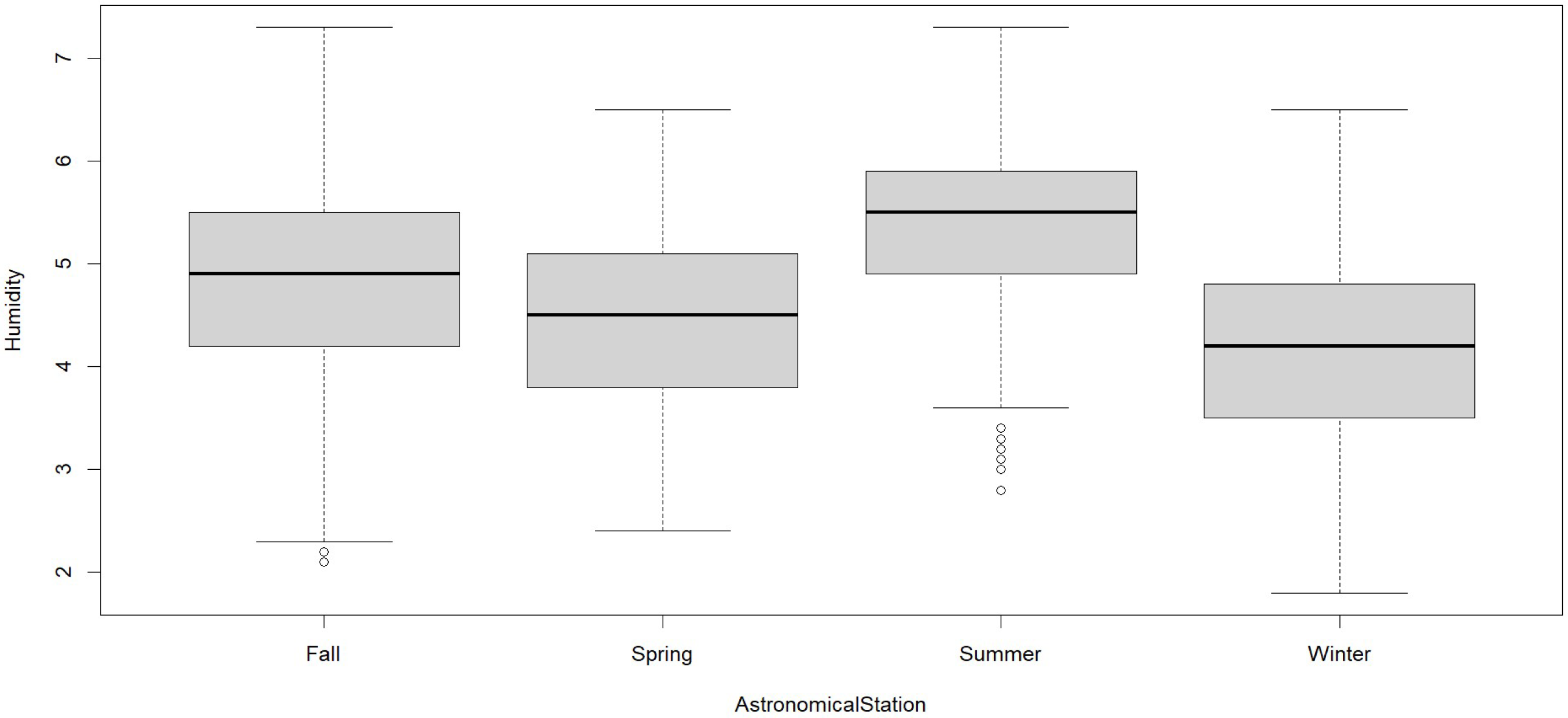
In
Figure 5, we observe that in summer, 50% have a humidity lower than 5.5, and the other 50% have a humidity higher than 5.5; secondly, in autumn, 50% have a humidity lower than 4.9, and the other 50% have a humidity higher than 4.9; thirdly, in spring, 50% have a humidity lower than 4.5, and the other 50% have a humidity higher than 4.5; and finally, in spring, 50% have a humidity lower than 4.2, and the other 50% have a humidity higher than 4.
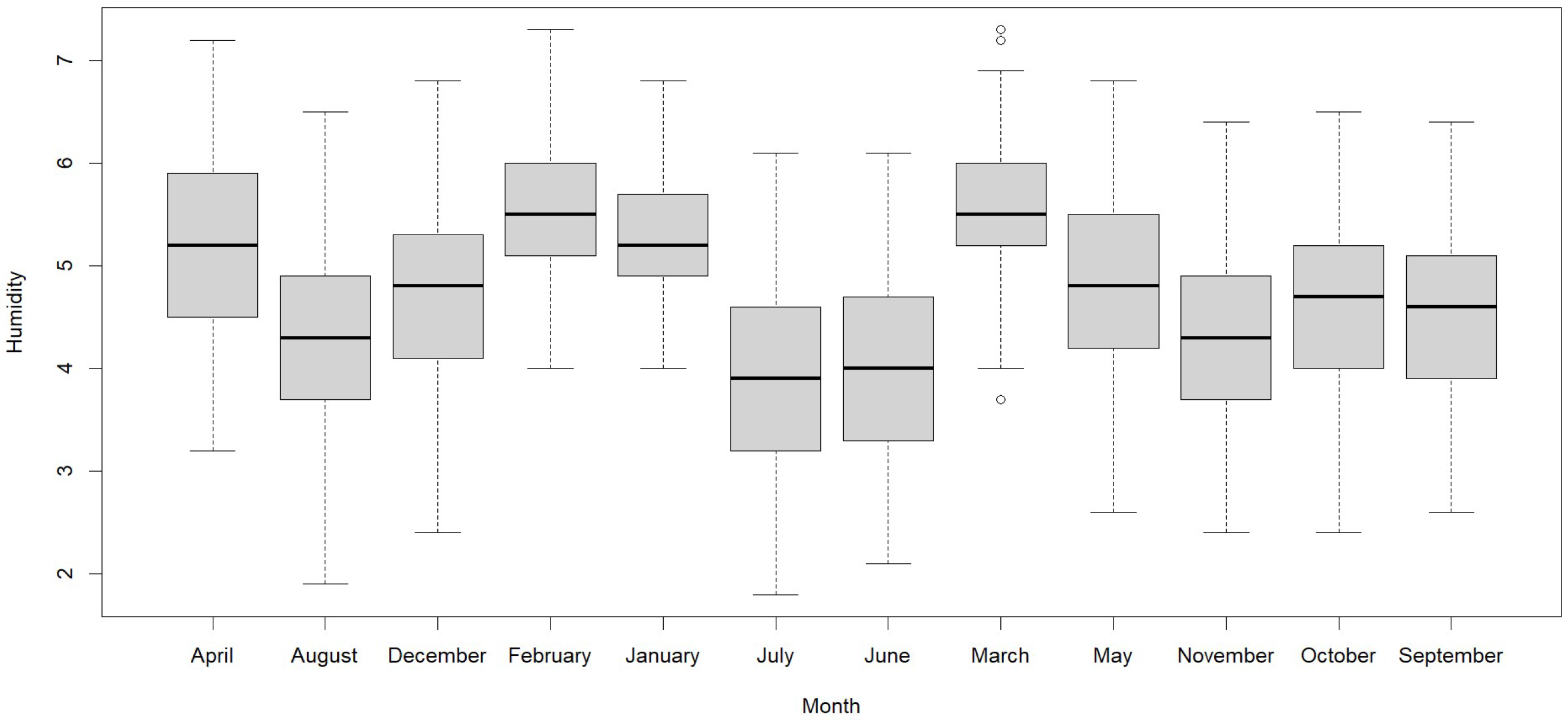
Humidity shows its highest value in January due to heavy rains and its lowest value in July due to the dry season of the year and the frost season. The absolute humidity shows that it is higher in summer, followed by autumn, due to the beginning and end of the rain. In
Figure 6, we observe that in February and March, 50% have a humidity lower than 5.5, and the other 50% have a humidity higher than 5.5. In second place, in January and April, 50% have a humidity lower than 5.2, and the other 50% have a humidity higher than 5.2. In third place, in May and December, 50% have a humidity lower than 5.2, and the other 50% have a humidity higher than 5.2.2. Thirdly, in May and December, 50% have a humidity lower than 4.8, and the other 50% have a humidity higher than 4.8. In October, 50% have a humidity lower than 4.7, and the other 50% have a humidity higher than 4.7. Finally, in the other months, 50% have a humidity lower than 4.6, and the other 50% have a humidity higher than 4.6.
In
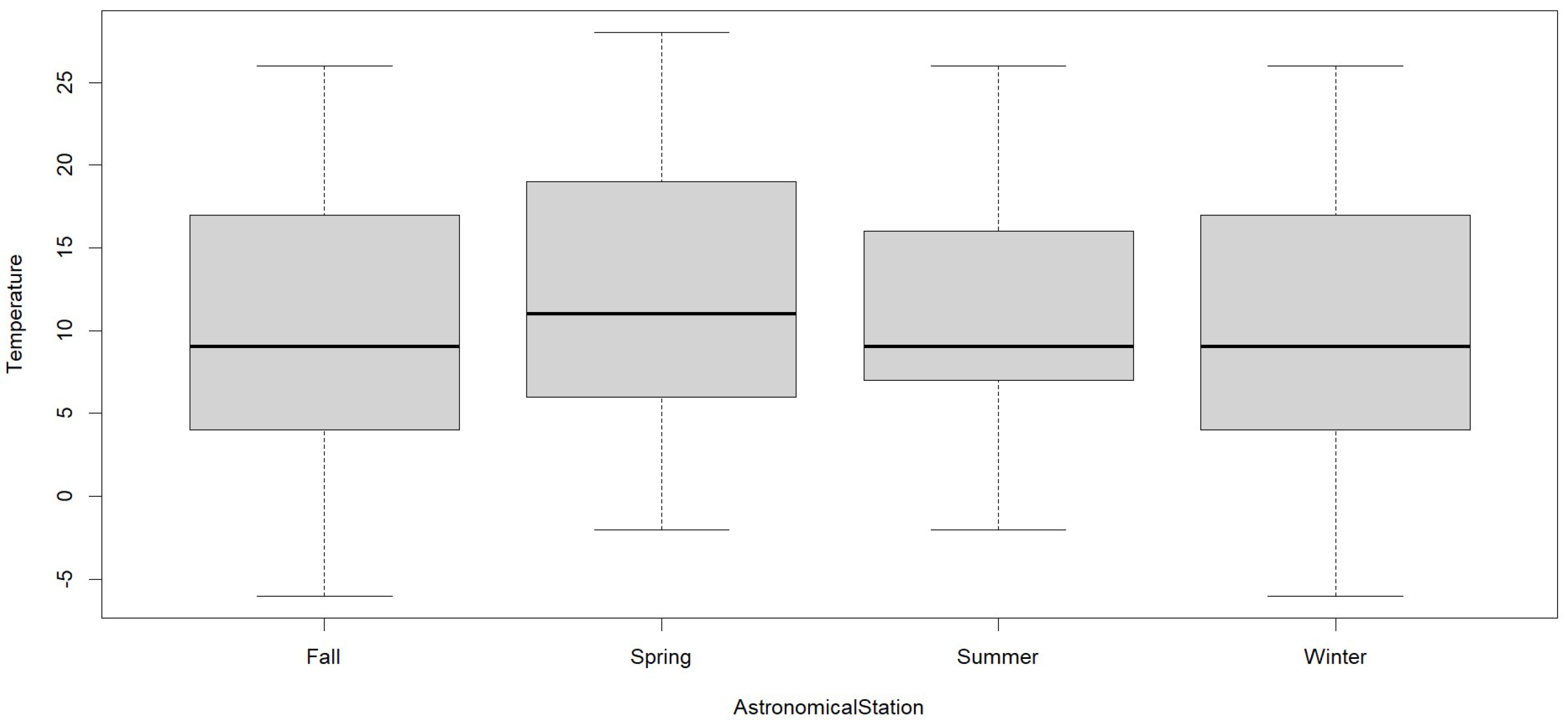
Figure 7, we observe that in spring, 50% have a temperature lower than 11 °C and the other 50% have a temperature higher than 11 °C, and there is a temperature tie in autumn, winter, and summer, with 50% having a temperature lower than 9 °C and the other 50% having a temperature higher than 9 °C.
In
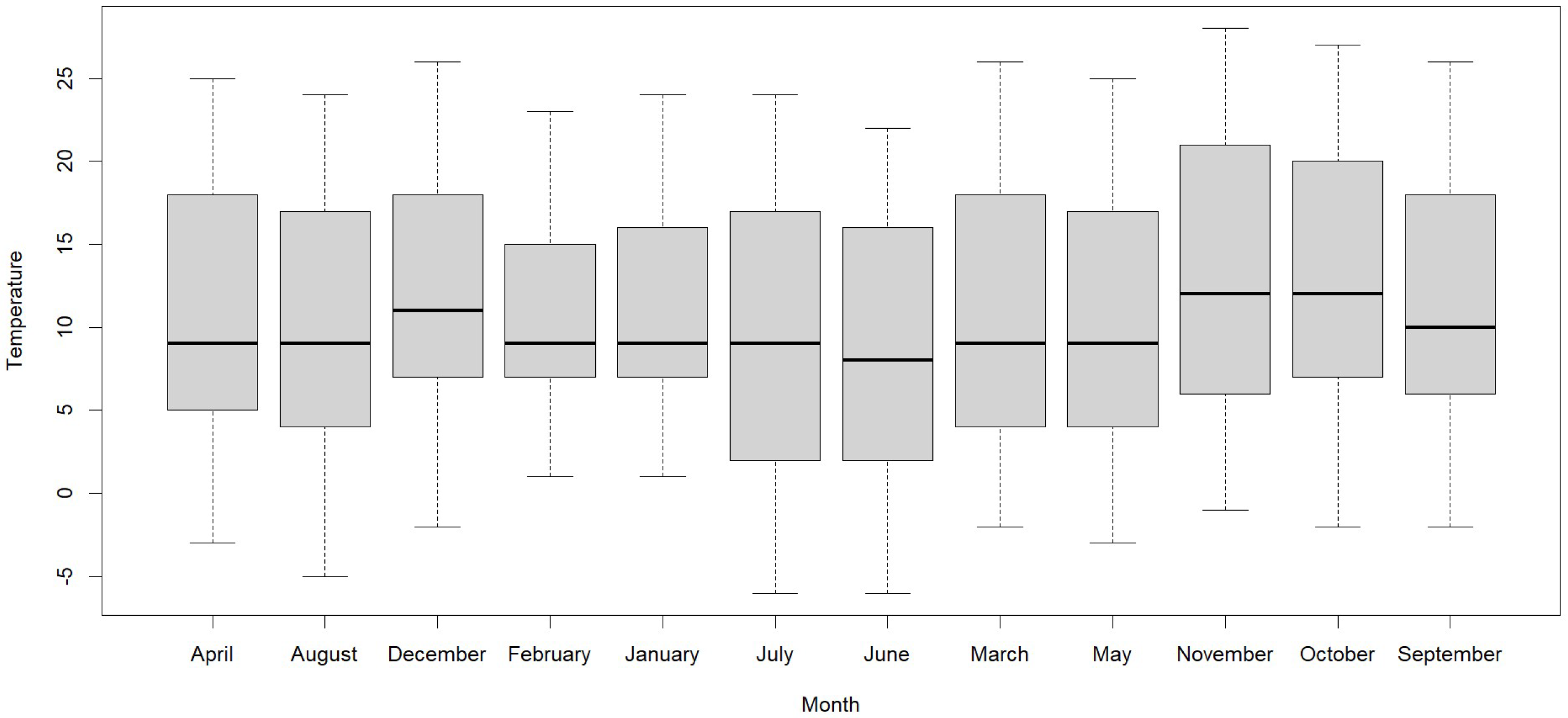
Figure 8, we observe that in October and November, 50% have a temperature lower than 12 °C, and the other 50% have a humidity higher than 12 °C. Secondly, in December, 50% have a temperature lower than 11 °C, and the other 50% have a temperature higher than 11 °C. Thirdly, in September, 50% have a temperature lower than 10 °C, and the other 50% have a temperature higher than 10 °C. Finally, in the other months, 50% have a temperature lower than 9 °C, and the other 50% have a temperature higher than 9.
The temperature reaches its lowest value in June due to the presence of morning frosts and its highest point in November due to the sunny season. These values of the air quality index, humidity, and temperature are crucial for planning and decision making related to public health and the environment because, for example, the highest AQI indicates that the smoke of the entire Mantaro Valley, where the astronomical center of Huachac is located should make educational campaigns of not burning agricultural waste. The highest average temperature was in spring due to the absence of rain and wind in the area, and the lowest was in winter due to the presence of morning frosts. The standard deviation indicates that the variability is higher in winter compared to the other seasons because, in these months, there is the presence of low temperatures as the highest. The minimum and maximum values vary according to the season, with the highest and lowest values associated with winter and spring, although the highest is in autumn with an AQI of 208 due to the fact that farmers prepare their land for planting and burn crop stubble.
In the investigation of the 16,543 observations, 80% (13,234) of the observations were taken for training and 20% (3309) for testing. During training, a resampling cross-validation with three repetitions yielded an RMSE = 25.36203, an Rsquared = 0.1483206 and an MAE = 20.51858.
The multivariate linear regression analysis with two regressor variables (humidity and temperature), as well as the predictor variable PM
2.5AQI, fulfilled the statistical prerequisites and yielded the results in R Studio 2024.04.2 Build 764 software shown below.
| >summary(lm) |
| Call: |
| lm(formula = .outcome ~ ., data = dat) |
| Residuals: |
| Min | 1Q | Median | 3Q | Max |
| −53.087 | −19.664 | −5.102 | 16.336 | 177.352 |
| Coefficients: |
| | Estimate | Std. Error | t value | Pr(>|t|) |
| (Intercept) | 83.40932 | 1.07213 | 77.798 | <2 × 10−16 *** |
| Humidity | −10.37024 | 0.23201 | −44.698 | <2 × 10−16 *** |
| Temperature | −0.12717 | 0.03169 | −4.013 | 6.04 × 10−5 *** |
| --- |
| *** represents the significance of the results., signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
| Residual standard error: 25.37 on 13,269 degrees of freedom |
| Multiple R-squared: 0.1478, Adjusted R-squared: 0.1477 |
| F-statistic: 1151 on 2 and 13,269 DF, p-value: <2.2 × 10−16 |
In these results, the significance of the regressor variables was highly significant with a
p-value less than
, allowing us to propose the multiple regression model for PM
2.5 shown in Equation (10).
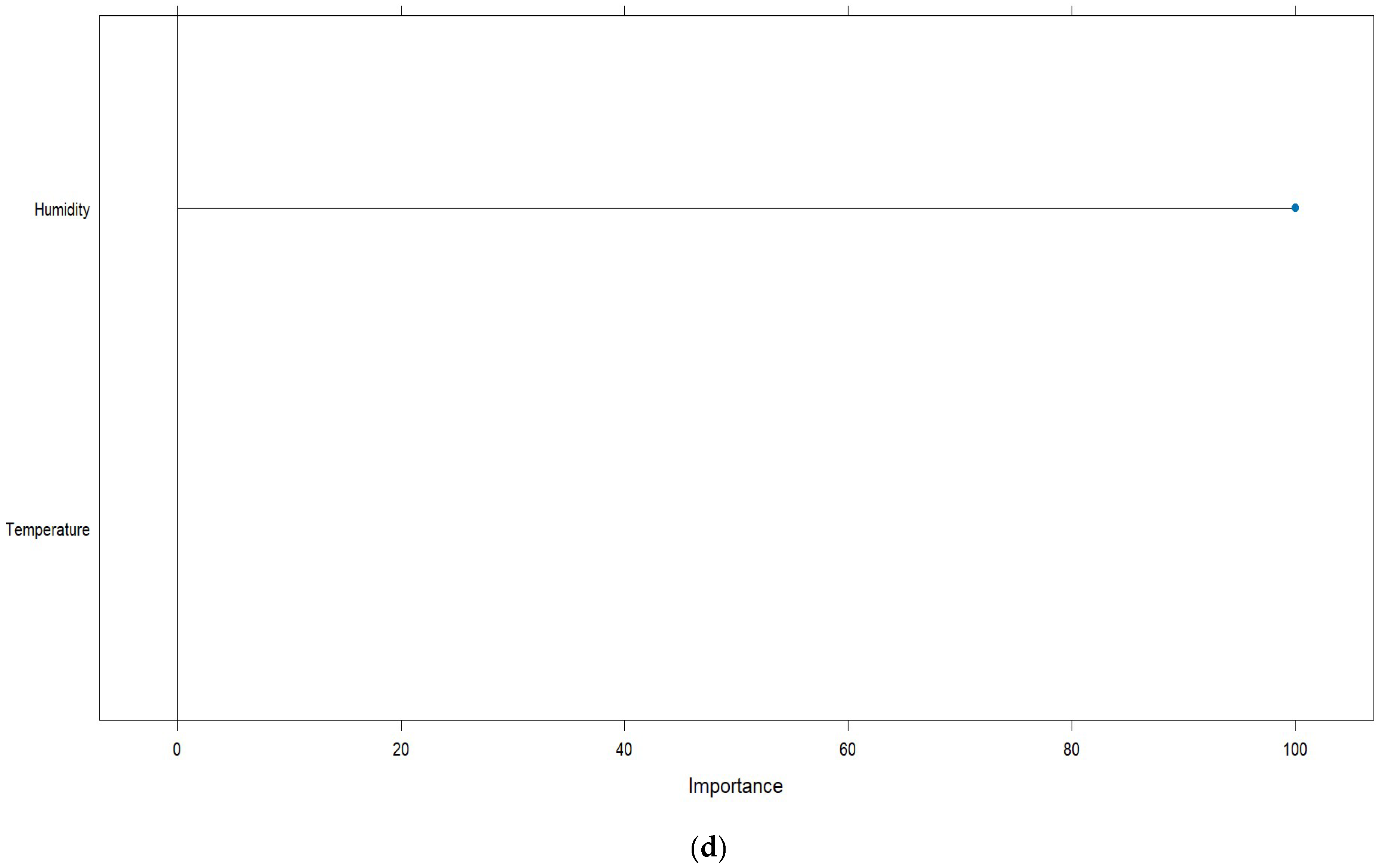
This indicates that both humidity and temperature are inversely proportional with PM2.5AQI for each unit increase in the predictor variables; in addition, the p-values in each of these variables are less than the significance level α = 0.05, which indicates that they have a significant effect and is corroborated by applying an analysis of variance of the model, also resulting in p-values less than α = 0.05 for both predictor variables. In addition, the Durbin–Watson test yields an autocorrelation of 0.881 and a DW of 0.238 with a p-value of less than α = 0.05, which indicates that there is almost no autocorrelation, which indicates the independence of the predictor variables, and all this is corroborated by the VIF of 1.08 for both variables, which indicates that both variables of the model are independent and there is no collinearity between them since it is very close to 1. Therefore, the model is found to be very predictively robust with a fairly high AIC of and BIC and with a low RMSE of 25.5 for the 16,544 data observed in the model with a p-value of less than 0.05.
Correlations of the predicted variable PM
2.5AQI with the predictor variables humidity and temperature were obtained. First, the correlation of PM
2.5AQI with humidity is −0.378, which shows a linear dependence and is inversely proportional, i.e., while PM
2.5AQI increases, absolute humidity decreases and vice versa, which means that the presence of humidity influences the decrease or increase in PM
2.5AQI present in the air. Likewise, we can see that the correlation between PM
2.5AQI and temperature has a correlation of −0.134, which indicates that it is also an inversely proportional correlation, which means that while PM
2.5AQI increases the temperature decreases, which gives us the idea that if the temperature increases, PM
2.5AQI decreases and also inversely, although this index shows that it is lower than the index presented by humidity, therefore it indicates that its linear influence on PM
2.5AQI is lower. On the other hand, the
p-value for humidity and temperature is less than 0.05, which confirms the hypothesis that in both cases, there is a linear dependence between the predicted variable PM
2.5AQI and the predictor variables of humidity and temperature. The graphs shown in
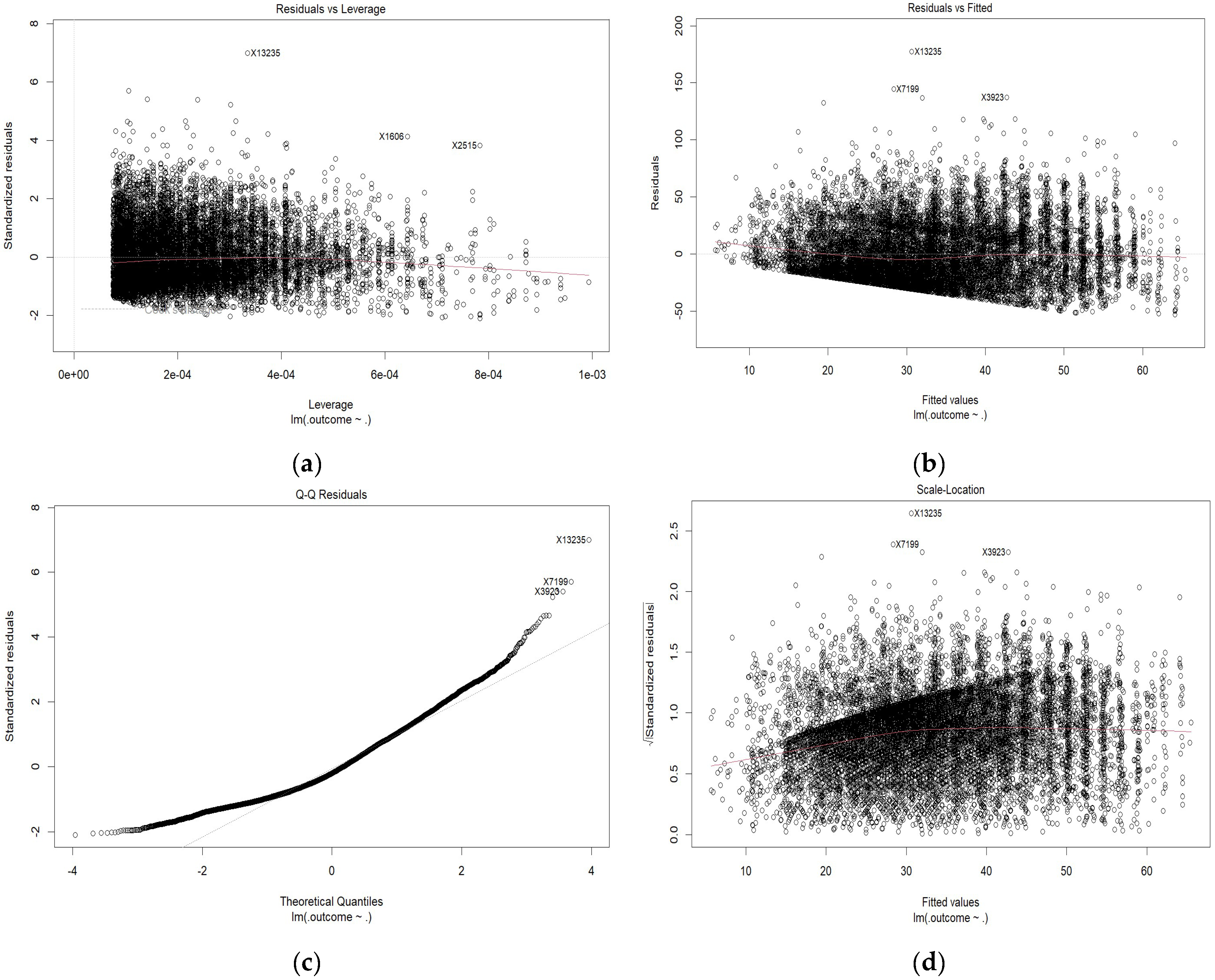
Figure 9 show the normalized residuals and fitted values, with residual quantiles and the root mean square error, for which the linear regression model meets all specifications and prerequisites for prediction.
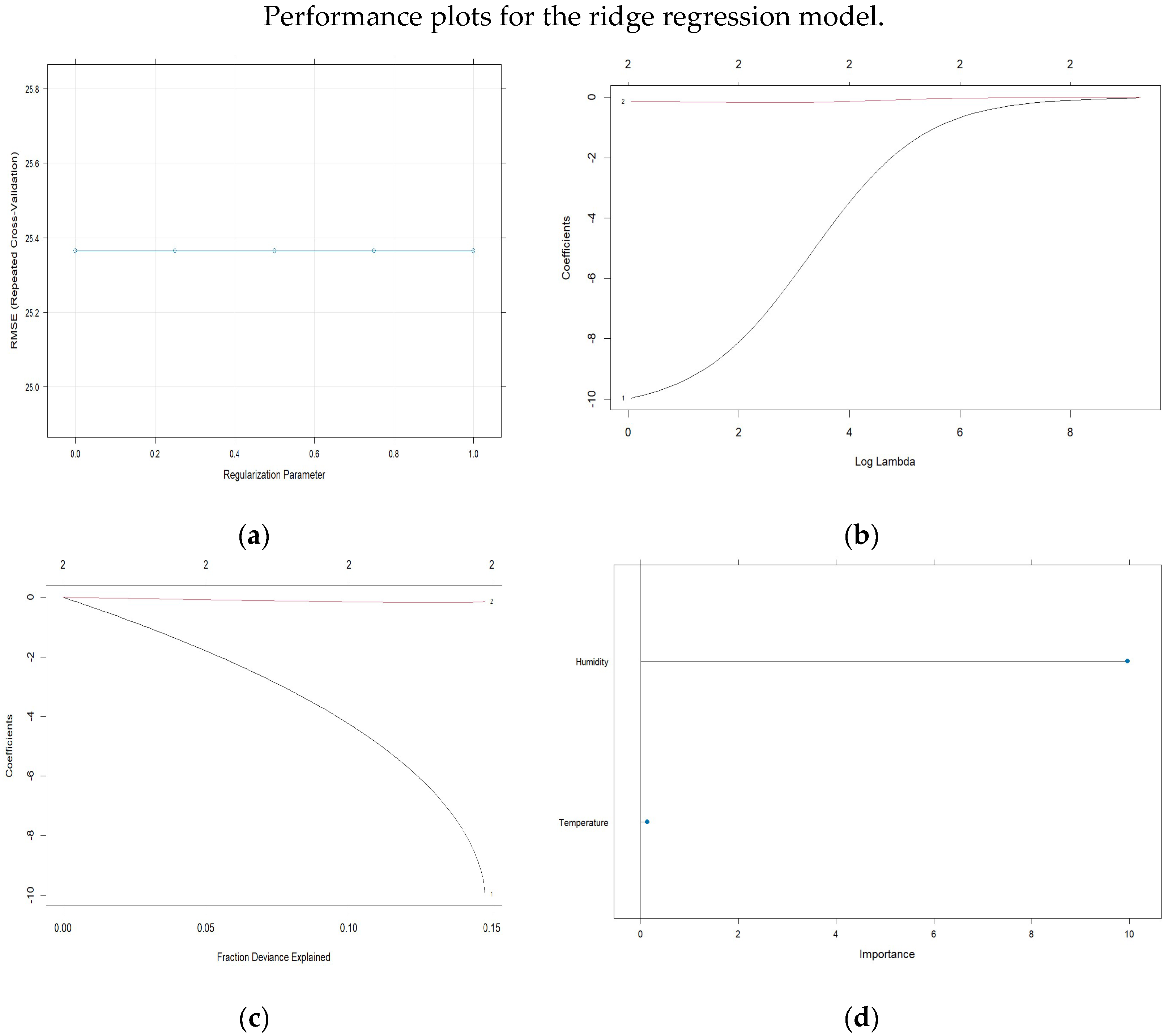
The results for the ridge regression model, with a training sample of 13,234 observations and a testing sample of 3309 observations, are presented in
Table 2, which shows the resampling metrics across the fit parameters.
Figure 10 shows the plots for the ridge regression model with cross-validation and the logarithms of the Lambda penalty values, as well as the values of the model coefficients and the significance of the regressor variables.
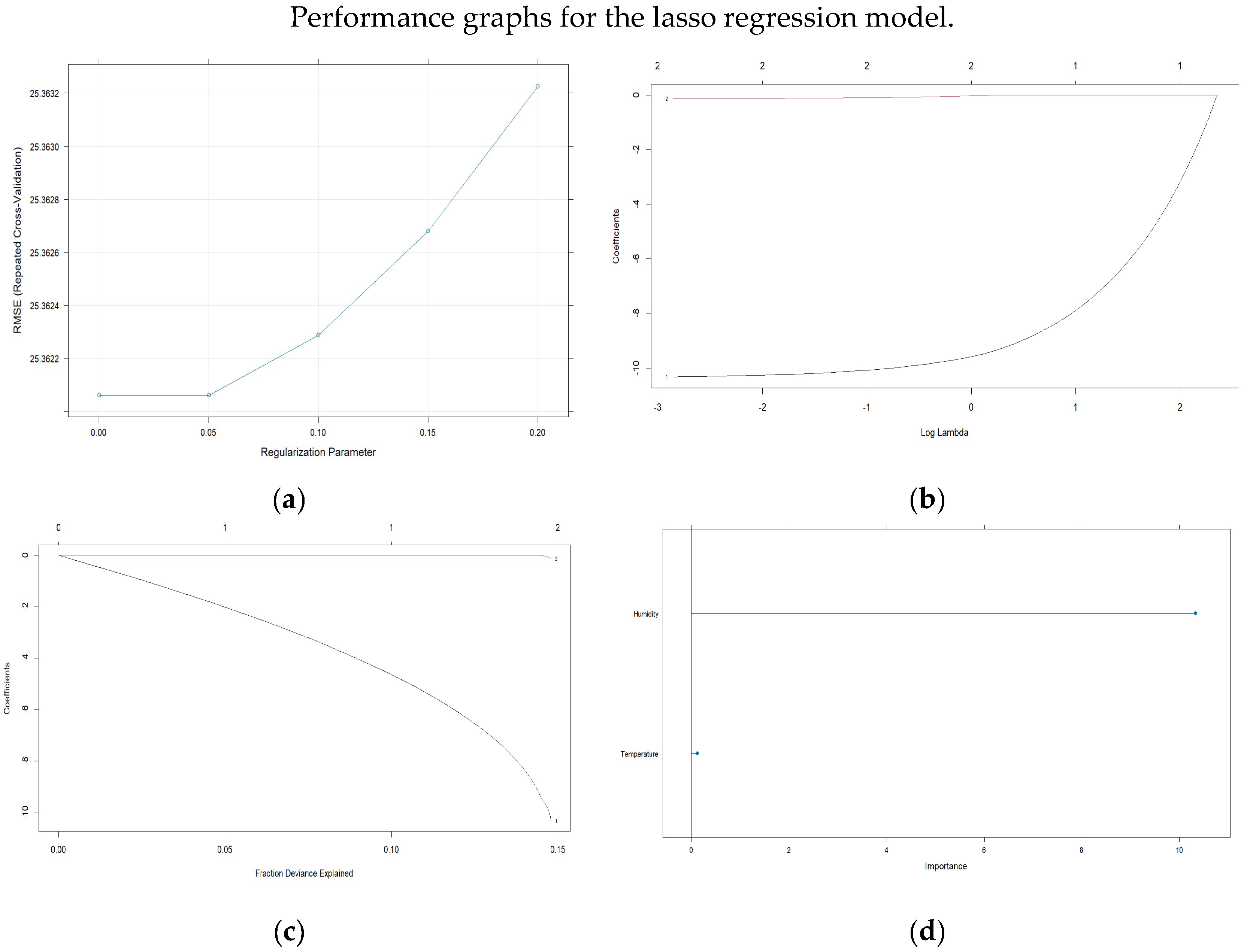
The results for the lasso regression model, with a training sample of 86,654 observations and a testing sample of 21,663 observations, are presented in
Table 3, which shows the metrics obtained through resampling and the fit parameters.
Figure 11 shows the graphs for the lasso regression model with cross-validation and the logarithms of the Lambda penalty values, as well as the values of the model coefficients and the significance of the regressor variables.
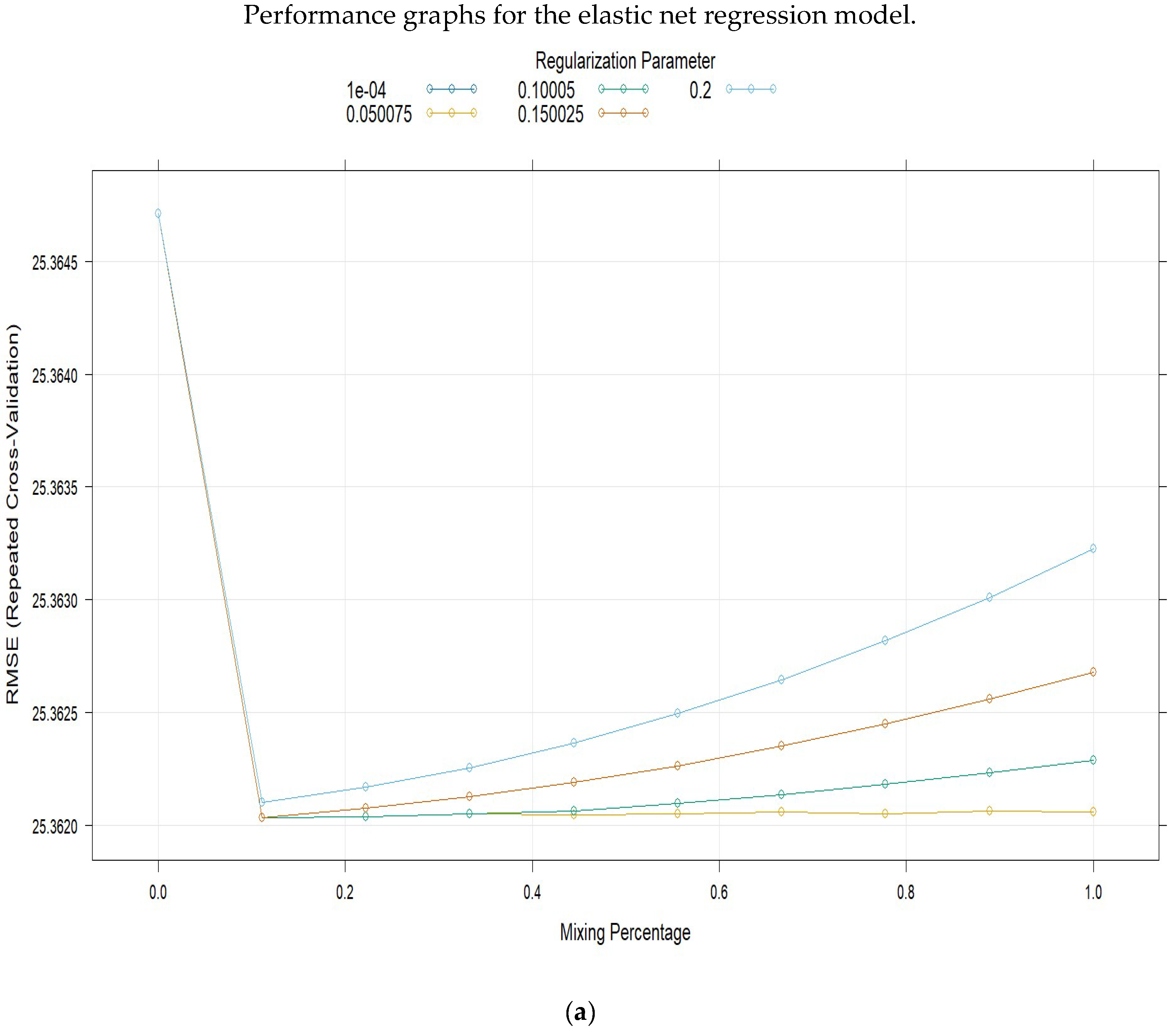
The results for the elastic net regression model, with a training sample of 13,234 observations and a testing sample of 3309 observations, are presented in
Table 4,
Table 5 and
Table 6, which show the resampling metrics obtained through the fit parameters.
Figure 12 shows the graphs for the elastic net regression model with cross-validation and the logarithms of the Lambda penalty values, as well as the values of the model coefficients and the significance of the regressor variables.
The best model that allowed the prediction of PM
2.5AQI is the thirteenth one, with
α = 0.1111111 and a Lambda of
λ = 0.150025; the model is shown in Equation (11).
This means that, for each year, the PM
2.5AQI decreases by 10.3022000; likewise, for temperature, the PM
2.5AQI decreases by 0.12688124. In the prediction for the mean squared error of the training set, a value of 25.36255 was obtained, and for the test set, a value of 25.84308 was obtained, resulting in a mean difference of 0.48053. This represents 98.1406% of the prediction efficiency with respect to the test.
4. Discussion
The LASSO (Least Absolute Shrinkage and Selection Operator) method applies regression procedures with parameter shrinkage to select predictor variables that matter significantly and mimic some variables that have little or no effect on the model by adjusting the maximum and minimum coefficients [
24]. In the MLP and SVM modeling of Qian, they found RMSE values of 52.74 and 35.88, respectively; however, this research presents an RMSE of 25.5, which indicates a more optimal model, as it is much lower in fit value with the actual values recorded. This is in parallel with Juan Soria’s study [
25], which presented a linear regression model for the prediction of PM2.5, finding a coefficient of 0.66105 μg/m
3 and an intercept of 5.57229 μg/m
3.
A linear regression model
with a coefficient of determination
on the concentration of PM2.5 and PM10 in Lima and Callao using SENAMHI data [
47], compared to the one found in this research of
0.1478; likewise [
27] found a linear regression equation between PM2.5 and PM10 in the industrial zone of the form
y = 4.485924 + 0.567541
x.
Geraldo-Campos et al. [
31] found lasso and ridge regularization models for the prediction of credit risk in reactive Peru with 501,298 companies analyzed, economic sector, granting entity, amount covered, and department as regressors, and risk level as a predictor. They determined a lasso regression model with
and an RMSE = 0.3573685, as well as a ridge regression model with
and an RMSE = 0.3573812, represented in Equation (12).
In this research, lasso (RMSE = 25.36206), ridge (RMSE = 25.36471), and elastic net (RMSE = 25.36203) models were found, where the best model found with an
α = 0.1111111 and a Lambda value
λ = 0.150025 is represented in Equation (13). Then, the choice of penalty values in regression models is crucial for achieving optimal performance by managing the trade-off between bias and variance, influencing both model complexity and predictive power [
48,
49].
This is further contrasted with Equation (13), finding the elastic net predictive regression model shown in Equation (14), which was used to predict teacher salary with
α = 0.5555556, a Lambda
λ = 0.2, and an RMSE of 895.3383.
Overall, the data reveal interesting patterns about the seasons of the year and their impact on air quality, humidity, and temperature. These findings could be useful to better understand how these variables change throughout the year and how they could affect people who are quite vulnerable to the environment around them because having polluted air can even be deadly in some cases [
50]. The research found that the increase in air quality in summer could have positive implications for public health in the central highlands, while the higher humidity in spring and summer could influence the comfort and well-being of people since these are times when most of the experiential tourism is generated in this area. Seasonal variability in temperature could also have consequences in various areas, from agriculture to the generation of the economy [
47].
Analysis of the data provided reveals significant differences between seasons in terms of air quality, humidity, and temperature. These findings could be important to better understand seasonal patterns in these variables and their potential impacts on society and the environment. The paper highlights the importance of considering seasonal variations when addressing air quality and climate issues and suggests further research to fully understand the implications of these findings.
PM2.5AQI values show significant variations throughout the year, with a peak in September due to the constant burning of stubble [
51] and agricultural waste by farmers prior to the annual planting of their products, which is detrimental to air quality. This merits a call to the local authorities to carry out environmental education campaigns because the presence of PM2.5 in the air often has fatal consequences, especially in vulnerable [
46]. Humidity and temperature also show interesting fluctuations during the months of the year, with humidity presenting higher values in January due to the presence of heavy and intense rains in the central highlands of Peru, [
50] which makes absolute humidity more concentrated at this time. The lowest temperature recorded in June was −6 °C, and the maximum reached 22 °C, showing significant variability in temperature due to the presence of morning frosts, according to the findings of Saavedra et al. [
49]. The data presented are within the ranges found by other researchers in terms of monthly variations in air quality, humidity, and temperature.
5. Conclusions
The best predictive model found is quite robust given that it meets the indicators in favor of the model LASSO regression analysis with a high AIC and BIC and a low RMSE for the 16,543 data analyzed. This is the thirteenth model, which emerged as the best predictor for the PM2.5 air quality index (AQI) with specific parameters: Alpha: 0.1111111 and Lambda: 0.150025. The model predicts a decrease in PM2.5AQI by 10.3022000 units per year, for temperature changes, PM2.5AQI decreases by 0.12688124 units, the mean squared error (MSE) for training is 25.36255, while for testing it is 25.84308, resulting in a mean difference of 0.48053, this indicates an impressive prediction efficiency of 98.1406% when comparing training to testing outcomes. These results highlight the effectiveness of regression models in predicting PM2.5AQI and provide a basis for future analysis and refinement of predictive techniques for management and planning of air quality improvement by government authorities in the Mantaro Valley.
The season with the highest PM2.5AQI was winter, with a value of 52.6 with a variability of 29.4, which is less than 100, indicating “Moderate” or there may be moderate health problems for people who are unusually sensitive to air pollution.
PM2.5AQI shows a peak in September due to smoke from stubble burning by farmers, while humidity peaks in January due to rainfall during that season and the minimum temperature in June due to the presence of frost.
These data are vital for understanding seasonal fluctuations in these environmental parameters, which have important implications for public health and environmental planning. The data found show that in general most of the year presents good air quality, showing some peaks of unsatisfactory AQI (208) as discordant or anomalous.
In conclusion, an efficient machine learning predictive model was obtained for the prediction of PM2.5AQI, which allows the measurement of future air quality and enables decision making in environmental care.
According to the monitoring protocol of the Ministry of Environment of Peru (MINAM), the number of monitoring stations should be proportional to the size of the population; to overcome this limitation, a greater number of monitoring stations should be considered in future research.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}